The Power of Randomization
Distributed Submodular Maximization on Massive
Datasets111The authors are listed alphabetically.
Abstract
A wide variety of problems in machine learning, including exemplar clustering, document summarization, and sensor placement, can be cast as constrained submodular maximization problems. Unfortunately, the resulting submodular optimization problems are often too large to be solved on a single machine. We develop a simple distributed algorithm that is embarrassingly parallel and it achieves provable, constant factor, worst-case approximation guarantees. In our experiments, we demonstrate its efficiency in large problems with different kinds of constraints with objective values always close to what is achievable in the centralized setting.
1 Introduction
A set function on a ground set is submodular if for any two sets . Several problems of interest can be modeled as maximizing a submodular objective function subject to certain constraints:
where is the family of feasible solutions. Indeed, the general meta-problem of optimizing a constrained submodular function captures a wide variety of problems in machine learning applications, including exemplar clustering, document summarization, sensor placement, image segmentation, maximum entropy sampling, and feature selection problems.
At the same time, in many of these applications, the amount of data that is collected is quite large and it is growing at a very fast pace. For example, the wide deployment of sensors has led to the collection of large amounts of measurements of the physical world. Similarly, medical data and human activity data are being captured and stored at an ever increasing rate and level of detail. This data is often high-dimensional and complex, and it needs to be stored and processed in a distributed fashion.
In these settings, it is apparent that the classical algorithmic approaches are no longer suitable and new algorithmic insights are needed in order to cope with these challenges. The algorithmic challenges stem from the following competing demands imposed by huge datasets: the computations need to process the data that is distributed across several machines using a minimal amount of communication and synchronization across the machines, and at the same time deliver solutions that are competitive with the centralized solution on the entire dataset.
The main question driving the current work is whether these competing goals can be reconciled. More precisely, can we deliver very good approximate solutions with minimal communication overhead? Perhaps surprisingly, the answer is yes; there is a very simple distributed greedy algorithm that is embarrassingly parallel and it achieves provable, constant factor, worst-case approximation guarantees. Our algorithm can be easily implemented in a parallel model of computation such as MapReduce [2].
1.1 Background and Related Work
In the MapReduce model, there are independent machines. Each of the machines has a limited amount of memory available. In our setting, we assume that the data is much larger than any single machine’s memory and so must be distributed across all of the machines. At a high level, a MapReduce computation proceeds in several rounds. In a given round, the data is shuffled among the machines. After the data is distributed, each of the machines performs some computation on the data that is available to it. The output of these computations is either returned as the final result or becomes the input to the next MapReduce round. We emphasize that the machines can only communicate and exchange data during the shuffle phase.
In order to put our contributions in context, we briefly discuss two distributed greedy algorithms that achieve complementary trade-offs in terms of approximation guarantees and communication overhead.
Mirzasoleiman et al. [10] give a distributed algorithm, called GreeDi, for maximizing a monotone submodular function subject to a cardinality constraint. The GreeDi algorithm partitions the data arbitrarily on the machines and on each machine it runs the classical Greedy algorithm to select a feasible subset of the items on that machine. The Greedy solutions on these machines are then placed on a single machine and the Greedy algorithm is used once more to select the final solution. The GreeDi algorithm is very simple and embarrassingly parallel, but its worst-case approximation guarantee222Mirzasoleiman et al. [10] give a family of instances where the approximation achieved is only if the solution picked on each of the machines is the optimal solution for the set of items on the machine. These instances are not hard for the GreeDi algorithm. We show in Sections A and B that the GreeDi algorithm achieves an approximation. is , where is the number of machines and is the cardinality constraint. Despite this, Mirzasoleiman et al. show that the GreeDi algorithm achieves very good approximations for datasets with geometric structure.
Kumar et al. [8] give distributed algorithms for maximizing a monotone submodular function subject to a cardinality or more generally, a matroid constraint. Their algorithm combines the Threshold Greedy algorithm of [4] with a sample and prune strategy. In each round, the algorithm samples a small subset of the elements that fit on a single machine and runs the Threshold Greedy algorithm on the sample in order to obtain a feasible solution. This solution is then used to prune some of the elements in the dataset and reduce the size of the ground set. The Sample&Prune algorithms achieve constant factor approximation guarantees but they incur a higher communication overhead. For a cardinality constraint, the number of rounds is a constant but for more general constraints such as a matroid constraint, the number of rounds is , where is the maximum increase in the objective due to a single element. The maximum increase can be much larger than even the number of elements in the entire dataset, which makes the approach infeasible for massive datasets.
