[table]capposition=top \newfloatcommandcapbtabboxtable[][\FBwidth]
TimeSearch: Hierarchical Video Search with Spotlight and Reflection for Human-like Long Video Understanding
Abstract
Large video-language models (LVLMs) have shown remarkable performance across various video-language tasks. However, they encounter significant challenges when processing long videos because of the large number of video frames involved. Downsampling long videos in either space or time can lead to visual hallucinations, making it difficult to accurately interpret long videos. Motivated by human hierarchical temporal search strategies, we propose TimeSearch, a novel framework enabling LVLMs to understand long videos in a human-like manner. TimeSearch integrates two human-like primitives into a unified autoregressive LVLM: 1) Spotlight efficiently identifies relevant temporal events through a Temporal-Augmented Frame Representation (TAFR), explicitly binding visual features with timestamps; 2) Reflection evaluates the correctness of the identified events, leveraging the inherent temporal self-reflection capabilities of LVLMs. TimeSearch progressively explores key events and prioritizes temporal search based on reflection confidence. Extensive experiments on challenging long-video benchmarks confirm that TimeSearch substantially surpasses previous state-of-the-art, improving the accuracy from 41.8% to 51.5% on the LVBench. Additionally, experiments on temporal grounding demonstrate that appropriate TAFR is adequate to effectively stimulate the surprising temporal grounding ability of LVLMs in a simpler yet versatile manner, which improves mIoU on Charades-STA by 11.8%. The code will be released.
1 Introduction

Large video-language models (LVLMs) have significantly advanced in video understanding [63, 22]. Traditionally, video understanding tasks such as action recognition [2], temporal grounding [18], and video question-answering [54] have primarily focused on short clips, typically ranging from a few seconds to a few minutes. However, the emergence of LVLMs has prompted a shift towards exploring their capabilities in understanding longer and more complex video sequences [47], which presents unique challenges in maintaining contextual coherence and managing computational resources efficiently.
Recent LVLMs frequently struggle to encode long videos due to the large number of frames involved, forcing aggressive downsampling strategies. For example, the advanced LLaVA-Video model uniformly samples only 64 frames regardless of video duration [63], leading to a significant loss of detailed temporal information, especially in hour-long videos. Existing approaches attempt to alleviate this issue through strategies like spatial pooling or token pruning [23, 62, 15, 61], or using memory banks that compress visual information into fixed-size representations [39, 58]. However, these methods uniformly overlook the actual duration and detailed temporal structures, causing critical information loss and temporal hallucinations.
In contrast, humans use a fundamentally different approach when interpreting long videos. Rather than exhaustively analyzing videos frame-by-frame, humans naturally adopt event segmentation and selective attention strategies [55]. As illustrated in Fig. 1 (b), humans review videos broadly to find relevant clues, then gradually focus on more specific sub-events for detailed inspection. Importantly, when the necessary information is not immediately clear, humans may revisit multiple candidate sub-events iteratively, reflecting on their relevance until they find satisfactory answers. Such a hierarchical, iterative search effectively reduces cognitive load by quickly filtering out irrelevant events [40]. Although human-like search has demonstrated effectiveness in image [48, 38] and text reasoning [52], its application to long video understanding remains unexplored.
Inspired by human cognitive strategies, we introduce TimeSearch, a hierarchical temporal search framework for long-video understanding. Similar to hierarchical event segmentation [55], TimeSearch progressively divides the video timeline into coarse-grained events and finer-grained sub-events, enabling efficient human-like search. Specifically, as illustrated in Fig. 1, the search begins at a coarse level, refining promising segments into more detailed sub-events, guided by confidence scores based on reflection. For efficiency, the initial segmentation adopts simple rule-based methods. However, naive rule-based segmentation alone is insufficient to effectively divide coarse-grained events into finer-grained sub-events. This highlights the need to integrate spotlight grounding and reflection to refine and accelerate the search process.
To identify subtle temporal details within promising sub-events accurately, we propose the Temporal Spotlight Grounding (TSG) primitive. Previous LVLMs [21, 63] have incorporated temporal instructions to improve understanding, yet they do not effectively align visual and temporal cues. To address this limitation, TSG employs a Temporal-Augmented Frame Representation (TAFR) that explicitly embeds temporal information into visual frame representations, enabling LVLMs to precisely associate visual content with corresponding timestamps. Additionally, to alleviate quantization errors introduced by frame sampling, we optimize the absolute timestamp representation, stabilizing temporal learning and enhancing grounding performance.
As humans hierarchically search through time, they continuously reflect on whether a specific sub-event warrants deeper inspection. Similarly, we leverage the self-reflection capability of LVLMs to guide the search process. Recent studies [26, 17, 65, 59] have demonstrated that large language models (LLMs) effectively assess their prediction confidence through additional multiple-choice or yes/no questions. Inspired by these findings, we first identify that LVLMs inherently possess a similar self-reflection capability—“they know what they do not know.” Thus, TimeSearch introduces the Temporal Spotlight Reflection (TSR) primitive, which generates confidence scores through generative question answering to assess the validity of spotlighted events and prioritize sub-events during the hierarchical search process.
TimeSearch integrates the TSG and TSR primitives and efficiently navigates LVLMs across temporal search. Extensive experiments demonstrate its superior performance across various challenging benchmarks, including VideoMME [6], MLVU [66], and LongVideoBench [47]. Notably, on the highly challenging LVBench dataset with hour-long videos [44], TimeSearch achieves new state-of-the-art accuracy, substantially surpassing previous methods. TimeSearch also substantially outperforms existing video grounding methods on temporal grounding tasks, such as Charades-STA [7], ActivityNet Captions [2], and ReXTime [3]. We conduct comprehensive ablation studies and reveal the sources of improvement. In summary, our contributions are threefold:
-
•
We propose TimeSearch, a hierarchical temporal search framework, clearly demonstrating that human-like coarse-to-fine exploration significantly improves long-video understanding. For instance, TimeSearch boosts accuracy on LVBench from 41.8% to 51.5%.
-
•
We reveal that LVLMs inherently possess strong temporal grounding capabilities, which can be effectively activated through a simple TAFR. Despite its simplicity, our method achieves approximately 11.8% higher mIoU than existing state-of-the-art temporal grounding models.
-
•
We show that LVLMs have strong self-reflection abilities that were previously seen only in LLMs. This finding allows for reflection-guided prioritization, improving the efficiency of temporal search.
2 Related Work
2.1 Large Video-Language Models
Most mainstream LVLMs enhance image-based multimodal models by incorporating multiple frames [23, 31, 57, 24]. These models typically consist of a visual encoder to extract frame features independently, a Projection Layer utilizing either an MLP [27, 24] or Q-Former [20, 5] to convert visual features into text hidden space, and LLMs to generate textual outputs. This straightforward architecture has proven effective in transitioning from images to videos, resulting in strong performance [23, 24]. Nevertheless, the per-frame visual encoder encounters challenges with low-density video signals, leading to increased computational costs and space usage for processing long-context videos. To tackle this issue, prior research has introduced techniques to compress visual tokens, like adaptive pooling [51], token pruning [15], and decoupled visual-motional tokenization [16]. However, they may sacrifice detailed information, occasionally resulting in temporal hallucinations when responding to questions about specific moments [46]. Furthermore, their memory usage grows linearly with the number of frames [24], rendering them impractical for long video understanding.
