Toward Reliable Designs of Data-Driven Reinforcement Learning Tracking Control for Euler-Lagrange Systems
Abstract
This paper addresses reinforcement learning based, direct signal tracking control with an objective of developing mathematically suitable and practically useful design approaches. Specifically, we aim to provide reliable and easy to implement designs in order to reach reproducible neural network-based solutions. Our proposed new design takes advantage of two control design frameworks: a reinforcement learning based, data-driven approach to provide the needed adaptation and (sub)optimality, and a backstepping based approach to provide closed-loop system stability framework. We develop this work based on an established direct heuristic dynamic programming (dHDP) learning paradigm to perform online learning and adaptation and a backstepping design for a class of important nonlinear dynamics described as Euler-Lagrange systems. We provide a theoretical guarantee for the stability of the overall dynamic system, weight convergence of the approximating nonlinear neural networks, and the Bellman (sub)optimality of the resulted control policy. We use simulations to demonstrate significantly improved design performance of the proposed approach over the original dHDP.
Index Terms:
Reinforcement learning, tracking control, direct heuristic dynamic programming (dHDP), backstepping.I Introduction
We consider the problem of data-driven optimal tracking control for Euler-Lagrange systems which are represented in a wide range of application problems. The evolution of such systems can be described by the solutions to the Euler-Lagrange equation. In classical mechanics, it is equivalent to Newton’s laws of motion. Such systems also have the advantage that they use the same generalized coordinate system that makes solving the solution of motion easier. The Euler-Lagrange mechanisms can be found in many familiar systems, such as marine navigation equipment, automatic machine tools, satellite-tracking antennas, remote control airplanes, automatic navigation systems on boats and planes, autofocus cameras, computer hard disk drive, and more. In the modern computer and control era, such mechanisms are still behind the robotic manipulators, wearable robots, ground vehicles, and many more applications in mechanical, electrical and electromechanical systems.
Tracking control has been studied extensively in control theoretic context where the tracking control designs are based on well defined mathematical models of the nonlinear dynamics. Well-established approaches include backstepping control [1], observer-based control [2] and nonlinear adaptive/robust control [3, 4]. Those important results have provided the foundation for nonlinear tracking control, yet, their applicability may be limited especially when the nonlinear dynamics are difficult or impossible to precisely model. As such, data-driven nonlinear tracking control designs are sought after. Common and natural approaches are the use of machine learning or neural networks techniques as they can learn directly from data by means of the universally approximating property.
Most of the existing data-driven tracking control results focus on stabilization of nonlinear dynamic systems [5]. As is well-known, real engineering applications require considerations of optimal control performance, not just stability to account for factors such as energy consumption, tracking error rate, and more. Therefore, optimal tracking control solutions of nonlinear systems are sought after. A classical formulation of the problem is to obtain nonlinear optimal tracking control solutions from solving the Hamilton-Jacobi-Bellman (HJB) equation. But solving the HJB equation poses great challenges for general nonlinear systems. One such challenge is a lack of closed-form analytical solution even if a mathematical description of the nonlinear dynamics is available. Additionally, traditional approaches to solving the HJB equations are backward in time and therefore, can only be solved offline. Data-driven nonlinear optimal tracking control designs provide new promises to address these challenges, yet, they face new obstacles.
Currently, there is only a handful of results concerning the theory, algorithm design and implementation of data-driven optimal tracking control. Central to these results [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24] are the use of reinforcement learning to establish an approximate solution to the HJB equation. Yet, few results have demonstrated that these methods are not only mathematically suitable but also practically useful in order to address real engineering problems in terms of providing reliable, easy to implement designs that lead to reproducible neural network-based solutions. In addressing the design of reinforcement learning based optimal tracking of coal gasification problem, the authors of [12] first applied offline neural network identifications to establish the necessary mathematical descriptions of the nonlinear system dynamics and the desired tracking trajectory in order to carry on the control design. As such, it is questionable if approaches based on similar ideas can potentially be useful for other applications as obtaining reproducible models will be the first barrier to overcome. This is not a trivial problem, as it requires great expertise and the subject is still under investigation because current neural network modeling results usually introduce large variances which depend on the designer and the hyperparameters used in learning the models. The authors of [24] proposed a tracking control solution based on dHDP [25] by making use of an additional neural network to provide an internal goal signal. This is theoretically suitable but it complicates the problem as discussed previously. The approximation errors are on top of the uncertainties introduced as approximation variances due to dHDP tracking solutions as pointed out in [26]. As such, the reproducibility of the approach is yet to be demonstrated systematically.
