The strong convergence phenomenon
Abstract.
In a seminal 2005 paper, Haagerup and Thorbjørnsen discovered that the norm of any noncommutative polynomial of independent complex Gaussian random matrices converges to that of a limiting family of operators that arises from Voiculescu’s free probability theory. In recent years, new methods have made it possible to establish such strong convergence properties in much more general situations, and to obtain even more powerful quantitative forms of the strong convergence phenomenon. These, in turn, have led to a number of spectacular applications to long-standing open problems on random graphs, hyperbolic surfaces, and operator algebras, and have provided flexible new tools that enable the study of random matrices in unexpected generality. This survey aims to provide an introduction to this circle of ideas.
2010 Mathematics Subject Classification:
60B20; 15B52; 46L53; 46L541. Introduction
The aim of this survey is to discuss recent developments surrounding the following phenomenon, which has played a central role in a series of breakthroughs in the study of random graphs, hyperbolic surfaces, and operator algebras.
Definition 1.1.
Let be a sequence of -tuples of random matrices of increasing dimension, and let be an -tuple of bounded operators on a Hilbert space. Then is said to converge strongly to if
for every and .
Here we recall that a noncommutative polynomial with matrix coefficients of degree is a formal expression
where are complex matrices. Such a polynomial defines a bounded operator whenever bounded operators are substituted for the free variables . When , this reduces to the classical notion of a noncommutative polynomial (we will then write ).
The significance of the strong convergence phenomenon may not be immediately obvious when it is encountered for the first time. Let us therefore begin with a very brief discussion of its origins.
The modern study of the spectral theory of random matrices arose from the work of physicists, especially that of Wigner and Dyson in the 1950s and 60s [129]. Random matrices arise here as generic models for real physical systems that are too complicated to be understood in detail, such as the energy level structure of complex nuclei. It is believed that universal features of such systems are captured by random matrix models that are chosen essentially uniformly within the appropriate symmetry class. Such questions have led to numerous developments in probability and mathematical physics, and the spectra of such models are now understood in stunning detail down to microscopic scales (see, e.g., [46]).
In contrast to these physically motivated models, random matrices that arise in other areas of mathematics often possess a much less regular structure. One way to build complex models is to consider arbitrary noncommutative polynomials of independent random matrices drawn from simple random matrix ensembles. It was shown in the seminal work of Voiculescu [126] that the limiting empirical eigenvalue distribution of such matrices can be described in terms of a family of limiting operators obtained by a free product construction. This is a fundamentally new perspective: while traditional random matrix methods are largely based on asymptotic explicit expressions or self-consistent equations satisfied by certain spectral statistics, Voiculescu’s theory provides us with genuine limiting objects whose spectral statistics are, in many cases, amenable to explicit computations. The interplay between random matrices and their limiting objects has proved to be of central importance, and will play a recurring role in the sequel.
While Voiculescu’s theory is extremely useful, it yields rather weak information in that it can only describe the asympotics of the trace of polynomials of random matrices. It was a major breakthrough when Haagerup and Thorbjørnsen [60] showed, for complex Gaussian (GUE) random matrices, that also the norm of arbitrary polynomials converges to that of the corresponding limiting object. This much more powerful property, which was the first instance of strong convergence, opened the door to many subsequent developments.
The works of Voiculescu and Haagerup–Thorbjørnsen were directly motivated by applications to the theory of operator algebras. The fact that polynomials of a family of operators can be approximated by matrices places strong constraints on the operator (von Neumann- or -)algebras generated by this family: roughly speaking, it ensures that such algebras are “approximately finite-dimensional” in a certain sense. These properties have led to the resolution of important open problems in the theory of operator algebras which do not a priori have anything to do with random matrices; see, e.g., [128, 99, 60].
The interplay between operator algebras and random matrices continues to be a rich source of problems in both areas; an influential recent example is the work of Hayes [65] on the Peterson–Thom conjecture (cf. section 5.4). In recent years, however, the notion of strong convergence has led to spectacular new applications in several other areas of mathematics. Broadly speaking, the importance of the strong convergence phenomenon is twofold.
-
Noncommutative polynomials are highly expressive: many complex structures can be encoded in terms of spectral properties of noncommutative polynomials.
-
Norm convergence is an extremely strong property, which provides access to challenging features of complex models.
Furthermore, new mathematical methods have made it possible to establish novel quantitative forms of strong convergence, which enable the treatment of even more general random matrix models that were previously out of reach.
We will presently highlight a number of themes that illustrate recent applications and developments surrounding strong convergence. The remainder of this survey is devoted to a more detailed introduction to this circle of ideas.
It should be emphasized at the outset that while I have aimed to give a general introduction to the strong convergence phenomenon and related topics, this survey is selectively focused on recent developments that are closest to my own interests, and is by no means comprehensive or complete. The interested reader may find complementary perspectives in surveys of Magee [88] and Collins [39], and is warmly encouraged to further explore the research literature on this subject.
1.1. Optimal spectral gaps
Let be a -regular graph with vertices. By the Perron-Frobenius theorem, its adjacency matrix has largest eigenvalue with eigenvector (the vector all of whose entries are one). The remaining eigenvalues are bounded by
The smaller this quantity, the faster does a random walk on mix. The following classical lemma yields a lower bound that holds for any sequence of -regular graphs. It provides a speed limit on how fast random walks can mix.
Lemma 1.2 (Alon–Boppana).
For any -regular graphs with vertices,
Given a universal lower bound on the nontrivial eigenvalues, the obvious question is whether there exist graphs that attain this bound. Such graphs have the largest possible spectral gap. One may expect that such heavenly graphs must be very special, and indeed the first examples of such graphs were carefully constructed using deep number-theoretic ideas by Lubotzky–Phillips–Sarnak [87] and Margulis [97]. It may therefore seem surprising that this property does not turn out to be all that special at all: random graphs have an optimal spectral gap [50].111Here we gloss over an important distinction between the explicit and random constructions: the former yields the so-called Ramanujan property , while the latter yields only which is the natural converse to Lemma 1.2 (cf. section 6.5).
Theorem 1.3 (Friedman).
For a random -regular graph on vertices,
We now explain that Theorem 1.3 may be viewed as a very special instance of strong convergence. This viewpoint will open the door to establishing optimal spectral gaps in much more general situations.
Let us begin by recalling that the proof of Lemma 1.2 is based on the simple observation that for any graph , the number of closed walks with a given length and starting vertex is lower bounded by the number of such walks in its universal cover . When is -regular, its universal cover is the infinite -regular tree. From this, it is not difficult to deduce that the maximum nontrivial eigenvalue of a -regular graph is asymptotically lower bounded by the spectral radius of the infinite -regular tree, which is [71, §5.2.2].
Theorem 1.3 therefore states, in essence, that the support of the nontrivial spectrum of a random -regular graph behaves as that of the infinite -regular tree. To make the connection more explicit, it is instructive to construct both the random graph and infinite tree in a parallel manner. For simplicity, we assume is even (the construction can be modified to the odd case as well).
Given a permutation , we can define edges between vertices by connecting each vertex to its neighbors and . This defines a -regular graph. To define a -regular graph, we repeat this process with permutations. If the permutations are chosen independently and uniformly at random from , we obtain a random -regular graph with adjacency matrix
where are i.i.d. random permutation matrices of dimension .222This is the permutation model of random graphs; see [50, p. 3] for its relation to other models.
To construct the infinite -regular tree in a parallel manner, we identify the vertices of the tree with the free group with free generators . Each vertex is then connected to its neighbors and for . This defines a -regular tree with adjacency matrix
where is defined by the left-regular representation , i.e., where is the coordinate vector of .
These models are illustrated in Figure 1.1 for , where the edges are colored according to their generator; e.g., and are the adjacency matrices of the red edges in the left and right figures, respectively.
In these terms, Theorem 1.3 states that
in probability. This is precisely the kind of convergence described by Definition 1.1, but only for one very special polynomial
Making a leap of faith, we can now ask whether the same conclusion might even hold for every noncommutative polynomial . That this is indeed the case is a remarkable result of Bordenave and Collins [19].
Theorem 1.4 (Bordenave–Collins).
Let and be defined as above. Then converges strongly to , that is,
for every and .333The reason that we must restrict to is elementary: the matrices have a Perron-Frobenius eigenvector , but the operators do not as (an infinite vector of ones is not in ). Thus we must remove the Perron-Frobenius eigenvector to achieve strong convergence.
Theorem 1.4 is a powerful tool because many problems can be encoded as special cases of this theorem by a suitable choice of . To illustrate this, let us revisit the optimal spectral gap phenomenon in a broader context.
In general terms, the optimal spectral gap phenomenon is the following. The spectrum of various kinds of geometric objects admits a universal bound in terms of that of their universal covering space. The question is then whether there exist such objects which meet this bound. In particular, we may ask whether that is the case for random constructions. Lemma 1.2 and Theorem 1.3 establish this for regular graphs. An analogous picture in other situations is much more recent:
-
It was shown by Greenberg [71, Theorem 6.6] that for any sequence of finite graphs with diverging number of vertices that have the same universal cover , the maximal nontrivial eigenvalue of is asymptotically lower bounded by the spectral radius of . On the other hand, given any (not necessarily regular) finite graph , there is a natural construction of random lifts with the same universal cover [71, §6.1]. It was shown by Bordenave and Collins [19] that an optimal spectral gap phenomenon holds for random lifts of any graph .
-
Any hyperbolic surface has the hyperbolic plane as its universal cover. Huber [77] and Cheng [35] showed that for any sequence of closed hyperbolic surfaces with diverging diameter, the first nontrivial eigenvalue of the Laplacian is upper bounded by the bottom of the spectrum of . Whether this bound can be attained was an old question of Buser [29]. An affirmative answer was obtained by Hide and Magee [69] by showing that an optimal spectral gap phenomenon holds for random covering spaces of hyperbolic surfaces.
The key ingredient in these breakthroughs is that the relevant spectral properties can be encoded as special instances of Theorem 1.4. How this is accomplished will be sketched in sections 5.1 and 5.2. In section 5.5, we will sketch another remarkable application due to Song [122] to minimal surfaces.
Another series of developments surrrounding optimal spectral gaps arises from a different perspective on Theorem 1.4. The map that assigns to each permutation the restriction of the associated permutation matrix to defines an irreducible representation of the symmetric group of dimension called the standard representation. Thus
where are independent uniformly distributed elements of . One may ask whether strong convergence remains valid if is replaced by other representations of . This and related optimal spectral gap phenomena in representation-theoretic settings are the subject of long-standing questions and conjectures; see, e.g., [119] and the references therein.
Recent advances in the study of strong convergence have led to major progress in the understanding of such questions [21, 32, 33, 90, 30]. One of the most striking results in this direction to date is the recent work of Cassidy [30], who shows that strong convergence for the symmetric group holds uniformly for all nontrivial irreducible representations of of dimension up to .444For comparison, all irreducible representations of have dimension . This makes it possible, for example, to study natural models of random regular graphs that achieve optimal spectral gaps using far less randomness than is required by Theorem 1.4. We will discuss these results in more detail in section 5.3.
1.2. Intrinsic freeness
We now turn to an entirely different development surrounding strong convergence that has enabled a sharp understanding of a very large class of random matrices in unexpected generality.
To set the stage for this development, let us begin by recalling the original strong convergence result of Haagerup and Thorbjørnsen [60]. Let be independent GUE matrices, that is, self-adjoint complex Gaussian random matrices whose off-diagonal elements have variance and whose distribution is invariant under unitary conjugation. The associated limiting object is a free semicircular family (cf. section 4.1). Define the random matrix
and the limiting operator
where are self-adjoint matrix coefficients.
Theorem 1.5 (Haagerup–Thorbjørnsen).
For and defined as above,555Here denotes the spectrum of , and we recall that the Hausdorff distance between sets is defined as .
It is a nontrivial fact, known as the linearization trick, that Theorem 1.5 implies that converges strongly to ; see section 2.5. This conclusion was used by Haagerup and Thorbjørnsen to prove an old conjecture that the invariant of the reduced -algebra of any countable free group with at least two generators is not a group. For our present purposes, however, the above formulation of Theorem 1.5 will be the most natural.
The result of Haagerup–Thorbjørnsen may be viewed as a strong incarnation of Voiculescu’s asymptotic freeness principle [126]. The limiting operators arise from a free product construction and are thus algebraically free (in fact, they are freely independent in the sense of Voiculescu). This makes it possible to compute the spectral statistics of by means of closed form equations, cf. section 4.1. The explanation for Theorem 1.5 provided by the asymptotic freeness principle is that since the random matrices have independent uniformly random eigenbases (due to their unitary invariance), they become increasingly noncommutative as which leads them to behave freely in the limit.
From the perspective of applications, however, the most interesting case of this model is the special case , that is, the random matrix defined by
where are independent standard Gaussians. Indeed, any self-adjoint random matrix with jointly Gaussian entries (with arbitrary mean and covariance) can be expressed in this form. This model therefore captures almost arbitrarily structured random matrices: if one could understand random matrices at this level of generality, one would capture in one fell swoop a huge class of models that arise in applications. However, since the matrices commute, the asymptotic freeness principle has no bearing on such matrices, and there is no reason to expect that has any significance for the behavior of .
It is therefore rather surprising that the spectral properties of arbitrarily structured Gaussian random matrices are nonetheless captured by those of in great generality. This phenomenon, developed in joint works of the author with Bandeira, Boedihardjo, Cipolloni, and Schröder [10, 11], is captured by the following counterpart of Theorem 1.5 (stated here in simplified form).
Theorem 1.6 (Intrinsic freeness).
For and be defined as above, we have
for all . Here is a universal constant,
and is the covariance matrix of the entries of .
Remark 1.7.
While Theorem 1.6 captures the edges of the spectrum of , analogous results for other spectral parameters (such as the spectral distribution) may be found in [10, 11]. These results are further extended to a large class of non-Gaussian random matrices in joint work of the author with Brailovskaya [23].
Theorem 1.6 states that the spectrum of behaves like that of as soon at the parameter is small. Unlike for the model , where noncommutativity is overtly introduced by means of unitarily invariant matrices, the mechanism for to behave as can only arise from the structure of the matrix coefficients . We call this phenomenon intrinsic freeness. It should not be obvious at this point why the parameter captures intrinsic freeness; the origin of this phenomenon (which was inspired in part by [60, 125]) and the mechanism that gives rise to it will be discussed in section 4.
In practice, Theorem 1.6 proves to be a powerful result as is indeed small in numerous applications, while the result applies without any structural assumptions on the random matrix . This is especially useful in questions of applied mathematics, where messy random matrices are par for the course. Several such applications are illustrated, for example, in [11, §3].
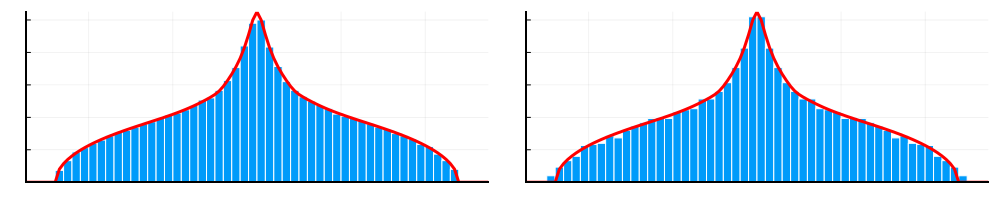
Another consequence of Theorem 1.6 is that the Haagerup–Thorbjørnsen strong convergence result extends to far more general situations. We only give one example for sake of illustration. A -sparse Wigner matrix is a self-adjoint real random matrix so that each row has exactly nonzero entries, each of which is an independent (modulo symmetry ) centered Gaussian with variance . In this case . Theorem 1.6 shows that if are independent -sparse Wigner matrices of dimension , then converges strongly to as soon as regardless of the choice of sparsity pattern. Unlike GUE matrices, such models need not possess any invariance and can have localized eigenbases. Even though this appears to dramatically violate the classical intuition behind asymptotic freeness, this model exhibits precisely the same strong convergence property as GUE (see Figure 1.2).
1.3. New methods in random matrix theory
The development of strong convergence has gone hand in hand with the discovery of new methods in random matrix theory. For example, Haagerup and Thorbjørnsen [60] pioneered the use of self-adjoint linerization (section 2.5), which enabled them to make effective use of Schwinger-Dyson equations to capture general polynomials (their work was extended to various classical random matrix models in [121, 7, 41]); while Bordenave and Collins [19, 21, 20] developed operator-valued nonbacktracking methods in order to efficiently apply the moment method to strong convergence.
More recently, however, two new methods for proving strong convergence have proved to be especially powerful, and have opened the door both to obtaining strong quantitative results and to achieving strong convergence in new situations that were previously out of reach. In contrast to previous approaches, these methods are rather different in spirit to those used in classical random matrix theory.
1.3.1. The interpolation method
The general principle captured by strong convergence (and by the earlier work of Voiculescu) is that the spectral statistics of families of random matrices behave of those of a family of limiting operators. In classical approaches to random matrix theory, however, the limiting operators do not appear directly: rather, one shows that the spectral statistics of these operators admit explicit expressions or closed-form equations, and that the random matrices obey these same expressions or equations approximately.
In contrast, the existence of limiting operators suggests that these may be exploited explicitly as a method of proof in random matrix theory. This is the basic idea behind the interpolation method, which was developed independently by Collins, Guionnet, and Parraud [40] to obtain a quantitative form of the Haagerup–Thorbjørnsen theorem, and by Bandeira, Boedihardjo, and the author [10] to prove the intrinsic freeness principle (Theorem 1.6).
Roughly speaking, the method works as follows. We aim to show that the spectral statistics of a random matrix behave as those of a limiting operator . To this end, one introduces a certain continuous interpolation between these objects, so that and . To bound the discrepancy between the spectral statistics of and , one can then estimate
where denotes the limiting trace (see section 2.1). If a good bound can be obtained for sufficiently general (we will choose for and ), convergence of the norm will follow as a consequence.
As stated above, this procedure does not make much sense. Indeed (a random matrix) and (a deterministic operator) do not even live in the same space, so it is unclear what it means to interpolate between them. Moreover, the general approach outlined above does not in itself explain why the derivative along the interpolation should be small: the latter is the key part of the argument that requires one to understand the mechanism that gives rise to free behavior. Both these issues will be explained in more detail in section 4, where we will sketch the main ideas behind the proof of Theorem 1.6.
