The low level of correlation observed in the CMB sky at large angular scales and the low quadrupole variance
Abstract
The angular two-point correlation function of the temperature of the cosmic microwave background (CMB), as inferred from nearly all-sky maps, is very close to zero on large angular scales. A statistic invented to quantify this feature, , has a value sufficiently low that only about 7 in 1000 simulations generated assuming the standard cosmological model have lower values; i.e., it has a –value of 0.007. As such, it is one of several unusual features of the CMB sky on large scales, including the low value of the observed CMB quadrupole, whose importance is unclear: are they multiple and independent clues about physics beyond the cosmological standard model, or an expected consequence of our ability to find signals in Gaussian noise? We find they are not independent: using only simulations with quadrupole values near the observed one, the –value increases from 0.007 to 0.08. We also find strong evidence that corrections for a “look-elsewhere effect” are large. To do so, we use a one-dimensional generalization of the statistic, and select along the one dimension for the statistic that is most extreme. Subjecting our simulations to this process increases the –value from 0.007 to 0.03; a result similar to that found in Planck XVI (2016). We argue that this optimization process along the one dimension provides an underestimate of the look-elsewhere effect correction for the historical human process of selecting the statistic from a very high-dimensional space of alternative statistics after having examined the data.
keywords:
methods: statistical – cosmology: cosmic background radiation1 Introduction
We view the continued success of a six-parameter model in describing the statistical properties of cosmic microwave background (CMB) temperature anisotropy maps with millions of resolution elements as one of the major takeaway messages from the Planck mission: a simple model works extremely well. This success includes agreement between model and data via multiple statistics, most prominently the two-point correlation function (Planck XV, 2014; Planck XI, 2016), but also via the higher-order correlations expected from gravitational lensing (Planck XVII, 2014; Planck XV, 2016) and relativistic effects of our motion with respect to cosmic rest (Planck XXVII, 2014).
The strongest challenge111While others have described challenges to the success of the six-parameter model arising from some internal tensions revealed by tests using the two-point correlation function, e.g. Addison et. al. (2016), they are not highly significant (Planck LI, 2016). to this takeaway message, based on CMB maps alone, may be the existence of relatively large-scale patterns that have been described as “anomalous.” Some of these large-scale CMB anomalies are: the existence of an unexpectedly large cold spot (Cruz, Mart nez–Gonz lez, & Vielva, 2006, 2007, 2010; Zhang & Huterer, 2010), the preference for odd parity modes (Kim & Naselsky, 2010a, b, 2011), a hemispherical power asymmetry (Eriksen et. al., 2004, 2007; Hoftuft et. al., 2009; Hansen et. al., 2009; Akrami et. al., 2014; Planck XXIII, 2014; Planck XVI, 2016), the alignment of the lowest multipoles with the geometry of the solar system and with each other (de Oliveira–Costa et. al., 2004; Hansen et. al., 2004; Schwarz et. al., 2004; Land & Magueijo, 2005a, b; Bennet et. al., 2011; Copi et. al., 2015b), the low variance in low-resolution maps (Planck XXIII, 2014; Planck XVI, 2016), and the lack of correlation on the largest angular scales (Bennett et. al., 2003; Spergel et. al., 2003; Hajian, 2007; Copi et. al., 2007, 2009; Bennet et. al., 2011; Gruppuso, 2014; Copi et. al., 2015a). For a recent review of large-scale CMB anomalies, see Schwarz et. al. (2015).
One of the apparent anomalies that has received a lot of attention is the low value of the real space two-point correlation function at large angular scales. This feature can be seen in the earliest observations of the correlation function of the CMB as observed by the Cosmic Background Explorer Differential Microwave Radiometer (COBE–DMR) (Hinshaw et. al., 1996), though it was not described in this way at the time. The lack of correlations at large angles received more attention with the Wilkinson Microwave Anisotropy Probe (WMAP) first year data (Spergel et. al., 2003), when the most widely used precise statistic created to capture this feature of the sky was defined: the statistic. Spergel et. al. (2003) initiated the use of , after having looked at the COBE–DMR and WMAP data, as a convenient way to show how unusual the lack of correlation of the CMB at large angles is under the assumption of CDM, making an a posteriori statistic. The statistic has since been used to confirm the presence of the anomaly in the WMAP 3 year (Copi et. al., 2007) and 5 year (Copi et. al., 2009) data, as well as in the first (Copi et. al., 2015a) and second (Planck XVI, 2016) Planck data releases.
We now define , starting with a generalized version:
| (1) |
where
| (2) |
is the two-point correlation function and is the angle between the two directions and . With , this becomes the standard definition of .
Use of this statistic enables one to quantify how unusual the observed feature is, given CDM (the null hypothesis). We use simulations to determine a distribution of values given CDM, and find the fraction of simulations with lower values than that inferred from the data. This fraction of simulations that exceeds the statistic in question is commonly called a –value. In a recent re-analysis of the observed lack of correlations on the CMB at large angles, Copi et. al. (2015a) calculated several values of the CMB using various WMAP and Planck maps, masks, and methods, and using simulations based on the CDM theory, found –values for of the observed cut-sky CMB. These vary from to . Alternatively, rather than use –values, one could perform a Bayesian analysis on in order to quantify how unexpected the observed value is. Efstathiou, Ma, & Hanson (2010) did such an analysis, in which they calculated an expected posterior distribution of theoretical values, given the observed value. This resulted in a very wide distribution of theoretical values, and the CDM value was not strongly disfavoured, indicating that is actually a poor discriminator of theoretical models. In this work, we do not use the Bayesian approach, but rather stick with the computation of –values.
There have been numerous theoretical attempts to define cosmologies for which a low value of is less unlikely. Some of these attempts examine basic features of CDM, such as the Gaussianity and statistical homogeneity/isotropy of the primordial fluctuations. For example, Copi et. al. (2009) showed that the low- modes of the CMB seem to work together to cause the lack of correlation on large angles, suggesting a correlation among the modes, indicating a violation of statistical isotropy. Non-trivial topology could be a possible way to explain the low correlation on large angles, because in topological models that employ the spherical multi-connected manifolds, the power at large scales is naturally suppressed (Stevens, Silk, & Scott, 1993; Niarchou & Jaffe, 2006). However, constraints on such manifolds arise from the null results of searches for matched circles on the CMB. In a more recent work, Aurich & Lustig (2014) explore CMB correlations in a cosmology incorporating the Hantzsche–Wendt manifold, which is interesting because this manifold could easily escape detection by matched circle pairs. They calculate the distribution of for an ensemble of simulations in this topology, finding it reduced by about a factor of 2 compared to CDM.
Here we argue that this attention is misplaced. We find the evidence is quite weak that the low value is due to anything other than either the low quadrupole value, or a human’s ability to identify unusual-looking features in a high-dimensional data set with many different ways it can be unusual, or both.
The role of the low-order multipoles and the quadrupole in particular in the lack of correlation at large angles has previously been investigated. Bernui et. al. (2006) examined the role of the low quadrupole in the correlation function by removing the quadrupole from both the observed WMAP data and the CDM model, and found a qualitatively better agreement between observation and theory than with the quadrupole included. Furthermore, both the quadrupole-removed WMAP and CDM correlation functions showed a lack of correlations at large angles, whereas the non-quadrupole-removed CDM correlation function did not, indicating that the low quadrupole is largely, though not entirely, responsible for the lack of correlation at large angles. Hajian (2007) pointed out that the contribution to from multipoles in the observed CMB is nearly equal and opposite to the contribution from the rest of the multipoles put together. Additionally, Copi et. al. (2009) found that by tuning the powers of the CDM prediction, they could obtain an expectation value lower than the observed value found from WMAP. However, no work of which we are aware has yet reconciled the low –value of the statistic at , with the larger –value of the low quadrupole at .
Despite this previous attention to the relationship between the low quadrupole and low correlation at large angles, we find an important result has been overlooked: namely, the impact of the low quadrupole on the distribution of values expected under CDM. We demonstrate that once the probability of is conditioned on the observed value of the quadrupole, the value of is no longer anomalous, as the –value rises to 0.08. This result has implications for solutions to the puzzle of low : any change to the model that suppresses the ensemble average of the quadrupole variance is helpful. For example, several groups have explored the possibility of an era in the early universe before slow-roll inflation in which a “fast-roll” caused a large scale suppression of power, effectively creating a cutoff in the primordial power spectrum which would be observable as a lack of correlations on large scales today (Contaldi et. al., 2003; Lello et. al., 2014; Liu et. al., 2014; Gruppuso & Sagnotti, 2014).
