Towards Improved Proxy-based Deep Metric Learning via Data-Augmented Domain Adaptation
Abstract
Deep Metric Learning (DML) plays an important role in modern computer vision research, where we learn a distance metric for a set of image representations. Recent DML techniques utilize the proxy to interact with the corresponding image samples in the embedding space. However, existing proxy-based DML methods focus on learning individual proxy-to-sample distance while the overall distribution of samples and proxies lacks attention. In this paper, we present a novel proxy-based DML framework that focuses on aligning the sample and proxy distributions to improve the efficiency of proxy-based DML losses. Specifically, we propose the Data-Augmented Domain Adaptation (DADA) method to adapt the domain gap between the group of samples and proxies. To the best of our knowledge, we are the first to leverage domain adaptation to boost the performance of proxy-based DML. We show that our method can be easily plugged into existing proxy-based DML losses. Our experiments on benchmarks, including the popular CUB-200-2011, CARS196, Stanford Online Products, and In-Shop Clothes Retrieval, show that our learning algorithm significantly improves the existing proxy losses and achieves superior results compared to the existing methods. Our code is available at https://github.com/Noahsark/DADA
Introduction
The fundamental task of Deep Metric Learning (DML) focuses on learning deep representation with a known similarity metric. DML is a crucial topic in computer vision since it has a wide range of applications, including image retrieval (Lee, Jin, and Jain 2008; Yang et al. 2018; Ren et al. 2021), person re-identification (Yi et al. 2014; Wojke and Bewley 2018; Dai et al. 2019), and image localization (Lu et al. 2015; Ge et al. 2020). Modern DML techniques utilize deep neural networks (DNN) to project image samples into a hidden space where similar data points are grouped within short distances while the dissimilar points are separated. The majority of DML approaches focus on optimizing the similarities between pairwise samples with various loss functions, ranging from contrastive losses (Hadsell, Chopra, and LeCun 2006), triplet losses (Schroff, Kalenichenko, and Philbin 2015) to cross-entropy losses (Boudiaf et al. 2020). With the increasing number of samples in the deep learning tasks, the basic pair or triplet losses face the difficulty of high computational complexity. Some approaches select informative samples by mining the hard or semi-hard samples (Wu et al. 2017; Katharopoulos and Fleuret 2018) while another group is devoted to comparing the sample clusters (Oh Song et al. 2017) or the statistics of the samples (Rippel et al. 2016).
Unlike the pair-based DML methods, the proxy-based approaches try to learn a group of trainable vectors, named proxy, instead of sweeping all sample pairs within the mini-batch or cluster (Movshovitz-Attias et al. 2017; Kim et al. 2020). Thus, the proxies capture the semantic information about the classes and optimize the uninformative sample-sample comparison with the proxy-sample relations. Based on the efficient proxy-sample distance metrics, later works further select the most informative proxy (Zhu et al. 2020) or assign each class with multiple proxies (Qian et al. 2019) to capture the intra-class structures. However, those existing proxy-based approaches simply guide the proxies by measuring their similarity with data samples where the learning process still faces a fundamental problem: the colossal distribution gap between the proxies and the data samples, since the proxies are initially sampled from a normal distribution that does not contain any semantic information. The distribution gap would slow the convergence speed and cause ambiguity and bias in the learning process. Initializing the proxy with representations of the data sample is one straightforward solution to this problem. However, the distribution of proxies still differs dramatically between the early and late training stages due to the poor quality of sample representations at the early stage. Additionally, it takes a significant amount of extra time and space to calculate the representations for every class in each iteration.
