Toward Real-World Single Image Super-Resolution:
A New Benchmark and A New Model
Abstract
Most of the existing learning-based single image super-resolution (SISR) methods are trained and evaluated on simulated datasets, where the low-resolution (LR) images are generated by applying a simple and uniform degradation (i.e., bicubic downsampling) to their high-resolution (HR) counterparts. However, the degradations in real-world LR images are far more complicated. As a consequence, the SISR models trained on simulated data become less effective when applied to practical scenarios. In this paper, we build a real-world super-resolution (RealSR) dataset where paired LR-HR images on the same scene are captured by adjusting the focal length of a digital camera. An image registration algorithm is developed to progressively align the image pairs at different resolutions. Considering that the degradation kernels are naturally non-uniform in our dataset, we present a Laplacian pyramid based kernel prediction network (LP-KPN), which efficiently learns per-pixel kernels to recover the HR image. Our extensive experiments demonstrate that SISR models trained on our RealSR dataset deliver better visual quality with sharper edges and finer textures on real-world scenes than those trained on simulated datasets. Though our RealSR dataset is built by using only two cameras (Canon 5D3 and Nikon D810), the trained model generalizes well to other camera devices such as Sony a7II and mobile phones.
1 Introduction

(a) Image captured by Sony a7II

(b) Bicubic
 (c) RCAN + BD
(c) RCAN + BD

(d) RCAN + MD

(e) RCAN + RealSR

(f) LP-KPN + RealSR
Single image super-resolution (SISR) [15] aims to recover a high-resolution (HR) image from its low-resolution (LR) observation. SISR has been an active research topic for decades [38, 57, 45, 47, 5] because of its high practical values in enhancing image details and textures. Since SISR is a severely ill-posed inverse problem, learning image prior information from the HR and/or LR exemplar images [15, 13, 55, 19, 14, 7, 24, 56, 11, 20, 46, 41] plays an indispensable role in recovering the details from an LR input image. Benefitting from the rapid development of deep convolutional neural networks (CNNs) [28], recent years have witnessed an explosive spread of training CNN models to perform SISR, and the performance has been consistently improved by designing new CNN architectures [9, 50, 42, 23, 44, 30, 62, 61] and loss functions [22, 29, 40].
Though significant advances have been made, most of the existing SISR methods are trained and evaluated on simulated datasets which assume simple and uniform degradation (i.e., bicubic degradation). Unfortunately, SISR models trained on such simulated datasets are hard to generalize to practical applications since the authentic degradations in real-world LR images are much more complex [54, 26]. Fig. 1 shows the SISR results of a real-world image captured by a Sony a7II camera. We utilize the state-of-the-art RCAN method [61] to train three SISR models using simulated image pairs (in DIV2K [45]) with bicubic degradation, multiple simulated degradations [60] and image pairs with authentic distortions in our dataset to be constructed in this paper. The results clearly show that, compared with the simple bicubic interpolator (Fig. 1(b)), the RCAN models trained on simulated datasets (Figs. 1(c)1(d)) do not show clear advantages on real-world images.
It is thus highly desired that we can have a training dataset consisting of real-world, instead of simulated, LR and HR image pairs. However, constructing such a real-world super-resolution (RealSR) dataset is a non-trivial job since the ground-truth HR images are very difficult to obtain. To the best of our knowledge, only two recent attempts have been made in the laboratory environment, where complicated devices were used to collect image pairs on very limited scenes [39, 26]. In this work, we aim to construct a more general and practical RealSR dataset using a flexible and easy-to-reproduce method. Specifically, we capture images of the same scene using fixed digital single-lens reflex (DSLR) cameras with different focal lengths. By increasing the focal length, finer details of the scene can be naturally recorded into the camera sensor. In this way, HR and LR image pairs on different scales can be collected. However, in addition to the change of field of view (FoV), adjusting focal length can result in many other changes in the imaging process, such as shift of optical center, variation of scaling factors, different exposure time and lens distortion. We thus develop an effective image registration algorithm to progressively align the image pairs such that the end-to-end training of SISR models can be performed. The constructed RealSR dataset contains various indoor and outdoor scenes taken by two DSLR cameras (Canon 5D3 and Nikon D810), providing a good benchmark for training and evaluating SISR algorithms in practical applications.
Compared with the previous simulated datasets, the image degradation process in our RealSR dataset is much more complicated. In particular, the degradation is spatially variant since the blur kernel varies with the depth of content in a scene. This motivates us to train a kernel prediction network (KPN) for the real-world SISR task. The idea of kernel prediction is to explicitly learn a restoration kernel for each pixel, and it has been employed in applications such as denoising [2, 34, 48], dynamic deblurring [43, 16] and video interpolation [35, 36]. Though effective, the memory and computational cost of KPN is quadratically increased with the kernel size. To obtain as competitive SISR performance as using large kernel size while achieving high computational efficiency, we propose a Laplacian pyramid based KPN (LP-KPN) which learns per-pixel kernels for the decomposed image pyramid. Our LP-KPN can leverage rich information using a small kernel size, leading to effective and efficient real-world SISR performance. Figs. 1(e) and 1(f) show the SISR results of RCAN [61] and LP-KPN models trained on our RealSR dataset, respectively. One can see that both of them deliver much better results than the RCAN models trained on simulated data, while our LP-KPN ( conv layers) can output more distinct result than RCAN (over 400 conv layers) using much fewer layers.
The contributions of this work are twofold:
-
•
We build a RealSR dataset consisting of HR and LR image pairs with different scaling factors. It provides, to the best of our knowledge, the first general purpose benchmark for real-world SISR model training and evaluation.
-
•
We present an LP-KPN model and validate its efficiency and effectiveness in real-world SISR.
Extensive experiments are conducted to quantitatively and qualitatively analyze the performance of our RealSR dataset in training SISR models. Though the dataset in its current version is built using only two cameras, the trained SISR models exhibit good generalization capability to images captured by other types of camera devices.
