Testing for Restricted Stochastic Dominance under Survey Nonresponse with Panel Data: Theory and an Evaluation of Poverty in Australia
Abstract
This paper lays the groundwork for a unifying approach to stochastic dominance testing under survey nonresponse that integrates the partial identification approach to incomplete data and design-based inference for complex survey data. We propose a novel inference procedure for restricted th-order stochastic dominance, tailored to accommodate a broad spectrum of nonresponse assumptions. The method uses pseudo-empirical likelihood to formulate the test statistic and compares it to a critical value from the chi-squared distribution with one degree of freedom. We detail the procedure’s asymptotic properties under both null and alternative hypotheses, establishing its uniform validity under the null and consistency against various alternatives. Using the Household, Income and Labour Dynamics in Australia survey, we demonstrate the procedure’s utility in a sensitivity analysis of temporal poverty comparisons among Australian households.
JEL Classification: C12;C14
Keywords: Empirical Likelihood; Panel Data; Stochastic Dominance; Nonresponse.
1 Introduction
This paper connects three bodies of literature:stochastic dominance testing, partial identification for incomplete data, and design-based inference for complex survey data (e.g. involving stages, clustering, and stratification). Although there is extensive literature on stochastic dominance testing (e.g., McFadden, 1989; Abadie, 2002; Barrett and Donald, 2003; Linton et al., 2005, 2010; Davidson and Duclos, 2013; Donald and Hsu, 2016; Lok and Tabri, 2021, among others), most methods fall short in practical applications because they assume complete datasets and rely on either random sampling or time series data processes. In empirical applications, data often come from complex socioeconomic surveys like the Current Population Survey, the Household, Income and Labour Dynamics in Australia (HILDA) Survey, and the Survey of Labour Income Dynamics, where nonresponse is common and data are not simple random samples. While the partial identification literature offers bounding approaches to address missing data issues (e.g., Blundell et al., 2007; Kline and Santos, 2013; Manski, 2016, among others), these often overlook the intricate designs of surveys, potentially leading to incorrect standard error estimations and subsequent distortions in tests’ size and power.
Conversely, the design-based inference literature accommodates survey design complexities but generally depends on designers’ handling of nonresponse who either posit point-identifying assumptions on nonresponse or specify a model of nonrandom missing data with reweighting/imputation (e.g., Berger, 2020; Şeker and Jenkins, 2015; Chen and Duclos, 2011; Qin et al., 2009, among others). Such assumptions may not hold when nonrespondents possess key characteristics influencing survey outcomes, such as income in socioeconomic surveys where the rich are often underrepresented (Bourguignon, 2018), rendering these inferences potentially misleading and not credible. It is also noteworthy that econometricians have considered design-based perspectives to inference in other contexts. See, for example, Bhattacharya (2005), who developed tests for Lorenz dominance, and Abadie et al. (2020), who focus on causal estimands in a regression framework. At the intersection of the three literatures is the testing procedure of Fakih et al. (2022). It is, however, limited in scope because it applies only to ordinal data generated from independent cross-sections and uses the worst-case bounds to account for nonresponse.
This paper bridges those bodies of literature. It provides the first asymptotic framework and inference procedure that integrates design-based inference with partial identification for handling incomplete data in econometrics, specifically for restricted stochastic dominance. Our approach effectively handles the survey’s complex design and the missing outcome data due to nonresponse. Importantly, it accommodates a broad spectrum of assumptions on nonresponse, enabling researchers to transparently perform sensitivity analyses of test conclusions by clearly linking them to various nonresponse scenarios.
To illustrate our approach, consider a data example on analyzing equivalized household net income (EHNI) data from the HILDA survey for 2001 (wave 1) and 2002 (wave 2). The objective is to detect a decline in poverty using the headcount ratio across a given range of poverty lines, , by seeking evidence for restricted stochastic dominance: for all in this interval, where represents the cumulative distribution function (CDF) for EHNI in wave . Strong evidence for this decline is usually sought through a test of Not against and rejecting in favor of (Davidson and Duclos, 2013). A significant challenge with implementing this test in practice is that the achieved sample is incomplete:
where "*" indicates missing data, and are the EHNI and response indicators for wave respectively, expressed in 2001 Australian dollars. Nonrespondents in wave 1 are not followed up, equating nonresponse in wave 1 to unit nonresponse and in wave 2 to wave nonresponse. The unit nonresponse rate is approximately 33%, while for wave 2, it is about 8%; item nonresponse is disregarded for simplicity.
Consequently, without any assumptions on nonresponse the EHNI CDFs are only partially identified. The first panel in Figure 1 reports the survey-weighted estimates of the worst-case identified sets of these CDFs over a given range of poverty lines, assuming that the theoretically largest and lowest values of EHNI are 1000000 and -150000. Observe that while these sets are wide, they are maximally credible in that they reflect the inherent uncertainties that cannot be eliminated through less plausible assumptions. However, since one set is a proper subset of the other, they are uninformative for comparing and in terms of restricted stochastic dominance.
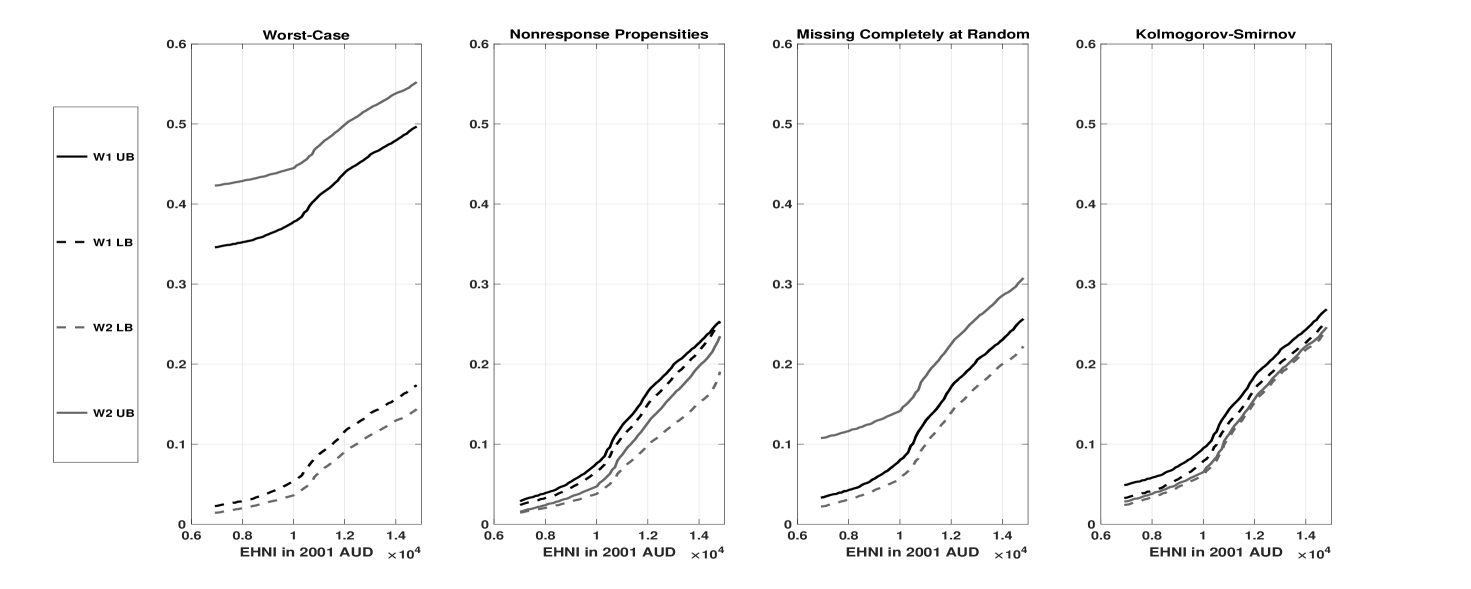
An alternative approach involves considering a range of assumptions on nonresponse, in the vast middle ground between the worst-case scenario (no assumptions) and the standard practice of assuming random nonresponse to point-identify and . This method allows consumers of economic research to draw their own conclusions based on their preferred assumptions. The subsequent panels in Figure 1 illustrate this by reporting estimates under various assumptions: U-shape bounds on nonresponse propensities conditional on EHNI (panel 2), the missing completely at random (MCAR) assumption for unit nonresponse combined with a worst-case scenario for wave nonresponse (panel 3), and a Kolmogorov-Smirnov neighborhood of the MCAR assumption for both nonresponse types (panel 4). While the sets in panel 3 are uninformative for comparing and using restricted stochastic dominance for the same reason as the worst-case scenario, panels 2 and 4 reveal that the upper boundaries of wave 2 identified sets are strictly below the lower boundaries of wave 1, presenting some evidence of a decline in poverty (i.e., ). Strong evidence for this decline under those nonresponse assumptions can be obtained by testing
| (1.1) |
and rejecting in favor of . Here, and represent the lower and upper boundaries of identified sets for and , respectively, under the maintained nonresponse assumptions. The point being that rejection of in favor of implies rejection of in favor of under the maintained nonresponse assumptions.
We propose a survey-weighted statistical testing procedure for test problems of the form (1.1). Our approach employs estimating functions with nuisance functionals (e.g., Godambe and Thompson, 2009, and Zhao et al., 2020) in a general framework that covers a broad spectrum of nonresponse assumptions through specifications of the nuisance functionals – see Section 2.2 for some examples. This approach is helpful for performing a sensitivity analysis of inferential conclusions of the test under different assumptions on nonresponse within our framework. We illustrate this point in Section 6 with an empirical example of poverty orderings (Foster and Shorrocks, 1988) using data from the HILDA Survey.
The testing procedure employs the pseudo-empirical likelihood method (Chen and Sitter, 1999; Wu and Rao, 2006) to formulate the test statistic, applicable across any predesignated order of stochastic dominance and range. It compares the statistic against a chi-squared distribution’s quantile with one degree of freedom. To derive the test’s asymptotic properties, we have developed a design-based framework for survey sampling from large finite populations. We establish the test’s asymptotic validity with uniformity, and its asymptotic power against both local and non-local alternatives, achieving consistency against distant alternatives. However, the test exhibits asymptotic bias against alternatives that rapidly converge to the null hypothesis boundary, which is not surprising, as the test is not asymptotically similar on the boundary.
In developing our testing method, we primarily addressed unit and wave nonresponse for simplicity, though the method can be adapted to include item nonresponse. We have also limited our analysis to temporal pairwise comparisons between wave one and any subsequent wave, which is particularly useful when assessing restricted stochastic dominance of an outcome variable from the survey’s start to a later period. Extending beyond these comparisons introduces significant methodological challenges due to the changing composition of the target population and the impact of nonresponse. Section 5.5 discusses these issues in depth and introduces a pseudo-empirical likelihood testing method based on the restricted tests (Aitchison, 1962) approach as well as technical details in the Appendix.
This paper is organised as follows. Section 2 introduces the testing problem of interest and presents examples of bounds on the dominance functions. Section 3 describes the pseudo-empirical likelihood ratio testing procedure and the decision rule. Section 4 introduces the large finite population asymptotic framework, and presents our results. Section 5 discusses the scope of our main results, their implications for empirical practice, and some directions of future research. Section 6 illustrates our testing procedure using HILDA survey data in testing for poverty orderings among Australian households, and Section 7 presents our conclusions.
2 Setup
Panel survey samples on the variable of interest are drawn from units in the first wave of a reference finite population who are also followed over time. The inference procedure of this paper uses data arising from panel surveys between wave 1 and a given subsequent wave. Borne in mind are two finite populations corresponding to the first wave and the subsequent wave of interest. Let denote a finite population characterized by the variables for each , where is the population total, is the outcome variable of interest, and 0/1 binary variable indicating the unit’s response to the survey in the reference population, for each . In the design-based approach (Neyman, 1934), the elements of are treated as constant for each . This approach is different from mainstream statistics and econometrics, and is the core of survey data estimation and inference.
