Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurate Segmentation Model Against Thresholds
Abstract
Weakly-supervised semantic segmentation (WSSS) has recently gained much attention for its promise to train segmentation models only with image-level labels. Existing WSSS methods commonly argue that the sparse coverage of CAM incurs the performance bottleneck of WSSS. This paper provides analytical and empirical evidence that the actual bottleneck may not be sparse coverage but a global thresholding scheme applied after CAM. Then, we show that this issue can be mitigated by satisfying two conditions; 1) reducing the imbalance in the foreground activation and 2) increasing the gap between the foreground and the background activation. Based on these findings, we propose a novel activation manipulation network with a per-pixel classification loss and a label conditioning module. Per-pixel classification naturally induces two-level activation in activation maps, which can penalize the most discriminative parts, promote the less discriminative parts, and deactivate the background regions. Label conditioning imposes that the output label of pseudo-masks should be any of true image-level labels; it penalizes the wrong activation assigned to non-target classes. Based on extensive analysis and evaluations, we demonstrate that each component helps produce accurate pseudo-masks, achieving the robustness against the choice of the global threshold. Finally, our model achieves state-of-the-art records on both PASCAL VOC 2012 and MS COCO 2014 datasets. The code is available at https://github.com/gaviotas/AMN.
1 Introduction
Weakly-supervised semantic segmentation (WSSS) requires only weak supervision (e.g., image-level labels [35, 36], scribbles [31], bounding boxes [19]) as opposed to the fully supervised model, which involves costly pixel-level annotations. In this work, we address WSSS using image-level labels because of its low labeling cost. The overall pipeline of WSSS consists of two stages. The pseudo-mask is first generated from an image classifier, and then it is used as supervision to train a segmentation network.
The prevalent technique for generating pseudo-masks is class activation mapping (CAM) [45]. It uses the intermediate classifier’s activation to compute the class activation map corresponding to its image-level label. The common practice of WSSS is to apply a global threshold to the activation map (i.e., assigning the object class if the activation is greater than the threshold) for obtaining the pseudo-mask. Existing methods point out that the pseudo-mask obtained from CAM only captures the most discriminative parts of the object, incurring the performance bottleneck. Therefore, most existing studies have expanded object coverage by manipulating the image [29, 39] or feature map [26, 18].
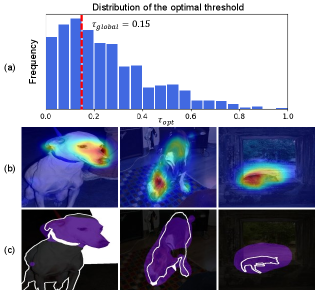
However, we argue that the performance bottleneck of WSSS comes from a global threshold applied after CAM; the sparse object coverage does not explain all. This threshold partitions each activation map into the foreground (object class) and background. Then, the pseudo-mask is generated by combining all foreground regions. Here, the choice of threshold critically affects the performance of WSSS. i) We further observe that a global threshold cannot provide an optimal threshold per image. Figure 1(a) visualizes the distribution of optimal threshold on the PASCAL VOC 2012 train set (For analysis, we obtain the best threshold per image using its ground-truth segmentation map). It shows that the optimal threshold per image quite differs from each other, and the global threshold is often far from the optimal one. ii) Besides, a global threshold for CAM does not always lead to sparse coverage. Figure 1(b) and (c) show several CAM examples and the corresponding masks generated by a global threshold, respectively; the third row shows that CAM and the thresholded mask overly capture the target object. These results clearly motivate us to rethink that the performance bottleneck of WSSS is closely related to the usage of a global threshold.
To tackle this problem, we first investigate why this problem happens. By tracing the procedure of CAM, we realize that global average pooling (GAP) applied to the last layer invokes this issue; the global threshold largely differs from the optimal threshold per image. The first stage of the WSSS framework trains the image classifier, whose score is computed via GAP. While GAP facilitates deriving the activation map, it averages the feature maps into a single classification score. The same value can be from totally different activations. For example, the same score can be from 1) high activations only in the most discriminative region (low optimal threshold to cover more regions), 2) moderate activations distributed over the entire object, or 3) small activations covering even outside the object (high optimal threshold to cover small regions).
Due to its averaging nature, GAP hinders achieving the accurate pseudo-mask via a global threshold. As a naïve solution, one might consider introducing a different threshold per image. However, this is prohibitive because finding a per-image threshold requires pixel-level annotation, violating the principle of weakly-supervised learning. Instead of controlling a threshold per image, our key idea is to manipulate the activation in a way that the resultant pseudo-mask is of high quality regardless of threshold values. To achieve robust performance, we can increase the activation gap between the foreground region and the background region; the thresholded masks are the same if the threshold value is within the gap. However, it can induce the model to capture the most discriminative parts only, resulting in consistent but poor quality.
To achieve high quality consistently, it is important to reduce the activation imbalance within the foreground and keep the large activation gap between the foreground and background simultaneously. We can achieve the two factors by assigning the two-level activation for the entire foreground pixels and background pixels (e.g., 1 and 0). In this way, the high activation in the most discriminative parts is penalized, but the low activation in the less discriminative parts is promoted. Meanwhile, the background activation can be deactivated. Naturally, this strategy can guarantee a large gap, enabling us to achieve the robust performance even with a global threshold.
Specifically, we introduce a robust and accurate activation manipulation network (AMN), which takes an image with its image-level label as the input and provides the high-quality pseudo-mask as the output. For that, we formulate a training objective using i) per-pixel classification with an effective constraint using ii) label conditioning. Since per-pixel classification does not rely on GAP, it bypasses the issue of having totally different activation maps for the same classification score. More importantly, it directly enforces the same large activation for the foreground (e.g., 1) and the same small activation for the background (e.g., 0). Here, it leads to reducing the activation imbalance inside the foreground and having a large gap between the foreground and background. Since we do not have pixel-level supervision to formulate per-pixel classification problems, the noisy pseudo-mask from CAM with conditional random field (CRF) [23] serves as the initial target for training AMN.
Moreover, we propose label conditioning to reduce the activation of non-target classes. The idea of label conditioning is to reformulate the label prediction problem by finding the best prediction out of the given classes ( is the number of classes given by the ground-truth image-level label per image) and background, instead of classes (i.e., a total of foreground classes and a background class). is always much less than and thereby the range of possible answers is clearly reduced. It makes the problem better-posed. More importantly, the activation of non-target classes is strictly suppressed by mapping to 0. It helps strengthen the foreground activation. As a result, with the same global threshold as the previous studies [1, 27, 25], AMN largely improves the quality of pseudo-mask and eventually records the state-of-the-art performances on the Pascal VOC 2012 and MS COCO 2014 benchmarks.
