The look-ahead effect of phenotypic mutations
Abstract
The evolution of complex molecular traits such as disulphide bridges often requires multiple mutations. The intermediate steps in such evolutionary trajectories are likely to be selectively neutral or deleterious. Therefore, large populations and long times may be required to evolve such traits. We propose that errors in transcription and translation may allow selection for the intermediate mutations if the final trait provides a large enough selective advantage. We test this hypothesis using a population based model of protein evolution. If an individual acquires one of two mutations needed for a novel trait, the second mutation can be introduced into the phenotype due to transcription and translation errors. If the novel trait is advantageous enough, the allele with only one mutation will spread through the population, even though the gene sequence does not yet code for the complete trait. The first mutation then has a higher frequency than expected without phenotypic mutations giving the second mutation a higher probability of fixation. Thus, errors allow protein sequences to ”look-ahead” for a more direct path to a complex trait.
∗ Both authors contributed equally to this work.
1Institute for Evolution and Biodiversity,
The Westphalian Wilhelms University of Muenster,
48149 Muenster, Germany
2Center for Computational Biology and Bioinformatics and Institute for Cell and Molecular Biology, Section of Integrative Biology, University of Texas, Austin, Texas 78712
Running Head: Look-ahead effect phenotypic mutations
Keywords: protein evolution, phenotype errors, mutation rates, complexity
Corresponding author:
Dion J. Whitehead
Institute for Evolution and Biodiversity,
The Westphalian Wilhelms University of Muenster,
Schlossplatz 4, D48149
Germany
Email: dion@uni-muenster.de
Phone: +49-(0)251-83-21633
Fax: +49-(0)251-83-21631
1 Introduction
According to a central principle of molecular evolution, the likelihood that a given mutation occurs is independent of the mutation’s phenotypic consequences. Organisms cannot choose specific mutations. This tenet was challenged by Cairns et al. (1988), who observed that under a certain selective pressure, E. coli cells appeared to acquire an excess of beneficial mutations. The idea that cells can somehow ‘direct’ evolution was thought provoking, and stimulated many investigations (for reviews see Bridges (1998); Foster (1999); Cairns (1998); Hall (1998); Rosenberg (2001)). While the notion that cells can directly decide in which genomic regions to increase their mutation rate has been mostly abandoned (Foster, 1998; Cairns, 1998), the original observations by Cairns et al. (1988) have been corroborated (see above reviews).
If mutations arise independently of their phenotypic consequences, then how can adaptations occur that require multiple amino acid mutations and for which the intermediate stages are either selectively neutral or disadvantageous? Large populations can climb multiple fitness peaks, even with disadvantageous intermediate alleles (Behe and Snoke, 2004; Weinreich and Chao, 2005). Although no new mechanisms are therefore required to explain the evolution of complex proteins (Lynch, 2005), we propose that errors in transcription and translation (phenotypic mutations) allow the selection of the intermediate mutations of a multiple-mutation requiring trait, and can thus speed up the evolution of complex traits.
Studies on the phenotypic mutation rate indicate that it is orders of magnitude larger than the genotypic mutation rate (Springgate and Loeb, 1975; Edelmann and Gallant, 1977): the global phenotypic non-synonymous mutation rate has been estimated to be mistranslations per codon (Ellis and Gallant, 1982; Shaw et al., 2002), compared with a genotypic mutation rate of between to (Drake et al., 1998). Consequently, for a protein of 300 residues, on average more than 1 in 10 copies of the protein will contain a mutation. Using mutation rates derived from the literature and conservative biological assumptions, we show via mathematical modeling and simulations that phenotypic mutations allow evolution to select for neutral intermediate alleles of a multi-mutation trait, actually selecting for proteins whose exact DNA sequence is not in the organism under selection. Evolution is then able to look ahead for evolutionary jackpots in sequence space.
Our theory is based on the following hypothetical scenario. A protein can increase the fitness of an individual if it evolved a specific trait. This trait requires two mutations, for example a disulphide bridge between two cysteine residues. Having only one of the required mutations is either selectively neutral or deleterious, however when an individual has only one mutation, small amounts of the protein with both mutations will be produced due to phenotypic mutations. If the presence of both mutations at low concentrations provides even a small fitness improvement then the allele with one mutation will spread though the population. As the frequency of the intermediate allele increases, there is a greater probability that if the second mutation occurs, it will be the presence of the first mutation, and thus provide the full fitness benefit.
The aim of this article is to show that adaptive phenotypic mutations can undergo positive selection under biologically plausible conditions, allowing proteins greater access to features involving multiple mutations. We thus introduce the notion of a ”look-ahead” effect. The name indicates that seemingly unsurmountable evolutionary barriers can be overcome thanks to phenotypic mutations which are not yet present in the genome. We wish to emphasize that the look-ahead concept is firmly grounded on the idea of chance and necessity and by no means insinuates a teleological feature of molecular evolution.
2 Materials and Methods
| Variables used in this work | |
|---|---|
| Phenotypic mutation rate from allele 1 to allele 2 | |
| Null mutation rate per residue | |
| Population size | |
| Number of residues available for the second mutation | |
| Selection coefficient for allele 2 | |
| Generational (DNA) mutation rate from allele 1 to allele 2 | |
Model assumptions:
We model the scenario of a protein evolving a trait that requires two mutations. The model is based on a population-genetics framework where a single gene can evolve into different alleles. We do not consider duplication and divergence of genes. In addition, the process described here will likely only occur for proteins with sufficiently long half-lives, as the protein must persist for some time to exert a phenotypic effect. As we model only a single gene, we expect our results to be more relevant for single-celled organisms and viruses than for multicellular organisms, which tend to have larger genomes and smaller effective population sizes than microorganisms.