Without loss of generality, let correspond to the reference population in wave 1 and its subsequent counterpart, so that period precedes period . In this setup,
| (2.1) |
where “” denotes the missing value code, with sampling unit from population (i.e., in wave 1) and followed through time to population (i.e., the subsequent wave). Unit nonresponse corresponds to the event in our setup since units that do not respond in wave 1 (i.e., population ) are not followed into later waves (i.e., population ). Wave nonresponse corresponds to the event , since the unit responds in wave 1 but not in the subsequent wave. The event does not occur in our setup since units that have not responded to the survey in the first wave are not followed in subsequent waves by design, so that , holds. We do not treat item nonresponse for simplicity and to avoid notational clutter. Its treatment is similar to that of the other kinds of nonresponse and requires the introduction of two more 0/1 binary variables to capture this behavior.
The objective of this paper is to compare the finite population distributions of the outcome variable arising from and using stochastic dominance under survey nonresponse. For each , the CDFs of under is defined as for each . Following Davidson (2008), for , , define the dominance functions by the recursion: and for . Tedious calculation of these integrals yields for and . We say that stochastically dominates at order , if . We have strict dominance when the inequality is strict over all points in the joint support . We make the following assumption on and .
Assumption 1.
is compact, for .
This assumption is natural in many applications, for example in the context of income and wealth distributions.
2.1 Hypotheses and Estimating Functions
The test problem of interest in practice is
| (2.2) |
where and the order are pre-designated by the researcher and depends on the context of the application; for example, in poverty analysis using the headcount ratio (i.e., ), this interval could be the set of feasible poverty lines. The null hypothesis states that does not stochastically dominate at the th order over the interval , and the alternative hypothesis is its negation; that is, strict restricted stochastic dominance of by at the th order.
The natural estimand in developing a statistical procedure for the test problem (2.2) is
| (2.3) |
Using the notion of estimating functions (Godambe and Thompson, 2009), we can define the contrasts (2.3) as the unique solution of census estimating equations, yielding their point-identification. However, nonresponse calls their point-identification into question. In an attempt to circumvent these identification challenges posed by missing data, survey designers have implemented assumptions that nonresponse is ignorable, such as MCAR and Missing at Random (MAR), which point-identify the dominance contrasts (2.3). While such assumptions enable the development of statistical procedures for tackling the testing problem (2.2), they are also typically implausible in practice as nonresponse is not necessarily ignorable.
It is productive to firstly consider the identification of the contrasts (2.3) under nonresponse. Given , by the Law of Total Probability, for each
| (2.4) |
with , and whose sums run through the elements of the two finite populations, and . Since , holds, it implies that , simplifying the representation of in (2.4) by dropping the conditional expectation . For population , this representation reveals that is not point-identified, since all terms in this representation are identifiable by the data, except for . The same outcome holds for population , but now the non-identifiable parts are
Consequently, the contrasts (2.3) are not point-identified unless one is willing to make strong assumptions on nonresponse in practice. The most appealing way to mitigate this identification problem created by nonrepsonse is for survey designers to improve the response rates of their surveys and to obtain validation data that delineates the nature of nonresponse. However, in the absence of this, the only way to conduct inference in the test problem (2.2) is by making assumptions that either directly or indirectly constrain the distribution of missing data. Of course, such assumptions are generally nonrefutable as the available data imply no constraints on the missing data. But this approach enables empirical researchers to draw their own conclusions using assumptions they deem credible enough to maintain.
Our approach is to develop a testing procedure based on bounds of the dominance contrasts that depend on observables and encode assumptions on nonresponse. Suppose that the sharp identified set of is given by and , where and are the respective lower and upper bounding functions of this set. Then the boundaries of these identified sets imply bounds on the contrasts:
| (2.5) |
The identified set (2.5) captures all the information on the contrasts under the maintained assumption on nonresponse. Now imposing sign restrictions on its bounds is advantageous as it leads to a method of inferring restricted stochastic dominance on the distributions in question. In particular, consider the testing problem:
| (2.6) |
Rejecting in favor of in (2.6) implies rejection of in favor of in (2.2) since
holds, .
Next, we present a general estimating function approach that targets the contrasts
. We also demonstrate this approach’s scope in applications with several important examples. For each , consider the estimating function , given by
| (2.7) | ||||
where is a vector of nuisance functionals. For a given vector , the estimand in this estimating function is the parameter . It solves the census estimating equations
| (2.8) |
and has the form
for each . This estimand targets under specifications of that encode the maintined nonresponse assumptions. The next section illustrates the scope of our approach using several examples.
2.2 Examples
To fix ideas, we introduce examples of sharp bounds that our general formulation covers. We defer a formal analysis to Section D in the Supplementary Material, where we also derive the identified sets of the dominance functions and under the informational assumptions of the examples.
The first example concerns the scenario where there is no information on the nonresponse-generating mechanism available to the practitioner. The worst-case bounds on the contrasts must be used in practice. These bounds summarize what the data, and only the data, say about the dominance contrast (2.3). While they may be wide in practice, it does not necessarily preclude their use for conducting distributional comparisons. Fakih et al. (2022) make this point but in the context of ordinal data and first-order stochastic dominance.
Example 1.
Worst-Case Bounds. Proposition D.1 reports the worst-case identified set of the dominance functions and describes their boundaries. The worst-case bounds on the dominance contrast can be derived using this result. In this scenario, the following specification of applies: for each ,
This specification defines , where for each ,
Under Assumption 1, these bounds are finite, as , holds.
The second example presents bounds that arise from imposing the MCAR assumption on unit nonresponders. While implausible for modeling this type of nonresponse in voluntary surveys, the dominant practice by survey-designers has been to use weights to implement this assumption.
Example 2.
MCAR for Unit Nonresponse. Assuming MCAR for unit nonresponse means
| (2.9) |
holds, for . Proposition D.2 reveals that this assumption point-identifies and only partially identifies , for each , since is not pinned down by the conditions (2.9). Thus, in conjunction with the WC lower bound for , the following specification of encodes conditions (2.9):
and . This specification defines , where for each ,
The third example presents bounds that arise from constraining the nonresponse propensities conditional on the outcome, based on ideas in Section 4.2 of Manski (2016). The interesting aspect of this example is that information in the form of shape constraints on for , and can be incorporated into our inference procedure.
Example 3.
Restrictions on Unit and Wave Nonresponse Propensities. This example constrains the distribution of missing data through bounds on the conditional probabilities and for . For each , suppose that
where , and and are CDFs that are predesignated by the practitioner and satisfy . Bounds on the probability similar to the above also hold, but with CDFs and . Furthermore, consider bounds on the probability : for each , , where and are CDFs that satisfy , and . In practice, shape constraints on the above conditional probabilities can be incorporated into our inference procedure by imposing them on the bounding functions.
Now consider the CDFs given by for each and for each . We define their dominance functions recursively: for , these functions are and for . Furthermore, we define the recursively defined functions on given by , for .
Proposition D.3 reports the identified sets of the dominance functions under these informational conditions. Using this result, the specification of , where for each , takes the form
Therefore, the following specification of encodes this assumption on unit and wave nonrepsonse: for each , , , and
The fourth example is a neighborhood-based approach to a sensitivity analysis of empirical conclusions to departures from the MCAR assumption for unit and wave nonresponse. It is based on Kline and Santos (2013), who put forward a construction using the maximal Kolmogorov-Smirnov distance between the distributions of missing and observed outcomes, which allows a determination of the critical level of selection for which hypotheses regarding the dominance contrast cannot be rejected.
Example 4.
The MCAR assumption for both unit and wave nonresponse is
| (2.10) | ||||
The approach of Kline and
Santos (2013) is to build neighborhoods for the non-identified CDFs,
and , according to the maximal Kolmogorov-Smirnov distance to quantify their divergence from the identified CDFs. Proposition D.4 reports the identified sets of the dominance functions under the conditions (D.7). For each , the boundary of the identified set depends on parameter . The parameters and represent the fraction in populations and , respectively, of unit nonresponders whose outcome variable is not well represented by the distribution and , respectively. Similarly, the parameter represent the fraction in population of wave nonresponders whose outcome variable is not well represented by the distribution .
Using this result, we obtain , where for each and
Therefore, the following specification of encodes this assumption on unit and wave nonrepsonse: for each
2.3 Sample Estimating Equations
In the above examples, the estimating function (2.7) depends only on observables and the nuisance parameter. For a maintained assumption on nonresponse, these examples show that there is a unique value of the nuisance parameter that encodes it into the contrasts . We denote this value of the nuisance parameter by . It can be consistently estimated using a plug-in procedure with the achieved sample and the inclusion probabilities for , where is defined in (2.1) for each , is a survey sample of units from population (i.e., wave 1). In practice the inclusion probabilities are reported as design weights, satisfying the normalization , where .
The estimator of solves the sample-analogue census estimating equations (2.8):
where is the plug-in estimator of . We can simplify this set of equations using the fact that the moment function equals zero for each , where is the subsample corresponding to the unit responders, and that
| (2.11) |
holds. As the ratio is positive, let be such that
| (2.12) |
Then, we simplify the sample-analogue of the census estimating equations as
for each ,
by substituting out using (2.11) and dividing out the common factor . The solution of the resulting equation is the sample-analogue estimator
| (2.13) |
where for each , is given by
| (2.14) | ||||
3 Testing Procedure
This section introduces the statistical procedure for implementing the hypothesis testing problem (2.6). The procedure is based on the empirical likelihood test of Davidson and Duclos (2013). The test focuses on the boundary of in (2.6). For a pair of CDFs and of the outcome variable of interest, the rejection probability will be highest on the subset of the boundary of the null hypothesis where we have exactly one such that . Therefore, we impose the restriction corresponding to the boundary of for a single . To maximize the pseudo-empirical likelihood function (PELF) under this restriction, for each , compute the maximum PELF whilst imposing , which is equivalent to . This corresponds to the maximization problem:
| (3.1) | ||||
where is a plug-in estimator of , and is the moment function (2.14). The moment condition in (3.1) imposes the restriction , by tilting the estimator through the probabilities on the subsample .
For a fixed denote by the maximized value of the constrained maximization problem (3.1). Additionally, let , which is the unconstrained maximum value of the PELF which corresponds to (3.1) omitting the constraint . Then the pseudo-empirical likelihood-ratio statistic for the test problem (2.6) is
| (3.2) |
where is an estimator of the design-effect
| (3.3) |
The variance calculation in the numerator of this expression is with respect to the randomness emanating from the survey’s design, so that coincides with in (3.3), except that we replace the design-variance with a consistent estimator of it. Such estimators are abundant and well-established, and which one to use in practice depends on how much information the practitioner has from the survey designers; e.g., joint selection probabilities enables the use of Taylor linearization, and the availability of replication design weights enables the use of the jackknife (see, for example, Chapter 4 of Fuller, 2009). For each , if the moment equality constraint in (3.1) holds in the population, so that then the denominator of , given by , is the Hájek estimator (Hájek, 1971) of the population variance
| (3.4) |
As the test statistic (3.2) is formulated piece-wise, we only implement the procedure if we observe for all , in the sample. For a fixed nominal level , the decision rule of the test is to
| (3.5) |
where is be the quantile of the chi-squared distribution with one degree of freedom. The next section presents the asymptotic framework for this testing procedure and establishes its asymptotic properties under the null and alternative hypotheses.
Remark 3.1.
The design-effect arises in the Taylor expansion of under the null and alternative hypotheses; see Lemmas C.2 and C.3 for results under the null, and see Lemmas C.5 and C.6 for results under the alternative. If we do not account for it as in (3.2), then the testing procedure would suffer from a size distortion under the null, since the distributional limit of the test statistic would be a scaled , with scale involving the design variance . Under the alternative, the test would suffer from distortion in type 2 error, and hence, distort its power. Thus, accounting for the survey’s design through the design-effect adjustment in , corrects these distortions.