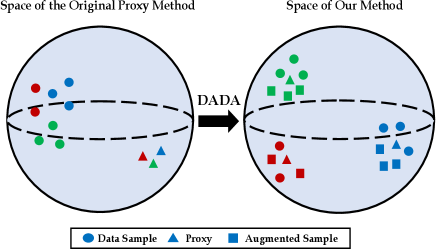
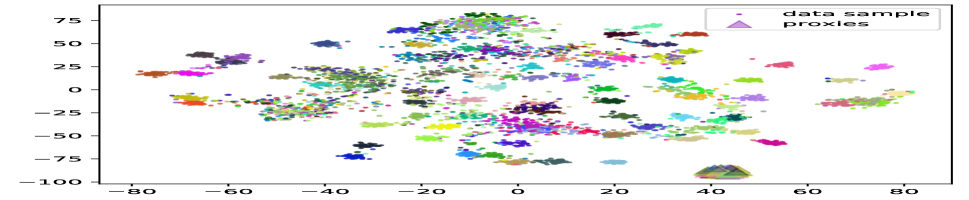
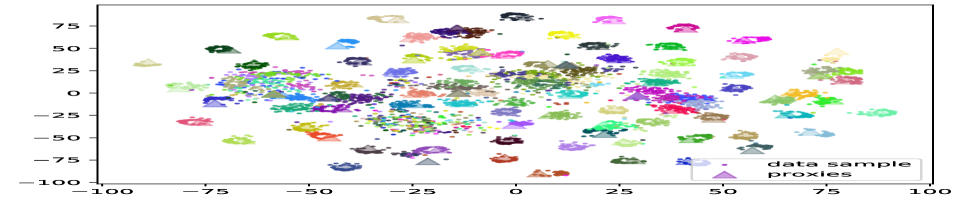
In this paper, we introduce a novel framework to solve these problems by aligning the distributions of the proxies and the data samples (as illustrated in Figure 1). Specifically, we utilize Adversarial Domain Adaptation (Wang and Deng 2018) techniques to minimize their distribution gap. To align those distributions, we propose a domain-level discriminator, which is a classifier to separate their domain properties. Note that the single domain discriminator would cause mode collapse (Goodfellow et al. 2020; Che et al. 2017) where the majority of data points are constrained to a local area so that their discriminative information is lost. To endorse their discriminative information, we leverage one additional category-level discriminator to evaluate the consistency of their class properties. We show that with these discriminators, the adversarial training signal can efficiently align the distributions of the data samples and the proxies.
However, there are still two difficulties in learning the distribution of the proxy space: (1) the limited number and diversity of the proxies and (2) the large initial gap between the proxies and the data samples. The limited number of proxies causes difficulties for discriminators in capturing the inter-class manifold structure, and the large domain gap further hinders their learning efficiency. To overcome these challenges, we propose a novel data-augmented domain as a bridge where the data samples and the proxies are evenly mixed to conduct an intermediate domain. This domain contains rich mixing samples holding information and statistics from both sides. We also propose to create mixture samples within the same categories to increase the density of the manifold. We demonstrate the mechanisms of our method in Figure 2. Our experiments show that the proposed method can easily plug into existing proxy-based losses to boost their performance dramatically. Our main contributions are three-fold:
-
•
We propose a novel adversarial learning framework to optimize the existing proxy-based DML by aligning the overall distributions of the data samples and the proxies at both domain and category levels.
-
•
We propose an additional data-augmented domain that contains mixup representations from both sides to further bridge the distribution gap. We show that our combined discriminators efficiently guide the proxies and the data samples to a hidden space under the same distribution, in which the proxy-based loss significantly increases its learning efficiency.
-
•
Our experiments demonstrate the effectiveness of our adversarial adaptation method on the image data samples and the proxies. We show that our approach increases the performance of existing proxy-based DML loss by a large margin, and our best result outperforms the state-of-the-art methods on four popular benchmarks.
