by
The Impact of Persona-based Political Perspectives on Hateful Content Detection
Abstract.
While pretraining language models with politically diverse content has been shown to improve downstream task fairness, such approaches require significant computational resources often inaccessible to many researchers and organizations. Recent work has established that persona-based prompting can introduce political diversity in model outputs without additional training. However, it remains unclear whether such prompting strategies can achieve results comparable to political pretraining for downstream tasks. We investigate this question using persona-based prompting strategies in multimodal hate-speech detection tasks, specifically focusing on hate speech in memes. Our analysis reveals that when mapping personas onto a political compass and measuring persona agreement, inherent political positioning has surprisingly little correlation with classification decisions. Notably, this lack of correlation persists even when personas are explicitly injected with stronger ideological descriptors. Our findings suggest that while LLMs can exhibit political biases in their responses to direct political questions, these biases may have less impact on practical classification tasks than previously assumed. This raises important questions about the necessity of computationally expensive political pretraining for achieving fair performance in downstream tasks.
1. Introduction
Large language models (LLMs) have demonstrated remarkable capabilities across various tasks, but their potential political biases remain a significant concern for AI ethics and deployment. This is particularly crucial for content moderation systems, where biased models could disproportionately impact detection rates across different user groups, compromising the overall fairness of content moderation systems. While pretraining models on politically diverse corpora has been shown to improve downstream task fairness (Feng et al., 2023), this approach requires significant computational resources that are often inaccessible to many researchers and organizations.
Recent work has explored persona-based prompting as a more accessible alternative for introducing diversity in model outputs. Fröhling et al. (2024) showed that injecting synthetic personas into prompts can increase data annotation diversity, while Bernardelle et al. (2024) showed that this approach can be used to influence the original political viewpoint of LLMs. However, less attention has been paid to understanding how these political perspectives manifest in practical applications.
Our work bridges this gap by investigating how persona-based prompting can influence real-world applications of LLMs in multimodal hate speech detection, specifically focusing on hateful memes. By having a model assume the perspective of different personas mapped to various points on the Political Compass Test (PCT) (Feng et al., 2023; Röttger et al., 2024), we examine whether their political positioning influences classification decisions for hate speech in memes. This methodology allows us to investigate whether this approach can achieve similar benefits to those observed in previous political pretraining approaches while being more computationally efficient and accessible. Our investigation addresses two questions:
-
RQ1:
How do personas’ positions on the PCT correlate with their classification decisions in a hate speech detection task?
-
RQ2:
Does injecting explicit political leaning into persona descriptors alter their classification behavior?
We observe that there is no correlation between persona’s positions on the political compass and their decisions when classifying potentially harmful content. This held true across our experiments, even after strengthening the ideological components of the personas through explicit descriptors. Furthermore, while our investigation confirms that LLMs can display distinct political leanings when directly questioned about political topics, our results suggest that, when using persona-based prompting, these inherent biases play a small role in classification scenarios. However, since our study focused specifically on hate speech detection across a limited set of datasets, these findings may not generalize to other tasks where political biases could have stronger effects.
2. Related Work
LLM bias and downstream task fairness
Previous work has shown that political biases in LLMs can significantly impact fairness in downstream tasks. Feng et al. (2023) showed that pretraining data’s political orientation affects model performance in tasks like hate speech detection and misinformation classification, with models exhibiting different biases based on their training corpora. Their work revealed that models pretrained on politically diverse sources show varying patterns in how they treat different identity groups and partisan content. This suggests that LLMs encode and propagate political biases from their training data, which can lead to unfair treatment of certain groups or perspectives in practical applications. While pretraining on politically diverse data can help address these biases, such approaches often require substantial data and computational resources.
Persona-based prompting
Recent work has explored persona-based prompting as a more accessible alternative for controlling model behavior and mitigating bias. Fröhling et al. (2024) introduced this approach to increase diversity in annotation tasks by injecting different persona descriptions into model prompts, showing that persona descriptions can help elicit a wider range of valid perspectives. Building on this, Bernardelle et al. (2024) showed that persona-based prompting can effectively modulate models’ political orientations without requiring expensive retraining. Their work revealed that carefully crafted persona prompts can shift model responses along the political spectrum, offering a promising method for achieving political diversity in language model outputs. This prompting-based approach provides a more flexible and resource-efficient way to control model behavior than pretraining-based methods, while still maintaining the ability to capture diverse political perspectives. While this body of work establishes the effectiveness of persona-based prompting, our work extends this research by evaluating how persona-based political perspectives influence performance on multimodal hateful content detection tasks.
3. Methodology
Data
Our study utilizes three datasets: PersonaHub for synthetic personas, and both the Hateful Memes dataset and MMHS150K for evaluating persona-based moderation capabilities.
We employ the complete collection of 200,000 synthetic personas from PersonaHub (Ge et al., 2024), which is publicly available.111https://huggingface.co/datasets/proj-persona/PersonaHub We map these personas onto the PCT to understand their ideological distribution along social and economic axes, by assessing their political perspectives through 62 distinct statements across six domains. The Hateful Memes dataset (Kiela et al., 2020) consists of 10,000 multimodal memes labeled as either hateful or non-hateful, with additional fine-grained annotations222https://github.com/facebookresearch/fine_grained_hateful_memes for protected groups and attack types provided separately by the dataset authors. Finally, MMHS150K (Gomez et al., 2020) provides 150,000 manually annotated tweets across six categories of possible attacks.
Vision model
For our multimodal analysis, we utilize IDEFICS-3 (Laurençon et al., 2024), a Vision-Language Model (VLM) built on Meta’s Llama-3.1-8B-Instruct architecture. This choice is motivated by its strong zero-shot performance on multimodal tasks and relatively small parameter count. Furthermore, its architecture, being based on Llama 3.1, allows for better consistency when comparing results with text-only experiments using similar model families.
