Throughput Maximization of DNN Inference: Batching or Multi-Tenancy?
Abstract
Deployment of real-time ML services on warehouse-scale infrastructures is on the increase. Therefore, decreasing latency and increasing throughput of deep neural network (DNN) inference applications that empower those services have attracted attention from both academia and industry. A common solution to address this challenge is leveraging hardware accelerators such as GPUs. To improve the inference throughput of DNNs deployed on GPU accelerators, two common approaches are employed: Batching and Multi-Tenancy. Our preliminary experiments show that the effect of these approaches on the throughput depends on the DNN architecture. Taking this observation into account, we design and implement DNNScaler which aims to maximize the throughput of interactive AI-powered services while meeting their latency requirements. DNNScaler first detects the suitable approach (Batching or Multi-Tenancy) that would be most beneficial for a DNN regarding throughput improvement. Then, it adjusts the control knob of the detected approach (batch size for Batching and number of co-located instances for Multi-Tenancy) to maintain the latency while increasing the throughput. Conducting an extensive set of experiments using well-known DNNs from a variety of domains, several popular datasets, and a cutting-edge GPU, the results indicate that DNNScaler can improve the throughput by up to 14x (218% on average) compared with the previously proposed approach, while meeting the latency requirements of the services.
1 Introduction
Deployment of interactive AI-powered services, also known as real-time ML, on warehouse-scale infrastructures is on the increase. The deep neural network (DNN) inference applications that empower these services have to meet the low-latency requirement of such real-time ML services. On the other hand, the service providers seek high throughput to serve more requests in a unit of time. They also desire high resource utilization to reduce their operational costs, and further improve their revenue. To this end, various hardware accelerators such as ASICs [39], FPGA-based accelerators [21] and GPU-based accelerators [28] are proposed for DNN inference. Since the GPUs have shown significant throughput improvement when employed for DNN inference, they are widely used in warehouse-scale infrastructures as DNN accelerators.
To gain high throughput when accelerating DNN inference, a common approach is Batching, which is widely used in previous works [20, 56]. It means processing input data in the form of batches, instead of processing them one by one. Batching helps to reuse the parameters of the DNN model for several inputs and also reduce the overhead of copying input data to GPU memory. [56, 18]. Another popular alternative is Multi-Tenancy [34, 9], where several different DNNs are co-located on a single GPU. Multi-Tenancy improves the throughput by sharing the computing resources between co-located DNNs. Although previous works have used Multi-Tenancy, they have not explored the case of co-locating several instances of the same DNN, in contrast to instances of different DNNs. In this work we consider this new approach for the first time (instances of the same DNN). Both Batching and Multi-Tenancy improve throughput via increasing resource utilization. While these approaches can increase the throughput, they negatively affect the tail latency of inference requests and elongate them [34]. Therefore they should be carefully used for real-time ML services.
In this paper, for the first time, we show the fact that the impact of Batching and Multi-Tenancy on the throughput depends on the DNN architecture. Based on the various features of a DNN, such as the number of parameters and computational complexity, either Batching or Multi-Tenancy can significantly improve the throughput of that DNN, while the other approach has no or negligible impact. Considering this observation, we design and implement our approach, called DNNScaler, which aims to maximize the throughput of real-time ML services deployed on GPU accelerators while meeting their latency requirements. DNNScaler consists of two modules: Profiler and Scaler. With the help of the Profiler module, it identifies the approach (Batching or Multi-Tenancy) that would be most beneficial for a DNN. After that, it adjusts the batch size (if Batching is selected) or the number of co-located instances (if Multi-Tenancy is selected) dynamically, considering the latency constraint, to maximize the throughput. Experimental results, using several DNNs and datasets and a Tesla P40 GPU, show that DNNScaler can improve the throughput by up to 14x compared to an approach that ignores the impact of Batching and Multi-Tenancy on the throughput of different DNNs. We make the following contributions in this paper:
-
•
We study the effect of Batching and Multi-Tenancy on throughput when deploying DNNs on a GPU accelerator. We examine various DNNs with varying architectures and features. By analyzing the results, for the first time, we show that the effectiveness of Batching and Multi-Tenancy highly depends on the DNN architecture. For some DNNs, Batching can significantly increase the throughput, while for others Multi-Tenancy remarkably improves throughput. In addition, to improve the throughput of a single DNN application, we suggest to deploy several instances of the same DNN, which is different from previous approaches that co-locate various DNNs on the same GPU.
-
•
We design a Profiler module that determines, at real-time, whether a DNN’s throughput would benefit from Batching or Multi-Tenancy. Another designed module, Scaler, aims to maximize the throughput while maintaining latency. In the presence of the Batching approach, it tunes the batch size as a control knob to achieve its goal. The other control knob, the number of co-located DNN instances, is used by Scaler when Multi-Tenancy is chosen for improving throughput. In the Scaler module, we use machine learning to estimate the latency of the DNN for different number of co-located instances.
-
•
Combining the Profiler and the Scaler modules, we implement our DNNScaler approach. The Profiler module detects the suitable approach (Batching or Multi-Tenancy), and the Scaler module adjusts the respective control knob (batch size or the number of co-located instances). Conducting an extensive set of experiments using a wide variety of DNNs with different datasets as inputs and leveraging a powerful server equipped with an Nvidia GPU, we show the superiority of DNNScaler over other approaches.
The rest of the paper is organized as follows: In Section 2, we discuss the impact of Batching and Multi-Tenancy approaches on the throughput of various DNNs. Then, we introduce our proposed approach, DNNScaler, in Section 3 and present the experimental results in Section 4. Related works are briefly discussed in Section 5, and the paper is concluded in Section 6.
2 DNN Inference: Batching or Multi-Tenancy?
The computing power and memory capacity of cutting-edge GPU accelerators used for DNN inference are on the increase. To improve the resource utilization of these accelerators, and hence, increase the throughput of applications, two common approaches are employed:
1) Batching: In this approach, input data is processed in the form of batches instead of processing each individual input (e.g., each image in image classification DNNs) separately. This approach has been widely employed by previous works [20, 57, 61, 18] to increase the throughput by better utilizing the computing resources of GPUs. Since the weights of DNNs are needed at least once per each input, Batching helps to reuse them for multiple inputs and reduce the data copy to GPU memory [57, 56].
2) Multi-Tenancy: Since the DNN inference graphs used for prediction usually consume less resources than the available resources of GPUs, it is possible to deploy several instances of the same graph to potentially leverage instance-level parallelism and achieve higher resource utilization and throughput. Multi-Tenancy or co-location of several workloads or kernels on a single GPU and related challenges have been studied in a large body of research [34, 8, 71, 9]. But none of them have considered multiple instances of the same DNN, as we consider in this work.
We have conducted a set of experiments to understand the impact of these two approaches on throughput and latency of DNN inference. We have employed four image classification DNNs (described in Table 1) with different sizes, architectures, and computational complexity to observe their performance under Batching and Multi-Tenancy. For the input data, we have used images from the ImageNet dataset [52]. For obtaining the computational complexity of DNNs, we have used TensorFlow Profiler [62]. The GPU accelerator we have used is a Tesla P40 GPU that has 3840 CUDA cores and 24 GB GDDR5 memory.
For Batching, we use batch sizes of 1 to 128 to study its impact on throughput and latency. We have conducted the experiments for bigger batch sizes (up to 1024 that is supported by our GPU), but we only show the results for up to the batch size of 128 for the sake of clarity. For Multi-Tenancy, we co-locate 1 to 8 instances of the same DNN with increments of one (e.g., one instance of Inception-V1 to eight instances of it). For Multi-Tenancy, the batch size for all the instances is one.
| DNN | No. Parameters |
|
||
|---|---|---|---|---|
| Inception-V1 | 6.6 M | 13.220736 | ||
| Inception-V4 | 42.7 M | 91.94925 | ||
| Mobilenet-V1-1 | 4.2 M | 8.420224 | ||
| ResNetV2-152 | 60.2 M | 120.084864 |
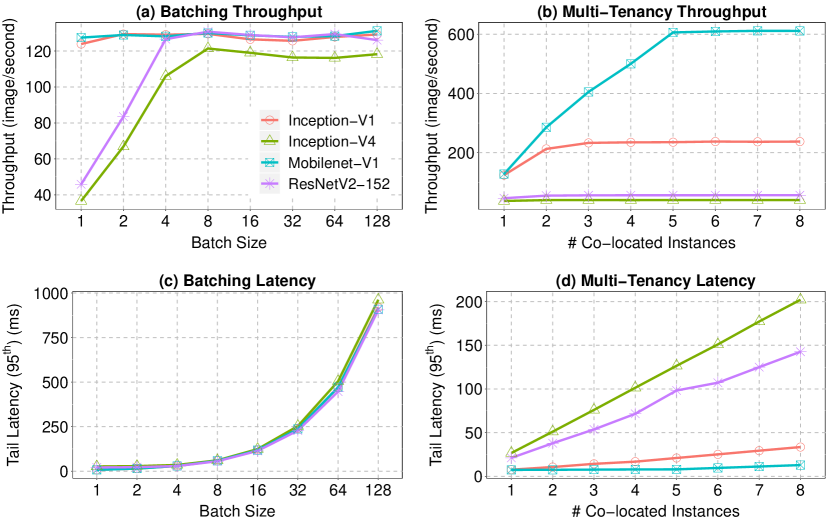
The results are depicted in Fig. 1. As can be seen, different DNNs show different behavior under each approach. Batching (Fig. 1(a)) can significantly improve the throughput of Inception-V4 and ResNetV2-152. However, it has a negligible effect on the other two ones. On the other hand, Multi-Tenancy (Fig. 1(b)) can improve the throughput of Inception-V1 and Mobilenet-V1-1, which could not leverage Batching. But, Multi-Tenancy has almost no effect on the throughput of Inception-V4 and ResNetV2-152. We can also see the effect of Batching and Multi-Tenancy on the latency in Fig. 1(c) and (d), respectively. Tail latency is defined as the percentile of the inference latency distribution in this work. Both bigger batch size and a larger number of co-located instances lead to higher latency. Since latency is an essential requirement of real-time applications, it should be factored in when designing and implementing any approach. Combining the results presented in Fig. 1 and the specifications of DNNs shown in Table 1 we conclude that:
1) Batching can significantly enhance the throughput of DNNs with a large number of parameters and high computational complexity (e.g., Inception-V4). In these networks, Batching helps to reuse the parameters for several inputs, and hence, reduce the data movement in GPU, which leads to an increase in throughput. For DNNs with a small number of parameters such as Inception-V1, however, Batching is not very effective. In these DNNs, the time needed for preparing and copying the input data to GPU dominates the time needed for copying the parameters, and hence, parameter reuse cannot improve the throughput noticeably. To observe this, we profile the share of kernels launched during execution of DNNs for Inception-V1 and Inception-V4. Results show that share of kernels related to data preparation and movement (e.g., redzone-checker, CUDA memcopy HtoD) in the total execution time is very significant in Inception-V1 (20.1% only for aforementioned kernels for BS = 16), and it becomes even more when increasing the batch size. For Inception-V4, however, those kernels do not consume a large portion of total execution time (e.g., 4.2% for BS = 16). For the profiling, we used the NVProf tool [50]. Due to large number of kernels profiled (68) and lack of space, we only presented the info for two kernels.
