The Calderón problem with finitely many unknowns is equivalent to convex semidefinite optimization
Abstract
We consider the inverse boundary value problem of determining a coefficient function in an elliptic partial differential equation from knowledge of the associated Neumann-Dirichlet-operator. The unknown coefficient function is assumed to be piecewise constant with respect to a given pixel partition, and upper and lower bounds are assumed to be known a-priori.
We will show that this Calderón problem with finitely many unknowns can be equivalently formulated as a minimization problem for a linear cost functional with a convex non-linear semidefinite constraint. We also prove error estimates for noisy data, and extend the result to the practically relevant case of finitely many measurements, where the coefficient is to be reconstructed from a finite-dimensional Galerkin projection of the Neumann-Dirichlet-operator.
Our result is based on previous works on Loewner monotonicity and convexity of the Neumann-Dirichlet-operator, and the technique of localized potentials. It connects the emerging fields of inverse coefficient problems and semidefinite optimization.
keywords:
Inverse coefficient problem, Calderón problem, finite resolution, semidefinite optimization, Loewner monotonicity and convexityAMS:
35R30, 90C221 Introduction
We consider the Calderón problem of determining the spatially dependent coefficient function in the elliptic partial differential equation
from knowledge of the associated (partial data) Neumann-Dirichlet-operator , cf. section 3.1 for the precise mathematical setting. The coefficient function is assumed to be piecewise constant with respect to a given pixel partition of the underlying imaging domain, so that only finitely many unknowns have to be reconstructed. We also assume that upper and lower bounds are known a-priori, so that the pixel-wise values of the unknown coefficient function can be identified with a vector in , where is the number of pixels.
In this paper, we prove that the problem can be equivalently reformulated as a convex optimization problem where a linear cost function is to be minimized under a non-linear convex semi-definiteness constraint. Given , the vector of pixel-wise values of is shown to be the unique minimizer of
where only depends on the pixel partition, and on the upper and lower bounds . The symbol “” denotes the semidefinite (or Loewner) order, and is shown to be convex with respect to this order, so that the admissable set of this optimization problem is convex.
We also prove an error estimate for the case of noisy measurements , and show that our results still hold for the case of finitely many (but sufficiently many) measurements.
Let us give some more remarks on the origins and relevance of this result. The Calderón problem [4, 5] has received immense attention in the last decades due to its relevance for non-destructive testing and medical imaging applications, and its theoretical importance in studying inverse coeffient problems. We refer to [22, 6] for recent theoretical breakthroughs, and the books [25, 26, 1] for the prominent application of electrical impedance tomography.
In practical applications, only a finite number of measurements can be taken and the unknown coefficient function can only be reconstructed up to a certain resolution. For the resulting finite-dimensional non-linear inverse problems, uniqueness results have been obtained only recently in [2, 11].
Numerical reconstruction algorithms for the Calderón problem and related inverse coefficient problems are typically based on Newton-type iterations or on minimizing a non-convex regularized data fitting functional. Both approaches highly suffer from the problem of local convergence, resp., local minima, and therefore require a good initial guess close to the unknown solution which is usually not available in practice. We refer to the above mentioned books [25, 26, 1] for an overview on this topic, and point out the result in [23] that shows a local convergence result for the Newton method for EIT with finitely many measurements and unknowns. For a specific infinite-dimensional setting, a convexification idea was developed in [19]. Moreover, knowing (i.e., infinitely many measurements) and the pixel partition, the values in can also be recovered one by one with globally convergent one-dimensional monotonicity tests, and these tests can be implemented as in [7, 8] without knowing the upper and lower conductivity bounds. But, to the knowledge of the author, these ideas do not carry over to the case of finitely many measurements, and, for this practically important case, the problem of local convergence, resp., local minima, remained unsolved.