2 Related Work
SISR datasets. There are several popular datasets, including Set5 [4], Set14 [59], BSD300 [32], Urban100 [19], Manga109 [33] and DIV2K [45] that have been widely used for training and evaluating the SISR methods. In all these datasets, the LR images are generally synthesized by a simple and uniform degradation process such as bicubic downsampling or Gaussian blurring followed by direct downsampling [10]. The SISR Models trained on these simulated data may exhibit poor performance when applied to real LR images where the degradation deviates from the simulated ones [12]. To improve the generalization capability, Zhang et al. [60] trained their model using multiple simulated degradations and Bulat et al. [6] used a GAN [17] to generate the degradation process. Although these more advanced methods can simulate more complex degradation, there is no guarantee that such simulated degradation can approximate the authentic degradation in practical scenarios which is usually very complicated [26].
It is very challenging to get the ground-truth HR image for an LR image in real-world scenarios, making the training and evaluation of real-world SISR models difficult. To the best of our knowledge, only two recent attempts have been made on capturing real-world image pairs for SISR. Qu et al. [39] put two cameras together with a beam splitter to collect a dataset with paired face images. Köhler et al. [26] employed hardware binning on the sensor to capture LR images and used multiple postprocessing steps to generate different versions of an LR image. However, both the datasets were collected in indoor laboratory environment and very limited number of scenes (31 face images in [39] and 14 scenes in [26]) were included. Different from them, our dataset is constructed by adjusting the focal length of DSLR cameras which naturally results in image pairs at different resolutions, and it contains scenes in both indoor and outdoor environments.
Kernel prediction networks. Considering that the degradation kernel in our RealSR dataset is spatially variant, we propose to train a kernel prediction network (KPN) for real-world SISR. The idea of KPN was first proposed in [2] to denoise Monte Carlo renderings and it has proven to have faster convergence and better stability than direct prediction [48]. Mildenhall et al. [34] trained a KPN model for burst denoising and obtained state-of-the-art performance on both synthetic and real data. Similar ideas have been employed in estimating the blur kernels in dynamic deblurring [43, 16] or convolutional kernels in video interpolation [35, 36]. We are among the first to train a KPN for SISR and we propose the LP-KPN to perform kernel prediction in the scale space with high efficiency.
3 Real-world SISR Dataset
To build a dataset for learning and evaluating real-world SISR models, we propose to collect images of the same scene by adjusting the lens of DSLR cameras. Sophisticated image registration operations are then performed to generate the HR and LR pairs of the same content. The detailed dataset construction process is presented in this section.
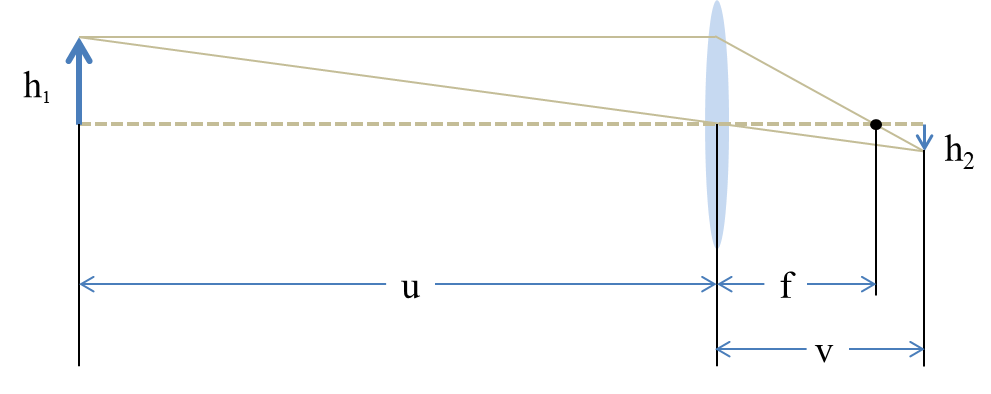
3.1 Image formation by thin lens
The DSLR camera imaging system can be approximated as a thin lens [53]. An illustration of the image formation process by thin lens is shown in Fig. 2. We denote the object distance, image distance and focal length by , and denote the size of object and image by and , respectively. The lens equation is defined as follows [53]:
| (1) |
The magnification factor is defined as the ratio of the image size to the object size:
| (2) |
In our case, the static images are taken at a distance (i.e., ) larger than 3.0m. Both and are fixed and is much larger than (the largest is 105mm). Combining Eq. (1) and Eq. (2), and considering the fact that , we have:
| (3) |
Therefore, is approximately linear to . By increasing the focal length , larger images with finer details will be recorded in the camera sensor. The scaling factor can also be controlled (in theory) by choosing specific values of .
3.2 Data collection
| Camera | Canon 5D3 | Nikon D810 | ||||
|---|---|---|---|---|---|---|
| Scale | 2 | 3 | 4 | 2 | 3 | 4 |
| # image pairs | 86 | 117 | 86 | 97 | 117 | 92 |
We used two full frame DSLR cameras (Canon 5D3 and Nikon D810) to capture images for data collection. The resolution of Canon 5D3 is , and that of Nikon D810 is . To cover the common scaling factors (e.g., ) used in most previous SISR datasets, both cameras were equipped with one 24105mm, /4.0 zoom lens. For each scene, we took photos using four focal lengths: 105mm, 50mm, 35mm, and 28mm. Images taken by the largest focal length are used to generate the ground-truth HR images, and images taken by the other three focal lengths are used to generate the LR versions. We choose 28mm rather than 24mm because lens distortion at 24mm is more difficult to correct in post-processing, which results in less satisfied quality in image pair registration.
The camera was set to aperture priority mode and the aperture was adjusted according to the depth-of-field (DoF) [52]. Basically, the selected aperture value should make the DoF large enough to cover the scene and avoid severe diffraction. Small ISO is preferred to alleviate noise. The focus, white balance, and exposure were set to automatic mode. The center-weighted metering option was selected since only the center region of captured images were used in our final dataset. For stabilization, the camera was fixed on a tripod and a bluetooth remote controller was used to control the shutter. Besides, lens stabilization was turned off and the reflector was pre-rised when taking photos.