2.2 Long Video Understanding
Understanding lengthy videos for LVLMs can be challenging due to the need to store and extract information effectively from hour-long videos. One common line involves using language as a bridge to summarize videos into concise captions [13, 56], resulting in the omission of vital visual signals. Another widely studied line involves memory-based methods for compressing video features into a limited memory bank, which is achieved by continually updating the memory bank during visual encoding [39]. Memory bank has also been applied to real-time streaming video understanding, potentially enabling unlimited length of frames while maintaining a constant space footprint [58]. A major drawback of these methodologies is their oversight of video duration and information density, particularly when utilizing a fixed space for a memory bank. For instance, Flash-VStream compresses both brief 10-second clips and hour-long movies into the same 681 tokens [58]. In addition, these black box methods lack interpretability as it is challenging to verify whether the pertinent details are accurately retrieved for reasoning.
2.3 Video Temporal Grounding
Temporal Grounding (TG) involves retrieving specific video moments based on query sentences [7, 9, 18] and user questions [3, 49]. LVLM-based TG models time localization as a text generation task through instruction tuning [36, 11, 12], which constructs varied instructions to enhance their instruction-following abilities. Previous research has focused on how to represent timestamps in LLMs. TimeChat [36] utilized a timestamp-aware visual encoder that binds frame embeddings with the timestamp embeddings of each frame. Momentor [35] introduces a temporal perception module to address the quantization errors associated with time tokens. Grounded-VideoLLM [42] and VTG-LLM [8] extend the LVLM’s vocabulary to learn absolute or relative time embeddings. To avoid numerical timestamps, HawkEye [45] innovatively categorizes video segments as four classes, i.e. ”beginning”, ”middle”, ”end” and ”throughout”, achieving a significant improvement. However, compared to traditional DETR-based models, LVLM-based TG still exhibits relatively poor performance [3, 45]. On the contrary, this study reveals that LVLMs can easily acquire exceptional numerical and temporal knowledge with simplified temporal representation.
Although employing TG to extract key events and aid video comprehension is intuitive, it has only been studied in the short video domain [53]. The limited number of video frames in current LVLMs hampers the application of long-video TG. To cope with long videos, a concurrent work CoS [14] applies binary frame classification to select relevant frames. However, frame-by-frame filtering overlooks event continuity, making it difficult to capture subtle temporal dynamics. In contrast, the proposed TimeSearch directly predicts the continuous time windows and is applicable to time understanding and grounding.
3 Methodology
In this section, we present TimeSearch framework, which enables LVLMs to perform hierarchical, human-like temporal search. We first introduce the Temporal Spotlight Grounding (TSG) primitive (Sec. 3.2) with Temporal-Augmented Frame Representation (TAFR). Next, we demonstrate the temporal self-reflection capability of LVLMs and propose the Temporal Spotlight Reflection (TSR) primitive. Finally, we describe the reflection-guided hierarchical temporal search algorithm (Sec. 3.4), illustrating how it efficiently navigates LVLMs in long events.
3.1 Preliminary: Unified Autoregressive Modelling
TimeSearch is built upon an autoregressive LVLM backbone, which sequentially predicts tokens conditioned on visual and textual contexts. An autoregressive LVLM generates an output sequence with length given a text condition x and a video condition by predicting tokens one at a time based on the previously generated tokens. Assuming that the LVLM is parameterized by , the conditional probability distribution of generating a sequence y given context and is defined as
| (1) |
where and . Taking VQA as an example, the LVLM predicts the distribution of the answer with a question and the instruction “Answer the following questions related to this video”. In practice, denotes the set of downsampled frame tokens from the original video for a fixed number of frames of , which are transformed by a separate visual encoder and projector as visual tokens. In the next sections, we will model the grounding and reflection mechanism in this unified autoregressive manner.
3.2 Temporal Spotlight Grounding
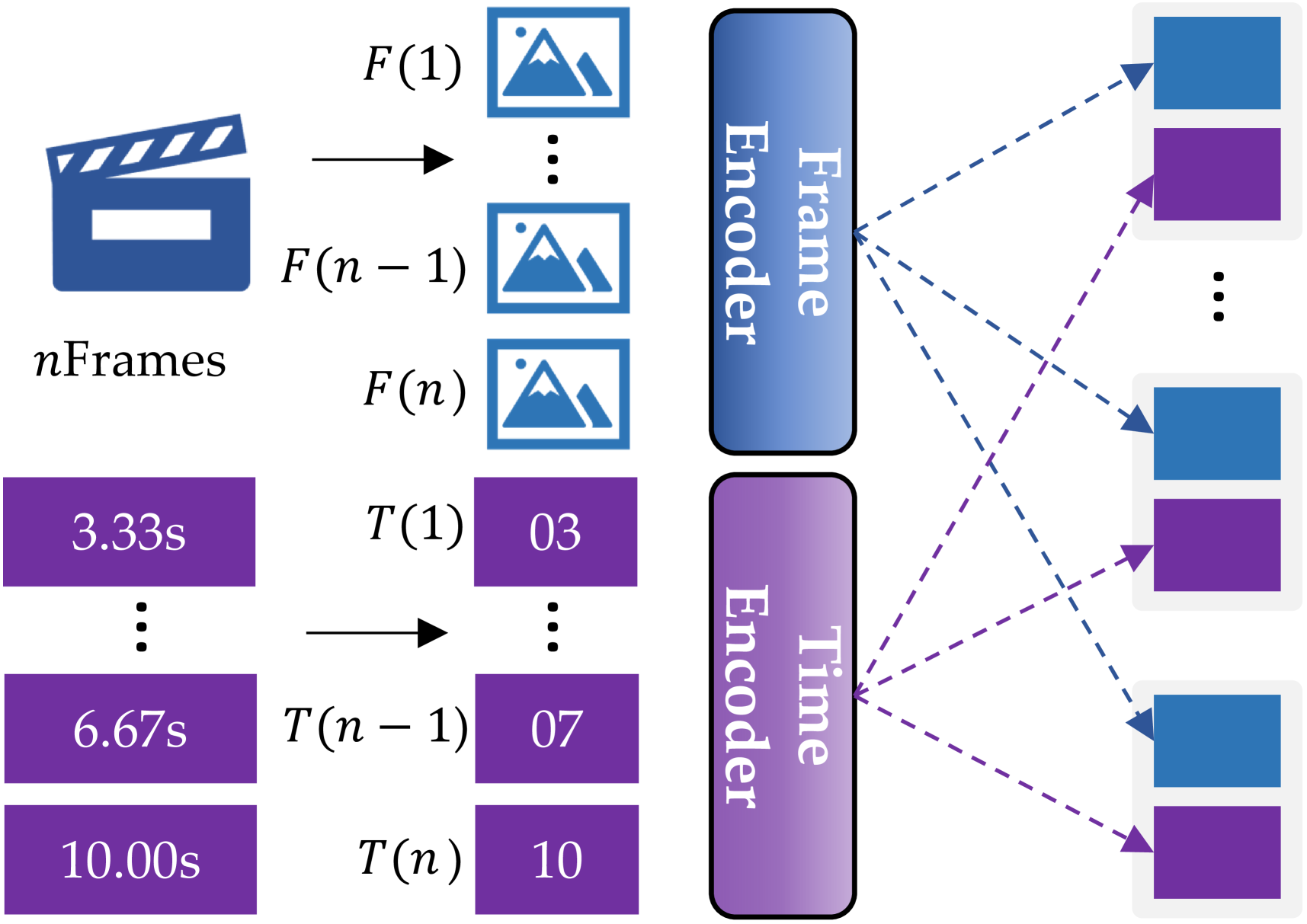
Temporal Spotlight Grounding (TSG) identifies the most relevant temporal windows according to the question, modeling continuous numerical timestamps as discrete digit generations [36, 8]. Given a question and the grounding instruction “Find the relevant windows”, the LVLM predicts text sequence . Then the text sequence is turned into a set of time ranges with size , where signifies the start and end timestamps of -th target clip. However, LVLMs naturally struggle to accurately handle numerical tasks [37], especially in temporal tasks involving precise numerical comparisons [50]. To alleviate this challenge and effectively activate the inherent temporal grounding capability of LVLMs, we propose a simple yet effective Temporal-Augmented Frame Representation (TAFR), which explicitly binds timestamps with visual frame representations.