Among those existing reinforcement learning based tracking control design, they often rely on a reference model from which a (continuously differential) desired tracking signal can be obtained [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]. While it may be feasible and useful for certain applications such as flight validation [27], the issue of constructing an appropriate reference model for general nonlinear system control purposes has not been thoroughly addressed. Actually, few published results are available either from a general theoretic perspective or from specific applications perspective. Even for a specific application, it is not considered an easy task [28]. It is therefore fair to say that choosing an appropriate reference model is quite challenging and it may have been taken for granted. This could be the reason that most results on tracking related work have focused on addressing tracking control algorithm design or improving convergence properties of tracking algorithms. As one can imagine, the problem can exacerbate for large scale, complex dynamic systems. Even worse for some applications, it is nearly impossible to accurately capture nonlinear dynamics using a mathematical model. It is also worth mentioning that, some reported results [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23] require generating a corresponding reference control, which can also be challenging and make some of these approaches less applicable. Another commonly implied assumption in many existing learning based tracking control is that the nonlinear dynamics are partially known (or specifically the input dynamics are known). This has simplified the problem but in the meantime, it limits their applicability.
To directly use a reference trajectory in place of a model reference structure, backstepping idea can be employed as it allows for the construction of both feedback control laws and associated Lyapunov functions in a systematic way [1]. The backstepping idea in this context was examined in [29, 30] with critic-only reinforcement learning control. However, their results are limited to partially known system dynamics. Alternatively, the dHDP construct allows for direct use of reference trajectory as well in the design of tracking control. The idea was demonstrated via simulations in [10, 24]. The results are promising, yet, they lack a theoretical support for (sub)optimality and stability analysis. Even though tracking control results in [10] were obtained for dHDP as well, our current approach is fundamentally different as we propose a new control strategy and we use an informative tracking error based stage cost instead of a binary cost. Specifically, the current study is motivated to circumvent some long-standing issues in reinforcement learning, including -learning and dHDP, that is to reduce the variances in the resulted action and/or critic networks after training and thus to improve the reproductivity and consistency of the trained actor/critic network outcomes even if they are trained by different designers.
In this paper, we aim at developing a new nonlinear tracking control design framework with a goal of making the design approach feasible for applications. In a previous study [26], we have shown that well initialized actor-critic neural networks in dHDP can significantly improve the quality of the optimal value function approximation and the optimal control policy. From the same study we realized the importance of finding an initially good estimate of a (locally) optimal solution to the Bellman equation. In this study, we create a backstepping control strategy to provide a feedback system stability framework and a dHDP online adaptation control strategy to provide a feed-forward compensation in order to obtain near optimal tracking control solution. In the feedback control performance objective, we take into account the feed-forward control input. As a result of this innovative solution approach, we can provide an overall system stability guarantee and also avoid the use of a reference model for the desired tracking trajectory. As such, we avoid the challenge of creating a reference model and also remove one source of approximation error. Because of using a reinforcement learning feed-forward control, we address unknown nonlinear dynamics via learning from data, i.e., our design is data-driven, not model dependent.
Our contributions of this work are as follows.
-
1)
We introduce a new reinforcement learning control design framework within a backstepping feedback construct. This allows us to avoid the need of a fully identified system model for backstepping-based control as well as the dependence on a reference model for the desired tracking trajectory for reinforcement learning based-control. Additionally, the backstepping feedback component provides a guideline to narrow down the representation domain to be explored by neural networks in dHDP and to increase the chance of reaching a good (sub)optimal solution.
-
2)
We provide a theoretical guarantee for the stability of the overall dynamic system, weight convergence of the approximating nonlinear neural networks, and the Bellman (sub)optimality of the resulted control policy.
-
3)
We provide simulations to not only demonstrate how the proposed design method works but also to show how the proposed algorithm can significantly improve reproducibility of the results under dHDP integrated with backstepping feedback stabilizing control.
The rest of the paper is organized as follows. Section II provides the problem formulation. Section III presents the backstepping design. Section IV develops the reinforcement learning control. Section V provides theoretical analyses of the proposed algorithm. Simulation and comparison results are presented in Section VI and the concluding remarks are given in Section VII.
II Problem Formulation
We consider a class of nonlinear dynamics described as Euler-Lagrange systems that govern the motion of rigid structures:
| (1) |
In Eq. (1), , , , and are unknown, denote the rigid link position, velocity, and acceleration vectors, respectively; denotes the inertia matrix; the centripetal-coriolis matrix; the gravity vector, friction; a disturbance; and represents the torque control input. The subsequent development is based on the assumption that and are measurable.
To carry on the development of tracking control of the dynamics in Eq. (1), we use the following general discrete-time state space representations where and denote link position and velocity, respectively. Applying the Euler discretization as in [31], systems as described by Eq. (1) can be rewritten as
| (2) |
where , , , denotes and denotes . The control objective is for the output to track a desired time-varying trajectory as closely as possible.