The new equivalent convex reformulation of the Calderón problem with finitely many unknowns presented in this work connects the emerging fields of inverse problems in PDEs and semidefinite optimization. It is based on previous works on Loewner monotonicity and convexity, and the technique of localized potentials [10, 17], and extends the recent work [14] to the Calderón problem. The origins of these ideas go back to inclusion detection algorithms such as the factorization and monotonicity method [18, 3, 27], and the idea of overcoming non-linearity in such problems [16].
The structure of this article is as follows. In section 2, we demonstrate on a simple, yet illustrative example how non-linear inverse coefficient problems such as the Calderón problem suffer from local minima. In section 3 we then formulate our main results on reformulating the Calderón problem as a convex minimization problem. In section 4 the results are proven, and section 5 contains some conclusions and an outlook.
2 Motivation: The problem of local minima
To motivate the importance of finding convex reformulations, we first give a simple example on how drastically inverse coefficent problems such as the Calderón problem can suffer from local minima. We consider
| (1) |
in the two-dimensional unit ball . The coefficient is assumed to be the radially-symmetric piecewise-constant function
with known radii , but unknown values , cf. figure 1 for a sketch of the setting with and .
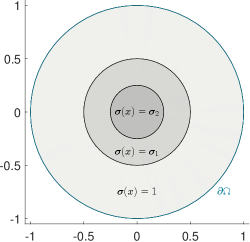
We aim to reconstruct the two unknown values from the Neumann-Dirichlet-operator (NtD)
For this simple geometry, the NtD can be calculated analytically. Using polar coordinates , it is easily checked that, for each , the function
solves (1) (in the weak sense) if fulfill the following four interface conditions
This is equivalent to solving the linear system
and from this we easily obtain that
The Dirichlet- and Neumann boundary values of are
so that
By rotational symmetry, the same holds with replaced by . Hence, with respect to the standard -orthonormal basis of trigonometric functions
the Neumann-Dirichlet-operator can be written as the infinite-dimensional diagonal matrix
with depending on as given above, and denoting the space of -functions with vanishing integral mean on .
We assume that we can only take finitely many measurements of . For this example, we choose the measurements to be the upper left -part of this matrix, i.e., the Galerkin projektion of to ,
and try to reconstruct from . Note that, effectively, we thus aim to reconstruct two unknowns from three independent measurements , , and .
 |
 |
We now demonstrate how standard least-squares data-fitting approaches for this inverse problem may suffer from local minima. We set and to be the true noiseless measurements of the associated NtD. The natural approach is to find an approximation by minimizing the least-squares residuum functional
| (2) |
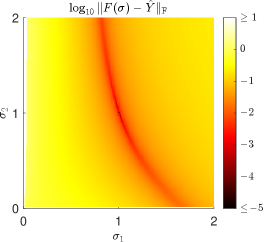
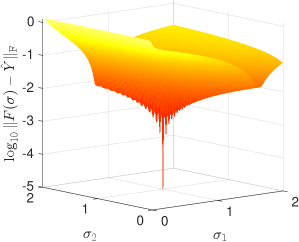
where denotes the Frobenius norm. Figure 2 shows the values of this residuum functional as a function of . It clearly shows a global minimum at the correct value but also a drastic amount of local minimizers.
Hence, without a good initial guess, local optimization approaches are prone to end up in local minimizers that may lie far away from the correct coefficient values, and global optimization approaches for such highly non-convex residuum functionals quickly become computationally infeasible for raising numbers of unknowns.
We demonstrate this problem of local convergence by applying the generic MATLAB solver lsqnonlin to the
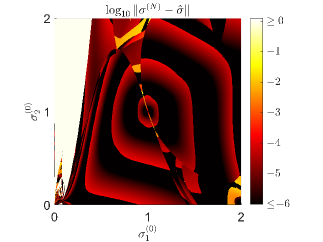
least-squares minimization problem (2) (with all options of lsqnonlin left on their default values). Figure 3 shows the Euklidian norm of the error
of the final iterate returned by lsqnonlin as a function of the initial value . It shows how some regions of starting values lead to inaccurate or even completely wrong results. Note that the values are plotted in logarithmic scale and cropped above and below certain thresholds to improve presentation. Also, in our example, increasing the number of measurements did not alleviate these problems,
and the performance of lsqnonlin did not change when providing the symbolically calculated Jacobian of .
 |
Our example illustrates how standard approaches to non-linear inverse coefficient problems (such as the Calderón problem) may lead to non-convex residuum functionals that are highly affected by the problem of local minimizers. Overcoming the problem of non-linearity requires overcoming this problem of non-convexity. In the next sections we will show that this is indeed possible. The Calderón problem with finitely many unknowns and measurements can be equivalently reformulated as a convex minimization problem.