2 Related work
Most WSSS techniques utilize CAM [45] to obtain localization maps from image-level labels. Considering the sparse coverage of CAM as the bottleneck of WSSS, many studies focused on expanding the seed activation of CAM. Specifically, [29, 16, 8] suggested erasing the most discriminative regions. CIAN [13] utilized the cross-image affinity. [5, 38] devised a self-supervised task. [26, 18] suggested a feature ensemble method. [30, 37] developed a class-wise co-attention mechanism. AdvCAM [27] proposed an anti-adversarial image manipulation method. [2, 1] implicitly exploit the boundary information with pixel-level affinity information, naturally expanding the object coverage until boundaries.
Another approach exploits additional information to refine the object boundaries or distinguish co-occurring objects [40, 12, 42]. [6, 41] combined saliency maps with class-specific attention cues to generate reliable pseudo-masks. EPS [28] utilized the saliency maps as the cues for boundaries and co-occurring pixels. DRS [20] suppressed the most discriminative parts to expand the object coverage and then refine the boundary with saliency map.
Several existing studies resolved the limitation of CAM-GAP by modifying the pooling methods [22, 3, 25]. SEC [22] argued that global max pooling (GMP) underestimates the object size and GAP sometimes overestimates it. Then, they proposed global weighted rank pooling. Araslanov et al. [3] claimed that CAM-GAP may penalize small segments and proposed normalized global weighted pooling (nGWP) instead of GAP. As a concurrent work, RIB [25] promotes less discriminative regions by collecting only non-discriminative regions for pooling. Unlike the methods suggested new pooling layers, we focus on the fact that GAP (in fact, any pooling methods will do) leads to having a different optimal threshold per image.
3 Preliminaries
Class activation mapping (CAM). In the WSSS framework, CAM is used to provide class activation maps corresponding to their image-level labels. Given a CNN and the input , and indicate the height and width of the input. The feature maps are average pooled and then multiplied by the weights for class from the classifier, resulting in the classification score. By multiplying back to the feature maps , we can compute the class activation map for class as follows:
| (1) |
where is the number of channels in feature maps.
All existing WSSS methods normalize into the range of [0 1] and then apply a global threshold to separate the foreground and background pixels. In this way, we can generate pixel-level masks from image-level labels.
Threshold matters in WSSS. GAP allows different activations to be mapped to the same classification score. Thus, the resultant can have various distributions of activations. As a result, as seen in Figure 1, no single threshold can be sufficient to derive the optimal pseudo-masks for different inputs. We investigate the conditions where the pseudo-mask is accurate and robust against different thresholds. The first condition (c1) is reducing the activation imbalance within the foreground as also pointed out in [24]. It guides the activation value cover the entire extent of the target object rather than focusing on the most discriminative part. The second condition (c2) is enforcing the large activation gap between the foreground and the background activation. It helps the pseudo-mask generation less sensitive against the threshold. By jointly satisfying c1 and c2, we argue that the activation is formed to distinguish the foreground and the background reasonably well with a global threshold. A simple toy example in Figure 2(a) illustrates that satisfying the two conditions can guarantee consistent and accurate performance regardless of threshold ; the same pseudo-mask is generated by choosing any within the gap. Figure 2(b) shows the opposite scenario, where it satisfies neither c1 nor c2; the performance is extremely sensitive to the choice of . The two cases illustrate that satisfying both c1 and c2 allows us to obtain accurate and robust pseudo-masks.
4 Activation Manipulation Network
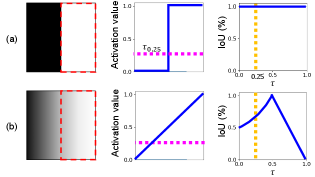
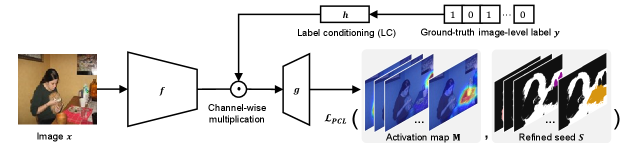
Our goal is to improve pseudo-mask quality by manipulating the activation map at the pixel-level, leading to robust performance against threshold choice. To this end, we propose an activation manipulation network (AMN) with two learning objectives. Firstly, we introduce a per-pixel classification loss, which reduces the activation imbalance inside foreground and provides the large gap between the foreground and the background (i.e., 1 when it is normalized into [0 1]). In addition, we propose a label conditioning module, which eliminates the activation from the non-target classes. It helps produce the foreground and background activation more accurately by reallocating the activation.
4.1 Overall training procedure
The training of the proposed WSSS framework consists of three stages: 1) seed generation, 2) pseudo-mask generation with the proposed AMN, and 3) final segmentation. For seed generation, we obtain noisy pixel-level annotations from image-level labels by applying CAM. Then, we apply conditional random field (CRF) [23]. CRF is the prevalent post-processing method and refines the initial seed by assigning an undefined region for less confident pixels. Specifically, we follow the procedure of Ahn et al. [1] to generate the refined seed . Secondly, given the image and its image-level label as inputs and the refined seed as the target output, we train AMN via a per-pixel classification loss (PCL) with label conditioning (LC). The network architecture for AMN is identical to that of the classification network for CAM with a small modification; replacing the GAP layer and the last classification layer with convolutional layers to predict pixel-level mask. Specifically, we adopt the atrous spatial pyramid pooling (ASPP) scheme [7]. To generate the final pseudo-masks, we improve the predicted mask quality using the well-known refinement technique, IRN [1]. Finally, we train a segmentation network with the generated pseudo-masks as supervision. Figure 3 visualizes the overall framework of AMN.
4.2 Per-pixel classification
Based on a case study in Section 3, we concluded that jointly achieving the two conditions can resolve the issue caused by the global threshold: reducing the imbalance within the foreground activation and having a large gap between the foreground and the background activations. Then, we devise an activation manipulation network (AMN) that satisfies the above two conditions. To achieve this goal, we introduce the per-pixel classification loss (PCL) because it directly enforces the two-level activation (e.g., 0 or 1), manipulating the activation (before thresholding) at the pixel-level.
Specifically, the two-level activation as the target signal can reduce the activation imbalance inside the foreground because the foreground should be assigned to the same activation value. Likewise, the two-level activation naturally retains the large activation gap between the foreground and background. Another advantage of PCL is that it does not rely on GAP. Since GAP yields different activation maps having the same classification score, discarding the GAP can be effective in handling a global threshold problem. To train the model with per-pixel classification, we need pixel-level supervision. Under the WSSS scenario, direct access to the pixel-level supervision is prohibited. We instead utilize the refined seed as noisy supervisory for training AMN. Finally, the balanced cross-entropy loss [17] is adopted for a per-pixel classification loss (PCL).
