The Wisdom of a Crowd of Brains:
A Universal Brain Encoder
Abstract
Image-to-fMRI encoding is important for both neuroscience research and practical applications. However, such “Brain-Encoders” have been typically trained per-subject and per fMRI-dataset, thus restricted to very limited training data. In this paper we propose a Universal Brain-Encoder, which can be trained jointly on data from many different subjects/datasets/machines. What makes this possible is our new voxel-centric Encoder architecture, which learns a unique “voxel-embedding” per brain-voxel. Our Encoder trains to predict the response of each brain-voxel on every image, by directly computing the cross-attention between the brain-voxel embedding and multi-level deep image features. This voxel-centric architecture allows the functional role of each brain-voxel to naturally emerge from the voxel-image cross-attention. We show the power of this approach to: (i) combine data from multiple different subjects (a “Crowd of Brains”) to improve each individual brain-encoding, (ii) quick & effective Transfer-Learning across subjects, datasets, and machines (e.g., 3-Tesla, 7-Tesla), with few training examples, and (iii) we show the potential power of the learned voxel-embeddings to explore brain functionality (e.g., what is encoded where in the brain).
1 Introduction
fMRI (functional MRI) has emerged as a powerful tool for measuring brain activity. This enables brain scientists to explore active brain areas during various functions and behaviors (Kanwisher et al., 1997; Epstein & Kanwisher, 1998; Downing et al., 2001; Tang et al., 2017; Heeger & Ress, 2002). However, a human can spend only limited time inside an fMRI machine. This results in fMRI-datasets too small to span the huge space of brain functionality or visual stimuli (natural images). Moreover, the variability in brain structure and function responses between different people (Riddle & Purves, 1995; Frost & Goebel, 2012; Conroy et al., 2013; Zhen et al., 2015) makes it difficult to combine data across individuals that have not been exposed to the same stimuli. All of these form severe limitations on current ability to analyze brain functionality.
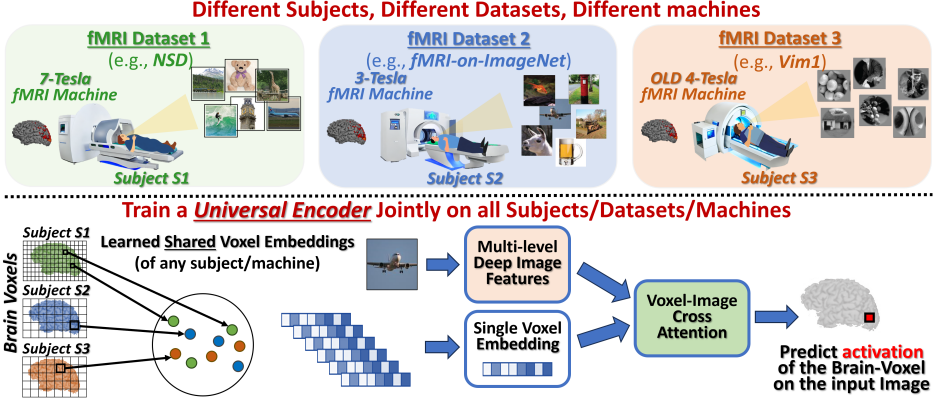
Image-to-fMRI encoding models, which predict fMRI responses to natural images, have greatly advanced the field. With the rise of deep learning, sophisticated encoding models have emerged (Yamins et al., 2014; Eickenberg et al., 2017; Wen et al., 2018c, a; Beliy et al., 2019; Gaziv et al., 2022), offering novel insights into brain function (Tang et al., 2024; Henderson et al., 2023; Gu et al., 2023; Luo et al., 2024, 2023). However, these models are primarily subject-specific and machine-specific, requiring extensive individual data (which is prohibitive) for effective training. This limits the practical use of existing brain-encoders, and prevents their ability to leverage cross-subject data. Attempts to create multi-subject encoders (e.g., (Van Uden et al., 2018; Khosla et al., 2020; Wen et al., 2018b; Gu et al., 2022)) have so far been very restrictive (see Sec. 2), showing no generalization across different datasets/machines.
In this paper, we introduce the first-ever Universal Image-to-fMRI Brain-Encoder, which jointly trains and integrates information from a collection of very different fMRI datasets acquired over the years (see Fig. 1). These multiple fMRI datasets provide multiple subjects exposed to very different image stimuli, scanned on different fMRI machines (3-Tesla, 7-Tesla), with varying number of brain-voxels (a “brain-voxel” is a tiny 3D cube of brain). What makes this possible is our new brain-voxel centric approach, which captures subject-specific and voxel-specific functionality, through a learned “voxel-embedding” vector. During training, each voxel-embedding learns to encode the unique visual functionality of the corresponding brain-voxel, while still leveraging shared patterns across different brain-voxels and different subjects (via all other shared network components). Our voxel-centric approach is in contrast to all previous fMRI-centric methods, which treat each fMRI scan as a single complete entity. They can thus exploit only shared information of the entire fMRI across different scans, overlooking the frequent similarity between different voxels within a single fMRI scan.
Our approach builds on the observation that similarity between individual voxels – both within & across brains, is more likely to occur than similarity between entire fMRI scans across different brains.
Our Encoder trains to predict the fMRI response of each brain-voxel on any input image, by aggregating the cross-attention between the brain-voxel embeddings and multi-level deep-features of the image. Each brain voxel (of every subject) has a corresponding voxel embedding. This embedding is merely a vector of size 256, which learns to capture what this brain-voxel is sensitive to: whether it attends to low-level image features or to high-level ones; whether it cares about the position of the feature in the image or not; etc. This voxel-embedding is initialized randomly, and is optimized end-to-end during training. Other than the voxel-specific embedding vectors, all other network weights are shared across all voxels of all subjects. The per-voxel Embedding puts a focus on individual voxel characteristics, independent of subject identity or fMRI dataset. This strategy provides several unique benefits: (i) The functional role of each brain-voxel naturally emerges. (ii) Being voxel-centric, the Universal Brain-Encoder architecture is indifferent to the number of voxels per fMRI scan, which enables joint training on data from fMRI machines of different scanning resolutions (e.g., 3T, 4T, 7T). (iii) Once trained, transfer learning to a new subject or a new fMRI dataset/machine requires only few new training examples.
The contributions of this paper are therefore:
-
•
The first-ever Universal Brain-Encoder, successfully integrates data from multiple diverse fMRI datasets (old & new), from many different subjects, and different fMRI machines (3T, 4T, 7T). This is made possible by our voxel-centric encoding model.
-
•
Combining data from “Crowds of Brains/Datasets” provides significantly more training data. This leads to a significant encoding improvement compared to any individually-trained subject-specific encoder.
-
•
Transfer-Learning to new subjects/datasets/machines is obtained with very few training data.
-
•
The learned “voxel-embeddings” provide a new tool to explore brain functionality, providing insights into what is encoded where in the brain. Such advanced brain exploration is facilitated by the enormous number of images collectively seen by the “crowd of brains/datasets” (which is prohibitive for any single subject).
2 Related Work
Visual Brain Encoders:
Methods for Mapping visual stimuli to brain activity (“Image-to-fMRI Encoding”), have significantly advanced over the years, with contributions to Neuroscience. Initially, these models utilized linear regression between hand-crafted image features, to predict fMRI responses on images (Kay et al., 2008; Naselaris et al., 2011). Over time, the field has evolved to incorporate deep learning approaches both for image feature extraction and training (Yamins et al., 2014; Eickenberg et al., 2017; Wen et al., 2018c, a; Beliy et al., 2019; Gaziv et al., 2022; Wang et al., 2023; Takagi & Nishimoto, 2023). These models are typically subject-specific, due to substantial differences between brain responses of different people (Riddle & Purves, 1995; Frost & Goebel, 2012; Conroy et al., 2013; Zhen et al., 2015). This restricts the encoder to subject-specific data, and limits its generalization across subjects.
Multi-Subject Brain Models: Efficiently integrating data from multiple subjects is challenging due to anatomical and functional differences between brains. While anatomical alignment (Mazziotta et al., 2001; Talairach, 1988; Fischl, 2012; Dale et al., 1999) aligns brains to a common anatomical space, it fails to provide accurate functional correspondences(Mazziotta et al., 2001; Haxby et al., 2011; Yamada et al., 2015; Brett et al., 2002; Wasserman et al., 2024). Although we deal here with Multi-Subject Brain Encoding, we review both Multi-Subject Encoding & Decoding.
Decoders:
In fMRI-to-Image decoding, the goal is to reconstruct an image given its corresponding fMRI brain recording. Recent advanced fMRI decoders leverage multi-subject data (e.g., ‘MindBridge’ (Wang et al., 2024), ‘MindEye2’ (Scotti et al., 2024b), (Gong et al., 2024) and (Han et al., 2024)), by projecting the subject-specific fMRIs of all subjects into a shared space, which is then fed into a shared image-decoding network. However, the problems of multi-subject fMRI Decoding & Encoding are fundamentally different. In multi-subject Decoding, the network inputs reside in different spaces (individual subject-specific fMRIs), whereas the network outputs reside in a shared space (the Image-Space). Thus projecting to a shared space before decoding is a valid solution. In contrast, in multi-subject Encoding, the inputs (images) reside in a shared space, whereas the outputs (individual subject-specific fMRIs) reside in completely different spaces. Thus the above approach of ‘MindBridge’&‘MindEye2’ will not apply to multi-subject Encoding, as projecting to a shared space will lose most subject-specific fMRI variability (output variability). This is resolved by our new voxel-centric model.
