The maximum length of shortest accepted strings for direction-determinate two-way finite automata
Abstract
It is shown that, for every , the maximum length of the shortest string accepted by an -state direction-determinate two-way finite automaton is exactly (direction-determinate automata are those that always remember in the current state whether the last move was to the left or to the right). For two-way finite automata of the general form, a family of -state automata with shortest accepted strings of length is constructed.
1 Introduction
A natural question about automata and related models of computation is the length of the shortest string an automaton accepts. A function mapping the size of an automaton to the maximum length of the shortest accepted string, with the maximum taken over all automata of that size, is a certain complexity measure for a family of automata.
For one-way finite automata, this measure is trivial: the length of the shortest string accepted by a nondeterministic finite automaton (NFA) with states is at most : this is the length of the shortest path to an accepting state. On the other hand, Ellul et al. [4] proved that the length of shortest strings not accepted by an -state NFA is exponential in . Similar questions were studied for other models and some variants of the problem. Chistikov et al. [2] investigated the length of shortest strings in counter automata. The length of shortest strings in formal grammars under intersections with regular languages was studied by Pierre [10], and recently by Shemetova et al. [11]. Alpoge et al. [1] investigated shortest strings in intersections of deterministic one-way finite automata (DFA).
The maximum length of shortest strings for deterministic two-way finite automata (2DFA) has been investigated in two recent papers. First of all, from the well-known proof of the PSPACE-completeness of the emptiness problem for 2DFA by Kozen [7] it is understood that the length of the shortest string accepted by an -state 2DFA can be exponential in . There is also an exponential upper bound on this length, given by transforming a 2DFA to an NFA: the construction by Kapoutsis [6] uses at most states, and hence the length of the shortest string is slightly less than . Overall, the maximum length of the shortest string is exponential, with the base bounded by 4.
The first attempt to determine the exact base was made by Dobronravov et al. [3], who constructed a family of -state 2DFA with shortest strings of length . The automata they have actually constructed belong to a special class of 2DFA: the direction-determinate automata. These are 2DFA with the set of states split into states accessible only by transitions from the right and states accessible only by transitions from the left: in other words, direction-determinate automata always remember the direction of the last transition in their state.
Later, Krymski and Okhotin [8] extended the method of Dobronravov et al. [3] to produce automata of a more general form, with longer shortest accepted strings. They constructed a family of non-direction-determinate 2DFA with shortest strings of length .
This paper improves these bounds. First, the maximum length of the shortest string accepted by -state direction-determinate 2DFA is determined precisely as . The upper bound on the length of the shortest string immediately follows from the complexity of transforming direction-determinate 2DFA to NFA, see Geffert and Okhotin [5]. A matching lower bound is proved by a direct construction of a family of -state automata.
The second result of this paper is that not remembering the direction helps to accept longer shortest strings: a family of -state non-direction-determinate automata with shortest strings of length is constructed. This is more than what is possible in direction-determinate automata.
2 Definitions
Definition 1.
A two-way deterministic finite automaton (2DFA) is a quintuple , in which:
-
•
is a finite alphabet, which does not contain two special symbols: the left end-marker () and the right end-marker ();
-
•
is a finite set of states;
-
•
is the initial state;
-
•
is a partial transition function;
-
•
is the set of accepting states, effective at the right end-marker ().
An input string is given to an automaton on a tape . The automaton starts at the left end-marker in the state . At each moment, if the automaton is in a state and sees a symbol , then, according to the transition function , it enters a new state and moves to the left or to the right depending on the direction . If the requested value is not defined, then the automaton rejects. The automaton accepts the string, if it ever comes to the right end-marker in any state from . The automaton can also loop.
The language recognized by an automaton , denoted by , is the set of all strings it accepts.
This paper also uses a subclass of 2DFA, in which one can determine the direction of the previous transition from the current state.
Definition 2 ([9]).
