Towards Gender-Neutral Face Descriptors for Mitigating Bias in Face Recognition
Abstract
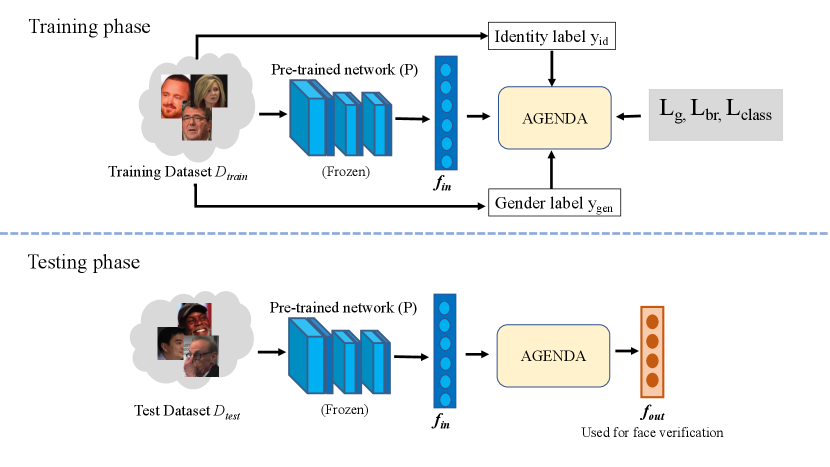
State-of-the-art deep networks implicitly encode gender information while being trained for face recognition. Gender is often viewed as an important attribute with respect to identifying faces. However, the implicit encoding of gender information in face descriptors has two major issues: (a.) It makes the descriptors susceptible to privacy leakage, i.e. a malicious agent can be trained to predict the face gender from such descriptors. (b.) It appears to contribute to gender bias in face recognition, i.e. we find a significant difference in the recognition accuracy of DCNNs on male and female faces. Therefore, we present a novel ‘Adversarial Gender De-biasing algorithm (AGENDA)’ to reduce the gender information present in face descriptors obtained from previously trained face recognition networks. We show that AGENDA significantly reduces gender predictability of face descriptors. Consequently, we are also able to reduce gender bias in face verification while maintaining reasonable recognition performance.
1 Introduction
In the past few years, the accuracy of face recognition networks has significantly improved (Schroff, Kalenichenko, and Philbin 2015; Taigman et al. 2014; Ranjan et al. 2019; Deng et al. 2019; Bansal et al. 2018). These improvements have led to the usage of face recognition systems in a large number of applications. This has raised concerns about bias against protected categories such as age, gender or race. A recent study performed by NIST (Grother, Ngan, and Hanaoka 2019) found evidence that characteristics such as gender and ethnicity impact the verification and matching performance of existing algorithms. Similarly, (Buolamwini and Gebru 2018) showed that most face-based gender classifiers perform better on male faces than female faces.
Several works (Wang et al. 2019a; Amini et al. 2019; Krishnapriya et al. 2020; Vangara et al. 2019; Nagpal et al. 2019; Furl, Phillips, and O’Toole 2002; Cavazos et al. 2019; Georgopoulos, Panagakis, and
Pantic 2020) have recently analyzed and proposed techniques to mitigate bias against race and skintone in face recognition. However, the issue of gender bias has not been widely explored. It is often assumed that gender imbalance in face recognition training datasets is a cause of gender bias in face recognition. However, (Albiero, Zhang, and Bowyer 2020) show that to obtain similar verification performance on male and female faces, we need to find the appropriate percentage of male and female identities (which may not be equal) in the training dataset. Finding such an appropriate mixture is not scalable. (Albiero and Bowyer 2020) show that minimizing the effect of gendered hairstyles improves the matching scores for genuine female pairs but does not improve that of impostor female pairs.
Recent studies (Dhar et al. 2020; Hill et al. 2019) have also shown that face recognition networks encode gender information while being trained for identity classification. This implies that face descriptors 111Face descriptors refer to the features extracted from the penultimate layer of a previously trained face recognition network. extracted from such networks can be trained to predict face gender. This can be viewed as privacy leakage since a malicious agent can learn private gender information about an individual without receiving prior authorization.
Privacy leakage in face representations is an important issue, as it can allow for the unauthorized extraction of private sensitive attributes (such as race, gender, and age). This issue of estimating soft biometric attributes in raw facial images has been studied in (Fu, Guo, and Huang 2010; Lu, Jain et al. 2004; Makinen and Raisamo 2008). To prevent gender leakage, (Othman and Ross 2014) propose a face-morphing strategy to suppress gender in face images, while preserving identity information. However, there does not exist such a study with respect to post-hoc utilization of face descriptors extracted from previously trained networks. In this regard, we investigate solutions to the following problems:
-
•
Privacy leakage in face descriptors.
-
•
Bias in face verification.
In our preliminary experiments (in Sec. 5.2), we find that face descriptors from which the gender is more difficult to predict generally demonstrate lower gender bias in face verification tasks. Therefore, we hypothesize that reducing the ability to predict gender in face descriptors will reduce gender bias in face verification tasks. To test this hypothesis, we present an Adversarial Gender De-biasing algorithm (AGENDA) (Fig. 1) that transforms face descriptors so that they can be used to accurately classify identity but not gender. Reducing the predictability of gender in face descriptors will impede malicious gender classifiers, thus reducing the possibility of gender leakage. Although in this work we focus on gender leakage and gender bias, with sufficient training data, AGENDA could be modified to reduce the leakage of other sensitive attributes like race and age.
We define gender bias (in Eq. 1) as the difference in the face verification performance on male and female faces. As a result of reducing gender predictability (either by using a baseline or AGENDA), we find that gender bias in face verification decreases considerably. Our technique can be used as a post-hoc de-biasing measure for face recognition networks that might exhibit biases. Moreover, our proposed technique does not rely on the gender mixture (i.e. % of male and female identities) of the training dataset. To summarize, the contributions of our paper are as follows:
-
•
To the best of our knowledge, we are the first to examine verification performance for gender agnostic face descriptors and analyze the subsequent reduction in gender bias.