Although the low value of is potentially understandable as due to a departure from CDM that reduces the ensemble average of the quadrupole, the question still remains of whether is compatible with CDM in the absence of any such modifications.
The standard criticism of the amount of attention given to the anomalies is the standard criticism of a posteriori statistics: their a posteriori nature makes their interpretation very challenging. Consider that for a map of the sky, even with a finite number of pixels or data points, there is an infinite variety of statistics that one can make up.222As a simple example, consider linear combinations of a finite number of data points. Given the freedom to choose arbitrary coefficients, there are an infinite number of possible combinations of these data. If one makes up 1,000 of them prior to examining some data set, then it is not evidence of a failure of a model if one of those statistics has a value that happens to be that extreme in only 1 out of 1,000 simulations. With a posteriori statistics, by definition, one creates the statistic after seeing the data. When such a statistic ends up having an extreme value, determining whether or not this indicates a failure of a model is difficult because it is not clear how many such statistics could have been made up, had the data looked different to begin with. Additionally, because the choice of statistic to use was informed by the data, this also makes simulation of the data creation and analysis process very difficult, and perhaps practically impossible. What statistic would a different, simulated data set, have led the analyst to choose? Now that an analyst is in the simulation loop, simulation is quite challenging, to say the least.
There are several features about the statistic which can be considered to have been selected a posteriori. Broadly speaking, the whole notion that is low at large angles is a posteriori. More specifically, the choices to square , to integrate this quantity over angles, and to select an upper integration limit of were all a posteriori choices, thereby making the significance of the value of difficult to interpret. In order to address the critique that the upper integration limit was selected a posteriori, the Planck team (Planck XVI, 2016) recently implemented a process in which this limit in the definition of was allowed to vary over the whole range of values . We repeat a similar process here, although with a different rationale. We know historically that there actually was no optimization over as a continuous variable – this point is indisputable as one can do the optimization and the result is not . However, the choice of a statistic tailored to capture the apparently unusual near-zero values of the correlation function on large angular scales was clearly an a posteriori selection. We view the statistic as a one-dimensional proxy for the very high-dimensional space of all possible statistics from which was selected. It is a useful proxy as the impact of a posteriori choice can then be calculated. When we consider the effects of the a posteriori choice of the statistic, by considering other possible statistics that one could calculate, the significance of the anomaly decreases. However, as we are using a one-dimensional proxy, we expect the impact of selection from the larger space is underestimated. 333For completeness, we mention that Efstathiou, Ma, & Hanson (2010), in addition to providing the Bayesian analysis we mentioned earlier, also suggested that a two-dimensional generalization of could illustrate the impact of a posteriori choice on –values but did not make any clear quantitative claims about this impact other than to suggest it could be “an order of magnitude or more.”
One research direction motivated by the anomaly that we do see as valuable is a search for testable predictions of the hypothesis that CDM is correct and the low value of is just a statistical fluke. Yoho et. al. (2014) use CDM realizations conditioned on the low value of to develop a priori statistics for use with future data sets, such as CMB polarization data, designed to test the hypothesis that the low measurement is just the consequence of an unlikely CDM realization. The conclusion of our work here is that the evidence is quite weak that the low value indicates anything other than a somewhat unlikely CDM realization. We hesitate to call it a fluke however, as it is only a highly unusual realization if one does not correct for a posteriori effects. Names aside, we expect that fluke-hypothesis tests have the potential to confirm the “fluke” interpretation we favor here, or provide stronger evidence against CDM.
The rest of this paper is organized as follows. In section 2 we describe the observational and simulated data and data processing needed to create –values. In section 3 we describe the effect of the low quadrupole on the observed value and how we include the low quadrupole in our filtered-CDM null hypothesis, and the effect that that has on the –value. In section 4 we describe a means to quantify the impact of the a posteriori choice by exploring a more generic statistic . We finish by combining these two methods and examining the resultant quadrupole-filtered look–elsewhere–corrected –values.
2 The Statistic
In order to calculate how unlikely the statistic for the observed CMB is, given a particular cosmological model, one has to calculate for the observed universe as well as for an ensemble of simulated universes, created based on that model. When compared to a suitably created ensemble of simulations, the –value of the statistic can be computed. In this analysis, we have treated the observed CMB map as similarly as possible to those created in simulations, for consistency. This includes the treatment of the pixelization, spatial frequency content, and masking.
2.1 CMB Observations
There are to date several (nearly) full-sky maps of the CMB that are suitable for use in calculating the correlation function , and the corresponding large angle statistic . Copi et. al. (2015a) used two different Galactic+foreground masks444A mask is a set of flags indicating which pixels of a map are to be excluded from use in further analysis. in their study: the WMAP 9-year KQ75y9 mask, which leaves unmasked per cent of the sky (), and a Planck-derived U74 mask, which has . They used each of these masks with several WMAP and Planck CMB maps, and in every case, the –values were considerably higher (meaning the observed was less unusual) for the smaller U74 mask (larger ) than those for the larger KQ75y9 mask (smaller ). This is also consistent with the results of Gruppuso (2014), who showed that larger masks (smaller ) make the significance of the anomaly larger (smaller –value) than with smaller masks. With an array of Galactic masks that ranged in sizes from to , they found a corresponding decrease in –value from per cent to per cent. (Note that within this range, the two mask used by Copi et. al. (2015a) were on the smaller end, or had larger .) Except where otherwise mentioned, in this analysis we use only one observed CMB map and mask combination: the Planck PR2 (2015) SMICA map with the (2015) Common mask.555 available at the Planck Legacy Archive http://pla.esac.esa.int/pla/#home
The Planck map and mask are stored in the healpix666 See http://healpix.sourceforge.net for information about healpix (G rski et. al., 2005) format at high angular resolution. For calculations of , high angular resolution is not needed, so we degrade the resolution of the mask and map from to following the procedure described by Planck XVI (2016): the map is first transformed to harmonic space using healpix, then a reweighing by the ratio of pixel window functions is applied, and then the harmonic coefficients are re-transformed back into a map at the lower resolution. The same thing is done to the mask, with the one additional step of defining a threshold value of 0.9, over which the mask pixel values are set to 1, and below which they are set to 0. The resulting mask leaves a fraction of the sky available for analysis. The low resolution of was chosen in order to reduce computational time while preserving the signal of interest, which is at large angular scales, and also to be consistent with the resolution used in previous analyses (e.g. Copi et. al. (2015a)).