On the negative side, Indyk et al. [5] studied coreset approaches to develop distributed algorithms for finding representative and yet diverse subsets in large collections. While succeeding in several measures, they also showed that their approach provably does not work for -coverage, which is a special case of submodular maximization with a cardinality constraint.
1.2 Our Contribution
In this paper, we show that we can achieve both the communication efficiency of the GreeDi algorithm and a provable, constant factor, approximation guarantee. Our algorithm is in fact the GreeDi algorithm with a very simple and crucial modification: instead of partitioning the data arbitrarily on the machines, we randomly partition the dataset. Our analysis may perhaps provide some theoretical justification for the very good empirical performance of the GreeDi algorithm that was established previously in the extensive experiments of [10]. It also suggests the approach can deliver good performance in much wider settings than originally envisioned.
The GreeDi algorithm was originally studied in the special case of monotone submodular maximization under a cardinality constraint. In contrast, our analysis holds for any hereditary constraint. Specifically, we show that our randomized variant of the GreeDi algorithm achieves a constant factor approximation for any hereditary, constrained problem for which the classical (centralized) Greedy algorithm achieves a constant factor approximation. This is the case not only for cardinality constraints, but also for matroid constraints, knapsack constraints, and -system constraints [6], which generalize the intersection of matroid constraints. Table 4 gives the approximation ratio obtained by the greedy algorithm on a variety of problems, and the corresponding constant factor obtained by our randomized GreeDi algorithm.
| Constraint | monotone approx. | non-monotone approx. | |
|---|---|---|---|
| cardinality | 0.12 | ||
| matroid | |||
| knapsack | |||
| -system |
Additionally, we show that if the greedy algorithm satisfies a slightly stronger technical condition, then our approach gives a constant factor approximation for constrained non-monotone submodular maximization. This is indeed the case for all of the aforementioned specific classes of problems. The resulting approximation ratios for non-monotone maximization problems are given in the last column of Table 4.
1.3 Preliminaries
MapReduce Model. In a MapReduce computation, the data is represented as pairs and it is distributed across machines. The computation proceeds in rounds. In a given, the data is processed in parallel on each of the machines by map tasks that output pairs. These pairs are then shuffled by reduce tasks; each reduce task processes all the pairs with a given key. The output of the reduce tasks either becomes the final output of the MapReduce computation or it serves as the input of the next MapReduce round.
Submodularity. As noted in the introduction, a set function is submodular if, for all sets ,
A useful alternative characterization of submodularity can be formulated in terms of diminishing marginal gains. Specifically, is submodular if and only if:
for all and .
The Lovász extension of a submodular function is given by:
For any submodular function , the Lovász extension satisfies the following properties: (1) for all , (2) is convex, and (3) for any . These three properties immediately give the following simple lemma:
Lemma 1.
Let be a random set, and suppose that (for ). Then, .
Proof.
We have:
where the first equality follows from property (1), the first inequality from property (2), and the final inequality from property (3). ∎
Hereditary Constraints. Our results hold quite generally for any problem which can be formulated in terms of a hereditary constraint. Formally, we consider the problem
| (1) |
where is a submodular function and is a family of feasible subsets of . We require that be hereditary in the sense that if some set is in , then so are all of its subsets. Examples of common hereditary families include cardinality constraints (), matroid constraints ( corresponds to the collection independent sets of the matroid), knapsack constraints (), as well as arbitrary combinations of such constraints. Given some constraint , we shall also consider restricted instances in which we are presented only with a subset , and must find a set with that maximizes . We say that an algorithm is an -approximation for maximizing a submodular function subject to a hereditary constraint if, for any submodular function and any subset the algorithm produces a solution with , satisfying , where is any feasible subset of .
2 The Standard Greedy Algorithm
Before describing our general algorithm, let us recall the standard greedy algorithm, Greedy, shown in Algorithm 1. The algorithm takes as input , where is a set of elements, is a hereditary constraint, represented as a membership oracle for , and is a non-negative submodular function, represented as a value oracle. Given , Greedy iteratively constructs a solution by choosing at each step the element maximizing the marginal increase of . For some , we let denote the set produced by the greedy algorithm that considers only elements from .
The greedy algorithm satisfies the following property:
Lemma 2.
Let and be two disjoint subsets of . Suppose that, for each element , we have . Then .
