The Causality Inference of Public Interest in Restaurants and Bars on COVID-19 Daily Cases in the US: A Google Trends Analysis
Abstract
The COVID-19 coronavirus pandemic has affected virtually every region of the globe. At the time of conducting this study, the number of daily cases in the United States is more than any other country, and the trend is increasing in most of its states. Google trends provide public interest in various topics during different periods. Analyzing these trends using data mining methods might provide useful insights and observations regarding the COVID-19 outbreak. The objective of this study was to consider the predictive ability of different search terms (i.e., bars and restaurants) with regards to the increase of daily cases in the US. In particular, we were concerned with searches for dine-in restaurants and bars. Data were obtained from Google trends API and COVID tracking project. We considered the causation of two different search query trends, namely restaurant and bars, on daily positive cases in top-10 states/territories of the United States with the highest and lowest daily new positive cases. In addition, to measure the linear relation of different trends, we used Pearson correlation. Our results showed for states/territories with higher numbers of daily cases, the historical trends in search queries related to bars and restaurants, which mainly happened after re-opening, significantly affect the daily new cases, on average. California, for example, had most searches for restaurants on June 7th, 2020, which affected the number of new cases within two weeks after the peak with the P-value of .004 for Granger’s causality test. Although a limited number of search queries were considered, Google search trends for restaurants and bars showed a significant effect on daily new cases for regions with higher numbers of daily new cases in the United States. We showed that such influential search trends could be used as additional information for prediction tasks in new cases of each region. This prediction can help healthcare leaders manage and control the impact of COVID-19 outbreaks on society and be prepared for the outcomes.
Keywords:
Coronavirus, COVID-19, Google Trends, Machine Learning, LSTM, Restaurants, Bars.I INTRODUCTION
The entire world has been affected significantly by a global virus pandemic. The first case of this virus was reported in China during December 2019, and the first case outside China was discovered in January 2020 [1]. During February, the World Health Organization called this virus COVID-19 [2].
Worldwide, there have been 14.4M confirmed cases, with 604K deaths, as of 19th of July 2020 [3]. The United States of America, with 3.83M confirmed cases and 143k deaths, is the most affected country around the world. In some states, the numbers are still increasing (e.g., California), while in some other states such as New York, the peak has passed, and the average daily new cases are decreasing.
Due to the rapid spreading of this virus, finding effective reasons can play a significant role in prevention policies. Using data mining and time series analysis methods, it is possible to investigate the impact of different phenomena on time series data. In economics, as an example, there are different studies that model the temporal relationship of two or more time series (e.g., the relationship between oil and gold price) using the same methods [4].
Google search trends can be useful for reflecting public interests/concerns during different periods [5]. During the COVID-19 outbreak, different studies have investigated the correlation of web-based data and cases of this virus. Kutlu et al. [6] investigated the correlation of dermatological diseases obtained by specific Google search trends with the COVID-19 outbreak. In addition, Google trends have been utilized to predict and monitor COVID-19 cases around the world [5, 7, 8, 9, 10, 11]. Multiple studies analyzed the data related to the US to correlate the search trends and COVID-19 cases [12, 13, 14, 15, 16, 17]. However, these studies did not consider the predictive ability of search trends on future confirmed cases.
In this paper, we considered the causality effect and predictive ability of search terms related to bars and restaurants on the daily new cases of the US in different regions. Along with the linear correlation analysis between search trends and COVID-19 cases, we have utilized the statistical causality methods to investigate the influential confidence of these methods on COVID-19 daily new cases.
II Methods
II-A Datasets
For our analysis, we obtained the daily cases of COVID-19 in the US using the COVID tracker project [18]. This project compiles the daily statistics, including the number of positive/negative tests, hospitalization, available ventilators, and the number of deaths from each US state and territory. For this study, we considered the data of approximately three months starting April 09, 2020, to July 07, 2020, which contains 5040 samples for 56 states/territories.
