The Kernel Spatial Scan Statistic
Abstract.
Kulldorff’s (1997) seminal paper on spatial scan statistics (SSS) has led to many methods considering different regions of interest, different statistical models, and different approximations while also having numerous applications in epidemiology, environmental monitoring, and homeland security. SSS provides a way to rigorously test for the existence of an anomaly and provide statistical guarantees as to how ”anomalous” that anomaly is. However, these methods rely on defining specific regions where the spatial information a point contributes is limited to binary 0 or 1, of either inside or outside the region, while in reality anomalies will tend to follow smooth distributions with decaying density further from an epicenter. In this work, we propose a method that addresses this shortcoming through a continuous scan statistic that generalizes SSS by allowing the point contribution to be defined by a kernel. We provide extensive experimental and theoretical results that shows our methods can be computed efficiently while providing high statistical power for detecting anomalous regions.
1. Introduction
We propose a generalized version of spatial scan statistics called the kernel spatial scan statistic. In contrast to the many variants (AMPVW06, ; Kul97, ; huang2007spatial, ; jung2007spatial, ; neill2006bayesian, ; jung2010spatial, ; kulldorff2009scan, ; FNN17, ; HMWN18, ; SSMN16, ) of this classic method for geographic information sciences, the kernel version allows for the modeling of a gradually dampening of an anomalous event as a data point becomes further from the epicenter. As we will see, this modeling change allows for more statistical power and faster algorithms (independent of data set size), in addition to the more realistic modeling.
To review, spatial scan statistics consider a baseline or population data set where each point has an annotated value . In the simplest case, this value is binary ( = person has cancer; = person does not have cancer), and it is useful to define the measured set as . Then the typical goal is to identify a region where there are significantly more measured points than one would expect from the baseline data . To prevent overfitting (e.g., gerrymandering), the typical formulation fixes a set of potential anomalous regions induced by a family of geometric shapes: disks (Kul97, ), axis-aligned rectangles (NM04, ), ellipses (Kul7.0, ), halfspaces (MP18a, ), and others (Kul7.0, ). Then given a statistical discrepancy function , where typically and , the spatial scan statistic SSS is
And the hypothesized anomalous region is so . Conveniently, by choosing a fixed set of shapes, and having a fixed baseline set , this actually combinatorially limits the set of all possible regions that can be considered (when computing the operator), since for instance, there can be only distinct disks which each contains a different subset of points. This allows for tractable (AMPVW06, ) (and in some cases very scalable (MP18b, )) combinatorial and statistical algorithms which can (approximately) search over the class of all shapes from that family. Alternatively, the most popular software, SatScan (Kul7.0, ) uses a fixed center set of possible epicenters of events, for simpler and more scalable algorithms.
However, the discreteness of these models has a strange modeling side effect. Consider a the shape model of disks , where each disk is defined by a center and a radius . Then solving a spatial scan statistic over this family would yield an anomaly defined by a disk ; that is, all points are counted entirely inside the anomalous region, and all points are considered entirely outside the anomalous region. If this region is modeling a regional event; say the area around a potentially hazardous chemical leak suspected of causing cancer in nearby residents, then the hope is that the center identifies the location of the leak, and determines the radius of impact. However, this implies that data points very close to the epicenter are affected equally likely as those a distance of almost but not quite away. And those data points that are slightly further than away from are not affected at all. In reality, the data points closest to the epicenter should be more likely to be affected than those further away, even if they are within some radius , and data points just beyond some radius should still have some, but a lessened effect as well.
Introducing the Kernel Spatial Scan Statistic. The main modeling change of the kernel spatial scan statistic (KSSS) is to prescribe these diminishing effects of spatial anomalies as data points become further from the epicenter of a proposed event. From a modeling perspective, given the way we described the problem above, the generalization is quite natural: we simply replace the shape class (e.g., the family of all disks ) with a class of non-binary continuous functions . The most natural choice (which we focus on) are kernels, and in particular Gaussian kernels. We define each by a center and a bandwidth as This provides a real value , in fact a probability, for each . We interpret this as: given an anomaly model , then for each the value is the probability that the rate of the measured event (chance that a person gets cancer) is increased.
Related Work on SSS and Kernels. There have been many papers on computing various range spaces for SSS (NM04, ; Tango2005, ; ACTW18, ; ICDMS2015, ) where a geometric region defines the set of points that included in the region for various regions such as disks, ellipses, rings, and rectangles. Other work has combined SSS and kernels as a way to penalize far away points, but still used binary regions, and only over a set of predefined starting points (DA04, ; DCTB2007, ; Patil2004, ). Another method (FNN17, ) uses a Kernel SVM boundary to define a region; this provides a regularized, but otherwise very flexible class of regions – but they are still binary. A third method (JRSA89, ), proposes an inhomogeneous Poisson process model for the spatial relationship between a measured cancer rate and exposure to single specified region (from industrial pollution source). This models the measured rate similar to our work, but does not search over a family of regions, and does not model a background rate.
Our contributions, and their challenges. We formally derive and discuss in more depth the KSSS in Section 2, and contrast this with related work on SSS. While the above intuition is (we believe) quite natural, and seems rather direct, a complication arises: the contribution of the data points towards the statistical discrepancy function (derived as a log-likelihood ratio) are no longer independent. This implies that and can no longer in general be scalar values (as they were with and ); instead we need to pass in sets. Moreover, this means that unlike with traditional binary ranges, the value of no longer in general has a closed form; in particular the optimal rate parameters in the alternative hypothesis do not have a closed form. We circumvent this by describing a simple convex cost function for the rate parameters. And it turns out, these can then be effectively solved for with a few steps of gradient descent for each potential choice of within the main scanning algorithm.
Our paper then focuses on the most intuitive Bernoulli model for how measured values are generated, but the procedures we derive will apply similar to the Poisson and Gaussian models we also derive. For instance, it turns out that the Gaussian model kernel statistical discrepancy function has a closed form.
