Towards human-like spoken dialogue generation between AI agents from written dialogue
Abstract
The advent of large language models (LLMs) has made it possible to generate natural written dialogues between two agents. However, generating human-like spoken dialogues from these written dialogues remains challenging. Spoken dialogues have several unique characteristics: they frequently include backchannels and laughter, and the smoothness of turn-taking significantly influences the fluidity of conversation. This study proposes CHATS — CHatty Agents Text-to-Speech — a discrete token-based system designed to generate spoken dialogues based on written dialogues. Our system can generate speech for both the speaker side and the listener side simultaneously, using only the transcription from the speaker side, which eliminates the need for transcriptions of backchannels or laughter. Moreover, CHATS facilitates natural turn-taking; it determines the appropriate duration of silence after each utterance in the absence of overlap, and it initiates the generation of overlapping speech based on the phoneme sequence of the next utterance in case of overlap. Experimental evaluations indicate that CHATS outperforms the text-to-speech baseline, producing spoken dialogues that are more interactive and fluid while retaining clarity and intelligibility.
1 Introduction
Large Language Models (LLMs) have profoundly influenced the field of natural language processing (NLP) and artificial intelligence (AI) (Zhao et al., 2023). LLMs, with their capacity to generate coherent and contextually relevant content, have enabled more natural text-based dialogues between humans and computers and paved the way for inter-computer communication. The recently proposed concept of Generative Agents (Park et al., 2023) underscores the potential of LLMs, where emulated agents within the model engage in autonomous dialogues, store information, and initiate actions. This emerging paradigm of agent-to-agent communication offers vast potential across various sectors, from entertainment to facilitating human-to-human information exchange. However, considering the dominance of spoken communication in human interactions, integrating voice into machine dialogues can provide a richer expression of individuality and emotion, offering a more genuine experience. A significant challenge then emerges: how can we transform written dialogues, whether generated by LLMs or humans, into human-like spoken conversations?
Although both written and spoken dialogues serve as mediums for communication, their characteristics and effects on the audience differ significantly. Spoken dialogues are imbued with unique elements such as backchannels, laughter, and smooth transitions between speakers. These are rarely captured fully in written form. For instance, a nod or a simple ”uh-huh” serves as a backchannel in spoken dialogues, subtly indicating the listener’s engagement and understanding (Yngve, 1970). Similarly, laughter can convey amusement, act as a bridge between topics, and ease potential tensions (Adelswärd, 1989). The smoothness of turn-takings in spoken dialogues, wherein one speaker naturally yields the floor to another, introduces a rhythm and fluidity that is challenging to reproduce in text (Stivers et al., 2009). Several approaches have been proposed to model these backchannels (Kawahara et al., 2016; Lala et al., 2017; Adiba et al., 2021; Lala et al., 2022), laughter (Mori et al., 2019; Tits et al., 2020; Bayramoğlu et al., 2021; Xin et al., 2023; Mori & Kimura, 2023), and turn-taking (Lala et al., 2017; Hara et al., 2018; Sakuma et al., 2023). However, most have focused on human-to-agent conversation or the task itself (e.g., laughter synthesis) and the agent-to-agent situation has not been evaluated.
A straightforward approach for transforming written dialogues into spoken dialogues involves employing a text-to-speech (TTS) system. Advancements in TTS have facilitated the generation of individual utterances at a quality comparable to human voice (Kim et al., 2021; Tan et al., 2022). Certain studies have focused on generating conversational speech by considering linguistic or acoustic contexts (Guo et al., 2021; Cong et al., 2021; Li et al., 2022; Mitsui et al., 2022; Xue et al., 2023). Furthermore, certain studies have equipped LLMs with TTS and automatic speech recognition to facilitate human-to-agent speech communication (Huang et al., 2023; Zhang et al., 2023; Wang et al., 2023; Rubenstein et al., 2023). However, these systems are fully turn-based, where each speaker utters alternatively, and the characteristics of spoken dialogues such as backchannels and turn-taking are neglected. Recently, SoundStorm (Borsos et al., 2023) has succeeded in generating high-quality spoken dialogue; however, it requires transcriptions for backchannels and is subject to a 30-s length constraint. Another approach introduced the dialogue generative spoken language model (dGSLM), which generates two-channel spoken dialogue autoregressively, achieving realistic agent-to-agent vocal interactions, laughter generation, and turn-taking (Nguyen et al., 2023). Although dGSLM’s operation based solely on audio is revolutionary, it cannot control utterance content via text. Moreover, as reported in section 4.4, generating meaningful content with dGSLM requires a vast dataset.
This study proposes CHATS (CHatty Agents Text-to-Speech), a system for transforming written dialogue into spoken dialogue, whose content is coherent with the input written dialogue but generated with backchannels, laughter, and smooth turn-taking. By conditioning dGSLM on the phonetic transcription of speaker’s utterance, our system can generate meaningful and contextually proper utterances on the speaker side. Simultaneously, it generates various backchannels and laughter without transcription on the listener side. The proposed system is designed to overcome the limitations of existing methods, including the turn-based nature of TTS systems and content control constraints of textless models. A collection of audio samples can be accessed through https://rinnakk.github.io/research/publications/CHATS/.
Our contributions are multi-fold:
-
•
Conversion from Spoken to Written Dialogue: Assuming a dataset that comprises recordings of spontaneous dialogues between two speakers, accompanied by their respective transcriptions, we note that the transcriptions inherently contain elements not typically found in standard written dialogues such as timestamps and listener responses like backchannels and laughter. Thus, we propose a method to convert those transcriptions into standard written formats. We combine a rule-based and machine learning-based approach to detect backchannels for excluding their transcriptions from written dialogues.
-
•
Exploration of Dual-Tower Transformer Architecture: Our system is built on top of dGSLM, whose core comprises a dual-tower Transformer to generate discrete acoustic tokens. We condition dGSLM with phonemes and investigate the effect of pre-training in TTS tasks on the textual fidelity. Furthermore, we introduce a pitch representation following Kharitonov et al. (2022) and analyze its effects on both textual fidelity and prosody.
-
•
Introduction of a Turn-Taking Mechanism: A novel mechanism for predicting the timing of spoken dialogues is introduced. This encompasses both the duration of pauses after utterances and instances where subsequent utterances overlapped with preceding ones, echoing the organic rhythm and fluidity of human conversations.
2 Written dialogue preparation via backchannel exclusion
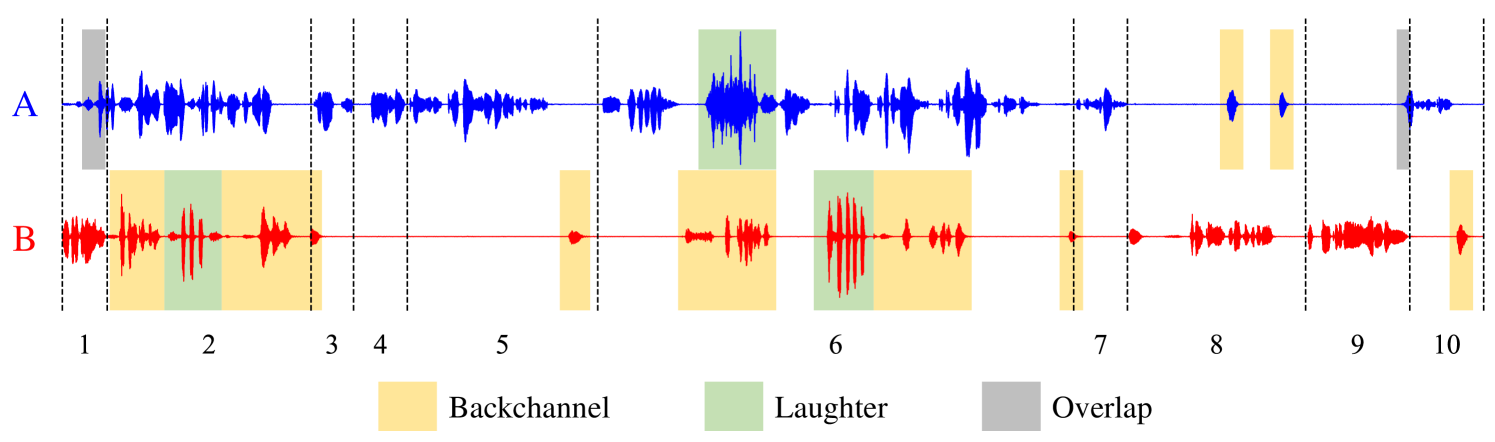
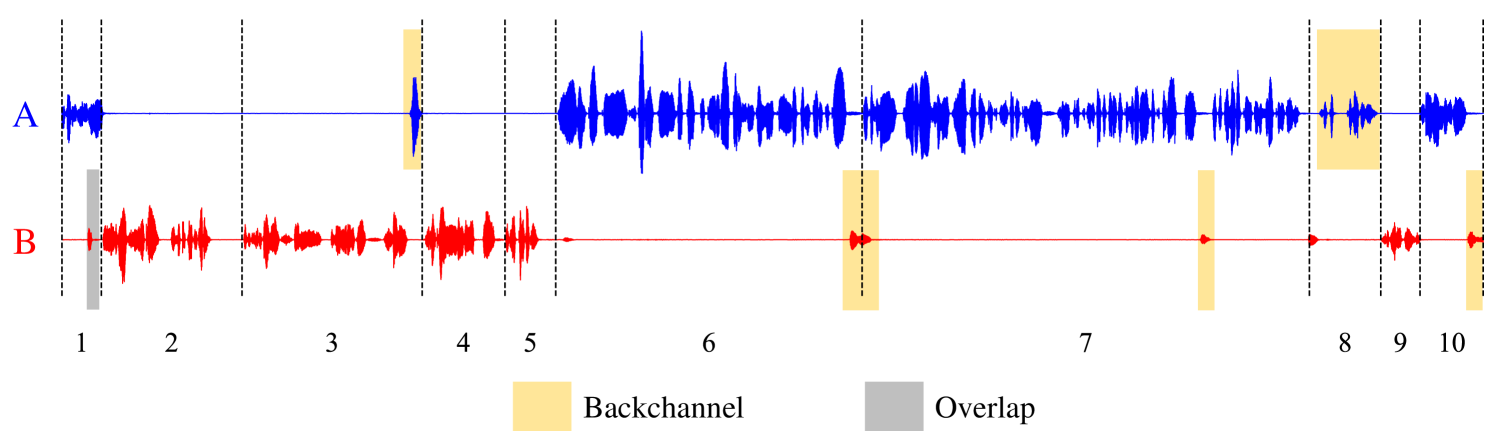
The distinction between spoken dialogue transcriptions and written dialogues is conspicuous. The former contains (1) the listener’s utterances including backchannels and laughter, and (2) temporal delineations for each utterance, which are typically absent in written dialogues. This is shown in Figure 1. To align the input with our system’s requirements, the spoken dialogue transcription format is converted to resemble written dialogues.