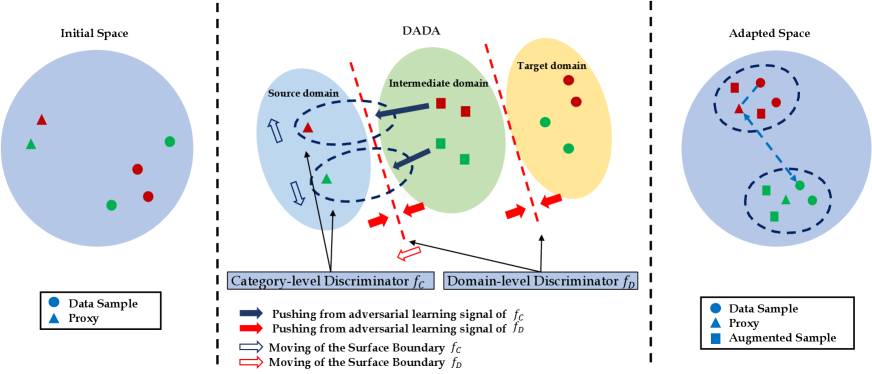
Related Work
Pair-based DML. Metric Learning in the computer vision area aims to learn a metric that measures the distance between a pair of image samples. Initially, the image samples inside a class and out of a class are regarded as positive and negative samples; and they are learned and projected to a low dimensional space (Hadsell, Chopra, and LeCun 2006; Oh Song et al. 2016). The samples in different classes are paired and measured with the contrastive loss (Chopra, Hadsell, and LeCun 2005; Hadsell, Chopra, and LeCun 2006). To further compare the ranking relation between pairs of samples, an additional sample is selected as an anchor to compare with both positive and negative samples with the triplet loss (Weinberger and Saul 2009; Wang et al. 2014; Cheng et al. 2016; Hermans, Beyer, and Leibe 2017) where the positive sample is ensured to be closer than the negative samples. Based on the triple loss, Sohn et al.(2016) propose SoftMax cross-entropy to compare the group of pairs to improve pair sampling.
The computational cost of these pair-based works is always high due to the workload of comparing each sample with all other samples within a given batch. Additionally, these methods reveal sensitivity to the size of the batch, where their performance may significantly drop if the size is too small.
Proxy-based DML. To further accelerate the sampling and clustering process, Movshovitz et al. (2017) leverage the proxy, a group of learnable representations, to compare data samples via the Neighbourhood component analysis (NCA) loss (Roweis, Hinton, and Salakhutdinov 2004). The motivation is to set image samples as anchors to compare with proxies of different classes instead of corresponding samples to reduce sampling times. Teh et al. (2020) further improve the ProxyNCA by scaling the gradient of proxies. Zhu et al. (2020) propose to sample the most informative negative proxies to improve the performance, while Kim et al. (2020) set the proxies as anchors instead of the samples to learn the inter-class structure. Yang et al. (2022) develop hierarchical-based proxy loss to boost learning efficiency. Roth et al. (2022) regular the distribution of samples around the proxies following a non-isotropic distribution. In contrast to these methods that compare the single sample-proxy pair, our method further refines the manifold structure by aligning the whole distributions between proxies and image samples via a novel adversarial domain adaptation framework.
Domain Adaptation and Adversarial Learning. Domain Adaptation initially aims to solve the lack of labeled data where the learned feature is domain-invariant so that classifiers can be easily shifted to the new data distribution. The basic idea is to match the feature distributions to decrease their domain shift between the source and target datasets (Quiñonero-Candela et al. 2008; Torralba and Efros 2011). One important branch of domain adaptation is Adversarial Learning (Goodfellow et al. 2020; HassanPour Zonoozi and Seydi 2022), where two or more models take part in the min-max game to generate domain-invariant features.
Ganin et al. (2015) first generate domain invariant features with adversarial training on neural networks. Tzeng et al. (2017) improve the discriminator that does not share the weight with the feature generator. Pei et al. (2018) utilize multiple discriminators assigned for each class to improve performance. Saito et al. (2018) minimize the prediction discrepancy of two discriminators on the target domain, while Lee et al. (2019) improve the method to compare their sliced Wasserstein distance instead. The primary application of adversarial learning is to produce synthetic textual or image data (Kingma and Welling 2013; Radford, Metz, and Chintala 2015; Isola et al. 2017). Ren et al. (2018; 2019) also applied this technique to enhance the quality of image captioning.
Recent studies have investigated the application of domain adaptation in image or textual retrieval tasks (Laradji and Babanezhad 2020; Pinheiro 2018). Wang et al. (2017) employ domain adaptation to align image and textural data using a single discriminator, whereas Ren et al. (2021) utilize multiple discriminators to get improved performance. In contrast to previous efforts, we propose aligning the distributions of data representations and proxies within the same image modality.