A 2DFA is called direction-determinate, if there is a partition of the set of states , with , such that for each transition , the state must belong to , and for each transition , the state is in .
The known upper bounds on the length of the shortest accepted string are different for direction-determinate 2DFA and for 2DFA of the general form. These bounds are inferred from the complexity of transforming two-way automata with states to one-way NFA: for 2DFA of the general form, as proved by Kapoutsis [6], it is sufficient and in the worst case necessary to use states in a simulating NFA, whereas for direction-determinate 2DFA the simulating 2DFA requires states in the worst case, see Geffert and Okhotin [5]. Since the shortest string in a language cannot be longer than the shortest path to an accepting state in an NFA, the following bounds hold.
Theorem 1 (Dobronravov et al. [3]).
Let , and let be a 2DFA with states, which accepts at least one string. Then the length of the shortest string accepted by is at most . If the automaton is direction-determinate, then the length of the shortest accepted string does not exceed .
The first result of this paper is that this upper bound for direction-determinate automata is actually precise.
3 Shortest accepted strings for direction-determinate automata
In this section, direction-determinate automata with the maximum possible length of shortest accepted strings, where is the number of states, will be constructed.
Automata are constructed for every and , where is the number of states reachable by transitions to the right and is the number of states reachable in the left direction. The following theorem shall be proved.
Theorem 2.
For every and there exists a direction-determinate 2DFA with the set of states , where and , such that the length of the shortest string it accepts is .
The automaton constructed in the theorem works as follows. While working on its shortest string, it processes every pair of consecutive symbols by moving back and forth between them, thus effectively comparing them to each other. Eventually it moves on to the next pair and processes it in the same way. It cannot come back to the previous pair anymore, because it has no transitions for that.
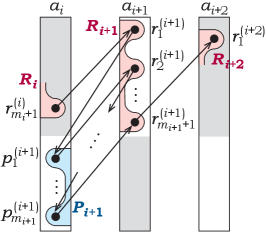
The automaton’s motion between two neighbouring symbols begins when it first arrives from the first symbol to the second in some state from . Then it moves back and forth, alternating between states from at the second symbol and states from at the first symbol, and finally leaves the second symbol to the right. Among the states visited by the automaton during this back-and-forth motion, the number of states from is greater by one than the number of states from . Two such sets of states will be denoted by a pair , where , and .
Proposition 1.
There are different pairs , such that , and .
Proof.
There are as many pairs as pairs , where . The number of pairs of the latter form is equal to the number of subsets of of size , that is, . ∎
Let the sets and be linearly ordered. Then one can define an order on the set of pairs as follows. In every such pair, let , where , and , where . There is a corresponding sequence to each pair, of the form , , , , …, , , , and different pairs are compared by the lexicographic order on these sequences. In Table 1, all pairs , for and , are given in increasing order, along with the corresponding sequences.
Let be the number of pairs. Then all pairs are enumerated in increasing order as , where and . In particular, the least pair is , because the corresponding sequence () is lexicographically the least. The greatest pair is .
The desired direction-determinate automaton with the shortest accepted string of length is defined over an alphabet , and the shortest accepted string will be . The set of states is defined as , where and . The initial state is . The only transition by the left end-marker () leads from the initial state to the least state in .
| (1a) | |||||
| For each symbol , transitions are defined in the states . If the automaton is at the symbol in any state from (except for the greatest state), then it moves to the left in the corresponding state from . | |||||
| (1b) | |||||
| For the greatest state in , there is no corresponding state in , and so the automaton moves to the right (and this is the only way to move from to , and hence the only way to advance from the symbol to the next symbol for the first time). | |||||
| (1c) | |||||
| In each state from , the automaton moves to the right in the next available state from . | |||||
| (1d) | |||||
There are no transitions at the right end-marker, and there is one accepting state: .
