Tensor-Based Synchronization and the
Low-Rankness of the Block Trifocal Tensor
Abstract
The block tensor of trifocal tensors provides crucial geometric information on the three-view geometry of a scene. The underlying synchronization problem seeks to recover camera poses (locations and orientations up to a global transformation) from the block trifocal tensor. We establish an explicit Tucker factorization of this tensor, revealing a low multilinear rank of independent of the number of cameras under appropriate scaling conditions. We prove that this rank constraint provides sufficient information for camera recovery in the noiseless case. The constraint motivates a synchronization algorithm based on the higher-order singular value decomposition of the block trifocal tensor. Experimental comparisons with state-of-the-art global synchronization methods on real datasets demonstrate the potential of this algorithm for significantly improving location estimation accuracy. Overall this work suggests that higher-order interactions in synchronization problems can be exploited to improve performance, beyond the usual pairwise-based approaches.
1 Introduction
Synchronization is crucial for the success of many data-intensive applications, including structure from motion, simultaneous localization and mapping (SLAM), and community detection. This problem involves estimating global states from relative measurements between states. While many studies have explored synchronization in different contexts using pairwise measurements, few have considered measurements between three or more states. In real-world scenarios, relying solely on pairwise measurements often fails to capture the full complexity of the system. For instance, in networked systems, interactions frequently occur among groups of nodes, necessitating approaches that can handle higher-order relationships. Extending synchronization to consider measurements between three or more states, however, increases computational complexity and requires sophisticated mathematical models. Addressing these challenges is vital for advancing various technological fields. For example, higher-order synchronization can improve the accuracy of 3D reconstructions in structure from motion by leveraging more complex geometric relationships. In SLAM, it enhances mapping and localization precision in dynamic environments by considering multi-robot interactions. Similarly, in social networks, it could lead to more accurate identification of tightly-knit groups. Developing efficient algorithms to handle higher-order measurements will open new research avenues and make systems more resilient and accurate.
In this work, we focus on a specific instance of the synchronization problem within the context of structure from motion in 3D computer vision, where each state represents the orientation and location of a camera. Traditional approaches rely on relative measurements encoded by fundamental matrices, which describe the relative projective geometry between pairs of images. Instead, we consider higher-order relative measurements encoded in trifocal tensors, which capture the projective information between triplets of images. Trifocal tensors uniquely determine the geometry of three views, even in the collinear case [1], making them more favorable than triplets of fundamental matrices for synchronization. To understand the structure and properties of trifocal tensors in multi-view geometry, we carefully study the mathematical properties of the block tensor of trifocal tensors. We then use these theoretical insights to develop effective synchronization algorithms.
Directly relevant previous works. In the structure from motion problem, synchronization has traditionally been done using incremental methods, such as Bundler [2] and COLMAP [3]. These methods process images sequentially, gradually recovering camera poses. However, the order of image processing can impact reconstruction quality, as error may significantly accumulate. Bundle adjustment [4], which jointly optimizes camera parameters and 3D points, has been used to limit drifting but is computationally expensive.
Alternatively, global synchronization methods have been proposed. These methods process multiple images simultaneously, avoiding iterative procedures and offering more rigorous and robust solutions. Global methods generally optimize noisy and corrupted measurements by exploiting the structure of relative measurements and imposing constraints. Many global methods solve for orientation and location separately, using structures on and the set of locations. Solutions for retrieving camera poses from pairwise measurements have been developed for camera orientations [5, 6, 7, 8, 9, 10], camera locations [11, 12, 13], and both simultaneously [14, 15, 16, 17]. Some methods explore the structure on fundamental or essential matrices [18, 19, 20].
Several attempts to extract information from trifocal tensors include works by: Leonardos et al. [21], which parameterizes calibrated trifocal tensors with non-collinear pinhole cameras as a quotient Riemannian manifold and uses the manifold structure to estimate individual trifocal tensors robustly; Larsson et al. [22], which proposes minimal solvers to determine calibrated radial trifocal tensors for use in an incremental pipeline, handling distorted images with constraints invariant to radial displacement; and Moulon et al. [23], which introduces a structure from motion pipeline, retrieving global rotations via cleaning the estimation graph and solving a least squares problem, and solving for translations by estimating trifocal tensors individually by linear programs. To our knowledge, no prior works develop a global pipeline where the synchronization operates directly on trifocal tensors.
Contribution of this work. The main contributions of this work are as follows:
-
•
We establish an explicit Tucker factorization of the block trifocal tensor when its blocks are suitably scaled, demonstrating a low multilinear rank of . Moreover, we prove that this rank constraint is sufficient to determine the scales and fully characterizes camera poses in the noiseless case.
-
•
We develop a method for synchronizing trifocal tensors by enforcing this low rank constraint on the block tensor. We validate the effectiveness of our method through tests on several real datasets in structure from motion.
2 Low-rankness of the block trifocal tensor
We first briefly review relevant background material in Section 2.1. Then we present the main new construction and theoretical results in Section 2.2.
2.1 Background
2.1.1 Cameras and 3D geometry
Given a collection of images of a 3D scene, let and denote the location and orientation of the camera associated with the image in the global coordinate system. Moreover, each camera is associated with a calibration matrix that encodes the intrinsic parameters of a camera, including the focal length, the principal points, and the skew parameter. Then, the camera matrix has the following form, and is defined up to nonzero scale. Three-dimensional world points are represented as vectors in homogeneous coordinates, and the projection of into the image corresponding to is . 3D world lines can be represented via Plücker coordinates as an vector. Then the projection of onto the image corresponding to is , where is the line projection matrix. It can be written as where is the -th row of the camera matrix and wedge denotes exterior product. Explicitly the element of the line projection matrix can be calculated as the determinant of the submatrix, where the -th row is omitted and the column are selected as the -th pair from . The elements on the second row are multiplied by .
To retrieve global poses, relative measurement of pairs or triplets of images is needed. Let and be any pair of corresponding keypoints in images and respectively, meaning that they are images of a common world point. The fundamental matrix is a matrix such that . It is known that encodes the relative orientation and translation through . The essential matrix corresponds to the calibrated case, where for all .
2.1.2 Trifocal tensors
Analogous to the fundamental matrix, the trifocal tensor is a tensor that relates the features across images and characterizes the relative pose between a triplet of cameras . The trifocal tensor corresponding to cameras can be calculated by
| (1) |
where is the -th row of , and is the submatrix of omitting the -th row. The trifocal tensor determines the geometry of three cameras up to a global projective ambiguity, or up to a scaled rigid transformation in the calibrated case. In addition to point correspondences, trifocal tensors satisfy constraints for corresponding lines, and mixtures thereof. For example, let be corresponding image lines in the views of cameras respectively, then the lines are related through the trifocal tensor by , where denotes the skew-symmetric matrix corresponding to cross product by . We refer to [1] for more details of the properties of a trifocal tensor. We include the standard derivation of the trifocal tensor in Section A.1.
Since corresponding lines put constraints on the trifocal tensor, one advantage of incorporating trifocal tensors into structure from motion pipelines is that trifocal tensors can be estimated purely from line correspondences or a mixture of points and lines. Fundamental matrices can not be estimated directly from line correspondences, so the effectiveness of pairwise methods for datasets where feature points are scarce is limited. Furthermore, trifocal tensors have the potential to improve location estimation. From pairwise measurements, one can only get the relative direction but not the scale and the location estimation in the pairwise setting is a “notoriously difficult problem" (quoting from pages 316-317 of [24]). However, trifocal tensors encode the relative scales of the direction and can greatly simplify the location estimation procedure. We refer to several works on characterizing the complexity of minimal problems for individual trifocal tensors [25, 26], and on developing methods for solving certain minimal problems [27],[28], [29], [30], [31], [32], [33]. We also refer to [34] for a survey paper on structure from motion, which discusses minimal problem solvers from the perspective of computational algebraic geometry.