4.3 Label conditioning
The original per-pixel classifier maps each pixel into one out of classes (i.e., a total of foreground classes and a background class). Meanwhile, label conditioning (LC) imposes that each pixel should be mapped into one out of classes, meaning -number of classes in the ground-truth image-level label per image and -background class. LC is effective in two aspects. Firstly, it helps distinguish objects with similar appearances unless they really appear together in the image. It prevents false predictions due to confusing textures (e.g., among the skin of horse, cow, or dog) by allowing activation only if its class is corresponding to any of the input ground-truth image-level label. Next, noisy pseudo-masks often include a considerable number of undefined regions. The model is thus data-hungry due to lack of supervisory signals. LC can act as auxiliary supervision, providing rich learning signals. As a result, adopting LC leads to reallocating the non-target class activation to the target class activation, increasing the overall activation of the foreground. This is particularly useful to promote the less discriminative regions of the foreground.
Here, we introduce an additional layer for LC such that the effects of LC only influence high-level features. This is because limiting the choice of classes at low-level features may add to unwanted bias to the representation. Instead, we encode the ground-truth image-level labels as a feature vector and then directly multiply this vector to the feature map . Finally, the activation map is computed as:
| (2) |
where , , and indicate a CNN backbone, convolutional layers to predict pixel-level masks, and a linear layer to map the label to the feature vector, respectively. By doing so, the feature vector of ground-truth image-level labels directly constrains the final map.
5 Experiments
5.1 Experimental setup
Dataset & evaluation metric. For performance evaluation, we use both PASCAL VOC 2012 [10] (CC-BY 4.0) and MS COCO 2014 [4] (CC-BY 4.0) datasets, the most popular benchmarks in the semantic segmentation task. PASCAL VOC 2012 contains 20 foreground object categories and one background category with 10,582 training images expanded by SBD [14], 1,449 validation images, and 1,456 test images. MS COCO 2014 dataset consists of 81 classes, including a background, with 82,783 and 40,504 images for training and validation. In all experiments, we only used image-level class labels for training. For an evaluation metric, we used mean Intersection over Union (mIoU), which is widely used to measure segmentation performance.
| CAM | PCL | LC | w/ CRF | w/ IRN [1] |
| ✓ | 54.3 | 66.3 | ||
| ✓ | ✓ | 62.1 | 69.1 | |
| ✓ | ✓ | ✓ | 65.3 | 72.2 |
Implementation details. We train the classification network to extract the seed activation map via CAM. Here, we adopt ResNet50 [15] pre-trained on ImageNet [9] as a backbone classification network, except for the additional layers. The CAM implementation follows the configuration from Ahn et al. [1]. For training AMN, we used an Adam [21] optimizer and the learning rate of 5e-6 for updating the backbone parameters and 1e-4 for updating parameters associated with a per-pixel classification head. We adopt label smoothing as a training technique to subside the noise in initial seed, as discussed in [34]. The additional hyper-parameters are found in supplementary material. For the segmentation network, we experimented with DeepLab-v2 with the ResNet101 backbone [7] and followed the default training settings of AdvCAM [27].
5.2 Ablation study
We investigate whether each component of AMN is effective. Considering the CAM with IRN as the baseline, we add a per-pixel classification loss (PCL) and a label conditioning (LC) in sequence and report their performances in Table 1. These results are from PASCAL VOC 2012 train set, thereby implying the quality of pseudo-masks. Compared to the baseline, adding PCL improves the mIoU by 2.8%. By additionally applying LC, the performance increases by 3.1%. Considering that the performance is already high, the additional gain by LC is impressive. Since LC suppresses any activation for non-target classes, it implicitly increases the activation of the target objects.
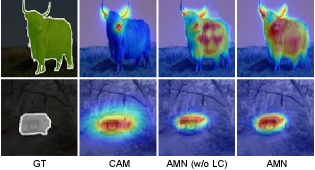
To confirm the effects of LC, we visualize the activation map with and without LC in Figure 4. The two classes having a similar appearance, such as cow and horse, can be hardly distinguishable using AMN without LC. When the image only has cow, Figure 4 shows that the results without LC are activated for both the cow and horse (the first image of (a) and (b)). Meanwhile, after adopting LC, it is clearly seen that only cow pixels are activated, but horse pixels are deactivated, as shown in the second images of Figures 4(a) and (b). From these results, we support that LC not only reduces non-target activations but also increases the foreground activations of the target objects. It can be interpreted that using the ground-truth image-level labels can subside the noise in our initial target (CAM with CRF), greatly increasing the performance.

We stress that LC is not applicable to the conventional image classifier because its target is already the image-level labels; LC on the image classifier can yield the model to return a trivial solution. Since AMN learns to manipulate pixel-level activation, adopting LC behaves as auxiliary supervision and leads to performance improvement.
In addition, we experimented to determine which layer of AMN is best for LC to affect. We use ResNet50 as the backbone, consisting of 4 resblocks. We applied LC after each residual block sequentially, and computed the feature vectors. The accuracy of pseudo-masks by applying LC differently is summarized in Table 2. The best performance was achieved when LC was applied to high-level features. Likewise, the performance deteriorated when applied to low-level features. Also, applying LC on multiple layers, including the last layer, did not help the performance either. These results show that the idea of LC should be carefully implemented, because class-specific information is not always useful for feature engineering. We conjecture that the last layer handles the semantics, thus it can effectively utilize the LC for improving the final decision.
| layer1 | layer2 | layer3 | layer4 | mIoU |
| ✓ | 48.2 | |||
| ✓ | 51.7 | |||
| ✓ | 61.2 | |||
| ✓ | 62.1 | |||
| ✓ | ✓ | 61.0 | ||
| ✓ | ✓ | ✓ | 51.4 | |
| ✓ | ✓ | 50.9 |
5.3 Sensitivity to threshold
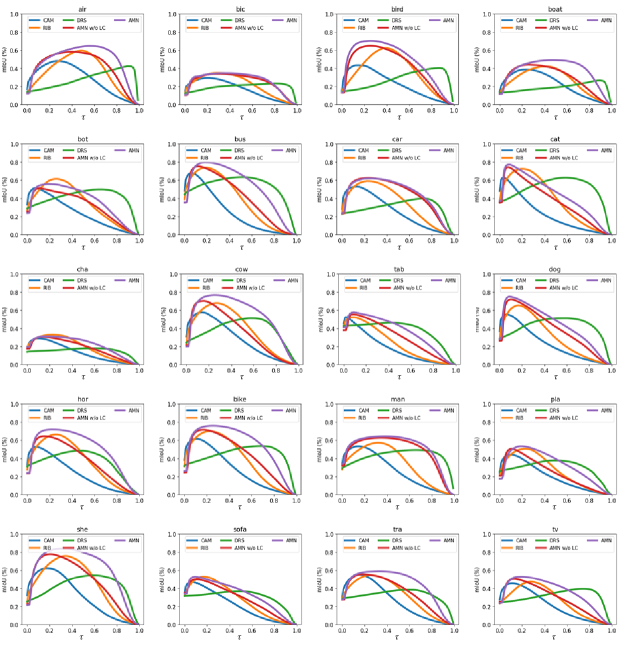
Quantitative evaluation. In this section, we evaluate the robustness of different methods under various thresholds. We apply different thresholds to the activation map, obtain the pseudo-mask accordingly, and then measure its accuracy (mIoU). For comparison, the baseline CAM [45], RIB [25], DRS [20] without saliency map, AMN without LC, and AMN are selected. Figure 6 presents mIoU.