-
•
We experimentally verify that face descriptors with low gender predictability generally demonstrate lower gender bias in face verification.
-
•
To further reduce gender predictability in face descriptors, we propose a method, AGENDA, that unlearns gender information in descriptors while training them for classification. Once trained, AGENDA can then be used to generate gender de-biased representations of face descriptors. When such representations are used for face verification, we find that AGENDA significantly outperforms the baseline with respect to bias reduction. Finally, we analyze the bias versus accuracy trade-off for face verification in male and female faces.
2 Related work
Bias in face recognition: Several empirical studies (Grother, Ngan, and Hanaoka 2019; Buolamwini and Gebru 2018; Drozdowski et al. 2020) have shown that many publicly available face recognition systems demonstrate bias towards attributes such as race and gender. (Wang et al. 2019a; Wang and Deng 2020) highlight the issue of racial bias in face recognition, and propose strategies to mitigate the same. In the context of gender bias, most experiments show that the face recognition performance on females is lower than that of males. Use of cosmetics by females has been assumed to play a major role in the resulting gender bias (Cook et al. 2019; Klare et al. 2012). However, (Albiero et al. 2020) show that cosmetics only play a minor role in the gender gap.
Building fairer training datasets: It has been speculated that the unequal percentage of male and female identities in training datasets might lead to gender bias in face recognition. However, (Albiero, Zhang, and Bowyer 2020) show that the bias is not mitigated when equal number of male and female identities are used for training. (Sattigeri et al. 2018) uses a GAN to generate a (Celeb-A (Liu et al. 2015) like) dataset which is less biased with respect to gender, for predicting attractiveness. However, such a method cannot be used to generate unbiased versions of large ‘in the wild datasets’ like MS-Celeb-1M. In contrast to these approaches, our proposed bias mitigation algorithm does not rely on the gender mixture or quality of the training dataset.
Adversarial techniques to suppress attributes: (Wu et al. 2018) introduce an approach to anonymize identity and private attributes in a given video, while performing activity recognition. (Wang et al. 2019b) present an adversarial approach to minimize gender leakage in object classification to mitigate bias. Similarly, (Alvi, Zisserman, and Nellåker 2018) propose a technique to adversarially minimize the predictability of multiple attributes - gender, pose and ancestral origin, while performing age classification. (Li et al. 2019) propose techniques to adversarially minimize gender predictability to reduce gender bias while predicting smile and presence of high-cheekbones. In some of the aforementioned experiments, the attribute under consideration is ephemeral to the target task. For example, in (Wu et al. 2018), an action is not specific to an identity. Similarly, the presence of smile in (Li et al. 2019) may not be unique to a single gender. In contrast, attributes like gender and race may not be ephemeral to face recognition. A given identity can be generally tied to a single gender or race. Therefore, because of the high level of entanglement between identity and gender or race, disentangling them is more involved.
Gender privacy: (Mirjalili, Raschka, and Ross 2018; Mirjalili and Ross 2017) introduce techniques to synthesize perturbed face images using an adversarial approach so that gender classifiers are confounded, but the performance of a commercial face-matcher (in terms of similarity score) is preserved. However, such perturbations have not been demonstrated for pre-trained face descriptors. It has been already shown in (Dhar et al. 2020; Hill et al. 2019) that face descriptors implicitly encode gender information during training. Therefore, a classifier can be easily trained to predict the face gender, using these descriptors as input. Inspired by existing adversarial methods to remove certain attributes, we propose a framework to reduce the gender information in pre-trained face descriptors, while making them efficient for the task of identity classification.
3 Problem statement
Our goal is to reduce gender information in face descriptors so that the ability of a classifier to predict the gender from these descriptors is reduced. From our initial experiments (section 5.2) we find that face descriptors that show low gender predictability demonstrate relatively lower gender bias in face recognition/verification. From this observation, we hypothesize that reducing gender predictability of face descriptors will considerably reduce the gender bias demonstrated by the descriptors. At this point, we quantitatively describe gender bias in the context of face verification. We define gender bias, at a given false positive rate (FPR) as the absolute difference between the verification performance for male-male and female-female pairs.
| (1) |
where and denote the true positive rate for the verification of male-male and female-female pairs respectively at a given FPR . We present a framework that generates de-biased descriptors that, when used for face verification, obtains low bias value and reasonable TPRf and TPRm at any given FPR.
4 Proposed approach
The key idea in our proposed approach - AGENDA, is to train a model to classify identities while discouraging it to predict gender. Firstly, for a given image , we extract a face descriptor using a pre-trained network .
| (2) |
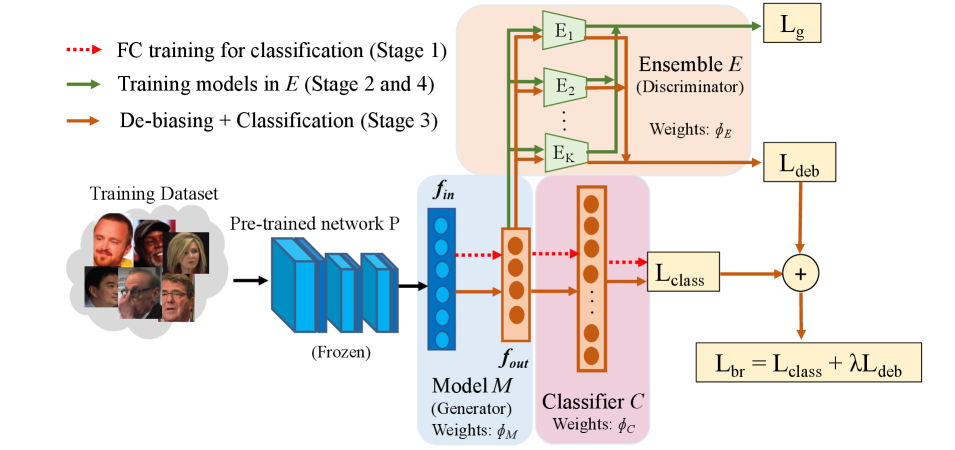
The AGENDA architecture (Fig. 2) is composed of three components:
(1) Generator model : A model that takes in face descriptor from a pre-trained network , and generates a lower dimensional descriptor . consists of a single linear layer with 256 units, followed by a PReLU layer. The weights of are denoted as .
