Tie Your Embeddings Down: Cross-Modal Latent Spaces for End-to-end Spoken Language Understanding
Abstract
End-to-end (E2E) spoken language understanding (SLU) systems can infer the semantics of a spoken utterance directly from an audio signal. However, training an E2E system remains a challenge, largely due to the scarcity of paired audio-semantics data. In this paper, we treat an E2E system as a multi-modal model, with audio and text functioning as its two modalities, and use a cross-modal latent space (CMLS) architecture, where a shared latent space is learned between the ‘acoustic’ and ‘text’ embeddings. We propose using different multi-modal losses to explicitly guide the acoustic embeddings to be closer to the text embeddings, obtained from a semantically powerful pre-trained BERT model. We train the CMLS model on two publicly available E2E datasets, across different cross-modal losses and show that our proposed triplet loss function achieves the best performance. It achieves a relative improvement of and respectively over an E2E model without a cross-modal space and a relative improvement of and over a previously published CMLS model using loss. The gains are higher for a smaller, more complicated E2E dataset, demonstrating the efficacy of using an efficient cross-modal loss function, especially when there is limited E2E training data available.
Index Terms— Spoken Language Understanding, End-to-end neural model, natural language processing, BERT, transformers, cross-modal learning
1 Introduction
Spoken language understanding (SLU) is the task of inferring the semantics of user-spoken utterances and is the core technology behind voice assistant systems like Alexa, Google Home, Siri and more. The traditional approach to SLU uses two distinct components to sequentially process a spoken utterance: an automatic speech recognition (ASR) model that transcribes the speech to a text transcript, followed by a natural language understanding (NLU) model that predicts the domain, intent and entities given the transcript [1]. However, this modular design admits a major drawback. The two component models (ASR and NLU) are trained independently with separate objectives. Errors encountered in the training of either model do not inform the other. For example, for an input utterance ‘turn on the light’, if the ASR hypothesis is missing a single word, the word error rate (WER) is . However, if the missing word is ‘on’ or ‘light’, the NLU model will produce an incorrect prediction with a high probability. On the other hand, the information needed by the NLU model to make a correct prediction will still be present if the missing word is ‘the’. Yet, the WER (the error metric the ASR is optimized for) does not differentiate this effect when looking at the final model performance. error metric the ASR is optimized for) does not reflect this effect on the NLU downstream component.
An increasingly popular approach to address this problem is to employ models that predict SLU output directly from a speech signal input [2, 3, 4, 5, 6, 7, 8]. This class of models, also referred to as speech-to-interpretation (S2I) models, are trained in an end-to-end (E2E) fashion to maximize the SLU prediction accuracy. Such models typically have smaller footprints than their modular counterparts, making them attractive candidates for performing SLU in resource constrained environments like devices on the edge. However, availability of sufficient quantity of good quality speech data with associated semantic labels is key to achieving comparable performance to the traditional, cascaded counterparts. A paucity of such datasets becomes a major bottleneck for these SLU systems.
A variety of methods, like knowledge transfer, data augmentation and component-wise pre-training have been explored to address this issue. For example, curriculum and transfer learning strategies are used in [9, 10] to gradually fine-tune the SLU model on increasingly relevant datasets, followed by finally training it on low-resource in-domain data. Authors in [5, 11] leverage the large amount of transcribed speech data to pre-train an ASR model on phoneme and word-level targets. This is then used to initialize the first few layers of the SLU model, that is fine-tuned on a smaller training set containing paired transcripts and SLU labels. This method leads to a near perfect accuracy on their datasets. However, a principled study performed by the authors in [12], revealed that most of these methods report high performance on SLU datasets of relatively low semantic complexity, often representing targeted SLU use-cases. As the complexity of the dataset increases and the SLU task becomes more sophisticated, the performance of these models starts degrading.
Authors in [13] attempt to address this problem by combining component pre-training, knowledge transfer and data augmentation approaches to create a robust SLU model. They employ the successful multi-modal learning approach of unifying the latent representation space across different modalities [14], and utilize the fact that the SLU model is essentially a multi-modal model, with speech and text functioning as its two modalities. One of the main advantages of this architecture is the common latent space that allows leveraging both acoustic and text-only data for model training. This cross-modal feature space leads to a better representation and gives the model a robust inductive bias for a semantically complex SLU task. BERT-based text embeddings [15] are used to ‘guide’ acoustic embeddings. An loss between the text and acoustic embeddings is used to explicitly tie the cross-modal latent representation space, leading to better intent classification accuracy.
