Towards High-Quality Temporal Action Detection with Sparse Proposals
Abstract
Temporal Action Detection (TAD) is an essential and challenging topic in video understanding, aiming to localize the temporal segments containing human action instances and predict the action categories. The previous works greatly rely upon dense candidates either by designing varying anchors or enumerating all the combinations of boundaries on video sequences; therefore, they are related to complicated pipelines and sensitive hand-crafted designs. Recently, with the resurgence of Transformer, query-based methods have tended to become the rising solutions for their simplicity and flexibility. However, there still exists a performance gap between query-based methods and well-established methods. In this paper, we identify the main challenge lies in the large variants of action duration and the ambiguous boundaries for short action instances; nevertheless, quadratic-computational global attention prevents query-based methods to build multi-scale feature maps. Towards high-quality temporal action detection, we introduce Sparse Proposals to interact with the hierarchical features. In our method, named SP-TAD, each proposal attends to a local segment feature in the temporal feature pyramid. The local interaction enables utilization of high-resolution features to preserve action instances details. Extensive experiments demonstrate the effectiveness of our method, especially under high tIoU thresholds. E.g., we achieve the state-of-the-art performance on THUMOS14 (45.7% on mAP@0.6, 33.4% on mAP@0.7 and 53.5% on mAP@Avg) and competitive results on ActivityNet-1.3 (32.99% on mAP@Avg). Code will be made available at https://github.com/wjn922/SP-TAD.
1 Introduction
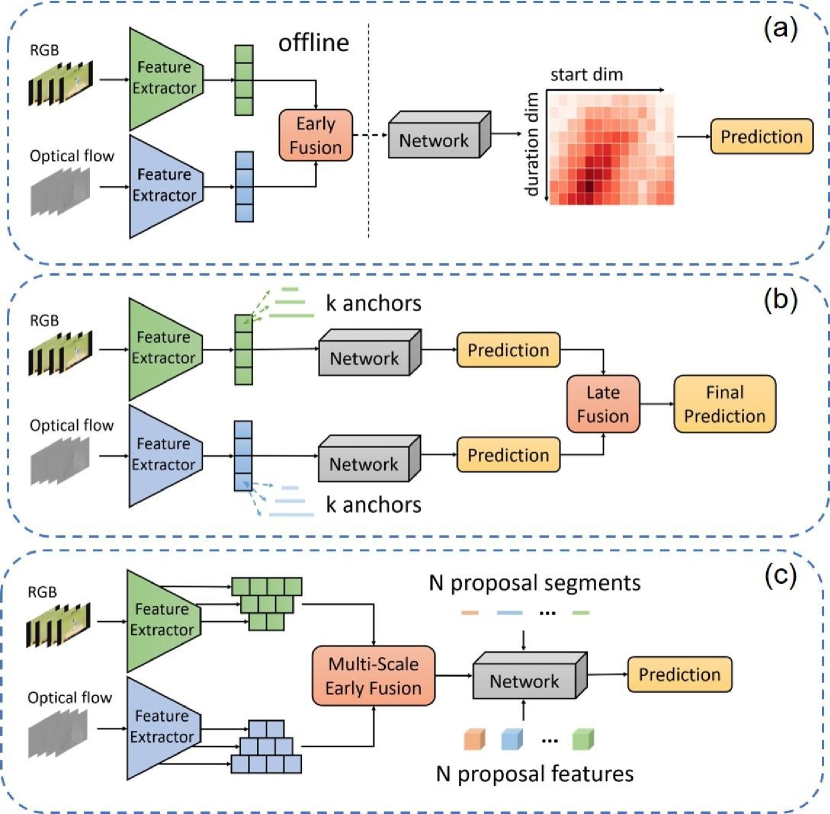
As video resources are growing rapidly in the real world, the task of temporal action detection (TAD) has received considerable critical attention. Given a long untrimmed video, the goal is to locate the temporal segments of person occurrence and predict the human action categories, which serves as a crucial technique in video understanding.
Previous works have established two well-developed method types and shown impressive performance in this task. (1) Anchor-based methods [20, 8]. They first design multi-scale anchors on every grid of feature sequence. Then, the network performs action classification and boundary regression on these candidates. Since the duration of ground-truth action instances varies dramatically in different videos, those methods suffer from huge computational consumption for placing dense proposal candidates and might have imprecise temporal boundaries. (2) Boundary-based methods [19, 43]. These methods tackle the inaccurate boundary problem in a bottom-up fashion, wherein each matching pair of the video sequence is evaluated. They discard the process of regression and directly generate the confidence scores for the densely distributed proposals. Nevertheless, they can only be used for temporal action proposal generation, thus requiring an external classifier for action classification.
The two well-established methods have been consistently improved and demonstrate their effectiveness with superior performance. However, they still have some limitations. First, these two kinds of methods largely depend on the dense proposal candidates, which would incur a heavy computational burden as the video gets longer. Second, they are vulnerable to artificial parameters, such as the anchor design and confidence threshold. Recently, the query-based methods [33, 25] have raised great interest in the research community. They only employ a small set of queries and thus the network has a simple pipeline as well as gets rid of hand-crafted design. In this paper, we propose a simple and effective framework towards high-quality temporal action detection with sparse proposals (SP-TAD), also belonging to the query-based family. The pipeline of our method is shown in Figure 1 (c).