First, the temporal metadata is omitted and the verbal content is retained. Successive utterances from an identical speaker are merged if they are separated by a silence of ms, and are referred to as inter-pausal units (IPUs). Subsequently, we remove the listener’s IPUs from the transcription. A hybrid approach of rule-based and machine learning techniques is used to identify and remove these IPUs as described below:
- Step 1
-
If one speaker’s IPU encompasses another’s, it is termed the speaker IPU (s-IPU), while the latter is termed the listener IPU (l-IPU). Any IPUs not fitting these definitions are labeled as undefined IPUs (u-IPUs).
- Step 2
-
A binary classifier is trained to ascertain whether a given IPU is an s-IPU or l-IPU using speech segments corresponding to s-IPUs and l-IPUs identified in step 1.
- Step 3
-
The classifier trained in step 2 is then applied to categorize the u-IPUs.
- Step 4
-
IPUs identified as l-IPUs in steps 1 or 3 are excluded from the transcription.
Consequently, the resulting written dialogues are composed exclusively of s-IPUs. Hereinafter, ”utterance” denotes an s-IPU unless otherwise specified. The binary classifier, or IPU classifier, receives content units which will be detailed in section 3.1.1.

3 CHATS
3.1 System architecture
Our system aims to transform written dialogues into their spoken counterparts by adopting a pipeline architecture inspired by Lakhotia et al. (2021), comprising three primary modules: speech-to-unit (s2u) module, unit language model (uLM), and unit-to-speech (u2s) module.
3.1.1 Speech-to-Unit (s2u) Module
The s2u module extracts a concise representation from speech signals, operating on the entirety of a spoken dialogue. It (1) facilitates easy modeling by the uLM and (2) retains the necessary detail for the u2s module to reconstruct a high-fidelity waveform. Following Kharitonov et al. (2022), our s2u module extracts two distinct representations:
- •
-
•
Pitch Units: These capture the tonal aspects of speech. It is a discrete representation of the speaker-normalized logarithm of the fundamental frequency ().
For the notation, these units are referred to as or simply when the th utterance need not be highlighted. Further, is the utterance index, is the timestep, is the audio channel, and is the codebook index associated with the content and pitch units, respectively. We assume in this study.
3.1.2 Unit Language Model (uLM)
The uLM is designed to generate content and pitch units for two channels based on written dialogue. In contrast to s2u and u2s modules, the uLM focuses on individual utterances, rather than entire dialogues, owing to inherent sequence length limitations. However, our uLM only requires the text of the current and next utterances to generate the current speech, thus facilitating sequential production of spoken dialogues without waiting for the generation of the entire written dialogue.
Model Architecture: The uLM architecture is based on dialogue Transformer language model (DLM) (Nguyen et al., 2023), which comprises two decoder-only Transformer towers that share parameters. We extend the DLM to include two input and output projection layers associated with the content and pitch streams, respectively, wherein the content and pitch unit sequences are prefixed with the tokens described in the subsequent paragraph. We refer to this extended DLM as MS-DLM (Multi-Stream DLM). The detailed architecture is depicted in Figure A.1.
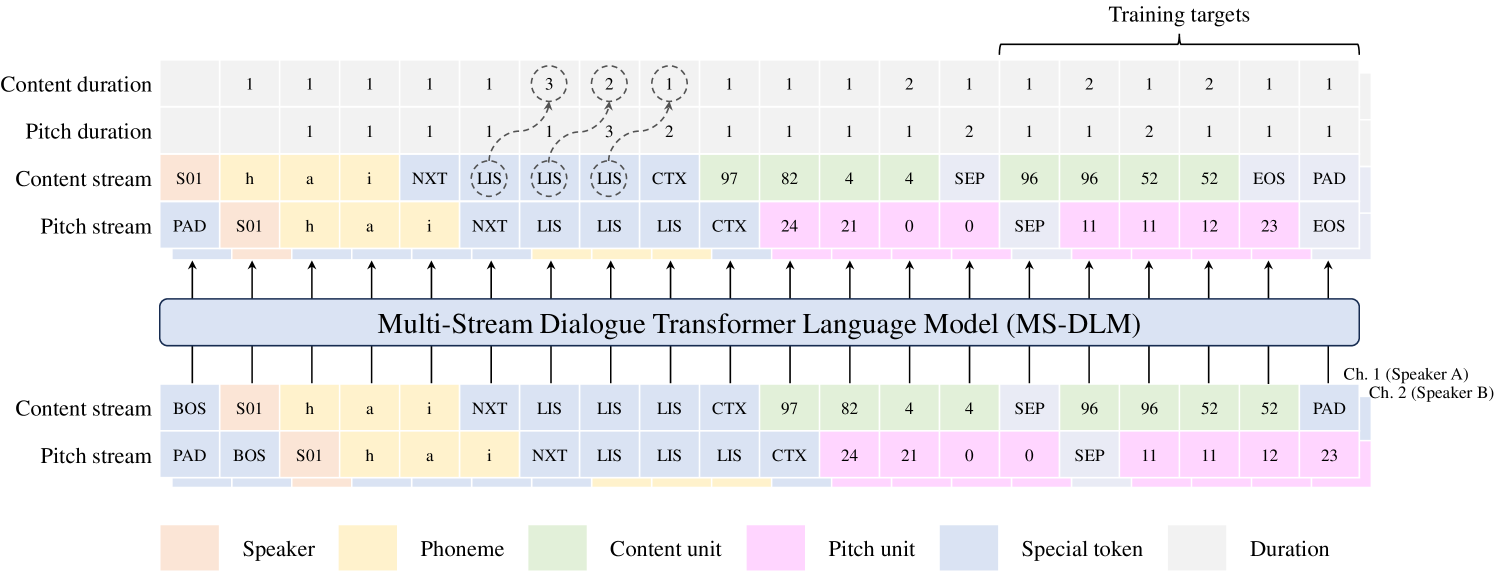
Prefix tokens: We design the input sequences of our uLM, shown in Figure 2, as follows:
| (1) |
where is the speaker ID of channel , is the number of phonemes in the th utterance, is the predetermined context length, and is the th phoneme of the th utterance if uttered by speaker , and otherwise substituted with listening (LIS) token. BOS, NXT, CTX, SEP tokens represent beginning of sentence, phonemes of the next utterance, context units, and separator, respectively. Building on the practices from Kharitonov et al. (2022), the uLM delays the pitch stream by one step considering their high correlation with content stream. Positions without tokens owing to this delay are filled with padding (PAD) tokens. Additionally, the target sequence obtained by shifting the input sequence by one step is appended with an end-of-sentence (EOS) token.
The conditioning of the uLM on the speaker ID compensates for the context length constraint, ensuring that the model retains each speaker’s unique characteristics. Further, phonemes of the th utterance are essential for handling overlaps, particularly if the th utterance disrupts the th one. With these prefix tokens, our uLM generates speaker’s unit sequences from phonemes conditionally, and listener’s unit sequences (may contain backchannels and laughter) unconditionally.