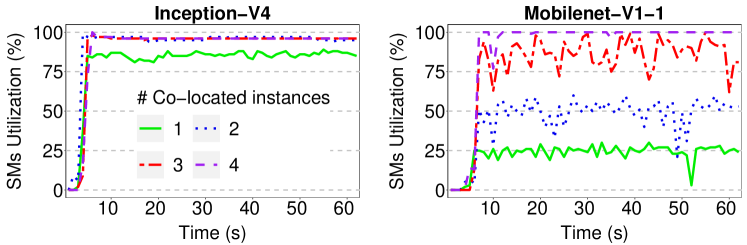
2) Small and simple DNNs with low computation requirements can most benefit from Multi-Tenancy. Since the GPU accelerators have large amount of computing resources, one instance of small DNNs cannot fully utilize them. Hence, the idle resources can be used by additional instances to process several inputs simultaneously. Therefore these DNNs can experience significant throughput improvement by Multi-Tenancy. The complex networks such as Inception-V4, however, utilize all or most of the computing resources of GPU by only one instance. Hence, co-locating several instances of them cannot yield throughput improvement since the instances should utilize the computing resources in a time-sharing manner. The resource utilization of GPU under the Multi-Tenancy approach (from one to four co-located DNN instances) for Mobilenet-V1-1 and Inception-V4 is depicted in Fig. 2.
Considering the aforementioned conclusions derived from preliminary experiments, we design and implement our approach which is discussed in detail in the next section.
3 Methodology
Our approach, DNNScaler, aims to maximize the throughput while meeting the latency constraint of real-time ML applications, by leveraging either Batching or Multi-tenancy based on the target DNN. First, we present the problem formulation and then describe the design and implementation of DNNScaler in detail. The acronyms used in the paper and their meaning are listed in Table 2.
| Acronym | Definition |
|---|---|
| B | Batching |
| BS | Batch Size |
| MT | Multi-Tenancy |
| MTL | Multi-Tenancy Level |
| DNN | Deep Neural Network |
| TI | Throughput Improvement |
| SLO | Service Level Objective |
| SM | Streaming Multiprocessor |
| FLOP | Floating Point Operation |
3.1 Problem Statement and Formulation
A DNN inference application is deployed on a GPU accelerator with a latency constraint stated in the form of Service Level Objective (SLO). Both throughput and latency of DNN are a function of the Batch Size (BS) or the Multi-Tenancy Level (MTL), depending on which approach is chosen (Throughput , Latency ). By MTL, we mean the number of co-located instances of the DNN on the GPU. The objective function is to maximize the throughput of the DNN during its execution time , while maintaining its latency below the SLO.
| (1) |
s.t.
| (2) |
This problem provides two control knobs for managing the throughput and latency: 1) We can use either Batching or Multi-Tenancy for increasing the throughput. 2) Depending on which one is selected, we fine-tune the batch size (for Batching) or the number of co-located instances (for Multi-Tenancy) to maintain the latency.
3.2 DNNScaler
Our proposed approach, DNNScaler, leverages the observations discussed in Section 2 when using the two control knobs (Batching and the batch size, or Multi-Tenancy and the number of co-located instances). Since Batching and Multi-Tenancy in this context sparks a sense of scaling-up and scaling-out of DNN inference applications, respectively, we have chosen the name DNNScaler for our approach. DNNScaler consists of two modules: Profiler and Scaler. The overall flow of DNNScaler is shown in Fig. 3(a), and its pseudo-code is presented in Algorithm 1. In the following, we explain these two modules.
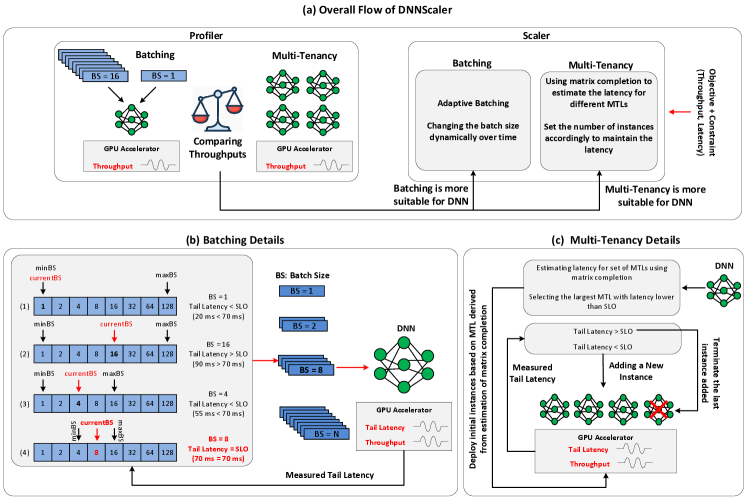
3.2.1 Profiler
The Profiler module probes the DNN to determine which of Batching or Multi-Tenancy can better improve the throughput. To determine which approach is more suitable for a DNN, the Profiler conducts a lightweight profiling at run-time. During this profiling phase, the throughput of the DNN for batch sizes of one (BS = 1) and (where in our experiments) is measured by the Profiler. Only a few batches are needed to be executed to measure the throughput of each BS, and calculate the throughput improvement obtained by over , as in (3):
| (3) |
After that, the throughput for the case of having co-located instances (MTL = n, where in our experiments) is measured. The throughput for a single instance is not needed because it is the same as Batching with BS = 1. Then, throughput improvement of Multi-Tenancy can be calculated as (4). Comparing the throughput improvement of Batching and Multi-Tenancy (see (5)) , the Profiler decides which approach is more suitable for the DNN and sends the gathered information to the next module, Scaler. The profiling is of the order of seconds, therefore its overhead on the system is negligible.
| (4) |
| (5) |
3.2.2 Scaler
The Scaler module receives the information from the Profiler that indicates which approach (Batching or Multi-Tenancy) is appropriate. Having this information, the Scaler aims to maintain the SLO of the DNN while trying to maximize its throughput. Looking again at Fig. 1, we see that for both Batching and Multi-Tenancy, increasing the batch size and the number of co-located instances can lead to higher throughput, but simultaneously leads to elongated latency. Hence, the Scaler module tries to find the largest batch size or the number of co-located instances (based on the approach proposed by the Profiler) that yields the latency below or equal to SLO. In the following, we describe how the Scaler module works with respect to the selected approach.
3.3 Dynamic Behavior of Scaler
In this section, we describe the dynamic behavior of the Scaler module of DNNScaler with respect to the approach determined by the Profiler module for a job. First, we discuss how Scaler adjusts the batch size when the Batching approach is selected. Then, we describe the Scaler mechanism for the case when Multi-Tenancy is selected for a job and explain how the number of co-located instances is determined dynamically with respect to latency and throughput.
3.3.1 Dynamic Batch Size Adjustment
When deploying a DNN on the GPU for inference, the common practice is to use a constant batch size. This constant batch size cannot be changed during the execution dynamically. In order to change it, the current instance should be terminated and a new one with another batch size should be launched, which imposes overhead on the system in the form of interruption in the service, increased latency, and reduced throughput. To address this issue, we implement dynamic batch sizing for DNN inference. The implementation imposes almost no overhead on latency or throughput, compared with a conventional constant batch size approach. Implementing the dynamic batch sizing helps us to design and implement the Scaler module more efficiently. The changes are in application side and how it interacts with the TensorFlow framework, without any need for changing TensorFlow.
In the design of the Scaler for the Batching approach, we consider the observation presented in Section 2. We saw that both latency and throughput have a direct relationship with batch size. The Scaler leverages this observation and employs a pseudo binary search mechanism to efficiently search for the most suitable batch size. The time complexity of the binary search is O (log n), and hence, the time overhead of Scaler would be negligible.