Experimental setup
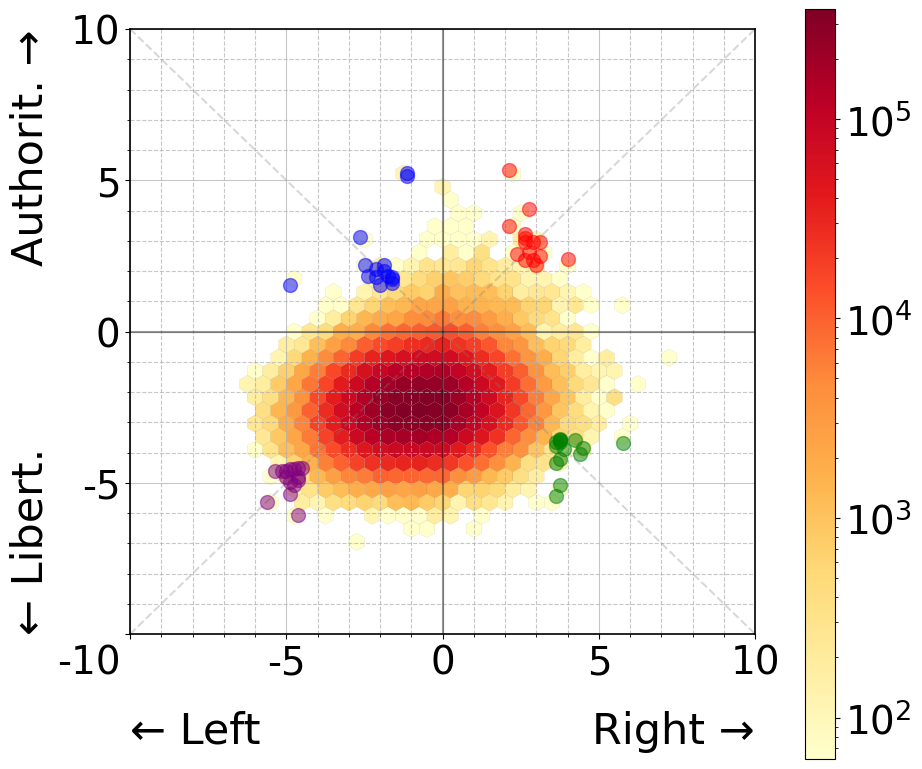
Our experimental design consists of two studies. In Study 1, from the 200,000 personas we selected 60 (15 per quadrant) based on a scoring system that balanced positional extremity with ideological consistency (see Appendix A), as shown in Figure 1(a). Using these personas, we conducted hateful content classification of 1,000 randomly selected memes from each dataset (Hateful Memes and MMHS150K) using standardized prompt templates (detailed in Appendix B). For each persona, we collected binary harm classification, targeted group identification, and attack method categorization.
To control for potential training data contamination, we replicated the experiment on the Hateful Memes test set, whose labels, to the best of our knowledge, are not publicly available, unlike those of MMHS150K.
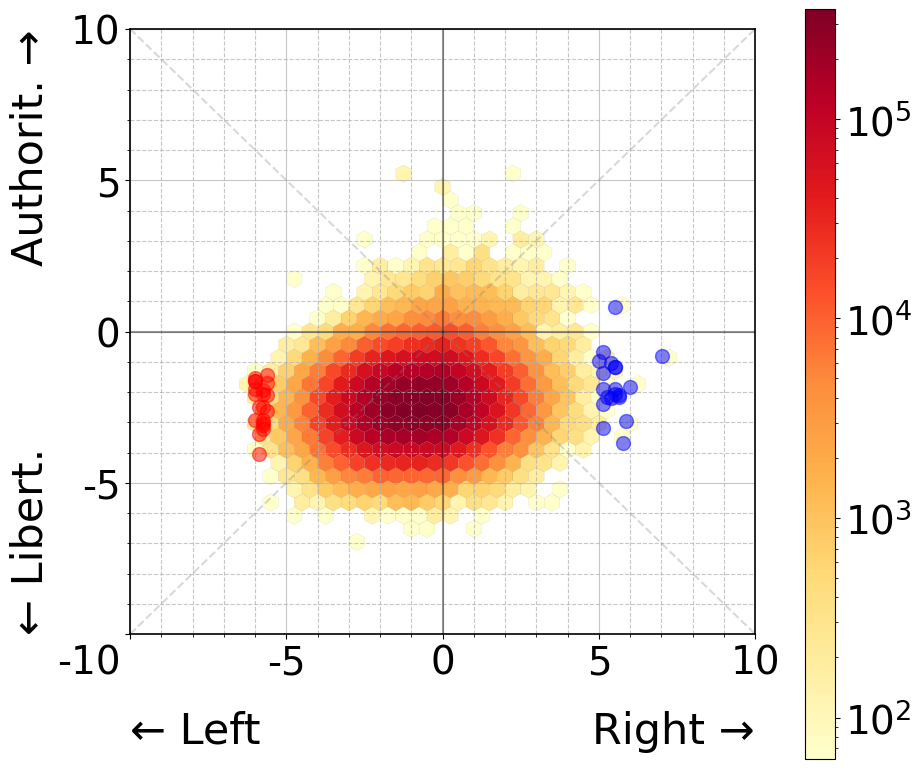
In Study 2, we focused solely on economic left-right positioning by selecting a sample of 40 personas drawn from the economic extremes (20 each from leftmost and rightmost positions). We then amplified their political orientations by explicitly labeling each persona with its respective ideological leaning (i.e., making right-wing personas more explicitly right-wing and left-wing personas more explicitly left-wing). The choice of directly testing personas with explicitly labeled ideological leanings was motivated by Study 1’s revelation of minimal correlation between political positioning and classification decisions. Study 2 thus served as a test of this finding, examining whether deliberately amplified personas could override the observed independence between political orientation and classification behavior.