We used Google Trends to obtain the public interest in bars and restaurant categories with daily resolution. We used the most popular query for each category from April 09, 2020, to July 07, 2020, for 45 available regions in Google trends API. For restaurants and bars, we chose “dine-in restaurants that are open near me” and “bars near me”, respectively. Google trend does not provide the number of queries per day. Instead, it provides a normalized number between 0 and 100, where 0 refers to “low volume of data for the query” while 100 refers to the “highest popularity for the term” [19]. To be consistent with Google trend values, we normalized the US daily new cases between 0 and 100 in our analysis.
Aggregating data from Google trends results and COVID-19 daily cases, and removing missing values, resulted in available data for 45 regions in the US. We categorized our analysis to two different groups: First, top-10 states/territories with the highest number of daily new cases as of July 7th, 2020 which consist of Texas (TX), Florida (FL), California (CA), Arizona (AZ), Georgia (GA), Louisiana (LA), Tennessee (TN), North Carolina (NC), Washington (WA) and Pennsylvania (PA). Second, top-10 states/territories with the lowest number of daily new cases as of July 7th, 2020: Kansas (KS), Hawaii (HI), New Hampshire (NH), Maine (ME), West Virginia (WV), Rhode Island (RI), Connecticut (CT), Montana (MT), Nebraska (NE) and Delaware (DE).
II-B Correlation and Causation
To analyze the linear correlation of two time-series, the Pearson correlation has been utilized. The value of such a correlation ranges from -1 to 1, which shows a negative and positive correlation, respectively. Our analysis measured the Pearson correlation between the trends of search queries (i.e., restaurants and bars) and the daily new cases of COVID-19 in each state.
In addition, we used Granger’s causality [20] to model the influence of a time series’ past values on the new values of another time series. Granger’s causality tests whether the past values of a time series X cause the current values of another time series Y. Hence, in this study, the null hypothesis is that X’s past values do not affect Y’s current values. If the P-value is less than the marginal value (.05), we can reject the null hypothesis. In our analysis, we reported P-values for each aforementioned search query’s influence on the daily new cases. One of the main assumptions of modeling the influence of time series on each other is their stationarity. To test such a characteristic, we used the Augmented Dickey-Fuller (ADF) test [21] as our unit root test. This test determines the effect of a trend in the creation of the time series. In other words, it determines how strongly a trend defines a time series. The alternative hypothesis in the ADF test is the stationarity of the time series.
In this study, since the time series were not stationary, we applied first differencing on search trends and second differencing on daily new cases to make all of the three series stationary. For statistical analysis, we used the Python Statsmodel package [22].
II-C Vector Autoregression
In our study, we leveraged the fact that search trends might impact the daily new cases in the future; hence a Vector Autoregression (VAR) [23] model for each region was fitted to the data. A VAR model takes into account the influence of the past values of time series X and Y on current values of time series Y with a given lag order. Lag order with the lowest Akaike’s Information Criterion (AIC) was picked in this study. Since symptoms may appear within 2-14 days after exposure to the COVID-19 virus [24], a maximum of 14 lags was used. The equation for the VAR model with two lags is summarized below:
In this model, represents the value of time series at time , which consists of a combination of previous lag values from and with different weights and random white noise, . We fitted a VAR model to perform Granger’s causality test.
II-D Long Short-Term Memory
Long Short-Term Memory (LSTM) [25] models are a type of recurrent neural network useful for time series prediction. These models capture the long term effect of time series as well as their most recent values. In this study, we utilized LSTMs to predict the daily new cases using two sets of features: 1) the historical values of the new cases time series and 2) using additional information from searching query time series. We used 70% of the data for training, and the rest were used for evaluation of the model. Root mean square error (RMSE) was selected as the performance metric. RMSE can be calculated as follows:
In this equation, is the number of samples, is the predicted value, and is the actual value of the time series.
The architecture of the used model is illustrated in Fig. 1. It consists of 3 LSTM layers along with dropout layers, and a fully connected layer at the end. Dropout layers were utilized to avoid overfitting, which is a typical problem in Machine Learning tasks. To train such a model, we used the TensorFlow package of Python.