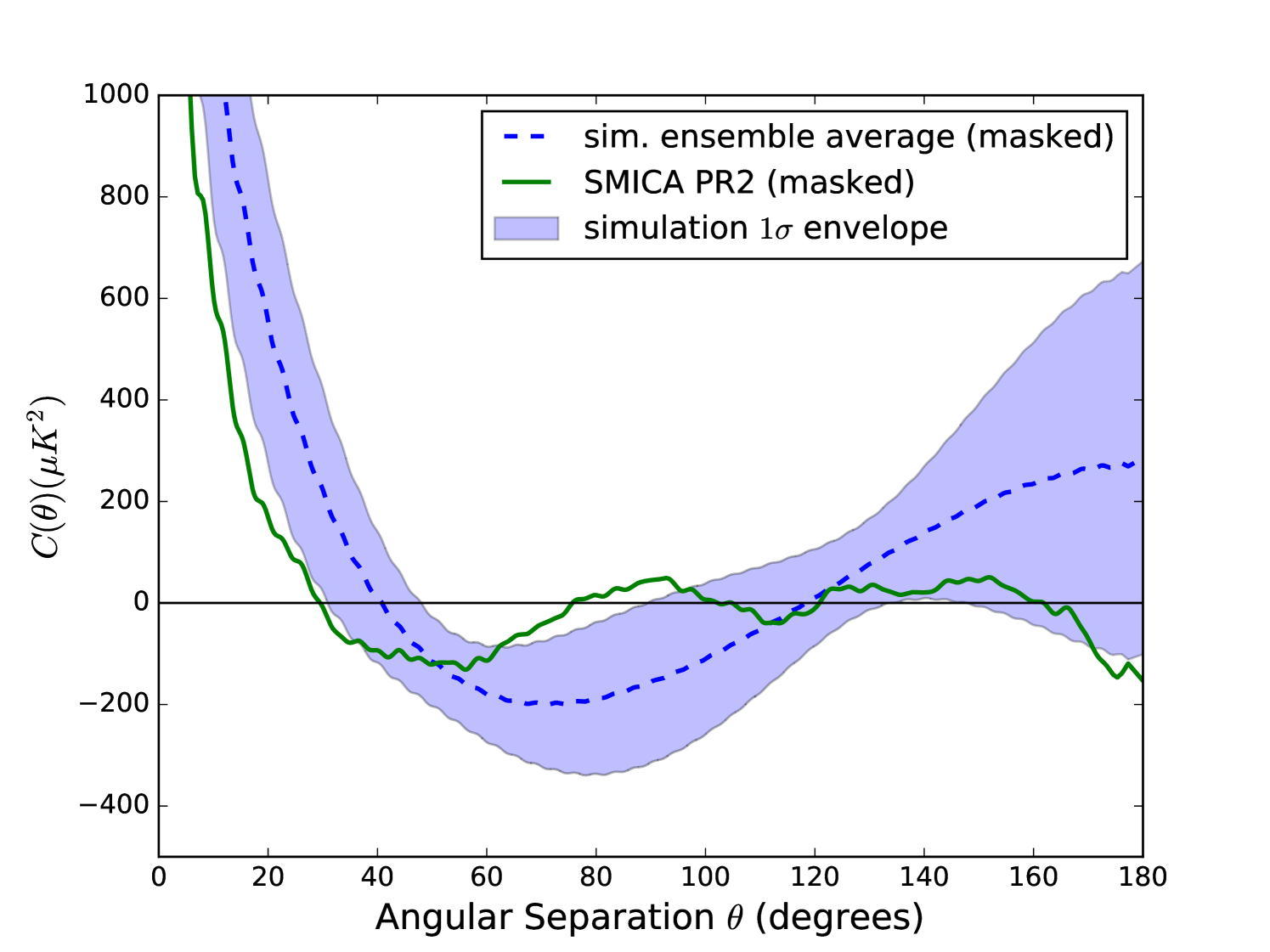
The power spectrum of the degraded SMICA map was calculated using spice.777 polspice available at http://www2.iap.fr/users/hivon/software/PolSpice/ This code applies the mask to the map and subtracts the monopole and dipole from the resultant cut-sky map as part of the process to find the cut-sky . To derive the correlation function shown in Fig. 1, we applied the transform
| (3) |
We used the upper limit of 100 following Copi et. al. (2015a), who showed that the effect on of using rather than a higher value was less than 1%.
In order to calculate for the SMICA map, we used the harmonic space method of Copi et. al. (2009). Combining equations 1 and 3, we evaluate
| (4) |
where the quantity
| (5) |
is an easily calculable function of (Copi et. al., 2009), and we have used the generalization to , with being a special case with .
Using our degraded SMICA map, we calculated and resulting in a value of , which when compared to our ensemble of simulations, has a –value of per cent (see the solid curves in Fig. 1 and Fig. 2). This value is quite close to the value found by Copi, O’Dwyer, & Starkman (2016), who used the same data set and methods, and is similar to those found by Copi et. al. (2015a), who used older Planck and WMAP data sets. The –values reported by Copi et. al. (2015a) range from about per cent to per cent, depending on the map, mask, and method used. For a more detailed comparison, see the appendix.
2.2 Creating Simulations
Simulations of the CMB were created using healpix based on a theoretical power spectrum created by class888 class available at http://class-code.net/. To create this power spectrum, we used the best fit 2015 Planck CDM parameters (Planck XIII, 2016): , , , , , , and , along with the WMAP value (Fixsen, 2009) . Prior to creating realizations, the power spectrum was dampened slightly with pixel window and Gaussian beam functions, since the observational data, as presented, contains pixel window and telescope beam effects.
The healpix simulations were then created at the same resolution () as our degraded-resolution SMICA map, with the same harmonic content () that is required to perform the calculation in equation 4.
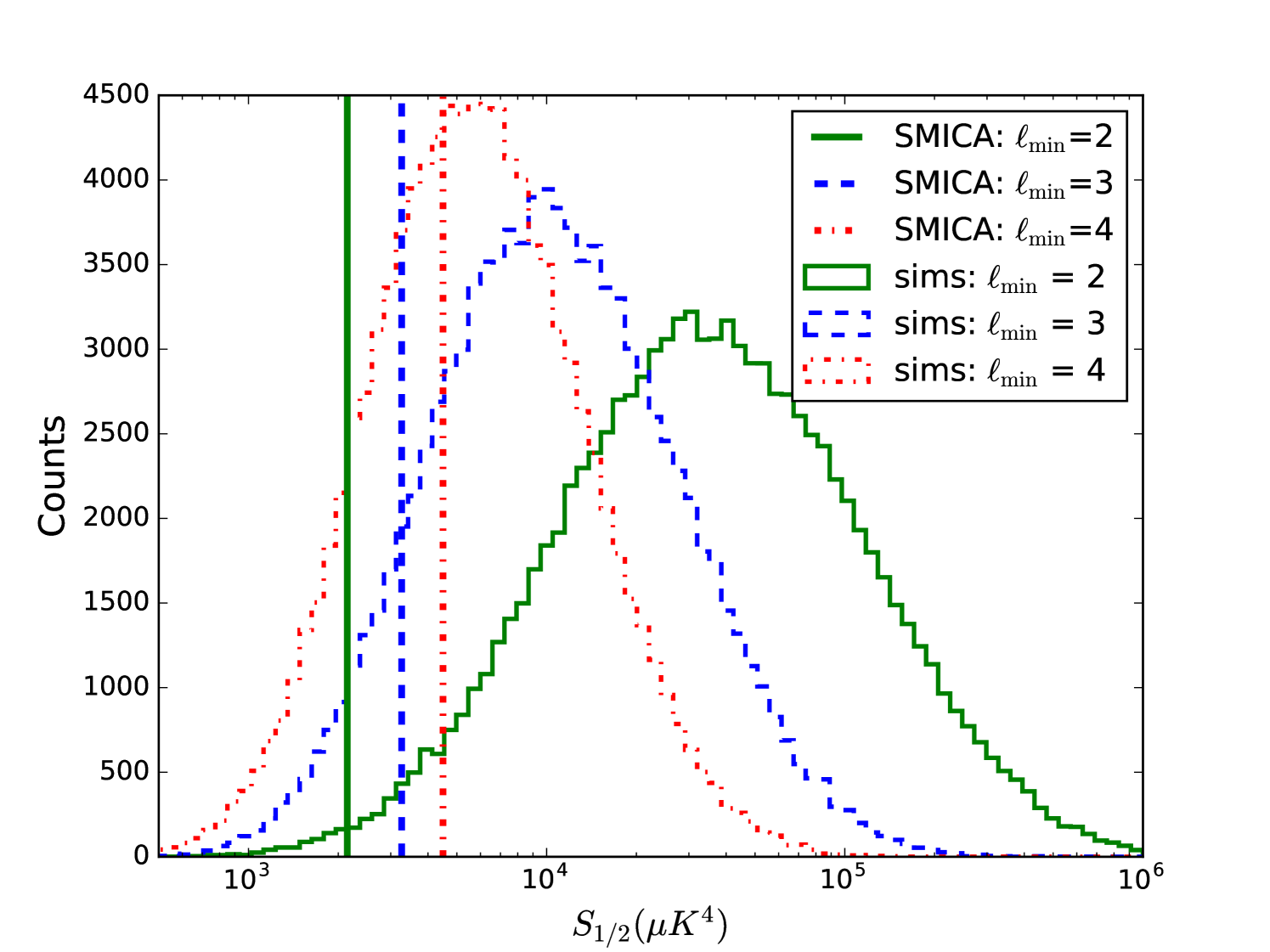
Each simulation was treated in the same way as the SMICA map: we fed each simulation into spice, which applied the degraded-resolution Common mask and removed the monopole and dipole in order to deliver an estimate of the power spectrum . We created two separate ensembles of power spectra: one with and one with members. The spectra in the smaller set were transformed via equation 3 in order to create the ensemble average autocorrelation function and band, shown in Fig. 1. Those in the larger set were used directly in equation 4 with in order to create an ensemble of values, shown in Fig. 2, with 3 different values of , the lowest multipole included in the summation.
3 Effect of the Low Quadrupole Power
The summation formulae for and (equations 3, 4) make it easy to examine the relative importance of each multipole to and . We found that removing the lowest multipoles from the calculation of for both simulations and for the SMICA data drastically increased the –value of the SMICA statistic (See Fig. 2). In fact, for the case, the SMICA value is quite near the middle of the simulated distribution. This shows that the low –value of the standard statistic is highly influenced by the and of the observed CMB.
