Towards Aggregated Asynchronous Checkpointing
Abstract.
High-Performance Computing (HPC) applications need to checkpoint massive amounts of data at scale. Multi-level asynchronous checkpoint runtimes like VELOC (Very Low Overhead Checkpoint Strategy) are gaining popularity among application scientists for their ability to leverage fast node-local storage and flush independently to stable, external storage (e.g., parallel file systems) in the background. Currently, VELOC adopts a one-file-per-process flush strategy, which results in a large number of files being written to external storage, thereby overwhelming metadata servers and making it difficult to transfer and access checkpoints as a whole. This paper discusses the viability and challenges of designing aggregation techniques for asynchronous multi-level checkpointing. To this end we implement and study two aggregation strategies, their limitations, and propose a new aggregation strategy specifically for asynchronous multi-level checkpointing.
1. Introduction
Checkpointing distributed HPC applications is a common task in various scenarios: resilience, job management, reuse of computational states. Typically, checkpoints are persisted to an external repository such as a parallel file system (PFS), whose aggregated I/O bandwidth is limited. Synchronous checkpointing strategies that block applications until all processes checkpoint to a PFS are projected to be impractical at exascale due to high overheads (Nicolae et al., 2019). To alleviate this issue, asynchronous multi-level checkpoint systems like VELOC (Nicolae et al., 2019) write checkpoints to fast, node-local storage and flushes them to the PFS in the background while the application resumes, thereby reducing the checkpoint overhead.
While flushing to the PFS, asynchronous checkpointing schemes share resources of the compute nodes (CPU cores, memory, network bandwidth) with the application processes, creating contention. Therefore, an important challenge is to maintain high throughput to the PFS in the presence of resource sharing, and mitigate the resource contention to avoid additional overheads that slow the application or extends the flush time. In this regard, VELOC adopts a one-file-per-process asynchronous flush strategy, which has two advantages: (1) it is simple, portable and efficient (no coordination, synchronization, or I/O locks); (2) it enables an independent strategy for mitigating contention on each compute node.
However, file-per-process strategies have limitations due to generating large numbers of files at scale and overwhelming the PFS. Specifically, a PFS experiences metadata bottlenecks when many files are accessed simultaneously (especially when stored in the same directory) (Arteaga and Zhao, 2011). Furthermore, it is difficult for developers to manage massive amounts of checkpoint files, especially in scenarios that involve: moving between data centers, verification of integrity, use in a producer-consumer workflow, etc. To alleviate these limitations, checkpoint aggregation (e.g. GenericIO (Habib et al., 2016)) can be used to combine checkpoints from processes into files, with typically set by the application and often fixed to one.
Although effective for synchronous checkpointing (Islam et al., 2012; Tseng et al., 2021; Habib et al., 2016), such aggregation strategies, to our knowledge, remain unexplored for asynchronous checkpointing. The main challenge in this context is designing efficient aggregation strategies that achieve high I/O bandwidth under concurrency to maintain a high speed of flushing, while also minimizing overhead caused by resource contention. This is a non-trivial challenge that involves a co-design of both aggregation and mitigation strategies.
In this paper, we discuss the benefits and challenges of solving the co-design problem mentioned above. Specifically, we focus on several aggregation strategies for VELOC (Nicolae et al., 2021, 2019), a production-ready checkpointing system used on large-scale HPC systems. Using these strategies, we identify key bottlenecks in the checkpointing process (Section 2) and discuss several future work directions to address them (Section 3).
2. Aggregation Strategies
In a study of asynchronous I/O interference, Tseng et. al. (Tseng et al., 2021) found that there is a trade-off between increasing the number of concurrent I/O threads (to flush to external storage faster) vs. the slowdown perceived by the application. Furthermore, there are trade-offs between the OS-level overheads incurred by the flushing strategy (read/write, mmap/write, sendfile) and the underlying PFS I/O implementation. For example, even if sendfile triggers the least context switches and therefore minimizes OS-level overheads, it performs small I/O requests to the PFS, which are handled by the latter inefficiently, thereby increasing both the application slowdown and the flush duration. These trade-offs are important to consider in the design of asynchronous checkpoint aggregation strategies.