1.3.2. The polynomial method
We now describe an entirely different method, developed in the recent work of Chen, Garza-Vargas, Tropp, and the author [32], which has led to a series of new developments.
Consider a sequence of self-adjoint random matrices with limiting operator ; one may keep in mind the example and in the context of Theorem 1.4. In many natural models, it turns out to be the case that spectral statistics of polynomial test functions can be expressed as
where is a rational function whose degree is controlled by the degree of the polynomial . Whenever this is the case, the fact that
is generally an immediate consequence. However, such soft information does not in itself suffice to reason about the norm.
The key observation behind the polynomial method is that classical results in the analytic theory of polynomials (due to Chebyshev, Markov, Bernstein, ) can be exploited to “upgrade” the above soft information to strong quantitative bounds, merely by virtue of the fact that is rational. The basic idea is to write
This is reminiscent of the interpolation method, where now instead of an interpolation parameter we “differentiate with respect to ”. In contrast to the interpolation method, however, the surprising feature of the present approach is that the derivative of can be controlled by means of completely general tools that do not require any understanding of the random matrix model. In particular, the analysis makes use of the following two classical facts about polynomials [34].
-
An inequality of A. Markov states that for every real polynomial of degree at most .
-
A corollary of the Markov inequality states that for any discretization of with spacing at most .
Applying these results to the numerator and denominator of the rational function yields with minimal effort a bound of the form
(the additional factor arises since we must restrict to the part of the interval where the spacing between the points is sufficiently small). Thus we obtain a strong quantitative bound in a completely soft manner.
In this form, the above method does not suffice to achieve strong convergence. To this end, two additional ingredients must be added.
-
1.
The above analysis requires the test function to be a polynomial. However, since the bound depends only polynomially on the degree of , one can use a Fourier-analytic argument to extend the bound to arbitrary smooth .
-
2.
The rate obtained above does not suffice to deduce convergence of the norm, since it can only ensure that has a bounded (rather than vanishing) number of eigenvalues outside the support of . To achieve strong convergence, we must expand to second (or higher) order and control the additional term(s).
Nonetheless, all these ingredients are essentially elementary and can be implemented with minimal problem-specific inputs.
The polynomial method will be discussed in detail in section 3, where we will illustrate it by giving an essentially complete proof of Theorem 1.4. That an elementary proof is possible at all is surprising in itself, given that previous methods required delicate and lengthy computations.
When it is applicable, the polynomial method has typically provided the best known quantitative results and has made it possible to address previously inaccessible questions. To date, this includes works of Magee and de la Salle [90] and of Cassidy [30] on strong convergence of high dimensional representations of the unitary and symmetric groups (see also [33]); strong convergence for polynomials with coefficients in subexponential operator spaces [33]; strong convergence of the tensor GUE model of graph products of semicircular variables (ibid.); a characterization of the unusual large deviations in Friedman’s theorem [32] as illustrated in Figure 1.3; and work of Magee, Puder and the author on strong convergence of uniformly random permutation representations of surface groups [92].
1.4. Organization of this survey
The rest of this survey is organized as follows.
Section 2 collects a number of basic but very useful properties of strong (and weak) convergence that are scattered throughout the literature. These properties also illustrate the fundamdental interplay between strong convergence and the operator algebraic properties of the limiting objects.
Section 3 provides a detailed illustration of the polynomial method: we will give an essentially self-contained proof of Theorem 1.4.
Section 4 is devoted to further discussion of the intrinsic freeness phenomenon. In particular, we aim to explain the mechanism that gives rise to it.
Section 5 discusses in more detail various applications of the strong convergence phenomenon that we introduced above. In particular, we aim to explain how the strong convergence property is used in these applications.
Finally, section 6 is devoted to a brief exposition of various open problems surrounding the strong convergence phenomenon.
2. Strong convergence
The aim of this section is to collect various general properties of strong convergence that are often useful. Many of these properties rely on operator algebraic properties of the limiting objects. We have aimed to make the presentation accessible to readers without any prior background in operator algebras.
2.1. -probability spaces
Let be an self-adjoint (usually random) matrix. We will be interested in understanding the empirical spectral distribution
(that is, is the fraction of the eigenvalues of that lies in the set ); and the spectral edges, that is, the extreme eigenvalues
or, more generally, the full spectrum as a set. In the models that we will consider, both these spectral features are well described by the corresponding features of a limiting operator as : convergence of the spectral distribution is weak convergence, and convergence of the spectral edges is strong convergence. These notions will be formally defined in the next section.666These notions capture the macroscopic features of the spectrum. A large part of modern random matrix theory is concerned with understanding the spectrum at the microscopic (or local) scale, that is, understanding the limit of the eigenvalues viewed as a point process. Such questions are rather different in spirit, as the behavior of the local statistics is expected to be universal and is not described by the spectral properties of limiting operators.
To do so, we must first give meaning to the spectral distribution and edges of the limiting operator . For the spectral edges, we may simply consider the norm or spectrum of which are well defined for bounded operators on any Hilbert space . However, the meaning of the spectral distribution of is not clear a priori. Indeed, since the empirical spectral distribution
is defined by the normalized trace,777We denote by the normalized trace of an matrix , and define by functional calculus (i.e., apply to the eigenvalues of while keeping the eigenvectors fixed). defining the spectral distribution of requires us to make sense of the normalized trace of infinite-dimensional operators. This is impossible in general, as any linear functional with the trace property for all must be trivial (this follows immediately by noting that when is infinite-dimensional, every element of can be written as the sum of two commutators [61]).
This situation is somewhat reminiscent of a basic issue of probability theory: one cannot define a probability measure on arbitrary subsets of an uncountable set, but must rather work with a suitable -algebra of sets for which the notion of measure makes sense. In the present setting, we cannot define a normalized trace for all bounded operators on an infinite-dimensional Hilbert space , but must rather work with a suitable algebra of operators on which the trace can be defined. These objects must satisfy some basic axioms.888We are a bit informal in our terminology: -algebras are usually defined as Banach algebras rather than as subalgebras of . However, as any -algebra may be represented in the latter form, our definition entails no loss of generality. What we call a trace should more precisely be called a tracial state. A crash course on the basic notions may be found in [106].
Definition 2.1 (-algebra).
A unital -algebra is an algebra of bounded operators on a complex Hilbert space that is self-adjoint ( implies ), contains the identity , and is closed in the operator norm topology.
Definition 2.2 (Trace).
A trace on a unital -algebra is a linear functional that is positive , unital , and tracial . A trace is called faithful if implies .
Definition 2.3 (-probability space).
A -probability space is a pair , where is a unital -algebra and is a faithful trace.
The simplest example of a -probability space is the algebra of matrices with its normalized trace . One may conceptually think of general -probability spaces as generalizations of this example.
Remark 2.4.
Most of the axioms in the above definitions are obvious analogues of the properties of . What may not be obvious at first sight is why we require to be closed in the norm topology. The reason is that it ensures that for any self-adjoint not only when is a polynomial (which follows merely from the fact that is an algebra), but also when is a continuous function, since the latter can be approximated in norm by polynomials. This property will presently be needed to define the spectral distribution.
Remark 2.5.
If we make the stronger assumption that is closed in the strong operator topology, is called a von Neumann algebra. This ensures that even when is a bounded measurable function. Von Neumann algebras form a major research area in their own right, but appear in this survey only in section 5.4.
Given a -probability space , we can now associate to each self-adjoint element , a spectral distribution by defining
for every continuous function . Indeed, that is positive and unital implies that is a positive and normalized linear functional on , so exists by the Riesz representation theorem.
This survey is primarily concerned with strong convergence, that is, with norms and not with spectral distributions. Nonetheless, it is generally the case that the only spectral statistics of random matrices that are directly computable are trace statistics (such as the moments ), so that a good understanding of weak convergence is prerequisite for proving strong convergence. In particular, we must understand how to recover the spectrum from the spectral distribution. It is here that the faithfulness of the trace plays a key role.
Lemma 2.6 (Spectral distribution and spectrum).
Let be a -probability space. Then for any self-adjoint , , we have and thus
Proof.
By the definition of support, if and only if there is a continuous nonnegative function so that and . On the other hand, by the spectral theorem, if and only if there is a continuous nonnegative function so that and . That therefore follows as if and only if , since is faithful and . ∎
We now introduce one of the most important examples of a -probability space. Another important example will appear in section 4.1.
Example 2.7 (Reduced group -algebras).
Let be a finitely generated group with generators , and be its left-regular representation, i.e., where is the coordinate vector of . Then
is called the reduced -algebra of . Here and in the sequel, denotes the -algebra generated by a family of operators (that is, the norm-closure of the set of all noncommutative polynomials in ).
The reduced -algebra of any group always comes equipped with a canonical trace that is defined for all by
where is the identity element. Note that:
-
It is straightforward to check that is indeed tracial: by linearity, it suffices to show that for all .
-
is also faithful: if , then for all by the trace property (since ), and thus .
Thus defines a -probability space.
Example 2.8 (Free group).
In the case that is a free group, we implicitly encountered the above construction in section 1.1. We argued there that the adjacency matrix of a random -regular graph is modelled by the operator
It follows immediately from the definition that the moments of the spectral distribution (defined by the canonical trace ) are given by
As the moments grow at most exponentially in , this uniquely determines . The density of was computed in a classic paper of Kesten [80, proof of Theorem 3], and is known as the Kesten distribution. Since the explicit formula for the density shows that , Lemma 2.6 yields
This explains the value of the norm that appears in Theorem 1.3.
2.2. Strong and weak convergence
We can now formally define the notions of weak and strong convergence of families of random matrices.
Definition 2.9 (Weak and strong convergence).
Let be a sequence of -tuples of random matrices, and let be an -tuple of elements of a -probability space .
-
is said to converge weakly to if for every
(2.1) -
is said to converge strongly to if for every
(2.2)
This definition appears to be slightly weaker than our initial definition of strong convergence in Definition 1.1, where we allowed for polynomials with matrix rather than scalar coefficients. We will show in section 2.4 that the apparently weaker definition in fact already implies the stronger one.
We begin by spelling out some basic properties, see for example [41, §2.1].
Lemma 2.10 (Equivalent formulations of weak convergence).
The following are equivalent.
-
a.
converges weakly to .
-
b.
Eq. (2.1) holds for every self-adjoint .
-
c.
For every self-adjoint , the empirical spectral distribution converges weakly to in probability.
Proof.
Since every polynomial can be written as for self-adjoint polynomials , the equivalence is immediate by linearity of the trace. Moreover, the implication is trivial since by the definition of the spectral distribution (and as is compactly supported).
On the other hand, since for every , (2.1) implies
in probability. As is compactly supported, convergence of moments implies weak convergence, and the implication follows. ∎
A parallel result holds for strong convergence.
Lemma 2.11 (Equivalent formulations of strong convergence).
The following are equivalent.
-
a.
converges strongly to .
-
b.
Eq. (2.2) holds for every self-adjoint .
-
c.
For every self-adjoint and , we have
-
d.
For every self-adjoint , we have
Proof.
Since for any operator and as is self-adjoint, it is immediate that . That is immediate as for any bounded self-adjoint operators .
To show that , we may choose for any a univariate real polynomial so that , where . Since (2.2) implies that with probability as , we obtain
with probability as by applying (2.2) to . That follows by taking .
To show that , choose so that for and otherwise. Since implies that in probability,
with probability as for every . On the other hand, for any , we may choose so that and for . Since implies that in probability,
with probability as for every . As can be covered by a finite number of such sets , the implication follows. ∎
The elementary equivalent formulations of weak and strong convergence discussed above are all concerned with the (real) eigenvalues of self-adjoint polynomials. In contrast, what implications weak or strong convergence may have for the empirical distributions of the complex eigenvalues of non-self-adjoint (or non-normal) polynomials is poorly understood; see section 6.9. We nonetheless record one easy observation in this direction [100, Remark 3.6].
Lemma 2.12 (Spectral radius).
Suppose that converges strongly to . Then
for every , where denotes the spectral radius of any (not necessarily normal) operator .
Proof.
This follows immediately from the fact that the spectral radius is upper semicontinuous with respect to the operator norm [62, §104]. ∎
2.3. Strong implies weak
While we have formulated weak and strong convergence as distinct phenomena, it turns out that strong convergence—or even merely a one-sided form of it—often automatically implies weak convergence. Such a statement should be viewed with suspicion, since the definition of weak convergence requires us to specify a trace while the definition of strong convergence is independent of the trace. However, it turns out that many -algebras have a unique trace, and this is precisely the setting we will consider.
Lemma 2.13 (Strong implies weak).
Let be a sequence of -tuples of random matrices, and let be an -tuple of elements of a -probability space . Consider the following conditions.
-
a.
For every
-
b.
converges weakly to .
-
c.
For every
Then , and if in addition has a unique trace.
Proof.
To prove , note that weak convergence implies
with probability for every , as . The conclusion follows by letting and applying Lemma 2.6.
To prove , let us first consider the special case that are nonrandom. Define a linear functional by
This is called the law of the family ; it has the same properties as the trace in Definition 2.2, but restricted only to polynomials. Note that by linearity, is fully determined by its value on all monomials.
Since for every monomial , the sequence is precompact in the weak∗-topology. Thus for every subsequence of the indices , there is a further subsequence so that pointwise for some law that satisfies the properties of a trace. On the other hand, condition ensures that
where the limits are taken along the subsequence. Thus extends by continuity to a trace on . Since the latter has the unique trace property, we must have , and thus we have proved weak convergence.
When are random, we note that condition implies (by Borel-Cantelli and as is separable) that for every subequence of indices , we can find a further subsequence along which for every a.s. The proof now proceeds as in the nonrandom case. ∎
The unique trace property turns out to arise frequently in practice. In particular, that has a unique trace for is a classical result of Powers [118], and a general characterization of countable groups so that has a unique trace is given by Breuillard–Kalantar–Kennedy–Ozawa [24]. In such situations, Lemma 2.13 shows that a strong convergence upper bound (condition ) already suffices to establish both strong and weak convergence in full. Establishing such an upper bound is the main difficulty in proofs of strong convergence.
2.4. Scalar, matrix, and operator coefficients
In Definition 2.9, we have defined the weak and strong convergence properties for polynomials with scalar coefficients. However, applications often require polynomials with matrix or even operator coefficients to encode the models of interest.999Let and be -probability spaces. If are elements of and is a polynomial with coefficients in , then lies in the algebraic tensor product . This viewpoint suffices for weak convergence. To make sense of strong convergence, however, we must define a norm on the tensor product. We will do so in the obvious way: Given and , we define the -algebra by and extend the trace accordingly. This construction is called the minimal tensor product of -probability spaces, and is often denoted . For simplicity, we fix the following convention: in this survey, the notation will always denote the minimal tensor product. We now show that such properties are already implied by their counterparts for scalar polynomials.
For weak convergence, this situation is easy.
Lemma 2.15 (Operator-valued weak convergence).
The following are equivalent.
-
a.
converges weakly to , i.e., for all
-
b.
For any -probability space and
Proof.
That is obvious. To prove , let us express concretely as with operator coefficients . Then clearly
where we denote for . Since yields for all , the conclusion follows. ∎
Unfortunately, the analogous equivalence for strong convergence is simply false at this level of generality; a counterexample can be constructed as in [33, Appendix A]. Nonetheless, strong convergence extends in complete generality to polynomials with matrix (as opposed to operator) coefficients. This justifies the apparently more general Definition 1.1 given in the introduction.
Lemma 2.16 (Matrix-valued strong convergence).
The following are equivalent.
-
a.
converges strongly to , i.e., for all
-
b.
For every and
Proof.
That is obvious. To prove , express as with , where denotes the standard basis of . We can therefore estimate
and analogously for . Here we used for the first inequality and the triangle inequality for the second. Thus yields
for probability as for every . Now note that since and for every , applying the above inequality to implies a fortiori that
for probability as . Taking completes the proof. ∎
Strong convergence of polynomials with operator coefficients requires additional assumptions. For example, if the coefficients are compact operators, strong convergence follows easily from Lemma 2.16 since compact operators can be approximated in norm by finite rank operators (i.e., by matrices).
A much weaker requirement is provided by the following property of -algebras. We give the definition in the form that is most relevant for our purposes; its equivalence to the original more algebraic definition (in terms of short exact sequences) is a nontrivial fact due to Kirchberg, see [115, Chapter 17] or [25].
Definition 2.17 (Exact -algebra).
A -algebra is called exact if for every finite-dimensional subspace and , there exists and a linear embedding such that
for every -algebra and .
We can now prove the following.
Lemma 2.18 (Operator-valued strong convergence).
Suppose that converges strongly to . Then we have
for every with coefficients in an exact -algebra .
Proof.
The exactness property turns out to arise frequently in practice. In particular, is exact [115, Corollary 17.10], as is for many other groups . For an extensive discussion, see [25, Chapter 5] or [6].
One reason that exactness is very useful in a strong convergence context is that it enables us construct complex strong convergence models by combining simpler building blocks, as will be explained briefly in section 5.4. Another useful application of exactness is that it enables an improved form of Lemma 2.13 with uniform bounds over polynomials with matrix coefficients of any dimension [90, §5.3].
2.5. Linearization
In the previous section, we showed that strong convergence of polynomials with scalar coefficients implies strong convergence of polynomials with matrix coefficients. If we allow for matrix coefficients, however, we can achieve a different kind of simplification: to establish strong convergence, it suffices to consider only polynomials with matrix coefficients of degree one. This nontrivial fact is often referred to as the linearization trick.
We first develop a version of the linearization trick for unitary families.
Theorem 2.19 (Unitary linearization).
Let be a sequence of -tuples of unitary random matrices, and let be an -tuple of unitaries in a -algebra . Then the following are equivalent.
-
a.
For every and self-adjoint of degree one,
-
b.
converges strongly to .
Theorem 2.19 is due to Pisier [114, 117], but the elementary proof we present here is due to Lehner [84, §5.1]. We will need a classical lemma.
Lemma 2.20.
For any operator in a -algebra , define its self-adjoint dilation in . Then and .
Proof.
