TLDW: Extreme Multimodal Summarisation of News Videos
Abstract
Multimodal summarisation with multimodal output is drawing increasing attention due to the rapid growth of multimedia data. While several methods have been proposed to summarise visual-text contents, their multimodal outputs are not succinct enough at an extreme level to address the information overload issue. To the end of extreme multimodal summarisation, we introduce a new task, eXtreme Multimodal Summarisation with Multimodal Output (XMSMO) for the scenario of TL;DW - Too Long; Didn’t Watch, akin to TL;DR. XMSMO aims to summarise a video-document pair into a summary with an extremely short length, which consists of one cover frame as the visual summary and one sentence as the textual summary. We propose a novel unsupervised Hierarchical Optimal Transport Network (HOT-Net) consisting of three components: hierarchical multimodal encoders, hierarchical multimodal fusion decoders, and optimal transport solvers. Our method is trained, without using reference summaries, by optimising the visual and textual coverage from the perspectives of the distance between the semantic distributions under optimal transport plans. To facilitate the study on this task, we collect a large-scale dataset XMSMO-News by harvesting 4,891 video-document pairs. The experimental results show that our method achieves promising performance in terms of ROUGE and IoU metrics. 111Our dataset and source code will be publicly available in GitHub.
Introduction
Summarisation aims to condense a given piece of information into a short and succinct summary that best covers its semantics with the least redundancy. This helps users quickly browse and understand long content by focusing on the most important ideas (Mani 2001). Summarisation on a single modality, such as video summarisation (Ma et al. 2020; Yuan et al. 2020), which aims to summarise a video into keyframes, and text summarisation (Mihalcea and Tarau 2004; See, Liu, and Manning 2017; Liu and Lapata 2019; Laban et al. 2020), which aims to summarise a document into a few sentences, has been actively studied for decades.
Video summarisation aims to summarise a video into keyframes (Luo, Papin, and Costello 2009; Wang et al. 2019; Yuan et al. 2020; Wang et al. 2020) that provide a compact yet informative representation of a video. The majority of existing methods focus on modelling the temporal dependency and spatio structure among frames (Apostolidis et al. 2021a). To address information overload issues, extreme video summarisation has been proposed as a sub-task of video summarisation (Gu and Swaminathan 2018; Ren et al. 2020; Apostolidis et al. 2021b), which aims to summarise a video into a cover frame. It involves high source compression and allows users to quickly discern the essence of a video and decide whether it is worth watching or not.

Text summarisation aims to condense a given document into a short and succinct summary that best covers the document’s semantics. The majority of existing methods are either extractive or abstractive. Extractive methods (Narayan, Cohen, and Lapata 2018b; Zhang, Wei, and Zhou 2019; Liu and Lapata 2019; Zhong et al. 2020) select salient sentences from a document to form its summary. Abstractive methods (See, Liu, and Manning 2017; Paulus, Xiong, and Socher 2018; Zhang et al. 2020; Laban et al. 2020) involve natural language generation to generate a summary for a given document. To further condense the text and address information overload issues, extreme text summarisation has been proposed as a sub-task of text summarisation. Extreme text summarisation (Narayan, Cohen, and Lapata 2018a; Lu, Dong, and Charlin 2020; Cachola et al. 2020; Sotudeh et al. 2021) aims to summarise a document into a one-sentence summary. It helps users quickly browse through the main information of a document.
While single-modal summarisation has been investigated for decades, with the rapid growth of multimedia data, there is an emerging interest on Multimodal Summarisation with Multimodal Output (MSMO) (Zhu et al. 2018, 2020; Li et al. 2020). MSMO aims to summarise a pair of a video or a set of images and a document into a visual-textual summary, since image and text could complement each other to help users to better obtain a more informative and visual understanding of events. However, most of the existing MSMO methods are designed for short visual inputs, such as short videos and multiple images, without considering the summary length. Given the increasing pace of producing multimedia data and the subsequent challenge in keeping up with the explosive growth of such rich content, these existing methods may be sub-optimal to address the imminent issue of information overload of multimedia data.
