The Good, the Bad, and the (Un)Usable:
A Rapid Literature Review on Privacy as Code
Abstract
Privacy and security are central to the design of information systems endowed with sound data protection and cyber resilience capabilities. Still, developers often struggle to incorporate these properties into software projects as they either lack proper cybersecurity training or do not consider them a priority. Prior work has tried to support privacy and security engineering activities through threat modeling methods for scrutinizing flaws in system architectures. Moreover, several techniques for the automatic identification of vulnerabilities and the generation of secure code implementations have also been proposed in the current literature. Conversely, such as-code approaches seem under-investigated in the privacy domain, with little work elaborating on (i) the automatic detection of privacy properties in source code or (ii) the generation of privacy-friendly code. In this work, we seek to characterize the current research landscape of Privacy as Code (PaC) methods and tools by conducting a rapid literature review. Our results suggest that PaC research is in its infancy, especially regarding the performance evaluation and usability assessment of the existing approaches. Based on these findings, we outline and discuss prospective research directions concerning empirical studies with software practitioners, the curation of benchmark datasets, and the role of generative AI technologies.
Index Terms:
privacy engineering, privacy as code, rapid literature review, usability, automated software engineeringI Introduction
Privacy engineering has become an imperative part of modern software development due to the emergence of strict legal frameworks such as the General Data Protection Regulation (GDPR) in the European Union [1]. Overall, it involves multiple activities (e.g., privacy requirements elicitation and threat modeling) that, altogether, seek to (i) bring privacy to the forefront of the development pipeline and (ii) facilitate compliance with these legal provisions and data protection standards alike [2]. Nonetheless, it remains a challenging task for many developers who do not count on extensive privacy training from either a technical or a legal perspective [3, 4]. In turn, privacy requirements are often seen as an afterthought, resulting in system designs and architectures devoid of data protection measurements and prone to personal information breaches [5].
To revert this tendency, prior work has introduced a wide array of methods and tools that support developers on privacy engineering activities [1]. These include privacy-aware methodologies for risk management and threat modeling that facilitate the selection and operationalization of Privacy-Enhancing Technologies (PETs) such as differential privacy, federated learning, and homomorphic encryption [6]. LINDDUN [7] is one of the most popular of these methods, which consists of a catalog of privacy threats that can be easily identified at the architectural level of an information system. That is, from an abstract representation of the key computing elements of the system under analysis and the information flows exchanged between them [8]. This approach, in which architectural models are leveraged to conduct privacy assessments, is followed by many other frameworks and standards such as ProPAN [9], PRIPARE [10], and the ISO 27550 [11]. Still, these techniques cannot guarantee full coverage, as architectural representations are often produced manually by analysts and do not necessarily correlate with the actual implementation of the system [8]. Consequently, gaps in the identification of privacy flaws may emerge depending on the precision and granularity of these representations [12, 13].
Motivation: Motivated by the limitations of architecture-centered methods, recent work started to explore techniques for the (semi) automatic identification of privacy properties in source code with minimum human intervention [14]. Such analysis techniques are already quite mature and well-investigated in the security domain [15]. For instance, static security analysis tools allow for the early identification of vulnerabilities by checking the syntax, logic, and structure of source code. Dynamic tools, on the other hand, do so by running the code and observing its behavior under specific user inputs and execution scenarios [16]. Although the latter has been fairly investigated in the privacy realm (though largely concentrated on Android) [17], the former remains underexplored and calls for a systematic assessment of the state-of-the-art. Particularly, a deep dive into the challenges and limitations of static analysis tools for privacy would help outline future research directions. Furthermore, given (i) the increasing number of tools targeting secure code generation available in the current literature and (ii) recent advances in generative Artificial Intelligence (AI) technologies, a knowledge synthesis of existing approaches addressing privacy-friendly implementations would also be beneficial.
Contribution and Research Questions: This work provides a quick yet actionable overview of Privacy as Code (PaC) methods and tools documented in the current literature. That is, on approaches elaborating either on (i) the automatic detection of privacy properties in source code, or (ii) the automatic generation of privacy-friendly implementations. Particularly, we delve into the scope, technicalities, and limitations of state-of-the-art approaches through a rapid literature review. All in all, we aim to answer the following Research Questions (RQs):
-
•
RQ1: What is the scope of the techniques implemented by PaC methods and tools? Code generated by PaC tools should implement one (or more) well-known privacy design strategies, such as minimizing, abstracting, or hiding users’ personal information [18]. Similarly, PaC analysis tools should be capable of identifying threats such as unawareness, data disclosure, or non-compliance [7]. Hence, to answer this RQ, we identify the privacy threats and design strategies addressed by the primary studies selected in this review.
-
•
RQ2: What are the core technical foundations of PaC methods and tools? Abstract source code representations, such as call graphs or abstract syntax trees, are fundamental to static analysis tools, as they help identify common programming mistakes. To answer this RQ, we summarize the code representation methods employed in the PaC literature and the programming languages covered by them.
-
•
RQ3: What are the main challenges and limitations of PaC methods and tools? Finally, we identify the issues and open challenges stemming from the current literature concerning the technical performance and usability of existing PaC approaches. Based on these findings, we elaborate and discuss a roadmap to guide future research endeavors around PaC methods and tools.