We first note that . To show that the spectrum is symmetric, it suffices to note that is unitarily conjugate to since with . ∎
The main step in the proof of Theorem 2.19 is as follows.
Lemma 2.21.
Fix and for . Then there exist , and for such that
for any family of unitaries in any -algebra .
Proof.
Let . Lemma 2.20 yields with . We therefore obtain for any
where the second equality used that has a symmetric spectrum.
Now note that the block matrix is self-adjoint, and we can choose sufficiently large so that it is positive definite. Then we may write for . Now view as an block matrix with blocks , so that . Therefore with . To conclude we let , , and define by padding with zero columns. ∎
We can now conclude the proof of Theorem 2.19.
Proof of Theorem 2.19.
Fix any of degree at most , and let be unitaries in any -algebra . Denote by all monomials of degree at most in the variables . Then we may clearly express for some matrix coefficients . Lemma 2.21 yields of degree at most so that
Iterating this procedure times and using Lemma 2.20, we obtain a self-adjoint of degree at most one and a real polynomial so that
for any -tuple of unitaries in any -algebra . As this identity therefore applies also to , the implication follows immediately. The converse implication follows from Lemma 2.16. ∎
We have included a full proof of Theorem 2.19 to give a flavor of how the linearization trick comes about. In the rest of this section, we briefly discuss two additional linearization results without proof.
The proof of Theorem 2.19 relied crucially on the unitary assumption. It is tempting to conjecture that its conclusion extends to the non-unitary case. Unfortuntately, a simple example shows that this cannot be true.
Example 2.22.
Consider any and of degree one, that is, . Then the spectral theorem yields
for every self-adjoint operator . Now let be self-adjoint operators with and . Since the right-hand side of the above identity is the supremum of a convex function of , it is clear that for every of degree one. But clearly while .
This example shows that the norms of polynomials of degree one cannot detect gaps in the spectrum of a self-adjoint operator, while higher degree polynomials can. Thus the norm of degree one polynomials does not suffice for strong convergence in the self-adjoint setting. However, it was realized by Haagerup and Thorbjørnsen [60] that this issue can be surmounted by requiring convergence not just of the norm, but rather of the full spectrum, of degree one polynomials.
Theorem 2.23 (Self-adjoint linearization).
Let be a sequence of -tuples of self-adjoint random matrices, and let be an -tuple of self-adjoint elements of a -algebra . The following are equivalent.
-
a.
For every and self-adjoint of degree one,
-
b.
For every and self-adjoint
We omit the proof, which may be found in [60] or in [59] (see also [99, §10.3]). Let us note that while this theorem only gives an upper bound, the corresponding lower bound will often follow from Lemma 2.13.
Finally, while we have focused on strong convergence, linearization tricks for weak convergence can be found in the paper [45] of de la Salle. For example, we state the following result which follows readily from the proof of [45, Lemma 1.1].
Lemma 2.24 (Linearization and weak convergence).
Let be a -probability space. Then in the setting of Theorem 2.23, the following are equivalent.
-
a.
For every and self-adjoint of degree one,
-
b.
converges weakly to .
Why is linearization useful? It is often the case that one can perform computations more easily for polynomials of degree one than for general polynomials. For example, linearization played a key role in the Haagerup–Thorbjørnsen proof of strong convergence of GUE matrices [60] because the matrix Cauchy transform of polynomials of degree one can be computed by means of quadratic equations. Similarly, polynomials of degree one make the moment computations in the works of Bordenave and Collins [19, 21, 20] tractable. However, the interpolation and polynomial methods discussed in section 1.3 do not rely on linearization.
2.6. Positivization
The linearization trick of the previous section states that if we work with general matrix coefficients, it suffices to consider only polynomials of degree one. We now introduce (in the setting of group -algebras) a complementary principle: if we admit polynomials of any degree, it suffices to consider only polynomials with positive scalar coefficients. This positivization trick due to Mikael de la Salle appears in slightly different form in [90, §6.2].101010The form of this principle that is presented here was explained to the author by de la Salle.
The positivization trick will rely on another nontrivial operator algebraic property that we introduce presently. Let us fix a finitely generated group with generators , let be its left-regular representation, and let be the canonical trace on . For simplicity, we will denote . Then for any , we can uniquely express
| (2.3) |
for some coefficients that vanish for all but a finite number of . Moreover, it is readily verified using the definition of the trace that
We can now introduce the following property.
Definition 2.25 (Rapid decay property).
The group is said to have the rapid decay property if there exists constants so that
for all and of degree .
The key feature of this property is the polynomial dependence on degree . This is a major improvement over the trivial bound obtained by applying the triangle inequality and Cauchy–Schwarz, which would yield such an inequality with an exponential constant .
While the rapid decay property appears to be very strong, it is widespread. It was first proved by Haagerup [57] for the free group , for which rapid decay property is known as the Haagerup inequality. The rapid decay property is now known to hold for many other groups, cf. [31].
We are now ready to introduce the positivization trick. For simplicity, we formulate the result for the case of the free group (see Remark 2.27).
Lemma 2.26 (Positivization).
Let be a sequence of -tuples of unitary random matrices, and let be defined as above for (that is, ). Then the following are equivalent.
-
a.
For every self-adjoint
-
b.
converges strongly to .
Proof.
The implication is trivial. To prove , fix any . We may clearly assume without loss of generality that all the monomials of are reduced (i.e., do not contain consecutive letters or ), so that the coefficients of are precisely those that appear in the representation (2.3).
Let us write for defined by taking the real (imaginary) parts of the coefficients of . Since the polynomials are self-adjoint with real coefficients, we can write for self-adjoint defined by keeping only the positive (negative) coefficients of . Then we can estimate by the triangle inequality
On the other hand, note that
We can therefore estimate
for some , where is the degree of and we have applied the rapid decay property of in the first and last inequality. Thus implies that
for every of degree at most and some constants .
Now note that, for every , applying the above to yields
Taking yields the strong convergence upper bound, and the lower bound now follows from Lemma 2.13 since has the unique trace property. ∎
The positivization trick is very useful in the context of the polynomial method, as we will see in section 3. Let us however give a hint as to its significance.
For a self-adjoint polynomial with positive coefficients, we may interpret (2.3) as defining the adjacency matrix of a weighted graph with vertex set , where we place an edge with weight between every pair of vertices with and . Thus, for example, computing the moments of is in essence a combinatorial problem of counting the number of closed walks in this graph. This greatly facilitates the analysis of such quantities; for example, we can obtain upper bounds by overcounting some of the walks.
For a general choice of , we may still view as a kind of adjacency matrix of a graph with complex edge weights. This is a much more complicated object, however, since the moments of this operator may exhibit cancellations between different walks and can therefore no longer by treated as a counting problem. The surprising consequence of the positivization trick is that for the purposes of proving strong convergence, we can completely ignore these cancellations and restrict attention only to the combinatorial situation.
Remark 2.27.
The only part of the proof of Lemma 2.26 where we used is in the very first step, where we argued that we may assume that the coefficients of agree with those in the representation (2.3). For other groups , it is not clear that this is the case unless we assume that the matrices also satisfy the group relations, i.e., that where is a (random) unitary representation of . Under the latter assumption, Lemma 2.26 extends directly to any with the rapid decay and unique trace properties.
Alternatively, when the positivization trick is applied to the polynomial method, it is possible to apply a variant of the argument directly to the limiting object that appears in the proof, avoiding the need to invoke properties of the random matrices. This form of the positivization trick is developed in [90, §6.2] (cf. Remark 3.11).
3. The polynomial method
The polynomial method, which was introduced in the recent work of Chen, Garza-Vargas, Tropp, and the author [32], has enabled significantly simpler proofs of strong convergence and has opened the door to various new developments. The method was briefly introduced in section 1.3.2 above. In this section, we aim to provide a detailed illustration of this method by using it to prove strong convergence of random permutation matrices (Theorem 1.4).
We will follow a simplified form of the treatment in [32]. The simplifications arise for two reasons: we will make no attempt to get good quantitative bounds, enabling us to to use crude estimates in various places; and we will take advantage of the idea of [90] to significantly simplify one part of the argument by exploiting positivization. Aside from the use of standard results on polynomials and Schwartz distributions, the proof given here is essentially self-contained.
Despite its simplicity, what makes the polynomial method work appears rather mysterious at first sight. We will conclude this section with a discussion of the new phenomenon that is captured by this method (section 3.6).
3.1. Outline
In the following, we fix independent random permutation matrices and the limiting model as in Theorem 1.4. More precisely, recall that , where and are the free generators and left-regular representation of . We will view as living in the -probability space where denotes the canonical trace.
For notational purposes, it will be convenient to define and for . We analogously define and , and similarly and , for . We will think of as fixed, and all constants that appear in this section may depend on .
We begin by outlining the key ingredients that are needed to conclude the proof. These ingredients will then be developed in the remainder of this section.
3.1.1. Polynomial encoding
The first step of the analysis is to show that the expected traces of monomials of are rational expressions of .
Lemma 3.1.
For every and , there exist real polynomials and of degree at most so that for all
3.1.2. Asymptotic expansion
Now fix a self-adjoint noncommutative polynomial . Then for every univariate real polynomial , since is again a noncommutative polynomial, we immediately obtain
| (3.2) |
Here and are defined, a priori, as linear functionals on the space of all univariate real polynomials (of course, also depend on the choice of , but we will view as fixed throughout the argument).
The core of the proof is now to show that the expansion (3.2) is valid not only for polynomial test functions , but even for arbitrary smooth test functions . It is far from obvious why this should be the case; for example, it is conceivable that there could exist smooth test functions for which weak convergence takes place at a rate slower than the rate for polynomial . If that were to be the case, then would not even make sense for smooth . We will show, however, that this hypothetical scenario is not realized.
Recall that a linear functional on is called a compactly supported (Schwartz) distribution (see [72, Chapter II]) if
holds for some constants and .
Proposition 3.2.
3.1.3. The infinitesimal distribution
As , Lemma 2.6 yields
The final ingredient of the proof is to show that satisfies the same bound. By the positivization trick, it suffices to assume that has positive coefficients.
Lemma 3.3.
For every choice of self-adjoint , we have
To prove Lemma 3.3 we face a conundrum: while we know abstractly that is a compactly supported distribution, we are only able to compute its value for polynomial test functions (as we have an explicit formula for in section 3.1.1). To surmount this issue, we will use the following general fact [32, Lemma 4.9]: for any compactly supported distribution , we have
Thus it suffices to show that
which is tractable as we have access to the moments of . It is this moment estimate that is greatly simplified by the assumption that has positive coefficients.
3.1.4. Proof of Theorem 1.4
We now use these ingredients to conclude the proof.
Proof of Theorem 1.4.
Fix and a self-adjoint with positive coefficients. Moreover, let be a nonnegative smooth function that vanishes in a neighborhood of and such that for .
We now turn to the proofs of the various ingredients described above.
3.2. Polynomial encoding
The aim of this section is to prove Lemma 3.1. We follow [85]; see also [105, 42]. We begin by noting that
so that it suffices to compute the rightmost expectation. Clearly
A tuple is realizable if the corresponding summand is nonzero. Denote by the set of all realizable tuples.
To bring out the dependence on dimension , we note that by symmetry, the expectation inside the above sum only depends on how many distinct pairs of indices appear for each permutation matrix. To encode this information, we associate to each a directed edge-colored graph as follows. Number each distinct value among by order of appearance, and assign to each a vertex. Now draw an edge colored from one vertex to another if or appears in the expectation, where are the values associated to the first and second vertex, respectively; see Figure 3.1.
Denote by the set of graphs thus constructed, and note that this set is independent of . For each such graph with vertices, we can recover all associated uniquely by assigning distinct values of to its vertices. There are ways to do this. If the graph has edges with color , then the corresponding expectation for each such is
since the random variable in the expectation is the event that for each , the permutation matrix has of its rows fixed as specified by the realizable tuple . Here we presumed that , which ensures that and .
In summary, we have proved the following.
Lemma 3.4.
For every and , we have
The proof of Lemma 3.1 is now straightforward.
Proof of Lemma 3.1.
We can rewrite the above lemma as
where is the total number of edges in . As every is connected by construction, we have and thus the right-hand side is a rational function of .
Define a polynomial of degree by
Since for all , it is clear that is a polynomial of degree at most for some constant (which depends on ). ∎
We can now read off the first terms in the -expansion. Recall that is called a proper power if for some , , and is called a non-power otherwise. Every can be written uniquely as for a non-power .
Corollary 3.5.
We have
Moreover, if for a non-power , then
where denotes the number of divisors of .
Proof.
If , it is obvious that . We therefore assume this is not the case. We may further assume that is cyclically reduced, since the left-hand side of Lemma 3.1 is unchanged under cyclic reduction. Then every vertex of any must have degree at least two.
For the first identity, it now suffices to note that there cannot exist with : this would imply that is a tree, which must have a vertex of degree one. Thus the expression in the proof of Lemma 3.1 yields .
We can similarly read off from the proof of Lemma 3.1 that
That implies (as each vertex has degree at least two) that is a cycle. As defines a closed nonbacktracking walk in , it must go around the cycle an integer number of times, so the possible lengths of cycles are the divisors of . ∎
3.3. The master inequality
We now proceed to the core of the polynomial method. Our main tool is the following inequality of A. Markov [34, p. 91].
Lemma 3.6 (Markov inequality).
For any real polynomial of degree and
As well known consequence of the Markov inequality is that a bound on a polynomial on a sufficiently fine grid extends to a uniform bound [34, p. 91]. For completeness, we spell out the argument in the form we will need it.
Corollary 3.7.
For any real polynomial of degree and , we have
Proof.
For any , its distance to the set is at most . Thus
by the Markov inequality. The conclusion follows. ∎
In the following, we fix a self-adjoint of degree . For every polynomial test function of degree , Lemma 3.1 yields
where are real polynomials of degree at most and is defined in the proof of Lemma 3.1. We define for as in (3.2), and denote by the sum of the moduli of the coefficients of . Note that all the above objects depend on the choice of , which we consider fixed.
The key idea is to use the Markov inequality to bound the derivatives of .
Lemma 3.8.
For any of degree , we have
for all , where is a constant (which depends on ).
Proof.
It is easily verified using the explicit expression for in the proof of Lemma 3.1 that there are constants (which depend on ) so that
for all . We now simply apply the chain rule. For the first derivative,
using Lemma 3.6. But Corollary 3.7 yields
where we used in the second inequality and that in the last inequality. The bound on is obtained in a completely analogous manner. ∎
We now easily obtain a quantitative form of (3.2).
Corollary 3.9 (Master inequality).
For every of degree and ,
as well as .
Proof.
The bound on follows immediately from Lemma 3.8 as . Now note that the left-hand side of the equation display in the statement equals
Thus the bound in the statement follows for from Lemma 3.8. On the other hand, when , we can trivially bound
by the triangle inequality, as is supported in , and using the bound on . The conclusion follows using . ∎
3.4. Extension to smooth functions
We are now ready to prove Proposition 3.2. To this end, we will show that Corollary 3.9 can be extended to smooth test functions using a simple Fourier-analytic argument.
Recall that the Chebyshev polynomial (of the first kind) is the polynomial of degree defined by . Any of degree can be written as
for some real coefficients . Note that the latter are merely the Fourier coefficients of the function defined by .
Proof of Proposition 3.2.
Fix any and let be its Chebyshev coefficients as above. As for all , we can estimate
using the estimate on in Corollary 3.9. Now note that is the th Fourier coefficient of the th derivative of . We can therefore estimate
by Cauchy–Schwarz and Parseval, where the last inequality is obtained by applying the chain rule to . Since this estimate holds for all , the definition of extends uniquely by continuity to any . In particular, extends to a compactly supported distribution.
3.5. The infinitesimal distribution
It remains to prove Lemma 3.3. As was explained in section 3.1.3, this result follows immediately from the following lemma, whose proof uses a spectral graph theory argument due to [49, Lemma 2.4].
Lemma 3.10.
Assume that has positive coefficients. Then
To set up the proof, let us fix a noncommutative polynomial of degree with positive coefficients. By homogeneity, we may assume without loss of generality that the coefficients sum to one. It will be convenient to express
where are random variables such that . Now let be independent copies of for , so that we have . Then we can apply Corollary 3.5 to compute
where denotes the set of non-powers in .111111Here we used that if , since .
Proof of Lemma 3.10.
We would like to argue that if a word , it must be a concatenation of words that reduce to . This is only true, however, if is cyclically reduced: otherwise the last letters of may cancel the first letters of the next repetition of , and the cancelled letters need not appear in our word. The correct version of this statement is that there exist with (where is the cyclic reduction of ) so that every word that reduces to is a concatenation of words that reduce to . Thus
To relate this bound to the spectral properties of , we make the simple observation that the indicators above can be expressed as matrix elements
If we substitute the formula in the above inequality, and then take the expectation with respect to each independent block of variables that lies entirely inside one of the matrix elements, we obtain
with
where , , , and we write and for simplicity.
The crux of the proof is now to note that as
it follows readily using Cauchy–Schwarz that
since each contains at most variables other than . As and , the conclusion follows directly from the expression for stated before the proof. ∎
Remark 3.11.
The proof of Lemma 3.10 relies on positivization: since all the terms in the proof are positive, we are able to obtain upper bounds by overcounting as in the first equation display of the proof. While this argument only applies in first instance to polynomials with positive coefficients, strong convergence for arbitrary polynomials then follows a posteriori by Lemma 2.26.
It is also possible, however, to apply a variant of the positivization trick directly to . This argument [90, §6.2] shows that the validity of Lemma 3.10 for polynomials with positive coefficients already implies its validity for all self-adjoint polynomials (even with matrix coefficients), so that the polynomial method can be applied directly to general polynomials. The advantage of this approach is that it yields much stronger quantitative bounds than can be achieved by applying Lemma 2.26. Since we have not emphasized the quantitative features of the polynomial method in our presentation, we do not develop this approach further here.
3.6. Discussion: on the role of cancellations
When encountered for the first time, the simplicity of proofs by the polynomial method may have the appearance of a magic trick. An explanation for the success of the method is that it uncovers a genuinely new phenomenon that is not captured by classical methods of random matrix theory. Now that we have provided a complete proof of Theorem 1.4 by the polynomial method, we aim to revisit the proof to highlight where this phenomenon arises. For simplicity, we place the following discussion in the context of random matrices with limiting operator ; the reader may keep in mind
in the context of Theorem 1.4 and its proof.