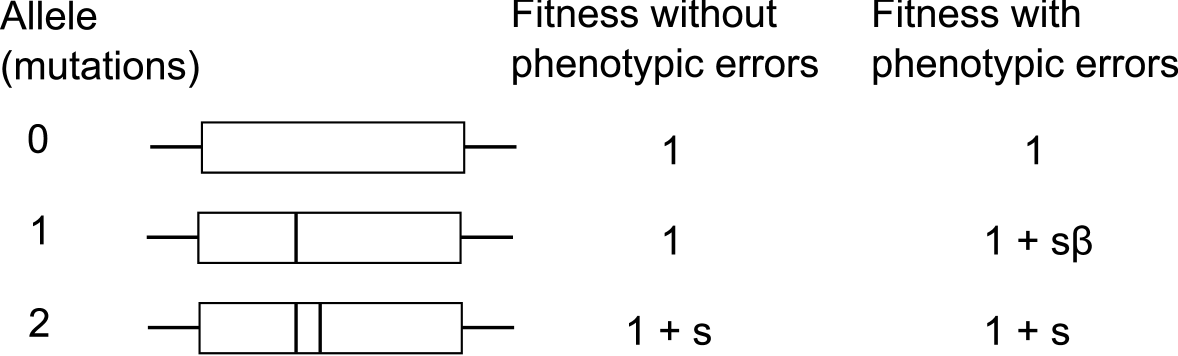
The model consists of the evolution of three non-recombining haploid genotypes, where each genotype contains one of the three alleles shown in Figure 1. The three different alleles are named according to number of relevant mutations, corresponding to zero mutations (allele 0), a single mutation (allele 1), and both mutations (allele 2) required for the adaptive feature. Having both mutations of the adaptive feature provides a selective advantage . We assume that the intermediate allele (allele 1) is selectively neutral if transcribed and translated without error. We specifically take into consideration errors in transcription and translation, that is, phenotypic mutations.
In the model, the population initially consists of one individual carrying allele 1 and individuals carrying allele 0. So long as allele 1 is present, allele 2 can be generated by mutations. The population evolves for a fixed time period, during which allele 2 can be generated by mutation and go to fixation.
In each generation, selection increases the frequency of the alleles according to their corresponding fitness values. Allele 0 has a fitness of 1. Allele 2 has a fitness of , where is the selection coefficient provided by the adaptive feature. The fitness of allele 1, the intermediate allele with only a single mutation, depends on the phenotypic error rate. Most phenotypic errors will be neutral or deleterious, however some will be beneficial. For simplicity, we assume that the length of the protein and the expression level are both constant. In addition, we also assume that the cost due to deleterious phenotypic errors is also constant. The effect of these parameters on this model will be the subject of future work. If there are no phenotypic mutations, allele 1 has the same fitness as allele 0. However, if phenotypic mutations occur, allele 1 can produce a small number of allele 2 proteins due to phenotypic errors. The fitness of allele 1 is therefore dependent on the number of such errors.
We assume that fitness is a linear sum of individual proteins, meaning that if some phenotypic variants of a protein have a higher fitness, then the overall fitness of that allele is proportionally increased.
We let be the number of residues that can potentially complement the first mutation to provide the full two-residue adaptive feature. These residues represent, e.g., the sites at which the second cysteine of a cysteine bridge could arise; other similar two-residue mutations that significantly improve functionality can be proposed. Two residues that comprise an adaptive trait are likely to co-evolve, because if a mutation occurs in one of the residues, selection strongly favors a compensatory mutation in the other. Based on a large data set, Martin et al. (2005) found that co-evolving residues are spatially near. Co-evolving residues were, on average, 98.6 amino-acids apart along the sequence, but had a mean spatial distance of 6.9 Å. This spatial distance can be compared to the width of the van der Waals volume of an amino-acid (5-6 Å), showing that most co-evolving residues are effectively in contact proximity. Therefore, is mostly independent of the size of the protein, as long as the protein is of sufficient length. Bloom et al. (2006) calculated the mean contact density (the mean number of residues in contact with a given residue) for 194 yeast proteins, and found that most residues have a mean contact density of seven to eight residues. In this work we use .
Given possible positions for the second residue, and assuming that each position requires a specific residue, the fraction of proteins of allele 1 containing the second (now highly beneficial) mutation is , where is the per codon non-synonymous phenotypic mutation rate. In this model, we use mistranslations per codon (Ellis and Gallant, 1982; Shaw et al., 2002). The fraction of allele-2 proteins contribute to the fitness, giving allele 1 a fitness of .
When considering genetic (i.e. inherited) mutations, for simplicity we neglect back mutations (e.g. from allele 1 to allele 0), and assume there are no recurrent mutations of allele 1 from allele 0 (the model starts with a single copy of allele 1). Allele 2 arises via a mutation from allele 1. We ignore the possibility of a double mutation directly from allele 0 to allele 2, as this probability is extremely small. The genetic mutation rate for allele 1 mutating into allele 2 is derived as follows: For microbes, the rate of mutations per nucleotide per generation is between to (Drake et al., 1998). Here we use as the non-synonymous mutation rate per codon per generation. The resulting mutation rate for changing allele 1 into allele 2 is .
Genes can also acquire null mutations, rendering the gene non-functional and therefore eliminating the organism. The null mutation rate for protein-encoding genes is on the order of per generation (Drake et al., 1998). However, this rate will depend on the length () of the protein. Assuming an average protein length of 300 residues, the per-residue null mutation rate is given by . For a protein of length , the null mutation rate is given by .
Simulations:
The numerical simulations were written in Java using the Colt scientific library (Colt Project, 2007) for the generation of random numbers. The analytic expressions were evaluated using both Mathematica and Python, the latter in conjunction with the SciPy package (SciPy, 2007). Source code for the numerical simulations is available on request from DJW.
The population in each simulation is represented by three numbers, corresponding to the abundance of each of the three alleles. As described, the initial abundances are for alleles , respectively. The simulation runs for a specified number of generations . We used throughout this work. Strictly speaking, is the number of generations in which allele 1 can mutate into allele 2; for later generations this possibility of mutation is disabled. If allele 2 is present at time , then the simulation is continued until allele 2 is either lost or has reached fixation. Generations are discrete, with mutations, selection, and drift occurring at each generation. During each generation we perform the following steps. First we check if either allele 0 or allele 2 has reached fixation; if so, we stop the simulation, as both cases are absorbing states. Next, for each allele we check for null mutations by drawing a random number from the Poisson distribution where the expected number of events is the null mutation rate multiplied by the total number of individuals with the given allele. Mutations from allele 1 to allele 2 are computed in a similar manner, where the expected number of events is multiplied by the number of allele 1 individuals. Then, after the possible production of the mutant allele 2, selection acts on the fitness of the alleles, where the frequency of each allele is multiplied by its corresponding fitness, for alleles , giving the new number of alleles in a possibly larger population. Finally, the next population of individuals is chosen by recursively sampling from the binomial distribution, representing random genetic drift. Allele 0 is first sampled with the mean=(frequency of allele 0), and the (number of trials)=. Allele 1 is then sampled from the combined allele 1 and 2 individuals. The number of simulations where allele 2 becomes fixed is divided by the total number of simulations, giving an estimate of the fixation probability. The number of simulations for each parameter set was between and .