II Background and Related Work
Privacy as Architecture: As mentioned earlier, several methods have been proposed to assess privacy threats in software architectures [12, 19]. At their core, these methods often require a model of the system under scrutiny to identify privacy issues in the information flows across architectural components. In the case of LINDUNN [7], these models are expressed as Data Flow Diagrams (DFDs) depicting processes, data stores, external entities, and the data exchanged between them. Similar to STRIDE [20] (a threat modeling methodology for security), LINDDUN defines a schema of prospective privacy threats types that may affect specific DFD elements (i.e., Linkability, Identifiability, Non-repudiation, Detectability, information Disclosure, Unawareness, and Non-Compliance). Such a schema is used in combination with threat trees and misuse cases to elicit privacy threat scenarios and suitable PETs to mitigate them. Some approaches like PRIPARE [10] are agnostic with regard to the modeling language and can be applied in a top-down fashion (i.e., to model privacy requirements). Others like ProPAN [9] and PriS [21] operate on architectural requirements that must be specified either as goal models or structured descriptions of the system’s context. In any case, these methods demand significant manual effort and expertise that average analysts may lack [4, 13].
Privacy as Code: The term PaC was coined by the Ethyca group in the 2022 Open Security Summit as they presented FIDES, an open-source toolkit for checking privacy compliance in source code [22]. It embraces the same spirit as “security as code” does in the context of DevSecOps, namely, the continuous integration of security principles (e.g., controls, policies, and best practices) directly and seamlessly into the software development pipeline [23, 24]. Although PaC seems a novel concept, prior investigations have actively contributed to it for quite some time. For instance, Ferrara et al. [25] provided some initial ideas on how static program analysis techniques could support the detection of sensitive data processing in software systems. Particularly, they propose extending these techniques with categories of sensitive data, sources, and leakage points. Alongside, Hjerppe et al. [26] introduced an annotation schema for Java classes and functions to facilitate the automatic detection of privacy violations in code, whereas Tang et al. [27] do so with the help of regular expressions and a standardized representation of personal data flows. All these methods have expanded the body of knowledge in PaC, mainly from a technical perspective. However, their challenges, limitations, and usability gaps have not been systematically investigated nor discussed in the current literature to the best of our knowledge.
III Methodology
To answer the RQs proposed in Section I, we conducted a rapid literature review on PaC methods and tools (Fig. 1). Rapid Reviews (RRs) are popular in the software engineering domain as they offer a quick overview of available evidence while omitting or simplifying some of the steps prescribed by systematic review frameworks (e.g., by using fewer databases and quality checks) [28]. Thereby, they allow a timely yet actionable summarization of the state-of-the-art. In the following subsections, we describe the steps and materials used in this study.
III-A Literature Search (Steps 1 to 3)