Assumption 1. The inertia matrix is symmetric, positive definite, and the following inequality holds:
| (3) |
where is a given positive constant, and denotes the Euclidean norm.
Assumption 2. The nonlinear disturbance term is bounded, i.e., .
In subsequent development, the desired trajectory is not defined by any reference model, but rather, is simply and directly provided. Our proposed new closed-loop, data-driven nonlinear tracking control solution is as shown in Fig. 1. There are two major components in the design. The backstepping design provides a feedback control structure, the feed-forward signal from the backstepping framework is then accounted for by using a dHDP online learning scheme. Even though the dHDP alone can theoretically be used for tracking control while preserving some qualitative properties such as those in [10], our current approach aims at improving reliability of the design and reproducibility of the results while maintaining theoretical suitability. Next, we provide a comprehensive introduction of the two constituent control design blocks.
III Backstepping To Provide Baseline Tracking Control
The control goal is to find (Fig.1) so that the output of the system Eq. (2) tracks the desired time-varying trajectory . The discrete-time backstepping scheme for the tracking problem of Eq. (2) with unknown, nonlinear system dynamics is derived step by step as follows. Refer to Fig.1, the two blocks play complementary roles in constructing the final control signal . The backstepping control block is designed as follows.
Step 1. To develop the backstepping design, a virtual control function is synthesized. Let be the deviation of from the target , i.e.,
| (4) |
From (2) and (4), we have
| (5) |
Then, we view as a virtual control in Eq. (5) and introduce the error variable
| (6) |
where is a stabilizing function for to be chosen as
| (7) |
where is a design constant. Then Eq. (5) becomes
| (8) |
Step 2. The final control law is synthesized to drive towards zero or a small value. The error variable as the forward signal is written as
| (9) |
where is written as:
| (10) |
The control input is selected as
| (11) |
where is a design constant, is an estimate of the combined unknown dynamics by neural networks, and is written as
| (12) |
Substituting Eq. (11) and Eq. (12) into Eq. (9) yields
| (13) |
where
| (14) |
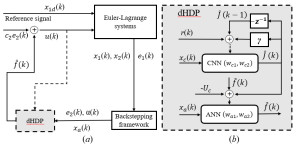
IV Reinforcement Learning To Provide Data-driven Feed-forward Input Control
The dHDP block is used to provide control input for unaddressed dynamics due to a lack of a mathematical description of system Eq. (1). Here we use dHDP as a basic structural framework to approximate the cost-to-go function and the optimal control policy at the same time [25, 32]. The dHDP has been shown a feasible tool for solving complex and realistic problems including the stabilization, tracking, reconfiguring control of Apache helicopters [33, 34, 35], damping low frequency oscillations in large power systems [36], and wearable robots with human in the loop [37, 38, 39]. We therefore consider the dHDP can potentially provide the necessary online learning capability in the backstepping design and together, we provide a new learning control method that improves the reproducibility of results when applied to meaningful real applications.
IV-A Basic Formulation
The dHDP based reinforcement learning feed-forward control is as shown in Fig. 1. The stage cost is defined as
| (15) |
where , are positive semi-definite matrices. Then, the cost-to-go is written as
| (16) |
where is a discount factor for the infinite-horizon tracking problem. We require to be a semi-definite function of the output error and control , so the cost function is well-defined. Based on Eq. (16), we formulate the following Bellman equation:
| (17) |
IV-B Actor-Critic Networks
The dHDP design follows that in [25] with an actor neural network and a critic neural network. Hyperbolic tangent is used as the transfer function in the actor-critic networks to approximate the control policy and the cost-to-go function.
IV-B1 Critic Neural Network
The critic neural network (CNN) consists of three layers of neurons, namely the input layer, the hidden layer and the output layer. The input and output of CNN are
| (18) |
| (19) |
where
| (20) |
In the above, and are the estimated weight matrices between the input and hidden, and output layers, respectively. is the hyperbolic tangent activation function,
| (21) |
From Eq. (17), the prediction error is formulated as
| (22) |
The weights of CNN are updated to minimize the following approximation cost
| (23) |
Gradient descent is used to adjust the critic weights. For the input-to hidden layer,
| (24) |
Similarly for the hidden-to-output layer,
| (25) |
In the above, is the learning rate.
IV-B2 Action Neural Network
In this algorithm, the action neural network (ANN) is to approximate the unknown dynamics in Eq. (12). The input to the ANN is , the respective output is given as follows:
| (26) |
where and are the estimated weight matrices.
The ANN weights are adjusted to minimize the following cost,
| (27) |
where
| (28) |
In the above, is the ultimate performance objective in the tracking control design paradigm, which is defined as under the current problem formulation; is defined in Eq. (14). The desired tracking performance will be achieved if approaches 0.