3 Results
3.1 Analytical fixation rate of allele 2
To calculate the fixation rate of allele 2 we have to consider the two fates of allele 1. Firstly, allele 1 can become lost. In this case allele 2 can only be generated during the period of drift of allele 1. The alternative fate of allele 1 is fixation. Then allele 2 can be generated either while allele 1 drifts to fixation or after allele 1 is already fixed. We would like to know how many mutation events from allele 1 to allele 2 are expected for either fate of allele 1. We let be the expected number of mutation events for when allele 1 is eventually fixed, and be the expected number of mutation events for the case when allele 1 is lost. We can calculate and from diffusion theory, by integrating over the sojourn times of allele 1. The corresponding calculations are cumbersome but straightforward, and for the sake of brevity we present the details in the Appendix (A.4 and A.5). For , allele 2 can be generated as allele 1 drifts to fixation, and also after allele 1 has already reached fixation. For , allele 2 can only be generated while allele 1 drifts.
Assuming that is the expected number of times allele 2 is generated, what is the probability that at least one copy goes to fixation? The probability of fixation of a single copy of allele 2 is Kimura (1962). (In Appendix A.1, we reproduce the exact expression for , as well as approximations for large and small .) Thus, if allele 2 is generated times, its probability of fixation is . Since the probability that allele 2 is generated times follows a Poisson distribution with mean , we find for the probability that at least one of the mutations to allele 2 goes to fixation
| (1) |
We calculate this probability separately for and , setting equal to either of these values. We assume that is sufficiently large so that allele 1 has time to reach fixation within this interval (we assume ). Then the probability that allele 2 is generated and goes to fixation (starting with a single copy of allele 1) is
| (2) |
The first half of the equation stems from the case when allele 1 eventually reaches fixation, where the probability that allele 1 becomes fixed, , is multiplied by the probability that at least one copy of allele 2 is generated and fixed. The second half corresponds to the case of loss of allele 1 from the population, where the probability of loss of allele 1, , is multiplied by the probability of at least one mutation from allele 1 to allele 2 and subsequent fixation of allele 2. Taking into account allele 2 mutations during allele 1 loss is important especially for small . Allele 1 is more likely to be lost than fixed for small , but can occasionally drift for long times before being lost.
In the limit , i.e., in the absence of phenotypic mutations, we find with Eqs. (A2), (A27), and (A35)
| (3) |
(We assume that , and neglect corrections of order 1 compared to . Note that we cannot simplify to 1, because for small , and are of the same order in .)
As we are interested in the effect of phenotypic mutations () compared to the case without phenotypic mutations (), we define the increase in the probability of fixation from advantagous phenotypic mutations (the look-ahead effect) as
| (4) |
We can broaden the assumption of to with good accuracy. For , if allele 1 is destined to reach fixation, then the probability of generating at least one copy of allele 2 that goes to fixation approaches 1. Therefore, , in this limit, and thus
| (5) |
Apart from a correction for the case when allele 2 occurs while allele 1 is destined for extinction, Equation (5) is just the ratio of the probability of allele-1 fixation in the presence and absence of phenotypic mutations, .
3.2 Simulations
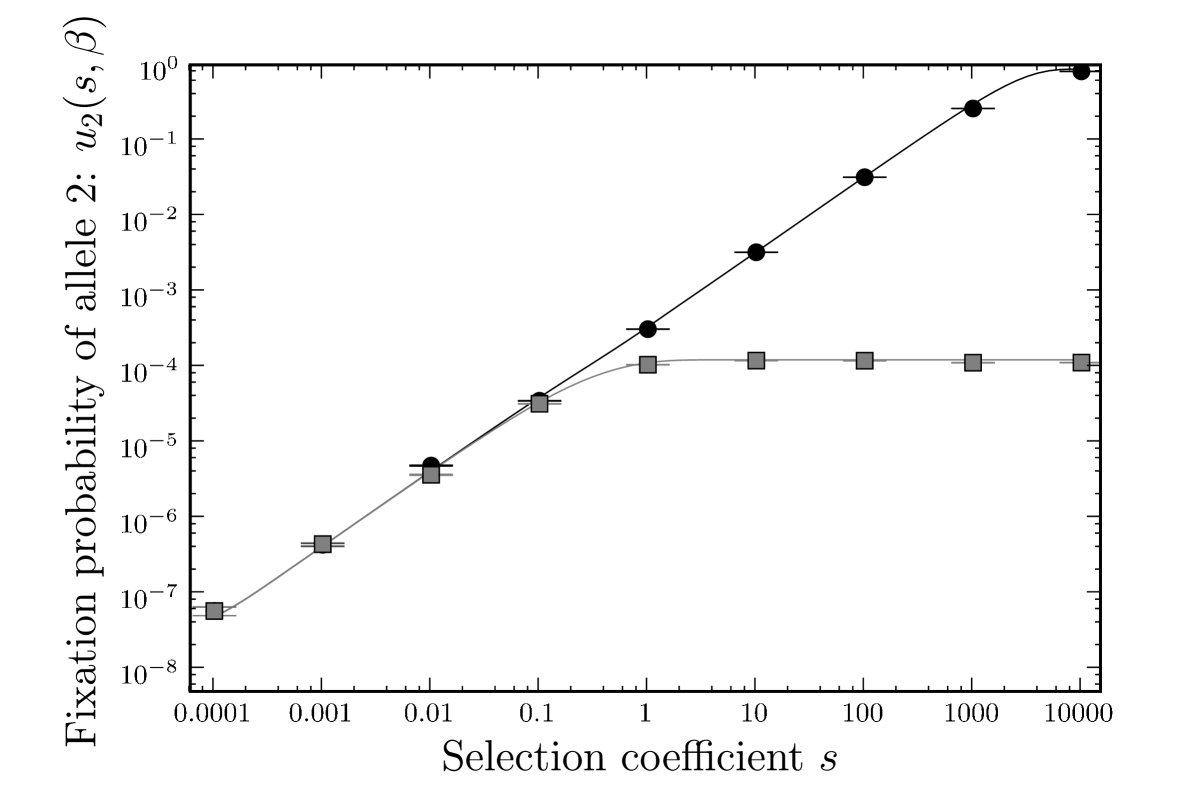
We confirmed our analytic results for the fixation probabilities and by numerical simulation, for different values of (Figure 2). With a population size , the effect of phenotypic mutations can be seen for , and increases for larger . For , the effect is too small and the intermediate allele is effectively neutral, meaning the fixation of allele 2 depends on the random fixation of the neutral allele 1. The look-ahead effect, , shows the simulation results compared to Equations (5), (6) and (7). Figure 3 shows the magnitude of the look-ahead effect for the same parameter settings. For large , the look-ahead effect can inflate the probability of fixation of allele 2 by several orders of magnitude.