To ensure the generality of our dataset, we took photos in both indoor and outdoor environment. Scenes with abundant texture are preferred considering that the main purpose of super-resolution is to recover or enhance image details. For each scene, we first captured the image at 105mm focal length and then manually decreased the focal length to take three down-scaled versions. scenes were captured, and there are no overlapped scenes between the two cameras. After discarding images having moving objects, inappropriate exposure, and blur, we have HR and LR image pairs in total. The numbers of image pairs for each camera at each scaling factor are listed in Table 1.
3.3 Image pair registration
Although it is easy to collect images on different scales by zooming the lens of a DSLR camera, it is difficult to obtain pixel-wise aligned image pairs because the zooming of lens brings many uncontrollable changes. Specifically, images taken at different focal lengths suffer from different lens distortions and usually have different exposures. Moreover, the optical center will also shift when zooming the focal length because of the inherent defect of lens. Even the scaling factors are varying slightly because the lens equation (Eq. (1)) cannot be precisely satisfied in practical focusing process. With the above factors, none of the existing image registration algorithms can be directly used to obtain accurate pixel-wise registration of two images captured under different focal length. We thus develop an image registration algorithm to progressively align such image pairs to build our RealSR dataset.
The registration process is illustrated in Fig. 3. We first import the images with meta information into PhotoShop to correct the lens distortion. However, this step cannot perfectly correct the lens distortion especially for the region distant from the optical center. We thus further crop the interested region around the center of the image, where distortion is not severe and can be well corrected. The cropped region from the image taken at 105mm focal length is used as the ground-truth HR image, whose LR counterparts are to be registered from the original images taken at 50mm, 35mm, or 28mm focal length. Since there is certain luminance and scale difference between images taken at different focal lengths, those popular keypoint based image registration algorithms such as SURF [3] and SIFT [31] cannot always achieve pixel-wise registration, which is necessary for our dataset. To obtain accurate image pair registration, we develop a pixel-wise registration algorithm which simultaneously considers luminance adjustment. Denote by and the HR image and the LR image to be registered, our algorithm minimizes the following objective function:
| (4) |
where is an affine transformation matrix, is a cropping operation which makes the transformed have the same size as , and are luminance adjustment parameters, is a robust -norm , e.g., -norm.
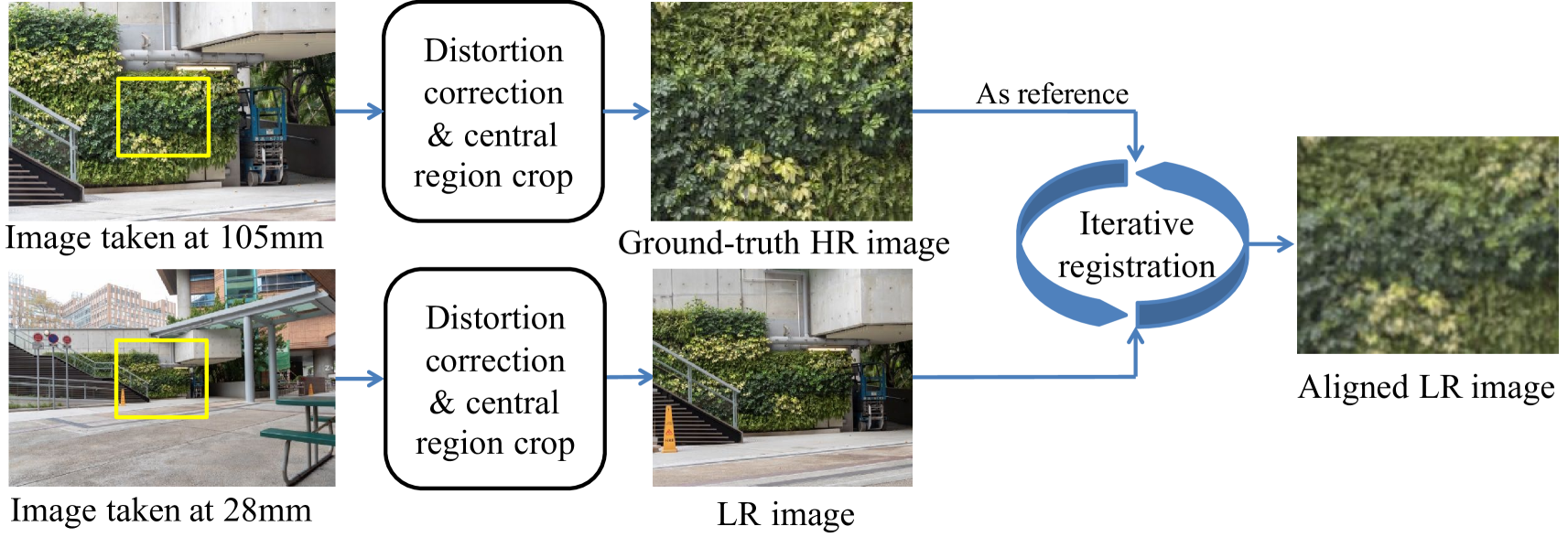
The above objective function is solved in an iterative manner. At the beginning, according to Eq. (3), the is initialized as a scaling transformation with scaling factor calculated as the ratio of two focal lengths. Let . With and fixed, the parameters for luminance adjustment can be obtained by and , which can ensure having the same pixel mean and variance as after luminance adjustment. Then we solve the affine transformation matrix with and fixed. According to [37, 58], the objective function w.r.t. is nonlinear, which can be iteratively solved by a locally linear approximation:
| (5) |
where is the Jacobian matrix of w.r.t. , and this objective function can be solved by an iteratively reweighted least square problem (IRLS) as follows [8]:
| (6) |
where , , is the weight matrix and denotes element-wise multiplication. Then we can obtain:
| (7) |
and can be updated by: .
We iteratively estimate the luminance adjustment parameters and the affine transformation matrix. The optimization process converges within iterations since our prior information of the scaling factor provides a good initialization of . After convergence, we can obtain the aligned LR image as .
