TLRM: Task-level Relation Module for GNN-based Few-Shot Learning
Abstract
Recently, graph neural networks (GNNs) have shown powerful ability to handle few-shot classification problem, which aims at classifying unseen samples when trained with limited labeled samples per class. GNN-based few-shot learning architectures mostly replace traditional metric with a learnable GNN. In the GNN, the nodes are set as the samples’ embedding, and the relationship between two connected nodes can be obtained by a network, the input of which is the difference of their embedding features. We consider this method of measuring relation of samples only models the sample-to-sample relation, while neglects the specificity of different tasks. That is, this method of measuring relation does not take the task-level information into account. To this end, we propose a new relation measure method, namely the task-level relation module (TLRM), to explicitly model the task-level relation of one sample to all the others. The proposed module captures the relation representations between nodes by considering the sample-to-task instead of sample-to-sample embedding features. We conducted extensive experiments on four benchmark datasets: mini-ImageNet, tiered-ImageNet, CUB--, and CIFAR-FS. Experimental results demonstrate that the proposed module is effective for GNN-based few-shot learning.
Index Terms:
Few-shot learning, Graph Neural Networks, Task-level RelationI Introduction
Deep Learning has been achieved great success in visual recognition tasks [1, 2, 3, 4], which depends on powerful model and amounts of labelled samples [5]. However, humans can learn new concepts with little examples, or none at all. The gap motivated researchers to study few-shot learning and zero-shot learning.
The goal of few-shot learning is to classify unseen samples, given just a small number of labeled samples in each class. It has attracted considerable attention [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]. One promising study is metric-based few-shot learning [6, 7, 8, 9, 10, 11, 12, 13]. Given just a query sample and a few labeled support samples, the embedding function extracts feature for all samples, and then a metric module measures distance between the query embedding and class embedding to give a recognition result. Recently, there have some studies of utilizing Graph Neural Networks (GNNs) [8, 10, 11, 18] to handle the few-shot classification task, which can be seen as a kind of metric learning method. In GNN-based few-shot learning model, all embedding features are connected to construct a graph. And each node is represented by the embedding feature of a sample. Then the graph classifies the unlabeled query by measuring the similarity between two samples.
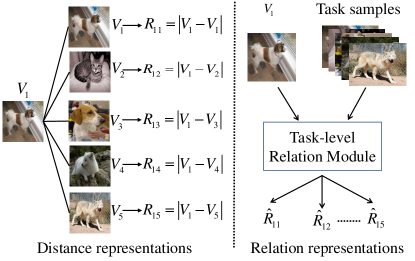
Even though GNN-based model have made significant advance in few-shot classification, they do suffer from distinct limitation. In the metric module of GNN-based methods, relation representation for a pair samples is obtained by calculating the absolute difference [8, 10, 11, 18]. It only considers the corresponding embedding features of the samples. Intuitively, pair-wise relationship is not only dependent on the distance between corresponding embedding features, but also related to all embedding features in a task. As shown in the left panel of Figure 1, there is no significant difference between the target sample and all other samples in the task. The distance representation between two samples neglects the specificity of the task and lacks discrimination. This will cause the problem that the similarity scores are not significantly different, so that the category of the target sample is not clear. To deal with the key challenge of how to learn relation representations with distinctive information, we propose a sample-to-task metric module, as shown in the right panel of Figure 1, which adopts a meta learning strategy to learn the relation representations. The main contributions of this paper are summarized as follows:
-
•
We propose an task-level relation module (TLRM). The proposed TLRM utilizes the attention mechanism to learn task-specific relation representations for each task.
-
•
The comprehensive experimental results on four benchmark datasets show that our proposed module is effective for GNN-based few-shot model. In addition, the results of semi-supervised few-shot classification and visualization of similarity scores are provided to further evaluate our module.