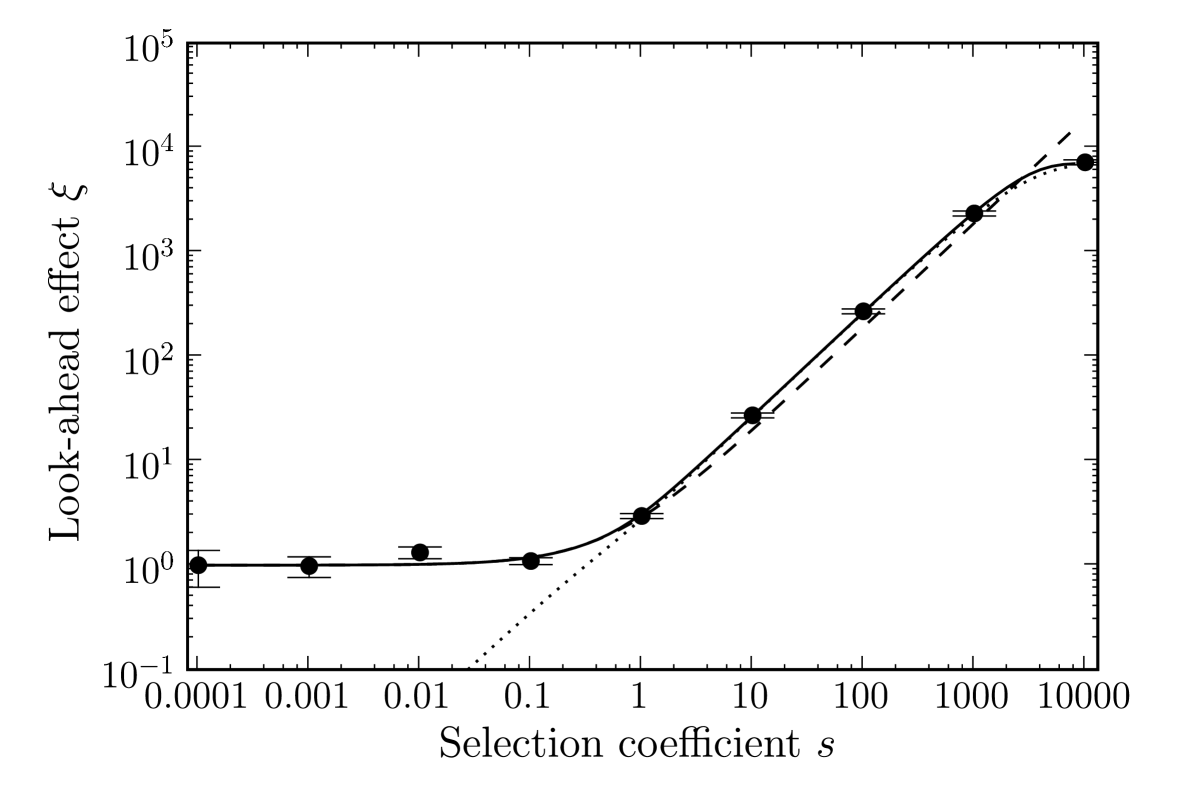
We also display the different analytic expressions for in Figure 3. The approximation (5), derived in the limit , works well for all values of . The approximation (6), derived for small , captures correctly the magnitude of at which the look-ahead effect starts to operate, i.e., . Similarly, approximation (7), valid for , approximates well for larger .
Figure 4 shows for different population sizes. As expected from the condition , the look-ahead effect will work with smaller selection coefficients in larger populations. For large , saturates at approximately .