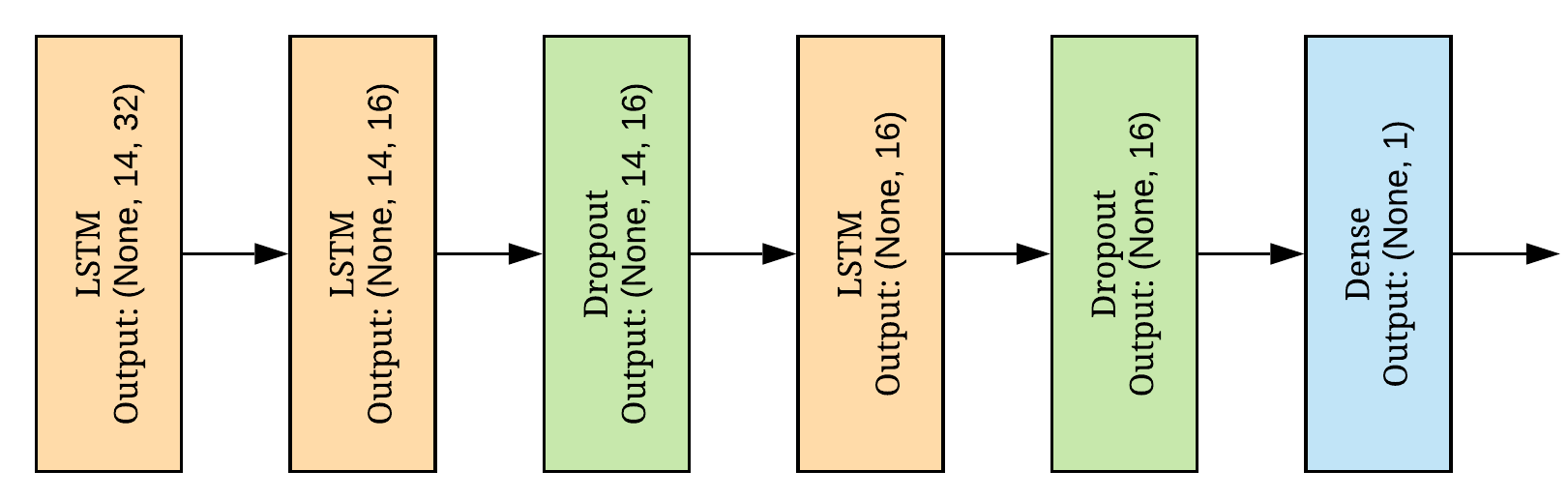
III Results
Observation. Search trends and the daily new cases can be different in each state/territory. Hence, the significance level of influence of search-related time series on the current values of daily new cases is different in each region. For the sake of comparison, Fig. 2 illustrates the moving average trend of “bar and restaurant” searches as well as the daily new cases in California (CA) and Delaware (DE).
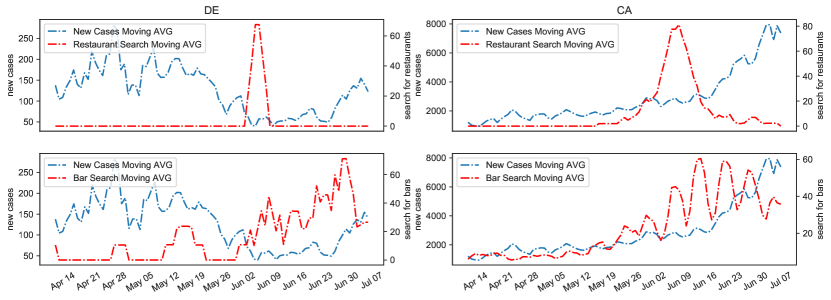
Fig. 2 shows for regions such as CA, there was a steep rise of restaurant searches peaking on June 7th. The daily new cases have a drastic increase within two weeks of such a peak. Considering the bar searches in CA, the plot shows an increasing trend with peak value on June 13th. However, in DE, the daily new cases are not profoundly affected by such search trends. One reason could be the lower population as it is reflected in the number of daily new cases. The other reason can be the high number of new daily cases in California at the time of re-opening restaurants and bars (+2000).