Training Objective: The model adopts both the edge unit prediction and delayed duration prediction techniques, proposed by Nguyen et al. (2023), for both content and pitch streams. The uLM predicts the unit and its duration only when . Our uLM is trained by minimizing the sum of edge unit prediction and edge duration prediction losses:
| (2) | ||||
| (3) | ||||
| (4) |
where is the total number of utterances in a dialogue, is the continuous duration prediction, and are prefix tokens and model parameters, respectively.
3.1.3 Unit-to-Speech (u2s) module
The u2s module is developed to solve an inverse problem of s2u module. It is trained to reconstruct the original waveform given content and pitch units extracted using the s2u module. As content and pitch units contain minimal speaker information, the u2s module also accepts a speaker embedding. Following Kharitonov et al. (2022), we adapt the discrete unit-based HiFi-GAN (Polyak et al., 2021).
3.2 Turn-taking mechanism (TTM)
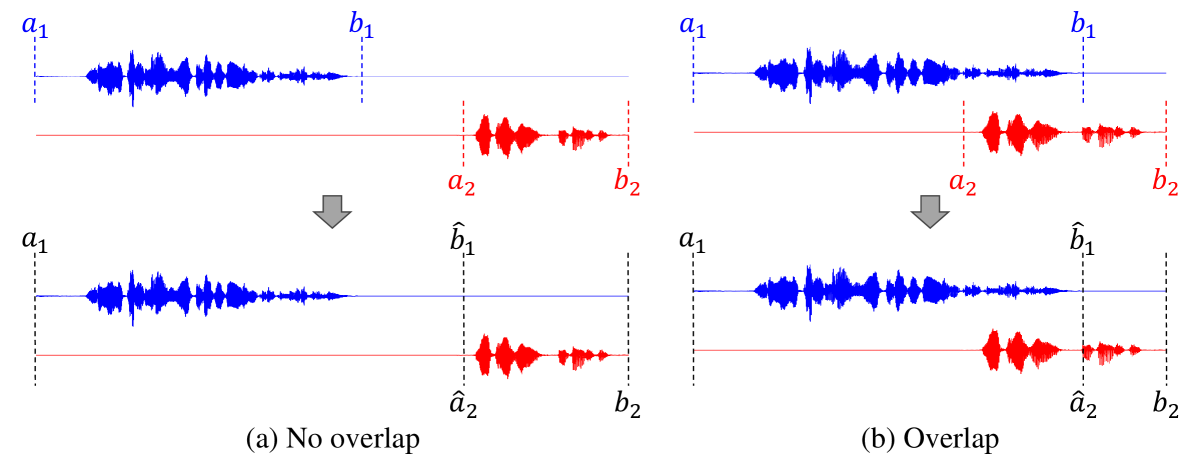
To simulate natural turn-taking, which includes overlapping speech, the uLM is trained using a simple and effective approach. Considering two successive utterances, turn-taking can be bifurcated into two scenarios: no overlap and overlap. These are shown in the top section of Figure 3. Let and be the start and end times of the th utterance, respectively. The conditions for no overlap and overlap can be described by and , respectively. These start and end times are modified as follows:
| (7) |
The modified time boundaries are shown in the bottom section of Figure 3. Following these alterations, our uLM is trained to predict the duration of trailing silence in the no overlap scenario, and pinpoint the onset of overlap in the overlap scenario. In the Overlap scenario, the uLM must generate the first seconds of the th utterance concurrently with the th utterance; thus we condition our uLM with the phonemes of the th utterance. Moreover, the uLM is tasked with the continuation of the th utterance in the overlap scenario, justifying our decision to condition the uLM using context units.
3.3 Data augmentation by context reduction
Although context units are included in the prefix tokens, they are not available during the initial steps of inference, which leads to suboptimal generation quality at the start of the dialogue. To address this, data augmentation is proposed, wherein the context is either removed or shortened. We augment the dataset by modifying the context length to for each training example. This augmentation is only performed for utterances that do not overlap with previous utterances, as the uLM must generate continuations of context units in the overlap scenario.
3.4 Inference procedure
Considering a written dialogue comprising utterances and speaker pair information , a corresponding spoken dialogue can be generated as follows. For each utterance indexed by , first, the prefix tokens are acquired. The phonemes of the th and th utterances are derived using a grapheme-to-phoneme tool, while the context units are sourced from the units generated in previous steps. If , the phonemes of the th utterance are excluded. Further, the context units may be absent or contain fewer than units for low . Then, the content and pitch units of the th utterance are generated autoregressively using the uLM. The process concludes when the EOS token is chosen as the content unit for any channel. Thereafter, the delayed pitch units are synchronized with the content units and concatenated to the units that were produced in the earlier steps. Subsequently, the two desired waveform channels are derived using the u2s module. Notably, since our system does not rely on input sentences that extend beyond two sentences ahead, it can facilitate continuous spoken dialogue generation when integrated with an LLM.
4 Experiments
4.1 Setup
Datasets: We used internal spoken dialogue dataset comprising 74 h of two-channel speech signals (equivalent to 147 h of single-channel speech signals). It includes 538 dialogues conducted by 32 pairs with 54 Japanese speakers (certain speakers appeared in multiple pairs) with their transcriptions. Additionally, we utilized the Corpus of Spontaneous Japanese (CSJ) (Maekawa, 2003) to pre-train our uLM. It contains single-channel speech signals with their phoneme-level transcriptions. All of these were utilized, excluding dialogue data, resulting in 523 h from 3,244 speakers. A detail of our internal dataset and complete procedure of preprocessing are described in appendix A.1.
Model, training, and inference: A simple 3-layer bidirectional LSTM was used for the IPU classifier described in section 2. For the s2u module, we utilized a pre-trained japanese-hubert-base111https://huggingface.co/rinna/japanese-hubert-base model for content unit extraction, and the WORLD vocoder (Morise et al., 2016) for pitch unit extraction. For the uLM model, a Transformer model comprising 6 layers, 4 of which were cross-attention layers, with 8 attention heads per layer and an embedding size of 512 was considered (Nguyen et al., 2023). This uLM was developed atop the DLM implementation found in the fairseq library222https://github.com/facebookresearch/fairseq (Ott et al., 2019). A single-channel variant of our uLM was pre-trained on the CSJ dataset. Subsequently, we finetuned a two-channel uLM on all of the s-IPUs from our spoken dialogue dataset. Model optimization was performed over 100k steps on two A100 80GB GPUs with a batch size of 30k tokens per GPU, requiring approximately 5 h for pre-training and 11 h for finetuning. During inference, nucleus sampling (Holtzman et al., 2020) with was adopted. The u2s module utilized the discrete unit-based HiFi-GAN (Kong et al., 2020; Polyak et al., 2021) with minor adjustments. This model was optimized over 500k steps on a single A100 80GB GPU with a batch size of 16 0.5-second speech segments, requiring approximately 32 h. Further details are provided in appendix A.2.
4.2 Utterance-level evaluation
| METHOD | PER |
|---|---|
| Ground Truth | 8.95 |
| Resynthesized | 11.49 |
| Baseline | 12.13 |
| w/o pretraining | 14.10 |
| Proposed | 13.03 |
| w/o pretraining | 15.32 |
| w/o augmentation | 59.35 |
| w/o context units | 14.12 |
| w/o next sentence | 12.79 |
First, we focused on the utterance-level generation quality of the proposed system. The fidelity of the generated speech to the input text was investigated by evaluating our system in the TTS setting. We generated speech waveform corresponding to all 4,896 utterances in the test set separately and measured their phoneme error rate (PER). To perform phoneme recognition, we finetuned japanese-hubert-base model with the CSJ dataset. We compared the performance of the proposed system (Proposed) with other systems, including 1) Ground Truth, the ground-truth recordings, 2) Resynthesized, where we combined s2u and u2s modules to resynthesize the original waveform, and 3) Baseline, a single-channel counterpart of Proposed trained without phonemes of next sentence and the turn-taking mechanism. Additionally, we ablated several components including pre-training on CSJ dataset (w/o pre-training), data augmentation by context reduction (w/o augmentation), context units (w/o context), and phonemes of next sentence (w/o next sentence). PERs for Ground Truth and Resynthesized include both grapheme-to-phoneme error and phoneme recognition error, while Baseline and Proposed include only the latter.
The results are summarized in Table 1. Although the PER for the Proposed system was slightly worse than for Baseline, the degradation was minute considering that it performed other tasks in addition to basic TTS, including generating the listener’s speech and predicting turn-taking. Pre-training and use of the context units were effective, and data augmentation was crucial because no context was given in the TTS setting. The Proposed w/o next sentence marginally outperformed Proposed in TTS setting; however, it often generated unnatural or meaningless content as overlapping segment. We investigated the effect of introducing pitch units in appendix B.