In the case of CAM and RIB, the accuracy decreases even by adding a small perturbation to their global threshold; the curves fluctuate rapidly upon . This is expected because GAP yields an imbalance in activation, thus the pseudo-mask is highly sensitive to . On the other hand, DRS and AMN without LC exhibit relatively gentle slopes, indicating robust performances to the changes in threshold. Note that DRS tends to decrease the high activation on the most discriminative parts, thereby it partially shares the philosophy of PCL. However, DRS only focuses on suppressing foreground activations while PCL i) promotes the less discriminative parts of the foreground and ii) reduces the background activation. For this reason, activation of PCL tends to distinguish foreground and background more accurately, whereas DRS always tends to have excessive foreground coverage. These side effects of DRS finally result in relatively low accuracy in general. The original DRS utilizes a saliency map as additional supervision to compensate for this issue, thus the disadvantage was well mitigated. AMN without LC alleviated the imbalance in activation for both the foreground and background. Consequently, we achieve high mIoU and robust performance against the threshold at the same time.
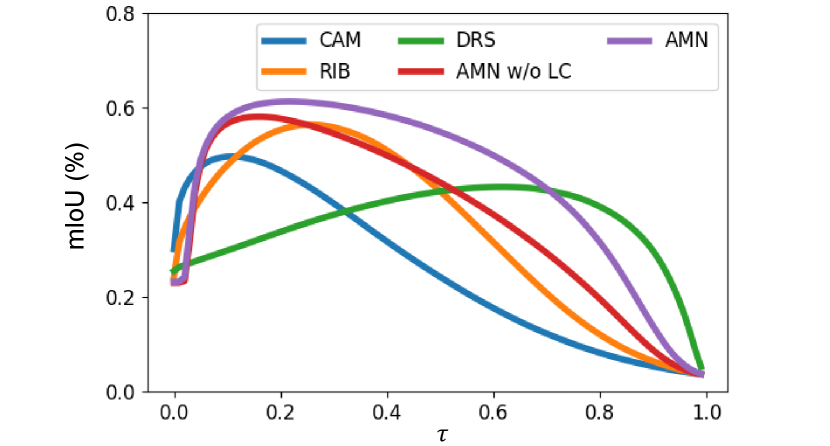
Final AMN uses LC, and it increases the prior probability of a class belonging to the input image-level label. It helps reduce wrong activation for wrong classes, reallocating them to the correct class. This effectively promotes the less discriminative part of the foreground. As a result, we can achieve more accurate and robust performance.
| Method | mIoU | |
| IRN [1]CVPR’16 | 66.3 | |
| SEAM [38]CVPR’20 | 63.6 | |
| MBMNet [32]ACMMM’20 | 66.8 | |
| CONTA [44]NeurIPS’20 | 67.9 | |
| AdvCAM [27]CVPR’21 | 69.9 | |
| RIB [25]NeurIPS’21 | 70.6 | |
| AMN (ours) | 72.2 |
Qualitative evaluation. Figure 5 shows the effect of each component of AMN qualitatively. Since PCL imposes each pixel to map either the foreground or background, it penalizes the high activation in the most discriminative parts as well as the noisy activation in the background. Meanwhile, PCL can increase the moderate activation in the less discriminative part. As a natural consequence, we observe that the map generated by PCL alone (AMN without LC) covers the full extent of the object more than the original CAM. Concretely, the result from CAM concentrated on the most discriminative regions, such as a cow’s face. Meanwhile, the resultant map by AMN without LC can capture the entire extent of the object. Depending on the object size, the CAM occasionally covers the object excessively, as seen in Figure 5 (the bottom image for CAM). Since PCL regularizes both the foreground and background activation, it achieves reasonable coverage of object extent.
LC provides additional supervision to undefined areas (originally less confident) and promotes the less discriminative parts of the foreground. Figure 5 shows that activation of AMN is evenly spread inside the foreground and reasonably covers the object, such as cow and car region. Besides, it shows a large activation gap between the object region and the background by promoting the less discriminative regions of the foreground. As we intended, LC helps reduce activation imbalance and increases the gap between the foreground and the background activation.

5.4 Comparisons with the state-of-the-arts
| Method | Backbone | Sup. | val | test |
| FickleNet [26]CVPR’19 | ResNet101 | I.+S. | 64.9 | 65.3 |
| OAA [18]ICCV’19 | ResNet101 | I.+S. | 65.2 | 66.4 |
| Multi-Est. [12]ECCV’19 | ResNet101 | I.+S. | 67.2 | 66.7 |
| MCIS [37]ECCV’20 | ResNet38 | I.+S. | 66.2 | 66.9 |
| SGAN [41]ACCESS’20 | ResNet101 | I.+S. | 67.1 | 67.2 |
| EPS [28]CVPR’21 | ResNet101 | I.+S. | 70.9 | 70.8 |
| DRS [20]AAAI’21 | ResNet101 | I.+S. | 71.2 | 71.4 |
| ICD [11]CVPR’20 | ResNet101 | I. | 64.1 | 64.3 |
| SEAM [38]CVPR’20 | ResNet38 | I. | 64.5 | 65.7 |
| SC-CAM [5]CVPR’20 | ResNet101 | I. | 66.1 | 65.9 |
| RRM [43]AAAI’20 | ResNet101 | I. | 66.3 | 66.5 |
| BES [33]ECCV’20 | ResNet101 | I. | 65.7 | 66.6 |
| CONTA [44]NeurIPS’20 | ResNet50 | I. | 66.1 | 66.7 |
| AdvCAM [27]CVPR’21 | ResNet101 | I. | 68.1 | 68.0 |
| RIB [25]NeurIPS’21 | ResNet101 | I. | 68.3 | 68.6 |
| AMN (ours) | ResNet101 | I. | 69.5† | 69.6† |
| ResNet101 | I. | 70.7‡ | 70.6‡ |
Accuracy of pseudo-masks. Similar to existing WSSS methods, we aim to improve the pseudo-mask quality and expect that it will eventually increase the accuracy of WSSS. We first evaluate the quality of pseudo-masks by comparing them with ground-truth masks. Table 3 compares mIoU of the proposed AMN with that of other state-of-the-art WSSS methods. For a fair comparison, we apply the best refinement scheme reported by each method for pseudo-mask generation. Our results achieve a gain of 5.9% over that of IRN [1], which can be regarded as a baseline, and the gain of 1.6% over RIB, the state-of-the-art method among the WSSS methods only with image-level labels.