In temporal action detection (TAD) task, we identify that an important issue lies in that the duration of action instances in a video varies drastically from several seconds to minutes, and it is difficult for the network to detect short instances. Feature pyramid network (FPN) [22] has been widely used in image object detection to solve the problem of large object scale variation. The recent query-based method RTD-Net [33] adopts global attention between the query feature and the global encoded feature, the quadratic-computational complexity prevents it from building multi-scale features. Some other works [12, 37, 18] construct the temporal feature pyramid network (TFPN) to mitigate the difficulty of temporal boundary localization. Nonetheless, they all build the TFPN upon the feature extracted from the last layer of the backbone, which contains the high-level representation of the video clip. The down-sample operation in TFPN architecture would further lose the information of short action instances, making it hard for accurate temporal boundary regression. In this work, we present a novel sparse interaction process where the proposal feature only interacts with the corresponding local segment feature. Therefore, we can directly use the intermediate layer outputs from backbone to construct the hierarchical feature maps. As the intermediate features have a higher temporal resolution so as to preserve the details of action instances with large variant duration, we show that it is a key element leading to high-quality temporal action detection.
The main contributions of this work are as follows.
-
•
We propose a simple and unified framework for temporal action detection. Given the RGB frames and optical flows, the whole network is optimized end-to-end from the raw two-stream inputs and outputs the predictions without late fusion. Our method adds a new member to the query-based family, which enjoys far fewer candidates and gets rid of the complex hand-crafted designs.
-
•
We present the sparse interaction between the proposal feature and corresponding segment feature. This local interaction enables utilization of high-resolution features which are output by the intermediate layers of backbone. It plays a critical role in high-quality temporal action detection and fast inference speed.
-
•
Extensive experiments show that SP-TAD outperforms the existing state-of-the-art methods on THUMOS14 and achieves competitive performance on ActivityNet-1.3.
2 Related Work
2.1 Action Recognition
With the rise of deep learning, action recognition has been rapidly developed from the combination of 2D convolutional networks and recurrent neural networks [9] to deep 3D convolutional networks [34]. Current deep learning methods can be categorized into two groups: two-stream networks and 3D convolutional networks. The former ones [31, 38, 11] adopt two branches to efficiently integrate spatial and temporal information. The latter ones [35, 41, 6] have a strong capacity to extract the compact spatial-temporal representations simultaneously. All these methods aim to generalize a model with strong robustness and establish correlation and hierarchy of spatial-temporal features in video stream. They are initially developed for action recognition and also served as the backbone for video feature extraction in various video tasks, e.g., temporal action detection and video captioning.
2.2 Temporal Action Detection
The pioneering works mainly follow two paradigms: (1) Two-stage scheme. These methods [21, 19, 43, 12] first generate a set of ranked temporal proposals and then classify each proposal for the action category. Most works of this stream are focused on improving the quality of the generated proposals. BSN [21] pinpoints local temporal boundaries with high probabilities and evaluates their global confidences. BMN [19] develops an end-to-end training pipeline and a boundary-matching strategy for confidence evaluation. DBG [17] takes a step forward from BSN by implementing boundary classification and action completeness regression to check through the densely distributed proposals. Some other works [47, 45, 28] take the generated proposals in the first stage as input for further boundary refinement and accurate action classification. However, these two-stage methods go through multiple training stages which have limited correlation, thus may lead to a sub-optimal solution. (2) One-stage scheme. Analogous to object detection, R-C3D [42] and TAL-Net [8] adopt the Faster-RCNN [29] like architecture and accomplish proposal generation and action classification in one network. SSAD [20] skips the process of proposal generation and introduces 1D temporal convolution to generate multiple anchors for temporal action detection. A2Net [44] and AFSD [18] visit the anchor-free mechanism, where the network predicts the distance to the temporal boundaries for each temporal location in the feature sequence. AFSD also proposes a novel boundary refinement strategy for precise temporal localization. The one-stage methods enjoy a simpler framework and less hype-parameters tuning.
2.3 Transformer in Computer Vision
Transformer [36] was first introduced for natural language processing (NLP) tasks and has raised great attention in the computer vision (CV) community recently [10, 40]. The self-attention mechanism in Transformer can dynamically generate global attention weights, which overcomes the disadvantages of convolutional neural networks (CNNs) for local modeling. Transformer has revealed its strong capacity for temporal action proposal generation task. ATAG [7] proposes an augmented Transformer to capture the long-range temporal contextual information of videos and results in better snippet-level actionness prediction. TAPG Transformer [39] adopt two complementary Transformer blocks to accomplish the task. One is used to predict the precise boundary scores, and the other learns the rich inter-proposal relationship for reliable proposal confidence evaluation.
Benefiting from Transformer, DETR [5] employs a series of object queries instead of anchors as candidates and opens a new view for object detection. Inspired by this work, query-based method has become the rising solution for temporal action detection because of its simplicity and flexibility. RTD-Net [33] leverages the Transformer decoder in which the queries interact with the global encoded feature for directly performing temporal action proposal generation. TadTR [25] restricts the queries to attend a small set of key snippets instead of all the snippets to improve the efficiency.
3 Approach
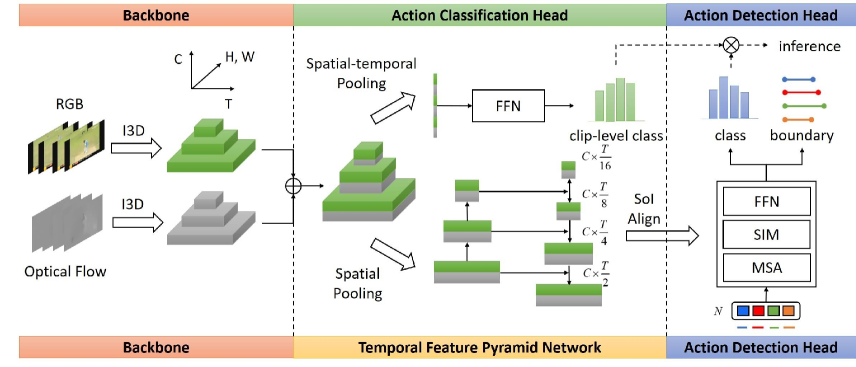
Overview.
