The pace of evolution across fitness valleys
Abstract
How fast does a population evolve from one fitness peak to another? We study the dynamics of evolving, asexually reproducing populations in which a certain number of mutations jointly confer a fitness advantage. We consider the time until a population has evolved from one fitness peak to another one with a higher fitness. The order of mutations can either be fixed or random. If the order of mutations is fixed, then the population follows a metaphorical ridge, a single path. If the order of mutations is arbitrary, then there are many ways to evolve to the higher fitness state. We address the time required for fixation in such scenarios and study how it is affected by the order of mutations, the population size, the fitness values and the mutation rate.
I Introduction
Evolutionary dynamics is based on natural selection, mutation and genetic drift nowak:2006bo . It can be illustrated as the dynamics of a population in an abstract, typically high-dimensional fitness landscape. Since individuals with higher fitness produce more offspring, the average density of individuals is highest close to the fitness maxima. Many such features as the stationary population density in the fitness landscape or the mutation rate under which a population can still be concentrated around a fitness maximum have been addressed eigen:1977aa ; eigen:1989aa ; wilke:2005aa ; nowak:1992aa . An important question is how a population evolves towards a fitness peak via several intermediate states. If the intermediate states have the same fitness as the initial state, then evolution to higher fitness states is neutral at first and thus poses no significant problems nimwegen:2000 . If the intermediate states have lower fitness than the initial state, then a fitness valley has to be overcome and it is more difficult to reach the fitness peak weinreich:2006aa ; poelwijk:2007aa . In this case, population stuck on a local peak cannot escape by natural selection alone, because there is no evolutionary trajectory with successively advantageous mutations. Instead, neutral genetic drift becomes important.
Here, we consider the dynamics of these systems from a different perspective. We address the average time a population needs to transfer from one peak to another one. For small mutation rates and finite populations, we calculate this average time analytically. When mutation rates are high, we can describe the system by a set of differential equations and obtain the relevant times from a numerical integration of the differential equations. In this framework, the relevant question is how fast a population evolves traulsen:2007ee .
In particular, we can address the question whether a population evolves faster from one peak to another via mutations if
-
(i)
mutations have to occur in a certain order, i.e. only a single evolutionary trajectory is available or
-
(ii)
the order of the mutations does not matter, i.e. there are evolutionary paths.
In the simplest case the intermediate fitness values are identical in both the cases and equal to that of the initial state. Thus the only difference remaining is the number of available paths. When the order of mutations is not fixed then multiple paths are available and the evolutionary dynamics will be faster when compared to a single path. We can then ask the question: Does a population evolve faster on a narrow ridge or a broad valley? This implies that we move away from the simplest case mentioned above and decrease the fitness in the intermediate states of the multiple paths compared to the fitness in the intermediate states of the single path. We show how the pace of evolution depends on the depth of the valley, the number of intermediate states and the size of the population.
In general, evolutionary dynamics depends crucially on the size of the population. In a small population a single mutation will typically reach fixation or extinction before another mutation can arise. The population moves as a whole step by step on the fitness landscape. For large populations, even for small mutation rates usually multiple types arise at the same time. This results in a non-zero population density in many states at the same time. For intermediate mutation rates, the population can either move stepwise across the fitness landscape or move several stpdf without getting concentrated in one of the intermediate states. This phenomenon has been termed stochastic tunneling iwasa:2004aa . If the mutation rates are too small, tunneling does not occur because it is unlikely that a second mutation arises before the first one has reached fixation or has gone extinct. If the mutation rates are high, tunneling occurs trivially, because the system can be approximated by differential equations for the densities in the different states. These different scenarios including the limiting cases of stepwise evolution (typical for small populations) and continuous evolution (typical for large populations) can also be observed when the population size is kept constant, but the mutation rates are increased. For computer simulations increasing the mutation rate is more convenient than simulating huge populations for moderate mutation rates.
One important example for an evolutionary process in which the timescales are of crucial importance is the somatic evolution of cancer frank:2007aa . Cancer progression has been investigated mathematically since the 1950s fisher:1959 ; nordling:1953 ; armitage:1954 . Of special interest are the tumor suppressor genes knudson:1971aa ; michor:2004aa . In a normal cell, there are two alleles of the tumor suppressor gene. The mutation in the first allele is neutral if the second wild-type allele can sufficiently perform the function. Inactivation of both the alleles confers a selective advantage to the cell and can lead to cancer progression. This is an example in which the order of mutations does not matter. Many cancers also require certain particular mutations that initiate cancer growth and pave the way for the accumulation of further mutations vogelstein:2004aa . Recently, it has been shown that after cancer initiation, a large number of different mutations may be involved in cancer progression sjoeblom:2006sj ; wood:2007ri ; jones:2008ty ; jones:2008ec . So far, it is unclear if the mutations have to occur in a specific order or if there is more variation in the order beerenwinkel:2007aa ; gerstung:2008aa .