3.6.1. The moment method
It is instructive to first recall the classical moment method that is traditionally used in random matrix theory. Let us take for granted that converges weakly to , so that
| (3.3) |
as with fixed. The premise of the moment method is that if it could be shown that this convergence remains valid when is allowed to grow with at rate , then a strong convergence upper bound would follow: indeed, since , we could then estimate
where we used that for .
There are two difficulties in implementing the above method. First, establishing (3.3) for can be technically challenging and often requires delicate combinatorial estimates. When is fixed, we can write an expansion
(this is immediate, for example, from (3.1)) and establishing (3.3) requires us to understand only the lowest-order term . In contrast, when the coefficients themselves grow faster than polynomially in , so that it is necessary to understand the terms in the expansion to all orders.
In the setting of Theorem 1.4, however, there is a more serious problem: (3.3) is not just difficult to prove, but actually fails altogether.
Example 3.12.
Consider the permutation model of -regular random graphs as in Theorem 1.3, so that where is the adjacency matrix. We claim that with probability at least . As , this implies
contradicting the validity of (3.3) for .
To prove the claim, note that any given point of is simultenously a fixed point of the random permutations with probability . Thus with probability at least , random graph has a vertex with self-loops which is disconnected from the rest of the graph, so that has eigenvalue with multiplicity at least two. The latter cleatly implies that .
Example 3.12 shows that the appearance of outliers in the spectrum with polynomially small probability presents a fundamental obstruction to the moment method. In random graph models, this situation arises due to the appearance of “bad” subgraphs, called tangles. Previous proofs [50, 18, 19] of optimal spectral gaps in this setting must overcome these difficulties by conditioning on the absence of tangles, which significantly complicates the analysis and has made it difficult to adapt these methods to more challenging models.121212A notable exception being the work of Anantharaman and Monk on random surfaces [4, 5].
3.6.2. A new phenomenon
The polynomial method is essentially based on the same input as the moment method: we consider the spectral statistics
where is any real polynomial of degree , and aim to compare these with the spectral statistics of . Since we have shown in Example 3.12 that each moment can be larger than its limiting value by a factor exponential in the degree, that is, for , it seems inevitable that must be poorly approximated by for high degree polynomials . The surprising feature of the polynomial method is that it defies this expectation: for example, a trivial modification of the proof of Corollary 3.9 yields the bound
| (3.4) |
which depends only polynomially on the degree .
There is of course no contradiction between these observations: if we choose in (3.4), then and we recover the exponential dependence on degree that was observed in Example 3.12. On the other hand, (3.4) shows that the dependence on the degree becomes polynomial when is uniformly bounded on the interval . Thus the polynomial method reveals an unexpected cancellation phenomenon that happens when the moments are combined to form bounded test functions .
The idea that classical tools from the analytic theory of polynomials, such as the Markov inequality, make it possible to capture such cancellations lies at the heart of the polynomial method. These cancellations would be very difficult to realize by a direct combinatorial analysis of the moments. The reason that this phenomenon greatly simplifies proofs of strong convergence is twofold. First, it only requires us to understand the -expansion of the moments to first order, rather than to every order as would be required by the moment method. Second, this eliminates the need to deal with tangles, since tangles do not appear in the first-order term in the expansion. (The tangles are however visible in the higher order terms, which gives rise to the large deviations behavior in Figure 1.3.)
Remark 3.13.
We have contrasted the polynomial method with the moment method since both rely only on the ability to compute moments . Beside the moment method, another classical method of random matrix theory is based on resolvent statistics such as . This approach was used by Haagerup–Thorbjørnsen [60] and Schultz [121] to establish strong convergence for Gaussian ensembles, where strong analytic tools are available. It is unclear, however, how such quantities can be computed or analyzed in the context of discrete models as in Theorem 1.4. Nonetheless, let us note that the recent works [76, 74, 75] have successfully used such an approach in the setting of random regular graphs.
4. Intrinsic freeness
The aim of this section is to explain the origin of the intrinsic freeness phenomenon that was introduced in section 1.2. Since Theorem 1.6 requires a number of technical ingredients whose details do not in themselves shed significant light on the underlying phenomenon, we defer to [10, 11] for a complete proof. Instead, we aim to give an informal discussion of the key ideas behind the proof: in particular, we aim to explain the underlying mechanism.
Before we can do so, however, we must first describe the limiting object and explain why it is useful in practice, which we will do in section 4.1. We subsequently sketch some key ideas behind the proof of Theorem 1.6 in section 4.2.
4.1. The free model
To work with Gaussian random matrices, we must recall how to compute moments of independent standard Gaussians : given any , the Wick formula [106, Theorem 22.3] states that
where denotes the set of pairings of (that is, partitions into blocks of size two). This classical result is easily proved by induction on using integration by parts. A convenient way to rewrite the Wick formula is to introduce for every and random variables with the same law as so that for , and are independent otherwise. Then
as the expectation in the sum factors as .
What happens if we replace the scalar Gaussians by independent GUE matrices ? To explain this, we need the following notion: a pairing has a crossing if there exist pairs so that . If we represent by drawing each element of as a vertex on a line, and drawing a semicircular arc between the vertices in each pair , the pairing has a crossing precisely when two of the arcs cross; see Figure 4.1.
Lemma 4.1.
We have
where denotes the set of noncrossing pairings.
Proof.
Define analogously to above. Then
by the Wick formula. Consider first a noncrossing pairing . Since pairs cannot cross, there must be an adjacent pair , and if this pair is removed we obtain a noncrossing pairing of . As ,131313This follows from a simple explicit computation using the following characterization of GUE matrices: is a self-adjoint matrix whose entries above the diagonal are i.i.d. complex Gaussians and entries on the diagonal are i.i.d. real Gaussians with mean zero and variance . we obtain
by repeatedly taking the expectation with respect to an adjacent pair.
On the other hand, if is an independent copy of , we can computefootnote 13
| (4.1) |
for any matrices that are independent of . Thus
as whenever is a crossing pairing. ∎
In view of Lemma 4.1, the significance of the following definition of the limiting object associated to independent GUE matrices is self-evident.
Definition 4.2 (Free semicircular family).
A family of self-adjoint elements of a -probability space such that
for all and is called a free semicircular family.
Free semicircular families can be constructed in various ways, guaranteeing their existence; see, e.g. [106, pp. 102–108]. Lemma 4.1 states that a family of independent GUE matrices converges weakly to a free semicircular family .
Remark 4.3.
The variables are called “semicircular” because their moments are the moments of the semicircle distribution. Thus Lemma 4.1 recovers the classical fact that the empirical spectral distribution of a GUE matrix converges to the semicircle distribution.
The intrinsic freeness principle states that both the spectral distribution and spectral edges of a self-adjoint Gaussian random matrix
are captured in a surprisingly general setting by those of the operator
This is unexpected, as this phenomenon does not arise as a limit of GUE type matrices which motivated the definition of and thus it is not clear where the free behavior of comes from. The latter will be explained in section 4.2.
Beside its fundamental interest, this principle is of considerable practical utility because the spectral statistics of the operator can be explicitly computed by means of closed form equations, as we will presently explain. Let us first show how to compute the spectral distribution .
Lemma 4.4 (Matrix Dyson equation).
For with , we denote by
the matrix Green’s function of . Then satisfies the matrix Dyson equation
and for all .
Proof.
We can construct all as follows: first choose the pair containing the first point; and then pair the remaining points by choosing any noncrossing pairings of the sets and . Thus
for by the definition of a free semicircular family. In the following, it will be convenient to allow also , where we define . In this case, the identity clearly remains valid provided that .
Now define the matrix moments
Applying the above identity yields for the recursion (with , )
When is sufficiently large, we can write , and the matrix Dyson equation follows readily from the recursion for . The equation remains valid for all with by analytic continuation.
The final claim follows as is the density of the Cauchy distribution with scale , so that is the density of the convolution which converges weakly to as . ∎
Lemma 4.4 shows that the spectral distribution of can be computed by solving a system of quadratic equations for the entries of . While these equations usually do not have a closed form solution, they are well behaved and are amenable to analysis and numerical computation [67, 2].
The spectral edges of can in principle be obtained from its spectral distribution (cf. Lemma 2.6). However, the following formula of Lehner [84], which we state without proof,141414The difficulty is to upper bound : as for any , Lemma 4.4 shows that is lower bounded by the right-hand side of Lehner’s formula. provides an often more powerful tool: it expresses the outer edges of the spectrum of in terms of a variational principle.
Theorem 4.5 (Lehner).
We have
where we denote for any self-adjoint operator .
Various applications of this formula are illustrated in [11]. On the other hand, in applications where the exact location of the edge is not important, the following simple bounds often suffice and are easy to use:
These bounds admit a simple direct proof [115, p. 208].
By connecting the spectral statistics of a random matrix to those of , the intrinsic freeness principle makes it possible to understand the spectra of complicated random matrix models that would be difficult to analyze directly. One may view the operator as a “platonic ideal”: a perfect object which captures the essence of the random matrices that exist in the real world.
4.2. Interpolation and crossings
We now aim to explain how the intrinsic freeness principle actually arises. In this section, we will roughly sketch the most basic ideas behind the proof of Theorem 1.6.
The most natural way to interpolate between and is to define
as in section 1.2, where are independent GUE matrices. Then when , while weakly as by Lemma 4.1. One may thus be tempted to approach intrinsic freeness by applying the polynomial method to . The problem with this approach, however, is that the small parameter that arises in the polynomial method is not as in Theorem 1.6, but rather . This is useless for understanding what happens when .
The basic issue here is that unlike classical strong convergence, the intrinsic freeness phenomenon is truly nonasymptotic in nature: it aims to capture an intrinsic property of that causes it to behave as the corresponding free model. Thus we cannot hope to deduce such a property from the asymptotic behavior of the model alone; the proof must explicitly explain where intrinsic freeness comes from, and why it is quantified by a parameter such as .
4.2.1. The interpolation method
Rather than using as an interpolating family, the proof of intrinsic freeness is based on a continuous interpolating family parametrized by . Roughly speaking, we would like to define
and apply the fundamental theorem of calculus as explained in section 1.3.1 to bound the discrepancy between the spectral statistics of and . The obvious problem with the above definition is that it makes no sense: is random matrix and is a deterministic operator, which live in different spaces. To implement this program, we will construct proxies for and that are high-dimensional random matrices of the same dimension.
To this end, we proceed as follows. Let be independent GUE matrices, and let be independent diagonal matrices with i.i.d. standard Gaussian entries on the diagonal. Then we define the random matrices
The significance of this definition is that
for all ; the first identity follows as is a block-diagonal matrix with i.i.d. copies of on the diagonal, while the second follows by Lemma 4.1 as . Thus does indeed interpolate between and in the limit as . (We emphasize that we now view as the interpolation parameter, as opposed to the interpolation parameter in the polynomial method.)
Now that we have defined a suitable interpolation, we aim to compute the rate of change of spectral statistics along the interpolation: if it is small, then the spectral statistics of and must be nearly the same. For simplicity, we will illustrate the method using moments , which suffices to capture the operator norm by the moment method.151515To achieve Theorem 1.6 in its full strength, one uses instead spectral statistics of the form for , . The computations involved are however very similar. We state the resulting expression informally; the computation is somewhat tedious (see the proof of [10, Lemma 5.4]) but uses only standard tools of Gaussian analysis.
Lemma 4.6 (Informal statement).
For any , we have
where is a suitably constructed (dependent) copy of and are independent copies of .
From a conceptual perspective, the expression of Lemma 4.6 should not be unexpected. Indeed, the explicit formulas for and that arise from the Wick formula and Definition 4.2, respectively, differ only in that the former has a sum over all pairings while the latter sums only over noncrossing pairings. Thus the difference between these two quantities is a sum over all pairings that contain at least one crossing. The point of the interpolation method, however, is that by changing infinitesimally we can isolate the effect of a single crossing—this is precisely what Lemma 4.6 shows. This key feature of the interpolation method is crucial for accessing the edges of the spectrum (see section 4.3).
4.2.2. The crossing inequality
By Lemma 4.6, it remains to control the effect of a single crossing. We can now finally explain the significance of the mysterious parameter : this parameter controls the contribution of crossings. The following result is a combination of [10, Lemma 4.5 and Proposition 4.6].
Lemma 4.7 (Crossing inequality).
Let be any independent and centered self-adjoint random matrices, and with . Then
for any matrices that are independent of .
Rather than reproduce the details of the proof of this inequality here, we aim to explain the intuition behind the proof.
Idea behind the proof of Lemma 4.7.
We first observe that it suffices by the Riesz–Thorin interpolation theorem [16, p. 202] to prove the theorem for the case . Thus the proof reduces to bounding the matrix alignment parameter
by
How can we do this? The basic intuition behind the proof is as follows. Note first that if is a GUE matrix, then . Thus
for any random matrix . If it were to be the case that is monotone as a function of and , then one could bound
using that for independent GUE matrices by (4.1).
Unfortunately, is not monotone as a function of and , so the above reasoning does not apply directly. However, we can use a trick to rescue the argument. The key observation is that the parameter can be “symmetrized” by applying the Cauchy–Schwarz inequality as is illustrated informally in Figure 4.2. This results in two symmetric terms—a single pair which is readily bounded by , and a double crossing that is a positive functional of (and hence monotone in) . We can thus apply the above logic to the double crossing to replace by a GUE matrix, which yields a factor . The term that remains can now be bounded using a similar argument.
∎
We can now sketch how all the above ingredients fit together. Combining Lemmas 4.6 and 4.7 with yields an inequality of the form
Using by Jensen’s inequality, we obtain a differential inequality that can be integrated by a straightforward change of variables. This yields (after taking ) the final inequality
This inequality captures the intrinsic freeness phenomenon for the moments of . Since the right-hand side depends only polynomially on the degree , however, one can apply the moment method as explained in section 3.6.1 to deduce also a bound on the operator norm by . In this manner, we achieve both weak convergence and norm convergence of to as .
Remark 4.8.
The matrix alignment parameter that appears in the proof of Lemma 4.7 (as well as the use of the Riesz–Thorin theorem in this context) was first introduced in the work of Tropp [125], which predates the discovery of the intrinsic freeness principle. Let us briefly explain how it appears there.
The idea of [125] is to mimic the classical proof of the Schwinger-Dyson equation for GUE matrices, see, e.g., [55, Chapter 2], in the context of a general Gaussian random matrix. Tropp observed that the error term that arises from this argument can be naturally bounded by , and that this parameter is small in some examples (e.g., for matrices with independent entries).
The reason this argument cannot give rise to generally applicable bounds is that it fails to capture the intrinsic freeness phenomenon. Indeed, the validity of the Schwinger-Dyson equation for GUE matrices requires that themselves behave as free semicircular variables; this is not at all the case in general, as the spectral distribution need not look anything like a semicircle. To ensure this is the case, [125] has to impose strong symmetry assumptions on that are close in spirit to the classical setting of Voiculescu’s asymptotic freeness.161616The paper [125] also develops another set of inequalities that are applicable to general Gaussian matrices, but are suboptimal by a dimension-dependent multiplicative factor. We do not discuss these inequalities as they are less closely connected to the topic of this survey.
In contrast, intrinsic freeness captures a more subtle property of random matrices: does not quantify whether itself behaves freely, but rather how sensitive the model is to whether the scalar variables are taken to be commutative or free. Consequently, when is small, the variables can be replaced by their free counterparts (i.e., “liberated”) with a negligible effect on the spectral statistics. This viewpoint paves the way to the development of the interpolation method which is key to subsequent developments.
4.3. Discussion: on the role of interpolation
To conclude this section, we aim to explain why the interpolation method plays an essential role in the development of intrinsic freeness. For simplicity we will assume in this section that , so that is a centered Gaussian matrix.
Since the moments of and can be easily computed explicitly, it is tempting to reason directly using the resulting expressions. More precisely, note that
| by the Wick formula, while | |||||
by Definition 4.2. Thus clearly the difference between these two expressions involves only a sum over crossing pairings, and we can control each term in the sum directly using Lemma 4.7. This elementary approach yields the inequality
where we used that the number of crossing pairings of is of order for a universal constant . In particular, we obtain
This inequality suffices to prove weak convergence of to as , but is far too weak to provide access to the edges of the spectrum. To see why, recall from section 3.6.1 that to bound the norm of the matrix by the moment method, we must control for . However, even when is a GUE matrix we only have , so that the error term in the above inequality diverges as when .
The reason for the inefficiency of this approach is readily understood. What we used is that the difference between the moments of and is a sum of terms with at least one crossing. However, most pairings of contain not just one crossing, but many (typically of order ) crossings at the same time. Unfortunately, Lemma 4.7 can only capture the effect of a single crossing: it cannot be iterated to obtain an improved bound in the presence of multiple crossings, as the Hölder type bound destroys the structure of the pairing. Thus we are forced to ignore the effect of multiple crossings, which results in a loss of information.
The key feature of the interpolation method that is captured by Lemma 4.6 is that when we move infinitesimally from to , the change of the moments is controlled by a single crossing rather than by many crossings at the same time. This is the reason why we are able to obtain an efficient bound using the somewhat crude crossing inequality provided by Lemma 4.7.
Remark 4.9.
In the special case that is a GUE matrix, we obtained a much better result than Lemma 4.7: the crossing identity (4.1) captures the effect of a crossing exactly. This identity can be iterated in the presence of multiple crossings, which results in the genus expansion for GUE matrices (see, e.g., [99, §1.7]). This is a rather special feature of classical random matrix models, however, and we do not know of any method that can meaningfully capture the effect of multiple crossings in the setting of arbitrarily structured random matrices.
5. Applications
In recent years, strong convergence has led to several striking applications to problems in different areas of mathematics, which has in turn motivated new developments surrounding the strong convergence phenomenon. The aim of this section is to briefly describe some of these applications. The discussion is necessarily at a high level, since the detailed background needed to understand each application is beyond the scope of this survey. Our primary aim is to give a hint as to why and how strong convergence enters in these different settings.
We will focus on applications where strong convergence enters in a non-obvious manner. In particular, we omit applications of the intrinsic freeness principle in applied mathematics, since it is generally applied in a direct manner to analyze complicated random matrices that arise in such applications.