Remark 1. From Eq. (13), we have that
| (29) |
To compute in Eq. (28), we use an initial estimate in place of in Eq. (29). In the error estimation process, the disturbance is zero as the feed-forward controller aims at learning the unknown system dynamics.
The weight update rule is again based on gradient descent. For the input-to hidden layer,
| (30) |
and for the hidden-to-output layer,
| (31) |
where is the weight associated with the input element from ANN, i.e., the part of which connect with , and is the learning rate.
Algorithm 1 summarizes the implementation procedure of the dHDP-based tracking control.
| Algorithm 1. Direct signal tracking control based on dHDP |
| Specify desired trajectory ; |
| Initialization: , , , , ; |
| Set hyperparameters : , , , ; |
| Calculate virtual control according to Eq. (7); |
| Calculate according to Eq. (6); |
| Calculate according to Eq. (15); |
| Backstepping design: |
| Calculate according to Eq. (26); |
| Calculate according to Eq. (11); |
| Take control input into Eq. (2); |
| Produce , according to Eq. (2), (15); |
| dHDP design: |
| Obtain by Eq. (7); |
| Calculate according to Eq. (6); |
| Calculate according to Eq. (19); |
| Calculate according to equation Eq. (22); |
| ; |
| Calculate (Remark 1) ; |
| ; |
| Iterate until converge. |
V Lyapunov Stability Analysis
In this section, we provide a theoretical analysis for the stability of the overall dynamic system, weight convergence of the actor and critic neural networks, and the Bellman (sub)optimality of the control policy.
V-A Preliminaries
Let , denote the optimal weights, that is,
| (32) |
Then, the optimal cost-to-go and unknown dynamics can be expressed as
| (33) |
where and are the reconstruction errors of the actor and critic neural networks, respectively.
Assumption 3. The optimal weights for the actor-critic networks exist and they are bounded by two positive constants and , respectively,
| (34) |
Then, the weight estimation errors of the actor and critic neural networks are described respectively as
| (35) |
Remark 2. A weight parameter convergence result was obtained for the dHDP in [40] under the condition that the weights between the input and hidden layers remain unchanged during learning. The result was later extended to allowing for all the weights in the actor and critic networks to adapt during learning [41]. Another study [10] addressed tracking control using dHDP for a Brunovsky canonical system. Such a system may be mathematically interesting but practically limiting. Additionally, the design in [10] requires reference models. In this study, we take reference of [40] and [41] to prove our new results on weight convergence for tracking control. Note that [40] and [41] are about regulation control, not tracking control. Notice also that both works lack a system stability result.
Lemma 1. Under Assumption 3, consider the weight vector of the hidden-to-output layer in CNN. Let
| (36) |
Then its first difference is given by
| (37) |
where is an approximation error of the critic output.
Proof of Lemma 1. The first difference of can be written as
| (38) |
With the updating rule in Eq. (25), can be rewritten as
| (39) |
Then, the first term in the brackets of Eq. (38) can be given as
| (40) |
As is a scalar, by using Eq. (35), we can rewrite the middle term in the above formula as follows:
| (41) |
Substituting Eq. (40) and Eq. (41) into Eq. (38), we obtain Lemma 1.
Lemma 2. Under Assumption 3, consider the weight vector of the hidden-to-output layer in ANN. Let
| (42) |
Then its first difference is bounded by
| (43) |
where is an approximation error of the action network output; ; is a weighting factor; and the lumped disturbance .
Proof of Lemma 2. The first difference of can be written as
| (44) |
With the updating rule in Eq. (31), can be rewritten as
| (45) |
Based on this expression, it is easy to obtain that
| (46) |
Substituting Eq. (46) into Eq. (44), we have
| (47) |
The second term in Eq. (46) can be given as
| (48) |
We have thus obtained Lemma 2.
Lemma 3. Under Assumption 3, consider the weight vector of the input-to-hidden layer in CNN. Let
| (49) |
Then its first difference is bounded by
| (50) |
where is a weighting factor and is a vector, with .
Proof of Lemma 3. The first difference of can be written as
| (51) |
With the updating rules in Eq. (24), can be written as
| (52) |
where . Following the same approach as earlier, we can express by
| (53) |
To facilitate the development, the following notation is introduced:
| (54) |
Then, we obtain
| (55) |
By introducing the property of trace function,
| (56) |
the last term in (55) can be expressed as
| (57) |
Therefore, substituting Eq. (56) and Eq. (57) into Eq. (52), we have Lemma 3.
Lemma 4. Under Assumption 3, consider the weight vector of the input-to-hidden layer in ANN. Let
| (58) |
Then its first difference is bounded by
| (59) |
where , and is a weighting factor.