Temporal-Augmented Frame Representation (TAFR)
is introduced to reduce the difficulty of LLM in understanding and generating numerical timestamps. Given a downsampled video represented by frames and their corresponding fractional timestamps , e.g., (0.00, 3.33, 6.67, 10.00), we first round these timestamps to the nearest integer. Then, to ensure a consistent token representation in TAFR, we apply left-zero padding, resulting in timestamps like (00, 03, 07, 10):
| (2) |
During training, we further align manually annotated timestamps with the rounded timestamps to mitigate quantization errors, as detailed in the Appendix.
In order to embed the absolute timestamp into each frame feature as illustrated in Fig. 2. Specifically, for each downsampled frame , we first extract its visual features through a visual encoder with a projection module [63], and then directly concatenate these features with their corresponding absolute timestamp embeddings:
| (3) |
where denotes the embedding layer of the LLM, represents the embedding dimension, and , denote the number of visual frame tokens and padded timestamp tokens, respectively. With this simple design, TAFR significantly strengthens the temporal grounding performance of LVLMs.
3.3 Temporal Spotlight Reflection

Previous research has demonstrated that generative LLMs can evaluate the correctness of their predictions through self-reflection mechanisms [65, 59, 26, 64], and produce well-calibrated confidence scores for True/False (TF) and multiple-choice (MC) questions [17]. We extend this observation from text-based LLMs to LVLMs and propose the Temporal Spotlight Reflection (TSR) primitive to assess the validity of temporal spotlight predictions.
For TF reflection, given a question , a TSG prediction and reflection instruction “Are the proposed relevant windows correct?”, the probability is formulated as
| (4) |
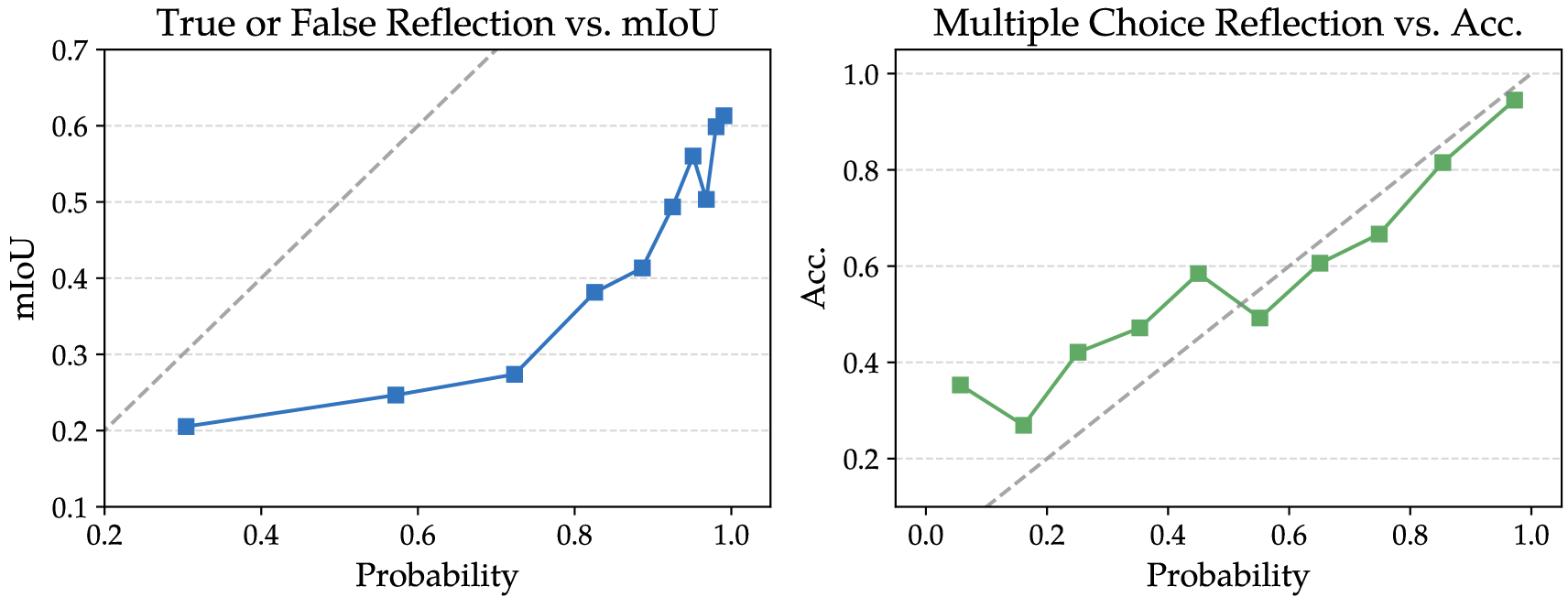
The TF reflection confidence positively correlates with grounding accuracy (IoU), thus providing an intrinsic measure of spotlight correctness without human annotations (Fig. 3, left).
For MC reflection tasks, the reflection confidence score is defined by selecting the maximum prediction probability from multiple choices. Given a set of candidate answers, the reflection confidence is computed as:
| (5) |
where is the reflection instruction, e.g., “Answer the options directly”. The calibration analysis in Fig. 3 (right) further confirms that LVLMs produce reliable reflection scores, especially at high-confidence levels.
3.4 Reflection-Guided Hierarchical Search
Given a video and a question , TimeSearch iteratively performs TSG to identify relevant temporal windows. At each step (SpotlightReflect), TSR evaluates the confidence of the currently spotlighted windows. If the reflection confidence is below a predefined threshold , we hierarchically split the event into three equal-sized overlapping sub-events (“beginning”, “middle” and “end”.), recursively exploring sub-events prioritized by reflection confidence scores , as illustrated in Fig. 4. TimeSearch adopts a priority queue to organize the order of sub-event searches. Priority queue allows backtracking to coarser-grained events to explore alternative search paths when current sub-events still do not yield enough information. The search terminates either when the confidence exceeds a threshold hyper-parameter , or when the sub-event duration falls below a minimal threshold . The identified temporal windows with the highest reflection confidence are subsequently used for video understanding tasks.

