\ul
Toward Effective Digraph Representation Learning: A Magnetic Adaptive Propagation based Approach
Abstract.
The -parameterized magnetic Laplacian serves as the foundation of directed graph (digraph) convolution, enabling this kind of digraph neural network (MagDG) to encode node features and structural insights by complex-domain message passing. As a generalization of undirected methods, MagDG shows superior capability in modeling intricate web-scale topology. Despite the great success achieved by existing MagDGs, limitations still exist: (1) Hand-crafted : The performance of MagDGs depends on selecting an appropriate -parameter to construct suitable graph propagation equations in the complex domain. This parameter tuning, driven by downstream tasks, limits model flexibility and significantly increases manual effort. (2) Coarse Message Passing: Most approaches treat all nodes with the same complex-domain propagation and aggregation rules, neglecting their unique digraph contexts. This oversight results in sub-optimal performance. To address the above issues, we propose two key techniques: (1) MAP is crafted to be a plug-and-play complex-domain propagation optimization strategy in the context of digraph learning, enabling seamless integration into any MagDG to improve predictions while enjoying high running efficiency. (2) MAP++ is a new digraph learning framework, further incorporating a learnable mechanism to achieve adaptively edge-wise propagation and node-wise aggregation in the complex domain for better performance. Extensive experiments on 12 datasets demonstrate that MAP enjoys flexibility for it can be incorporated with any MagDG, and scalability as it can deal with web-scale digraphs. MAP++ achieves SOTA predictive performance on 4 different downstream tasks.
1. Introduction
As high-order structured data, the directed graph (digraph) offers a new perspective to model intricate web-scale information by capturing node relationships. Its exceptional representational capacity at the data level has driven advancements in graph mining at the model level, drawing significant attention in recent years (Song et al., 2022; Platonov et al., 2023). Notably, although existing undirected GNNs can achieve satisfactory performance, the loss of directed information undeniably limits their potential, especially when addressing topological heterophily challenges (i.e., whether connected nodes have similar features or same labels) (Maekawa et al., 2023; Rossi et al., 2023; Sun et al., 2024). Therefore, researchers have increasingly focused on utilizing digraphs for modeling complex web scenarios, including recommendation (Zhao et al., 2021; Virinchi and Saladi, 2023) and social networks (Bian et al., 2020; Schweimer et al., 2022). Based on this, web mining problems can be translated into node- (Tong et al., 2020a; Zhang et al., 2021a; Li et al., 2024a), link- (Kollias et al., 2022a; Zhang et al., 2024; Ma et al., 2024), and graph-level (Thost and Chen, 2021; Liang et al., 2023; Luo et al., 2023) tasks.
To achieve effective digraph learning, a promising approach is -parameterized magnetic Laplacian , which forms the foundation of digraph convolution from a spectral perspective to simultaneously encode node features and structural insights by message passing in the complex domain. Specifically, it is an adaptation of the standard Laplacian by incorporating complex-valued weights to account for the influence of a magnetic field on edges, which is particularly beneficial for investigating network properties when the edges are formulated as the asymmetry topology (e.g., digraphs) (Chung, 2005; Chat et al., 2019). Notably, the weights of denoted as , where represents the magnetic potential or phase linked to the directed edge and determines the strength of direction, reflecting the integration of the magnetic vector potential along the edge from node to . Intuitively, it can also be viewed as the spatial phase angle between connected nodes in the complex domain, describing the direction and granularity of spatial message passing.
Building upon this concept, digraph neural networks based on the -parameterized magnetic Laplacian (MagDGs) implicitly execute eigen-decomposition during convolution (Zhang et al., 2021a, b; He et al., 2022a; Lin and Gao, 2023a; Zou et al., 2024; Li et al., 2024a). This approach captures crucial structural insights (i.e., key properties of the digraph, such as connectivity) under the influence of the magnetic field, guiding optimal node encoding principles within the directed topology. Despite recent remarkable efforts in designing MagDGs, inherent limitations still exist:
(1) Limited Understanding of -parameterized Magnetic Laplacian in Digraph Learning. Intuitively, determines the strength of direction for each edge in the digraph, manifested in the spatial phase angle between every connected node in the complex domain. For its direct impact on propagation and message (i.e., propagated results) aggregation, selecting an appropriate is crucial. However, related studies have primarily concentrated on spectral graph theory, providing guidance on selection from a strictly topological perspective and evaluating these principles in graph signal processing (Furutani et al., 2020), community detection (Fanuel et al., 2017), and clustering (Fanuel et al., 2018). Despite their effectiveness, directly applying these methods in digraph learning is not suitable, as node profiles (i.e., node features and labels) are seldom considered in spectral graph theory and above applications. In digraph learning, both node profiles and topology play equally crucial roles, and therefore, relying solely on topological measurements to define the -parameterized magnetic Laplacian is insufficient and can mislead the message passing in the complex domain. To fill this gap, existing approaches treat as a hyperparameter, finely tuning it for different datasets and downstream tasks. Although this strategy performs well in data-driven contexts, it often fails to thoroughly explore the optimal range of , which increases manual cost, particularly in web-scale scenarios.
Solution: In Sec. 3 and Sec. 5, we conduct a comprehensive empirical study and theoretical analysis from topological and feature perspectives to explore the key insights behind the -parameterized magnetic Laplacian in the context of digraph learning.
(2) Lack of Fine-grained Message Passing in the Complex Domain. Most existing methods directly utilize identical to achieve coarse-grained graph propagation in the complex domain. This strategy assigns the same spatial phase angle to every directed edge, thereby employing the same propagation rules for all edges and neglecting their uniqueness. Furthermore, most approaches apply a simple averaging function during message aggregation after graph propagation. This approach overlooks the varying contributions from different depths of structural insights encoded in the propagation, which are crucial for attaining optimal node representations. Obviously, this coarse-grained message passing in the complex domain leads to sub-optimal predictive performance. Meanwhile, real-world web mining applications with intricate directed topology heavily depend on the semantic contexts, which encompasses a comprehensive characterization based on their features and unique topology. Hence, it is necessary to introduce a fine-grained message passing to capture such semantic context.
Solution. Motivated by the key insights obtained by Sec. 3, we propose two pivotal techniques: (i) MAP, a plug-and-play strategy seamlessly integrated with any existing MagDG, optimizes graph propagation in the complex domain through a weight-free angle-encoding strategy in the spatial phase, improving predictions while maintaining scalability. (ii) MAP++, a new magnetic-based digraph learning framework, further quantifies the influence of node profiles and directed topology in the complex domain through a learnable strategy. It achieves SOTA performance by flexible and adaptive edge-wise graph propagation and node-wise message aggregation.
Our contributions. (1) New Perspective. To the best of our knowledge, this paper is the first attempt to investigate the key insights of -parameterized magnetic Laplacian in digraph learning. We provide comprehensive empirical studies and highlight the integrated impact of node profiles and topology. (2) Plug-and-play Strategy. We first propose MAP, which encodes spatial phase angles in a weight-free manner to tailor propagation rules for each node, seamlessly integrating with MagDGs to improve predictions. (3) New Method. To pursue superior performance, we propose MAP++, which utilizes learnable mechanisms to further optimize complex domain message passing, achieving edge-wise propagation and node-wise aggregation. (4) SOTA Performance. Evaluations on 12 datasets, including large-scale ogbn-papers100M, prove that MAP has a substantial positive impact on prevalent methods (up to 4.81% improvement) and MAP++ achieves the SOTA performance (up to 3.47% higher).
2. Preliminaries
2.1. Notations and Problem Formulation
We consider a digraph with nodes, edges. Each node has a feature vector of size and a one-hot label of size , the feature and label matrix are represented as and . can be described by an asymmetrical adjacency matrix . Downstream tasks include node-level and link-level.
Node-level Classification. Suppose is the labeled set, the semi-supervised node classification paradigm aims to predict the labels for nodes in the unlabeled set with the supervision of .
Link-level Prediction. (1) Existence: predict if exists in the edge sets; (2) Direction: predict the edge direction of pairs of nodes for which either or ; (3) Three-class link classification: classify an edge , or . For convenience, we call it Link-C.
Data-centric Plug-and-play MAP: This approach encodes spatial phase angles in a weight-free manner by considering the characteristics of digraph data from both topological and feature perspectives. It optimizes existing MagDGs by replacing their predefined rigid graph propagation equations (i.e., Hand-crafted ).
Model-centric MAP++: Building on MAP, this method introduces additional learnable parameters to enable adaptive edge-wise graph propagation and node-wise message aggregation. The learnable modules from the above two perspectives can be selectively applied based on the computational capabilities, offering flexibility.
2.2. Directed Graph Neural Networks
Prevalent Message Passing. In undirected scenarios, prevalent approaches (Hamilton et al., 2017; Veličković et al., 2018; Xu et al., 2018; Frasca et al., 2020; Huang et al., 2021; Li et al., 2024b) adhere to strict symmetric message passing. This strategy entails the design of graph Propagation and the subsequent message Aggregation, facilitating the establishment of relationships among a node and its neighbors. For the current node , the -th -parameterized aggregator is denoted as:
| (1) |
where , denotes the one-hop neighbors of . To obtain node embeddings in digraphs, it’s crucial to consider the direction of edges. Hence, the current node initially employs learnable weights separably for its out-neighbors and in-neighbors to obtain multi-level aggregated representations followed by the Combination after directed message passing:
| (2) | ||||
Building upon this concept, DGCN (Tong et al., 2020b) and DiGCN (Tong et al., 2020a) incorporate neighbor proximity to increase the receptive field (RF) of each node. DIMPA (He et al., 2022b) increases the node RF by aggregating more neighbors during the graph propagation. NSTE (Kollias et al., 2022b) is motivated by the 1-WL graph isomorphism test to design the message aggregation. ADPA (Sun et al., 2024) explores appropriate directed patterns to conduct graph propagation. Despite their effectiveness, these methods inevitably introduce additional trainable weights and heavily rely on well-designed neural architectures that hinder their deployment.