In this work, we further explore the multi-modal view of SLU models by experimenting with different approaches to learn a robust cross-modal latent space. Specifically, we experiment with (i) different loss functions to tie the acoustic and text embeddings; and (ii) using adversarial training methods on the E2E SLU model. We try two other loss functions apart from the loss – pairwise ranking loss and triplet loss. These loss functions have shown to be more effective, than the loss, in learning joint feature representations in the regimen of image processing for learning tied image-sentence representations [16, 17, 18, 19]. Our goal is to have the encoders generate embeddings in the same latent space, so that the origin of the embeddings becomes indistinguishable. A method alternative to the previous losses is the use of adversarial training, where a classifier is trained to detect the modality of a given embedding and forces the (audio) encoder to output acoustic embeddings that can fool this classifier, pushing them to be closer to the structure of textual embeddings.
We train the so-called cross-modal latent space (CMLS) E2E SLU model architecture defined in [13] on two publicly available SLU datasets [5, 20] and study the effect of these cross-modal embedding losses and of the adversarial training on the intent accuracy of the model. We show that the triplet loss has the best performance across both these datasets. It achieves a relative improvement of and respectively111For the dataset in [5] and [20] in order. over an E2E model without a cross-modal space and a relative improvement of and over the model from [13] that uses the loss. A visual inspection of the acoustic embeddings via a t-SNE plot, reveals that the embeddings learned using the best performing CMLS loss (triplet loss) are able to better separate the utterances belonging to different intents, even if they are acoustically similar, when compared to the embeddings from a model that does not have a CMLS setup.
To the best of our knowledge, this is the first attempt to systematically apply losses that have shown success in learning cross-modal representations in relatively mature textual-visual or speech-visual multi-modal domains, to SLU models for improving the SLU tasks. We hypothesize that using an appropriate loss function and cross-modal training methodology is key to achieving tighter coupling and hence better performance, as the SLU tasks get more complex.
In the Section 2 we detail our methodology where we explain the CMLS model architecture that we implemented and the different embedding losses used . This is followed by our experimental setup and model configurations used for training in Section 3. We also discuss the results in Section 3 across the two datasets and perform some analyses on the differences in the cross-modal representations learned across the different loss functions. We conclude with key findings and future directions of this work in Section 4.
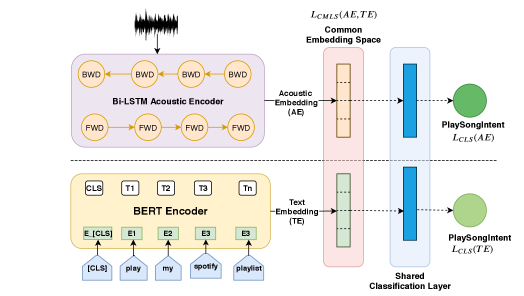
2 Cross-Modal Latent Spaces
A major challenge in building an efficient E2E SLU system is the availability of appropriate datasets. While there is a plethora of ASR and NLU specific datasets available, the is a scarcity of good quality E2E SLU datasets that have paired utterance audio and semantic labels, to allow for an end-to-end training of the model. An approach to overcome this, is building a system that has a tied space for multiple modalities. This presents the advantage of leveraging different, modality specific datasets that can help achieve better generalization for the final SLU task. The tied cross-modal space can be achieved by unifying representations across modalities. An example would be, projecting the acoustic and text-only data into the same embedding space, and learning the parameters of this joint space to optimize the SLU task-loss. This enables us to train an SLU model in an end-to-end fashion on the smaller E2E dataset, but also leverage the large amount of ASR- or text-only datasets to learn a robust latent space for the final task.
A first solution to learning such a cross-modal latent space (CMLS) between the acoustic and text modalities in an E2E SLU model was proposed in [13]. The ‘text’ modality latent space is represented by using the encoded representation of an utterance text from a pre-trained BERT model. Whereas, the ‘acoustic’ modality is represented by using a multi-layer Bi-LSTM model to create an acoustic embedding of the utterance audio. Along with the task-specific classification loss222A cross-entropy loss on intent classification is used., they use an loss between the text and acoustic embeddings, to explicitly tie the cross-modal space. A shared classification layer is jointly trained on both the acoustic embedding (AE) and text embedding (TE).