2.1.3 Tucker decomposition and the multilinear rank of tensors
We review basic material on the Tucker decomposition and the multilinear rank of a tensor. We refer to [35] for more details while adopting its notation. Let be an order tensor. The mode- flattening (or matricization) is the rearrangement of into a matrix by taking mode- fibers to be columns of the flattened matrix. By convention, the ordering of the columns in the flattening follows lexicographic order of the modes excluding . Symbols and denote the Kronecker product and the Hadamard product respectively. The norm on tensors is defined as . The -rank of is the column rank of and is denoted as rank. Let =rank. Then the multilinear rank of is defined as mlrank() = . The -mode product of with a matrix is a tensor in such that
Then, the Tucker decomposition of is a decomposition of the following form:
where is the core tensor, and are the factor matrices. Without loss of generality, the factor matrices can be assumed to have orthonormal columns. Given the multilinear rank of the core tensor , the Tucker decomposition approximation problem can be written as
| (2) |
A standard way of solving (2) is the higher-order singular value decomposition (HOSVD). The HOSVD is computed with the following steps. First, for each calculate the factor matrix as the leading left singular vectors of . Second, set the core tensor as . Though the solution from HOSVD will not be the optimal solution to (2), it satisfies a quasi-optimality property: if is the optimal solution, and the solution from HOSVD, then
| (3) |
2.2 Low Tucker rank of the block trifocal tensor and one shot camera retrieval
Suppose we are given a set of camera matrices with and scales fixed on each camera matrix. Define the block trifocal tensor to be the tensor, where the sized block is the trifocal tensor corresponding to the triplet of cameras . We assume for all blocks that have overlapping indices, the corresponding tensor is also calculated using the formula (1). We summarize key properties of in 1 and Theorem 1. The proof of Proposition 1 is by direct computation and can be found in Section A.3.
Proposition 1.
We have the following observations for the block trifocal tensor . For all distinct , we have the following properties:
-
(i)
-
(ii)
The blocks are rearrangements of elements in the fundamental matrix up to signs.
-
(iii)
The and blocks encode the epipoles.
-
(iv)
The horizontal slices of are skew symmetric.
-
(v)
When all cameras are calibrated, three singular values of are equal.
Theorem 1 (Tucker factorization and low multilinear rank of block trifocal tensor).
The block trifocal tensor admits a Tucker factorization, , where , , and . If the cameras that produce are not all collinear, then . If the cameras that produce are collinear, then .
Proof.
We can explicitly calculate that . The details of the calculation are in Section A.2. The specific forms for are the following. The horizontal slices of the core are
The factor matrices are and , where are the camera matrices and are the corresponding line projection matrices.
Now, we suppose that the cameras are not collinear. We first show that and both have full rank. From [1], the null space of a camera matrix is generated by the camera center. For the sake of contradiction, suppose that rank() < 4. Then there exists such that and . This means that for all . Then, is the camera centre for all cameras, which means that the cameras are centered at one point and are collinear. Similarly, every vector in the null space of the line projection matrix is a line that passes through the camera centre [1]. For the sake of contradiction, suppose that rank() < 6. Then there exists such that and . This implies that for all , which means that is a line that passes through all of the camera centers. Again the cameras are collinear, which is a contradiction. Next we write the flattening of the block trifocal tensor as . Then has rank 6, and has rank 16. Given the specific form of , where it is easy to check rank() = 6. Thus, rank() = 6. Similarly, we can show that rank() = 4, and rank() = 4. This implies that the multilinear rank of the block trifocal tensor is when the cameras are not collinear.
When the cameras are collinear, the individual factors in each flattening may be rank deficient, so that rank() , rank() , and rank() . This implies mlrank() . ∎
The theorem inspires a straightforward way of retrieving global poses from the block trifocal tensor, which we summarize in the following claim.
Proposition 2 (One shot camera pose retrieval).
Given the block trifocal tensor produced by cameras , the cameras can be retrieved from up to a global projective ambiguity using the higher-order SVD. The cameras will be the leading singular vectors of or .
Using the higher-order SVD on , we can get a Tucker decomposition of the block trifocal tensor . Though the Tucker factorization is not unique [35], as we can apply an invertible linear transformation to one of the factor matrices and apply the inverse onto the core tensor, this invertible linear transformation can be interpreted as the global projective ambiguity for projective 3D reconstruction algorithms. Thus, the cameras can be retrieved by taking the leading four singular vectors of the mode-2 and mode-3 flattenings of the block tensor.
Very importantly however, in practice each trifocal tensor block in can be estimated from image data only up to an unknown multiplicative scale [1]. The following theorem establishes the fact that the multilinear rank constraints provide sufficient information for determining the correct scales. In the statement denotes blockwise scalar multiplication, thus the -block of is .
Theorem 2.
Let be a block trifocal tensor corresponding to calibrated or uncalibrated cameras in generic position. Let be a block scaling with nonzero iff are not all equal. Assume that has multilinear rank where denotes blockwise scalar multiplication. Then there exist such that whenever are not all the same.
Sketch.
Theorem 2 is the basic guarantee for our algorithm development below. We stress that the ambiguities brought by are not problematic for purposes of recovering the camera matrices by 2. Indeed, where is the diagonal matrix with each entry of triplicated, etc. Hence the camera matrices can still be recovered up to individual scales (as expected) and a global projective transformation, from the higher-order SVD.
3 Synchronization of the block trifocal tensor
In this section, we develop a heuristic method for synchronizing the block trifocal tensor by exploiting the multilinear rank of from Theorem 1. Let denote the estimated block trifocal tensor, and the ground truth. Assume that there are images and a set of trifocal tensor estimates where and is the set of indices whose corresponding trifocal tensor is estimated. Note that each estimated trifocal tensor will have an unknown scale associated with it. We always assume that we observe the blocks, as they will be . We formulate the block trifocal tensor by plugging in the estimates and setting the unobserved positions () to tensors of all zeros. Let denote the block tensor where the blocks are ones for and zeros otherwise. Let denote the opposite. In our experiments, we observe that the HOSVD is quite robust against noise for retrieving camera poses, which arises e.g., from numerical sensitivities when first estimating relative poses [37]. Therefore we develop an algorithm that projects onto the set of tensors that have multilinear rank of while completing the tensor and retrieving an appropriate set of scales. Specifically, we can write our problem as
| (4) |
where , each block is uniform, blocks are zero for , and satisfies a normalization condition like to avoid its vanishing. However, we drop this normalization constant in our implementation as we never observe vanishing in practice. (For convenience, we formulate this section with the notation of and Hadamard multiplication, rather than and blockwise scalar multiplication from Theorem 2.) Furthermore in problem (4), denotes the exact projection onto the set . Note that though HOSVD provides an efficient way to project onto , it is quasi-optimal and not the exact projection. The exact projection is much harder to calculate, and in general NP-hard. The algorithm below adopts an alternating projection strategy to estimate the best set of scales.