For simplicity, we consider only very simple fitness landscapes here in which the fitness in all the intermediate states is identical. In natural systems, these fitness values will differ and also the mutation rate may not be constant. In addition, sometimes the order of mutations will matter and sometimes, it will not. Thus, sometimes a particular mutation will be a prerequisite to obtain a new function, but sometimes new mutations do not require any prerequisites. For example, this is the case in the evolution of resistance to lactam antibiotics studied by weinreich:2005aa and weinreich:2006aa . However, here we focus on a very simple model to highlight the general aspects of the dynamics by analytical and numerical considerations.
This paper is organized as follows. We begin with the description of the two ways to order the mutations, the single path and the hypercube. We then derive analytical approximations of the fixation times for small mutation rates and discuss the effect of the different parameters on the fixation times. Next, we address the dynamics for intermediate and high mutation rates. Finally, we explore biological examples which can be modeled using this approach.
II Model
To model evolutionary dynamics in a haploid population of size , we use the Moran process nowak:2006bo ; moran:1962ef . In each time step, one individual is selected at random, but proportional to fitness. It produces one offspring, which replaces a randomly chosen individual. In one generation, each individual reproduces on average once. During reproduction, mutations occur with probability . We are interested in the time it takes until mutations reach fixation in the population, starting from a homogeneous population in the initial state without any mutants. Moreover, we aim to explore the dynamical features of this process. We restrict ourselves to two different cases that allow the derivation of some analytical results.
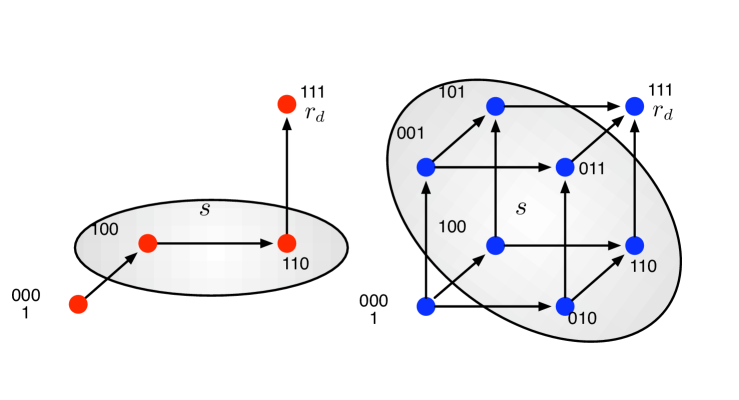
II.1 Single path
If the mutations can occur only in a particular order, we have a single evolutionary path, see Fig. 1 for an illustration. Individuals in the initial state have fitness and individuals in the final state have fitness . It is instructive to characterize an individual by a string of sites, which can either be wild-type or mutated. If the order of mutations is fixed, then a particular mutation requires another particular mutation as a prerequisite. For simplicity, we assume that all the intermediate states have the same fitness (). For , the joint effect of the set of mutations make up for the loss of fitness caused by the individually deleterious mutations. This can be considered as a very special case of epistasis weinreich:2005ab .
II.2 Hypercube
If the order of mutations does not matter, evolutionary dynamics takes place on a hypercube in dimensions cf. Fig. 1. Thus, there are different types of individuals. In the initial state, we have possible mutations. In the next step, mutations are available. Consequently, we have possible paths to fixation. Again, we assume and . Further, all individuals with some, but not all mutations have fitness .
If the mutation probability is small, we do not need to make specific assumptions on the mutation process. But when the mutation probability increases, we can no longer be certain that only a single mutation occurs during reproduction. For simplicity, we do not consider the possibility of backward mutations. Although back mutations are often relevant, especially to escape from evolutionary dead ends dePristo:2007pi , it is not straightforward to define the speed of evolution in a system with backward mutations. This is due to the fact that for sufficiently high mutation rates, fixation in the final state might never occur. Other definitions of the end state of the system become arbitrary to a certain extend. The probability that the offspring of an individual with mutations has mutations () is
| (1) |
This equation is valid for the hypercube, where the order of mutations does not matter. Here, is the number of different types of mutants with additional mutations, is the probability that mutations occur at sites and is the probability that no mutation occurs at the remaining sites. For the single path, there is only one possibility to arrange the mutations. Thus, for , is identical to Eq. (1), except that the binomial factor has to be dropped. The probability that no mutation occurs follows from normalization, . Our analytical calculations for small mutation rates as well as the considerations for high mutation rates are independent of the precise form of the mutation rates. However, we need to specify the form of the mutation probabilities to perform our numerical simulations for intermediate and high mutation rates.
