Towards Geometric-Photometric Joint Alignment for Facial Mesh Registration
Abstract
This paper presents a Geometric-Photometric Joint Alignment (GPJA) method, which aligns discrete human expressions at pixel-level accuracy by combining geometric and photometric information. Common practices for registering human heads typically involve aligning landmarks with facial template meshes using geometry processing approaches, but often overlook dense pixel-level photometric consistency. This oversight leads to inconsistent texture parametrization across different expressions, hindering the creation of topologically consistent head meshes widely used in movies and games. GPJA overcomes this limitation by leveraging differentiable rendering to align vertices with target expressions, achieving joint alignment in both geometry and photometric appearances automatically, without requiring semantic annotation or pre-aligned meshes for training. It features a holistic rendering alignment mechanism and a multiscale regularized optimization for robust convergence on large deformation. The method utilizes derivatives at vertex positions for supervision and employs a gradient-based algorithm which guarantees smoothness and avoids topological artifacts during the geometry evolution. Experimental results demonstrate faithful alignment under various expressions, surpassing the conventional non-rigid ICP-based methods and the state-of-the-art deep learning based method. In practical, our method generates meshes of the same subject across diverse expressions, all with the same texture parametrization. This consistency benefits face animation, re-parametrization, and other batch operations for face modeling and applications with enhanced efficiency.
keywords:
Geometry registration , Facial performance capture , Face modeling[zjlab] organization=Zhejiang Lab,addressline=Kechuang Avenue, Yuhang District, city=Hangzhou, postcode=311121, state=Zhejiang, country=China \affiliation[hefei] organization=Hefei University of Technology,addressline=Rd.Tunxi No.193, city=Hefei, postcode=230009, state=Anhui, country=China
1 Introduction
Nowadays, professional studios in industry and academia commonly use synchronized multiview stereo setups for facial scanning [1, 2, 3], ensuring high-fidelity results in controlled settings. These setups aim to generate topology-consistent meshes for different subjects with various facial expressions. Typically, conventional pipelines [4] involve constructing raw scans from multiview images, followed by manual processes like marker point tracking, clean-up, or key-framing [5], which is labor-intensive and time-consuming, limiting its application in film, gaming, AR/VR industry. To fulfill automatic registration, geometry-based methods have been widely employed [6, 7, 8, 9, 10]. However, these methods primarily focus on geometric alignment but failing to ensure photometric consistency at dense pixel-level. To remedy this issue, this paper aims to achieve a joint alignment in terms of geometry and photometric appearances. To this end, two challenges need to be addressed.
The first challenge is to establish a proper deformation field to guide the alignment process, especially for the challenging areas such as mouths and eyes. Previous attempts have been made to construct correspondences by landmarks or optical flow to aid the photometric alignment [4, 6]. However, the offset vectors obtained through these methods often introduce errors. Moreover, since they are extracted from 2D images, these vectors are insufficient for guiding deformation of 3D geometry. [11] employed implicit volumetric representation to combine shape and appearance recovery for realistic rendering, which lacks explicit geometry constraints. In response to the challenge, we propose a differentiable rendering [12, 13] based registration framework to generate topology-consistent facial meshes from multiview images. In particular, our approach includes a Holistic Rendering Alignment (HRA) which incorporates constraints from color, depth and surface normals, facilitating alignment through automatic differentiation without explicit correspondence computation.
The second challenge for facial mesh registration is generating faithful output meshes while preserving the topological structure. Aligning discrete facial expressions involves large-step geometry deformation, which is susceptible to topological artifacts. Previous works addressed this with specialized constraints [8, 10], but at the cost of a complex pipeline. Other approaches [14, 15, 7, 16] utilize parametric models to fit the facial images for mesh creation. Although these methods are highly efficient, they struggle with diverse identities and complex expressions due to their limited expressive capabilities. To overcome this, we resort to a multiscale regularized optimization that combines a modified gradient descent algorithm [17], with coarse-to-fine remeshing scheme. Starting with the coarsest template, the mesh is tessellated periodically while updating the vertices with a robust regularized geometry optimization for the constraints collected from HRA. Our multiscale regularized approach is simple to implement and ensures smoothness and robust convergence, without the need for extensive training data.
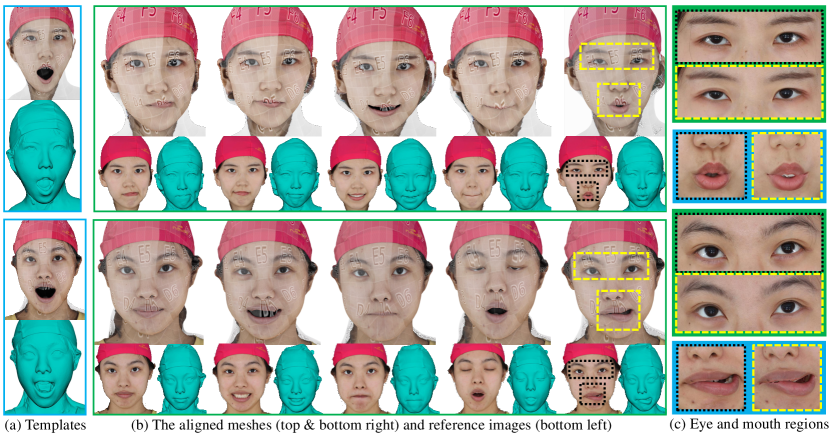
We validate our method through experiments on seven subjects from the FaceScape [18] dataset, covering diverse facial expressions, as shown in Fig. 1. The joint alignment is examined by both geometric and image metrics, demonstrating the effectiveness of our approach. The aligned meshes produced by our method are of high quality, free from topological errors, and accurately warped even in challenging regions like mouths and eyes.
Our contributions are summarized as following:
-
1.
A simple and novel method named GPJA achieving joint alignment in geometry and photometric appearances at dense pixel-level for facial meshes.
-
2.
A holistic rendering alignment mechanism based on differentiable rendering that effectively generates the deformation field for joint alignment, without any semantic annotation.
-
3.
A multiscale regularized optimization strategy that ensures robust convergence and produces high-quality, topologically consistent aligned meshes.
2 Related Work
Our research focuses on the registration of facial meshes for topology-consistent geometry on discrete expressions. This section provides a literature review relevant to our study.
Geometry Processing Methods. Non-rigid registration is a well established technique in geometry processing for warping a template mesh to raw scans [19, 20, 21, 22]. The Iterative Closest Point (ICP) algorithm is a commonly used framework [6, 20, 23] for registration. With a template based on 3D Morphable Models (3DMMs) of strong geometric priors [6, 24, 7, 8, 9, 18, 25, 10] as initialization, ICP minimizes the error between landmarks on the template and the scans, resulting in a rough alignment. Then, a fine-tuning stage involves searching for valid correspondences in the spatial neighborhood, and warping the template leveraging data fidelity and smoothness terms. Previous works have explored regularization terms [26, 27] and correspondences [28, 29] in ICP-based algorithms. In addition to registration, there are also face tracking methods [30, 31] that rely on coefficient regression of rigged blendshapes, which are primarily used for expression transfer rather than high-fidelity reconstruction. Overall, these methods are limited in achieving pixel-level photometric consistency, where our method is successfully capable of.
