Toward quantitative fractography using convolutional neural networks
Abstract
The science of fractography revolves around the correlation between topographic characteristics of the fracture surface and the mechanisms and external conditions leading to their creation. While being a topic of investigation for centuries, it has remained mostly qualitative to date. A quantitative analysis of fracture surfaces is of prime interest for both the scientific community and the industrial sector, bearing the potential for improved understanding on the mechanisms controlling the fracture process and at the same time assessing the reliability of computational models currently being used for material design. With new advances in the field of image analysis, and specifically with machine learning tools becoming more accessible and reliable, it is now feasible to automate the process of extracting meaningful information from fracture surface images. Here, we propose a method of identifying and quantifying the relative appearance of intergranular and transgranular fracture events from scanning electron microscope images. The newly proposed method is based on a convolutional neural network algorithm for semantic segmentation. The proposed method is extensively tested and evaluated against two ceramic material systems (,) and shows high prediction accuracy, despite being trained on only one material system (). While here attention is focused on brittle fracture characteristics, the method can be easily extended to account for other fracture morphologies, such as dimples, fatigue striations, etc.
Department of Continuum Mechanics and Structural Analysis. University Carlos III of Madrid. Avda. de la Universidad, 30. 28911 Leganés, Madrid, Spain.
Sertec, AEROSERTEC Group, Avda. Rita Levi Monatalcini, 14, 28906 Getafe, Madrid, Spain.
Faculty of Mechanical Engineering, Technion - Israel Institute of Technology, Haifa, Israel.
Correspondence: Shmuel Osovski (shmuliko@technion.ac.il)
The fracture process of materials is governed by both extrinsic (e.g. imposed loading, environmental conditions) and intrinsic (microstructure) characteristics. One may thus expect, that the fracture surface will contain evidence regarding the influence of both the intrinsic and extrinsic characteristics of the fracture process. Fractography is a powerful tool employed to study fracture surfaces and extract information regarding material properties and factors leading to failure. The main objective of fractography is the topographic characterization of the fractured surfaces, aiming to identify and classify the different operating fracture mechanisms, and correlating them with the material’s microstructure, its mechanical behavior, and the conditions leading to failure. While the study of fracture surfaces dates back to the sixteenth century [1], the lack of quantitative robust methods to describe the complex geometries which compose the fracture surface, has rendered these studies to be mostly qualitative in nature.
Currently, the quantitative and qualitative examination of the fracture surfaces is a cumbersome process, performed manually by experienced personnel,thus demanding substantial labor and qualifications. Moreover, the heavy reliance on the human factor in the process is prone to errors in quantitative estimations. The automation of this process and the quantitative study of fracture surface has posed a long standing challenge. In terms of industrial relevance, the strength of quantitative, automated fractography lies mostly in the ease and reliability of finding the root cause of fracture in failure analysis of components, a process which today is only performed by very experienced individuals. In terms of scientific value, it holds the promise of unraveling new and exciting insights as to the way materials fail. It is sufficient to mention just some of the lessons learned through careful fractographic analysis to realize the importance of making new progress in the field. Among those are the micro-mechanisms leading to ductile fracture [2], the process of cleavage in metals [3] and the origin of striations in fatigue fracture [4].
In the context of brittle fracture of ceramic materials, two primary modes of crack propagation are often observed: transgranular and intergranular. The former mode (transgranular) results from crack propagation through a cleavage mechanism of the grains, while in the later (intergranular) the crack propagation is facilitated through grain separation along grain boundaries. The two propagation modes provide evidence as to the grain boundaries strength, environmental conditions and material anisotropy. In many scenarios, both crack growth mechanisms will be activated and their relative occurrence can testify as to the applied loading rate [5, 6], chemical environment and loading history [7], as well as to the presence of changes in the initial microstructure [8].