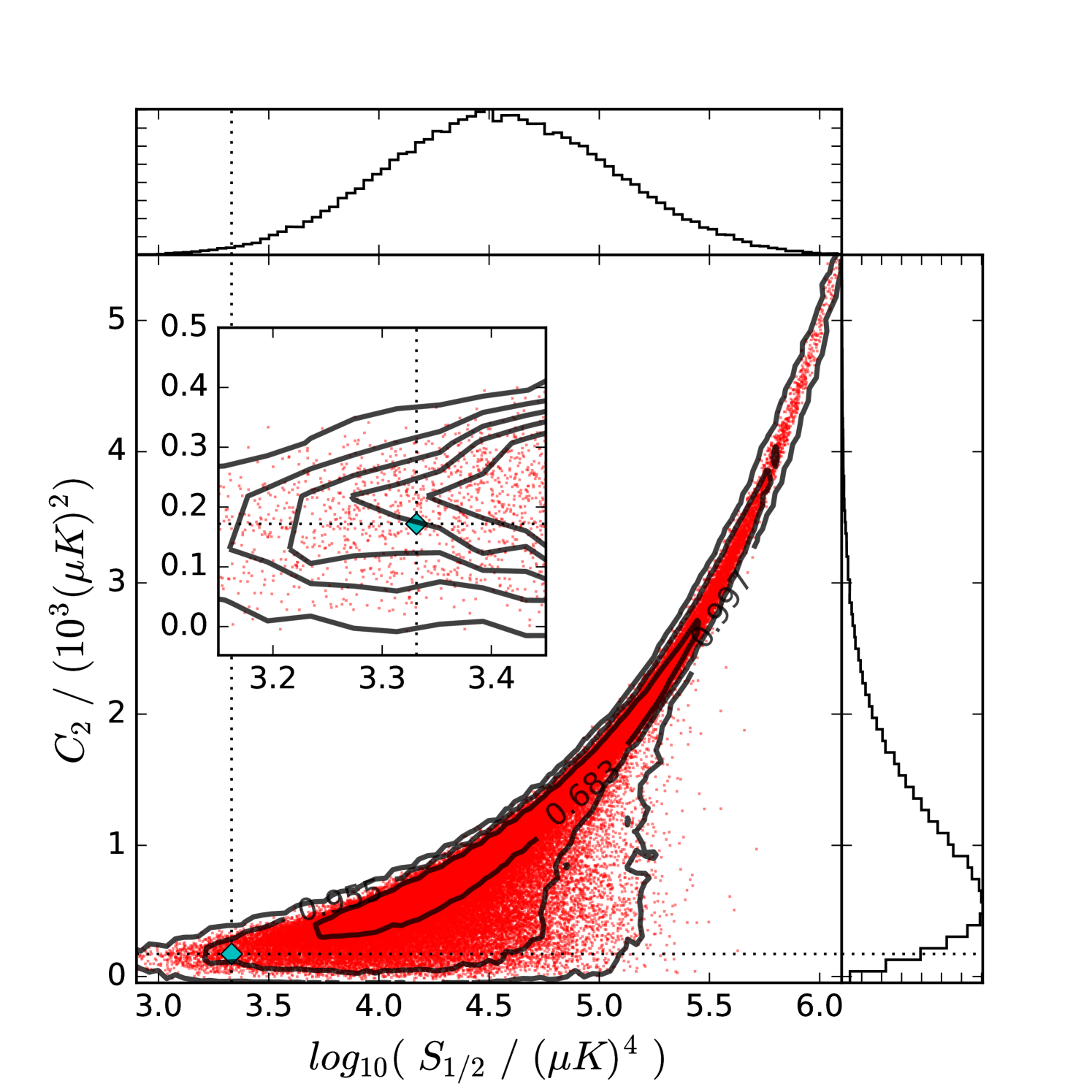
Here we revisit the question of the connection between and . In particular, we ask how dependent the anomaly is on the low observed value of . In our CDM model, the ensemble average quadrupole variance is , whereas for the degraded and masked SMICA map, we measure a quadrupole variance of only , which is lower than the ensemble average value by a factor of 0.156. However, the low observed quadrupole variance is by itself not exceedingly anomalous. To see this, we created an ensemble of simulated CMB skies, masked them, and measured their and values (see Fig. 3). In this ensemble, the cut-sky SMICA has a –value of per cent, which is much higher than the –value of per cent. This is consistent with a similar analysis by Efstathiou (2003), who calculated –values using two differently measured WMAP values of and ,999The variances presented by Efstathiou (2003) were given in terms of . which resulted in –values of and per cent, respectively. This suggests, as Copi et. al. (2009) point out, that the low quadrupole variance anomaly is not the same as the anomaly.
This joint distribution allows us to look at the ensemble relationships between the two values. As can be seen in the scatter plot and density contours of Fig. 3, the distribution has a golf-club like appearance, such that the upper right of the plot shows a thin and narrow structure, while the lower left is wedge shaped. The thin distribution in the upper right indicates that at high values, and are correlated with each other. However, this correlation breaks down at lower values, in the wedge-shaped part of the distribution. At these low values, a low value of indicates that must also be low, but the inverse, that a low value of indicates a low value of , is not true. However, as we show below, conditioning an ensemble to only include low values of does have a significant impact on the distribution of values, and increases the SMICA –value substantially.
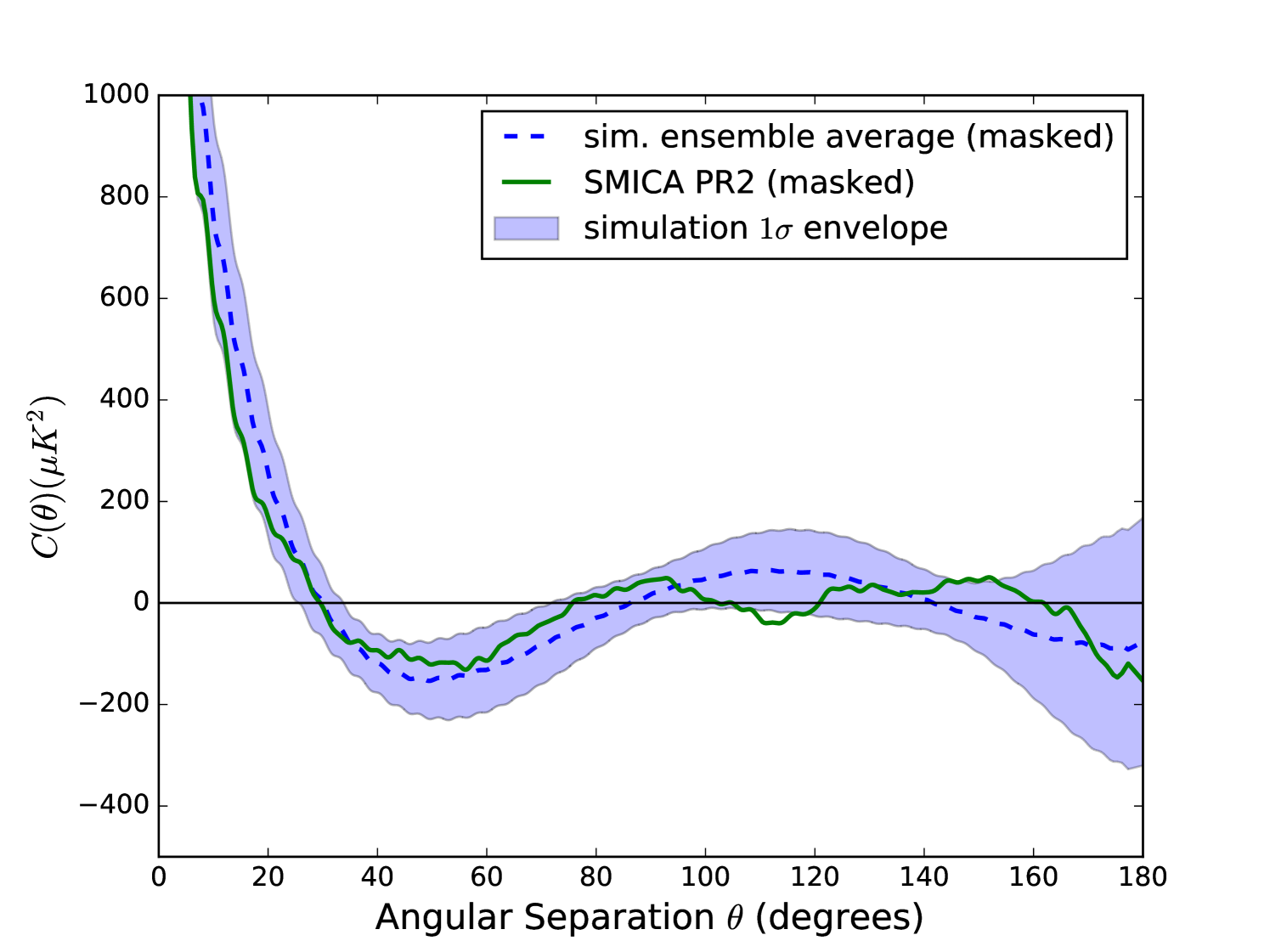
We implemented a constraint on the quadrupole variance of our cut-sky simulations by generate–and–test filtering. We first created a simulation, masked it, then measured its quadrupole variance and compared it to the CDM expectation value. If of the simulation fell between 0.1 and 0.2 times the CDM expectation value (where 0.1 and 0.2 were chosen to simply bracket the observed ratio of 0.156 with round numbers), it was included in the ensemble of simulations. If not, we threw it out. We kept creating simulations until we had reached the desired number in the ensemble: .