3.1 Higher-order SVD with a hard threshold (HOSVD-HT)
The key idea for our algorithm is to use the relative scales on the rank truncated tensor as a heuristic to retrieve scales for the estimated block tensor. There are two main challenges for calculating the rank truncated tensor. First, the exact projection onto is expensive and difficult to calculate. Second, many blocks in the block tensor will be unknown if the corresponding images of the block lacks corresponding point and directly projecting the uncompleted tensor will be inaccurate. We apply an HOSVD framework with imputations to tackle the challenges. Regarding the first challenge, HOSVD is a simple, efficient, and quasi-optimal (3) projection onto . Though inexact, it is a reliable approximation. For the second challenge, the tensor must be completed. We adopt the matrix completion idea of HARD-IMPUTE [38], where the matrix is filled-in iteratively with the rank truncated matrix obtained using the hard-thresholded SVD. In other words, we complete the missing blocks with the corresponding blocks in the rank truncated tensor. We define three hyperparameters that correspond to the thresholding parameters of the hard-thresholded SVD on modes of the block tensor respectively. Specifically, for each mode- flattening , we calculate the full SVD . Since our tensor will scale cubically with the number of cameras, we suggest using a randomized SVD. We refer to [39] for different randomized strategies. Assume the singular values on the diagonal of are sorted in descending order, as usual. We return the factor matrix as the top left singular vectors in , where . Our adapted truncation method is summarized by Algorithm 1.
From now on, we refer to hard-thresholded HOSVD as HOSVD-HT and denote the operation as .
3.2 Scale recovery
HOSVD-HT provides an efficient way for projecting onto the set of tensors with with truncated rank. To recover scales, we use the rank truncated tensor’s relative scale as a heuristic to adjust the scale on our estimated block trifocal tensor . For each step, we solve
| (5) |
where we drop the normalization condition on because in practice it is not needed. We solve (5) for each observed block separately. Denoting as , we have
| (6) |
Recall that our strategy for completing the tensor is to impute the tensor with the entries from the rank truncated tensor using HOSVD-HT. Specifically, given the current imputed tensor , we calculate and the new scales . Then update with
| (7) |
3.3 Synchronization algorithm
Now we summarize our synchronization framework in Algorithm 2.
We have observed that the algorithm can overfit, as the recovered scales will experience sudden and huge leaps. Our stopping criteria for the algorithm is when we observe sudden jumps in the variance of the new scales or when we exceed a maximum number of iterations. Another challenge in structure from motion datasets is that estimations may be highly corrupted. The HOSVD framework mainly consists of retrieving a dominant subspace from each flattening. Thus, it is natural to replace the SVD on each flattening with a more robust subspace recovery method, such as the Tyler’s M estimator (TME) [40] or a recent extension of TME that incorporates the information of the dimension of the subspace in the algorithm [41]. We refer to Appendix A.5.2 for more details and provide an implementation there.
4 Numerical experiments
We conduct experiments of Algorithm 2 on two benchmark real datasets, the EPFL datasets [42] and the Photo Tourism datasets [11]. We observe that the algorithm performs better in the calibrated setting, and since the calibration matrix is usually known in practice, we restrict our scope of experiments to calibrated trifocal tensors. We compare against three state-of-the-art synchronization based on two view measurements, NRFM [18] and LUD [12]. NRFM relies on nonconvex optimization and requires a good initialization. We test NRFM with an initialization obtained from LUD and with a random initialization. We also test BATA [43] initialized with MPLS [9]. We refer to A.6 in the appendix for a comprehensive summary of numerical results including rotation and translation estimation errors. We include our code in the following github repository: TrifocalSync.
4.1 EPFL dataset
For EPFL, we follow the experimental setup and adopt code from [44] and test an entire structure from motion pipeline. We first describe the structure from motion pipeline for EPFL experiements.
-
•
Step 1 (feature detection and feature matching). We obtain matched features across pairs of images using a modern deep learning based feature detection and matching algorithm, GlueStick [45]. Though we do not implement this in our experiments, there have been methods developed to further screen corrupted keypoint matches or obtain matches robustly, such as [46, 47, 48]. Key points across a triplet of cameras is matched from pairs and is included only if it appears in all the pair combinations of the three images.
-
•
Step 2 (estimation and refinement of trifocal tensors). With the triplet matches, we calculate the trifocal tensors with more than 11 correspondences. To have an even sparser graph, one can skip the estimation of trifocal tensors and rely on the imputation for images that have less than a number bigger than 11 point correspondences. This can further speed up the trifocal tensor estimation process. We apply STE from [41] to find 40% of the correspondences as inliers, then use at most inlier point correspondences to linearly estimate the trifocal tensor. To refine the estimates, we apply bundle adjustment on the inliers and delete triplets with reprojection error larger than 1 pixel.
-
•
Step 3 (synchronization). We synchronize the estimated block trifocal tensor with a robust variant of SVD using the framework described in Algorithm 2. The robustness comes from replacing SVD with a robust subspace recovery method [41]. More details can be found in Section A.5.2. Recall that the cameras we retrieve are up to a global projective ambiguity. When comparing with ground truth poses, we first align our estimated cameras with the ground truth cameras by finding a projective transformation. Then we round the cameras to calibrated cameras and compare.
We test our full pipeline on two EPFL datasets on a personal machine with 2 GHz Intel Core i5 with 4 cores and 16GB of memory. To test NRFM [18], LUD [12] and BATA [43] initialized with MPLS [9], we estimate the corresponding essential matrices using the GC-ransac [49]. We did not include blocks corresponding to two views in our trifocal tensor pipeline. The mean and median translation errors are summarized in Figure 1 here and more comprehensive results can be found in Table 1 and Table 2 in the appendix.
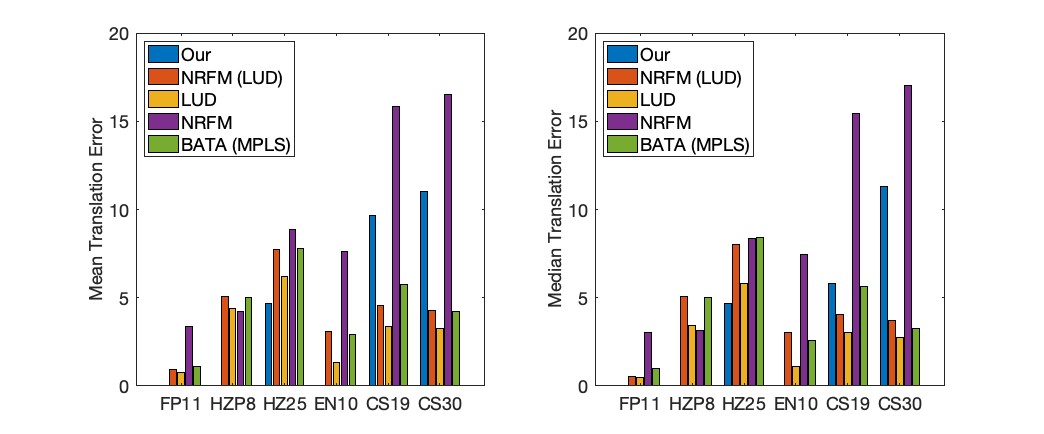
The EPFL datasets generally have a plethora of point correspondences, so that the trifocal tensors are estimated accurately. When the dataset focuses on a single scene, our algorithm retrieves locations competitively. Our algorithm achieves the best location estimation for 4 out of 6 datasets. The translation error bars are not visible for FP11, HZP8, EN10 due to the accuracy that we achieve. However, our pipeline is incapable of accurately processing CastleP19 and CastleP30. The main reason is that our algorithm relies on having a very dense observation graph to ensure high completion rate. CastleP19 and CastleP30 are datasets where the camera scans portions of the general area sequentially, so that not many triplets have overlapping features. Our method is not suitable for this type of dataset. However, it is possible to apply our algorithm in parallel on groups of neighboring frames, so that the completion rate is high in each group. Then the results can be merged to obtain a larger reconstruction. Rotations for the two view methods are estimated via rejecting outliers from iteratively applying [10]. We also compare against [43] for location estimation, where we initialize with a state-of-the-art global rotation estimation method [9]. Our algorithm achieves superior rotation estimation for only 2 out of the 6 datasets. See Table 1 and 2 in the appendix for comprehensive errors.