Encoders:
Few attempts have been made to leverage multi-subject data for Image-to-fMRI Encoding. Van Uden et al. (2018) integrated data from multiple subjects, but required them to be exposed to same images, which is very restrictive. Our approach requires NO shared data between subjects. Wen et al. (2018b) and Gu et al. (2022) finetune models of one subject to another. This allows per subject adaption, but largely limits the information sharing as they are not trained jointly. Lastly, Khosla et al. (2020) use a model with part shared and part subject-specific. However, to obtain good results they predict only a small subset of voxels which have high correlation across brains.
Finally, all previous methods (both Encoding and Decoding) are predominantly fMRI-centric. Namely, they treat each fMRI scan as a single entity, relying on shared embeddings of entire fMRI scans across subjects. Thus they can only exploit shared representations of entire fMRIs across different scans, overlooking the frequent similarity between individual brain-voxels within a single fMRI scan (a single brain), as well as across different brains. In contrast, our Voxel-centric model fundamentally shifts away from this paradigm by sharing network weights across all brain voxels – both within and across brains. Since similarity between individual voxels (within and across brains) is more frequent than similarity of entire fMRI scans, our model can effectively integrate multi-subject data.
3 The Universal-Encoder
Our Universal Encoder facilitates joint training on multi-subject data from diverse fMRI datasets, with subjects exposed to completely different image stimuli and scanned on fMRI machines with very differing resolutions (see Fig. 1).
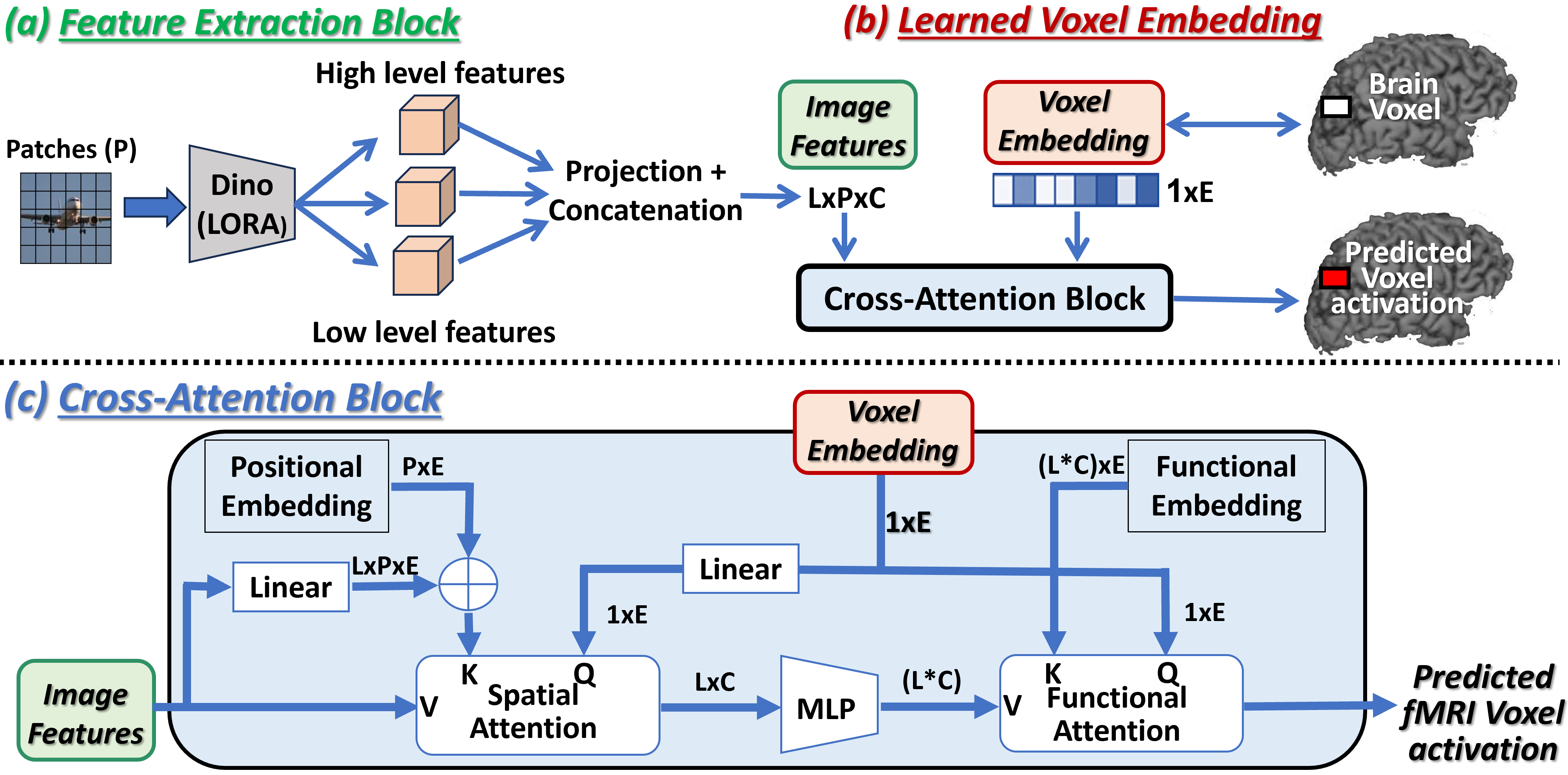
3.1 Overview of the Approach
Our Universal-Encoder learns to predict the activation of each individual brain-voxel (a small cube volume within the brain) to each viewed image. A high-level overview of our Encoder’s main components is provided in Fig 1 (with a detailed description in Fig 2). The model’s underlying assumptions and limitations are provided in Appendix B.
The core innovation of our encoder lies in the voxel-centric architecture, as well as in the brain-image cross-attention mechanism. Each brain-voxel of each subject is assigned a unique corresponding “voxel-embedding” (a vector of size 256 – Fig. 2b). This embedding vector is initialized randomly and is optimized during training to learn to predict the fMRI response of that brain-voxel on any image (via our voxel-image cross-attention mechanism).
Since this embedding is voxel-specific (not image-specific), yet learns to predict this voxel’s activation on any image, it must therefore encode inside its vector the “functionality” of this specific brain-voxel (i.e., what it is sensitive to in visual data): whether it attends to low-level image features or to high-level semantic ones; whether it cares about the position of the feature within the image or not; etc.
The shared network components (shared across all brain-voxels of all subjects) include the feature extraction block (Fig2a), and the voxel-image cross-attention block (Fig.2c). Given any image, our encoder extracts from it various image features (from low-level to high-level) using a DINO-v2 (Oquab et al., 2023) adapted model as our feature extraction block. It outputs image features from different intermediate layers of DINO, allowing each brain-voxel to attend to the appropriate semantic levels of features that align with its functionality. These image features, along with a specific voxel-embedding, are processed through the cross-attention block, to effectively integrate and predict the voxel’s activation in response to the given image. Note that this architecture is indifferent to the number of brain-voxels in each fMRI scan, hence applies to any fMRI scan.
Our training process optimizes all 3 components simultaneously – the voxel embedding, the feature extraction block, and the cross-attention block – with the sole goal of predicting the voxel fMRI response to the input image. This joint learning framework develops meaningful voxel embeddings, that not only improve voxel response prediction, but also implicitly ‘encodes’ its functional role in the brain. Our encoder and all associated weights are shared across all brain-voxels (for all subjects/datasets/machines), differing only in the per-voxel embeddings. This design ensures that each brain-voxel embedding is determined by its functional role, rather than by its physical location in the brain or the subject’s identity. The shared voxel embedding space supports integration of information across different voxels (whether within a single brain or across different brains). Importantly, our approach does not require subjects to view the same images, nor to be scanned on the same machine. This allows, for the first time, to integrate information from numerous fMRI datasets, collected by different groups around the globe over many years! We refer to this as the “Wisdom of a Crowd of Brains”.
The ability of our Universal-Encoder to integrate data from multiple subjects within/across fMRI datasets is empirically evaluated in Sec. 4. We further demonstrate the ability of our Encoder to learn the functional role of each brain-voxel, and map functionally-similar brain-voxels (within the same brain, and across different brains) to nearby Voxel-Embeddings. This provides a powerful tool to explore the human brain on huge amounts of data collectively acquired by many brains, thus discover new functional brain regions. This is demonstrated in Sec. 5.
3.2 Architecture and Training
Our encoder architecture receives 2 inputs: (i) an image, (ii) a brain-voxel index (which is merely a pointer to this brain-voxel’s Embedding vector). It outputs a single scalar value – the predicted fMRI response of this voxel on that image. The encoder architecture comprises 3 main components: (i) the shared image features extraction block (Fig.2a), (ii) the voxel embedding vectors (Fig.2b), (iii) the shared Voxel-Image cross-attention block (Fig.2c).
Image Features Extraction Block:
(Fig. 2a). This block utilizes an adapted DINO model (Oquab et al., 2023) to derive multi-scale image features. Features are extracted from L=5 intermediate layers of the DINO-v2 VIT-L/14 model (layers 1,6,12,18,24), where lower layers capture low-level image features and higher layers provide more semantic information. This hierarchical feature extraction is crucial, as voxels in the visual cortex correspond to a range of image attributes – from simple visual details to complex semantic content. Each layer’s features are projected to a lower-dimension C (via a linear layer), and are then concatenated along another dimension of length L (the number of layers). Since DINO operates on P image patches, the final feature output is of size L×P×C. In order to transform Dino features into features suitable for predicting brain activity, we used a LoRA inspired approach (Hu et al., 2021), that is more suitable for data-limited settings (see A.2 for details).