As shown in Fig. 3(b), the Scaler module for the Batching approach works as follows: it starts with a default batch size of one (BS=1) and processes a certain number of batches and measures their tail latency. If the tail latency is less than the SLO of the DNN multiplied by a coefficient (), then Scaler sets the batch size equal to the value in the median of the current batch size and the largest possible batch size (BS=128 in this work). If the current batch size is the largest possible one (due to the limitation of GPU memory, the batch size cannot be larger than a certain value), then it means no further throughput improvement is possible. Otherwise, if the tail latency is greater than the SLO, the Scaler sets the batch size as the value in the median of the lowest possible batch size and the current batch size. In this case, the current batch size being the smallest one means that the SLO of the DNN cannot be met. Finally, if the latency is between SLO and , then Scaler does not change anything and continues with the current batch size. We use coefficient to avoid excessive batch size changes. The suitable value of can be found empirically by observing the behavior of a few DNNs under different values of it. We have in this work.
The Scaler does not stop after finding a suitable batch size, but continues to monitor the latency. Detecting a tail latency above the SLO or below , it starts adjusting the batch size again. Readjustment is needed when the tail latency is affected by parameters such as variation in the input dataset, GPU temperature, and frequency of GPU. Even the user can decide to change the SLO during runtime.
3.3.2 Dynamic MT Level Adjustment
Multi-tenancy shows a similar behavior to batching (for the DNNs that can benefit from it). Increasing the number of co-located instances can improve the throughput (and also increases the latency). Similar to batching that we used BS = 128 as the upper bound of batch size, for multi-tenancy we have chosen MTL = 10 as the maximum number of co-located instances based on the memory capacity of our GPU. This number also can be determined for various settings (such as different GPUs) by a lightweight profiling. Therefore a similar approach to Batching (binary search) can be employed to find the best value for MTL (i.e., the number of co-located instances). However, unlike Batching where we implemented a dynamic batch sizing with negligible overhead, for Multi-Tenancy there is no such lightweight mechanism to change the number of co-located instances on the fly.
Frequently launching and terminating instances imposes significant overhead. Therefore, we need an alternative approach with low overhead. One solution is to profile the latency of the DNN for all the possible number of instances (MTL = 1 to MTL = N). In the next step, to adjust the value of MTL for a specific SLO, we can simply select the largest one (to maximize throughput) that has latency lower than SLO. However, the overhead of profiling all the possible values of MTL itself leads to significant overhead, which is in contrast with our initial goal, which was to avoid overhead of frequent launching and terminating instances.
To tackle this challenge, we employ a machine learning based approach called matrix completion [7] to estimate the latency for all the possible values of MTL. Using matrix completion, we need to profile results of the latency of DNN for a few values of MTL (two in our work). Since we already have this information from the profiling phase (for MTL = 1 and MTL = 8), we do not impose any further overhead to the system. Having the latency of MTL = 1 and MTL = 8, matrix completion can estimate the latency for other number of co-located instances (i.e., other values of MTL). Then, we use these estimated values to select the MTL considering the SLO. Fig. 4 shows how the matrix completion is employed to estimate the latency of different MTLs. With matrix completion we can jump to a solution immediately without changing the value of MTL frequently, in contrast to a brute force approach.
Since the estimated values of matrix completion are not 100% accurate, we have devised an additive-increase-multiplicative-decrease (AIMD) scheme[18, 15] to complement it. We start the co-location with MTL suggested by matrix completion. If the latency is lower than SLO, then we start adding instances one by one until tail latency is greater than SLO. In this point, we only need to terminate the last instance to keep the tail latency below the constraint. That is the point where we can have the highest possible throughput while maintaining the SLO. If we reach to the maximum MTL, e.g., MTL = 10, (where no further instances can be deployed) before violating the SLO, we can stop adding new instances and there would be no need for terminating any instance. On the other hand, if the latency of MTL suggested by matrtix completion is higher than SLO (which means that latency is underestimated), we decrease the number of instances by steps of one and terminate them, until the latency is lower than SLO, and then stop. The flow of Scaler for Multi-tenancy approach is presented in Fig. 3(c).
Note that the main difference between our work and previous Multi-Tenancy approaches, which forms one of the contributions of the paper, is that they consider DNNs co-located from different jobs and try to mitigate the impact of interference on their performance. But we consider the case where the co-located instances are from the same DNN and belong to the same job and work with each other to improve the total throughput.
For the BS, we used binary search to find upper bound of it (128) that does not lead to out of memory (OOM) error by a few short experiments. For finding upper bound of MTL (10), first the minimum amount of memory needed for a DNN is determined considering its size and computational complexity, and then the upper value of MTL is calculated based on this value (for the largest DNN) and the memory capacity of GPU (and also overhead of several instances working together).

Matrix Completion, an ML approach, is used to recover missing entries of a matrix that is partially observed. It employs Singular Value Decomposition (SVD) to reduce the dimensions of the matrix. It also needs to know the rank of the matrix of interest. The rows or columns of matrix with rank span an -dimensional space. Applying SVD on the matrix yields a factorization of the form , where , and represent different similarity concepts features of .
and
Having matrices , , and and applying PQ-reconstruction leads to matrix that estimates the missing values of . We use convex optimization by TFOCS (Templates for First-Order Conic Solvers) [6] tool to estimate matrix in this work.
Since DNNScaler is proposed for real-time applications, it is very important that they experience little to no interrupt in their work. Both the Batching and Multi-Tenancy approaches of DNNScaler assure that the applications can continue their work with no interruption. None of adjusting the batch size or the number of co-located instances prevents the DNNs from serving the new requests. Moreover, both mechanisms can quickly respond to bursty workloads and avoid violating latency constraints, as some inference workloads arrive in a burst and not uniformly [2, 5].
4 Evaluation
4.1 Experimental Setup
Platform. We run our experiments on a dual-socket Xeon server. It has two E5-2680 v4 Xeon chips where each of the chips has 28 cores running at 2.4 GHz. The server has 128 GB of DDR4 memory. Ubuntu 16.04 with kernel 4.4 is installed on the server with Python 2.7, CUDA 11.0, and TensorFlow 1.15. The server is equipped with a PCI Express Gen3 Nvidia Tesla P40 GPU Accelerator. The Tesla P40 leverages Nvidia Pascal architecture and has 3840 CUDA cores. The total memory capacity of GPU is 24 GB GDDR5 memory, its idle power is around 50W, and its maximum power limit is 250W.
Networks and Dataset. To show the adaptive nature of our approach, we use DNNs from different domains. Since computer vision, and in particular image classification, is a popular field and numerous DNNs are designed for this application, we employ 16 image classification networks with two datasets in our experiments. One dataset is ImageNet [52], which is a popular dataset that is widely used in previous works [30, 41, 48, 19], and the other one is Caltech-256 [25], which is collected by researchers from the California Institute of Technology. For these DNNs, throughput is defined as number of images processed per second (image/second). From the natural language processing (NLP) domain, we employ a DNN for text classification [40], which we call TextClassif in this paper. For the input data of this DNN, we use Sentiment140 [1] and IMDB Reviews [46] datasets. For this DNN, the throughput is defined as the number of sentences processed per second. DeepVS [37] is another DNN we use in our experiments that targets video saliency prediction and the throughput is defined as the number of frames processed per second. Finally, we employ DeepSpeech2 [3], which is an end-to-end DNN for speech recognition and define the throughput as the number of speech files processed per second. The selected DNNs cover a wide range of applications, as well as DNN types: from CNNs to RNNs, to LSTMs. These DNNs have varying sizes and architectures, and consequently, different computational complexity. The specifications of the networks and datasets are presented in Table 3.
System Comparison. Clipper [18] is an approach proposed for online serving of inference requests considering a predefined latency SLO. Clipper employs an additive-increase-multiplicative-decrease (AIMD) scheme to find the optimal batch size that maximizes the throughput while meeting the latency SLO. It starts from the minimum batch size and additively increases it by a fixed step (four in this work) until tail latency surpasses the SLO. At this point, Clipper performs a small multiplicative back-off and reduces the BS by 10%.
| DNN | Abberviation | Domain | Dataset | ||||
|---|---|---|---|---|---|---|---|
| Inception-V1 [59] | Inc-V1 | Image Classification | ImageNet & Caltech-256 | ||||
| Inception-V2 [33] | Inc-V2 | ||||||
| Inception-V3 [60] | Inc-V3 | ||||||
| Inception-V4 [58] | Inc-V4 | ||||||
| Mobilenet-V1-1 [31] | MobV1-1 | ||||||
| Mobilenet-V1-05 [31] | MobV1-05 | ||||||
| Mobilenet-V1-025 [31] | MobV1-025 | ||||||
| Mobilenet-V2-1 [53] | MobV2-1 | ||||||
| Mobilenet-V2-14 [53] | MobV2-14 | ||||||
| NASNET-Large [74] | NAS-Large | ||||||
| NASNET-Mobile [74] | NAS-Mob | ||||||
| PNASNET-Large [45] | PNAS-Large | ||||||
| PNASNET-Mobile [45] | PNAS-Mob | ||||||
| ResNet-V2-50 [29] | ResV2-50 | ||||||
| ResNet-V2-101 [29] | ResV2-101 | ||||||
| ResNet-V2-152 [29] | ResV2-152 | ||||||
| TextClassif [40] | - | NLP |
|
||||
| DeePVS [37] | - |
|
|
||||
| DeepSpeech2 [3] | DeepSpeech |
|
LibriSpeech [51] |
Workload. In our experiments, we have a workload consists of 30 DNN inference jobs. SLO of each job is stated in the form of tail latency target in milliseconds. We measured the average latency of one input for BS = 1 and MTL = 1. Then, we considered a coefficient (> 1) of this value for SLO of each job to have tight and relaxed SLOs. The list of jobs is presented in Table 4.