III Small mutation rates
III.1 The pace of evolution for small mutation rates
For small mutation probabilities, double mutations can be neglected. Since mutations occur rarely, we can calculate the average time until mutations are fixed in the population analytically. Let us first address the evolutionary dynamics when mutants with fitness are already present in a resident population of fitness , but no new mutations occur. This scenario is relevant when mutation rates are sufficiently small. The probability to increase the number of mutants from to is
| (2) |
Similarly, the number of mutants decreases from to with probability
| (3) |
The probability that mutants take over the entire population is given by nowak:2006bo ; karlin:1975xg ; ewens:2004qe ; crow:1970ck
| (4) |
If a mutant reaches fixation, the average number of generations this process takes is given by goel:1974aa ; antal:2006aa
| (5) |
For a neutral process with , this reduces to . For sufficiently large , this is the maximum conditional fixation time of a mutant. Even for disadvantageous mutants () the conditional fixation time is smaller than antal:2006aa . Since there are mutations per generation, the time between two mutations is . Thus, for a mutant reaches fixation before the next one arises and mutations will not occur when a mutant is already present. Thus the population evolves by a process where the mutations occur one after the other, which has been termed periodic selection atwood:1951aa and theoretically described as the strong-selection weak-mutation regime gillespie:1983aa ; gillespie:2004bo .
The total time until a mutation reaches fixation in a population is the sum of the waiting time until a successful mutant occurs and the fixation time of the mutant . The waiting time is the inverse of the mutation rate divided by the probability that a particular mutant is successful,
| (6) |
For , we have , but remains approximately constant. Thus, for small mutation rates. In principle, we could calculate in the presence of mutations. But since our approximation is only valid for small mutation rates, this will be a minor correction.
For , the population is homogeneous most of the time. Only occasionally, a mutant arises and reaches fixation or goes to extinction. The total time until mutations are fixed in the population is the sum of the waiting times for the successful mutants plus the time of the fixation events. For a single path with initial fitness , intermediate fitness and final fitness , we find for the total time
| (7) | ||||
For small , we have and hence the total time can be approximated by
| (8) |
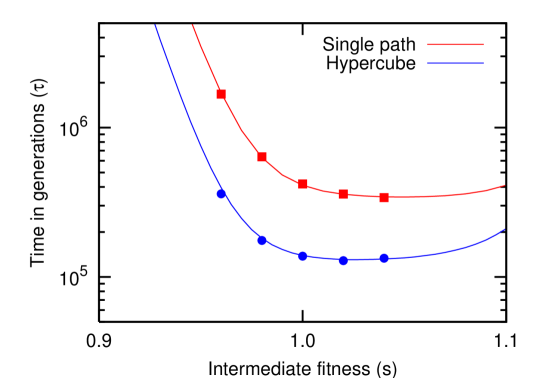
Consider now a “fitness valley”, in which the intermediate states have fitness , but the final state has fitness . To move from the fitness peak in the initial state to the fitness state in the final state, first a disadvantageous mutation has to be fixed in the population. Since , the waiting time of such an event is very long. The waiting time for the neutral mutations, and the waiting time for a successful mutation, are significantly shorter. Thus, is dominated by for and sufficiently high in a fitness valley. Fig. 2 shows a good agreement between exact numerical simulations and our analytical approximation for small mutation rates Eq. (8).
If the order of mutations is arbitrary, evolutionary dynamics occurs on a hypercube. In this case, the whole process will be faster, as we have possible paths instead of a single one. Now, the waiting times in the different states depend on the number of mutations that are still available. For the total time , we obtain,
| (9) | ||||
Note that the time of the fixations alone is identical for the hypercube and the single path. Neglecting these fixation times for small ( as ) yields
| (10) |
Since and it is obvious that , i.e. evolutionary dynamics is faster if the order of mutations is arbitrary. For fitness valleys with and a large population size, is dominated by . As more mutations are available, this is always faster than the corresponding equation for a single path, see Fig. 2.
III.2 Thresholds of the waiting times
Next, we derive expressions for some interesting thresholds of the waiting times in the limit of small mutation rates. Since evolutionary dynamics is always faster if many paths are available, we now compare a fitness valley in which many paths are available to a single path in which the order of mutations is important, but fitness does not decrease in the course of evolution. The basic question we address here is, whether it is faster to cross a broad valley or a narrow ridge in fitness space. In other words, we compare to . Since we consider only small mutation rates , we neglect the fixation times here, although they will not be identical in the two scenarios. For , the single path is neutral. We decrease in the hypercube until we have identical waiting times. This yields an implicit expression for ,
| (11) |
From this equation, we can numerically determine for any given . For large , Eq. (11) simplifies to
| (12) |
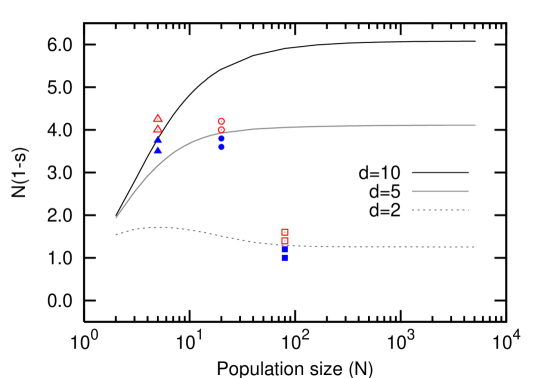
where we used for large . Thus, the quantity becomes constant for large , see Fig. 3. Thus, we can now say how broad and deep a fitness valley has to be to lead to the same cumulative waiting time as a single neutral path.