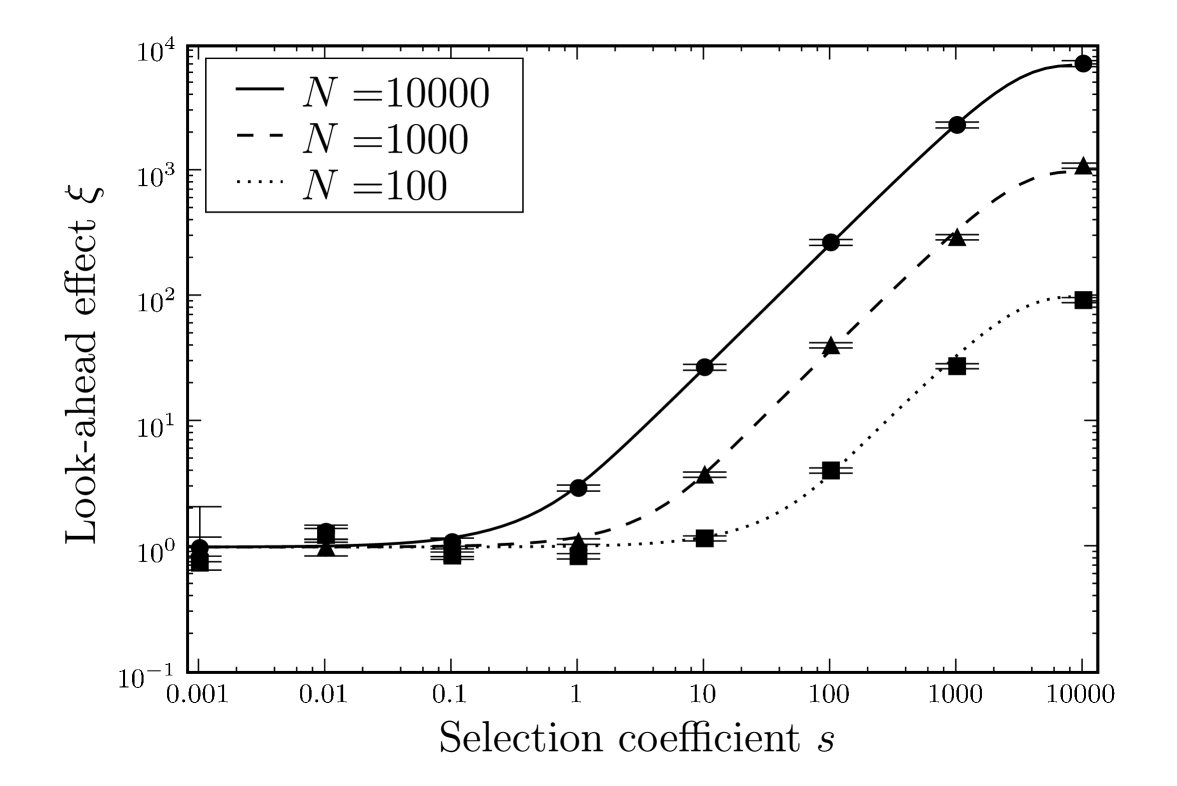
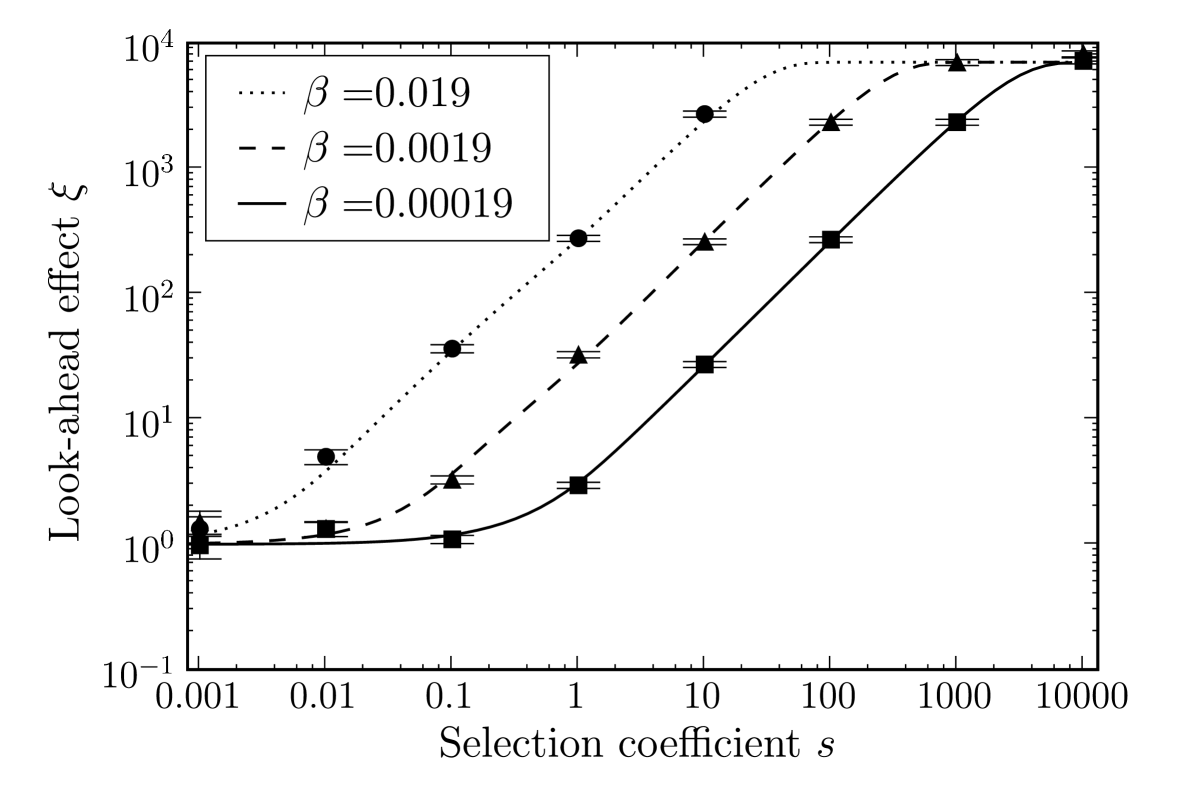
We studied the effect of different values of the phenotypic error rate (Fig. 5). As the error rate increases, the look-ahead effect increases by the same order of magnitude. For a very high phenotypic error rate of , the look-ahead effect is present for very small values of . However, such a high error rate is likely to be severely detrimental, and in our model we do not take into account the loss of overall fitness for increasing phenotypic error rates. Conversely for smaller , the look-ahead effect is restricted to large .
4 Discussion
We have described a model demonstrating the consequences of positive phenotypic mutations on the evolution of a single gene. We have compared numerical simulations with the analytical approximations and found them to be in good agreement. When phenotypic mutations exert an effect on fitness, selection can operate on the intermediate allele of a complex trait, which otherwise (without phenotypic mutations) would be neutral. We refer to selection for the intermediate allele as the look-ahead effect, because this effect allows evolution to select for sequences not yet in the genome.
The approximation for small , Eq.(6), shows most clearly the relationship between the parameters. The look-ahead effect is proportional to , , and , and sets in when is on the order of . For large , the look-ahead effect saturates. The asymptotic value of is approximately for . Therefore, large populations have two advantages over small populations in terms of the look-ahead effect: the effect sets in for smaller values of , and saturates at a larger asymptotic value . Of course, even in the absence of the look-ahead effect, larger populations can more easily traverse multiple local fitness peaks (Weinreich and Chao, 2005).