| Job # | DNN | Dataset | SLO (ms) |
|
Steady MTL/BS | Job # | DNN | Dataset | SLO (ms) |
|
Steady MTL/BS | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Inc-V1 | ImageNet | 35 | MT | MTL = 8 | 16 | Inc-V3 | CalTech | 322 | B | BS = 37 | ||||
| 2 | Inc-V2 | ImageNet | 53 | MT | MTL = 9 | 17 | Inc-V4 | CalTech | 139 | B | BS = 10 | ||||
| 3 | Inc-V4 | ImageNet | 419 | B | BS = 28 | 18 | MobV1-1 | CalTech | 89 | MT | MTL = 10 | ||||
| 4 | MobV1-05 | ImageNet | 199 | MT | MTL = 10 | 19 | MobV1-05 | CalTech | 60 | MT | MTL = 10 | ||||
| 5 | MobV1-025 | ImageNet | 186 | MT | MTL = 10 | 20 | MobV1-025 | CalTech | 104 | MT | MTL = 10 | ||||
| 6 | MobV2-1 | ImageNet | 81 | MT | MTL = 10 | 21 | MobV2-1 | CalTech | 129 | MT | MTL = 10 | ||||
| 7 | NAS-Large | ImageNet | 417 | B | BS = 13 | 22 | PNAS-Large | CalTech | 524 | B | BS =19 | ||||
| 8 | NAS-Mob | ImageNet | 85 | MT | MTL = 10 | 23 | PNAS-Mob | CalTech | 321 | B | BS = 50 | ||||
| 9 | PNAS-Mob | ImageNet | 82 | MT | MTL = 10 | 24 | ResV2-50 | CalTech | 31 | B | BS = 1 | ||||
| 10 | ResV2-50 | ImageNet | 45 | MT | MTL = 6 | 25 | ResV2-101 | CalTech | 107 | B | BS = 10 | ||||
| 11 | ResV2-101 | ImageNet | 72 | B | BS = 4 | 26 | TextClassif | Sentiment140 | 3.5 | B | BS = 102 | ||||
| 12 | ResV2-152 | ImageNet | 206 | B | BS =14 | 27 | TextClassif | IMDB | 3 | B | BS = 76 | ||||
| 13 | ResV2-101 | ImageNet | 107 | B | BS = 7 | 28 | DeepSpeech | LibriSpeech | 1250 | B | BS = 28 | ||||
| 14 | Inc-V1 | CalTech | 48 | MT | MTL = 10 | 29 | DeePVS | LEDOV | 3000 | MT | MTL = 6 | ||||
| 15 | Inc-V2 | CalTech | 116 | B | BS = 16 | 30 | DeePVS | DHF1K | 5000 | MT | MTL = 8 |
4.2 Profiling Results
We have profiled the DNNs using the Profiler module to identify the proper approach for each of them. For Batching, we use BS=1 and BS=32, and for Multi-Tenancy we use MTL = 1 and MTL = 8. These values (BS = 32 and MTL= 8) are chosen based on our early observations. We have seen that BS = 32 and MTL = 8 are big enough to show which approach can give higher throughput improvement. These can be chosen differently for other GPUs or DNNs, if needed. The percentage of improvement (over base throughput of MTL = 1 and BS = 1) yield by each approach for several jobs is shown in Table 5. The DNNScaler Method column in Table 4 is filled by the results obtained from profiling. The results further emphasize our observations from preliminary experiments that one of the Batching or Multi-Tenancy works better for a DNN in terms of throughput improvement. For networks with a low amount of computational complexity and a low number of parameters, such as the Mobilenet, we see remarkable throughput improvement (e.g., 335% in Job 19) by Multi-Tenancy, while the same DNNs cannot benefit from Batching significantly. On the other hand, large and complex networks with a high number of parameters such as Inception-V4 can experience high throughput improvement by Batching, but not by Multi-Tenancy (see Job 3).
As can be seen, the dataset also affects the performance of Batching and Multi-Tenancy, and hence, the approach selected for the DNNs. For example, in image classification DNNs, the image size is important as it should be readjusted before being fed to the network. This adjustment depends on the dataset, and affects the overall performance of DNN. Therefore, for some DNNs such as Inception-V2, the Multi-Tenancy approach yields better throughput for the ImageNet dataset, but Batching has better performance for the Caltech dataset. The length of sentences also affects the performance of TextClassif, and hence, it shows different behavior for Sentiment140 and IMDB Reviews datasets with respect to latency. The longer sentences of IMBD Reviews take more time to be processed.
| Job # | Base Throughput (BS=1 & MTL=1) | Multi-Tenancy Throughput | Batching Throughput | ||||
|---|---|---|---|---|---|---|---|
| MTL=8 |
|
BS=32 |
|
||||
| 1 | 118.66 | 237.28 | 99.96 | 125.67 | 5.91 | ||
| 2 | 104.46 | 169.85 | 62.59 | 125.33 | 19.97 | ||
| 3 | 36.81 | 39.61 | 7.63 | 116.41 | 216.28 | ||
| 9 | 48.49 | 148.28 | 205.81 | 125.44 | 158.70 | ||
| 10 | 103.62 | 137.43 | 32.63 | 126.55 | 22.13 | ||
| 11 | 62.75 | 78.63 | 25.32 | 125.99 | 100.79 | ||
| 15 | 102.82 | 169.31 | 64.67 | 235.05 | 128.61 | ||
| 19 | 241.14 | 1050.58 | 335.67 | 267.84 | 11.07 | ||
| 26 | 492.00 | 2163.80 | 339.80 | 7145.89 | 1352.43 | ||
| 29 | 15.46 | 41.27 | 166.89 | 19.82 | 28.16 | ||
4.3 Throughput and Power Efficiency
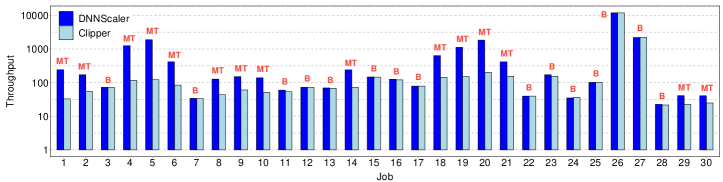
Throughput is a crucial parameter factored in when designing and deploying real-time ML services [27, 17]. Therefore we study the throughput of DNNScaler to understand how much it can improve the performance of applications compared with Clipper. Fig. 5 shows the throughput of DNNScaler and Clipper for all the jobs. Note that a base-10 log scale is used for the Y axis. On average, DNNScaler improves the throughput by 218% compared with Clipper. For the jobs that DNNScaler uses the Batching approach, the improvement is not as very significant (e.g., 1% improvement in Job 7). However, for jobs such as Jobs 1 and 2 where DNNScaler employs the Multi-Tenancy approach, the throughput improvement is as significant as 14x (Job 5). We clearly see that our proposed Multi-Tenancy approach, which determines the number of co-located instances dynamically with respect to SLO, can successfully leverage the GPU resources and significantly increase the throughput, compared with Batching strategy of Clipper. These results confirm our earlier observation that wise usage of Multi-Tenancy for some DNNs can better utilize the GPU resources, and hence, yield better throughput than Batching.
Another essential feature of real-time ML systems is power efficiency. Power is of high importance in warehouse-scale infrastructures and datacenters since it has a substantial share in operational costs [24, 47]. We compare DNNScaler and Clipper regarding power efficiency as well. We define power efficiency as the throughput per watt achieved by each approach. Since there is not much difference between performance of DNNScaler and Clipper, when DNNScaler uses Batching, only the results for jobs performed using Multi-tenancy by DNNScaler are shown in Table 6.
Clipper employing large batches leads to high power consumption, but without expected throughput improvement, which leads to poor power efficiency. DNNScaler, on the other hand, can achieve high throughput using Multi-Tenancy, and hence, better power efficiency. While DNNScaler consumes more power than Clipper (44% on average for jobs shown in Table 6), its throughput improvement (435% on average) can definitely compensate for it. Hence, DNNScaler can deliver significant power efficiency improvement compared with Clipper (up to 11x in Job 5, and 288% on average). We can conclude that DNNScaler can remarkably enhance the power efficiency of real-time ML infrastructures.