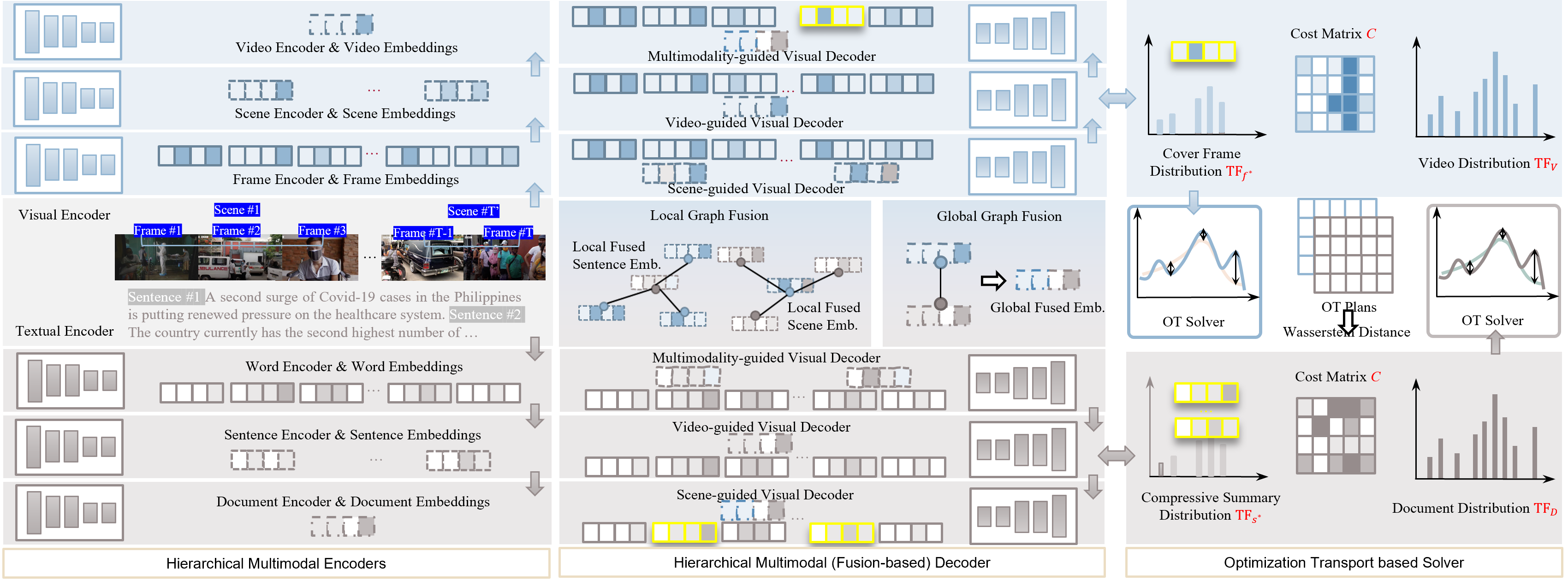
In this paper, we introduce a new task, eXtreme Multimodal Summarisation with Multimodal Output (XMSMO), for the scenario TLDW which stands for Too Long; Didn’t Watch). As shown in Figure 1, XMSMO aims to summarise a pair of a video and its corresponding document into a multimodal summary with an extremely short length. That is, an extreme multimodal summary consists of one cover frame as the visual summary and one sentence as the textual summary. To solve this new task, we propose a novel unsupervised Hierarchical Optimal Transport Network (HOT-Net) architecture including three components, the hierarchical multimodal encoders, the hierarchical multimodal (fusion-based) decoders and the optimal transport solvers.
Specifically, the hierarchical visual encoder formulates the representations of a video from three levels including frame-level, scene-level and video-level; the hierarchical textual encoder formulates the representations of a document from three-levels as well: word-level, sentence-level and document-level. Then, the hierarchical decoder formulates the cross-modal representations in a local-global manner and evaluates candidate cover frames and candidate words, which are used to form a visual summary and a compressive textual summary, respectively. Note that a compressive textual summary offers a balance between the conciseness issue of extractive summarisation and the factual hallucination issue of abstractive summarisation. Finally, our optimal transport-based unsupervised training strategy is devised to mimic human judgment on the quality of an extreme multimodal summary in terms of the visual and textual coverage. The coverage is measured by a Wasserstein distance with an optimal transport plan measuring the distance between the semantic distributions of the summary and the original content. In addition, textual fluency and cross-modal similarity are further considered, which can be important to obtain a high quality multimodal summary.
Additionally, to facilitate the study on this new task XMSMO and evaluate our proposed HOT-Net, we built the first dataset of such kind, namely XMSMO-News, by harvesting 4,891 video-document pairs as input and cover frame-title pairs as multimodal summary output from the British Broadcasting Corporation (BBC) News Youtube channel from year 2013 to 2021.
In summary, the key contributions of this paper are:
-
•
We introduce a new task, eXtreme Multimodal Summarisation with Multiple Output (XMSMO) as TLDW, which stands for Too Long; Didn’t Watch. It aims to summarise a video-document pair into an extreme multimodal summary (i.e., one cover frame as the visual summary and one sentence as the textual summary).
-
•
We propose a novel unsupervised Hierarchical Optimal Transport Network (HOT-Net). The hierarchical encoding and decoding are conducted across both the visual and textual modalities, and optimal transport solvers are introduced to guide the summaries to maximise their semantic coverage.