3 Setting and main results
3.1 The partial data Calderón problem
Let , be a Lipschitz bounded domain, let denote the outer normal on , and let be a relatively open boundary part. denotes the subset of -functions with positive essential infima, and denote the spaces of - and -functions with vanishing integral mean on .
For , the partial data (or local) Neumann-Dirichlet-operator
is defined by where solves
| (3) |
Occasionally, we will also write for the solution of (3) in the following to highlight the dependence on the conductivity coefficient and the Neumann boundary data .
It is well-known (and easily follows from standard elliptic PDE theory) that is a compact self-adjoint operator from to . The question, whether uniquely determines , is known as the (partial data) Calderón problem.
3.2 The Calderón problem with finitely many unknowns
We will now introduce the Calderón problem with finitely many unknowns, and formulate our first main result on its equivalent convex reformulation.
The setting with finitely many unknowns
We assume that is decomposed into pixels, i.e.,
where are non-empty, pairwise disjoint subdomains with Lipschitz boundaries. We furthermore assume that the pixels are numbered according to their distance from the boundary part , so that the following holds: For any we define
and assume that, for all , the complement of in is connected and contains a non-empty relatively open subset of .
We will consider conductivity coefficients that are piecewise constant with respect to this pixel partition, and assume that we know upper and lower bounds, . Hence,
and denoting the characteristic functions on . In the following, with a slight abuse of notation, we identify such a piecewise constant function with its coefficient vector . Accordingly, we consider as a non-linear operator
and consider the problem to
Here, and in the following, denotes the space of all vectors in containing only positive entries. Also, throughout this work, we write “” for the componentwise order on .
Convex reformulation of the Calderón problem
Let “” denote the semidefinite (or Loewner) order on the space of self-adjoint operators in , i.e., for all , and ,
Note that, for a compact selfadjoint operator , the eigenvalues can only accumulate in zero by the spectral theorem. Hence, either possesses a maximal eigenvalue , or zero is the supremum (though not necessarily the maximum) of the eigenvalues. In the latter case we still write for the ease of notation. Thus, for compact selfadjoint ,
| (4) |
Our first main result is that the Calderón problem with infinitely many measurements can be equivalently formulated as a uniquely solvable convex non-linear semidefinite program, and to give an error estimate for noisy measurements. Our arguments also yield unique solvability of the Calderón problem and its linearized version in our setting with finitely many unknowns. We include this as part of our theorem for the sake of completeness. It should be stressed though that uniqueness is known to hold for general piecewise analytic coefficients, cf. [20, 21] for the non-linear Calderón problem, and [16] for the linearized version. For more general results on the question of uniqueness we refer to the recent uniqueness results cited in the introduction, and the references therein.
Theorem 1.
There exists , and , so that for all , and , the following holds:
-
(a)
The convex semi-definite optimization problem
(5) possesses a unique minimizer and this minimizer is .
-
(b)
Given , and a self-adjoint operator
the convex semi-definite optimization problem
(6) possesses a minimizer . Every such minimizer fulfills
where denotes the weighted maximum norm
Moreover, the non-linear mapping
is injective, and its Fréchet derivative is injective for all .
Let us stress that the constants , and , in Theorem 1 only depend on the domain , the pixel partition and the a-priori known bounds . Moreover, note that (5), and (6), are indeed convex optimization problems since is convex with respect to the Loewner order so that the admissible sets in (5), and (6) are closed convex sets (cf. Corollary 5). The admissible sets in (5), and (6) are also non-empty since, in both cases, they contain .