Suppose a long untrimmed video contains human action instances and the action instance set is represented by , where , and represent the start timestamp, end timestamp and action category of the -th action instance, respectively. The goal of temporal action detection (TAD) is to predict a set containing the action proposals with the action classes. should locate the ground-truth action instances precisely and predict the action categories correctly. To achieve this goal, we propose a simple and unified architecture named SP-TAD. As illustrated in Figure 2, SP-TAD is an end-to-end training framework for the two-stream inputs. It mainly consists of four parts: 3D backbone networks, a temporal feature pyramid network, an action detection head and an action classification head.
Specifically, for a given video, we first generate the video clips with the shape and extract the corresponding optical flows. SP-TAD receives the two-stream inputs of a video and extracts the 3D features from them separately. The intermediate layer outputs of backbone networks are used to build the 3D hierarchical feature maps. Afterward, we perform average spatial pooling on the concatenated 3D features to get the 1D sequences and construct a temporal feature pyramid network upon them. The 1D multi-scale features are fed into the action detection head to obtain the temporal segments and action categories results. For the action classification head, it receives the spatial-temporal pooled features from 3D hierarchical feature maps as input and predicts the clip-level action classes probabilities. During training, we apply bipartite matching to create a unique alignment [5] between the predicted results and ground-truth action instance. The whole network is optimized end-to-end using the combination of set prediction loss [5] and action classification loss.
3.1 SP-TAD
3.1.1 Backbone
We adopt the widely-used I3D network [6] as our feature extractor for both RGB frames and optical flows, as it has the ability to model temporal information and proves its superior performance in action recognition. The last three stage outputs from I3D network are extracted to build the three-level hierarchical 3D feature maps. For a video clip with shape , the temporal strides and spatial strides of the three-level features are [2, 4, 8] and [8, 16, 32], respectively. Finally, the same level features of RGB and flow streams are concatenated along the channel dimension.
3.1.2 Temporal Feature Pyramid Network
After obtaining the three-level 3D feature maps from the backbone network, we first perform average spatial pooling to get the three-level 1D feature sequences. The features are further transformed by 1D convolutional layers with the output channel as 256. Then, the semantic information of high-level features is passed to low-level features in a top-down fashion. And a 1D max-pooling layer with stride as 2 is added upon the highest level feature. In this way, we construct a four-level feature pyramid with the minimal temporal resolution as . Since the lower level features have a higher temporal resolution, they are responsible for predicting short action instances.
3.1.3 Action Detection Head
The action detection head receives the multi-level features generated by the temporal feature pyramid network (TFPN) and then predicts the temporal segments and action categories of action instances. The key elements of action detection head design are learnable proposal segments and corresponding proposal features. We set the number of proposal candidates as a small value (e.g., ), which should be larger than the maximum ground-truth action instances number for all videos clips in a dataset. The proposal segments are 2-d parameters, indicating the normalized center location and duration of a temporal segment. These proposal segments could be set as any size and placed randomly over the feature sequence during initialization, avoiding sophisticated candidate proposal design. The proposal feature encodes the rich instance information for each proposal candidate, playing a similar role as the object query in DETR [5]. The main distinction lies in that every proposal feature only interacts with the corresponding Segment-of-Interest (SoI) feature instead of the global encoded feature, which could be seen as local attention.
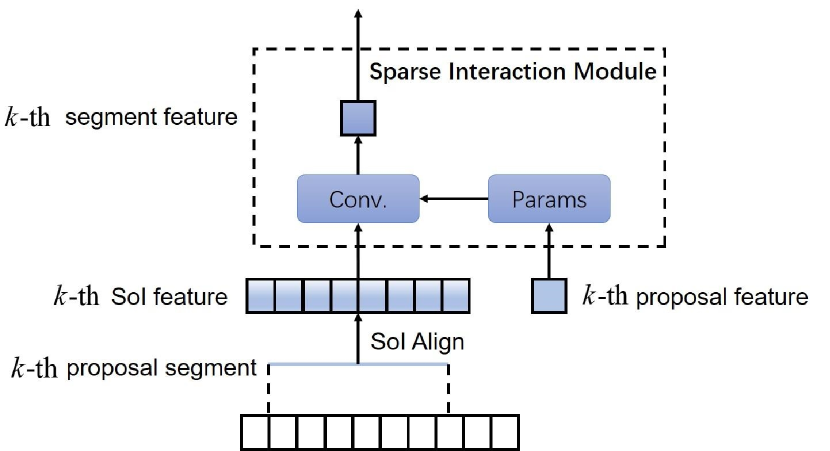
In the action detection head, the proposal features first pass through the multi-head self-attention (MSA) module [36] to model the relations between each other and then are fed into the sparse interaction module (SIM).
Figure 3 illustrates the sparse interaction between the -th proposal feature and corresponding SoI feature in the sparse interaction module. Firstly, due to the ambiguous temporal boundary of an action instance, for the original proposal segment with the region , it will be expanded to , where and is empirically as 5. Then, we use the expanded proposal segment to extract the SoI feature from temporal feature pyramid via 1D SoI Align operation [43], where is the aligned temporal resolution. For a proposal segment which represents a temporal length of , the corresponding SoI feature is extracted from the -th level feature determined by:
| (1) |
where is the highest level index, and is the temporal length of the input video clip.
Meanwhile, the proposal feature produces two parameters with size and via linear transformation. Afterward, the extracted SoI feature performs matrix multiplication with these two parameters successively. Therefore, the interaction process can be seen as the SoI feature propagating through two 1D convolutional layers. This design helps our model can fully exploit the high-resolution features from the backbone intermediate layers due to its efficiency.
The outputs features from SIM, called segment features, are further fed into the two-layer feed-forward network (FFN) to obtain the final segment representation. Lastly, two parallel branches are built upon the action detection head to get the final classification scores and boundary regression predictions of action instances. The classification branch is a linear layer with Sigmoid activation for predicting the probability of each action class. And the regression branch consists of a 3-layer feed-forward network with ReLU activation for temporal boundary regression.