To achieve photometric alignment, industry-standard methods often involve re-topologizing frame-by-frame using the professional software like Wrap4D [32], which requires significant time and resources [33]. For automatic pipelines, researchers have explored incorporating optical flow [34, 35, 36] into the fine-tuning stage of facial mesh registration. However, optical flow alone is inadequate for handling significant differences between the source template and target scans, as well as occlusion changes around the eyes and mouth [37]. It is even worse for discrete expression scenarios due to the lack of temporal coherence and large deformation. In contrast, our method effectively handles significant deformation, visibility changes and asymmetry.
Another challenge in facial mesh registration is maintaining smooth contours in facial features [38], which is difficult due to occlusions and color changes. Previous approaches have used user-guided methods [33] or contour extraction [37] to address these challenges, but they either involve lengthy workflows or specific treatments, which hinder efficient topology-consistent mesh creation. On the other hand, our method achieves pixel-level alignment without any semantic annotation.
Deep Learning Based Methods. Recent advancements in deep learning approaches for generating topology-consistent meshes include ToFu [39], which predicts probabilistic distributions of vertices on the face mesh to reconstruct registered face geometry. TEMPEH [40] enhances ToFu with a transformer-based architecture, while NPHM [41] models head geometry using a neural field representation that parametrizes shape and expressions in disentangled latent spaces. Although these methods prioritize geometric alignment, they do not guarantee rigorous photometric consistency. ReFA [42] introduces a recurrent network operating in the texture space for predicting positions and texture maps. Although these deep learning methods represent progress in facial mesh registration, they require a substantial amount of registered data processed with classical ICP-based algorithms. Besides, out-of-domain expressions may be limited by insufficient training data. In our work, no additional training data is needed except for a semi-automatic created template mesh with textures.
In addition to mesh-based representations, implicit volumetric representations have gained popularity in reconstruction. Several studies have extended NeRF [43] and 3D Gaussian Splatting [44] for dynamic face reconstruction [45, 46, 47, 48, 49]. The pipeline typically begins with explicit parametric models, followed by estimating a deformation field represented by multi-layer perceptrons. Finally, a volumetric renderer is used to generate densities and colors. However, volumetric rendering-based methods lack supervision for aligning mesh-represented geometry and generally do not produce production-ready geometries despite decent rendering results [42].
3 Preliminaries
Before discussing the details of our methodology, we first introduce differentiable rendering as background information to provide context for our approach.
Given a 3D scene containing mesh-based geometries, lights, materials, textures, cameras etc., a renderer synthesizing a 2D image P of each screen pixel (x,y) can be formulated as:
| (1) |
where the function represents the rendering process, encompassing various computations such as shading, interpolation, projection, and anti-aliasing. The output P of this function can be RGB colors, normals, depths, or label images. In our scenario, the parameter to be optimized is the positions of mesh vertices denoted by . symbolizes a set of scene parameters known in advance, including camera poses, lighting, texture color, and other relevant factors.
Differentiable rendering augments renderers by providing additional derivatives with respect to certain scene parameters, which is a valuable tool for inverse problems [13, 50]. The objective of inverse rendering is to recover some specific scene parameters through gradient-based optimization on a scalar loss function which is usually defined as the sum of pixel-wise differences between the rendered images and the reference image at the j-th camera pose across views. In this work, we adopt the -norm for loss functions.
| (2) |
In our joint alignment registration setting, the derivative obtained through differentiable rendering plays a key role, as it guides the template mesh to fit the target expressions. This process avoids the explicit computation of correspondences, such as optical flow, facial landmarks, or other semantic information.
4 Joint Alignment of Facial Meshes
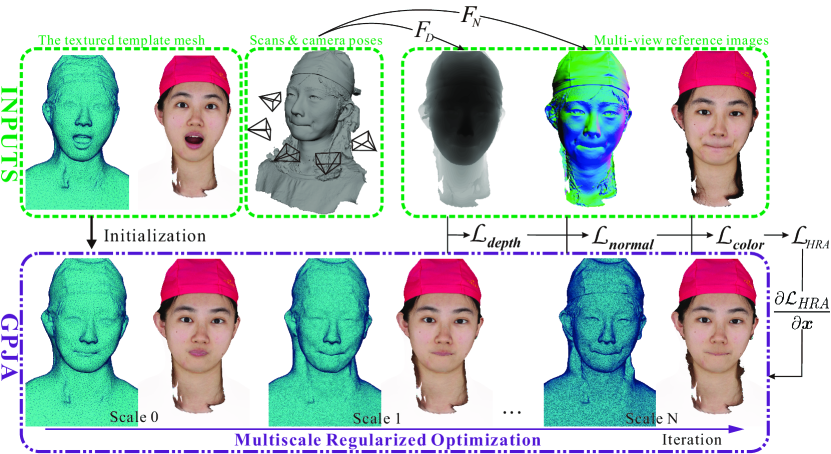
Our work addresses the challenge of registering the same subject across diverse facial expressions. Fig. 2 depicts the pipeline of our method. Starting with a textured template mesh and raw scans, each iteration computes deformation from HRA and optimizes the vertices through multiscale regularized optimization. As a result, the outputs of GPJA share a joint alignment across all expressions within the subject.
4.1 Holistic Rendering Alignment
Motivation. While geometric alignment has been well studied, previous photometric alignment approaches mainly consider sparse facial landmarks, resulting in two main limitations: coarse alignment lacking fine details and unreliability under occlusions and extreme expressions, as shown in Fig. 3(a). Other photometric algorithms [35, 4] attempt to learn deformation from optical flow obtained in the 2D images, but are prone to false correspondences as shown in Fig. 3(b) ,and suffer from ambiguities when elevating to the 3D space.
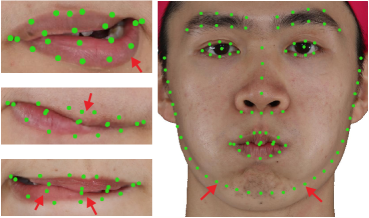
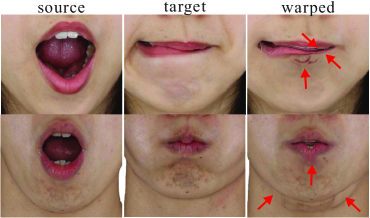
Instead of making remedies for landmarks or optical flows, we leverage differentiable rendering, which automatically computes derivatives to guide the deformation of the template mesh into both geometric and photometric alignment. This approach eliminates correspondence errors from facial landmarks [6] or optical flow offset vectors [35]. Furthermore, differentiable rendering operates directly in 3D space, effectively handling occlusions in the eye and mouth regions.
With the above consideration, we propose a Holistic Rendering Alignment (HRA) mechanism, incorporating multiple cues with the aid of differentiable rendering. HRA collects constraints from three different aspects, i.e., color, depth, and surface normals:
| (3) |
Color Constraint. seeks to impose constraints for photometric alignment by comparing the rendered image with the observed multiview color images. In practice, we found that the deformation around the inner lip is sometimes affected by occlusion changes, resulting in inaccurate lip contours. To address this issue, we deliberately exclude the interior mouth from the color constraint by a masking strategy.
As illustrated in Fig. 4, a binary mask image is manually created in accordance with the color texture of the given template . The mask image labels the interior mouth region, which corresponds to the mouth socket of .