Model Size MVBench MLVU LongVideoBench VideoMME LVBench Long Overall Average Duration 16 651 473 2386 1010 4101 Proprietary Models GPT-4V [33] - 43.7 49.2 60.7 53.5 59.9 - GPT-4o [34] - 64.6 64.6 66.7 65.3 71.9 34.7 Gemini-1.5-Pro [41] - 60.5 - 64.4 67.4 75.0 33.1 Open-Sourced LVLMs InternVL2 [4] 8B 65.8 64.0 54.6 - - Qwen2-VL [43] 7B 67.0 - - - 63.3 - Qwen2.5-VL [1] 7B - - - - 65.1 45.3 LLaVA-OneVision [19] 7B 56.7 64.7 56.3 - - - LLaVA-OneVision [19] 72B 59.4 68.0 61.3 - - 26.9 Open-Sourced Long-Video LVLMs VideoLLaMA2 [57] 7B 54.6 48.5 - 42.1 47.9 - LongVA [60] 7B - 56.3 - 46.2 52.6 - LLaMA-VID [23] 7B 41.9 33.2 - - - 23.9 Kangaroo [28] 8B 61.0 61.0 54.8 46.7 56 39.4 Oryx [29] 7B 63.9 67.5 55.3 50.3 58.3 - Oryx-1.5 [29] 7B 67.6 67.5 56.3 51.2 58.8 - Open-Sourced LVLMs w/ TimeSearch LLaVA-Video [63] 7B 57.7 64.4 58.3 52.4 63.4 41.3 w/ TimeSearch 58.1 68.1 60.9 53.9 64.0 50.0 InternVL2.5 [63] 8B 70.1 67.1 60.6 52.2 63 41.8 w/ TimeSearch 70.3 70.0 63.3 53.9 64.4 51.5 Ours 7B 58.9 69.3 60.8 49.8 60.8 49.1
4 Experiments
4.1 Implementation Details.
Spotlight and Global Video Input.
Within the identified time window , frames can be densely sampled from the spotlighted segments for video understanding. These dense frames are appended after the globally sparsely sampled frames, thereby retaining the ability to answer questions about the global video context. Fig. 5 illustrates the overall pipeline for question-answering tasks. In practice, the number of global frames is set to 64, while the maximum number of spotlight frames is 16. We conducted a detailed analysis of the impact of spotlight frames in Sec. 4.4.
Instruction Tuning.
We implemented TimeSearch based on the LLaVA-Video [63] architecture for simplicity. The entire training was completed within eight hours using 128 A100 GPUs. To enhance reflection and spotlight capabilities without sacrificing general performance, we applied LoRA [10] with a rank of 32 to the LLM, freezing all other parameters. Further training details and hyperparameters are elaborated in the Appendix.
4.2 Benchmarks and Metrics
Video Question Answering.
We evaluate TimeSearch on three long-video MC benchmarks, including LongVideoBench [47], MLVU [66] and LVBench [44], which are designed to comprehensively evaluate long-term video understanding and covering videos ranging from minute-level to hour-level durations. We also report results on short-video benchmarks like MVBench [22] and VideoMME [6]. We evaluate models on the validation sets and report the accuracy metric.
Video Temporal-Sentence Grounding.
We evaluate the zero-shot temporal grounding capability on the widely used benchmarks, including Charades-STA [7] and ActivityNet-Captions [2]. Since the QVHighlight dataset was used during training, we report its results only in the ablation experiments to ensure fairness. We adopt the moment retrieval metrics as previous works [36, 25], i.e. Recall@1 with IoU threshold and and mIoU.
Video Temporal-Question Grounding.
ReXTime is crafted to assess temporal reasoning abilities within multiple video events, concentrating on understanding cause-and-effect relationships across various events. Rextime assesses both VQA and grounding abilities by measuring accuracy and recall@1 with IoU thresholds of and .
Model Charades-STA ActivityNet-Captions ReXTime R@0.3 R@0.5 R@0.7 mIoU R@0.3 R@0.5 R@0.7 mIoU R@0.3 R@0.5 mIoU VQA CG-DETR [32] 70.4 58.4 36.3 50.1 - - - - 31.3 16.6 23.8 - UniVTG [25] 72.6 60.2 38.6 52.1 - - - - 41.3 26.8 28.1 - LITA [12] - - - - - - - - 29.49 16.29 21.49 34.44 SeViLA [53] 27.0 15.0 5.8 18.3 31.6 19.0 10.1 23.0 - - - - Valley [30] 28.4 1.8 0.3 21.4 30.6 13.7 8.1 21.9 - - - - VideoChat2 [22] 38.0 14.3 3.8 24.6 40.8 27.8 9.3 27.9 - - - - Momenter [35] 42.6 26.6 11.6 28.5 42.9 23.0 12.4 29.3 - - - - VTimeLLM [11] 51.0 27.5 11.4 31.2 44.0 27.8 14.3 30.4 28.8 17.4 20.1 36.1 TimeChat [36] 46.7 32.2 15.7 - - - - - 14.4 7.6 11.6 40.0 HawkEye [45] 50.6 31.4 14.5 33.7 49.1 29.3 10.7 32.7 - - - - GroundedVideo-LLM [42] 54.2 36.4 19.7 36.8 46.2 30.3 19.0 36.1 - - - - Ours 73.6 52.4 24.5 48.6 61.0 43.0 26.1 43.9 48.4 36.4 36.7 76.5
4.3 Comparison with State-of-the-arts
Video Question Answering Performance.
As shown in Table 1, TimeSearch consistently outperforms existing open-source LVLMs on benchmarks covering short to extremely long videos. Notably, on the challenging LVBench dataset (average video duration 4101 seconds), our approach significantly improves accuracy from 41.8% (InternVL2.5 baseline) to 51.5%, surpassing previous methods. Additionally, notable improvements are observed on LongVideoBench (2.7% accuracy increase) and VideoMME-Long (1.7% increase), validating its effectiveness for long-duration video understanding. Crucially, TimeSearch maintains competitive performance on short video tasks such as MVBench. Furthermore, the consistent performance gains across different LVLM architectures (e.g., an 8.7% increase on LVBench with LLaVA-Video) demonstrate the robustness and versatility of TimeSearch. Our unified model, which integrates temporal grounding capabilities, achieves 49.1% accuracy on LVBench, confirming that effective temporal search integration does not compromise overall video reasoning ability.
Temporal Grounding Performance.
As shown in Table 2, TimeSearch demonstrates substantial advantages over existing grounding LVLMs. On Charades-STA and ActivityNet Captions datasets, it significantly improves mIoU by approximately 11.8% compared to previous state-of-the-art methods (e.g., GroundedVideo-LLM). Additionally, on the ReXTime temporal-question grounding dataset, our method achieves notable improvements (mIoU increased by 8.6%, Recall@0.5 improved by 9.6%), accompanied by a significant VQA accuracy gain (from 40.0% to 76.5% compared to TimeChat), clearly validating its capability to reason about events temporally.