-
•
We construct a new large-scale dataset XMSMO-News for the research community to facilitate research in this new direction. Experimental results on this dataset demonstrate that our method outperforms other baselines in terms of ROUGE and IoU metrics.
Related Work
In this section, we first review existing deep learning-based extreme unimodal summarisation methods in two categories, video-based and text-based, since they are closely related to our study. We also review existing multimodal summarisation with multimodal output methods which share similar input and output modalities with our study.
Extreme Video Summarisation
Extreme video summarisation methods can be conceptualized as a frame ranking task, which scores the frames in a video as the output. A deep learning method based on a CNN-based autoencoder architecture was first proposed (Gu and Swaminathan 2018), which was trained by a reconstruction loss considering the representativeness and aesthetic quality of the selected frames. The scoring was improved by Ren et al. (2020) by considering the quality of faces, and it utilised a Siamese architecture, which was optimized by a piece-wise ranking loss using pairs of frames. Apostolidis et al. (2021b) proposed a generative adversarial network which introduced a reinforcement learning scheme by rewarding the representativeness and aesthetic quality. Note that most of these methods encode a video as a sequence of frames directly, whilst the semantic hierarchical structure of a video has not been adequately explored.
Extreme Text Summarisation
The extreme text summarisation task was first explored by Narayan, Cohen, and Lapata (2018a) who formulated a sequence-to-sequence learning problem, where the input was a source document and the output was an extreme summary. A supervised encoder-decoder framework was studied and a topic model was incorporated as an additional input to involve the document-level semantic information and guide the summary to be consistent with the document theme. Cachola et al. (2020) introduced multitask learning and incorporated the title generation as a scaffold task to improve the learning ability regarding the salient information. These methods relied on integrating the knowledge from pre-trained embedding models to generate abstractive summaries. As a result, these generative models are highly prone to external hallucination and it is possible to generate contents unfaithful to the original document, which was shown by Maynez et al. (2020).
Multimodal Summarisation with Multimodal Output
Multimodal summarisation with multimodal output task was first studied by Zhu et al. (2018), which took a document and an image set as the input. A supervised attention based encoder-decoder framework was devised. For encoding, a textual encoder and a visual encoder formulate the document and visual representations, respectively. For decoding, a textual decoder generates a textual summary, and a visual decoder selects the most representative image as a visual summary. Additionally, a multimodal attention layer was incorporated to fuse the textual and visual context information. To alleviate the modality-bias issue, a multitask learning was applied to jointly consider the two MSMO subtasks: summary generation and text-image relation recognition (Zhu et al. 2020). A hierarchical intra- and inter-modality correlation between the image and text inputs was studied to enhance the multimodal context representation (Zhang et al. 2022). Li et al. (2020) extended visual inputs to short videos, and introduced self-attentions to improve the multimodal context representation. Nonetheless, most of these methods encode the video and document inputs directly without considering their semantic hierarchical structure. Moreover, these existing methods have been mainly studied in a supervised manner. To the best of our knowledge, our work is the first unsupervised method for MSMO.
Methodology
As shown in Figure 2, our proposed eXtreme Multimodal Summarisation method, namely unsupervised Hierarchical Optimal Transport Network (HOT-N), consists of three components, the hierarchical multimodal encoders, the hierarchical multimodal (fusion-based) decoders and the optimal transport solvers. Specifically, the hierarchical visual encoder formulates frame-level, scene-level and video-level representations of a video . The hierarchical textual encoder formulates word-level, sentence-level and document-level representations of a document . Then, the hierarchical visual decoder selects an optimal frame as an extreme visual summary, and the hierarchical textual decoder produces an extreme textual summary based on the cross-modal guidance. Finally, the optimal transport solvers conduct unsupervised learning to optimise the encoders and the decoders in pursuit of the best semantic coverage of the obtained summaries.
Hierarchical Multimodal Encoders
Visual Encoder
Given an input video , it can be represented as a sequence of frames . By grouping the consecutive frames with similar semantics, the video can be segmented into a sequence of scenes , where consists of the video frames from the -th to the -th frame, where indicates the start index of the frame and indicates the end index of the frame for the -th scene in the video. The hierarchical visual encoder learns the scene-level and video-level representations based on and , respectively.
To characterize a video frame , a pre-trained neural network can be introduced. The CLIP model (Radford et al. 2021) is adopted in this study since it is the state-of-the-art multi-modal embedding model. For the sake of convenience, we use the the symbol to represent this pre-trained feature of the -th frame. To further model the scene-level features, a pooling method is introduced, which is denoted as a function . In detail, for the -th scene, its representation can be obtained by observing its associated frame-level features , as:
| (1) |
Particularly, a generalized pooling operator (GPO) (Chen et al. 2021) is adopted as the pooling method in this study, since it is shown to be an effective and efficient pooling strategy for different features. With the scene-level features, a pooled global (i.e., video-level) representation can be derived as:
| (2) |
where is a video-level pooling function based on a GPO operator.