The second major challenge is that there is no longer a combinatorial limit on the number of distinct ranges to consider. There are an infinite set of potential centers to consider, even with a fixed bandwidth, and each could correspond to a different value. However, there is a Lipschitz property on as a function of the choice of center ; that is if we change to by a small amount, then we can upperbound the change in to by a linear function of . This implies a finite resolution needed to consider on the set of center points: we can lay down a fixed resolution grid, and only consider those grid points. Notably: this property does not hold for the combinatorial SSS version, as a direct effect of the problematic boundary issue of the binary ranges.
We combine the insight of this Lipschitz property, and the gradient descent to evaluate for a set of center points , in a new algorithm KernelGrid. We can next develop two improvements to this basic algorithm which make the grid adaptive in resolution, and round the effect of points far from the epicenter; embodied in our algorithm KernelFast, these considerably increase the efficiency of computing the statistic (by x) without significantly decreasing their accuracy (with provable guarantees). Moreover, we create a coreset of the full data set , independent of the original size that provably bounds the worst case error .
We empirically demonstrate the efficiency, scalability, and accuracy of these new KSSS algorithms. In particular, we show the KSSS has superior statistical power compared to traditional SSS algorithms, and exceeds the efficiency of even the heavily optimized version of those combinatorial Disk SSS algorithms.
2. Derivation of the Kernel Spatial Scan Statistic
In this section we will provide a general definition for a spatial scan statistic, and then extend this to the kernel version. It turns out, there are two reasonable variations of such statistics, which we call the continuous and binary settings. In each case, we will then define the associated kernelized statistical discrepancy function under the Bernoulli , Poisson , and Gaussian models. These settings are the same in the Bernoulli model, but different in the other two models.
General derivation. A spatial scan statistic considers a spatial data set , each data point endowed with a measured value , and a family of measurement regions . Each region specifies the way a data point is associated with the anomaly (e.g., affected or not affected). Then given a statistical discrepancy function which measures the anomalousness of a region , the statistic is . To complete the definition, we need to specify and , which it turns out in the way we define are more intertwined that previously realized.
To define we assume a statistical model in how the values are realized, where data points affected by the anomaly have generated at rate and those unaffected generated at rate .
Then we can define a null hypothesis that a potential anomalous region has no effect on the rate parameters so ; and an alternative hypothesis that the region does have an effect and (w.l.o.g.) .
For both the null and alternative hypothesis, and a region , we can then define a likelihood, denoted and , respectively. The spatial scan statistic is then the log-likelihood ratio (LRT)
Now the main distinction with the kernel spatial scan statistic is that is specified with a family of kernels so that each specifies a probability that is affected by the anomaly. This is consistent with the traditional spatial scan statistic (e.g., with as disks ), where this probability was always or . Now this probability can be any continuous value. Then we can express the mean rate/intensity for each of the underlying distributions from which is generated, as a function of , , and . Two natural and distinct models arise for kernel spatial scan statistics.
Continuous Setting. In the continuous setting, which will be our default model, we directly model the mean rate as a convex combination between and as,
Thus each (with nonzero value) has a slightly different rate. Consider a potentially hazardous chemical leak suspected of causing cancer, this model setting implies that the residents who live closer to the center ( is larger) of potential leak would be affected more (have elevated rate) compared to the residents who live farther away. The kernel function models a decay effect from a center, and smooths out the effect of distance.
Binary Setting. In the second setting, the binary setting, the mean rate is defined
To clarify notation, each part of the model associated with this setting (e.g., ) will carry a to distinguish it from the continuous setting. In this case, as with the traditional SSS, the rate parameter for each is either or , and cannot take any other value. However, this rate assignment is not deterministic, it is assigned with probability , so points closer to the epicenter (larger ) have higher probability of being assigned a rate . The rate for each is a mixture model with known mixture weight determined by .
The null models. We show that the choice of model, binary setting, vs continuous setting, does not change the null hypothesis (e.g. ).
2.1. Bernoulli
Under the Bernoulli model, the measured value , and these values are generated independently. Consider a value indicating that someone is diagnosed with cancer. Then an anomalous region may be associated with a leaky chemical plant, where the residents nearby the plant have an elevated rate of cancer , whereas the background population may have lower rate of cancer. That is, the cancer occurs through natural mutation at a rate , but if exposed to certain chemicals, there is another mechanism to get cancer that occurs at rate (for a total rate of ). Under the binary model, any exposure to the chemical triggers this secondary mechanism, and so the chance of exposure is modeled as proportional to , and rate at is is modeled well by the binary setting. Alternatively, the rate of the secondary mechanism may increase as the amount of exposure to the chemical increases (those living closer are exposed to more chemicals), with rate modeled in the continuous setting. These are both potentially the correct biological model, so we analyze both of them.
For this model we can define two subsets of as and .
In either setting the null likelihood is defined
then
which is maximized over at as,
The continuous setting. We first deriving the continuous setting , starting with the likelihood under the alternative hypothesis.
This is a product of the rate of measured and baseline.
and so
Unfortunately, we know of no closed form for the maximum of over the choice of and therefore this form cannot be simplified further than
The binary setting. We continue deriving the binary setting , starting with
and so
Similarly as in the continuous setting, there is no closed form of the maximum of over choices of ,, so we write the form below.
Equivalence. It turns out, under the Bernoulli model, these two settings have equivalent statistics to optimize.
Lemma 2.1.
The and are exactly same, hence = which implies that the Bernoulli model under two settings are equivalent to each other.
Proof.
We simply expand the binary setting as follows.
Since the and , then = . ∎
2.2. Gaussian
The Gaussian model can be used to analyze spatial datasets with continuous values (e.g., temperature, rainfall, or income), which we assume varies with a normal distribution with a fixed known standard deviation . Under this model, both the continuous and binary settings are again both well motivated.