While this method of an explicit embedding loss, added to the task-specific loss, led to an improved performance over the baseline model, there are more effective ways of mapping representations from different modalities into a common space. In the regimen of computer vision, an established approach is to map embeddings of different modalities (e.g. images and captions) into the same embedding space using the pair wise ranking loss or the triplet loss. While the loss forces the embeddings to approximate each other in a canonical way using the distance, we rely on alternative multi-modal losses to build a stronger CMLS model in this work. We use the same E2E SLU model setup as in [13], but use three different losses to learn a robust CMLS model. In the next subsection 2.1, we outline our model architecture and describe each loss in detail in subsection 2.2, followed by subsection 2.4 which addresses our approach on adversarial training.
2.1 Model Architecture
Our proposed CMLS model consists of three sub-modules as shown in Figure 1: an acoustic encoder, a BERT encoder, and a shared classification layer. The acoustic encoder is a multi-layer Bi-LSTM network that computes the acoustic embedding (AE) from the acoustic features of the utterance audio. This is done by max-pooling the last layer Bi-LSTM states across the time dimension to obtain a fixed-dimensional vector that summarizes the input audio, independent of the length of the input signal. In order to obtain the text embedding (TE) of the input utterance, we use a pre-trained BERT model that takes the utterance text as an input. As is common in BERT-based encoders, the last layer transformer-encoder representation of the [CLS] token is used as the text-embedding of the utterance. The shared classification layer is a fully-connected network, followed by a softmax to predict the semantic label (intent in our case). It produces an intent prediction using both the AE and TE separately, resulting in computing an embedding specific classification loss as shown in Figure 1.
Explicit loss to tie the AE and TE is specified by , that can be one of the three losses that we define in the following section. The discriminator network for the adversarial training (not shown in the Figure) is composed of linear layers. Depending on the dataset, we optimized the number of layers, units per layer and the weight of the adversarial loss.
We back-propagate the embedding and SLU task losses only to the acoustic branch. This is due to the limited amount of training data available, where the BERT model would overfit because of its size. As mentioned in more detail later in section 2.3, the joint loss seen by the acoustic branch is constructed by combining AE specific classification loss and one of the aforementioned embedding loss (). The BERT-based text pipeline is only used during training to guide the AEs and is discarded for inference. This architecture has the advantage of being easily extensible to support more modalities during training while at the same time keeping the resource footprint constrained during inference. The CMLS model is not limited to using a BERT model, the method is agnostic to the type of embeddings used.
2.2 Embedding losses
We evaluate three different loss functions ( loss, pairwise ranking loss and triplet loss) to tie the embeddings originating from two modalities together into a common latent space.
2.2.1 loss
Introduced in [13] to tie the latent space, the loss is computed as follows:
| (1) |
where denotes the acoustic embedding and denotes the text embedding of the same utterance. expresses the distance between and .
2.2.2 Pairwise Ranking Loss
Moving beyond the loss, the pairwise ranking loss [21] allows us to train the network using the following loss formulation:
| (2) |
where, denotes the acoustic embedding and denotes the text embedding. and need not necessarily represent the same utterance. is a binary variable indicating if and have the same intent () or a different one () and is the margin which controls the minimum distance between the negative pairs. This is a tunable hyperparameter.
If both samples belong to the same intent, the loss forces them to be closer together (similar to the loss), but if they originate from different intents, then the loss is and this pushes the embeddings further apart.
2.2.3 Triplet Loss
In contrast to other losses, the triplet loss [22, 23] uses three examples: the current training example, called anchor and , are positive and negative examples respectively. Formula 3 shows how the loss is computed.
| (3) |
In our case, the anchor is the acoustic embedding and the positive example is the text embedding of an utterance with the same intent. Similarly, the negative example is the text embedding of an utterance with a different intent. For example, the anchor could be the acoustic embedding of ‘could you please increase the brightness’ and the positive example could be the text embedding of ‘it’s too dark in here’ which both have the IncreaseBrightness intent. The negative example, on the other hand, could be the text embedding of ‘change the lights to green’ which has the ChangeColor intent.
The triplet loss aims at minimizing the intra-class variance while maximizing the inter class variance: samples within the same class are forced to be closer together in the feature space, while samples from different classes are pushed further apart. Figure 2 shows embeddings in the latent space. Using the triplet loss, the acoustic embeddings are shifted to minimize the distance between semantically similar words, while also maximizing the distance of semantically different words, even if they are acoustically close.