The -parameterized magnetic Laplacian driven MagDGs. To address these issues, recent studies employ the -parameterized magnetic Laplacian to define complex-domain message passing, explicitly modeling both the presence and direction of edges through real and imaginary components. Specifically, magnetic Laplacian is a complex-valued Hermitian matrix that encodes the asymmetric nature of a digraph via the -parameterized complex part of its entries. This introduces a complex phase, influenced by a magnetic field, to the edge weights, extending the conventional graph Laplacian into the complex domain to more effectively capture asymmetry. The above -parameterized magnetic Laplacian is formally defined as:
| (3) | ||||
where is the degree matrix of , determines the strength of direction. The real part in indicates the presence and the imaginary part indicates the direction. Since we only consider unsigned digraphs, there exists . Moreover, due to the periodicity of the , we have . When setting , directed information becomes negligible. For , we have whenever there is an edge from to only. Based on this, we can formally define the magnetic graph operator (MGO) with self-loop () to form the foundation of digraph convolution as follows:
| (4) |
This MGO enables graph propagation in the complex domain, elegantly encoding deep structural insights concealed in digraphs with asymmetric topology. Subsequently, we can instantiate the trainable message aggregation based on the propagated results. The above -parameterized complex-domain message passing (proposed by MagNet (Zhang et al., 2021a)) can be formally defined as:
| (5) | ||||
Based on this foundation, MSGNN (He et al., 2022a) extends this complex domain pipeline to directed signed graphs by varying the range of . MGC (Zhang et al., 2021b) adopts a truncated version of PageRank named Linear-Rank to construct a filter bank to improve the graph propagation. Framelet-Mag (Lin and Gao, 2023a) employs Framelet-based filtering to decompose the magnetic Laplacian into components of different scales and frequencies for better predictive performance. LightDiC (Li et al., 2024a) optimizes the MagDG framework by decoupling graph propagation and message aggregation for scalability in large-scale scenarios.
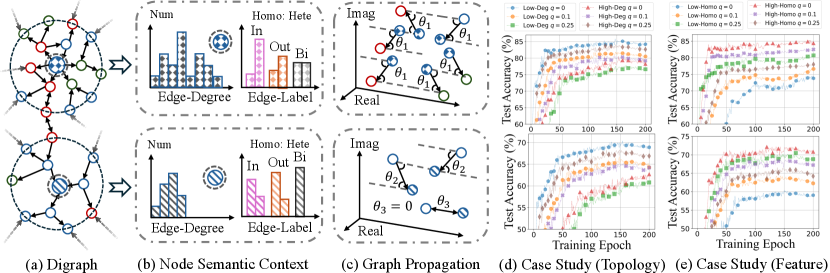
3. Empirical Investigation
As mentioned in Sec. 1 and Sec. 2.2, despite the remarkable efforts of existing MagDGs in improving complex-domain graph propagation, two limitations still exist. To address them, we provide comprehensive empirical analysis in terms of: (1) Illustrations: We clarify the node semantic context driven by directed topology and visualize the naive graph propagation in existing MagDGs. Specifically, we choose two central nodes from Fig. 1 (a) and perform statistical analysis from topological and feature perspectives in Fig. 1 (b), where Edge-Degree denotes the sum of node degrees linked by two-hop edges of the current node and Edge-Label is the proportion of connected nodes with same or different labels (i.e., homophily and heterophily (Ma et al., 2021; Luan et al., 2022; Zheng et al., 2022)) in different directions (i.e., incoming, outgoing, and bidirected edges). Based on central nodes, we provide a visualization of the complex domain message passing in Fig. 1 (c) highlighted by spatial phase angles (i.e., ). Notably, we select two representative digraph datasets of different scales for comprehensive comparison. Compared to toy-sized Cora, large-scale arXiv better reflect the scalability challenges encountered in web-scale graph mining and the complexities of directed topology. (2) Case Studies: In Fig. 1 (d) and (e), we use various magnetic parameters combined with 3-layer LightDiC (Li et al., 2024a) to evaluate the node performance with different semantic contexts across these two datasets. Similar to (1), we utilize node degrees and homophily to collectively support the semantic context. Specifically, in CoraML and arXiv, we classify nodes with degrees less than or equal to 3 and 5 as Low-Deg and other nodes as High-Deg, where Low-Deg at the digraph’s periphery with fewer connections and High-Deg located at the center of densely connected communities. Meanwhile, for both datasets, we identify nodes with homophily less than and greater than 0.5 as Low-Homo and High-Homo, where node homophily (Pei et al., 2020) quantifies the similarity between the labels of the current node and its neighbors based on features, with higher values suggesting a higher probability of sharing the same label.
Observation 1: Due to the intricate directed topology and feature correlation, nodes within the same digraph and RF may exhibit significantly diverse semantics. As shown in Fig. 1 (a,b), nodes within the same digraph and two-hop RF exhibit significant statistical disparities from both topological and feature perspectives, highlighting distinct contexts. Intuitively, applying the same propagation rules to all nodes in digraphs inevitably results in high-bias performance.
Observation 2: The predefined rigid edge-wise exacerbates the coarse-grained graph propagation above in the complex domain, further amplifying the adverse effects of overlooking the uniqueness of nodes. Existing MagDGs adopt the same for all edges and assign identical phase angles to all node pairs in Fig. 1 (c). Given the semantic differences between the node and its neighbors with the complex computation between real and imaginary components, fine-grained propagation is necessary.
Key insight 1: From the topological perspective, High-Deg poses greater prediction challenges than Low-Deg. Fortunately, higher emphasizes direction, aiding High-Deg in discerning intricate neighborhoods. In Fig. 1 (d), and respectively yield optimal performance for Low-Deg and High-Deg, as indicated by the blue and brown curves across two datasets. A deeper analysis can be pursued by investigating the trade-off of undirected () information and directed () information in graph propagation as described in Eq. (3). For Low-Deg, results in a straight acquisition of knowledge from neighbors without additional directed information, thereby mitigating potential feature confusion issues arising from fewer neighbors. As for High-Deg, enables fine-grained discrimination of massive neighbors based on edge direction. This facilitates the discovery of neighborhood knowledge that favors the current node for accurate predictions.
Key insight 2: From the feature perspective, Low-Homo poses tougher prediction challenges than High-Homo. Fortunately, higher facilitates Low-Homo for fine-grained propagation by emphasizing edge direction. As depicted in Fig. 1 (e), we observe that and respectively result in optimal performance for High-Homo and Low-Homo, as indicated by the red and green curves. Notably, higher are particularly emphasized for discerning edge direction, especially in the context of the intricate directed topology of large-scale arXiv, depicted by the brown and green curves. For Low-Homo, enables effective differentiation between similar and dissimilar neighborhoods, thereby preventing the loss of node uniqueness due to naive propagation. As for High-Homo, which exhibits similarity among neighborhoods, achieves a straightforward yet effective approach to propagation, mitigating knowledge dilution introduced by additional directed information.
4. Magnetic Adaptive Propagation
Motivated by the above key insights, in this paper, we propose two technologies: MAP and MAP++, offering a plug-and-play solution for existing MagDGs and a new MagDG framework, respectively. The core of our methods is the thorough integration of directed topology and node features, aimed at circulating the most appropriate magnetic field potential to directed edges. In other words, we strive to ensure the quality of complex domain message passing by adaptive edge-wise graph propagation and node-wise message aggregation. Specifically, MAP first identifies the topological context of directed edges by quantifying the comprehensive centrality of start and end nodes, highlighting the direction of frequently activated edges (motivated by Key insight 1). Subsequently, MAP quantifies the correlation between connected nodes in a weight-free manner throughout the edge projection in the complex plane. This process highlights the direction of edges linked by dissimilar nodes (motivated by Key insight 2). Building upon this foundation, MAP++ further introduces a learnable mechanism to achieve adaptive spatial phase angle encoding and weighted message aggregation to improve performance. The complete algorithm description and complexity analysis can be found in Appendix A.1.
4.1. Topology-related Uncertainty Encoding
Drawing from the empirical study, we conclude that frequently activated directed edges generate intricate information flows that compromise the uniqueness of node representations. Based on this, we provide a more generalized and thorough perspective: these intricate information flows driven by frequently activated directed edges introduce additional topological uncertainty to node representations, significantly disturbing their prediction, as evidenced by Fig. 1 (d).
As Key insight 1 highlighted, the directed information introduced by increased can be construed as supplementary encoding of topological uncertainty, thereby regulating graph propagation to avoid node confusion. In other words, this directed information enhances the capacity to discern complex information flows, enabling fine-grained graph propagation, and thereby improving node discrimination. Consequently, we aim to understand this topology-related uncertainty. It first identifies frequently activated directed edges through connected nodes and then applies fine-grained encoding to their magnetic field potentials for personalized propagation.
In a highly connected digraph, nodes frequently interact with their neighbors. By employing random walks (Pearson, 1905), we can capture these interactions and introduce Shannon entropy to measure node centrality (Li and Pan, 2016) from a global perspective. Meanwhile, by adopting cluster connectivity, we can further offer a description of node centrality from a local perspective, which closely correlates with neighbor connectivity. The above processes are defined as:
| (6) | ||||
where and are the in and out-degrees in the digraph. is the triple motifs of node . Notably, in contrast to directed structural entropy defined by the previous work (Li and Pan, 2016), we address the limitation of only walking in the forward direction by incorporating reverse walking. This modification is motivated by the non-strongly connected nature of most digraphs, where the proportion of complete walk paths declines sharply. This decline suggests that most walk sequences fail to capture sufficient information beyond the immediate neighborhood of the starting node. Consequently, strictly adhering to edge directions in walks (forward-only) results in severe walk interruptions, which ultimately degrades the effectiveness of . Furthermore, we add self-loops for sink nodes to obtain . This prevents the scenario where the adjacency matrix might be a zero power and ensures that the sum of landing probabilities is 1.
Obviously, if connected nodes and exhibit large and , they are positioned at the core of the digraph and contribute to the frequently activated during graph propagation, which introduces topological uncertainty to node representations. Notably, we have noticed that some spectral graph theory studies provide guidance on selecting from a strictly topological perspective. However, it is crucial to emphasize that these methods are not directly applied in node profile-driven classification tasks, thereby inherent limitations are present. For more experimental results and analysis, please refer to Sec. 6.2. To break this limitation, we directly assign a larger for from the topological perspective and combine the subsequent feature-oriented encoding, which is defined as:
| (7) |
4.2. Feature-related Correlation Encoding
At this point, we have achieved topology-related uncertainly encoding for frequently activated directed edges. However, node features equally play a pivotal role in digraph learning. Therefore, we aim to fully leverage the correlation of connected nodes to further fine-tune the magnetic field potentials on directed edges. Motivated by Key insight 2, we conclude the following principles: (1) A smaller for connected nodes with high feature similarity, disregarding directed information to mitigate knowledge dilution. (2) A larger for connected nodes with low feature similarity, emphasizing directed information to enhance knowledge discernibly. These principles enable the current node to acquire more beneficial knowledge.