(See text for more details)
Per-Voxel Embedding:
(Fig. 2b). Each brain voxel of each subject is assigned a voxel-specific vector of length E=256. This E-dimensional vector (“Embedding”) is initialized randomly, and is optimized during training to accurately predict this voxel’s fMRI activation on different images (predicted from the cross-attention between the voxel-embedding and the image features). Since this embedding is voxel-specific (not image-specific), it must learn to encode inside its vector the “functionality” of this specific brain-voxel (i.e., what it cares about in images). Note that: (i) While each optimized embedding is voxel-specific, the remaining network components are shared by all voxels of all subjects. This allows to train all the shared components of our Encoder on data from multiple subjects/datasets/machines, even if they have significantly different numbers of brain voxels. (ii) Such joint training further facilitates the mapping of brain voxels from different brains of different subjects to the same embedding space. This allows for shared functional regions across different brains (who have never seen any shared data), to naturally surface out and be discovered. This is discussed in Sec. 5, with a few such examples shown in Fig. 7. (iii) Note that unlike the common use of the term “embedding” in Deep-Learning, our voxel-embeddings are not an output of any sub-network. These embedding vectors are initialized randomly, and are optimized individually during training along with all other shared network components.
Cross-Attention Block:
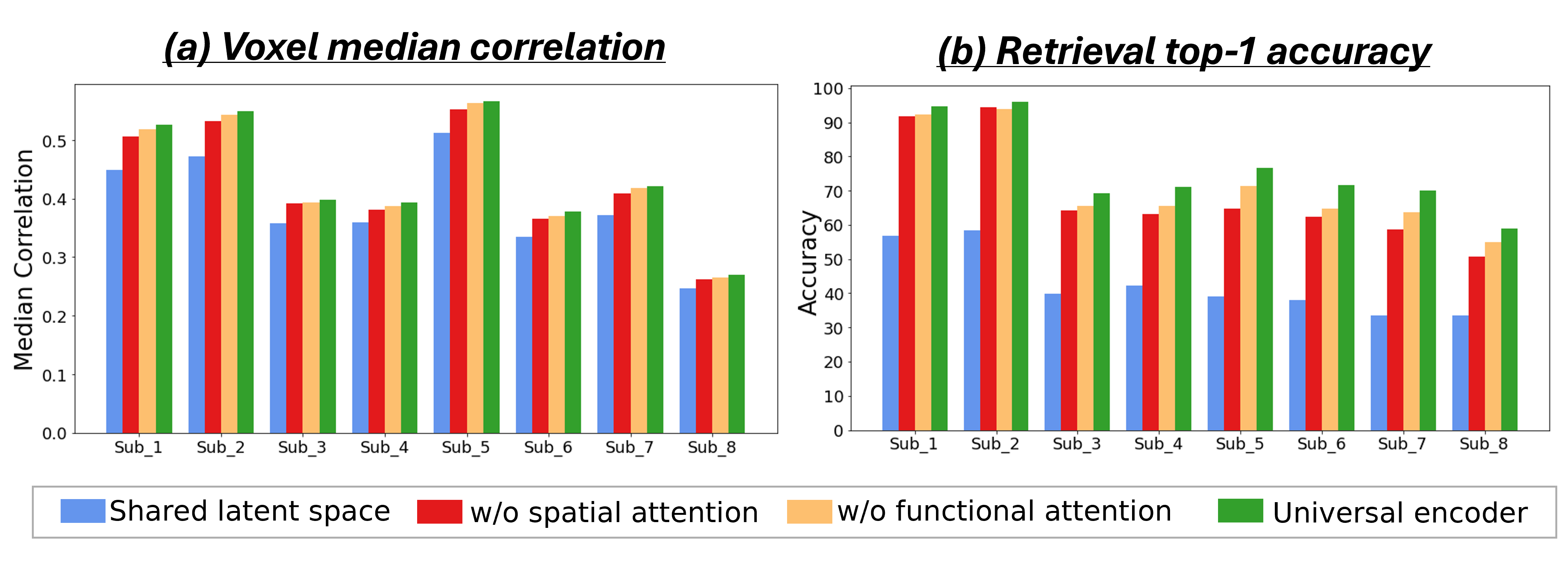
(Fig. 2c). The voxel-image cross-attention block establishes the connection between voxel functionality and relevant visual information. This block includes 3 components: (i) Spatial-attention, (ii) MLPs, and (iii) Functional-attention. The Spatial-attention component allows the voxel embedding to select relevant locations within the image, while the Functional-attention component selects the relevant features at these locations. Both components are essential, as different brain voxels have varying image receptive fields (some voxels have small, localized receptive fields, while others are influenced by the entire image), and different functionalities (e.g., low-level versus high-level semantic features).
More specifically:
(i) Given the features of the input image (referred to as “input features” from here on),
the Spatial attention enables each voxel to focus on its corresponding spatial location within the image, effectively selecting features from the appropriate image patches. Using attention notations, the “Values” V are the input features, with dimension L×P×C. The “Query” vector is the Voxel-Embedding, transformed by a linear layer which preserves its size (1×E).
The ”Keys” K are derived by adding a learned per-patch positional-embedding (size P×E) to the input features projected to the embedding size E.
The output is calculated by for each of the L layers separately (a weighted summation across the spatial dimension P), outputting vectors of size L×C.
(ii) The spatially averaged features are then fed to MLPs (a separate 2-layered MLP for each of the L image-feature layers), maintaining the dimensions L×C.
(iii) Lastly, the Functional-attention performs a weighted summation of the
spatially-attended features to derive a single scalar voxel activation.
In this layer, represents the flattened MLP output (size 1x(L*C) ), is the voxel embedding itself, and K is learned functional-embedding that has an entry for each of the LXC features
(size (L*C)E).
The output is calculated via . This block outputs the voxel prediction as a scalar value.
Training:
The model is trained end-to-end to correctly predict the voxel fMRI activation on each input image. The loss is: where and are the predicted and measured fMRI activations, respectively, and =0.1. Training the Universal-Encoder jointly on 8 NSD subjects (see “Datasets” below), takes 1 day on a single Quadro RTX 8000 GPU. Inference time (full Image-to-fMRI encoding) takes 50 ms per-image. See further training details in appendix A.3.
4 Experiments & Evaluations
We first present the datasets and the quantitative metrics used for evaluating the performance of the Universal Encoder. Then (Sec. 4.1), we demonstrate the ability of our Universal-Encoder to jointly train on multiple different subjects who were never exposed to any shared data, thus exploiting the union of all their different training sets. We further show that this exceeds the performance of any individual subject in the cohort. We then show (Sec. 4.2) that old fMRI datasets with limited low-resolution can be significantly improved by leveraging a new high-quality 7T dataset. Finally (Sec. 4.3), we show that an already trained Universal-Encoder can be easily adapted to new subjects/datasets with minimal amount of new training data, using Transfer-Learning.
Data & Datasets:
We use publicly available fMRI datasets, which contain pairs of images and their corresponding fMRI scans. These capture the brain activity of different subjects viewing images. Each fMRI scan provides measurements of neural activity in small volumes of the cortex (the “brain-voxels” in this paper). After pre-processing (performed by the groups who collected these data), each brain voxel is represented by a single scalar value (the average neural activation within that brain voxel).
We experimented with 3 prominent fMRI datasets: (i) The old “vim1” dataset (Kay et al., 2008; Naselaris et al., 2009; Kay et al., 2011), which has 1750 train and 120 test grayscale images, and their corresponding 4-Tesla fMRI scans for 2 subjects. (ii) The “fMRI-on-ImageNet” scans (Horikawa & Kamitani, 2017b) comprising 1200 train and 50 test pairs of natural images from ImageNet, with 3-Tesla fMRI recordings on 5 subjects. (iii) The ”Natural Scenes Dataset” (NSD) (Allen et al., 2022), a new 7-Tesla dataset with 8 subjects, each having around 9000 unique subject-specific images, and 1000 images shared across all subjects (which we use as our test set). This results in a total of 73,000 images, all taken from the COCO dataset (Deng et al., 2009). A few example images from each of the 3 datasets are displayed in Fig. 1. A subset of visually sensitive brain voxels was either provided by the dataset or selected based on SNR (see Appendix A.1)
Evaluation Metrics:
We evaluate our Universal-Encoder (its ability to correctly predict the fMRI responses of different subjects to a variety of images),
using 2 quantitative measures.
Given a set of Test images with ground-truth fMRI per subject, we first predict the fMRI responses of those N images with our Encoder. We
then compute:
(i) Pearson Correlation (per voxel) –
Normalized correlation between the sequence of predicted fMRI activations of each brain-voxel (on all Test images), versus the ground-truth fMRI activations of that voxel on those images.
(ii) Image Retrieval (per image) –
For each real fMRI scan in the test set (denoted “Query”), we aim to retrieve (detect) its corresponding Test-image which produced it out of a set of N images (the Test-image and N-1 random distractors).
To do so, we first predict the fMRIs of all N images in the set (using our Universal-Encoder).
We then search for the Nearest-Neighbor (NN) of the real test-fMRI (Query) among the set of N predicted fMRIs (using Pearson correlation). If the fMRI predicted from the Test-image is retrieved as the NN, it obtains a “Rank-1” score. If it is retrieved as the NN, it obtains a “Rank-k” score. The reported Top-1 accuracy is the percent of test-fMRIs which obtained a Rank-1 score. Top-5 accuracy is the percent of test-fMRIs which obtained a score Rank-5 (i.e., the corresponding test image was among the first 5 NNs).