2.3 Combination of the Losses
The entire model is trained jointly and the total loss can be written as shown in Formula 4, where denotes the classification loss and denotes the embedding loss. and are hyperparameters that control the weights of the different losses in the sum.
| (4) |
2.4 Adversarial Training
A popular approach for adversarial training are GANs (generative adversarial networks) [24], where two networks are trained in tandem. One (the generator network) is trained to generate/alter data samples and a second one (the discriminator network) is trained to classify whether the samples are generated by the generator or if they are ‘real’ samples. The generator is trained to fool the discriminator about the origin of the samples. For CMLS, we face a similar scenario where we have multiple sources of samples while the objective is to generate embeddings which are invariant w.r.t. the source (here: acoustics or text). We therefore use a discriminator network for adversarial training. This network tries to predict if the corresponding embedding originates from the audio domain or the text domain. Mathematically, we have a neural network that takes as input the embedding from the common embedding space and outputs the probability that the embedding is from the text domain. We assign a target of to the text modality and to the acoustic modality. We denote the acoustic encoder by and the BERT model by . The full adversarial objective can be written as in Formula 5. denotes the parameters of the respective networks.
| (5) |
3 Experiments and Results
In this section, we describe the datasets, model parameters, training configurations, and analyze our results333Source code is available at https://github.com/alexa/alexa-end-to-end-slu.
3.1 Datasets
We use two publicly available SLU datasets to train and evaluate our model – Fluent Speech Commands (FSC) [5] and Snips SLU SmartLights [20]. Both these datasets contain utterance text, corresponding audio and a semantic class label.
FSC is one of the largest public SLU datasets, containing utterances. Each utterance text is associated with a triplet - action, object and location. This triplet, functions as the ‘intent’ label of the utterance, and becomes our target semantic class to be predicted. There are a total of 31 unique intent classes in the dataset. Snips is a smaller SLU dataset, making the prediction task challenging. It contains utterances and 6 intent classes. Since this dataset does not have its own train/test/validation splits, we created a 80-10-10 split for train, validation and test respectively.
We train two separate models corresponding to each dataset and study the effect of the losses and adversarial training for each of these datasets.
3.2 Feature Extraction
A Hamming window of the length 25 ms with frame rate of 10 ms is used to segment the audio files. We used the torchaudio library to compute 40-dimensional MFCC features from the audio files directly. We set the number of triangular Mel-frequency bins to 80.
3.3 Model Training and Hyper-Parameters
The CMLS-SLU model described in section 2.1, consists of a 4-layer and 3-layer Bi-LSTM acoustic encoder for FSC and Snips respectively, with 512 hidden units per layer. The text-encoder comprises of a pre-trained BERT model444We use the BERT-base-cased models. from [25], where the encoded representation of the [CLS] token from the last encoder layer is used as the text-embedding of the utterance. The shared classification layer has an input size of 768 (the size of the embeddings) and the number of outputs depends on the dataset (31 for FSC and 6 for Snips SLU).
The cross-modal coupling between the acoustic and the text embeddings is achieved by using the three different losses defined in section 2.2. For each loss type, we train a new CMLS model and evaluate the results on the corresponding test split per dataset. A thing to note here is that the CMLS model trained on an embedding loss is the same as proposed in [13] and is therefore used as a basis of comparison for us to see the effectiveness of better cross-modal losses.
In order to show the efficacy of tying the text-acoustic cross-modal embedding spaces, we also train a baseline model that just contains the multi-layer Bi-LSTM acoustic encoder, with a fully connected layer to perform intent classification, without any text encoder present. Furthermore, we also note the intent accuracy results noted by the authors of the FSC in their work [5] to compare the performance of the CMLS models on this dataset. Since we do not pre-train the acoustic layers of our model, we use their non-pretrained model results for comparison.
We perform a hyper-parameter search across different parameter combinations and use early stopping on the validation loss to select the best performing model for each embedding loss type. We applied Adam optimizer [26] with = 0.9, = 0.98, and = 1e-9. The learning rates for the acoustic encoder and BERT were set to 1e-3 and 2e-5, respectively for FSC which were decayed when the loss on the validation set plateaued. For Snips we used the 1cycle learning rate policy with the max learning rate set to 6e-3. For the adversarial generator network, we also performed a hyper-parameter search to tune the parameters for each dataset. The parameters are listed in Table 1 and differ between the two datasets.
| Dataset | # units | # layers | loss weight |
|---|---|---|---|
| FSC | 256 | 2 | 0.1 |
| Snips SLU | 512 | 1 | 0.3 |
3.4 Results
We first present our results using different loss functions for each dataset and conclude with results of our adversarial experiments.