With recent progress in the fields of materials design, grain boundary engineering and computational modeling of fracture, it is now feasible to find an optimal microstructure along with establishing the processing routes to manufacture it. In the field of brittle fracture, the role of grain boundary properties on transgranular fracture and the resulting fracture toughness was recently addressed [9] using finite elements calculations, leading to the conclusion that microstructural engineering with respect to grain morphology can lead to enhanced performance. Similar observations were made for metastable Ti alloys where the fracture process is predominantly along grain boundaries [10]. The use of computational models for microstructural design, requires that they can be validated against experiments. While crack growth resistance curves can be reproduced in simulations and compared with experimental data, combining those with quantitative data extracted directly from experimentally obtained fracture surfaces will tremendously increase the reliability of such models. One such comparison, for example, is the relative area fractions of transgranular and intergranular crack propagation modes obtained from experiments and numerical simulations[9]
Some of the initial approaches toward the automation of fractographic features extraction utilized computer vision and image processing techniques to classify and characterize the optical microscopy or the Scanning Electron Microscopy (SEM) fracture images. Hu et. al.[11] employed edge detection and peak finding algorithms to determine the fatigue crack growth from optical microscope fracture images, while in the work of Kosarevych[12] the histogram of brightness information enabled the feature segmentation of SEM fracture images. Similarly, various texture analysis methods (gray level co-occurrence matrix, run length statistical analysis, box-counting, Fourier power spectrum, etc.) were utilized to identify different fracture surface morphologies and characterizing micrographs or fractographs of several steels[13, 14]. Focusing our attention back to brittle fracture mechanisms, Yang et. al[15] proposed an automated procedure for the quantification of transgranular vs intergranular fracture from SEM images. The method proposed by Yang et. al[15] is based on analyzing local intensity profiles obtained by SEM secondary-electron detector. The profiles are then analyzed with respect to the average grain size and following the procedure detailed in [15], regions are determined as transgranular or intergranular. While offering an automated method for quantification of brittle fracture surfaces, this method still requires additional inputs from the user which reduces its robustness. Similarly, the application of this method requires the user to follow several restricting assumptions regarding the size distribution of microstructural features, and will pose a challenge for highly irregular surfaces, where achieving the required contrast simultaneously with a larger depth of focus becomes problematic for images taken over large areas.
More recently, advances in machine learning and artificial intelligence have captured the attention of the materials characterization community as a way to classify and quantify data available from various characterization techniques. Microstructure classification and defect analysis have been shown to be feasible through the usage of machine learning methods[16, 17, 18, 19]. In the field of fractography, a few attempts to use these methods to develop computerized models for quantitative fractography have been published. More specifically, Bastidas-Rodriguez et. al[20] combined texture analysis techniques with non-linear machine learning classifiers (artificial neural networks and support vector machine) in order to classify optical microscope fracture images in three different modes: brittle sudden, ductile sudden and fatigue. Additionally, in a recent work [21] convolutional neural networks have been used for the detection of dimples and edges on SEM ductile fracture images of titanium alloys. To the best of our knowledge, this is the only published work using exclusively machine learning methods for classification of fracture surfaces.
Here, we present a new method for the automatic topographic characterization of fracture surfaces, based on Convolutional Neural Network (CNN) Semantic Segmentation[22]. The architecture of modern deep learning algorithms for semantic segmentation is divided into two main parts: the encoder and the decoder part. The encoder is usually the backbone architecture of some of the most efficient convolutional neural networks classifiers, such as VGG [23], ResNet [24] or GoogLeNet [25]. Using this architecture for the encoder, besides the obvious benefit of using a well-proven network, allows us to make use of transfer learning [26, 27]. As a result of previous research work, one can find pre-trained weights for each one of the above mentioned encoder architectures on different datasets [28, 29], and by fine-tuning[27] them it is possible to achieve high accuracy training for a new dataset. This method significantly reduces the computation time for training and performs considerably better when compared to random weights initialization. This is extremely useful when training networks for a relatively small training dataset. The CNN, after being trained on SEM fracture images of brittle material, is able to classify every pixel of any new SEM image of the same material. During the training process the network is using a dataset consisted of SEM images of fracture surfaces of Magnesium Aluminate Spinel () samples, in order to learn how to extract characteristic features of the different fracture modes that will allow it to perform accurate predictions on any new image; this function is graphically demonstrated in Figure 1 .