Textual Encoder
A document can be viewed as a sequence consisting of words as or a sequence of sentences . The -th sentence consists of consecutive words in from the -th to the -th word. Similar to the visual encoder, a hierarchical textual encoder is introduced to learn the sentence-level and the document-level representation.
A pre-trained CLIP model is introduced to formulate the word-level features, which is denoted as for the -th word. Next, a pooling mechanism is adopted to formulate the sentence-level features. In detail, the -th sentence-level features can be computed as:
| (3) |
Finally, the global representation of the document can be derived based on the sentence-level features:
| (4) |
where is a document-level pooling function based on GPO.
Hierarchical Multimodal Fusion
To attend and fuse the representations from the visual and textual modalities, we adopt a graph-based attention mechanism (Veličković et al. 2018). This formulation helps easily extend the attention layer to future additional modalities, such as an audio modality. Each modality feature can be treated as a vertex feature of a graph. The relationships between modalities are formulated by graph convolution to attend over the other modality, which then updates the representations of each modality. Particularly, a hierarchical local, which focuses between scene and sentence levels, and global, which focuses between video and document levels, observations are introduced by a graph fusion strategy.
For local multimodal fusion, the representations of the scenes and sentences are fed into graph fusion modules and . The resulted representation, which can be viewed as an information exchange between modalities, are fed into an average pooling operator to obtain the local multimodal context representations and :
| (5) | ||||
| (6) | ||||
For global multimodal fusion, the global representations of the document and video are fed into a graph fusion module :
| (7) |
Hierarchical Multimodal Decoders
Visual Decoder
Our visual decoder consists of three stages: 1) scene-guided frame decoding, 2) video-guided frame decoding, and 3) cross-modality-guided frame decoding. It aims to evaluate the probability of a particular frame being a cover frame.
To produce a scene-aware decoding outcome of evaluating each frame, a scene-guided visual decoder derives a latent decoding for frames from to , , as follows:
| (8) | ||||
where is a bi-directional GRU (Bahdanau, Cho, and Bengio 2015) and is a multimodal scene guidance, which can be viewed as a prior knowledge. Next, to produce a video-guided frame decoding outcome, we have:
| (9) | ||||
where is a bi-directional GRU and is a unimodal video guidance as a prior knowledge. Finally, to produce a global multimodal context-aware decoding, we adopt a Bi-GRU decoder with the guidance of the cross-modal embedding :
| (10) | ||||
To this end, the optimal frame is obtained with a frame-wise linear layer activated with a softmax function:
| (11) |
Textual Decoder
Similar to the visual decoder, the textual decoder also consists of three stages: 1) sentenced-guided word decoding, 2) document-guided word decoding, and 3) cross-modality-guided word decoding. It aims to evaluate the probability of a word being selected in a compressive summary.
To produce a sentence-aware decoding outcome, a sentence decoder derives a latent decoding for words from to , , where indicates the start index of the word and indicates the end index of the word for the -th sentence in the document, as follows:
| (12) | ||||
where is a bi-directional GRU and is used as a prior knowledge for the multimodal sentence guidance. Then, to produce a document-level textual decoding, we have:
| (13) | ||||
where is a bi-directional GRU and is a unimodal document guidance. Finally, to produce a global cross-modal context-aware decoding for each word, a Bi-GRU decoder is adopted with the guidance of the global multimodal embedding :
| (14) | ||||
As a result, the optimal compressive summary with length is obtained by:
| (15) |
Note that the selected words are ranked in line with their scores obtained from the linear layer with a softmax activation. Thus, the sentence can be constructed with these words and their orders.
Optimal Transport-Guided Semantic Coverage
Our method is trained without reference summaries by mimicking the human judgment on the quality of a multimodal summary, which minimises a quartet loss of visual coverage, textual coverage, textual fluency, and cross-modal similarity.
Document Coverage
Intuitively, a high-quality summary is supposed to be close to the original document regarding their semantic distributions. We measure the Wasserstein distance (Kusner et al. 2015) between the document and the selected sentence . It is the minimal cost required to transport the semantics from to , measuring the semantic coverage of on .
Given a dictionary, the number of the -th token (i.e, a word in a dictionary) occurred in can be counted as . As a result, the semantic distribution of the document can be defined with the normalized term frequency of each token. In detail, for the -th element of , we have:
| (16) |
The semantic distribution of the selected sentence can be derived in a similar manner. The normalized term frequency of the -th token in is:
| (17) |
Note that and have an equal total token quantities of and can be completely transported from one to the other mathematically.