Consider an insect infestation, as it affects agriculture. Here we assume fields of crops are measured at discrete locations , and each has an observed yield rate , which under the null models varies normally around a value . In the continuous setting, the yield rate at is effected proportional to , depending on how close it is to the epicenter. This may for instance model that fewer insects reach further from the epicenter, and the yield rate is effected relative to the number of insects that reach the field . In the binary setting, it may be that if insects reach a field, then they dramatically change the yield rate (e.g., they eat and propagate until almost all of the crops are eaten). In the latter scenario, the correct model is binary one, with a mixture model of two rates governed by , the closeness to the epicenter.
In either setting the null likelihood is defined as,
then
which is maximized over at as,
The continuous setting. We first derive the continuous setting and terms free of and would be treated as constant then ignored, starting with,
and so
Fortunately, there is a closed form for the maximum of over the choice of by setting the and . Hence we come up with the closed form solution of Gaussian Kernel statistical discrepancy shown by the theorem below.
Theorem 2.2.
Gaussian kernel statistical discrepancy function is
where , , , using the following terms , , , , and .
Proof.
For the alternative hypothesis, the log-likelihood is
The optimal values of minimize
By setting the partial derivatives wrt and of equal to , we have,
and
and these two can be further simplified to,
and
We replace these terms by notations defined in the theorem,
and
Then we can solve the optimum value of and as, and .
Hence we have the closed form
∎
The binary Setting. Now we derive the binary setting , starting
and so,
Different from the continuous setting we know of no closed form for the maximum of over and . Hence,
Equivalence. Different from the Bernoulli models, the Gaussian models under the binary setting and continuous setting are not equivalent to each other. Under the continuous setting,
however, under the binary setting, each data point follow a two components Gaussian mixture model where the mixture weight is given by and , and so it is not a Gaussian distribution anymore.
2.3. Poisson
In the Poisson model the measured value is discrete and non-negative, but it can now take any positive integer value with . This can for instance model the number of check-ins or comments posted at each geo-located business (this can be a proxy for instance for the number of customers). An event, e.g., a festival, protest, or other large impromptu gathering could be modeled spatially by a kernel , and it affects the rates at each in the two different settings.
In the continuous setting, the closer a distance a restaurant is from the center of the event (modeled by ) the more the usual number of check-ins (modeled by ) will trend towards . On the hand, in the binary setting, only certain businesses are affected (e.g., a coffee shop, but not a fancy dinner location), but if it is affected, its rate is elevated all the way from to . Perhaps advertising at a festival encouraged people to patronize certain restaurants, or a protest encouraged them to give bad reviewers to certain nearby restaurants – but not others. Hence, these two settings relate to two different ways an event could affect Poisson check-in or comment rates.
In either setting, the null likelihood is defined as,
then
which is maximized over at as,
The continuous setting. We first derive the continuous setting , starting with,
so
There is no closed form for the maximum of over the choice of and and hence
The binary setting. We continue deriving the binary setting , starting with
so
Same as the continuous setting, there is no closed form of , hence,
Equivalence. In the Poisson model the binary setting and the continuous setting are not equivalent to each other. Under the continuous setting,
however under the binary setting follows a mixture Poisson model which is not a Poisson distribution anymore and the mixture weight is given by and .
3. Computing the Approximate KSSS
The traditional SSS can combinatorially search over all disks (SSSS, ; MP18a, ; Kul97, ) to solve for or approximate , evaluating exactly. Our new KSSS algorithms will instead search over a grid of possible centers , and approximate with gradient descent, yet will achieve the same sort of strong error guarantees as the combinatorial versions. Improvements will allow for adaptive gridding, pruning far points, and sampling.
3.1. Approximating with GD
We cannot directly calculate , since it does not have a closed form. Instead we run gradient descent over on for a fixed . Since we have shown is convex over this will converge, and since Lemma A.8 bounds its Lipschitz constant at it will converge quickly. In particular, from starting points , after steps we can bound
for the found rate parameters . Since , then after steps we are guaranteed to have . We always initiate this procedure on with the found on a nearby , and as a result found that running for of steps is sufficient. Each step of gradient descent takes to compute the gradient.
3.2. Gridding and Pruning
Computing on every center in is impossible, but Lemma A.4 shows that with close to the true maximum , then will approximate the true maximum. From Lemma A.4 we have . To get a bound of we need that or rearanging that . Placing center points on a regular grid with sidelength will ensure the a center point will be close enough to the true maximum.
Assume that , which w.l.o.g. we assume , where is a unitless resolution parameter which represents the ratio of the domain size to the scale of the anomalies. Next define a regular orthogonal grid over at resolution . This contains points. We compute the scan statistic choose as each point in . This algorithm, denoted KernelGrid and shown in Algorithm 1, can be seen to run in time, using iterations of gradient decent (in practice ).
Lemma 3.1.
returns for a center so in time , which in the worst case is .
Adaptive Gridding. We next adjust the grid resolution based on the density of . We partition the domain with a coarse grid with side length (from Lemma A.3). For a cell in this grid, let denote the region which expands the grid cell the length of one grid cell in either direction. For any center , all points which are within a distance of from must be within . Hence, by Lemma A.3 we can evaluate for any only inspecting .
Moreover, by the local density argument in Lemma A.5, we can describe a new grid inside of each with center separation only depending on the local number of points . In particular we have for with
To guarantee that all have another center so that we set the side length in as
so the number of grid points in is
Now define as the union of these adaptively defined subgrids over each coarse grid cell. Its total size is
where the last inequality follows from Cauchy-Schwarz, and that each point appears in cells . This replaces dependence on the domain size in the size of the grid , with a mere logarithmic dependence on in . We did not minimize constants, and in practice we use significantly smaller constants.
Moreover, since this holds for each , and the same gridding mechanism is applied for each , this holds for all . We call the algorithm that extends Algorithm 1 to use this grid in place of KernelAdaptive.