4.2 Photo Tourism
We conduct experiments on the Photo Tourism datasets. The Photo Tourism datasets consist of internet images of real world scenes. Each scene has hundreds to thousands of images. The datasets [11] provide essential matrix estimates, and we estimate the trifocal tensors from the given essential matrices. To limit the computational cost for tensors, we downsample the datasets by choosing cameras with observations more than a certain percentage in the corresponding block frontal slice while maintaining a decent number of cameras. Note that this may not be the optimal way of extracting a dense subset in general. The maximum number of cameras we select for each dataset is 225 cameras. The largest dataset Piccadilly has 2031 cameras initially. We randomly sample 1000 cameras and then run our procedure. For Roman Forum and Piccadilly, the two view methods further deleted cameras from the robust rotation estimation process or parallel rigidity test. We rerun and report the trifocal tensor synchronization algorithm with the further downsampled data. We initialize the hard thresholding parameters for HOSVD-HT by first imputing the trifocal tensor with small random entries and then calculating the singular values for each of the flattenings. We take to be the tertile singular value for each mode- flattening. We then keep this parameter fixed for the synchronization process. Recall that the blocks in the block trifocal tensor correspond to elements in the essential matrix . We also include these essential matrix estimations in the block trifocal tensor. The Photo Tourism experiments were run on an HPC center with 32 cores, but the only procedure that can benefit from parallel computing in a single experiment is the scale retrieval. Mean and median translation errors are summarized in Figure 2. Fully comprehensive results can be found in Tables 3 and 4 in Section A.6.
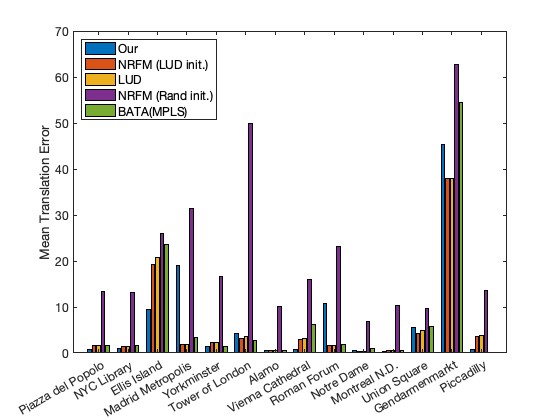
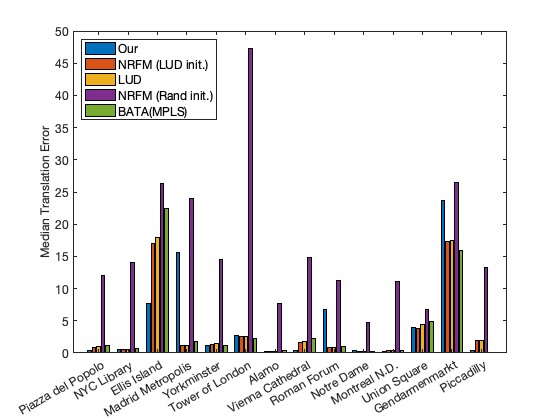
Our method is able to achieve competitive translation errors on 8 of the 14 datasets tested. Similar to the observation in the EPFL experiments, our algorithm performs well when the viewing graph is dense, or in other words, when the estimation percentage is high. We achieve better locations in 6 out of 8 datasets where the estimation percentage exceeds 60%, and better locations in only 2 out of 6 datasets where the estimation percentage falls below 60%. We achieve reasonable rotation estimations for 10 out of 14 datasets, but not as good as LUD. See Table 4 for a comprehensive result. Since the block trifocal tensor scales cubically with respect to the number of cameras, our algorithm runtime is longer than most two view global methods. This could be alleviated by synchronizing dense subsets in parallel and merging the results to construct a larger reconstruction.
Additional remark: Trifocal tensors can be estimated from line correspondences or a mix of point and line correspondences, while fundamental matrices are estimated from only point correspondences. There are many situations where accurate point correspondences are in short supply but there is a plethora of clear and distinct lines. For example, see datasets in a recent SfM method using lines [50]. We demonstrate the potential of our method to be adapted to process datasets with only lines or very few points. Due to the limited availability of well annotated line datasets, we provide a small synthetic experiment that simulates a case where only lines correspondences are present. We first generate 20 random camera matrices, then we generate 25 lines that are projected on and shared across all images. We add about 0.02 percent of noise in terms of the relative frobenius norms between the line equation parameters and the noise. We estimate the trifocal tensor of three different views from line correspondences linearly. One remark is that our synchronization method works well only when the signs of the initial unknown scales are mostly uniform. We manually use ground truth trifocal tensors to correct the sign of the scale. This has not been an issue in the previous experiments due to bundle adjustment for EPFL and the overall good estimations in Photo Tourism. In practice, the sign of the scale on a trifocal tensor can be corrected via triangulation of points or reconstruction of lines, and correcting the sign using the depths of the reconstructed points or intersecting line segments. We synchronize the trifocal tensors with Algorithm 2 and were able to achieve a mean rotation error of 0.61 degrees, median rotation error of 0.49 degrees, mean location error of 0.76, and median location error of 0.74.
5 Conclusion
In this work, we introduced the block tensor of trifocal tensors characterizing the three-view geometry of a scene. We established an explicit Tucker factorization of the block trifocal tensor and proved it has a low multilinear rank of under appropriate scaling. We developed a synchronization algorithm based on tensor decomposition that retrieves an appropriate set of scales, and synchronizes rotations and translations simultaneously. On several real data benchmarks we demonstrated state-of-the-art performance in terms of camera location estimation, and saw particular advantages on smaller and denser sets of images. Overall, this work suggests that higher-order interactions in synchronization problems have the potential to improve performance over pairwise-based methods.
There are several limitations to our tensor-based synchronization method. First, our rotation estimations are not as strong as our location estimations. Second, our algorithm performance is affected by the estimation percentage of trifocal tensors within the block trifocal tensor. One could incorporate more robust completion methods and explore new approaches for processing sparse triplet graphs. Further, our block trifocal tensor scales cubically in terms of the number of cameras and becomes computationally expensive for large datasets. We can develop methods for extracting dense subgraphs, synchronizing in parallel, then merging results to obtain a larger reconstruction, similarly to the distributed algorithms of [51] and [52]. Moreover, our synchronization method’s success depends on accurate trifocal tensor estimations, and it motivates further work on robust estimation of multi-view tensors. Algorithm 2 could also be made more robust by adding outlier rejection techniques. Finally we plan to extend our theory by proving convergence of our algorithm and exploring structures for even higher-order tensors, such as quadrifocal tensors.
Acknowledgement
D.M. and G.L. were supported in part by NSF award DMS 2152766. J.K. was supported in part by NSF awards DMS 2309782 and CISE-IIS 2312746, the DOE award SC0025312, and start-up grants from the College of Natural Science and Oden Institute at the University of Texas at Austin.