(2) Classifier : A classifier that takes in the output of () and generates a prediction vector for identity classification. The weights of are denoted as .
(3) Ensemble of discriminators : An ensemble of gender prediction models represented as . Each of these models is a simple MLP network with an input layer size of 256 units, a SELU activated (Klambauer et al. 2017) linear layer with 128 units, and a sigmoid activated output layer with 2 units followed by softmax. We collectively denote the weights of all the models in as and weights of model as .
We now interpret AGENDA as an adversarial approach. is a generator that should ideally generate gender agnostic descriptors . is fed to the ensemble of gender prediction models which acts as a discriminator. should be able to accurately predict the gender using . Our aim is to train to generate descriptors that can fool in terms of gender prediction, and can also be used to classify identities. Therefore, we need to impose two constraints on : (i.) a penalty term that preserves the identity information, and (ii.) a penalty term that minimizes the gender predictability of . To this end, we propose a bias reducing classification loss , which is explained in section 4.1.
4.1 Bias reducing classification loss
After extracting the descriptor from a pre-trained face recognition network, we pass it through to obtain a lower dimensional descriptor .
| (3) |
First constraint: To make proficient at classifying identities we provide it to classifier and use cross-entropy classification loss to train both and .
| (4) |
| (5) |
is a one hot identity label and is the corresponding softmaxed output of classifier .
Training discriminators: generates which is fed to ensemble . Each of the gender prediction models in , denoted , are used for computing cross entropy loss for gender classification. is computed as the sum of cross-entropy losses for each .
| (6) |
| (7) |
is the binary gender label for the input face descriptor, and represents the respective softmaxed outputs of in the ensemble.
Training generator (second constraint): After training , is trained to transform into gender agnostic descriptor . We then provide to each model in ensemble :
| (8) |
The outputs represent the gender probability scores. If an optimal classifier operating on were to always produce a posterior probability of 0.5 for both male and female classes then this implies that no gender information is present in the descriptor. To this end, we define the adversarial loss for the model in to be:
| (9) |
Here, we use an ensemble of gender prediction models instead of a single model because we want to be gender agnostic with respect to multiple gender predictors. This approach was motivated by the work of (Wu et al. 2018) to solve ‘the challenge’. After computing the adversarial loss for model with respect to all the models in , we select the one for which the loss is maximum. We term this loss as debiasing loss .
| (10) |
The idea is that we would like to penalize with respect to the strongest gender predictor for which it was not able to fool. This approach was introduced in (Wu et al. 2018). is then combined with to compute a bias reducing classification loss as follows:
| (11) |
Here, is used to weight the de-biasing loss.
4.2 Stage-wise Training
We now explain the various stages of training AGENDA.
Stage 1 - Initializing and training and : Using input descriptors from a pre-trained network, we train and from scratch for iterations using (Eq. 5).
Stage 2 - Initializing and training : Once is trained to perform classification, we feed the outputs of to an ensemble of gender prediction models. is trained from scratch to classify gender for iterations using (Eq. 7). remain unchanged in this stage.
Stage 3 - Update model and classifier : Here, is trained to generate descriptors that are proficient in classifying identities and are relatively gender-agnostic. is fed to the ensemble and the classifier , the outputs of which result in (Eq. 10) and (Eq. 5) respectively. We combine them to compute (Eq. 11) for training and for iterations, while remains locked. While computing , the gradient updates for are propagated to and those for are propagated to both and .
Stage 4 - Update ensemble (discriminator): In stage 3, is trained to generate gender-debiased descriptors to fool the models in , whereas in stage 4, models in are re-trained to classify gender using . Therefore, we run stages 3 and 4 alternatively, for episodes, after which we re-initialize and re-train all the models in (as done in stage 2). Here, one episode indicates an instance of running stages 3 and 4 consecutively. In stage 4, we heuristically choose one of the models in , and train it for iterations or until it reaches an accuracy of on the validation set. and remain locked in this stage. The motivation for training a single model in at a time is deferred to discussion in the supplementary material. The full details of training are described in Algorithm 1.
5 Experiments
5.1 Pre-trained networks and evaluation dataset
We separately evaluate the face descriptors, obtained from the penultimate layer of following two pre-trained networks:
Arcface : Resnet-101 trained on MS1MV2 222https://github.com/deepinsight/insightface/wiki/Dataset-Zoo with Additive Angular margin (Arcface) loss (Deng et al. 2019). There are 59,563 males and 22,499 females in this dataset.
Crystalface : Resnet-101 trained on a mixture of UMDFaces333http://umdfaces.io/(Bansal et al. 2017b), UMDFaces-Videos3(Bansal et al. 2017a) and MS-Celeb-1M (Guo et al. 2016), with crystal loss (Ranjan et al. 2019). There are 39,712 males and 18,308 females in this dataset.