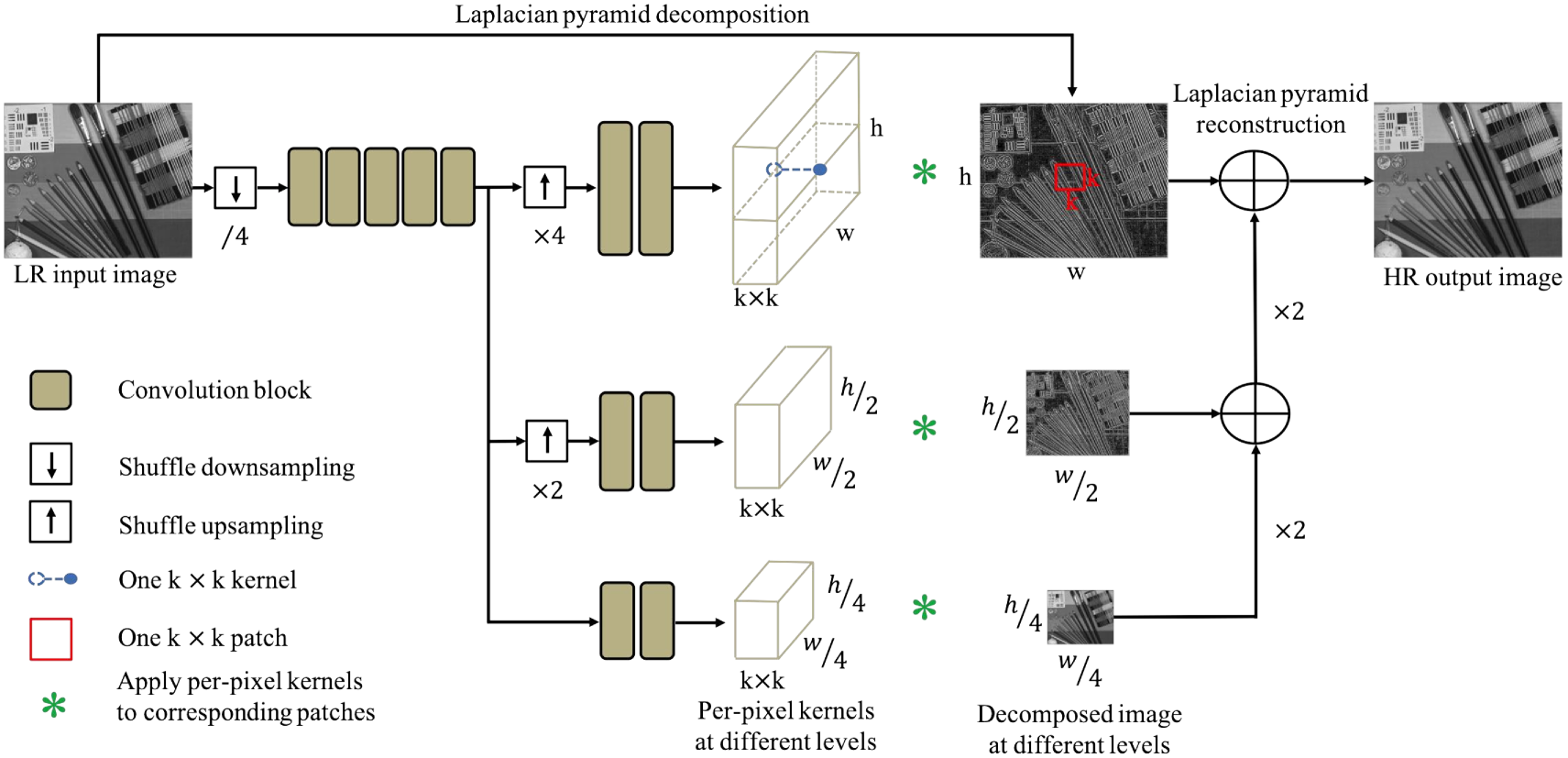
4 Laplacian Pyramid based Kernel Prediction Network
In Section 3, we have constructed a new real-world super-resolution (RealSR) dataset, which consists of pixel-wise aligned HR and LR image pairs of size . Now the problem turns to how to learn an effective network to enhance to . For LR images in our RealSR dataset, the blur kernel varies with the depth in a scene [51] and the DoF [52] changes with the focal length. Training an SISR model which directly transforms the LR image to the HR image, as done in most of the previous CNN based SISR methods, may not be the cost-effective way. We therefore propose to train a kernel prediction network (KPN) which explicitly learns an individual kernel for each pixel. Compared with those direct pixel synthesis networks, KPN has proven to have advantages in efficiency, interpretability and generalization capability in tasks of denoising, dynamic deblurring, etc., [2, 34, 48, 43, 16, 27].
The KPN takes the as input and outputs a kernel tensor , in which each vector in channel dimension can be reshaped into a kernel . The reshaped per-pixel kernel is applied to the neighborhood of each pixel in the input LR image to reproduce the HR output. The predicted HR image, denoted by , is obtained by:
| (8) |
where represents a neighborhood of pixel and denotes the inner product operation.
Eq. (8) shows that the output pixel is a weighted linear combination of the neighboring pixels in the input image. To obtain good performance, a large kernel size is necessary to leverage richer neighborhood information, especially when only a single frame image is used. On the other hand, the predicted kernel tensor grows quadratically with the kernel size , which can result in high computational and memory cost in practical applications. In order to train a both effective and efficient KPN, we propose a Laplacian pyramid based KPN (LP-KPN).