Granger’s Causality Test. Due to the inclusion of a large number of states/territories in our analysis (45), we picked top-10 regions in the US with the highest and lowest daily new cases as of July 7th, 2020. Table I summarizes the P-values for testing the null hypothesis (the coefficients corresponding to past values of the second time series are zero) for the first group. P-values below .05 represents the rejection of the null hypothesis, which shows the effect of searching queries on daily new cases for each region.
| causing -> caused | Texas | Florida | California | Arizona | Georgia | Louisiana | Tennessee | North Carolina | Washington | Pennsylvania |
|---|---|---|---|---|---|---|---|---|---|---|
| Restaurant search -> new cases | 0.108 | 0.35 | 0.004 | 0.003 | 0.30 | <0.001 | 0.091 | 0.53 | <0.001 | 0.108 |
| Bar search -> new cases | 0.019 | 0.15 | <0.001 | 0.042 | 0.001 | <0.001 | 0.075 | 0.19 | 0.016 | 0.013 |
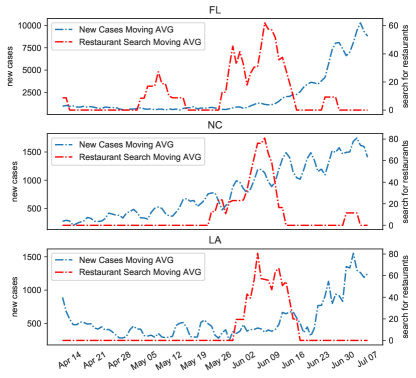
Based on Table I, California has small P-values, which shows the influence of the aforementioned search queries on daily new cases; hence, they can be used to predict daily new cases. Florida and North Carolina are two examples of states that the effect of restaurants is rejected with the Granger’s Causality Test; however, Louisiana clearly is affected by restaurant searches. Fig. 3 illustrates the moving average of daily new cases and restaurant search trends for these three states. Based on Fig. 3, the high P-value for Florida is because of the first peak in the restaurant search, which did not change the daily new cases trends. North Carolina has an overall increasing trend, causing the effect of the search to be marginal. However, Louisiana is influenced by the sudden changes in restaurant search trends, which clearly have affected the daily new cases.
Similarly, Table II summarizes the P-values for Granger’s causality test for the second group (i.e., top-10 regions with the lowest daily new cases).
| causing -> caused | Kansas | Hawaii | New Hampshire | Maine | West Virginia | Rhode Island | Connecticut | Montana | Nebraska | Delaware |
|---|---|---|---|---|---|---|---|---|---|---|
| Restaurant search -> new cases | 0.99 | <0.001 | 0.88 | 0.077 | 0.081 | 0.54 | 0.99 | <0.001 | 0.99 | 1.0 |
| Bar search -> new cases | 0.014 | 0.001 | 0.05 | 0.11 | 0.45 | 0.28 | 0.008 | 0.073 | 0.083 | <0.001 |
Comparison between Tables I and II shows that regions with higher daily cases are more affected by restaurant and bar searches on average.
Pearson Correlation To show the linear relationship of time series, the Pearson correlation is utilized. Tables III and IV summarize these correlations with corresponding P-values for each group. Based on these two tables, the linear correlation between the search trends related to bars/restaurants and daily new cases in regions with a higher number of daily cases is more substantial, on average, compared to regions with lower daily cases.
| Correlation (r [P-value]) | Texas | Florida | California | Arizona | Georgia | Louisiana | Tennessee | North Carolina | Washington | Pennsylvania |
|---|---|---|---|---|---|---|---|---|---|---|
| Restaurant vs. New cases | -0.17 [0.111] | -0.19 [0.072] | -0.0 [0.966] | -0.11 [0.301] | -0.2 [0.065] | -0.13 [0.235] | -0.18 [0.081] | 0.17 [0.107] | -0.11 [0.29] | -0.23 [0.027] |
| Bar vs. New cases | 0.11 [0.289] | 0.41 [<0.001] | 0.47 [0.0] | 0.31 [0.003] | 0.31 [0.003] | 0.12 [0.264] | 0.39 [<0.001] | 0.73 [<0.001] | 0.13 [0.209] | -0.52 [<0.001] |
| Correlation (r [P-value]) | Kansas | Hawaii | New Hampshire | Maine | West Virginia | Rhode Island | Connecticut | Montana | Nebraska | Delaware |
|---|---|---|---|---|---|---|---|---|---|---|
| Restaurant vs. New cases | -0.05 [.62] | -0.08 [.43] | -0.08 [.45] | -0.08 [.42] | 0.09 [.35] | -0.08 [.42] | -0.06 [.55] | -0.01 [.85] | -0.05 [.61] | -0.17 [.097] |
| Bar vs. New cases | -0.20 [.057] | 0.22 [.030] | -0.11 [.27] | 0.13 [.21] | 0.11 [.28] | -0.61 [<.001] | -0.22 [.035] | 0.19 [.070] | 0.007 [.94] | -0.18 [.087] |
New Cases Prediction. We used LSTM models to predict the value of daily new cases for a given region. We utilized the search trend time series as additional information to adjust the predicted values. The RMSE scores for test data for top-10 highest and lowest daily new cases are summarized in Tables V and VI. These tables show the results for:
-
1.