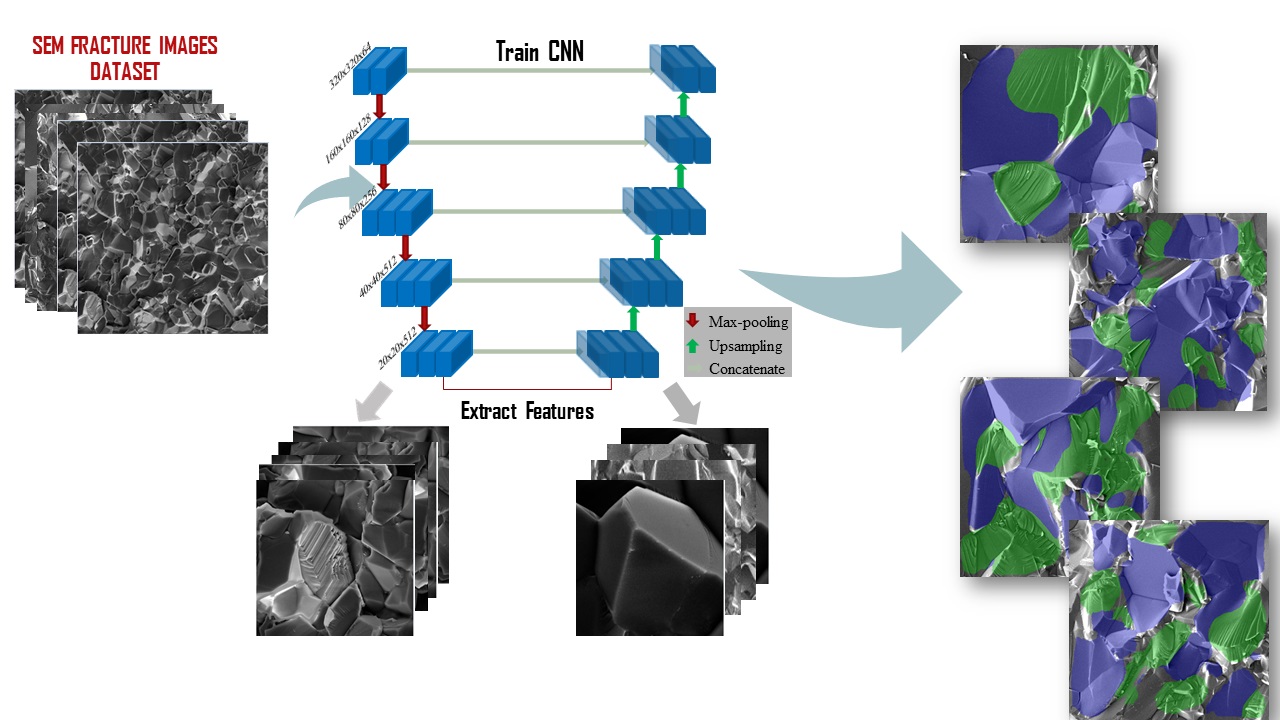
Results and discussion
The aim of quantitative fractography is to find well defined mathematical descriptors which represent the complex topographic morphology of fracture surfaces. These complex morphologies encode the interlacing of the material’s microstructure and intrinsic mechanical properties with the externally applied loads and environmental conditions[30]. For brittle materials, such as ceramics, the fracture process is often observed to take place using two alternating micromechanisms: transgranular and intergranular crack growth. In real life scenarios, a combination of the two is often observed on the fracture surface. The presence of each mechanism can attest to the material’s inherent microstructure, the strength of the grain boundaries and the conditions which led to its failure. For example, when exposed to corrosive agents, ceramics often exhibit a transition toward intergranular dominated crack growth, while rapid cracks are more prone to exhibit transgranular fracture. Unfortunately, the process of quantifying the relative occurrence of each mechanism as observed on the fracture surface is cumbersome and highly user biased. The existence of two different modes and the need of topographic characterization of the fractures is what makes the task at hand challenging. Moreover, when going from one material system to the other, the size of the features on the fracture surface as well as their height fluctuations can vary drastically. Simple classification or object detection algorithms based on deep learning methods are not able to effectively tackle these challenges. The capability of the semantic segmentation algorithms to classify every pixel in the SEM images allows the topographic characterization of the fracture surface, making this approach ideal for a fractographic analysis. Several network architectures were considered and the U-net architecture (see Methods section) was found to yield slightly better results and hence, the results presented in this work are the predictions of the U-net algorithm on the images of the test dataset. Fig. 2 shows one of the SEM images used for the training of the network and the corresponding annotation.