Step 1 consists of defining the RQs to be answered by the RR, which, in this case, correspond to those presented in Section I. Next, we selected the engine and the string of keywords for the automated search of sources (Step 2). We chose Scopus111https://www.scopus.com/ as our only search engine as it collects up-to-date information from some of the most relevant software engineering libraries (e.g., ACM and IEEE Xplore). For defining and streamlining the search string, we opportunistically built a reference set of papers (i.e., [26] and [29]) addressing PaC. Such a reference set was used to test different combinations of search terms while ensuring relevant results (both papers should be included in the search output). After some iterations, we agreed on the query depicted in Fig. 2 and proceeded to process the literature items obtained from the automated search (Step 3), which account for 472 references in total.
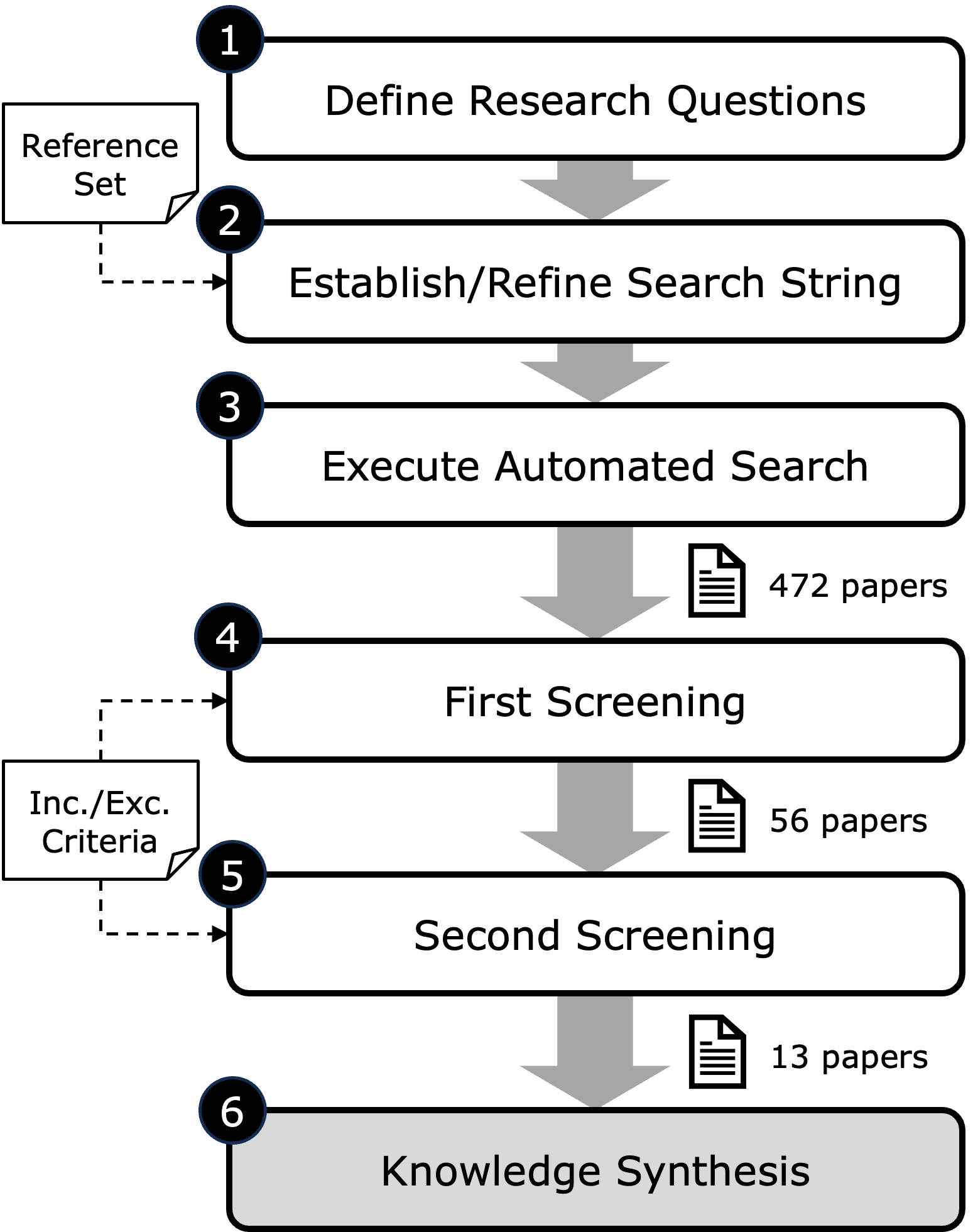
III-B Data Extraction (Steps 4 to 6)
We assessed the relevance of each reference gathered in Step 3 based on the following inclusion/exclusion criteria:
-
•
Inclusion criteria: Studies should describe privacy methods or tools that work at the code level. That is, either by (i) analyzing privacy threats in source code or (ii) generating privacy-friendly implementations. They should also achieve a certain level of automation in both cases and be published in peer-reviewed outlets (i.e., journals, conferences, or workshops). To further reduce the scope of our analysis, we focused exclusively on studies dated 2016 or later, namely, after the European Union formally adopted the GDPR.
-
•
Exclusion criteria: Studies addressing privacy solely on an architectural level were excluded. Same with papers not written in the English language and published before 2016. Grey literature, such as blog posts, white papers, and opinion pieces, was not taken into consideration. Sources from low-quality outlets (e.g., unknown venues) were also removed to reach a high standard of scientific evidence.
These criteria were first applied to the title and abstract of each of the 472 sources (Step 4), resulting in 56 papers that were then scrutinized in full (Step 5). At the end of this process, we retained 13 sources (see Table I) that underwent a knowledge synthesis process (Step 6). For this, we followed a lightweight open coding approach in which one author extracted emerging themes and patterns from the data under the lens of the proposed RQs. Another author reviewed these themes afterward and, if discrepancies arose, these were resolved through a negotiated agreement.
(“code”<OR>“tool”<OR>“static analysis”) <AND>
(“privacy analysis”<OR>“privacy protection”
<OR>“data privacy”)
<AND> (“compliance”<OR>“GDPR”)
IV Results and Discussion
The RR study was conducted in April 2024. In the next subsections, we report the findings of the knowledge synthesis process (summarized in Table II). All study materials, including the code book and annotated spreadsheets, are publicly available in the paper’s Replication Package222https://doi.org/10.5281/zenodo.14671296.
IV-A Scope and techniques (RQ1)
IV-A1 Code analysis
We observed that most PaC approaches in the literature focus on the analysis of privacy properties in source code (11 sources). Furthermore, they often apply some sort of static taint analysis technique to detect streams of confidential information flowing (either explicitly or implicitly) out of the system’s trust boundaries (e.g., to the Internet) [30]. For this, these techniques must first identify which types of sensitive data and leakage points exist in the system and how such data can be accessed (and leaked) across different program statements (e.g., method calls). Then, by reconstructing the control flows of the program, they can spot tainted execution paths in which sensitive data reach a leakage point without proper sanitization (e.g., non-encrypted).