The results of this ensemble selection process are shown in Fig. 4 and Fig. 5. Comparing these to the previous versions without filtering (Fig. 1 and Fig. 2), we see that the ensemble of correlation functions has changed shapes considerably, converging toward the line indicating zero, and the distribution has correspondingly lowered toward zero. The SMICA value (unchanged) therefore appears to be in a much less unlikely place in this distribution, with a –value of per cent. This non-anomalous –value suggests that, at the very least, is not independent from the low quadrupole. Once we condition on the observed quadrupole value, the observed value is not that rare.
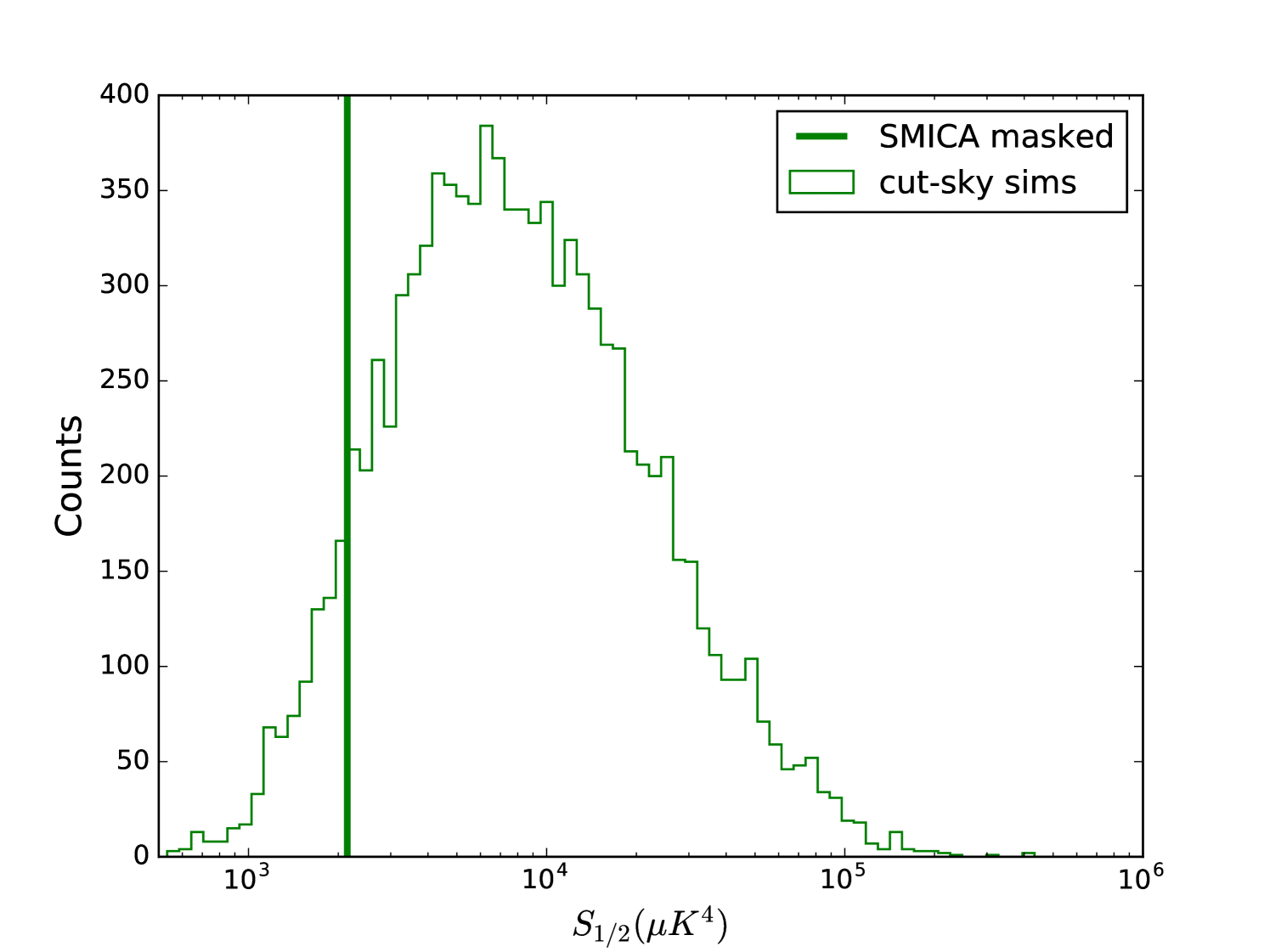
Finally, we look back at the joint distribution, and generalize the notion of the –value to this 2 dimensional space. To do so, we created iso-probability density contours by approximating the probability density using kernel density estimation. Some of these contours are shown in Fig. 3, labelled by what fraction of the total number of points they contain. The SMICA value lies in a region which has a probability density that is not extremely low, lying just within the per cent contour, indicating a 2D –value of per cent, less than a deviation from the densest region. To compare this to the 1D cases we need to consider that the definition of –value that we have been using is only a 1-tailed statistic, and does not account for outliers that are extreme in the opposite direction, at equal or lower probability density. (Our density contours in 2D account for high and low values in all directions.) Therefore, to approximate an equivalent 2-tailed statistic, we multiply the 1-tailed 1D –values by 2, giving us 2-tailed 1D –values of per cent for , and per cent for , which is clearly an underestimate given the asymmetry of the 1D distribution. Thus we see that the observed values in the joint space occupy a probability density that is similar, in terms of how extreme it is, to the one-dimensional case of . We conclude that there is no new evidence in this joint space for anomalous behavior.
4 Effect of the a Posteriori Choice
The previous section provides a better description of the influence of the low quadrupole on the lack of correlations at large angles then was available before, suggesting that modifications to CDM which lower the expected quadrupole contribution to would help reduce the anomalous nature of . However, we are still interested in whether is consistent with CDM without any such modification. To that end, we now turn to addressing what is perhaps the most often criticized aspect of : that it was created to capture a feature of the data by analysts who had already taken a look at the data. That is, was created a posteriori.101010For a reductio ad absurdum description of a posteriori statistic selection in the context of CMB and anomalies, see Frolop & Scott (2016).
If, prior to looking at the data, one came up with 1,000 statistics to calculate from the data, and then applied them to the data, assuming they were all uncorrelated, one would expect a uniform distribution of –values between 0 and 1. The expectation value for the number of statistics with –values between 0 and 0.001 would be 1. Even if they were correlated, one could still perform simulations that would naturally take these correlations into account, and use them to calculate the probability that one of the statistics returned a –value of less than 0.001, by counting the fraction of simulations for which this is the case; that is, we calculate the –value of the –value. Such a probability we call the look–elsewhere–corrected (LEC) –value.
To perform the analogous calculation for a single a posteriori statistic, one chosen after inspection of the data, the simulation process would include the process of inspecting the data and inventing a statistic to capture what is perceived to be an unusual feature. This is obviously challenging, if not impossible, as it requires an automated model of the analyst him or herself, so that the simulated data are processed by the simulated analyst who identifies the unusual feature and creates a statistic designed to capture that feature in a single number.