Specifically, the accuracy (mIoU) in dining table / tv was 41.9 / 54.2 with RIB, but 62.8 / 63.1 with ours on PASCAL VOC 2012 train set. dining table usually exhibits extremely strong activation on the most discriminative parts (i.e., an extreme imbalance in activation), thus the optimal threshold for this class is much smaller than the global threshold. Although existing WSSS methods aim at expanding the object coverage, their effects are designed at image-level, thus cannot suppress strong activation at pixel-level. Meanwhile, AMN explicitly regularized the pixel-level activation, therefore capable of handling extreme activation.
| Method | Backbone | Sup. | val |
| SGAN [41]ACESS’20 | VGG16 | I.+S. | 33.6 |
| EPS [28]CVPR’21 | VGG16 | I.+S. | 35.7 |
| ADL [8]TPAMI’20 | VGG16 | I. | 30.8 |
| CONTA [44]NeurIPS’20 | ResNet50 | I. | 33.4 |
| IRN [1]CVPR’19 | ResNet101 | I. | 41.4 |
| RIB [25]NeurIPS’21 | ResNet101 | I. | 43.8 |
| AMN (ours) | ResNet101 | I. | 44.7† |
On the other hand, the optimal threshold for tv significantly varies depending on the image. That means, no single threshold is meaningful. Thanks to the robust nature of AMN, we could achieve considerable gain on tv regardless of images. These results are consistent with our motivation; threshold matters in WSSS and AMN can effectively resolve this issue. A quantitative evaluation of the pseudo-mask for each class is provided in supplementary material.
Accuracy of segmentation maps. For quantitative comparison, we report the mIoU scores of our method and recent WSSS methods on PASCAL VOC 2012 validation and test images. The competitors are chosen to represent the best-performing models in the last three years. On PASCAL VOC 2012 benchmark, we achieved 69.5% and 69.6% mIoU using the ImageNet pretrained backbone, and 70.7% and 70.6% mIoU with MS COCO pretrained backbone. This is a new state-of-the-art record for WSSS methods only using the image-level labels; comparable to EPS [28] using both image-level labels and saliency maps.
Analogous to the observation in the pseudo-mask, our achievement is particularly affected by a large improvement in several classes that have performed poorly in the past. Specifically, the segmentation result (mIoU) in dining table / tv was 37.5 / 54.9 with RIB, but 53.8 / 57.5 with ours on PASCAL VOC 2012 validation set. These results are consistent with the pseudo-mask accuracy. Our method handles the strong imbalance in activation at the pixel-level (dining table) and is robust against the threshold choice (tv). More results on per-class mIoU scores are provided in supplementary material. Figure 7 shows the qualitative examples of segmentation results on PASCAL VOC 2012 validation set. These results confirm that our method covers the full extent of the objects correctly, especially dining table, which was not possible by previous methods.
To investigate our performance on the large-scale benchmark, we adopt the MS COCO 2014 dataset. Not all competitors provide their evaluation on MS COCO 2014. For this reason, we only compare our method with five competitors. Table 5 summarizes the comparison results on MS COCO 2014 validation set. AMN achieves 44.7% mIoU, breaking a new state-of-the-art record. This demonstrates that AMN is also effective on large-scale benchmarks. More qualitative comparisons and results on per-class segmentation mIoU scores for MS COCO 2014 are in supplementary material.

5.5 Discussion
Limitation. Although LC helps disambiguate the confusing foreground classes (e.g., visually similar to each other), it cannot handle the case where they appear together in the input image or the background is similar to the foreground object. For example, the table in Figure 8(a) is misclassified as chair pixels upon similar appearance. Similarly, the metal ring in Figure 8(b) is mispredicted as bicycle pixels due to its shared shape. In addition, our method cannot overcome the contextual bias (i.e., co-occurrence) and inaccurate boundary problem, which is inherited by CAM. Since the classifier is not designed to separate the foreground and background, activation maps from the classifier do not capture precise object boundaries, especially for complex shapes (e.g., the rough boundary of bicycles and chairs). Figures 8(c) and (d) show that our method cannot distinguish the co-occurring pixels in a railroad-train pair and a boat-water pair, respectively.
Negative societal impact. Since our framework consists of three training stages, it incurs more carbon emissions and power consumption. In future work, we plan to reduce the training stages, integrating the classifier and AMN.
6 Conclusions
In this paper, we identified that the optimal thresholds largely vary in the images, and this issue can significantly affect the performance of WSSS. To address this issue, we devised a new activation manipulation strategy for achieving robust and accurate performances. Toward this goal, we showed that jointly satisfying the two conditions can sufficiently resolve this problem. That is, we should reduce the imbalance in activation and increase the gap between the foreground and the background activation at the same time. For that, we developed an activation manipulation network (AMN) with a per-pixel classification loss and an image-level label conditioning module. Extensive experiments show that each component of AMN is effective, AMN helps induce robust pseudo-masks against the threshold, and finally achieved a new state-of-the-art performance in both PASCAL VOC 2012 and MS COCO 2014 datasets.
Acknowledgements. This research was supported by the NRF Korea funded by the MSIP (NRF-2022R1A2C3011154, 2020R1A4A1016619), the IITP grant funded by the MSIT (2020-0-01361/YONSEI UNIVERSITY, 2021-0-02068/Artificial Intelligence Innovation Hub), and the Korea Medical Device Development Fund grant (202011D06).
References
- [1] Jiwoon Ahn, Sunghyun Cho, and Suha Kwak. Weakly supervised learning of instance segmentation with inter-pixel relations. In CVPR, 2019.
- [2] Jiwoon Ahn and Suha Kwak. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In CVPR, 2018.
- [3] Nikita Araslanov and Stefan Roth. Single-stage semantic segmentation from image labels. In CVPR, 2020.