Proof of Lemma 4. The first difference of can be written as
| (60) |
With the updating rule in Eq. (30), can be rewritten as
| (61) |
Let us consider
| (62) |
Then, by using the property of trace function and , the last term in Eq. (62) is bounded by
| (63) |
We have the statement of Lemma 4 by substituting Eq. (61) and Eq. (62) into Eq. (60).
V-B Stability, convergence, and (sub)optimality results
With Lemmas 1-4 in place, we are now in a position to provide results on closed-loop stability of the system, convergences of the neural networks in dHDP, and the Bellman (sub)optimality of the resulted control policy.
Definition 1. (Uniformly Ultimately Boundedness of a discrete time dynamical system [42, 43]) A dynamical system is said to be uniformly ultimately bounded with ultimate bound if for any and there exists a positive number independent of , such that for all whenever .
In the following, can represent tracking errors , or weight approximation errors , , which are related to the stable system or the weight convergence of the actor and critic neural networks, respectively.
Theorem 1. (Stability Result) Let Assumption 2 and Assumption 3 hold, and the tracking errors and defined in Eq. (4) and Eq. (6), respectively. Then the considered system is uniformly ultimately bounded by their respective initial errors if in Eq. (8) and in Eq. (11) satisfy the following condition,
| (64) |
where is given in Eq. (3).
Proof of Theorem 1. We introduce a candidate Lyapunov function:
| (65) |
The first difference of is given as
| (66) |
by substituting and from Eq. (8) and (13), we have
| (67) |
Based on Eq. (3), and also let , we obtain
| (68) |
and can be bounded by
| (69) |
where , and are the upper bound of in Eq. (43), in Eq. (33), and in Eq. (2), respectively.
Therefore, for , chosen from Eq. (64), and
| (70) |
the first difference .
According to Definition 1 and the bounded initial states and weights, this demonstrates that the errors and are uniformly ultimately bounded from time step to , and the boundness of control input can also be ensured according to Eq. (11).
Theorem 2. (Weight Convergence) Under Assumption 3 and the stage cost as given in Eq. (15) and based on Theorem 1, let the weights of the actor and critic neural networks be updated according to Eq. (24), (25), (30) and (31), respectively. Then and are uniformly ultimately bounded provided that the following conditions are met:
| (71) |
Remark 3. With , , , provided in Eq. (16), (42), (49) and (58), respectively, we can choose , to satisfy (71) by setting and .
Proof of Theorem 2. We introduce a candidate of Lyapunov function:
| (72) |
where , , and are shown in Eq. (36), (42), (49) and (58). Then the first difference of is given as
| (73) |
where is defined as
| (74) |
for and satisfying Eq. (71) and also by selecting and , we obtain
| (75) |
Applying the Cauchy–Schwarz inequality, we have
| (76) |
where , , , , , , , , and are the upper bounds of , , , , , , , , and , respectively.
Therefore, if that is, and then for , with constraints from (70), and
| (77) |
the first difference holds.
From Definition 1, this result means that the estimation errors and are uniformly ultimately bounded from the time step to , respectively.
Remark 4. Given Assumption 3, and that the initial states and weights are bounded, then the initial stage cost and initial output of actor network are bounded. As the feed-forward input in Eq. (33) is realized via actor network with bounded optimal weights, we have that the initial approximation error of the actor network is bounded. From Definition 1, in Eq. (68) and in Eq. (74), the tracking errors , and the estimation errors and are bounded from step to the next step , and the control law is bounded from step to the next step as well. Then the resulted stage cost is bounded. By mathematical induction, we have the tracking error , and the estimation errors , uniformly ultimately bounded.
Remark 5. Results of Theorem 1 and Theorem 2 hold under less restrictive conditions than those in [40, 41] that require bounded stage cost. We require an initially bounded system state and actor-critic network weights only.
Theorem 3. ((Sub)optimality Result) Under the conditions of Theorem 2, the Bellman optimality is achieved within finite approximation error. Meanwhile, the error between the obtained control law and optimal control is uniformly ultimately bounded.
Proof of Theorem 3. From the approximate cost-to-go in Eq. (20) and the cost-to-go expressed in Eq. (33), we have
| (78) |
Similarly, from (11), (26) and (33), we have
| (79) |
where , and are the upper bound of , and . This comes directly as and are both uniformly ultimately bounded as the time step increases as shown in Theorem 2. It demonstrates that the Bellman optimality is achieved within finite approximation errors.
VI Simulation Study
We use two examples to demonstrate how the proposed algorithm works and how it improves reproducibility of results over the original dHDP for data-driven tracking control.
Example 1. We consider a single-link robot manipulator with the following motion equation:
| (80) |
where ; and are the mass and the half length of the manipulator, respectively. The values of , , , and initial state are different in different simulation cases below (refer to Table I). Note that, the model in Eq. (80) is to provide a simulated environment in place of a real physical environment. That is to say that the proposed approach is data-driven.