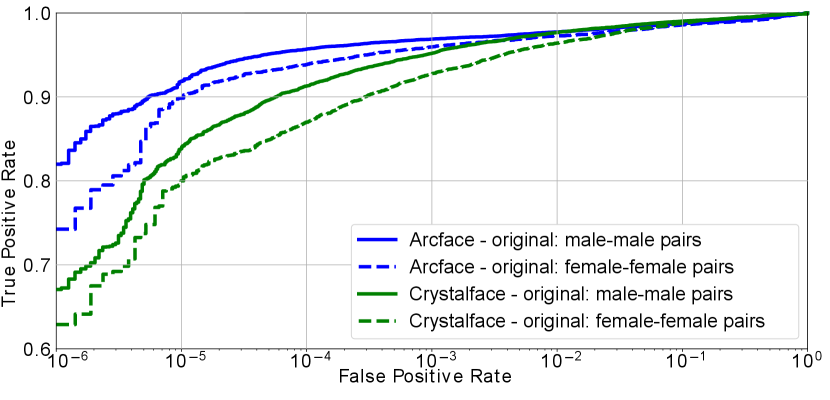
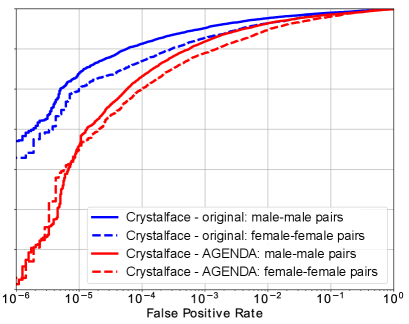
For evaluation, we use the aligned faces in the IJB-C dataset, and follow the 1:1 face verification protocol defined in (Maze et al. 2018). The alignment is done using (Ranjan et al. 2017). However, instead of verifying all the pairs, we only verify male-male and female-female pairs. There are 6.4 million male-male and 2.1 million female-female pairs defined in the protocol. The gender labels are provided in the dataset. Using Arcface and Crystalface we extract 512 dimensional face descriptors for the aligned faces in the IJB-C dataset which are then used for verification of male-male and female-female pairs. The gender-wise verification plots for Crystalface and Arcface descriptors are provided in Fig. 3.
5.2 Relation between gender predictability and bias
We compare the predictability (i.e. ability to classify gender) of face descriptors extracted from Arcface and Crystalface networks. We train a logistic regression classifier on 60k IJB-C face descriptors (30k males and females) to classify gender and test it on 20k IJB-C descriptors (10k males and females). The images for training and testing are selected randomly, and the face descriptors are extracted using the pre-trained networks (Arcface or Crystalface). Note that there is no overlap between identities in train and test split. From the results in Table 1, we find that descriptors extracted using Arcface show relatively low gender predictability than Crystalface descriptors. In Table 1, we also find that the gender bias (computed using Eq. 1 and plots shown in Fig 3) is lower in most FPRs when Arcface descriptors are used for face verification, as comapred to Crystalface descriptors. This shows that face descriptors with low gender predictability appear to demonstrate lower gender bias in face verification, thus forming the basis of our initial hypothesis (mentioned in Sec. 1). Therefore, we propose techniques to reduce the predictability of gender in face descriptors while making them proficient in identity classification.
| FPR | |||||||||||||
| Network | Acc. | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias |
| Arcface | 76.01 | 0.82 | 0.74 | 0.08 | 0.92 | 0.90 | 0.02 | 0.96 | 0.93 | 0.03 | 0.97 | 0.96 | 0.01 |
| Crystalface | 80.50 | 0.67 | 0.63 | 0.04 | 0.84 | 0.8 | 0.04 | 0.92 | 0.87 | 0.05 | 0.96 | 0.93 | 0.03 |
5.3 Baseline: CorrPCA
Since our hypothesis involves removing gender specific information from face descriptors, we propose a naive approach, termed as ‘Correlation-based PCA’ (CorrPCA) for this task. We first compute the eigenspace of the descriptors and isolate the eigenvectors that encode gender information. After this, we remove these eigenvectors and transform the test face descriptors using the remaining subspace. A similar approach was used in the early nineties (Turk and Pentland 1991) to reduce the impact of illumination on PCA features.
Isolating gender specific components: We first randomly select 80k (40k males and females) aligned face images from MS-Celeb-1M dataset. Then, we extract the 512-dimensional descriptors for these images, using a given pre-trained network (Arcface/Crystalface). We then compute the eigenspace of the descriptors using PCA. Using each eigenvector in , we transfrom the original descriptors as follows :
| (12) |
Here, is a row in (i.e. an eigenvector of ), and is the corresponding component of each descriptor. Now, for all the 80k images, we have a vector and a label vector , with gender labels for all the sampled images. After this, we compute the Spearmann correlation coefficient between and . We select the eigenvectors in for which this correlation is lower than and denote them collectively as a subspace . Thus, is a subspace that has relatively lower gender information. We find that the number of eigenvectors in the subspace is 504 and 487 for the descriptors of Arcface and Crystalface respectively.
Transforming test face descriptors using remaining components: We then extract the 512-dimensional descriptors for the IJB-C dataset using the given pre-trained network (Arcface/Crystalface), to obtain the transformed descriptors . Finally, we transform using the subspace spanned by into a new feature space . We use in this protocol, for both networks. We evaluate the gender leakage and gender bias of the transformed descriptor sets for IJB-C dataset in Sec. 5.5.
5.4 Training details for AGENDA
For training AGENDA, we use a combination of UMDFaces, UMDFaces-Videos and MS-Celeb-1M datasets. The face alignment and gender labels are obtained using (Ranjan et al. 2017). We perform our experiments using input face descriptors from Arcface and Crystalface, extracted for these datasets. The hyperparameter information for AGENDA is provided below:
Stage 1: iterations, learning rate .
Stage 2: iterations, learning rate . Here, we use and for Arcface and Crystalface, respectively.
Stage 3: iterations,learning rate . We compute using and , when using from Arcface and Crystalface respectively.
Stage 4: iterations, learning rate (same as stage 2). and for Arcface and Crystalface, respectively.
In all the aforementioned training stages, we use an Adam optimizer and a batch size of 400, and we ensure that each batch is balanced in terms of gender.
5.5 Results
Evaluating gender leakage: We follow the same steps as in section 5.2 for computing the gender classification accuracy (Table 1) of raw face descriptors. We present the accuracy of the logistic regression classifier trained on face descriptors obtained from CorrPCA and AGENDA in Table 2. We find that for both Arcface, the Crystalface, the classification accuracy goes down when the face descriptors are transformed using AGENDA or CorrPCA framework, which indicates that gender leakage from the descriptors is likely reduced.