The framework of our LP-KPN is shown in Fig. 4. As in many SR methods [30, 47], our model works on the Y channel of YCbCr space. The Laplacian pyramid decomposes an image into several levels of sub-images with downsampled resolution and the decomposed images can exactly reconstruct the original image. Using this property, the Y channel of an LR input image is decomposed into a three-level image pyramid {}, where , , and . Our LP-KPN takes the LR image as input and predicts three kernel tensors {} for the image pyramid, where , , and . The learned kernel tensors {} are applied to the corresponding image pyramid {}, using the operation in Eq. (8), to restore the Laplacian decomposition of HR image at each level. Finally, the Laplacian pyramid reconstruction is conducted to obtain the HR image. Benefitting from the Laplacian pyramid, learning three kernels can equally lead to a receptive field with size at the original resolution, which significantly reduces the computational cost compared to directly learning one kernel.
The backbone of our LP-KPN consists of residual blocks, with each residual block containing convolutional layers and a ReLU function (similar structure to [30]). To improve the efficiency, we shuffle [42] the input LR image with factor (namely, the image is shuffled to images) and input the shuffled images to the network. Most convolutional blocks are shared by the three levels of kernels except for the last few layers. One and one shuffle operation are performed to upsample the spatial resolution of the latent image representations at two lower levels, followed by individual convolutional blocks. Our LP-KPN has a total of convolutional layers, which is much less than the previous state-of-the-art SISR models [30, 62, 61]. The detailed network architecture can be found in the supplementary material. The -norm loss function is employed to minimize the pixel-wise distance between the model prediction and the ground-truth HR image .
5 Experiments
Experimental setup. The number of image pairs in our RealSR dataset is reported in Table 1. We randomly selected image pairs at each scaling factor for each camera to form the testing set, while using the remaining image pairs as training set. Except for cross-camera testing, images from both the Canon and Nikon cameras were combined for training and testing. Following the previous work [30, 61, 47], the SISR results were evaluated using PSNR and SSIM [49] indices on the Y channel in the YCbCr space. The height and width of images lie in the range of [700, 3100] and [600, 3500], respectively. We cropped the training images into patches to train all the models. Data augmentation was performed by randomly rotating , , and horizontally flipping the input. The mini-batch size in all the experiments was set to .
All SISR models were initialized using the method in [18]. The Adam solver [25] with the default parameters (, and ) was adopted to optimize the network parameters. The learning rate was fixed at and all the networks were trained for iterations. All the comparing models were trained using the Caffe [21] toolbox, and tested using Caffe MATLAB interface. All the experiments were conducted on a PC equipped with an Intel Core i7-7820X CPU, 128G RAM and a single Nvidia Quadro GV100 GPU (32G).
5.1 Simulated SISR datasets vs. RealSR dataset
To demonstrate the advantages of our RealSR dataset, we conduct experiments to compare the real-world super-resolution performance of SISR models trained on simulated datasets and RealSR dataset. Considering that most state-of-the-art SISR models were trained on DIV2K [45] dataset, we employed the DIV2K to generate simulated image pairs with bicubic degradation (BD) and multiple degradations (MD) [60]. We selected three representative and state-of-the-art SISR networks, i.e., VDSR [23], SRResNet [29] and RCAN [61], and trained them on the BD, MD and RealSR training datasets for each of the three scaling factors (, , ), leading to a total of SISR models. To keep the network structures of SRResNet and RCAN unchanged, the input images were shuffled with factor for the three scaling factors , , , respectively.
| Metric | Scale | Bicubic | VDSR [23] | SRResNet [29] | RCAN [61] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BD | MD | Our | BD | MD | Our | BD | MD | Our | |||
| PSNR | |||||||||||
| SSIM | |||||||||||
 Image captured by Canon 5D3
Image captured by Canon 5D3



 HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR




 VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
|
 Image captured by Nikon D810
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
Image captured by Nikon D810
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
|
We applied the trained SISR models to the RealSR testing set, and the average PSNR and SSIM indices are listed in Table 2. The baseline bicubic interpolator is also included for comparison. One can see that, on our RealSR testing set, the VDSR and SRResNet models trained on the simulated BD dataset can only achieve comparable performance to the simple bicubic interpolator. Training on the MD dataset brings marginal improvements over BD, which indicates that the authentic degradation in real-world images is difficult to simulate. Employing a deeper architecture, the RCAN (400 layers) can improve (0.2dB0.3dB) the performance over VDSR and SRResNet on all cases.
Using the same network architecture, SISR models trained on our RealSR dataset obtain significantly better performance than those trained on BD and MD datasets for all the three scaling factors. Specifically, for scaling factor , the models trained on our RealSR dataset have about dB improvement on average for all the three network architectures. The advantage is also significant for scaling factors and . In Fig. 5, we visualize the super-resolved images obtained by different models. As can be seen, the SISR results generated by models trained on simulated BD and MD datasets tend to have blurring edges with obvious artifacts. On the contrary, models trained on our RealSR dataset recover clearer and more natural image details. More visual examples can be found in the supplementary file.
5.2 SISR models trained on RealSR dataset
To demonstrate the efficiency and effectiveness of the proposed LP-KPN, we then compare it with SISR models, including VDSR, SRResNet, RCAN, a baseline direct pixel synthesis (DPS) network and four KPN models with kernel size . The DPS and the four KPN models share the same backbone as our LP-KPN. All models are trained and tested on our RealSR dataset. The PSNR and SSIM indices of all the competing models as well as the bicubic baseline are listed in Table 3.
| Method | PSNR | SSIM | ||||
|---|---|---|---|---|---|---|
| Bicubic | ||||||
| VDSR [23] | ||||||
| SRResNet [29] | ||||||
| RCAN [61] | ||||||
| DPS | ||||||
| KPN, = | ||||||
| KPN, = | ||||||
| KPN, = | ||||||
| KPN, = | ||||||
| Our, = | ||||||
One can notice that among the four direct pixel synthesis networks (i.e., VDSR, SRResNet, RCAN and DPS), RCAN obtains the best performance because of its very deep architecture (over 400 layers). Using the same backbone with less than layers, the KPN with kernel size already outperforms the DPS. Using larger kernel size consistently brings better results for the KPN architecture, and it obtains comparable performance to the RCAN when the kernel size increases to . Benefitting from the Laplacian pyramid decomposition strategy, our LP-KPN using three different kernels achieves even better results than the KPN with kernel. The proposed LP-KPN obtains the best performance but with the lowest computational cost for all the three scaling factors. The detailed complexity analysis and visual examples of the SISR results by the competing models can be found in the supplementary file.