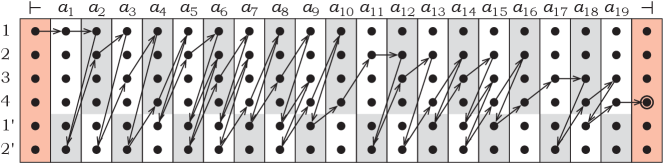
The computation of the automaton on the string is illustrated in Figure 1. The automaton gradually advances, and moves between every two subsequent symbols, and , according to the sets and . Transitions at expect that there is to the left, whereas transitions at expect to the right. As long as every symbol is followed by the next symbol in order, these expectations will be fulfilled each time, and the automaton accepts in the end.
Lemma 1.
The automaton accepts the string .
Proof.
It is claimed that the automaton , executed on the string , eventually arrives to each symbol in the state . This is proved by induction on .
Base case : the first transition (1a) moves the automaton to the state . The first pair is , and so .
Induction step. Assume that the automaton comes to the symbol in the state . Then it makes a transition (1c) to the right in the state . Then it executes the sequence of transitions (1b), (1d), defined by the pair , moving back and forth between and , and passing through the states , , , …, , . And so it comes to the symbol in the state , as shown in Figure 2.
In the end, the automaton comes to the last symbol in the state . Then it makes a transition (1c) and moves to the right end-marker in the state . And this is the accepting state , because the last pair is . Therefore, the string is accepted. ∎
It is claimed that the automaton cannot accept any shorter string. It cannot accept the empty string; if it did, then the first transition would lead to the right end-marker in the state 1, and the automaton would reject, because . Next, it will be shown that each accepted string begins with the symbol and ends with the symbol . Finally, it will be proved that the automaton cannot skip any number, that is, the number of every next symbol, as compared to the number of the previous symbol, cannot increase by more than . If the number decreases or does not change, this would make the string only longer; but in order to reach from without skipping any number, the automaton would have to move through all symbols of the alphabet, and therefore an accepted string cannot be shorter than symbols.
Lemma 2.
Every string accepted by the automaton begins with the symbol .
Proof.
Let the automaton accept some string that starts from some symbol . The transition from the initial configuration leads the automaton to the state at the first symbol . As , the state is .
Transitions by the symbol are defined only in states from , and hence , for otherwise the automaton immediately rejects. If there is at least one more state in , then the transition in the state by moves the automaton to the left. Then the automaton returns to the left end-marker, and then either loops or rejects, because there is only one transition defined there. Therefore, there are no other states in besides , and so, , which implies . ∎
Lemma 3.
Every string accepted by the automaton ends with the symbol .
Proof.
Let a string accepted by end with a symbol . To accept, the automaton should move from to the right using the transition (1c), and it arrives to the right end-marker in the state . As the only accepting state is , and the automaton rejects at the right end-marker in all other states, this state must be . Because the state is the least in , it follows that and . Therefore, this is the last pair, and . ∎
Lemma 4.
No string accepted by the automaton may contain any substring of the form , where .
Proof.
The proof is by contradiction. Suppose that accepts a string that contains a substring , with . In order to accept, the automaton should eventually reach this symbol for the first time, moving to it from the symbol . To make this transition, the automaton should be at in some state from (indeed, if it were in the state from , then it would have been at already at the previous step). Then the automaton must use the transition (1c) to move from to , and this transition leads to the state . For the computation to go onward, this state should lie in . Moreover, the state should be the least in , for otherwise the pair would be less than the pair . Also cannot be the only state in : if not, then would either coincide with or be less than .
It can be concluded that , and the next transition from this state leads to the state , moving to the symbol . For the automaton to have a transition in the state at , this state should belong to . In addition, it should be the least among the state in , because if there were a lesser state , then the second term in the sequence for would be , and this pair would be greater than . This leads to the equality .
By analogous arguments, one can prove that the sequences for and for must coincide and continue infinitely. This is impossible, because the numbers of states increase, and there finitely many of them. ∎
Corollary 1 (from Theorem 2).
For every , there is a direction-determinate 2DFA with states, such that the length of the shortest string it accepts is .