4.3 Dialogue-level evaluation
Next, we evaluated the spoken dialogue generation quality of the proposed system. We quantified how close the generated spoken dialogues were to the recorded ones from two aspects: listener’s and turn-taking events. For comparison, we prepared two additional systems including 1) dGSLM (Nguyen et al., 2023), a system that shares the architecture with Proposed, but unconditionally generates two channels of speech waveform and uses only the content units, and 2) Baseline, the same system described in section 4.2 but operated alternatively to generate spoken dialogue. As Baseline cannot generate the listener’s tokens, we filled them with the most frequently used content and pitch units corresponding to unvoiced frames. Furthermore, Proposed w/o TTM was evaluated to investigate the effectiveness of our turn-taking mechanism.
We created written dialogues that excluded listener’s events for the test set as detailed in section 2. Next, we generated the entire spoken dialogues from those written dialogues. For dGSLM, we utilized 30 s of speech prompts from the test set to generate the subsequent 90 s (Nguyen et al., 2023). As the resulting dialogues for dGSLM were three times longer than the original test set, we divided the results (e.g., backchannel frequency and duration) by three.
4.3.1 Listener’s event evaluation
| METHOD | [s] | [s] | ||||
|---|---|---|---|---|---|---|
| Ground Truth | 1854 | 9453 | 19.61 | 1518 | 16588 | 9.15 |
| dGSLM | 1710 | 6141 | 27.84 | 1678 | 12378 | 13.56 |
| Baseline | 76 | 3656 | 2.08 | 151 | 11713 | 1.29 |
| Proposed | 1535 | 6668 | 23.02 | 1322 | 14001 | 9.44 |
| w/o TTM | 1756 | 5273 | 33.30 | 1480 | 14052 | 10.53 |
| METHOD | MAE | |
|---|---|---|
| Ground Truth | 0.00 | 1.00‡ |
| dGSLM | 0.09 | 0.63‡ |
| Baseline | 0.18 | 0.40‡ |
| Proposed | 0.07 | 0.54‡ |
| w/o TTM | 0.14 | 0.54‡ |
We applied the Silero Voice Activity Detector (VAD)333https://github.com/snakers4/silero-vad to the generated spoken dialogues and performed hybrid IPU classification for each IPU as in section 2. We then counted the number of backchannels and all utterances along with their durations and . The results are summarized in Table 2. Although the backchannel frequency and duration for Proposed were lower than for Ground Truth, the proportion of backchannels in all utterances was closest to the Ground Truth in terms of both frequency and duration. dGSLM tended to produce too many backchannels, whereas Baseline produced too few. Further, Proposed w/o TTM produced excessive backchannels. We conjecture that the uLM generates overlapped segments twice without the TTM (as the last part of the th utterance and the first part of the th utterance), resulting in unwanted backchannels. Laughter frequency and duration were evaluated similarly in appendix C.
While the overall frequency of backchannels is summarized in Table 2, it actually varies from speaker to speaker. To further probe the speaker characteristics, we computed the proportion of backchannels for each speaker. The mean absolute error (MAE) and Pearson correlation coefficient between the Ground Truth and generated dialogues were calculated. The results are listed in Table 3. Proposed achieved the lowest MAE and exhibited a positive correlation with Ground Truth. These results demonstrate that the proposed system can produce backchannels in appropriate frequency, and the speaker characteristics are preserved in the generated spoken dialogues.
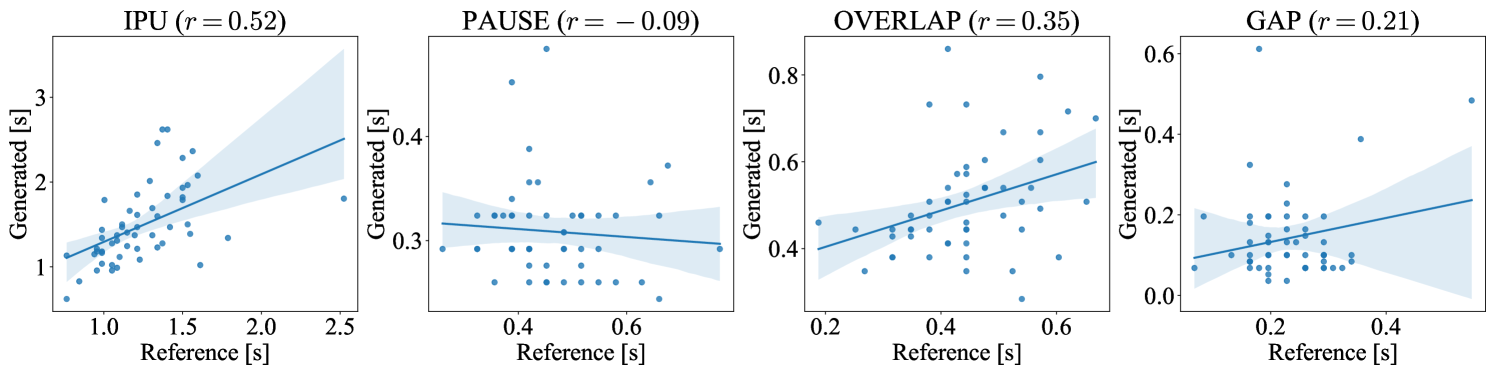
4.3.2 Turn-taking event evaluation
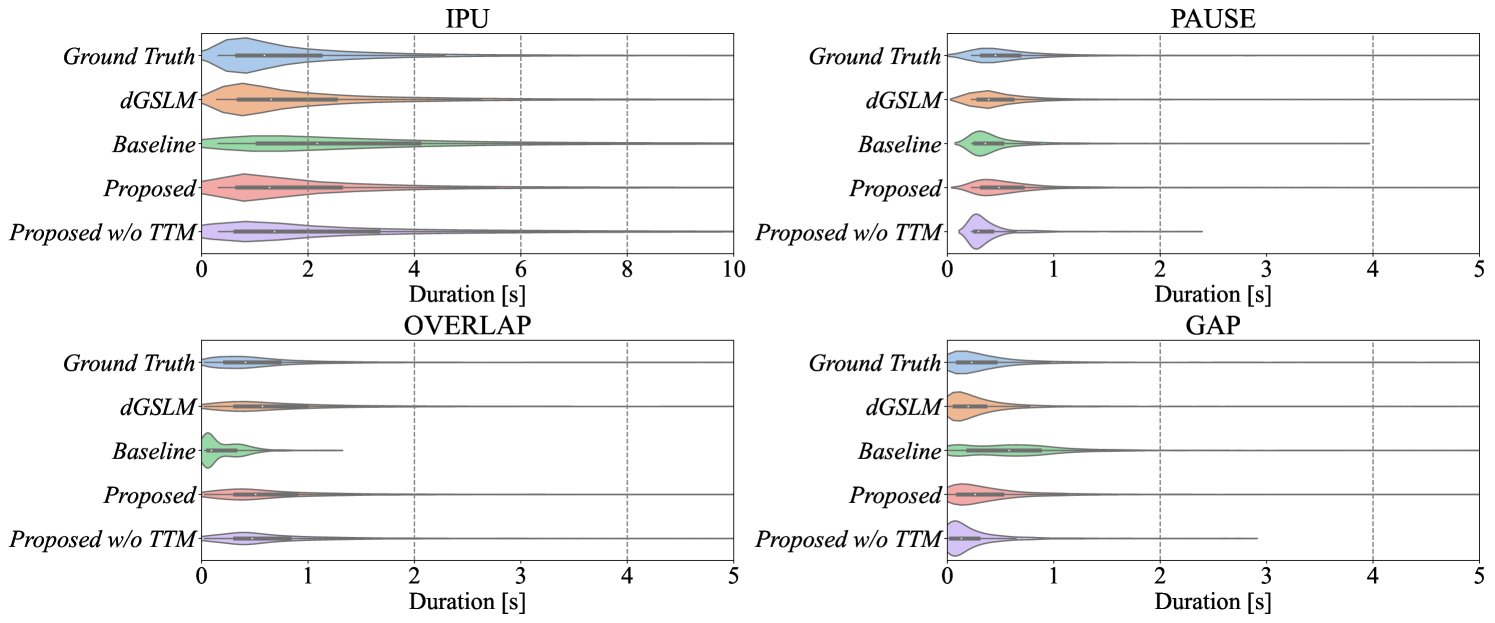
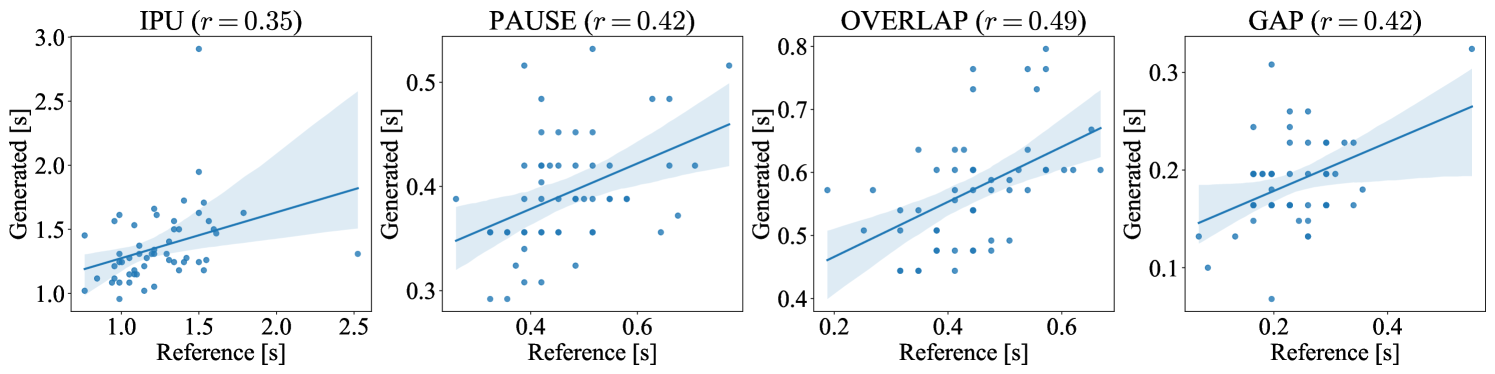
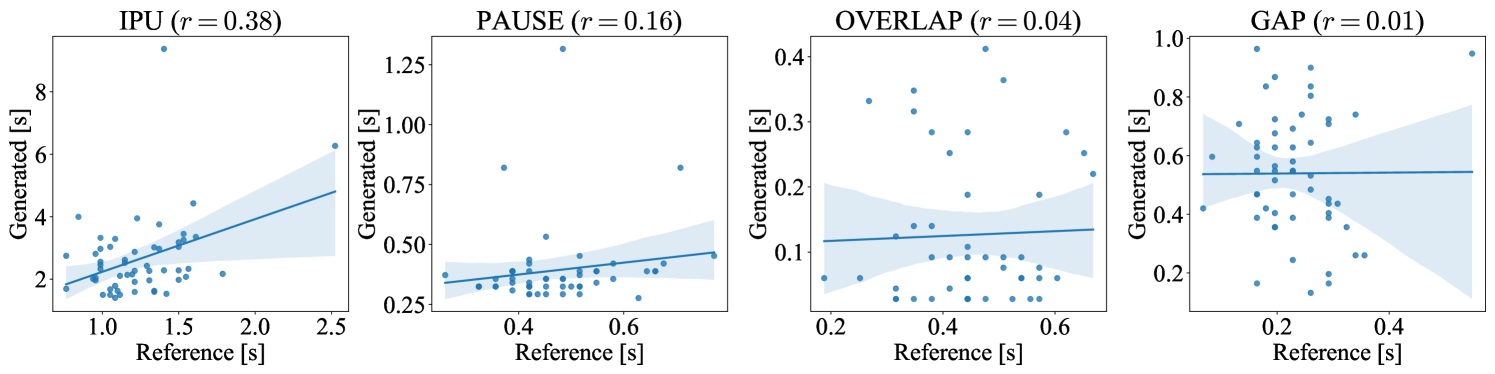
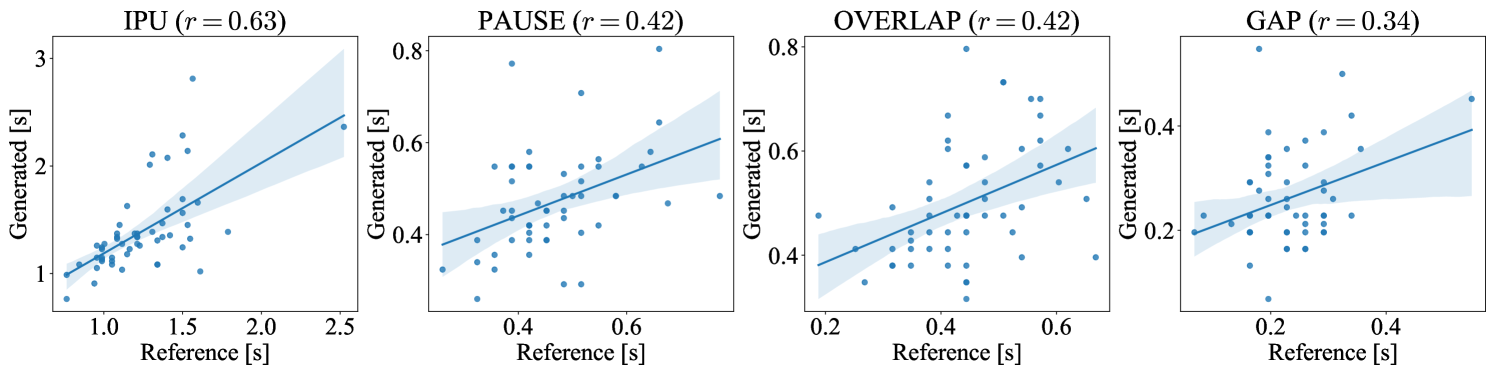