Normally, it is the user of PaC tools (e.g., a privacy analyst) the one responsible for identifying (i) the personal data items in the code and (ii) the program statements processing them (often referred to as sources and sinks, respectively). This task is typically supported through annotation schemas and guidelines provided with the tools for the sake of consistency. For instance, Hjerppe et al. [26] defined a set of rules and tags for labeling Java classes processing personal data, whereas Ferrara et al. [30] prescribed a categorization of sensitive data and leakage points to annotate API methods and parameters. Another approach by Ferreira et al. [31] requires a user-defined list of personal data in the form of database tables and column names, while in some other cases, this is done in a more automated fashion through advanced NLP techniques. Such is the case of Grünewald and Schurbert [32], who applied Named Entity Recognition (NER) to create inventories of personal data stored across distributed web services, or Zhao et al. [17], who used a Bi-directional Long Short Term-Memory (LSTM) mechanism together with similarity metrics to map privacy policies to code variables.
When analyzed under the lens of LINDDUN, we can see that the scope of PaC analysis tools typically covers data disclosure and non-compliance threats, which is achieved (to a large extent) through the identification of unforeseen and unauthorized flows of personal data in the system’s code. Although a thorough GDPR compliance check would also require a definition of the corresponding privacy policies and relevant legal provisions (e.g., like in [31]), most approaches contribute to maintaining a record of the data processing activities in the software under scrutiny (Article 30). Other methods, like the one proposed by Grünewald et al. [33], address unawareness threats more explicitly through transparency vocabularies and domain-specific languages used to delimit the purpose and retention periods of data processing activities. Further information about the presence of pseudo-identifiers in database operations (i.e., read and write queries) can also support the identification of additional privacy threats such as linkability, as shown by Kunz et al. [29].
| Source | Year | Type | Approach | OS Tool |
| Ferrara et al. [30] | 2018 | conference | analyze | NO |
| Hjerppe et al. [26] | 2020 | conference | analyze | YES |
| Grünewald et al. [33] | 2021 | workshop | analyze | YES |
| Grünewald and Schurbert [32] | 2022 | conference | analyze | YES |
| Pallas et al. [34] | 2022 | conference | generate | YES |
| Zhao et al. [17] | 2022 | conference | analyze | YES |
| Ferreira et al. [31] | 2023 | conference | analyze | YES |
| Tang et al. [27] | 2023 | conference | analyze | NO |
| Hjerppe et al. [35] | 2023 | journal | analyze | YES |
| Kunz et al. [29] | 2023 | journal | analyze | NO |
| Goldsteen et al. [36] | 2023 | journal | generate | YES |
| Tang and Østvold [14] | 2024 | workshop | analyze | NO |
| Morales et al. [37] | 2024 | conference | analyze | NO |
IV-A2 Code generation
Only two PaC generation techniques were identified among the selected primary studies. One, proposed by Pallas et al. [34], consists of a collection of schema directives that enforce data minimization strategies in GraphQL web APIs. Such directives define post-processing steps (e.g., hashing) to be applied on precomputed data fields before returning them through the API. This approach is available as a plug-in for Apollo, a toolkit for building GraphQL solutions, and can be extended with custom access-control policies and information reduction methods. The second technique, by Goldsteen et al. [36], also addresses data minimization but in the context of Machine Learning (ML) projects and data-centric development pipelines. Like in the previous case, it implements data minimization strategies that can help reduce the amount of personal data needed to perform ML predictions. However, it also defines methods for anonymizing the training data of ML models while minimizing the impact on the model’s performance. For this, a surrogate model is trained and used to identify (and generalize) groups of samples that behave similarly. All in all, this approach and the one of Pallas et al. [34], narrow their scope to techniques for minimizing, hiding, or generalizing (abstracting) personal information in source code implementations.
IV-B Technical foundations (RQ2)
| Aspect | Approach | Sources |
| Technique | Static taint analysis | [30, 26, 35, 17, 31, 27, 29, 37, 14] |
| Other | [33, 32, 36, 34] | |
| Abstraction | Abstract Syntax Trees | [26, 35, 17, 27, 37, 14] |
| Code Property Graphs | [29] | |
| Call Graphs | [17, 14] | |
| Bytecode | [37] | |
| Other | [30, 31, 37] | |
| None | [33, 34, 36] | |
| Languages | Java | [30, 26, 27, 14, 35] |
| Javascript | [31, 27, 14] | |
| Python | [17, 29, 36] | |
| Go | [29] | |
| TypeScript | [27] | |
| Other (query, spec.) | [32, 33, 34, 37] | |
| Privacy threats | Data disclosure | [33, 32, 30, 26, 35, 17, 31, 27, 29, 37, 14] |
| Non compliance | [33, 32, 30, 26, 35, 17, 31, 27, 29, 37, 14] | |
| Unawareness | [33, 29, 31] | |
| Other | [29] | |
| Privacy design strategies | Minimize | [34, 36] |
| Abstract | [34, 36] | |
| Hide | [34] |
As mentioned earlier, source code abstractions play a major role in static analysis tools targeting the identification of security issues, and it is not the exception for PaC ones. As shown in Table II, most PaC analysis tools use abstract representations of the source code under analysis to spot personal data leakage within program statements. Among them, Abstract Syntax Trees (ASTs) are the most popular ones with 5 out of 11 approaches adopting it as part of their technical foundations. At their core, ASTs represent and organize a code’s syntax (e.g., statements, expressions, and control structures) into the nodes of a tree-like structure. ASTs are general-purpose data structures that do not focus on privacy per se. Hence, PaC methods either (i) enrich them with privacy properties or (ii) use them in tandem with other code abstractions to support the analysis of personal/sensitive information flows. For instance, Tang et al. [27] add personal data tags to ASTs using regular expressions and a predefined list of identifiers, whereas Zhao et al. [17] use Call Graphs (CGs) to obtain the corresponding privacy delivery path (i.e., how information is exchanged across subroutines).