| Job # | Power (W) | Throughput |
|
|||||
|---|---|---|---|---|---|---|---|---|
| DNNScaler | Clipper | DNNScaler | Clipper | DNNScaler | Clipper | |||
| 1 | 87.70 | 55.04 | 241.62 | 32.88 | 2.75 | 0.60 | ||
| 2 | 89.82 | 57.98 | 172.26 | 54.81 | 1.92 | 0.95 | ||
| 4 | 74.96 | 54.61 | 1254.10 | 116.08 | 16.73 | 2.13 | ||
| 5 | 63.04 | 51.78 | 1888.50 | 121.57 | 29.96 | 2.35 | ||
| 6 | 90.58 | 59.96 | 415.70 | 84.59 | 4.59 | 1.41 | ||
| 8 | 71.57 | 55.74 | 127.60 | 44.02 | 1.78 | 0.79 | ||
| 9 | 73.33 | 57.88 | 150.60 | 60.54 | 2.05 | 1.05 | ||
| 10 | 118.06 | 64.17 | 138.84 | 50.63 | 1.18 | 0.79 | ||
| 14 | 87.74 | 57.32 | 239.30 | 71.89 | 2.73 | 1.25 | ||
| 18 | 109.84 | 65.80 | 634.90 | 144.58 | 5.78 | 2.20 | ||
| 19 | 75.94 | 54.34 | 1118.60 | 151.41 | 14.73 | 2.79 | ||
| 20 | 63.30 | 52.41 | 1839.80 | 200.78 | 29.07 | 3.83 | ||
| 21 | 90.63 | 65.25 | 414.50 | 155.09 | 4.57 | 2.38 | ||
| 29 | 122.44 | 86.39 | 40.93 | 22.51 | 0.33 | 0.26 | ||
| 30 | 132.19 | 88.98 | 40.72 | 24.72 | 0.31 | 0.28 | ||
4.4 DNNScaler Results in Detail
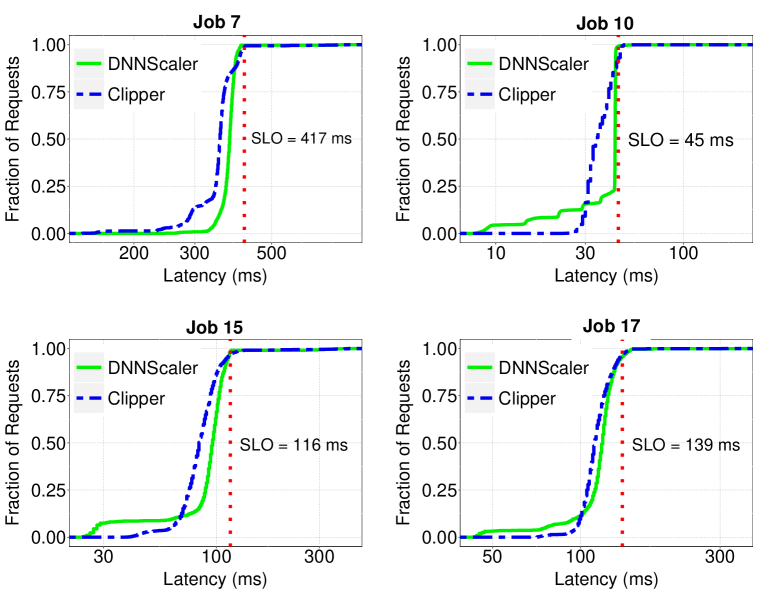
To better understand the behavior of DNNScaler, we go deeper into the details and discuss the results for a few jobs. First, we depict the latency trace of a few jobs to show how both DNNScaler and Clipper can meet the SLO. The cumulative distribution of latency of requests for four jobs is depicted in Fig. 6. As can be seen, for both DNNScaler and Clipper, 95% or more of the requests have a latency smaller or equal to SLO. This emphasizes the success of both approaches in meeting the SLO of jobs.
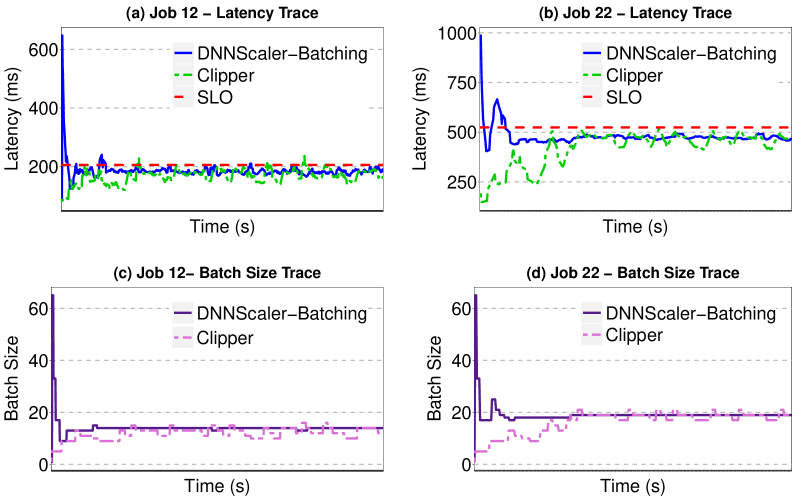
Next, we discuss the Batching results for two jobs in Fig. 7(a)(c) and Fig. 7(b)(d), respectively. Since Clipper also uses the Batching mechanism, we show its results as well and compare them with DNNScaler. Both DNNScaler and Clipper start with BS = 1. Since the initial latency is lower than SLO, both of them increase batch size to achieve higher throughput. The pseudo-binary mechanism of DNNScaler jumps to a relatively big batch size, but when it detects the significant SLO violation, it immediately reduces the batch size and finds the suitable one after trying a few ones by applying its search routine. The Clipper’s AIMD mechanism tries to adjust the batch size as well, but with a slower rate than DNNScaler, and consequently, it reaches the stable state later than DNNScaler. The ability of DNNScaler to quickly find the suitable batch size helps it to immediately adapt to possible changes in SLO or slowdown of GPU due to an applied power cap. Later in Section 4.5, we study the behavior of DNNScaler under varying SLO.
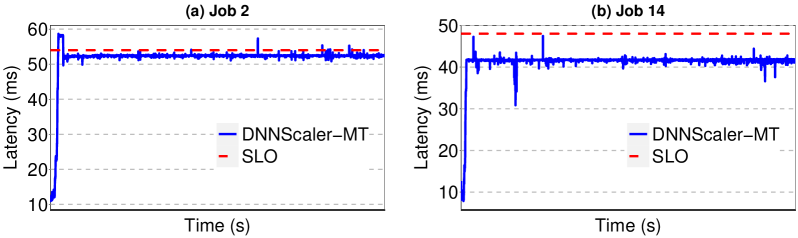
After that, we explore the DNNScaler behavior for the Multi-Tenancy approach. The detailed results for two jobs are depicted in Fig. 8. For Job 2 (Fig. 8(a)), DNNScaler initially employs the latency estimations of different MTLs from matrix completion and compares them with the SLO to decide the maximum number of DNN instances it should launch to maximize the throughput, while meeting the latency constraint. But it detects the SLO violation after launching the instances, meaning that the estimation was not 100% accurate (as expected). Hence, it terminates one instance and since the new latency meets the SLO, it continues with the remaining number of instances. For Job 14, DNNScaler deploys the maximum number of allowed instances (MTL = 10) based on matrix completion estimation. After deployment of the instances, the latency is still below SLO, but since there is no room for adding extra instances on GPU, it continues with current ones.
In both Batching and Multi-Tenancy, some short-live spikes are observed in latency that violate the SLO. They happen due to some reasons (e.g., OS processes) rather than DNNScaler settings. Thereby, they are skipped to avoid excessive changes which leads to performance degradation. For long spikes that affect the tail latency significantly, DNNScaler readjusts the control knobs to mitigate them according to Algorithm 1.
4.5 Sensitivity Analysis
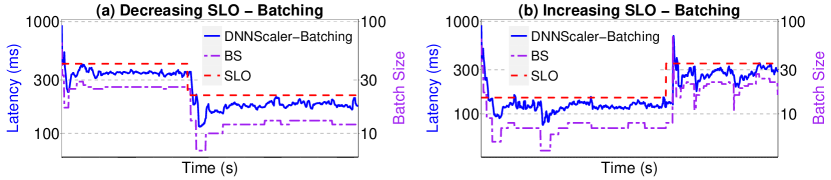
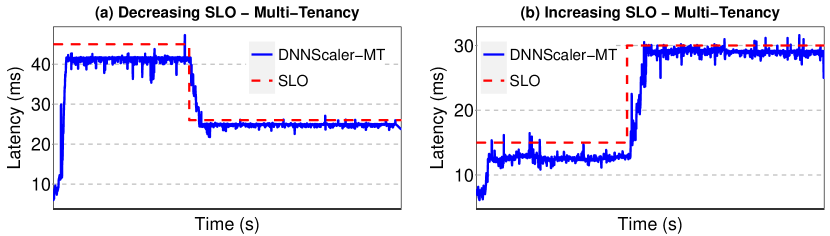
During the execution of an application, any change in external and/or internal parameters of the system can affect the latency and/or the SLO of the applications. For example, the user that has submitted the job might decide to change the SLO, or a power cap might be applied on GPU, that affects its frequency, and consequently, the latency of the job. As we have mentioned earlier in Section 3.2.2, DNNScaler is designed to adapt to such changes during the runtime. To evaluate the efficacy of DNNScaler to adapt to such changes, we conduct another set of experiments. We consider two scenarios for each approach of DNNScaler (Multi-tenancy and Batching). In one scenario, the SLO decreases during the runtime of the job, and in the other one, it increases. For Multi-Tenancy, we employ the Inception-V1, and for Batching we employ Inception-V4. The results are shown in Fig. 9 for Batching and in Fig. 10 for Multi-Tenancy.
For the Batching approach, we see how the DNNScaler adaptively changes the batch size to meet the new SLO. In Fig 9(a), as the SLO drops down, DNNScaler significantly reduces the batch size to avoid SLO violation. On the other hand, in the presence of an increasing SLO (see Fig. 9(b)), DNNScaler tries to employ a larger batch size to gain higher throughput. Note that a base-10 log scale is used for the Y axis. The left Y axis shows the latency and the right one shows the batch size.