The feedback gain parameters and in Eq. (64) are chosen as and . The CNN and ANN in Fig.1 each has six hidden nodes. The discount factor in Eq. (16) is chosen as 0.95. The continuous time system dynamics in Eq. (80) is discretized by the Runge-Kutta discretization method with .
The per sample mean square error (MSE) defined below is used in Algorithm 1 to terminate ANN and CNN weight update procedure, and also, it is used for scheduling learning rates.
| (81) |
where is the number of data samples between time stamps and .
In the following, we demonstrate the effectiveness of the proposed algorithm by first comparing it with dHDP tracking control without backstepping and then, feedback stabilizing control [1], where the feedback stabilizing control law is . In all the simulation studies below, a trial consists of 6000 consecutive samples.
VI-A Tracking by dHDP with and without backstepping
In this comparison study, we set , , , , , and . A total of 50 trials were conducted to obtain results reported here. We define a trial a success if the MSE of the last 3000 samples (denoted as MSE) is less than the MSE of first 3000 samples (denoted as MSE). The dHDP alone reached 14% success rate under the comparison settings. The MSE of the successful cases is 1.454. In comparison, the success rate of the proposed algorithm is 100% and the MSE is 2.135. Typical tracking trials are shown in Fig. 2 and the weights of actor-critic network are shown in Fig. 3. Performance improvement is apparent.
| case | initial state | success rate | # reset | |||
|---|---|---|---|---|---|---|
| 1 | (-0.1, 0.1) | C | (1,1) | N/A | 96% | 2 |
| 2 | (0.1, -0.1) | C | (1,1) | N/A | 82% | 16 |
| 3 | (0.2, -0.2) | C | (1,1) | N/A | 80% | 24 |
| 4 | (-0.2, 0.2) | C | (1,1) | N/A | 94% | 5 |
| 5 | (-0.1, 0.1) | C | (1,1) | Pulse | 76% | 28 |
| 6 | (-0.1, 0.1) | C | (1,1) | Gaus | 84% | 12 |
| 7 | (-0.1, 0.1) | C | (1,2) | N/A | 60% | 26 |
| 8 | (-0.1, 0.1) | C | (2,2) | N/A | 50% | 35 |
| 9 | (-0.1, 0.1) | V | (1,1) | N/A | 90% | 8 |
|
|
|
|
VI-B Reproducibility of the proposed scheme
While the previous evaluation has illustrated the effectiveness of the proposed tracking control design, we are now in a position to perform a comprehensive evaluation. To do so, nine different scenarios (Table I) are used to quantitatively evaluate the reproducibility of results using the proposed algorithm. In obtaining the results, a trial is successful if the MSE is less than that of feedback stabilizing control method in one trial. In Table I, “C” denotes a constant 5, “V” a constant 5 plus random Gaussian with mean = 0 and std = 0.50, a “Pulse” disturbance is appearing only at , and “Gaus” represents Gaussian noise with mean = 0 and std = 8.25, respectively. The success rate over 50 trials is shown in Table I where the reproducibility of the proposed algorithm is verified.
VI-C Reproducibility with reset after failure
To test if the proposed method can lead to 100% success, we use a “reset” mechanism. Previously we defined a trial as a simulation containing 6000 time samples starting from a given initial state and randomly initialized weights in ANN and CNN. Now we define an episode containing multiple trials until reaching success. Each trial in an episode has 6000 time samples. An episode starts from a given initial state and randomly initialized ANN and CNN weights. But if a trial ends with a failure, only the ANN and CNN weights are reset to random values for the next trial. The “# of reset” in Table Table I is the number of resets occurred in 50 episodes. Note that, the “success rate” column reports results from subsection B in the above. The average MSE of the last successful trial over the 50 episodes is shown in Fig. 4. For comparison, we also show the MSE from applying feedback stabilizing control. It can be seen that the proposed algorithm outperforms feedback stabilizing control.
Example 2. We now consider a two-link robot manipulator with the following motion equation
| (82) |
where , the inertia matrix is given by
the centripetal-coriolis matrix is given by
where , ; , , and ; and are the models for the static and the dynamic friction, respectively.
The feedback gain parameters and in Eq. (64) are chosen as and . The CNN and ANN in Fig.1 each has eight hidden nodes. The discount factor in Eq. (16) is chosen as 0.95, the initial states are and and the learning rate , are 0.01. We use a sampling time period of and the initialization of is .
A comparison of tracking performance shows that the MSE of the stabilizing control is for and for while the MSE of the dHDP-based is for and for , respectively. This example again verifies the effectiveness of the proposed tracking control design.