Fig. 3 shows a qualitative visual example of the Retrieval-Ranking test (for Subject1 of the NSD dataset). Fig. 3a displays the real and the Encoder-predicted fMRIs for a few sample test images. As can be seen, there is high similarity between the real fMRI scan and the Encoder-predicted one. Fig. 3b shows the top-5 retrieved images (out of N=1000) for a few example “Query” test-fMRIs. The ground-truth test-image of each Query test-fMRI is displayed in the leftmost column of Fig. 3b. The retrieved images are ranked by the similarity of their Encoder-predicted fMRI to the real “Query” fMRI scan of the test image. As can be seen, there are many distracting (very similar) images among the 1000 test images. Yet, our Universal-Encoder is able to obtain an average retrieval-rank score of 1.85 (out of 1000) for Subject 1 (averaged over all 1000 Query test-fMRIs). Appendix Fig. S13 further demonstrates that our image-to-fMRI encoder preserves relevant image information, as evidenced by successful fMRI-to-image reconstructions.
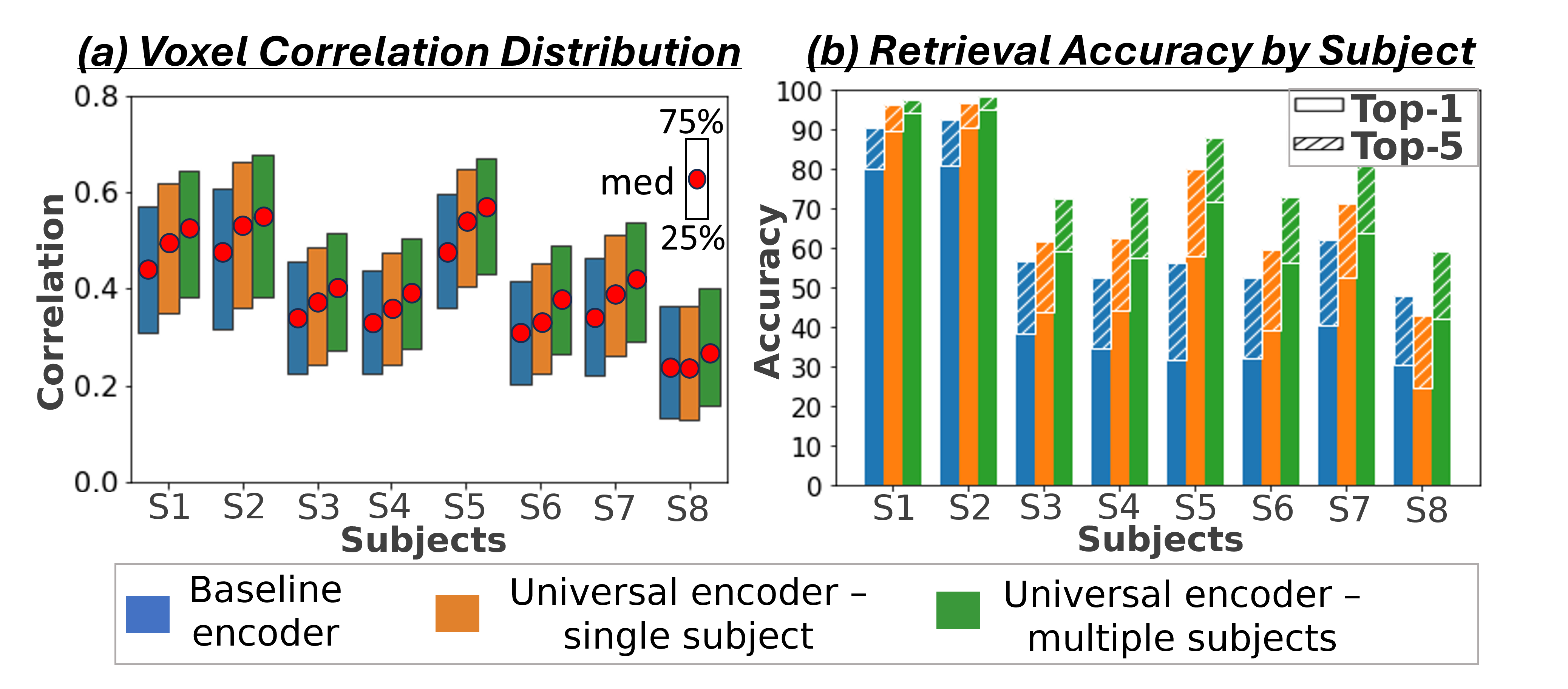
4.1 The Wisdom of a “Crowd of Brains”
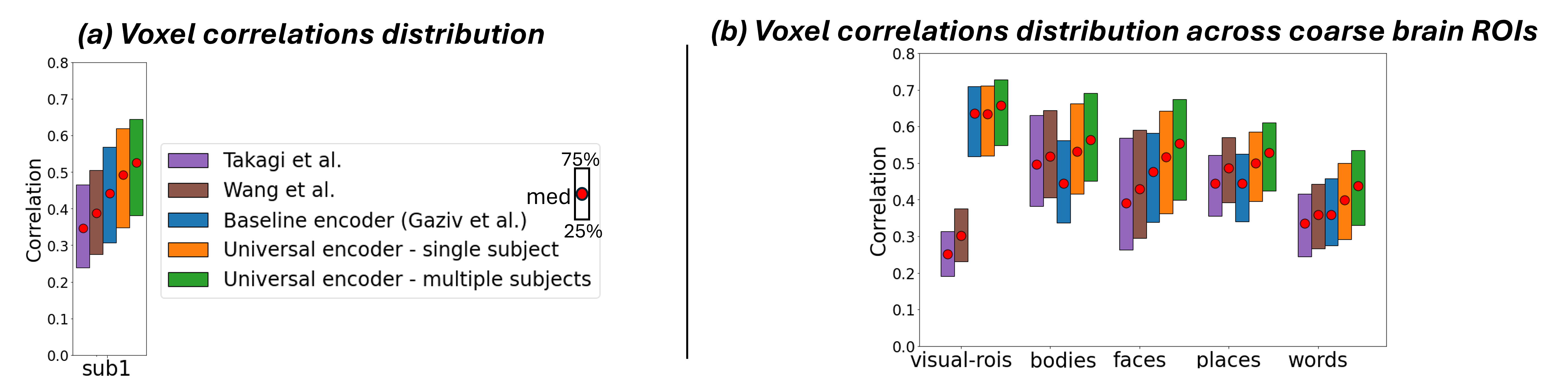
We first demonstrate the Universal-Encoder’s ability to exploit data from multiple subjects, without any shared-data. For this we use the 7-Tesla NSD dataset. We train on union of all 8 subject-specific images (72,000 non-shared data), and test on the 1,000 shared images (the images that all 8 subjects saw). We compared 3 models in our evaluation: (i) As a baseline, we used the image-to-fMRI encoder of (Gaziv et al., 2022), trained separately for each subject on their subject-specific training-set (“Baseline encoder”). (ii) Our Universal-Encoder trained on each subject separately (“Universal Encoder - single subject”), and (iii) Our Universal-Encoder trained on all 8 subjects jointly, using their combined training-sets, and tested on each subject individually (“Universal Encoder - multiple subjects”). A comparison to two other prominent encoder models (Wang et al., 2023; Takagi & Nishimoto, 2023) (which have lower performance), is further provided in the appendix Fig. S8.
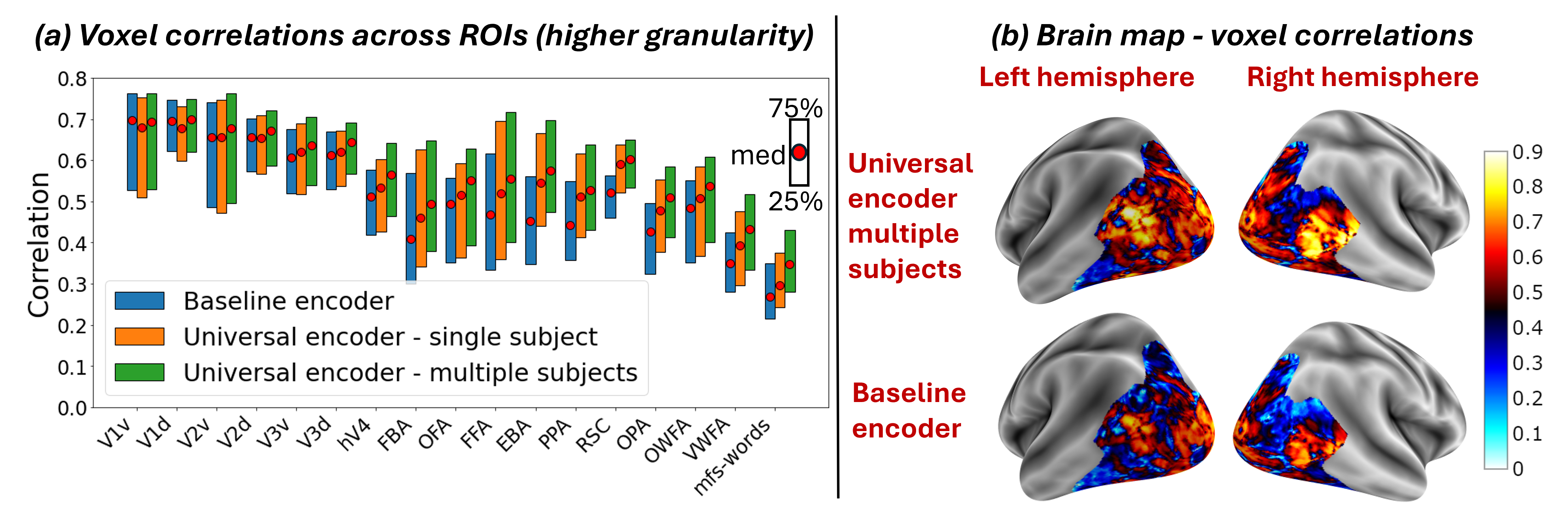
Fig. 4a shows the median Pearson correlation value (along with the th & th percentiles), computed between the predicted activations and the ground-truth activations for all fMRI voxels. These are computed per subject, for each of the 3 models. Our Universal-Encoder, even when trained on a single subject, performs consistently better than the Baseline-encoder. Moreover, when our Universal-Encoder is trained jointly on the training sets of all subjects, it consistently outperforms all subject-specific models. It obtains notable improvements for both the “best” subjects (Subject1: 7% improvement) and the “worst” subject (Subject8: 15% improvement). Statistical significance of the performance gap is assessed in Appendix C, confirming significant superiority of the Universal-Encoder. Per-region results are further presented in Fig. S10.