The objective of the training dataset annotation process is to classify the areas of the SEM images that presented the most characteristic features of each micro-fracture mode, while the areas with unclear classification or ambiguous features are labeled as background. This partial annotation was inevitable. The results presented herein can be improved, given a larger, annotated, training set. All of the data used to train the CNN presented here, as well as the source code is freely available on-line with the aim of establishing a large database of fracture surfaces and extending our work to other materials and failure mechanisms.
During the training process, the algorithm uses the categorical cross-entropy loss in order to determine the deviation between the network predictions and the ground truth data provided by us with the annotated images. The gradient of the loss with respect to the weights is used to perform the updating of the weights during the back-propagation stage of the training. Recording the evolution of the loss allows us to monitor the training process. Similarly, at the end of each epoch the categorical cross-entropy loss of the algorithm’s predictions on the validation dataset is computed. The calculation of the prediction accuracy from the loss values is straightforward. It is important to stress that these accuracy values are with respect to the partial annotations that we have manually created from the SEM images. Hence, they do not represent the exact accuracy of the network predictions, but they constitute a very important indication of the efficiency of the algorithm. The training accuracy saturates around a mean value of 72.5%, while the accuracy on the validation dataset is approximately 71%.
After the completion of the training, the trained weights of each layer of the network are exported and saved. Importing these trained weights to a prediction algorithm enables the classification of every pixel in a new SEM image of the fracture surface. The test dataset of the SEM images is used to perform the final evaluation of the algorithm. Following the standard procedures for evaluation of an algorithm in machine learning, the test images have not been used during the training. Although, the network has been trained with images of size pixels, it is capable of performing predictions in SEM images of any size, as long as the GPU or CPU memory of the computer can handle the image size.
Figure 3 shows the predictions of the algorithm on the small images ( pixels) and on larger images ( pixels) of the test dataset. The areas with the blue color are the intergranular fracture modes, while the green areas are the transgranular modes. The areas that were left uncolored represent the areas of the background class.








From Figure 3 it is evident that the semantic segmentation algorithm is able to classify a large percentage of the images’ area with high accuracy. The image size does not influence the classification efficiency. In fact, the classifications performed for the larger images exhibit higher accuracy, even though the training is performed on the smaller images. The fact that the classified areas do not cover the entire surface of the image is easily rationalized if we consider that the annotated areas of the images used for the training also do not cover the entire image. The introduction of the background class was necessary since manually annotating every pixel of the training and validation dataset is very time-consuming, however it reduces the prediction efficiency. The algorithm tries to learn how to classify the background pixels even though these pixels do not follow a certain pattern, which leads to misclassifications. Additionally, there exist regions (e.g. pixels with high brightness) which cannot be classified into one of the two fracture modes either due to the lack of texture or due to their ambiguity even in the eyes of the human user.
In order to evaluate more accurately the efficiency of the algorithm, we decided to perform one additional test. The 8 images of the test dataset presented here have been annotated, but this time we manually labeled every pixel as intergranular or transgranular, omitting the background labeling that was applied during training. An example of this fully-annotated image can be seen in Fig.4, while in Fig.4 we show the algorithm’s classification mask of this particular image. The small number of these images permitted such classification. Additionally, the test images have been filtered in order to remove the pixels with high brightness (pixel intensity 220). The calculation of the Intersection over Union (IoU) between the classified and the labeled image (ground truth) is a more precise measurement of the accuracy of the network’s ability to classify pixels in the image as belonging to one of the two fracture modes.


The IoU is defined as the fraction of the overlap area between the annotations and the predictions of each fracture mode and the union area between them. The mean value of the IoU for the intergranular mode for the eight prediction images is 77.3%, while for the transgranular mode is 63.3%. The total mean accuracy is 71.2%, which is very close to the validation accuracy that was computed during training.
The evaluation of the capability of the algorithm in predicting correctly the fracture mode of each pixel is obscured by the introduction of the background labeling. The existence of a label, which does not express any fracture mode, does not allow the correct evaluation of the algorithm’s accuracy. This is not an unusual issue in semantic segmentation algorithms[31]. To address this issue a void class is introduced and assigned for each pixel that has not been annotated in the training dataset[32, 31]. Similar approach was followed by the Microsoft research group [33] where the void labeling was used for pixels located in the boundaries of different classes or in general imposed difficulties in labeling, making the annotation process very slow. In both cases these pixels have been excluded from the ground truth during the evaluation of the accuracy in the test dataset predictions.