5.1. Random lifts of graphs
We begin by recalling some basic notions that can be found, for example, in [71, §6].
Let be a connected graph. A connected graph is said to cover if there is a surjective map that maps the local neighborhood of each vertex in bijectively to the local neighborhood of in (the local neighborhood consists of the given vertex and the edges incident to it).171717This definition is slightly ambiguous if has a self-loop, which we gloss over for simplicity.
Every connected graph has a universal cover which covers all other covers of . Given a base vertex in , one can construct by choosing its vertex set to be the set of all finite non-backtracking paths in starting at , with two vertices being joined by an edge if one of the paths extends the other by one step; thus is a tree (the construction does not depend on the choice of ).
It is clear that if is any -regular graph, then is the infinite -regular tree. In particular, all -regular graphs have the same universal cover. In this setting, we have an optimal spectral gap phenomenon: for any sequence of -regular graphs with diverging number of vertices, the maximum nontrivial eigenvalue is asymptotically lower bounded by the spectral radius of the universal cover (Lemma 1.2), and this bound is attained by random -regular graphs (Theorem 1.3).
It is expected that the optimal spectral gap phenomenon is a very general one that is not specific to the setting of -regular graphs. Progress in this direction was achieved only recently, however, and makes crucial use of strong convergence. In this section, we will describe such a phenomenon in the setting of non-regular graphs; the setting of hyperbolic surfaces will be discussed in section 5.2 below.
5.1.1. Random lifts
From the perspective of the lower bound, there is nothing particularly special about -regular graphs beside that they all have the same universal cover. Indeed, for any sequence of graphs with diverging number of vertices that have the same universal cover, the maximum nontrivial eigenvalue is asymptotically lower bounded by the spectral radius of the universal cover. This follows by a straightforward adaptation of Lemma 1.2, cf. [71, Theorem 6.6].
What may be less obvious, however, is how to construct a model of random graphs that share the same universal cover beyond the regular setting. The natural way to think about this problem, which dates back to Friedman [49] (see also [3]), is as follows. Fix any finite connected base graph ; we will then construct random graphs with an increasing number of vertices by choosing a sequence of random finite covers of . By construction, the universal cover of all these graphs coincides with the universal cover of the base graph.
To this end, let us explain how to construct finite covers of a finite connected graph . Fix an arbitrary orientation for every edge , and denote by the set of oriented edges. Fix also and a permutation for each . Then we can construct a graph with
and
In other words, is obtained by taking copies of , and scrambling the endpoints of the copies of each edge according the permutation (see Figure 5.1). Then is a cover of with covering map .
Conversely, it is not difficult to see that any finite cover of can be obtained in this manner by some choice of and (as all fibers of a covering map must have the same cardinality , called the degree of the cover), and that the set of graphs thus constructed is independent of the choice of orientation .
Remark 5.1.
need not be connected for every choice of ; for example, if each is the identity permutation, then consists of disjoint copies of . It is always the case, however, that each connected component of is a cover of .
The above construction immediately gives rise to the natural model of random covers of graphs: given a finite connected base graph , a random cover of degree is obtained by choosing the permutations in the above construction independently and uniformly at random from . This model is commonly referred to as the random lift model in graph theory (as a cover of degree of a finite graph is sometimes referred to in graph theory as an -lift).
5.1.2. Old and new eigenvalues
From now on, we fix the base graph and its random lifts as above. Then it is clear from the construction that the adjacency matrix of can be expressed as
where is the coordinate basis of and are i.i.d. random permutation matrices of dimension . The significance of strong convergence for this model is now obvious: we have encoded the adjacency matrix of the random lift model as a polynomial of degree one with matrix coefficients of i.i.d. permutation matrices, to which Theorem 1.4 can be applied.
Before we can do so, however, we must clarify the nature of the optimal spectral gap phenomenon in the present setting. In first instance, one might hope to establish the obvious converse to the lower bound, that is, that converges to the spectral radius of the universal cover . Such a statement cannot be true in general, however, for the following reason. Note that for any , we have
where denotes the adjacency matrix of . Thus any eigenvalue of is also an eigenvalue of , since the corresponding eigenvector of lifts to an eigenvector of : in other words, the eigenvalues of the base graph are always inherited by its covers. In particular, if the base graph happens to have an eigenvalue that is strictly larger than , then for all .
For this reason, the best we can hope for is to show that the new eigenvalues of , that is, those eigenvalues that are not inherited from , are asymptotically bounded by the spectral radius of . More precisely, denote by
the restriction of to the space spanned by the new eigenvalues. Then we aim to show that converges to the spectral radius of . This is the correct formulation of the optimal spectral gap phenomenon for the random lift model: indeed, a variant of the lower bound shows that for any sequence of covers of with diverging number of vertices, the maximum new eigenvalue is asymptotically lower bounded by the spectral radius of [49, §4].
As was noted by Bordenave and Collins [19], the validity of the optimal spectral gap phenomenon for random lifts, conjectured by Friedman [49], is now a simple corollary of strong convergence of random permutation matrices.
Corollary 5.2 (Optimal spectral gap of random lifts).
Fix any finite connected graph , and denote by the spectral radius of its universal cover . Then
Proof.
It follows immediately from Theorem 1.4 that with
where are the generators of a free group and is the left-regular representation of . It remains to show that in fact .
To see this, note that by construction, is an adjacency matrix of an infinite graph with vertex set . Moreover, all vertices reachable from an initial vertex have the form where is a path in and we define for . Note that this description is not unique: two paths define the same vertex if reduces to the same element of . Thus the vertices reachable from are uniquely indexed by paths so that is reduced, i.e., by nonbacktracking paths. We have therefore shown that is the adjecency matrix of an infinite graph, each of whose connected components is isomorphic to . ∎
Corollary 5.2 may be viewed as a far-reaching generalization of Theorem 1.3. Indeed, the permutation model of random -regular graphs is a special case of the random lift model, obtained by choosing the base graph to consist of a single vertex with self-loops (often called a “bouquet”).
Even though Corollary 5.2 is only concerned with the new eigenvalues of , it implies the classical spectral gap property whenever the base graph satisfies . Another simple consequence is that whenever the base graph satisfies , the random lift is connected with probability ; this holds if and only if has at least two cycles [73, Theorem 2].
5.2. Buser’s conjecture
Let be a hyperbolic surface, that is, a connected Riemannian surface of constant curvature . Then has the hyperbolic plane as its universal cover, and we can in fact obtain as a quotient of the hyperbolic plane by a Fuchsian group (i.e., a discrete subgroup of ) which is isomorphic to the fundamental group .
If is a closed hyperbolic surface, its Laplacian has discrete eigenvalues
The following is the direct analogue in this setting of Lemma 1.2.
Lemma 5.3 (Huber [77], Cheng [35]).
For any sequence of closed hyperbolic surfaces with diverging diameter, we have
The significance of the value is that it is the bottom of the spectrum of the Laplacian on the hyperbolic plane.
It is therefore natural to ask whether there exist closed hyperbolic surfaces with arbitrarily large diameter (or, equivalently in this setting, arbitrarily large genus) that attain this bound. The existence of such surfaces with optimal spectral gap, a long-standing conjecture181818Curiously, Buser has at different times conjectured both existence [29] and nonexistence [28] of such surfaces. On the other hand, the (very much open) Selberg eigenvalue conjecture in number theory [120] predicts that a specific class of noncompact hyperbolic surfaces have this property. of Buser [29], was resolved by Hide and Magee [69] by means of a striking application of strong convergence.
5.2.1. Random covers
The basic approach of the work of Hide and Magee is to prove an optimal spectral gap phenomenon for random covers of a given base surface , in direct analogy with the random lift model for graphs. To explain how such covers are constructed, we must first sketch the analogue in the present setting of the covering construction described in section 5.1.1.
Let us begin with an informal discussion. The action of a Fuchsian group on defines a Dirichlet fundamental domain whose translates tile ; is a polygon whose sides are given by and for some generating set of . Then is obtained from by gluing each pair of sides and . See Figure 5.2 and [12, Chapter 9].
To construct a candidate -fold cover of , we fix copies of the fundamental domain and permutations . We then glue the side to the corrsponding side , that is, we scramble the gluing of the sides between the copies of . Unlike in the case of graphs, however, it need not be the case that every choice of yields a valid covering: if we glue the sides without regard for the corners of , the resulting surface may develop singularities. The additional condition that is needed to obtain a valid covering is that must satisfy the same relations as ; that is, we must choose for some .
More formally, this construction can be implemented as follows. Fix a base surface and a homomorphism . Define
where we let act on as . Then is an -fold cover of , and every -fold cover of arises in this manner for some choice of ; cf. [64, pp. 68–70] or [53, §14a and §16d].
To define a random cover of we may now simply choose a random homomorphism , or equivalently, choose to be random permutations. The major complication that arises here is that these permutations cannot in general be chosen independently, since they must satisfy the relations of . For example, if is a closed orientable surface of genus , then is the surface group
where . In this case, the random permutations must be chosen to satisfy , which precludes them from being independent. The reason this issue does not arise for graphs is that the fundamental group of every graph is free, and thus there are no relations to be satisfied.
The above obstacle has been addressed in three distinct ways.
-
1.
While the fundamental group of a closed hyperbolic surface is never free, there are finite volume noncompact hyperbolic surfaces with a free fundamental group; e.g., the thrice punctured sphere has and admits a finite volume hyperbolic metric with three cusps. Thus random covers of such surfaces can be defined using independent random permutation matrices. Hide and Magee [69] proved an optimal spectal gap phenomenon for this model; this leads indirectly to a solution to Buser’s conjecture by compactifying the resulting surfaces.
-
2.
Louder and Magee [86] showed that surface groups can be approximately embedded in free groups by mapping each generator of to a suitable word in the free group. This gives rise to a non-uniform random model of covers of closed hyperbolic surfaces by choosing that maps each generator of to the coresponding word in independent random permutation matrices.
-
3.
Finally, the most natural model of random covers of closed surfaces is to choose uniformly at random, that is, choose uniformly at random among the set of tuples that satisfy the relation of . This corresponds to choosing an -fold cover of uniformly at random [91]. The challenge in analyzing this model is that have a complicated dependence structure that cannot be reduced to independent random permutations.
These three approaches give rise to distinct models of random covers. The advantage of the first two approaches is that their analysis is based on strong convergence of independent random permutations (Theorem 1.4). This suffices for proving the existence of covers with optimal spectral gaps, i.e., to resolve Buser’s conjecture, but leaves unclear whether optimal spectral gaps are rare or common. That typical covers of closed surfaces have an optimal spectral gap was recently proved by Magee, Puder, and the author [92] by resolving the strong convergence problem for uniformly random (cf. section 6.1).
The aim of the remainder of this section is to sketch how the optimal spectral gap problem for the Laplacian of a random cover is encoded as a strong convergence problem. This reduction proceeds in an analogous manner for the three models described above. We therefore fix in the following a base surface and a sequence of random homomorphisms as in any of the above models. The key assumption that will be needed, which holds in all three models, is that the random matrices defined by
| converge strongly to the operators defined by | ||||
Here we implicitly identify with the corresponding permutation matrix, and denotes the left-regular representation of .
Remark 5.4.
Beside models of random covers of hyperbolic surfaces, another important model of random surfaces is obtained by sampling from the Weil–Petersson measure on the moduli space of hyperbolic surfaces of genus ; this may be viewed as the natural notion of a typical surface of genus . In a recent tour-de-force, Anantharaman and Monk [4, 5] proved that the Weil–Petersson model also exhibits an optimal spectral gap phenomenon by using methods inspired by Friedman’s original proof of Theorem 1.3. In contrast to random cover models, it does not appear that this problem can be reduced to a strong convergence problem. However, it is an interesting question whether a form of the polynomial method, which plays a key role in [92], could be used to obtain a new proof of this result.
5.2.2. Exploiting strong convergence
In contrast to the setting of random lifts of graphs, it is not immediately clear how the Laplacian spectrum of random surface covers relates to strong convergence. This connection is due to Hide and Magee [69]; for expository purposes, we sketch a variant of their argument [70].
We begin with some basic observations. Any lifts to a function in by composing it with the covering map . As
it follows precisely as for random lifts of graphs that the spectrum of the base surface is a subset of that of any of its covers . What we aim to show is that the smallest new eigenvalue of , that is, the smallest eigenvalue of its restriction to the orthogonal complement of functions lifted from , converges to the bottom of the spectrum of . In other words, we aim to prove that
This leads us to consider the heat operators and .
Recall that is an integral operator on with a smooth kernel . The Laplacian on is obtained by restricting the Laplacian on to functions that are invariant under . In particular, this implies that may be viewed as an integral operator on with kernel
by parameterizing as , where is the fundamental domain of the action of on . See, for example, [17, §3.7] or [70, §2].
In the following, we identify , and denote by the integral operator on with kernel . In this notation, the above expression can be rewritten in the more suggestive form
| In particular, we have | ||||
Since is a homomorphism, each can be written as a word in the random permutation matrices associated to the generators of . Thus is nearly, but not exactly, a noncommutative polynomial of with matrix coefficients:
-
The above sum is over all with no bound on the word length . However, as decays rapidly as a function of (this can be read off from the explicit expression for [69] or from general heat kernel estimates [70]), the size of the coefficients decays rapidly as function of . The infinite sum is therefore well approximated by a finite sum.
We therefore conclude that is well approximated in operator norm by a noncommutative polynomial in with matrix coefficients. In particular, we can apply strong convergence to conclude that
with
It remains to observe that the operator is in disguise. To see this, note that the map defined by is a.e. invertible, as the translates of the fundamental domain tile . Thus defines an isomorphism . We can now readily compute for any
where we used that .
Remark 5.5.
There are several variants of the above argument. The original work of Hide and Magee [69] used the resolvent instead of . The heat operator approach of Hide–Moy–Naud [70, 103] has the advantage that it extends to surfaces with variable negative curvature by using heat kernel estimates. For hyperbolic surfaces, another variant due to Hide–Macera–Thomas [68] uses a specially designed function with the property that is already a noncommutative polynomial of with operator coefficients, avoiding the need to truncate the sum over . The advantage of this approach is that it leads to much better quantitative estimates, since the truncation of the sum is the main source of loss in the previous arguments. Finally, Magee [88] presents a more general perspective that uses the continuity of induced representations under strong convergence.
5.3. Random Schreier graphs
In this section, we take a different perspective on random regular graphs that will lead us in a new direction.
Definition 5.6.
Given and an action of the symmetric group on a finite set , the Schreier graph is the -regular graph with vertex set , where each vertex has neighbors for (allowing for multiple edges and self-loops).
The permutation model of random -regular graphs that was introduced in section 1.1 is merely the special case where is the natural action of permutations of on the points of , and are independent and uniformly distributed random elements of .
We may however ask what happens if we consider other actions of the symmetric group. Following [51, 30], denote by the set of all -tuples of distinct elements of . Then we obtain the natural action by letting act on each element of the tuple, that is, . If we again choose to be i.i.d. uniform random elements of , then
yields a new model of random -regular graphs that generalizes the permutation model. The interesting aspect of these graphs is that even though the number of vertices grows rapidly as we increase , the number of random bits that generate the graph is fixed independently of . We may therefore think of the model as becoming increasingly less random as is increased.191919A different, much less explicit approach to derandomization of random graphs from a theoretical computer science perspective may be found in [101, 107].
What is far from obvious is whether the optimal spectral gap of the random graph persists as we increase . Let us consider the two extremes.
-
The case is the permutation model of random regular graphs, which have an optimal spectral gap by Theorem 1.3.
-
The case corresponds to the Cayley graph of with the random generators , since . Whether random Cayley graphs of have an optimal spectral gap is a long-standing question (see section 6.2) that remains wide open: it has not even been shown that the maximum nontrivial eigenvalue is bounded away from the trivial eigenvalue in this setting.
The intermediate values of interpolate between these two extremes. In a major improvement over previously known results, Cassidy [30] recently proved that the optimal spectral gap persists in the range for some .
Theorem 5.7.
Denote by the adjacency matrix of where are i.i.d. uniform random elements of . Then
as whenever , for any .
This yields a natural model of random -regular graphs with vertices that has an optimal spectral gap using only bits of randomness, as compared to bits for ordinary random regular graphs.
Theorem 5.7 arises from a much more general result about strong convergence of representations of . To motivate this result, note that we can write
where maps to the permutation matrix defined by its action on . Then is clearly a group representation of , so it decomposes as a direct sum of irreducible representations . Theorem 5.7 now follows from the following result about strong convergence of irreducible representations of that vastly generalizes Theorem 1.4 (which is the special case where is the standard representation, so that ). For expository purposes, we state the result in a slightly more general form than is given in [30].
Theorem 5.8.
Let be i.i.d. uniform random elements of , and let be defined as in Theorem 1.4. Then
in probability for every , , and , where the maximum is taken over irreducible representations of .
Proof.
The irreducible representations are indexed by Young diagrams . The argument in [47, §6] shows that for any and sufficiently large , every irreducible representation with has the property that the first row of either or of the conjugate diagram has length at least . In the first case, the conclusion
| (5.1) |
follows from the proof of [30, Theorem 1.9].
The above results are made possible by a marriage of two complementary developments: new representation-theoretic ideas due Cassidy, and the polynomial method for proving strong convergence. Here, we merely give a hint of the underlying phenomenon, and refer to [30] for the details.
Fix , and consider the sequence of Young diagrams (for ) so that removing the first row of yields ; in particular, the first row has length . Then the sequence of representations is called stable [48]. As was the case in section 3, any stable representation has the property that
is a rational function of . Moreover, as in Corollary 3.5,
| (5.2) |
if is a non-power, where are free generators of ; see [63]. These facts already suffice, by the polynomial method, for proving a form of Theorem 5.8 that applies to representations of polynomial dimension for any fixed [32]. This falls far short, however, of Theorem 5.8.
The key new ingredient that is developed in [30] is a major improvement of (5.2): when is a non-power, it turns out that in fact
The surprising aspect of this bound is that it exhibits more cancellation as the dimension of the representation increases—contrary to what one may expect, since the model becomes “less random”. This phenomenon therefore captures a kind of pseudorandomness in high-dimensional representations. This is achieved in [30] by combining a new representation of the stable characters of with ideas from low-dimensional topology. The improved estimate makes it possible to Taylor expand the rational function to much higher order in the polynomial method, enabling it to reach representations of quasi-exponential dimension.