An important strategy used in the action detection head is the iterative refinement, which is a commonly-used technique [4, 5, 48, 32] to improve the performance. We stack the action detection heads and get the predictions of each head. The predicted proposal segments and segment features at each stage serve as the initial proposal segments and proposal features for the next stage so as to be consistently refined. The auxiliary loss is added at intermediate stages to stabilize the training process. We show here the iterative refinement is also the key element towards high-quality temporal action detection.
3.1.4 Action Classification Head
Action recognition [38, 6] has been comprehensively studied for a long period and I3D network achieves fairly high accuracy in predicting the action labels of a video clip. Thus, we add the action classification head to predict the video/clip-level action classes probabilities so as to further adjust the classification scores of predicted action instances. Specifically, we directly perform the average spatial-temporal pooling on the three-level 3D features output by the backbone network and feed the pooled feature to a linear layer with Sigmoid activation. The training targets are all action categories happening in the video clip.
3.2 Training and Inference
3.2.1 Training Loss Function
The predicted action instances set generated by the action detection head contains samples, which is larger than the maximum number of ground-truth action instances in a dataset. As with DETR [5], we expand the target set to the size by padding which indicates no action instance. Then, we adopt the set prediction loss on these two fixed-size sets. And we use the binary cross entropy loss for the action classification head. The overall training loss to optimize the whole network is constituted by these two parts:
| (2) |
where , , and are weight coefficients.
The first part of Equation (2) is the set prediction loss. It first finds the optimal bipartite matching between predictions and ground-truth action instances by optimizing the matching cost. This provides a one-to-one label assignment pattern, i.e., only those predictions matched with the ground-truth action instances are denoted as positive samples. Therefore, for the -th prediction , there exists a unique instance in target set to align with it. Finally, the set prediction loss is computed by the weighted sum of classification loss and regression loss. is the focal loss [23] for action classification of action instances. and are L1 loss and generalized tIoU loss [30] between the normalized segment locations of predicted samples and ground-truth instances. They together contribute to the boundary regression.
| (3) | ||||
where is the total number of positive samples.
3.2.2 Inference
The inference process of the SP-TAD is simple. Given a video, predicted action instances associated with the classification probabilities and temporal segments are retrieved from the last action detection head. The classification probabilities are further adjusted by multiplying the video/clip-level action classes scores produced by the action classification head.
4 Experiments
| Type | Method | Backbone | One-stage | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg |
| Anchor-based | SSAD[20] | TS | ✓ | 43.0 | 35.0 | 24.6 | - | - | - |
| TURN[13] | C3D | ✓ | 44.1 | 34.9 | 25.6 | - | - | - | |
| R-C3D[42] | C3D | ✓ | 44.8 | 35.6 | 28.9 | - | - | - | |
| CBR[14] | TS | ✓ | 50.1 | 41.3 | 31.0 | 19.1 | 9.9 | 30.3 | |
| TAL-Net[8] | I3D | ✓ | 53.2 | 48.5 | 42.8 | 33.8 | 20.8 | 39.8 | |
| GTAN[26] | P3D | ✓ | 57.8 | 47.2 | 38.8 | - | - | - | |
| PBRNet[24] | I3D | ✓ | 58.5 | 54.6 | 51.3 | 41.8 | 29.5 | 47.1 | |
| AFSD[18] | I3D | ✓ | 67.3 | 62.4 | 55.5 | 43.7 | 31.1 | 52.0 | |
| Boundary-based | SSN[47] | TS | 51.0 | 41.0 | 29.8 | - | - | - | |
| BSN[21] | TS | 53.5 | 45.0 | 36.9 | 28.4 | 20.0 | 36.8 | ||
| BMN[19] | TS | 56.0 | 47.4 | 38.8 | 29.7 | 20.5 | 38.5 | ||
| DBG[17] | TS | 57.8 | 49.4 | 42.8 | 33.8 | 21.7 | 41.1 | ||
| G-TAD[43] | TS | 54.5 | 47.6 | 40.2 | 30.8 | 23.4 | 39.3 | ||
| BU-TAL[46] | I3D | 53.9 | 50.7 | 45.4 | 38.0 | 28.5 | 43.3 | ||
| Query-based | RTD-Net[33] | I3D | 58.5 | 53.1 | 45.1 | 36.4 | 25.0 | 43.6 | |
| TadTR[25] | I3D | ✓ | 62.4 | 57.4 | 49.2 | 37.8 | 26.3 | 46.6 | |
| SP-TAD (Ours) | I3D | ✓ | 69.2 | 63.3 | 55.9 | 45.7 | 33.4 | 53.5 |
4.1 Datasets and Setup
Datasets.
We conduct our experiments on two popular datasets: THUMOS14 [15] dataset contains 1,010 and 1,574 untrimmed videos with 200 class categories in validation and testing set, respectively. For the temporal action localization task, there are 200 validation videos and 213 testing videos with temporal annotation of 20 action classes. ActivityNet-1.3 [3] dataset contains 19,994 untrimmed videos of 200 action categories; all videos are temporally annotated. Additionally, they are divided into training, validation and testing set by the ratio of 2:1:1.
Implementation Details.
On THUMOS14 dataset, we encode the videos at 10 frames per second (fps) with the spatial resolution as . Following the previous practice [19, 18], we use the sliding windows to generate consecutive video clips. As the 98% action instances of the dataset are less than 25.6s, we set the temporal length of each clip as 256 frames. The temporal strides between the adjacent video clips are set as 30 and 128 during training and inference phase, respectively. Because the adjacent clips have overlaps, which would produce redundant predictions, we adopt the soft-NMS [1] as post-process. For ActivityNet-1.3, as each video only contains 1.5 action instances on average, we encode each video to the fixed temporal length of 768 frames. On both datasets, random crop and horizontal flipping are applied as the image level data augmentation during training. The spatial size of the cropped image is set as . The number of learnable proposals on each sample is selected as 50 for THUMOS14 and 100 for ActivityNet-1.3.