Lemma 3.2.
returns for a center so in time , which in the worst case is .
Pruning. For both gridding methods the runtime is roughly the number of centers times the time to compute the gradient . But via Lemma A.3 we can ignore the contribution of far away points, and thus only need those in the gradient computation.
However, this provides no worst-case asymptotic improvements in runtime for KernelGrid, or KernelAdaptive since all of may reside in a cell. But in the practical setting we consider, this does provide a significant speedup as the data is usually spread over a large domain that is many times the size of .
We will define two new methods KernelPrune and KernelFast (shown in Algorithm 2) where the former extends KernelGrid method, and latter extends KernelAdaptive with pruning. In particular, we note that bounds in Lemma 3.2 hold for KernelFast.
3.3. Sampling
We can dramatically improve runtimes on large data sets by sampling a coreset iid from , according to Lemma A.7. With probability we need samples, where is the number of center evaluations, and can be set to the grid size. For KernelGrid and in AdaptiveGrid . We restate the runtime bounds with sampling to show they are independent of .
Lemma 3.3.
with sample size returns for a center so in time , with probability . In the worst case the runtime is .
Lemma 3.4.
with sample size returns for a center so in time , with probability . In the worst case the runtime is .
3.4. Multiple Bandwidths
We next show a sequence of bandwidths, such that one of them is close to the used in any (assuming some reasonable but large range on the values ), and then take the maximum over all of these experiments. If the sequence of bandwidths is such that then .
Lemma 3.5.
A geometrically increasing sequence of bandwidths with is sufficient so for any bandwidth .
Proof.
To guarantee a error on the bandwidth there must be a nearby bandwidth . Therefore if then if .
From Lemma A.6 we can use the Lipshitz bound at to note that . Setting this less than we can rearrange to get that . That is , which can be rearranged to get . Since when is in , we have . ∎
Running our KSSS over a large sequence of bandwidths is simple and merely increases the runtime by a factor. Our experiments in Section 4.4 suggest that choosing to bandwidths should be sufficient (e.g., for scales ).
4. Experiments
We compare our new KSSS algorithms to the state-of-the-art methods in terms of empirical efficiency, statistical power, and sample complexity, on large spatial data sets with planted anomalies.
Data sets. We run experiments on two large spatial data sets recording incidents of crime, these are used to represent the baseline data . The first contains geo-locations of all crimes in Philadelphia from 2006-2015, and has a total size of ; a subsample is shown in Figure 1. The second is the well-known Chicago Crime Dataset from 2001-2017, and has a total size of ; which is the size of the Philadelphia set.
In modeling crime hot spots, these may often be associated with an individual or group of individuals who live at a fixed location. Then the crimes they may commit would often be centered at that location, and be more likely to happen nearby, and less likely further away. A natural way to model this decaying crime likelihood would be with a Gaussian kernel — as opposed to a uniform probability within a fixed radius, and no increased probability outside that zone. Hence, our KSSS is a good model to potentially detect such spatial anomalies.
Planting anomalous regions. To conduct controlled experiments, we use a spatial data sets above, but choose the values in a synthetic way. In particular, we plant anomalous regions , and then each data point is assigned to a group (with probability ) or (otherwise). Those will be assigned through a Bernoulli process at rate , that is with probability and otherwise; those are assigned at rate . Given a region , this could model a pattern crimes (those with may be all vehicle theft or have suspect matching a description), where may represent the epicenter of the targeted pattern of crime. We use and .
We repeat this experiment with planted regions and plot the median on the Phileadelphia data set to compare our new algorithms and to compare sample complexity properties against existing algorithms. We use planted regions on the Chicago data set to compare scalability (these take considerably longer to run). We attempt to fix the size so , by adjusting the fixed and known bandwidth parameter on each planted region. We set for Philadelphia, and for Chicago, so the region contains a fairly small region with about or of the data.
Evaluating the models. A statistical power test, plants an anomalous region (for instance as described above), and then determines how often an algorithm can recover that region; it measures recall. However, all considered algorithms typically do not recover the exact same region as the one planted, so we measure how close to the planted region the recovered one is. To do so we measure:
-
•
distance been found centers , smaller is better.
-
•
, the larger the better; it may be larger than
-
•
the extended Jaccard similarity defined
where ; larger is better.
We plot medians over trials; the targeted and hence measured values have variance because planted regions may not be the optimal region, since the values are generated under a random process. When we cannot control the -value (when using time) we plot a kernel smoothing over different parameters on trials.