The color constraint is defined as the summation of the element-wise absolute difference between the rendered image and the reference image, weighted by the mask.
| (4) |
where the shading function is defined as rendering diffuse objects with the lighting estimated from the capture setup in spherical harmonics forms [53], remarks projective matrix of the -th camera, and denotes element-wise multiplication. By synthesizing a binary image using , where the interior mouth is assigned zeros and the rest with ones, Equation 4 can mask out the interior mouth for color constraint for faithful lip contours. Experimental results confirm the effectiveness of this mask operation.
Depth Constraint. pursues to achieve geometric alignment. The color images observed in real-world scenes exhibit inconsistencies due to variations in shading and imaging formulation across views and expressions. Therefore, the derivatives of color constraint inevitably introduce bias and noise, making disturbances for accurate alignment. By including the depth term in HRA, we provide strong supervision for preserving geometric fidelity during registration, ensuring robust outputs.
The depth constraint measures the depth disparity between the deformed template and the target scan:
| (5) |
where represents the depth rendering operation[54] based on the perspective projection function, and denotes vertex coordinates of the scan with vertices.
Normal Constraint. assists with fidelity preservation. While the color and depth terms establish guidance for overall alignment, discrepancies in color tones and texture-less areas can cause artifacts on aligned meshes. The normal constraint compensates for these issues, leading to improved alignment and sharper details with fewer vertices.
In specific, the normal constraint penalties the disparity of surface normals between the deformed template and the target scan.
| (6) |
where represents the process of computing and projecting surface normals, as implemented in deferred shading [55].
4.2 Multiscale Regularized Optimization
The HRA mechanism steers deformation towards joint alignment, yet its derivative vectors are noisy because of shading and imaging variations. Since the derivatives lack regularization, applying them directly as update steps to each vertex could lead to topological errors [17, 57]. A common way to tackle this is adding a regularization term [28, 56], like the ARAP energy [58] or the Laplacian differential representation [19]. However, these solutions introduce problems in tuning the regularization weight for outputs with both smooth and non-smooth regions [17], and implementing a robust solution scheme for non-linear optimization [59]. To overcome these challenges, we propose a multiscale regularized optimization for generating high-quality aligned meshes.
Vertex Optimization. We follow the work of [17] to update vertices iteratively. It suggests that the second-order optimization like Newton’s method is better for smoothing geometry, and the computationally expensive Hessian matrix can be replaced by re-parametrization of with the introduced variables to ensure the smoothness of recovered :
| (7) |
| (8) |
where means the learning rate, denotes identity matrix, and is the regularization weight. is a discrete Laplacian operator defined on a mesh with vertices and edges :
| (9) |
where is the cotangent weight described in [60].
Multiscale Learning. The coarse-to-fine multiscale learning scheme, based on the tessellation technique [61], periodically decreases the average edge length of the triangle mesh while retaining the shape and the texture parametrization. The multiscale scheme allows for parameter adjustment at each scale to capture fine details without distorting the topology. In particular, the Laplacian matrix is updated for each tessellation step as the topology changes. The template mesh , initially at the coarsest level, undergoes more rigid deformations with a higher regularization parameter to fit the overall target expressions. As the mesh is tessellated to finer scales, is decreased to capture more details.
The multiscale regularized optimization offers several advantages: (1) it produces high-quality meshes effectively with significantly reduced distortion and self-intersection artifacts; (2) it converges robustly without additional training data or priors other than the textured template. The iterative optimization process can be observed in the supplementary videos.
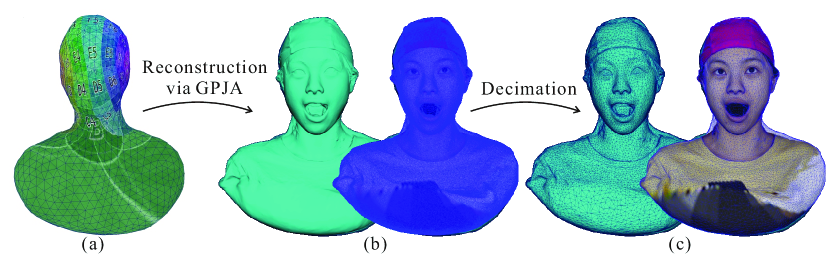
4.3 Textured Template Mesh Creation
To adapt to the proposed pipeline, we construct a reliable textured template mesh which is used throughout the joint alignment for different expressions per subject. As illustrated in Fig. 5, we deliberately choose the mouth-open expression from each subject to reconstruct it into the template mesh. This is because the mouth socket is crucial for accommodating flexible movements during deformation. Initially, we manually sculpt a coarse genus-0 mesh with pre-designed texture parametrization, resembling a bust sculpture. This genus-0 surface is appropriate for representing the head geometry due to similar topological structures without loss of generality .
The genus-0 bust mesh as initialization is then processed through the GPJA pipeline. At this stage, only the depth constraint in HRA is applied. After the depth guiding reconstruction, a tessellated mesh is established. The geometry is then fixed, and the texture color map is updated through the color constraint via gradient descent, shown in Fig. 5(b). Finally, the tessellated mesh is decimated using seam-aware simplification [62] while preserving the texture parametrization, resulting in the creation of the textured template mesh as the startup mesh in Fig. 2.
Although the template is subject-specific, all expressions share a common texture space, which enables batch re-parametrization. This offers a practical way for topology-consistent meshes of large datasets.
5 Experiments and Analysis
Experiment Setup. As an early exploration of semantic annotation-free photometric alignment, many existing public datasets (LYHM [25], and NPHM [41], etc.) that primarily consist of 3D scans or registered meshes rather than original images are unsuitable for GPJA. We also found FaMoS [40] inappropriate due to its sparse down-sampled RGB views and subjects with noticeable facial markers. Following our investigation, the FaceScape dataset emerged as the most fitting benchmark with high-resolution images from dense viewpoints and uniform lighting conditions for discrete facial expressions.
In order to thoroughly assess GPJA’s capability, seven subjects, including four publishable ones (Subject 122, 212, 340 and 344), are chosen, and we deliberately selected 10 highly different expressions for each subject. The selection process eliminates redundant and similar expressions. Additionally, we prioritize expressions with significant deformation and occlusion compared to the neutral expression, where landmark detection is less accurate as shown in Fig. 3. This process ensures that the chosen expressions cover a range of challenging scenarios and effectively evaluate the algorithm’s performance. Six to eight images, covering frontal and side views, are used as references.
GPJA is implemented with Nvdiffrast [12] as the differentiable renderer and LargeSteps [17] as the optimizer. The rendering uses the Lambertian reflection model under uniform lighting, which is a reasonable simplification of FaceScape’s acquisition environment. The multiscale optimization involves remeshing 4 times, increasing the vertex count from 16K to 250K. The learning rate is set to one-tenth of the face length. For the first two levels, the regularization parameter is set to 200 and 120, while for the remaining levels, it is set to 80 and 50. Gradients of only one constraint are back-propagated per iteration, with three constraints being iterated in rotation. Convergence is achieved within 1500 iterations per expression, taking approximately 15 minutes on a single NVIDIA RTX 3080 graphics card.