The I3D backbone networks are initialized with the parameters pre-trained on Kinetics dataset [16]. We use the AdamW [27] optimizer with the weight decay of 0.0001 to train the network and we set the batch size as 16. The learning rate is 0.0001 for the first 12 epochs and 0.00001 for the following 4 epochs.
Evaluation Metrics.
For the temporal action detection task, mean Average Precision (mAP) is calculated as the evaluation metric. On ActivityNet-1.3, mAP with tIoU thresholds and average mAP under tIoU thresholds are reported. On THUMOS14, we compute the mAP with tIoU thresholds and average mAP.
4.2 Main Results
THUMOS14
The comparison results of the state-of-the-art methods on THUMOS14 are summarized in Table 1. It can be seen that SP-TAD outperforms all the previous methods by a large margin, especially under high tIoU thresholds. For instance, SP-TAD achieves significant improvement from 43.7% to 45.7% on mAP@0.6 and from 31.1% to 33.4% on mAP@0.7 compared with the previous best method AFSD [18]. It should be noted that AFSD has already been far ahead of the performance over other methods. Our model only employs a set of sparse queries to achieve the remarkable performance while AFSD uses dense anchors as candidates. When compared with the two-stage methods which generate proposals first and then classify the action categories, SP-TAD not only has a simple and unified framework, but also shows superior performance over them.
| Method | 0.5 | 0.75 | 0.95 | Avg |
|---|---|---|---|---|
| Anchor-based | ||||
| TAL-Net[8] | 38.23 | 18.30 | 1.30 | 20.22 |
| SSAD[20] | 44.39 | 29.65 | 7.09 | 29.17 |
| AFSD[18] | 52.38 | 35.27 | 6.47 | 34.39 |
| Boundary-based | ||||
| SSN[47] | 39.12 | 23.48 | 5.49 | 23.98 |
| BSN[21] | 46.45 | 29.96 | 8.02 | 30.03 |
| BMN[19] | 50.07 | 34.78 | 8.29 | 33.85 |
| G-TAD[43] | 50.36 | 34.60 | 9.02 | 34.09 |
| BU-TAL[46] | 43.37 | 33.91 | 9.21 | 30.12 |
| Query-based | ||||
| RTD-Net[33] | 47.21 | 30.68 | 8.61 | 30.83 |
| TadTR[25] | 49.08 | 32.58 | 8.49 | 32.27 |
| SP-TAD (Ours) | 50.06 | 32.92 | 8.44 | 32.99 |
ActivityNet-1.3
Table 2 illustrates the temporal action detection performance of different methods on ActivityNet-1.3 validation set. It can be seen that our model outperforms other query-based methods on mAP@Avg. On the other hand, we observe that anchor-based and boundary-based methods have higher performance over the query-based methods, this is because the former two methods generate massive candidates and select the top 100 predictions from them, while the last one only predicts 100 proposals or less for each video. It should be noted that query-based methods have competitive performance under high tIoU thresholds, indicating that the methods have precise temporal boundaries.
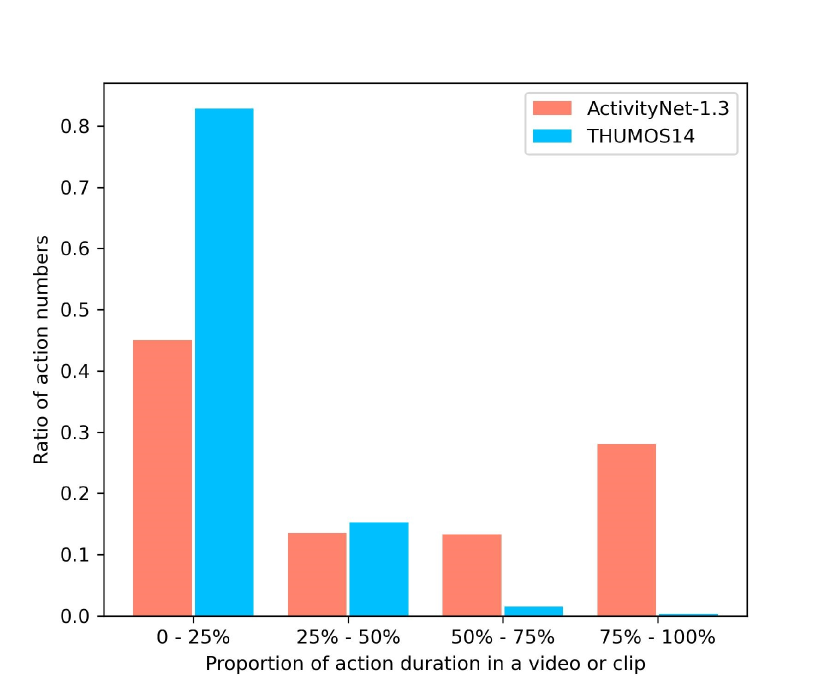
Moreover, we compare the action number distribution between ActivityNet-1.3 and THUMOS14 in Figure 4, where x-axis indicates the percentage of action length in a video or clip and y-axis represents the ratio of action number in a specified interval to all the action number in the dataset. Particularly, on THUMOS14, we first use the sliding windows with an overlap ratio of 0.5 to slide on the video. Then a ground-truth action instance is recorded when its tIoA111For two temporal segments and , tIoA of is defined as . to the truncated window is larger than 0.5. This is also the strategy for selecting samples during the training phase. It could be seen that the data distribution of these two datasets is quite different. On THUMOS14, over 80% action instances take up less than 25% duration time in a video clip and there are hardly any action instances belonging to the long instances; while ActivityNet-1.3 has a more even distribution regarding the duration time of action instances. Thus, it better highlights the advantage of our method.