VII Conclusion
This study aims at developing a mathematically suitable and practically useful, data-driven tracking control solution. Toward this goal, we introduce a new dHDP-based tracking control algorithm that takes advantage of the potential closed-loop system stability framework of the backstepping design for Euler-Lagrange systems. Such design approach also removes the dependence on a reference model for the desired tracking trajectory. Based on the proposed algorithm, we have shown stability of the overall dynamic system, weight convergence of the actor-critic neural networks, and (sub)optimality of the Bellman solution. Our simulations show improved reproducibility and tracking error of the tracking control design. As the dHDP has been shown feasible to solve complex engineering application problems, it is expected that this algorithm also has the potential for applications of tracking control of nonlinear dynamic systems.
References
- [1] M. Krstic, P. V. Kokotovic, and I. Kanellakopoulos, Nonlinear and adaptive control design. John Wiley & Sons, Inc., 1995.
- [2] H. K. Khalil and J. W. Grizzle, Nonlinear systems. Prentice hall Upper Saddle River, NJ, 2002, vol. 3.
- [3] H. Nijmeijer and A. Van der Schaft, Nonlinear dynamical control systems. Springer, 1990, vol. 175.
- [4] A. Isidori, Nonlinear control systems. Springer Science & Business Media, 2013.
- [5] K. Sun, J. Qiu, H. R. Karimi, and H. Gao, “A novel finite-time control for nonstrict feedback saturated nonlinear systems with tracking error constraint,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019.
- [6] B. Fan, Q. Yang, X. Tang, and Y. Sun, “Robust adp design for continuous-time nonlinear systems with output constraints,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 6, pp. 2127–2138, 2018.
- [7] H. Fu, X. Chen, W. Wang, and M. Wu, “Mrac for unknown discrete-time nonlinear systems based on supervised neural dynamic programming,” Neurocomputing, vol. 384, pp. 130–141, 2020.
- [8] M.-B. Radac and R.-E. Precup, “Data-driven model-free tracking reinforcement learning control with vrft-based adaptive actor-critic,” Applied Sciences, vol. 9, no. 9, p. 1807, 2019.
- [9] H. Zhang, Q. Wei, and Y. Luo, “A novel infinite-time optimal tracking control scheme for a class of discrete-time nonlinear systems via the greedy hdp iteration algorithm,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 38, no. 4, pp. 937–942, 2008.
- [10] L. Yang, J. Si, K. S. Tsakalis, and A. A. Rodriguez, “Direct heuristic dynamic programming for nonlinear tracking control with filtered tracking error,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 39, no. 6, pp. 1617–1622, 2009.
- [11] H. Zhang, L. Cui, X. Zhang, and Y. Luo, “Data-driven robust approximate optimal tracking control for unknown general nonlinear systems using adaptive dynamic programming method,” IEEE Transactions on Neural Networks, vol. 22, no. 12, pp. 2226–2236, 2011.
- [12] Q. Wei and D. Liu, “Adaptive dynamic programming for optimal tracking control of unknown nonlinear systems with application to coal gasification,” IEEE Transactions on Automation Science and Engineering, vol. 11, no. 4, pp. 1020–1036, 2014.
- [13] H. Modares and F. L. Lewis, “Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning,” Automatica, vol. 50, no. 7, pp. 1780–1792, 2014.
- [14] B. Kiumarsi and F. L. Lewis, “Actor–critic-based optimal tracking for partially unknown nonlinear discrete-time systems,” IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 1, pp. 140–151, 2015.
- [15] R. Kamalapurkar, H. Dinh, S. Bhasin, and W. E. Dixon, “Approximate optimal trajectory tracking for continuous-time nonlinear systems,” Automatica, vol. 51, pp. 40–48, 2015.
- [16] H. Modares, F. L. Lewis, and Z.-P. Jiang, “H tracking control of completely unknown continuous-time systems via off-policy reinforcement learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 10, pp. 2550–2562, 2015.
- [17] B. Luo, D. Liu, T. Huang, and D. Wang, “Model-free optimal tracking control via critic-only q-learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 27, no. 10, pp. 2134–2144, 2016.
- [18] C. Mu, Z. Ni, C. Sun, and H. He, “Data-driven tracking control with adaptive dynamic programming for a class of continuous-time nonlinear systems,” IEEE Transactions on Cybernetics, vol. 47, no. 6, pp. 1460–1470, 2017.
- [19] W. Gao and Z.-P. Jiang, “Learning-based adaptive optimal tracking control of strict-feedback nonlinear systems,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 6, pp. 2614–2624, 2018.
- [20] D. Wang, D. Liu, Y. Zhang, and H. Li, “Neural network robust tracking control with adaptive critic framework for uncertain nonlinear systems,” Neural Networks, vol. 97, pp. 11–18, 2018.