Metrics. As GPJA achieves joint alignment, we evaluate the method’s effectiveness from both geometric and photometric perspectives. Geometric alignment is assessed using raw face scans as ground truth, with L1-Chamfer distance and normal consistency reported. The distance is computed via the point-mesh approach to reduce the influence of vertex counts. Moreover, we calculate the F-Score with thresholds of 0.5mm and 1.0mm for a statistical error analysis. For photometric alignment, multiview reference images are used as ground truth, while rendered images are generated from aligned meshes with the common template’s texture map at the same camera poses. Standard image metrics such as PSNR, SSIM, and LPIPS are employed for evaluation.
| Subject 7 | Subject 32 | Subject 122 | Subject 212 | Subject 340 | Subject 344 | Subject 350 | ||||||||
| C.D. | N.C. | C.D. | N.C. | C.D. | N.C. | C.D. | N.C. | C.D. | N.C. | C.D. | N.C. | C.D. | N.C. | |
| NICP | 0.477 | 0.910 | 0.355 | 0.942 | 0.404 | 0.943 | 0.614 | 0.915 | 0.383 | 0.944 | 0.340 | 0.936 | 0.428 | 0.912 |
| NPHM | 0.347 | 0.958 | 0.377 | 0.970 | 0.325 | 0.968 | 0.429 | 0.949 | 0.285 | 0.973 | 0.338 | 0.957 | 0.489 | 0.937 |
| GPJA | 0.229 | 0.981 | 0.147 | 0.992 | 0.264 | 0.984 | 0.180 | 0.980 | 0.215 | 0.981 | 0.224 | 0.975 | 0.239 | 0.970 |
| F@0.5 | F@1.0 | F@0.5 | F@1.0 | F@0.5 | F@1.0 | F@0.5 | F@1.0 | F@0.5 | F@1.0 | F@0.5 | F@1.0 | F@0.5 | F@1.0 | |
| NICP | 0.708 | 0.852 | 0.800 | 0.918 | 0.738 | 0.901 | 0.549 | 0.799 | 0.743 | 0.913 | 0.792 | 0.922 | 0.746 | 0.879 |
| NPHM | 0.814 | 0.923 | 0.778 | 0.925 | 0.825 | 0.945 | 0.731 | 0.899 | 0.858 | 0.956 | 0.814 | 0.938 | 0.682 | 0.872 |
| GPJA | 0.909 | 0.960 | 0.957 | 0.975 | 0.880 | 0.959 | 0.921 | 0.963 | 0.912 | 0.961 | 0.912 | 0.960 | 0.891 | 0.957 |
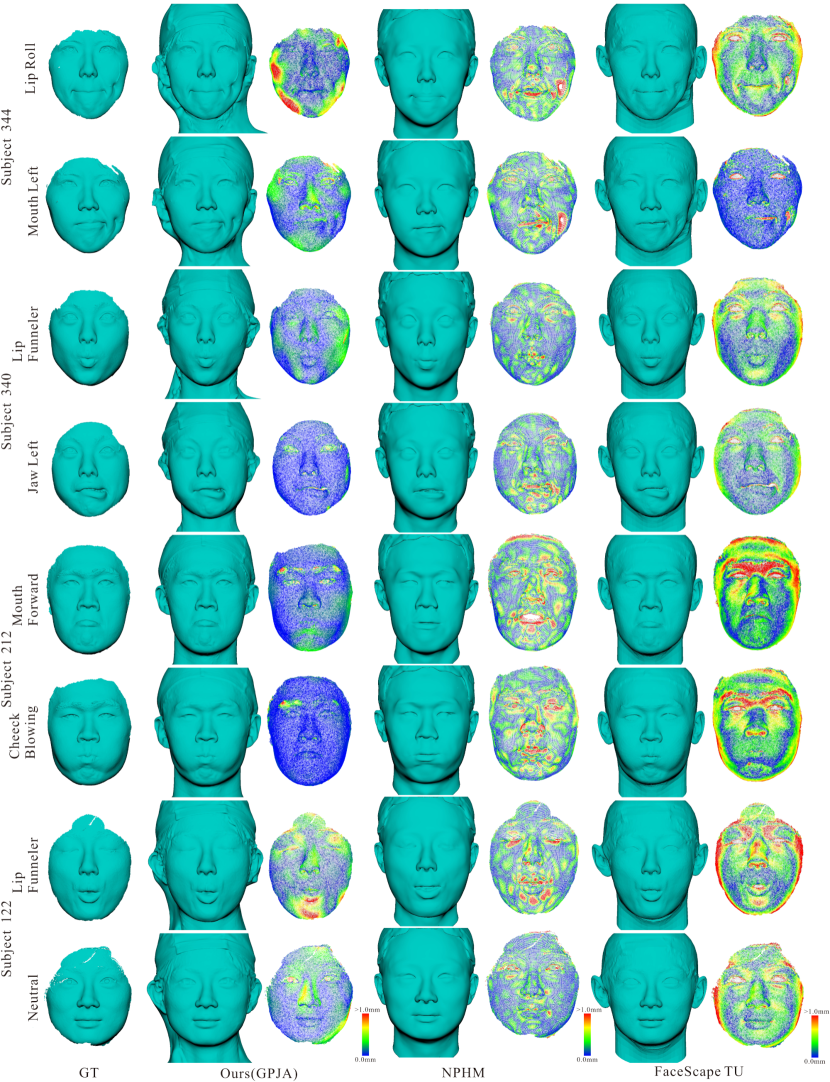
Result Analysis on Geometric Alignment. We compare our GPJA against two registration methods. The first is FaceScape topologically uniform(TU) meshes obtained through NICP [18] which is a variant of the standard ICP registration method in 3D face domain [57]. The second is the state-of-the-art deep learning method NPHM [41], which is trained on a dataset comprising 87 subjects and 23 different facial expressions.
Quantitative and qualitative comparisons of geometric alignment are presented in Table 1 and Fig. 6. Table 1 shows that GPJA outperforms NPHM and NICP across all subjects, achieving the lowest L1-Chamfer distance and highest normal consistency, indicating superior geometric alignment. GPJA also consistently achieves higher F-Scores at both thresholds, with F-Scores@0.5mm particularly emphasizing its statistical superiority.
As depicted in Fig. 6, the error visualization exhibits the distribution of errors across the face, demonstrating that our method achieves higher fidelity, even in challenging regions such as the lips and eyes. The primary limitation of NPHM is its lack of fidelity in capturing details. This deficiency is particularly evident in errors concentrated around the mouth of subject 212 and wrinkles of subject 344. Fig. 6 also reveals two main drawbacks in FaceScape TU meshes. First, subject 122’s lip-funneler expression, where the eyes should be closed, incorrectly shows the opposite. This is a common issue resulting from inaccurate landmarks in the ICP-based method. Secondly, the face rim areas (foreheads and cheeks) in TU meshes are observed with higher geometric errors due to excessive conformation to the template shape. Additionally, both NPHM and TU meshes incorrectly stitch non-facial areas like the skull, ears, and neck using templates. In contrast, GPJA aligns these regions more accurately, showcasing its robustness in capturing full heads.
Result Analysis on Photometric Alignment. Previous registration methods neglect photometric evaluations due to a lack of consideration for joint alignment, hence we provide qualitative evaluation for comparisons.