According to Eq. (3), the complex plane is established by the -parameterized magnetic Laplacian. Each directed edge is depicted as a vector within this complex plane and its projection on the -axis(real part) is edge existence, while the projection on the -axis(imaginary part) is edge direction. For connected nodes and , dissimilar features lead to a larger with a greater angle for , indicating shorter projection along the -axis and longer projection along the -axis. This emphasizes direction during graph propagation and aligns with the previously mentioned principles. Consequently, we can directly leverage the correlation of features between connected nodes to encode the magnetic field potential of the corresponding directed edge, where node embeddings are obtained from -parameterized backbone MagDG. The above process can be formally defined as:
| (8) |
4.3. MAP Framework
Now, we have achieved fine-grained magnetic field potential encoding for directed edges, considering both topological and feature perspectives. This is reflected in the adaptive spatial phase angles of connected nodes in the complex domain. To pursue scalability, we reformulate the originally rigid -parameterized magnetic Laplacian from Eq. (3) in a weight-free manner to obtain the optimized graph propagation kernel . It can be formally defined as:
| (9) |
where is the initial magnetic field potential parameter. Since and lie within the range , can be adaptively scaled, thereby eliminating the need for manual adjustment.
4.4. MAP++ Framework
Despite the progress made by MAP, the weight-free method often encounters limited improvement. Furthermore, most MagDGs directly stack linear layers to implement message passing, resulting in strict dependencies between the current and the previous layer. This coupled architecture can only support shallow MagDGs with limited RFs and toy-size datasets, as deeper ones would suffer from the over-smoothing problem, out-of-memory (OOM) error, and out-of-time (OOT) error, especially in web-scale sparse digraphs. To break the above limitations, we propose MAP++ as follows:
Step 1: Edge-wise Graph Propagation. Based on the MAP, we first utilize a lightweight neural architecture parameterized by to further encode magnetic field potentials for each directed edge. In this strategy, we aim to enable iterative optimization through the training, which is formally defined as:
| (10) |
where denotes the element-wise matrix multiplication. Notably, this approach is only for small- and medium-scale datasets due to scalability. To increase the RF of nodes, we conduct -step complex-domain graph propagation, correspondingly getting a list of propagated features (i.e., messages) under different steps as follows:
| (11) |
Due to the learnable , gradients flow towards propagated features. Thus far, we have achieved edge-wise graph propagation by integrating adaptive magnetic field potential during training.
Step 2: Node-wise Message Aggregation. Recent studies (Frasca et al., 2020; Sun et al., 2021; Zhang et al., 2021c) have highlighted that the optimal RF varies for each node, influenced by the intricate semantic context. This insight is especially critical for digraphs in the complex domain, where multi-level structural encoding in Eq.(11) often provides valuable prompts within the coupling of real and imaginary components. Therefore, we advocate explicitly learning the importance and relevance of multi-granularity knowledge within different RF in a node-adaptive manner to boost predictions. This process can be defined as follows:
| (12) | ||||
where is the non-linear activation function. This mechanism is designed to construct a personalized multi-granularity representation fusion for each node, facilitating the weighted message aggregation. As the training progresses, the MAP++ gradually accentuates the importance of neighborhood regions in the complex domain that contribute more significantly to the target nodes.
5. Theoretical Analysis
Now, we have achieved adaptive magnetic field potential modeling for directed edges. To further investigate the effectiveness of our approach and ensure theoretical interpretability, we build upon insights from related studies (Singer, 2011; He et al., 2024) by extending the angular synchronization framework to graph attribute synchronization problem, which incorporates node features and directed topology.
Graph Attribute Synchronization. The conventional angular synchronization problem aims to estimate a set of unknown angles from noisy measurements of their pairwise offsets (Singer, 2011). The noise associated with these measurements is uniformly distributed over the interval . Based on this, we have:
Definition 0.
In the graph , each node is associated with an angle . Given noisy measurements of angle offsets , the angular synchronization problem aims to estimate the angles . The distribution of is divided into two categories: reliable (good) edges and unreliable (bad) edges
| (13) | ||||
Based on this, the adaptive phase matrix in MAP functions as a weighted adjacency matrix, reflecting the presence of edges and capturing the offsets, analogous to . By treating it as a noisy node feature offset matrix, we can generate attribute for each node based on the node features and directed topology and have:
Definition 0.
The graph attribute synchronization problem aims to estimate a set of unknown attributes based on their noisy adaptive complex-domain offsets , which are defined as:
| (14) |
This formulation demonstrates how the attributes can be inferred from the topology and phase information by leveraging the feature-related relationships between nodes. For the numerous zero values in the matrix , we treat them as noisy data.
Spectral Analysis in MAP. According to the related studies (Singer, 2011; Cucuringu et al., 2012; Cucuringu, 2016), solving the above graph attribute synchronization problem typically involves constructing a Hermitian matrix. We first investigate the MAP encoding process (see Sec. 4.1-4.2) and have:
Theorem 3.
The adaptive phase matrix encoding by MAP is skew-symmetric, and is Hermitian, where .
Based on this, we define the optimization objective as:
| (15) |
This formulation effectively captures complex-domain offsets from topology and feature perspectives. However, it remains a non-convex problem, making it difficult to solve in practice. Here, we introduce the relaxation: let and impose the constraint . This leads to the following optimization objective:
| (16) |
Obviously, the maximizer is given by , where is the normalized top eigenvector satisfying and , where is the largest eigenvalue of . Thus, the estimated attributes can be defined as: .
Although the adaptive phase matrix contains noise, which may cause discrepancies in estimations, but these discrepancies decrease as the noise reduces. Notably, even with significant noise, the eigenvector method can effectively recover attributes given enough noise-free equations. Furthermore, we demonstrate that if the adaptive phase matrix is devoid of noise, the estimated attributes correspond to true attributes. Based on this, we have the following theorems.
Theorem 4.
The correlation between the estimated node attributes and the true attributes is positively correlated with the number of nodes and inversely proportional to the square of the noise rate.
Theorem 5.
If is noise-free, represents the unique exact solution to the graph attribute synchronization problem.
Until now, we have provided the generalization of MAP to the graph attribute synchronization, offering theoretical robustness to our approach. Notably, traditional methods often rely on spectral methods based on rigid topology analysis to assign fixed for each edge (see Appendix A.10), which limits the flexibility and adaptability of the synchronization process. In contrast, MAP enables personalized values for each edge, considering not only the direction but also encoding uncertainty and correlation. In a nutshell, MAP significantly enhances optimization capabilities for attribute synchronization by offering a more nuanced approach to the assignment of . For detailed proofs of the above theorems, please refer to Appendix A.2-A.4. Additionally, we acknowledge that the recently proposed GNNSync (He et al., 2024) also provides a theoretical analysis from the perspective of graph attribute synchronization. For a further discussion of our approach and GNNSync, please see Appendix A.5.
6. Experiments
In this section, we aim to offer a comprehensive evaluation and address the following questions to verify the effectiveness of our proposed MAP and MAP++: Q1: As a hot-and-plug strategy, what is the impact of MAP on the existing MagDGs? Q2: How does MAP++ perform as a new digraph learning model? Q3: If MAP and MAP++ are effective, what contributes to their performance? Q4: What is the running efficiency of them? Q5: How robust is MAP and MAP++ when dealing with sparse scenarios? To maximize the usage for the constraint space, we will introduce datasets, baselines, and experiment settings in Appendix A.6-A.9.
6.1. Performance Comparison
A Hot-and-plug Optimization Module. To answer Q1, we present the performance enhancement facilitated by MAP in Table 1 and Table 2. We observe that MAP significantly benefits all methods. This is attributed to its adaptive encoding of magnetic field potentials for directed edges, thereby customizing propagation rules. Notably, due to the different numerical ranges of the metrics, the improvements at the node level are more pronounced. Meanwhile, the coupling architectures and the additional computational overhead result in scalability issues for MagNet and Framelet, leading to OOM errors when dealing with the billion-level dataset. Although MGC decouples the graph propagation, its advantages require multiple propagations to fully manifest, leading to incomplete training within 12 hours and resulting in OOT errors. For detailed algorithmic complexity analysis, please refer to Appendix A.1.
A New MagDG. To answer Q2, we present the experimental results in Table 3 and observe that MAP++ consistently outperforms all baselines. Notably, we do not conduct additional evaluations of MAP++ on link-level downstream tasks. This is because, as shown in Table 2, performance improvements are already anticipated. Given the limited space, we prioritized incorporating more SOTA undirected GNNs to ensure a fair comparison. However, their reliance on symmetric message-passing limits the recognition of complex directed relationships, leading to sub-optimal performance.