- [21] B. Zhao and D. Liu, “Event-triggered decentralized tracking control of modular reconfigurable robots through adaptive dynamic programming,” IEEE Transactions on Industrial Electronics, vol. 67, no. 4, pp. 3054–3064, 2019.
- [22] C. Mu and Y. Zhang, “Learning-based robust tracking control of quadrotor with time-varying and coupling uncertainties,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 1, pp. 259–273, 2019.
- [23] H. Dong, X. Zhao, and B. Luo, “Optimal tracking control for uncertain nonlinear systems with prescribed performance via critic-only adp,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020.
- [24] Z. Ni, H. He, and J. Wen, “Adaptive learning in tracking control based on the dual critic network design,” IEEE Transactions on Neural Networks and Learning Systems, vol. 24, no. 6, pp. 913–928, 2013.
- [25] J. Si and Y.-T. Wang, “Online learning control by association and reinforcement,” IEEE Transactions on Neural networks, vol. 12, no. 2, pp. 264–276, 2001.
- [26] L. Yang, J. Si, K. S. Tsakalis, and A. A. Rodriguez, “Performance evaluation of direct heuristic dynamic programming using control-theoretic measures,” Journal of Intelligent and Robotic Systems, vol. 55, no. 2-3, pp. 177–201, 2009.
- [27] N. T. Nguyen, Model Reference Adaptive Control: A Primer. Springer, 2018.
- [28] G. R. G. da Silva, A. S. Bazanella, and L. Campestrini, “On the choice of an appropriate reference model for control of multivariable plants,” IEEE Transactions on Control Systems Technology, vol. 27, no. 5, pp. 1937–1949, 2019.
- [29] H. Zargarzadeh, T. Dierks, and S. Jagannathan, “Optimal control of nonlinear continuous-time systems in strict-feedback form,” IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 10, pp. 2535–2549, 2015.
- [30] Z. Wang, X. Liu, K. Liu, S. Li, and H. Wang, “Backstepping-based lyapunov function construction using approximate dynamic programming and sum of square techniques,” IEEE Transactions on Cybernetics, vol. 47, no. 10, pp. 3393–3403, 2016.
- [31] F. A. Miranda-Villatoro, B. Brogliato, and F. Castanos, “Multivalued robust tracking control of lagrange systems: Continuous and discrete-time algorithms,” IEEE Transactions on Automatic Control, vol. 62, no. 9, pp. 4436–4450, 2017.
- [32] J. Si, A. G. Barto, W. B. Powell, and D. Wunsch, Handbook of learning and approximate dynamic programming. John Wiley & Sons, 2004, vol. 2.
- [33] R. Enns and J. Si, “Apache helicopter stabilization using neural dynamic programming,” Journal of Guidance, Control, and Dynamics, vol. 25, no. 1, pp. 19–25, 2002.
- [34] ——, “Helicopter flight-control reconfiguration for main rotor actuator failures,” Journal of Guidance, Control, and Dynamics, vol. 26, no. 4, pp. 572–584, 2003.
- [35] ——, “Helicopter trimming and tracking control using direct neural dynamic programming,” IEEE Transactions on Neural networks, vol. 14, no. 4, pp. 929–939, 2003.
- [36] C. Lu, J. Si, and X. Xie, “Direct heuristic dynamic programming for damping oscillations in a large power system,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 38, no. 4, pp. 1008–1013, 2008.
- [37] Y. Wen, J. Si, X. Gao, S. Huang, and H. Huang, “A new powered lower limb prosthesis control framework based on adaptive dynamic programming.” IEEE Transactions on Neural Networks and Learning Systems, vol. 28, no. 9, pp. 2215–2220, 2017.
- [38] Y. Wen, J. Si, A. Brandt, X. Gao, and H. Huang, “Online reinforcement learning control for the personalization of a robotic knee prosthesis,” IEEE Transactions on Cybernetics, 2019.
- [39] Y. Zhang, S. Li, K. J. Nolan, and D. Zanotto, “Adaptive assist-as-needed control based on actor-critic reinforcement learning.” in The IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 4066–4071.
- [40] F. Liu, J. Sun, J. Si, W. Guo, and S. Mei, “A boundedness result for the direct heuristic dynamic programming,” Neural Networks, vol. 32, pp. 229–235, 2012.
- [41] Y. Sokolov, R. Kozma, L. D. Werbos, and P. J. Werbos, “Complete stability analysis of a heuristic approximate dynamic programming control design,” Automatica, vol. 59, pp. 9–18, 2015.
- [42] A. N. Michel, L. Hou, and D. Liu, Stability of dynamical systems. Springer, 2008.
- [43] J. Sarangapani, Neural network control of nonlinear discrete-time systems. CRC press, 2018.