Taken more broadly, high dimensional representations of finite and matrix groups form a natural setting for the study of strong convergence and give rise to many interesting questions. For the unitary group , strong convergence was established earlier by Bordenave and Collins [21] for representations of polynomial dimension , and by Magee and de la Salle [90] for representations of quasi-exponential dimension (further improved in [33] using complementary ideas). On the other hand it is a folklore conjecture (see, e.g., [119, Conjecture 1.6]) that any sequence of representations of of diverging dimension should give rise to optimal spectral gaps; Theorem 5.8 is at present the best known result in this direction. Analogous questions for finite simple groups of Lie type remain entirely open.
5.4. The Peterson–Thom conjecture
In this section, we discuss a very different application of strong convergence to the theory of von Neumann algebras, which has motivated many recent works in this area.
Recall that a von Neumann algebra is defined as a unital -algebra, but is closed in the strong operator topology rather than the operator norm topology; see Remark 2.5. An important example is the free group factor
i.e., the closure of in the strong operator topology. Von Neumann algebras are much “bigger” than -algebras and thus much less well understood; for example, it is not even known whether or not and are isomorphic for , which is one of the major open problems in this area.
However, the subclass of amenable von Neumann algebras—the counterpart in this context of the notion of an amenable group—is very well understood due to the work of Connes [43]. For example, amenable von Neumann algebras can be characterized as those that are approximately finite dimensional, i.e., the closure in the strong operator topology of an increasing net of matrix algebras. It is therefore natural to try to gain a better understanding of non-amenable von Neumann algebras such as by studying the collection of its amenable subalgebras. The following conjecture of Peterson and Thom [113]—now a theorem due to the works to be discussed below—is in this spirit: it states that two distinct maximal amenable subalgebras of cannot have a too large overlap.
Theorem 5.9 (Peterson–Thom conjecture).
Let . If and are distinct maximal amenable von Neumann subalgebras of , then is not diffuse.
A von Neumann algebra is called diffuse if it has no minimal projection. Being non-diffuse is a strong constraint: if is not diffuse, then the spectral distribution of every self-adjoint must have an atom. (Here and below, we always compute laws with respect to the canonical trace on .)
Example 5.10.
Let be the von Neumann subalgebra of generated by , where are free generators of . Then are maximal amenable, but is trivial and thus certainly not diffuse.
The affirmative solution of the Peterson-Thom conjecture was made possible by the work of Hayes [65], who in fact provides a much stronger result. For every von Neumann subalgebra , Hayes defines a quantity called the -bounded entropy in the presence of , see [66, §2.2 and Appendix], that satisfies for every and if is amenable. Hayes’ main result is that the converse of this property also holds—thus providing an entropic characterization of amenable subalgebras of .
Theorem 5.11 (Hayes).
is amenable if and only if .
Theorem 5.9 follows immediately from Theorem 5.11 using the following subadditivity property of the -bounded entropy [66, §2.2]:
whenever is diffuse, where is the von Neumann algebra generated by . Indeed, it follows that if are amenable and is diffuse then is amenable, so cannot be maximal amenable.
Theorem 5.11 is not stated as such in [65]. The key insight of Hayes was that the validity of Theorem 5.11 can be reduced (in a highly nontrivial fashion) to proving strong convergence of a certain random matrix model. This problem was outside the reach of the methods that were available when [65] was written, and thus Theorem 5.11 was given there as a conditional statement. Hayes’ work strongly influenced new developments on the random matrix side, and the requisite strong convergence has now been proved by several approaches [15, 20, 90, 111, 33]. This has in turn not only completed the proofs of Theorems 5.9 and 5.11, but also led to new developments on the operator algebras side [66].
In the remainder of this section, we aim to discuss the relevant strong convergence problem, and to give a hint as to how it gives rise to Theorem 5.11.
5.4.1. Tensor models
Let be independent Haar-distributed random unitary matrices of dimension , and let be the standard generators of as defined in section 1.1. That strongly converges to is a consequence of the Haagerup-Thorbjørnsen theorem for GUE matrices, as was shown by Collins and Male [41]. The basic question posed by Hayes is whether strong convergence continues to hold if we consider the tensor product of two independent copies of this model. More precisely:
Question.
Let be an independent copy of . Is it true that the family
| of random unitaries of dimension converges strongly to | ||||
as ?202020Recall that we always denote by the minimal tensor product, see section 2.4. (Alternatively, one may replace by independent GUE matrices and by a free semicircular family.)
The main result of Hayes [65, Theorem 1.1] states that an affirmative answer to this question implies the validity of Theorem 5.11.
Because and are independent, it is natural to attempt to apply strong convergence of each copy separately. To this end, note that for any noncommutative polynomial , we can write
where is a noncommutative polynomial with matrix coefficients of dimension that depend only on . We can now condition on and think of as a determinstic polynomial with matrix coefficients. In particular, one may hope to use strong convergence of to to show that
| (5.3) |
as . If (5.3) holds, then the proof of strong convergence of the tensor model is readily completed. Indeed, we may now write where is a polynomial with operator coefficients that depend only on . Since is exact, Lemma 2.18 yields
as . Finally, as
the desired strong convergence property is established.
This argument reduces the question of strong convergence of the tensor product of two independent families of random unitaries to a question about strong convergence (5.3) of a single family of random unitaries for polynomials with matrix coefficients. The latter is far from obvious, however. While norm convergence of any fixed polynomial with matrix coefficients is an automatic consequence of strong convergence of (Lemma 2.16), here the polynomial and the dimension of the matrix coefficients changes with . This cannot follow from strong convergence alone, but may be obtained if the proof of strong convergence provides sufficiently strong quantitative estimates.
The question of strong convergence of polynomials with matrix coefficients of increasing dimension was first raised by Pisier [116] in his study of subexponential operator spaces. Pisier noted that (5.3) can fail for matrix coefficients of dimension (see [33, Appendix A]); while a careful inspection of the quantitative estimates in the strong convergence proof of Haagerup–Thorbjørnsen yields that (5.3) holds for matrix coefficients of dimension . This leaves a huge gap between the upper and lower bound, and in particular excludes the case that is required to prove Theorem 5.11.
Recent advances in strong convergence have led to a greatly improved understanding of this problem by means of several independent methods [20, 90, 111, 33], all of which suffice to complete the proof of Theorem 5.11. The best result to date, obtained by the polynomial method [33], is that strong convergence in the GUE and Haar unitary models remains valid for matrix coefficients of dimension . Let us briefly sketch how this is achieved.
The arguments that we developed in section 3 for random permutation matrices can be applied in a very similar manner to random unitary matrices. In particular, one obtains as in the proof of Proposition 3.2 an estimate of the form
Here is any noncommutative polynomial with matrix coefficients of dimension , is an absolute constant, is a constant that depends only on the degree of , and are Schwartz distributions that are supported in . If we choose a test function that vanishes in the latter interval, we obtain
as has dimension . Repeating the proof of Theorem 1.4 now yields strong convergence whenever the right-hand side is , that is, for . This does not suffice to prove the Peterson-Thom conjecture.
The above estimate was obtained by Taylor expanding the rational function in the polynomial method to first order. Nothing is preventing us, however, from expanding to higher order ; then a very similar argument yields
where all are Schwartz distributions. The new ingredient that now arises is that we must show that the support of each is included in . Surprisingly, a very simple technique that is developed in [33] (see also [110, 109]) shows that this property follows automatically in the present setting from concentration of measure. This yields strong convergence for for any . Reaching is harder and requires several additional ideas.
5.4.2. Some ideas behind the reduction
In the remainder of this section, we aim to give a hint as to how the purely operator-algebraic statement of Theorem 5.11 is reduced to a strong convergence problem. Since we cannot do justice to the details of the argument within the scope of this survey, we must content ourselves with an impressionistic sketch. From now on, we fix a nonamenable with , and aim to prove a contradiction.
The starting point for the proof is the following theorem of Haagerup and Connes [58, Lemma 2.2] that provides a spectral characterization of amenability.
Theorem 5.12 (Haagerup–Connes).
A tracial von Neumann algebra is nonamenable if and only if there is a nontrivial projection that commutes with every element of , and unitaries , so that satisfy
Here denotes the complex conjugate of an operator .212121More concretely, if is a matrix, then it conjugate may be identified with the elementwise complex conjugate of ; while if is a polynomial in the standard generators of , then its conjugate may be identified with the polynomial where the coefficients of are the complex conjugates of the coefficients of .
The above spectral property is very much false for matrices: if where are unitary matrices and is nontrivial projection that commutes with them, and we define the unit norm vector , then
| (5.4) |
Of course, this just shows that is amenable.
Since we assumed that is nonamenable, we can choose as in Theorem 5.12. To simplify the discussion, let us suppose that are polynomials of the standard generators of : this clearly need not be true in general, and we will return to this issue at the end of this section. Let
Then strong convergence of implies that there exists with
| (5.5) |
with probability as . The crux of the proof is now to show that implies “microstate collapse”: with high probability, there is a unitary matrix so that for all . Thus (5.5) contradicts (5.4), and we have achieved the desired conclusion.
We now aim to explain the origin of microstates collapse without giving a precise definition of . Roughly speaking, measures the growth rate as of the metric entropy with respect to the metric
of the set of families of -dimensional matrices whose law lies in a weak∗ neighborhood of the law of (recall that the notion of a law was defined in the proof of Lemma 2.13; in particular, weak∗ convergence of laws is equivalent to weak convergence of matrices). As converges weakly to , the following is essentially a consequence of the definition: if , then for all sufficiently large, there is a set so that
and can be covered by balls of radius in the metric . In particular, this implies that at least one of these balls must have probability greater than ; in other words, there exist nonrandom so that
We now conclude by a beautiful application of the concentration of measure phenomenon [83], which states in the present context that for any set such that , taking an -neighborhood of with respect to the metric yields . Thus we finally obtain
Since is an independent copy of and thus satisfies the same property, it follows that with probability .
While we have overlooked many details in the above sketch of the proof, we made one simplification that is especially problematic: we assumed that are polynomials of the standard generators . In general, however, all we know is that can be approximated by such polynomials in the strong operator topology. This does not suffice for our purposes, since such an approximation need not preserve the conclusion of Theorem 5.12 on the norm of (tensor products of) . Indeed, from a broader perspective, it seems surprising that strong convergence has anything meaningful to say about the von Neumann algebra : strong convergence is a statement about norms of polynomials, so it would appear that it should not provide any meaningful information on objects that live outside the norm-closure of the set of polynomials of the standard generators.
This issue is surmounted in [65] by using that any given can be approximated by in a special way: not only do in the strong operator topology, but in addition are contractive completely positive maps (this uses exactness of ). Consequently, even though the approximation does not preserve the norm, it preserves the upper bound on the norm that appears in Theorem 5.12. Since only the upper bound is needed in the proof, this suffices to make the rest of the argument work.
5.5. Minimal surfaces
We finally discuss yet another unexpected application of strong convergence to the theory of minimal surfaces.
An immersed surface in a Riemannian manifold is called a minimal surface if it is a critical point (or, what is equivalent in this case, a local minimizer) of the area under compact perturbations; think of a soap film. Minimal surfaces have fascinated mathematicians since the 18th century and are a major research topic in geometric analysis; see [98, 38] for an introduction.
We will use a slightly more general notion of a minimal surface that need only be immersed outside a set of isolated branch points (at which the surface can self-intersect locally), cf. [56]. These objects, called branched minimal surfaces, arise naturally when taking limits of immersed minimal surfaces. For simplicity we will take “minimal surface” to mean a branched minimal surface.
A basic question one may ask is how the geometry of a minimal surface is constrained by that of the manifold it sits in. For example, a question in this spirit is: can an -dimensional sphere—a manifold with constant positive curvature—contain a minimal surface that has constant negative curvature? It was shown by Bryant [26] that the answer is no. Thus the following result of Song [122], which shows the answer is “almost” yes in high dimension, appears rather surprising.
Theorem 5.13 (Song).
There exist closed minimal surfaces in Euclidean unit spheres so that the Gaussian curvature of satisfies
The minimal surfaces in this theorem arise from a random construction: one finds, by a variational argument, a sequence of minimal surfaces in finite-dimensional spheres that are symmetric under the action of a set of random rotations. Strong convergence is applied in the analysis in a non-obvious manner to understand the limiting behavior of these surfaces.
In the remainder of this section, we aim to give an impressionistic sketch of some of the ingredients of the proof of Theorem 5.13. Our primary aim is to give a hint of the role that strong convergence plays in the proof.
5.5.1. Harmonic maps
We must first recall the connection between minimal surfaces and harmonic maps. If is a map from a Riemann surface to a Riemannian manifold , its Dirichlet energy is defined by
A critical point of the energy is called a harmonic map. If is weakly conformal (i.e., conformal away from branch points), then coincides with the area of the surface in . Thus a weakly conformal map is harmonic if and only if is a minimal surface in . See, e.g., [102, §4.2.1].
This viewpoint yields a variational method for constructing minimal surfaces. Clearly any minimizer of the energy is, by definition, a harmonic map. In general, such a map is not guaranteed to be weakly conformal. However, this will be the case if we take to be a surface with a unique conformal class—the thrice punctured sphere—and then a minimizer of automatically defines a minimal surface in . We will make this choice of from now on.222222More generally, one obtains minimal surfaces by minimizing the energy both with respect to the map and with respect to the conformal class of ; see [102, Theorem 4.8.6].
The construction in [122] uses a variant of the variational method which produces minimal surfaces that have many symmetries. Let us write , and consider a unitary representation with finite range which we view as acting on the unit sphere of with its standard Euclidean metric. The following variational problem is considered in [122]:
where is the fundamental domain of the action of on . To interpret this variational problem, note that a -equivariant map can be identified with a map on the surface , where232323As has finite range, is a finite index subgroup of and thus is a finite cover of . This construction of covering spaces is different than the one considered in section 5.2.
Since a minimizer in minimizes the Dirichlet energy, it defines242424Even though has punctures, taking the closure of yields a closed surface. This is a nontrivial property of harmonic maps, see [102, §4.6.4]. a minimal surface in that has many symmetries (it contains many rotated copies of the image of the fundamental domain).
Once a minimizer has been chosen for every , we can take to obtain a limiting object. Indeed, if we embed each in the unit sphere of an infinite-dimensional Hilbert space , we can view all on the same footing. Then the properties of harmonic maps furnish enough compactness to ensure that converges along a subsequence to a limiting map , which is -equivariant for some unitary representation .
5.5.2. An infinite-dimensional model
So far, it is not at all clear why choosing our energy-minimizing maps to have many symmetries helps our cause. The reason is that certain equivariant maps into the infinite-dimensional sphere turn out to have remarkable properties, which will make it possible to realize them as the limit of the finite-dimensional minimal surfaces constructed above.
Recall that minimal surfaces in the spheres cannot have constant negative curvature. The situation is very different, however, in infinite dimension: one can isometrically embed the hyperbolic plane in the Hilbert sphere by means of an energy-minimizing map. What is more surprising is that this phenomenon is very rigid: any energy-minimizing map that is equivariant with respect to a certain class of representations is necessarily an isometry.
More precisely, we have the following [122, Corollary 2.4]. Here two unitary representations and are said to be weakly equivalent if any matrix element of can be approximated uniformly on compacts by finite linear combinations of matrix elements of , and vice versa.
Theorem 5.14.
Let be a unitary representation of that is weakly equivalent to the regular representation . Then any -equivariant energy-minimizing map must satisfy , where denotes the hyperbolic metric on (so is the metric on with constant curvature ).
The proof of this result is one of the main ingredients of [122]. Very roughly speaking, one first produces a single and that satisfy the conclusion of the theorem by an explicit construction; weak equivalence is then used to transfer the conclusion to other and as in the theorem.
Theorem 5.14 explains the utility of constructing equivariant minimal surfaces: if we choose the sequence of representations in such a way that the limiting representation is weakly equivalent to the regular representation, then this will automatically imply that the metrics on the minimal surfaces converge to the metric with constant curvature .
5.5.3. Weak containment and strong convergence
At first sight, none of the above appears to be related to strong convergence. However, the following classical result [13, Theorem F.4.4] makes the connection immediately obvious.
Proposition 5.15.
Let be a finitely generated group with generating set , and let and be unitary representations. Then the following are equivalent:
-
1.
and are weakly equivalent.
-
2.
for all .
In the present setting, is the thrice punctured sphere whose fundamental group is . Thus we can define a random representation with finite range by choosing and , where are independent random permutation matrices of dimension and we identified . Since Theorem 1.4 yields
it follows from Proposition 5.15 that the limiting representation must be weakly equivalent to the regular representation. Thus we obtain a sequence of random minimal surfaces in with the desired property.
6. Open problems
Despite rapid developments on the topic of strong convergence in recent years, many challenging questions remain poorly understood. We therefore conclude this survey by highlighting a number of open problems and research directions.
6.1. Strong convergence without freeness
Until recently, nearly all known strong convergence results were concerned with polynomials of independent random matrices, and thus with limiting objects that are free. As we have seen in section 5.2, however, it is of considerable interest in applications to achieve strong convergence in non-free settings; for example, to establish optimal spectral gaps for random covers of hyperbolic manifolds, one needs models of random permutation matrices that converge strongly to the regular representation of the fundamental group of the base manifold. Such questions are challenging, in part, because they give rise to complicated dependent models of random matrices.
The systematic study of strong convergence to the regular representation of non-free groups was pioneered by Magee; see the survey [88]. To date, a small number of positive results are known in this direction:
-
Louder and Magee [86] show that there are models of random permutation matrices that strongly converge to the regular representation of any fully residually free group: that is, a group that locally embeds in a free group. The prime example of finitely residually free groups are surface groups.
-
Magee and Thomas [93] show that there are models of random unitary (but not permutation!) matrices that strongly converge to the regular representation of any right-angled Artin group; these are obtained from GUE matrices that act on overlapping factors of a tensor product (see also [33, §9.4]). This also implies a strong convergence result for any group that virtually embeds in a right-angled Artin group, such as fundamental groups of closed hyperbolic -manifolds.