Because the selection coefficient depends on the environment, a valid question is how often does reach sufficiently high levels so that the look-ahead effect can operate. For microbial species such as bacteria, sufficiently large should be reasonably common. Many bacteria experience highly fluctuating (Smit et al., 2001) and structured (Baquero and Negri, 1997) environments, where growth is limited by the lack of a key trait. An obvious and extreme example is antibiotic resistance. Evolving a defense against an antibiotic molecule can involve only a few amino acids (Palzkill et al., 1994), and those individuals that can generate an enzyme capable of degrading the antibiotic, even if briefly or weakly, will have a very large fitness increase. In fact, if the efficacy of the antibiotic is 100% on susceptible genotypes, a mutation providing only moderate resistance has an infinite selective advantage. And even for very small antibiotic concentrations, mutants differing by only two amino acids at a single -lactamase gene can be selected effectively (Baquero et al., 1997, 1998). Thus, bacteria may frequently experience environments in which a large fitness increase (large ) is only a few mutations away. Similarly, in bacteriophages, selective coefficients of 10 or more are not uncommon, even for individual mutations (Bull et al., 2000).
Our work is entirely theoretical, but we expect that it will be possible to experimentally verify our predictions in future work. For experimentally observing the look-ahead effect, we would need a system where and are both large, while (the phenotypic mutation rate) can be modified. The values of both and used in this work are well within biologically realistic ranges achievable in a microbiological laboratory. Conditions for large may be created with e.g. antibiotic resistance, which is a common laboratory workhorse. Unfortunately, many antibiotics function by reducing translation fidelity (Ogle and Ramakrishnan, 2005), and thus would conflate and . Changing could involve a mutated ribosome. Ribosomes appear to be optimized for accurate and efficient translation of mRNA (Baxter-Roshek et al., 2007), and several examples of altered ribosome fidelity exist, both increasing (Vila-Sanjurjo et al., 2003) and decreasing fidelity (Friedman et al., 1968). Specific regions of the ribosome rRNA sequence have been identified as influencing fidelity (O’Connor et al., 1997), and various agents can reduce fidelity, e.g., streptomycin, magnesium, and ethanol (Friedman et al., 1968). Few mutations may be sufficient to alter the fidelity of a ribosome, for example, a single mutation in the S5 ribosomal protein in E. coli increases frameshifting and nonsense mutations (Kirthi et al., 2006). In yeast, mutations in the 18S RNA have been found that both increase and decrease translational fidelity (Konstantinidis et al., 2006).
In this work, we have calculated the look-ahead effect from a comparison between the two cases of and . The latter may not be experimentally possible; any experiment will likely compare two different positive values of . Nevertheless, Figure 5 shows that a larger look-ahead effect can be achieved with a higher , where increasing by one order of magnitude both increases the look-ahead effect by an order of magnitude and lowers the smallest where an effect is observed. Of course, our model does not take into account the loss of fitness or other confounding effects from a higher phenotypic mutation rate. Thus, a balance must be found in having two different values of that are different enough to measure, while at the same time minimizing the confounding effects. The most obvious consequence of increasing the phenotypic mutation rate is that overall fitness may be reduced, for example in E. coli, where a higher translational error rate activates stress responses (Fredriksson et al., 2007), or in mouse, where such errors are implicated in neurodegeneration caused by misfolded proteins that aggregate (Lee et al., 2006). Increasing translational fidelity may not come without fitness cost either. The hyperaccurate mutations in the 18S RNA in yeast (Konstantinidis et al., 2006) cause an increase in oxidative stress. This observation suggests that cells consume more energy to achieve hyperaccuracy. It may also partially explain why the phenotypic error rate is much higher than the genotypic error rate, as there is possibly a direct disadvantage in reducing the phenotypic error rate, rather than only reducing the selective advantage that occurs if the phenotypic error rate is reduced, as discussed in Buerger et al. (2006).
Buerger et al. (2006) asked whether evolution has selected for the current phenotypic error rate, which does not differ significantly between eukaryotes and prokaryotes (Ellis and Gallant, 1982; Shaw et al., 2002) even though the source of errors is different. They suggested that the increase in fitness becomes incrementally smaller for improvements to transcription and translation fidelity. We would like to speculate that the phenotypic error rate is on the border between minimal costs (of e.g. misfolded proteins) and maximum payoff (via the look-ahead effect).
The goal of our analysis was to demonstrate that the look-ahead effect is theoretically possible, and as such, we intentionally excluded confounding factors for the sake of clarity. There are several aspects not considered in our model that may play important roles. For example, in this work we did not consider the expression level. For low expressed genes, the mutation from allele 1 to allele 2 will occur less frequently compared to highly expressed genes. However, if allele 2 is produced it will be at a higher concentration (of allele 2 mutant proteins in a population of allele 1 proteins), as the overall copy number of allele 1 is low. This difference in expression levels is likely reduced in a large population, where beneficial mutations occur with sufficient frequency. Another factor related to the expression level is translational robustness. It has been proposed that highly expressed genes are under selection to properly fold despite phenotypic mutations, and consequently evolve slower (Drummond et al., 2005; Wilke and Drummond, 2006). If a gene is robust to translational errors, then it can tolerate a larger variety of mutations, of which some may be intermediates to a new adaptive multi-residue trait. Thus, translational robustness may increase the sequences available for experimentation at the phenotypic level. However, if the intermediate allele is itself not robust to errors in translation, then it will not be neutral, and may be selected against. The location of the protein trait will also influence the viability of the intermediate allele: mutations near the surface of the protein are less likely to disrupt the protein compared to mutations in the core (Tokuriki et al., 2007).
In conclusion, we propose that organisms can experiment with protein sequences that are mutationally close to the current sequence, but not yet in the genome. This effect allows selection for intermediates of complex traits, opening up a more direct route to the trait and thus reducing the time needed for fixation in the population.
5 Acknowledgements
D.J.W. would like to thank January Weiner for stimulating discussions and Maya Amago for helpful suggestions. D.J.W. and E.B.B. were supported by an HFSP program grant. C.O.W. was supported by NIH grant AI 065960.