Next, we address the effect of the intermediate fitness , which has an important influence on the cumulative waiting time . Fig. 2 shows how the waiting time decreases with increasing fitness in the intermediate states . If comes very close to the fitness in the final state, the waiting time increases. This increase is seen both in the single path and the hypercube. An increase in the intermediate state fitness will not always lead to a reduction in waiting times. Instead, the fixation times reach a minimum when the fitness growth is constant between any two consecutive states weinreich:2005tx ; traulsen:2007ee . For the hypercube, the fastest trajectory will be steeper than on a single path: at first, many mutations are available and a big fitness increase is not necessary. Later, fewer mutations are available and thus, the fitness should increase faster. The precise form of the trajectory will in this case depend on the number of mutations and the population size . We note that a similar reasoning can be applied to construct a fitness landscape that allows to cross a fitness valley fastest: the fastest trajectory has the same form regardless if a fitness peak is approached () or a fitness minimum is approached (). Thus, the fastest way to cross a fitness valley is to descend to the minimum with exponentially decreasing fitness and to increase from the minimum again with exponentially increasing fitness.
Now, we turn to the effect of the intermediate fitness on the individual waiting times. Eqs. (8) and (10) both consist of three terms each. The first term denotes the time required to leave the initial state. The second term is the time spent in moving through all the intermediate states. This second term is independent of , because the transitions are neutral. The last term denotes the time required to reach the ultimate state from the penultimate state. For small values of , the probability to fixate the disadvantageous mutation is very small. Thus, the total time is dominated by the first term. When is increased to a threshold value , then the time for leaving the first state is identical to the waiting time in the intermediate states. For the hypercube, is given by , which reduces to
| (13) |
This equation can be solved numerically for specific values of and . For the single path, the right hand side of this equation has to be replaced by . For , the time to cross the intermediate states is larger than the waiting time in the first state. On the hypercube, we can define a second threshold for which the waiting time in the first state is the same as the time required to reach the final state from the penultimate state. This arises because the effective mutation rate in state is times larger than the effective mutation rate in state . The threshold is given by or
| (14) |
Again, has to be determined numerically. For a single path, the factor in Eq. (14) has to be dropped. Thus, the threshold occurs for and is simply given by .
The fixation time is also strongly influenced by the number of mutations . A larger increases the length of the path and usually also the fixation times. For the single path, this increase results only from the increase in the time required to cross the intermediate states, because the time for leaving the initial state and the time to reach the final state from the penultimate state are independent of . The time required to reach the ultimate state from the penultimate state is also independent of for the hypercube, but the time required to leave the initial state decreases with increasing . This is because as increases, there are more states available in the first error class and thus the effective rate of mutation out of the initial state increases. As for the single path, the time to cross the intermediate states increases with in the hypercube. For the hypercube, this interplay can lead to a non-monotonic dependence of the fixation time on . For example, for and , the fixation time decreases with for , but it increases with for . In contrast, the fixation time always increases monotonically with for the single path.
Increasing the fitness of the final state increases the advantage of the final state over the intermediate states. This will result in the decrease in the time required for the population to make the last move. Increasing has no effect on the time required to cross the intermediate states or the time required to move away from the initial state. As a result, those two times remain constant even as increases, both in the single path and the hypercube.