4 Asymptotic Framework and Results
Given a sampling scheme for wave 1, denote by the set of all possible samples from the sampling frame according to the survey’s design. Given a sample , the survey follows those same sampled units through time to period to generate a panel survey between periods and , yielding the dataset: . For each , let . This set collects all possible finite populations . Then the set of all finite populations for both periods and of sizes and is given by:
Following Rubin-Bleuer and Kratina (2005), for a fixed finite population the probability sampling design associated with a sampling scheme on is the function:
| (4.1) |
such that,
-
(i)
is a sigma-algebra generated by ;
-
(ii)
; and
-
(iii)
.
The design probability space is with for all and . Under this setup the survey sample size, , is a random variable and all uncertainty is generated from the probability sampling scheme . We follow the notation in finite population literature to indicate that “" means the sample, , is drawn from the population . Therefore, for a fixed , and denote the expectation and variance taken over all possible samples from with respect to the probability space . The survey design-weights satisfy the normalization (2.11), where is the inclusion probability of element into the sample. The next sections employ this finite population framework to establish the asymptotic properties of the proposed testing procedure in (3.5), as and diverge.
4.1 Asymptotic Null Properties
Firstly, we define the set of finite populations that are compatible with the null hypothesis . For any this set is given by
where for each . Then, the true population, , satisfies if and only if . For any , the size of the test is given by: . For a fixed , is the probability of rejecting taken over all possible samples from under the probability sampling design (4.1). Therefore, the size of the test is the largest rejection probability over all finite populations in the model . To approximate the asymptotic size, we embed into a hypothetical sequence of models that satisfy enough restrictions so that for a given nominal level :
| (4.2) |
The approach to proving (4.2) uses a characterization of it in terms of sequences of finite populations, where for all and and the asymptotic distribution of is calculated along this hypothetical infinite sequence. Recall that means the statistic, is a function of the survey samples selected from population .
The bounds generated from nonresponse assumptions that we consider are sharp. Under Assumption 1, this sharpness implies holds, for each , where is the space of uniformly bounded measurable functions from into . The reason is that the worst-case bounds are finite everywhere on under this assumption (see Example 1), so that being unbounded on results in bounds that are not sharp. Let denote the vector space of 4-dimensional valued functions, with each component an element of . For , the norm of this space is .
Next, we describe the conditions on the surveys’ designs for obtaining (4.2). For a given sequence of finite populations the conditions we impose on the designs of the surveys are given by the following assumption.
Assumption 2.
Fix . For a sequence of finite populations we impose the following conditions on the survey’s design.
-
1.
.
-
2.
as .
-
3.
as .
-
4.
.
-
5.
as ,
where denotes weak convergence and is a zero mean Gaussian process. -
6.
satisfies
as . -
7.
The above conditions hold for all subsequences of .
These conditions are versions of commonly used large-sample properties in the survey sampling and partial identification inference literatures; see, for example, Zhao et al. (2020) and Andrews and Soares (2010). Condition 1 imposes the divergence of the mean subsample size of as the population totals diverge. Condition 2 imposes the design-consistency of in the norm . Condition 3 imposes design-consistency of , with uniformity over , which can be justified by the preceding condition and the Continuous Mapping Theorem, as the estimand is a linear function of the nuisance parameter. Condition 4 imposes positive design-variance for the statistic . Condition 5 requires that a design-based functional central limit theorem holds for the standardized version of . Condition 6 imposes design-consistency of the design-variance’s estimator, with uniformity over . Condition 7 is important for establishing (4.2) via Theorem 1 below.
The embedding sequence of null models for developing (4.2) is made precise in the following definition.
Definition 1.
Proof.
See Appendix B.1. ∎
An important distinction between our framework and the conventional approach in the literature on inference for finite populations is that, like Fakih et al. (2022), we develop the behavior of the test over a set of sequences of finite populations, whereas that literature’s focus has been on a single sequence of that sort (e.g., Wu and Rao, 2006, and Zhao et al., 2020). The result of Theorem 1 shows that this distinction is analogous to the difference between uniform and pointwise asymptotics in the partial identification literature.
The next result establishes the uniform asymptotic validity of the testing procedure, which is essential for reliable inference in large finite populations where the test statistic’s limiting distribution is discontinuous as a function of the underlying population sequence.
Proof.
See Appendix B.2. ∎
The key technical steps in the proof of Theorem 2 is to determine the asymptotic distribution of along sequences that drift to/on the boundary of the model of the null hypothesis where the rejection probability is highest. We show that the limiting distribution for those sequences is . Hence, the test achieves level- asymptotically. Consequently, a rejection of based on this test using a small significance level constitutes very strong evidence in favor of , and hence, is very strong evidence in favor of defined in (2.2), under the maintained nonresponse assumptions.
4.2 Asymptotic Power Properties
We now develop asymptotic properties of the testing procedure along sequences of finite populations under the alternative hypothesis . In a similar vein to the method used to prove the results for asymptotic size, let be the embedding sequence where
for each . In this formulation, the true population, , satisfies if and only if . Thus, corresponds to the model of the alternative hypothesis .
For any , test power is given by when . Along a sequence of finite populations under the alternative hypothesis, the asymptotic power is given by
| (4.4) |
As and is a fixed critical value the stochastic behavior the test statistic drives the asymptotic power of the testing procedure. We impose the following conditions on the sequences of finite populations under , which are useful for deriving the asymptotic behavior of the test statistic.
Assumption 3.
For a given sequence of finite populations , we impose the following conditions on the survey’s design:
-
1.
as .
-
2.
For each :
-
(i)
.
-
(ii)
.
-
(iii)
, where is given by (3.4).
-
(i)
The conditions of Assumption 3 are commonly imposed on the sampling design of surveys (e.g., see Assumption 3 of Wang, 2012). Condition 1 imposes a restriction on the design so that the average sample size and the sample size of have a similar growth rate with increasing population sizes. On Condition 2, Part (i) imposes diminishing design-variance to zero as the population sizes diverge, Part (ii) pins the rate of decrease of the design-variance in (i) with respect to the average sample size of . and Part (iii) imposes finite limiting population variance.
Next we describe the embedding of the sequences of finite populations under the alternative hypothesis with respect to which we compute limiting power (4.4).
Definition 2.
The index set of binding inequalities enters the calculation of the limit (4.4) for the sequences of finite populations in this setup. The following function plays a central role in characterizing the impact of this set on limiting power: for a given sequence of finite populations , define the function
| (4.5) |
We have the following result.
Theorem 3.
Proof.
See Appendix B.3. ∎
5 Discussion
This section presents a discussion of the scope of our main results and implications for empirical practice. Section 5.1 discusses the interpretation of . Section 5.2 compares the method of this paper with that of Fakih et al. (2022), and Section 5.3 compares and contrasts our method to other tests in the moment inequalities inference literature. Section 5.4 describes the adjustments of our method for inferring that dominates . Finally, Section 5.5 puts forward an adjustment of calibration to enable pairwise comparisons with waves beyond the first one.
5.1 Interpreting
For a given order of stochastic dominance and range , this paper’s statistical procedure aims to infer for all using a paired sample from a panel survey with a maintained assumption on nonresponse. The inference relies on ranking the bounds of these dominance functions, where a rejection event implies throughout the interval (see testing problem (2.6)). Under the null hypothesis , an exists within where , a condition that allows elsewhere within the interval. This ambiguity makes uninformative due to the partial identification of . Failure to reject this hypothesis yields no definitive conclusions about the populations’ rankings under restricted th order stochastic dominance. In such a situation, we recommend empirical researchers perform a sensitivity analysis of this empirical conclusion (i.e., non-rejection of ) with respect to plausible assumptions on the nonresponse-generating process, using our testing procedure. Additionally, considering higher orders of dominance may be beneficial, especially in poverty and inequality analysis (e.g., Atkinson, 1970, 1987; Foster and Shorrocks, 1988; Deaton, 1997). Section 6 provides an empirical illustration using HILDA survey data.
5.2 Comparison to Fakih et al. (2022)
Fakih et al. (2022) developed a pseudo-empirical likelihood testing procedure for a test problem akin to (1.1), but for, first-order stochastic dominance, ordinal variables, worst-case bounds, and survey data from independent cross-sections. While their procedure is beneficial for such applications, it is narrow in scope. The worst-case bounds can be uninformative in practice, and they do not consider data arising from panel surveys to capture dynamics. Furthermore, the data are discrete and they focus on first-order dominance, which excludes important applications, such poverty and inequality analysis (e.g., Foster and Shorrocks, 1988; Deaton, 1997), collusion detection in industrial organization (Aryal and Gabrielli, 2013), and the ranking of strategies in management sciences (e.g., Harris and Mapp, 1986; Fong, 2010; Minviel and Benoit, 2022). See also Chapter 1 of Whang (2019) and the references therein for other applications of stochastic dominance.
Contrastingly, this paper’s setup is more complex than the setup of Fakih et al. (2022). Paired data from panel surveys possess more complex forms of nonresponse. Unit and item nonresponse can occur within period and wave nonresponse across periods, as well as attrition where sampled units who have previously responded permanently exit the survey. Furthermore, the testing procedure enables the incorporation of prior assumptions on nonresponse, allowing researchers to examine the informational content of their assumptions and their impacts on the inferences made. Another important difference is in the treatment of the design-effect in the statistical procedure. This paper’s procedure employs an estimator of the design-effect as it must be estimated in practice. By contrast, the procedure of Fakih et al. (2022) ignores design-effect estimation as it assumes that it is asymptotically equal to unity with uniformity — see Condition (v) of Assumption 1 in their paper. While they do explain how to adjust their procedure to include an estimator of the design-effect, they do not explicitly account for it in the statements of their results. Reliable estimation of the design-effect becomes more important when considering high order of stochastic dominance, since asymptotically the design-variance would be based on the behaviour of random functions with powers of , which could have a profound effect on the testing procedure.
5.3 Comparison to Other Tests
This paper contributes to the vast literature on inference for parameters defined by moment inequalities. While most testing procedures in this literature assume random sampling and test for the opposite of our hypotheses our focus is different. In the context of this paper, those procedures, such as that of Andrews and Shi (2017), apply to the test problems
but under the random sampling assumption. Unlike typical approaches that infer non-dominance from a null of dominance, we posit a null of non-dominance to infer strict dominance, addressing the methodological challenge where failure to reject the null does not necessarily confirm it, unless test power is high (Davidson and Duclos, 2013, p. 87). This choice reflects our testing objective, which is to infer strict dominance.
Few tests in the moment inequalities literature consider a null of non-dominance, with notable exceptions by Fakih et al. (2022), Davidson and Duclos (2013), and a test proposed by Kaur et al. (1994) based on the minimum -statistic for second-order stochastic dominance under complete data and random sampling. Davidson and Duclos (2013) also adapt it for first-order stochastic dominance. Our Supplementary Material’s Lemmas C.2 and C.3 demonstrate that under the null hypothesis , the statistic is asymptotically equivalent to the square of a -statistic. Additionally, Lemmas C.5 and C.6 confirm analogous results under local alternatives, establishing the asymptotic local equivalence of our pseudo-empirical likelihood test and the test using the minimum of the squared -statistics. Therefore, practitioners can also use the minimum -statistic instead of our pseudo-empirical likelihood ratio statistic (3.2) and obtain asymptotically valid tests by comparing it to a quantile from the distribution using the same decision rule (3.5).