Proposed Method
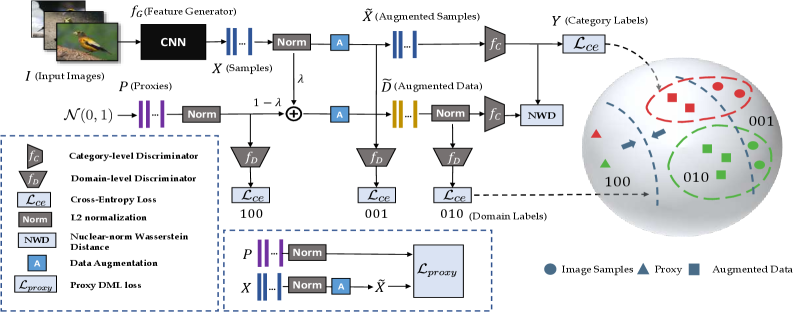
We propose a new framework to close the gap between the distributions of the data samples and the proxies for proxy-based DML losses that are already in place. We utilize the adversarial domain adaptation technique to transfer data samples and proxies to domain invariant feature space. To overcome the limitation of the number of proxies, we also conduct a novel strategy to augment data as a bridge between the samples and proxies, which demonstrates a smooth learning process.
Preliminary
Deep Metric Learning (DML) Consider a set of data samples with raw images and its corresponding class label ; we learn a projection function , which project the input data samples to a hidden embedding space (or metric space) . We define the projected features set as . The primal goal of Deep Metric Learning (DML) is to refine the projector function , which is usually constructed with convolutional deep neural networks (CNN) as the backbone, to generate the projected features that can be easily measured with defined distance metric based on the semantic similarity between sample and . Here we adopt the distance metric as the cosine similarity. Before delivering features to any loss, we use L2 normalization to eliminate the effect of differing magnitudes.
Proxy-based DML To boost the learning efficiency, a group of DML methods pre-define a set of learnable representations , named proxy, to represent subsets or categories of data samples. Typically there is one proxy for each class so that the number of proxies is the same as the number of classes . The proxies are also optimized with other network parameters. The first proxy-based method, Proxy-NCA (Movshovitz-Attias et al. 2017), or its improved version Proxy-NCA++ (Teh, DeVries, and Taylor 2020), utilizes the Neighborhood Component Analysis (NCA) (Goldberger et al. 2004) loss to conduct this optimization. The later loss Proxy-Anchor (PA) (Kim et al. 2020) inversely sets the proxy as the anchor and measures all proxies for each minibatch of samples. The PA loss can be presented as
|
|
(1) |
where denotes the set of positive samples for a proxy ; is its complement set; is the scale factor; and is the margin. Since the PA updates all proxies for each mini-batch, the model has higher learning efficiency in capturing the structure of samples beyond the mini-batches. We propose these two fundamental proxy-based losses (PNCA++ and PA) that achieve competitive results as our baselines.
Domain Data Augmentation
To reduce the distribution gap between the data samples and the proxies, we transform the proxy-based DML into a domain adaptation problem. We regard the data samples as data points in the source domain, while the initialed proxies are data points in the target domain. We noticed that the number of proxies in the target domain is especially limited compared to the data samples because the basic proxy method only assigns a single proxy for each class. The unbalanced samples and proxies would cause learning biases in modeling the distributions. Also, the proxies are initialized from a normal distribution and do not contain any related semantic information, which also causes difficulty in aligning their distribution to the data sample domain.
To overcome these difficulties, we propose a novel data augmentation strategy to create an intermediate domain to balance the amount of data points for domain adaptation. Specifically, we interpolate the space with mixed features from data set and proxy set . For each data sample and its corresponding proxy , we create a data feature :
| (2) |
where is the linear interpolation coefficient that sampled from beta distribution with and that decide its probability density function. The new data contains semantic information between the data sample and proxies and shares their distribution statistics. Therefore pushing is equal to pushing both samples and proxies , and their distribution is closer to the data sample domain than the original proxies.
In addition, we further propose extending the number of training instances by augmenting the data-proxy pairs within the same class. For each pair of samples and their corresponding augmented data inside the mini-batch, we propose the following mixing:
| (3) | |||
where are also sampled from distribution. Then we mix the new samples and inside the mini-batch to ensure the number of data samples with the same label . Combined with the original mini-batch, the augmented data sample set and the augmented proxy set are noted as and , and the size of mini-batch is also extended accordingly. We then normalize the composed features in and with L2 normalization to constrain them on a unit hypersphere embedding space where the magnitude is fixed to 1.