Following Nguyen et al. (2023), we examined the distribution of four turn-taking events: 1) IPU, a speech segment in one speaker’s channel delimited by a VAD silence of ms on both sides, 2) overlap, a section with voice signals on both channels, 3) pause, a silence segment between two IPUs of the same speaker, and 4) gap, a silence segment between two IPUs by distinct speakers. The results are summarized in Figure 4. Both dGSLM and Proposed exhibited similar distribution to the Ground Truth, confirming that the proposed system could mimic human-like turn-taking. The distribution of Baseline, particularly for overlaps, deviated significantly from that of the Ground Truth because theoretically it cannot generate any overlaps. The durations of pauses and gaps were underestimated for Proposed w/o TTM, which is congruent with the idea that the TTM is helpful for estimating appropriate silence durations following each utterance.
| METHOD | IPU | PAUSE | OVERLAP | GAP | ||||
|---|---|---|---|---|---|---|---|---|
| MAE | MAE | MAE | MAE | |||||
| Ground Truth | 0.00 | 1.00‡ | 0.00 | 1.00‡ | 0.00 | 1.00‡ | 0.00 | 1.00‡ |
| dGSLM | 0.25 | 0.35† | 0.09 | 0.42‡ | 0.13 | 0.50‡ | 0.06 | 0.42‡ |
| Baseline | 1.40 | 0.38‡ | 0.14 | 0.16 | 0.32 | 0.04 | 0.33 | 0.01 |
| Proposed | 0.24 | 0.63‡ | 0.08 | 0.42‡ | 0.10 | 0.42‡ | 0.08 | 0.34† |
| w/o TTM | 0.34 | 0.52‡ | 0.16 | 0.09 | 0.11 | 0.35‡ | 0.12 | 0.21 |
We analyzed the speaker characteristics following the procedure detailed in section 4.3.1. For each speaker, we calculated the median durations of the four turn-taking events. Subsequently, we determined the MAE and Pearson’s values between Ground Truth and each system. The results are listed in Table 4. The performance of Proposed was consistently superior to Baseline and Proposed w/o TTM, and it achieved comparable results to dGSLM. Moreover, dGSLM leveraged 30 s of recorded speech, whereas Proposed did not. Therefore, we conclude that the proposed system effectively utilized the speaker information in the prompt tokens, facilitating the reproduction of the general aspects of turn-taking and the specific characteristics of each individual speaker.
4.4 Human evaluation
Finally, we measured the subjective quality of the generated spoken dialogue. For each speaker pair, we randomly extracted two 10-turn dialogues, each lasting 15–45 seconds, from the test set, leading to a total of 64 dialogues. We generated the corresponding spoken dialogue segments using the Baseline and Proposed systems. For dGSLM, we used 30 s of the recorded speech segments preceding these dialogues as prompts and generated 30 s continuations for each one. Each dialogue segment was assessed based on three distinct criteria: 1) Dialogue Naturalness, evaluating the fluidity of the dialogue and the naturalness of the interaction, 2) Meaningfulness, determining the comprehensibility of what is spoken, and 3) Sound Quality, checking for noise or distortion in the speech signal. Each item was rated on a 5-point scale from 1–5 (bad to excellent). Twenty-four workers participated in the evaluation and each rated 25 samples.
| METHOD | Dialogue Naturalness | Meaningfulness | Sound Quality |
|---|---|---|---|
| Ground Truth | 4.85±0.08 | 4.81±0.09 | 4.75±0.09 |
| Resynthesized | 4.48±0.12 | 4.55±0.12 | 3.82±0.18 |
| dGSLM | 2.68±0.24 | 1.18±0.07 | 2.93±0.20 |
| Baseline | 3.01±0.20 | 3.43±0.18 | 3.22±0.18 |
| Proposed | 3.30±0.18 | 3.58±0.17 | 3.38±0.18 |
The results are presented in Table 5. The Proposed system outscored both the dGSLM and Baseline systems across all metrics. Particularly, it recorded a significantly higher score in Dialogue Naturalness compared to the Baseline system ( in the Student’s t-test). Thus, features such as backchannels, laughter, and seamless turn-taking, rendered possible by the proposed system, are vital for generating natural spoken dialogues. Interestingly, dGSLM had low scores in both Meaningfulness and Dialogue Naturalness. This finding is at odds with the results from a previous study (Nguyen et al., 2023). We hypothesize that this decline in performance was owing to the smaller dataset used (2,000 h in the previous study vs. 74 h in this study). However, considering that Meaningfulness of dGSLM was low in the previous study as well, our system’s text conditioning capability proves to be highly effective for generating meaningful spoken dialogue.