Remark 2.
Our arguments also yield the Lipschitz stability result
3.3 The case of finitely many measurements
The equivalent convex reformulation is also possible for the case of finitely many measurements. Let be given with dense span in . For some number of measurements , we assume that we can measure the Galerkin projection of to the span of , i.e., that we can measure , for all . Accordingly, we define the matrix-valued forward operator
| (7) |
where denotes the space of symmetric matrices.
Then, the problem of reconstructing an unknown conductivity on a fixed partition with known bounds from finitely many measurements can be formulated as the problem to
As in the infinite-dimensional case, we write “” for the Loewner order on the space of symmetric matrices , i.e., for all ,
Also, for , the largest eigenvalue is denoted by , and we have that
Our second main result is that also the Calderón problem with finitely many measurements can be equivalently reformulated as a uniquely solvable convex non-linear semi-definite program, provided that sufficiently many measurements are being taken. Again, our arguments also yield unique solvability of the Calderón problem and its linearized version, and we include this as part of our theorem for the sake of completeness. Note that this uniqueness result has already been shown in [11] by arguments closely related to those in this work.
Theorem 3.
If the number of measurements is sufficiently large, then:
-
(a)
The non-linear mapping
is injective on , and its Fréchet derivative is injective for all .
-
(b)
There exists , and , so that for all , and , the following holds:
-
(i)
The convex semi-definite optimization problem
(8) possesses a unique minimizer and this minimizer is .
-
(ii)
Given , and with , the convex semi-definite optimization problem
(9) possesses a minimizer . Every such minimizer fulfills
where the weighted maximum norm is defined as in Theorem 1.
-
(i)
The constants , and , and also the number of measurements in Theorem 3 only depend on the domain , the pixel partition and the a-priori known bounds . Also, as in the case of infinitely many measurements, (8) and (9) are linear optimization problems over non-empty, closed, and convex, feasibility sets, and our arguments also yield the Lipschitz stability result
| (10) |
4 Proof of the main results
In the following, the -th unit vector is denoted by . We write for the vector containing only ones, and we write for the vector containing ones in all entries except the -th. We furthermore split , where
Note that we use the usual convention of empty sums being zero, so that , and .
4.1 The case of infinitely many measurements
In this subsection, we will prove Theorem 1, where the measurements are given by the infinite-dimensional Neumann-Dirichlet operator .
Let us sketch the main ideas and outline the proof first. We will start by summarizing some known results on the monotonicity and convexity of the forward mapping
This will show that the admissible sets of the optimization problems (5) and (6) are indeed convex sets. It also yields the monotonicity property that, for all ,
Using localized potentials arguments in the form of directional derivatives, we then derive a converse monotonicity result showing that
| (11) |
for all . Clearly, this implies that is a minimizer of the optimization problem (5). By proving a slightly stronger variant of (11), we also obtain uniqueness of the minimizer and the error estimate in Theorem 1(b).
Monotonicity, convexity, and localized potentials
We collect several known properties of the forward mapping in the following lemma. We also rewrite the localized potentials arguments from [10, 17] as a definiteness property of the directional derivatives of . The latter will be the basis for proving a converse monotonicity result in the next subsection.
Lemma 4.
-
(a)
is Fréchet differentiable with continuous derivative
is compact and selfadjoint for all , and . Moreover,
for all , , (12) for all . (13) -
(b)
is monotonically decreasing, i.e. for all
(14) Also, for all , and ,
(15) -
(c)
is convex, i.e. for all , and ,
(16) -
(d)
For all , , and , it holds that
(17)
Proof.
It is well known that is continuously Fréchet differentiable (cf., e.g., [24, Section 2], or [9, Appendix B]). Given some direction the derivative
is the selfadjoint compact linear operator associated to the bilinear form
where, again, we identify with the piecewise constant function
, resp., denote the solutions of (3) with Neumann boundary data , resp., . Clearly, this implies (12). Assertion (13) is shown in [16, Lemma 2.1], so that (a) is proven.