Other abstractions such a Code Property Graphs (CPGs) [29] and Java bytecode [37] have also been employed in the PaC literature. The former consists of DFDs enhanced with taint labels extracted from code annotations or comments (e.g., @Identifier) indicating the presence of (pseudo-) identifiers and database operations. In the case of the latter, it corresponds to an intermediate low-level representation of Android application code which is packaged inside APK files along with other resources. Such a representation is used to statically examine the information flows in Android source code with the help of third-party tools like FlowDroid [38]. From Table II, we observe that most PaC tools focus on code written in Java/Javascript followed by applications implemented in Python. Some approaches also provide evidence about their applicability to other programming languages like Go (e.g., [29]) or TypeScript (e.g., [27]) but, in most cases, tools tend to concentrate on a single language. Other techniques addressing web services seek for privacy-related statements inside GraphQL queries [34], Infrastructure as Code files [32], and OpenAPI specifications [33].
IV-C Challenges and limitations (RQ3)
Like in the security domain, PaC tools struggle to achieve high levels of performance and scalability. Whereas some approaches are capable of checking systems consisting of several lines of code and dependencies (e.g., [29, 17]), their scalability is mainly impaired by the relatively high number of false positive warnings they produce. This translates into additional efforts from developers and code reviewers to exclude non-relevant results, namely information flows that may seem privacy-relevant at a glance, but actually are not [31, 29]. Such a limitation is particularly challenging when parsing code written in JavaScript or Python as variables can change their types at runtime [39]. On the other hand, the coverage of PaC tools is not perfect and highly dependent on predefined lists of “items of interest” (e.g., personal data types) and the precision of the rules (e.g., regular expressions) or the tools (e.g., FlowDroid) used for their identification. In turn, relevant sinks, sources, and data flows may be overlooked, significantly affecting the reliability of these techniques [14].
In terms of scope, there is a clear lack of PaC tools that (i) focus on the automatic generation of privacy-compliant code, and (ii) can run across multiple programming languages. Large Language Models (LLMs) like GPT-4 or LLaMa could help bridge these issues thanks to their advanced NLP capabilities. In fact, LLMs are being actively investigated to support the automatic generation of security-aware code from NL descriptions (e.g., [40]). Hence, many of these approaches could be, in principle, extrapolated to the privacy domain with minimum effort (e.g., by crafting privacy-aware code generation/analysis prompts). Still, privacy assessments are highly influenced by contextual factors (e.g., social norms or culture) that current LLM technologies struggle to navigate [41]. This could, for instance, lead to incomplete or biased privacy judgments resulting in critical data flows being systematically ignored. Certainly, current PaC approaches may also make such omissions. However, the privacy assumptions behind LLMs are much more difficult to expose than those of the state-of-the-art methods, which are often encoded as rules (e.g., regular expressions) easy to scrutinize. Therefore, transparency and explainability will become major challenges for the next generation of LLM-based PaC solutions.
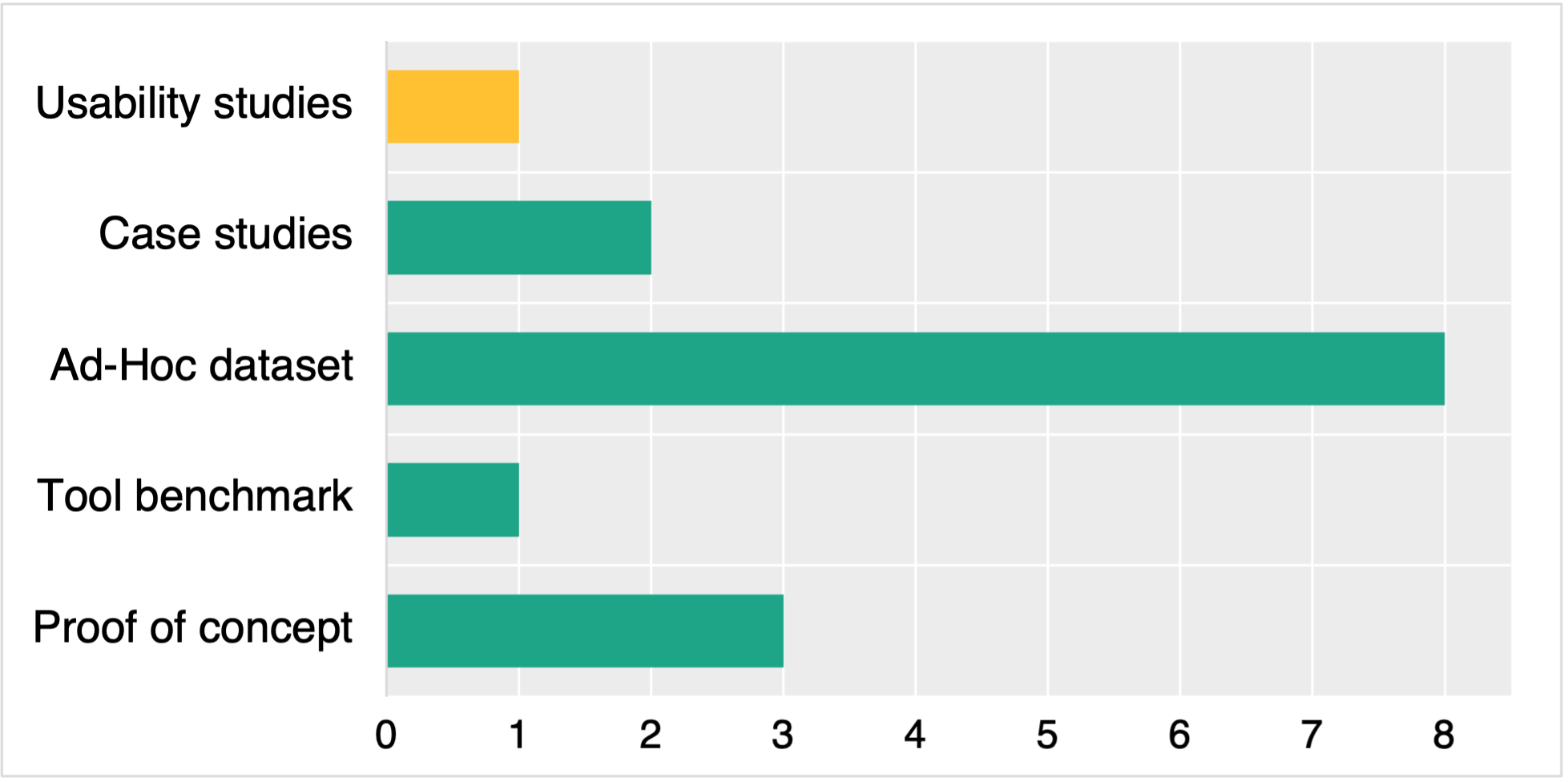