Domain-level Discriminator
Based on the augmented data, our goal is to refine the set , and the original proxy set to domain invariant representations that share the same distribution to help the proxy-based losses. We follow the principle idea of adversarial domain adaptation (Ganin et al. 2016) to estimate the domain divergence by learning a domain-level discriminator. Specifically, we learn a classifier that minimizes the risk of domain prediction (to predict if the data comes from a unique domain) between the set , and .
Generally, we would label the data from a specific domain with the one-hot label as the prediction target. Since we have three different domains including the augmented data domain and our labeling space is symmetric, we would simply assume the features are labeled as while are labeled as , and the initial proxies are labeled as for convenience. Specifically, we estimate the domain classifier as an MLP with a single hidden layer and a ReLU function. The hidden layer is then projected to a 3-dimensional head as the logits prediction of the domains. To optimize the with a low prediction risk on the labeling space, we conduct the cross-entropy objective as follows
|
|
(4) |
where is the cross entropy loss and is the total number of samples after the data augmentation. The parameters of the classifier are optimized to minimize the adversarial loss in training. Recall that the feature is generated from the projection function . Thus, the parameters of generator are optimized to fool the discriminator in the opposite direction. Since in the target domain contains features that mixed from and proxies , optimizing the equals optimizing the generator in the source domain while updating the original proxies . Thus, the adversarial learning signal of would help both generator and the original proxies to maintain the domain invariant representations to fool the classifier.
Category-level Discriminator
One drawback of the domain-level discriminator described above is that the discriminate information, especially the inter-class correlation, is ignored in the optimization process. Losing the discriminative information will cause all data points to be concentrated on a local area or a surface, which would cause inter-class ambiguity and confuse the metric learning losses. To solve this problem, we further propose a category-level discriminator that learns to predict the class of data samples and compare the discrepancy of predictions between the data samples and mixture proxies.
Specifically, we optimize a classifier with the feature generator to predict the category label from mixture data samples with the classification loss as
| (5) |
The cross-entropy loss would provide a supervised learning signal to to maintain the discriminative information during the DML training process.
We note that the data samples that share the distributions would also share the labeling space with the target proxy domain. To further align the distributions, we propose to constrain the samples from the source domain and augmented data from the target domain to have a low discrepancy of predictions from our category classifier . Thus, one additional goal of is to learn the maximized discrepancy of the category prediction between the data samples and mixture proxies while the are later optimized to minimize this discrepancy.
To measure the discrepancy of the category probabilities, we empirically adopt the discrepancy introduced in (Chen et al. 2022) that utilizes the Nuclear-norm Wasserstein Distance (NWD). The NWD is demonstrated to be the upper bound of the Frobenius-norm, which estimates the correlations of the predictions (Cui et al. 2020). Thus, we compare the NWD between the logistic predictions of from the augmented samples and data . The loss , which measures the NWD can be described as,
| (6) |
where denotes the nuclear-norm of , which is defined as the sum of its singular values.
The Combined Loss and Training Progress
We adopt the paradigm of adversarial learning to alternatively update the gradient of our feature generator and the discriminators and discussed above. To this end, we train our combined loss by playing the min-max game as follows,
| (7) |
where is the pre-defined hyperparameter that balances the contribution between the domain-level and category-level discriminators. Empirically, we do not set another weight between classification loss and discrepancy loss . We also need the original proxy-based loss in Eq. 1 to do the basic DML of the sample-proxy pair in training. Note that the augmented data set is only for domain adaptation progress; the original only operates and original proxies . Thus, our combined training progress can be described as the following two sub-processes:
| (8) | |||
| (9) |
where parameters and are updated in first phase and and the proxies are updated with in the second phase. Even if gradient reversal layers are accepted for achieving adversarial training in earlier domain adaptation works, we empirically conclude that a separate training phase would be more feasible for us in our search for stable training parameters. The full training progress can be referred to in Algorithm 1.