4.4 Ablation Study and Analysis
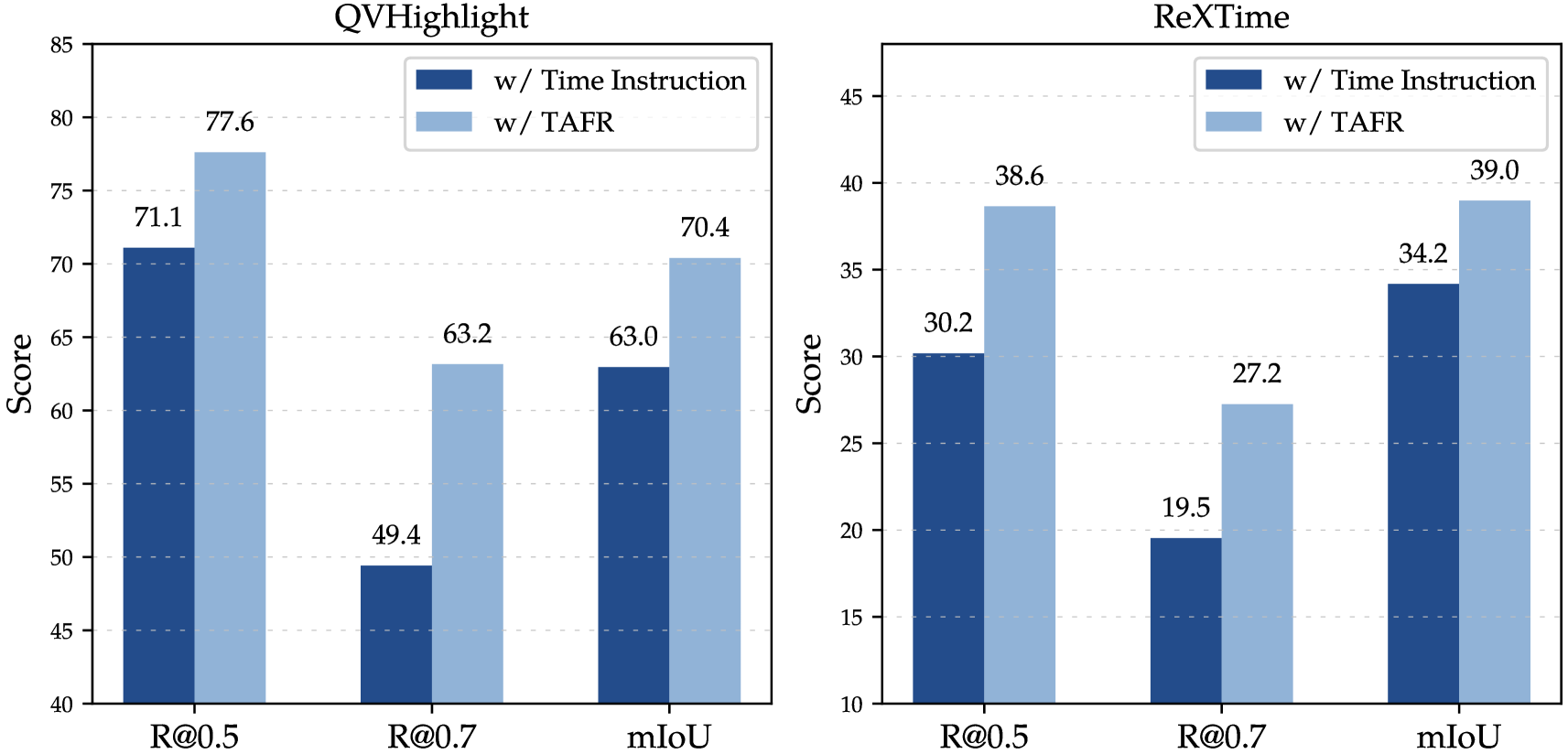
Effectiveness of TAFR.
We first quantitatively validate the effectiveness of TAFR by comparing it to the widely used Time Instructions on the QVHighlight and ReXTime datasets. As shown in Fig. 6, overall, compared to the time instruction, TAFR significantly improves the model’s ability of moment retrieval, especially at high IoU thresholds (i.e. R@0.7). Specifically, when replacing TAFR with time instruction on the QVHighlight, R@0.7 dropped sharply by 13.8% while R@0.5 dropped 6.5%. Although previous LVLMs are capable of recognizing relevant events, they struggle to accurately establish associations between events and timelines without the guidance of TAFR. This indicates that explicitly binding timestamps to frame information is crucial for enhancing temporal understanding. TAFR also provides consistent improvements on the challenge RexTime benchmark, which requires a strong ability to reason across time.
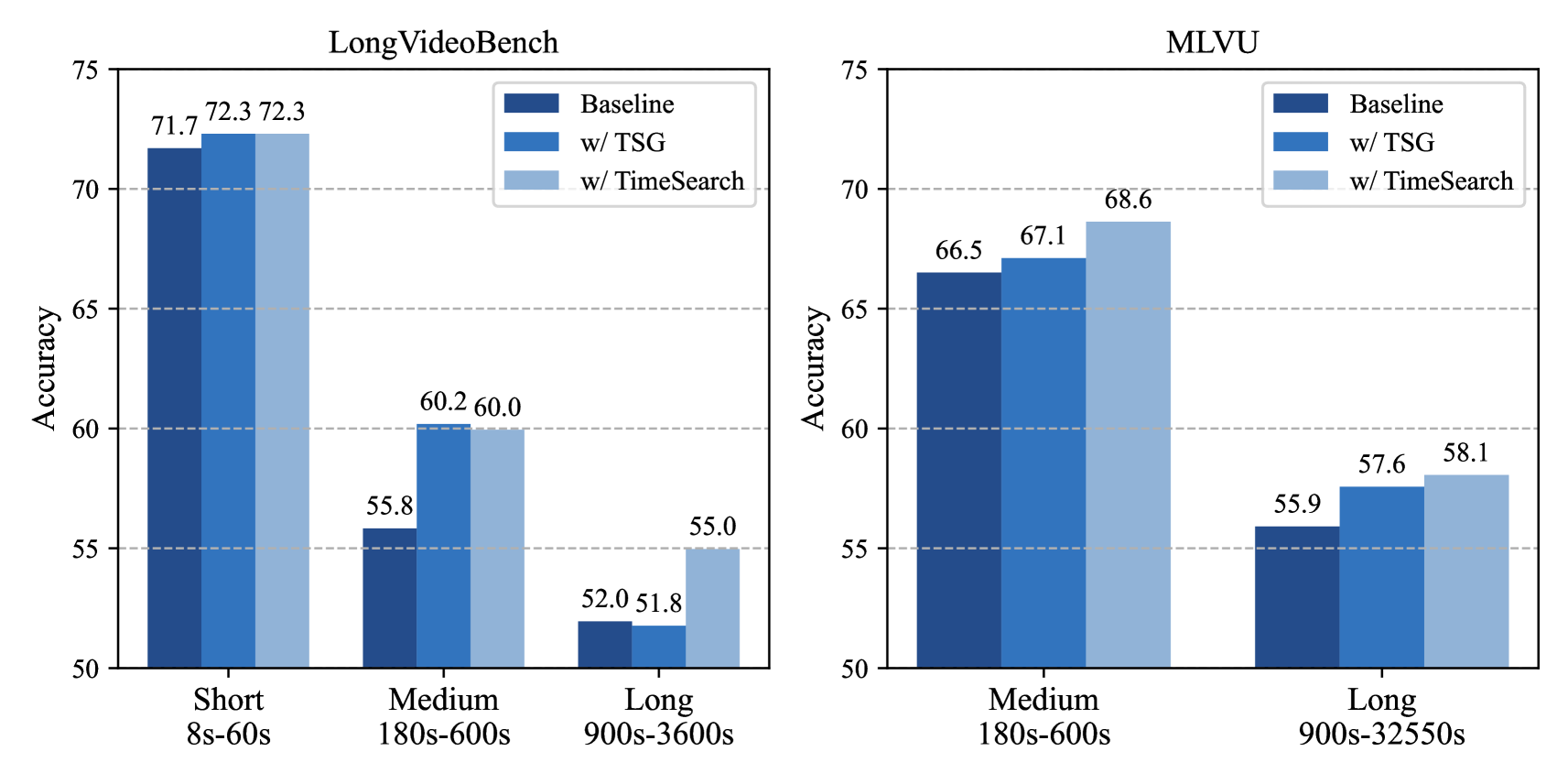
Robustness to Various Video Lengths.