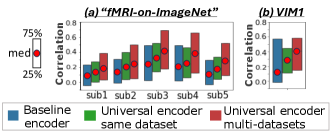
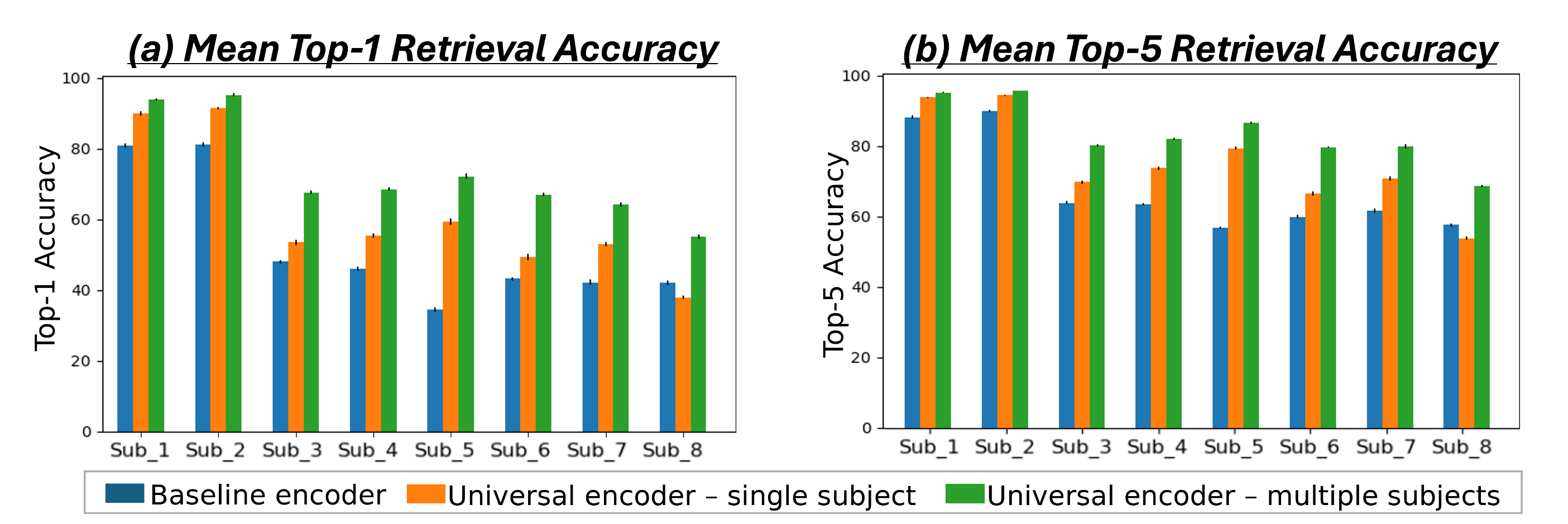
Fig. 4b presents quantitative Retrieval results evaluated per subject for all 3 models. It shows the percent of times the correct image (corresponding to the ”Query” fMRI) was ranked st (Top-1) and among the Top-5 retrieved images. The results indicate superior performance of the multi-subject Universal-Encoder compared to the 2 other models in both Top-1 & Top-5. Statistical significance of the Universal Encoder’s improvement over other models is verified in Appendix C & Table.S2. Our experiments demonstrate the model’s ability to effectively aggregate data from multiple subjects (who viewed different images), while enhancing the performance of each subject individually.
4.2 The Wisdom of a “Crowd of Datasets”
The Universal-Encoder can combine fMRI data from multiple datasets, each with its own scanning resolution and unique image domain (e.g., B/W vs. color images). This allows training the Universal Encoder jointly on high-quality (7T) and lower-quality (3T) datasets, thus significantly enhancing the encoding performance of old lower-quality datasets. Fig. 5 demonstrates this by training the encoder on the NSD dataset alongside two low-resolution datasets: VIM1 and “fMRI-on-ImageNet”, and testing the encoding performance on individual subjects within those datasets.
Fig. 5a compares 3 models for the “fMRI-on-ImageNet” dataset: (i) Single-subject encoder of (Gaziv et al., 2022) (“Baseline encoder”), (ii) Our Universal-Encoder trained on all subjects in “fMRI-on-ImageNet” (“Universal Encoder - same dataset”), and (iii) Universal-Encoder trained on subjects from both “fMRI-on-ImageNet” and NSD (“Universal Encoder - multi datasets”). Our multi-subject same-dataset encoder (green) outperforms the single-subject baseline model (blue). Adding data from NSD yields even further improvement (red). Median correlation, 75th & 25th percentiles are shown. Fig. 5b shows results for VIM1 dataset. Here too, adding training data from NSD significantly enhances encoding performance on VIM1.
4.3 Transfer-Learning to New Subjects/Datasets
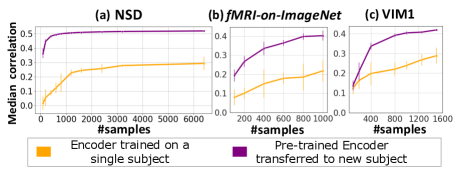
When a new subject/dataset is encountered, it is not necessary to train the universal-Encoder from scratch. Instead, we can add a new subject via quick Transfer-Learning, which is particularly useful when the new subject-specific data is scarce. In our transfer-learning, all weights of the pre-trained Universal-Encoder remain fixed, and only the 256-dimensional Voxel-Embeddings of the new subject are optimized. This allows rapid and effective transfer learning, with very little new training data.
To demonstrate this, we pre-train the Universal-Encoder on 6 subjects from the 7T NSD dataset (Subjects 2-7), freeze it, and then apply Transfer-Learning to new subjects (with NO shared data): Subject1 in NSD, and subjects in entirely different (older) fMRI datasets (“fMRI-on-ImageNet” (subject3) & VIM1 (subject1)). Each plot in Fig. 6 compares: (i) Transfer-Learning of the pre-trained Universal-Encoder to the new subject, with varying numbers of subject-specific training data (purple curve), and (ii) a dedicated subject-specific model, trained from scratch on the subject-specific data only (orange curve). The x-axis shows the number of subject-specific training examples, and the y-axis shows mean and standard deviation of the median Pearson correlation between the predicted and real fMRI scan from the new subject’s test-set (over 5 runs with different random initialization & data sub-sampling).
The transferred Universal-Encoder significantly outperforms any single-subject model on all datasets. Transfer-Learning to Subject1 within NSD (Fig. 6a) obtains 77% improvement for any number of training examples. Moreover, as few as 100 subject-specific training examples suffice to obtain better results than a subject-specific model trained on the entire train-set (9000 examples). A similar gap in performance is achieved for Subject8.
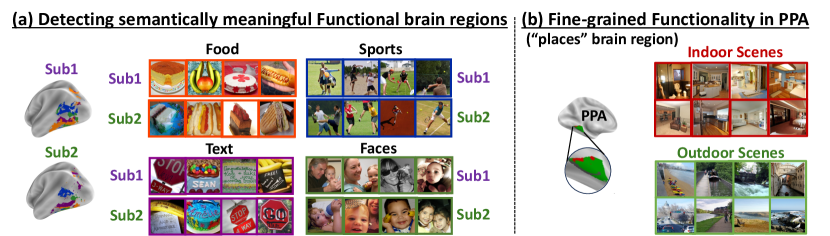
Fig. 6b (”fMRI-on-ImageNet”) & Fig. 6c (VIM1) demonstrate transfer learning from a new 7-Tesla dataset to older lower-resolution 3T or 4T datasets. These were scanned on very different types of images (e.g., VIM1 was scanned on B/W images with a circular black mask), and have much smaller train-sets. Transfer-Learning shows a significant improvement for any number of training data, with an improvement 84% for ‘fMRI-on-ImageNet’ & 45% for VIM1, using the entire (small) subject-specific train-set (significance testing over model initialization in Table. S3).
5 Exploring the Brain using Voxel-Embeddings
As part of training, our Universal-Encoder aims to learn the functional-role of each brain voxel. It maps functionally-similar brain voxels (within the same brain & across different brains) to similar voxel-embeddings. This provides a potentially powerful means to explore the human brain and discover new functional regions. What facilitates such advanced brain exploration is the enormous number of images that a large “crowd of brains” has collectively been exposed to (which is prohibitive for any single subject). In this section, we demonstrate initial promising findings, suggesting that our learned voxel-embeddings capture semantically-meaningful brain functionalities, and may potentially serve as a new powerful means to explore the human brain.