- [4] Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco-stuff: Thing and stuff classes in context. In CVPR, 2018.
- [5] Yu-Ting Chang, Qiaosong Wang, Wei-Chih Hung, Robinson Piramuthu, Yi-Hsuan Tsai, and Ming-Hsuan Yang. Weakly-supervised semantic segmentation via sub-category exploration. In CVPR, 2020.
- [6] Arslan Chaudhry, Puneet K. Dokania, and Philip H. S. Torr. Discovering class-specific pixels for weakly-supervised semantic segmentation. In BMVC, 2017.
- [7] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI, 2017.
- [8] Junsuk Choe, Seungho Lee, and Hyunjung Shim. Attention-based dropout layer for weakly supervised single object localization and semantic segmentation. TPAMI, 2020.
- [9] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- [10] Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective. IJCV, 2015.
- [11] Junsong Fan, Zhaoxiang Zhang, Chunfeng Song, and Tieniu Tan. Learning integral objects with intra-class discriminator for weakly-supervised semantic segmentation. In CVPR, 2020.
- [12] Junsong Fan, Zhaoxiang Zhang, and Tieniu Tan. Employing multi-estimations for weakly-supervised semantic segmentation. In ECCV, 2020.
- [13] Junsong Fan, Zhaoxiang Zhang, Tieniu Tan, Chunfeng Song, and Jun Xiao. Cian: Cross-image affinity net for weakly supervised semantic segmentation. In AAAI, 2020.
- [14] Bharath Hariharan, Pablo Arbeláez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. In ICCV, 2011.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [16] Qibin Hou, PengTao Jiang, Yunchao Wei, and Ming-Ming Cheng. Self-erasing network for integral object attention. In NeurIPS, 2018.
- [17] Zilong Huang, Xinggang Wang, Jiasi Wang, Wenyu Liu, and Jingdong Wang. Weakly-supervised semantic segmentation network with deep seeded region growing. In CVPR, 2018.
- [18] Peng-Tao Jiang, Qibin Hou, Yang Cao, Ming-Ming Cheng, Yunchao Wei, and Hong-Kai Xiong. Integral object mining via online attention accumulation. In ICCV, 2019.
- [19] Anna Khoreva, Rodrigo Benenson, Jan Hosang, Matthias Hein, and Bernt Schiele. Simple does it: Weakly supervised instance and semantic segmentation. In CVPR, 2017.
- [20] Beomyoung Kim, Sangeun Han, and Junmo Kim. Discriminative region suppression for weakly-supervised semantic segmentation. In AAAI, 2021.
- [21] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [22] Alexander Kolesnikov and Christoph H Lampert. Seed, expand and constrain: Three principles for weakly-supervised image segmentation. In ECCV, 2016.
- [23] Philipp Krähenbühl and Vladlen Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. In NeurIPS, 2011.
- [24] Hyeokjun Kweon, Sung-Hoon Yoon, Hyeonseong Kim, Daehee Park, and Kuk-Jin Yoon. Unlocking the potential of ordinary classifier: Class-specific adversarial erasing framework for weakly supervised semantic segmentation. In ICCV, 2021.
- [25] Jungbeom Lee, Jooyoung Choi, Jisoo Mok, and Sungroh Yoon. Reducing information bottleneck for weakly supervised semantic segmentation. In NeurIPS, 2021.
- [26] Jungbeom Lee, Eunji Kim, Sungmin Lee, Jangho Lee, and Sungroh Yoon. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference. In CVPR, 2019.
- [27] Jungbeom Lee, Eunji Kim, and Sungroh Yoon. Anti-adversarially manipulated attributions for weakly and semi-supervised semantic segmentation. In CVPR, 2021.
- [28] Seungho Lee, Minhyun Lee, Jongwuk Lee, and Hyunjung Shim. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In CVPR, 2021.
- [29] Kunpeng Li, Ziyan Wu, Kuan-Chuan Peng, Jan Ernst, and Yun Fu. Tell me where to look: Guided attention inference network. In CVPR, 2018.
- [30] Xueyi Li, Tianfei Zhou, Jianwu Li, Yi Zhou, and Zhaoxiang Zhang. Group-wise semantic mining for weakly supervised semantic segmentation. In AAAI, 2021.
- [31] Di Lin, Jifeng Dai, Jiaya Jia, Kaiming He, and Jian Sun. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In CVPR, 2016.
- [32] Weide Liu, Chi Zhang, Guosheng Lin, Tzu-Yi Hung, and Chunyan Miao. Weakly supervised segmentation with maximum bipartite graph matching. In ACMMM, 2020.
- [33] Chen Liyi, Wu Weiwei, Chenchen Fu, Xiao Han, and Yuntao Zhang. Weakly supervised semantic segmentation with boundary exploration. In ECCV, 2020.
- [34] Michal Lukasik, Srinadh Bhojanapalli, Aditya Menon, and Sanjiv Kumar. Does label smoothing mitigate label noise? In ICML, 2020.
- [35] Deepak Pathak, Philipp Krahenbuhl, and Trevor Darrell. Constrained convolutional neural networks for weakly supervised segmentation. In ICCV, 2015.
- [36] Pedro O Pinheiro and Ronan Collobert. From image-level to pixel-level labeling with convolutional networks. In CVPR, 2015.
- [37] Guolei Sun, Wenguan Wang, Jifeng Dai, and Luc Van Gool. Mining cross-image semantics for weakly supervised semantic segmentation. In ECCV, 2020.
- [38] Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In CVPR, 2020.
- [39] Yunchao Wei, Jiashi Feng, Xiaodan Liang, Ming-Ming Cheng, Yao Zhao, and Shuicheng Yan. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In CVPR, 2017.
- [40] Yunchao Wei, Xiaodan Liang, Yunpeng Chen, Xiaohui Shen, Ming-Ming Cheng, Jiashi Feng, Yao Zhao, and Shuicheng Yan. Stc: A simple to complex framework for weakly-supervised semantic segmentation. TPAMI, 2016.
- [41] Qi Yao and Xiaojin Gong. Saliency guided self-attention network for weakly and semi-supervised semantic segmentation. IEEE Access, 2020.
- [42] Yu Zeng, Yunzhi Zhuge, Huchuan Lu, and Lihe Zhang. Joint learning of saliency detection and weakly supervised semantic segmentation. In ICCV, 2019.
- [43] Bingfeng Zhang, Jimin Xiao, Yunchao Wei, Mingjie Sun, and Kaizhu Huang. Reliability does matter: An end-to-end weakly supervised semantic segmentation approach. In AAAI, 2020.
- [44] Dong Zhang, Hanwang Zhang, Jinhui Tang, Xian-Sheng Hua, and Qianru Sun. Causal intervention for weakly-supervised semantic segmentation. In NeurIPS, 2020.