Overall, TimeSearch demonstrates noticeable improvements for medium-length and ultra-long videos. Specifically, for medium-length videos (i.e., 180s-600s), we observed that simply applying the TSG to supplement event details can yield consistent gains. Empirically, despite the significant loss of temporal dynamics in frame sampling, the TSG module can still identify windows relevant to the questions based on limited visual cues. As the video length increases (i.e., over 900s ), it becomes increasingly challenging for TSG to focus on useful events through sparse frames. The event segmentation and search strategies are more effective and result in significant improvements. Notably, for short videos, the framework maintains original performance as expected.
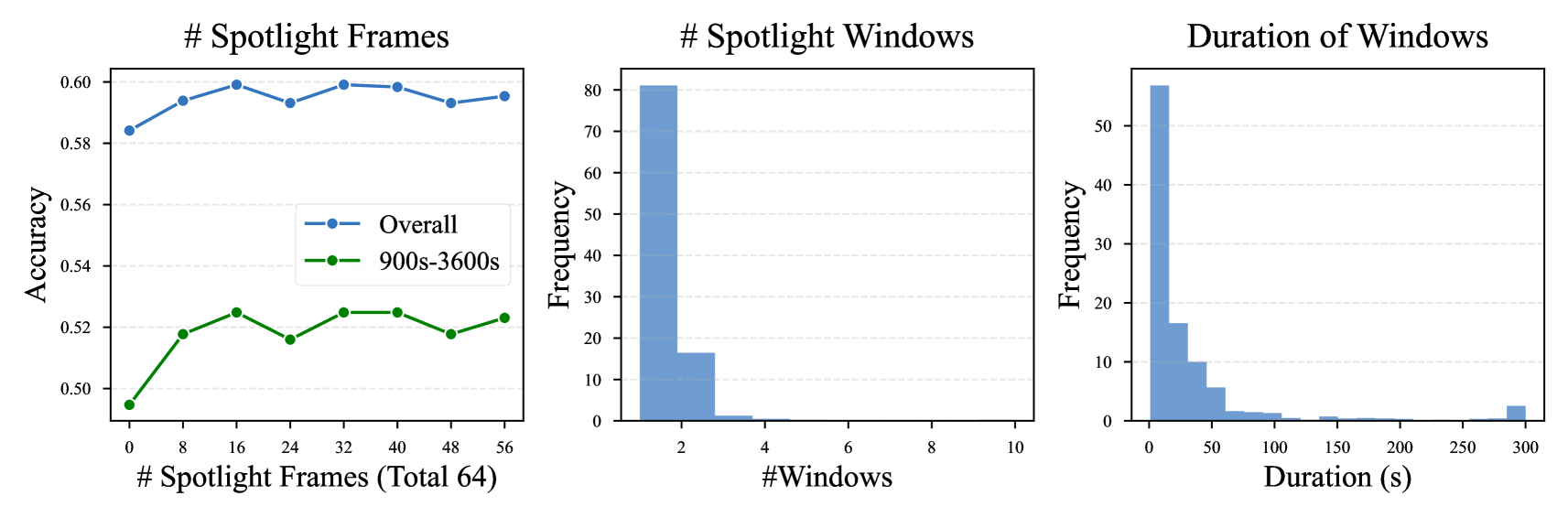
Impact of the Spotlight Frames.
We conducted experiments by varying the number of spotlight frames while keeping the total frame budget fixed at 64. Overall, as shown in Fig. 8 (left), introducing spotlight frames yields a significant boost in accuracy for both general cases and long videos. Our results suggest that 16 is an optimal setting, as it preserves global awareness while ensuring precise event retrieval. It is worth noting that when the maximum spotlight frames increased to 56 (i.e., the minimum number of global frames was 8), there was no significant drop in accuracy. For a more in-depth understanding, we further analyze the number of spotlight windows and their duration distributions in Fig. 8 (middle and right). The histogram of spotlight window counts reveals that most examples require only one or two spotlight windows, suggesting that many questions can be effectively answered with a small number of targeted events. Moreover, the spotlight duration histogram indicates that a majority of spotlighted events are relatively short (under 50 seconds). Overall, these findings highlight that a small number of well-chosen short spotlights is sufficient for significant improvements in long-video understanding, validating the effectiveness of our reflection-guided temporal search strategy in selecting relevant video moments efficiently. Qualitative analysis in the appendix reveals the challenges improved by TimeSearch.
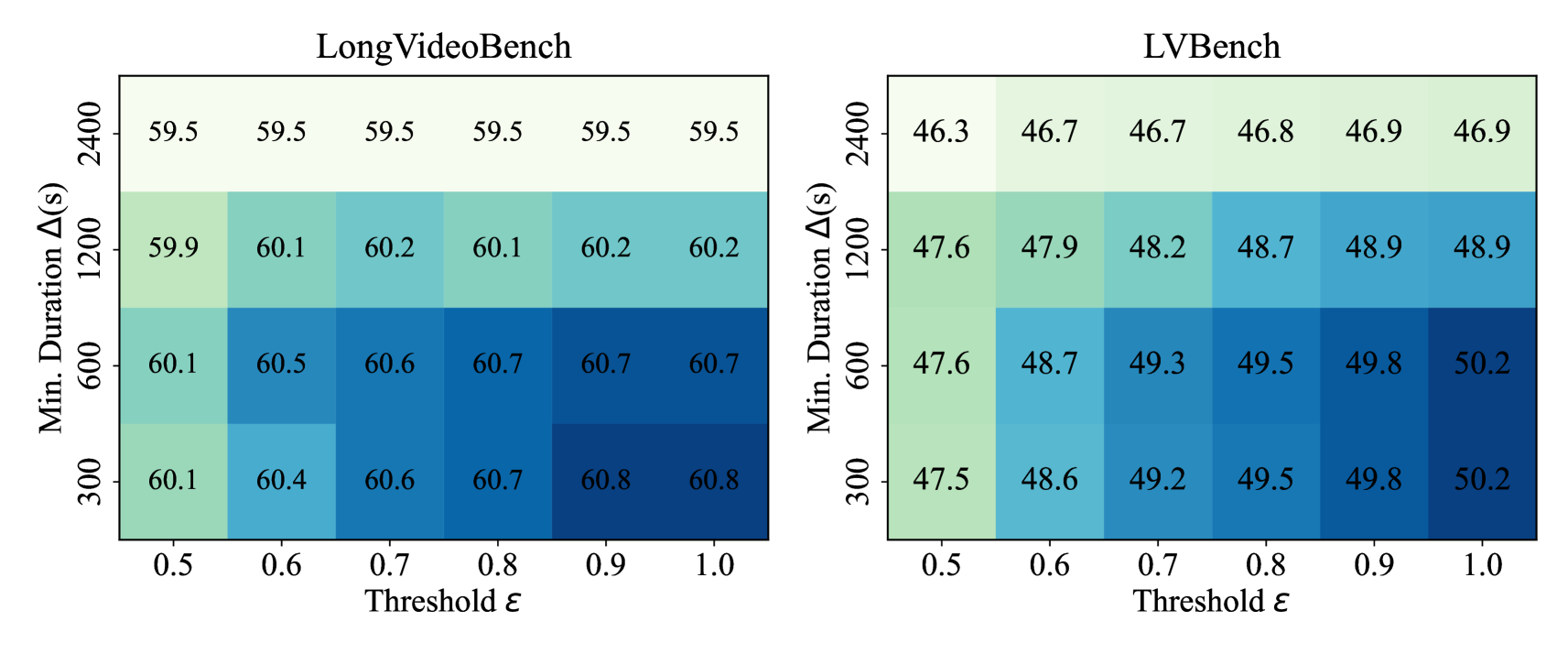
Effectiveness and Efficiency Trade-off in Search.