| Models | Actor | Empire | arXiv | Papers | Improv. |
|---|---|---|---|---|---|
| MagNet | 32.4±0.5 | 78.5±0.4 | 64.5±0.6 | OOM | 4.28 |
| +MAP | 34.0±0.4 | 82.8±0.4 | 68.0±0.4 | OOM | |
| MGC | 33.9±0.5 | 79.1±0.3 | 63.8±0.1 | OOT | 4.96 |
| +MAP | 35.2±0.3 | 82.8±0.4 | 67.6±0.2 | OOT | |
| Framelet | 33.1±0.6 | 79.8±0.3 | 64.7±0.1 | OOM | 4.54 |
| +MAP | 34.8±0.6 | 83.6±0.2 | 68.4±0.2 | OOM | |
| LightDiC | 33.6±0.4 | 78.8±0.2 | 65.6±0.2 | 65.4±0.2 | 5.12 |
| +MAP | 35.5±0.4 | 83.0±0.3 | 69.1±0.1 | 68.7±0.3 |
| Datasets | Slashdot (Link) | Epinions(Link) | Improv. | ||
| Tasks | Exist. | Direct. | Exist. | Direct. | |
| MagNet | 90.3±0.1 | 92.4±0.1 | 91.6±0.0 | 91.5±0.1 | 2.76 |
| +MAP | 92.1±0.0 | 93.2±0.1 | 93.2±0.1 | 93.4±0.1 | |
| MGC | 90.1±0.1 | 92.3±0.1 | 91.8±0.1 | 91.4±0.0 | 2.39 |
| +MAP | 91.9±0.1 | 93.4±0.0 | 93.0±0.0 | 93.0±0.1 | |
| Framelet | 90.5±0.0 | 92.5±0.1 | 91.5±0.1 | 91.0±0.1 | 2.46 |
| +MAP | 92.3±0.1 | 93.1±0.0 | 93.3±0.1 | 93.1±0.1 | |
| LightDiC | 90.2±0.1 | 92.4±0.0 | 91.6±0.0 | 91.2±0.1 | 2.81 |
| +MAP | 92.5±0.1 | 93.6±0.1 | 93.1±0.0 | 93.2±0.0 | |
| Models | CoraML | CiteSeer | WikiCS | Papers |
| GCNII | 80.84±0.5 | 62.55±0.6 | 77.42±0.3 | OOM |
| GATv2 | 81.31±0.9 | 62.82±1.0 | 77.03±0.4 | OOM |
| OptBG | 81.58±0.8 | 62.76±0.7 | 77.58±0.5 | 66.70±0.2 |
| NAG | 81.96±0.7 | 63.12±0.8 | 77.32±0.6 | OOM |
| GAMLP | 82.18±0.8 | 62.94±0.9 | 77.87±0.7 | 66.92±0.3 |
| D-HYPR | 81.72±0.5 | 63.87±0.7 | 77.76±0.2 | OOM |
| HoloNet | 81.53±06 | 64.13±0.8 | 78.66±0.3 | OOM |
| DGCN | 81.25±0.5 | 63.54±0.8 | 77.44±0.3 | OOM |
| DiGCN | 81.62±0.4 | 63.99±0.9 | 78.41±0.6 | OOM |
| NSTE | 81.87±0.6 | 63.63±0.7 | 77.63±0.4 | OOM |
| DIMPA | 82.05±0.9 | 63.14±0.9 | 77.94±0.3 | OOM |
| Dir-GNN | 81.93±0.7 | 64.29±0.8 | 78.09±0.4 | OOM |
| LightDiC | 81.76±0.4 | 64.19±0.6 | 78.35±0.2 | 66.83±0.2 |
| ADPA | 82.43±0.8 | 64.50±0.9 | 78.24±0.3 | 67.42±0.3 |
| MAP++ | 84.87±0.4 | 67.58±0.8 | 81.60±0.3 | 69.47±0.3 |
6.2. Ablation Study
| Model | CiteSeer | Tolokers | WikiTalk |
|---|---|---|---|
| Node-C | Node-C | Link-C | |
| MagNet | 64.21±0.63 | 79.04±0.22 | 90.42±0.15 |
| MagNet + MAP | 66.87±0.56 | 80.15±0.32 | 91.30±0.16 |
| w/o Topology (Local) | 66.53±0.78 | 79.84±0.48 | 91.11±0.13 |
| w/o Topology (Global) | 66.12±0.45 | 79.51±0.25 | 90.96±0.18 |
| w/o Feature Encoding | 65.60±0.50 | 79.34±0.36 | 90.78±0.12 |
| LightDiC | 63.96±0.38 | 79.18±0.19 | 90.21±0.10 |
| LightDiC + MAP | 67.25±0.37 | 80.36±0.27 | 91.05±0.14 |
| w/o Topology (Local) | 66.82±0.52 | 80.15±0.43 | 90.86±0.11 |
| w/o Topology (Global) | 66.46±0.39 | 79.73±0.32 | 90.74±0.15 |
| w/o Feature Encoding | 65.21±0.35 | 79.50±0.25 | 90.58±0.13 |
| MAP++ | 67.58±0.77 | 80.78±0.21 | 91.46±0.13 |
| w/o Edge-wise Prop | 67.10±0.84 | 80.36±0.28 | 91.12±0.15 |
| w/o Node-wise Agg | 66.49±0.65 | 80.12±0.24 | 90.78±0.12 |
The Key Design of MAP and MAP++. To answer Q3, we present experimental results in Table 4, evaluating the effectiveness of (1) Topology-related uncertainty and Feature-related correlation encoding in Sec. 4.3; (2) Edge-wise graph propagation and node-wise message aggregation in Sec. 4.4. We draw the following conclusions: (1) Local structural encoding models neighbor in a fine-grained manner, reducing the prediction variance of MagNet from 0.48 to 0.32 on the Tolokers. (2) Global structural encoding enhances performance upper bounds by regulating propagation granularity comprehensively. (3) Feature correlation is directly relevant to downstream tasks, thereby crucial for performance improvement. Specifically, it boosts LightDiC’s accuracy from 65.21 to 67.25 in CiteSeer. (4) Based upon these concepts, MAP++ introduces parameterized propagation kernels and attention-based message aggregation to further optimize predictions, leading to significant improvements.
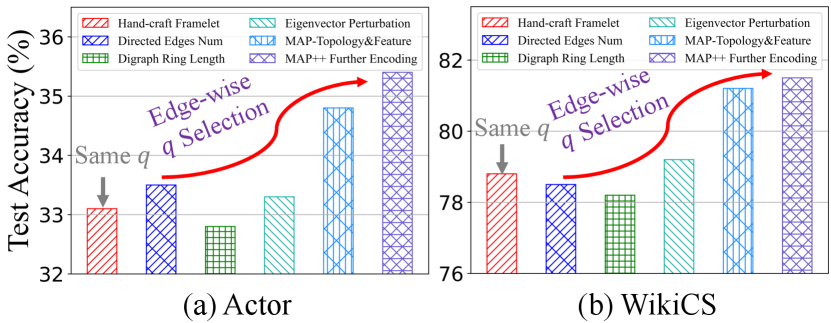

Selection in Spectral Graph Theory. As mentioned in Sec. 1, some studies provide selection guidance from a topology perspective (see Appendix A.10). In this section, we review relevant studies and compare their strategies with MAP and MAP++ in the context of digraph learning shown in Fig. 2. Drawing from experimental findings, we discern notable performance benefits exhibited by MAP and MAP++, highlighting the notion that previous approaches may not yield satisfactory results in digraph learning due to their limited incorporation of node profiles. Moreover, the performance of MAP++ validates the advantage of further encoding the magnetic field potentials of directed edges by learnable mechanisms.
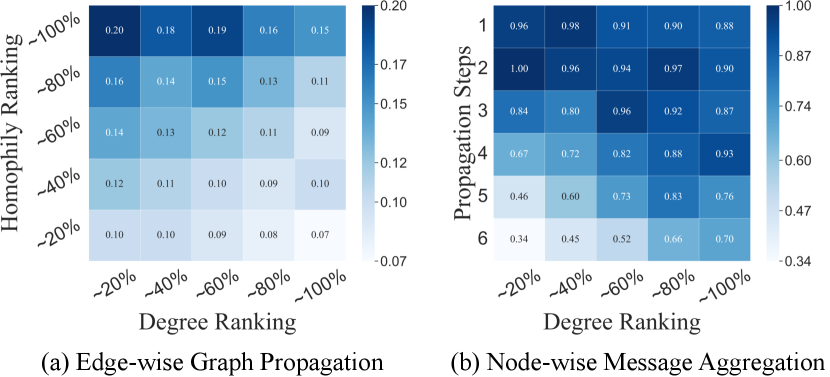
The Visualization of MAP++. To directly demonstrate the effectiveness of MAP++, we provide visualization in Fig. 3: (a) The average of directed edges within different nodes (topology-based degree ranking and feature-based homophily ranking). (b) The average attention weights of propagated features within different nodes (topology-based degree ranking) and propagation steps. Following observations validate our key insights in Sec. 3: (1) Fig. 3 (a) shows that smaller are chosen for pairs with higher-homophily, while larger are selected for pairs with higher degrees. The increase in as homophily decreases underscores the importance of node attributes in digraph learning. (2) Fig. 3 (b) shows that 1-3 step features hold significant importance, similar to 1-3 layer DiGNNs. For higher-degree nodes, the weights for larger steps decrease rapidly to prevent over-smoothing by limiting irrelevant information.
6.3. Efficiency Comparison
Convergence Improvement. To answer Q4, we present the experimental results in Fig. 4, where we observe that MAP significantly aids existing MagDGs in achieving faster and more stable convergence, along with higher accuracy. For instance, in WikiCS, MAP assists MGC in achieving rapid convergence around the 20th epoch, saving nearly half of the training cost. Notably, due to the sparse node features in Tolokers and the intricate topology in large-scale arXiv, all methods inevitably suffer from over-fitting issues and slow convergence. However, integrating MAP significantly enhances the training efficiency of all baselines and mitigates these issues.
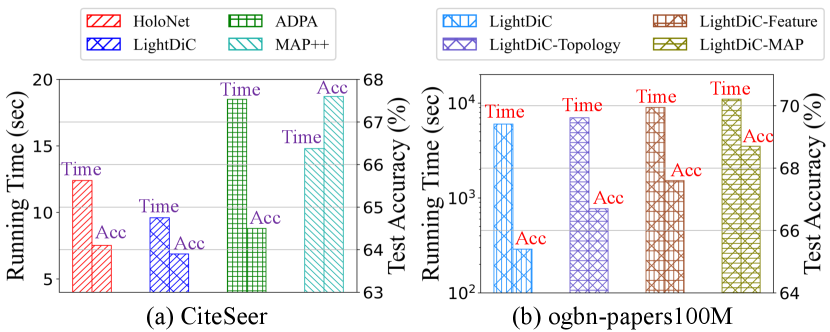
Runtime Overhead. We provide an efficiency visualization in Fig. 5. Despite the additional computational cost introduced by MAP for fine-grained graph propagation, the time overhead remains within acceptable limits and brings considerable performance improvement. This is facilitated by topology-related one-step pre-processing and intermittent feature-related encoding during training. Meanwhile, while MAP++ introduces extra trainable parameters, its overall time overhead remains lower than the most competitive ADPA, thanks to its decoupled design. Moreover, it exhibits significant performance advantages compared to other baselines.
6.4. Performance under Sparse Scenarios
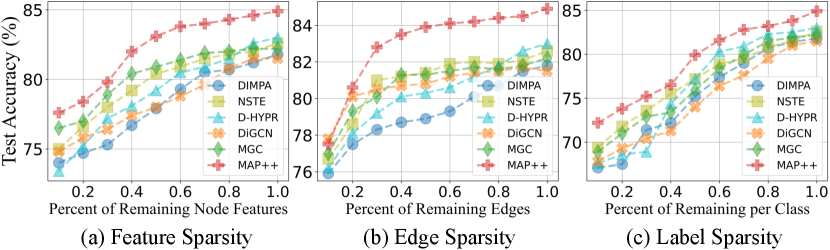
To answer Q5, we present experimental results in Fig. 6. For feature sparsity, we introduce partial missing features for unlabeled nodes. Consequently, methods relying solely on node quantity, such as D-HYPR, suffer performance degradation. Conversely, DiGCN, MGC, and MAP++ demonstrate resilience, as their high-order propagation partially compensates for the missing features. Regarding edge sparsity, since all baselines rely on topology to obtain high-quality node embeddings, they all face severe degradation. However, we observe that MAP++ outperforms others due to its fine-grained message passing. As for the label sparsity, we observe a similar trend to the feature sparsity. These findings collectively underscore the robustness enhancements achieved by MAP++ over baselines.