This design allows us to evaluate both the baseline impact of political positioning on hate speech detection and the effect of explicit ideological manipulation while reducing the complexity of the annotation process by removing the social dimension from consideration.
Agreement analysis
To quantify classification consistency across political orientations, we calculated pairwise Cohen’s Kappa scores between all personas, resulting in 1,770 unique agreement measurements for Study 1’s 60 personas. We analyzed these measurements at two levels: intra-quadrant agreement (average agreement between personas within the same political quadrant) and inter-quadrant agreement (average agreement between personas from different quadrants). This approach enables us to determine whether personas with similar political orientations exhibit more consistent classification behavior compared to those with opposing viewpoints. For Study 2, we applied the same agreement analysis methodology but focused on comparing agreement patterns between and within just two groups (economic left versus right) to examine whether explicit ideological amplification affects classification consistency.
Computational resources
All experiments were conducted on a single NVIDIA RTX 4090 GPU. PCT answer generation for 200,000 personas required approximately 48 hours, while meme classification with 60 and 40 personas took 8 and 6 hours respectively. Total computation time across all experiments was approximately 80 hours.
| Category | Accuracy | Macro F1 | Weighted F1 |
|---|---|---|---|
| Hateful Memes | |||
| Harmfulness (T/F) | 0.908 | 0.890 | 0.907 |
| Target Group | 0.876 | 0.733 | 0.874 |
| Attack Method | 0.743 | 0.310 | 0.724 |
| MMHS150K | |||
| Harmfulness (T/F) | 0.593 | 0.555 | 0.623 |
| Target Group | 0.540 | 0.296 | 0.587 |
4. Results
Vision model performance
Before analyzing agreement patterns between different personas, we first evaluated IDEFICS-3’s hate speech detection capabilities when employing our persona-based prompting approach. This initial performance assessment is crucial, as meaningful analysis of persona agreement patterns requires the model to demonstrate competent classification abilities. To assess whether the introduction of personas impacts model performance, we also ran a baseline evaluation using standard classification prompts without personas. Both approaches achieved nearly identical performance (detailed in Appendix C), indicating that persona-based prompting preserves the model’s classification capabilities. As shown in Table 1, IDEFICS-3 prompted with persona descriptions obtains strong performance on the Hateful Memes dataset, achieving high scores in harmfulness detection (accuracy: 0.908, F1: 0.890) and target identification (accuracy: 0.876, F1: 0.733), with performance gradually declining for more nuanced tasks like attack method classification (accuracy: 0.743, macro F1: 0.310). The model shows moderate performance on the MMHS150K dataset with accuracy scores around 0.5-0.6 across both tasks. While these results exceed random chance, the substantial drop in performance could stem from MMHS150K’s broader scope and more nuanced content, making it a more demanding benchmark for hate speech detection.