2.1. POSIX-based aggregation
The first strategy we implement is a POSIX-based aggregation strategy that aims to highlight the bottlenecks during asynchronous flushing. To this end, we leverage the multi-level checkpointing support introduced by VELOC (Nicolae et al., 2021): (1) each process writes its checkpoint in a blocking fashion to a file on node-local storage, e.g. in-memory or to an SSD (denoted the local phase); (2) once files are written locally, the process continues with application computation and a separate asynchronous post-processing engine (denoted the active backend in VELOC) running on each compute node writes the node-local files (generated by processes co-located on the same node) to an offset in a shared file located on the PFS (denoted the flush phase). The offset of each node-local checkpoint in the remote file is calculated using a prefix-sum algorithm over all participating processes. Note that with this strategy, the active backend running on each node can parallelize writing the local checkpoints using a number of I/O threads that can be used to match the desired trade-off between application slowdown and flushing duration. This can be configured for each active backend independently.
Thanks to its simplicity, the POSIX-based aggregation strategy incurs minimal preparation and synchronization overheads, much like VELOC’s default asynchronous strategy that writes each checkpoint to a different file on the PFS (i.e. no intercommunication between processes during the flush phase). Therefore, we can conclude that this strategy is unlikely to cause more interference or slowdown in the presence of an application. However, the flushing duration is significantly higher compared to the default VELOC and GenericIO. This extended flush time is caused by false sharing: to facilitate parallel processing, files are striped on the PFS into chunks that are stored on different I/O servers. If the writes of local checkpoints do not align to the stripe sizes, then the writes will compete for the same stripe, despite using non-overlapping file regions. As a consequence, more advanced POSIX-based aggregation strategies need to address the negative impact of false sharing.
2.2. MPI-IO based aggregation
A second strategy we implement on top of VELOC is based on MPI-IO, which is also used by GenericIO and was optimized for synchronous aggregation. Specifically, the same prefix-sum algorithm is applied to determine the offset of each node-local checkpoint in the larger file on the PFS, then the active backend issues a collective MPI-IO write at operation (instead of independent POSIX writes). The underlying collective write implementation is based on two key observations: (1) the number of processes (MPI ranks) is typically much larger than the number of I/O servers, therefore it is suboptimal to issue more concurrent I/O writes than there are I/O servers available to execute them; (2) only one MPI rank is allowed to write to a PFS stripe due to false sharing. Based on these observations, MPI-IO implements optimizations such as gathering the data from multiple MPI ranks on I/O leaders, which are then responsible for concurrently writing files on the PFS. The number of I/O leaders can be adjusted to match the number of I/O servers. Furthermore, each leader can be assigned a set of stripes that is disjoint from the sets of stripes of all other leaders, thereby eliminating false sharing.
While more advanced, an MPI-IO based aggregation strategy has limited applicability in the area of asynchronous checkpointing for several reasons. First, it introduces high communication overheads which is needed to gather the data from multiple processes to the I/O leaders. While this does not cause any interference in synchronous mode (because the application is blocked during checkpointing), it can become a bottleneck in asynchronous mode, because the application may need to perform its own communications during the gathering phase, thereby competing for network bandwidth. Second, since it is based on a collective operation, it assumes all MPI ranks need to participate in the checkpointing process and all data needs to be ready simultaneously in all MPI ranks, introducing synchronization during the flush phase. However, a key feature of multi-level checkpointing strategies is that the MPI ranks write their checkpoints to node-local storage and flush to the PFS independent of the progress or state of other participating processes, then continue executing the application code.
Thus, it is up to the active backends to self-organize in order to optimize the aggregation asynchronously. One potential solution is to perform a collective MPI-IO write on all active backends, where each active backend contributes with its set of node-local checkpoints. However, such a strategy introduces two bottlenecks: (1) the MPI-IO standard does not allow more than a single contiguous memory region to be written to a file, whereas each active backend may need to contribute with multiple such regions (mapped to independent node-local checkpoint files); (2) even if such a MPI-IO collective write were implemented, it places an unnecessary restriction on the active backends to be ready at the same time to facilitate communication and data exchange, which increases the initialization overheads. To address these issues, we propose a multi-phase solution that invokes multiple successive MPI-IO collective write calls, one for each node-local checkpoint.