4.3 Comparison of Inference Speed
Thanks to the sparse interaction design, our model can not only utilize the high-resolution features to achieve superior performance, but also have high efficiency due to local attention. To verify this statement, we compare the inference speed between our method and other state-of-the-art end-to-end training methods. For a fair comparison, we use the RGB frames as inputs to the network. As shown in Table 3, our model can process the videos at 5574 FPS on a single V100 GPU, which is much faster than the existing methods.
4.4 Ablation Study
In this section, we conduct several ablation studies on THUMOS14, aiming to explore the key elements that make for high-quality temporal action detection.
4.4.1 The Effect of Unified Backbone
Most of the previous works [19, 43, 46, 33] adopt an offline feature extractor to obtain the video features in advance and then design the network to process the fixed features. We hypothesize that fixed video features would limit the capacity of the current TAD methods because of the misalignment between different datasets. The recent works [24, 18] jointly train the backbone but do not explicitly explore the effect of the unified backbone in the network.
We gradually increase the learning rate for training backbone while keeping the learning rate for other parts unchanged as . Specifically, when the learning rate of backbone equals 0, the backbone could be seen as an offline feature extractor. From Table 4, we observe the consistent improvement by increasing the learning rate, which clearly proves that the unified backbone in the network would benefit the TAD task.
| Backbone Lr | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg |
|---|---|---|---|---|---|---|
| 0 | 65.1 | 58.3 | 49.5 | 39.1 | 27.6 | 48.0 |
| 65.4 | 59.6 | 51.0 | 40.1 | 28.6 | 48.9 | |
| 67.2 | 62.1 | 51.8 | 42.1 | 29.7 | 50.6 | |
| 69.2 | 63.3 | 55.9 | 45.7 | 33.4 | 53.5 |
4.4.2 The Effect of Temporal Feature Pyramid
The previous works neglect the features output by the intermediate layers of the backbone. However, we contend that these features preserve rich temporal information and play a key role in high-quality temporal action detection. Here we study different kinds of features as the input to the action detection head:
-
•
“Single Level” means only using the last layer output of the backbone.
-
•
“High Level TFP” represents that building the four-level temporal feature pyramid upon the highest level features from the backbone.
-
•
“Inter Level TFP” is the four-level feature pyramid used in our model, which uses the intermediate layer outputs of the backbone to construct the hierarchical feature maps.
From Table 5, we find that “Single Level” feature performs even better than the “High Level TFP”. This is because most of the aligned SoI features are extracted from the higher levels of temporal feature pyramid and they have lower temporal resolution than the “Single Level” feature. These high-level features would lose the details of short action instances and thus degenerate the performance instead. A straightforward but effective solution is using the intermediate outputs from the backbone to construct a temporal feature pyramid. It achieves significant performance gain, especially for high tIoU thresholds, as illustrated in the last row of Table 5.
| Features | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg |
|---|---|---|---|---|---|---|
| Single Level | 67.5 | 61.2 | 52.7 | 41.8 | 29.4 | 50.2 |
| High Level TFP | 65.8 | 59.9 | 51.5 | 40.0 | 28.1 | 49.0 |
| Inter Level TFP | 69.2 | 63.3 | 55.9 | 45.7 | 33.4 | 53.5 |
4.4.3 The Effect of Iterative Refinement
We study the effect of the number of stacked action detection heads in Table 6. The first row of Table 6 clearly shows that the model has an extremely poor performance of 43.6% on mAP@Avg without the iterative refinement process, while the performance would be greatly improved by increasing head number to 2, bringing a gain of 6.0% on mAP@Avg. This proves the effectiveness and necessity of iterative refinement. It also indicates that a good initialization for the proposal segments would reduce the prediction difficulty for the action detection head. As head number gradually increases, the performance gain becomes smaller and it saturates at the stage of 4. The iterative refinement is another important element for high-quality temporal action detection.
| Head | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg |
|---|---|---|---|---|---|---|
| 1 | 60.1 | 54.4 | 45.7 | 34.7 | 23.1 | 43.6 |
| 2 | 66.0 | 59.4 | 55.5 | 41.1 | 30.0 | 49.6 |
| 4 | 69.2 | 63.3 | 55.9 | 45.7 | 33.4 | 53.5 |
| 6 | 65.4 | 59.4 | 52.1 | 42.3 | 30.4 | 49.9 |
4.4.4 The Effect of Action Classification Head
The action recognition results have achieved fairly high thanks to the development of strong 3D backbones. Therefore, we add an action classification head to predict the probability distribution of different actions. It could be used to rectify the classification scores predicted by the action detection head during inference phase. As illustrated in Table 7, it improves the mAP@Avg from 52.1% to 53.5% on THUMOS14 testing set, proving this strategy is an effective way to correct the classification error by action detection head.
| Cls Head | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg |
|---|---|---|---|---|---|---|
| 67.2 | 61.6 | 54.7 | 44.3 | 32.6 | 52.1 | |
| ✓ | 69.2 | 63.3 | 55.9 | 45.7 | 33.4 | 53.5 |
4.4.5 The Choice of Video Clip Length
| Clip length | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg |
|---|---|---|---|---|---|---|
| 224 | 68.5 | 62.6 | 55.0 | 43.6 | 31.7 | 53.3 |
| 256 | 69.2 | 63.3 | 55.9 | 45.7 | 33.4 | 53.5 |
| 288 | 68.3 | 62.4 | 54.4 | 43.7 | 31.6 | 51.3 |
| 320 | 67.2 | 62.1 | 53.4 | 43.1 | 30.7 | 49.9 |
In real applications, a long untrimmed video would contain several action instances with large duration variance. Therefore, applying the sliding windows on the video is a useful technique for accurate temporal action detection. We vary the length of sliding window from 224 to 320 while keeping the overlap ratio as 0.5 during inference. The results are summarized in Table 8. A window with the length of 256 can cover 98% action instances in all the videos, thus it would be a suitable choice. When the length decreases to 224, the network can still achieve strong performance but would falsely detect the over-long action instances. On the other hand, increasing the length of sliding window means that the action segments would take less proportion in a clip, which makes it harder to detect the short action instances. It is reasonable to expect a slight performance drop by adopting a larger window.