Brain-parcellations which define functional brain regions do exist. Although functionally-driven, these maps are typically integrated across many subjects via pure anatomical alignment. This results in a single coarse functional brain division, which is shared by all subjects, and overlooks individual differences. We aim to find a division that is functionally-consistent across different subjects, without requiring shared anatomical mapping, thus allowing for individual anatomical (and functional) differences.
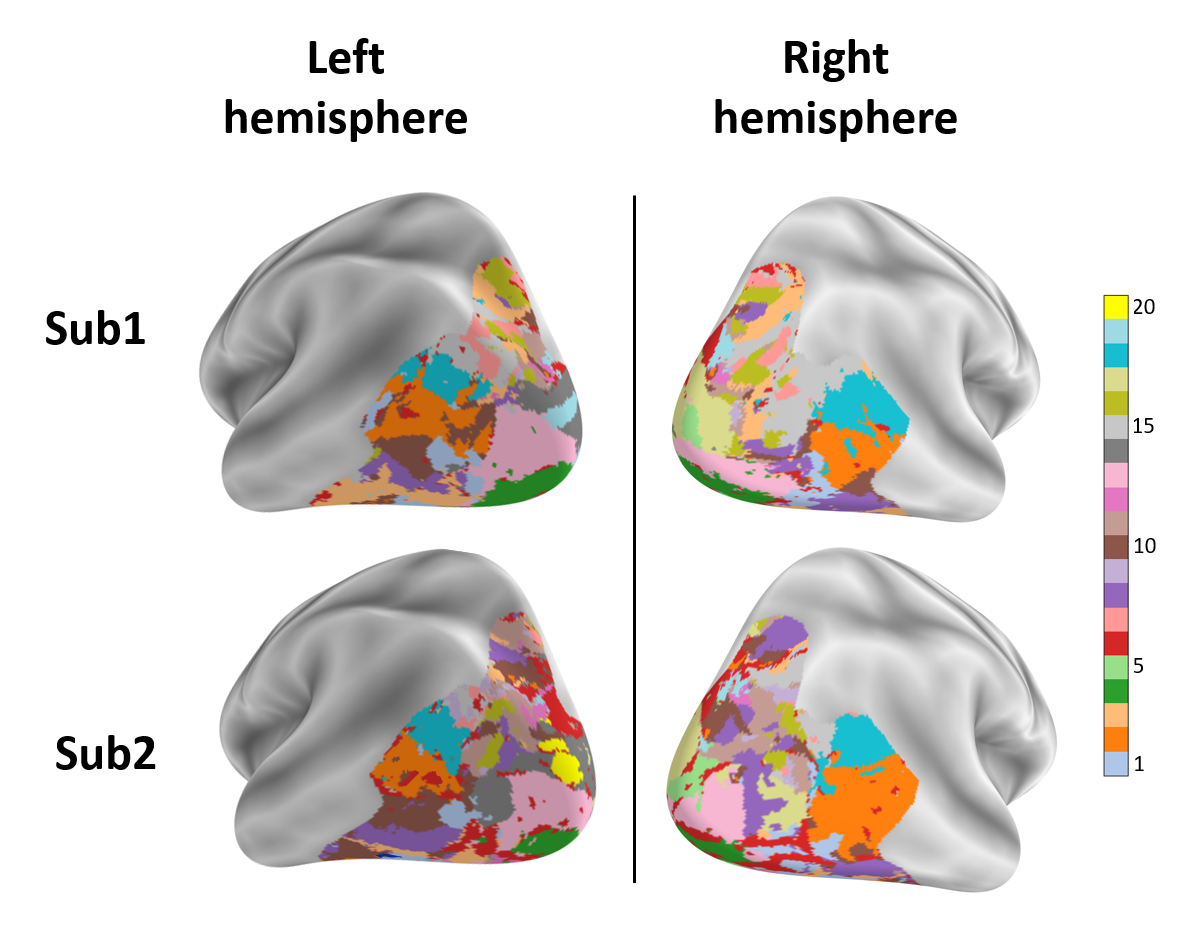
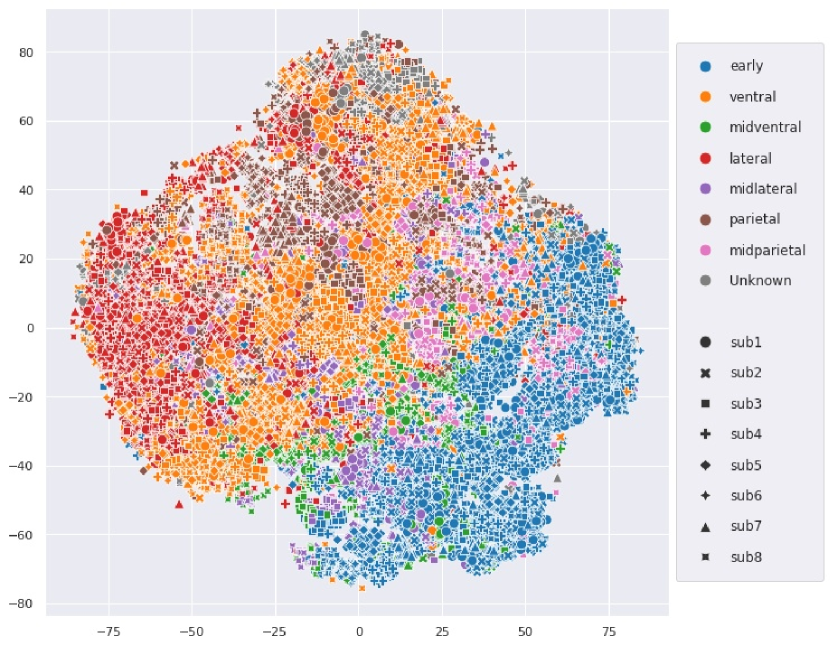
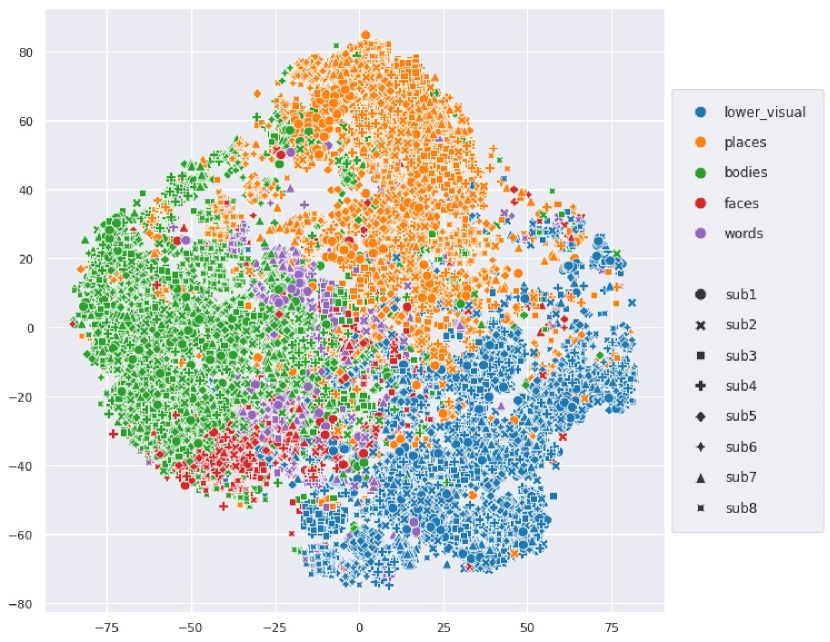
To automatically detect functional regions shared across different brains, we performed the following experiment: We applied k-means clustering to all voxel-embeddings of multiple “good” subjects (subjects with high prediction accuracy) from the 7T NSD dataset. Large clusters of voxel-embeddings indicate the detection of some joined functionality (learned independently by many different brain-voxels). Since high similarity of independently-learned voxel-embeddings is unlikely to occur at random, this indicates that they most likely encode something meaningful.
To unveil the functional roles of each detected embedding cluster, we examine which images induce the highest fMRI activation per cluster (averaged over all voxels within the cluster). Fig. 7a displays an example of the top 4 (out of 20) interesting discovered clusters (displayed on the brain with different colors), along with corresponding top images (with highest activation per cluster) for NSD Subjects 1&2. Each cluster in Fig. 7a shows a distinct functional-role, being strongly activated by images of Food, Faces, Text, Outdoor-Scenes, respectively. It is interesting to note that: (i) These shared functional regions across brains automatically surfaced out, although the 2 subjects viewed different images; (ii) While the shared regions across the 2 subjects are in nearby anatomical brain locations, they are not anatomically aligned! These results show that our voxel-embeddings capture functional roles rather than individual identities, providing a potentially powerful tool to discover shared&unique brain functionalities across different people. Additional detected voxel-embedding clusters can be viewed in Appendix Figs. S14,S15.
We further explored the ability to detect finer-grained functionality within known brain regions. Fig. 7b shows such an example - the detection of functionally-meaningful clusters (sub-regions) within the PPA brain region (an area corresponding to places/scenes). Two clear and distinct sub-regions have emerged on their own from our voxel-embedding clustering – Indoor-Scenes vs. Outdoor-Scenes. This demonstrates the potential power of our voxel-embeddings to uncover new functional regions beyond predefined anatomical boundaries. Additional visualizations are found in the appendix: e.g., fine-grained clustering of EBA brain region (Fig. S16), T-SNE visualization for voxel-embeddings of all subjects (Figs. S17 & S18).