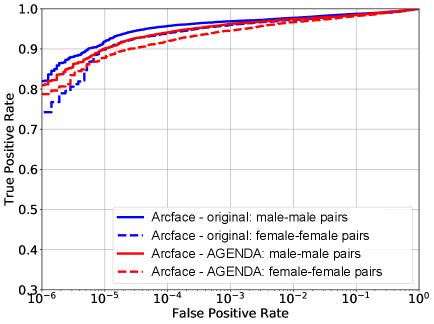
Evaluating verification performance and bias: We first evaluate the 1:1 verification performance obtained by CorrPCA-transformed IJB-C face descriptors. From Table 3b, we can infer that this method helps to reduce the gender bias in Crystalface, whereas the bias and performance in Arcface remains mostly unchanged. Following that, we evaluate the verification performance and corresponding bias obtained after using AGENDA. After AGENDA training, we feed the 512 dimensional (extracted from Arcface/Crystalface) of aligned IJB-C images to the trained model (Fig. 2), that generates 256 dimensional gender de-biased descriptors . We then use to perform gender-wise IJB-C 1:1 face verification. From Fig. 4. We find that when using from Arcface, the bias is reduced (especially in low FPRs), without catastrophically losing verification performance. This is done by improving female-female verification at low FPRs, while slightly decreasing male-male verification. Similarly, for from Crystalface, we find that the gender bias is reduced at low FPRs. The bias is especially close to 0 after FPR .
From Table 3b, we can infer that AGENDA consistently outperforms CorrPCA in terms of bias reduction at almost all the FPRs under consideration. For FPRs not reported in Table 3b, the gender bias in verification is exactly same for CorrPCA, AGENDA and the original pre-trained network.
| Network | Arcface | Crystalface | ||||
| Method | Original | CorrPCA | AGENDA | Original | CorrPCA | AGENDA |
| Gender classifn acc. | 76.01 | 72.33 | 64.01 | 80.50 | 75.74 | 67.25 |
| Females misclassified (%) | 39.15 | 36.08 | 51.10 | 36.63 | 37.70 | 43.82 |
| Males miscalssified (%) | 8.83 | 20.68 | 20.88 | 4.3 | 10.8 | 23.31 |
| FPR | ||||||||||||
| Method | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias |
| Original | 0.82 | 0.74 | 0.08 | 0.92 | 0.90 | 0.02 | 0.96 | 0.93 | 0.03 | 0.97 | 0.96 | 0.01 |
| CorrPCA | 0.82 | 0.76 | 0.06 | 0.92 | 0.90 | 0.02 | 0.96 | 0.93 | 0.03 | 0.97 | 0.96 | 0.01 |
| AGENDA | 0.81 | 0.79 | 0.02 | 0.90 | 0.89 | 0.01 | 0.94 | 0.93 | 0.01 | 0.96 | 0.95 | 0.01 |
| FPR | ||||||||||||
| Method | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias |
| Original | 0.67 | 0.63 | 0.04 | 0.84 | 0.8 | 0.04 | 0.92 | 0.87 | 0.05 | 0.96 | 0.93 | 0.03 |
| CorrPCA | 0.67 | 0.65 | 0.02 | 0.84 | 0.81 | 0.03 | 0.91 | 0.87 | 0.04 | 0.95 | 0.93 | 0.02 |
| AGENDA | 0.32 | 0.32 | 0.0 | 0.67 | 0.67 | 0.0 | 0.83 | 0.81 | 0.02 | 0.92 | 0.90 | 0.02 |
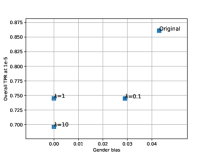
5.6 Ablation study - AGENDA
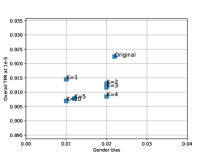
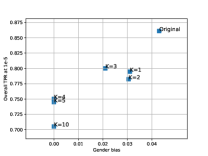
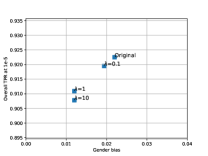
Here, we evaluate two hyperparameters used for training the AGENDA framework on Arcface and Crystalface : (a.) the number of gender prediction models in the ensemble used to compute (Eq. 10). (b.) the weight for defined in Eq. 11. We analyze how changing these hyperparameters vary the resultant bias reduction and verification performance at a fixed in IJB-C dataset.
Varying K :We experiment with and . Here, we fix all the other hyperparameters and use the same values specified in Sec. 5.4. In Fig. 5(a) and (b), we find that in Arcface, changing does not have much effect on gender bias or verification TPR at FPR . However, for Crystalface, we find that as we increase , the gender bias keeps decreasing which in turn leads to drop in verification performance at FPR . We find that at , the bias drops to 0, and as we further keep increasing , the verification performance decreases.
Varying : We fix and evaluate for training the AGENDA framework using . All the other hyperparameters use the same values specified in in Sec. 5.4. The results are presented in Fig. 5(c) and (d). For both Arcface and Crystalface, as we keep on increasing the value of , the gender bias keeps generally decreasing and the verification TPR keeps decreasing.
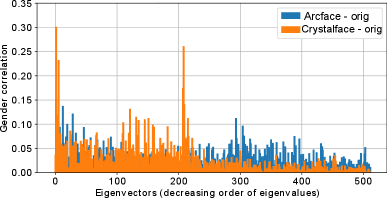
5.7 Analysis of performance drop
Gender is an important face attribute that helps deep networks recognize faces. So, minimizing its predictability by using AGENDA is expected to decrease the overall performance as a side-effect. As seen in Fig. 4, the verification performance in Crystalface reduces considerably as compared to Arcface, after AGENDA is applied. To understand this behavior, we analyze the distribution of the feature space of both Arcface and Crystalface. For this, we first randomly select 80k images (40k males and females) from the IJB-C dataset, and extract their face descriptors using a given pre-trained network (Arcface or Crystalface). Using PCA, we compute the eigenspace of this set of face descriptors. As done in the implementation of our CorrPCA baseline, we compute the gender correlation of each of the 512 eigenvectors in the eigenspace (Fig. 6).