4 Longer shortest strings for automata of the general form
The main result of this section is the construction of a family of 2DFA with shortest strings of length , where is the number of states in an automaton. This is more than the maximum possible length of shortest strings for direction-determinate automata; in other words, forgetting the direction is useful.
Theorem 3.
For each there exists a 2DFA with states, such that the shortest string it accepts is of length .
Proof.
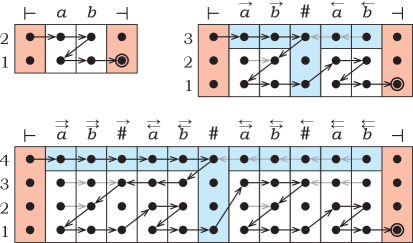
The automata and the shortest strings they accept are constructed inductively; for small values of they are given in Figure 3.
For the inductive proof to work, the following set of properties is ensured for every .
Claim.
For each there exists a 2DFA with no transitions by end-markers, no initial state and no accepting states, with the set of states , and there exists a string of length , such that the following two properties hold.
-
1.
If starts at any symbol of in the state , then it eventually leaves this string by a transition from its rightmost symbol to the right in the state .
-
2.
If for some non-empty string there exists a position, in which the automaton can start in the state and eventually leave the string by a transition from its rightmost symbol to the right in the state , then is at least as long as .
The first observation is that Theorem 3 follows from this claim. Let , and let and be an automaton and a string that satisfy the conditions in the claim. Then is supplemented with an initial state , a set of accepting states and a single transition by the left end-marker: from the state to the state ; no transitions by the right end-marker are defined. The resulting automaton becomes a valid 2DFA, and it accepts the string as follows: from the initial state at it moves to the first symbol of in the state , then, by the first point of the claim, the automaton eventually leaves to the right in the state , and thus arrives to the right end-marker in an accepting state.
To see that every string accepted by is of length at least , let be any accepted string. It is not empty, because on the empty string the automaton steps on the right end-marker in the state and rejects. Then, after the first step the automaton is at the first symbol of in the state . It cannot return to , because it has already used the only transition at this label, and if it ever comes back, it will reject or loop. Also the automaton cannot come to in states other than . In order to accept, it must arrive to in the state , and this is the first and the only time when it leaves the string . Then, by the second point of the claim, the length of cannot be less than the length of .
It remains to prove the claim, which is done by induction on .
Base case: .
The automaton for is constructed as follows. The alphabet is , and the set of states is . The transition function is defined by
The string is , and the computation of on is presented in Figure 3 (top left). To be precise, computations starting in the state either at or at both end by leaving the string to the right in the state , as claimed. There are only two shorter non-empty strings: and . If the automaton starts on the string in the state , then it moves to the right in the state ; on , it moves to the left in the state . In either case, it does not go to the right in the state . Thus, the second point of the claim is satisfied. The length of the string is .
Induction step: .
Let an -state 2DFA and a string satisfy the claim. The -state automaton satisfying the claim is constructed as follows. Let .
-
•
Its alphabet is , where and
-
•
The set of states is .
-
•
The transition function is defined as follows. In the new state , the automaton moves by all symbols with arrows in the directions pointed by the arrows.
In all old states , on symbols with arrows, the new automaton works in the same way as the automaton on the corresponding symbols without arrows. By the new separator symbol , only two transitions are defined. In the state , the automaton moves to the left in the state , thus starting the automaton on the substring to the left. And if the automaton gets to in the state (which happens after concluding the simulation of on the substring to the left), then the automaton moves to the right in the state to start the simulation of also on the substring to the right of the separator . The rest of transitions are undefined.