A transportation cost matrix is introduced to measure the semantic similarity between the tokens. Given a pre-trained tokeniser and token embedding model, define to represent the feature embedding of the -th token. The transport cost from the -th token to the -th one is computed based on the cosine similarity:
| (18) |
Note that the method to obtain token representations follows the same method that we formulate for word representations by a pre-trained model.
Then, an optimal transport plan matrix in pursuit of minimizing the transportation cost can be obtained by solving the following optimization problem:
| (19) | |||
To this end, the Wasserstein distance can be defined as:
| (20) |
which is associated with the optimal transport plan. By minimizing , a high-quality summary sentence is expected to be obtained.
Video Coverage
In parallel, a good cover frame is supposed to be close to the original video regarding their perceptual similarity. We measure the loss of visual coverage by computing the Wasserstein distance between the corresponding colour signatures of the mean of video frames in and the cover frame . It can be viewed as the minimal cost required to transport the semantics from to .
By denoting as the mean of the video frames in , we define and as the colour signatures of and , respectively. In detail, we have:
| (21) | ||||
where and are the points in the colour space, and and are the corresponding weights of the points.
An optimal transport plan matrix in pursuit of minimizing the transportation cost between and can be obtained by solving the following optimization problem:
| (22) | |||
where is a transport plan. Then, a Wasserstein distance measuring the distance between the two colour signatures can be derived as:
| (23) |
which is associated with the optimal transport plan. By minimizing , a high-quality summary frame is expected to be the cover frame.
Textual Fluency and Cross-modal Consistency
Inspired by Laban et al. (2020), we adopt a pre-trained language model to measure the fluency of the textual summary . The loss can be defined as:
| (24) |
where computes the probability of being a sentence.
The semantic consistency should exist between the cover frame and the one-sentence summary. To formulate this, we measure the cross-modal similarity between the two embeddings of the cover frame and the one-sentence summary . The loss can be defined based on a cosine similarity:
| (25) |
In summary, four losses have been obtained to measure the summarisation quality: , , and . To this end, a loss function to optimize the proposed architecture can be formulated as follows:
| (26) |
where , , and are the hyper-parameters controlling the weights of each loss term.
Experimental Results and Discussions
Dataset
To the best of our knowledge, there is no existing large-scale dataset for XMSMO. Hence, we collected the first large-scale dataset of such kind, XMSMO-News, from the British Broadcasting Corporation (BBC) News Youtube channel 222https://www.youtube.com/c/BBCNews. We used the Pytube library to collect 4,891 quartets of video, document, cover frame, and one-sentence summary from the year 2013 to 2021. We used the video description as the document and video title as the one-sentence summary, as these visual and textual summaries were professionally created by the BBC. 333We removed the trailing promotional text from the video title and video description. We then split the quartets randomly into the train, validation, and test sets at a ratio 90:5:5.
Table 1 shows the statistics and the comparison of XMSMO-News with other benchmarks on multimodal summarisation with multimodal output. The major differences are regarding the input and output lengths: XMSMO-News has an average duration of 345.5 seconds, whereas (Li et al. 2020) has 60 seconds only.
| Dataset | XMSMO-News | VMSMO | MSMO |
| #Train/Val/Test | 4382/252/257 | 180000/2460/2460 | 293965/10355/10262 |
| Language | English | Chinese | English |
| Visual Input | Video | Video | Multi-images |
| Textual Input | Document | Document | Document |
| Visual Output | Cover frame | Cover frame | One image |
| Textual Output | One-sentence | Arbitrary length | Multi-sentence |
| Frames/Video | 8827.4 | 1500.0 | 6.6 |
| Video Duration(s) | 345.5 | 60.0 | - |
| Tokens/Document | 101.7 | 96.8 | 723.0 |
| Tokens/Summary | 12.4 | 11.2 | 70.0 |
| Annotation | Full | Partial1 | Partial2 |
-
1,2
1) Not all ground-truth data is available; 2) No visual ground-truth on training and validation splits.
Implementation Details
We used the PyTorch library for the implementation of our method. We set the hidden size of GPO and GRU to 512. For the pre-trained CLIP model and the pre-trained token embedding model BERT (base version) used for computing the loss of textual coverage, we obtained them from HuggingFace 444https://huggingface.co. To detect the scenes of a video, we utilised the PySceneDetect library 555http://scenedetect.com/en/latest/. For video preprocessing, we extracted one of every 360 frames to obtain 120 frames as candidate frames. All frames were resized to 640x360. We trained HOT-Net using AdamW (Loshchilov and Hutter 2018) with a learning rate of 0.01 and a batch size of 3 for about 72 hours. All experiments were run on a GeForce GTX 1080Ti GPU card.