Proof.
Suppose for contradiction that . We first note that, if , then ; this follows from the fact that each iteration of the Greedy algorithm chooses the element with the highest marginal value whose addition to the current solution maintains feasibility for . Therefore, if , the former solution contains an element of . Let be the first element of that is selected by Greedy on the input . Then Greedy will also select on the input , which contradicts the fact that . ∎
3 A Randomized, Distributed Greedy Algorithm for Monotone Submodular Maximization
Algorithm. We now describe our general, randomized distributed algorithm, RandGreeDi, shown in Algorithm 2. Suppose we have machines. Our algorithm runs in two rounds. In the first round, we randomly distribute the elements of the ground set to the machines, assigning each element to a machine chosen independently and uniformly at random. On each machine , we execute to select a feasible subset of the elements on that machine. In the second round, we place all of these selected subsets on a single machine, and run some algorithm Alg on this machine in order to select a final solution . We return whichever is better: the final solution or the best solution amongst all the from the first phase.
Analysis. We devote the rest of this section to the analysis of the RandGreeDi algorithm. Fix , where is a hereditary constraint, and is any non-negative, monotone submodular function. Suppose that Greedy is an -approximation and Alg is a -approximation for the associated constrained monotone submodular maximization problem of the form (1). Let and suppose that is a feasible set maximizing .
Let denote the distribution over random subsets of where each element is included independently with probability . Let be the following vector. For each element , we have
Our main theorem follows from the next two lemmas, which characterize the quality of the best solution from the first round and that of the solution from the second round, respectively. Recall that is the Lovász extension of .
Lemma 3.
For each machine ,
Proof.
Consider machine . Let denote the set of elements assigned to machine in the first round. Let . We make the following key observations.
Lemma 4.
Proof.
Recall that . Since and is hereditary, . Since Alg is a -approximation, we have
| (2) |
Consider an element . For each machine , we have
The first equality follows from the fact that is included in if and only if it is included in . The second equality follows from the fact that the distribution of is identical to . The third equality follows from the fact that the distribution of conditioned on is identical to the distribution of where . Therefore
| (3) |
By combining (2), (3), and Lemma 1, we obtain
∎
Theorem 5.
Suppose that Greedy is an -approximation algorithm and Alg is a -approximation algorithm for maximizing a monotone submodular function subject to a hereditary constraint . Then RandGreeDi is (in expectation) an -approximation algorithm for the same problem.
Proof.
Let , be the set of elements on the last machine, and be the solution produced on the last machine. Then, the output produced by RandGreeDi satisfies and . Thus, from Lemmas 3 and 4 we have:
| (4) | ||||
| (5) |
By combining (4) and (5), we obtain
In the second inequality, we have used the fact that is convex and for any constant . ∎
If we use the standard greedy algorithm for Alg, we obtain the following simplified corollary of Theorem 5.
Corollary 6.
Suppose that Greedy is an -approximation algorithm for maximizing a monotone submodular function, and use Greedy as the algorithm Alg in RandGreeDi. Then, the resulting algorithm is (in expectation) an -approximation algorithm for the same problem.
4 Non-Monotone Submodular Functions
We consider the problem of maximizing a non-monotone submodular function subject to a hereditary constraint. Our approach is a slight modification of the randomized, distributed greedy algorithm described in Section 3, and it builds on the work of [4]. Again, we show how to combine the standard Greedy algorithm, together with any algorithm Alg for the non-monotone case in order to obtain a randomized, distributed algorithm for the non-monotone submodular maximization.
Algorithm. Our modified algorithm, NMRandGreeDi, works as follows. As in the monotone case, in the first round we distribute the elements of uniformly at random amongst the machines. Then, we run the standard greedy algorithm twice to obtain two disjoint solutions and on each machine. Specifically, each machine first runs Greedy on to obtain a solution , then runs Greedy on to obtain a disjoint solution . In the second round, both of these solutions are sent to a single machine, which runs Alg on to produce a solution . The best solution amongst and all of the solutions and is then returned.
Analysis. We devote the rest of this section to the analysis of the algorithm. In the following, we assume that we are working with an instance of non-negative, non-monotone submodular maximization for which the Greedy algorithm has the following property:
| () |
The standard analysis of the Greedy algorithm shows that () is satisfied with constant for hereditary constraints such as matroids, knapsacks, and -systems (see Table 4).