In our case, these pixels are the background pixels, and when excluded from the ground truth images, the IoU values increase significantly. The IoU of the intergranular and the transgranular mode for the same test images become 93% and 87.4%, respectively. The total mean IoU value of the algorithm raises to 91.1%.
Finally, the F-measure of this binary classification is computed using the following formula [31]:
| (1) |
where we consider as positive the intergranural pixels and negative the transgranural pixels. The tp, fp and fn are the true positive, false positive and false negative pixels and is set to 1.
The resulting F-measure is 90.7%, and it is in agreement with the computed mean IoU value.
0.1 Transferability
Once the functionality and accuracy of the algorithm in the test dataset of the fracture SEM images of the samples was evaluated, the next step is the investigation of the transferability of the algorithm and trained network to a different ceramic material, for which no additional training was performed. To this end, we have obtained broken samples and, subsequently, SEM images of the fracture surface were acquired. is a brittle material, but the fracture surface has different characteristics and morphology than the previously studied fracture surface. Since the classification on the new images is performed using the previously trained weights, we were able to asses the ability of the trained network to accurately classify intergranular and transgranular regions in materials for which it was not trained.
The test dataset for the new samples consisted of 6 SEM images cropped to a size of pixels. The performance evaluation on the was conducted over the same overall number of pixels as in the original test dataset (). In Fig.5, we present the classification of four SEM images of the fracture surfaces.
 |
 |
 |
 |
To evaluate the accuracy of the algorithm on these new fracture images we used the same tools as before. Initially, the SEM images were filtered by removing the high brightness areas and the mean value for the total IoU accuracy is computed to be 78%. Subsequently, following the evaluation methodology applied for the test dataset, we removed the void (or background) annotated pixel areas and we computed again the mean value of the total IoU and the F-measure, and the results are 94% and 82.4%, respectively.
These results show that the performance of the algorithm in a new material, without any additional training, remained highly accurate. Nevertheless, we acknowledge that a more extensive testing of the algorithm in different ceramic material samples will provide a clearer picture. Furthermore, it is important to add that it will be straightforward to identify which features are completely new in any new dataset and the previous training can be easily optimized by only adding annotations of features that differentiate the new dataset from the previous training dataset. With this training methodology, the optimization of the algorithm will not require a new extensive annotated dataset and it will not be as time-consuming as the initial training.
Summary
In this work, we have utilized a pre-trained convolutional neural network designed for semantic segmentation purposes (U-net architecture) to study the fracture surface of samples. By fine tuning the weights of the various layers of the network we were able to achieve a total mean IoU value of on the SEM test dataset. To test the flexibility and robustness of this approach, additional broken samples of Alumina () were imaged and subjected to the same analysis without further training of the model for this specific materials. Despite the large differences in the microstructural feature sizes, the performance of the algorithm remained high, exhibiting a total mean IoU value of , possibly due to the large dominance of the intergranular fracture which is better classified in our training set.
The approach presented here, provides a robust and user independent tool for quantitative analysis of ceramic’s fracture surfaces, which can be utilized to study large areas on the fracture surface with ease. The proposed method can be easily integrated into the engineering failure analysis process, independently of the expertise level of the failure analysis engineer.
While our preliminary investigation suggests that a good transition between different material systems is possible, even in the case of major changes in the morphological characteristics of the fracture surface it is safe to hypothesize that only a small additional training phase on the newly observed feature is required to further fine tune the model. Furthermore, the extension of the model to accommodate other classes of features, (e.g. dimples) seems to be straightforward by introducing and training the algorithm to recognize the new class. A study as to the feasibility and robustness of this hypothesis is the objective of our future work.
0.2 Network Architecture.
In the work presented here, the encoder part of the network is constructed according to the architecture of the VGG16 network without including the last two fully connected layers and the Softmax classifier. The building unit of the VGG network is a 3x3 convolutional layer that is repeated 2 or 3 times, depending on the layer position in the network, followed by a ReLu activation [34] layer and a 2x2 stride max pooling layer. The total amount of layers in this network is 16, hence the name VGG16. Depending on the decoder architecture but also on the connections between the encoder and decoder, different architectures are proposed in the scientific literature. We have implemented three different network architectures, which are considered the most efficient for the task of semantic segmentation [35, 36, 37], and after comparing their efficiency we chose the U-net that performed better for the task at hand. Additionally, the ability of this architecture to achieve high accuracy training with small datasets was a very compelling feature.