To prove (d), let . Then, for all ,
where . Since is open and disjoint to , and the complement of is connected to , we can apply the localized potentials result in [17, Thm. 3.6, and Section 4.3] to obtain a sequence of boundary currents with
Hence, for sufficiently large ,
which proves (d). ∎
Corollary 5.
For every self-adjoint operator , the set
is a closed convex set in .
Proof.
This follows immediately from the continuity and convexity of , which was shown in part (a) and (c) of Lemma 4. ∎
A converse monotonicity result
We will now utilize the properties of the directional derivatives (17) in order to derive the converse monotonicity result (11) (or, more precisely, a slightly stronger version of it). The following arguments stem on the ideas of [13, 14], where (11) is proven with . The main technical difficulty compared to these previous works, is that the localized potentials results for the Calderón problem are weaker than those known for the Robin problem considered in [13, 14]. This corresponds to the fact that (17) does not contain the term . We overcome this difficulty by a compactness and scaling approach.
Lemma 6.
For all constants , and , there exists , so that
| (18) |
Proof.
Lemma 7.
There exist
| (19) |
so that for all , and all ,
| (20) |
where is the diagonal matrix with diagonal elements .
Proof.
Lemma 8.
Let be a diagonal matrix with entries , and assume that, for some ,
| (22) |
Then
| (23) |
and, for all ,
| (24) |
Proof.
From the preceding lemmas, we can now deduce our converse montonicity result.
Corollary 9.
There exist , and , so that the following holds.
-
(a)
For all , and ,
and thus, a fortiori, for ,
-
(b)
For all ,
and thus, a fortiori, for ,
-
(c)
The non-linear forward mapping is injective.
-
(d)
For all , the linearized forward mapping is injective.
Proof.
Lemma 7 yields a diagonal matrix with diagonal elements , so that
Since
is a continuous mapping from , we obtain by compactness that
Setting , (a) follows from Lemma 8.
(b) follows from (a) as the convexity property (13) yields that
Clearly, (b) implies injectivity of . Since this holds for arbitrary large intervals , we obtain injectivity on all of , so that (c) is proven. Likewise, (d) follows from (a). ∎
Proof of Theorem 1 and Remark 2
We can now prove Theorem 1 with , and as given by Corollary 9. First note that Corollary 5 ensures that (5) and (6) are linear optimization problems on convex sets.
Let , and . Then is feasible for the optimization problem (5). For every other feasible , , the feasibility yields that , so that by Corollary 9(b). Hence, is the unique minimizer of the convex semi-definite optimization problem (5), and thus (a) is proven.
To prove (b), let , and be self-adjoint with . Since the constraint set of (6) is non-empty and compact, and the cost function is continuous, there exists a minimizer . Since also is feasible for (6), it follows that . By contraposition of Corollary 9(b) we obtain that
Hence, (b) follows, and the same argument also yields the Lipschitz stability result in Remark 2. The injectivity results are proven in Corollary 9,(c) and (d).
4.2 The case of finitely many measurements
We will now treat the case of finitely many measurements. As introduced in subsection 3.3, let have dense span in , and consider the finite-dimensional forward operator
with .
Monotonicity, convexity, and localized potentials
Again, we start by summarizing the monotonicity, convexity, and localized potentials properties of the forward operator.
Lemma 10.
-
(a)
is Fréchet differentiable with continuous derivative
is symmetric for all , and . Moreover,
for all , , (25) for all . (26) -
(b)
is monotonically decreasing, i.e. for all
(27) Also, for all , and ,
(28) -
(c)
is convex, i.e. for all , and ,
(29) -
(d)
For all , there exists , so that
(30)
Proof.
For all , , and , we have that
Hence, the monotonicity and convexity properties (a), (b), and (c), immediately carry over from that of the infinite-dimensional forward operator in Lemma 4.