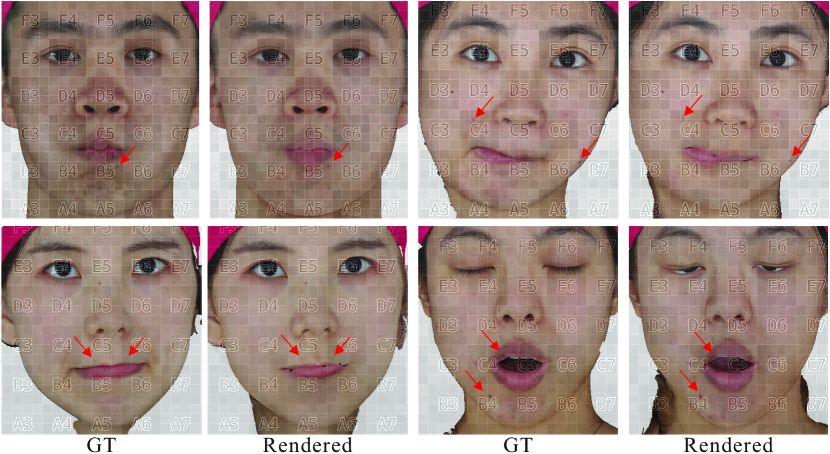
There are two key evidences illustrating the lack of photometric alignment in FaceScape, as shown in Fig. 7: (a) The texture maps for the same subject exhibit discrepancies across different expressions, signifying the absence of a unified parametrization; (b) Deviations are observed between the contours of lips on the texture maps and those on the meshes, revealing misalignment between the geometry and texture. Similar issues are also present in NPHM meshes, although they are not accompanied by texture coordinates. Fig. 8 reveals that NPHM generates false lips that ought to be invisible, which implies the method’s insufficient ability to align based solely on geometric features.
| PSNR↑ | SSIM↑ | LPIPS↓ | |
| Subject 7 | 24.75 | 0.7810 | 0.06868 |
| Subject 32 | 20.79 | 0.6621 | 0.07516 |
| Subject 122 | 23.56 | 0.7443 | 0.07081 |
| Subject 212 | 25.51 | 0.7699 | 0.09368 |
| Subject 340 | 24.10 | 0.7378 | 0.06802 |
| Subject 344 | 23.08 | 0.7569 | 0.06791 |
| Subject 350 | 25.38 | 0.7320 | 0.07857 |
| Average | 23.88 | 0.7406 | 0.07469 |

In contrast, GPJA ensures photometric consistency by applying the shared color texture to match reference images of different expressions. A comparison between the ground truth and our rendered images in Fig. 9 convincingly shows the photometric alignment achieved by our registration method. The last row of Fig. 9 illustrates that the discrepancy between the ground truth and the rendered images is primarily attributed to variations in skin tone across facial expressions. Notably, as depicted in Fig. 10, the rendered images exhibit pixel-level consistency in characteristic areas such as the mouth, eyes, and mole features across various facial expressions, despite occlusion changes. Moreover, Table 2 provides the image metrics for our experiment. The quantitative results are superior than PSNR of 23.61, SSIM of 0.6460, and LPIPS of 0.09677 achieved by the NeRF-style pipeline NeP [63] (tested on the first 100 subjects of FaceScape), which produces photo-realistic reconstruction through per-frame color generation without alignment.


| Geometric error↓ | PSNR↑ | SSIM↑ | LPIPS↓ | |
| GPJA | 0.167 | 24.06 | 0.7523 | 0.07511 |
| Ablation | ||||
| w/o | 0.377 | 24.49 | 0.7498 | 0.07578 |
| w/o | 0.455 | 23.67 | 0.7535 | 0.07544 |
| w/o | 0.447 | 22.04 | 0.7364 | 0.07820 |
Ablations. The HRA mechanism plays a crucial role in correctly warping the template into joint alignment. To validate HRA’s effectiveness, we conduct two ablation experiments to confirm its benefits.
We first validate the contribution of each constraints from HRA mechanism, which is supported by Table 3. In the case where all constraints are utilized, the geometric error is minimized. As a visualized example, Fig. 11 reveals that the normal term significantly contributes to the sharpness of details and alleviates incorrect bumps on texture-less regions like cheeks. However, Table 3 show close image metrics in comparison. We speculate the reason is that with the color constraint guiding the deformation, the geometric distortion can not manifest itself in color renderings.
In the second ablation, we study the effectiveness of the masking strategy for color constraint. We synthesize the label image for the mouth socket using , and overlap it with the ground truth to examine the contours around the inner mouth. Fig. 12 illustrates that when the inner mouth is not masked out, the vertices around it are disturbed and distorted. Hence, intentionally masking out the inner mouth facilitates correct tracing of the mouth contours.
Applications. The core strength of GPJA lies in its ability to achieve joint alignment with a shared texture space across expressions. This consistency enables efficient batch processing for a variety of applications, such as animation and re-parametrization, as demonstrated below.
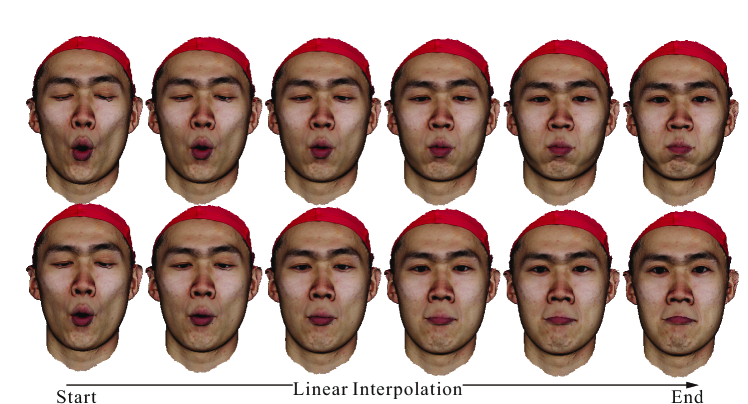
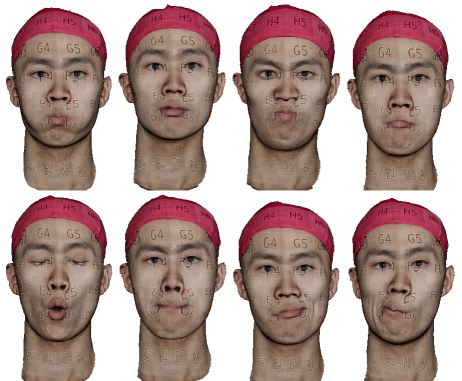
The meshes generated by GPJA for the same subject share a common parametrization, though the vertex sampling varies. We perform remeshing on these meshes via a common triangulation on the texture space. The remeshed results can then be linearly interpolated for face animation as presented in Fig. 13 and the supplementary video.
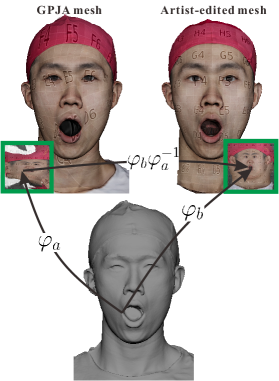
When an artist-edited, UV-unwrapped facial mesh is available, as illustrated in Fig. 14(a), the texture embeddings of input meshes yield a continuous map from the texture coordinates of the GPJA-generated meshes to those of the artist-edited mesh. Thereafter, the interpolation operator is applied directly to propagate the artist-edited parametrization across all expressions shown in Fig. 14(b).