3.4.1 Fluent Speech Commands
The results on the FSC dataset are shown in Table 2. We train three different CMLS SLU models on FSC, one per loss type. All the loss types are able to perform better (or equal to, in the case of ranking loss) than the baseline model. Triplet loss achieves the best performance with a relative improvement of over the baseline model and relative over the loss model from [13]. When compared to the original accuracy reported on the FSC dataset by the authors in [5] for their non-pre-trained model (), we see that the triplet loss achieves the best performance here too with a relative improvement of . The loss is also able to beat the reported accuracy from [5] by relative. Both these results indicate the importance of having a cross-modal latent space, using a pre-trained text encoder in an E2E SLU model.
| Model | Accuracy (%) |
|---|---|
| Baseline (Only acoustic, no CMLS) | 96.31 |
| CMLS - loss (model in [13]) | 97.31 |
| CMLS - Pairwise ranking loss | 96.31 |
| CMLS - Triplet Loss | 97.65 |
3.4.2 Snips SLU
We repeat the experiments on the Snips SLU dataset, the results of which are shown in Table 3. Similar to our previous observation, the CMLS SLU model is able to beat the performance of the baseline model, for all the embedding loss types, achieving a relative improvement of on average. The triplet loss has the best performance on this dataset too, with a relative improvement of over the baseline and over the loss model from [13]. Since this dataset is a more challenging dataset, owing to its small size, these performance improvements are notable. Moreover, these results also indicate that, agnostic of the SLU dataset used, having an explicit signal to learn a robust cross-modal embedding space, using a semantically powerful text-encoder as a guide, is important to achieve a robust SLU performance.
| Model | Accuracy (%) |
|---|---|
| Baseline (Only acoustic, no CMLS) | 70.84 |
| CMLS - loss (model in [13]) | 72.89 |
| CMLS - Pairwise ranking loss | 72.29 |
| CMLS - Triplet Loss | 74.10 |
| Model | Accuracy (%) |
|---|---|
| Baseline (FSC data, only acoustic, no CMLS) | 96.31 |