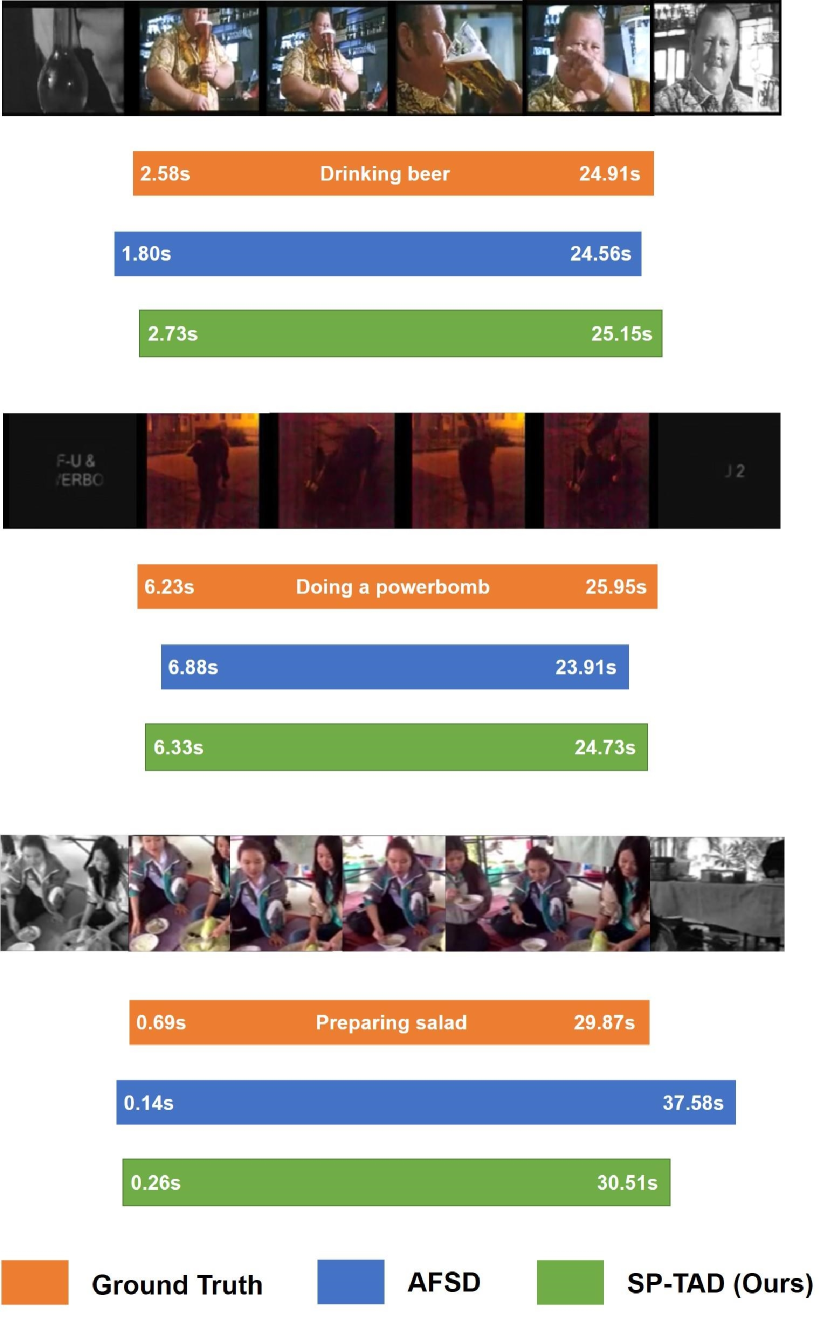
4.5 Visualization Results
In this section, we compare the visualization results of our method and the state-of-the-art method AFSD [18] on ActivityNet-1.3. From Figure 5, we can observe that the temporal boundaries of our method are more close to the ground-truth action instances. This phenomenon indicates that our method performs better under high tIoU threshold, which is also supported in Table 2.
5 Conclusion
In this paper, we present a simple and effective framework for high-quality temporal action detection, named SP-TAD. Our model belongs to the query-based family which enjoys the simple pipeline by introducing a small set of learnable proposals and gets rid of the hand-crafted anchor design. It is a unified framework and thus can be optimized end-to-end from raw two-stream inputs. Moreover, we propose the novel sparse interaction that enables utilization of high-resolution features, leading to the high performance and fast inference speed. We also identify the key elements for producing high-quality temporal segments: the unified backbone, intermediate outputs form the backbone and the iterative refinement strategy. Experiments demonstrate that our model achieves state-of-the-art performance on THUMOS14 and competitive results on ActivityNet-1.3.
References
- [1] Navaneeth Bodla, Bharat Singh, Rama Chellappa, and Larry S Davis. Soft-nms–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, pages 5561–5569, 2017.
- [2] Shyamal Buch, Victor Escorcia, Bernard Ghanem, Li Fei-Fei, and Juan Carlos Niebles. End-to-end, single-stream temporal action detection in untrimmed videos. In Procedings of the British Machine Vision Conference 2017. British Machine Vision Association, 2019.
- [3] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 961–970, 2015.
- [4] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6154–6162, 2018.
- [5] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer, 2020.