The code is developed in Python on top of an existing implementation (https://github.com/ divamgupta/image-segmentation-keras), and the building and training of the model is performed with Keras [38] Application Programming Interface(API), using Tensorflow [39, 40] as a backend.
The SEM input images used for the training of the network have a size of pixels, and after applying the consecutive convolution and max pooling layers of the encoder the size of the resulting feature maps is reduced to pixels. The role of the decoder is to retrieve the accurate localization of these features and convert the feature maps into pixel-wise predictions on the input images. The main tool of this upsampling process is the transpose convolution (or deconvolution) layer. These deconvolution layers perform the reverse operation of the typical convolution layers and their weights are trainable parameters of the network, which allows the network to adjust them during the training and learn how to accurately localize the features in any new input image.
The encoder and decoder structure of the U-net architecture is identical, with the only difference being the replacement of the max pooling operations in the encoder stage with a 2x2 transpose convolutions in the decoder stage. The symmetrical architecture of the network allows the concatenation of the output of each encoder layer with the output of the corresponding decoder layer, before being fed to the next decoder layer. With these modifications, the network can utilize larger number of feature channels and subsequently propagate more information through the layers and producing higher resolution feature maps. This interconnection between the encoder and decoder also allows the network to be effectively trained with a smaller dataset.
0.3 SEM imaging and Training.
The training dataset is constructed using SEM images of the fracture surface of Magnesium Aluminate Spinel () samples. The fracture experiments were conducted by D. Blumer[41]. The fracture surfaces were prepared and scanned using an high resolution FEG-SEM( TESCAN MIRA 3), following the general guidelines for fractography of ceramics [42]. All images were taken at a resolution of pixels and subsequently cropped to desired dimensions. For the purpose of constructing a training dataset, the images were cropped to pixels size. The final dataset is composed of 605 training images, 105 validation images and 30 test images (used for the final assessment of the prediction accuracy of each algorithm). The training and validation images are annotated using the open source online VGG Image Annotator [43, 44] in three different labels: intergranular , transgranular and background. The annotation was a manual time-consuming task and the inclusion of the third classification label (the ”background” label) was a necessity in order to simplify this rigorous process. Moreover, ambiguities as to the nature of several features were eliminated by annotating them using the ”background” class. In the resulted dataset, each annotated image contains on average 40 classified areas of intergranular and transgranular fracture modes, while the rest of the pixels are classified as ”background”.
The weights of each algorithm are trained for 40 epochs with Adam Stochastic gradient-based optimization method [45], with initial learning rate of , and . Each epoch consisted of 200 iterations followed by 100 validation iterations. The training was performed on a personal computer, equipped with an NVIDIA® GeForce® RTX 2080 Ti Graphics Processing Unit(GPU). Taking advantage of the GPU support of the Tensorflow operations, the training duration is significantly reduced. For a relatively small batch size (batch size = 4), since the memory size of our GPU is limited, the training time for the different networks was approximately 150 sec per epoch.
0.4 Materials.
Fractured specimens made of transperent () Spinel specimens were acquired from the dynamic fracture laboratory at the Technion[41]. The () specimens consisted of two populations in terms of microstructure. The first exhibited a bi-modal grain size distribution with sub-micron grains and grains at the order of several microns. The second population has gone through a thermomechanical treatment to facilitate abnormal grain growth, resulting in the appearance of several grains as large as 140 microns[41]. The () samples used for this study are sintered specimens with 2% porosity. The average grain size was 4 microns.
0.5 Data availability
The training and validation dataset used for the training of the network and their annotations are published in Materials Data Facility(MDF) with DOI: https://doi.org/10.18126/vu60-4htj. The source code is available at https://github.com/SteliosTsop/QF-image-segmentation-keras.
Acknowledgments
The financial support provided by the Pazy foundation young researchers award Grant 1176 (SO) and the European Union’s Horizon2020 Programme (Excellent Science, Marie-Sklodowska-Curie Actions) under REA grant agreement (Project OUTCOME, TS, Rxx, SO), is gratefully acknowledged. The authors would also like to thank Aerosertec(www.aerosertec.com) for providing the facilities and computational power for the training of the network.Finally, we would like to thank Dr. D.Rittel and D.Blumer for providing the Magnesium Aluminate Spinel () fractured samples.