II Related work
Meta Learning in Few-shot Learning: Meta Learning framework is an effective study for few-shot learning, which mainly focuses on how to learn and utilize meta-level knowledge to adapt to new tasks quickly and well. One of the excellent studies is model-agnostic meta-learning (MAML) [19]. The MAML learned initialization parameters by cross-task training strategy such that the base learner can rapidly generalize new tasks using a few support samples. Subsequently, many MAML variants [20, 21, 22, 23, 24, 25] have been developed.
Metric Learning in Few-shot Learning: On the metric learning side, most of algorithms consist of embedding function extracting features for instances and metric function for measuring sample between the query embedding and class embedding. Koch et al. [9] used siamese network to compute the pair-wise distance between samples. Prototypical networks [6] firstly built a prototype representation of each class and measured the samples between the query embedding and class’s prototype by using euclidean distance. Matching network [26] used a neural network with external memories to map samples to embedding features, which considers full context in a task. TADAM [27] introduced a metric scaling factor to optimize the similarity metric of prototypical nets. Zheng et al. [28] believed that the average prototype ignores the different importance of different support samples and proposed principal characteristic nets.
Fixed metric methods will restrict the embedding function to produce discriminative representations. Sung et al. [7] introduced relation network (RN) for few-shot learning. The relation network learns to learn a deep distance metric by a neural network. However, due to the inherent local connectivity of CNN, the RN can be sensitive to the spatial position relationship of semantic objects in two compared images. To address this problem, Wu et al. [29] introduced a deformable feature extractor (DFE) to extract more efficient features, and designed a dual correlation attention mechanism (DCA) to deal with its inherent local connectivity. Hou et al. [30] proposed a cross attention network for few-shot classification, which is designed to model the semantic relevance between class and query features.
GNN-based methods in Few-shot Learning: Recently, most approaches are proposed to exploit GNN in the field of few-shot learning task. Specifically, Garcia et al. [8] first utilized GNN to solve few-shot learning problem, where all embedding features extracting by a convolutional neural network are densely connected. Liu et al. [11] proposed a transductive propagation network (TPN). The TPN utilizes the entire query set for transductive inference. To further exploit intra-cluster similarity and inter-cluster dissimilarity, kim et al. [10] proposed an edge-labeling graph neural network. Then in order to explicitly model the distribution-level relation, Yang et al. [18] proposed distribution propagation graph network (DPGN).
In the existing GNN-based few-shot learning methods, pair-wise distance representations are absolute difference of the embedding features. However, when the classes in the task are similar, it will lead to the problem of insufficient discrimination in metric representations. So, in this paper, we focus on learning distinctive relation information through an task-level relation module.
III The Proposed Method
III-A GNN-based few-shot learning
| Model | Trans. | mini-ImageNet | tiered-ImageNet | CUB-200-2011 | CIFAR-FS |
|---|---|---|---|---|---|
| EGNN (CVPR 19) | No | ||||
| EGNN + TLRM | No | ||||
| TPN (ICLR 18) | Yes | ||||
| EGNN | Yes | ||||
| DPGN (CVPR 20) | Yes | ||||
| EGNN + TLRM | Yes | ||||
| DPGN + TLRM | Yes |
| Model | Trans. | mini-ImageNet | tiered-ImageNet | CUB-200-2011 | CIFAR-FS |
|---|---|---|---|---|---|
| EGNN | No | ||||
| EGNN + TLRM | No | ||||
| TPN | Yes | ||||
| EGNN | Yes | ||||
| DPGN | Yes | ||||
| EGNN + TLRM | Yes | ||||
| DPGN + TLRM | Yes |
-
*
“No” means non-transductive method, and “Yes” means transductive method.