We thank Shaohan Li and Feng Yu for helpful discussions on processing EPFL and Photo Tourism. We also thank Hongyi Fan for helpful advice and references on estimating trifocal tensors.
References
- [1] Richard Hartley and Andrew Zisserman. Multiple View Geometry in Computer Vision. Cambridge University Press, 2003.
- [2] Noah Snavely, Steven Seitz, and Richard Szeliski. Photo Tourism: Exploring photo collections in 3D. In Proceedings of the ACM Special Interest Group on Computer Graphics and Interactive Techniques Conference, SIGGRAPH 2006, pages 835–846, 2006.
- [3] Johannes Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, pages 4104–4113, 2016.
- [4] Bill Triggs, Philip McLauchlan, Richard Hartley, and Andrew Fitzgibbon. Bundle adjustment — A modern synthesis. In Bill Triggs, Andrew Zisserman, and Richard Szeliski, editors, Vision Algorithms: Theory and Practice, pages 298–372, Berlin, Heidelberg, 2000. Springer Berlin Heidelberg.
- [5] Venu Madhav Govindu. Lie-algebraic averaging for globally consistent motion estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2004, volume 1, pages 1–8, 2004.
- [6] Richard Hartley, Jochen Trumpf, Yuchao Dai, and Hongdong Li. Rotation averaging. International Journal of Computer Vision, 103:267–305, 2013.
- [7] Avishek Chatterjee and Venu Madhav Govindu. Robust relative rotation averaging. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4):958–972, 2018.
- [8] Avishek Chatterjee and Venu Madhav Govindu. Efficient and robust large-scale rotation averaging. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2013, pages 521–528, 2013.
- [9] Yunpeng Shi and Gilad Lerman. Message passing least squares framework and its application to rotation synchronization. In Proceedings of the International Conference on Machine Learning, ICML 2020, pages 8796–8806, 2020.
- [10] Mica Arie-Nachimson, Shahar Kovalsky, Ira Kemelmacher-Shlizerman, Amit Singer, and Ronen Basri. Global motion estimation from point matches. In Proceedings of the International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, 3DIMPVT 2012, pages 81–88, 2012.
- [11] Kyle Wilson and Noah Snavely. Robust global translations with 1DSfM. In Proceedings of the European Conference on Computer Vision, EECV 2014, pages 61–75, 2014.
- [12] Onur Ozyesil and Amit Singer. Robust camera location estimation by convex programming. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, pages 2674–2683, 2015.
- [13] Thomas Goldstein, Paul Hand, Choongbum Lee, Vladislav Voroninski, and Stefano Soatto. ShapeFit and ShapeKick for robust, scalable structure from motion. In Proceedings of the European Conference on Computer Vision, EECV 2016, pages 289–304, 2016.
- [14] David Rosen, Luca Carlone, Afonso Bandeira, and John Leonard. SE-Sync: A certifiably correct algorithm for synchronization over the special Euclidean group. International Journal of Robotics Research, 38(2-3):95–125, 2019.
- [15] Federica Arrigoni, Beatrice Rossi, and Andrea Fusiello. Spectral synchronization of multiple views in SE(3). SIAM Journal on Imaging Sciences, 9(4):1963–1990, 2016.
- [16] Mihai Cucuringu, Yaron Lipman, and Amit Singer. Sensor network localization by eigenvector synchronization over the Euclidean group. ACM Transactions on Sensor Networks, 8(3), 2012.
- [17] Jesus Briales and Javier Gonzalez-Jimenez. Cartan-Sync: Fast and global SE(d)-synchronization. IEEE Robotics and Automation Letters, 2(4):2127–2134, 2017.
- [18] Soumyadip Sengupta, Tal Amir, Meirav Galun, Tom Goldstein, David Jacobs, Amit Singer, and Ronen Basri. A new rank constraint on multi-view fundamental matrices, and its application to camera location recovery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, pages 4798–4806, 2017.
- [19] Yoni Kasten, Amnon Geifman, Meirav Galun, and Ronen Basri. Algebraic characterization of essential matrices and their averaging in multiview settings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, pages 5895–5903, 2019.
- [20] Yoni Kasten, Amnon Geifman, Meirav Galun, and Ronen Basri. GPSfM: Global projective SFM using algebraic constraints on multi-view fundamental matrices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, pages 3264–3272, 2019.
- [21] Spyridon Leonardos, Roberto Tron, and Kostas Daniilidis. A metric parametrization for trifocal tensors with non-colinear pinholes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, pages 259–267, 2015.
- [22] Viktor Larsson, Nicolas Zobernig, Kasim Taskin, and Marc Pollefeys. Calibration-free structure-from-motion with calibrated radial trifocal tensors. In Proceedings of the European Conference on Computer Vision, EECV 2020, pages 382–399, 2020.
- [23] Pierre Moulon, Pascal Monasse, and Renaud Marlet. Global fusion of relative motions for robust, accurate and scalable structure-from-motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2013, pages 3248–3255, 2013.
- [24] Onur Ozyesil, Vladislav Voroninski, Ronen Basri, and Amit Singer. A survey of structure from motion. Acta Numerica, 26:305–364, 2017.
- [25] Joe Kileel. Minimal problems for the calibrated trifocal variety. SIAM Journal on Applied Algebra and Geometry, 1(1):575–598, 2017.
- [26] Timothy Duff, Kathlen Kohn, Anton Leykin, and Tomas Pajdla. PLMP-point-line minimal problems in complete multi-view visibility. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, pages 1675–1684, 2019.
- [27] Ricardo Fabbri, Timothy Duff, Hongyi Fan, Margaret Regan, David da Costa de Pinho, Elias Tsigaridas, Charles Wampler, Jonathan Hauenstein, Peter Giblin, Benjamin Kimia, Anton Leykin, and Tomas Pajdla. Trifocal relative pose from lines at points. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):7870–7884, 2023.
- [28] David Nister and Henrik Stewenius. A minimal solution to the generalised 3-point pose problem. Journal of Mathematical Imaging and Vision, 27(1):67–79, 2007.
- [29] Ali Elqursh and Ahmed Elgammal. Line-based relative pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011, pages 3049–3056, 2011.
- [30] Yubin Kuang and Kalle Astrom. Pose estimation with unknown focal length using points, directions and lines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2013, pages 529–536, 2013.
- [31] Zuzana Kukelova, Joe Kileel, Bernd Sturmfels, and Tomas Pajdla. A clever elimination strategy for efficient minimal solvers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, pages 4912–4921, 2017.
- [32] Pedro Miraldo, Tiago Dias, and Srikumar Ramalingam. A minimal closed-form solution for multi-perspective pose estimation using points and lines. In Proceedings of the European Conference on Computer Vision, ECCV 2018, pages 474–490, 2018.
- [33] Joe Kileel, Zuzana Kukelova, Tomas Pajdla, and Bernd Sturmfels. Distortion varieties. Foundations of Computational Mathematics, 18:1043–1071, 2018.
- [34] Joe Kileel and Kathlén Kohn. Snapshot of algebraic vision. arXiv preprint arXiv:2210.11443, 2022.
- [35] Tamara Kolda and Brett Bader. Tensor decompositions and applications. SIAM Review, 51(3):455–500, 2009.
- [36] Tommi Muller, Adriana Duncan, Eric Verbeke, and Joe Kileel. Algebraic constraints and algorithms for common lines in cryo-EM. Biological Imaging, pages 1–30, Published online 2024.
- [37] Hongyi Fan, Joe Kileel, and Benjamin Kimia. On the instability of relative pose estimation and RANSAC’s role. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2022, pages 8935–8943, 2022.