To prove (d), it clearly suffices to show that, for all ,
We argue by contradiction, and assume that there exists , so that
| (31) |
By compactness, after passing to a subsequence, we can assume that , and for some , and . Since (31) also implies that
it follows by continuity that
However, since have dense span in , this would imply that
and thus contradict Lemma 4. ∎
As in the infinite-dimensional case, the continuity and convexity properties of the forward mapping yield that the admissible set of the optimization problems (8) and (9) is closed and convex.
Corollary 11.
For all , and every symmetric matrix , the set
is a closed convex set in .
Proof.
This follows from Lemma 10. ∎
A converse monotonicity result
We will now show that the converse monotonicity result in Corollary 9 still holds for the case of finitely many (but sufficiently many) measurements.
Lemma 12.
There exist , and , so that for sufficiently large , the following holds.
-
(a)
For all , and ,
and thus, a fortiori, for ,
-
(b)
For all ,
and thus, a fortiori, for ,
-
(c)
The non-linear forward mapping is injective.
-
(d)
For all , the linearized forward mapping is injective.
Proof.
Using Lemma 7, we obtain a diagonal matrix with diagonal elements , so that for all
By the same compactness argument as in the proof of Lemma 10(d), it follows that there exists with
Using compactness again we get that
and thus
Setting , and applying Lemma 8 with , , in place of , assertion (a) follows. Assertion (b)–(d) follow as in Corollary 9. ∎
Proof of Theorem 3
5 Conclusions and Outlook
We conclude this work with some remarks on the applicability of our results and possible extensions. The Calderón problem is infamous for its high degree of non-linearity and ill-posedness. The central point of this work is to show that the high non-linearity of the problem does not inevitably lead to the problem of local convergence (resp., local minima) demonstrated in section 2, but that convex reformulations are possible. In that sense, our result proves that it is principally possible to overcome the problem of non-linearity in the Calderón problem with finitely many unknowns.
Let us stress that this is purely a theoretical existence result and that our proofs are non-constructive in three important aspects: We show that there exists a number of measurements that uniquely determine the unknown conductivity values and allow for the convex reformulation, but we do not have a constructive method for calculating the required number of measurements. We show that the problem is equivalent to minimizing a linear functional under a convex constraint, but we do not have a constructive method for calculating the vector defining the linear functional. Also, we derive an error bound for the case of noisy measurements, but we do not have a constructive method for determining the error bound constant .
For the simpler, but closely related, non-linear inverse problem of identifying a Robin coefficient [15, 13, 14], constructive answers to these three issues are known. [14] gives an explicit (and easy-to-check) criterium to identify whether the number of measurements is sufficiently high for uniqueness and convex reformulation, and to explicitly calculate the stability constant in the error bound. The criterion is based on checking a definiteness property of certain directional derivatives in only finitely many evaluations points. A similar approach might be possible for the Calderón problem considered in this work, but the directional derivative arguments are technically much more involved and the extension of the arguments in [14] is far from trivial. Moreover, for the Robin problem one can simply choose , but this is based on stronger localized potentials results that do not hold for the Calderón problem. Finding methods to constructively characterize for the Calderón problem will be an important topic for further research. At that point, let us however stress again that our result shows that only depends on the given setting (i.e., the domain and pixel partition and the upper and lower conductivity bounds), but not on the unknown solution. Hence, for a fixed given setting, one could try to determine in an offline phase, e.g., by calculating for several samples of , and adapting to these samples.
References
- [1] A. Adler and D. Holder. Electrical impedance tomography: methods, history and applications. CRC Press, United States, 2021.
- [2] G. S. Alberti and M. Santacesaria. Calderón’s inverse problem with a finite number of measurements. In Forum of Mathematics, Sigma, volume 7. Cambridge University Press, 2019.
- [3] M. Brühl and M. Hanke. Numerical implementation of two noniterative methods for locating inclusions by impedance tomography. Inverse Problems, 16(4):1029, 2000.
- [4] A. P. Calderón. On an inverse boundary value problem. In W. H. Meyer and M. A. Raupp, editors, Seminar on Numerical Analysis and its Application to Continuum Physics, pages 65–73. Brasil. Math. Soc., Rio de Janeiro, 1980.