Moreover, econometricians have also considered design-based approaches to inference for Lorenz dominance but for particular survey designs (e.g., Zheng, 2002; Bhattacharya, 2005, 2007). While Lorenz dominance tests are similar in spirit to various stochastic dominance tests in the literature, their treatment is different as their test statistics are more complicated functionals of the underlying distribution functions. Importantly, these testing procedures have demonstrated that complex sampling designs can greatly affect the estimates of standard errors required for inference. However, they are applicable to complete data, which is their main drawback, as nonresponse is inevitable in socioeconomic surveys.
5.4 Testing Dominates
In our framework, populations and represent wave 1 and a subsequent wave, respectively, and interest centers on establishing that dominates at a predesignated order and over a range . The practitioner may also be interested in establishing that dominates , which entails considering the testing problem
| (5.1) |
The framework of Section 2 covers this scenario through specifying appropriately to obtain the sharp upper bound on the contrast , so that estimation and testing can proceed as described above.
We repeat the same examples as in Section 2.2 but for the testing problem (5.1), and relegate those details to Appendix E.1 for brevity. The technical derivations of the bounds in each example follow steps similar to the ones in the examples of Section 2.2. The general idea with this set of examples is to carefully specify to obtain the desired form of .
5.5 Comparisons of Two Waves Beyond Wave 1
This section presents a discussion of how to carry out inference for stochastic dominance with two populations beyond the first wave within our framework. Firstly, it points to a limitation of a leading practice in the literature called calibration that has been used to address nonresponse. Second, it proposes a bounds approach to inference for stochastic dominance based on restricted tests (Aitchison, 1962). This approach combines the basic idea of calibration with the framework of the previous sections in the paper.
A longitudinal weight between these waves must be utilized instead of the design weights to compare populations of two subsequent waves beyond the first. The idea behind longitudinal weights is to reflect the finite population at the initial wave of the comparison by accounting for the dynamic nature of the panel, where the achieved sample in wave 1 evolves with time due to following rules and population changes. The process of calibration estimation obtains such weights. The seminal paper of Deville and Sarndal (1992) formalized the general concept and techniques of calibration estimation in the context of survey sampling with complete data to improve estimators’ efficiency and ensure coherency with population information. The idea of using extra information to enhance inference has a long tradition in statistics and econometrics; see, for example, Aitchison (1962); Imbens and Lancaster (1994); Parente and Smith (2017).
The calibration estimator uses calibrated weights, which are as close as possible, according to a given distance measure, to the original sampling design weights while also respecting a set of constraints, which represent known auxiliary population benchmarks/information, to ensure the resulting weighted estimates match (typically external) high-quality totals or means of the initial wave in the comparison.111See Wu and Lu (2016) for examples of distance measures used in calibration. This method is ideal for incorporating such information in the setup with complete responses and a representative sample of the target population.
Calibration is also widely applied under nonresponse, but with the achieved sample of responding units – a procedure that is known as weighting (see Chapter 5 of Sarndal and Lundstrom, 2005). Under nonresponse, weighting thus relies on the assumption that the supports of the outcome variable conditional on response and nonresponse coincide. While suitable for specific empirical applications, this assumption can be untenable in other applications. It is implausible when there are reasons to expect that the missing units tend to belong to a subpopulation of the target population. For example, a widely shared view of household surveys is that the missing incomes correspond to households at the top of the income distribution (e.g., Lustig, 2017; Bourguignon, 2018). The issue is that the achieved sample on the outcome variable (i.e., of responding units) in the first wave is biased because it represents a subpopulation of the target population. Following the units of this sample over time could perpetuate their selectivity bias in subsequent waves, where the known auxiliary population benchmarks/information in the subsequent waves may not be compatible with the subpopulation that the achieved sample represents. Consequently, calibrating design weights using the achieved (biased) sample can result in misleading inferences.
The challenge with calibration in our missing data setup is that the achieved sample is generally not representative of the target population. The achieved sample could represent a subpopulation of the target population, which may not satisfy the auxiliary information. If there are known auxiliary benchmarks/information on that subpopulation, then the design weights can be calibrated using this sample and auxiliary benchmarks/information. This calibration approach can be combined with our bounds approach of the previous sections to develop a statistical procedure for inference on stochastic dominance for the target populations under nonresponse. The known auxiliary benchmarks/information on the subpopulations may be derived from or implied by their counterparts on the target population in the form of subpopulation totals or means, for instance.
More concretely, now represents the population of the initial wave in the comparison and now represents the later wave. The subpopulation is the one the sample represents, where is the 0/1 binary variable indicating on response in the population corresponding to the first wave of the survey. Let where be the population value of the auxiliary variable for each , and is the subpopulation total. The information we have is the constraint , but because of nonresponse, the data on this auxiliary variable will have missing values, which would be the units . If there are known bounds on , i.e., for all in the subpopulation , then using the aforementioned bounds, the following inequality restrictions must hold
| (5.2) |
Employing the information (5.2) in testing entails the consideration of the restricted testing problem:
| (5.3) | ||||
where the bounds, and , account for nonresponse through the use of side information or a maintained assumption on nonresponse.
A testing procedure using the method of pseudo-empirical likelihood is feasible since it can implement the information (5.2) as additional constraints in formulating the pseudo-empirical likelihood-ratio statistic. These constraints are imposed under both the null and alternative hypotheses for internal consistency (Wu and Lu, 2016), so that the transformed design weights are compatible with subpopulation . We conjecture the asymptotic form of the test statistic is equivalent to generalized likelihood ratio statistic for a cone-based testing problem on a multivariate normal mean vector (e.g., Theorem 3.4 of Raubertas et al., 1986). There are challenges with implementing the testing procedure, as the subset of inequalities in (5.2) that are active/binding enters the design effect; see Appendix E.2 for the details. This set is unknown and difficult to estimate reliably, which can profoundly impact the overall reliability of the testing procedure. It renders the distribution as non-pivotal, which creates challenges for calculation of its quantiles. One possible avenue forward is to adapt the bootstrap procedure of Wang et al. (2022) to the setup of inequality restrictions in order circumvent this computational difficulty – we leave it for future research.
6 Empirical Application
The empirical analysis aims to investigate the temporal orderings of poverty among Australian households using data from the HILDA panel survey. This survey’s design, described in detail by Watson and Wooden (2002), is complex, involving multiple stages, clustering, stratification, and unequal probability sampling. The unit of observation is the household, which means that each household contributes one data point to the dataset. We use equivalized household net income (EHNI) based on the OECD’s equivalence scale as the measure of material resources available to a household .222This scale assigns a value of 1 to the first household member, of 0.7 to each additional adult and of 0.5 to each child. The equivalization adjustments of households’ net incomes are essential for meaningful comparisons between different types of households, as it accounts for variations in household size and composition and considering the economies of scale that arise from sharing dwellings.
The HILDA panel survey has been conducted annually since 2001 and provides reports that present selected empirical findings on Australian households and individuals across the survey waves. A recent issue, Wilkins et al. (2022), indicates an upward trend in the median and average EHNI. This suggests a steady decline in household poverty between 2001 and 2022, as shown in Figures 3.1 and 3.2 of their report. However, this empirical evidence is rather weak and potentially misleading as it does not consider (i) household poverty lines, which concerns the lower tails of the EHNI distributions, and (ii) a poverty index.
Our empirical analysis utilizes restricted stochastic dominance (RSD) orderings to effectively rank distributions of households’EHNI in terms of poverty. The concept of poverty orderings based on RSD conditions was introduced by Foster and Shorrocks (1988) to provide robust comparisons of poverty. This approach overcomes the challenge of defining a single poverty line to identify and categorize households as poor. Instead, it compares distributions across a range of poverty lines. In this context, the range of poverty lines corresponds to different levels of EHNI for various types of households. A household is considered to be in poverty if its EHNI falls below its corresponding poverty line. By employing RSD orderings and considering multiple poverty lines, our analysis offers a more comprehensive and nuanced understanding of poverty and avoids the limitations of relying on a single threshold to define poverty.
The robust comparison of households’ EHNI distributions using the HILDA survey data is complicated by the presence of nonresponse, because the distributions are only partially identified. In producing their annual reports, the survey designers have implemented the following assumptions on nonresponse. They address unit nonresponse through re-weighting responding households by distributing the weight of nonresponding households to other like responding households, assuming nonrespondents are the same as respondents. In other words, they implement the MCAR assumption for unit nonresponse – see Watson and Fry (2002) for more details. Furthermore, they address wave and item nonresponse through imputation.
The assumptions made by the survey designers on nonresponse, specifically unit and wave nonresponse, are implausible in practice. There is descriptive empirical evidence showing nonresponse rates tend to be highest at both ends of the income distribution. For example, logistic regression analyses demonstrate a U-shaped relationship between unit nonresponse and median weekly household incomes (see Table A3.1 in Watson and Fry, 2002) and wave nonresponse is also U-shaped with respect to individual EHNI (see Table 10.2 in Watson and Wooden, 2009). However, the imputation of missing household incomes in the case of item nonresponse is considered reliable due to the availability of comprehensive information on partially responding households’ characteristics and the income components of responding individuals. This additional information allows for reasonably accurate imputations – see Watson and Wooden (2004) for an example of their imputation method for missing income data in wave 2.
The empirical analysis focuses on the first four waves, and uses the forgoing evidence on nonresponse to establish bounds on dominance contrasts, which are then implemented in our statistical procedure. The rest of this section is organized as follows. Section 6.1 describes the dataset and Section 6.2 presents our results with a discussion.
6.1 Description of Dataset
We have focused on pairwise comparisons between the first wave and waves 2, 3, and 4. In the notation introduced earlier, represents the population of Australian households in 2001, which corresponds to wave 1. would then represent either of the population of Australian households in the years 2002, 2003, and 2004, corresponding to waves 2, 3, and 4, respectively.
In the first wave of the HILDA survey, there were 12252 addresses issued which resulted in 804 addresses being identified as out of scope (as they were vacant, non-residential, or all members of the household were not living in Australia for 6 months or more). In addition, there were 245 households added to the sample due to multiple households living at one address. This resulted in in-scope households of which 7682 responded. These responding households are followed through time.
Households can grow, split, and dissolve over time, which creates unbalanced panels. As the split households’s were followed, to form a balanced panel, we double counted the split households, but equally distributed their design weights. For example, between waves 1 and 2, 712 of (responding) households in wave 1 split. This approach yields a balanced panel with unit responding households a from a sample size of . Table 1 reports the values of and for all of the wave pairs based on this construction of the balanced panel. There are other balancing approaches and we do not take a stand on which one to favour; see, for example, the "fare shares approach" described in Taylor (2010) for a different re-balancing method.
Now we provide details on estimation of the fractions , , and . A standard approach uses the survey design weights in their estimation. However, the HILDA survey does not provide the subset of those weights corresponding to unit nonresponding households. This means the practitioner only has access to and not . Furthermore, the survey team has scaled the provided weights so that , where is the total number of Australian households in 2001. Despite this setup, we can still estimate , , and as follows. Estimate as , which is an unweighted estimator of on account of not having the complete set of weights. Since the provided weights satisfy , we re-scale them so that the resulting weights sum to . Then we estimate and as and , respectively. Table 1 reports the estimates of these fractions for all wave pairs.
| Population | Deflation Factor | ||||||
|---|---|---|---|---|---|---|---|
| Waves 1 and 2 | 12405 | 8395 | 0.3233 | 0.0855 | 0.5912 | 1.03 | |
| Waves 1 and 3 | 12876 | 8865 | 0.3115 | 0.1275 | 0.561 | 1.06 | |
| Waves 1 and 4 | 13255 | 9244 | 0.3026 | 0.1601 | 0.5373 | 1.08 |
The weights we use in the statistical procedure and in the derivation of our results are obtained by re-scaling so that they sum to . The range of poverty lines we consider are reported in Table 1, all denominated in 2001 AUD using the deflation factors obtained from the Reserve Bank of Australia’s inflation calculator.333The inflation calculator’s URL is https://www.rba.gov.au/calculator/. The poverty line ranges are based on the tables reported in Wilkins (2001, 2002, 2003, 2004) after equivalizing them according to the OECD equivalence scale.