| Triplet Loss training (FSC data) | 97.65 |
| Adversarial training (FSC data) | 96.34 |
| Baseline (Snips data, only acoustic, no CMLS) | 70.84 |
| SLU Triplet Loss training (Snips data) | 74.10 |
| SLU Adversarial training (Snips data) | 72.89 |
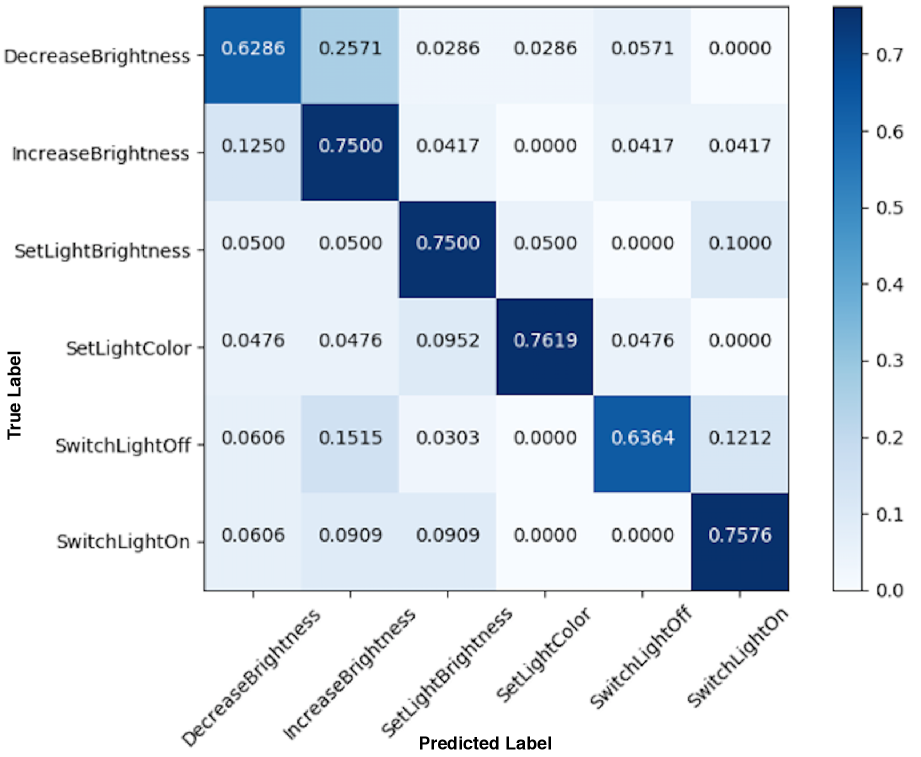
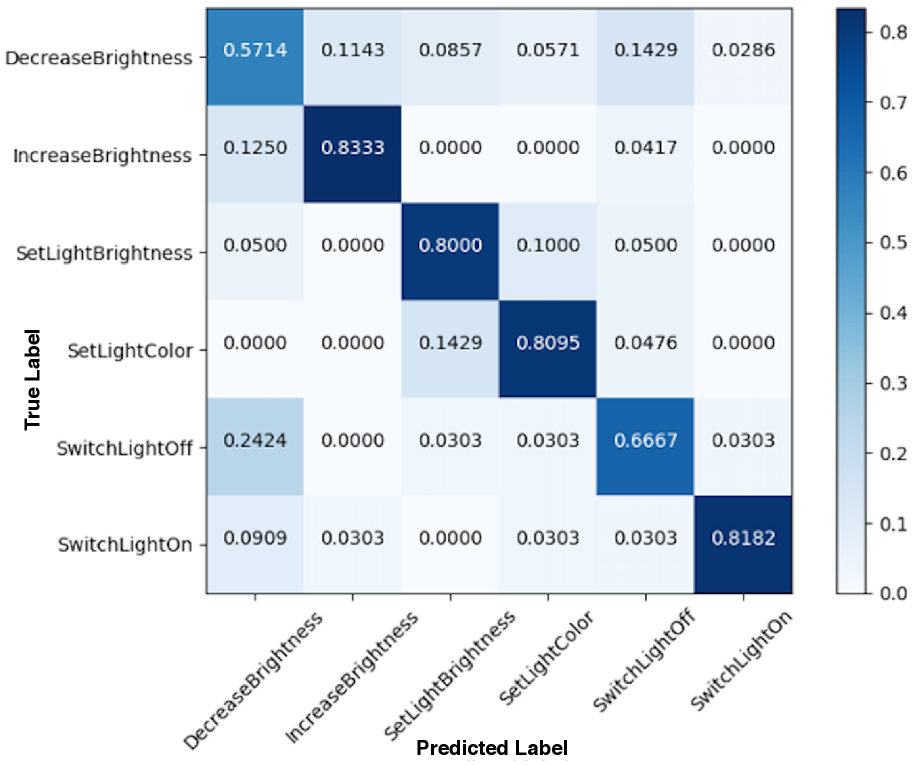
Furthermore, we evaluate the predictive power and the false positive rate of our best performing CMLS model (triplet loss) against that of the baseline model. We plot the confusion matrices for the six intents of the Snips dataset, as predicted by the baseline model (Figure 4) and the CMLS model (Figure 4). We can see that the baseline model has less predictive power and higher false positive rate. This is especially true for intents that are semantically opposite but acoustically close, such as IncreaseBrightness and DecreaseBrightness, where we observe the false positive rate of the baseline model () is higher than the CMLS model (). These results further support the superiority of our model in distinguishing intents with similar acoustic features but completely opposite semantic.
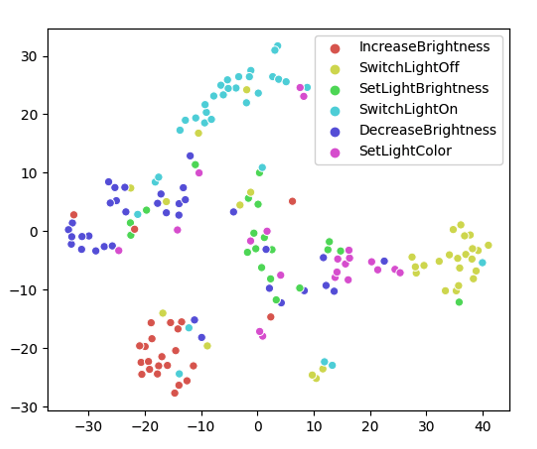
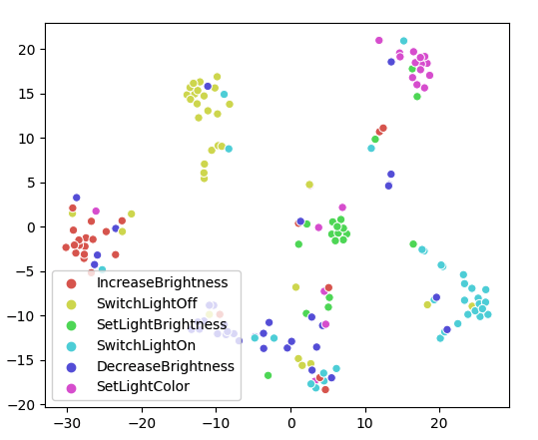
We also explore the acoustic embedding representations learned by both for the CMLS and the baseline model. Specifically, we investigate whether the acoustic embeddings pertaining to a particular intent are close to each other or not. For this purpose, we cluster the 768-dimensional hidden acoustic embedding vectors using t-SNE for the test split of the Snips dataset. The vectors are scatter-plotted and color-coded using the ground truth intent, depicted in Figure 6 (baseline) and Figure 6 (CMLS with triplet loss). A visual inspection of these plots reveals that for the CMLS model, the acoustic embedding clusters pertaining to individual intents are well-separated, having little intra-class variance compared to those obtained from the baseline model. These results further support that our CMLS model better maps audio features to related semantic outputs when compared to models that only use a single modality for the E2E neural SLU task.