The difficult aspect of the above procedure is the automation of the human process of selection of a statistic from a very high-dimensional array of possibilities. In the following we adopt a crude, but calculable, approximation of this process as the selection of one statistic from a merely one-dimensonal space of alternatives. We create this one dimensional space by extending one single aspect of the already well defined statistic: the choice of the upper endpoint of the integral, . As described above, we have generalized to , which has an arbitrary upper integration limit, chosen from the whole range of possible values: .
Note that we are not claiming that this is the procedure that was followed historically. We know it is not because, as we will see, the choice of that returns the most extreme vaue of from the real data is rather than . The resulting LEC –value we obtain should be viewed as merely indicative of the type of correction that is plausible. We suspect that, if anything, our replacement of the high-dimensional space of alternative statistics with a one-dimensional one underestimates the size of the correction.
We proceed by using the generalized integral (equation 1) and calculating as a function of over the whole range of values for an ensemble of CMB simulations (without filtering this time). Then, to save computational time, we choose a subsample of these, the first curves, to evaluate further. For each function in the subsample we find, for each value of , a rank in the entire set of curves. We divide these ranks by and they become (1-tailed) –values, as a function of : . Then, for each simulation in the subsample, we find its minimum –value and corresponding and values. In order to treat the SMICA data in the same manner, we throw it in as just another member of this ensemble and find its optimal , , and values with resect to the ensemble as well. Finally, using the ensemble of –values, we can calculate the LEC –value.
The result of this process is shown111111 plotting package corner.py available at https://github.com/dfm/corner.py in Fig. 6, where the SMICA value is indicated by the blue horizontal and vertical lines. In this ensemble, the SMICA map, optimized for minimum –value, has , , and a nominal per cent. This is lower than the –value of per cent that we calculated earlier, which is as expected due to the optimization process. The LEC –value is per cent.
To calculate the error on the LEC –value, we estimated the sample variance of these quantities by doing some calculations with smaller ensembles. These smaller ensembles were constructed as subsets of the same set of simulations that we used before, but with members chosen randomly, and with curves calculated using only the corresponding curves, rather than the entire set of of them, as we did previously.121212This is a variation on the jackknife resampling test. Interestingly, these fell into two groups, with 27 of them having values near 0.35, and 5 of them being near -0.1. For those near , the average –value was per cent, and for those near , the average –value was per cent. There does not appear to be a big difference in –values between the two groups, but since our first sample had an value of 0.37, we compare it to the first group. Supposing that the sample variance is dominated by the number of curves used in the calculation, we expect the sample variance of these –values to be approximately equal to the Poisson noise associated with the number of simulations used. Since the average –value of per cent corresponds to 33 out of 10000 samples, we hypothesized that these 27 optimal –values were drawn from a Poisson distribution with mean 33, and performed a Kolmogorov–Smirnov goodness-of-fit test. This resulted in a Kolmogorov–Smirnov –value of 0.24, suggesting that these values are consistent with being drawn from a Poissonian distribution, as hypothesized. Therefore, we also suppose that the –value that we obtained using curves, also subject to a sample variance, can also be thought of as being drawn from a Poissonian distribution. Using the only –value that we have () to derive an estimate of the mean, we find the square root of the Poissonian variance to be , constraining our measured –value to be per cent.
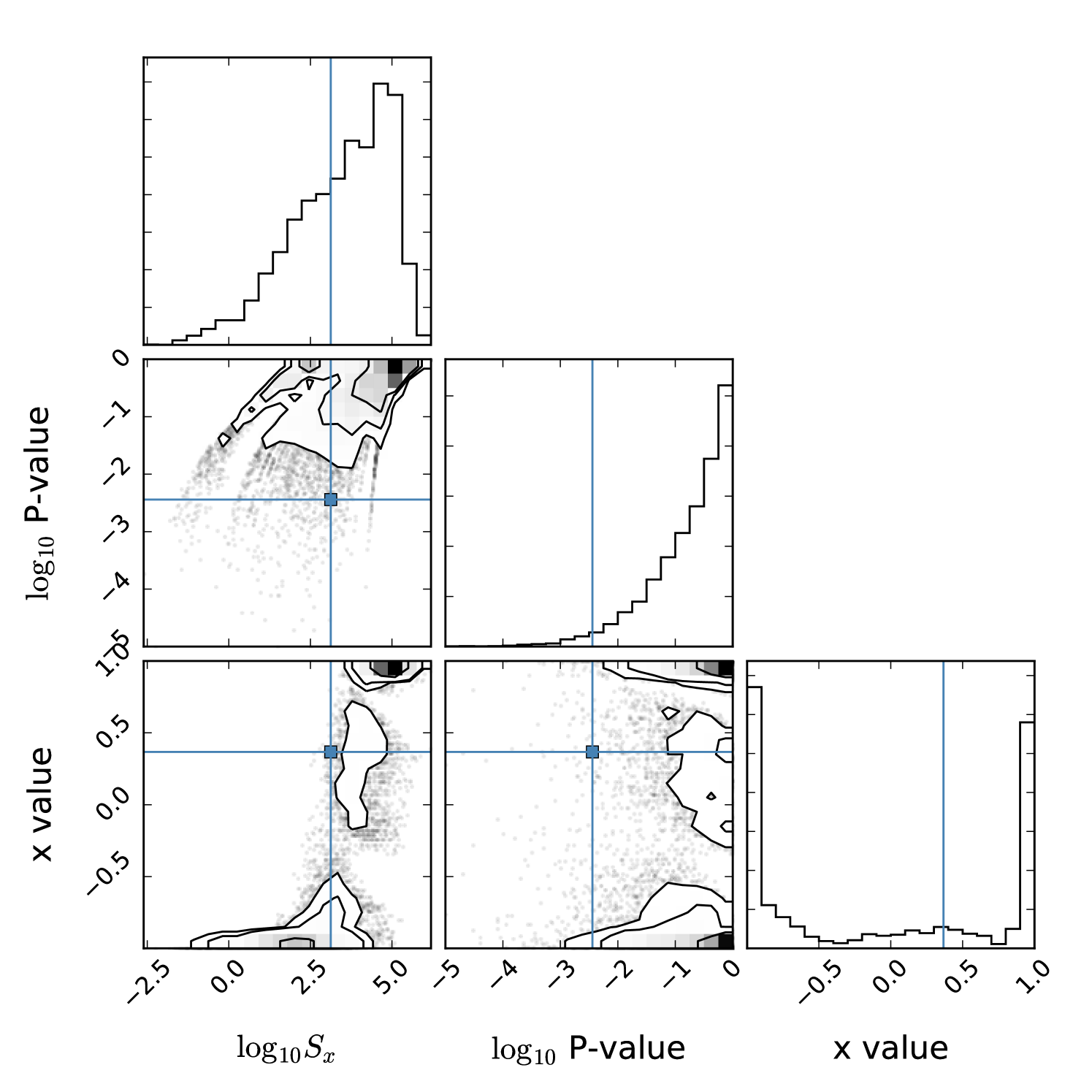
We need to now also account for the fact that we checked the entire range of possible values in order to find this optimal –value (account for the look-elsewhere effect). We do this by examining the fraction of simulated data sets with x-optimized –values less than the SMICA value of per cent, the LEC –value. For this ensemble, this value is per cent. Using the small sample variance for the SMICA –value described above, this corresponds to .
The Planck team (Planck XVI, 2016) recently implemented a very similar process to this that was meant to account for the look-elsewhere effect caused by the a posteriori choice of the integration endpoint, and their analysis produced an LEC –value of per cent131313The Planck Collaboration used the opposite sense of –value, such that they calculated the probability of finding values higher than the observed value, rather than lower than the observed value. for the SMICA map. However, their analysis was based on only simulations, whereas we used . However, their simulations were much more extensive than ours were. Their simulations were based on their “8th Full Focal Plane simulation set” (FFP8), which includes simulation of instrumental, scanning, and data analysis effects, whereas ours were simply based only on a theoretical power spectrum with some simple Gaussian beam and pixel window smoothing. Using the a similar procedure as above to estimate sampling uncertainties (with and ) we find that their result is consistent with ours to within using their sampling uncertainties. It is reassuring to note that these two methods gave reasonably consistent results.