The analysis is similar to the approach from the previous section. We define as before. We modify the definition of the vector as follows. For each element , we have
Proof.
Consider machine and let be the set of elements assigned to machine in the first round. Let
Note that, since and is hereditary, we have .
It follows from Lemma 2 that
| (6) | ||||
| (7) |
By combining the equations above with the greedy property (), we obtain
| (8) | ||||
| (9) |
Now we observe that
| ( is submodular) | |||||
| () | |||||
| ( is non-negative) | (10) |
By combining (8), (9), and (10), we obtain
| (11) |
Since the distribution of is the same as , for each element , we have
| (12) |
By combining (11), (12), and Lemma 1, we obtain
| (By (11)) | ||||
| (By (12) and Lemma 1) |
∎
Lemma 8.
Proof.
Recall that , , and . Since and is hereditary, . Since Alg is a -approximation, we have
| (13) |
Consider an element . For each machine , we have
The first equality above follows from the fact that is included in iff is included in either or . The second equality follows from the fact that the distribution of is the same as . The third equality follows from the fact that the distribution of conditioned on is identical to the distribution of where . Therefore
| (14) |
By combining (13), (14), and Lemma 1, we obtain
∎
We can now combine Lemmas 8 and 7 to obtain our main result for non-monotone submodular maximization.
Theorem 9.
Proof.
Let , , and be the set of elements on the last machine, and be the solution produced on the last machine. Then, the output produced by RandGreeDi satisfies and . Thus, from Lemmas 7 and 8 we have:
| (15) | ||||
| (16) |
By combining (15) and (16), we obtain
In the second inequality, we have used the fact that is convex and for any constant . ∎
We remark that one can use the following approach on the last machine [4]. As in the first round, we run Greedy twice to obtain two solutions and . Additionally, we select a subset using an unconstrained submodular maximization algorithm on , such as the Double Greedy algorithm of [1], which is a -approximation. The final solution is the best solution among . If Greedy satisfies property , then it follows from the analysis of [4] that the resulting solution satisfies . This gives us the following corollary of Theorem 9:
Corollary 10.
Consider the problem of maximizing a submodular function subject to some hereditary constraint and suppose that Greedy satisfies () for this problem. Let Alg be the algorithm described above that uses Greedy twice and Double Greedy. Then NMRandGreeDi achieves (in expectation) an -approximation for the same problem.
5 Experiments
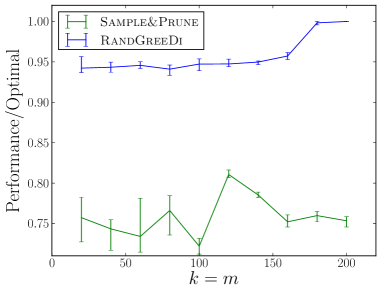
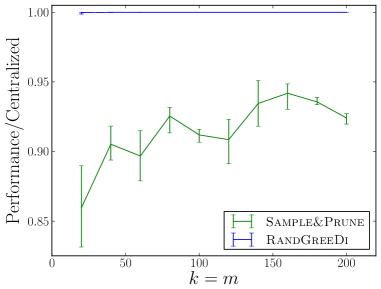
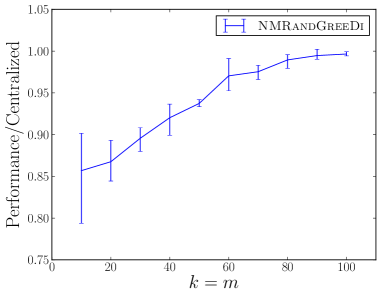
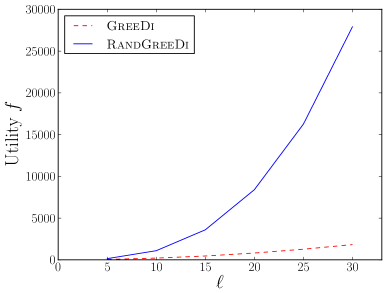
We experimentally evaluate and compare the following distributed algorithms for maximizing a monotone submodular function subject to a cardinality constraint: the RandGreeDi algorithm described in Section 3, the deterministic GreeDi algorithm of [10], and the Sample&Prune algorithm of [8]. We run these algorithms in several scenarios and we evaluate their performance relative to the centralized Greedy solution on the entire dataset.