the baseline model which uses only the past values of new cases time series for the prediction,
-
2.
the model that uses the past values of restaurant searches along with the past values of new cases time series,
-
3.
and, finally, the model that combines the information from the daily cases and bar searches time series.
| Model | Texas | Florida | California | Arizona | Georgia | Louisiana | Tennessee | North Carolina | Washington | Pennsylvania |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 18.00 | 48.21 | 24.19 | 31.35 | 29.90 | 39.84 | 35.88 | 19.74 | 26.44 | 18.70 |
| Baseline + Restaurants | 32.44 | 43.84 | 21.86 | 45.32 | 33.46 | 29.36 | 32.51 | 22.91 | 23.92 | 18.10 |
| Baseline + Bars | 44.50 | 32.55 | 19.89 | 26.20 | 36.39 | 43.51 | 38.09 | 26.68 | 22.75 | 24.68 |
Table V shows that regions with a significant causality effect, the RMSE improves on average. CA is an example of such an improvement.
| Model | Kansas | Hawaii | New Hampshire | Maine | West Virginia | Rhode Island | Connecticut | Montana | Nebraska | Delaware |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 28.41 | 51.49 | 12.09 | 20.92 | 26.18 | 5.37 | 3.47 | 29.58 | 5.49 | 20.73 |
| Baseline + Restaurants | 25.56 | 43.64 | 8.10 | 14.57 | 22.55 | 8.88 | 3.91 | 43.34 | 8.22 | 20.42 |
| Baseline + Bars | 34.43 | 49.01 | 15.30 | 21.96 | 24.15 | 6.01 | 4.68 | 43.27 | 8.67 | 12.81 |
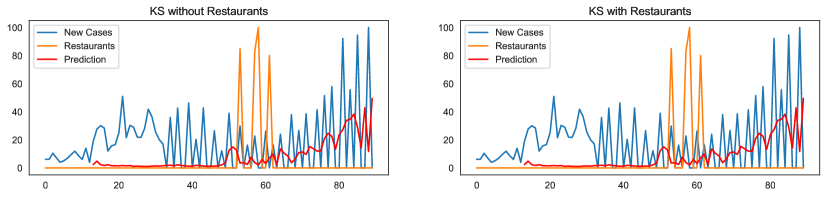
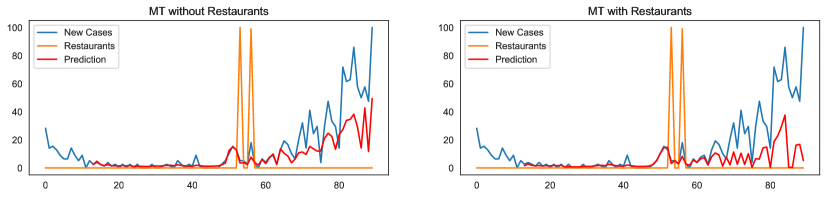
Table VI shows for some states, although there is no causality effect for the restaurants, the value of RMSE improves. On the other hand, for states like Montana (MT), which Granger’s Causality Test shows a significant effect, the RMSE has been increased. By investigating the time series for these two states (Figs. 4 and 5), we can interpret such inconsistencies for two reasons. First, for states such as Kansas (KS), the improved value is because of the fluctuation in the new cases time series, making the prediction unreliable. Second, as Figs. 4 and 5 show, the impulses in restaurant searches for KS and MT are point impulses. These unit jumps cannot improve the prediction of the time series, although they appear in causality tests.