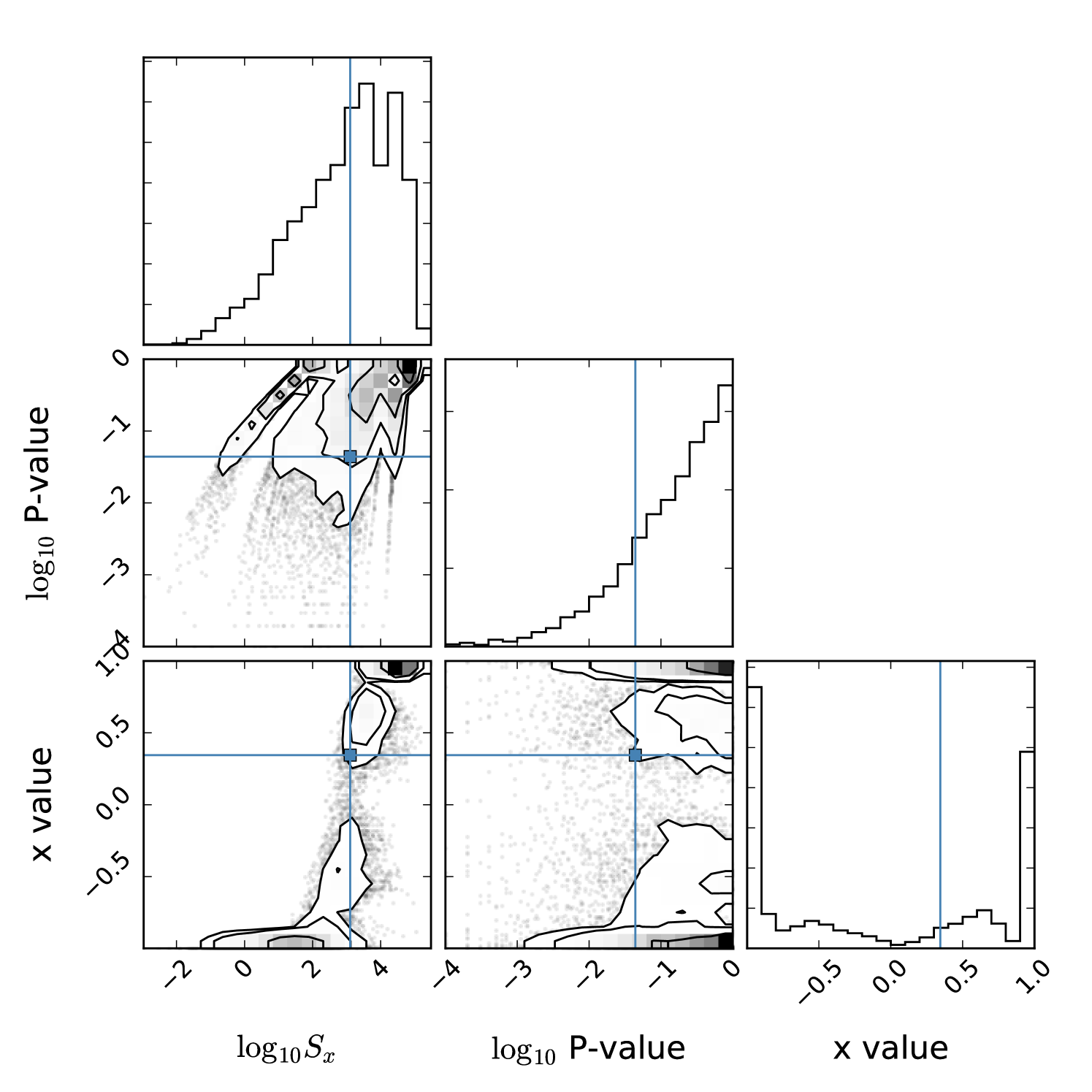
Finally, we combine both methods described here: the ensemble filtering by , as well as the optimization. In order to reduce computational time, we simply used quadrupole-filtered curves for this.141414The choice of using fewer () simulations is also justified by the larger resultant –value: large numbers of simulations are necessary for high –value resolution, which is needed when –values are small. Large numbers of simulations are therefore not needed for larger –values. The result is shown in Fig. 7. In this ensemble, optimized for –value, the SMICA data produced and , similar to the values found without filtering, but a much higher nominal –value of per cent, and an even higher LEC –value of per cent.
5 Summary and Conclusions
Others have previously noted connections between the low quadrupole and the near-zero correlation function on large angular scales, as quantified in the statistic. Here we quantitatively investigated the relationship between these statistics as expected in the CDM model. We found that if one conditions on the observed low quadrupole power then the distribution of values in the CDM model is shifted to much lower values and as a result the observed has a –value of 0.08 rather than its unconditioned value of 0.007. We pointed out that departures from CDM that suppress the quadrupole will thus naturally make the observed less unusual and potentially take it from a –value one might call “anomalous” to one that is merely “somewhat unusual”, if that.
Second, we revisited the exercise in Planck XVI (2016), where was generalized to in order to investigate the impact of the a posteriori choice of the integration cutoff at They found that the process of optimizing the value of with the observed data leads to a -value that is smaller than what one finds by doing the same process with 21 out of 1000 simulations; i.e., they found a look–elsewhere–corected (LEC) –value of 2.1%. Repeating this exercise with 100 times as many simulations (but without the simulation of as many aspects of the instrument), we found an LEC –value of per cent. Our result is consistent with the per cent value at the level given their uncertainties that we estimated from their finite number of samples.
Third, we combined these two techniques of both conditioning on the observed low quadrupole power and optimizing over values. This resulted in a quadrupole-filtered LEC –value of per cent. Our point here is not that a proper calculation of the –value has to include conditioning on the low quadrupole, but rather that these are by no means independent phenomena: One cannot point to both the low quadrupole and low as independent indicators of anomalous behavior on large scales.
The main thing we offer regarding the LEC –value for (quadrupole-filtered or not) is our interpretation of the result. We view the selection of from the one-dimensional space of alternative statistics given by as a proxy for the choice of out of a very high-dimensional space of all possible statistics derivable from or . The value of the proxy is that it allows for calculation of an LEC –value. Since the dimensionality of the alternative space is much lower than that of the space of all possible statistics, it arguably leads to an underestimate of the look-elsewhere correction. In conclusion, we have quantitatively demonstarted that a posteriori selection provides a viable explanation of the low observed value of . The correct explanation for low might lie with physics beyond CDM but there is not yet compelling evidence in favor of such an alternative conclusion. Tests of the so-called “fluke hypothesis” (Yoho et. al., 2014; O’Dwyer et. al., 2016) have the potential to alter this situation.
Acknowledgements
We thank Brent Follin, Silvia Galli, Marius Millea, Marcio O’Dwyer, and Douglas Scott for useful conversations.
Some of the results in this paper have been derived using the healpix (G rski et. al., 2005) package.
The theoretical power spectrum was computed using the class (Blas, Lesgourges, & Tram, 2011) package.
The cut-sky power spectra were calculated using the polspice (aka spice) (Chon et. al., 2004) package.