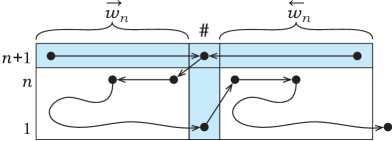
Note that once the automaton leaves the state , it never returns to it, because there are no transitions to from any other state. Let be a string homomorphism which removes the arrow from the top of every symbol, that is, for all . The automaton works in the states on symbols from as works on the corresponding symbols from . Then, if for some , it follows that the automaton , having started in the state at any symbol of , eventually leaves the string by moving to the right in the state . Furthermore, if for some string , then the automaton , having started in the state at any symbol of , cannot leave the string by moving to the right in the state .
The string is defined as , where and for every string . The length of is , as desired.
First, it is proved that the automaton works on the string as stated in the first point of the claim. Let start its computation on the string at any symbol in the state , as shown in Figure 4. By the symbols in , the automaton moves to the right, maintaining the state ; by the symbols in , it moves to the left in . Thus, wherever the automaton begins, it eventually arrives to the separator in the state . Next, the automaton moves to the last symbol of in the state . Since , the automaton operates on as on , and leaves by a transition to the right in the state . Then arrives to the separator again, now in the state , and moves to the first symbol of in the state . As , the automaton works as on , and leaves (and the whole string ) by moving to the right in the state .
Turning to the second point of the claim, it should be proved that computations of a certain form are impossible on any strings shorter than . Let be a string, and let there be a position in , such that the automaton , having started at this position in the state , eventually leaves the string by a transition to the right in the state . It is claimed that .
Consider the computation of leading out of to the right in the state . It begins in the state , and the automaton maintains the state at all symbols except . In order to reach the state , there should be a moment in the computation on when the automaton arrives at some symbol in the state . Let be the prefix of to the left of this , and let be the suffix to the right of this ; note that the substrings and may contain more symbols . It is sufficient to prove that and .
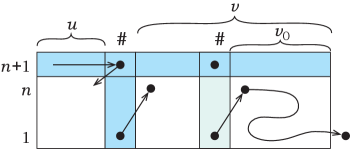
Consider first the case of the suffix . Let be the longest suffix of that does not contain the symbol ; then the symbol preceding in is the separator , as shown in Figure 5. Once the automaton steps from the last in to the right, it arrives to the first symbol of in the state (by the unique transition to the right at ). The string cannot be empty, because . Once the automaton is inside , it cannot return to anymore, since it has already used the only transition to the right from , and cannot use it again without looping. Therefore, the automaton starts on the string in the state , and, operating as , eventually leaves this string to the right in the state . Then by the induction hypothesis, and hence .
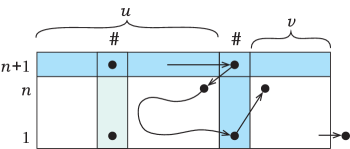
Now consider the prefix . Once the automaton comes in the state to the separator between and , it moves to the last symbol of in the state . In order to leave the string to the right and proceed further, it must return to the separator in the state , because there are no transitions by any states at this separator. If there are no symbols in , or if there are some, but the automaton does not reach them, then the entire computation of on takes place on a certain suffix of that does not contain , as illustrated in Figure 6. This computation follows a computation of on a string from . Then, by the induction hypothesis, this suffix is not shorter than , and therefore .
The remaining case is when the automaton comes to some symbol inside the string . Let be the maximal suffix of not containing any symbols , as in Figure 7. The automaton visits the separator to the left of , and then immediately moves from this separator back to the first symbol of in the state (the string is non-empty, because it is followed by , which has no transitions in the state ). Returning back to to the left of is not an option, since the unique transition by to the right has been used already. Therefore, the automaton leaves by a transition to the right, and comes to the separator between and . In order to continue the computation, it should come there in the state . By the induction hypothesis for this computation on , the length of is at least . Then the length of the entire is also at least .