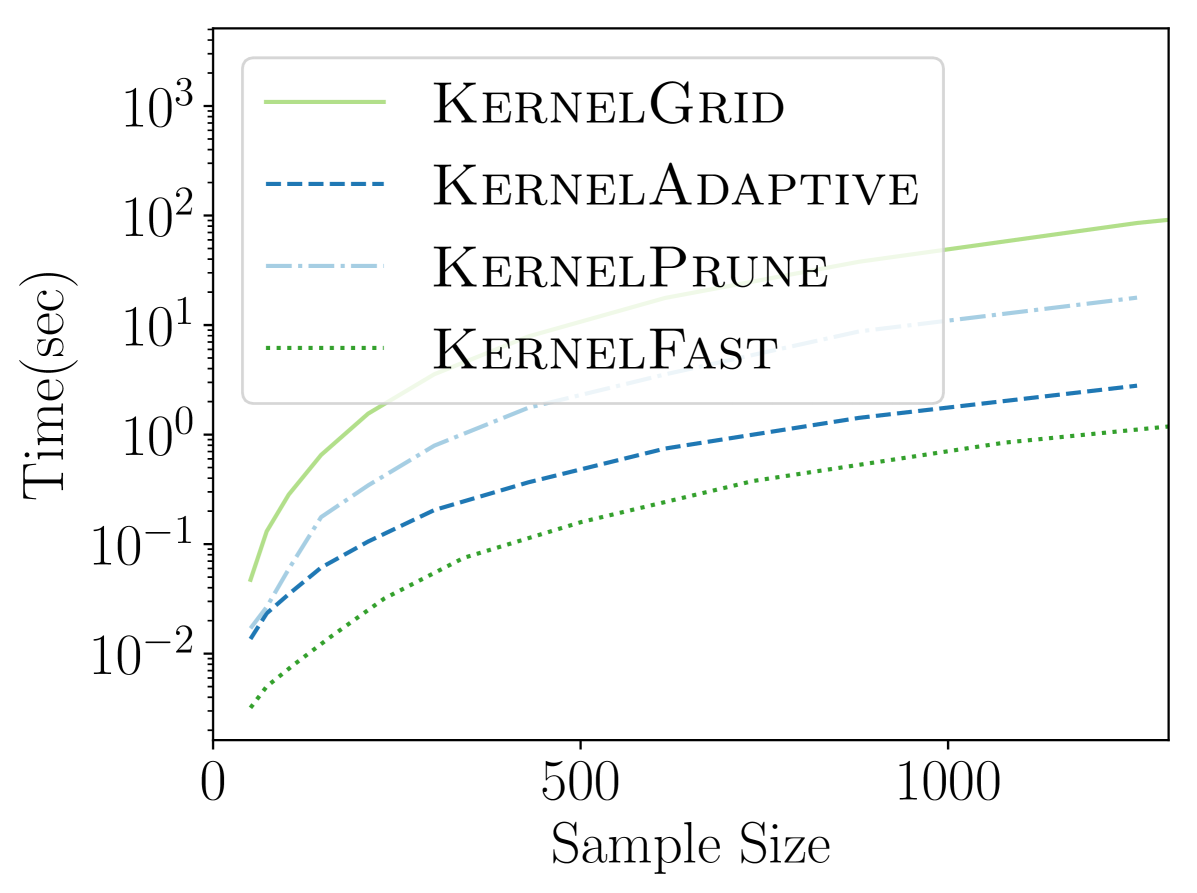
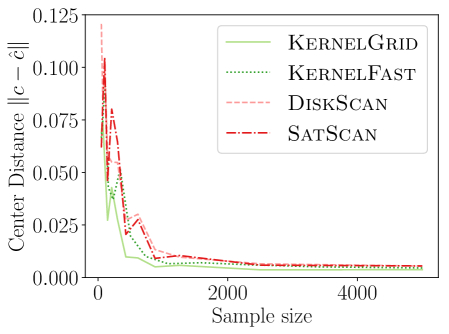
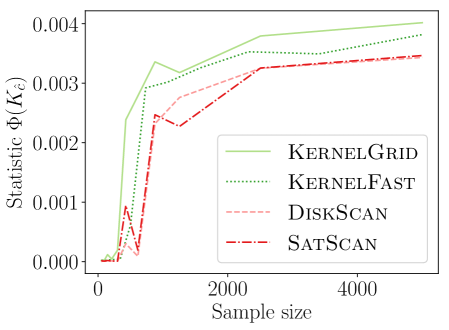
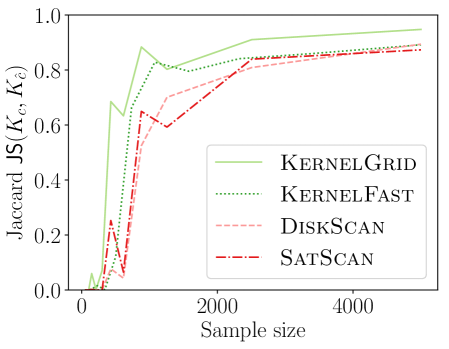
4.1. Comparing New KSSS Algorithms
We first compare the new KSSS algorithms against each other, as we increase the sample size and the corresponding other griding and pruning parameters to match the expected error from sample size as dictated in Section 3.2.
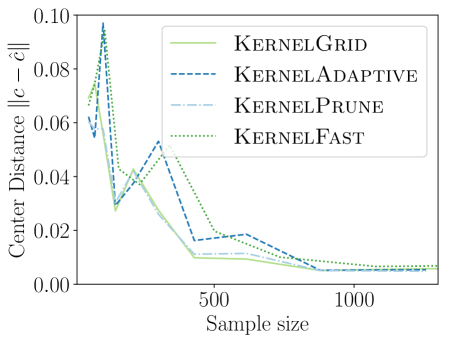
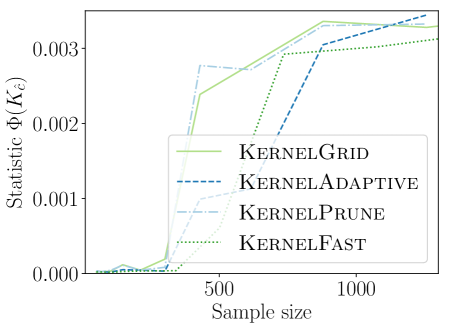
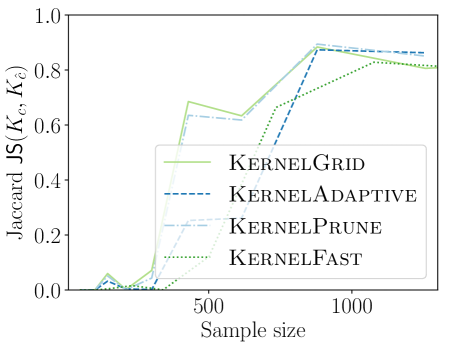
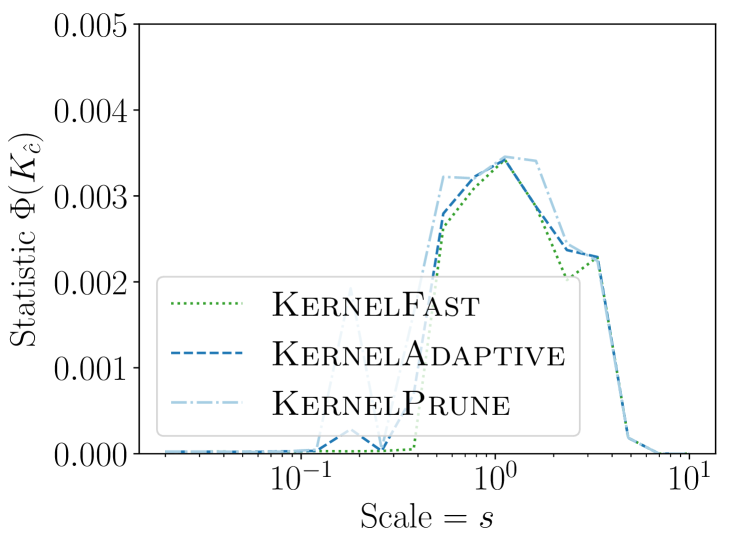
We observe in Figure 2 that all of the new KSSS algorithms achieve high power at about the same rate. In particular, when the sample size reaches about , they have all plateaued near their best values, with large power: the center distance is close to , near maximum, and almost . At medium sample sizes , KernelAdaptive and KernelFast have worse accuracy, yet reach maximum power around the same sample size – so for very small sample size, we recommend KernelPrune.