Conclusion & Discussion:
This paper presents the first-ever Universal Image-to-fMRI Brain-Encoder, which can integrate data from many different subjects and different fMRI datasets collected over the years. This is facilitated by a new voxel-centric architecture, which learns individual “voxel-embedding” per brain-voxel, via cross-attention with hierarchical image features. In this voxel-centric model, the functional role of individual brain voxels naturally emerges, leading to better encoding performance and providing a new potential tool to explore brain functionality (i.e., what is encoded where in the brain).
Acknowledgments
This research was funded by the European Union (ERC grant No. 101142115).
References
- Allen et al. (2022) Allen, E. J., St-Yves, G., Wu, Y., Breedlove, J. L., Prince, J. S., Dowdle, L. T., Nau, M., Caron, B., Pestilli, F., Charest, I., et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence. Nature neuroscience, 25(1):116–126, 2022.
- Beliy et al. (2019) Beliy, R., Gaziv, G., Hoogi, A., Strappini, F., Golan, T., and Irani, M. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fmri. Advances in Neural Information Processing Systems, 32, 2019.
- Brett et al. (2002) Brett, M., Johnsrude, I. S., and Owen, A. M. The problem of functional localization in the human brain. Nature reviews neuroscience, 3(3):243–249, 2002.
- Conroy et al. (2013) Conroy, B. R., Singer, B. D., Guntupalli, J. S., Ramadge, P. J., and Haxby, J. V. Inter-subject alignment of human cortical anatomy using functional connectivity. NeuroImage, 81:400–411, 2013.
- Dale et al. (1999) Dale, A. M., Fischl, B., and Sereno, M. I. Cortical surface-based analysis: I. segmentation and surface reconstruction. Neuroimage, 9(2):179–194, 1999.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Downing et al. (2001) Downing, P. E., Jiang, Y., Shuman, M., and Kanwisher, N. A cortical area selective for visual processing of the human body. Science, 293(5539):2470–2473, 2001.
- Eickenberg et al. (2017) Eickenberg, M., Gramfort, A., Varoquaux, G., and Thirion, B. Seeing it all: Convolutional network layers map the function of the human visual system. NeuroImage, 152:184–194, 2017.
- Epstein & Kanwisher (1998) Epstein, R. and Kanwisher, N. A cortical representation of the local visual environment. Nature, 392(6676):598–601, 1998.
- Fischl (2012) Fischl, B. Freesurfer. Neuroimage, 62(2):774–781, 2012.
- Frost & Goebel (2012) Frost, M. A. and Goebel, R. Measuring structural–functional correspondence: spatial variability of specialised brain regions after macro-anatomical alignment. Neuroimage, 59(2):1369–1381, 2012.
- Gaziv et al. (2022) Gaziv, G., Beliy, R., Granot, N., Hoogi, A., Strappini, F., Golan, T., and Irani, M. Self-supervised natural image reconstruction and large-scale semantic classification from brain activity. NeuroImage, 254:119121, 2022.
- Gifford et al. (2023) Gifford, A. T., Lahner, B., Saba-Sadiya, S., Vilas, M. G., Lascelles, A., Oliva, A., Kay, K., Roig, G., and Cichy, R. M. The algonauts project 2023 challenge: How the human brain makes sense of natural scenes. arXiv preprint arXiv:2301.03198, 2023.
- Gong et al. (2024) Gong, Z., Zhang, Q., Bao, G., Zhu, L., Liu, K., Hu, L., and Miao, D. Mindtuner: Cross-subject visual decoding with visual fingerprint and semantic correction. arXiv preprint arXiv:2404.12630, 2024.
- Gu et al. (2022) Gu, Z., Jamison, K., Sabuncu, M., and Kuceyeski, A. Personalized visual encoding model construction with small data. Communications Biology, 5(1):1382, 2022.
- Gu et al. (2023) Gu, Z., Jamison, K., Sabuncu, M. R., and Kuceyeski, A. Human brain responses are modulated when exposed to optimized natural images or synthetically generated images. Communications Biology, 6(1):1076, 2023.
- Han et al. (2024) Han, I., Lee, J., and Ye, J. C. Mindformer: A transformer architecture for multi-subject brain decoding via fmri. arXiv preprint arXiv:2405.17720, 2024.
- Haxby et al. (2011) Haxby, J. V., Guntupalli, J. S., Connolly, A. C., Halchenko, Y. O., Conroy, B. R., Gobbini, M. I., Hanke, M., and Ramadge, P. J. A common, high-dimensional model of the representational space in human ventral temporal cortex. Neuron, 72(2):404–416, 2011.
- Heeger & Ress (2002) Heeger, D. J. and Ress, D. What does fmri tell us about neuronal activity? Nature reviews neuroscience, 3(2):142–151, 2002.
- Henderson et al. (2023) Henderson, M. M., Tarr, M. J., and Wehbe, L. A texture statistics encoding model reveals hierarchical feature selectivity across human visual cortex. Journal of Neuroscience, 43(22):4144–4161, 2023.
- Horikawa & Kamitani (2017a) Horikawa, T. and Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nature Communications, 8(1):1–15, 5 2017a. ISSN 20411723. doi: 10.1038/ncomms15037.
- Horikawa & Kamitani (2017b) Horikawa, T. and Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nature communications, 8(1):15037, 2017b.
- Hu et al. (2021) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Kanwisher et al. (1997) Kanwisher, N., McDermott, J., and Chun, M. M. The fusiform face area: a module in human extrastriate cortex specialized for face perception. Journal of neuroscience, 17(11):4302–4311, 1997.
- Kay et al. (2008) Kay, K. N., Naselaris, T., Prenger, R. J., and Gallant, J. L. Identifying natural images from human brain activity. Nature, 452(7185):352–355, 2008.
- Kay et al. (2011) Kay, K. N., Naselaris, T., and Gallant, J. L. fmri of human visual areas in response to natural images. CRCNS. org, 2011.
- Khosla et al. (2020) Khosla, M., Ngo, G. H., Jamison, K., Kuceyeski, A., and Sabuncu, M. R. A shared neural encoding model for the prediction of subject-specific fmri response. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part VII 23, pp. 539–548. Springer, 2020.
- Luo et al. (2024) Luo, A., Henderson, M., Wehbe, L., and Tarr, M. Brain diffusion for visual exploration: Cortical discovery using large scale generative models. Advances in Neural Information Processing Systems, 36, 2024.
- Luo et al. (2023) Luo, A. F., Henderson, M. M., Tarr, M. J., and Wehbe, L. Brainscuba: Fine-grained natural language captions of visual cortex selectivity. arXiv preprint arXiv:2310.04420, 2023.
- Mazziotta et al. (2001) Mazziotta, J., Toga, A., Evans, A., Fox, P., Lancaster, J., Zilles, K., Woods, R., Paus, T., Simpson, G., Pike, B., et al. A probabilistic atlas and reference system for the human brain: International consortium for brain mapping (icbm). Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, 356(1412):1293–1322, 2001.
- Naselaris et al. (2009) Naselaris, T., Prenger, R. J., Kay, K. N., Oliver, M., and Gallant, J. L. Bayesian reconstruction of natural images from human brain activity. Neuron, 63(6):902–915, 2009.
- Naselaris et al. (2011) Naselaris, T., Kay, K. N., Nishimoto, S., and Gallant, J. L. Encoding and decoding in fmri. Neuroimage, 56(2):400–410, 2011.
- Oquab et al. (2023) Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Riddle & Purves (1995) Riddle, D. and Purves, D. Individual variation and lateral asymmetry of the rat primary somatosensory cortex. Journal of Neuroscience, 15(6):4184–4195, 1995.
- Scotti et al. (2024a) Scotti, P., Banerjee, A., Goode, J., Shabalin, S., Nguyen, A., Dempster, A., Verlinde, N., Yundler, E., Weisberg, D., Norman, K., et al. Reconstructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors. Advances in Neural Information Processing Systems, 36, 2024a.
- Scotti et al. (2024b) Scotti, P. S., Tripathy, M., Villanueva, C. K. T., Kneeland, R., Chen, T., Narang, A., Santhirasegaran, C., Xu, J., Naselaris, T., Norman, K. A., et al. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data. arXiv preprint arXiv:2403.11207, 2024b.
- Takagi & Nishimoto (2023) Takagi, Y. and Nishimoto, S. High-resolution image reconstruction with latent diffusion models from human brain activity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14453–14463, 2023.
- Talairach (1988) Talairach, J. 3-dimensional proportional system; an approach to cerebral imaging. co-planar stereotaxic atlas of the human brain. Thieme, pp. 1–122, 1988.
- Tang et al. (2017) Tang, I.-C., Tsai, Y.-P., Lin, Y.-J., Chen, J.-H., Hsieh, C.-H., Hung, S.-H., Sullivan, W. C., Tang, H.-F., and Chang, C.-Y. Using functional magnetic resonance imaging (fmri) to analyze brain region activity when viewing landscapes. Landscape and Urban Planning, 162:137–144, 2017.
- Tang et al. (2024) Tang, J., Du, M., Vo, V., Lal, V., and Huth, A. Brain encoding models based on multimodal transformers can transfer across language and vision. Advances in Neural Information Processing Systems, 36, 2024.
- Van Uden et al. (2018) Van Uden, C. E., Nastase, S. A., Connolly, A. C., Feilong, M., Hansen, I., Gobbini, M. I., and Haxby, J. V. Modeling semantic encoding in a common neural representational space. Frontiers in neuroscience, 12:378029, 2018.
- Wang et al. (2023) Wang, A. Y., Kay, K., Naselaris, T., Tarr, M. J., and Wehbe, L. Better models of human high-level visual cortex emerge from natural language supervision with a large and diverse dataset. Nature Machine Intelligence, 5(12):1415–1426, 2023.