The top-256 eigenvectors encode more identity information than the bottom ones, since the networks are trained to classify identity. We find that the gender correlation of these identity encoding (top-256) eigenvectors of Crystalface is generally higher than Arcface. This seems to indicate that gender and identity are more entangled in face descriptors from Crystalface than Arcface. Therefore, the drop in verification performance, when the descriptors are gender de-biased is also expected to be more for Crystalface, since the verification performance depends on identity information encoded in the descriptors.
5.8 Effect of Triplet Probabilistic Embedding
In (Ranjan et al. 2019), the face descriptors from Crystalface are not directly used for verification. Instead, the descriptors undergo triplet probabilistic embedding (TPE) (Sankaranarayanan et al. 2016) for generating a template representation of a given identity. TPE is an embedding learned to generate more discriminative, low-dimensional representations of given input descriptors, that have been shown to achieve better verification results. We apply TPE on the descriptors obtained using Crystalface and find that TPE improves the overall verification performance, but it also increases bias at all FPRs. For comparison, we apply TPE after transforming the Crystalface descriptors with AGENDA. From Table 4, we can infer that the gender bias in the verification results obtained after applying TPE on AGENDA-transformed descriptors is lower than when TPE is applied on original face descriptors of Crystalface. The details of training TPE are provided in the supplementary material.
| FPR | ||||||||||||
| Method | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias | TPRm | TPRf | Bias |
| Orig. + TPE | 0.80 | 0.69 | 0.11 | 0.88 | 0.84 | 0.04 | 0.93 | 0.89 | 0.04 | 0.96 | 0.94 | 0.02 |
| AGENDA +TPE | 0.57 | 0.51 | 0.06 | 0.75 | 0.73 | 0.02 | 0.88 | 0.85 | 0.03 | 0.93 | 0.91 | 0.02 |
6 Conclusion
Implicit encoding of gender in face descriptors during training may lead to privacy leakage as such descriptors can be trained to classify face gender. Moreover, the expression of gender also appears to contribute to gender bias when such descriptors are used for face verification. We address the issue of annonymizing the gender of face descriptors. Our initial experiments show that face descriptors showing lower gender predictability generally demonstrate lower gender bias in face verification. Motivated by this finding and the need for anonymizing the gender of face representations, we propose a framework - AGENDA, that adversarially reduces gender information from face descriptors, while training them to classify identities. The results of our experiments with AGENDA and CorrPCA provide evidence in support of our hypothesis that reduction of gender predictability in face descriptors will decrease gender bias in face verification. AGENDA significantly outperforms our PCA-based baseline in terms of bias reduction. The efficacy of AGENDA is evaluated on face descriptors from two SOTA recognition networks. However, gender is an important facial attribute, and we find that reducing gender information leads to slight decrease in verification accuracy. In the near future, we intend to apply and modify CorrPCA and AGENDA to reduce the information of other attributes like age and race in face recognition features; and apply a combination of several de-biasing losses to reduce the strength of multiple attributes simultaneously.
Acknowledgement
The authors would like to thank P. Jonathon Phillips, Ankan Bansal, Aniket Roy and Rajeev Ranjan for their helpful suggestions. This research is based upon work supported by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via IARPA R&D Contract No. 2019-022600002. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon.
References
- Albiero and Bowyer (2020) Albiero, V.; and Bowyer, K. W. 2020. Is Face Recognition Sexist? No, Gendered Hairstyles and Biology Are. arXiv preprint arXiv:2008.06989 .
- Albiero et al. (2020) Albiero, V.; KS, K.; Vangara, K.; Zhang, K.; King, M. C.; and Bowyer, K. W. 2020. Analysis of gender inequality in face recognition accuracy. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision Workshops, 81–89.
- Albiero, Zhang, and Bowyer (2020) Albiero, V.; Zhang, K.; and Bowyer, K. W. 2020. How Does Gender Balance In Training Data Affect Face Recognition Accuracy? arXiv preprint arXiv:2002.02934 .
- Alvi, Zisserman, and Nellåker (2018) Alvi, M.; Zisserman, A.; and Nellåker, C. 2018. Turning a blind eye: Explicit removal of biases and variation from deep neural network embeddings. In Proceedings of the European Conference on Computer Vision (ECCV), 0–0.
- Amini et al. (2019) Amini, A.; Soleimany, A. P.; Schwarting, W.; Bhatia, S. N.; and Rus, D. 2019. Uncovering and mitigating algorithmic bias through learned latent structure. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, 289–295.
- Bansal et al. (2017a) Bansal, A.; Castillo, C. D.; Ranjan, R.; and Chellappa, R. 2017a. The do’s and don’ts for CNN-based face verification. In Proceedings of the IEEE International Conference on Computer Vision, 2545–2554.
- Bansal et al. (2017b) Bansal, A.; Nanduri, A.; Castillo, C. D.; Ranjan, R.; and Chellappa, R. 2017b. Umdfaces: An annotated face dataset for training deep networks. In 2017 IEEE International Joint Conference on Biometrics (IJCB), 464–473. IEEE.
- Bansal et al. (2018) Bansal, A.; Ranjan, R.; Castillo, C. D.; and Chellappa, R. 2018. Deep Features for Recognizing Disguised Faces in the Wild. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 10–106. IEEE.
- Buolamwini and Gebru (2018) Buolamwini, J.; and Gebru, T. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, 77–91.