IV DISCUSSION
IV-A Principal Results
To the best of our knowledge, this study is the first analysis that considers the predictive ability of Google search trends, namely restaurants and bars, on daily new cases of COVID-19 in the US. This study uses statistical methods to validate such an effect on daily new cases.
Granger’s causality test shows that in some regions, the effect of restaurants on daily new cases is significant. California is an example of such states. On May 18th, the governor of California announced the easing of criteria for counties to re-open faster than the state, and on May 25th he announced plans for the re-opening of in-store shopping [26]. Consequently, there was an increase in restaurant searches, and the peak of the searches happened on June 7th. The daily new cases drastically increased within two weeks of the escalation in dine-in restaurant searches.
Similarly, such a trend in bar searches happened in California (Fig. 2). Regardless of the seasonal effect of time series, which shows a higher number of searches for bars during weekends, the average trend in bar searches increased. However, North Carolina is not influenced by restaurant searches (Table I). The reason is that this state has an increasing average trend regardless of the other time series (Fig. 3). Therefore the P-value for Granger’s causality is high (.53).
This study suggests that the effect of restaurant and bar searches is higher in the regions with higher daily new cases compared to the regions that have a lower number of positive cases reporting every day. On average, in the regions with a higher number of daily new cases, more significant Granger’s casualties and higher values of Pearson correlation support this fact.
We used artificial intelligence models to improve the prediction results of new cases using additional information, namely Google trends. These Google trends for restaurants and bars can be useful depending on the time series structure. Prediction in time series uses the information of previous values (lags) to estimate the current values.
IV-B Limitations
There are several limitations to this study. We only used the most popular search queries suggested by Google for each category. People use different search terms to find the information they are looking for. Moreover, we only considered the effect of restaurants and bars on daily cases. The other limitation of our study can be the limited number of samples for each region (88 samples on average). This limitation affects the prediction results to a certain degree.
V CONCLUSION
In conclusion, we investigated the causality effect of search queries related to restaurants and bars on daily new cases in the US regions with high and low daily cases. We showed that for most of the regions with a high number of daily new cases, the effect of search queries on bars and restaurants is higher; hence, they can be used as additional information for prediction tasks.
References
- [1] A comprehensive timeline of the coronavirus pandemic at 6 months, from China’s first case to the present, accessed July 21, 2020. [Online]. Available: https://www.businessinsider.com/coronavirus-pandemic-timeline-history-major-events-2020-3
- [2] Y.-R. Guo, Q.-D. Cao, Z.-S. Hong, Y.-Y. Tan, S.-D. Chen, H.-J. Jin, K.-S. Tan, D.-Y. Wang, and Y. Yan, “The origin, transmission and clinical therapies on coronavirus disease 2019 (covid-19) outbreak–an update on the status,” Military Medical Research, vol. 7, no. 1, pp. 1–10, 2020.
- [3] Worldometer. COVID coronavirus Outbreak., accessed July 19, 2020. [Online]. Available: https://www.worldometers.info/coronavirus/
- [4] J. Šimáková, “Analysis of the relationship between oil and gold prices,” Journal of finance, vol. 51, no. 1, pp. 651–662, 2011.
- [5] S. M. Ayyoubzadeh, S. M. Ayyoubzadeh, H. Zahedi, M. Ahmadi, and S. R. N. Kalhori, “Predicting covid-19 incidence through analysis of google trends data in iran: data mining and deep learning pilot study,” JMIR Public Health and Surveillance, vol. 6, no. 2, p. e18828, 2020.
- [6] Ö. Kutlu, “Analysis of dermatologic conditions in turkey and italy by using google trends analysis in the era of the covid-19 pandemic,” Dermatologic therapy, p. e13949, 2020.
- [7] C. Li, L. J. Chen, X. Chen, M. Zhang, C. P. Pang, and H. Chen, “Retrospective analysis of the possibility of predicting the covid-19 outbreak from internet searches and social media data, china, 2020,” Eurosurveillance, vol. 25, no. 10, p. 2000199, 2020.