In Figure 3 we see that the improvements from KernelGrid up to KernelFast are tremendous; a speed-up of roughly x to x improvement. By considering KernelPrune and KernelAdaptive we see most of the improvement comes from the adaptive gridding, but the pruning is also important, itself adding x to x speed up.
4.2. Power vs. Sample Size
We next compare our KSSS algorithms against existing, standard Disk SSS algorithms. As comparison, we first consider a fast reimplementation of SatScan (Kul97, ; Kul7.0, ) in C++. To make-even the comparison, we consider the exact same center set (defined on grid ) for potential epicenters, and consider all possible radii of disks. Second, we compare against a heavily-optimized DiskScan algorithm (MP18b, ) for Disks, which chooses a very small “net” of points to combinatorially reduce the set of disks scanned, but still guarantee -accuracy (in some sense similar to our adaptive approaches). For these algorithms we maximize Kuldorff’s Bernoulli likelihood function (Kul97, ), whose has a closed for over binary ranges .
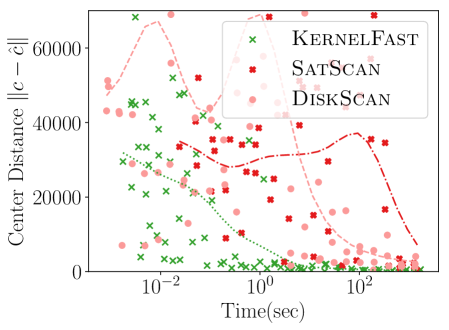
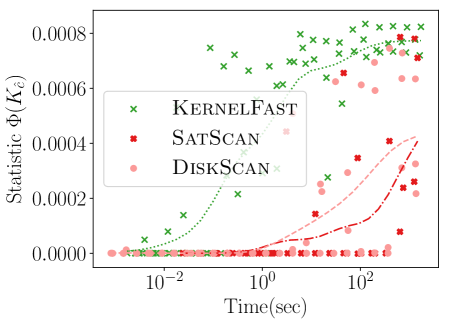
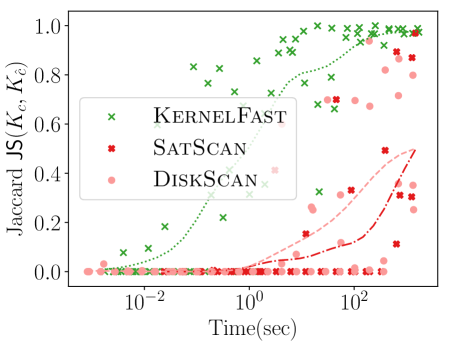
Figure 4 shows the power versus sample size (representing how many data points are available), using the same metrics as before. The KSSS algorithms perform consistently significantly better – to see this consider a fixed value in each plot. For instance the KSSS algorithms reach , and after about 1000 data samples, whereas it takes the Disk SSS algorithms about 2500 data samples.
4.3. Power vs. Time
We next measure the power as a function of the runtime of the algorithms, again the new KSSS algorithms versus the traditional Disk SSS algorithms. We increase the sample size as before, now from the Chicago dataset, and adjust other error parameters in accordance to match the theoretical error.
Figure 5 shows KernelFast significantly outperforms SatScan and DiskScan in these measures in orders of magnitude less time. It efficiently reaches small distance to the planted center faster (10 seconds vs 1000 or more seconds). In 5 seconds it achieves of 0.0006, and 0.00075 in 100 seconds; whereas in 1000 seconds the Disk SSS only reaches 0.0004. Similarly for Jaccard similarity, KernelFast reaches 0.8 in 5 seconds, and 0.95 in 100 seconds; whereas in 1000 seconds the Disk SSS algorithms only reach 0.5.