Exemplar based clustering. Our experimental setup is similar to that of [10]. Our goal is to find a representative set of objects from a dataset by solving a -medoid problem [7] that aims to minimize the sum of pairwise dissimilarities between the chosen objects and the entire dataset. Let denote the set of objects in the dataset and let be a dissimilarity function; we assume that is symmetric, that is, for each pair . Let be the function such that for each set . We can turn the problem of minimizing into the problem of maximizing a monotone submodular function by introducing an auxiliary element and by defining for each set .
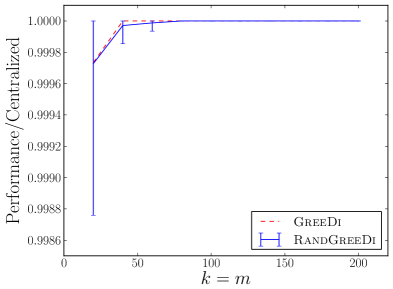
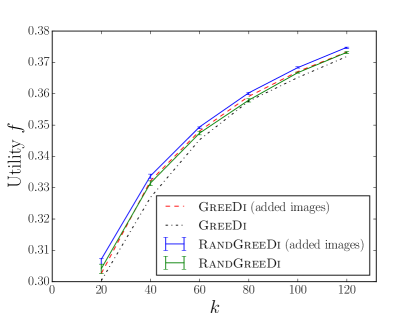
Tiny Images experiments: In our experiments, we used a subset of the Tiny Images dataset consisting of RGB images [12], each represented as dimensional vector. We subtracted from each vector the mean value and normalized the result, to obtain a collection of -dimensional vectors of unit norm. We considered the distance function for every pair of vectors. We used the zero vector as the auxiliary element in the definition of .
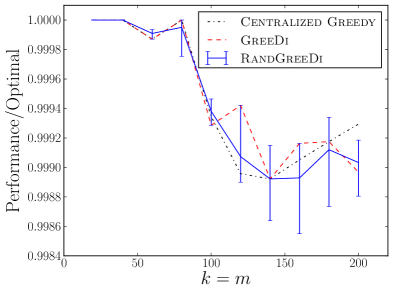
In our smaller experiments, we used 10,000 tiny images, and compared the utility of each algorithm to that of the centralized greedy. The results are summarized in Figures 1(c) and 1(f).
In our large scale experiments, we used one million tiny images, and machines. In the first round of the distributed algorithm, each machine ran the Greedy algorithm to maximize a restricted objective function , which is based on the average dissimilarity taken over only those images assigned to that machine. Similarly, in the second round, the final machine maximized an objective function based on the total dissimilarity of all those images it received . We also considered a variant similar to that described by [10], in which 10,000 additional random images from the original dataset were added to the final machine. The results are summarized in Figure 1(i).
Remark on the function evaluation. In decomposable cases such as exemplar clustering, the function is a sum of distances over all points in the dataset. By concentration results such as Chernoff bounds, the sum can be approximated additively with high probability by sampling a few points and using the (scaled) empirical sum. The random subset each machine receives can readily serve as the samples for the above approximation. Thus the random partition is useful for for evaluating the function in a distributed fashion, in addition to its algorithmic benefits.
Maximum Coverage experiments. We ran several experiments using instances of the Maximum Coverage problem. In the Maximum Coverage problem, we are given a collection of subsets of a ground set and an integer , and the goal is to select of the subsets in that cover as many elements as possible.
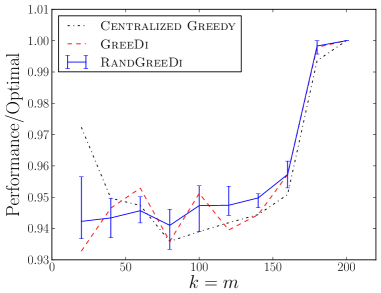
Kosarak and accidents datasets555The data is available at http://fimi.ua.ac.be/data/.: We evaluated and compared the algorithms on the datasets used by Kumar et al. [8]. In both cases, we computed the optimal centralized solution using CPLEX, and calculated the actual performance ratio attained by the algorithms. The results are summarized in Figures 1(a), 1(d), 1(b), 1(e).
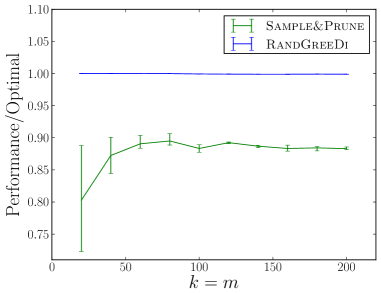
Synthetic hard instances: We generated a synthetic dataset with hard instances for the deterministic GreeDi. We describe the instances in Section B. We ran the GreeDi algorithm with a worst-case partition of the data. The results are summarized in Figure 1(h).