- [8] M. Effenberger, A. Kronbichler, J. I. Shin, G. Mayer, H. Tilg, and P. Perco, “Association of the covid-19 pandemic with internet search volumes: a google trendstm analysis,” International Journal of Infectious Diseases, 2020.
- [9] J. Ciaffi, R. Meliconi, M. P. Landini, and F. Ursini, “Google trends and covid-19 in italy: could we brace for impact?” Internal and Emergency Medicine, p. 1, 2020.
- [10] A. Mavragani, “Tracking covid-19 in europe: infodemiology approach,” JMIR public health and surveillance, vol. 6, no. 2, p. e18941, 2020.
- [11] A. Husnayain, A. Fuad, and E. C.-Y. Su, “Applications of google search trends for risk communication in infectious disease management: A case study of covid-19 outbreak in taiwan,” International Journal of Infectious Diseases, 2020.
- [12] X. Yuan, J. Xu, S. Hussain, H. Wang, N. Gao, and L. Zhang, “Trends and prediction in daily new cases and deaths of covid-19 in the united states: An internet search-interest based model,” Exploratory research and hypothesis in medicine, vol. 5, no. 2, p. 1, 2020.
- [13] Y.-R. Hong, J. Lawrence, D. Williams Jr, and A. Mainous Iii, “Population-level interest and telehealth capacity of us hospitals in response to covid-19: cross-sectional analysis of google search and national hospital survey data,” JMIR Public Health and Surveillance, vol. 6, no. 2, p. e18961, 2020.
- [14] A. Walker, C. Hopkins, and P. Surda, “The use of google trends to investigate the loss of smell related searches during covid-19 outbreak,” in International Forum of Allergy & Rhinology. Wiley Online Library, 2020.
- [15] I. Husain, B. Briggs, C. Lefebvre, D. M. Cline, J. P. Stopyra, M. C. O’Brien, R. Vaithi, S. Gilmore, and C. Countryman, “How covid-19 public interest in the united states fluctuated: A google trends analysis.” JMIR Public Health and Surveillance, 2020.
- [16] N. C. Jacobson, D. Lekkas, G. Price, M. V. Heinz, M. Song, A. J. O’Malley, and P. J. Barr, “Flattening the mental health curve: Covid-19 stay-at-home orders are associated with alterations in mental health search behavior in the united states,” JMIR mental health, vol. 7, no. 6, p. e19347, 2020.
- [17] A. Rajan, R. Sharaf, R. S. Brown, R. Z. Sharaiha, B. Lebwohl, and S. Mahadev, “Association of search query interest in gastrointestinal symptoms with covid-19 diagnosis in the united states: Infodemiology study,” JMIR Public Health and Surveillance, vol. 6, no. 3, p. e19354, 2020.
- [18] The COVID Tracking Project., accessed July 21, 2020. [Online]. Available: https://covidtracking.com/
- [19] FAQ about Google Trends data, accessed July 21, 2020. [Online]. Available: https://support.google.com/trends/answer/4365533?hl=en
- [20] C. W. Granger, “Investigating causal relations by econometric models and cross-spectral methods,” Econometrica: journal of the Econometric Society, pp. 424–438, 1969.
- [21] W. A. Fuller, Introduction to statistical time series. John Wiley & Sons, 2009, vol. 428.
- [22] S. Seabold and J. Perktold, “statsmodels: Econometric and statistical modeling with python,” in 9th Python in Science Conference, 2010.
- [23] S. Johansen et al., Likelihood-based inference in cointegrated vector autoregressive models. Oxford University Press on Demand, 1995.
- [24] Symptoms of Coronavirus, accessed July 20, 2020. [Online]. Available: https://www.cdc.gov/coronavirus/2019-ncov/symptoms-testing/symptoms.html
- [25] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [26] Timeline of COVID-19 policies, cases, and deaths in your state - Johns Hopkins Coronavirus Resource Center, accessed July 20, 2020. [Online]. Available: https://coronavirus.jhu.edu/data/state-timeline/new-confirmed-cases/california/53