The reflection confidence threshold and the minimum sub-event duration govern the search procedure. These hyper-parameters jointly mediate the effectiveness-efficiency trade-off. From an effectiveness perspective, as validated in Fig. 9, higher and lower values improve accuracy at the cost of increased search steps. Reducing from 2400s to 600s with elevates LVBench accuracy from 46.8% to 49.5%, while finer-grained searches with do not result in improvements. Regarding efficiency, the best-case complexity remains constant when exceeds the video length, while the worst-case complexity scales linearly. Specifically, when is larger than the video length, the search only executes a single step. In contrast, when is smaller than the video length, setting forces exhaustive traversal of all sub-events. The search prioritizes high-confidence segments through a priority queue, emulating human-like coarse-to-fine understanding. Empirical experiments demonstrate that requires only an average of 1.6 search steps while maintaining 99.5% of peak accuracy on LongVideoBench when .
5 Conclusion
This paper has introduced TimeSearch, a novel framework for long-video understanding that emulates a human-like hierarchical temporal search. TimeSearch uses a temporal spotlight grounding method to retrieve key events and a temporal reflection mechanism to verify predictions and guide the search direction. TimeSearch has achieved state-of-the-art performance across diverse video benchmarks and demonstrated significant gains in long-video QA and temporal grounding tasks. Ablation studies confirm the effectiveness of each component and underscore the importance of specialized designs for ultra-long video analysis. TimeSearch bridges the gap between human cognitive strategies and model-based video analysis, providing a robust and interpretable solution for long video tasks.
References
- Bai et al. [2025] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- Caba Heilbron et al. [2015] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In CVPR, pages 961–970, 2015.
- Chen et al. [2024a] Jr-Jen Chen, Yu-Chien Liao, Hsi-Che Lin, Yu-Chu Yu, Yen-Chun Chen, and Yu-Chiang Frank Wang. Rextime: A benchmark suite for reasoning-across-time in videos. In NeurIPS, 2024a.
- Chen et al. [2024b] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024b.
- Dai et al. [2023] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. In NeurIPS, 2023.
- Fu et al. [2024] Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024.
- Gao et al. [2017] Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. In ICCV, pages 5267–5275, 2017.
- Guo et al. [2024] Yongxin Guo, Jingyu Liu, Mingda Li, Xiaoying Tang, Xi Chen, and Bo Zhao. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. arXiv preprint arXiv:2405.13382, 2024.
- Hendricks et al. [2018] Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with temporal language. 2018.
- Hu et al. [2022] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022.
- Huang et al. [2024a] Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In CVPR, 2024a.
- Huang et al. [2024b] De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. Lita: Language instructed temporal-localization assistant. arXiv preprint arXiv:2403.19046, 2024b.
- Islam et al. [2024] Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Nagarajan, Lorenzo Torresani, and Gedas Bertasius. Video recap: Recursive captioning of hour-long videos. In CVPR, 2024.
- Jian et al. [2025] Hu Jian, Cheng Zixu, Si Chenyang, Li Wei, and Gong Shaogang. Cos: Chain-of-shot prompting for long video understanding. arXiv preprint arXiv:2502.06428, 2025.
- Jin et al. [2024a] Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In CVPR, 2024a.
- Jin et al. [2024b] Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, and Yadong Mu. Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization. In ICML, 2024b.
- Kadavath et al. [2022] Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, and Jared Kaplan. Language models (mostly) know what they know. CoRR, abs/2207.05221, 2022.
- Lei et al. [2021] Jie Lei, Tamara L Berg, and Mohit Bansal. Detecting moments and highlights in videos via natural language queries. In NeurIPS, pages 11846–11858, 2021.
- Li et al. [2024a] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024a.
- Li et al. [2023a] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023a.
- Li et al. [2023b] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023b.
- Li et al. [2024b] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In CVPR, 2024b.
- Li et al. [2023c] Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. arXiv preprint arXiv:2311.17043, 2023c.
- Lin et al. [2023a] Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122, 2023a.
- Lin et al. [2023b] Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. Univtg: Towards unified video-language temporal grounding. In ICCV, 2023b.
- Lin et al. [2022] Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. Trans. Mach. Learn. Res., 2022, 2022.
- Liu et al. [2023] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023.
- Liu et al. [2024a] Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xiaoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu. Kangaroo: A powerful video-language model supporting long-context video input. arXiv preprint arXiv:2408.15542, 2024a.
- Liu et al. [2024b] Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Oryx mllm: On-demand spatial-temporal understanding at arbitrary resolution. arXiv preprint arXiv:2409.12961, 2024b.
- Luo et al. [2023] Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Da Li, Pengcheng Lu, Tao Wang, Linmei Hu, Minghui Qiu, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability. arXiv preprint arXiv:2306.07207, 2023.
- Maaz et al. [2024] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. 2024.
- Moon et al. [2023] WonJun Moon, Sangeek Hyun, SuBeen Lee, and Jae-Pil Heo. Correlation-guided query-dependency calibration in video representation learning for temporal grounding. arXiv preprint arXiv:2311.08835, 2023.
- OpenAI [2023] OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023.
- OpenAI [2024] OpenAI. Gpt-4o. https://openai.com/index/hello-gpt-4o/, 2024.
- Qian et al. [2024] Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat-Seng Chua, Yueting Zhuang, and Siliang Tang. Momentor: Advancing video large language model with fine-grained temporal reasoning. In ICML, 2024.
- Ren et al. [2024] Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. In CVPR, 2024.
- Schwartz et al. [2024] Eli Schwartz, Leshem Choshen, Joseph Shtok, Sivan Doveh, Leonid Karlinsky, and Assaf Arbelle. Numerologic: Number encoding for enhanced llms’ numerical reasoning. arXiv preprint arXiv:2404.00459, 2024.
- Shen et al. [2024] Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration. arXiv preprint arXiv:2411.16044, 2024.
- Song et al. [2024] Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. In CVPR, 2024.
- Sweller [1994] John Sweller. Cognitive load theory, learning difficulty, and instructional design. Learning and instruction, 4(4):295–312, 1994.