As can be seen in Fig. 10(a), when the SLO is relaxed, DNNScaler creates ten instances of the DNN model and deploys them on the GPU to increase the throughput. As the SLO is reduced by almost half, DNNScaler immediately detects it and starts terminating the extra instances to meet the SLO. It eliminates five instances to meet the new tight SLO. In Fig 10(b), we see the results for DNNScaler (Multi-Tenancy approach) in an increasing SLO scenario. At first, DNNScaler only creates four instances for deployment on GPU. In the middle of the execution, when it detects new increased SLO, it deploys more instances to exploit the gap between SLO and latency in favor of throughput.
4.6 Discussion
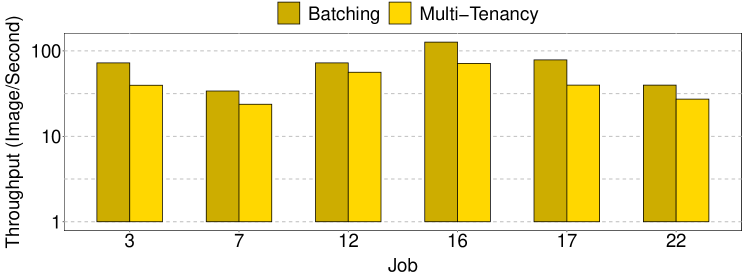
Sole Employment of Multi-Tenancy. No previous work has used the Multi-Tenancy approach to increase the throughput of a single DNN, similar to our work. Therefore, in the experimental results section, we have no comparison with an approach that only uses Multi-Tenancy for all the jobs (i.e., we have Clipper that only uses Batching for all the jobs, but there is not an approach that only uses Multi-Tenancy). Not having such comparison makes it difficult to understand what is the impact of Multi-Tenancy on jobs such as 3 and 7 (see Table 4) and how the Batching approach selected by DNNScaler can improve their throughput compared against Multi-Tenancy.
To address these questions, in this section, we compare the throughput of the Batching and Multi-Tenancy approaches for 6 jobs from Table 4 that have been executed by the Batching approach (according to DNNScaler decision) in earlier experiments. The Multi-Tenancy approach we have used for these jobs is exactly the Multi-Tenancy approach of DNNScaler that has been used for other jobs. The result is shown in Fig. 11. Our goal is to verify that the DNNScaler’s decision of employing the Batching approach for these jobs was a correct one, and that Multi-Tenancy cannot improve their throughput more than Batching. We see that in all the jobs, Batching yields higher throughput than Multi-Tenancy, so we conclude that DNNScaler has selected the correct approach for them.
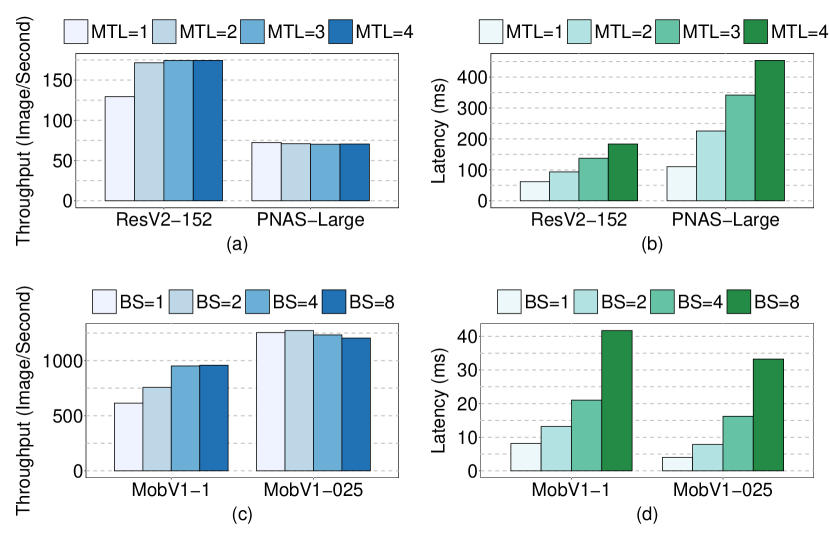
Combining Batching and Multi-Tenancy. A question that can rise is that why not combining the two approaches to leverage benefits of both of them. For example, in the Multi-Tenancy we mentioned that we use BS = 1 for all the instances. But, what if we use larger batch size for them? To answer this question, we conduct another set of experiments. We consider two DNNs that were executed by Batching (ResV2-152 and PNAS-Large) and two ones that were executed by Multi-tenancy (MobV1-1 and MobV1-025). For ResV2-152 and PNAS-Large, we select a fixed batch size of 8 (BS=8, constant) and increase the number of co-located instances from 1 to 4 (MTL=1 to MTL=4), and measure the throughput and latency of the DNNs for each MTL. ResV2-152 experiences notable throughput improvement when going from MTL=1 to MTL=2, however, the improvement for MTL=3 and MTL=4 is negligible. PNAS-Large, on the other hand, not only experiences no throughput improvement, but even suffers from reduction in throughput. As expected, the latency of both of them increases as enlarging the MTL.
For MobV1-1 and MobV1-025, we consider a fixed number of co-located instances of 5 (MTL=5, constant) and change the batch size from 1 to 8 (BS=1, BS=2, BS=4, BS=8). Again, we see that one of them (MobV1-1) can benefit from the combination of Batching and Multi-Tenancy in term of throughput, while the other one (MobV1-025) experiences no throughput improvement and only suffers from higher latency. We observe that the largest network (PNAS-Large) and the smallest one (MobV1-025) cannot benefit from the combination, while the two other ones can benefit up to a certain level. We conclude that combining the Batching and Multi-Tenancy can lead to throughput improvement in some DNNs, but for the other ones it only elongates the inference latency with no benefits in throughput. Hence, identifying the proper cases of combining Batching and Multi-Tenancy based on different aspects of the system such as the size and computational complexity of DNNs, as well as the computing and memory capacity of the GPU, can be a future research direction.
5 Related Work
While DNNs continue to deliver state-of-the-art results for various machine learning domains such as computer vision, their extremely growing computational requirements have surpassed the growth in computing capacity of conventional CPUs [17]. Therefore, it is essential to investigate new hardware platforms, beyond traditional CPUs, to address the ever-growing computational demand of DNNs. To this end, a wide variety of DNN accelerators are designed and implemented that aim to achieve various goals such as low-latency, high-throughput, or energy-efficiency [73, 54, 10, 23, 17, 38]. Increasing throughput while achieving low-latency is specially explored to address the requirements of real-time ML services deployed on warehouse-scale infrastructures [21, 27, 26]. These accelerators employ different computing cores such as ASICs [12, 39, 13], FPGAs [72, 69, 43], and GPUs [55, 67, 44] or different computing paradigms such as processing in/near-memory [63, 22, 4, 36, 14] for accelerating DNN inference. GPU accelerators are a favorable choice for DNN accelerators due to their programmability and scalability features [49]. To further improve the performance of DNN inference on GPU accelerators, various techniques such as Batching and Multi-Tenancy are proposed, among others.
Batching. Using Batching to increase the DNN inference throughput has been studied and employed in a large body of previous works [20, 11, 61, 56, 70, 57]. Studies show that Batching can improve the throughput and energy-efficiency of DNN inference on GPU accelerators [20, 32]. However, it elongates the latency of DNN inference as well, so it should be employed carefully. Pervasive CNN (P-CNN) [57] leverages Batching to improve the throughput of CNNs on GPUs. It uses big batch sizes for background tasks to maximize throughput and reach energy-efficiency. When selecting the batch size for such tasks, P-CNN considers the GPU memory. For interactive and real-time tasks, however, P-CNN selects small batch sizes to avoid unacceptable response time. Clipper [18] forms batches of inputs from concurrent stream of prediction queries to leverage the benefits of Batching. It dynamically changes the batch size using an additive-increase-multiplicative-decrease (AIMD) scheme to find the optimal one that maximizes the throughput while meeting the latency requirement.
Multi-Tenancy. A large body of research has focused on challenges and opportunities of Multi-Tenancy and co-location of DNN inference [68, 35, 66, 16]. PERSEUS [42] and Jain et al. [34] studied the impact of Multi-Tenancy on performance, cost, and latency of co-located DNN models. They showed that while co-location can help to improve the throughput, resource utilization, and energy efficiency of GPUs, it has a negative impact on latency. Approaches such as Baymax [9] and Laius [71] try to mitigate the impact of co-location on the latency of interactive jobs that share the GPU with throughput-oriented jobs. They aim to maximize the throughput of throughput-oriented job while meeting the latency of interactive job by reallocation of time slots [9] or computing resources [71] of GPU. These approaches usually consider the co-location of two or more different applications on a GPU and try to manage their latency or throughput with respect to some priority criteria. In our approach, however, we consider the case where a various number of instances from the same application are co-located on a GPU, and we try to improve the overall throughput of that application while meeting its latency SLO. Moreover, we first evaluate that application to see if this type of Multi-Tenancy can help to improve its throughput, and then proceed with the next steps. But the other approaches usually consider the throughput of the mixture of applications, and not a single one.
6 Conclusion
In this paper, we performed an extensive set of analysis, revealing that DNNs can be categorized in two groups: the ones that experience high throughput from Batching and the ones that achieve high throughput by Multi-Tenancy. Based on this observation, we proposed the DNNScaler approach to improve the throughput of real-time ML services with latency constraint. The DNNScaler Profiler module can successfully determine the approach that is more suitable for a specific DNN with a lightweight profiling mechanism. Based on the output of the Profiler module, the Scaler module employs one of the adaptive batching (for the Batching approach) or instance co-location management (for the Multi-Tenancy approach) to maintain the latency while maximizing the throughput. The experimental results show that DNNScaler can improve the throughput by up to 14x (218% on average) compared to the Clipper approach that only leverages Batching, and not Multi-Tenancy. Furthermore, we analyzed the sensitivity of both Batching and Multi-Tenancy approaches of DNNScaler.