6 Conclusion
We propose an innovative geometric-photometric joint alignment approach for facial mesh registration through the utilization of differentiable rendering techniques, demonstrating robust performance under various facial expressions with visibility changes. Unlike previous methods, our semantic annotation-free approach does not require marker point tracking or pre-aligned meshes for training. It is fully automatic and can be executed on a consumer GPU. Experiments show that our method achieve high geometric accuracy, surpassing conventional ICP-based techniques and the state-of-the-art method NPHM. We also validate the photometric alignment by comparing rendered images with captured multiview images, demonstrating pixel-level alignment in key facial areas, including the eyes, mouth, nostrils, and even freckles.
Our method currently adopts a relatively simple lighting and reflection model, which limits its performance under varying lighting conditions and skin highlights. Additionally, features such as teeth and the tongue may occasionally lead to inaccuracies in aligning the mouth contours. Future improvements will focus on optimizing efficiency, enhancing the rendering function to simulate more complex effects, and implementing cross-subject alignment based on genus-0 properties.
References
-
[1]
P. F. U. Gotardo, J. Riviere, D. Bradley, A. Ghosh, T. Beeler, Practical dynamic facial appearance modeling and acquisition, ACM Trans. Graph. 37 (6) (2018) 232.
doi:10.1145/3272127.3275073.
URL https://doi.org/10.1145/3272127.3275073 -
[2]
J. Riviere, P. F. U. Gotardo, D. Bradley, A. Ghosh, T. Beeler, Single-shot high-quality facial geometry and skin appearance capture, ACM Trans. Graph. 39 (4) (2020) 81.
doi:10.1145/3386569.3392464.
URL https://doi.org/10.1145/3386569.3392464 -
[3]
L. Zhang, C. Zeng, Q. Zhang, H. Lin, R. Cao, W. Yang, L. Xu, J. Yu, Video-driven neural physically-based facial asset for production, ACM Trans. Graph. 41 (6) (2022) 208:1–208:16.
doi:10.1145/3550454.3555445.
URL https://doi.org/10.1145/3550454.3555445 -
[4]
G. Fyffe, K. Nagano, L. Huynh, S. Saito, J. Busch, A. Jones, H. Li, P. E. Debevec, Multi-view stereo on consistent face topology, Comput. Graph. Forum 36 (2) (2017) 295–309.
doi:10.1111/cgf.13127.
URL https://doi.org/10.1111/cgf.13127 -
[5]
T. Beeler, F. Hahn, D. Bradley, B. Bickel, P. A. Beardsley, C. Gotsman, R. W. Sumner, M. H. Gross, High-quality passive facial performance capture using anchor frames, ACM Trans. Graph. 30 (4) (2011) 75.
doi:10.1145/2010324.1964970.
URL https://doi.org/10.1145/2010324.1964970 -
[6]
B. Amberg, S. Romdhani, T. Vetter, Optimal step nonrigid ICP algorithms for surface registration, in: 2007 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2007), 18-23 June 2007, Minneapolis, Minnesota, USA, IEEE Computer Society, 2007.
doi:10.1109/CVPR.2007.383165.
URL https://doi.org/10.1109/CVPR.2007.383165 -
[7]
T. Li, T. Bolkart, M. J. Black, H. Li, J. Romero, Learning a model of facial shape and expression from 4d scans, ACM Trans. Graph. 36 (6) (2017) 194:1–194:17.
doi:10.1145/3130800.3130813.
URL https://doi.org/10.1145/3130800.3130813 -
[8]
S. Z. Gilani, A. S. Mian, F. Shafait, I. Reid, Dense 3d face correspondence, IEEE Trans. Pattern Anal. Mach. Intell. 40 (7) (2018) 1584–1598.
doi:10.1109/TPAMI.2017.2725279.
URL https://doi.org/10.1109/TPAMI.2017.2725279 -
[9]
S. C. Lee, M. Kazhdan, Dense point-to-point correspondences between genus-zero shapes, Comput. Graph. Forum 38 (5) (2019) 27–37.
doi:10.1111/cgf.13787.
URL https://doi.org/10.1111/cgf.13787 -
[10]
Z. Fan, S. Peng, S. Xia, Towards fine-grained optimal 3d face dense registration: An iterative dividing and diffusing method, Int. J. Comput. Vis. 131 (9) (2023) 2356–2376.
doi:10.1007/S11263-023-01825-7.
URL https://doi.org/10.1007/s11263-023-01825-7 -
[11]
G. Gafni, J. Thies, M. Zollhöfer, M. Nießner, Dynamic neural radiance fields for monocular 4d facial avatar reconstruction, in: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, Computer Vision Foundation / IEEE, 2021, pp. 8649–8658.
doi:10.1109/CVPR46437.2021.00854.
URL https://openaccess.thecvf.com/content/CVPR2021/html/Gafni_Dynamic_Neural_Radiance_Fields_for_Monocular_4D_Facial_Avatar_Reconstruction_CVPR_2021_paper.html -
[12]
S. Laine, J. Hellsten, T. Karras, Y. Seol, J. Lehtinen, T. Aila, Modular primitives for high-performance differentiable rendering, ACM Trans. Graph. 39 (6) (2020) 194:1–194:14.
doi:10.1145/3414685.3417861.
URL https://doi.org/10.1145/3414685.3417861 -
[13]
M. Nimier-David, D. Vicini, T. Zeltner, W. Jakob, Mitsuba 2: a retargetable forward and inverse renderer, ACM Trans. Graph. 38 (6) (2019) 203:1–203:17.
doi:10.1145/3355089.3356498.
URL https://doi.org/10.1145/3355089.3356498 -
[14]
V. Blanz, T. Vetter, A morphable model for the synthesis of 3d faces, in: W. N. Waggenspack (Ed.), Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 1999, Los Angeles, CA, USA, August 8-13, 1999, ACM, 1999, pp. 187–194.
URL https://dl.acm.org/citation.cfm?id=311556 -
[15]
O. Aldrian, W. A. P. Smith, Inverse rendering of faces with a 3d morphable model, IEEE Trans. Pattern Anal. Mach. Intell. 35 (5) (2013) 1080–1093.
doi:10.1109/TPAMI.2012.206.
URL https://doi.org/10.1109/TPAMI.2012.206 -
[16]
S. Ploumpis, E. Ververas, E. O. Sullivan, S. Moschoglou, H. Wang, N. E. Pears, W. A. P. Smith, B. Gecer, S. Zafeiriou, Towards a complete 3d morphable model of the human head, IEEE Trans. Pattern Anal. Mach. Intell. 43 (11) (2021) 4142–4160.
doi:10.1109/TPAMI.2020.2991150.
URL https://doi.org/10.1109/TPAMI.2020.2991150 -
[17]
B. Nicolet, A. Jacobson, W. Jakob, Large steps in inverse rendering of geometry, ACM Trans. Graph. 40 (6) (2021) 248:1–248:13.
doi:10.1145/3478513.3480501.
URL https://doi.org/10.1145/3478513.3480501 -
[18]
H. Yang, H. Zhu, Y. Wang, M. Huang, Q. Shen, R. Yang, X. Cao, Facescape: A large-scale high quality 3d face dataset and detailed riggable 3d face prediction, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, Computer Vision Foundation / IEEE, 2020, pp. 598–607.
doi:10.1109/CVPR42600.2020.00068.