7. Conclusion
In recent years, MagDGs have stood out for edge direction modeling through the complex domain, inheriting insights from undirected graph learning. However, the extension of the -parameterized magnetic Laplacian to digraph learning remains under-explored. To emphasize such a research gap, we provide valuable empirical studies and theoretical analysis to obtain the -parameterized criteria for digraph learning. Based on this, we introduce two key techniques: MAP and MAP++. The achieved SOTA performance, coupled with flexibility and scalability, serves as compelling evidence of the practicality of our approach. A promising direction involves tailoring complex-domain graph propagation. Furthermore, an in-depth analysis of magnetic potential modeling from the perspective of topological dynamics shows great potential.
References
- (1)
- Akiba et al. (2019) Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD.
- Bian et al. (2020) Tian Bian, Xi Xiao, Tingyang Xu, Peilin Zhao, Wenbing Huang, Yu Rong, and Junzhou Huang. 2020. Rumor detection on social media with bi-directional graph convolutional networks. In Proceedings of the Association for the Advancement of Artificial Intelligence, AAAI.
- Bojchevski and Günnemann (2018) Aleksandar Bojchevski and Stephan Günnemann. 2018. Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via Ranking. In ICLR Workshop on Representation Learning on Graphs and Manifolds.
- Brody et al. (2022) Shaked Brody, Uri Alon, and Eran Yahav. 2022. How attentive are graph attention networks? International Conference on Learning Representations, ICLR (2022).
- Chat et al. (2019) Bilal A Chat, Hilal A Ganie, and S Pirzada. 2019. Bounds for the skew Laplacian spectral radius of oriented graphs. Carpathian Journal of Mathematics 35, 1 (2019), 31–40.
- Chen et al. (2023) Jinsong Chen, Kaiyuan Gao, Gaichao Li, and Kun He. 2023. NAGphormer: A tokenized graph transformer for node classification in large graphs. In International Conference on Learning Representations, ICLR.
- Chen et al. (2020) Ming Chen, Zhewei Wei, Zengfeng Huang, Bolin Ding, and Yaliang Li. 2020. Simple and deep graph convolutional networks. In International Conference on Machine Learning, ICML.
- Chung (2005) Fan Chung. 2005. Laplacians and the Cheeger inequality for directed graphs. Annals of Combinatorics 9 (2005), 1–19.
- Cucuringu (2016) Mihai Cucuringu. 2016. Sync-rank: Robust ranking, constrained ranking and rank aggregation via eigenvector and SDP synchronization. IEEE Transactions on Network Science and Engineering 3, 1 (2016), 58–79.
- Cucuringu et al. (2012) Mihai Cucuringu, Yaron Lipman, and Amit Singer. 2012. Sensor network localization by eigenvector synchronization over the Euclidean group. ACM Transactions on Sensor Networks (TOSN) 8, 3 (2012), 1–42.
- Fanuel et al. (2018) Michaël Fanuel, Carlos M Alaíz, Ángela Fernández, and Johan AK Suykens. 2018. Magnetic eigenmaps for the visualization of directed networks. Applied and Computational Harmonic Analysis 44, 1 (2018), 189–199.
- Fanuel et al. (2017) Michaël Fanuel, Carlos M Alaiz, and Johan AK Suykens. 2017. Magnetic eigenmaps for community detection in directed networks. Physical Review E 95, 2 (2017), 022302.
- Frasca et al. (2020) Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael Bronstein, and Federico Monti. 2020. Sign: Scalable inception graph neural networks. arXiv preprint arXiv:2004.11198 (2020).
- Furutani et al. (2020) Satoshi Furutani, Toshiki Shibahara, Mitsuaki Akiyama, Kunio Hato, and Masaki Aida. 2020. Graph signal processing for directed graphs based on the hermitian laplacian. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, ECML-PKDD. Springer.
- Geisler et al. (2023) Simon Geisler, Yujia Li, Daniel J Mankowitz, Ali Taylan Cemgil, Stephan Günnemann, and Cosmin Paduraru. 2023. Transformers meet directed graphs. In International Conference on Machine Learning, ICML. PMLR.
- Grave et al. (2018) Edouard Grave, Piotr Bojanowski, Prakhar Gupta, Armand Joulin, and Tomas Mikolov. 2018. Learning word vectors for 157 languages. arXiv preprint arXiv:1802.06893 (2018).
- Griffiths and Schroeter (2018) David J Griffiths and Darrell F Schroeter. 2018. Introduction to quantum mechanics. Cambridge university press.
- Guo and Wei (2023) Yuhe Guo and Zhewei Wei. 2023. Graph Neural Networks with Learnable and Optimal Polynomial Bases. (2023).
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. Advances in Neural Information Processing Systems, NeurIPS (2017).
- He et al. (2022a) Yixuan He, Michael Perlmutter, Gesine Reinert, and Mihai Cucuringu. 2022a. Msgnn: A spectral graph neural network based on a novel magnetic signed laplacian. In Learning on Graphs Conference, LoG.
- He et al. (2022b) Yixuan He, Gesine Reinert, and Mihai Cucuringu. 2022b. DIGRAC: Digraph Clustering Based on Flow Imbalance. In Learning on Graphs Conference, LoG.
- He et al. (2024) Yixuan He, Gesine Reinert, David Wipf, and Mihai Cucuringu. 2024. Robust angular synchronization via directed graph neural networks. International Conference on Learning Representations, ICLR (2024).
- He et al. (2023) Yixuan He, Xitong Zhang, Junjie Huang, Benedek Rozemberczki, Mihai Cucuringu, and Gesine Reinert. 2023. PyTorch Geometric Signed Directed: A Software Package on Graph Neural Networks for Signed and Directed Graphs. In Learning on Graphs Conference, LoG. PMLR.
- Horn and Johnson (2012) Roger A Horn and Charles R Johnson. 2012. Matrix analysis. Cambridge university press.
- Hu et al. (2020) Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. Advances in Neural Information Processing Systems, NeurIPS (2020).
- Huang et al. (2021) Qian Huang, Horace He, Abhay Singh, Ser-Nam Lim, and Austin R Benson. 2021. Combining label propagation and simple models out-performs graph neural networks. International Conference on Learning Representations, ICLR (2021).
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, ICLR.
- Koke and Cremers (2023) Christian Koke and Daniel Cremers. 2023. HoloNets: Spectral Convolutions do extend to Directed Graphs. arXiv preprint arXiv:2310.02232 (2023).
- Kollias et al. (2022a) Georgios Kollias, Vasileios Kalantzis, Tsuyoshi Idé, Aurélie Lozano, and Naoki Abe. 2022a. Directed graph auto-encoders. In Proceedings of the Association for the Advancement of Artificial Intelligence, AAAI.
- Kollias et al. (2022b) Georgios Kollias, Vasileios Kalantzis, Tsuyoshi Idé, Aurélie Lozano, and Naoki Abe. 2022b. Directed Graph Auto-Encoders. In Proceedings of the Association for the Advancement of Artificial Intelligence, AAAI.
- Leskovec et al. (2010) Jure Leskovec, Daniel Huttenlocher, and Jon Kleinberg. 2010. Signed networks in social media. In Proceedings of the SIGCHI conference on human factors in computing systems.
- Leskovec and Krevl (2014) Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford large network dataset collection. (2014).
- Lhoest et al. (2021) Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, et al. 2021. Datasets: A community library for natural language processing. arXiv preprint arXiv:2109.02846 (2021).
- Li and Pan (2016) Angsheng Li and Yicheng Pan. 2016. Structural information and dynamical complexity of networks. IEEE Transactions on Information Theory 62, 6 (2016), 3290–3339.
- Li et al. (2024a) Xunkai Li, Meihao Liao, Zhengyu Wu, Daohan Su, Wentao Zhang, Rong-Hua Li, and Guoren Wang. 2024a. LightDiC: A Simple Yet Effective Approach for Large-Scale Digraph Representation Learning. Proceedings of the VLDB Endowment (2024).
- Li et al. (2024b) Xunkai Li, Jingyuan Ma, Zhengyu Wu, Daohan Su, Wentao Zhang, Rong-Hua Li, and Guoren Wang. 2024b. Rethinking Node-wise Propagation for Large-scale Graph Learning. In Proceedings of the ACM Web Conference, WWW.
- Liang et al. (2023) Jiaxuan Liang, Jun Wang, Guoxian Yu, Wei Guo, Carlotta Domeniconi, and Maozu Guo. 2023. Directed acyclic graph learning on attributed heterogeneous network. IEEE Transactions on Knowledge and Data Engineering (2023).
- Likhobaba et al. (2023) Daniil Likhobaba, Nikita Pavlichenko, and Dmitry Ustalov. 2023. Toloker Graph: Interaction of Crowd Annotators. (2023). https://doi.org/10.5281/zenodo.7620795
- Lin and Gao (2023a) Lequan Lin and Junbin Gao. 2023a. A Magnetic Framelet-Based Convolutional Neural Network for Directed Graphs. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP.
- Lin and Gao (2023b) Lequan Lin and Junbin Gao. 2023b. A Magnetic Framelet-Based Convolutional Neural Network for Directed Graphs. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP.
- Luan et al. (2022) Sitao Luan, Chenqing Hua, Qincheng Lu, Jiaqi Zhu, Mingde Zhao, Shuyuan Zhang, Xiao-Wen Chang, and Doina Precup. 2022. Revisiting heterophily for graph neural networks. Advances in Neural Information Processing Systems, NeurIPS (2022).
- Luo et al. (2023) Yuankai Luo, Veronika Thost, and Lei Shi. 2023. Transformers over Directed Acyclic Graphs. Advances in Neural Information Processing Systems, NeurIPS (2023).
- Ma et al. (2021) Yao Ma, Xiaorui Liu, Neil Shah, and Jiliang Tang. 2021. Is homophily a necessity for graph neural networks? International Conference on Learning Representations, ICLR (2021).
- Ma et al. (2024) Zitong Ma, Wenbo Zhao, and Zhe Yang. 2024. Directed Hypergraph Representation Learning for Link Prediction. In International Conference on Artificial Intelligence and Statistics, AISTATS.
- Maekawa et al. (2023) Seiji Maekawa, Yuya Sasaki, and Makoto Onizuka. 2023. Why Using Either Aggregated Features or Adjacency Lists in Directed or Undirected Graph? Empirical Study and Simple Classification Method. arXiv preprint arXiv:2306.08274 (2023).
- Massa and Avesani (2005) Paolo Massa and Paolo Avesani. 2005. Controversial users demand local trust metrics: An experimental study on epinions. com community. In Proceedings of the Association for the Advancement of Artificial Intelligence, AAAI.