Conducting in-depth evaluations of PaC methods is still an open challenge, given the absence of well-established ground truth datasets [27]. As depicted in Fig. 3, most methods employ ad-hoc datasets for their evaluation [26, 17, 32, 27, 36, 29, 37, 14] or elaborate on case studies [31, 35], while others are simply reduced to conceptual demonstrations [30, 33, 34]. Hence, the performance of these tools is not measured properly outside their specific testing conditions, leaving many questions about their generalizability unanswered. Moreover, only one source compares their results against other (commercial) methods alike [32], whereas another one conducts a usability study of the proposed tool [31]. Considering the significant amount of manual work these approaches require (e.g., code annotations), a thorough assessment of their operability and ease of use becomes critical. This should be fostered through an Open Source (OS) culture across PaC researchers in which they are encouraged to make their tools publicly available for further investigations (e.g., empirical studies with software practitioners).
V Study Limitations
A single database (Scopus) was used in this study, which may have limited to some extent the number of reviewed sources. Furthermore, the proposed inclusion/exclusion criteria and the search query could also have constrained the selection of relevant PaC approaches. Nevertheless, the application of a forward snowballing iteration and the use of a reference set helped us to mitigate this threat. Regarding the screening and knowledge synthesis process, these were initially conducted by a single researcher. As described in Section III, another author closely reviewed the outputs of these steps to avoid confirmation and interpretation biases, respectively.
VI Conclusion and Future Work
All in all, PaC is a paradigm that promises to make privacy-by-design principles more accessible and actionable to software practitioners. Still, current approaches cannot guarantee full compliance on their own and exhibit significant limitations in terms of scope, performance, and usability. Moreover, although PaC’s promise of (full) automation seems appealing, one must bear in mind that privacy requires a thorough assessment of the context in which (personal) information flows across. In principle, this suggests that human judgment cannot be completely factored out from the development of privacy-friendly code despite the recent advances in Generative AI technologies. Instead, future PaC endeavors should actively support practitioners with methods and artifacts that help them navigate the complexities of contextual variables (e.g., trust assumptions, data sensitivity, and social norms). Therefore, large-scale evaluations of current and upcoming approaches are imperative in light of the sociotechnical factors influencing their adoption and technical soundness.
References
- Riva et al. [2020] G. M. Riva, A. Vasenev, and N. Zannone, “Sok: Engineering privacy-aware high-tech systems,” in Proceedings of the 15th International Conference on Availability, Reliability and Security, 2020, pp. 1–10.
- Iwaya et al. [2023] L. H. Iwaya, M. A. Babar, and A. Rashid, “Privacy engineering in the wild: Understanding the practitioners’ mindset, organizational aspects, and current practices,” IEEE Transactions on Software Engineering, vol. 49, no. 9, pp. 4324–4348, 2023.
- Aljeraisy et al. [2021] A. Aljeraisy, M. Barati, O. Rana, and C. Perera, “Privacy Laws and Privacy by Design Schemes for the Internet of Things: A Developer’s Perspective,” ACM Comput. Surv., vol. 54, no. 5, May 2021.