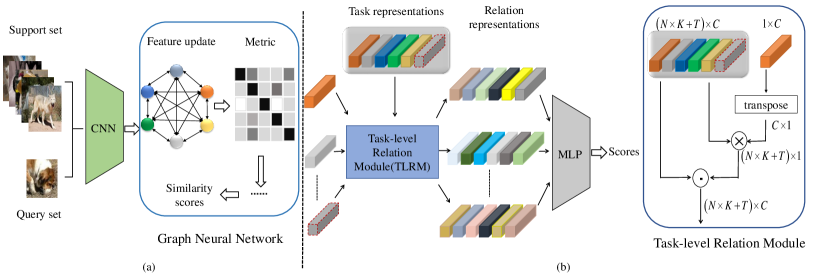
As shown in Figure 2 (a), GNN-based few-shot model usually consists of a CNN for extracting features and a GNN for propagating labels from labeled nodes to unlabeled according to similarity scores between nodes. In the training and testing process, GNN-based few-shot model usually adopts the episodic mechanism, in which each episode (task) consists of the support set and the query set . And the support set contains labeled support samples and the query set contains unseen samples in a -way -shot problem.
Generally, the CNN as backbone of extracting features has two different types the -layer convolution network (ConvNet) [11, 10] and the -layer residual network (ResNet-) used in [18]. The GNN consists of layers to process the graph. Let be embedding features for all nodes extracted by the CNN, be relation representations between nodes, and be similarity score between node and . Given and from the layer , node feature update is firstly conducted by a neighborhood aggregation procedure. And node is updated as
| (1) |
where is the feature (node) transformation network. Then, the relation representation is obtained by calculating the absolute difference between two vector nodes. It can be denoted as
| (2) |
Finally, the relation representation is input into a Multilayer Perceptron (MLP) to capture the similarity scores between nodes
| (3) |
Where is transformation network. The goal of GNN-based few-shot learning is to learn function , and to classify query sample by . Note that the relationship is obtained by measuring the distance between two corresponding node, which is node-to-node and task-agnostic.
III-B Task-level Relation Module
In this paper, attention mechanism is employed to transform sample embedding to relation representations with consideration to task-specific embedding. Note that the relation representation is task-specific and not only the distance between nodes. We denote it as Task-level Relation Module (TLRM). The proposed TLRM can avoid direct comparison relative relationship irrelevant local representations. As shown in Figure 2 (b), given the feature representations , the relation representations can be obtained. The implementation details are performed as follows.
For node , the attention value between the target embedding and all other samples in the task can be obtained by adopting method commonly used in the attention mechanism. The attention value is performed as follows
| (4) |
Where , which represents the similarity between nodes comparing to all other embedding in the task. reflects the matching degree of node to node . When the degree is higher, is bigger. The matching degree is performed as follows
| (5) |
Where, first, the feature representation of target sample is reshaped to through a transpose operation and is the vector multiplication operation. And then, is used to encode and the relation representations can be obtained, which can be denoted as
| (6) |
The relation representation models the relation representation between node and , which is a task-level relation representation of sample to comparing to all the other samples. Afterwards, is fed to an MLP to capture the relation score for performing further classification
| (7) |
IV Experiments and Discussions
IV-A Datasets and setups
To evaluate our module, we select two GNN-based few-shot models: EGNN and DPGN, and four standard few-shot learning benchmarks: mini-ImageNet [26], tiered-ImageNet [31], CUB-- [32] and CIFAR-FS [33].
For the sake of fairness, all experiments employed the same setups as EGNN and DPGN. EGNN used ConvNet, and DPGN used ResNet- for extracting features. In training process, the Adam optimizer was used in all experiments with the initial learning rate . And the learning rate was decayed by per iterations. The weight decay was set as . For all datasets, -way -shot and -way -shot experiments were conducted. We randomly sampled tasks and then reported the mean accuracy along with its confidence interval.