- [45] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In CVPR, 2016.
Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurate Segmentation Model Against Thresholds
Supplementary Material
Appendix A Implementation Details
Activation manipulation network. For training AMN, we used an Adam [21] optimizer and the learning rate of 5e-6 for updating the backbone parameters and 1e-4 for updating parameters associated with a per-pixel classification head. Both parameter groups adopt the weight decay of 1e-4. The batch size is 16, and the total training epoch is 5. In addition, we adopted label smoothing as a training technique to subside the noise in initial seed, as discussed in [34]. Note that label smoothing strategy has the hyper-parameter that determines the level of smoothing (i.e., the greater indicates the stronger effect of label smoothing). In our experiment, we empirically chose and the same value was applied in all experimental settings. Specifically, given a class label at pixel of the refined seed , the target label distribution at is denoted as and it is rewritten as follows:
| (3) |
For a per-pixel classification loss (PCL), we adopted balanced cross-entropy loss [17] as follows:
| (4) |
| (5) |
where is the softmax function, is the activation map from AMN ( is the class activation map from the classifier), is the set of classes that are present in the image (excluding background) and is the background class. denotes the number of pixels belonging to class .
Segmentation network. For the segmentation network, we adopted DeepLab-v2-ResNet101 and followed the default training settings of AdvCAM [27] for PASCAL VOC 2012. Input images are randomly scaled to and cropped to ( for MS COCO 2014) for training. We used the SGD optimizer with the batch size of 10 (20 for MS COCO 2014), the momentum of , and the weight decay of . The number of training iterations is 30k and the initial learning rate is with the polynomial learning rate decay , where is set to . We used balanced cross-entropy loss [17] as in AdvCAM [27].
Appendix B Additional Analysis
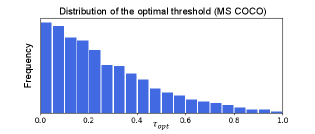
Distribution of optimal thresholds on MS COCO 2014. Figure 1 shows the distribution of optimal threshold in the PASCAL VOC 2012. Here, we further investigate whether the same observation holds in MS COCO 2014, which is a large-scale, popular benchmark dataset for semantic segmentation. To efficiently derive the distribution of optimal threshold using MS COCO 2014, we randomly sample 10% of MS COCO 2014 and find the optimal threshold for each image. Figure A.1 shows that the optimal threshold per image is distributed over a wide range from 0 to 1. This result confirms that our observation in PASCAL VOC 2012 consistently holds in a different dataset; the global threshold is not sufficient to generate the optimal pseudo-masks.
Effects of encoding features. In Section 4.3, we encode label vectors by transforming it into feature vectors for label conditioning. To differentiate the effect of label vector from the effect of encoding any vectors, we conduct additional experiments; 1) encoding a one-vector, 2) encoding the label vector + a random vector and 3) encoding the label vector. Table A.1 compares three cases by reporting the accuracy (mIoU) of pseudo-masks. With a one-vector, no distinct gain is observed over AMN without LC. This implies that the encoding operation itself does not make much difference. In addition, we observe the accuracy gain when encoding noisy labels (i.e., the ground-truth label vector summed up with a noise vector). Since this noisy label also reduces the possible choices, it helps reduce non-target activation to some extent. As expected, the ground-truth image-level labels can lead a noticeable gain, achieving the best accuracy among all.
| AMN | AMN | AMN | AMN | |
| w/o LC | w/ ones | w/ label + noise | ||
| mIoU | 58.2% | 58.6% | 60.5% | 62.1% |
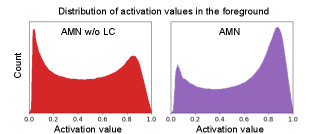
Effect of label conditioning. Additionally, we observe the histogram of foreground activation values on PASCAL VOC 2012 train set. For this empirical study, we focus on the activation values appearing inside the target objects using ground-truth segmentation mask. As shown in Figure A.2, the effects of LC increase the foreground activations of the target objects–the values within [0.8 1.0] greatly increase and the values within [0.0 0.2] sufficiently decrease. This is coherent with our observation in Figure 4, where LC reduces the horse activation in the cow image and then the cow is correctly activated after applying LC. Overall, we confirm that LC is effective to achieve accurate and robust segmentation performance.
Appendix C Per-class Performance
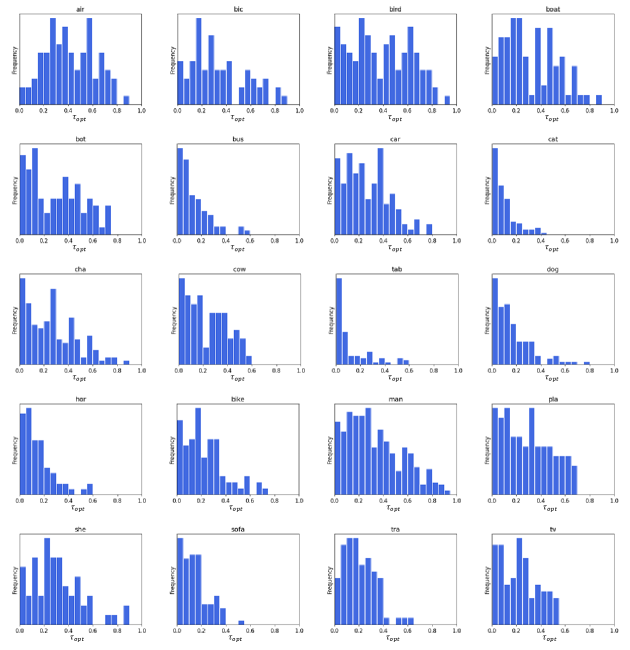
In Figure 1(a), we showed that the optimal threshold per image quite differs from each other. Herein, Figure A.3 shows the distribution of the optimal threshold per image within the same class on PASCAL VOC 2012 train set. From these results, we find that the distribution of the optimal threshold is widely distributed in most classes and the different class has different tendency; a class-wise global threshold is also largely different from each other.
Figure A.4 shows per-class mIoU of the pseudo-masks according to thresholds on PASCAL VOC 2012 train set. Although the different class exhibits different characteristics in optimal thresholds, AMN tends to generate more accurate and robust pseudo-masks (e.g., the pseudo-mask accuracy of man increases a lot, but that of sofa is almost same).