- Mernyei and Cangea (2020) Péter Mernyei and Cătălina Cangea. 2020. Wiki-CS: A Wikipedia-Based Benchmark for Graph Neural Networks. arXiv preprint arXiv:2007.02901 (2020).
- Ngo (2005) Khiem V Ngo. 2005. An approach of eigenvalue perturbation theory. Applied Numerical Analysis & Computational Mathematics 2, 1 (2005), 108–125.
- Ordozgoiti et al. (2020) Bruno Ordozgoiti, Antonis Matakos, and Aristides Gionis. 2020. Finding large balanced subgraphs in signed networks. In Proceedings of the ACM Web Conference, WWW.
- Pearson (1905) Karl Pearson. 1905. The problem of the random walk. Nature 72, 1865 (1905), 294–294.
- Pei et al. (2020) Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. 2020. Geom-gcn: Geometric graph convolutional networks. In International Conference on Learning Representations, ICLR.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In Proceedings of Conference on Empirical Methods in Natural Language Processing, EMNLP.
- Platonov et al. (2023) Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. 2023. A critical look at the evaluation of GNNs under heterophily: are we really making progress? International Conference on Learning Representations, ICLR (2023).
- Rossi et al. (2023) Emanuele Rossi, Bertrand Charpentier, Francesco Di Giovanni, Fabrizio Frasca, Stephan Günnemann, and Michael Bronstein. 2023. Edge Directionality Improves Learning on Heterophilic Graphs. in Proceedings of The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, ECML-PKDD Workshop (2023).
- Schweimer et al. (2022) Christoph Schweimer, Christine Gfrerer, Florian Lugstein, David Pape, Jan A Velimsky, Robert Elsässer, and Bernhard C Geiger. 2022. Generating simple directed social network graphs for information spreading. In Proceedings of the ACM Web Conference, WWW.
- Singer (2011) Amit Singer. 2011. Angular synchronization by eigenvectors and semidefinite programming. Applied and computational harmonic analysis 30, 1 (2011), 20–36.
- Song et al. (2022) Zixing Song, Xiangli Yang, Zenglin Xu, and Irwin King. 2022. Graph-based semi-supervised learning: A comprehensive review. IEEE Transactions on Neural Networks and Learning Systems (2022).
- Sun et al. (2021) Chuxiong Sun, Hongming Gu, and Jie Hu. 2021. Scalable and adaptive graph neural networks with self-label-enhanced training. arXiv preprint arXiv:2104.09376 (2021).
- Sun et al. (2024) Henan Sun, Xunkai Li, Zhengyu Wu, Daohan Su, Rong-Hua Li, and Guoren Wang. 2024. Breaking the Entanglement of Homophily and Heterophily in Semi-supervised Node Classification. In International Conference on Data Engineering, ICDE.
- Thost and Chen (2021) Veronika Thost and Jie Chen. 2021. Directed acyclic graph neural networks. arXiv preprint arXiv:2101.07965 (2021).
- Tong et al. (2020a) Zekun Tong, Yuxuan Liang, Changsheng Sun, Xinke Li, David Rosenblum, and Andrew Lim. 2020a. Digraph inception convolutional networks. Advances in Neural Information Processing Systems, NeurIPS (2020).
- Tong et al. (2020b) Zekun Tong, Yuxuan Liang, Changsheng Sun, David S Rosenblum, and Andrew Lim. 2020b. Directed graph convolutional network. arXiv preprint arXiv:2004.13970 (2020).
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2018. Graph attention networks. In International Conference on Learning Representations, ICLR.
- Virinchi and Saladi (2023) Srinivas Virinchi and Anoop Saladi. 2023. BLADE: Biased Neighborhood Sampling based Graph Neural Network for Directed Graphs. In Proceedings of the ACM International Conference on Web Search and Data Mining, WSDM.
- Wang et al. (2020) Kuansan Wang, Zhihong Shen, Chiyuan Huang, Chieh-Han Wu, Yuxiao Dong, and Anshul Kanakia. 2020. Microsoft academic graph: When experts are not enough. Quantitative Science Studies 1, 1 (2020), 396–413.
- Xu et al. (2018) Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. 2018. Representation learning on graphs with jumping knowledge networks. In International Conference on Machine Learning, ICML.
- Zhang et al. (2021b) Jie Zhang, Bo Hui, Po-Wei Harn, Min-Te Sun, and Wei-Shinn Ku. 2021b. MGC: A complex-valued graph convolutional network for directed graphs. arXiv e-prints (2021), arXiv–2110.
- Zhang et al. (2021c) Wentao Zhang, Yuezihan Jiang, Yang Li, Zeang Sheng, Yu Shen, Xupeng Miao, Liang Wang, Zhi Yang, and Bin Cui. 2021c. ROD: reception-aware online distillation for sparse graphs. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD.
- Zhang et al. (2022) Wentao Zhang, Ziqi Yin, Zeang Sheng, Yang Li, Wen Ouyang, Xiaosen Li, Yangyu Tao, Zhi Yang, and Bin Cui. 2022. Graph Attention Multi-Layer Perceptron. Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD (2022).
- Zhang et al. (2021a) Xitong Zhang, Yixuan He, Nathan Brugnone, Michael Perlmutter, and Matthew Hirn. 2021a. Magnet: A neural network for directed graphs. Advances in Neural Information Processing Systems, NeurIPS (2021).
- Zhang et al. (2024) Yusen Zhang, Yusong Tan, Songlei Jian, Qingbo Wu, and Kenli Li. 2024. DGLP: Incorporating Orientation Information for Enhanced Link Prediction in Directed Graphs. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP.
- Zhao et al. (2021) Xinxiao Zhao, Zhiyong Cheng, Lei Zhu, Jiecai Zheng, and Xueqing Li. 2021. UGRec: modeling directed and undirected relations for recommendation. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR.
- Zheng et al. (2022) Xin Zheng, Yixin Liu, Shirui Pan, Miao Zhang, Di Jin, and Philip S Yu. 2022. Graph neural networks for graphs with heterophily: A survey. arXiv preprint arXiv:2202.07082 (2022).
- Zhou et al. (2022) Honglu Zhou, Advith Chegu, Samuel S Sohn, Zuohui Fu, Gerard De Melo, and Mubbasir Kapadia. 2022. D-HYPR: Harnessing Neighborhood Modeling and Asymmetry Preservation for Digraph Representation Learning. Proceedings of the ACM International Conference on Information and Knowledge Management, CIKM (2022).
- Zou et al. (2024) Chunya Zou, Andi Han, Lequan Lin, Ming Li, and Junbin Gao. 2024. A Simple Yet Effective Framelet-Based Graph Neural Network for Directed Graphs. IEEE Transactions on Artificial Intelligence 5, 4 (2024), 1647–1657.
Appendix A Outline
The appendix is organized as follows:
- A.1:
-
Algorithm and Complexity Analysis.
- A.2:
-
The Proof of Theorem 3.
- A.3:
-
The Proof of Theorem 4.
- A.4:
-
The Proof of Theorem 5.
- A.5:
-
Our Approach and GNNSync.
- A.6:
-
Dataset Description.
- A.7:
-
Compared Baselines.
- A.8:
-
Hyperparameter Settings.
- A.9:
-
Experiment Environment.
- A.10:
-
Selection in Spectral Graph Theory.
A.1. Algorithm and Complexity Analysis
For a more comprehensive presentation, we provide the complete algorithm of MAP and MAP++ in Algorithm 1 and Algorithm 2.
| Type | Model | Pre-processing | Training | Inference | Memory |
|---|---|---|---|---|---|
| Others | D-HYPR | ||||
| HoloNet | |||||
| Directed | DGCN | ||||
| DiGCN | |||||
| NSTE | - | ||||
| DIMPA | |||||
| Dir-GNN | |||||
| ADPA | |||||
| Magnetic | MagNet | ||||
| MGC | |||||
| Framelet | |||||
| LightDiC | |||||
| MAP++ |
In this section, we provide an overview of recently proposed digraph neural networks and conduct a comprehensive analysis of their theoretical time and space complexity, as summarized in Table 5. To begin with, we clarify that the training and inference time complexity of the DGCN with layers and aggregators can be bounded by , where represents the total cost of the weight-free sparse-dense matrix multiplication in from Eq. (2), with DGCN utilizing GCN as the mechanism of aggregation function, and being the total cost of the feature transformation achieved by applying learnable aggregator weights. At first glance, may appear to be the dominant term, considering that the average degree in scale-free networks is typically much smaller than the feature dimension , thus resulting in . However, in practice, the feature transformation can be performed with significantly less cost due to the improved parallelism of dense-dense matrix multiplications. Consequently, emerges as the dominating complexity term of DGCN, and the execution of full neighbor propagation becomes the primary bottleneck for achieving scalability.
Building upon this, we first analyze two methods (hyperbolic for D-HYPR and frequency-response filters for HoloNet), D-HYPR (Zhou et al., 2022) and HoloNet (Koke and Cremers, 2023), which do not belong to the general message-passing paradigm. For D-HYPR, its core lies in projecting the digraph into -dimension hyperbolic space and designing trainable aggregators based on -order RF and -times aggregation. Consequently, its time complexity can be bounded by . As for HoloNet, it abandons the message-passing mechanism and focuses on digraph learning from a spectral perspective using holomorphic filters. The key lies in Fourier transform-based spectral decomposition, with the algorithm’s time complexity bounded by . Regarding the subsequent filter and corresponding learning mechanism design, it primarily depends on the size of the filter banks, hence can be bounded by .
Regarding methods following the prevalent directed message passing illustrated in Sec 2.2, DiGCN (Tong et al., 2020a) is similar to DGCN as they both use -order NP as pre-processing, but the generated real symmetric adjacency matrix is different. DiGCN extends approximate personalized PageRank for constructing digraph Laplacian as pre-processing with time complexity of , which is equivalent to the undirected symmetric adjacency matrix. NSTE (Kollias et al., 2022b) performs an additional aggregation based on the -order proximity in each learnable aggregator, which is bounded by . DIMPA (He et al., 2022b) extends the RF by considering incoming and outgoing edges independently in each aggregation step . Dir-GNN (Rossi et al., 2023) extends the -order based on edge direction and encodes it using two independent sets of parameters in trainable aggregators. Therefore, its time complexity can be bounded by . ADPA (Sun et al., 2024) further employs a hierarchical attention mechanism to fuse messages for both propagation operators and receptive fields, bounded respectively by and . The existing methods follow directed spatial message-passing mechanisms, which inherently rely on directed edges for aggregator design, making it challenging to handle large-scale digraphs. Furthermore, their use of two sets of independent learnable weights to encode source and target nodes results in a large , which further exacerbates the computational costs.