- Cavazos et al. (2019) Cavazos, J. G.; Phillips, P. J.; Castillo, C. D.; and O’Toole, A. J. 2019. Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
- Cook et al. (2019) Cook, C.; Howard, J.; Sirotin, Y.; and Tipton, J. 2019. Fixed and Varying Effects of Demographic Factors on the Performance of Eleven Commercial Facial Recognition Systems. IEEE Transactions on Biometrics, Behavior, and Identity Science 40(1).
- Deng et al. (2019) Deng, J.; Guo, J.; Niannan, X.; and Zafeiriou, S. 2019. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In CVPR.
- Dhar et al. (2020) Dhar, P.; Bansal, A.; Castillo, C. D.; Gleason, J.; Phillips, P. J.; and Chellappa, R. 2020. How are attributes expressed in face DCNNs? To appear in 15th IEEE Intl. Conf. Automatic Face and Gesture Recognition, arXiv preprint arXiv:1910.05657 .
- Drozdowski et al. (2020) Drozdowski, P.; Rathgeb, C.; Dantcheva, A.; Damer, N.; and Busch, C. 2020. Demographic Bias in Biometrics: A Survey on an Emerging Challenge. arXiv preprint arXiv:2003.02488 .
- Fu, Guo, and Huang (2010) Fu, Y.; Guo, G.; and Huang, T. 2010. Age synthesis and estimation via faces: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 32(11): 1955–1976.
- Furl, Phillips, and O’Toole (2002) Furl, N.; Phillips, P. J.; and O’Toole, A. 2002. Face recognition algorithms and the other-race effect: Computational mechanisms for a developmental contact hypothesis. Cognitive Science 26: 797–815. doi:10.1016/S0364-0213(02)00084-8.
- Georgopoulos, Panagakis, and Pantic (2020) Georgopoulos, M.; Panagakis, Y.; and Pantic, M. 2020. Investigating Bias in Deep Face Analysis: The KANFace Dataset and Empirical Study. arXiv preprint arXiv:2005.07302 .
- Grother, Ngan, and Hanaoka (2019) Grother, P.; Ngan, M.; and Hanaoka, K. 2019. Face Recognition Vendor Test (FRVT) Part 3: Demographic Effects. National Institute of Standards and Technology .
- Guo et al. (2016) Guo, Y.; Zhang, L.; Hu, Y.; He, X.; and Gao, J. 2016. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. In European Conference on Computer Vision, 87–102. Springer.
- He et al. (2015) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2015. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, 1026–1034.
- Hill et al. (2019) Hill, M. Q.; Parde, C. J.; Castillo, C. D.; Colon, Y. I.; Ranjan, R.; Chen, J.-C.; Blanz, V.; and O’Toole, A. J. 2019. Deep convolutional neural networks in the face of caricature. Nature Machine Intelligence 1(11): 522–529.
- Klambauer et al. (2017) Klambauer, G.; Unterthiner, T.; Mayr, A.; and Hochreiter, S. 2017. Self-normalizing neural networks. In Advances in neural information processing systems, 971–980.
- Klare et al. (2012) Klare, B. F.; Burge, M. J.; Klontz, J. C.; Bruegge, R. W. V.; and Jain, A. K. 2012. Face recognition performance: Role of demographic information. IEEE Transactions on Information Forensics and Security 7(6): 1789–1801.
- Krishnapriya et al. (2020) Krishnapriya, K.; Albiero, V.; Vangara, K.; King, M. C.; and Bowyer, K. W. 2020. Issues Related to Face Recognition Accuracy Varying Based on Race and Skin Tone. IEEE Transactions on Technology and Society 1(1): 8–20.
- Li et al. (2019) Li, A.; Guo, J.; Yang, H.; and Chen, Y. 2019. Deepobfuscator: Adversarial training framework for privacy-preserving image classification. arXiv preprint arXiv:1909.04126 .
- Liu et al. (2015) Liu, Z.; Luo, P.; Wang, X.; and Tang, X. 2015. Deep Learning Face Attributes in the Wild. In Proceedings of International Conference on Computer Vision (ICCV).
- Lu, Jain et al. (2004) Lu, X.; Jain, A. K.; et al. 2004. Ethnicity identification from face images. In Proceedings of SPIE, volume 5404, 114–123.
- Makinen and Raisamo (2008) Makinen, E.; and Raisamo, R. 2008. Evaluation of gender classification methods with automatically detected and aligned faces. IEEE transactions on pattern analysis and machine intelligence 30(3): 541–547.
- Maze et al. (2018) Maze, B.; Adams, J.; Duncan, J. A.; Kalka, N.; Miller, T.; Otto, C.; Jain, A. K.; Niggel, W. T.; Anderson, J.; Cheney, J.; et al. 2018. IARPA janus benchmark-c: Face dataset and protocol. In 2018 International Conference on Biometrics (ICB), 158–165. IEEE.
- Mirjalili, Raschka, and Ross (2018) Mirjalili, V.; Raschka, S.; and Ross, A. 2018. Gender privacy: An ensemble of semi adversarial networks for confounding arbitrary gender classifiers. In 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), 1–10. IEEE.
- Mirjalili and Ross (2017) Mirjalili, V.; and Ross, A. 2017. Soft biometric privacy: Retaining biometric utility of face images while perturbing gender. In 2017 IEEE International joint conference on biometrics (IJCB), 564–573. IEEE.
- Nagpal et al. (2019) Nagpal, S.; Singh, M.; Singh, R.; Vatsa, M.; and Ratha, N. 2019. Deep Learning for Face Recognition: Pride or Prejudiced? arXiv preprint arXiv:1904.01219 .
- Othman and Ross (2014) Othman, A.; and Ross, A. 2014. Privacy of facial soft biometrics: Suppressing gender but retaining identity. In European Conference on Computer Vision, 682–696. Springer.
- Ranjan et al. (2019) Ranjan, R.; Bansal, A.; Zheng, J.; Xu, H.; Gleason, J.; Lu, B.; Nanduri, A.; Chen, J.-C.; Castillo, C. D.; and Chellappa, R. 2019. A fast and accurate system for face detection, identification, and verification. IEEE Transactions on Biometrics, Behavior, and Identity Science 1(2): 82–96.