IV Intermediate mutation rates
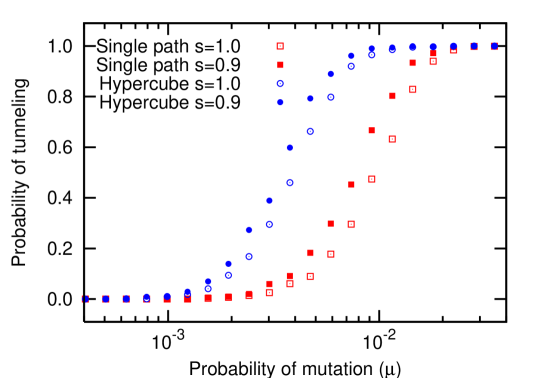
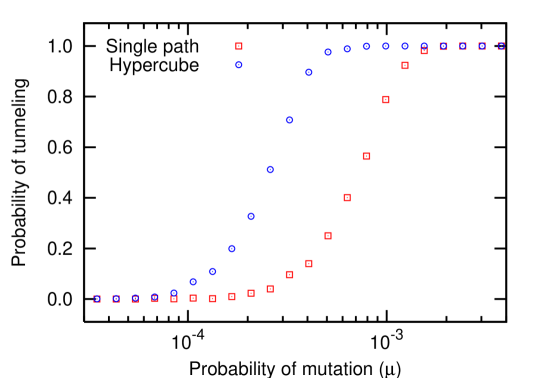
The analytical approach is only valid as long as the mutation rate is small, . For higher mutation rates, the population does not have to consist of at most two different types at any time. Instead, mutations can be fixed in the population without sequentially fixing one after the other. This process has been termed stochastic tunneling and is of great importance in the context of cancer initiation iwasa:2004aa ; michor:2004aa ; nowak:2004bb ; beerenwinkel:2007aa . Tunneling across fitness valleys is more likely than tunneling across a flat fitness landscape (see Fig. 4). Even for , the evolutionary dynamics is characterized by a doubly stochastic process, which makes analytical approaches tedious iwasa:2004aa . As discussed above, for the population usually contains at most two different types. In this case, the probability of stochastic tunneling will be very small. On the other hand, for , at least one mutant is produced per generation. Thus, the probability of stochastic tunneling approaches . For , the mutations are sometimes fixed sequentially and sometimes via stochastic tunneling. Fig. 5 shows how the tunneling probability increases from to in this interval.
For intermediate mutation rates, it is likely that the population contains more than two different types. The types with beneficial mutations will compete for fixation. This process is termed clonal interference crow:1970ck ; fisher:1930fi ; muller:1932aa ; gerrish:1998aa ; park:2007aa . Clonal interference has been considered to slow down adaptation, but recently it has been shown that it can have a positive influence on a rugged fitness landscape gerrish:1998aa ; wilke:2004aa ; jain:2007aa .
The states in a single path can be characterized by the number of mutations. In the hypercube, the states are characterized by the types of mutations that have already occurred. Thus, there are many different types that have undergone a specific number of mutations. However, all types that have already accumulated mutations can be pooled into the error class . The number of different types in the error class is given by .
In a single path, a population is said to tunnel across a state if it passes through a state without ever reaching fixation in that state. Analogously, in a hypercube a population said to tunnel across an error class if it passes through that error class without ever reaching fixation in it. Within the error classes, tunneling can occur across individual states, but also across several states at once. This means that the whole population passes only across that particular state and not across any other, without ever reaching fixation in that particular state. Tunneling across an error class can also occur in a second way: the population can use all of the available states in the error class, but the total number of individuals in the error class never reaches . Thus, the probability of tunneling via the individual states is always lower than the probability of tunneling across the error classes. Fig. 6 shows the relation between the different probabilities of tunneling in the hypercube with respect to the rate of mutation for the special case .
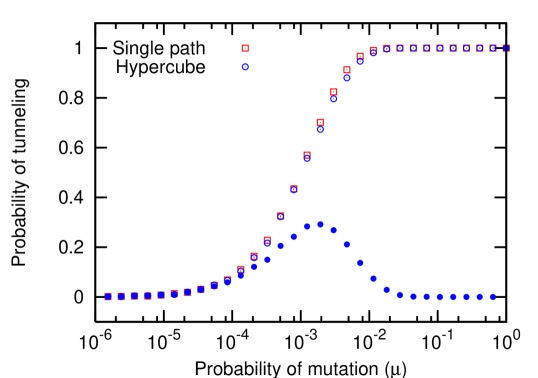
Due to higher effective rates of mutation, the probability of tunneling across a hypercube is expected to be greater than or equal to the probability of tunneling across a single path. However, numerical simulations reveal that for the probability of tunneling in a single path is higher than in the hypercube. This is a special case: for in a hypercube, the number of states into which the initial state can mutate into is . The effective rate of mutations is thus twice as much as in the single path. The number of states which can be mutated into next is one, both in the single path and the hypercube. Thus the rate at which the individuals are pushed into the first state is higher in hypercube than in the single path while the rate of individuals being pushed out is the same. Thus there is a higher probability of reaching fixation in the first error class in a hypercube (see Fig. 6). We only observe this effect for , for , the probability of tunneling is higher in a hypercube than in a single path, as expected (see Fig. 4).