Finding diverse yet relevant items. We evaluated our NMRandGreeDi algorithm on the following instance of non-monotone submodular maximization subject to a cardinality constraint. We used the objective function of Lin and Bilmes [9]: , where is a redundancy parameter and is a similarity matrix. We generated an similarity matrix with random entries and we set . The results are summarized in Figure 1(g).
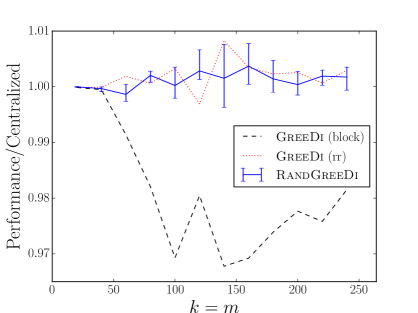
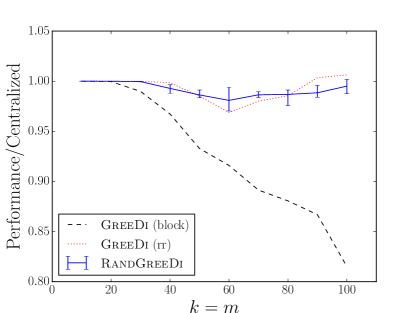
Matroid constraints. In order to evaluate our algorithm on a matroid constraint, we considered the following variant of maximum coverage: we are given a space containing several demand points and facilities (e.g. wireless access points or sensors). Each facility can operate in one of modes, each with a distinct coverage profile. The goal is to find a subset of at most facilities to activate, along with a single mode for each activated facility, so that the total number of demand points covered is maximized. In our experiment, we placed 250,000 demand points in a grid in the unit square, together with a grid of facilities. We modeled coverage profiles as ellipses centered at each facility with major axes of length , minor axes of length rotated by where and are chosen randomly for each ellipse. We performed two series of experiments. In the first, there were facilities, each with coverage profiles, while in the second there were facilities, each with coverage profiles.
The resulting problem instances were represented as ground set comprising a list of ellipses, each with a designated facility, together with a partition matroid constraint ensuring that at most one ellipse per facility was chosen. As in our large-scale exemplar-based clustering experiments, we considered 3 approaches for assigning ellipses to machines: assigning consecutive blocks of ellipses to each machine, assigning ellipses to machines in round-robin fashion, and assigning ellipses to machines uniformly at random. The results are summarized in Figures 1(j) and 1(k); in these plots, GreeDi(rr) and GreeDi(block) denote the results of GreeDi when we assign the ellipses to machines deterministically in a round-robin fashion and in consecutive blocks, respectively.
In general, our experiments show that random and round robin are the best allocation strategies. One explanation for this phenomenon is that both of these strategies ensure that each machine receives a few elements from several distinct partitions in the first round. This allows each machine to return a solution containing several elements.
Acknowledgements. We thank Moran Feldman for suggesting a modification to our original analysis that led to the simpler and stronger analysis included in this version of the paper.
References
- [1] Niv Buchbinder, Moran Feldman, Joseph Naor, and Roy Schwartz. A tight linear time (1/2)-approximation for unconstrained submodular maximization. In Foundations of Computer Science (FOCS), 2012 IEEE 53rd Annual Symposium on, pages 649–658. IEEE, 2012.
- [2] Jeffrey Dean and Sanjay Ghemawat. Mapreduce: Simplified data processing on large clusters. Commun. ACM, 51(1):107–113, January 2008.
- [3] M L Fisher, G L Nemhauser, and L A Wolsey. An analysis of approximations for maximizing submodular set functions—II. Mathematical Programming Studies, 8:73–87, 1978.
- [4] Anupam Gupta, Aaron Roth, Grant Schoenebeck, and Kunal Talwar. Constrained non-monotone submodular maximization: Offline and secretary algorithms. In Internet and Network Economics, pages 246–257. Springer, 2010.
- [5] Piotr Indyk, Sepideh Mahabadi, Mohammad Mahdian, and Vahab S Mirrokni. Composable core-sets for diversity and coverage maximization. In Proceedings of the 33rd ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, pages 100–108. ACM, 2014.