- [38] Rahul Mazumder, Trevor Hastie, and Robert Tibshirani. Spectral regularization algorithms for learning large incomplete matrices. Journal of Machine Learning Research, 11:2287–2322, 2010.
- [39] Nathan Halko, Per-Gunnar Martinsson, and Joel Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM Review, 53(2):217–288, 2011.
- [40] David Tyler. A distribution-free M-estimator of multivariate scatter. Annals of Statistics, pages 234–251, 1987.
- [41] Feng Yu, Teng Zhang, and Gilad Lerman. A subspace-constrained Tyler’s estimator and its applications to structure from motion. arXiv preprint arXiv:2404.11590, 2024.
- [42] Christoph Strecha, Wolfgang Von Hansen, Luc Van Gool, Pascal Fua, and Ulrich Thoennessen. On benchmarking camera calibration and multi-view stereo for high resolution imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, pages 1–8, 2008.
- [43] Bingbing Zhuang, Loong-Fah Cheong, and Gim Hee Lee. Baseline desensitizing in translation averaging. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018), June 2018.
- [44] Laura Julia and Pascal Monasse. A critical review of the trifocal tensor estimation. In Proceedings of the Pacific Rim Symposium on Image and Video Technology, PSIVT 2017, Revised Selected Papers 8, pages 337–349. Springer, 2018.
- [45] Rémi Pautrat, Iago Suárez, Yifan Yu, Marc Pollefeys, and Viktor Larsson. Gluestick: Robust image matching by sticking points and lines together. In Proceedings of the IEEE/CVF International Conference on Computer Vision, CVPR 2023, pages 9706–9716, 2023.
- [46] Yunpeng Shi, Shaohan Li, Tyler Maunu, and Gilad Lerman. Scalable cluster-consistency statistics for robust multi-object matching. In Proceedings of the International Conference on 3D Vision, 3DV 2021, pages 352–360, 2021.
- [47] Yunpeng Shi, Shaohan Li, and Gilad Lerman. Robust multi-object matching via iterative reweighting of the graph connection laplacian. Advances in Neural Information Processing Systems, 33:15243–15253, 2020.
- [48] Shaohan Li, Yunpeng Shi, and Gilad Lerman. Fast, accurate and memory-efficient partial permutation synchronization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2022, pages 15735–15743, 2022.
- [49] Daniel Barath and Jiří Matas. Graph-cut ransac. In Proceedings of the IEEE conference on computer vision and pattern recognition, CVPR 2018, pages 6733–6741, 2018.
- [50] Shaohui Liu, Yifan Yu, Rémi Pautrat, Marc Pollefeys, and Viktor Larsson. 3d line mapping revisited. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, pages 21445–21455, 2023.
- [51] Shaohan Li, Yunpeng Shi, and Gilad Lerman. Efficient detection of long consistent cycles and its application to distributed synchronization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, pages 5260–5269, 2024.
- [52] Andrea Porfiri Dal Cin, Luca Magri, Federica Arrigoni, Andrea Fusiello, and Giacomo Boracchi. Synchronization of group-labelled multi-graphs. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, pages 6433–6443. IEEE, 2021.
- [53] Joe Harris. Algebraic Geometry: A First Course, volume 133. Springer Science & Business Media, 1992.
- [54] Ying Sun, Prabhu Babu, and Daniel Palomar. Regularized Tyler’s scatter estimator: Existence, uniqueness, and algorithms. IEEE Transactions on Signal Processing, 62(19):5143–5156, 2014.
Appendix A Appendix / supplemental material
A.1 Derivation of the trifocal tensor
To provide a better intuition for the trifocal tensor, we briefly summarize the derivation of the trifocal tensor from [1] and [21] under the general setup of uncalibrated cameras.
Let be the form of the camera matrix for . Let be a line in the 3D world scene, and the corresponding projections in the images respectively. Each back projects to a plane in , and since correspond to the same in the 3D world scene, must be rank deficient and its kernel will generically be spanned by . Then,
will also be rank-deficient, implying that the columns of are linearly dependent. This means that there exist such that . We can choose , , so that
Then, the canonical trifocal tensor centered at camera 1 is defined as
| (8) |
where is the -th standard basis vector. The trifocal tensor will be the tensor , where the ’s are stacked along the first mode. The line incidence relation is then . Other combinations of point and line incidence relations are also encoded by the trifocal tensor; see [1] for details. The construction for calibrated cameras is the same, just with in calibrated form.
A.2 Proof details for Theorem 1
We include a detailed calculation for the Tucker factorization of the block trifocal tensor. Recall that each individual trifocal tensor corresponding to the cameras can be calculated as
The last equality can be easily checked since is sparse. For example, when , is the determinant of the submatrix dropping the -th row and keeping columns 1 and 2, which is . The only nonzero elements in the first horizontal slice are and . Then, the nonzero elements in the sum when will be exactly .
Then, since will be the stackings of , is the stacking of camera matrices in Theorem 1, each block in will be calculated by exactly the corresponding , , blocks in respectively using the calculations above.
A.3 Proof details for 1
Proof for (i).
We have
since is a matrix and the submatrix above will always have two identical rows.
Proof for (ii): Consider the element of the block trifocal tensor, . It can be written as
Thus, when , clearly as we will have identical rows again. When , we first observe that since we just swap two rows. Second,
where . This is exactly the bilinear relationship in [1] defining the fundamental matrix element up to a possible negative sign.
Proof for (iii): We can only show this for blocks from symmetry. The elements in blocks can be calculated as
Elements are nonzero only when , and they correspond to determinants of matrices with three rows from one and one row from . By [1], these are exactly the elements of the epipoles. When , the order of the rows in the determinant corresponding to camera is , when , the order is and there is a negative sign in front of the determinant, and when , the order is . Since the first and last case are even permutations of the rows of , and the second case is corrected by a negative sign, is exactly the epipole.
Proof for (iv): On a horizontal slice, the camera along the 1st mode is fixed, and blocks symmetric across the diagonal is calculated by cameras, which the 2nd and 3rd mode cameras are swapped. Then, we will simply be swapping rows in (1), which means that we will simply be changing signs for elements symmetric across the diagonal, implying skew symmetry.
Proof for (v): Now assume that we have a block trifocal tensor whose corresponding cameras are all calibrated. Let be the line projection matrix, is the stacked camera matrix, and is the core tensor. The flattening in the 1st mode can be written as , where is a matrix. For the proof, we calculate the eigenvalue of
The second and third line uses two Kronecker product properties: and as long as and are defined.
We first calculate .
We assume that the cameras are centered at the origin, i.e. . Then we have
| (9) |
so that
| (10) |
We have an explicit form for :
| (11) |
Let and let denote the entry in . Let .
We first show that is diagonal by direct computation:
We then calculate the spectral decomposition of . With a slight abuse of notation, let denote the -th column of . The rank- stacked line projection matrix would have columns ordered according to
and since the second row in for each camera is it holds
Or equivalently, the stacked wedge products between columns. Let be the thin singular value decomposition of , so that is a orthonormal matrix, is a diagonal matrix where all diagonal entries are nonzero, and is a orthonormal matrix.
Then,
Since is orthonormal, is still a diagonal matrix. We just need to establish the fact that three of the diagonal entries are the same.
For one camera, equals
where the matrix is symmetric and we reduce redundancy by omitting the entries below the diagonal. For cameras,
where means the dot product between the th and th column
The SVD of is , where is orthonormal matrix, is diagonal matrix. However, since we have an submatrix in , we deduce that n appears as an eigenvalue 3 times for , where we can use the determinant identity for block matrices. We check that this indeed holds by a computer calculation, generating random instances of ’s and calculating the eigenvalues for .