Author contributions
S.O conceived the research. S.O and S.T performed the fractography and wrote the manuscript. R.H.M. was an industrial advisor to the project. Coding, annotations and fine tuning of the CNN were done by S.T. {addendum}
The authors declare that they have no competing financial interests.
References
References
- [1] Mills, K., Davis, J. R., Destefani, J. & Dieterich, D. ASM Handbook, Volume 12-Fractography (Asm International Materials Park, OH, 1987).
- [2] Tipper, C. The fracture of metals. Metallurgia 39, 133–137 (1949).
- [3] Pineau, A., Benzerga, A. A. & Pardoen, T. Failure of metals i: Brittle and ductile fracture. Acta Materialia 107, 424–483 (2016).
- [4] Pineau, A., McDowell, D. L., Busso, E. P. & Antolovich, S. D. Failure of metals ii: Fatigue. Acta Materialia 107, 484–507 (2016).
- [5] Zhang, Q. B. & Zhao, J. Effect of loading rate on fracture toughness and failure micromechanisms in marble. Engineering Fracture Mechanics 102, 288–309 (2013).
- [6] Hu, G., Chen, C., Ramesh, K. & McCauley, J. Mechanisms of dynamic deformation and dynamic failure in aluminum nitride. Acta materialia 60, 3480–3490 (2012).
- [7] Shemtov-Yona, K., Özcan, M. & Rittel, D. Fractographic characterization of fatigued zirconia dental implants tested in room air and saline solution. Engineering Failure Analysis 96, 298–310 (2019).
- [8] Biezma, M. V., Berlanga, C. & Argandona, G. Relationship between microstructure and fracture types in a uns s32205 duplex stainless steel. Materials Research 16, 965–969 (2013).
- [9] Kraft, R. & Molinari, J. A statistical investigation of the effects of grain boundary properties on transgranular fracture. Acta Materialia 56, 4739–4749 (2008).
- [10] Osovski, S., Needleman, A. & Srivastava, A. Intergranular fracture prediction and microstructure design. International Journal of Fracture 216, 135–148 (2019).
- [11] Hu, W., Wiliem, A., Lovell, B., Barter, S. & Liu, L. Automation of Quantitative Fractography for Determination of Fatigue Crack Growth Rates with Marker Loads. In 29th ICAF Symposium – Nagoya, June (2017).
- [12] Kosarevych, R. Y., Student, O. Z., Svirs’Ka, L. M., Rusyn, B. P. & Nykyforchyn, H. M. Computer analysis of characteristic elements of fractographic images. Materials Science 48, 474–481 (2013).
- [13] Kenjiro, K., Minoshima, K. & Shoich, I. Recognition of Different Fracture Surface Morphologies using Computer Image Processing Technique. JSME international journal. Ser. A, Mechanics and material engineering 36, 220–227 (1993).
- [14] Characterization of micrographs and fractographs of Cu-strengthened HSLA steel using image texture analysis. Measurement: Journal of the International Measurement Confederation 47, 130–144 (2014). URL http://dx.doi.org/10.1016/j.measurement.2013.08.030.
- [15] Yang, W.-J., Yu, C.-T. & Kobayashi, A. S. Sem quantification of transgranular vs intergranular fracture. Journal of the American Ceramic Society 74, 290–295 (1991).
- [16] Chowdhury, A., Kautz, E., Yener, B. & Lewis, D. Image driven machine learning methods for microstructure recognition. Computational Materials Science 123, 176–187 (2016). URL http://dx.doi.org/10.1016/j.commatsci.2016.05.034.
- [17] Zhang, Y. & Ngan, A. H. Extracting dislocation microstructures by deep learning. International Journal of Plasticity 115, 18–28 (2019). URL https://doi.org/10.1016/j.ijplas.2018.11.008.
- [18] Li, W., Field, K. G. & Morgan, D. Automated defect analysis in electron microscopic images. npj Computational Materials 4, 1–9 (2018). URL http://dx.doi.org/10.1038/s41524-018-0093-8.
- [19] Gola, J. et al. Advanced microstructure classification by data mining methods. Computational Materials Science 148, 324–335 (2018). URL https://doi.org/10.1016/j.commatsci.2018.03.004.