- Wang et al. (2024) Wang, S., Liu, S., Tan, Z., and Wang, X. Mindbridge: A cross-subject brain decoding framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11333–11342, 2024.
- Wasserman et al. (2024) Wasserman, N., Beliy, R., Urbach, R., and Irani, M. Functional brain-to-brain transformation with no shared data. arXiv preprint arXiv:2404.11143, 2024.
- Wen et al. (2018a) Wen, H., Shi, J., Chen, W., and Liu, Z. Deep residual network predicts cortical representation and organization of visual features for rapid categorization. Scientific reports, 8(1):3752, 2018a.
- Wen et al. (2018b) Wen, H., Shi, J., Chen, W., and Liu, Z. Transferring and generalizing deep-learning-based neural encoding models across subjects. NeuroImage, 176:152–163, 2018b.
- Wen et al. (2018c) Wen, H., Shi, J., Zhang, Y., Lu, K.-H., Cao, J., and Liu, Z. Neural encoding and decoding with deep learning for dynamic natural vision. Cerebral cortex, 28(12):4136–4160, 2018c.
- Yamada et al. (2015) Yamada, K., Miyawaki, Y., and Kamitani, Y. Inter-subject neural code converter for visual image representation. NeuroImage, 113:289–297, 2015.
- Yamins et al. (2014) Yamins, D. L., Hong, H., Cadieu, C. F., Solomon, E. A., Seibert, D., and DiCarlo, J. J. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the national academy of sciences, 111(23):8619–8624, 2014.
- Zhen et al. (2015) Zhen, Z., Yang, Z., Huang, L., Kong, X.-z., Wang, X., Dang, X., Huang, Y., Song, Y., and Liu, J. Quantifying interindividual variability and asymmetry of face-selective regions: a probabilistic functional atlas. Neuroimage, 113:13–25, 2015.
Appendix
Appendix A Further Technical Details
A.1 fmri datasets
The datasets utilized in our study comprise BOLD fMRI responses to various natural images, recorded over multiple scanning sessions. Peak BOLD responses corresponding to each stimulus were estimated, resulting in a scalar value for each voxel for each image. Each dataset underwent unique pre-processing procedures, detailed in their respective publications (Kay et al., 2008; Naselaris et al., 2009; Horikawa & Kamitani, 2017a; Allen et al., 2022).
Two additional processing steps may be needed: voxel selection from the total of all brain voxels and per voxel normalization. For each voxel, in each run, Z-scoring normalization was performed. A ’run’ refers to one continuous period of fMRI scanning, and this normalization process standardizes the voxel responses across different runs, enhancing the comparability and consistency of the data.
NSD Dataset.
“fMRI-on-ImageNet” Dataset.
For the fMRI-on-ImageNet dataset (Horikawa & Kamitani, 2017b), a relevant set of around 5,000 voxels was already provided. We implemented Z-scoring normalization ourselves for this dataset.
VIM1 Dataset.
For the VIM1 dataset (Kay et al., 2008; Naselaris et al., 2009), we selected the best 7,000 voxels according to the highest Signal-to-Noise Ratio (SNR). SNR is calculated as the ratio of the variance of averaged (repeated) measurements for different stimuli to the average variance of measurements for the same stimuli. This approach ensures the selection of voxels most representative of neural activity in response to diverse visual stimuli. Z-scoring normalization was also implemented for this dataset.
A.2 Training and Lora Modification
The Lora adaptation (Hu et al., 2021) is done by adding learned low rank matrices to weights in the original network. In the original paper the value projection and query projection weights (,) in the self attention block are modified. We only modify the output projection weights() of the self attention block.
A.3 Training
The model is trained end-to-end (Adam optimizer with learning rate of 1e-3). The model’s objective is to correctly predict the voxel fMRI activation on each input image. Each training batch contains 32 randomly selected images (we randomly sample 5000 voxel indices per image, with their corresponding fMRI activations). Each subject (brain) has its own unique voxel indices. Our loss function is: where and are the predicted and measured fMRI activations, respectively, and =0.1. Training the Universal-Encoder jointly on 8 NSD subjects (see “Datasets” below), takes 1 day on a single Quadro RTX 8000 GPU. Inference time (Image-to-fMRI encoding) takes 50 ms per-image.
Appendix B Limitations
There are two main underlying assumptions in this work that are commonly taken in most works in this area. The assumptions are that the fMRI response is memory-less and replicable. By memory-less, we mean that previous images seen by the subject do not affect the response to the current image. We wanted our model to be as general as possible and applicable to many datasets; adding memory dependence would hinder this. By replicable, we mean that the same response for an image will be measured regardless of when the subject sees the image. This is important when averaging multiple responses to the same image, a general practice in the field due to the low SNR of the fMRI signal.
Moreover, it is important to note that there is significant variability in measured signal quality across subjects. The brain exploration we demonstrate is done for subjects with relatively high SNR. For subjects with poor signal quality, it is harder to obtain a good estimation of voxel functionality, and we would likely not achieve as good results for meaningful segmentation of brain regions.
Appendix C Statistical Tests
We conducted statistical tests to evaluate the significance of the Universal Encoder’s performance across the various metrics assessed.
To evaluate the statistical significance of the prediction correlation gap between our multi-subject Universal Encoder’s and the other two models as reported in 4.1 and shown in
Fig. 4a , we performed a repeated measures ANOVA test. The analysis, based on the predicted voxel correlations of the 8 NSD subjects, revealed a significant performance gap between models: F-value of 72.74 and p-value of 0 (Num DF=2, Den DF=14).
Additionally, we tested the prediction correlations of individual voxels (across all subjects) against a null hypothesis. The null hypothesis was based on the distribution of correlations between pairs of independent Gaussian random vectors of size N = 982, matching the number of image-fMRI pairs in the test set. The one-sided statistical significance was estimated by comparing the predicted voxel correlations for each subject on the test set with those from the null distribution. We applied a statistical threshold of P 0.05, correcting for multiple comparisons using the FDR procedure. Our results indicate that the majority of voxel predictions by the Universal Encoder are statistically significant, with an average of 98% across all subjects. Detailed results in Table S1.
| Subj1 | Subj2 | Subj3 | Subj4 | Subj5 | Subj6 | Subj7 | Subj8 | |
|---|---|---|---|---|---|---|---|---|
| Total Voxels | 39,548 | 39,548 | 39,548 | 39,548 | 39,548 | 39,198 | 39,198 | 39,511 |
| Significantly Predicted Voxel | 39,299 | 39,024 | 38,612 | 39,059 | 39,252 | 38,665 | 38,754 | 36,850 |
| Significant Voxel Percentage | 99.37% | 98.68% | 97.63% | 98.77% | 99.25% | 98.64% | 98.87% | 93.26% |
Furthermore, we present the significance of the retrieval results reported in 4.1 and shown in Fig. 4b. We performed a t-test by repeating the retrieval experiment 10 times with random image distractors and comparing the average retrieval performance per repeat of our multi-subject Universal Encoder against a competing model. The resulting p-values are presented in Table S2, where the highest p-value observed is approximately . This illustrates the significance of the Universal Encoder’s improvements when trained on multiple subjects, compared to the other models. The results were corrected for multiple comparisons using the FDR procedure.
Lastly, we present the the significance of the transfer learning results reported in 4.3 and shown in Figure 6. We performed a t-test on the median Pearson correlation between predicted and real fMRI scans, comparing transfer learning with our universal encoder against baseline model, over 5 runs with different random model initializations, this was done for each of the dataset. Table S3 contains the estimated p-values. The results were corrected for multiple comparisons using the FDR procedure.
| Subject | Universal encoder - multiple subjects | Universal encoder - multiple subjects |
|---|---|---|
| Vs Universal encoder - single subject | Vs Baseline encoder | |
| 1 | 3.795e-14 | 1.284e-23 |
| 2 | 9.275e-13 | 8.783e-16 |
| 3 | 9.848e-19 | 2.831e-25 |
| 4 | 5.274e-19 | 3.413e-22 |
| 5 | 1.407e-15 | 6.501e-22 |
| 6 | 3.413e-22 | 1.337e-23 |
| 7 | 7.104e-16 | 3.633e-21 |
| 8 | 8.491e-21 | 1.824e-21 |
| Samples | NSD | fMRI-on-ImageNet | VIM1 |
|---|---|---|---|
| 100 | 4.85e-08 | 2.27e-05 | 1.66e-01 |
| 200 | 2.69e-06 | 4.12e-07 | 1.15e-02 |
| 400 | 1.68e-08 | 7.42e-05 | 2.56e-04 |
| 600 | 1.49e-06 | 9.32e-07 | |
| 800 | 1.87e-05 | 9.22e-05 | 4.89e-06 |
| 1000 | 2.38e-05 | 1.39e-04 | |
| 1200 | 5.18e-07 | ||
| 1250 | 3.97e-05 | ||
| 1500 | 1.07e-04 | ||
| 1600 | 3.64e-07 | ||
| 2400 | 2.69e-06 | ||
| 3200 | 2.41e-08 | ||
| 6400 | 2.01e-05 |
Appendix D Additional Figures
| Voxel Embedding Dimension | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|
| Median Pearson Correlation | 0.5170 | 0.5221 | 0.5221 | 0.5227 | 0.5243 |

| MAE | MSE | Lpips | SSIM | |
|---|---|---|---|---|
| Reconstruction from GT fMRI | 4.063 | 26.965 | 0.712 | 0.139 |
| Reconstruction from our encoded fMRI | 4.089 | 27.002 | 0.710 | 0.123 |