We do not expect the EHNI population distribution to change rapidly across the first 4 waves. We encode this restriction by setting for . Furthermore, we have set , where the upper and lower bounds are larger and smaller, respectively, than the observed values, because of the high incidence of unit nonresponse. Of course, this assumption is irrefutable; however, it is credible since there is evidence from logistic regression analyses reported in Table A3.1 of Watson and Fry (2002) demonstrating a U-shaped relationship between unit nonresponse and median weekly household incomes of different neighborhoods. In consequence, the EHNI of unit nonresponders is likely to be in the tails of the EHNI population distribution. In practice, one can also study the sensitivity of outcomes based on it.
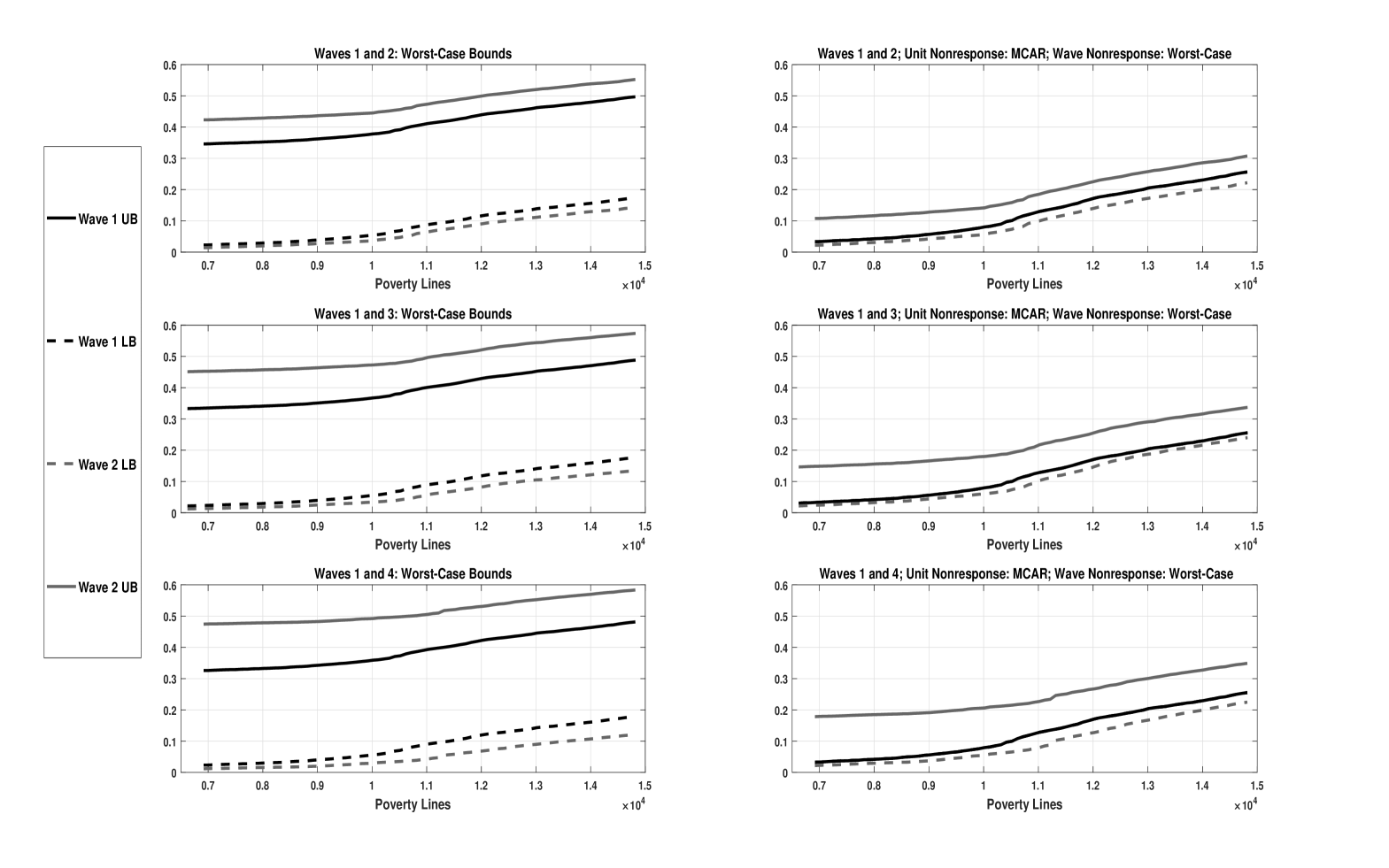
Figure 2 reports estimates of the bounds on the dominance functions and under two sets of assumptions on nonresponse for each pair of waves in our study. The left figure depicts their worst-case bounds. These bounds summarize what the data, and only the data, say about and . They are instructive since it establishes “a domain of consensus among researchers who may hold disparate beliefs about what assumptions are appropriate” (Horowitz and Manski, 2006). However, they are not informative in our setup because we find the identified set of is a proper subset of its counterpart for each pair of waves. The right panels of the figure depict the bounds under the MCAR assumption on unit nonresponse without any assumption on wave nonresponse. The HILDA survey implements this assumption on unit nonresponse in its data releases. It is a very strong assumption that point-identifies . Without any assumptions on wave nonresponse, is only partially identified. As with the worst-case bounds, these bounds are also not informative because the point estimate of is an element of ’s identified set, for each pair of waves.
6.2 Results
We would like to evaluate the dynamics of poverty between waves 1 and 2, waves 1 and 3, and waves 1 and 4, using the headcount ratio for each poverty line in their respective range . Therefore, the testing problem of interest is given by (5.1) with ; that is
| (6.1) |
This section reports the results of a sensitivity analysis of the event “Reject ” in the forgoing test problem for each pair of waves at the 5% significance level, using nonresponse assumptions based on Examples 3 and 4, which present alternative perspectives on how missing data differ from observed outcomes. In those examples, the focus was on the contrast , and in this testing problem, we must consider the contrast instead. Using the results of Propositions D.3 and D.4, which report the forms of and for these two types of neighborhood assumptions, we can derive the corresponding identified sets of the contrast of interest.
6.2.1 Neighborhood of MCAR: Kolmogorov-Smirnov Distance
The result of Proposition D.4 delivers the forms of and . In particular, for each and , the dominance functions are given by and .
Next, we report results of the sensitivity analysis of the event “Reject ” in the test problem (6.1) for each pair of waves, with respect all values of the triple in the 3-dimensional grid . Let denote the subset of where this rejection of the null occurs for the waive pairs and , for . Interestingly, we did not find considerable deviations from the MCAR assumptions at the 5% significance level, as the tests did not reject this null hypothesis for the majority of points in for each pair of waves. Specifically, we have obtained and , where the MCAR assumption arises under the parameter specification . The implication is that the decline in poverty over time is not robust to deviations from the MCAR assumption with respect to the Kolmogorov-Smirnov distances between and for , and between and .
The non-rejections arise because in (6.1) occurs in the sample, forcing the test statistic to equal zero. Therefore, we cannot conclude anything informative about the ranking of the two EHNI distributions using first-order restricted stochastic dominance, for in and . Hence, we have also considered sensitivity with respect to the poverty index by testing using second-order restricted dominance (i.e., ) and the values of in for . Ranking EHNI distributions using second-order restricted dominance corresponds to ranking them robustly according to the per capita income gap poverty index. Using the same significance level, the tests did not reject this null hypothesis for the majority of points in and . Let be the set where this rejection of the null occurs for the waive pairs and , for . They are given by and . The situation is similar to the case of first-order restricted dominance above: the decline in poverty over time, now with respect to per capita income gap, is not robust to deviations from the MCAR assumption with respect to the Kolmogorov-Smirnov distances between and for , and between and .
6.2.2 A U-Shape Restriction on Nonresponse Propensities
This section’s sensitivity analysis refines the worst-case bounds on the contrasts using the descriptive empirical evidence on the U-shaped form of the unit and wave nonresponse propensities with respect to income measures. This evidence on nonresponse are from exploratory logistic regressions whose estimation output is reported in Table A3.1 in Watson and Fry (2002) and Table 10.2 in Watson and Wooden (2009) for unit and wave nonresponse, respectively. Furthermore, they have found no statistically significant relationship with the income measures, which can be considered as weak evidence for this U-shaped form. It should be noted, however, that the validity of their tests rely on the correct specification of their model, which is likely misspecified. Thus, to take account of their findings and the likely misspecification of their model, we implement the U-shaped restriction on and through the structure described in Example 3.
For each and , an application of Bayes’ Theorem to the conditional probability reveals its form as , with a similar expression for . Therefore, we can encode this shape information on the nonresponse propensities using the bounds
| (6.2) | ||||
| (6.3) |
where , , , , , and are CDFs on the common support , satisfying for and , and have U-shaped densities. Proposition D.3 describes the bounds on the contrast implied by this assumption for . For , they are given by
| (6.4) | ||||
| (6.5) |
for each . Within our estimating function approach, they arise under the following specification of : for each , , , and .
Given the form of the bounds on the dominance contrast, we only need to specify , and to implement them. We specify them as elements of the family of Generalized Arcsine parametric family. This family has U-shaped PDFs given by
where is a shape parameter, and is the support. This parametric family is ordered with respect to the parameter as follows: , where and for . The sensitivity analysis studies the sensitivity of the empirical outcome with respect to configurations of , and in this parametric family. Notably, the uniform distribution is not an member of this parametric family. Hence, the inequalities (6.2) and (6.3) do not define a neighbourhood of the MCAR nonresponse propensities under this parametric shape restriction.
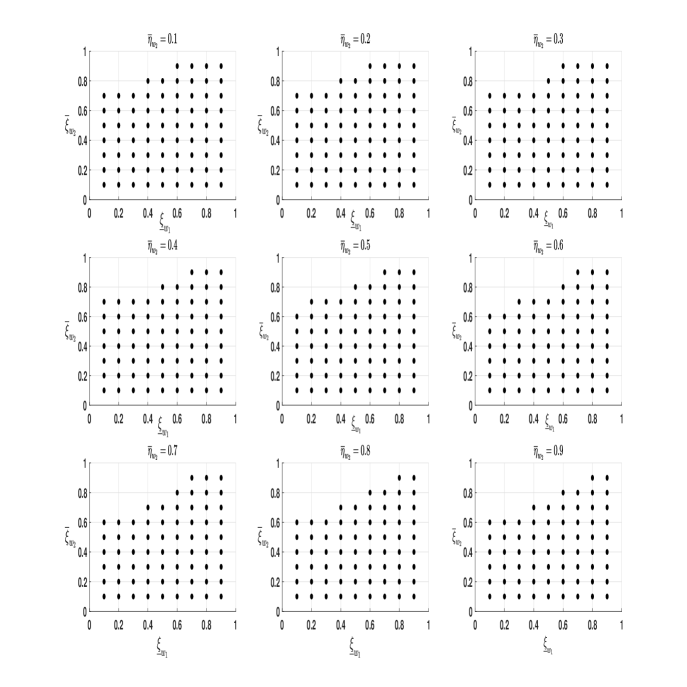
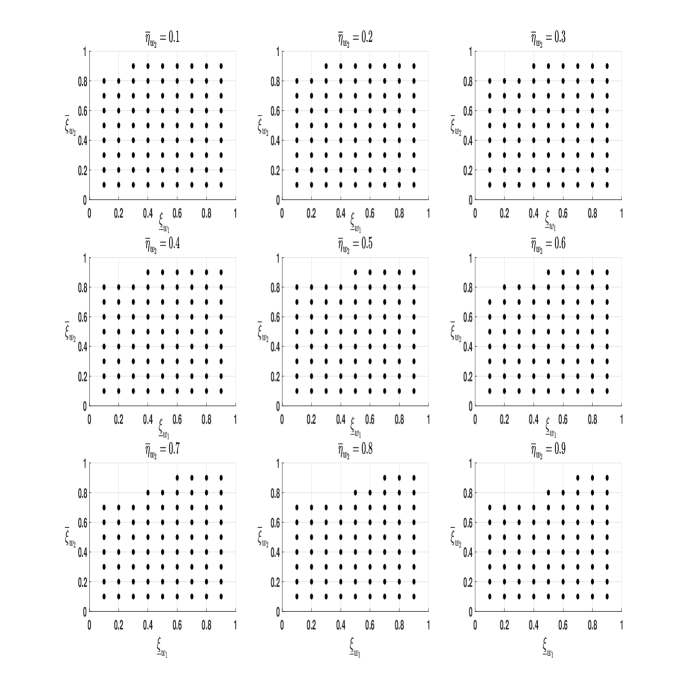
Next, we report the results of the sensitivity analysis of the event “Reject ” in the test problem (6.1) for each wave pair, with respect to the choice of , and within the Generalized Arcsine parametric family, where and are described in (6.4) and (6.5), respectively. Let , and . The testing procedure was implemented for all values of the triple in the 3-dimensional grid .