| Model | |||
|---|---|---|---|
| EGNN | |||
| EGNN + TLRM | |||
| DPGN | |||
| DPGN + TLRM |
| Model | mini-ImageNet | |
|---|---|---|
| EGNN | ||
| EGNN+TLRM | ||
IV-B Results and discussions for few-shot classification
Experimental results for -way -shot and -way -shot classification are shown in Table I and Table II. We can see that EGNN or DPGN with our TLRM have higher accuracy than the ones without TLRM on mini-ImageNet, tiered-ImageNet, and CUB--. Meanwhile, partial experimental results on the CIFAR-FS dataset dropped slightly, the reason of which might lie in the categories in the CIFAR-FS dataset are highly distinguishable. In addition, the CUB-- dataset is the most widely used benchmark for fine-grained image classification, which has significant intra-class variance and inter-class similarity. Fine-grained image task is more challenging in few-shot learning. Clearly, the improvement on the CUB-- dataset is significant in Table I and Table II, which shows that the relationship representation obtained by our module is more discriminative than previous method for tasks with high similarity. And overall, our method is simple and effective.
Semi-supervised experiments were conducted in -way -shot setting on mini-ImageNet with two backbones, in which the support samples are only partially labeled. The results are presented in Table III. Notably, the EGNN and DPGN with our TLRM outperforms the previous backbones especially when the labeled samples portion was decreased.
IV-C Ablation studies
In order to investigate the effect of our proposed TLRM on different layer of GNN, ablation studies were conducted with , , and on mini-ImageNet with EGNN backbone. It can be observed from Table IV that the proposed TLRM plays a significant role in each layer of EGNN.
IV-D Visualization of similarity scores
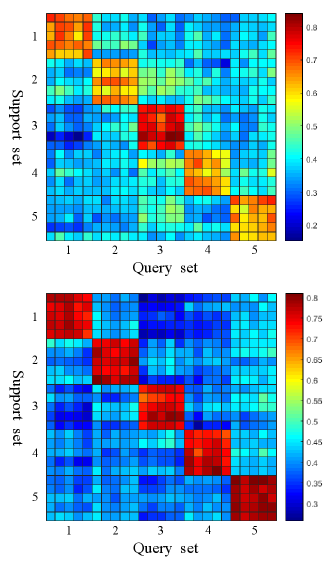
For further analysis, Figure 3 shows similarity scores in the last layer of EGNN. The similarity scores are the average of 10000 tasks in setting of 5-way 5-shot and 5 queries for each class. The 25 samples in vertical axis are support set, and 25 samples in horizontal axis are query set. Notably, EGNN with our module not only contributes to predicting more accurately but also reduces the similarity score between samples in different classes and increases the similarity score between samples in the same classes.
V Conclusions
In this paper, we propose an task-level relation module to capture the relation representations by employing all the embedding features in a single task. By considering all the samples in the task, our method can hold discriminative relation features for each node pair. Experimental results demonstrate that it improves the performance of recently proposed GNN-based methods on four benchmark datasets: mini-ImageNet, tiered-ImageNet, CUB--, and CIFAR-FS.
References
- [1] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in CVPR, 2014.
- [2] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
- [3] D. Chang, Y. Ding, J. Xie, A. Bhunia, X. Li, Z. Ma, M. Wu, J. Guo, and Y. Song, “The devil is in the channels: Mutual-channel loss for fine-grained image classification,” IEEE Transactions on Image Processing, vol. 29, pp. 4683–4695, 2020.
- [4] Y. Ding, Z. Ma, S. Wen, J. Xie, D. Chang, Z. Si, M. Wu, and H. Ling, “Ap-cnn: Weakly supervised attention pyramid convolutional neural network for fine-grained visual classification,” IEEE Transactions on Image Processing, vol. 30, pp. 2826–2836, 2021.
- [5] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. Berg, and F. Li, “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015.
- [6] J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” in NIPS, 2017.
- [7] F. Sung, Y. Yang, L. Zhang, T. Xiang, P. Torr, and T. Hospedales, “Learning to compare: Relation network for few-shot learning,” in CVPR, 2018.
- [8] V. Garcia and J. Bruna, “Few-shot learning with graph neural networks,” in ICLR, 2018.
- [9] G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for one-shot image recognition,” in ICML, 2015.