URL https://openaccess.thecvf.com/content_CVPR_2020/html/Yang_FaceScape_A_Large-Scale_High_Quality_3D_Face_Dataset_and_Detailed_CVPR_2020_paper.html -
[19]
O. Sorkine, D. Cohen-Or, Y. Lipman, M. Alexa, C. Rössl, H. Seidel, Laplacian surface editing, in: J. Boissonnat, P. Alliez (Eds.), Second Eurographics Symposium on Geometry Processing, Nice, France, July 8-10, 2004, Vol. 71 of ACM International Conference Proceeding Series, Eurographics Association, 2004, pp. 175–184.
doi:10.2312/SGP/SGP04/179-188.
URL https://doi.org/10.2312/SGP/SGP04/179-188 -
[20]
S. Rusinkiewicz, M. Levoy, Efficient variants of the ICP algorithm, in: 3rd International Conference on 3D Digital Imaging and Modeling (3DIM 2001), 28 May - 1 June 2001, Quebec City, Canada, IEEE Computer Society, 2001, pp. 145–152.
doi:10.1109/IM.2001.924423.
URL https://doi.org/10.1109/IM.2001.924423 -
[21]
A. Baden, K. Crane, M. Kazhdan, Möbius registration, Comput. Graph. Forum 37 (5) (2018) 211–220.
doi:10.1111/cgf.13503.
URL https://doi.org/10.1111/cgf.13503 -
[22]
J. Yang, M. Zhao, Y. Wu, X. Jia, Accurate and robust registration of low overlapping point clouds, Comput. Graph. 118 (2024) 146–160.
doi:10.1016/J.CAG.2023.12.003.
URL https://doi.org/10.1016/j.cag.2023.12.003 -
[23]
H. Li, R. W. Sumner, M. Pauly, Global correspondence optimization for non-rigid registration of depth scans, Comput. Graph. Forum 27 (5) (2008) 1421–1430.
doi:10.1111/j.1467-8659.2008.01282.x.
URL https://doi.org/10.1111/j.1467-8659.2008.01282.x - [24] J. Booth, A. Roussos, S. Zafeiriou, A. Ponniah, D. Dunaway, A 3d morphable model learnt from 10,000 faces, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5543–5552.
-
[25]
H. Dai, N. E. Pears, W. A. P. Smith, C. Duncan, Statistical modeling of craniofacial shape and texture, Int. J. Comput. Vis. 128 (2) (2020) 547–571.
doi:10.1007/s11263-019-01260-7.
URL https://doi.org/10.1007/s11263-019-01260-7 -
[26]
C. Wu, D. Bradley, M. H. Gross, T. Beeler, An anatomically-constrained local deformation model for monocular face capture, ACM Trans. Graph. 35 (4) (2016) 115:1–115:12.
doi:10.1145/2897824.2925882.
URL https://doi.org/10.1145/2897824.2925882 -
[27]
N. E. Pears, H. Dai, W. A. P. Smith, H. Sun, Laplacian ICP for progressive registration of 3d human head meshes, in: 17th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2023, Waikoloa Beach, HI, USA, January 5-8, 2023, IEEE, 2023, pp. 1–7.
doi:10.1109/FG57933.2023.10042743.
URL https://doi.org/10.1109/FG57933.2023.10042743 -
[28]
G. K. L. Tam, Z. Cheng, Y. Lai, F. C. Langbein, Y. Liu, A. D. Marshall, R. R. Martin, X. Sun, P. L. Rosin, Registration of 3d point clouds and meshes: A survey from rigid to nonrigid, IEEE Trans. Vis. Comput. Graph. 19 (7) (2013) 1199–1217.
doi:10.1109/TVCG.2012.310.
URL https://doi.org/10.1109/TVCG.2012.310 -
[29]
P. Bourquat, D. Coeurjolly, G. Damiand, F. Dupont, Hierarchical mesh-to-points as-rigid-as-possible registration, Comput. Graph. 102 (2022) 320–328.
doi:10.1016/J.CAG.2021.10.016.
URL https://doi.org/10.1016/j.cag.2021.10.016 - [30] S. Bouaziz, Y. Wang, M. Pauly, Online modeling for realtime facial animation, ACM Transactions on Graphics (ToG) 32 (4) (2013) 1–10.
- [31] Y. Seol, W.-C. Ma, J. P. Lewis, Creating an actor-specific facial rig from performance capture, in: Proceedings of the 2016 Symposium on Digital Production, 2016, pp. 13–17.
-
[32]
X. Li, Y. Cheng, X. Ren, H. Jia, D. Xu, W. Zhu, Y. Yan, Topo4d: Topology-preserving gaussian splatting for high-fidelity 4d head capture, CoRR abs/2406.00440 (2024).
arXiv:2406.00440, doi:10.48550/ARXIV.2406.00440.
URL https://doi.org/10.48550/arXiv.2406.00440 -
[33]
D. Dinev, T. Beeler, D. Bradley, M. Bächer, H. Xu, L. Kavan, User-guided lip correction for facial performance capture, Comput. Graph. Forum 37 (8) (2018) 93–101.
doi:10.1111/cgf.13515.
URL https://doi.org/10.1111/cgf.13515 -
[34]
S. Lin, Y. Lai, R. R. Martin, S. Jin, Z. Cheng, Color-aware surface registration, Comput. Graph. 58 (2016) 31–42.
doi:10.1016/J.CAG.2016.05.007.
URL https://doi.org/10.1016/j.cag.2016.05.007 -
[35]
F. Prada, M. Kazhdan, M. Chuang, A. Collet, H. Hoppe, Motion graphs for unstructured textured meshes, ACM Trans. Graph. 35 (4) (2016) 108:1–108:14.
doi:10.1145/2897824.2925967.
URL https://doi.org/10.1145/2897824.2925967 -
[36]
C. Cao, D. Bradley, K. Zhou, T. Beeler, Real-time high-fidelity facial performance capture, ACM Trans. Graph. 34 (4) (2015) 46:1–46:9.
doi:10.1145/2766943.
URL https://doi.org/10.1145/2766943 -
[37]
P. Garrido, M. Zollhöfer, C. Wu, D. Bradley, P. Pérez, T. Beeler, C. Theobalt, Corrective 3d reconstruction of lips from monocular video, ACM Trans. Graph. 35 (6) (2016) 219:1–219:11.
doi:10.1145/2980179.2982419.
URL https://doi.org/10.1145/2980179.2982419 -
[38]
A. Bermano, T. Beeler, Y. Kozlov, D. Bradley, B. Bickel, M. H. Gross, Detailed spatio-temporal reconstruction of eyelids, ACM Trans. Graph. 34 (4) (2015) 44:1–44:11.
doi:10.1145/2766924.
URL https://doi.org/10.1145/2766924 -
[39]
T. Li, S. Liu, T. Bolkart, J. Liu, H. Li, Y. Zhao, Topologically consistent multi-view face inference using volumetric sampling, in: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, IEEE, 2021, pp. 3804–3814.
doi:10.1109/ICCV48922.2021.00380.
URL https://doi.org/10.1109/ICCV48922.2021.00380 -
[40]
T. Bolkart, T. Li, M. J. Black, Instant multi-view head capture through learnable registration, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, IEEE, 2023, pp. 768–779.
doi:10.1109/CVPR52729.2023.00081.
URL https://doi.org/10.1109/CVPR52729.2023.00081 -
[41]
S. Giebenhain, T. Kirschstein, M. Georgopoulos, M. Rünz, L. Agapito, M. Nießner, Learning neural parametric head models, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, IEEE, 2023, pp. 21003–21012.
doi:10.1109/CVPR52729.2023.02012.