- Ranjan et al. (2017) Ranjan, R.; Sankaranarayanan, S.; Castillo, C. D.; and Chellappa, R. 2017. An all-in-one convolutional neural network for face analysis. In 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), 17–24. IEEE.
- Sankaranarayanan et al. (2016) Sankaranarayanan, S.; Alavi, A.; Castillo, C. D.; and Chellappa, R. 2016. Triplet Probabilistic Embedding for Face Verification and Clustering. In 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS).
- Sattigeri et al. (2018) Sattigeri, P.; Hoffman, S. C.; Chenthamarakshan, V.; and Varshney, K. R. 2018. Fairness GAN. arXiv preprint arXiv:1805.09910 .
- Schroff, Kalenichenko, and Philbin (2015) Schroff, F.; Kalenichenko, D.; and Philbin, J. 2015. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 815–823.
- Taigman et al. (2014) Taigman, Y.; Yang, M.; Ranzato, M.; and Wolf, L. 2014. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1701–1708.
- Turk and Pentland (1991) Turk, M.; and Pentland, A. 1991. Face recognition using eigenfaces. In Proceedings. 1991 IEEE computer society conference on computer vision and pattern recognition, 586–587.
- Vangara et al. (2019) Vangara, K.; King, M. C.; Albiero, V.; Bowyer, K.; et al. 2019. Characterizing the Variability in Face Recognition Accuracy Relative to Race. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 0–0.
- Wang and Deng (2020) Wang, M.; and Deng, W. 2020. Mitigating Bias in Face Recognition Using Skewness-Aware Reinforcement Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9322–9331.
- Wang et al. (2019a) Wang, M.; Deng, W.; Hu, J.; Tao, X.; and Huang, Y. 2019a. Racial Faces in the Wild: Reducing Racial Bias by Information Maximization Adaptation Network. In Proceedings of the IEEE International Conference on Computer Vision, 692–702.
- Wang et al. (2019b) Wang, T.; Zhao, J.; Yatskar, M.; Chang, K.-W.; and Ordonez, V. 2019b. Balanced datasets are not enough: Estimating and mitigating gender bias in deep image representations. In Proceedings of the IEEE International Conference on Computer Vision, 5310–5319.
- Wu et al. (2018) Wu, Z.; Wang, Z.; Wang, Z.; and Jin, H. 2018. Towards privacy-preserving visual recognition via adversarial training: A pilot study. In Proceedings of the European Conference on Computer Vision (ECCV), 606–624.
Appendix A Motivation for training one model in
In Stage 4 of Sec. 4.2, we heuristically choose a model in the ensemble and re-train it to classify gender using (from model ) as input. This is also described in Step 26 and 28 of Algorithm 1. In this section we describe the motivation for that decision.
The main idea here is to ensure that the ensemble of models predicting gender is diverse. The desire for diversity relates to the ‘the challenge’ described by (Wu et al. 2018) which, in the context of our work, implies that must be transformed such that gender cannot be extracted using any model. The overarching idea for holding all but one model in ensemble constant within one training episode is to restrict from learning to embed gender information in successively larger regions of the descriptor space. The remainder of this section elaborates on what we mean by this.
Treating and as random variables, let be the likelihood of male face descriptors and be the likelihood of female face descriptors. In order to guarantee that the mutual information between and gender is zero, and must be equal almost everywhere for where is the support of (i.e. the set of values which ).
For the purpose of this motivation we suppose our objective is to minimize the measure of set , thus ensuring that contains no information about gender.
Further, let represent the region of where any model within ensemble predicts the probability of male and female to be non-equal. Supposing that is composed entirely of optimal classifiers, then would be equal to .
Suppose that and are and after the th episode of training from Algorithm 1. As an alternative, consider a version of the algorithm where every model in is trained at each episode, rather than training only one at a time. Since is trained to confuse using , a plausible strategy is that will be updated so that . This strategy minimizes the debiasing loss , since each model in ensemble is successfully fooled, but does not necessarily reduce the measure of . This strategy is also, in some sense, easier than the true objective of minimizing , since does not need to disentangle and remove the representation of gender from . Instead, could modify the representation so that the same information is present, but represented in an alternative subset of the descriptor space.
The strategy of holding all but one of the models in constant is an attempt to mitigate this potential issue. Again, assuming each model in to be optimal, then by training only a single model within at each episode, , thus preventing from oscillating between two disjoint regions of feature space. Furthermore, in an ideal scenario with unlimited training time and memory, should be equal to the total number of training episodes. This would ensure that can never encode gender information the same way twice, which would successively make it more likely to actually reduce the measure of . In practice, however, the total memory and training time is limited, so is chosen to be as large as practical.
Appendix B Details for training TPE
To learn a triplet probabilistic embedding , we use the descriptors from Crystalface (extracted for UMD-Faces (Bansal et al. 2017b) dataset). This embedding is then used to transform the 512 dimensional IJB-C (Maze et al. 2018) descriptors (extracted using Crystalface) to obtain 128-dimensional face descriptors, which are used for 1:1 face verification. The results of this experiment are provided in ‘Orig +TPE’ in Table 4 of Sec. 5.8. We perform the same experiment with the AGENDA-transformed descriptors of Crystalface, where a new TPE matrix is learned and used to transform the IJB-C descriptors before performing 1:1 verification. The results of this experiment are provided in ‘AGENDA +TPE’ in Table 4 of Sec. 5.8. We find that the results obtained after applying TPE on AGENDA-transformed features have relatively lower bias.
For training both, and , we use a fixed learning rate of and a batch size of 32. The training for computing such a matrix using the descriptors from Crystalface (or its AGENDA counterpart) generally converges after 10k iterations. For a given set of descriptors, we compute its TPE matrix ten times and finally compute the average of the resulting matrices. We use this matrix to transform the test descriptors. More details about TPE are provided in (Sankaranarayanan et al. 2016).