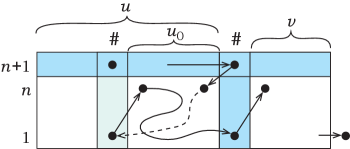
This confirms that and completes the proof. ∎
5 Conclusion
The maximum length of the shortest accepted string for direction-determinate 2DFA has been determined precisely, whereas for 2DFA of the general form, a lower bound of the order has been established. The known upper bound on this length is of the order . Bounds on the maximum length of shortest strings for small values of the number of states are given in Table 2.
| direction-determinate | 2DFA of the general form | |||
|---|---|---|---|---|
| 2DFA | lower bound | computed values | upper bound | |
| 2 | 1 | 2 | 2 | 3 |
| 3 | 2 | 5 | 6 | 14 |
| 4 | 5 | 11 | 17 | 55 |
| 5 | 9 | 23 | 32 | 209 |
| 6 | 19 | 47 | 791 | |
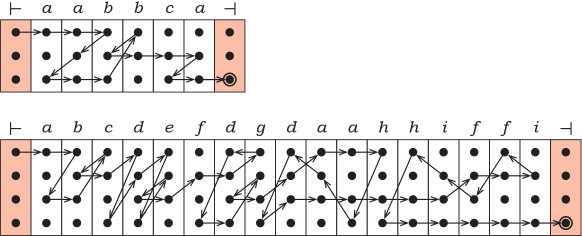
In the table, besides the theoretical bounds, there are also some computed values of the length of shortest strings in some automata. The example for was obtained by exhaustive search, while the examples for and were found by heuristic search. Therefore, the maximum length of the shortest string for 3-state automata is now known precisely, for 4-state automata it is at least 17 and possibly more, and the given length of strings for 5 states is most likely much less than possible. The computations of the automata found for and on their shortest strings are presented in Figure 8.
It should be noted that these computed values exceed the theoretical lower bound proved in this paper, and are much less than the known upper bound . Thus, the bounds for 2DFA of the general form are still in need of improvement.
References
- [1] L. Alpoge, Th. Ang, L. Schaeffer, J. Shallit, “Decidability and shortest strings in formal languages”, Descriptional Complexity of Formal Systems (DCFS 2011, Limburg, Germany, 25–27 July 2011), LNCS 6808, 55–67.
- [2] D. Chistikov, W. Czerwinski, P. Hofman, M. Pilipczuk, M. Wehar, “Shortest paths in one-counter systems”, FoSSaCS 2016: Foundations of Software Science and Computation Structures, LNCS 9634, 462–478.
- [3] E. Dobronravov, N. Dobronravov, A. Okhotin, “On the length of shortest strings accepted by two-way finite automata”, Fundamenta Informaticae, 180:4 (2021), 315–331.
- [4] K. Ellul, B. Krawetz, J. Shallit, M.-w. Wang, “Regular expressions: new results and open problems”, Journal of Automata, Languages and Combinatorics, 10:4 (2005), 407–437.
- [5] V. Geffert, A. Okhotin, “One-way simulation of two-way finite automata over small alphabets”, NCMA 2013 (Umeå, Sweden, 13–14 August 2013).
- [6] C. A. Kapoutsis, “Removing bidirectionality from nondeterministic finite automata”, Mathematical Foundations of Computer Science (MFCS 2005, Gdansk, Poland, 29 August–2 September 2005), LNCS 3618, 544–555.
- [7] D. Kozen, “Lower bounds for natural proof systems”, FOCS 1977, 254–266.
- [8] S. Krymski, A. Okhotin, “Longer shortest strings in two-way finite automata”, In: G. Jirásková, G. Pighizzini (Eds.), Descriptional Complexity of Formal Systems, LNCS 12442, 2020, 104–116.
- [9] M. Kunc, A. Okhotin, “Reversibility of computations in graph-walking automata”, Information and Computation, 275 (2020), article 104631.
- [10] L. Pierre, “Rational indexes of generators of the cone of context-free languages”, Theoretical Computer Science, 95:2 (1992), 279–305.
- [11] E. N. Shemetova, A. Okhotin, S. V. Grigorev, “Rational index of languages with bounded dimension of parse trees”, DLT 2022, 263–273.