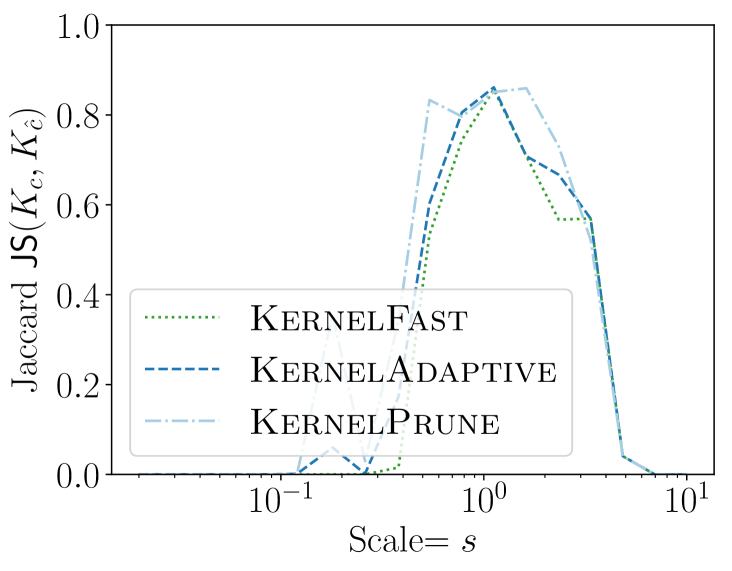
4.4. Sensitivity to Bandwidth
So far we chose to be the bandwidth of the planted anomaly (this is natural if we know the nature of the event). But if the true anomaly bandwidth is not known or only known in some range then our method should be insensitive to this parameter. On the Philadelphia dataset we consider geometrically increasing bandwidths scaled so for original bandwidth we considered where . In Figure 6 we show the accuracy using Jaccard similarity and the -value found, over trials. Our KSSS algorithms are effective at fitting events with , indicating quite a bit of lee-way in which to use. That is, the sample complexity would not change, but the time complexity may increase by a factor of only x - x if we also search over a range of .
5. Conclusion
In this work, we generalized the spatial scan statistic so that ranges can be more flexible in their boundary conditions. In particular, this allows the anomalous regions to be defined by a kernel, so the anomaly is most intense at an epicenter, and its effect decays gradually moving away from that center. However, given this new definition, it is no longer possible to define and reason about a finite number of combinatorially defined anomalous ranges. Moreover, the log-likelihood ratio test derived do not have closed form solutions and as a result we develop new algorithmic techniques to deal with these two issues. These new algorithms are guaranteed to approximately detect the kernel range which maximizes the new discrepancy function up to any error precision, and the runtime depends only on the error parameter. We also conducted controlled experiments on planted anomalies which conclusively demonstrated that our new algorithms can detect regions with few samples and in less time than the traditional disk-based combinatorial algorithms made popular by the SatScan software. That is, we show that the newly proposed Kernel Spatial Scan Statistics theoretically and experimentally outperform the existing Spatial Scan Statistic methods.
References
- [1] D. Agarwal, A. McGregor, J. M. Phillips, S. Venkatasubramanian, and Z. Zhu. Spatial scan statistics: Approximations and performance study. In KDD, 2006.
- [2] E. Arias-Castro, R. M. Castro, E. Tánczos, and M. Wang. Distribution-free detection of structured anomalies: Permutation and rank-based scans. JASA, 113:789–801, 2018.
- [3] P. J. Diggle. A point process modelling approach to raised incidence of a rare phenomenon in the vicinity of a prespecified point. J. R. Statist. Soc. A, 153(3):349–362, 1990.
- [4] L. Duczmal and R. Assunção. A simulated annealing strategy for the detection of arbitrarily shaped spatial clusters. Computational Statistics & Data Analysis, 45(2):269 – 286, 2004.
- [5] L. Duczmal, A. L. Cançado, R. H. Takahashi, and L. F. Bessegato. A genetic algorithm for irregularly shaped spatial scan statistics. Computational Statistics & Data Analysis, 52(1):43 – 52, 2007.
- [6] Y. N. Dylan Fitzpatrick and D. B. Neill. Support vector subset scan for spatial outbreak detection. Online Journal of Public Health Informatics, 2017.
- [7] E. Eftelioglu, S. Shekhar, D. Oliver, X. Zhou, M. R. Evans, Y. Xie, J. M. Kang, R. Laubscher, and C. Farah. Ring-shaped hotspot detection: A summary of results. Proceedings - IEEE International Conference on Data Mining, ICDM, 2015:815–820, 01 2015.
- [8] W. Herlands, E. McFowland, A. Wilson, and D. Neill. Gaussian process subset scanning for anomalous pattern detection in non-iid data. In AIStats, 2018.
- [9] L. Huang, M. Kulldorff, and D. Gregorio. A spatial scan statistic for survival data. Biometrics, 63(1):109–118, 2007.
- [10] I. Jung, M. Kulldorff, and A. C. Klassen. A spatial scan statistic for ordinal data. Statistics in medicine, 26(7):1594–1607, 2007.
- [11] I. Jung, M. Kulldorff, and O. J. Richard. A spatial scan statistic for multinomial data. Statistics in medicine, 29(18):1910–1918, 2010.
- [12] M. Kulldorff. A spatial scan statistic. Communications in Statistics: Theory and Methods, 26:1481–1496, 1997.
- [13] M. Kulldorff. SatScan User Guide. http://www.satscan.org/, 9.6 edition, 2018.
- [14] M. Kulldorff, L. Huang, and K. Konty. A scan statistic for continuous data based on the normal probability model. Inter. Journal of Health Geographics, 8:58, 2009.
- [15] M. Matheny and J. M. Phillips. Computing approximate statistical discrepancy. ISAAC, 2018.
- [16] M. Matheny and J. M. Phillips. Practical low-dimensional halfspace range space sampling. ESA, 2018.
- [17] M. Matheny, R. Singh, L. Zhang, K. Wang, and J. M. Phillips. Scalable spatial scan statistics through sampling. In SIGSPATIAL, 2016.
- [18] D. B. Neill and A. W. Moore. Rapid detection of significant spatial clusters. In KDD, 2004.
- [19] D. B. Neill, A. W. Moore, and G. F. Cooper. A bayesian spatial scan statistic. In Advances in neural information processing systems, pages 1003–1010, 2006.
- [20] G. P. Patil and C. Taillie. Upper level set scan statistic for detecting arbitrarily shaped hotspots. Environmental and Ecological Statistics, 11(2):183–197, Jun 2004.