As for methods following the complex domain message passing, MAP++, MGC (Zhang et al., 2021b), and LightDiC (Li et al., 2024a) follow the decoupled paradigm, MageNet (Zhang et al., 2021a) and Framelet (Lin and Gao, 2023b) combines the propagation and training process into a deep coupled architecture. In the pre-processing, all approaches achieve a time complexity of to obtain the magnetic Laplacian, with the introduction of a complexity due to the complex-valued matrix. Then, MGC conducts multiple graph propagation approximately with significantly larger , bounded by . Framelet employs a spectral decomposition similar to HoloNet. However, Framelet extends the concept of wavelet transforms by integrating short-duration signals from different frequency bands to achieve more comprehensive data processing in signal representation. In contrast, MAP++ and LightDiC perform only a finite number of graph propagation with small , bounded by . In the training, as the magnetic Laplacian involves real and imaginary parts, the fully square recursive computation cost of MagNet and Framelet grows exponentially with the increase of the number of nodes and edges, reaching and . In contrast, MGC performs complex-valued forward propagation with a complexity of , while LightDiC further decouples the complex-valued matrices and reduces the computation complexity to by employing the simple linear logistic regression. Although their neural architectures are simple, they often encounter performance limitations when dealing with complex digraphs. Therefore, in MAP++, we introduce edge-wise graph propagation and node-wise message aggregation. Notably, the former operates only on directed structural entropy and local clustering coefficients, resulting in negligible computational overhead. Meanwhile, the computational complexity of the latter is strictly bounded by . Furthermore, during iterative training, we can intentionally reduce the encoding frequency to further reduce overhead.
A.2. The Proof of Theorem 3
Proof.
To prove the skew-symmetry of and the Hermitian property of , we begin by analyzing the relationships established in Eq. (7)-(9).
From Eq. (7), we observe that , indicating that the topological contribution to the parameter between nodes and is symmetric. Similarly, from Eq. (8), we find that , confirming that the feature-based contribution to is also symmetric. Therefore, by combining these two components in Eq. (9), we conclude that meaning that the overall parameter is symmetric with respect to nodes and .
Next, using this symmetry, we examine the matrix , which encodes the phase differences between nodes in the complex domain. Specifically, we have:. This relationship confirms that is skew-symmetric, meaning that . Here, for any real skew-symmetric matrix , the matrix is Hermitian. is skew-symmetric, it follows that is a Hermitian matrix. This property is crucial in ensuring that the matrix captures the directed dependencies between nodes in a way that preserves the necessary mathematical structure for subsequent analysis. In summary, the symmetry of leads to the skew-symmetry of , and as a result, is Hermitian, confirming the desired properties. ∎
A.3. The Proof of Theorem 4
Proof.
We suppose the proportion of noisy offsets in is . Let be the normalized vector defined as . With a probability of , the edge is good and . On the other hand, with a probability of , the edge is bad. The matrix can be decomposed as , where is a noise matrix.
According to (Singer, 2011), the correlation between and can be predicted by using regular perturbation theory for solving the eigenvector equation in an asymptotic expansion. In quantum mechanics (Griffiths and Schroeter, 2018), the asymptotic expansions of the non-normalized eigenvector is given by
| (17) |
Because , the angle between the eigenvector and the vector of true attributes satisfies the asymptotic relation
| (18) |
The expected values of the numerator terms in Eq. (18) are given by
| (19) | ||||
and
| (20) | ||||
because the variance of is given by (Singer, 2011) and . Based on the above three formulas, we can derive the following:
| (21) |
In the vast majority of cases, and , thus we further obtain the following formula:
| (22) |
This formulation indicates that when approaches infinity, the angle between and tends to zero and the correlation between them approaches . We further infer that even for extremely small values, the eigenvector method effectively retrieves the attributes if there are sufficient equations, meaning if is adequately large. ∎
A.4. The Proof of Theorem 5
Proof.
Since is noise-free, we define as an matrix where for all . As the is symmetric, it possesses a complete set of real eigenvalues , along with corresponding real orthonormal eigenvectors . We can express in terms of its eigenvalues and eigenvectors as follows:
| (23) |
Next, let be an diagonal matrix with diagonal elements . It is evident that is a unitary matrix, satisfying . We then construct the Hermitian matrix by conjugating with :
| (24) |
The eigenvalues of remain the same as those of , namely . The corresponding eigenvectors of , satisfying , are given by
| (25) |
Next, we observe the entries of :
| (26) |
According to the Perron-Frobenius theorem (Horn and Johnson, 2012), since is a non-negative matrix, the components of the top eigenvector associated with the largest eigenvalue are all positive:
| (27) |
Consequently, we examine the complex phases of the coordinates of the top eigenvector . Thus, the complex phases of the coordinates of are identical to the true attributes:
| (28) |
∎
A.5. Our Approach and GNNSync
The attribute synchronization problem we propose can also be addressed by GNNSync (He et al., 2024). It reframes the synchronization problem as a theoretically grounded digraph learning task, where angles are estimated by designing a specific GNN architecture to extract graph embeddings and leveraging newly introduced loss functions. This method has demonstrated superior performance in high-noise environments. Notably, our proposed MAP framework can further enhance the attribute synchronization process when integrated with GNNSync in the following two significant ways.
Firstly, MAP can act as an encoder within the GNNSync framework, generating higher-quality node embeddings compared to DIMPA used in the original implementation. By more effectively encoding both node features and topology, MAP improves the overall learning capability of the model. Secondly, the adaptive phase matrix introduced by MAP enables personalized encoding of directed edges, capturing critical directed information. This personalized encoding allows the generated node attributes to more accurately reflect the underlying characteristics of each node, ultimately improving the performance of the synchronization task. Through these enhancements, the MAP framework positions itself as a powerful tool for advancing the capabilities of GNNSync and other similar methods in digraph learning and attribute synchronization.
A.6. Dataset Description
| Datasets | #Nodes | #Edges | #Features | #Classes | #Train/Val/Test | Description |
| CoraML | 2,995 | 8,416 | 2,879 | 7 | 140/500/2,355 | citation network |
| CiteSeer | 3,312 | 4,591 | 3,703 | 6 | 120/500/2,692 | citation network |
| Actor | 7,600 | 26,659 | 932 | 5 | 48%/32%/20% | actor network |
| WikiCS | 11,701 | 290,519 | 300 | 10 | 580/1,769/5,847 | weblink network |
| Tolokers | 11,758 | 519,000 | 10 | 2 | 50%/25%/25% | crowd-sourcing network |
| Empire | 22,662 | 32,927 | 300 | 18 | 50%/25%/25% | article syntax network |
| Rating | 24,492 | 93,050 | 300 | 5 | 50%/25%/25% | rating network |
| ogbn-arXiv | 169,343 | 2,315,598 | 128 | 40 | 91k/30k/48k | citation network |
| ogbn-papers100M | 111,059,956 | 1,615,685,872 | 128 | 172 | 1207k/125k/214k | citation network |
| Slashdot | 75,144 | 425,702 | 100 | Link-level | 80%/15%/5% | social network |
| Epinions | 114,467 | 717,129 | 100 | Link-level | 80%/15%/5% | social network |
| WikiTalk | 2,388,953 | 5,018,445 | 100 | Link-level | 80%/15%/5% | co-editor network |
In our experiments, we evaluate the performance of our proposed MAP and MAP++ on 12 digraph benchmark datasets. The 12 publicly available digraph datasets are sourced from multiple domains, highlighting the comprehensive nature of our experiments. Specifically, they include 4 citation networks (CoraML, Citeseer, ogbn-arXiv, and ogbn-papers100M) in (Bojchevski and Günnemann, 2018; Mernyei and Cangea, 2020; Hu et al., 2020), actor network (Actor) (Pei et al., 2020), web-link network (WikiCS) in (Mernyei and Cangea, 2020), crowd-sourcing network (Toloklers) (Platonov et al., 2023), e-commerce network (Rating) (Platonov et al., 2023), syntax network (Empire) (Platonov et al., 2023), 2 social networks (Slashdot and Epinions) in (Ordozgoiti et al., 2020; Massa and Avesani, 2005), and co-editor network (Leskovec et al., 2010). The dataset statistics are shown in Table 6 and more descriptions can be found later.
Notably, given MAP and MAP++ focus on providing tailored solutions for complex domain message passing based on the magnetic Laplacian, and considering that directed information is disregarded in undirected graphs, we opted not to use undirected graphs as validation datasets and instead focused our efforts on digraph benchmark datasets.
We need to clarify that we are using the directed version of the dataset instead of the one provided by the PyG library (CoraML, CiteSeer)111https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html, WikiCS paper222https://github.com/pmernyei/wiki-cs-dataset and the raw data given by the OGB (ogb-arxiv)333https://ogb.stanford.edu/docs/nodeprop/. Meanwhile, we remove the redundant multiple and self-loop edges to further normalize the 10 digraph datasets. In addition, for Slashdot, Epinions, and WikiTalk, the PyGSD (He et al., 2023) library reveals only the topology and lacks the corresponding node features and labels. Therefore, we generate the node features using eigenvectors of the regularised topology. Building upon this foundation, the description of all digraph benchmark datasets is listed below:
CoraML and CiteSeer (Bojchevski and Günnemann, 2018) are two citation network datasets. In these two networks, papers from different topics are considered nodes, and the edges are citations among the papers. The node attributes are binary word vectors, and class labels are the topics the papers belong to.
Actor (Pei et al., 2020) is an actor co-occurrence network in which nodes denote actors, and edges signify actors appearing together on Wikipedia pages. Node features are bag-of-words vectors derived from keywords found on these Wikipedia pages. They are categorized into five groups based on the terms found in the respective actor’s Wikipedia page.
WikiCS (Mernyei and Cangea, 2020) is a Wikipedia-based dataset for bench-marking GNNs. The dataset consists of nodes corresponding to computer science articles, with edges based on hyperlinks and 10 classes representing different branches of the field. The node features are derived from the text of the corresponding articles. They were calculated as the average of pre-trained GloVe word embeddings (Pennington et al., 2014), resulting in 300-dimensional node features.
Tolokers (Platonov et al., 2023) is derived from the Toloka crowdsourcing platform (Likhobaba et al., 2023). Nodes correspond to tolokers (workers) who have engaged in at least one of the 13 selected projects. An edge connects two tolokers if they have collaborated on the same task. The objective is to predict which tolokers have been banned in one of the projects. Node features are derived from the worker’s profile information and task performance statistics.