Appendix A Appendix
Here, we present the details of our analytic derivations.
A.1 Probability of fixation
According to (Kimura, 1962), the probability of fixation of a single allele with selection coefficient is given by
| (A1) |
For , this expression simplifies to
| (A2) |
whereas for , this expression simplifies to
| (A3) |
A.2 A single allele drifting to fixation or loss
We first consider a single allele with selective advantage drifting to fixation or extinction, and ask how many mutations this allele generates until it is either fixed or lost. We will treat these two cases separately. Let be the expected number of mutations generated while the allele drifts to fixation, and let be the expected number of mutations generated while the allele drifts to extinction. We calculate these two quantities using diffusion theory, by integrating the sojourn times of the allele over all frequencies.
For an allele with selective coefficient and starting at frequency , Nagylaki (1974) calculated its mean sojourn time between frequencies and as
| (A4) |
Here,
| (A5) | ||||
| (A6) | ||||
| (A7) | ||||
| (A8) |
and is the Heaviside step function. We want to integrate expressions involving from to . Since corresponds to a single copy of the allele that drifts to fixation, values of less than are not relevant for our analysis. Therefore, we discard the term proportional to in Eq. (A4), and use in what follows
| (A9) |
A.3 Number of mutations conditional on fixation
For the sojourn time conditional on fixation, , Nagylaki (1974) finds
| (A10) |
Using this expression, we have
| (A11) |
Plugging the expressions for , , , and into , we arrive at
| (A12) |
This expression corresponds to the one by Ewens (1973). Note that for . Therefore, we can extend the lower limit of integration to 0 in Eq. (A11), and rewrite as
| (A13) |
with
| (A14) |
The integral can be rewritten as
| (A15) |
where is the Euler-Mascheroni constant and is the exponential integral,
| (A16) |
For , we find
| (A17) |
For , we obtain the asymptotic expansion
| (A18) |
using Abramowitz and Stegun (1964) 5.1.51,
| (A19) |
A.4 Number of mutations conditional on extinction
For the sojourn time conditional on extinction, , Nagylaki (1974) finds
| (A20) |
Using this expression, we have
| (A21) |
Plugging the expressions for , , , and into , we find
| (A22) |
We rewrite as
| (A23) |
with
| (A24) |
The integral can be rewritten as
| (A25) |
where is the hyperbolic cosine integral,
| (A26) |
For , we find
| (A27) |
For , we obtain the asymptotic expansion
| (A28) |
using
| (A29) |
[This expansion follows directly from the definitions of , , and .]
A.5 Number of mutations within a given time interval
We now extend the derivations in Section A.3 to calculate the number of mutations to allele 2 generated within a certain time interval , conditional on fixation of allele 1. We assume that is sufficiently large so that allele 1 has time to reach fixation within this interval. We only consider the case conditional on fixation because no new mutations are generated once allele 1 has gone extinct.
We calculate , where is the total number of mutations generated once the first mutation has reached fixation. We have
| (A30) |
where is the time to fixation of a mutation with selective advantage . This time is given by the integral over all sojourn times,
| (A31) |
with
| (A32) |
A partial fraction decomposition of the integrand reveals that , and thus we have
| (A33) |
Combining this result with Eqs. (A13) and (A30), we find
| (A34) |
Note that for .
A.6 for
A.7 for
| (A40) |
Likewise, in this limit we can simplify Eq. (3) to
| (A41) |
giving
| (A42) |
Furthermore, for , this expression simplifies to
| (A43) |
If , then in the limit .
References
- Abramowitz and Stegun (1964) Abramowitz, M., and I. A. Stegun, 1964 Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Dover, New York, ninth dover printing, tenth gpo printing edition.
- Baquero and Negri (1997) Baquero, F., and M. C. Negri, 1997 Selective compartments for resistant microorganisms in antibiotic gradients. Bioessays 19: 731–736.
- Baquero et al. (1997) Baquero, F., M. C. Negri, M. I. Morosini, and J. Blázquez, 1997 The antibiotic selective process: concentration-specific amplification of low-level resistant populations. Ciba Found Symp 207: 93–105; discussion 105–11.
- Baquero et al. (1998) Baquero, F., M. C. Negri, M. I. Morosini, and J. Blázquez, 1998 Selection of very small differences in bacterial evolution. Int Microbiol 1: 295–300.
- Baxter-Roshek et al. (2007) Baxter-Roshek, J. L., A. N. Petrov, and J. D. Dinman, 2007 Optimization of ribosome structure and function by rRNA base modification. PLoS ONE 2: e174.
- Behe and Snoke (2004) Behe, M. J., and D. W. Snoke, 2004 Simulating evolution by gene duplication of protein features that require multiple amino acid residues. Protein Sci 13: 2651–64.
- Bloom et al. (2006) Bloom, J. D., D. A. Drummond, F. H. Arnold, and C. O. Wilke, 2006 Structural determinants of the rate of protein evolution in yeast. Mol Biol Evol 23: 1751–1761.
- Bridges (1998) Bridges, B. A., 1998 The role of DNA damage in stationary phase (’adaptive’) mutation. Mutat Res 408: 1–9.
- Buerger et al. (2006) Buerger, R., M. Willensdorfer, and M. A. Nowak, 2006 Why are phenotypic mutation rates much higher than genotypic mutation rates? Genetics 172: 197–206.
- Bull et al. (2000) Bull, J. J., M. R. Badgett, and H. A. Wichman, 2000 Big-benefit mutations in a bacteriophage inhibited with heat. Mol Biol Evol 17: 942–950.
- Cairns (1998) Cairns, J., 1998 Mutation and cancer: the antecedents to our studies of adaptive mutation. Genetics 148: 1433–1440.
- Cairns et al. (1988) Cairns, J., J. Overbaugh, and S. Miller, 1988 The origin of mutants. Nature 335: 142–5.
- Colt Project (2007) Colt Project, 2007 Colt: Open Source Libraries for High Performance Scientific and Technical Computing in Java. Http://dsd.lbl.gov/ hoschek/colt/index.html.