As a result, in the thin SVD of , we have where , . Then in
we see that is a diagonal matrix where three of the entries are the same. By the uniqueness of the eigenvalues, we see that we have a spectral decomposition of , so that three of the singular values of are equal. ∎
A.4 Proof details for Theorem 2
Proof.
Note blockwise multiplication by a rank- tensor with nonzero entries preserves multilinear rank, since it is a Tucker product by invertible diagonal matrices. Therefore, without loss of generality we may assume for all . Below we will prove it follows if exactly one of equals , and if none of equal and the indices are not all the same, for some constant . This will immediately imply the theorem, because taking and achieves whenever are not all the same.
We consider the matrix flattenings and in of the block trifocal tensor and its scaled counterpart, with rows corresponding to the second mode of the tensors. By Theorem 1 and assumptions, the flattenings have matrix rank , thus all of their minors vanish. The argument consists of considering several carefully chosen submatrices of to prove the existence of a constant as above. Index the rows and columns of the flattenings by and respectively, for and , so that e.g., .
Step 1: The first submatrix of we consider has column labels , , , , and row labels , , where . Explicitly, it is
which we abbreviate as
| (12) |
with asterisk denoting the corresponding entry in . As a function of , the determinant of (12) is a degree polynomial, which must be divisible by and (because if then clearly the bottom two rows of (12) are linearly independent, and if we have a submatrix of with the bottom two rows scaled uniformly). So the determinant of is a scalar multiple of . Note that the multiple is a polynomial function of the cameras and . We claim that generically the multiple is nonzero; and to see this, it suffices to exhibit a single instance of (calibrated) cameras where the determinant of (12) does not vanish identically for all due to the polynomiality (e.g., see [53]). We check that this indeed holds by a computer calculation, generating numerical instances of and randomly. Thus the vanishing of the minor in (12) implies , whence since . An analogous calculation with gives .
Step 2: Next consider the submatrix of with column labels , , , , and row labels , , , , , where are distinct. It looks like
| (13) |
with asterisks denoting entries of . Similarly to the previous case, the determinant of (13) must be a scalar multiple of where the scale depends polynomially on . By a computer computation, we find that the scale is nonzero for random instances of cameras (alternatively, note the polynomial system in step 1 is a special case of the present one). It the scale is generically nonzero, hence . An analogous calculation with gives .
Step 3: Consider the submatrix of with column labels , , , , and row labels , , , , , for distinct. It looks like
| (14) |
The determinant of (14) is a scalar multiple of . By a direct computer computation as before, it is a nonzero multiple generically (alternatively, note the polynomial system in step 1 is a special of the present one). We deduce . An analogous calculation with gives .
In particular, combining with step 2 it follows , because . From this, step 1 and step 2, we have that the -scale does not depend on the ordering of its indices, provided there is a among the indices.
Step 4: Consider the submatrix of with column labels , , , , and row labels , , , , , for distinct. It looks like
| (15) |
The determinant of (15) is a scalar multiple of . By a direct computer computation, it is a nonzero multiple generically (alternatively, note the polynomial system in step 1 is a special case of the present one). We deduce .
Putting together what we know so far, all -scales with a single -index agree. Indeed, this follows from so all -scales with a single -index and two repeated indices agree, combined with and the last sentence of step 3. Let denote this common scale.
Step 5: Consider the submatrix of with column labels , , , , and row labels , , , , , for distinct. It looks like
| (16) |
As a function of and , the determinant of (16) is a scalar multiple of (the second factor is present because it corresponds to scaling the bottom two rows and rightmost column of a submatrix of each by , which preserves rank deficiency). By a direct computer computation, we find that the scale is nonzero for a random instance of , therefore it is nonzero generically. It follows . An analogous calculation with gives .
Step 6: Consider the submatrix of with column labels , , , , and row labels , , , , , for distinct. It looks like
| (17) |
Similarly to the previous step, the determinant of (17) must be a scalar multiple of . By a direct computer computation, it is a nonzero multiple generically. We deduce .
Step 7: Consider the submatrix of with column labels , , , , and row labels , , , , , for distinct. It looks like
| (18) |
The determinant of (18) is a scalar multiple of . By a direct computer computation, it is a nonzero multiple generically (alternatively, note the polynomial system in step 5 is a special case of the present case). We deduce .
At this point, by steps 5,6,7 we have that all -scales with no -indices and not all indices the same must equal . Combined with the second paragraph of step 4, this shows satisfies the property announced at the start of the proof. Therefore the proof is complete. ∎
A.5 Implementation details
A.5.1 Estimating trifocal tensors from three fundamental matrices
Given three cameras and the corresponding fundamental matrices , we can calculate the trifocal tensor using the following procedure detailed in [1]. Specifically, from calculate an initial estimate of the cameras . Then, and should be skew-symmetric matrices. This gives 20 linear equations in terms of the entries in , which can be used to solve for the trifocal tensor. Note that there are no geometrical constraints when calculating , and there will be no guarantee of the quality of the estimation.
A.5.2 Higher-order regularized subspace-constrained Tyler’s estimator (HOrSTE) for EPFL
We describe the robust variant of SVD that we used for the EPFL experiments in Section 4. Numerically, it performs more stably and accurately than HOSVD-HT, yet it is an iterative procedure and each iteration requires an SVD of the flattening. This becomes computationally expensive when becomes large and the number of iterations are also large. However, since the number of cameras for the EPFL dataset are below 20 cameras, the computational overhead is not too great.
In HOSVD, a low dimensional subspace is estimated using the singular value decomposition and taking the leading left singular vectors for each mode- flattening. The Tyler’s M Estimator (TME) [40] is a robust covariance estimator of a dimensional dataset . It minimizes the objective function
| (19) |
such that is positive definite and has trace 1. The TME estimator can be applied to robustly find an dimensional subspace by taking the leading eigenvectors of the covariance matrix of TME. To compute the TME, [40] proposes an iterative algorithm, where
| (20) |
TME doesn’t exist when , but a regularized TME has been proposed by [54]. The iterations become
| (21) |
where is a regularization parameter, and is the identity matrix. TME does not assume the dimension of the subspace is predetermined. In the case when is prespecified, [41] improves the TME estimator by incorporating the information into the algorithm and develops the subspace-constrained Tyler’s Estimator (STE). For each iteration, STE equalizes the trailing eigenvalues of the estimated covariance matrix and uses a parameter to shrink the eigenvalues. The iterative procedure for STE is summarized into 3 steps:
-
1.
Calculate the unnormalized TME, .
-
2.
Perform the eigendecomposition of , and set the trailing eigenvalues as .
-
3.
Calculate , which is the normalized covariance matrix. Repeat steps 1-3 until convergence.
Similar to the regularized TME, STE can also be regularized to succeed in situations where there are fewer inliers, and can improve the robustness of the algorithm. The regularized STE differs from STE in only the first step, which is replaced by
-
1.*
Calculate the unnormalized regularized TME,
We apply the regularized STE to the HOSVD framework, and call the resulting projection the higher-order regularized STE (HOrSTE). It is performed via the following steps:
-
1.
For each , calculate the factor matrices as the leading left singular vectors from regularized STE applied to .
-
2.
Set the core tensor as .