V High mutation rates
For , the stochastic features of the dynamics become less important. In this case, the system can be described by a set of deterministic differential equations for the fraction of the population that has mutations jain:2007aa . Obviously, we have . Transitions out of state occur with probability , where is the average fitness of the population. This includes all the reproductive events except for the one where a type is produced. Transitions into state occur with probability . Thus, the fraction of individuals in the initial state follows the differential equation
| (15) |
The probability that an offspring is of type is given by . The difference between the hypercube and the single path only occurs in the quantity , which is given above for both cases. The sum in is over all individuals with or less mutations and is the fitness of individuals with mutations. This leads to the differential equation for the fraction of individuals with mutations,
| (16) |
where . Of course, the special case recovers Eq. (15). This set of differential equations describes how the system moves from state to state . In general, only a numerical solution of this system of equations is feasible. While this allows us to infer details of the dynamics, our main interest is the time required for fixation of number of mutations. Thus, we solve the differential equation numerically using a standard Runge-Kutta algorithm press:2007aa . To find an equivalent to the fixation time in a stochastic simulation, we average between fixation () and the time when there are on average less than individuals outside the final state (). Thus, the fixation time is the time when the solution of the differential equation crosses .
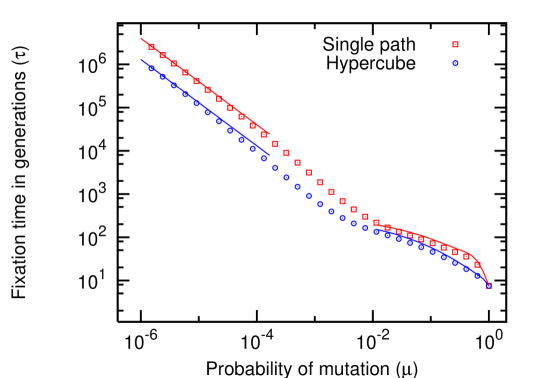
Fig. 7 shows an overview of the fixation times, covering the full range of mutation rates. For small mutation rates, we have sequential fixation of mutations and the time can be well approximated by Eqs. (8) and (10). For high mutation rates, the numerical solution of Eq. (16) leads to a good approximation for the fixation times.
VI Discussion
We have determined the average time during which a population moves from a certain initial state to a final state of higher fitness. The initial and the final states are separated by a fixed number of mutations . The mutations jointly confer a fitness advantage to the final mutant which can be represented by a peak in the fitness landscape. If the intermediate mutations need to occur in a specific order for the evolution of the final mutant then it corresponds to the single path. Otherwise, evolution occurs on a hypercube and there are ways of reaching the final state.
We have explored the simplest system in which the fitness in all intermediate states is the same. As expected, the fixation times on a hypercube are shorter than on a single path, due to the presence of multiple paths available in a hypercube. This observation leads to the question: for which parameters does the hypercube show shorter fixation times than the single path, even with an added disadvantage? The fitness in the intermediate states was then set to lower values than the ones in the single path. Up to a certain threshold value of the fitness of the intermediate states, the hypercube shows shorter fixation times than in the single path. The value of the threshold depends on the population size, total number of required mutations and the fitness in the final state.
The fixation times for large populations largely depend on the fitness function and are qualitatively independent of the order of mutations. Let us first focus on a flat landscape: when the intermediate states have a fitness equal to the fitness of the initial wild-type, then for small mutation rates large populations have shorter fixation times than small populations. This is because the neutral rate of evolution does not depend on the population size. But the waiting time for fixation of the last mutation becomes shorter with larger population size. For intermediate mutation rates, tunneling starts earlier in larger populations. This leads to a marked decrease in the fixation time with larger population size. For high mutation rates, the time to fixation is no longer dominated by the time for the first mutant to reach the final state, but by the time until all individuals are in that state. Due to this, for high mutation rates the time required for fixation can be shorter in smaller population as compared to larger populations. Next, we focus on fitness valley: If the fitness landscape consists of a valley with reduced fitness of the intermediate states, small populations have an advantage for small mutation rates, as they can easily leave the initial state and enter the valley. But for high mutation rates, large populations reach fixation faster, because they can explore states within and beyond the fitness valley more easily.
Our numerical simulations reveal that tunneling can be neglected even when the mutation rate exceeds , at least by one order of magnitude. Thus, Eqs. (8) and (10) provide good estimates for the fixation times even in relatively large populations. Concrete values for fixation times are collected in Table 1. They reveal that even in long-term studies of experimental evolution, it is difficult to observe the consecutive fixation of neutral mutants cooper:2003aa . Consecutive fixation of advantageous mutants, however, is significantly faster. For example, while Table 1 reveals a fixation time of generations on a single path for , and , an optimal choice of the intermediate fitness values traulsen:2007ee would lead to a fixation time of generations.
| Single Path | Hypercube | Single Path | Hypercube | |
|---|---|---|---|---|
While we have focused on the simplest possible system which allows analytical approximations, experimental studies reveal of course a much higher complexity. weinreich:2006aa studied experimentally the point mutations in the -lactamase gene of bacteria. lactam antibiotics are commonly used, but the bacteria can develop resistance to the drugs. Five point mutations in a particular allele of the -lactamase gene increases the resistance of the bacteria to cefotaxime by a factor of . Theoretically the mutations leading from the wild-type allele to the resistant allele can occur in ways. These can be represented by a hypercube of . But in only of the trajectories, the intermediate mutations are either neutral with respect to the initial state or beneficial. Weinreich and colleagues have shown that these have the highest probability of realization. For all beneficial intermediates the fastest way to reach the final state would be when the relative fitness increase between any two consecutive mutations is constant traulsen:2007ee , but usually in nature several different mutations are available and the population first evolves to states that provide the highest selective advantage.