Figure 3 reports the results of these tests using scatter plots, and all tests were conducted at the 5% significance level. The scatter of black dots in each panel of these figures correspond to the subset of given by . The subset of is where non-rejection of has occurred. Let , , be the set but corresponding to the tests for pairwise comparison of waves 1 and 2, 1 and 3, and 1 and 4, respectively. Furthermore, define for . From these figures observe that and , hold. These subset relationships also hold for each subfigure of Figures 3(a) - 3(c). This result is expected since the wave nonresponse rates, given by in Table 1, double when moving from comparisons between waves 1 and 2 to that of waves 1 and 4. This doubling has lowered the worst-case lower bound of population in the comparisons, enabling more configurations of the contrasts within the Generalized Arcsine parametric family to satisfy in the sample, and hence, a chance at rejecting .
Despite the prevalence of nonresponse, overall, the rejection event is a little sensitive to values of , as consists of most elements of and consists only of elements of where the test statistic equalled zero, for . In fact, the rejection event’s sensitivity declines with comparisons of wave 1 with later waves, as is almost the entire grid . This empirical finding provides credible evidence at the 5% significance level that poverty among Australian households has declined between years 2001 to 2002, 2001 and 2003, and 2001 and 2004, according to the headcount ratio over their corresponding set of poverty lines given in Table 1.
7 Conclusion
We have proposed a comprehensive design-based framework for executing tests of restricted stochastic dominance with paired data from survey panels that accounts for the identification problem created by nonresponse. The methodology employs an estimating function procedure with nuisance functionals that can encode a broad spectrum of assumptions on nonreponse. Hence, practitioners can use our framework to perform a sensitivity analysis of testing conclusions based on the assumptions they are willing to entertain. We have illustrated the scope of our procedure using data from the HILDA survey in studying the sensitivity of their documented decrease in poverty between 2001 and 2004 in Australia using two types of assumptions on nonresponse. The first assumption embodies the divergence between missing data and observed outcomes through the Kolmogorov-Smirnov distance, while the second assumption constrains the shape of unit and wave nonresponse with incomes. We have found this decrease in poverty is (i) sensitive to departures from ignorability with the Kolmogorov-Smirnov neighborhood assumption, and (ii) relatively robust within a class of nonresponse propensities whose boundary is modeled semiparmetrically using CDFs of the Generalized Arcsine family of distributions.
8 Acknowledgement
Rami Tabri expresses gratitude to Brendan K. Beare, Elie T. Tamer, Isaiah Andrews, Aureo de Paula, Mervyn J. Silvapulle, and Christopher Walker for their valuable feedback. Special thanks to the Economics Department at Harvard University and the HILDA team at the Melbourne Institute: Applied Economic and Social Research, University of Melbourne, for their hospitality during his visit. We also thank Sarah C. Dahmann for her assistance with the data preparation for the empirical illustration
References
- Abadie (2002) Abadie, A. (2002). Bootstrap tests for distributional treatment effects in instrumental variable models. Journal of the American Statistical Association 97(457), 284–292.
- Abadie et al. (2020) Abadie, A., S. Athey, G. W. Imbens, and J. M. Wooldridge (2020). Sampling-based versus design-based uncertainty in regression analysis. Econometrica 88(1), 265–296.
- Aitchison (1962) Aitchison, J. (1962). Large-sample restricted parametric tests. Journal of the Royal Statistical Society: Series B (Methodological) 24(1), 234–250.
- Andrews and Shi (2017) Andrews, D. W. and X. Shi (2017). Inference based on many conditional moment inequalities. Journal of Econometrics 196(2), 275–287.
- Andrews and Soares (2010) Andrews, D. W. and G. Soares (2010). Inference for Parameters Defined by Moment Inequalities using Generalized Moment Selection. Econometrica 78(1), 119–157.
- Aryal and Gabrielli (2013) Aryal, G. and F. M. Gabrielli (2013). Testing for collusion in asymmetric first-price auctions. International Journal of Industrial Organization 31, 26–35.
- Atkinson (1970) Atkinson, A. B. (1970). On the Measurement of Inequality. Journal of Economic Theory 2, 244–263.
- Atkinson (1987) Atkinson, A. B. (1987). On the measurement of poverty. Econometrica 55(4), 749–764.
- Barrett and Donald (2003) Barrett, G. F. and S. G. Donald (2003). Consistent tests for stochastic dominance. Econometrica 71(1), 71–104.
- Berger (2020) Berger, Y. G. (2020). An empirical likelihood approach under cluster sampling with missing observations. Annals of the Institute of Statistical Mathematics 72, 91–121.
- Bhattacharya (2005) Bhattacharya, D. (2005). Asymptotic inference from multi-stage samples. Journal of Econometrics 126(1), 145–171.
- Bhattacharya (2007) Bhattacharya, D. (2007). Inference on inequality from household survey data. Journal of Econometrics 137(2), 674–707.
- Blundell et al. (2007) Blundell, R., A. Gosling, H. Ichimura, and C. Meghir (2007). Changes in the distribution of male and female wages accounting for employment composition using bounds. Econometrica 75(2), 323–363.
- Bourguignon (2018) Bourguignon, F. (2018). Simple adjustments of observed distributions for missing income and missing people. Journal of Economic Inequality 16, 171–188.
- Chen and Sitter (1999) Chen, J. and R. R. Sitter (1999). A pseudo empirical likelihood approach to the effective use of auxiliary information in complex surveys. Statistica Sinica 9, 385–406.
- Chen and Duclos (2011) Chen, W.-H. and J.-Y. Duclos (2011). Testing for poverty dominance: an application to canada. The Canadian Journal of Economics / Revue canadienne d’Economique 44(3), 781–803.
- Şeker and Jenkins (2015) Şeker, S. D. and S. P. Jenkins (2015). Poverty trends in turkey. Journal of Economic Inequality 13(3), 401–424.
- Davidson (2008) Davidson, R. (2008). Stochastic dominance. In M. Vernengo, E. P. Caldentey, and B. J. R. Jr (Eds.), The New Palgrave Dictionary of Economics. Palgrave Macmillan.
- Davidson and Duclos (2013) Davidson, R. and J.-Y. Duclos (2013). Testing for restricted stochastic dominance. Econometric Reviews 32(1), 84–125.
- Deaton (1997) Deaton, A. (1997). The Analysis of Household Surveys: A Microeconometric Approach to Development Policy. International Bank for Reconstruction and Development/The World Bank.
- Deville and Sarndal (1992) Deville, J.-C. and C.-E. Sarndal (1992). Calibration estimators in survey sampling. Journal of the American Statistical Association 87(418), 376–382.
- Donald and Hsu (2016) Donald, S. G. and Y.-C. Hsu (2016). Improving the power of tests of stochastic dominance. Econometric Reviews 35(4), 553–585.
- Fakih et al. (2022) Fakih, A., P. Makdissi, W. Marrouch, R. V. Tabri, and M. Yazbeck (2022). A stochastic dominance test under survey nonresponse with an application to comparing trust levels in lebanese public institutions. Journal of Econometrics 228(2), 342–358.
- Fong (2010) Fong, W. M. (2010). A stochastic dominance analysis of yen carry trades. Journal of Banking & Finance 34(6), 1237–1246.
- Foster and Shorrocks (1988) Foster, J. E. and A. F. Shorrocks (1988). Poverty orderings. Econometrica 56(1), 173–177.
- Fuller (2009) Fuller, W. A. (2009). Sampling Statistics. Wiley.
- Godambe and Thompson (2009) Godambe, V. and M. E. Thompson (2009). Chapter 26 - estimating functions and survey sampling. In C. Rao (Ed.), Handbook of Statistics, Volume 29 of Handbook of Statistics, pp. 83–101. Elsevier.
- Hájek (1971) Hájek, J. (1971). Comment on An Essay on the Logical Foundations of Survey Sampling, Part One. In A. DasGupta (Ed.), Selected Works of Debabrata Basu. Springer.
- Harris and Mapp (1986) Harris, T. R. and H. P. Mapp (1986). A stochastic dominance comparison of water-conserving irrigation strategies. American Journal of Agricultural Economics 68(2), 298–305.
- Hayes (2008) Hayes, C. (2008). Hilda standard errors: A users guide. HILDA Project Technical Paper Series 2/08, Melbourne Institute of Applied Economic & Social Research, The University of Melbourne.
- Horowitz and Manski (2006) Horowitz, J. L. and C. F. Manski (2006). Identification and estimation of statistical functionals using incomplete data. Journal of Econometrics 132(2), 445–459.
- Imbens and Lancaster (1994) Imbens, G. W. and T. Lancaster (1994). Combining micro and macro data in microeconometric models. The Review of Economic Studies 61(4), 655–680.
- Kaur et al. (1994) Kaur, A., B. Prakasa Rao, and H. Singh (1994). Testing for Second Order Stochastic Domiance of Two Distributions. Econometric Theory 10, 849–866.
- Kline and Santos (2013) Kline, P. and A. Santos (2013). Sensitivity to missing data assumptions: Theory and an evaluation of the u.s. wage structure. Quantitative Economics 4(2), 231–267.
- Linton et al. (2005) Linton, O., E. Maasoumi, and Y.-J. Whang (2005). Consistent testing for stochastic dominance under general sampling schemes. The Review of Economic Studies 72(3), 735–765.
- Linton et al. (2010) Linton, O., K. Song, and Y.-J. Whang (2010). An Improved Bootstrap Test for Stochastic Dominance. Journal Of Econometrics 154, 186–202.
- Lok and Tabri (2021) Lok, T. M. and R. V. Tabri (2021). An improved bootstrap test for restricted stochastic dominance. Journal of Econometrics.
- Lustig (2017) Lustig, N. (2017). The mising rich in household surveys: causes and correction approaches. Technical Report 75, Tulane University.
- Manski (2016) Manski, C. F. (2016). Credible interval estimates for official statistics with survey nonresponse. Journal of Econometrics 191(2), 293–301.
- McFadden (1989) McFadden, D. (1989). Testing for stochastic dominance. In T. B. Fomby and T. K. Seo (Eds.), Studies in the Economics of Uncertainty, pp. 113–134. Springer.
- Minviel and Benoit (2022) Minviel, J. J. and M. Benoit (2022). Economies of diversification and stochastic dominance analysis in french mixed sheep farms. Agricultural and Resource Economics Review 51(1), 156–177.
- Neyman (1934) Neyman, J. (1934). On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selection. Journal of the Royal Statistical Society 97(4), 558–625.