While our findings indicate advancements in spoken dialogue generation, certain areas require further refinement to match human-level performance. Notably, the Sound Quality of the Resynthesized is behind that of the Ground Truth, suggesting the necessity for improved s2u and u2s modules with enhanced speech coding. Moreover, the Proposed system trails in Dialogue Naturalness when compared to both the Ground Truth and Resynthesized. Thus, our future efforts will focus on accumulating a more extensive dialogue dataset and refining our method accordingly.
5 Conclusion
This study proposed CHATS, a system that generates spoken dialogues from written ones. We proposed conditioning uLM with speaker, text, and past speech to achieve coherent spoken dialogue. Additionally, we proposed a mechanism for handling the timing for turn-taking or speech continuation explicitly. We performed a detailed analysis on the generated spoken dialogue, which showed that the proposed system reproduced the ground-truth distribution of backchannel frequency and turn-taking event durations well. Further, the results of our human evaluations demonstrated that the proposed system produced more natural dialogue than the baseline system, which used a TTS model to generate spoken dialogue. We verified that the innovative capability of the proposed system to generate backchannels and laughter without transcriptions was effective in mimicking human dialogue and creating natural spoken dialogue. However, there is still ample room for improvement. To further bridge the divide between human and generated dialogues, we plan to expand our study to a larger dataset for better naturalness and sound quality. Additionally, we will explore the advantages of conditioning our model on raw text to better understand the context of written dialogues. Furthermore, evaluating our system from the aspect of speaking style consistency and expressiveness is a valuable research direction.
References
- Adelswärd (1989) Viveka Adelswärd. Laughter and dialogue: The social significance of laughter in institutional discourse. Nordic Journal of Linguistics, 12(2):107–136, Dec. 1989.
- Adiba et al. (2021) Amalia Istiqlali Adiba, Takeshi Homma, and Toshinori Miyoshi. Towards immediate backchannel generation using attention-based early prediction model. In Proc. ICASSP, pp. 7408–7412, online, Jun. 2021.
- Arthur & Vassilvitskii (2007) David Arthur and Sergei Vassilvitskii. K-means++ the advantages of careful seeding. In Proc. eighteenth annual ACM-SIAM symposium on Discrete algorithms, pp. 1027–1035, New Orleans, Louisiana, U.S.A., Jan. 2007.
- Bayramoğlu et al. (2021) Öykü Zeynep Bayramoğlu, Engin Erzin, Tevfik Metin Sezgin, and Yücel Yemez. Engagement rewarded actor-critic with conservative Q-learning for speech-driven laughter backchannel generation. In Proc. ICMI, pp. 613–618, Montreal, Canada, Oct. 2021.
- Borsos et al. (2023) Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour, and Marco Tagliasacchi. SoundStorm: Efficient parallel audio generation. arXiv preprint arXiv:2305.09636, May 2023.
- Cong et al. (2021) Jian Cong, Shan Yang, Na Hu, Guangzhi Li, Lei Xie, and Dan Su. Controllable context-aware conversational speech synthesis. In Proc. INTERSPEECH, pp. 4658–4662, online, Sep. 2021.
- Gillick et al. (2021) Jon Gillick, Wesley Deng, Kimiko Ryokai, and David Bamman. Robust laughter detection in noisy environments. In Proc. INTERSPEECH, pp. 2481–2485, online, Sep. 2021.
- Guo et al. (2021) Haohan Guo, Shaofei Zhang, Frank K Soong, Lei He, and Lei Xie. Conversational end-to-end TTS for voice agents. In Proc. SLT, pp. 403–409, online, Jan. 2021.
- Hara et al. (2018) Kohei Hara, Koji Inoue, Katsuya Takanashi, and Tatsuya Kawahara. Prediction of turn-taking using multitask learning with prediction of backchannels and fillers. In Proc. INTERSPEECH, pp. 991–995, Hyderabad, India, Sep. 2018.
- Holtzman et al. (2020) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In Proc. ICLR, online, Apr. 2020.
- Hsu et al. (2021) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, Oct. 2021.
- Huang et al. (2023) Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, and Shinji Watanabe. AudioGPT: Understanding and generating speech, music, sound, and talking head. arXiv preprint arXiv:2304.12995, Apr. 2023.
- Kawahara et al. (2016) Tatsuya Kawahara, Takashi Yamaguchi, Koji Inoue, Katsuya Takanashi, and Nigel G Ward. Prediction and generation of backchannel form for attentive listening systems. In Proc. INTERSPEECH, pp. 2890–2894, San Francisco, U.S.A., Sep. 2016.
- Kharitonov et al. (2022) Eugene Kharitonov, Ann Lee, Adam Polyak, Yossi Adi, Jade Copet, Kushal Lakhotia, Tu Anh Nguyen, Morgane Riviere, Abdelrahman Mohamed, Emmanuel Dupoux, and Wei-Ning Hsu. Text-free prosody-aware generative spoken language modeling. In Proc. ACL, pp. 8666–8681, Dublin, Ireland, May 2022.
- Kim et al. (2021) Jaehyeon Kim, Jungil Kong, and Juhee Son. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In Proc. ICML, pp. 5530–5540, online, Jul. 2021.
- Kingma & Ba (2015) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proc. ICLR, San Diego, U.S.A, May 2015.
- Kong et al. (2020) Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. In Proc. NeurIPS, volume 33, pp. 17022–17033, online, Dec. 2020.
- Lakhotia et al. (2021) Kushal Lakhotia, Eugene Kharitonov, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Benjamin Bolte, Tu-Anh Nguyen, Jade Copet, Alexei Baevski, Abdelrahman Mohamed, and Emmanuel Dupoux. On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9:1336–1354, 2021.
- Lala et al. (2017) Divesh Lala, Pierrick Milhorat, Koji Inoue, Masanari Ishida, Katsuya Takanashi, and Tatsuya Kawahara. Attentive listening system with backchanneling, response generation and flexible turn-taking. In Proc. SIGdial, pp. 127–136, Saarbrücken, Germany, Aug. 2017.
- Lala et al. (2022) Divesh Lala, Koji Inoue, Tatsuya Kawahara, and Kei Sawada. Backchannel generation model for a third party listener agent. In Proc. HAI, pp. 114–122, Christchurch, New Zealand, Dec. 2022.
- Li et al. (2022) Jingbei Li, Yi Meng, Chenyi Li, Zhiyong Wu, Helen Meng, Chao Weng, and Dan Su. Enhancing speaking styles in conversational text-to-speech synthesis with graph-based multi-modal context modeling. In Proc. ICASSP, pp. 7917–7921, Singapore, May 2022.
- MacQueen (1967) James MacQueen. Some methods for classification and analysis of multivariate observations. In Proc. fifth Berkeley symposium on mathematical statistics and probability, volume 1, pp. 281–297, Oakland, California, U.S.A., Jan. 1967.
- Maekawa (2003) Kikuo Maekawa. Corpus of spontaneous Japanese: Its design and evaluation. In Proc. ISCA & IEEE Workshop on Spontaneous Speech Processing and Recognition, Tokyo, Japan, Apr. 2003.
- Mitsui et al. (2022) Kentaro Mitsui, Tianyu Zhao, Kei Sawada, Yukiya Hono, Yoshihiko Nankaku, and Keiichi Tokuda. End-to-end text-to-speech based on latent representation of speaking styles using spontaneous dialogue. In Proc. INTERSPEECH, pp. 2328–2332, Incheon, Korea, Sep. 2022.
- Mori & Kimura (2023) Hiroki Mori and Shunya Kimura. A generative framework for conversational laughter: Its ‘language model’ and laughter sound synthesis. In Proc. INTERSPEECH, pp. 3372–3376, Dublin, Ireland, Aug. 2023.
- Mori et al. (2019) Hiroki Mori, Tomohiro Nagata, and Yoshiko Arimoto. Conversational and social laughter synthesis with WaveNet. In Proc. INTERSPEECH, pp. 520–523, Graz, Austlia, Sep. 2019.
- Morise et al. (2016) Masanori Morise, Fumiya Yokomori, and Kenji Ozawa. WORLD: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Transactions on Information and Systems, 99(7):1877–1884, Jul. 2016.
- Nguyen et al. (2023) Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello, Robin Algayres, Benoit Sagot, Abdelrahman Mohamed, and Emmanuel Dupoux. Generative spoken dialogue language modeling. Transactions of the Association for Computational Linguistics, 11:250–266, 2023.
- Ott et al. (2019) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. fairseq: A fast, extensible toolkit for sequence modeling. In Proc. NAACL (Demonstrations), pp. 48–53, Minneapolis, Minnesota, U.S.A., Jun. 2019.