In another experimental study the sequence space of the 5s rRNA of a marine bacterium, Vibrio proteolyticus was explored lee:1997 . The sequences from Vibrio proteolyticus and Vibrio alginolyticus differ in only four positions. All the possible intermediates were constructed by the authors and the fitness of each was calculated chao:1985aa . Two of the valid intermediates have a fitness lower than the initial wild-type. We have shown how such fitness valleys can be crossed by exploring the phenomenon of tunneling or multiple mutations (for high mutation rates). Thus, the population does not need to move in a Wrightian fashion (the whole population moving as a whole across the valley).
The theory discussed herein deals with basic evolutionary concepts which are important to the kind of biological examples described above. More complex properties of the experimental studies like more general cases of epistasis and compensatory mutations can easily be incorporated, but there is a huge number of possibilities. Even if we are only interested in the ordering of fitness values, we can have up to distinct epistatic patterns. Thus, one should rather focus on concrete systems instead. For example, one could simulate the dynamics in a system with experimentally derived fitness values and mutation rates. Not all the paths of a hypercube might be accessible for selection, but still some of them might prove to be significant depending upon the particular values of the parameters, such as fitness values and population size. Our goal here was to characterize the simplest features of the dynamics of a population crossing a fitness valley. This approach can be helpful when more realistic scenarios are addressed.
VII Acknowledgment
We thank Andrew Murray for initiating this project. C.S.G. and A.T. are grateful for financial support from the Emmy-Noether program of the DFG. M.A.N. is supported by the John Templeton Foundation, the NSF/NIH joint program in mathematical biology (NIH Grant R01GM078986), the Bill and Melinda Gates Foundation (Grand Challenges Grant 37874), and J. Epstein.
References
- (1) Nowak MA (2006) Evolutionary Dynamics. Harvard University Press, Cambridge, MA.
- (2) Eigen M, Schuster P (1977) The hypercycle. A principle of natural self-organization. Part A: Emergence of the hypercycle. Die Naturwiss 64:541–565.
- (3) Eigen M, McCaskill J, Schuster P (1989) The molecular quasi-species. Adv Chem Phys 75:149–263.
- (4) Wilke C (2005) Quasispecies theory in the context of population genetics. BMC Evol. Biol. 5:44.
- (5) Nowak MA (1992) What is a quasispecies? Trends in Ecology and Evolution 7:118–121.
- (6) van Nimwegen E, Crutchfield J (2000) Metastable evolutionary dynamics: crossing fitness barriers or escaping via neutral paths? Bull Math Biol 62:799–848.
- (7) Weinreich D, Delaney N, DePristo M, Hartl D (2006) Darwinian evolution can follow only very few mutational paths to fitter proteins. Science 312:111–114.
- (8) Poelwijk FJ, Kiviet DJ, Weinreich DM, Tans SJ (2007) Empirical fitness landscales reveal accessible evolutionary paths. Nature 445:383–386.
- (9) Traulsen A, Iwasa Y, Nowak MA (2007) The fastest evolutionary trajectory. J. Theor. Biol. 249:617–623.
- (10) Iwasa Y, Michor F, Nowak MA (2004) Stochastic tunnels in evolutionary dynamics. Genetics 166:1571–1579.
- (11) Frank SA (2007) Evolutionary Dynamics of Cancer. Princeton Univ. Press.
- (12) Fisher J (1959) Multiple-mutation theory of carcinogenesis. Nature 181:651–652.
- (13) Nordling C (1953) A new theory on cancer inducing mechanism. Br J Cancer 7:68–72.
- (14) Armitage P, Doll R (1954) The age distribution of cancer and a multi-stage theory of carcinogenesis. Br J Cancer 8:1–12.
- (15) Knudson AG (1971) Mutation and cancer: Statistical study of retinoblastoma. Proc. Natl. Acad. Sci. U.S.A. 68:820–823.
- (16) Michor F, Iwasa Y, Nowak MA (2004) Dynamics of cancer progression. Nat. Rev. Cancer 4:197–205.
- (17) Vogelstein B, Kinzler K (2004) Cancer genes and the pathways they control. Nat. Med. 10:789–799.