These results shows that IDEFICS-3 can effectively perform hate speech detection while maintaining distinct persona-based perspectives, though with varying degrees of success across different tasks and datasets, providing a solid foundation for our main investigation into how these personas might agree or disagree in their classifications.
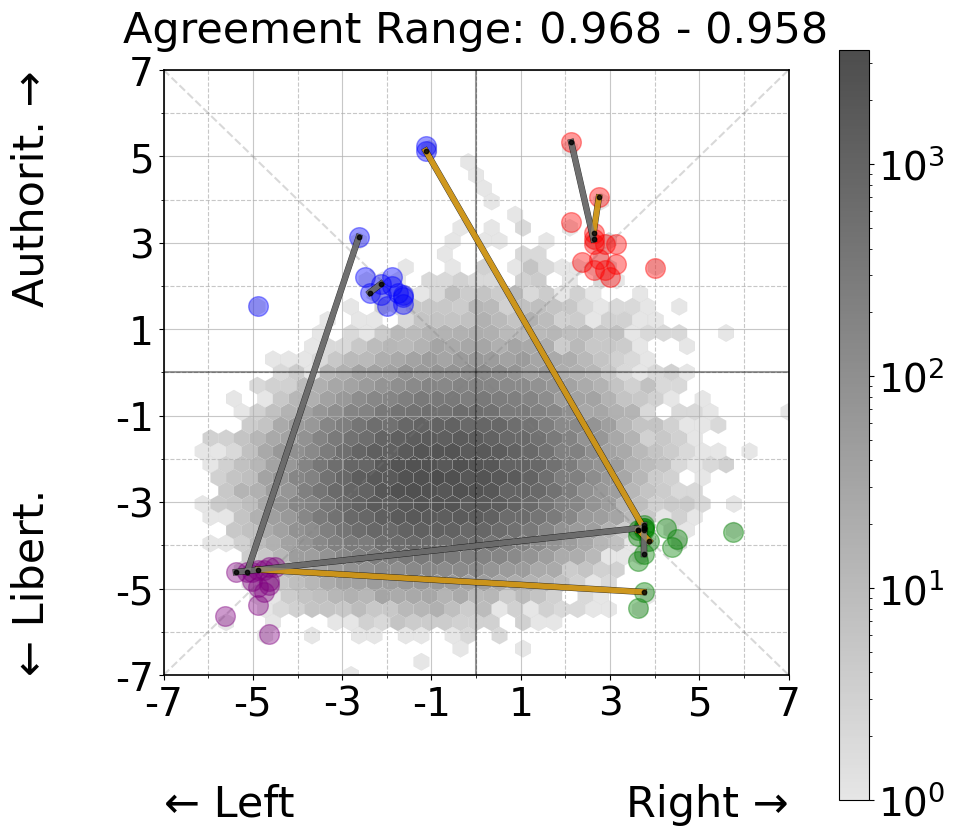
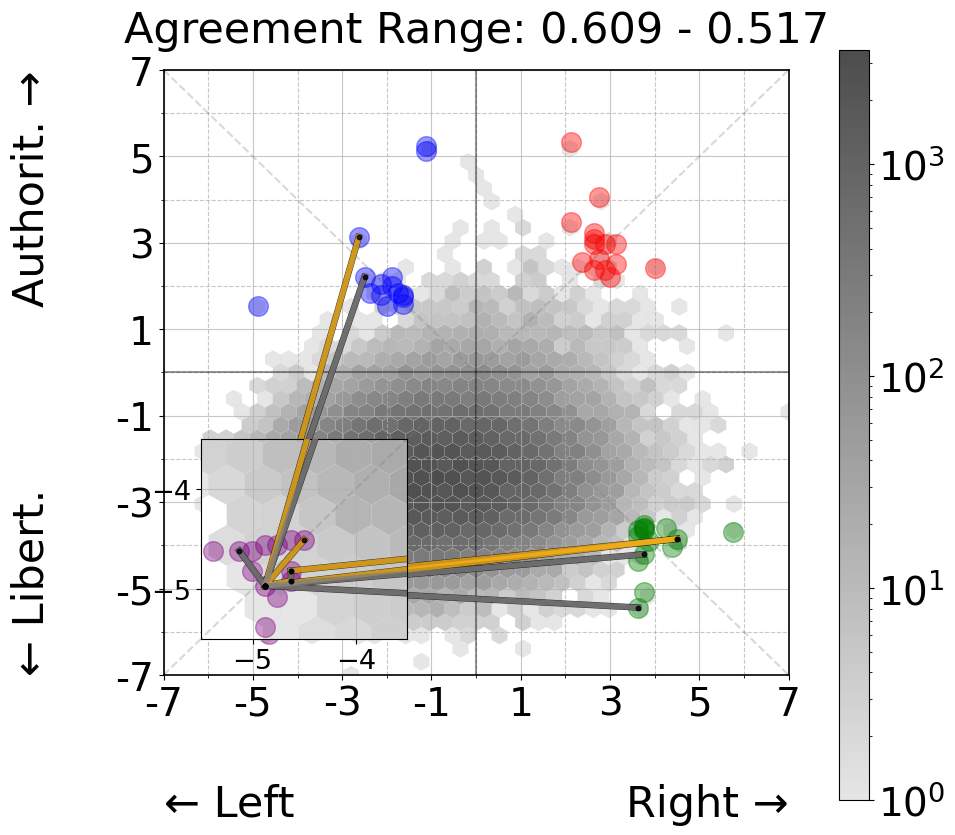
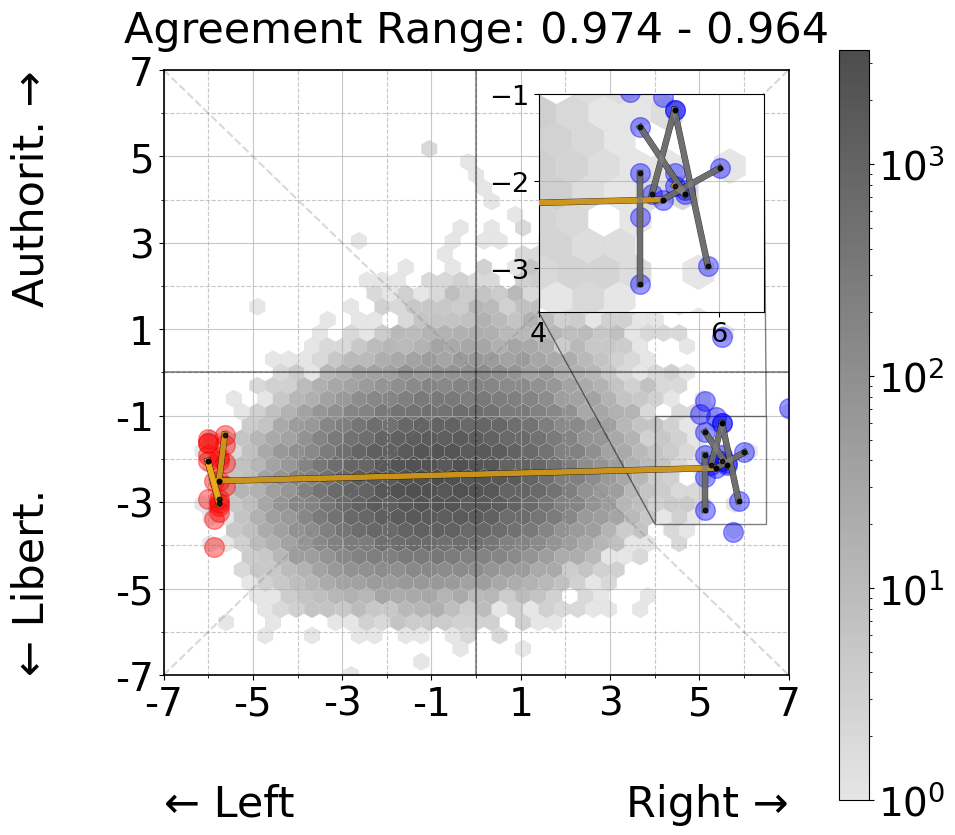
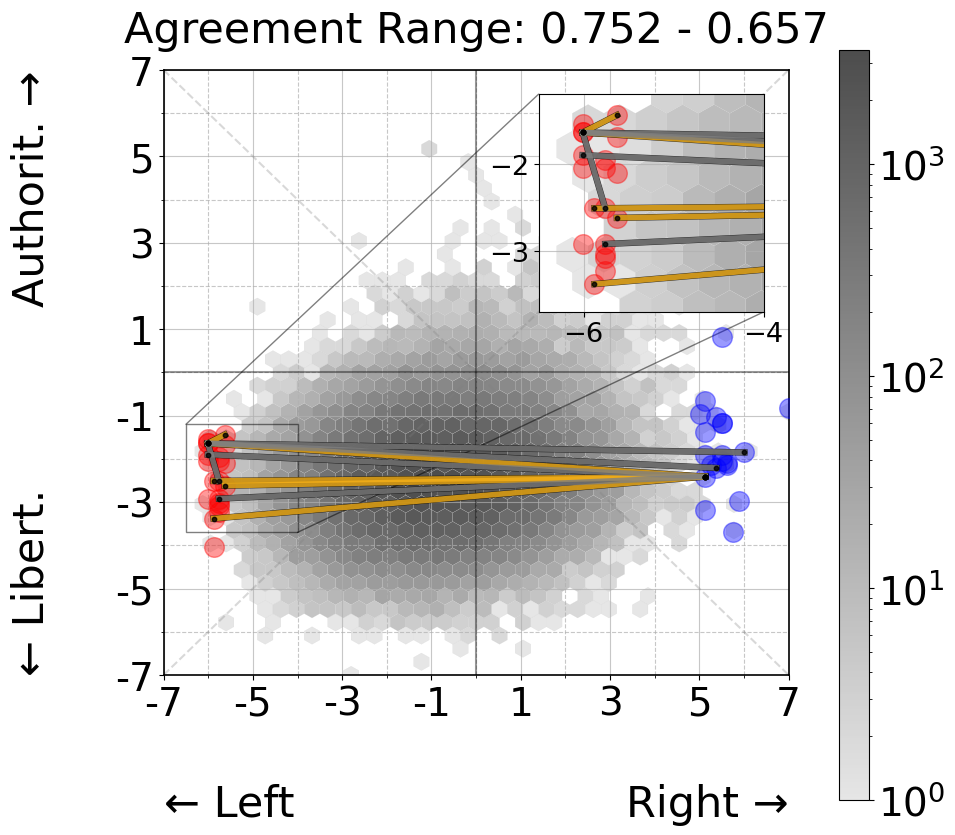
Study 1 - Persona Agreement
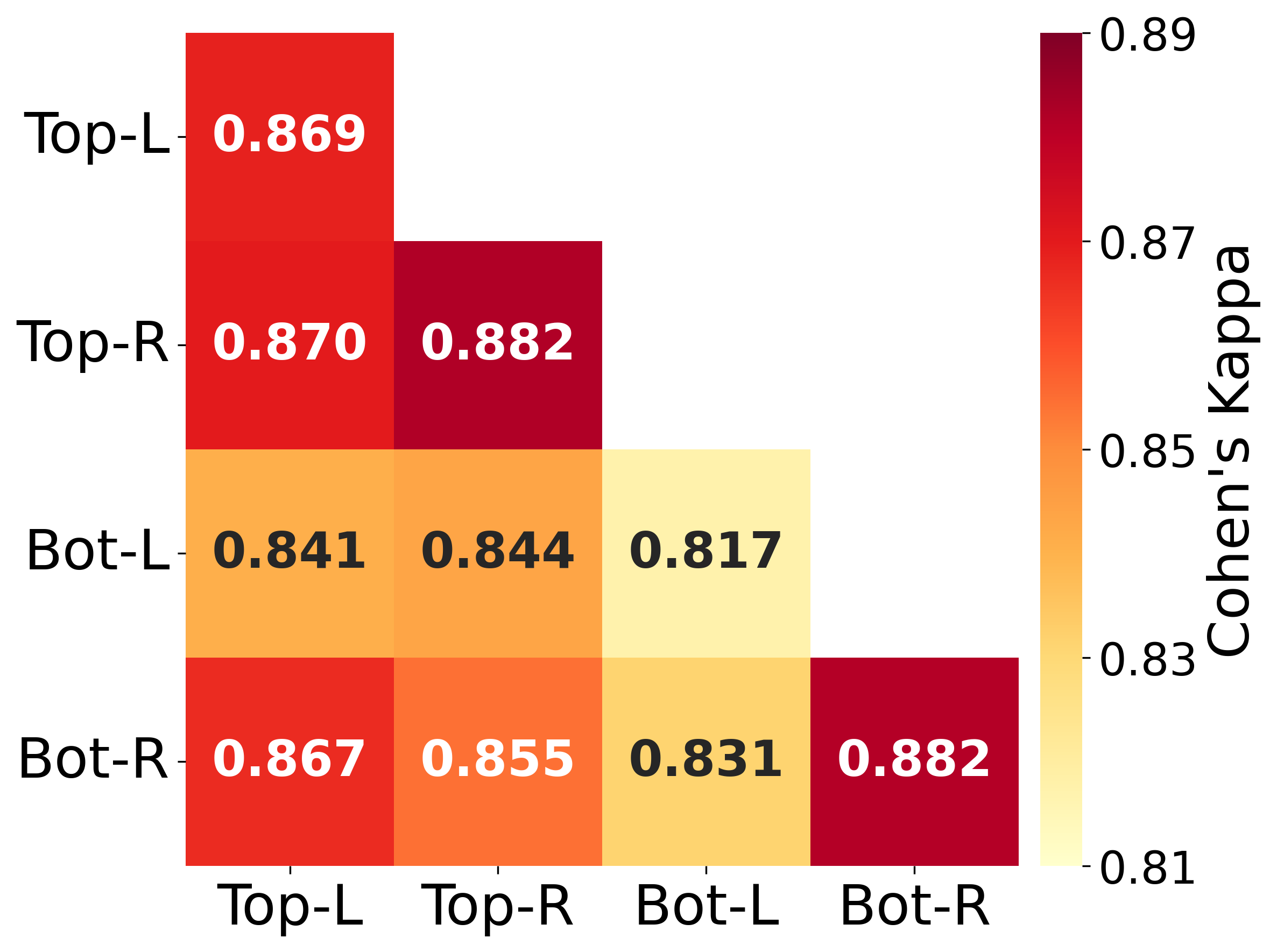
Our analysis of agreement between the 60 selected personas reveals surprisingly consistent classification behavior across political quadrants. For the Hateful Memes dataset, as shown in Figure 2(a), we observe high agreement both within quadrants (mean Cohen’s = 0.863 ± 0.032 SD) and between quadrants (mean Cohen’s = 0.851 ± 0.015 SD). The minimal difference between intra- and inter-quadrant agreement suggests that a persona’s political positioning has little influence on their classification decisions. Results from the MMHS150K dataset (Figure 2(b)) mirror these patterns, with comparable levels of agreement both within quadrants (diagonal mean = 0.817, SD = 0.020) and between quadrants (off-diagonal mean = 0.806, SD = 0.013). The consistency across the two datasets suggests that these agreement patterns might reflect genuine characteristics of persona-based classification rather than dataset-specific artifacts.