- Park et al. (2023) Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, Apr. 2023.
- Polyak et al. (2021) Adam Polyak, Yossi Adi, Jade Copet, Eugene Kharitonov, Kushal Lakhotia, Wei-Ning Hsu, Abdelrahman Mohamed, and Emmanuel Dupoux. Speech resynthesis from discrete disentangled self-supervised representations. In Proc. INTERSPEECH, pp. 3615–3619, online, Sep. 2021.
- Radford et al. (2023) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Proc. ICML, pp. 28492–28518, Honolulu, Hawaii, U.S.A., Jul. 2023.
- Rubenstein et al. (2023) Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, Dirk Padfield, James Qin, Danny Rozenberg, Tara Sainath, Johan Schalkwyk, Matt Sharifi, Michelle Tadmor Ramanovich, Marco Tagliasacchi, Alexandru Tudor, Mihajlo Velimirović, Damien Vincent, Jiahui Yu, Yongqiang Wang, Vicky Zayats, Neil Zeghidour, Yu Zhang, Zhishuai Zhang, Lukas Zilka, and Christian Frank. AudioPaLM: A large language model that can speak and listen. arXiv preprint arXiv:2306.12925, Jun. 2023.
- Sakuma et al. (2023) Jin Sakuma, Shinya Fujie, and Tetsunori Kobayashi. Response timing estimation for spoken dialog systems based on syntactic completeness prediction. In Proc. SLT, pp. 369–374, Doha, Qatar, Jan. 2023.
- Stivers et al. (2009) Tanya Stivers, Nicholas J. Enfield, Penelope Brown, Christina Englert, Makoto Hayashi, Trine Heinemann, Gertie Hoymann, Federico Rossano, Jan Peter De Ruiter, Kyung-Eun Yoon, and Stephen C. Levinson. Universals and cultural variation in turn-taking in conversation. Proceedings of the National Academy of Sciences, 106(26):10587–10592, Jun. 2009.
- Tan et al. (2022) Xu Tan, Jiawei Chen, Haohe Liu, Jian Cong, Chen Zhang, Yanqing Liu, Xi Wang, Yichong Leng, Yuanhao Yi, Lei He, Frank Soong, Tao Qin, Sheng Zhao, and Tie-Yan Liu. NaturalSpeech: End-to-end text to speech synthesis with human-level quality. arXiv preprint arXiv:2205.04421, May 2022.
- Tits et al. (2020) Noé Tits, Kevin El Haddad, and Thierry Dutoit. Laughter synthesis: Combining seq2seq modeling with transfer learning. In Proc. INTERSPEECH, pp. 3401–3405, online, Oct. 2020.
- Wang et al. (2023) Tianrui Wang, Long Zhou, Ziqiang Zhang, Yu Wu, Shujie Liu, Yashesh Gaur, Zhuo Chen, Jinyu Li, and Furu Wei. VioLA: Unified codec language models for speech recognition, synthesis, and translation. arXiv preprint arXiv:2305.16107, May 2023.
- Xin et al. (2023) Detai Xin, Shinnosuke Takamichi, Ai Morimatsu, and Hiroshi Saruwatari. Laughter synthesis using pseudo phonetic tokens with a large-scale in-the-wild laughter corpus. In Proc. INTERSPEECH, pp. 17–21, Dublin, Ireland, Aug. 2023.
- Xue et al. (2023) Jinlong Xue, Yayue Deng, Fengping Wang, Ya Li, Yingming Gao, Jianhua Tao, Jianqing Sun, and Jiaen Liang. M2-CTTS: End-to-end multi-scale multi-modal conversational text-to-speech synthesis. In Proc. ICASSP, pp. 1–5, Rhodes Island, Greece, Jun. 2023.
- Yngve (1970) Victor H Yngve. On getting a word in edgewise. In Chicago Linguistics Society, 6th Meeting, pp. 567–578, Chicago, U.S.A., 1970.
- Zhang et al. (2023) Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv preprint arXiv:2305.11000, May 2023.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models. arXiv preprint arXiv:2303.18223, Sep. 2023.
Appendix A Experimental setup details
A.1 Dataset and preprocessing
We collected audio recordings of 74 h comprising 538 dialogues conducted by 32 pairs with 54 Japanese speakers (certain speakers appeared in multiple pairs). These dialogues were divided into 474/32/32 for train/valid/test sets, respectively (valid and test sets included all speaker pairs). For the recording sessions, two speakers entered separate soundproof rooms, where they could see and hear each other through glass and via headphones, respectively. Conversations occurred freely and captured in two-channel 96 kHz/24 bit audio.
The recorded 538 dialogues yielded audio files, which were downsampled to 16 and 24 kHz for the s2u and u2s modules, respectively. To eliminate volume discrepancies between different channels and speaker pairs, we calculated the average dBFS of each audio file, and used these averages to normalize the volume levels. Subsequently, the Silero VAD444https://github.com/snakers4/silero-vad was employed for voice activity detection. Further, we utilized the large model of whisper555https://github.com/openai/whisper(Radford et al., 2023) for automatic speech recognition on the detected speech segments. Manual corrections for start times, end times, and transcriptions were made for 645 of 1,076 files. Transcripts were automatically converted into phonemes using Open JTalk666https://open-jtalk.sourceforge.net/.
A.2 Model, Training, and Inference
IPU Classifier:
For the IPU classification task, we employed a 3-layer bidirectional LSTM with the input embedding and hidden dimensions of 256 and 512, respectively. Training was conducted on a single A100 80GB GPU with a batch size of 8,192 tokens, using the Adam optimizer (Kingma & Ba, 2015) with an initial learning rate of and betas of and . Our training set comprised 49,339 s-IPUs and 27,794 l-IPUs, and the model was trained over 20k steps. The checkpoint with the lowest validation loss was selected for final use. When tested on an evaluation set containing 2,604 s-IPUs and 1,930 l-IPUs, our classifier achieved an accuracy of 87.83%.
s2u module:
For the s2u module, we used japanese-hubert-base777https://huggingface.co/rinna/japanese-hubert-base model, a pre-trained HuBERT base model trained on 19k h of Japanese speech, as a frontend for the content unit extractor. It encodes 16 kHz speech into 768-dimensional continuous vectors at 50 Hz. The k-means++ (Arthur & Vassilvitskii, 2007) clustering model was trained on our spoken dialogue dataset described in appendix A.1. In line with Nguyen et al. (2023), the number of clusters was set to 500. The number of bins for pitch unit extraction was 32, one of which was designated for unvoiced frames. The WORLD vocoder (Morise et al., 2016) was used to extract pitch every 20 ms, yielding pitch units at 50 Hz.
uLM:
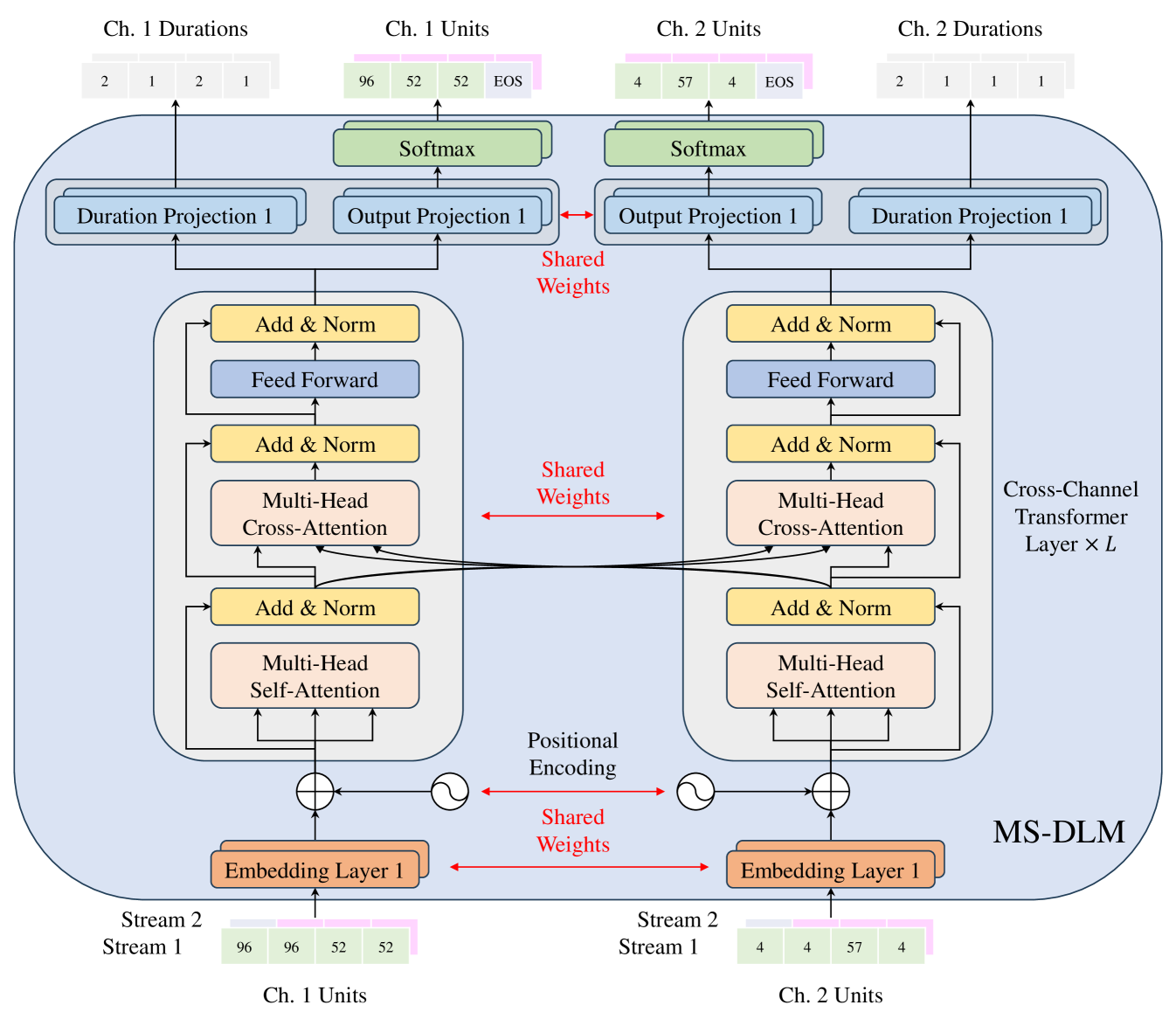
For the uLM model, we used MS-DLM depicted in Figure A.1. We adopted the same hyperparameters as described by Nguyen et al. (2023), utilizing a Transformer model comprising 6 layers, 4 of which were cross-attention layers, with 8 attention heads per layer and an embedding size of 512. The context length was 500, corresponding to a 10-s waveform. The uLM’s vocabulary included 500 content units (with 32 shared with pitch units), 39 phonemes, 9 special tokens, and a combined total of 3,298 speaker IDs (comprising entries). Special tokens included BOS, EOS, PAD, NXT, CTX, SEP, LIS, as described in section 3.1.2, UNK for unknown input, and LAU for explicitly including laughter in the phoneme sequences. However, outputs are limited to the content/pitch units, PAD, and EOS tokens by setting the output probabilities for other tokens to zero.