- Parente and Smith (2017) Parente, P. M. and R. J. Smith (2017). Tests of additional conditional moment restrictions. Journal of Econometrics 200(1), 1–16.
- Qin et al. (2009) Qin, J., B. Zhang, and D. H. Y. Leung (2009). Empirical likelihood in missing data problems. Journal of the American Statistical Association 104(488), 1492–1503.
- Raubertas et al. (1986) Raubertas, R. F., C.-I. C. Lee, and E. V. Nordheim (1986). Hypothesis tests for normal means constrained by linear inequalities. Communications in Statistics - Theory and Methods 15(9), 2809–2833.
- Rubin-Bleuer and Kratina (2005) Rubin-Bleuer, S. and I. S. Kratina (2005). On the two-phase framework for joint model and design-based inference. The Annals of Statistics 33(6), 2789–2810.
- Sarndal and Lundstrom (2005) Sarndal, C. E. and S. Lundstrom (2005). Estimation in Surveys with Nonresponse. Wiley & Sons.
- Taylor (2010) Taylor, M. F. (2010). British Household Panel Survey User Manual Volume A: Introduction, Technical Report and Appendices. University of Essex.
- Wang (2012) Wang, J. C. (2012). Sample distribution function based goodness-of-fit test for complex surveys. Computational Statistics & Data Analysis 56(3), 664–679.
- Wang et al. (2022) Wang, Z., L. Peng, and J. K. Kim (2022, 04). Bootstrap Inference for the Finite Population Mean under Complex Sampling Designs. Journal of the Royal Statistical Society Series B: Statistical Methodology 84(4), 1150–1174.
- Watson and Fry (2002) Watson, N. and T. R. Fry (2002). The household, income and labour dynamics in australia (hilda) survey: Wave 1 weighting. HILDA Project Technical Paper Series 03/02, Melbourne Institute of Applied Economic & Social Research, The University of Melbourne.
- Watson and Wooden (2002) Watson, N. and M. Wooden (2002). The household, income and labour dynamics in australia (hilda) survey: Wave 1 survey methodology. HILDA Project Technical Paper Series 01/02, Melbourne Institute of Applied Economic & Social Research, The University of Melbourne.
- Watson and Wooden (2004) Watson, N. and M. Wooden (2004). Assessing the quality of the hilda survey wave 2 data. HILDA Project Technical Paper Series 5/04, Melbourne Institute of Applied Economic & Social Research, The University of Melbourne.
- Watson and Wooden (2009) Watson, N. and M. Wooden (2009). Identifying Factors Affecting Longitudinal Survey Response, Chapter 10, pp. 157–181. John Wiley & Sons, Ltd.
- Whang (2019) Whang, Y.-J. (2019). Econometric Analysis of Stochastic Dominance: Concepts, Methods, Tools and Applications. Cambridge University Press.
- Wilkins (2001) Wilkins, R. (2001). Poverty lines: Australia september quarter 2001. Online Newsletter. Melbourne Institute of Applied Economic and Social Research, The University of Melbourne.
- Wilkins (2002) Wilkins, R. (2002). Poverty lines: Australia march quarter 2002. Online Newsletter. Melbourne Institute of Applied Economic and Social Research, The University of Melbourne.
- Wilkins (2003) Wilkins, R. (2003). Poverty lines: Australia december quarter 2003. Online Newsletter. Melbourne Institute of Applied Economic and Social Research, The University of Melbourne.
- Wilkins (2004) Wilkins, R. (2004). Poverty lines: Australia september quarter 2004. Online Newsletter. Melbourne Institute of Applied Economic and Social Research, The University of Melbourne.
- Wilkins et al. (2022) Wilkins, R., E. Vera-Toscano, F. Botha, M. Wooden, and T.-A. Trinh (2022). The 17th annual statistical report of the hilda survey. Hilda statistical report series, Melbourne Institute of Applied Economic & Social Research, The University of Melbourne.
- Wu and Lu (2016) Wu, C. and W. W. Lu (2016). Calibration weighting methods for complex surveys. International Statistical Review / Revue Internationale de Statistique 84(1), 79–98.
- Wu and Rao (2006) Wu, C. and J. N. K. Rao (2006). Pseudo-empirical likelihood ratio confidence intervals for complex surveys. The Canadian Journal of Statistics / La Revue Canadienne de Statistique 34(3), 359–375.
- Zhao et al. (2020) Zhao, P., D. Haziza, and C. Wu (2020). Survey weighted estimating equation inference with nuisance functionals. Journal of Econometrics 216(2), 516–536.
- Zheng (2002) Zheng, B. (2002). Testing lorenz curves with non-simple random samples. Econometrica 70(3), 1235–1243.
Appendix A Appendix
This appendix provides the supplementary material to the paper. It is organized as follows.
- •
- •
- •
- •
Appendix B Proofs of Theorems 1 - 3
B.1 Proof of Theorem 1
Proof.
The proof follows steps identical to those in the proof of Theorem 1 in Fakih et al. (2022), but with adjustments for the test statistic. We first show (4.2) (4.3). The proof proceeds by the direct method. Suppose that (4.2) holds, and let Then
| (B.1) |
holds. Taking the limit superiors on both sides of the inequality (B.1) implies the inequality (4.3). As the sequence was arbitrary, this inequality holds for all such sequences.
Now we shall prove the reverse direction:(4.3) (4.2). The proof proceeds by contraposition. Suppose that (4.2) does not hold, i.e.,
| (B.2) |
Then we have to construct a sequence such that
to prove the result. To that end, the condition (B.2) implies the largest subsequential limit of the sequence exceeds Thus, there is a sequence such that the limit of exceeds e.g., the limit is equal to where Now let be such that For each there exists such that
| (B.3) |
Now taking limit superior of both sides of (B.3) with respect to yields
Thus, we have constructed a sequence of populations with the desired property. This concludes the proof. ∎
B.2 Proof of Theorem 2
Proof.
We proceed by the direct method. Fix an . This proof demonstrates that the testing procedure is uniformly asymptotically valid by showing that the test has level for all possible subsequences of finite populations based on sequences in . The subsequences where the asymptotic size (4.3) will be largest is where we have dominance within sample and we are on the boundary of the model of the null hypothesis . Let denote the event of dominance in sample, that is: Let be a subsequence of . We focus on subsequences that give the event the highest probability (as otherwise ). Fix an arbitrarily, and let . Observe that , so that under Conditions 5 and 7 of Assumption 2, as , must converges weakly to a Gaussian process with mean
Therefore, , which equals . Now using the weak convergence of , this probability simplifies to
| (B.4) |
This probability (B.4) will be highest for subsequences of finite populations within the model of the null hypothesis where we have a unique such that and . This corresponds to finite populations in the boundary of the model of the null hypothesis . Thus, consider two types of subsequences of finite populations. Firstly, subsequences that drift on the boundary: . Secondly, subsequences of the finite populations that drift to the boundary of the null model from its interior. Starting with the first case, as we are on the boundary for each , we have at least one such that . For a given let . Then using the definition of the LR test statistic (3.2): for each
| (B.5) |
holds. Now by Lemma C.2 and taking the limit superior on both sides of (B.5), it follows that
since
and the limiting distribution of is .
Now focusing on the second case, we have that the subsequence of finite populations drifting to the boundary as and let be such that and for all . We utilise the inequality (B.5) and replace with . Then taking the limit superior over both sides and applying Lemma C.3, we must have that holds, since
Note that Lemma C.3 establishes that limiting distribution of as . This concludes the proof. ∎
B.3 Proof of Theorem 3
Proof.
There are two possible cases for the sequences of finite populations which we examine under the alternative. Firstly, we consider sequences of finite populations that are uniformly bounded away from the boundary of the null hypothesis. Secondly, we consider sequences of finite populations that converges to , the boundary of the model of the null hypothesis as .
Proceeding under the first case via the direct method, fix an . Consider a sequence of finite populations . For any we have that for all . Let denote the event of dominance within sample: i.e., the event . Using that for all and arguments similar to those in the proof of Theorem 2, it follows that . Consequently, the event occurs with probability tending to unity as , and hence, with probability tending to unity as . Now for each , applying Lemma C.5 to the sequence , we have that . Accordingly, the form of implies . Since the critical value is fixed and finite, it follows that . This concludes the proof for this case.
Now focusing on the second case, we again proceed via the direct method. Let ; therefore, the sequence of finite populations . Consequently, there will be at least one such that . Let . By contrast with the previous case, the limiting probability of the event is ,
by arguments similar to those in the proof of Theorem 2. As this limiting probability is not necessarily equal to unity, we investigate the asymptotic power of the test on the event , since for each the equalities
, hold, because . Hence, , holds. Now Lemma C.5 establishes that , holds, for each . Furthermore, Lemma C.6 establishes that , holds, for each . Therefore, on the event and asympotically, the rejection event is characterized as . Hence, equals the limiting probability
.
By Lemma C.6, this resulting limit equals
as we show the statistics converge in distribution to pointwise in . This concludes the proof.
∎
Appendix C Technical Lemmas
C.1 Solution to PELF (3.1)
Here we develop the solution to the PELF, described by (3.1). For a given population suppose we have access to a panel survey sample . Firstly, we determine the solution to the unconstrained problem . Then for each , we determine the solution to the constrained optimisation problem denoted by . The unconstrained optimisation problem is described by:
The First Order Conditions are, taking them with respect to i for generality:
| (C.2) | ||||
| (C.3) |
Multiplying (C.2) by and then summing over
| using (C.3) and (2.12) | ||||
| (C.4) |
Then substituting (C.4) into (C.2) and solving for , we obtain:
| (C.5) |
Therefore, using (C.5) we have that the unrestricted log-likelihood is given by:
| (C.6) |
The constrained maximisation problem of the PELF corresponds to the following optimisation problem, where the last restriction imposes the moment equality for corresponding to the boundary of the null hypothesis :
| (C.7) | ||||
| subject to | ||||
The corresponding Lagrangian is given by:
The First Order Conditions are
| (C.8) | ||||
| (C.9) | ||||
| (C.10) |
Interpreting this result, is the cost of imposing the null hypothesis . The more readily the data fits the constraint, the easier it is to impose the constraint, and so will converge to zero, resulting in the unconstrained value for the .
The following lemma is helpful for developing the technical result sin the subsequent sections.
Proof.
The proof proceeds by the direct method. Observe that
where the last equality holds under Assumption 1, as it implies that and for . ∎
C.2 Lemmas for Proof of Theorem 2
The following Lemmas derive the asymptotic distribution of for subsequences of sequences of that drift on/to the boundary of the model of the null hypothesis .
C.2.1 Lemma C.2
Lemma C.2.
Let , and be the same as in Theorem 1. Let . For a sequence of finite populations , suppose there is a subsequence such that . For each let
Then, .
Proof.
The proof proceeds using the direct method. For simplicity, we drop . By the compactness of the set , exists. Note that is non-random and depends only on the sequence of finite populations. Using (C.12), notice that can be rewritten as:
| (C.13) |
Then using (C.13), we substitute this into (C.10)
| (C.14) |
where . Equation (C.14) is equivalent to a convergent alternating series in , so as . Therefore as , ignoring terms beyond the first order, is asymptotically equivalent to:
| (C.15) |
Let . Now using the result (C.12) for in :
| (C.16) |
Since Lemma C.1 establishes that is uniformly bounded, and is tending to zero in probability and in design, we then use the standard expansion: , with .
C.2.2 Lemma C.3
Lemma C.3.
Let , and be the same as in Theorem 1. Let . For a sequence of finite populations , suppose there is a subsequence such that: and such that and , where
Then .
Proof.