2.3. Preliminary evaluation
We evaluate the two strategies introduced in Section 2.1 and Section 2.2 in a series of experiments that involve a micro-benchmark running on an increasing number of MPI ranks and an increasing number of compute nodes. Each MPI rank writes a checkpoint that is 1 GiB large. The testbed used for our experiments is Argonne National Lab’s Theta supercomputer, a Cray XC40 11.60 Petaflops system, equipped with a Lustre parallel file system (Nicolae et al., 2021, 2019). We compare the two strategies with two additional baseline approaches: the default VELOC multi-level asynchronous strategy (one file per MPI rank) and a synchronous I/O aggregation strategy using GenericIO (GIO) (Habib et al., 2016). The aggregation performed by all approaches is ).
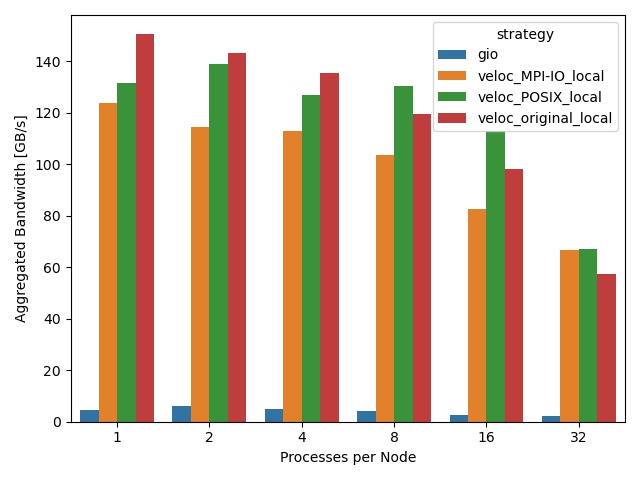
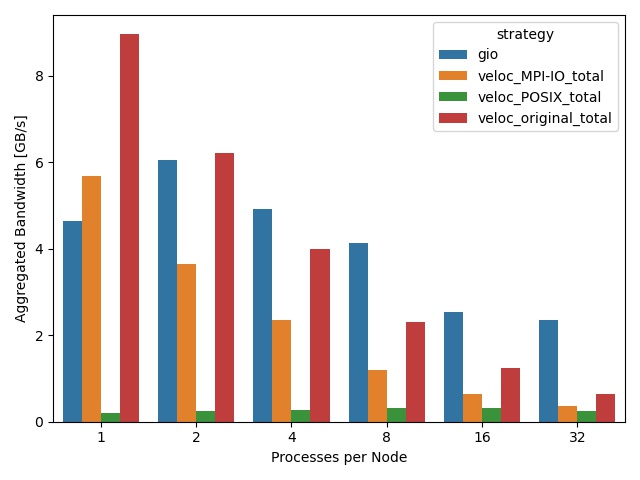
Figure 1 shows the throughput during the local checkpoint phase for the aforementioned checkpoint strategies. Since VELOC is writing to local storage (SSD or memory hierarchy), it is orders of magnitudes faster than GenericIO, which is writing directly to the PFS. Note that all three VELOC strategies exhibit similar throughput, which means the prefix sum employed by the aggregation approaches introduces a negligible overhead during the local checkpointing phase.
Figure 2 shows the throughput for the compared strategies during the flush phase. As can be observed, both the POSIX and MPI-IO based strategies show a significantly lower throughput compared with the original one file per MPI rank strategy, which can be attributed to false sharing in the case of the former, and, respectively, to the fact that we invoke multiple MPI-IO collective calls, which perform suboptimally.
Thus, we can conclude that a simple aggregation strategy based on POSIX or MPI-IO is not sufficient and there is significant room for improvement to reach and potentially even surpass the default, embarrassingly parallel one-file per MPI rank flush strategy.
3. Future work
Based on the study described in Section 2, we propose an aggregation strategy specifically designed for asynchronous multi-level checkpointing. Assuming the checkpoints need to be flushed to a set of fixed-sized stripes on the PFS (which may form a single or up to files), we elect leaders among the active backends. Similar to synchronous aggregation strategies, the active backends that are not designated as leaders will send their checkpointing data to one (or multiple) of the leaders. The decision of which active backends becomes a leader and who is supposed to send their checkpointing data can be determined dynamically based on several factors, such as: (1) size of the node-local checkpoints (e.g., an active backend with small node-local checkpoints should send them to an active backend with larger node-local checkpoints to minimize communication over the network); (2) the current load of each compute node (e.g., nodes with the least CPU/memory/network pressure are less likely to cause bottlenecks and therefore should become leaders); (3) network topology (e.g., leaders should gather the checkpointing data from active backends that are in close proximity).