Baselines
To evaluate our proposed method HOT-Net, we compared it with the following state-of-the-art baseline methods, including PEGASUS (Zhang et al. 2020) - the state-of-the-art method of text summarisation, CA-SUM (Apostolidis et al. 2022) - the state-of-the-art method of video summarisation, zero-shot CLIP (Radford et al. 2021) - the state-of-the-art multi-modal embedding model with a linear classification layer to perform multimodal summarisation. The baseline models PEGASUS and CLIP were obtained from HuggingFace ; CA-SUM was obtained from the author’s Github 666https://github.com/e-apostolidis/CA-SUM; VMSMO was obtained from the author’s Github 777https://github.com/iriscxy/VMSMO with modifications on the latest libraries’ update and bug fixing.
| Method | Textual Evaluation | Visual Evaluation | Overall Evaluation | |||
| ROUGE-1 | ROUGE-2 | ROUGE-L | Frame Accuracy | IoU | ||
| PEGASUS (Zhang et al. 2020) | 4.36 | 0.12 | 4.00 | - | - | - |
| CA-SUM (Apostolidis et al. 2022) | - | - | - | 0.57 | 0.69 | - |
| VMSMO (Li et al. 2020) | Divergence | Divergence | Divergence | 0.57 | 0.69 | 0.49 |
| CLIP (Radford et al. 2021) | 4.14 | 0.08 | 3.80 | 0.54 | 0.63 | 0.89 |
| HOT-Net (Ours) visual only | - | - | - | 0.60 | 0.68 | - |
| HOT-Net (Ours) textual only | 3.85 | 0.05 | 3.60 | - | - | - |
| HOT-Net (Ours) w/o multimodal fusion | 3.99 | 0.05 | 3.73 | 0.56 | 0.70 | 0.93 |
| HOT-Net (Ours) w/o local-level multimodal fusion | 4.45 | 0.06 | 4.16 | 0.59 | 0.70 | 0.98 |
| HOT-Net (Ours) w/o global-level multimodal fusion | 3.65 | 0.06 | 3.45 | 0.58 | 0.68 | 0.88 |
| HOT-Net (Ours) w/o fluency loss | 4.58 | 0.06 | 4.28 | 0.57 | 0.68 | 0.98 |
| HOT-Net (Ours) w/o cross-modal loss | 4.58 | 0.06 | 4.28 | 0.57 | 0.68 | 0.98 |
| HOT-Net (Ours) | 4.64 | 0.07 | 4.33 | 0.57 | 0.68 | 0.99 |
Quantitative Analysis
For the quantitative evaluation of a textual summary, the commonly used ROUGE metric (Lin 2004) for text summarisation is adopted. For the visual summary, the commonly used Intersection over Union (IoU) (Sharghi, Laurel, and Gong 2017) and frame accuracy (Messaoud et al. 2021) metrics for video summarisation are adopted.
The ROUGE metric evaluates the content consistency between a generated summary and a reference summary. In detail, the ROUGE-n F-scores calculates the number of overlapping n-grams between a generated summary and a reference summary. The ROUGE-L F-score considers the longest common subsequence between a generated summary and a reference summary. IoU metric evaluates the high-level semantic information consistency by counting the number of overlap concepts between the ground-truth cover frame and the generated one. Frame accuracy metric is to compare lower-level visual features, the ground-truth cover frame and generated cover frame are considered to be matching when pixel-level Euclidean distance is smaller than a predefined threshold. To evaluate the overall performance on both modalities, we compute the overall evaluation as , where the best IoU and the best ROUGE-L are the best scores among all the evaluated methods.
The experimental results of HOT-Net on XMSMO-News are shown in Table 2 including ROUGE-1, ROUGE-2. and ROUGE-L F-scores, and IoU. Our method outperforms the baseline models in terms of ROUGE-1 and ROUGE-L, which demonstrate the quality of the generated extreme textual summary, and achieves promising results in terms of frame accuracy and IoU, which demonstrate the quality of the generated extreme visual summary. HOT-Net underperforms in terms of ROUGE-2, which may be due to the trade-off between informativeness and fluency. PEGASUS was trained on massive text corpora which may help improve the fluency of natural language generation. This trade-off is further discussed in the Qualitative Analysis section.

Ablation Study
To study the effect of the proposed mechanisms, we compare a number of different settings of HOT-Net and the results can be found in Table 2. We first observe that multimodal learning improves the modelling by comparing to the visual or textual only method. Our fusion strategy is also important to obtain high-quality textual summaries. The hierarchical mechanism does not have much impact on the results of the visual summary, which may be due to that the overall model architecture has achieved its best possible potential in terms of producing a visual summary. Additionally, the fluency loss and cross-modal loss improve the textual summary as well.