-
Magee, Puder, and the author [92] show that uniformly random permutation representations of the fundamental groups of orientable closed hyperbolic surfaces strongly converge to the regular representation.
On the other hand, not every discrete group admits a strongly convergent model: there cannot be a model of random permutation matrices that strongly converges to the regular representation of (a very special case of a right-angled Artin group) [88, Proposition 2.7], or a model of random unitary matrices that converges strongly to the regular representation of with [89]. Thus existence of strongly convergent models cannot be taken for granted.
To give a hint of the difficulties that arise in non-free settings, recall that the fundamental group of a closed orientable surface of genus is
The most natural random matrix model of this group is obtained by sampling -tuples of random permutation matrices uniformly at random from the set of such matrices that satisfy . This constraint introduces complicated dependencies, which causes the model to behave very differently than independent random permutation matrices. For example, unlike in the setting of section 3, the expected traces of monomials of these matrices are not even analytic, let alone rational, as a function of .
For surface groups, one can use the representation theory of to analyze this model; in particular, this enabled Magee–Naud–Puder [91] to show that its spectral statistics admit an asymptotic expansion in . The proof of strong convergence of this model in [92] is made possible by an extension of the polynomial method to models that admit “good” asymptotic expansions.
However, even for models that look superficially similar to surface groups, essentially nothing is known. For example, perhaps the the simplest fundamental group of a (non-orientable, finite volume) hyperbolic -manifold is
This is the fundamental group of the Gieseking manifold, which is obtained by gluing the sides of a tetrahedron [94, §V.2]. Whether sampling uniformly from the set of permutation matrices with yields a strongly convergent model is not known. Such questions are of considerable interest, since they provide a route to extending Buser’s conjecture to higher dimensions.
6.2. Random Cayley graphs
Let be i.i.d. uniform random elements of , and let be an irreducible representation of . The results in section 5.3 show that the random matrices strongly converge to the regular representation of the free generators of for any sequence of irreducible representations with . What happens beyond this regime is a mystery: it may even be the case that strong convergence holds for any irreducible representations with .
Such questions are of particular interest since they are closely connected to the expansion of random Cayley graphs of finite groups. Let us recall that the Cayley graph is the graph whose vertex set is , and whose edges are defined by connecting each vertex to its neighbors and for . Its adjacency matrix is therefore given by
where is the left-regular representation of . It is a folklore question whether there are sequences of finite groups so that, if generators are chosen independently and uniformly at random, the assocated Cayley graph has an optimal spectral gap. This question is open for any sequence of finite groups.
Now recall that every irreducible representation of a finite group is contained in its regular representation with multiplicity equal to its dimension. Thus
where the supremum is over all nontrivial irreducible representations (the trivial repesentation is removed by restricting to ). Thus in order to establish optimal spectral gaps for Cayley graphs, we must understand the random matrices defined by all irreducible representations .
Note that random Cayley graphs of cannot have an optimal spectral gap with probability , as there is a nontrivial -dimensional representation (the sign representation). The latter produces a single eigenvalue that is distributed as twice the sum of independent Bernoulli variables, which exceeds the lower bound of Lemma 1.2 with constant probability. Thus we interpret the optimal spectral gap question to mean whether all eigenvalues, except those coming from the trivial and sign representations, meet the lower bound with probability . That this is the case is a well known conjecture, see, e.g., [119, Conjecture 1.6]. However, to date it has not even been shown that such graphs are expanders, i.e., that their nontrivial eigenvalues are bounded away from the trivial eigenvalue as ; nor is there any known construction of Cayley graphs of that achieve an optimal spectral gap. The only known result, due to Kassabov [79], is that there exists a choice of generators for which the Cayley graph is an expander.
The analogous question is of significant interest for other finite groups, such as (here we may take either or ). In some ways, these groups are considerably better understood than the symmetric group: in this setting, Bourgain and Gamburd [22] (see also [123]) show that random Cayley graphs are expanders, while Lubotzky–Phillips–Sarnak [87] and Margulis [97] provide a determinstic choice of generators for which the Cayley graph has an optimal spectral gap. That random Cayley graphs of these groups have an optimal spectral gap is suggested by numerical evidence [82, 81, 119]. However, the study of strong convergence in the context of such groups has so far remained out of reach.
Remark 6.1.
The above questions are concerned with random Cayley graphs with a bounded number of generators. If the number of generators is allowed to diverge with the size of the group, rather general results are known: expansion follows from a classical result of Alon and Roichman [1], while optimal spectral gaps were obtained by Brailovskaya and the author in [23, §3.2.3].
6.3. Representations of a fixed group
In section 5.3 and above, we always considered strong convergence in the context of a sequence of groups of increasing size and a representation of each . It is a tantalizing question [21] whether strong convergence might even arise when the group is fixed, and we take a sequence of irreducible representations of of dimension tending to infinity. Since the entropy of the random generators that are sampled from the group is now fixed, strong convergence would have to arise in this setting entirely from the pseudorandom behavior of high-dimensional representations.
This situation cannot arise, of course, for a finite group , since it has only finitely many irreducible representations. The question makes sense, however, when is a compact Lie group. The simplest model of this kind arises when , which has a single sequence of irreducible representations where is the standard representation. The question is then, if are sampled independently from the Haar measure on , whether strongly converges to the regular representation of the free generators of . A special case of this question is discussed in detail by Gamburd–Jakobson–Sarnak [54], who present numerical evidence in its favor.
Let us note that while strong convergence of representations of a fixed group is poorly understood, the corresponding weak convergence property is known to hold in great generality. For example, if are sampled independently from the Haar measure on any compact connected semisimple Lie group , and if is any sequence of irreducible representations of with , then converges weakly to ; see [9, Proposition 7.2(1)].
6.4. Deterministic constructions
To date, all known instances of the strong convergence phenomenon require random constructions (except in amenable situations, cf. [88, §2.1]). This is in contrast to the setting of graphs with an optimal spectral gap, for which explicit deterministic constructions exist and even predate the understanding of random graphs [87, 97]. It remains a major challenge to achieve strong convergence by a deterministic construction.
A potential candidate arises from the celebrated works of Lubotzky–Phillips–Sarnak [87] and Margulis [97], who show that the Cayley graph of defined by a certain explicit deterministic choice of generators has an optimal spectral gap. We may therefore ask, by extension, whether the matrices obtained by applying the regular representation of to these generators converge strongly to the regular representation of the free generators of (cf. section 6.2). This question was raised by Voiculescu [127, p. 146] in an early paper that motivated the development of strong convergence of random matrices by Haagerup and Thorbjørnsen. However, the deterministic question remains open, and the methods of [87, 97] appear to be powerless for addressing this question.
Another tantalizing candidate is the following simple model. Let be a prime and be the projective line over ; thus may take the values . acts on by Möbius transformations
this is just the linear action of if we parametrize by homogeneous coordinates . Let be the homomorphism defined by this action, that is, is the permutation of the elements of that maps to . The question is whether the permutation matrices
converge strongly to the regular representation
for any . Numerical evidence [27, 82, 81, 119] supports this phenomenon, but a mathematical understanding remains elusive.
The above convergence was conjectured by Buck [27] for diffusion operators—that is, for polynomials with positive coefficients—and by Magee (personal communication) for arbitrary polynomials. Note, however, that these two conjectures are actually equivalent by the positivization trick (cf. Lemma 2.26 and Remark 2.27) since satisfies the rapid decay and unique trace properties [31, 14].
6.5. Ramanujan constructions
Recall that if is the adjacency matrix of a -regular graph with vertices, the lower bound of Lemma 1.2 states that
as to infinity. In this survey, we have said that a sequence of graphs has an optimal spectral gap if satisfies this bound in reverse, that is, if
However, a more precise question that has attracted significant attention in the literature is whether it is possible for graphs to have their nontrivial eigenvalues be strictly bounded by the spectral radius of the universal cover, without an error term: that is, can one have -regular graphs with vertices such that
for arbitrarily large ? Graphs satisfying this property are called Ramanujan graphs. Ramanujan graphs do indeed exist and can be obtained by several remarkable constructions; we refer to the breakthrough papers [87, 97, 96, 75].
Whether there can be a stronger notion of strong convergence that generalizes Ramanujan graphs is unclear. For example, one may ask whether there exist permutation matrices so that
| (6.1) |
for every polynomial , where are as defined in Theorem 1.4. It cannot be the case that (6.1) holds simultaneously for all in fixed dimension , since that would imply by Lemma 2.13 that embeds in . However, we are not aware of an obstruction to the existence of so that (6.1) holds for all polynomials with a bound on the degree that diverges sufficiently slowly with . A weaker form of this question is whether for each , there exist (which may now depend on ) for arbitrarily large so that (6.1) holds.
The interest in Ramanujan graphs stems in part from an analogy with number theory: the Ramanujan property of a graph is equivalent to the validity of the Riemann hypothesis for its Ihara zeta function [124, Theorem 7.4]. In the setting of hyperbolic surfaces, the analogous “Ramanujan property” that a hyperbolic surface has is equivalent to the validity of the Riemann hypothesis for its Selberg zeta function [104, §6]. An important conjecture of Selberg [120] predicts that a specific family of hyperbolic surfaces has this property. However, no such surfaces have yet been proved to exist. The results in section 5.2 therefore provide additional motivation for studying “Ramanujan forms” of strong convergence.
6.6. The optimal dimension of matrix coefficients
The strong convergence problem for polynomials of -dimensional random matrices with matrix coefficients of dimension was discussed in section 5.4.1 in the context of the Peterson-Thom conjecture. While only the case is needed for that purpose, the optimal range of for which strong convergence holds remains open: for both Gaussian and Haar distributed matrices, it is known that strong convergence holds when and can fail when [33]. Understanding what lies in between is related to questions in operator space theory [116, §4].
From the random matrix perspective, an interesting feature of this question is that there is a basic obstacle to going beyond subexponential dimension that is explained in [33, §1.3.1]. While strong convergence is concerned with understanding extreme eigenvalues of a random matrix , essentially all known proofs of strong convergence are based on spectral statistics such as which count eigenvalues. However, when the expected number of eigenvalues of away from the support of the spectrum of may not go to zero even in situations where strong convergence holds, because polynomials with matrix coefficients can have outlier eigenvalues with very large multiplicity. Thus going beyond coefficients of exponential dimension appears to present a basic obstacle to any method of proof that uses trace statistics.
6.7. The optimal scale of fluctuations
The largest eigenvalue of a GUE matrix has fluctuations of order , and the exact (Tracy-Widom) limit distribution is known. The universality of this phenomenon has been the subject of a major research program in mathematical physics [46], and corresponding results are known for many classical models of random matrix theory. In a major breakthrough, Huang–McKenzie–Yau [75] recently showed that the largest nontrivial eigenvalue of a random regular graph has the same behavior, which implies the remarkable result that about of random regular graphs are Ramanujan.
It is natural to expect that except in degenerate situations, the same scale and edge statistics should arise in strong convergence problems. However, to date the optimal scale of fluctuations has only been established for the norm of quadratic polynomials of Wigner matrices [52]. For polynomials of arbitrary degree and for a broader class of models, the best known rate is achieved both by the interpolation [110, 109] and polynomial [33] methods.
There is, in fact, a good reason why this is the case. The model considered by Parraud in [110, 109] is somewhat more general in that it considers polynomials of both random and deterministic matrices (see section 6.8 below). In this setting, however, one can readily construct examples where is the true order of the fluctuations: for example, one may take the sum of a GUE matrix and a deterministic matrix of rank one [112]. The random matrix scale can therefore only be expected to appear for polynomials of random matrices alone.
6.8. Random and deterministic matrices
Let be i.i.d. GUE matrices, and let be deterministic matrices of the same dimension. It was realized by Male [95] that the Haagerup–Thorbjørnsen theorem admits the following extension: if it is assumed that converges strongly to some limiting family of operators , then converges strongly to where the free semicircular family is taken to be freely independent of in the sense of Voiculescu. This joint strong convergence property of random and deterministic matrices was extended to Haar unitaries by Collins and Male [41], and was developed in a nonasymptotic form by Collins, Guionnet, and Parraud [40, 108, 110, 109]. The advantage of this formulation is that it encodes a variety of applications that cannot be achieved without the inclusion of deterministic matrices.
To date, however, strong convergence of random and deterministic matrices has only been amenable to analytic methods, such those of Haagerup–Thorbjørnsen [60] or the interpolation methods of [40, 10]. Thus a counterpart of this form of strong convergence for random permutation matrices remains open. The development of such a result is motivated by various applications [8, 36, 37].
6.9. Complex eigenvalues
In contrast to the real eigenvalues of self-adjoint polynomials, complex eigenvalues of non-self-adjoint polynomials are much more poorly understood. While an upper bound on the spectral radius follows directly from strong convergence by Lemma 2.12, a lower bound on the spectral radius and convergence of the empirical distribution of the complex eigenvalues remain largely open. The difficulty here is reversed from the study of strong convergence, where an upper bound on the norm is typically the main difficulty and both a lower bound on the norm and weak convergence follow automatically by Lemma 2.13.
It is not even entirely obvious at first sight how the complex eigenvalue distribution of a non-self-adjoint operator in a -probability space should be defined. The natural object of this kind, whose definition reduces to the complex eigenvalue distribution in the case of matrices, is called the Brown measure [99, Chapter 11]. It is tempting to conjecture that if a family of random matrices strongly converges to a family of limiting operators , then the empirical distribution of the complex eigenvalues of any noncommutative polynomial should converge to . To date, this has only been proved in the special case of quadratic polynomials of independent complex Ginibre matrices [44].
One may similarly ask whether the intrinsic freeness principle extends to complex eigenvalues of non-self-adjoint random matrices. For example, is there a counterpart of Theorem 1.6 for complex eigenvalues, and if so what are the objects that should appear in it? No results of this kind have been obtained to date.
Acknowledgments
I first learned about strong convergence a decade or so ago from Gilles Pisier, who asked me about its connection with the study of nonhomogeneous random matrices. Only many years later did I come to fully appreciate the significance of this question. An informal -seminar organized by Peter Sarnak at Princeton during Fall 2023 further led to many fruitful interactions.
I am grateful to Michael Magee and Mikael de la Salle who taught me various things about this topic that could not easily be found in the literature, and to Ben Hayes and Antoine Song for explaining the material in sections 5.4–5.5 to me. It is a great pleasure to thank all my collaborators, acknowledged throughout this survey, with whom I have thought about these problems.
Last but not least, I thank the organizers of Current Developments in Mathematics for the invitation to present this survey.
The author was supported in part by NSF grant DMS-2347954. This survey was written while the author was at the Institute for Advanced Study in Princeton, NJ, which is thanked for providing a fantastic mathematical environment.
References
- [1] N. Alon and Y. Roichman. Random Cayley graphs and expanders. Random Structures Algorithms, 5(2):271–284, 1994.
- [2] J. Alt, L. Erdős, and T. Krüger. The Dyson equation with linear self-energy: spectral bands, edges and cusps. Doc. Math., 25:1421–1539, 2020.
- [3] A. Amit, N. Linial, J. Matoušek, and E. Rozenman. Random lifts of graphs. In Proceedings of the Twelfth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ’01, pages 883–894, 2001.
- [4] N. Anantharaman and L. Monk. Friedman-Ramanujan functions in random hyperbolic geometry and application to spectral gaps, 2023. arXiv:2304.02678.
- [5] N. Anantharaman and L. Monk. Friedman-Ramanujan functions in random hyperbolic geometry and application to spectral gaps II, 2025. arXiv:2502.12268.
- [6] C. Anantharaman-Delaroche. Amenability and exactness for groups, group actions and operator algebras, 2007. ESI lecture notes, HAL:cel-00360390.
- [7] G. W. Anderson. Convergence of the largest singular value of a polynomial in independent Wigner matrices. Ann. Probab., 41(3B):2103–2181, 2013.
- [8] B. Au, G. Cébron, A. Dahlqvist, F. Gabriel, and C. Male. Freeness over the diagonal for large random matrices. Ann. Probab., 49(1):157–179, 2021.
- [9] N. Avni and I. Glazer. On the Fourier coefficients of word maps on unitary groups. Compos. Math., 2025. To appear.
- [10] A. S. Bandeira, M. T. Boedihardjo, and R. van Handel. Matrix concentration inequalities and free probability. Invent. Math., 234(1):419–487, 2023.
- [11] A. S. Bandeira, G. Cipolloni, D. Schröder, and R. van Handel. Matrix concentration inequalities and free probability II. Two-sided bounds and applications, 2024. Preprint arxiv:2406.11453.
- [12] A. F. Beardon. The geometry of discrete groups, volume 91 of Graduate Texts in Mathematics. Springer-Verlag, New York, 1995. Corrected reprint of the 1983 original.
- [13] B. Bekka, P. de la Harpe, and A. Valette. Kazhdan’s property (T), volume 11 of New Mathematical Monographs. Cambridge University Press, Cambridge, 2008.
- [14] M. Bekka, M. Cowling, and P. de la Harpe. Some groups whose reduced -algebra is simple. Inst. Hautes Études Sci. Publ. Math., (80):117–134, 1994.
- [15] S. Belinschi and M. Capitaine. Strong convergence of tensor products of independent GUE matrices, 2022. Preprint arXiv:2205.07695.
- [16] C. Bennett and R. Sharpley. Interpolation of operators, volume 129 of Pure and Applied Mathematics. Academic Press, Inc., Boston, MA, 1988.
- [17] N. Bergeron. The spectrum of hyperbolic surfaces. Universitext. Springer, Cham; EDP Sciences, Les Ulis, 2016. Appendix C by Valentin Blomer and Farrell Brumley, Translated from the 2011 French original by Brumley [2857626].
- [18] C. Bordenave. A new proof of Friedman’s second eigenvalue theorem and its extension to random lifts. Ann. Sci. Éc. Norm. Supér. (4), 53(6):1393–1439, 2020.
- [19] C. Bordenave and B. Collins. Eigenvalues of random lifts and polynomials of random permutation matrices. Ann. of Math. (2), 190(3):811–875, 2019.
- [20] C. Bordenave and B. Collins. Norm of matrix-valued polynomials in random unitaries and permutations, 2024. Preprint arxiv:2304.05714v2.