3.4.3 Adversarial Training
Training our system with the adversarial discriminator network to tie the embedding space, we observe improvements over the baseline, but the triplet loss still remains the strongest candidate for aligning the embedding space, see Table 4. The adversarial training is very sensitive and as outlined in Section 3.3 the optimal tuning parameters are dataset dependent (Table 1). Based on these results, it will be interesting to see if a combination of triplet loss and adversarial training complement each other and if the adversarial training will become more robust when applied to a larger dataset.
4 Conclusion
In this work, we take a multi-modal view of the E2E SLU model and experiment with a cross-modal latent space (CMLS) setup wherein we learn a shared latent space between the two modalities of the SLU model – ‘speech’ and ‘text’. The CMLS setup helps us leverage modality-specific datasets, that are usually more abundant than E2E SLU datasets, enabling us to achieve a higher SLU performance even on a smaller E2E dataset. This is done in two ways: using the popular multi-modal losses to explicitly tie the acoustic and text embeddings and by using adversarial training to move the acoustic embeddings closer to the text embeddings. This is done because the text embeddings are extracted from a semantically powerful BERT-based text encoder, that has been trained on massive amount of textual data and has shown to capture the semantics very well across a variety of tasks. We show that triplet loss has the best performance and hypothesize that this loss also helps the model recognize off-target instances that are acoustically similar (sound the same) but are semantically far apart (e.g ‘increase’, ‘decrease’). Due the way that it is formulated, it not only minimizes the distance between the target and positive candidates but also maximizes the distance between the target and the audio embeddings that are acoustically close but far apart semantically. We perform a visual analysis of the acoustic embeddings learned in a cross-modal and non cross-modal way and notice that the cross-modal embeddings not only have have lower false-accept rates but also show better clustering with lower intra-class variance for semantically different intent classes. Even though adversarial training was not able to beat the triplet loss in a CMLS setup for these datasets, it still performed better than the baseline model that does not have a cross-modal space.
In the future, we plan to combine the adversarial training with the explicit embedding losses in one joint setup and see the combined effects of these methods. Moreover, we plan to run these experiments on datasets of higher semantic complexity than the ones that we used in this work, and experiment with more sophisticated architectures for the acoustic encoders. When tying the embeddings, we restricted ourselves to forcing only the acoustic encoder to adjust to the text encoder’s latent space because of the limited size of our datasets. Using larger datasets, having both encoders approximate their outputs to each other may also lead to further performance improvements. This distributes the stress of approximating the tied space between all of the encoders, that may be beneficial in the case where utterances are similar in one space, but different in another (e.g. acoustically similar utterances with different semantics).
References
- [1] Cheongjae Lee, Sangkeun Jung, Kyungduk Kim, Donghyeon Lee, and Gary Geunbae Lee, “Recent approaches to dialog management for spoken dialog systems,” Journal of Computing Science and Engineering, vol. 4, no. 1, pp. 1–22, 2010.
- [2] Martin Radfar, Athanasios Mouchtaris, and Siegfried Kunzmann, “End-to-end neural transformer based spoken language understanding,” in Interspeech 2020,th Annual Conference of the International Speech Communication Association, 2020, pp. 500–505.
- [3] Parisa Haghani, Arun Narayanan, Michiel Bacchiani, Galen Chuang, Neeraj Gaur, Pedro Moreno, Rohit Prabhavalkar, Zhongdi Qu, and Austin Waters, “From audio to semantics: Approaches to end-to-end spoken language understanding,” in 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2018, pp. 720–726.