- Bednar et al. [2019] K. Bednar, S. Spiekermann, and M. Langheinrich, “Engineering privacy by design: Are engineers ready to live up to the challenge?” The Information Society, vol. 35, no. 3, pp. 122–142, 2019.
- Senarath and Arachchilage [2018] A. Senarath and N. A. Arachchilage, “Why developers cannot embed privacy into software systems? an empirical investigation,” in Proceedings of the 22nd International Conference on Evaluation and Assessment in Software Engineering 2018, 2018, pp. 211–216.
- Boteju et al. [2023] M. Boteju, T. Ranbaduge, D. Vatsalan, and N. A. G. Arachchilage, “Sok: Demystifying privacy enhancing technologies through the lens of software developers,” arXiv preprint arXiv:2401.00879, 2023.
- Wuyts et al. [2020] K. Wuyts, L. Sion, and W. Joosen, “LINDDUN GO: A lightweight approach to privacy threat modeling,” in IEEE European Symposium on Security and Privacy Workshops. IEEE, 2020, pp. 302–309.
- Tuma et al. [2019] K. Tuma, R. Scandariato, and M. Balliu, “Flaws in flows: Unveiling design flaws via information flow analysis,” in 2019 IEEE International Conference on Software Architecture (ICSA). IEEE, 2019, pp. 191–200.
- D´ıaz Ferreyra et al. [2020] N. E. Díaz Ferreyra, P. Tessier, G. Pedroza, and M. Heisel, “PDP-ReqLite: A lightweight approach for the elicitation of privacy and data protection requirements,” in ESORICS International Workshops. Springer, 2020.
- Notario et al. [2015] N. Notario, A. Crespo, Y.-S. Martín, J. M. Del Alamo, D. Le Métayer, T. Antignac, A. Kung, I. Kroener, and D. Wright, “Pripare: integrating privacy best practices into a privacy engineering methodology,” in 2015 IEEE Security and Privacy Workshops. IEEE, 2015, pp. 151–158.
- [11] “ISO/IEC TR 27550:2019 Information technology — Security techniques — Privacy engineering,” Tech. Rep. ISO/IEC TR 27550:2019, available: https://www.iso.org/standard/72024.html.
- Pattakou et al. [2018] A. Pattakou, A.-G. Mavroeidi, V. Diamantopoulou, C. Kalloniatis, and S. Gritzalis, “Towards the design of usable privacy by design methodologies,” in 2018 IEEE 5th International Workshop on Evolving Security & Privacy Requirements Engineering (ESPRE). IEEE, 2018, pp. 1–8.
- Galvez and Gurses [2018] R. Galvez and S. Gurses, “The odyssey: Modeling privacy threats in a brave new world,” in 2018 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW). IEEE, 2018, pp. 87–94.
- Tang and Østvold [2024] F. Tang and B. M. Østvold, “Finding Privacy-Relevant Source Code,” in 2024 IEEE International Conference on Software Analysis, Evolution and Reengineering-Companion (SANER-C). IEEE, 2024, pp. 111–118.
- Ami et al. [2024] A. S. Ami, K. Moran, D. Poshyvanyk, and A. Nadkarni, “" false negative-that one is going to kill you": Understanding industry perspectives of static analysis based security testing,” in 2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 3979–3997.
- Song et al. [2019] D. Song, J. Lettner, P. Rajasekaran, Y. Na, S. Volckaert, P. Larsen, and M. Franz, “Sok: Sanitizing for security,” in 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1275–1295.
- Zhao et al. [2022] Y. Zhao, G. Yi, F. Liu, Z. Hui, and J. Zhao, “A Framework for Scanning Privacy Information based on Static Analysis,” in 2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS). IEEE, 2022, pp. 1135–1145.
- Hoepman [2018] J.-H. Hoepman, “Privacy design strategies (the little blue book),” 2018.
- Senarath et al. [2019] A. Senarath, M. Grobler, and N. A. G. Arachchilage, “Will they use it or not? investigating software developers’ intention to follow privacy engineering methodologies,” ACM Transactions on Privacy and Security (TOPS), vol. 22, no. 4, pp. 1–30, 2019.
- Van Landuyt and Joosen [2022] D. Van Landuyt and W. Joosen, “A descriptive study of assumptions in stride security threat modeling,” Software and Systems Modeling, pp. 1–18, 2022.
- Kalloniatis et al. [2008] C. Kalloniatis, E. Kavakli, and S. Gritzalis, “Addressing privacy requirements in system design: the pris method,” Requirements Engineering, vol. 13, pp. 241–255, 2008.
- Piana [2022] T. L. Piana. (2022) Privacy As Code: Open-Source Developer Tools For Data Privacy. https://www.youtube.com/watch?v=qy\_O-13RzXA. Presented at the Open Security Summit 2022.
- Vakhula et al. [2023] O. Vakhula, I. Opirskyy, and O. Mykhaylova, “Research on security challenges in cloud environments and solutions based on the" security-as-code" approach,” in Proceedings of the Workshop Cybersecurity Providing in Information and Telecommunication Systems (CPITS 2024), 2023, pp. 55–69.