- [5] A. P. Calderón. On an inverse boundary value problem. Comput. Appl. Math., 25(2–3):133–138, 2006.
- [6] P. Caro and K. M. Rogers. Global uniqueness for the Calderón problem with Lipschitz conductivities. In Forum of Mathematics, Pi, volume 4. Cambridge University Press, 2016.
- [7] H. Garde. Reconstruction of piecewise constant layered conductivities in electrical impedance tomography. Communications in Partial Differential Equations, pages 1–16, 2020.
- [8] H. Garde. Simplified reconstruction of layered materials in EIT. Applied Mathematics Letters, 126:107815, 2022.
- [9] H. Garde and S. Staboulis. Convergence and regularization for monotonicity-based shape reconstruction in electrical impedance tomography. Numerische Mathematik, 135(4):1221–1251, 2017.
- [10] B. Gebauer. Localized potentials in electrical impedance tomography. Inverse Probl. Imaging, 2(2):251–269, 2008.
- [11] B. Harrach. Uniqueness and Lipschitz stability in electrical impedance tomography with finitely many electrodes. Inverse Problems, 35(2):024005, 2019.
- [12] B. Harrach. An introduction to finite element methods for inverse coefficient problems in elliptic PDEs. Jahresber. Dtsch. Math. Ver., 123(3):183–210, 2021.
- [13] B. Harrach. Uniqueness, stability and global convergence for a discrete inverse elliptic Robin transmission problem. Numerische Mathematik, 147(1):29–70, 2021.
- [14] B. Harrach. Solving an inverse elliptic coefficient problem by convex non-linear semidefinite programming. Optim. Lett., 16(5):1599–1609, 2022.
- [15] B. Harrach and H. Meftahi. Global uniqueness and Lipschitz-stability for the inverse Robin transmission problem. SIAM Journal on Applied Mathematics, 79(2):525–550, 2019.
- [16] B. Harrach and J. K. Seo. Exact shape-reconstruction by one-step linearization in electrical impedance tomography. SIAM Journal on Mathematical Analysis, 42(4):1505–1518, 2010.
- [17] B. Harrach and M. Ullrich. Monotonicity-based shape reconstruction in electrical impedance tomography. SIAM Journal on Mathematical Analysis, 45(6):3382–3403, 2013.
- [18] A. Kirsch. Characterization of the shape of a scattering obstacle using the spectral data of the far field operator. Inverse problems, 14(6):1489, 1998.
- [19] M. V. Klibanov, J. Li, and W. Zhang. Convexification of electrical impedance tomography with restricted Dirichlet-to-Neumann map data. Inverse Problems, 2019.
- [20] R. Kohn and M. Vogelius. Determining Conductivity by Boundary Measurements. Comm. Pure Appl. Math., 37:289–298, 1984.
- [21] R. Kohn and M. Vogelius. Determining conductivity by boundary measurements II. Interior results. Comm. Pure Appl. Math., 38:643–667, 1985.
- [22] K. Krupchyk and G. Uhlmann. The Calderón problem with partial data for conductivities with 3/2 derivatives. Communications in Mathematical Physics, 348(1):185–219, 2016.
- [23] A. Lechleiter and A. Rieder. Newton regularizations for impedance tomography: convergence by local injectivity. Inverse Problems, 24(6):065009, 18, 2008.
- [24] A. Lechleiter and A. Rieder. Newton regularizations for impedance tomography: convergence by local injectivity. Inverse Problems, 24(6):065009, 2008.
- [25] J. L. Mueller and S. Siltanen. Linear and nonlinear inverse problems with practical applications. SIAM, United States, 2012.
- [26] J. K. Seo and E. J. Woo. Nonlinear inverse problems in imaging. John Wiley & Sons, United States, 2012.
- [27] A. Tamburrino and G. Rubinacci. A new non-iterative inversion method for electrical resistance tomography. Inverse Problems, 18(6):1809, 2002.