5.3 Cross-camera testing
To evaluate the generalization capability of SISR models trained on our RealSR dataset, we conduct a cross-camera testing. Images taken by two cameras are divided into training and testing sets, separately, with testing images for each camera at each scaling factor. The three scales of images are combined for training, and models trained on one camera are tested on the testing sets of both cameras. The LP-KPN and RCAN models are compared in this evaluation, and the PSNR indexes are reported in Table 4.
It can be seen that for both RCAN and LP-KPN, the cross-camera testing results are comparable to the in-camera setting with only about dB and dB gap, respectively, while both are much better than bicubic interpolator. This indicates that the SISR models trained on one camera can generalize well to the other camera. This is possibly because our RealSR dataset contains various degradations produced by the camera lens and image formation process, which share similar properties across cameras. Between RCAN and LP-KPN models, the former has more parameters and thus is easier to overfit to the training set, delivering slightly worse generalization capability than LP-KPN. Similar observation has been found in [2, 48, 34].
| Tested | Scale | Bicubic | RCAN | LP-KPN | ||
|---|---|---|---|---|---|---|
| (Trained) | (Trained) | |||||
| Canon | Nikon | Canon | Nikon | |||
| Canon | ||||||
| Nikon | ||||||
 Image captured by iPhone X
Image captured by iPhone X


 Bicubic
RCAN + BD
RCAN + MD
Bicubic
RCAN + BD
RCAN + MD

 RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
|
|
Image captured by Google Pixel 2
Bicubic
RCAN + BD
RCAN + MD
RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
|
5.4 Tests on images outside our dataset
To further validate the generalization capability of our RealSR dataset and LP-KPN model, we evaluate our trained model as well as several competitors on images outside our dataset, including images taken by one Sony a7II DSLR camera and two mobile cameras (i.e., iPhone X and Google Pixel 2). Since there are no ground-truth HR versions of these images, we visualize the super-resolved results in Fig. 1 and Fig. 6. In all these cases, the LP-KPN trained on our RealSR dataset obtains better visual quality than the competitors, recovering more natural and clearer details. More examples can be found in the supplementary file.
6 Conclusion
It has been a long standing problem for SISR research that the models trained on simulated datasets can hardly be generalized to real-world images. We made a good attempt to address this issue, and constructed a real-world super-solution (RealSR) dataset with authentic degradations. One Canon and one Nikon cameras were used to collect 595 HR and LR image pairs, and an effective image registration algorithm was developed to ensure accurate pixel-wise alignment between image pairs. A Laplacian pyramid based kernel prediction network was also proposed to perform efficient and effective real-world SISR. Our extensive experiments validated that the models trained on our RealSR dataset can lead to much better real-world SISR results than trained on existing simulated datasets, and they have good generalization capability to other cameras. In the future, we will enlarge the RealSR dataset by collecting more image pairs with more types of cameras, and investigate new SISR model training strategies on it.
7 Supplementary Material
7.1 Sample images of the RealSR dataset
Currently, the proposed RealSR dataset contains HR-LR image pairs covering a variety of image contents. To ensure the diversity of our RealSR dataset, images are captured in indoor, outdoor and laboratory environments. Several examples of our RealSR dataset are shown in Fig. 7. It provides, to the best of our knowledge, the first general purpose benchmark for real-world SISR model training and evaluation. The RealSR dataset will be made publicly available.

(a) Laboratory scenes

(b) Indoor scenes

(c) Outdoor scenes
7.2 The details of our network architecture
The network architecture of our proposed Laplacian pyramid based kernel prediction network (LP-KPN) is shown in Table 5. In this table, “ conv” denotes a convolutional layer with filters of size which is immediately followed by a ReLU nonlinearity. Each residual block contains two convolutional layers with the same number of filters on both layers. The stride size for all convolution layers is set to and the number of filters in each layer is set to , except for the last layer where is set to . The structure of the residual block is shown in Fig. 8, which is same as [30]. We use the shuffle operation [42] to downsample and upsample the the image.
| Layer | Activation size | ||||
|---|---|---|---|---|---|
| Input | |||||
| Shuffle, /4 | |||||
| conv, pad 1 | |||||
| Residual blocks, 64 filters | |||||
| conv, pad 1 | |||||
| Shuffle, | Shuffle, | - | |||
| conv, pad 1 | conv, pad 1 | conv, pad 1 | |||
| conv, pad 1 | conv, pad 1 | conv, pad 1 | |||
| conv, pad 1 | conv, pad 1 | conv, pad 1 | |||
| Per-pixel conv by Eq. (8) | Per-pixel conv by Eq. (8) | Per-pixel conv by Eq. (8) | |||
| Output (Laplacian pyramid reconstruction) | |||||
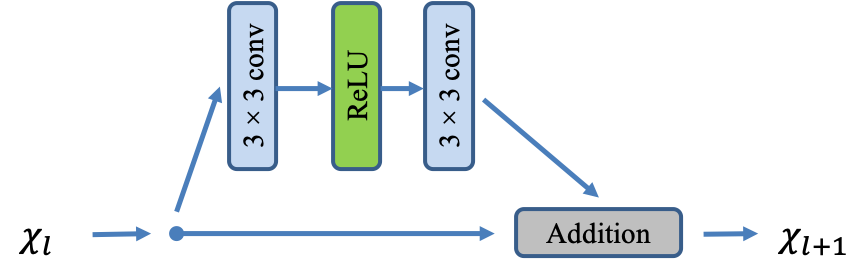
 Image captured by Canon 5D3
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
Image captured by Canon 5D3
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
|
 Image captured by Canon 5D3
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
Image captured by Canon 5D3
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
|
 Image captured by Nikon D810
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
Image captured by Nikon D810
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
|
 Image captured by Nikon D810
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
Image captured by Nikon D810
HR
Bicubic
SRResNet + BD
SRResNet + MD
SRResNet + RealSR
VDSR + MD
VDSR + RealSR
RCAN + BD
RCAN + MD
RCAN + RealSR
|
7.3 More visual results by SISR models trained on simulated SISR datasets and our RealSR dataset
In this subsection, we provide more visual results by SISR models trained on simulated SISR datasets (BD and MD [60]) and our proposed RealSR dataset. Two images captured by Canon 5D3, two images captured by Nikon D810 and their super-resolved results are shown in Fig. 9. Again, the models trained on our RealSR dataset consistently obtain better visual quality compared to their counterparts trained on simulated datasets.