References
- [1] Sentiment140. http://help.sentiment140.com/. Accessed: November 15, 2021.
- [2] Ahsan Ali, Riccardo Pinciroli, Feng Yan, and Evgenia Smirni. Batch: machine learning inference serving on serverless platforms with adaptive batching. In International Conference for High Performance Computing, Networking, Storage and Analysis (SC), pages 1–15. IEEE, 2020.
- [3] Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, Jie Chen, Jingdong Chen, Zhijie Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Ke Ding, Niandong Du, Erich Elsen, Jesse Engel, Weiwei Fang, Linxi Fan, Christopher Fougner, Liang Gao, Caixia Gong, Awni Hannun, Tony Han, Lappi Johannes, Bing Jiang, Cai Ju, Billy Jun, Patrick LeGresley, Libby Lin, Junjie Liu, Yang Liu, Weigao Li, Xiangang Li, Dongpeng Ma, Sharan Narang, Andrew Ng, Sherjil Ozair, Yiping Peng, Ryan Prenger, Sheng Qian, Zongfeng Quan, Jonathan Raiman, Vinay Rao, Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Kavya Srinet, Anuroop Sriram, Haiyuan Tang, Liliang Tang, Chong Wang, Jidong Wang, Kaifu Wang, Yi Wang, Zhijian Wang, Zhiqian Wang, Shuang Wu, Likai Wei, Bo Xiao, Wen Xie, Yan Xie, Dani Yogatama, Bin Yuan, Jun Zhan, and Zhenyao Zhu. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of The 33rd International Conference on Machine Learning, pages 173–182. PMLR, 2016.
- [4] Aayush Ankit, Izzat El Hajj, Sai Rahul Chalamalasetti, Geoffrey Ndu, Martin Foltin, R. Stanley Williams, Paolo Faraboschi, Wen-mei W Hwu, John Paul Strachan, Kaushik Roy, and Dejan S. Milojicic. Puma: A programmable ultra-efficient memristor-based accelerator for machine learning inference. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 715–731, 2019.
-
[5]
AWS.
Digital insight scales up or down rapidly for their bursty inference
workloads.
https://aws.amazon.com/blogs/startups/digital-insight-scales-up-or-down-rapidly-
for-their-bursty-inference-workloads/. Accessed: July 20, 2021. - [6] Stephen R Becker, Emmanuel J Candès, and Michael C Grant. Templates for convex cone problems with applications to sparse signal recovery. Mathematical programming computation, 3(3):165, 2011.
- [7] Emmanuel J Candès and Benjamin Recht. Exact matrix completion via convex optimization. Foundations of Computational mathematics, 9(6):717–772, 2009.
- [8] Guoyang Chen, Yue Zhao, Xipeng Shen, and Huiyang Zhou. Effisha: A software framework for enabling effficient preemptive scheduling of gpu. In Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 3–16, 2017.
- [9] Quan Chen, Hailong Yang, Jason Mars, and Lingjia Tang. Baymax: Qos awareness and increased utilization for non-preemptive accelerators in warehouse scale computers. ACM SIGPLAN Notices, 51(4):681–696, 2016.
- [10] Tianshi Chen, Zidong Du, Ninghui Sun, Jia Wang, Chengyong Wu, Yunji Chen, and Olivier Temam. Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. ACM SIGARCH Computer Architecture News, 42(1):269–284, 2014.
- [11] Y. Chen, J. Emer, and V. Sze. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. In ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), pages 367–379, 2016.
- [12] Yu-Hsin Chen, Tushar Krishna, Joel S Emer, and Vivienne Sze. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE journal of solid-state circuits, 52(1):127–138, 2016.
- [13] Yunji Chen, Tao Luo, Shaoli Liu, Shijin Zhang, Liqiang He, Jia Wang, Ling Li, Tianshi Chen, Zhiwei Xu, Ninghui Sun, and Olivier Temam. Dadiannao: A machine-learning supercomputer. In 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, pages 609–622. IEEE, 2014.
- [14] Ping Chi, Shuangchen Li, Cong Xu, Tao Zhang, Jishen Zhao, Yongpan Liu, Yu Wang, and Yuan Xie. Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory. ACM SIGARCH Computer Architecture News, 44(3):27–39, 2016.
- [15] Dah-Ming Chiu and Raj Jain. Analysis of the increase and decrease algorithms for congestion avoidance in computer networks. Computer Networks and ISDN systems, 17(1):1–14, 1989.
- [16] Yujeong Choi and Minsoo Rhu. Prema: A predictive multi-task scheduling algorithm for preemptible neural processing units. In 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 220–233. IEEE, 2020.
- [17] Eric Chung, Jeremy Fowers, Kalin Ovtcharov, Michael Papamichael, Adrian Caulfield, Todd Massengill, Ming Liu, Daniel Lo, Shlomi Alkalay, Michael Haselman, Maleen Abeydeera, Logan Adams, Hari Angepat, Christian Boehn, Derek Chiou, Oren Firestein, Alessandro Forin, Kang Su Gatlin, Mahdi Ghandi, Stephen Heil, Kyle Holohan, Ahmad El Husseini, Tamas Juhasz, Kara Kagi, Ratna K. Kovvuri, Sitaram Lanka, Friedel van Megen, Dima Mukhortov, Prerak Patel, Brandon Perez, Amanda Rapsang, Steven Reinhardt, Bita Rouhani, Adam Sapek, Raja Seera, Sangeetha Shekar, Balaji Sridharan, Gabriel Weisz, Lisa Woods, Phillip Yi Xiao, Dan Zhang, Ritchie Zhao, and Doug Burger. Serving dnns in real time at datacenter scale with project brainwave. IEEE Micro, 38(2):8–20, 2018.
- [18] Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J Franklin, Joseph E Gonzalez, and Ion Stoica. Clipper: A low-latency online prediction serving system. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), pages 613–627, 2017.
- [19] Aditya Dhakal, Sameer G Kulkarni, and KK Ramakrishnan. Gslice: controlled spatial sharing of gpus for a scalable inference platform. In Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC), pages 492–506, 2020.
- [20] Zhou Fang, Tong Yu, Ole J Mengshoel, and Rajesh K Gupta. Qos-aware scheduling of heterogeneous servers for inference in deep neural networks. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pages 2067–2070, 2017.
- [21] Jeremy Fowers, Kalin Ovtcharov, Michael Papamichael, Todd Massengill, Ming Liu, Daniel Lo, Shlomi Alkalay, Michael Haselman, Logan Adams, Mahdi Ghandi, Stephen Heil, Prerak Patel, Adam Sapek, Gabriel Weisz, Lisa Woods, Sitaram Lanka, Steven K. Reinhardt, Adrian M. Caulfield, Eric S. Chung, and Doug Burger. A configurable cloud-scale dnn processor for real-time ai. In 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), pages 1–14. IEEE, 2018.
- [22] Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, and Christos Kozyrakis. Tetris: Scalable and efficient neural network acceleration with 3d memory. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, pages 751–764, 2017.
- [23] Pin Gao, Lingfan Yu, Yongwei Wu, and Jinyang Li. Low latency rnn inference with cellular batching. In Proceedings of the Thirteenth EuroSys Conference, pages 1–15, 2018.
- [24] Hadi Goudarzi and Massoud Pedram. Hierarchical sla-driven resource management for peak power-aware and energy-efficient operation of a cloud datacenter. IEEE Transactions on Cloud Computing, 4(2):222–236, 2015.
- [25] G Griffin, A Holub, and P Perona. The caltech-256: Caltech technical report. vol, 7694:3, 2007.
- [26] Udit Gupta, Samuel Hsia, Vikram Saraph, Xiaodong Wang, Brandon Reagen, Gu-Yeon Wei, Hsien-Hsin S Lee, David Brooks, and Carole-Jean Wu. Deeprecsys: A system for optimizing end-to-end at-scale neural recommendation inference. In ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pages 982–995. IEEE, 2020.
- [27] Udit Gupta, Carole-Jean Wu, Xiaodong Wang, Maxim Naumov, Brandon Reagen, David Brooks, Bradford Cottel, Kim Hazelwood, Mark Hempstead, Bill Jia, Hsien-Hsin S. Lee, Andrey Malevich, Dheevatsa Mudigere, Mikhail Smelyanskiy, Liang Xiong, and Xuan Zhang. The architectural implications of facebook’s dnn-based personalized recommendation. In 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 488–501. IEEE, 2020.
- [28] Johann Hauswald, Yiping Kang, Michael A Laurenzano, Quan Chen, Cheng Li, Trevor Mudge, Ronald G Dreslinski, Jason Mars, and Lingjia Tang. Djinn and tonic: Dnn as a service and its implications for future warehouse scale computers. In 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), pages 27–40. IEEE, 2015.
- [29] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In European conference on computer vision (ECCV), pages 630–645. Springer, 2016.
- [30] Parker Hill, Animesh Jain, Mason Hill, Babak Zamirai, Chang-Hong Hsu, Michael A Laurenzano, Scott Mahlke, Lingjia Tang, and Jason Mars. Deftnn: Addressing bottlenecks for dnn execution on gpus via synapse vector elimination and near-compute data fission. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 786–799, 2017.
- [31] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [32] Yoshiaki Inoue. Queueing analysis of gpu-based inference servers with dynamic batching: A closed-form characterization. arXiv preprint arXiv:1912.06322, 2019.