- [4] Dmitriy Serdyuk, Yongqiang Wang, Christian Fuegen, Anuj Kumar, Baiyang Liu, and Yoshua Bengio, “Towards end-to-end spoken language understanding,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5754–5758.
- [5] Loren Lugosch, Mirco Ravanelli, Patrick Ignoto, Vikrant Singh Tomar, and Yoshua Bengio, “Speech model pre-training for end-to-end spoken language understanding,” arXiv preprint arXiv:1904.03670, 2019.
- [6] Yuan-Ping Chen, Ryan Price, and Srinivas Bangalore, “Spoken language understanding without speech recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 6189–6193.
- [7] Yao Qian, Rutuja Ubale, Vikram Ramanaryanan, Patrick Lange, David Suendermann-Oeft, Keelan Evanini, and Eugene Tsuprun, “Exploring asr-free end-to-end modeling to improve spoken language understanding in a cloud-based dialog system,” in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 569–576.
- [8] Sahar Ghannay, Antoine Caubrière, Yannick Estève, Nathalie Camelin, Edwin Simonnet, Antoine Laurent, and Emmanuel Morin, “End-to-end named entity and semantic concept extraction from speech,” in 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2018, pp. 692–699.
- [9] Antoine Caubrière, Natalia Tomashenko, Antoine Laurent, Emmanuel Morin, Nathalie Camelin, and Yannick Estève, “Curriculum-based transfer learning for an effective end-to-end spoken language understanding and domain portability,” arXiv preprint arXiv:1906.07601, 2019.
- [10] Natalia Tomashenko, Antoine Caubrière, and Yannick Estève, “Investigating adaptation and transfer learning for end-to-end spoken language understanding from speech,” 2019.
- [11] Swapnil Bhosale, Imran Sheikh, Sri Harsha Dumpala, and Sunil Kumar Kopparapu, “End-to-end spoken language understanding: Bootstrapping in low resource scenarios.,” in Interspeech, 2019, pp. 1188–1192.
- [12] Joseph P. McKenna, Samridhi Choudhary, Michael Saxon, Grant P. Strimel, and Athanasios Mouchtaris, “Semantic complexity in end-to-end spoken language understanding,” arXiv preprint arXiv:2008.02858, 2020.
- [13] Yinghui Huang, Hong-Kwang Kuo, Samuel Thomas, Zvi Kons, Kartik Audhkhasi, Brian Kingsbury, Ron Hoory, and Michael Picheny, “Leveraging unpaired text data for training end-to-end speech-to-intent systems,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7984–7988.
- [14] Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y Ng, “Multimodal deep learning,” in ICML, 2011.
- [15] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [16] Ryan Kiros, Ruslan Salakhutdinov, and Richard S. Zemel, “Unifying visual-semantic embeddings with multimodal neural language models,” 2014.
- [17] Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc’Aurelio Ranzato, and Tomas Mikolov, “Devise: A deep visual-semantic embedding model,” in Advances in neural information processing systems, 2013, pp. 2121–2129.
- [18] Fartash Faghri, David J. Fleet, Jamie Ryan Kiros, and Sanja Fidler, “Vse++: Improving visual-semantic embeddings with hard negatives,” 2017.
- [19] Bokun Wang, Yang Yang, Xing Xu, Alan Hanjalic, and Heng Tao Shen, “Adversarial cross-modal retrieval,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 154–162.
- [20] Alaa Saade, Alice Coucke, Alexandre Caulier, Joseph Dureau, Adrien Ball, Théodore Bluche, David Leroy, Clément Doumouro, Thibault Gisselbrecht, Francesco Caltagirone, Thibaut Lavril, and Maël Primet, “Spoken language understanding on the edge,” 2018.
- [21] Yuncheng Li, Yale Song, and Jiebo Luo, “Improving pairwise ranking for multi-label image classification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3617–3625.
- [22] Gal Chechik, Varun Sharma, Uri Shalit, and Samy Bengio, “Large scale online learning of image similarity through ranking,” in Iberian Conference on Pattern Recognition and Image Analysis. Springer, 2009, pp. 11–14.
- [23] Florian Schroff, Dmitry Kalenichenko, and James Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
- [24] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems 27, Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Eds., pp. 2672–2680. Curran Associates, Inc., 2014.
- [25] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al., “Huggingface’s transformers: State-of-the-art natural language processing,” ArXiv, pp. arXiv–1910, 2019.
- [26] Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.