Furthermore, when replicating our analysis on the Hateful Memes test set, we found nearly identical agreement patterns (diagonal mean = 0.831, off-diagonal mean = 0.828), indicating that the observed consistency in classification behavior is not due to model memorization of training data.
These findings suggest that persona-based prompting alone may not be sufficient to replicate the ideological influences on hate speech detection observed with political pretraining approaches. Despite clear differences in political positioning, personas demonstrate consistent classification behavior, suggesting that more direct interventions - such as specialized pretraining on politically diverse corpora - may be needed to impact how content is evaluated for harmfulness meaningfully. This raises important questions about the limitations of prompt-based approaches compared to pretraining methods for achieving diverse classifications on hate speech detection tasks. While LLMs can display distinct political leanings when directly questioned about political topics, when using persona-based prompting, these inherent biases play a smaller role in classification scenarios than we initially expected.
Study 2 - Persona political injection
In Study 2, we examined whether explicit ideological amplification of economically left and right personas would increase divergence in classification behavior.
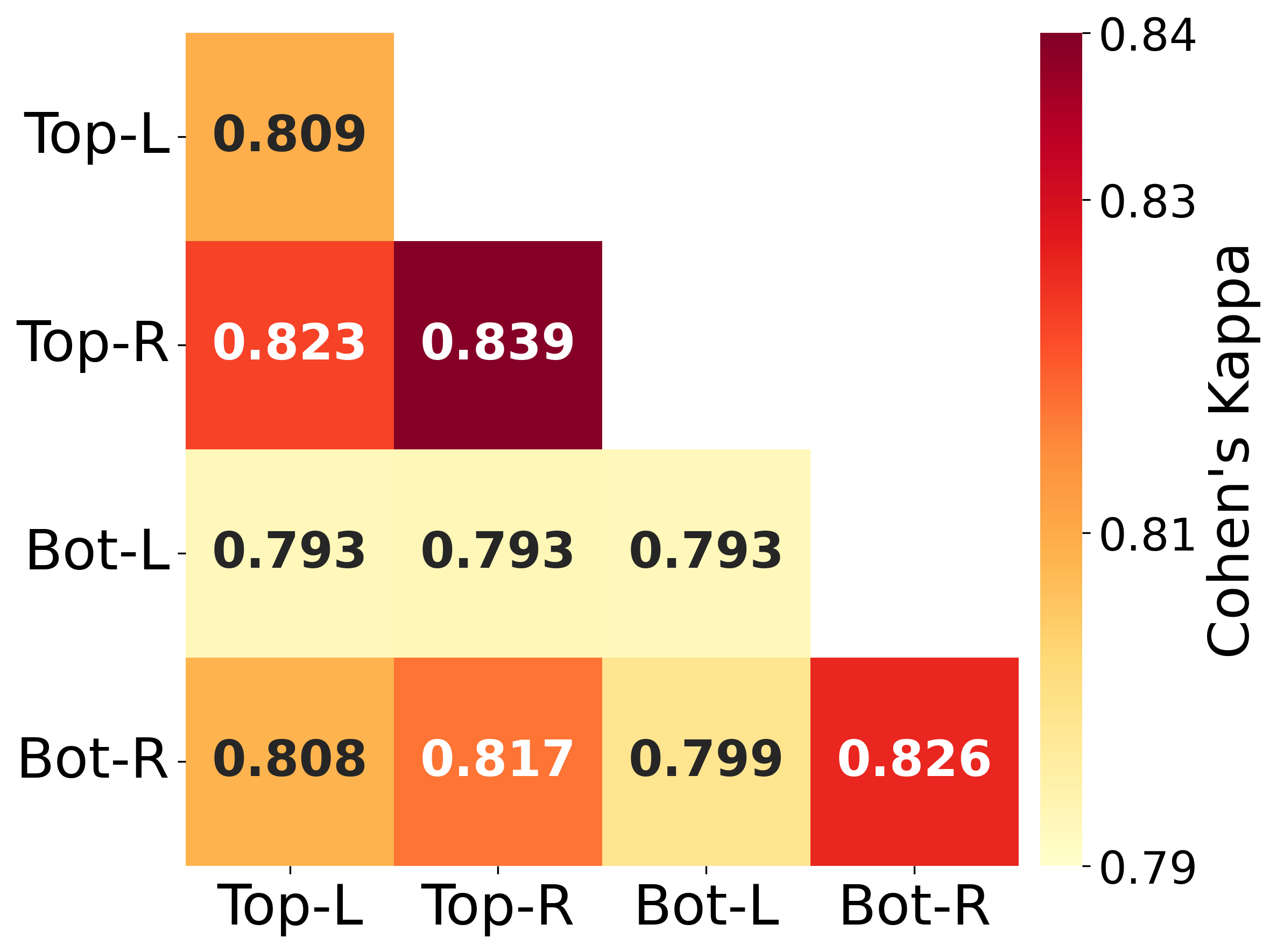
For the Hateful Memes dataset, agreement levels remained high and uniform (right-leaning k = 0.906, left-leaning k = 0.879, inter-group k = 0.875), closely mirroring Study 1 and suggesting minimal impact of ideological reinforcement on classification.