- [21] S. Speakman, S. Somanchi, E. M. III, and D. B. Neill. Penalized fast subset scanning. Journal of Computational and Graphical Statistics, 25(2):382–404, 2016.
- [22] T. Tango and K. Takahashi. A flexibly shaped spatial scan statistic for detecting clusters. Inter. J. of Health Geographics, 4:11, 2005.
- [23] V. Vapnik and A. Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities. Theo. of Prob and App, 16:264–280, 1971.
Appendix A Approximating the Bernoulli KSSS
In the following sections, we focus on the Bernoulli model and for notational simplicity use , . Sometimes we also use .
The values of and are bounded between and , but at these extremes can be unbounded. Instead we will bound structural properties of , by assuming .
Lemma A.1.
When then
Proof.
Consider first the derivatives of the alternative hypothesis with respect to and .
from this we can see that at the maximum , when then
Since , hence and then we can derive
As a result
Similarly
and following similar steps we ultimately find
This implies simple bounds on as well.
Lemma A.2.
When then
Proof.
From Lemma A.1 we can state that
for any and therefore for . In the case that we have that
for any . Therefore or . ∎
A.1. Spatial Approximation of the KSSS
In this section we define useful lemmas that can be used to spatially approximate the KSSS by either ignoring far away points or restricting the set of centers spatially.
Truncating Kernels. We argue here that we can consider a simpler set of truncated kernels in place of so replacing at with a corresponding without affecting and hence by more than and additive -error. Specifically, define any using as
Lemma A.3.
For any data set , center , and error
Proof.
The key observation is that for then . Since , then
as well; where .
Next we rewrite as
Thus since for and for by Lemma A.2, then we can analyze each term of the average as of a quantity at least . If that quantity changes by at most , then that term changes by at most
by taking the derivative of at . Hence each term changes by at most , and takes the average over these terms, so the main claim holds. ∎
Center Point Lipschitz Bound. Next we show that is stable with respect to small changes in its epicenter
Lemma A.4.
The magnitude of the gradient with respect to the center of for any considered is bounded by
Proof.
We take the derivative of in direction (a unit vector in ) at magnitude . First analyze the Gaussian kernel under such a shift as , so as we have
This maximized for so
since it is maximized at .
Now examine which expands to
Since at both and , then as long as and are bounded the associated terms are also . We bound these by taking the derivative of the equation , from Lemma A.1. with respect to :
The first term for some constant at and from Lemma A.2 and since is bounded. Hence
Therefore if for any then and are bounded. This holds for any considered, as otherwise since the alternative hypothesis is equal to the null hypothesis .
This bound suggests a further improvement for centers that have few points in their neighborhood. We will state this bound in terms of a truncated kernel, but it also applies to non truncated kernels through Lemma A.3.
Lemma A.5.
For a truncated kernel , if we shift the center to so , then
where is a disk centered at of radius .
Proof.
From the previous proof for a regular kernel
Adapting to truncated kernel , then this magnitude times would provide a bound, but a bad one since the derivative is unbounded for on the boundary. Rather, we analyze the sum over in three cases. For , these have both and , so do not contribute. For the derivative is unbounded, but and by Lemma A.3, so the total contribution of these terms in the average is at most . What remains is to analyze the such that , where the derivative bound applies. However, we will not use the same approach as in the non-truncated kernel.
We write this contribution in terms as the sum over and separately as , focusing only on points in (and thus double counting ones near the bounary) where
To bound , observe that , and . Thus
To bound , we use that , that , and from the previous proof that . Thus
Since we can combine these contributions as
A.2. Bandwidth Approximations of the KSSS
We mainly focus on solving for a fixed bandwidth . Here we consider the stability in the choice in in case this is not assumed, and needs to be searched over.
Lemma A.6.
For a fixed , , and we have .
Proof.
Let , , then . We derive the derivative for with respect to .
By two observations, and , simplify
And by Lemma A.1 we bound the sums over and over each by and hence the absolute value by
A.3. Sampling Bounds
Sampling can be used to create a coreset of a truely massive data set while retaining the ability to approximately solve . In particular, we consider creating an iid sample from .
Lemma A.7.
For sample of size , then for different centers , with probability at least , for all estimates from of satisfy
Proof.
To approximate we will use a standard Chernoff-Hoeffding bound: for independent random variables , so , and then the average concentrates as Set
and each th sample maps to the th random variable
Since for and for by Lemma A.2 we have . Plugging these quantities into CH bound yields
Solving for finds Then taking a union bound over centers, reveals that with probability at least , this holds by setting
At this point, we almost have the desired bound; however, it has a factor in in place of the desired . One should believe that it is possible to get rid of the dependence on , since given one sample with the above bound, the dependence on has been reduced to logarithmic. We can apply the bound again, and the dependence is reduced to and so on. Ultimately, it can be shown that we can directly replace with in the bounds using a classic trick [23] of considering two samples and , and arguing that if they yield results close to each other, then this implies they should both be close to . We omit the standard, but slightly unintuitive details. ∎
A.4. Convexity in and
We next show that is convex and has a Lipschitz bound in terms of and . However, such a bound does not exist using as the gradient is unbounded on the boundary. We instead define a set of constraints related to at the optimal that allow a Lipschitz constant.
Lemma A.8.
The following optimization problem is convex with Lipschitz constant , and contains .
| (1) | ||||
Proof.
The set of constraints follow from Lemma A.2 and from this bound we know that the optimal and will be contained in this domain. As each constraint is a linear combination of and , and hence convex, the space of solutions is also convex. Now since is an affine transformation of and so it is both convex and concave with respect to . The logarithm function is a concave and non-decreasing function, hence both and are concave. The sum of these concave functions is still a concave function, and thus and hence is convex.
The task becomes to show the absolute value of first order partial derivatives are bounded for and in this domain. We have that for (the argument for is symmetric)
where the steps follow from the triangle inequality, by , and that for and for . ∎