Qualitative Analysis
Figure 3 compares the summaries produced by HOT-Net and the baseline methods, and the reference summary of a sample in the XMSMO-News dataset. The example demonstrates that our proposed HOT-Net method produces factually correct and reasonably fluent extreme textual summary that captures the essence of the document even without supervision. In comparison, as highlighted in red colour, PEGASUS produces a fluent but unfaithful summary with information that does not occur in the original document. Most of the methods agree on the choice of the cover frame, whilst ours and CA-SUM are closer to the ground-truth.
Conclusion
In this paper, we have introduced a new task - eXtreme Multimodal Summarisation with Multimodal Output (XMSMO), which aims to summarise a video-document pair into an extreme multimodal summary, consisting of one cover frame as the visual summary and one sentence as the textual summary. We present a novel unsupervised deep learning architecture, which consists of three components: hierarchical multimodal encoders, hierarchical multimodal fusion decoders, and optimal transport solvers. In addition, we construct a new large-scale dataset XMSMO-News to facilitate research in this new direction. Experimental results demonstrate the effectiveness of our method. In the future, we will explore the metric space to measure the optimal transport plan in a more efficient and effective manner. Moreover, we will explore improved ways to learn and identity the information that humans would consider to be important, such as a frame containing the face of a key character.
References
- Apostolidis et al. (2021a) Apostolidis, E.; Adamantidou, E.; Metsai, A. I.; Mezaris, V.; and Patras, I. 2021a. Video Summarization Using Deep Neural Networks: A Survey. Proceedings of the IEEE.
- Apostolidis et al. (2021b) Apostolidis, E.; Adamantidou, E.; Mezaris, V.; and Patras, I. 2021b. Combining Adversarial and Reinforcement Learning for Video Thumbnail Selection. In International Conference on Multimedia Retrieval (ICMR).
- Apostolidis et al. (2022) Apostolidis, E.; Balaouras, G.; Mezaris, V.; and Patras, I. 2022. Summarizing Videos Using Concentrated Attention and Considering the Uniqueness and Diversity of the Video Frames. In International Conference on Multimedia Retrieval (ICMR).
- Bahdanau, Cho, and Bengio (2015) Bahdanau, D.; Cho, K.; and Bengio, Y. 2015. Neural machine translation by jointly learning to align and translate.
- Cachola et al. (2020) Cachola, I.; Lo, K.; Cohan, A.; and Weld, D. 2020. TLDR: Extreme Summarization of Scientific Documents. In Findings of the Association for Computational Linguistics: EMNLP 2020.
- Chen et al. (2021) Chen, J.; Hu, H.; Wu, H.; Jiang, Y.; and Wang, C. 2021. Learning the best pooling strategy for visual semantic embedding. In IEEE conference on computer vision and pattern recognition (CVPR).
- Gu and Swaminathan (2018) Gu, H.; and Swaminathan, V. 2018. From Thumbnails to Summaries-A Single Deep Neural Network to Rule Them All. In IEEE International Conference on Multimedia and Expo (ICME).
- Kusner et al. (2015) Kusner, M.; Sun, Y.; Kolkin, N.; and Weinberger, K. 2015. From Word Embeddings To Document Distances. In International Conference on Machine Learning (ICML).
- Laban et al. (2020) Laban, P.; Hsi, A.; Canny, J.; and Hearst, M. A. 2020. The Summary Loop: Learning to Write Abstractive Summaries Without Examples. In Annual Meeting of the Association for Computational Linguistics (ACL).
- Li et al. (2020) Li, M.; Chen, X.; Gao, S.; Chan, Z.; Zhao, D.; and Yan, R. 2020. VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Lin (2004) Lin, C.-Y. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out.
- Liu and Lapata (2019) Liu, Y.; and Lapata, M. 2019. Text Summarization with Pretrained Encoders. In Conference on Empirical Methods in Natural Language Processing and the International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).
- Loshchilov and Hutter (2018) Loshchilov, I.; and Hutter, F. 2018. Decoupled Weight Decay Regularization. In International Conference on Learning Representations (ICLR).
- Lu, Dong, and Charlin (2020) Lu, Y.; Dong, Y.; and Charlin, L. 2020. Multi-XScience: A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Luo, Papin, and Costello (2009) Luo, J.; Papin, C.; and Costello, K. 2009. Towards Extracting Semantically Meaningful Key Frames From Personal Video Clips: From Humans to Computers. IEEE Trans. Circuits Syst. Video Technol., 19(2): 289–301.
- Ma et al. (2020) Ma, M.; Mei, S.; Wan, S.; Hou, J.; Wang, Z.; and Feng, D. D. 2020. Video summarization via block sparse dictionary selection. Neurocomputing.