- [21] C. Bordenave and B. Collins. Strong asymptotic freeness for independent uniform variables on compact groups associated to nontrivial representations. Invent. Math., 237(1):221–273, 2024.
- [22] J. Bourgain and A. Gamburd. Uniform expansion bounds for Cayley graphs of . Ann. of Math. (2), 167(2):625–642, 2008.
- [23] T. Brailovskaya and R. van Handel. Universality and sharp matrix concentration inequalities. Geom. Funct. Anal., 34(6):1734–1838, 2024.
- [24] E. Breuillard, M. Kalantar, M. Kennedy, and N. Ozawa. -simplicity and the unique trace property for discrete groups. Publ. Math. Inst. Hautes Études Sci., 126:35–71, 2017.
- [25] N. P. Brown and N. Ozawa. -algebras and finite-dimensional approximations, volume 88 of Graduate Studies in Mathematics. American Mathematical Society, Providence, RI, 2008.
- [26] R. L. Bryant. Minimal surfaces of constant curvature in . Trans. Amer. Math. Soc., 290(1):259–271, 1985.
- [27] M. W. Buck. Expanders and diffusers. SIAM J. Algebraic Discrete Methods, 7(2):282–304, 1986.
- [28] P. Buser. Cubic graphs and the first eigenvalue of a Riemann surface. Math. Z., 162(1):87–99, 1978.
- [29] P. Buser. On the bipartition of graphs. Discrete Appl. Math., 9(1):105–109, 1984.
- [30] E. Cassidy. Random permutations acting on -tuples have near-optimal spectral gap for , 2024. Preprint arxiv:2412.13941v2.
- [31] I. Chatterji. Introduction to the rapid decay property. In Around Langlands correspondences, volume 691 of Contemp. Math., pages 53–72. Amer. Math. Soc., Providence, RI, 2017.
- [32] C.-F. Chen, J. Garza-Vargas, J. A. Tropp, and R. van Handel. A new approach to strong convergence. Ann. of Math., 2025. To appear.
- [33] C.-F. Chen, J. Garza-Vargas, and R. van Handel. A new approach to strong convergence II. The classical ensembles, 2025. Preprint arxiv:2412.00593.
- [34] E. W. Cheney. Introduction to approximation theory. AMS, Providence, RI, 1998.
- [35] S. Y. Cheng. Eigenvalue comparison theorems and its geometric applications. Math. Z., 143(3):289–297, 1975.
- [36] G. Cohen, I. Cohen, and G. Maor. Tight bounds for the Zig-Zag product. In 2024 IEEE 65th Annual Symposium on Foundations of Computer Science—FOCS 2024, pages 1470–1499. IEEE Computer Soc., Los Alamitos, CA, [2024] ©2024.
- [37] G. Cohen, I. Cohen, G. Maor, and Y. Peled. Derandomized squaring: an analytical insight into its true behavior. In 16th Innovations in Theoretical Computer Science Conference, volume 325 of LIPIcs. Leibniz Int. Proc. Inform., pages Art. No. 40, 24. Schloss Dagstuhl. Leibniz-Zent. Inform., Wadern, 2025.
- [38] T. H. Colding and W. P. Minicozzi, II. A course in minimal surfaces, volume 121 of Graduate Studies in Mathematics. American Mathematical Society, Providence, RI, 2011.
- [39] B. Collins. Moment methods on compact groups: Weingarten calculus and its applications. In ICM—International Congress of Mathematicians. Vol. 4. Sections 5–8, pages 3142–3164. EMS Press, Berlin, [2023] ©2023.
- [40] B. Collins, A. Guionnet, and F. Parraud. On the operator norm of non-commutative polynomials in deterministic matrices and iid GUE matrices. Camb. J. Math., 10(1):195–260, 2022.
- [41] B. Collins and C. Male. The strong asymptotic freeness of Haar and deterministic matrices. Ann. Sci. Éc. Norm. Supér. (4), 47(1):147–163, 2014.
- [42] B. Collins, S. Matsumoto, and J. Novak. The Weingarten calculus. Notices Amer. Math. Soc., 69(5):734–745, 2022.
- [43] A. Connes. Classification of injective factors. Cases . Ann. of Math. (2), 104(1):73–115, 1976.
- [44] N. A. Cook, A. Guionnet, and J. Husson. Spectrum and pseudospectrum for quadratic polynomials in Ginibre matrices. Ann. Inst. Henri Poincaré Probab. Stat., 58(4):2284–2320, 2022.
- [45] M. de la Salle. Complete isometries between subspaces of noncommutative -spaces. J. Operator Theory, 64(2):265–298, 2010.
- [46] L. Erdős and H.-T. Yau. A dynamical approach to random matrix theory, volume 28 of Courant Lecture Notes in Mathematics. Courant Institute of Mathematical Sciences, New York; American Mathematical Society, Providence, RI, 2017.
- [47] P. Etingof. Representation theory in complex rank, I. Transform. Groups, 19(2):359–381, 2014.
- [48] B. Farb. Representation stability. In Proceedings of the International Congress of Mathematicians—Seoul 2014. Vol. II, pages 1173–1196. Kyung Moon Sa, Seoul, 2014.
- [49] J. Friedman. Relative expanders or weakly relatively Ramanujan graphs. Duke Math. J., 118(1):19–35, 2003.
- [50] J. Friedman. A proof of Alon’s second eigenvalue conjecture and related problems. Mem. Amer. Math. Soc., 195(910):viii+100, 2008.
- [51] J. Friedman, A. Joux, Y. Roichman, J. Stern, and J.-P. Tillich. The action of a few random permutations on -tuples and an application to cryptography. In STACS 96 (Grenoble, 1996), volume 1046 of Lecture Notes in Comput. Sci., pages 375–386. Springer, Berlin, 1996.
- [52] J. Fronk, T. Krüger, and Y. Nemish. Norm convergence rate for multivariate quadratic polynomials of Wigner matrices. J. Funct. Anal., 287(12):Paper No. 110647, 59, 2024.
- [53] W. Fulton. Algebraic topology, volume 153 of Graduate Texts in Mathematics. Springer-Verlag, New York, 1995. A first course.
- [54] A. Gamburd, D. Jakobson, and P. Sarnak. Spectra of elements in the group ring of . J. Eur. Math. Soc. (JEMS), 1(1):51–85, 1999.
- [55] A. Guionnet. Asymptotics of random matrices and related models, volume 130 of CBMS Regional Conference Series in Mathematics. American Mathematical Society, Providence, RI, 2019. The uses of Dyson-Schwinger equations, Published for the Conference Board of the Mathematical Sciences.
- [56] R. D. Gulliver, II, R. Osserman, and H. L. Royden. A theory of branched immersions of surfaces. Amer. J. Math., 95:750–812, 1973.
- [57] U. Haagerup. An example of a nonnuclear -algebra, which has the metric approximation property. Invent. Math., 50(3):279–293, 1978/79.
- [58] U. Haagerup. Injectivity and decomposition of completely bounded maps. In Operator algebras and their connections with topology and ergodic theory (Buşteni, 1983), volume 1132 of Lecture Notes in Math., pages 170–222. Springer, Berlin, 1985.
- [59] U. Haagerup, H. Schultz, and S. Thorbjørnsen. A random matrix approach to the lack of projections in . Adv. Math., 204(1):1–83, 2006.
- [60] U. Haagerup and S. Thorbjørnsen. A new application of random matrices: is not a group. Ann. of Math. (2), 162(2):711–775, 2005.
- [61] P. R. Halmos. Commutators of operators. II. Amer. J. Math., 76:191–198, 1954.
- [62] P. R. Halmos. A Hilbert space problem book, volume 17 of Encyclopedia of Mathematics and its Applications. Springer-Verlag, New York-Berlin, second edition, 1982. Graduate Texts in Mathematics, 19.
- [63] L. Hanany and D. Puder. Word measures on symmetric groups. Int. Math. Res. Not. IMRN, (11):9221–9297, 2023.
- [64] A. Hatcher. Algebraic topology. Cambridge University Press, Cambridge, 2002.
- [65] B. Hayes. A random matrix approach to the Peterson-Thom conjecture. Indiana Univ. Math. J., 71(3):1243–1297, 2022.
- [66] B. Hayes, D. Jekel, and S. Kunnawalkam Elayavalli. Consequences of the random matrix solution to the Peterson-Thom conjecture. Anal. PDE, 18(7):1805–1834, 2025.
- [67] J. W. Helton, R. Rashidi Far, and R. Speicher. Operator-valued semicircular elements: solving a quadratic matrix equation with positivity constraints. Int. Math. Res. Not. IMRN, (22):Art. ID rnm086, 15, 2007.
- [68] W. Hide, D. Macera, and J. Thomas. Spectral gap with polynomial rate for random covering surfaces, 2025. Preprint arxiv:2505.08479.
- [69] W. Hide and M. Magee. Near optimal spectral gaps for hyperbolic surfaces. Ann. of Math. (2), 198(2):791–824, 2023.
- [70] W. Hide, J. Moy, and F. Naud. On the spectral gap of negatively curved surface covers, 2025. Preprint arxiv:2502.10733.
- [71] S. Hoory, N. Linial, and A. Wigderson. Expander graphs and their applications. Bull. Amer. Math. Soc. (N.S.), 43(4):439–561, 2006.
- [72] L. Hörmander. The analysis of linear partial differential operators. I. Classics in Mathematics. Springer-Verlag, Berlin, 2003. Distribution theory and Fourier analysis.
- [73] B. Huang and M. Rahman. On the local geometry of graphs in terms of their spectra. European J. Combin., 81:378–393, 2019.
- [74] J. Huang, T. McKenzie, and H.-T. Yau. Optimal eigenvalue rigidity of random regular graphs, 2024. Preprint arxiv:2405.12161.
- [75] J. Huang, T. McKenzie, and H.-T. Yau. Ramanujan property and edge universality of random regular graphs, 2024. Preprint arxiv:2412.20263.
- [76] J. Huang and H.-T. Yau. Spectrum of random -regular graphs up to the edge. Comm. Pure Appl. Math., 77(3):1635–1723, 2024.
- [77] H. Huber. Über den ersten Eigenwert des Laplace-Operators auf kompakten Riemannschen Flächen. Comment. Math. Helv., 49:251–259, 1974.
- [78] G. D. James. The representation theory of the symmetric groups, volume 682 of Lecture Notes in Mathematics. Springer, Berlin, 1978.
- [79] M. Kassabov. Symmetric groups and expander graphs. Invent. Math., 170(2):327–354, 2007.
- [80] H. Kesten. Symmetric random walks on groups. Trans. Amer. Math. Soc., 92:336–354, 1959.
- [81] J. Lafferty and D. Rockmore. Numerical investigation of the spectrum for certain families of Cayley graphs. In Expanding graphs (Princeton, NJ, 1992), volume 10 of DIMACS Ser. Discrete Math. Theoret. Comput. Sci., pages 63–73. Amer. Math. Soc., Providence, RI, 1993.
- [82] J. D. Lafferty and D. Rockmore. Fast Fourier analysis for over a finite field and related numerical experiments. Experiment. Math., 1(2):115–139, 1992.
- [83] M. Ledoux. The concentration of measure phenomenon, volume 89 of Mathematical Surveys and Monographs. American Mathematical Society, Providence, RI, 2001.
- [84] F. Lehner. Computing norms of free operators with matrix coefficients. Amer. J. Math., 121(3):453–486, 1999.
- [85] N. Linial and D. Puder. Word maps and spectra of random graph lifts. Random Structures Algorithms, 37(1):100–135, 2010.
- [86] L. Louder, M. Magee, and W. Hide. Strongly convergent unitary representations of limit groups. J. Funct. Anal., 288(6):Paper No. 110803, 2025.
- [87] A. Lubotzky, R. Phillips, and P. Sarnak. Ramanujan graphs. Combinatorica, 8(3):261–277, 1988.
- [88] M. Magee. Strong convergence of unitary and permutation representations of discrete groups, 2024. Proceedings of the ECM, to appear.
- [89] M. Magee and M. de la Salle. is not purely matricial field. C. R. Math. Acad. Sci. Paris, 362:903–910, 2024.
- [90] M. Magee and M. de la Salle. Strong asymptotic freeness of Haar unitaries in quasi-exponential dimensional representations, 2024. Preprint arXiv:2409.03626.
- [91] M. Magee, F. Naud, and D. Puder. A random cover of a compact hyperbolic surface has relative spectral gap . Geom. Funct. Anal., 32(3):595–661, 2022.
- [92] M. Magee, D. Puder, and R. van Handel. Strong convergence of uniformly random permutation representations of surface groups, 2025. Preprint arxiv:2504.08988.
- [93] M. Magee and J. Thomas. Strongly convergent unitary representations of right-angled Artin groups, 2023. Preprint arxiv:2308.00863.
- [94] W. Magnus. Noneuclidean tesselations and their groups, volume Vol. 61 of Pure and Applied Mathematics. Academic Press [Harcourt Brace Jovanovich, Publishers], New York-London, 1974.
- [95] C. Male. The norm of polynomials in large random and deterministic matrices. Probab. Theory Related Fields, 154(3-4):477–532, 2012. With an appendix by Dimitri Shlyakhtenko.
- [96] A. W. Marcus, D. A. Spielman, and N. Srivastava. Interlacing families I: Bipartite Ramanujan graphs of all degrees. Ann. of Math. (2), 182(1):307–325, 2015.
- [97] G. A. Margulis. Explicit group-theoretic constructions of combinatorial schemes and their applications in the construction of expanders and concentrators. Problemy Peredachi Informatsii, 24(1):51–60, 1988.
- [98] W. H. Meeks, III and J. Pérez. The classical theory of minimal surfaces. Bull. Amer. Math. Soc. (N.S.), 48(3):325–407, 2011.
- [99] J. A. Mingo and R. Speicher. Free probability and random matrices, volume 35 of Fields Institute Monographs. Springer, New York; Fields Institute for Research in Mathematical Sciences, Toronto, ON, 2017.
- [100] A. Miyagawa. A short note on strong convergence of -Gaussians. Internat. J. Math., 34(14):Paper No. 2350087, 8, 2023.
- [101] S. Mohanty, R. O’Donnell, and P. Paredes. Explicit near-Ramanujan graphs of every degree, 2019. Preprint arXiv:1909.06988v3.
- [102] J. D. Moore. Introduction to global analysis, volume 187 of Graduate Studies in Mathematics. American Mathematical Society, Providence, RI, 2017. Minimal surfaces in Riemannian manifolds.
- [103] J. Moy. Spectral gap of random covers of negatively curved noncompact surfaces, 2025. Preprint arxiv:2505.07056.
- [104] M. R. Murty. An introduction to Selberg’s trace formula. J. Indian Math. Soc. (N.S.), 52:91–126, 1987.
- [105] A. Nica. On the number of cycles of given length of a free word in several random permutations. Random Structures Algorithms, 5(5):703–730, 1994.
- [106] A. Nica and R. Speicher. Lectures on the combinatorics of free probability. Cambridge, 2006.
- [107] R. O’Donnell and X. Wu. Explicit near-fully X-Ramanujan graphs, 2020. Preprint arXiv:2009.02595.
- [108] F. Parraud. On the operator norm of non-commutative polynomials in deterministic matrices and iid Haar unitary matrices, 2021. Preprint arXiv:2005.13834.
- [109] F. Parraud. Asymptotic expansion of smooth functions in deterministic and iid Haar unitary matrices, and application to tensor products of matrices, 2023. Preprint arXiv:2302.02943.
- [110] F. Parraud. Asymptotic expansion of smooth functions in polynomials in deterministic matrices and iid GUE matrices. Comm. Math. Phys., 399(1):249–294, 2023.
- [111] F. Parraud. The spectrum of a tensor of random and deterministic matrices, 2024. Preprint arXiv:2410.04481.
- [112] S. Péché. The largest eigenvalue of small rank perturbations of Hermitian random matrices. Probab. Theory Related Fields, 134(1):127–173, 2006.
- [113] J. Peterson and A. Thom. Group cocycles and the ring of affiliated operators. Invent. Math., 185(3):561–592, 2011.
- [114] G. Pisier. A simple proof of a theorem of Kirchberg and related results on -norms. J. Operator Theory, 35(2):317–335, 1996.
- [115] G. Pisier. Introduction to operator space theory, volume 294 of London Mathematical Society Lecture Note Series. Cambridge University Press, Cambridge, 2003.
- [116] G. Pisier. Random matrices and subexponential operator spaces. Israel J. Math., 203(1):223–273, 2014.
- [117] G. Pisier. On a linearization trick. Enseign. Math., 64(3-4):315–326, 2018.
- [118] R. T. Powers. Simplicity of the -algebra associated with the free group on two generators. Duke Math. J., 42:151–156, 1975.
- [119] I. Rivin and N. T. Sardari. Quantum chaos on random Cayley graphs of . Exp. Math., 28(3):328–341, 2019.
- [120] P. Sarnak. Selberg’s eigenvalue conjecture. Notices Amer. Math. Soc., 42(11):1272–1277, 1995.
- [121] H. Schultz. Non-commutative polynomials of independent Gaussian random matrices. The real and symplectic cases. Probab. Theory Related Fields, 131(2):261–309, 2005.
- [122] A. Song. Random harmonic maps into spheres, 2025. Preprint arxiv:2402.10287v2.
- [123] T. Tao. Expansion in finite simple groups of Lie type, volume 164 of Graduate Studies in Mathematics. American Mathematical Society, Providence, RI, 2015.
- [124] A. Terras. Zeta functions of graphs, volume 128 of Cambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, 2011. A stroll through the garden.
- [125] J. A. Tropp. Second-order matrix concentration inequalities. Appl. Comput. Harmon. Anal., 44(3):700–736, 2018.
- [126] D. Voiculescu. Limit laws for random matrices and free products. Invent. Math., 104(1):201–220, 1991.
- [127] D. Voiculescu. Around quasidiagonal operators. Integral Equations Operator Theory, 17(1):137–149, 1993.
- [128] D.-V. Voiculescu, N. Stammeier, and M. Weber, editors. Free probability and operator algebras. Münster Lectures in Mathematics. European Mathematical Society (EMS), Zürich, 2016. Lecture notes from the masterclass held in Münster, September 2–6, 2013.
- [129] E. P. Wigner. Random matrices in physics. SIAM Review, 9(1):1–23, 1967.