A single-channel variant of our uLM was pre-trained on the CSJ dataset, where we simplified the prefix tokens by omitting the phonemes of the next utterance and context units. The refined prefix tokens took the following form:
| (8) |
Consequently, this phase of pre-training can be regarded as a conventional text-to-speech training. This pre-training employed two A100 80GB GPUs, each managing a batch size of 30,000 tokens. Optimization was performed over 100k steps using an Adam optimizer (Kingma & Ba, 2015) with an inverse square root learning rate schedule, whose initial learning rate was set to , warmup steps to 10k steps, and maximum learning rate to . This required approximately 5 h.
Subsequently, we finetuned a two-channel uLM on all of the s-IPUs present in our spoken dialogue dataset, which contained 82,060 utterances. As our uLM shares the weight across two Transformer towers, two-channel uLM were warm-started with the pre-trained single-channel uLM weights. Finetuning was conducted in the same configuration as pre-training; however, the maximum learning rate was , requiring approximately 11 h.
For decoding, we adopted nucleus sampling (Holtzman et al., 2020) with . Through empirical observation, we discerned that the top-20 sampling, as utilized for dGSLM (Nguyen et al., 2023), produced speech signals misaligned with the input phonemes. This misalignment likely stems from units with marginally lower probabilities, such as the top-19 or top-20 units, correlating with pronunciations incongruent with the desired phoneme.
u2s module:
Our u2s module received a global speaker ID with 50 Hz content and pitch units. These discrete values were embedded into 128-dimensional continuous vectors, which were then summed to produce 50 Hz input features. These features were subsequently upsampled by factors of to obtain a 24 kHz waveform. Following Kong et al. (2020), we trained our u2s module with the Adam optimizer, setting an initial learning rate to and betas at and . The model was optimized over 500k steps on a single A100 80GB GPU with a batch size of 16 0.5-second speech segments, requiring approximately 32 h. Our training set consisted all of the VAD speech segments from our spoken dialogue dataset, totalling 130,050 utterances. During inference, we decoded the waveform for each channel and utterance individually, as excessive GPU memory would be required to process the entire 5–10 minute dialogue at once.
Appendix B Effects of introducing pitch units
To explore the effect of the pitch units, we calculated PER for systems without pitch units in the same manner as described in section 4.2. Additionally, we extracted values from the generated speech using the WORLD vocoder, calculated the mean and variance of the voiced frames, and averaged them across all utterances. The results are summarized in Table B.1. Interestingly, the removal of pitch units worsened the PER for Resynthesized, whereas it improved the PER for Baseline and Proposed systems. Thus, the requirement to predict the pitch units rendered it difficult to predict the accurate pronunciation, which is mostly determined by the content units. However, the statistics of systems with pitch units were consistently closer to those of Ground Truth than their pitch-ablated counterparts, indicating that the pitch units were effective for generating expressive speech uttered in spoken dialogues.
| METHOD | PER | mean [Hz] | var [Hz2] |
|---|---|---|---|
| Ground Truth | 8.95 | 191.6 | 2831.6 |
| Resynthesized | 11.49 | 189.2 | 2509.8 |
| w/o pitch units | 12.20 | 177.0 | 2202.8 |
| Baseline | 12.13 | 181.8 | 2271.1 |
| w/o pitch units | 11.61 | 173.7 | 1802.5 |
| Proposed | 13.03 | 186.2 | 2639.4 |
| w/o pitch units | 11.17 | 178.1 | 2234.4 |
Appendix C Laughter evaluation
We applied an open-source laughter detection model888https://github.com/jrgillick/laughter-detection (Gillick et al., 2021) to the generated spoken dialogues. We then counted the instances of laughter and calculated their total duration. The results are summarized in Table C.1. The frequency and duration of laughter generated by the proposed system were closer to those of the Ground Truth compared to those of the Baseline and dGSLM regardless of the existence of a turn-taking mechanism. Note that the Baseline, which cannot generate laughter on the listener side, generated a certain amount of laughter because the input written dialogue often contained laughter. dGSLM could not utilize such written information, which led to an underestimation of laughter frequency.
| METHOD | Frequency | Duration |
|---|---|---|
| Ground Truth | 1268 | 2975 |
| dGSLM | 998 | 2443 |
| Baseline | 1011 | 2373 |
| Proposed | 1275 | 2810 |
| w/o TTM | 1280 | 3010 |
Appendix D Speaker-specific characteristics of turn-taking events
Appendix E Generation case studies
We present examples of written dialogues (Table E.1, Table E.2) and the generated spoken dialogues using the proposed system (Figure E.1, Figure E.2). These examples correspond to the test-set sample 1 and 2 of our demo page999https://rinnakk.github.io/research/publications/CHATS/. Although the original dialogues are in Japanese, we provide their English translation for better readability. As we expected, the entire spoken dialogue closely follows the input written dialogue, with appropriate generation of backchannels and laughter on the listener side. Additionally, some utterances slightly overlap with previous ones, facilitating natural turn-taking. Furthermore, our system can generate laughter on the speaker side by explicitly including a laughter tag (LAU) in the written dialogue, as demonstrated in the sixth segment of Figure E.2. However, upon closer examination of the fourth utterance of Figure E.2, it is observed that the laughter from speaker B is not generated, and instead, the generation of speaker A’s utterance begins. This indicates areas for improvement such as ensuring accurate synthesis of the input text content and addressing the issue of too rapid onset of utterance overlap.
| Script (automatically translated from Japanese) | |
|---|---|
| 1 | A: I do watch it. |
| 2 | B: Oh, that’s cool, it’s live-action, huh, with effects. |
| 3 | B: So that means, um, editing it, the actual |
| 4 | B: movements are done by humans, |
| 5 | B: kind of giving it a try. |
| 6 | A: I just, like, tried adding light, like, at the moment the racket hits the ball, |
| 7 | A: like, when the ball, um, lands on the court, there’s an effect where the landing spot crumbles, like a hole opens up in the court. |
| 8 | B: Woah |
| 9 | B: You go that far. |
| 10 | A: Yes, that’s right. |
| Script (automatically translated from Japanese) | |
|---|---|
| 1 | B: It’s pretty rare, isn’t it? |
| 2 | A: Hmm, you’d go there yourself, right, especially for fast food. |
| 3 | A: At least, right. |
| 4 | B: (LAU) |
| 5 | A: It’s cheaper, and I feel more at ease at conveyor belt sushi places. |
| 6 | A: Right? You can eat a lot (LAU), exactly, in the end, that’s what it comes down to, eventually, that’s where we go. |
| 7 | A: It’s really amazing. |
| 8 | B: Yeah, chain stores are, in a sense, remarkable. |
| 9 | B: Alright, can we conclude this for now? |
| 10 | A: Yes, is that okay? |