- Drake et al. (1998) Drake, J. W., B. Charlesworth, D. Charlesworth, and J. F. Crow, 1998 Rates of spontaneous mutation. Genetics 148: 1667–86.
- Drummond et al. (2005) Drummond, D. A., J. D. Bloom, C. Adami, C. O. Wilke, and F. H. Arnold, 2005 Why highly expressed proteins evolve slowly. Proc Natl Acad Sci U S A 102: 14338–14343.
- Edelmann and Gallant (1977) Edelmann, P., and J. Gallant, 1977 Mistranslation in E. coli. Cell 10: 131–7.
- Ellis and Gallant (1982) Ellis, N., and J. Gallant, 1982 An estimate of the global error frequency in translation. Mol Gen Genet 188: 169–72.
- Ewens (1973) Ewens, W. J., 1973 Conditional diffusion processes in population genetics. Theor Popul Biol 4: 21–30.
- Foster (1998) Foster, P. L., 1998 Adaptive mutation: has the unicorn landed? Genetics 148: 1453–1459.
- Foster (1999) Foster, P. L., 1999 Mechanisms of stationary phase mutation: a decade of adaptive mutation. Annu Rev Genet 33: 57–88.
- Fredriksson et al. (2007) Fredriksson, A., M. Ballesteros, C. N. Peterson, O. Persson, T. J. Silhavy, et al., 2007 Decline in ribosomal fidelity contributes to the accumulation and stabilization of the master stress response regulator sigmaS upon carbon starvation. Genes Dev 21: 862–874.
- Friedman et al. (1968) Friedman, S. M., R. Berezney, and I. B. Weinstein, 1968 Fidelity in protein synthesis. The role of the ribosome. J Biol Chem 243: 5044–5048.
- Hall (1998) Hall, B. G., 1998 Adaptive mutagenesis: a process that generates almost exclusively beneficial mutations. Genetica 102-103: 109–125.
- Kimura (1962) Kimura, M., 1962 On the probability of fixation of mutant genes in a population. Genetics 47: 713–9.
- Kirthi et al. (2006) Kirthi, N., B. Roy-Chaudhuri, T. Kelley, and G. M. Culver, 2006 A novel single amino acid change in small subunit ribosomal protein S5 has profound effects on translational fidelity. RNA 12: 2080–2091.
- Konstantinidis et al. (2006) Konstantinidis, T. C., N. Patsoukis, C. D. Georgiou, and D. Synetos, 2006 Translational fidelity mutations in 18S rRNA affect the catalytic activity of ribosomes and the oxidative balance of yeast cells. Biochemistry 45: 3525–3533.
- Lee et al. (2006) Lee, J. W., K. Beebe, L. A. Nangle, J. Jang, C. M. Longo-Guess, et al., 2006 Editing-defective tRNA synthetase causes protein misfolding and neurodegeneration. Nature 443: 50–55.
- Lynch (2005) Lynch, M., 2005 Simple evolutionary pathways to complex proteins. Protein Sci 14: 2217–25; discussion 2226–7.
- Martin et al. (2005) Martin, L. C., G. B. Gloor, S. D. Dunn, and L. M. Wahl, 2005 Using information theory to search for co-evolving residues in proteins. Bioinformatics 21: 4116–4124.
- Nagylaki (1974) Nagylaki, T., 1974 The moments of stochastic integrals and the distribution of sojourn times. Proc Natl Acad Sci U S A 71: 746–749.
- O’Connor et al. (1997) O’Connor, M., C. L. Thomas, R. A. Zimmermann, and A. E. Dahlberg, 1997 Decoding fidelity at the ribosomal A and P sites: influence of mutations in three different regions of the decoding domain in 16S rRNA. Nucleic Acids Res 25: 1185–1193.
- Ogle and Ramakrishnan (2005) Ogle, J. M., and V. Ramakrishnan, 2005 Structural insights into translational fidelity. Annu Rev Biochem 74: 129–177.
- Palzkill et al. (1994) Palzkill, T., Q. Q. Le, K. V. Venkatachalam, M. LaRocco, and H. Ocera, 1994 Evolution of antibiotic resistance: several different amino acid substitutions in an active site loop alter the substrate profile of beta-lactamase. Mol Microbiol 12: 217–229.
- Rosenberg (2001) Rosenberg, S. M., 2001 Evolving responsively: adaptive mutation. Nat Rev Genet 2: 504–15.
- SciPy (2007) SciPy, 2007 Scientific Tools for Python. Http://www.scipy.org/.
- Shaw et al. (2002) Shaw, R. J., N. D. Bonawitz, and D. Reines, 2002 Use of an in vivo reporter assay to test for transcriptional and translational fidelity in yeast. J Biol Chem 277: 24420–6.
- Smit et al. (2001) Smit, E., P. Leeflang, S. Gommans, J. van den Broek, S. van Mil, et al., 2001 Diversity and seasonal fluctuations of the dominant members of the bacterial soil community in a wheat field as determined by cultivation and molecular methods. Appl Environ Microbiol 67: 2284–2291.
- Springgate and Loeb (1975) Springgate, C. F., and L. A. Loeb, 1975 On the fidelity of transcription by Escherichia coli ribonucleic acid polymerase. J Mol Biol 97: 577–91.
- Tokuriki et al. (2007) Tokuriki, N., F. Stricher, J. Schymkowitz, L. Serrano, and D. S. Tawfik, 2007 The stability effects of protein mutations appear to be universally distributed. J Mol Biol 369: 1318–1332.
- Vila-Sanjurjo et al. (2003) Vila-Sanjurjo, A., W. K. Ridgeway, V. Seymaner, W. Zhang, S. Santoso, et al., 2003 X-ray crystal structures of the WT and a hyper-accurate ribosome from Escherichia coli. Proc Natl Acad Sci U S A 100: 8682–8687.
- Weinreich and Chao (2005) Weinreich, D. M., and L. Chao, 2005 Rapid evolutionary escape by large populations from local fitness peaks is likely in nature. Evolution Int J Org Evolution 59: 1175–1182.
- Wilke and Drummond (2006) Wilke, C. O., and D. A. Drummond, 2006 Population genetics of translational robustness. Genetics 173: 473–481.