- Das and Chu [2023] B. S. Das and V. Chu, Security as Code. " O’Reilly Media, Inc.", 2023.
- Ferrara et al. [2018a] P. Ferrara, L. Olivieri, and F. Spoto, “Tailoring taint analysis to gdpr,” in Privacy Technologies and Policy: 6th Annual Privacy Forum, APF 2018, Barcelona, Spain, June 13-14, 2018, Revised Selected Papers 6. Springer, 2018, pp. 63–76.
- Hjerppe et al. [2019] K. Hjerppe, J. Ruohonen, and V. Leppänen, “Annotation-Based Static Analysis for Personal Data Protection,” in IFIP Int. Summer School on Privacy and Identity Management. Springer, 2019, pp. 343–358.
- Tang et al. [2023] F. Tang, B. M. Østvold, and M. Bruntink, “Helping Code Reviewer Prioritize: Pinpointing Personal Data and its Processing,” in New Trends in Intelligent Software Methodologies, Tools and Techniques, vol. 371. IOS Press, 2023, pp. 109–124.
- Cartaxo et al. [2020] B. Cartaxo, G. Pinto, and S. Soares, “Rapid reviews in software engineering,” Contemporary Empirical Methods in Software Engineering, pp. 357–384, 2020.
- Kunz et al. [2023] I. Kunz, K. Weiss, A. Schneider, and C. Banse, “Privacy Property Graph: Towards Automated Privacy Threat Modeling Via Static Graph-Based Analysis,” Proceedings on Privacy Enhancing Technologies, 2023.
- Ferrara et al. [2018b] P. Ferrara, L. Olivieri, and F. Spoto, “Tailoring Taint Analysis to GDPR,” in Privacy Technologies and Policy: 6th Annual Privacy Forum, APF 2018, Barcelona, Spain, June 13-14, 2018, Revised Selected Papers 6. Springer, 2018, pp. 63–76.
- Ferreira et al. [2023] M. Ferreira, T. Brito, J. F. Santos, and N. Santos, “RuleKeeper: GDPR-aware Personal Data Compliance for Web Frameworks,” in IEEE Symposium on Security and Privacy. IEEE, 2023, pp. 2817–2834.
- Grünewald and Schurbert [2022] E. Grünewald and L. Schurbert, “Scalable Discovery and Continuous Inventory of Personal Data at Rest in Cloud Native Systems,” in International Conference on Service-Oriented Computing. Springer, 2022, pp. 513–529.
- Grünewald et al. [2021] E. Grünewald, P. Wille, F. Pallas, M. C. Borges, and M.-R. Ulbricht, “TIRA: An OpenAPI Extension and Toolbox for GDPR Transparency in RESTful Architectures,” in 2021 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW). IEEE, 2021, pp. 312–319.
- Pallas et al. [2022] F. Pallas, D. Hartmann, P. Heinrich, J. Kipke, and E. Grünewald, “Configurable Per-Query Data Minimization for Privacy-Compliant Web APIs,” in International Conference on Web Engineering, T. Di Noia, I.-Y. Ko, M. Schedl, and C. Ardito, Eds., 2022, pp. 325–340.
- Hjerppe et al. [2023] K. Hjerppe, J. Ruohonen, and V. Leppänen, “Extracting LPL Privacy Policy Purposes From Annotated Web Service Source Code,” vol. 22, no. 1. Springer, 2023, pp. 331–349.
- Goldsteen et al. [2023] A. Goldsteen, O. Saadi, R. Shmelkin, S. Shachor, and N. Razinkov, “AI Privacy Toolkit,” SoftwareX, vol. 22, p. 101352, 2023.
- Morales et al. [2024] G. Morales, K. Pragyan, S. Jahan, M. B. Hosseini, and R. Slavin, “A Large Language Model Approach to Code and Privacy Policy Alignment,” in 2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2024, pp. 79–90.
- Arzt et al. [2014] S. Arzt, S. Rasthofer, C. Fritz, E. Bodden, A. Bartel, J. Klein, Y. Le Traon, D. Octeau, and P. McDaniel, “FlowDroid: Precise context, flow, field, object-sensitive and lifecycle-aware taint analysis for Android apps,” ACM sigplan notices, vol. 49, no. 6, pp. 259–269, 2014.
- Staicu et al. [2019] C.-A. Staicu, D. Schoepe, M. Balliu, M. Pradel, and A. Sabelfeld, “An empirical study of information flows in real-world javascript,” in Proceedings of the 14th ACM SIGSAC Workshop on Programming Languages and Analysis for Security, 2019, pp. 45–59.
- Black et al. [2024] G. S. Black, B. P. Rimal, and V. M. Vaidyan, “Balancing Security and Correctness in Code Generation: An Empirical Study on Commercial Large Language Models,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2024.
- Brown et al. [2022] H. Brown, K. Lee, F. Mireshghallah, R. Shokri, and F. Tramèr, “What does it mean for a language model to preserve privacy?” in Proceedings of the 2022 ACM conference on fairness, accountability, and transparency, 2022, pp. 2280–2292.