- Team et al. [2024] Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Wang et al. [2024a] Haibo Wang, Zhiyang Xu, Yu Cheng, Shizhe Diao, Yufan Zhou, Yixin Cao, Qifan Wang, Weifeng Ge, and Lifu Huang. Grounded-videollm: Sharpening fine-grained temporal grounding in video large language models. arXiv preprint arXiv:2410.03290, 2024a.
- Wang et al. [2024b] Peng Wang, Shuai Bai, and et. al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024b.
- Wang et al. [2024c] Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. Lvbench: An extreme long video understanding benchmark, 2024c.
- Wang et al. [2024d] Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. Hawkeye: Training video-text llms for grounding text in videos. arXiv preprint arXiv:2403.10228, 2024d.
- Wang et al. [2024e] Yuxuan Wang, Yueqian Wang, Dongyan Zhao, Cihang Xie, and Zilong Zheng. Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models. arXiv preprint arXiv:2406.16338, 2024e.
- Wu et al. [2024] Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding, 2024.
- Wu and Xie [2024] Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. CVPR, 2024.
- Xiao et al. [2024] Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can i trust your answer? visually grounded video question answering. In CVPR, 2024.
- Xie [2024] Zikai Xie. Order matters in hallucination: Reasoning order as benchmark and reflexive prompting for large-language-models. CoRR, abs/2408.05093, 2024.
- Xu et al. [2024] Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning. arXiv preprint arXiv:2404.16994, 2024.
- Yao et al. [2023] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In NeurIPS, 2023.
- Yu et al. [2023] Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering. In NeurIPS, 2023.
- Yu et al. [2019] Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. In AAAI, 2019.
- Zacks and Swallow [2007] Jeffrey M Zacks and Khena M Swallow. Event segmentation. Current directions in psychological science, 16(2):80–84, 2007.
- Zhang et al. [2023a] Ce Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, and Gedas Bertasius. A simple llm framework for long-range video question-answering, 2023a.
- Zhang et al. [2023b] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023b.
- Zhang et al. [2024a] Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory-based real-time understanding for long video streams. 2024a.
- Zhang et al. [2024b] Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction. CoRR, abs/2408.15240, 2024b.
- Zhang et al. [2024c] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024c.
- Zhang et al. [2024d] Qizhe Zhang, Aosong Cheng, Ming Lu, Zhiyong Zhuo, Minqi Wang, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. [cls] attention is all you need for training-free visual token pruning: Make vlm inference faster. arXiv preprint arXiv:2412.01818, 2024d.
- Zhang et al. [2024e] Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference. arXiv preprint arXiv:2410.04417, 2024e.
- Zhang et al. [2024f] Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024f.
- Zhang et al. [2024g] Yuan Zhang, Fei Xiao, Tao Huang, Chun-Kai Fan, Hongyuan Dong, Jiawen Li, Jiacong Wang, Kuan Cheng, Shanghang Zhang, and Haoyuan Guo. Unveiling the tapestry of consistency in large vision-language models. arXiv preprint arXiv:2405.14156, 2024g.
- Zheng et al. [2023] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In NeurIPS, 2023.
- Zhou et al. [2024] Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024.
Supplementary Material
A Absolute Timestamp Calibration
As stated in the main text, we utilize quantized integer timestamps to reduce the learning difficulty. However, the frame rate during frame extraction is often low for long videos, while manual annotations are done at a high frame rate. As a result, not every frame corresponding to a manually annotated time can be sampled. For example, the sampled frames are located at 0s,3s,…67s,70s,73s,77s,80s,83s,86s,89s and the target windows are serialized as [[72, 82], [84, 89]].This problem introduces potential optimization challenges for text-oriented objectives. To address this, we propose the Absolute Temporal Calibration (ATC) method, which precisely aligns the annotated timestamps with the video decoding and frame extraction times. This calibration adjusts the annotated timestamps accurately to the video’s specific frame time, thus preventing the model from performing unnecessary frame interpolation during the learning process. Specifically, in the example above, the target windows will first be adjusted to [[73, 83], [83, 89]]. Subsequently, we will merge the overlapping windows caused by quantization errors, i.e. calibrated target is [[73, 89]]. ATC ensures that the model can focus on temporal understanding without dealing with temporal discrepancies, thereby enhancing the model’s learning efficiency and temporal accuracy.
B Instruction Tuning
The objective of Instruction Tuning is to equip the model with the ability to understand the Temporal-Augmented Frame Representation (TAFR).
| Tasks | Sources | Instructions | # of Samples |
| Spotlight | QVHighlights [18] | Given the video and the query, find the relevant windows. | 7218 |
| Grounded-VideoLLM [42] | Provide the timestamps that correspond to the Answer. | 51918 | |
| Reflection | ReXTime [3] | Proposed time range: {r}. Is the proposed time range relevant to the question? | 19390 |
| Grounded-VideoLLM [42] | Proposed time range: {r}. Is the proposed time range relevant to the question? | 15220 | |
| General Answering | Grounded-VideoLLM [42] | General Video-QA instructions | 107806 |
| LLaVA-Video [63] | General Video-QA instructions | 79389 | |
| NextQA [49] | Please respond with only the letter of the correct answer. | 6278 | |
| Spotlighted Answering | Moment-10M [35] | Please watch the clip of {r} and answer the question. | 42071 |
| Grounded-VideoLLM [42] | Please answer the question base on the detail clip of {r}. | 17214 |
Datasets
As shown in Tab. 1 in the appendix, the training dataset is composed of four distinct tasks, all derived from existing open-source datasets. By introducing specialized instructions, we enhance the model’s capabilities in a cost-effective manner. The ”Answering” capability is divided into two components: General Answering, which covers basic question-answering tasks like the most of LVLMs, and spotlighted answering, where answers are enriched using grounded video clips identified through a prior search for relevant spotlighted content.
C Qualitative Analysis
To further illustrate how TimeSearch addresses challenges inherent in long-video understanding, we conduct a series of case studies on tasks involving temporal perception and chronological relations [47]. A core difficulty for LVLMs lies in insufficient temporal details, which often leads to misinterpretations of events. TimeSearch mitigates this issue by integrating human-like Spotlight and Reflection mechanisms, allowing for more precise event retrieval.
For example, Fig. 1 illustrates a case spanning 275 seconds, in which a man is sitting in front of a mirror. At the global (coarse) sampling level, only sparse frames can be observed, making it difficult to discern the subtle motion of his hands. The TSG component in TimeSearch addresses this issue by spotlighting a more fine-grained window from the 249th to the 275th second. Within this localized segment, the frame rate is increased, revealing that the man’s hands are clasped together—an action easily missed under low-frequency sampling. This example demonstrates how TSG adaptively zooms in on the essential moments of a long video, capturing subtle actions that would otherwise be overlooked. Additionally, Fig. 2 and Fig. 3 showcase object attribute change and appearance order cases.
Figure 4 illustrates how TimeSearch discerns sequential relationships between events in an ultra-long video through a hierarchical, coarse-to-fine search. In this example, TimeSearch first identifies a large time window that roughly contains the relevant events. Upon noticing the disappearance of the white car, the search narrows to the 600-second sub-event window. Within this finer scope, TimeSearch uses spotlight frames to focus on critical moments, identifying the appearance of a red car and a person. By progressively refining, TimeSearch effectively captures the sequential flow of events, mimicking the way humans would search through long videos by zooming in on key events.