- [6] T A Jenkyns. The efficacy of the "greedy" algorithm. In Proceedings of the 7th Southeastern Conference on Combinatorics, Graph Theory, and Computing, pages 341–350. Utilitas Mathematica, 1976.
- [7] Leonard Kaufman and Peter J Rousseeuw. Finding groups in data: an introduction to cluster analysis, volume 344. John Wiley & Sons, 2009.
- [8] Ravi Kumar, Benjamin Moseley, Sergei Vassilvitskii, and Andrea Vattani. Fast greedy algorithms in mapreduce and streaming. In Proceedings of the twenty-fifth annual ACM symposium on Parallelism in algorithms and architectures, pages 1–10. ACM, 2013.
- [9] Hui Lin and Jeff A. Bilmes. How to select a good training-data subset for transcription: Submodular active selection for sequences. In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH), Brighton, UK, September 2009.
- [10] Baharan Mirzasoleiman, Amin Karbasi, Rik Sarkar, and Andreas Krause. Distributed submodular maximization: Identifying representative elements in massive data. In Advances in Neural Information Processing Systems, pages 2049–2057, 2013.
- [11] George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. An analysis of approximations for maximizing submodular set functions—I. Mathematical Programming, 14(1):265–294, 1978.
- [12] Antonio Torralba, Robert Fergus, and William T Freeman. 80 million tiny images: A large data set for nonparametric object and scene recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 30(11):1958–1970, 2008.
- [13] Laurence A. Wolsey. Maximising real-valued submodular functions: Primal and dual heuristics for location problems. Mathematics of Operations Research, 7(3):pp. 410–425, 1982.
Appendix A Improved Deterministic GreeDI analysis
Let be an arbitrary collection of elements from , and let be the set of machines that have some element of placed on them. For each let be the set of elements of placed on machine , and let (note that ). Similarly, let be the set of elements returned by the greedy algorithm on machine . Let denote the element chosen in the th round of the greedy algorithm on machine , and let denote the set of all elements chosen in rounds through . Finally, let , and .
We consider the marginal values:
for each . Note that because each element was selected by in the th round of the greedy algorithm on machine , we must have
| (20) |
for all and . Moreover, the sequence is non-increasing for all . Finally, define and for all . We are now ready to prove our main claim.
Theorem 11.
Let be a set of elements from that maximizes . Then,
Proof.
For every we have
| (21) |
where the first inequality follows from monotonicity of , and the last two from submodularity of .
Let be the smallest value such that:
| (22) |
Note that some such value must must exist, since for , both sides are equal to zero. We now derive a bound on each term on the right of (A).
Lemma 12.
.
Proof.
Lemma 13.
.
Proof.
We consider two cases:
Case: .
We have , and by (20) we have for every machine . Therefore:
Case: .
By submodularity of and (20), we have
Moreover, since the sequence is nonincreasing for all ,
Therefore,
Thus, in both cases, we have as required. ∎ Applying Lemmas 12 and 13 to the right of (A), we obtain
completing the proof of Theorem 11. ∎
Corollary 14.
The distributed greedy algorithm gives a approximation for maximizing a monotone submodular function subject to a cardinality constraint , regardless of how the elements are distributed.
Appendix B A tight example for Deterministic GreeDI
Here we give a family of examples that show that the GreeDI algorithm of Mirzasoleiman et al. cannot achieve an approximation better than .
Consider the following instance of Max -Coverage. We have machines and . Let be a ground set with elements, . We define a coverage function on a collection of subsets of as follows. In the following, we define how the sets of are partitioned on the machines.
On machine , we have the following sets from : , , …, . We also pad the machine with copies of the empty set.
On machine , we have the following sets. There is a single set from , namely . Additionally, we have sets that are designed to fool the greedy algorithm; the -th such set is . As before, we pad the machine with copies of the empty set.
The optimal solution is , and it has a total coverage of .
On the first machine, Greedy picks the sets from and copies of the empty set. On each machine , Greedy first picks the sets , since each of them has marginal value greater than . Once Greedy has picked all of the ’s, the marginal value of becomes zero and we may assume that Greedy always picks the empty sets instead of .
Now consider the final round of the algorithm where we run Greedy on the union of the solutions from each of the machines. In this round, regardless of the algorithm, the sets picked can only cover (using the set ) and one additional item per set for a total of elements. Thus the total coverage of the final solution is at most . Hence the approximation is at most .