- [33] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
- [34] Paras Jain, Xiangxi Mo, Ajay Jain, Harikaran Subbaraj, Rehan Sohail Durrani, Alexey Tumanov, Joseph Gonzalez, and Ion Stoica. Dynamic space-time scheduling for gpu inference. arXiv preprint arXiv:1901.00041, 2018.
- [35] Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wencong Xiao, and Fan Yang. Analysis of large-scale multi-tenant GPU clusters for DNN training workloads. In USENIX Annual Technical Conference (ATC), pages 947–960, 2019.
- [36] Yu Ji, Youyang Zhang, Xinfeng Xie, Shuangchen Li, Peiqi Wang, Xing Hu, Youhui Zhang, and Yuan Xie. Fpsa: A full system stack solution for reconfigurable reram-based nn accelerator architecture. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 733–747, 2019.
- [37] Lai Jiang, Mai Xu, Tie Liu, Minglang Qiao, and Zulin Wang. Deepvs: A deep learning based video saliency prediction approach. In Proceedings of the european conference on computer vision (ECCV), pages 602–617, 2018.
- [38] Weiwen Jiang, Edwin H-M Sha, Xinyi Zhang, Lei Yang, Qingfeng Zhuge, Yiyu Shi, and Jingtong Hu. Achieving super-linear speedup across multi-fpga for real-time dnn inference. ACM Transactions on Embedded Computing Systems (TECS), 18(5s):1–23, 2019.
- [39] Norman P. Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, Rick Boyle, Pierre-luc Cantin, Clifford Chao, Chris Clark, Jeremy Coriell, Mike Daley, Matt Dau, Jeffrey Dean, Ben Gelb, Tara Vazir Ghaemmaghami, Rajendra Gottipati, William Gulland, Robert Hagmann, C. Richard Ho, Doug Hogberg, John Hu, Robert Hundt, Dan Hurt, Julian Ibarz, Aaron Jaffey, Alek Jaworski, Alexander Kaplan, Harshit Khaitan, Daniel Killebrew, Andy Koch, Naveen Kumar, Steve Lacy, James Laudon, James Law, Diemthu Le, Chris Leary, Zhuyuan Liu, Kyle Lucke, Alan Lundin, Gordon MacKean, Adriana Maggiore, Maire Mahony, Kieran Miller, Rahul Nagarajan, Ravi Narayanaswami, Ray Ni, Kathy Nix, Thomas Norrie, Mark Omernick, Narayana Penukonda, Andy Phelps, Jonathan Ross, Matt Ross, Amir Salek, Emad Samadiani, Chris Severn, Gregory Sizikov, Matthew Snelham, Jed Souter, Dan Steinberg, Andy Swing, Mercedes Tan, Gregory Thorson, Bo Tian, Horia Toma, Erick Tuttle, Vijay Vasudevan, Richard Walter, Walter Wang, Eric Wilcox, and Doe Hyun Yoon. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, pages 1–12, 2017.
- [40] Yoon Kim. Convolutional neural networks for sentence classification. CoRR, abs/1408.5882, 2014.
- [41] Youngsok Kim, Joonsung Kim, Dongju Chae, Daehyun Kim, and Jangwoo Kim. layer: Low latency on-device inference using cooperative single-layer acceleration and processor-friendly quantization. In Proceedings of the Fourteenth EuroSys Conference, pages 1–15, 2019.
- [42] Matthew LeMay, Shijian Li, and Tian Guo. Perseus: Characterizing performance and cost of multi-tenant serving for cnn models. In IEEE International Conference on Cloud Engineering (IC2E), pages 66–72, 2020.
- [43] Huimin Li, Xitian Fan, Li Jiao, Wei Cao, Xuegong Zhou, and Lingli Wang. A high performance fpga-based accelerator for large-scale convolutional neural networks. In International Conference on Field Programmable Logic and Applications (FPL), pages 1–9, 2016.
- [44] Yang Li, Zhenhua Han, Quanlu Zhang, Zhenhua Li, and Haisheng Tan. Automating cloud deployment for deep learning inference of real-time online services. In IEEE INFOCOM 2020-IEEE Conference on Computer Communications, pages 1668–1677. IEEE, 2020.
- [45] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), pages 19–34, 2018.
- [46] Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics.
- [47] Ioannis Manousakis, Íñigo Goiri, Sriram Sankar, Thu D Nguyen, and Ricardo Bianchini. Coolprovision: Underprovisioning datacenter cooling. In Proceedings of the Sixth ACM Symposium on Cloud Computing (SoCC), pages 356–367, 2015.
- [48] Vicent Sanz Marco, Ben Taylor, Zheng Wang, and Yehia Elkhatib. Optimizing deep learning inference on embedded systems through adaptive model selection. ACM Transactions on Embedded Computing Systems (TECS), 19(1):1–28, 2020.
- [49] Seyed Morteza Nabavinejad, Mohammad Baharloo, Kun-Chih Chen, Maurizio Palesi, Tim Kogel, and Masoumeh Ebrahimi. An overview of efficient interconnection networks for deep neural network accelerators. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 10(3):268–282, 2020.
- [50] Nvidia. Cuda profiler. https://docs.nvidia.com/cuda/profiler-users-guide/index.html. Accessed: December 2, 2021.
- [51] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015.
- [52] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [53] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4510–4520, 2018.
- [54] Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Strachan, Miao Hu, R Stanley Williams, and Vivek Srikumar. Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars. ACM SIGARCH Computer Architecture News, 44(3):14–26, 2016.
- [55] Haichen Shen, Lequn Chen, Yuchen Jin, Liangyu Zhao, Bingyu Kong, Matthai Philipose, Arvind Krishnamurthy, and Ravi Sundaram. Nexus: a gpu cluster engine for accelerating dnn-based video analysis. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, pages 322–337, 2019.
- [56] Yongming Shen, Michael Ferdman, and Peter Milder. Escher: A cnn accelerator with flexible buffering to minimize off-chip transfer. In IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), pages 93–100, 2017.
- [57] Mingcong Song, Yang Hu, Huixiang Chen, and Tao Li. Towards pervasive and user satisfactory cnn across gpu microarchitectures. In 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1–12. IEEE, 2017.
- [58] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [59] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–9, 2015.
- [60] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826, 2016.
- [61] Xuehai Tang, Peng Wang, Qiuyang Liu, Wang Wang, and Jizhong Han. Nanily: A qos-aware scheduling for dnn inference workload in clouds. In 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), pages 2395–2402. IEEE, 2019.
- [62] TensorFlow. Tensorflow porfiler. https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras. Accessed: December 2, 2021.
- [63] Kodai Ueyoshi, Kota Ando, Kazutoshi Hirose, Shinya Takamaeda-Yamazaki, Mototsugu Hamada, Tadahiro Kuroda, and Masato Motomura. Quest: Multi-purpose log-quantized dnn inference engine stacked on 96-mb 3-d sram using inductive coupling technology in 40-nm cmos. IEEE Journal of Solid-State Circuits, 54(1):186–196, 2018.
- [64] W. Wang, J. Shen, J. Xie, M. Cheng, H. Ling, and A. Borji. Revisiting video saliency prediction in the deep learning era. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
- [65] Wenguan Wang, Jianbing Shen, Fang Guo, Ming-Ming Cheng, and Ali Borji. Revisiting video saliency: A large-scale benchmark and a new model. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [66] Zhenning Wang, Jun Yang, Rami Melhem, Bruce Childers, Youtao Zhang, and Minyi Guo. Quality of service support for fine-grained sharing on gpus. In Proceedings of the 44th Annual International Symposium on Computer Architecture, pages 269–281, 2017.
- [67] Ziheng Wang. Sparsert: Accelerating unstructured sparsity on gpus for deep learning inference. In Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques, pages 31–42, 2020.
- [68] Mengze Wei, Wenyi Zhao, Quan Chen, Hao Dai, Jingwen Leng, Chao Li, Wenli Zheng, and Minyi Guo. Predicting and reining in application-level slowdown on spatial multitasking gpus. Journal of Parallel and Distributed Computing, 141:99–114, 2020.
- [69] Xuechao Wei, Yun Liang, and Jason Cong. Overcoming data transfer bottlenecks in fpga-based dnn accelerators via layer conscious memory management. In 2019 56th ACM/IEEE Design Automation Conference (DAC), pages 1–6. IEEE, 2019.
- [70] Shaojun Zhang, Wei Li, Chen Wang, Zahir Tari, and Albert Y Zomaya. Dybatch: Efficient batching and fair scheduling for deep learning inference on time-sharing devices. In IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), pages 609–618, 2020.
- [71] Wei Zhang, Weihao Cui, Kaihua Fu, Quan Chen, Daniel Edward Mawhirter, Bo Wu, Chao Li, and Minyi Guo. Laius: Towards latency awareness and improved utilization of spatial multitasking accelerators in datacenters. In Proceedings of the ACM International Conference on Supercomputing, pages 58–68, 2019.
- [72] Xiaofan Zhang, Junsong Wang, Chao Zhu, Yonghua Lin, Jinjun Xiong, Wen-mei Hwu, and Deming Chen. Dnnbuilder: an automated tool for building high-performance dnn hardware accelerators for fpgas. In 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pages 1–8. IEEE, 2018.
- [73] Jingyang Zhu, Zhiliang Qian, and Chi-Ying Tsui. Lradnn: High-throughput and energy-efficient deep neural network accelerator using low rank approximation. In 2016 21st Asia and South Pacific Design Automation Conference (ASP-DAC), pages 581–586. IEEE, 2016.
- [74] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8697–8710, 2018.