7.4 The computational cost of competing models and their visual results when trained on our RealSR dataset
The running time and the number of parameters of the competing models are listed in Table 6. One can see that although larger kernel size can consistently bring better results for the KPN architecture, the number of parameters will also greatly increase. Benefitting from the Laplacian pyramid decomposition strategy, our LP-KPN using kernel can achieve better results than the KPN using kernel, and it uses much less parameters. Specifically, our LP-KPN model contains less than parameters of the RCAN model [61] and it runs about 3 times faster than RCAN. The visual examples of the SISR results by the competing models are shown in Fig. 10. Though all the SISR models in Fig. 10 are trained on our RealSR dataset and they all achieve good results, our LP-KPN still obtains the best visual quality among the competitors.
| VDSR [23] | SRResNet [29] | RCAN [61] | DPS | KPN, = | KPN, = | KPN, = | KPN, = | Our, = | ||
| PSNR | ||||||||||
| SSIM | ||||||||||
| Parameters | M | M | M | M | M | M | M | M | M | |
| Times (sec.) | ||||||||||
 Image captured by Canon 5D3
Image captured by Canon 5D3

 HR
Bicubic
VDSR
SRResNet
HR
Bicubic
VDSR
SRResNet

 RCAN
Direct Synth
KPN ()
Our
RCAN
Direct Synth
KPN ()
Our
|
 Image captured by Nikon D810
HR
Bicubic
VDSR
SRResNet
RCAN
Direct Synth
KPN ()
Our
Image captured by Nikon D810
HR
Bicubic
VDSR
SRResNet
RCAN
Direct Synth
KPN ()
Our
|
 Image captured by Sony a7II
Bicubic
RCAN + BD
RCAN + MD
RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
Image captured by Sony a7II
Bicubic
RCAN + BD
RCAN + MD
RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
|
|
Image captured by iPhone X
Bicubic
RCAN + BD
RCAN + MD
RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
|
|
Image captured by Google Pixel 2
Bicubic
RCAN + BD
RCAN + MD
RCAN + RealSR
KPN ( = 19) + RealSR
LP-KPN + RealSR
|
7.5 More super-resolved results on images outside our dataset
In this subsection, we provide more super-resolved results on images outside our dataset, including images taken by one Sony a7II DSLR camera and two mobile cameras (i.e., iPhone X and Google Pixel 2). The visual examples are shown in Fig. 11.
References
- [1] http://www.vision.ee.ethz.ch/ntire19/.
- [2] S. Bako, T. Vogels, B. McWilliams, M. Meyer, J. Novák, A. Harvill, P. Sen, T. Derose, and F. Rousselle. Kernel-predicting convolutional networks for denoising monte carlo renderings. ACM Trans. Graph., 36(4):97–1, 2017.
- [3] H. Bay, T. Tuytelaars, and L. Van Gool. Surf: Speeded up robust features. In ECCV, pages 404–417, 2006.
- [4] M. Bevilacqua, A. Roumy, C. Guillemot, and M. L. Alberi-Morel. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. 2012.
- [5] Y. Blau, R. Mechrez, R. Timofte, T. Michaeli, and L. Zelnik-Manor. The 2018 PIRM challenge on perceptual image super-resolution. In ECCV, 2018.
- [6] A. Bulat, J. Yang, and G. Tzimiropoulos. To learn image super-resolution, use a gan to learn how to do image degradation first. In ECCV, 2018.
- [7] H. Chang, D.-Y. Yeung, and Y. Xiong. Super-resolution through neighbor embedding. In CVPR, 2004.
- [8] R. Chartrand and W. Yin. Iteratively reweighted algorithms for compressive sensing. In ICASSP, 2008.
- [9] C. Dong, C. C. Loy, K. He, and X. Tang. Learning a deep convolutional network for image super-resolution. In ECCV, 2014.
- [10] W. Dong, L. Zhang, G. Shi, and X. Li. Nonlocally centralized sparse representation for image restoration. IEEE Transactions on Image Processing, 22(4):1620–1630, 2013.
- [11] W. Dong, L. Zhang, G. Shi, and X. Wu. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization. IEEE Transactions on Image Processing, 20(7):1838–1857, 2011.
- [12] N. Efrat, D. Glasner, A. Apartsin, B. Nadler, and A. Levin. Accurate blur models vs. image priors in single image super-resolution. In ICCV, 2013.
- [13] G. Freedman and R. Fattal. Image and video upscaling from local self-examples. ACM Transactions on Graphics (TOG), 30(2):12, 2011.
- [14] W. T. Freeman, E. C. Pasztor, and O. T. Carmichael. Learning low-level vision. International journal of computer vision, 40(1):25–47, 2000.
- [15] D. Glasner, S. Bagon, and M. Irani. Super-resolution from a single image. In ICCV, pages 349–356, 2009.
- [16] D. Gong, J. Yang, L. Liu, Y. Zhang, I. Reid, C. Shen, A. Van Den Hengel, and Q. Shi. From motion blur to motion flow: a deep learning solution for removing heterogeneous motion blur. In CVPR, 2017.
- [17] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPs, 2014.
- [18] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
- [19] J.-B. Huang, A. Singh, and N. Ahuja. Single image super-resolution from transformed self-exemplars. In CVPR.
- [20] K. Jia, X. Wang, and X. Tang. Image transformation based on learning dictionaries across image spaces. IEEE transactions on pattern analysis and machine intelligence, 35(2):367–380, 2013.