A.6 Additional numerical results
In this section, we include comprehensive results for the rotation and translation errors for the EPFL and Photo Tourism experiments. Table 1 and 2 contains all results for EPFL datasets. Table 3 contains the location estimation errors for Photo Tourism. Table 4 contains the rotation estimation errors for Photo Tourism. In Table 4, we only report the rotation errors for LUD for all the methods that we compared against, as they are mostly the same since they used the same rotation averaging method.
| Our | LUD | NRFM(LUD) | NRFM | BATA(MPLS) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | ||||||||||
| FountainP11 | 0.008 | 0.007 | 0.91 | 0.54 | 0.75 | 0.46 | 3.37 | 3.03 | 1.12 | 1.01 |
| HerzP8 | 0.02 | 0.02 | 5.06 | 5.06 | 4.37 | 3.42 | 4.24 | 3.14 | 5.04 | 5.03 |
| HerzP25 | 4.70 | 4.68 | 7.75 | 8.00 | 6.20 | 5.82 | 8.85 | 8.38 | 7.77 | 8.41 |
| EntryP10 | 0.05 | 0.02 | 3.08 | 3.02 | 1.34 | 1.11 | 7.63 | 7.43 | 2.90 | 2.58 |
| CastleP19 | 9.64 | 5.80 | 4.58 | 4.04 | 3.37 | 3.02 | 15.81 | 15.43 | 5.77 | 5.62 |
| CastleP30 | 11.00 | 11.33 | 4.27 | 3.72 | 3.24 | 2.75 | 16.54 | 17.04 | 4.23 | 3.26 |
| Our | LUD | BATA(MPLS) | ||||
|---|---|---|---|---|---|---|
| Dataset | ||||||
| FountainP11 | 0.09 | 0.08 | 0.05 | 0.05 | 0.06 | 0.05 |
| HerzP8 | 0.12 | 0.12 | 0.33 | 0.34 | 0.44 | 0.39 |
| HerzP25 | 2.01 | 1.11 | 0.18 | 0.19 | 0.26 | 0.23 |
| EntryP10 | 0.15 | 0.11 | 0.25 | 0.25 | 0.27 | 0.25 |
| CastleP19 | 56.24 | 11.71 | 0.24 | 0.22 | 0.27 | 0.25 |
| CastleP30 | 38.84 | 4.58 | 0.13 | 0.13 | 0.19 | 0.15 |
| Dataset | Our Approach | NRFM(L) | LUD | NRFM(R) | BATA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset | n | Est. % | ||||||||||
| Piazza del Popolo | 185 | 72.3 | 0.78 | 0.45 | 1.63 | 0.85 | 1.66 | 0.86 | 13.45 | 12.06 | 1.63 | 1.10 |
| NYC Library | 127 | 64.7 | 1.01 | 0.53 | 1.39 | 0.48 | 1.49 | 0.57 | 13.06 | 14.03 | 1.59 | 0.68 |
| Ellis Island | 194 | 70.3 | 9.56 | 7.73 | 19.31 | 16.97 | 20.71 | 17.96 | 26.08 | 26.38 | 23.63 | 22.50 |
| Tower of London | 130 | 34.1 | 4.15 | 2.66 | 3.26 | 2.49 | 3.54 | 2.51 | 49.99 | 47.33 | 2.70 | 2.26 |
| Madrid Metropolis | 190 | 35.9 | 18.93 | 15.53 | 1.91 | 1.19 | 1.94 | 1.20 | 31.48 | 24.02 | 3.33 | 1.72 |
| Yorkminster | 196 | 37.2 | 1.46 | 1.14 | 2.31 | 1.39 | 2.35 | 1.45 | 16.67 | 14.46 | 1.37 | 1.15 |
| Alamo | 224 | 94.3 | 0.62 | 0.28 | 0.53 | 0.31 | 0.53 | 0.31 | 10.04 | 7.68 | 0.55 | 0.33 |
| Vienna Cathedral | 197 | 97.8 | 0.73 | 0.33 | 2.96 | 1.64 | 3.15 | 1.79 | 16.08 | 14.76 | 6.16 | 2.18 |
| Roman Forum(PR) | 111 | 51.1 | 10.71 | 6.75 | 1.59 | 0.89 | 1.63 | 0.93 | 23.23 | 11.20 | 1.85 | 1.04 |
| Notre Dame | 214 | 96.6 | 0.57 | 0.34 | 0.38 | 0.21 | 0.38 | 0.21 | 6.87 | 4.75 | 1.02 | 0.26 |
| Montreal N.D. | 162 | 97.0 | 0.38 | 0.24 | 0.56 | 0.37 | 0.57 | 0.38 | 10.33 | 11.15 | 0.58 | 0.41 |
| Union Square | 144 | 28.6 | 5.64 | 3.99 | 4.31 | 3.76 | 4.85 | 4.38 | 9.59 | 6.69 | 5.77 | 4.83 |
| Gendarmenmarkt | 112 | 89.7 | 45.34 | 23.63 | 37.93 | 17.35 | 37.92 | 17.41 | 62.69 | 26.42 | 54.38 | 15.91 |
| Piccadilly(PR) | 169 | 55.4 | 0.73 | 0.39 | 3.68 | 1.90 | 3.71 | 1.93 | 13.55 | 13.34 | - | - |
| Our Approach | LUD | MPLS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| dataset | N | n | Est. % | Our Runtime (s) | ||||||
| Piazza del Popolo | 307 | 185 | 72.3 | 1.26 | 0.61 | 0.72 | 0.43 | 0.69 | 0.41 | 13531 |
| NYC Library | 306 | 127 | 64.7 | 2.80 | 1.58 | 1.16 | 0.61 | 1.19 | 0.57 | 4465 |
| Ellis Island | 223 | 194 | 70.3 | 4.61 | 1.11 | 1.16 | 0.50 | 0.99 | 0.49 | 13816 |
| Tower of London | 440 | 130 | 34.1 | 2.28 | 1.31 | 1.63 | 1.28 | 1.66 | 1.37 | 4242 |
| Madrid Metropolis | 315 | 190 | 35.9 | 28.85 | 4.60 | 1.27 | 0.61 | 1.54 | 1.15 | 11764 |
| Yorkminster | 410 | 196 | 37.2 | 2.33 | 1.97 | 1.34 | 1.09 | 1.89 | 1.04 | 13115 |
| Alamo | 564 | 224 | 94.3 | 1.10 | 0.76 | 1.07 | 0.68 | 1.09 | 0.68 | 17513 |
| Vienna Cathedral | 770 | 197 | 97.8 | 0.74 | 0.46 | 0.40 | 0.28 | 0.39 | 0.28 | 12499 |
| Roman Forum(PR) | 989 | 111 | 51.1 | 11.86 | 3.39 | 0.40 | 0.28 | 1.07 | 0.65 | 2162 |
| Notre Dame | 547 | 214 | 96.6 | 0.78 | 0.50 | 0.67 | 0.43 | 0.68 | 0.43 | 17430 |
| Montreal N.D. | 442 | 162 | 97.0 | 0.50 | 0.35 | 0.49 | 0.32 | 0.49 | 0.31 | 7241 |
| Union Square | 680 | 144 | 28.6 | 20.70 | 5.29 | 1.82 | 1.34 | 2.00 | 1.56 | 4355 |
| Gendarmenmarkt | 655 | 112 | 89.7 | 22.95 | 15.24 | 18.42 | 10.25 | 17.42 | 8.41 | 2432 |
| Piccadilly(PR) | 1000 | 169 | 55.4 | 2.01 | 0.96 | 6.12 | 2.95 | - | - | 11230 |