Analysis of the MMHS150K dataset showed stronger intra-group cohesion compared to inter-group agreement. Right-leaning personas demonstrated the highest internal agreement (k = 0.859), followed by left-leaning personas (k = 0.849). The inter-group agreement was lower (k = 0.807). This distinction might be attributed to MMHS150K’s broader scope and more nuanced content, which could provide more opportunities for ideological differences to manifest in classification decisions.
Nevertheless, the overall high agreement scores indicate that persona-induced political ideology, even when explicitly emphasized, plays a relatively minor role in hate speech detection.
Agreement Patterns
To gain a deeper understanding of how agreement manifests between personas, we analyzed strong and weak agreement patterns across two experimental conditions. For the 60 personas distributed across all political quadrants (Figure 3, left panels), we observe no clear ideological clustering in agreement patterns. The highest agreement pairs (0.968 - 0.958) span both within and across quadrants, connecting ideologically distant personas just as frequently as ideologically aligned ones. Similarly, the weakest agreement pairs (0.609 - 0.517) show no consistent pattern with respect to political positioning, with low agreement occurring both within and between quadrants. This supports our earlier finding that political quadrant placement has minimal impact on classification decisions.
However, when examining the 40 personas from economic extremes (Figure 3, right panels), a different pattern emerges. While we still observe a strong agreement between opposing economic positions (yellow line crossing between left and right), the majority of high-agreement pairs (0.974 - 0.964) cluster within their respective economic sides. We observe a similar pattern when examining weaker agreement pairs (0.752 - 0.657), where most instances of disagreement occur between personas from opposing economic positions. This suggests that while explicit economic positioning may not have a strong impact on classification behavior, it does introduce some systematic variation in agreement patterns that wasn’t apparent in the more general political quadrant analysis.
5. Conclusion
Our research reveals that political ideology, when implemented through persona-based prompting, has minimal impact on hate speech detection in multimodal contexts. The study found consistent classification patterns across different political orientations, even when these orientations were deliberately emphasized. This suggests that the underlying mechanisms governing hate speech detection in LLMs may be deeply embedded in the model’s training, and not really susceptible to prompt-based modification. Therefore, persona-based prompting may be insufficient for capturing ideological nuances in content moderation systems.
Limitations
The scope and generalizability of our findings are primarily constrained by our reliance on the IDEFICS-3 architecture and the two chosen datasets, and may not generalize to other models or different datasets. Additionally, our persona-based approach might not fully capture the complex decision-making patterns of human content moderators, mitigated by the fact that we are shifting the focus to political leaning instead of the specific persona descriptions. Furthermore, while we attempted to control for potential training data contamination by testing on held-out datasets, we cannot completely rule it out. Finally, the study relies heavily on Western political frameworks through the PCT, which may not fully capture ideological distinctions relevant to other cultural contexts.
Future Work
Future research could extend this work in several directions: 1) investigating whether our observations hold across different model architectures and sizes to establish the generalizability of our results; 2) examining how persona-based prompting influences other content moderation tasks; 3) conducting a direct experimental comparison between persona-based prompting and political pretraining methods to quantitatively assess their relative effectiveness in achieving politically diverse perspectives.
Acknowledgments
This work is partially supported by the Swiss National Science Foundation (SNSF) under contract number CRSII5_205975 and by an Australian Research Council (ARC) Future Fellowship Project (Grant No. FT240100022).
References
- (1)
- Bernardelle et al. (2024) Pietro Bernardelle, Leon Fröhling, Stefano Civelli, Riccardo Lunardi, Kevin Roitero, and Gianluca Demartini. 2024. Mapping and Influencing the Political Ideology of Large Language Models using Synthetic Personas. arXiv preprint arXiv:2412.14843 (2024).
- Feng et al. (2023) Shangbin Feng, Chan Young Park, Yuhan Liu, and Yulia Tsvetkov. 2023. From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 11737–11762.
- Fröhling et al. (2024) Leon Fröhling, Gianluca Demartini, and Dennis Assenmacher. 2024. Personas with Attitudes: Controlling LLMs for Diverse Data Annotation. arXiv preprint arXiv:2410.11745 (2024).
- Ge et al. (2024) Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. 2024. Scaling synthetic data creation with 1,000,000,000 personas. arXiv preprint arXiv:2406.20094 (2024).
- Gomez et al. (2020) Raul Gomez, Jaume Gibert, Lluis Gomez, and Dimosthenis Karatzas. 2020. Exploring hate speech detection in multimodal publications. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 1470–1478.
- Kiela et al. (2020) Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. 2020. The hateful memes challenge: Detecting hate speech in multimodal memes. Advances in neural information processing systems 33 (2020), 2611–2624.
- Laurençon et al. (2024) Hugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon. 2024. Building and better understanding vision-language models: insights and future directions. arXiv preprint arXiv:2408.12637 (2024).
- Röttger et al. (2024) Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Kirk, Hinrich Schuetze, and Dirk Hovy. 2024. Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 15295–15311.
Appendix A Persona Selection Methodology
Our persona selection process aimed to identify individuals with well-defined political positions while maintaining representation across the political spectrum. We developed a systematic scoring approach that favors personas with both extreme and clearly aligned ideological stances within their respective quadrants.
A.1. Selection Criteria and Metrics
For each persona with coordinates on the Political Compass Test (PCT), we computed two fundamental metrics:
A.1.1. Extremity Score
We quantified the extremity of a persona’s political position using their Euclidean distance from the origin:
This metric favors personas with strong political convictions, as indicated by their distance from centrist positions.