- [6] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- [7] Shuning Chang, Pichao Wang, Fan Wang, Hao Li, and Jiashi Feng. Augmented transformer with adaptive graph for temporal action proposal generation. arXiv preprint arXiv:2103.16024, 2021.
- [8] Yu-Wei Chao, Sudheendra Vijayanarasimhan, Bryan Seybold, David A Ross, Jia Deng, and Rahul Sukthankar. Rethinking the faster r-cnn architecture for temporal action localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1130–1139, 2018.
- [9] Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2625–2634, 2015.
- [10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. Proceedings of the International Conference on Learning Representations, 2020.
- [11] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019.
- [12] Jialin Gao, Zhixiang Shi, Guanshuo Wang, Jiani Li, Yufeng Yuan, Shiming Ge, and Xi Zhou. Accurate temporal action proposal generation with relation-aware pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 10810–10817, 2020.
- [13] Jiyang Gao, Zhenheng Yang, Kan Chen, Chen Sun, and Ram Nevatia. Turn tap: Temporal unit regression network for temporal action proposals. In Proceedings of the IEEE international conference on computer vision, pages 3628–3636, 2017.
- [14] Jiyang Gao, Zhenheng Yang, and Ram Nevatia. Cascaded boundary regression for temporal action detection. arXiv preprint arXiv:1705.01180, 2017.
- [15] Y.-G. Jiang, J. Liu, A. Roshan Zamir, G. Toderici, I. Laptev, M. Shah, and R. Sukthankar. THUMOS challenge: Action recognition with a large number of classes. http://crcv.ucf.edu/THUMOS14/, 2014.
- [16] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017.
- [17] Chuming Lin, Jian Li, Yabiao Wang, Ying Tai, Donghao Luo, Zhipeng Cui, Chengjie Wang, Jilin Li, Feiyue Huang, and Rongrong Ji. Fast learning of temporal action proposal via dense boundary generator. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11499–11506, 2020.
- [18] Chuming Lin, Chengming Xu, Donghao Luo, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Yanwei Fu. Learning salient boundary feature for anchor-free temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3320–3329, 2021.
- [19] Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, and Shilei Wen. Bmn: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3889–3898, 2019.
- [20] Tianwei Lin, Xu Zhao, and Zheng Shou. Single shot temporal action detection. In Proceedings of the 25th ACM international conference on Multimedia, pages 988–996, 2017.
- [21] Tianwei Lin, Xu Zhao, Haisheng Su, Chongjing Wang, and Ming Yang. Bsn: Boundary sensitive network for temporal action proposal generation. In European Conference on Computer Vision, pages 3–19, 2018.
- [22] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- [23] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 2980–2988, 2017.
- [24] Qinying Liu and Zilei Wang. Progressive boundary refinement network for temporal action detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11612–11619, 2020.
- [25] Xiaolong Liu, Qimeng Wang, Yao Hu, Xu Tang, Song Bai, and Xiang Bai. End-to-end temporal action detection with transformer. arXiv preprint arXiv:2106.10271, 2021.
- [26] Fuchen Long, Ting Yao, Zhaofan Qiu, Xinmei Tian, Jiebo Luo, and Tao Mei. Gaussian temporal awareness networks for action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 344–353, 2019.
- [27] Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam, 2018.
- [28] Zhiwu Qing, Haisheng Su, Weihao Gan, Dongliang Wang, Wei Wu, Xiang Wang, Yu Qiao, Junjie Yan, Changxin Gao, and Nong Sang. Temporal context aggregation network for temporal action proposal refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 485–494, 2021.
- [29] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28:91–99, 2015.
- [30] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 658–666, 2019.
- [31] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. arXiv preprint arXiv:1406.2199, 2014.
- [32] Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, and Ping Luo. SparseR-CNN: End-to-end object detection with learnable proposals. arXiv preprint arXiv:2011.12450, 2020.
- [33] Jing Tan, Jiaqi Tang, Limin Wang, and Gangshan Wu. Relaxed transformer decoders for direct action proposal generation. arXiv preprint arXiv:2102.01894, 2021.
- [34] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015.
- [35] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6450–6459, 2018.
- [36] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pages 6000–6010, 2017.
- [37] Chenhao Wang, Hongxiang Cai, Yuxin Zou, and Yichao Xiong. Rgb stream is enough for temporal action detection. arXiv preprint arXiv:2107.04362, 2021.
- [38] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision, pages 20–36. Springer, 2016.
- [39] Lining Wang, Haosen Yang, Wenhao Wu, Hongxun Yao, and Hujie Huang. Temporal action proposal generation with transformers. arXiv preprint arXiv:2105.12043, 2021.
- [40] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv preprint arXiv:2102.12122, 2021.
- [41] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European conference on computer vision (ECCV), pages 305–321, 2018.
- [42] Huijuan Xu, Abir Das, and Kate Saenko. R-c3d: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE international conference on computer vision, pages 5783–5792, 2017.
- [43] Mengmeng Xu, Chen Zhao, David S Rojas, Ali Thabet, and Bernard Ghanem. G-tad: Sub-graph localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10156–10165, 2020.
- [44] Le Yang, Houwen Peng, Dingwen Zhang, Jianlong Fu, and Junwei Han. Revisiting anchor mechanisms for temporal action localization. IEEE Transactions on Image Processing, 29:8535–8548, 2020.
- [45] Runhao Zeng, Wenbing Huang, Mingkui Tan, Yu Rong, Peilin Zhao, Junzhou Huang, and Chuang Gan. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7094–7103, 2019.
- [46] Peisen Zhao, Lingxi Xie, Chen Ju, Ya Zhang, Yanfeng Wang, and Qi Tian. Bottom-up temporal action localization with mutual regularization. In European Conference on Computer Vision, pages 539–555. Springer, 2020.
- [47] Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xiaoou Tang, and Dahua Lin. Temporal action detection with structured segment networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 2914–2923, 2017.
- [48] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020.