- [21] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In ACM MM, 2014.
- [22] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.
- [23] J. Kim, J. Kwon Lee, and K. Mu Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, 2016.
- [24] K. I. Kim and Y. Kwon. Single-image super-resolution using sparse regression and natural image prior. IEEE transactions on pattern analysis and machine intelligence, 32(6):1127–1133, 2010.
- [25] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2014.
- [26] T. Köhler, M. Bätz, F. Naderi, A. Kaup, A. Maier, and C. Riess. Bridging the simulated-to-real gap: Benchmarking super-resolution on real data. arXiv preprint arXiv:1809.06420, 2018.
- [27] S. Kong and C. Fowlkes. Image reconstruction with predictive filter flow. arXiv preprint arXiv:1811.11482, 2018.
- [28] Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. nature, 521(7553):436, 2015.
- [29] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, 2017.
- [30] B. Lim, S. Son, H. Kim, S. Nah, and K. Mu Lee. Enhanced deep residual networks for single image super-resolution. In CVPRW, pages 136–144, 2017.
- [31] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2):91–110, 2004.
- [32] D. Martin, C. Fowlkes, D. Tal, and J. Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In null, page 416. IEEE, 2001.
- [33] Y. Matsui, K. Ito, Y. Aramaki, A. Fujimoto, T. Ogawa, T. Yamasaki, and K. Aizawa. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools and Applications, 76(20):21811–21838, 2017.
- [34] B. Mildenhall, J. T. Barron, J. Chen, D. Sharlet, R. Ng, and R. Carroll. Burst denoising with kernel prediction networks. In CVPR, 2018.
- [35] S. Niklaus, L. Mai, and F. Liu. Video frame interpolation via adaptive convolution. In CVPR, 2017.
- [36] S. Niklaus, L. Mai, and F. Liu. Video frame interpolation via adaptive separable convolution. In ICCV, 2017.
- [37] J.-M. Odobez and P. Bouthemy. Robust multiresolution estimation of parametric motion models. Journal of visual communication and image representation, 6(4):348–365, 1995.
- [38] S. C. Park, M. K. Park, and M. G. Kang. Super-resolution image reconstruction: a technical overview. IEEE signal processing magazine, 20(3):21–36, 2003.
- [39] C. Qu, D. Luo, E. Monari, T. Schuchert, and J. Beyerer. Capturing ground truth super-resolution data. ICIP, 2016.
- [40] M. S. Sajjadi, B. Scholkopf, and M. Hirsch. Enhancenet: Single image super-resolution through automated texture synthesis. In ICCV, 2017.
- [41] S. Schulter, C. Leistner, and H. Bischof. Fast and accurate image upscaling with super-resolution forests. In CVPR, 2015.
- [42] W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In CVPR.
- [43] J. Sun, W. Cao, Z. Xu, and J. Ponce. Learning a convolutional neural network for non-uniform motion blur removal. In CVPR, 2015.
- [44] Y. Tai, J. Yang, and X. Liu. Image super-resolution via deep recursive residual network. In CVPR, 2017.
- [45] R. Timofte, E. Agustsson, L. Van Gool, M.-H. Yang, and L. Zhang. Ntire 2017 challenge on single image super-resolution: Methods and results. In CVPRW, 2017.
- [46] R. Timofte, V. De Smet, and L. Van Gool. Anchored neighborhood regression for fast example-based super-resolution. In ICCV, 2013.
- [47] R. Timofte, S. Gu, J. Wu, and L. Van Gool. Ntire 2018 challenge on single image super-resolution: methods and results. In CVPRW, 2018.
- [48] T. Vogels, F. Rousselle, B. McWilliams, G. Röthlin, A. Harvill, D. Adler, M. Meyer, and J. Novák. Denoising with kernel prediction and asymmetric loss functions. ACM Transactions on Graphics (TOG), 37(4):124, 2018.
- [49] Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, et al. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- [50] Z. Wang, D. Liu, J. Yang, W. Han, and T. Huang. Deep networks for image super-resolution with sparse prior. In ICCV, 2015.
- [51] Wikipedia contributors. Circle of confusion — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Circle_of_confusion&oldid=885361501, 2019. [Online; accessed 6-March-2019].
- [52] Wikipedia contributors. Depth of field — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Depth_of_field&oldid=886691980, 2019. [Online; accessed 6-March-2019].
- [53] Wikipedia contributors. Lens (optics) — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Lens_(optics)&oldid=882234499, 2019. [Online; accessed 6-March-2019].
- [54] C.-Y. Yang, C. Ma, and M.-H. Yang. Single-image super-resolution: A benchmark. In ECCV, 2014.
- [55] J. Yang, Z. Lin, and S. Cohen. Fast image super-resolution based on in-place example regression. In CVPR.
- [56] J. Yang, J. Wright, T. S. Huang, and Y. Ma. Image super-resolution via sparse representation. IEEE transactions on image processing, 19(11):2861–2873, 2010.
- [57] W. Yang, X. Zhang, Y. Tian, W. Wang, and J.-H. Xue. Deep learning for single image super-resolution: A brief review. arXiv preprint arXiv:1808.03344, 2018.
- [58] H. Yong, D. Meng, W. Zuo, and L. Zhang. Robust online matrix factorization for dynamic background subtraction. IEEE transactions on pattern analysis and machine intelligence, 40(7):1726–1740, 2018.
- [59] R. Zeyde, M. Elad, and M. Protter. On single image scale-up using sparse-representations. In International conference on curves and surfaces, pages 711–730. Springer, 2010.
- [60] K. Zhang, W. Zuo, and L. Zhang. Learning a single convolutional super-resolution network for multiple degradations. In CVPR.
- [61] Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y. Fu. Image super-resolution using very deep residual channel attention networks. In ECCV, 2018.
- [62] Y. Zhang, Y. Tian, Y. Kong, B. Zhong, and Y. Fu. Residual dense network for image super-resolution. In CVPR, 2018.