- (18) Sjöblom T, Jones S, Wood L, Parsons D, Lin J, et al. (2006) The consensus coding sequences of human breast and colorectal cancers. Science 314:268–274.
- (19) Wood LD, Parsons DW, Jones S, Lin J, Sjöblom T, et al. (2007) The genomic landscapes of human breast and colorectal cancers. Science 318:1108–1113.
- (20) Jones S, Chen WD, Parmigiani G, Diehl F, Beerenwinkel N, et al. (2008) Comparative lesion sequencing provides insights into tumor evolution. Proc. Natl. Acad. Sci. U.S.A. 105:4283–4288.
- (21) Jones S, Zhang X, Parsons DW, Lin JCH, Leary RJ, et al. (2008) Core signaling pathways in human pancreatic cancers revealed by global genomic analyses. Science 321:1801–1806.
- (22) Beerenwinkel N, Antal T, Dingli D, Traulsen A, Kinzler KW, et al. (2007) Genetic progression and the waiting time to cancer. PLoS Comput. Biol. 3:e225.
- (23) Gerstung M, Beerenwinkel N (2008) Waiting time models of cancer progression. Mathematical Population Studies, to appear. arXiv:0807.3638
- (24) Weinreich D (2005) The rank ordering of genotypic fitness values predicts genetic constraint on natural selection on landscapes lacking sign epistasis. Genetics 171:1397–1405.
- (25) Moran PAP (1962) The Statistical Processes of Evolutionary Theory. Oxford: Clarendon Press, Oxford.
- (26) Weinreich DM, Watson R, Chao L (2005) Perspective: sign epistasis and genetic constraint on evolutionary trajectories. Evolution 56:1165–1174.
- (27) DePristo MA, Hartl DL, Weinreich DM (2007) Mutational reversions during adaptive protein evolution. Mol. Biol. Evol. 24:1608–1610.
- (28) Karlin S, Taylor HMA (1975) A First Course in Stochastic Processes. London: Academic, 2nd edition edition.
- (29) Ewens WJ (2004) Mathematical Population Genetics. Springer, New York.
- (30) Crow JF, Kimura M (1970) An Introduction to Population GeneticsTheory. Harper and Row, New York, NY.
- (31) Goel N, Richter-Dyn N (1974) Stochastic Models in Biology. Academic Press, New York.
- (32) Antal T, Scheuring I (2006) Fixation of strategies for an evolutionary game in finite populations. Bull Math Biol 68:1923–1944.
- (33) Atwood KC, Schneider KL, Ryan FJ (1951) Periodic selection in escherichia coli. Proc. Natl. Acad. Sci. U.S.A. 37:146–155.
- (34) Gillespie JH (1983) Some properties of finite populations experiencing strong selection and weak mutation. Am Nat. 121:691–708.
- (35) Gillespie JH (2004 (2nd edition)) Population Genetics : A Concise Guide. The Johns Hopkins University Press.
- (36) Weinreich DM, Chao L (2005) Rapid evolutionary escape by large populations from local fitness peaks is likely in nature. Evolution 59:1175–1182.
- (37) Nowak MA, Michor F, Komarova NL, Iwasa Y (2004) Evolutionary dynamics of tumor suppressor gene inactivation. Proc. Natl. Acad. Sci. U.S.A. 101:10635–10638.
- (38) Fisher RA (1930) The Genetical Theory of Natural Selection. Clarendon Press, Oxford.
- (39) Muller HJ (1932) Some genetic aspects of sex. Am Nat 66:118–138.
- (40) Gerrish PJ, Lenski RE (1998) The fate of competing beneficial mutations in a asexual population. Genetica 102/103:127–144.
- (41) Park SC, Krug J (2007) Clonal interference in large populations. Proc. Natl. Acad. Sci. U.S.A. 104:18135–18140.
- (42) Wilke C (2004) The speed of adaptation in large asexual populations. Genetics 167:2045–2053.
- (43) Jain K, Krug J (2007) Deterministic and stochastic regimes of asexual evolution on rugged fitness landscapes. Genetics 175:1275–1288.
- (44) Press WH, Teukolsky SA, Vetterling WT, Flannery BP (2007) Numerical Recipes 3rd Edition: The Art of Scientific Computing. New York: Cambridge University Press.
- (45) Cooper T, Rozen D, Lenski RE (2003) Parallel changes in gene expression after 20,000 generations of evolution in escherichia coli. Proc. Natl. Acad. Sci. U.S.A. 100:1072–1077.
- (46) Lee TH, DSouza LM, Fox GE (1997) Equally parsimonious pathways through an RNA sequence space are not equally likely. J. Mol. Evol. 45:278–284.
- (47) Chao L, McBroom SM (1985) Evolution of transposable elements: an IS10 insertion increases fitness in Escherichia coli. Molecular Biology and Evolution 2:359–369.