- [10] J. Kim, T. Kim, S. Kim, and C. Yoo, “Edge-labeling graph neural network for few-shot learning,” in CVPR, 2019.
- [11] Y. Liu, J. Lee, M. Park, S. Kim, E. Yang, S. Hwang, and Y. Yang, “Learning to propagate labels: Transductive propagation network for few-shot learning,” in ICLR, 2018.
- [12] W. Li, J. Xu, J. Huo, L. Wang, Y. Gao, and J. Luo, “Distribution consistency based covariance metric networks for few-shot learning,” in AAAI, 2019.
- [13] W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo, “Revisiting local descriptor based image-to-class measure for few-shot learning,” in CVPR, 2019.
- [14] X. Li, J. Wu, Z. Sun, Z. Ma, J. Cao, and J. Xue, “Bsnet: Bi-similarity network for few-shot fine-grained image classification,” IEEE Transactions on Image Processing, vol. 30, pp. 1318–1331, 2021.
- [15] C. Xu, Y. Fu, C. Liu, C. Wang, J. Li, F. Huang, L. Zhang, and X. Xue, “Learning dynamic alignment via meta-filter for few-shot learning,” in CVPR, 2021.
- [16] H. Zhang, P. Koniusz, S. Jian, H. Li, and P. Torr, “Rethinking class relations: Absolute-relative supervised and unsupervised few-shot learning,” in CVPR, 2021.
- [17] B. Zhang, X. Li, Y. Ye, Z. Huang, and L. Zhang, “Prototype completion with primitive knowledge for few-shot learning,” in CVPR, 2021.
- [18] L. Yang, L. Li, Z. Zhang, X. Zhou, E. Zhou, and Y. Liu, “DPGN: Distribution propagation graph network for few-shot learning,” in CVPR, 2020.
- [19] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in ICML, 2017.
- [20] M. Jamal and G. Qi, “Task agnostic meta-learning for fewshot learning,” in CVPR, 2019.
- [21] A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanua, S. Osindero, and R. Hadsell, “Meta-learning with latent embedding optimization,” in ICLR, 2019.
- [22] X. Jiang, M. Havaei, F. Varno, G. Chartrand, N. Chapados, and S. Matwin, “Learning to learn with conditional class dependencies,” in ICLR, 2019.
- [23] S. Ravi and H. Larochelle, “Optimization as a model for few-shot learning,” in ICLR, 2017.
- [24] T. Munkhdalai and H. Yu, “Meta networks,” in ICML, 2017.
- [25] H. Li, W. Dong, X. Mei, C. Ma, F. Huang, and B. Hu, “LGM-Net: learning to generate matching networks for few-shot learning,” in ICML, 2019.
- [26] O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” in NIPS, 2016.
- [27] B. Oreshkin, A. Lacoste, and P. Rodriguez, “TADAM: task dependent adaptive metric for improved few-shot learning,” in NIPS, 2018.
- [28] Y. Zheng, R. Wang, J. Yang, L. Xue, and M. Hu, “Principal characteristic networks for few-shot learning,” Visual communication and Image Representation, vol. 59, pp. 563–573, 2019.
- [29] Z. Wu, Y. Li, L. Guo, and K. Jia, “PARN: position-aware relation networks for few-shot learning,” in ICCV, 2019.
- [30] R. Hou, H. Chang, B. Ma, S. Shan, and X. Chen, “Cross attention network for few-shot classification,” in NIPS, 2019.
- [31] M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. Tenenbaum, H. Larochelle, and R. Zemel, “Meta-learning for semi-supervised few-shot classification,” in ICLR, 2018.
- [32] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The Caltech-UCSD Birds-200-2011 Dataset,” Tech. Rep. CNS-TR-2011-001, California Institute of Technology, 2011.
- [33] L. Bertinetto, J. Henriques, P. Torr, and A. Vedaldi, “Meta-learning with differentiable closedform solvers,” in ICML, 2019.