The observed CMB data and mask were provided by the Planck Legacy Archive (http://pla.esac.esa.int/pla/#home)
References
- Addison et. al. (2016) Addison, G. E., Huang, Y., Watts, D. J., Bennett, C. L., Halpern, M., Hinshaw, G., Weiland, J. L., 2016, ApJ, 818, 132
- Akrami et. al. (2014) Akrami, Y., Fantaye, Y., Shafieloo, A., Eriksen, H. K., Hansen, F. K., Banday, A. J., G rski, K. M., 2014, ApJ, 784L, 42
- Aurich & Lustig (2014) Aurich, R., Lustig, S., 2014, CQGra, 31, 5009
- Bennett et. al. (2003) Bennett, C. L., Halpern, M., Hinshaw, G., Jarosik, N., Kogut, A., Limon, M., Meyer, S. S., Page, L., Spergel, D. N., Tucker, G. S., Wollack, E., Wright, E. L., Barnes, C., Greason, M. R., Hill, R. S., Komatsu, E., Nolta, M. R., Odegard, N., Peiris, H. V., Verde, L., Weiland, J. L., 2003, ApJS, 148, 1
- Bennet et. al. (2011) Bennett, C. L., Hill, R. S., Hinshaw, G., Larson, D., Smith, K. M., Dunkley, J., Gold, B., Halpern, M., Jarosik, N., Kogut, A., Komatsu, E., Limon, M., Meyer, S. S., Nolta, M. R., Odegard, N., Page, L., Spergel, D. N., Tucker, G. S., Weiland, J. L., Wollack, E., Wright, E. L., 2011, ApJS 192, 17
- Bernui et. al. (2006) Bernui, A., Villela, T., Wuensche, C.A., Leonardi, R., Ferreira, I., 2006, A&A, 454, 409
- Blas, Lesgourges, & Tram (2011) Blas, D., Lesgourgues, J., Tram, T., 2011, JCAP 1107, 034
- Chon et. al. (2004) Chon, G., Challinor, A., Prunet, S., Hivon, E., Szapudi, I., 2004, MNRAS, 350, 914
- Contaldi et. al. (2003) Contaldi, C. R., Peloso, M., Kofman, L., Linde, S., 2003, JCAP, 07, 002
- Copi, O’Dwyer, & Starkman (2016) Copi, C. J., O’Dwyer, M., Starkman, G. D., 2016, MNRAS, 463, 3305
- Copi et. al. (2007) Copi, C. J., Huterer, D., Schwarz, D. J., Starkman, G. D., 2007, Phys. Rev. D, 75, 023507
- Copi et. al. (2009) Copi, C. J., Huterer, D., Schwarz, D. J., Starkman, G. D., 2009, MNRAS 399, 295
- Copi et. al. (2015a) Copi, C. J., Huterer, D., Schwarz, D. J., Starkman, G. D., 2015, MNRAS 451, 2978
- Copi et. al. (2015b) Copi, C. J., Huterer, D., Schwarz, D. J., Starkman, G. D., 2015, MNRAS 449, 3458
- Cruz, Mart nez–Gonz lez, & Vielva (2006) Cruz, M., Tucci, M., Mart nez–Gonz lez, E., Vielva, P., 2006, MNRAS, 369, 57
- Cruz, Mart nez–Gonz lez, & Vielva (2007) Cruz, M., Cay n, L., Mart nez–Gonz lez, E., Vielva, P., Jin, J., 2007, ApJ, 655, 11
- Cruz, Mart nez–Gonz lez, & Vielva (2010) Cruz, M., Mart nez–Gonz lez, E., Vielva, P., 2010, ASSP, 14, 275
- de Oliveira–Costa et. al. (2004) de Oliveira–Costa, A., Tegmark, M., Zaldarriaga, M., Hamilton, A., 2004, Phys. Rev. D., 69, 063516
- Efstathiou (2003) Efstathiou, G., 2003, MNRAS, 346, L26
- Efstathiou, Ma, & Hanson (2010) Efstathiou, G., Ma, Y., Hanson, D., 2010, MNRAS, 407, 2530
- Eriksen et. al. (2004) Eriksen, H. K., Hansen, F. K., Banday, A. J., G rski, K. M., Lilje, P. B., 2004, ApJ, 605, 14
- Eriksen et. al. (2007) Eriksen, H. K., Banday, A. J., G rski, K. M., Hansen, F. K., Lilje, P. B., 2007, ApJ, 660, L81
- Fixsen (2009) Fixsen, D.J., 2009, ApJ, 707, 916
- Foreman–Mackey (2016) Foreman–Mackey, D., 2016, JOSS, 24
- Frolop & Scott (2016) Frolop, A., Scott, D., 2016, arXiv:1603.09703
- G rski et. al. (2005) G rski, K.M., Hivon, E., Banday, A.J., Wandelt, B.D., Hansen, F.K., Reinecke, M., Bartelmann, M., 2005, Ap.J., 622, 759
- Gruppuso (2014) Gruppuso, A., 2014, MNRAS 437, 2076
- Gruppuso & Sagnotti (2014) Gruppuso, A., Sagnotti, A., 2014, IJMPD, 24, 1544008-469
- Hansen et. al. (2004) Hansen, F. K., Cabella, P., Marinucci, D., Vittorio, N., 2004, ApJL, 607, L67
- Hansen et. al. (2009) Hansen, F. K., Banday, A. J., G rski, K. M., Eriksen, H. K., Lilje, P. B., 2009, ApJ, 704, 1448
- Hajian (2007) Hajian, A., 2007, preprint (astro-ph/0702723)
- Hinshaw et. al. (1996) Hinshaw, G., Branday, A. J., Bennett, C. L., Gorski, K. M., Kogut, A., Lineweaver, C. H., Smoot, G. F., Wright, E. L., 1996, ApJ, 464, L25
- Hoftuft et. al. (2009) Hoftuft, J., Eriksen, H. K., Banday, A. J., G rski, K. M., Hansen, F. K.; Lilje, P. B., 2009, ApJ, 699, 985
- Kim & Naselsky (2010a) Kim, J., Naselsky, P., 2010, ApJ, 714, 265
- Kim & Naselsky (2010b) Kim, J., Naselsky, P., 2010, Phys. Rev. D., 82, 0603002
- Kim & Naselsky (2011) Kim, J., Naselsky, P., 2011, ApJ, 739, 79
- Land & Magueijo (2005a) Land, K., and Magueijo, J., 2005, Phys. Rev. D., 72, 101302
- Land & Magueijo (2005b) Land, K., and Magueijo, J., 2005, Phys. Rev. D., 95, 071301
- Liu et. al. (2014) Liu, Z., Guo, Z., Piao, Y., 2014, EPJC, 74, 3006L
- Lello et. al. (2014) Lello, L., Boyanovsky, D., Holman, R., 2014, Phys. Rev. D., 89, 063533
- Niarchou & Jaffe (2006) Niarchou, A., and Jaffe, A. H., 2006, AIPC, 848, 774
- O’Dwyer et. al. (2016) O’Dwyer, M., Copi, C. J., Knox, L., Starkman, G. D., 2016, arXiv:1608.02234
- Planck XV (2014) Planck Collaboration XV, 2014, A&A, 571, A15
- Planck XVII (2014) Planck Collaboration XVII, 2014, A&A, 571, A17
- Planck XXIII (2014) Planck Collaboration XXIII, 2014, A&A, 571, A23
- Planck XXVII (2014) Planck Collaboration XXVII, 2014, A&A, 571, A27
- Planck XI (2016) Planck Collaboration XI, 2016, A&A, 594, A11
- Planck XIII (2016) Planck Collaboration XIII, 2016, A&A, 594, A13
- Planck XV (2016) Planck Collaboration XV, 2016, A&A, 594, A15
- Planck XVI (2016) Planck Collaboration XVI, 2016, A&A, 594, A16
- Planck LI (2016) Planck Collaboration LI, 2016, arXiv: 1608.02487
- Schwarz et. al. (2004) Schwarz, D. J., Starkman, G. D., Huterer, D., Copi, C. J., 2004, Phys. Rev. Let., 93, 221301
- Schwarz et. al. (2015) Schwarz, D.J., Copi, C.J., Huterer, D., Starkman, G., 2015, arXiv: 1510.07929v1
- Spergel et. al. (2003) Spergel, D. N., Verde, L., Peiris, H. V., Komatsu, E., Nolta, M. R., Bennett, C. L., Halpern, M., Hinshaw, G., Jarosik, N., Kogut, A., Limon, M., Meyer, S. S., Page, L., Tucker, G. S., Weiland, J. L., Wollack, E., Wright, E. L., 2003, ApJS, 148, 175
- Stevens, Silk, & Scott (1993) Stevens, D., Scott, D., Silk, J., 1993, Phys Rev Lett, 71, 20
- Yoho et. al. (2014) Yoho, A., Copi, C. J., Starkman, G. D., Kosowsky, A., 2014, MNRAS, 442, 2392
- Zhang & Huterer (2010) Zhang, R., Huterer, D., 2010, APh, 33, 69
Appendix A Comparison to other Results
In order to help verify our methods, we approximately repeated one of the calculations done by Copi et. al. (2015a), attempting to use the same methods and data that they had used, in order to obtain the same results. One of the data sets which they used included the Planck PR1 SMICA map and the so-called U74 mask, for which Copi et. al. (2015a) found , and using an ensemble of simulations, a –value of per cent. We obtained the publicly available PR1 SMICA map and the U73 mask, but did not attempt to reproduce the U74 map, which was designed as an approximation to U73, since it was not publicly available at the time of the previous analysis. We also modified our mask and map degradation procedures slightly to match what Copi et. al. (2015a) did in their analysis: they used the healpix ud_grade function, rather than the harmonic space window-weighting method, as well as a mask threshold of 0.8, rather than our 0.9.
We nearly reproduced their result, finding , and with an ensemble of simulations, found a –value of per cent. To estimate the sampling uncertainty, as in section 4, we suppose that our measured –value was drawn from a Poissonian distribution and calculate the standard deviation as per cent. Thus the difference between our p-value and that of Copi et. al. (2015a) is about . This difference in –values is likely due to the difference in the masks that we used (U73 vs. U74).