URL https://doi.org/10.1109/CVPR52729.2023.02012 -
[42]
S. Liu, Y. Cai, H. Chen, Y. Zhou, Y. Zhao, Rapid face asset acquisition with recurrent feature alignment, ACM Trans. Graph. 41 (6) (2022) 214:1–214:17.
doi:10.1145/3550454.3555509.
URL https://doi.org/10.1145/3550454.3555509 -
[43]
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, R. Ng, Nerf: Representing scenes as neural radiance fields for view synthesis, in: A. Vedaldi, H. Bischof, T. Brox, J. Frahm (Eds.), Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part I, Vol. 12346 of Lecture Notes in Computer Science, Springer, 2020, pp. 405–421.
doi:10.1007/978-3-030-58452-8\_24.
URL https://doi.org/10.1007/978-3-030-58452-8_24 - [44] B. Kerbl, G. Kopanas, T. Leimkühler, G. Drettakis, 3d gaussian splatting for real-time radiance field rendering., ACM Trans. Graph. 42 (4) (2023) 139–1.
-
[45]
A. Pumarola, E. Corona, G. Pons-Moll, F. Moreno-Noguer, D-nerf: Neural radiance fields for dynamic scenes, in: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, Computer Vision Foundation / IEEE, 2021, pp. 10318–10327.
doi:10.1109/CVPR46437.2021.01018.
URL https://openaccess.thecvf.com/content/CVPR2021/html/Pumarola_D-NeRF_Neural_Radiance_Fields_for_Dynamic_Scenes_CVPR_2021_paper.html -
[46]
Y. Zheng, V. F. Abrevaya, M. C. Bühler, X. Chen, M. J. Black, O. Hilliges, I M avatar: Implicit morphable head avatars from videos, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, IEEE, 2022, pp. 13535–13545.
doi:10.1109/CVPR52688.2022.01318.
URL https://doi.org/10.1109/CVPR52688.2022.01318 -
[47]
S. Athar, Z. Xu, K. Sunkavalli, E. Shechtman, Z. Shu, Rignerf: Fully controllable neural 3d portraits, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, IEEE, 2022, pp. 20332–20341.
doi:10.1109/CVPR52688.2022.01972.
URL https://doi.org/10.1109/CVPR52688.2022.01972 - [48] Y. Xu, B. Chen, Z. Li, H. Zhang, L. Wang, Z. Zheng, Y. Liu, Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1931–1941.
- [49] S. Qian, T. Kirschstein, L. Schoneveld, D. Davoli, S. Giebenhain, M. Nießner, Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20299–20309.
-
[50]
J. Munkberg, W. Chen, J. Hasselgren, A. Evans, T. Shen, T. Müller, J. Gao, S. Fidler, Extracting triangular 3d models, materials, and lighting from images, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, IEEE, 2022, pp. 8270–8280.
doi:10.1109/CVPR52688.2022.00810.
URL https://doi.org/10.1109/CVPR52688.2022.00810 -
[51]
A. Prados-Torreblanca, J. M. Buenaposada, L. Baumela, Shape preserving facial landmarks with graph attention networks, in: 33rd British Machine Vision Conference 2022, BMVC 2022, London, UK, November 21-24, 2022, BMVA Press, 2022.
URL https://bmvc2022.mpi-inf.mpg.de/0155.pdf - [52] C. Liu, et al., Beyond pixels: exploring new representations and applications for motion analysis, Ph.D. thesis, Massachusetts Institute of Technology (2009).
-
[53]
R. Ramamoorthi, P. Hanrahan, An efficient representation for irradiance environment maps, in: L. Pocock (Ed.), Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 2001, Los Angeles, California, USA, August 12-17, 2001, ACM, 2001, pp. 497–500.
doi:10.1145/383259.383317.
URL https://doi.org/10.1145/383259.383317 - [54] A. Harltey, A. Zisserman, 6.2.3 depth of points, in: Multiple view geometry in computer vision (2. ed.), Cambridge University Press, 2006.
- [55] H. Nguyen, Chapter 22. baking normal maps on the gpu, in: Gpu Gems 3, Addison-Wesley Professional, 2007.
-
[56]
B. Deng, Y. Yao, R. M. Dyke, J. Zhang, A survey of non-rigid 3d registration, Comput. Graph. Forum 41 (2) (2022) 559–589.
doi:10.1111/CGF.14502.
URL https://doi.org/10.1111/cgf.14502 -
[57]
Y. Jung, H. Kim, G. Hwang, S. Baek, S. Lee, Mesh density adaptation for template-based shape reconstruction, in: E. Brunvand, A. Sheffer, M. Wimmer (Eds.), ACM SIGGRAPH 2023 Conference Proceedings, SIGGRAPH 2023, Los Angeles, CA, USA, August 6-10, 2023, ACM, 2023, pp. 53:1–53:10.
doi:10.1145/3588432.3591498.
URL https://doi.org/10.1145/3588432.3591498 -
[58]
O. Sorkine, M. Alexa, As-rigid-as-possible surface modeling, in: A. G. Belyaev, M. Garland (Eds.), Proceedings of the Fifth Eurographics Symposium on Geometry Processing, Barcelona, Spain, July 4-6, 2007, Vol. 257 of ACM International Conference Proceeding Series, Eurographics Association, 2007, pp. 109–116.
doi:10.2312/SGP/SGP07/109-116.
URL https://doi.org/10.2312/SGP/SGP07/109-116 -
[59]
P. Schmidt, J. Born, D. Bommes, M. Campen, L. Kobbelt, Tinyad: Automatic differentiation in geometry processing made simple, Comput. Graph. Forum 41 (5) (2022) 113–124.
doi:10.1111/CGF.14607.
URL https://doi.org/10.1111/cgf.14607 -
[60]
M. Desbrun, M. Meyer, P. Schröder, A. H. Barr, Implicit fairing of irregular meshes using diffusion and curvature flow, in: W. N. Waggenspack (Ed.), Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 1999, Los Angeles, CA, USA, August 8-13, 1999, ACM, 1999, pp. 317–324.
doi:10.1145/311535.311576.
URL https://doi.org/10.1145/311535.311576 -
[61]
M. Botsch, L. Kobbelt, A remeshing approach to multiresolution modeling, in: J. Boissonnat, P. Alliez (Eds.), Second Eurographics Symposium on Geometry Processing, Nice, France, July 8-10, 2004, Vol. 71 of ACM International Conference Proceeding Series, Eurographics Association, 2004, pp. 185–192.
doi:10.2312/SGP/SGP04/189-196.
URL https://doi.org/10.2312/SGP/SGP04/189-196 -
[62]
S. Liu, Z. Ferguson, A. Jacobson, Y. I. Gingold, Seamless: seam erasure and seam-aware decoupling of shape from mesh resolution, ACM Trans. Graph. 36 (6) (2017) 216:1–216:15.
doi:10.1145/3130800.3130897.
URL https://doi.org/10.1145/3130800.3130897 -
[63]
L. Ma, X. Li, J. Liao, X. Wang, Q. Zhang, J. Wang, P. V. Sander, Neural parameterization for dynamic human head editing, ACM Trans. Graph. 41 (6) (2022) 236:1–236:15.
doi:10.1145/3550454.3555494.
URL https://doi.org/10.1145/3550454.3555494