Table A.2 shows the per-class mIoU of the pseudo-mask results on PASCAL VOC 2012 train set. For comparison, we report the per-class mIoU of RIB [25]. Since RIB does not present the per-class mIoU of the pseudo-masks, we reproduced their results based on the official implementation of RIB111https://github.com/jbeomlee93/RIB. Table A.2 and Table A.4 show the per-class mIoU of the segmentation results on PASCAL VOC 2012 and MS COCO 2014 datasets, respectively. Specifically, for MS COCO 2014 validation set, we observe the strong gains in several classes; dining table / airplane are 11.6 / 61.3 with RIB, but 17.2 / 65.5 with ours. These results are consistent with the PASCAL VOC 2012; our method handles the strong imbalance in activation at the pixel-level (dining table) and is robust against the threshold choice (airplane). This demonstrates that AMN is also effective on large-scale benchmarks.
Appendix D Qualitative Examples
Figure A.5 shows qualitative examples and failure cases of segmentation results from AMN on PASCAL VOC 2012 validation set and MS COCO 2014 validation set. Our method effectively covers the full extent of the objects. Meanwhile, we still have some failure cases: 1) confusing objects (e.g., sofa and chair), 2) co-occurrence problem (e.g., railroad and train, 3) shape bias (e.g., tv/monitor).
bkg aero bike bird boat bottle bus car cat chair cow table dog horse motor person plant sheep sofa train tv mIOU RIB∗ 88.9 70.3 44.5 74.5 62.3 77.8 83.3 73.9 85.9 40.8 82.4 41.9 79.7 83.4 80.6 69.0 59.5 83.7 63.9 60.8 54.2 69.6 AMN (Ours) 90.2 75.3 40.1 77.4 67.9 73.4 85.6 78.9 80.7 36.5 86.1 62.8 78.7 83.4 81.0 74.4 62.4 89.4 62.8 65.3 63.1 72.2
bkg aero bike bird boat bottle bus car cat chair cow table dog horse motor person plant sheep sofa train tv mIOU Results on PASCAL VOC 2012 val set: AdvCAM 90.0 79.8 34.1 82.6 63.3 70.5 89.4 76.0 87.3 31.4 81.3 33.1 82.5 80.8 74.0 72.9 50.3 82.3 42.2 74.1 52.9 68.1 RIB 90.3 76.2 33.7 82.5 64.9 73.1 88.4 78.6 88.7 32.3 80.1 37.5 83.6 79.7 75.8 71.8 47.5 84.3 44.6 65.9 54.9 68.3 AMN (Ours) 90.6 79.0 33.5 83.5 60.5 74.9 90.0 81.3 86.6 30.6 80.9 53.8 80.2 79.6 74.6 75.5 54.7 83.5 46.1 63.1 57.5 69.5 Results on PASCAL VOC 2012 test set: AdvCAM 90.1 81.2 33.6 80.4 52.4 66.6 87.1 80.5 87.2 28.9 80.1 38.5 84.0 83.0 79.5 71.9 47.5 80.8 59.1 65.4 49.7 68.0 RIB 90.4 80.5 32.8 84.9 59.4 69.3 87.2 83.5 88.3 31.1 80.4 44.0 84.4 82.3 80.9 70.7 43.5 84.9 55.9 59.0 47.3 68.6 AMN (Ours) 90.7 82.8 32.4 84.8 59.4 70.0 86.7 83.0 86.9 30.1 79.2 56.6 83.0 81.9 78.3 72.7 52.9 81.4 59.8 53.1 56.4 69.6
Class IRN RIB Ours Class IRN RIB Ours Class IRN RIB Ours Class IRN RIB Ours Class IRN RIB Ours background 80.5 82.0 82.8 dog 56.2 63.5 67.9 kite 28.8 37.1 43.9 broccoli 52.6 45.4 45.9 cell phone 51.6 54.1 57.7 person 45.9 56.1 53.7 horse 58.1 63.6 65.3 baseball bat 12.6 15.3 16.1 carrot 37.0 34.6 31.3 microwave 42.7 45.2 43.2 bicycle 48.9 52.1 49.3 sheep 64.6 69.1 71.9 baseball glove 7.9 8.1 6.5 hot dog 48.4 49.7 47.0 oven 31.0 35.9 35.5 car 31.3 43.6 38.9 cow 63.8 68.3 70.3 skateboard 27.1 31.8 29.6 pizza 55.9 58.9 57.5 toaster 16.4 17.8 24.3 motorcycle 64.7 67.6 67.1 elephant 79.3 79.5 81.4 surfboard 40.7 29.2 44.6 donut 50.0 53.1 57.3 sink 33.3 33.0 31.4 airplane 62.0 61.3 65.5 bear 74.6 76.7 79.9 tennis racket 49.7 48.9 45.6 cake 38.6 40.7 40.1 refrigerator 40.0 46.0 45.6 bus 60.4 68.5 68.1 zebra 79.7 80.2 82.4 bottle 30.9 33.1 33.0 chair 17.7 20.6 23.6 book 29.9 31.1 29.5 train 51.1 51.3 56.3 giraffe 72.3 74.1 76.5 wine glass 24.3 27.5 31.7 couch 32.6 36.8 36.6 clock 41.3 41.9 47.6 truck 32.2 38.1 38.9 backpack 19.1 18.1 15.5 cup 27.3 27.4 28.8 potted plant 10.5 17.0 19.2 vase 28.4 27.5 30.9 boat 36.7 42.3 41.6 umbrella 57.3 60.1 62.4 fork 16.9 15.9 16.3 bed 33.8 46.2 44.5 scissors 41.2 41.0 39.2 traffic light 48.7 47.8 49.6 handbag 9.0 8.6 7.2 knife 15.6 14.3 16.3 dining table 6.7 11.6 17.2 teddy bear 56.4 62.0 63.9 fire hydrant 74.9 73.4 74.3 tie 24.0 28.6 28.7 spoon 8.4 8.2 8.4 toilet 63.4 63.9 65.4 hair drier 16.2 16.7 21.3 stop sign 76.8 76.3 70.8 suitcase 45.2 49.2 48.6 bowl 17.0 20.7 24.4 tv 35.5 39.7 43.5 toothbrush 16.7 21.0 25.0 parking meter 67.3 68.3 63.2 frisbee 53.8 53.6 56.6 banana 62.4 59.8 61.1 laptop 39.3 48.2 51.8 bench 31.4 39.7 35.0 skis 8.0 9.7 11.4 apple 43.3 48.5 45.9 mouse 27.9 22.4 30.0 mean 41.4 43.8 44.7 bird 55.5 57.5 60.0 snowboard 25.5 29.4 30.3 sandwich 37.9 36.9 35.8 remote 41.4 38.0 38.4 cat 68.2 72.4 71.2 sports ball 33.6 38.0 33.9 orange 60.1 62.5 62.9 keyboard 52.9 50.9 48.7