Empire (Platonov et al., 2023) is based on the Roman Empire article from the English Wikipedia (Lhoest et al., 2021), each node in the graph corresponds to a non-unique word in the text, mirroring the article’s length. Nodes are connected by an edge if the words either follow each other in the text or are linked in the sentence’s dependency tree. Thus, the graph represents a chain graph with additional connections.
Rating (Platonov et al., 2023) is derived from the Amazon co-purchasing network metadata available in the SNAP444https://snap.stanford.edu/ (Leskovec and Krevl, 2014). Nodes are products, and edges connect items bought together. The task involves predicting the average rating given by reviewers, categorized into five classes. Node features are based on the mean FastText embeddings (Grave et al., 2018) of words in the product description. To manage graph size, only the largest connected component of the 5-core is considered.
Ogbn-arxiv and ogbn-papers100M (Hu et al., 2020) are two citation graphs indexed by MAG (Wang et al., 2020). For each paper, we generate embeddings by averaging the word embeddings from both its title and abstract. These word embeddings are computed using the skip-gram model, which captures the semantic relationships between words based on their context. This approach allows us to create a comprehensive representation of the paper’s content.
Slashdot (Ordozgoiti et al., 2020) is from a technology-related news website with user communities. The website introduced Slashdot Zoo features that allow users to tag each other as friends or foes. The dataset is a common signed social network with friends and enemies labels. In our experiments, we only consider friendships.
Epinions (Massa and Avesani, 2005) is an online social network centered around ”who-trusts-whom” dynamics relationship systems, where users can indicate trust or distrust tags in the reviews and opinions uploaded by other users. This network captures social interactions and the formation of trust within the community. For the purposes of our experiments, we focus solely on the ”trust” relationships, excluding the ”distrust” connections to streamline our analysis.
WikiTalk (Leskovec et al., 2010) includes all users and discussions from the inception of Wikipedia until January 2008. The network comprises nodes, where each node represents a Wikipedia user, and a directed edge from node to node indicates that user edited user ’s talk page at least once. For our analysis, we extract the largest weakly connected component.
A.7. Compared Baselines
The baselines we employ are as follows: (1) Directed prevalent message passing-based approaches: DGCN (Tong et al., 2020b), DiGCN (Tong et al., 2020a), DIMPA (He et al., 2022b), NSTE (Kollias et al., 2022b), Dir-GNN (Rossi et al., 2023), and ADPA (Sun et al., 2024); (2) Directed MagDGs: MagNet (Zhang et al., 2021a), MGC(Zhang et al., 2021b), Framelet-Mag (Framelet) (Lin and Gao, 2023b), LightDiC (Li et al., 2024a). (3) Undirected methods and other digraph neural networks: GCN (Kipf and Welling, 2017), GAT (Veličković et al., 2018), GCNII (Chen et al., 2020), GATv2 (Brody et al., 2022), OptBasisGNN (Guo and Wei, 2023) (OptBG), NAGphormer (Chen et al., 2023) (NAG), GAMLP (Zhang et al., 2022), D-HYPR (Zhou et al., 2022), and HoloNet (Koke and Cremers, 2023). Notably, to verify the generalization of our proposed MAP and MAP++, we compare the undirected GNNs in digraphs with coarse undirected transformation (i.e., convert directed edges into undirected edges). The descriptions of them can be found later in this section. To alleviate the influence of randomness, we repeat each experiment 10 times to represent unbiased performance and running time (second report). Meanwhile, we present experiment results with various baselines in separate modules, avoiding abundant charts and validating the generalizability of our proposed methods.
DGCN (Tong et al., 2020b): DGCN proposes the first and second-order proximity of neighbors to design a new message-passing mechanism, which in turn learns aggregators based on incoming and outgoing edges using two sets of independent learnable parameters.
DiGCN (Tong et al., 2020a): DiGCN notices the inherent connections between graph Laplacian and stationary distributions of PageRank, it theoretically extends personalized PageRank to construct real symmetric Digraph Laplacian. Meanwhile, DiGCN uses first-order and second-order neighbor proximity to further increase RF.
DIMPA (He et al., 2022b): DIMPA represents source and target nodes separately. It performs a weighted average of the multi-hop neighborhood information to capture the local network information.
NSTE (Kollias et al., 2022b): NSTE is inspired by the 1-WL graph isomorphism test, which uses two sets of trainable weights to encode source and target nodes separately. Then, the information aggregation weights are tuned based on the parameterized feature propagation process.
Dir-GNN (Rossi et al., 2023): Dir-GNN introduces a versatile framework tailored for heterophilous settings. It addresses edge directionality by conducting separate aggregations of incoming and outgoing edges. Demonstrated to match the expressivity of the directed Weisfeiler-Lehman test, Dir-GNN outperforms conventional MPNNs in accurately modeling digraphs.
ADPA (Sun et al., 2024): ADPA adaptively explores suitable directed k-order neighborhood operators to conduct weight-free graph propagation and employs two hierarchical node-adaptive attention mechanisms to acquire optimal node representations.
MagNet (Zhang et al., 2021a): MagNet utilizes complex numbers to model directed information, it proposes a spectral GNN for digraphs based on a complex Hermitian matrix known as the magnetic Laplacian. Meanwhile, MagNet uses additional trainable parameters to combine the real and imaginary filter signals separately to achieve better prediction performance.
MGC (Zhang et al., 2021b): MGC introduces the magnetic Laplacian, a discrete operator with the magnetic field, which preserves edge directionality by encoding it into a complex phase with an electric charge parameter. By adopting a truncated variant of PageRank named Linear-Rank, it designs and builds a low-pass filter for homogeneous graphs and a high-pass filter for heterogeneous graphs.
Framelet (Lin and Gao, 2023b): Framelet utilizes the framelet transform to enhance the representation of digraph signals. These framelets are constructed using the complex-valued magnetic Laplacian, enabling signal processing in both real and complex domains simultaneously.
LightDiC (Li et al., 2024a): LightDiC is a scalable adaptation of digraph convolution built upon the magnetic Laplacian, which performs topology-related computations during offline pre-processing.
GCN (Kipf and Welling, 2017): GCN is guided by a localized first-order approximation of spectral graph convolutions. This model’s scalability is directly proportional to the number of edges, and it learns intermediate representations in hidden layers that capture both the topology and node features.
GCNII (Chen et al., 2020): GCNII incorporates initial residual and identity mapping. Theoretical and empirical evidence is presented to demonstrate how these techniques alleviate the over-smoothing problem.
GAT (Veličković et al., 2018): GAT utilizes attention mechanisms to quantify the importance of neighbors for message aggregation. This strategy enables implicitly specifying different weights to different nodes in a neighborhood, without depending on the graph structure upfront.
GATv2 (Brody et al., 2022): GATv2 introduces a variant with dynamic graph attention mechanisms to improve GAT. This strategy provides better node representation capabilities and enhanced robustness when dealing with graph structure as well as node attribute noise.
OptBasisGNN (Guo and Wei, 2023): OptBasisGNN revolutionizes GNNs by redefining polynomial filters. It dynamically learns suitable polynomial bases from training data, addressing fundamental adaptability.
NAGphormer (Chen et al., 2023) treats each node as a sequence containing a series of tokens. For each node, it aggregates the neighborhood features from different hops into different representations.
GAMLP (Zhang et al., 2022): GAMLP is designed to capture the inherent correlations between different scales of graph knowledge to break the limitations of the enormous size and high sparsity level of graphs hinder their applications under industrial scenarios.
D-HYPR (Zhou et al., 2022): D-HYPR introduces hyperbolic from diverse neighborhoods. This conceptually simple yet effective framework extends seamlessly to digraphs with cycles and non-transitive relations, showcasing versatility in various downstream tasks.
HoloNet (Koke and Cremers, 2023): HoloNet demonstrates that spectral convolution can extend to digraphs. By leveraging advanced tools from complex analysis and spectral theory, HoloNet introduces spectral convolutions tailored for digraphs.
A.8. Hyperparameter Settings
The hyperparameters in the baseline models are set according to the original paper if available. Otherwise, we perform a hyperparameter search via the Optuna (Akiba et al., 2019). For both our proposed methods, MAP and MAP++, their satisfactory flexibility in method and neural architecture design obviates the need for additional hyperparameter search. However, we recommend exploring the number of graph propagation steps and the dimension of hidden embeddings within the range of and to further enhance predictive performance. Regarding the experimental results of Dir-GNN and HoloNet on the Empire dataset, we would like to clarify that we ensured a fair comparison by using a class-balanced dataset split instead of the pre-split datasets used in Dir-GNN and HoloNet.
A.9. Experiment Environment
The experiments are conducted on the machine with Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz, and NVIDIA A100 80GB PCIe and CUDA 12.2. The operating system is Ubuntu 18.04.6 with 216GB memory. As for software versions in the environment, we use Python 3.9 and Pytorch 1.11.0.
A.10. Selection in Spectral Graph Theory
(1) Directed Edges Num (Geisler et al., 2023): It posits that the potential governs the magnitude of the induced phase shift by each edge. Specifically, in its application to digraph-level classification and regression, assumes a role akin to the lowest frequency in sinusoidal positional encodings (typically . Following the sinusoidal encoding convention, one could fix to a suitable value for the largest expected graphs. However, in their experiments, they found that scaling the potential with the number of nodes and the quantity of directed edges leads to marginally better performance. In other words, they suggest opt for with as the relative potential and as the graph-specific normalizer. This normalizer is an upper bound on the number of directed edges in a simple path, calculated as , where denotes the count of purely directed edges ( where .
(2) Digraph Ring Length (Fanuel et al., 2018, 2017): It proposes a unique perspective on the , suggesting its suitability for positional encodings. Specifically, in graph visualization, the selection of is related to the ring length. If the ring length is , then . They advocate for selecting as a rational number, such as , which proves effective for visualizing graphs comprising directed triangles. In this context, each edge within a directed triangle induces a shift, resulting in a cumulative shift of 360 degrees for the triangle.
(3) Eigenvector Perturbation (Furutani et al., 2020): It claims that the choice of the rotation parameter influences the graph Fourier transform. They propose an expedient method to select for graph signal processing. Let be the tolerance of the smallest eigenvalue of the Hermitian Laplacian of an unweighted directed graph , that is . Then, they denote the eigenvalue and associated eigenvector of the symmetrized Laplacian of as and , respectively. According to eigenvalue perturbation theory (Ngo, 2005), they obtain . Thus, one can choose depending only on the average degree and the tolerance of the smallest eigenvalue .