Following identical steps as in Lemma C.2, we have:
Under the restriction of the boundary of the null hypothesis :
since as . By definition of , the second term inside the brackets does not affect the limiting behaviour of the test statistic. Therefore, is asymptotically equivalent to
and now applying Conditions 3 - 7 of Assumption 2 to the components of this expression yields
Therefore, along it follows that
∎
C.3 Lemmas for Proof of Theorem 3
The following two Lemmas describe the asymptotic behaviour of the test statistic under the alternative hypothesis. The first Lemma focuses on sequences of finite populations that are uniformly bounded away from the boundary, corresponding to for all , where is given by (4.5). The second Lemma focuses on sequences of finite populations that converge towards the boundary of the model of the null hypothesis where there exists one or more such that .
The following result is helpful in establishing these intermediate technical results.
Lemma C.4.
Given finite population , under Assumption 3, for each the design-effect satisfies
| (C.18) |
and this limit is finite and positive.
Proof.
The proof proceed by the direct method. Using the representation of the design-effect, in (3.3), note that
| (C.19) | ||||
| (C.20) |
Now Condition 1 of Assumption 3 implies that . Furthermore, the denominator in this expression is a consistent estimator of in (3.4). Combining these two points with the implications of Conditions 2(i) and 2(ii) of Assumption 3 yield
| (C.21) |
Since and are both positive and finite by Assumption 3, the probability limit of as is finite and positive. ∎
C.3.1 Lemma C.5
Lemma C.5.
Proof.
We proceed via the direct method. Fix an arbitrarily. Following identical steps in Lemma C.2 to obtain (C.16):
where is given by (C.15). By the duality of the of the optimisation problem (C.7), we have that:
| (C.22) |
Where is given by:
Thus, by applying duality, we have that for any arbitrary :
| (C.23) |
We now choose dependent on the sequence of finite populations such that as , that is:
This property on is necessary to ensure that the expansion , where , is valid. Note that by Lemma C.1, is uniformly bounded on . Setting as:
| (C.24) |
Then using the second order logarithm expansion on (C.23) and substituting (C.24) for we get:
| (C.25) |
Hence, asymptotically,
| (C.26) |
Conditions 4 and 5 of Assumption 2 and Lemma C.4 imply the first term on the right side in (C.26) converges in distribution to
The second term on the right side in (C.26) converges to . Since the denominator is finite and positive, this limit is determined by the value of . As , the limit of the second term diverges to . Finally, the limit of third term on the right side in (C.26) is by Condition 5 of Assumption 2 and Lemma C.4.
C.3.2 Lemma C.6
Lemma C.6.
Proof.
The asymptotic power of the test will be lowest for sequences of finite populations that converge to the boundary of the model of the alternative hypothesis . This will be where for every finite the finite population is in but converges to the model of the null hypothesis in the limit. That is, for one or more we will have . Let be the set . Fix an . Following identical steps as in Lemma C.2, we obtain:
Using Conditions 4 and 5 of Assumption 2 and that for ,
For each , the random variable is distributed as standard normal; therefore, . ∎
Appendix D Technical Results for the Examples in Section 2.2
This section presents the identified sets of for each and , associated with the Examples in Section 2.2. These sets are characterized in terms of sharp bounds
and the results of this section describe the bounds under the informational setups of the examples.
D.1 Example 1: Worst-Case Bounds
Proposition D.1.
For each and , the worst-case bounds are
where , for .
Proof.
The proof proceeds by the direct method. Let , and fix and . The law of total probability expansion of , given by (2.4), is
Note that is not identified, but can be bounded from below and above by 0 and , respectively. These bounds on that conditional expectation imply the desired bounds on by direct substitution. Now since and were arbitrary, the above bounds hold for each and .
Let , and fix and . The law of total probability expansion of , given by (2.4), is
Note that and not identified, but are bounded from below by 0 and from above by . These bounds on that conditional expectation imply the desired bounds on by direct substitution. Now since and were arbitrary, the above bounds hold for each and . ∎
D.2 Example 2
Recall that the assumption of MCAR for unit nonresponse means
| (D.1) |
holds, for , and that this condition does not imply any restrictions on wave nonrepsonse. We have the following result.
Proposition D.2.
Proof.
The proof proceeds by the direct method. Let , and fix and . The law of total probability expansion of , given by (2.4), is
Condition (D.1) implies
holds, for each . Hence, is point-identified and given by
for each , implying the desired result.
Let , and fix and . The law of total probability expansion of , given by (2.4), is
Condition (D.1) implies
holds, for each . Consequently, only in this expansion is not identified, but it is bounded from below by 0 and from above by . These bounds on that conditional expectation imply the desired bounds on by direct substitution. Now since and were arbitrary, the above bounds hold for each and . ∎
D.3 Example 3: Neighborhood of MCAR
Recall that the neighborhood condition in Example 3 specifies the following system of inequalities for the conditional probabilities , , and
:
| (D.2) | ||||
| (D.3) |
where , , , , , and are CDFs that are predesignated by the practitioner which satisfy , for , and .
Let
which are CDFs. Hence, we can define the dominance functions recursively: for , these functions are and for . Finally, for we also introduce the following recursively defined functions defined on : , for .
Proposition D.3.
Proof.
The proof proceeds by the direct method. We start with population . For and , the Law of Total Probability applied to yields
Next, apply Bayes’ Theorem to to express it in terms of , substitute this resulting expression into the above representation of , and solving for , yields
As , we substitute out in the above expression using the inequalities (D.2) to obtain
As was arbitrary, the above derivation holds for each .
Now we focus on . Fix . Since and , we can integrate all sides to obtain
Since and are mixtures of products of CDFs, we can use integration by parts to obtain expressions for and , given by
and
respectively. Now recognizing that , , and
we are done with , as was arbitrary.
Now we focus on . Let . Since and , we can integrate all sides of these inequalities to obtain
Noting that
we can apply the same integration by parts technique, as in the case , to the first terms of these expressions to simplify them, and for the remaining terms we interchange integration and expectation to simply them. Implementing these operations results in
where we have used , ,
and an identical expression as the preceding one but with replaced with .
Proceeding by induction on , once we have expressions for and , we can repeat similar steps to those for the case of , but with appropriate adjustments, to obtain the expressions for and for each . We omit the details for brevity.
Turning to population , we only provide a brief description for deriving and , as it follows steps identical to those for population , but with a minor adjustment. The adjustment is that unlike the derivations for population , we now must account for the two set of inequalities (D.2) and (D.3), representing the restrictions on the parameter space, which now include restrictions on wave nonresponse. For and , we apply the Law of Total Probability to and use Bayes’ Theorem to obtain
Now we can use the inequalities (D.2) and (D.3) for to substitute out the propensities and derive the bounds and , so that . Since was arbitrary, these inequalities hold for each . Now we can integrate all sides of this inequality, to obtain the bounds and for each , which like with population , the derivations invovle the use of Integration by Parts and interchanging expectation and integration. Proceeding by induction on , once we have expressions for and , we can repeat similar derivations, but with appropriate adjustments, to obtain the expressions for and for each . We omit the details for brevity. ∎
D.4 Example 4: KS Neighborhood of MCAR
Recall that Example 4 is based on Kline and Santos (2013), who put forward a construction using the maximal Kolmogorov-Smirnov distance between the distributions of missing and observed outcomes. Their approach builds a neighborhood for the CDFs
according to the maximal Kolmogorov-Smirnov distance using the conditions in (D.7). Let be such that
| (D.4) | ||||
| (D.5) | ||||
| (D.6) |
which are predesignated by the practitioner, where MCAR means
| (D.7) | ||||
Proposition D.4.
Proof.
The proof proceeds by the direct method. Throughout, we adopt the convention . For , the restrictions (D.4) - (D.6) yields bounds via the decomposition having the form
for each , where are unknown CDFs. Focusing on population , let , the Law of Total Probability applied to yields
Now since is a CDF, , holds, implying the worst-case CDF bounds , where
These bounds are sharp. Here, we have and . As was arbitrary, we done with the case . For , we integrate all sides of as such
and recognizing that , , and , we must obtain the forms of and to complete the proof in this case. Towards that end, using integration by parts
and
Now for , integrate all sides of as such
and recognizing that , , and , we must obtain the forms of and to complete the proof in this case. We have
and
Proceeding by induction on , once we have expressions for and , we can repeat similar steps to those for the case of , but with appropriate adjustments, to obtain the expressions for and for each . We omit the details for brevity.
Turning to population , let , the Law of Total Probability applied to yields
Now since and are CDFs, , holds, implying the worst-case CDF bounds , where
To derive the bounds, we follows steps identical to those for above, except that we now replace and with and , respectively, and calculate the integrals accordingly. We omit the details for brevity. ∎
Appendix E Technical Details for Section 5
E.1 Examples of Bounds for The Testing Problem (5.1)
Example 5.
WC Bounds. The WC bounds can be recovered using the following specification: for each ,
where . Hence, by definition, for each . It defines , where for each ,
Example 6.
MCAR for Unit Nonresponse. In conjunction with the WC upper bound for , the following specification encodes this MCAR assumption: for each ,
It defines , where for each ,
Example 7.
Neighborhood Assumption for Unit and Wave Nonresponse. The following specification of delivers the desired bounds: for each
This specification defines , where for each ,
Example 8.
Kline and Santos (2013). In conjunction with the WC bounds on wave nonresponse, the following specification of encodes this assumption on unit and wave nonrepsonse: for each ,
It defines , where for each ,
where .
E.2 Section 5.5
This section provides the details on the statistical procedure for the testing problem (5.3). It is based on calibration via pseudo-empirical likelihood as in Wu and Rao (2006). When represents a wave beyond the first one, the event can occur, which was not possible when represented the population of the first wave. In words, this event corresponds to the sampled unit not responding in wave but responding in wave . The event in the setup of this section now corresponds to unit either being a unit nonresponder, or a wave nonresponder that did not respond in waves and but responded in other waves. This distinction between different types of nonresponse within this event can be meaningful when their characteristics differ (e.g., poor and wealthy individuals). The foregoing general estimating function approach that targets the estimand must be adjusted now to incorporate events of the form . For each , consider the following estimating function , given by
| (E.1) | ||||
where is a vector of nuisance functionals. The nuisance functions, as in the previous sections of this paper, serves as a vehicle to encode side information of maintained assumptions on nonresponse.
For a given value , the solution of the census estimating equations
is
for each .
Now we introduce notation regarding the sampled units. Let denote the survey sample of the target population in the first wave of the panel, and let , which consists of units that have responded in the first wave. As those units are followed over time, define
| (E.2) |
to be the set of units that are followed form the first wave that have responded in either of the waves corresponding to and . Also, let for each , where is a plug-in estimator of than can depend on . Furthermore, define the moment functions
| (E.3) |
for each . Finally, let , and let denote the subvector of corresponding to the active/binding inequalities in (5.2)
Accordingly, the following pseudo-empirical likelihood statistic defines a restricted testing procedure for the test problem (5.3):
| (E.4) |
where
| (E.5) | ||||
| (E.6) | ||||
and with the solution of (E.6). The design-effect in this scenario is associated with the estimator ,
| (E.7) |
where for each
| (E.8) | ||||
| (E.9) |
and is an estimator of the design variance . In estimation of this design-variance, one must estimate using its sample version:
where is exactly but based on an estimator of the set of active/binding inequalities.
Let . For a fixed nominal level , the decision rule of the test is to
| (E.10) |
where is be the quantile of the distribution for the random variable
| (E.11) |
where , and is the limit of the covariance matrix
as , with defined in (4.5).
Some remarks are in order.
Remark E.1.
The reason the set of active/binding inequalities in (5.2) enters the design effect is because they would enter the Taylor expansion of , and the inactive/slack inequalities do not because their Lagrange multipliers would be zero on account of complementary slackness.
Remark E.2.
Remark E.3.
This procedure uses an asymptotic critical value, where justification of the asymptotic form of , given by (E.11), is through an application of a central limit theorem. This asymptotic form of the test statistic is for a cone-based testing problem on a multivariate normal mean vector :
| (E.12) |