These decisions can be implemented by piggy-backing additional information during the prefix-sum. In the previously mentioned strategies, the prefix-sum operation calculates the offset in the shared, remote file. In this strategy, we will statically assign each leader a set of offsets aligned to the stripe size. The prefix-sum propagates through all the processes and informs non-leaders 1) who the leaders are; 2) how much data to send to each (since some non-leaders may contain more data than can fit into a single leader’s remaining stripes, it may need to be broken up among various leaders). Then, by applying the same strategy independently, the nodes can take different roles without the need for further agreement protocols, which has two advantages: (1) it is a lightweight protocol that introduces a minimal runtime overhead; (2) this only requires active backends to synchronize to perform the leader election, alleviating one of the limitations of collective operations.
4. Conclusion
This paper discusses the opportunities for aggregation in asynchronous multi-level checkpointing and the challenges of designing efficient techniques in this context. To this end, we show that false sharing exhibited by POSIX-based I/O writes to shared files on the PFS, as well as state-of-art optimization techniques for synchronous I/O aggregation (e.g. MPI-IO) suffer from bottlenecks and limitations when directly applied in the context of multi-level asynchronous checkpointing. As a consequence, we contribute a study of these limitations and outline the basic ideas behind a proposal for a dedicated aggregation strategy specifically designed for asynchronous multi-level checkpointing that alleviates the identified limitations.
Acknowledgements.
Clemson University and Argonne National Lab are acknowledged for generous allotment of compute time on the Palmetto cluster and Theta super computer. This material is based upon work supported by the National Science Foundation under Grant No. SHF-1910197. The material was supported by U.S. Department of Energy, Office of Science, under contract DE-AC02-06CH11.357References
- (1)
- Arteaga and Zhao (2011) Dulcardo Arteaga and Ming Zhao. 2011. Towards Scalable Application Checkpointing with Parallel File System Delegation. In 2011 IEEE Sixth International Conference on Networking, Architecture, and Storage. 130–139. https://doi.org/10.1109/NAS.2011.42
- Habib et al. (2016) Salman Habib, Adrian Pope, Hal Finkel, Nicholas Frontiere, Katrin Heitmann, David Daniel, Patricia Fasel, Vitali Morozov, George Zagaris, Tom Peterka, and et al. 2016. HACC: Simulating sky surveys on state-of-the-art supercomputing architectures. New Astronomy 42 (Jan 2016), 49–65. https://doi.org/10.1016/j.newast.2015.06.003
- Islam et al. (2012) Tanzima Zerin Islam, Kathryn Mohror, Saurabh Bagchi, Adam Moody, Bronis R. de Supinski, and Rudolf Eigenmann. 2012. MCREngine: A scalable checkpointing system using data-aware aggregation and compression. In SC ’12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. 1–11. https://doi.org/10.1109/SC.2012.77
- Nicolae et al. (2019) Bogdan Nicolae, Adam Moody, Elsa Gonsiorowski, Kathryn Mohror, and Franck Cappello. 2019. VeloC: Towards High Performance Adaptive Asynchronous Checkpointing at Large Scale. In 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 911–920. https://doi.org/10.1109/IPDPS.2019.00099
- Nicolae et al. (2021) Bogdan Nicolae, Adam Moody, Gregory Kosinovsky, Kathryn Mohror, and Franck Cappello. 2021. VELOC: VEry Low Overhead Checkpointing in the Age of Exascale. CoRR abs/2103.02131 (2021). arXiv:2103.02131 https://arxiv.org/abs/2103.02131
- Tseng et al. (2021) Shu-Mei Tseng, Bogdan Nicolae, Franck Cappello, and Aparna Chandramowlishwaran. 2021. Demystifying asynchronous I/O Interference in HPC applications. The International Journal of High Performance Computing Applications 35 (2021), 391–412. Issue 4.