A.1.2. Quadrant Alignment Score
To ensure selected personas clearly represent their quadrant’s ideology, we calculated their alignment with the quadrant’s diagonal axis. The alignment score is computed differently for each quadrant pair:
For top-right (TR) and bottom-left (BL) quadrants:
For top-left (TL) and bottom-right (BR) quadrants:
This measure represents the perpendicular distance from the persona’s position to their quadrant’s principal diagonal, normalized by to maintain consistency with the extremity score scale.
A.2. Composite Selection Score
We combined these metrics into a final selection score using a weighted sum with quadrant-specific normalization:
Where:
-
•
is the extremity score normalized within quadrant
-
•
is the alignment score normalized within quadrant
-
•
is the diagonal weight parameter (set to 0.4 in our experiments)
The normalization is performed separately within each quadrant :
Where represents the set of all personas in quadrant . This quadrant-specific normalization ensures fair comparison of personas within each ideological region.
A.3. Selection Process
For each quadrant, we:
-
(1)
Computed the composite score for all personas
-
(2)
Ranked personas by their composite scores
-
(3)
Selected the top 15 personas per quadrant
This methodology yielded a balanced set of 60 personas (15 per quadrant) that exhibit both strong ideological positions and clear quadrant alignment, ensuring robust representation across the political spectrum while minimizing ambiguous or centrist positions.
Appendix B Personas and Prompt Templates
This appendix details the prompt templates and evaluation methodology used in our experimental studies for classifying harmful content.
B.1. Prompt Templates
To perform the classification, we used Study 1 Prompt Template, inserting each of the 60 selected persona descriptions into the [PERSONA] placeholder when prompting the visual model333Note: The provided prompt templates were used for classification on the Hateful Memes dataset. Similar templates were used for MMHS150K with labels modified to match the dataset’s annotation schema..
B.1.1. Study 1 Prompt Template
The following template was used for classification in Study 1, with [PERSONA] replaced by each of the 60 selected persona descriptions:
Taking on the perspective of [PERSONA], analyze this meme in two steps:
- (1)
First, classify if this meme is harmful or not:
Answer with only: HARMFUL or NOT_HARMFUL- (2)
If you answered HARMFUL:
Targeted groups affected (TG:) (choose 1): disability, race, religion, nationality, sex
Attack methods used (AM:) (choose 1): contempt, mocking, inferiority, slurs, exclusion, dehumanizing, inciting_violenceWhen executing this task, think carefully about how a person with the described perspective would interpret the meme.
B.1.2. Study 2 Prompt Template
The following template was used for classification in Study 2, focusing on explicit economic left-right positioning:
Analyze this meme taking on the perspective of the following politically [LEFT or RIGHT] leaning persona: [PERSONA].
- (1)
First, classify if this meme is harmful or not:
Answer with only: HARMFUL or NOT_HARMFUL- (2)
If you answered HARMFUL:
Targeted groups affected (TG:) (choose 1): disability, race, religion, nationality, sex
Attack methods used (AM:) (choose 1): contempt, mocking, inferiority, slurs, exclusion, dehumanizing, inciting_violenceWhen executing this task, think carefully about how a person with the described [LEFT or RIGHT] leaning perspective would interpret the meme.
B.2. Example Personas
To provide concrete examples of the personas used in our studies, we present below a selection of three representative personas from each quadrant of the political compass.
Authoritarian Right (Top-Right) Examples
-
•
A local politician who values the pastor’s endorsement for their conservative agenda
-
•
A fresh graduate who idolizes her supervisor for his conservative science perspectives
-
•
A business developer trying to bring new investments to the region, regardless of environmental cost
Authoritarian Left (Top-Left) Examples
-
•
A high-ranking military strategist who believes in a strong defense system
-
•
A traditionalist school principal who believes in the old-school methods and resists change
-
•
A young adult who is searching for meaning in life and is drawn to the cult leader’s philosophy
Libertarian Right (Bottom-Right) Examples
-
•
A rival department head who is skeptical about the effectiveness of e-learning
-
•
A rival fuel broker vying for the same clients, employing aggressive tactics to win contracts
-
•
A representative from a telecommunications company advocating for less restrictive regulations on satellite deployment
Libertarian Left (Bottom-Left) Examples
-
•
A graduate student advocating for fair working conditions and organizing protests
-
•
A discriminant sports fan who doesn’t follow college basketball
-
•
A socialist advocate who argues that free trade perpetuates inequality and exploitation
Appendix C Baseline Model Performance without Personas
| Category | Accuracy | Macro F1 | Weighted F1 |
|---|---|---|---|
| Hateful Memes | |||
| Harmfulness (T/F) | 0.919 | 0.898 | 0.916 |
| Target Group | 0.786 | 0.510 | 0.745 |
| Attack Method | 0.725 | 0.190 | 0.650 |
| MMHS150K | |||
| Harmfulness (T/F) | 0.607 | 0.581 | 0.621 |
| Target Group | 0.533 | 0.278 | 0.557 |
Table 2 shows IDEFICS-3’s performance on the classification tasks when using standard prompts without personas. Prompts used are the same as the ones used in Appendix B but without the persona-related part. The model with persona-prompting achieves comparable or better results across all metrics. While harmfulness detection shows similar performance (within 1-2 percentage points difference), persona-prompting notably improves performance on more complex tasks - target group identification accuracy increases by 9 percentage points (from 0.786 to 0.876) and macro F1 score improves by 22.3 percentage points (from 0.510 to 0.733). Similarly, for attack method classification, the persona-prompted version shows stronger performance with a 12 percentage point improvement in macro F1 score (from 0.190 to 0.310) and better accuracy (0.743 vs 0.725). These results suggest that persona-based prompting not only enables investigation of potential ideological influences but can also enhance the model’s classification capabilities, particularly for more nuanced multi-class tasks.