- Mani (2001) Mani, I. 2001. Automatic summarization. John Benjamins Publishing.
- Maynez et al. (2020) Maynez, J.; Narayan, S.; Bohnet, B.; and McDonald, R. 2020. On Faithfulness and Factuality in Abstractive Summarization. In Annual Meeting of the Association for Computational Linguistics (ACL).
- Messaoud et al. (2021) Messaoud, S.; Lourentzou, I.; Boughoula, A.; Zehni, M.; Zhao, Z.; Zhai, C.; and Schwing, A. G. 2021. DeepQAMVS: Query-Aware Hierarchical Pointer Networks for Multi-Video Summarization. In International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR).
- Mihalcea and Tarau (2004) Mihalcea, R.; and Tarau, P. 2004. TextRank: Bringing Order into Text. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Narayan, Cohen, and Lapata (2018a) Narayan, S.; Cohen, S. B.; and Lapata, M. 2018a. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Narayan, Cohen, and Lapata (2018b) Narayan, S.; Cohen, S. B.; and Lapata, M. 2018b. Ranking Sentences for Extractive Summarization with Reinforcement Learning. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT).
- Paulus, Xiong, and Socher (2018) Paulus, R.; Xiong, C.; and Socher, R. 2018. A Deep Reinforced Model for Abstractive Summarization. In International Conference on Learning Representations (ICLR).
- Radford et al. (2021) Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; and Sutskever, I. 2021. Learning Transferable Visual Models From Natural Language Supervision. In Meila, M.; and Zhang, T., eds., International Conference on Machine Learning (ICML).
- Ren et al. (2020) Ren, J.; Shen, X.; Lin, Z.; and Měch, R. 2020. Best Frame Selection in a Short Video. In IEEE Winter Conference on Applications of Computer Vision (WACV).
- See, Liu, and Manning (2017) See, A.; Liu, P. J.; and Manning, C. D. 2017. Get To The Point: Summarization with Pointer-Generator Networks. Annual Meeting of the Association for Computational Linguistics (ACL).
- Sharghi, Laurel, and Gong (2017) Sharghi, A.; Laurel, J. S.; and Gong, B. 2017. Query-focused video summarization: Dataset, evaluation, and a memory network based approach. In IEEE conference on computer vision and pattern recognition (CVPR).
- Sotudeh et al. (2021) Sotudeh, S.; Deilamsalehy, H.; Dernoncourt, F.; and Goharian, N. 2021. TLDR9+: A Large Scale Resource for Extreme Summarization of Social Media Posts. In Workshop on New Frontiers in Summarization.
- Veličković et al. (2018) Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; and Bengio, Y. 2018. Graph Attention Networks. In International Conference on Learning Representations (ICLR).
- Wang et al. (2020) Wang, J.; Bai, Y.; Long, Y.; Hu, B.; Chai, Z.; Guan, Y.; and Wei, X. 2020. Query Twice: Dual Mixture Attention Meta Learning for Video Summarization. In ACM International Conference on Multimedia (ACMMM).
- Wang et al. (2019) Wang, J.; Wang, W.; Wang, Z.; Wang, L.; Feng, D.; and Tan, T. 2019. Stacked memory network for video summarization. In ACM International Conference on Multimedia (ACMMM).
- Yuan et al. (2020) Yuan, L.; Tay, F. E. H.; Li, P.; and Feng, J. 2020. Unsupervised Video Summarization With Cycle-Consistent Adversarial LSTM Networks. IEEE Transactions on Multimedia.
- Zhang et al. (2020) Zhang, J.; Zhao, Y.; Saleh, M.; and Liu, P. 2020. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning (ICML).
- Zhang et al. (2022) Zhang, L.; Zhang, X.; Pan, J.; and Huang, F. 2022. Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization. AAAI Conference on Artificial Intelligence.
- Zhang, Wei, and Zhou (2019) Zhang, X.; Wei, F.; and Zhou, M. 2019. HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization. In Annual Meeting of the Association for Computational Linguistics (ACL).
- Zhong et al. (2020) Zhong, M.; Liu, P.; Chen, Y.; Wang, D.; Qiu, X.; and Huang, X. 2020. Extractive Summarization as Text Matching. In Annual Meeting of the Association for Computational Linguistics (ACL).
- Zhu et al. (2018) Zhu, J.; Li, H.; Liu, T.; Zhou, Y.; Zhang, J.; and Zong, C. 2018. MSMO: Multimodal Summarization with Multimodal Output. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Zhu et al. (2020) Zhu, J.; Zhou, Y.; Zhang, J.; Li, H.; Zong, C.; and Li, C. 2020. Multimodal summarization with guidance of multimodal reference. In AAAI Conference on Artificial Intelligence.