- [20] Bastidas-Rodriguez, M. X., Prieto-Ortiz, F. A. & Espejo, E. Fractographic classification in metallic materials by using computer vision. Engineering Failure Analysis 59, 237–252 (2016). URL http://dx.doi.org/10.1016/j.engfailanal.2015.10.008.
- [21] Konovalenko, I., Maruschak, P., Prentkovskis, O. & Junevičius, R. Investigation of the Rupture Surface of the Titanium Alloy Using Convolutional Neural Networks. Materials 11, 2467 (2018).
- [22] Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K. & Yuille, A. L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv preprint arXiv:1412.7062 (2014).
- [23] Simonyan, K. & Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR 1–14 (2014). URL http://arxiv.org/abs/1409.1556. 1409.1556.
- [24] He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2016-Decem, 770–778 (2016). arXiv:1512.03385v1.
- [25] Szegedy, C. et al. Going deeper with convolutions. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 07-12-June, 1–9 (2015). arXiv:1409.4842v1.
- [26] Donahue, J. et al. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. CoRR abs/1310.1 (2013). URL http://arxiv.org/abs/1310.1531. 1310.1531.
- [27] Zeiler, M. D. & Fergus, R. Visualizing and Understanding Convolutional Networks. CoRR abs/1311.2 (2013). URL http://arxiv.org/abs/1311.2901. 1311.2901.
- [28] Lin, T.-Y. et al. Microsoft COCO: Common Objects in Context. In Fleet, D., Pajdla, T., Schiele, B. & Tuytelaars, T. (eds.) Computer Vision – ECCV 2014, 740–755 (Springer International Publishing, Cham, 2014).
- [29] Russakovsky, O. et al. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision 115, 211–252 (2015). arXiv:1409.0575v3.
- [30] Barak, Y., Srivastava, A. & Osovski, S. Correlating fracture toughness and fracture surface roughness via correlation length scale. International Journal of Fracture 1–12 (2019).
- [31] Thoma, M. A Survey of Semantic Segmentation. CoRR abs/1602.0, 1–16 (2016). URL http://arxiv.org/abs/1602.06541. 1602.06541.
- [32] Gould, S., Rodgers, J., Cohen, D., Elidan, G. & Koller, D. Multi-class segmentation with relative location prior. International Journal of Computer Vision 80, 300–316 (2008).
- [33] Shotton, J., Winn, J., Rother, C. & Criminisi, A. TextonBoost: Joint appearance, shape and context modeling for multi-class object recognition and segmentation. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 3951 LNCS, 1–15 (2006).
- [34] Nair, V. & Hinton, G. E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, 3 (2010). URL https://www.cs.toronto.edu/ hinton/absps/reluICML.pdf. 1111.6189v1.
- [35] Long, J., Shelhamer, E. & Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015).
- [36] Badrinarayanan, V., Kendall, A. & Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE transactions on pattern analysis and machine intelligence 39, 2481–2495 (2017). URL http://www.ncbi.nlm.nih.gov/pubmed/28060704. arXiv:1511.00561v3.
- [37] Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 9351, 234–241 (2015). arXiv:1505.04597v1.
- [38] Chollet, F. & Others. Keras. url{https://keras.io} (2015).
- [39] Abadi, M. et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. vol. abs/1603.0 (2016). URL http://arxiv.org/abs/1603.04467. 1603.04467.
- [40] Martin, A. et al. {TensorFlow}: Large-Scale Machine Learning on Heterogeneous Systems (2015). URL https://www.tensorflow.org/.
- [41] Blumer, D. & Rittel, D. The influence of microstructure on the static and dynamic strength of transparent magnesium aluminate spinel (mgal2o4). Journal of the European Ceramic Society 38, 3618–3634 (2018).
- [42] Quinn, G. D. Fractography of ceramics and glasses (National Institute of Standards and Technology Washington, DC, 2016).
- [43] Dutta, A. & Zisserman, A. The {VIA} Annotation Software for Images, Audio and Video. arXiv preprint arXiv:1904.10699 (2019).
- [44] Dutta, A., Gupta, A. & Zissermann, A. {VGG} Image Annotator ({VIA}). http://www.robots.ox.ac.uk/˜vgg/software/via/ (2016).
- [45] Kingma, D. P. & Ba, J. Adam: A Method for Stochastic Optimization. CoRR 1–15 (2014). URL http://arxiv.org/abs/1412.6980. 1412.6980.