Method Reference Settings CUB-200 CARS-196 SOP Arch/Dim R@1 R@2 R@4 R@1 R@2 R@4 R@1 R@10 R@100 PNCA (Movshovitz-Attias et al. 2017) CVPR17’ BN/512 49.2 61.9 67.9 73.2 82.4 86.4 73.7 – – ProxyGML(Zhu et al. 2020) NeurIPS20’ BN/512 66.6 77.6 86.4 85.5 91.8 95.3 78.0 90.6 96.2 DiVA(Milbich et al. 2020) ECCV20’ R50/512 69.2 79.3 – 87.6 92.9 – 79.6 91.2 – S2SD(Roth et al. 2021) ICML21’ R50/512 70.1 79.7 71.6 89.5 93.9 72.9 80.0 91.4 – DCML-Proxy(Zheng et al. 2021a) CVPR21’ R50/512 65.2 76.4 84.8 81.2 89.8 94.6 – – – DCML-MDW(Zheng et al. 2021a) CVPR21’ R50/512 68.4 77.9 86.1 85.2 91.8 96.0 79.8 90.8 95.8 DRML(Zheng et al. 2021b) ICCV21’ BN/512 68.7 78.6 86.3 86.9 92.1 95.2 71.5 85.2 93.0 PA+AVSL(Zhang et al. 2022) CVPR22’ R50/512 71.9 81.7 88.1 91.5 95.0 97.0 79.6 91.4 96.4 PA+NIR(Roth, Vinyals, and Akata 2022) CVPR22’ R50/512 69.1 79.6 – 87.7 92.5 – 80.7 91.5 – HIST(Lim et al. 2022) CVPR22’ R50/512 71.4 81.1 88.1 89.6 93.9 96.4 81.4 92.0 96.7 DAS(Liu et al. 2022) ECCV22’ R50/512 69.2 79.3 87.0 87.8 93.2 96.0 80.6 91.8 96.7 MS+CRT(Kan et al. 2022) NeurIPS22’ R50/512 64.2 75.5 84.1 83.3 89.8 93.9 79.0 91.1 96.5 PNCA++(Teh, DeVries, and Taylor 2020) ECCV20’ R50/512 69.0 79.8 87.3 86.5 92.5 95.7 80.7 92.0 96.7 PNCA+DADA(R50) Ours R50/512 71.4 81.1 87.6 90.5 93.4 96.8 81.2 91.8 96.5 PA(Kim et al. 2020) CVPR20’ BN/512 68.4 79.2 86.8 86.1 91.7 95.0 79.1 90.8 96.2 PA+DADA(BN) Ours BN/512 69.8 80.4 87.1 89.4 92.1 96.2 79.6 91.0 96.3 PA (R50) (Kim et al. 2020) CVPR20’ R50/512 69.7 80.0 87.0 87.7 92.9 95.8 80.0 91.7 96.6 PA+DADA(R50) Ours R50/512 72.9 81.9 88.3 92.1 95.2 97.1 81.0 92.1 96.2
Experiments
We present our performance study and discuss the experimental results in this section.
Datasets and Metrics
We use the standard benchmarks CUB-200-2011 (CUB200) (Wah et al. 2011) with 11,788 bird images and 200 classes, and CARS196 (Krause et al. 2013) that contains 16,185 car images and 196 classes. We also evaluate our method on larger Stanford Online Products (SOP) (Oh Song et al. 2016) benchmark that includes 120,053 images with 22,634 product classes, and In-shop Clothes Retrieval (In-Shop) (Liu et al. 2016) dataset with 25,882 images and 7982 classes. We follow the data split that is consistent with the standard settings of existing DML works (Teh, DeVries, and Taylor 2020; Kim et al. 2020; Venkataramanan et al. 2022; Zheng et al. 2021b; Roth, Vinyals, and Akata 2022; Lim et al. 2022; Zhang et al. 2022). We adopt the Recall@K (K=1,2,4 in CUB200 and CARS196, K=1,10,100 in SOP, and K=1,10,20,30 in In-Shop) proposed in existing works to evaluate the accuracy of ranking. We also evaluate it with Mean Average Precision at R (MAP@R) which is based on the idea of MAP and R-precision, which is a more informative DML metric (Musgrave, Belongie, and Lim 2020).
Implementation Details
We train our model in a machine that contains a single RTX3090 GPU with 24GB memory. The Implementation is based on the existing RDML (Roth et al. 2020)
Backbones and Preprocessing. In this paper, we propose two basic backbones to evaluate our learning algorithm: the ResNet50(He et al. 2016) and the InceptionBN (Ioffe and Szegedy 2015). They are pre-trained on ImageNet1K(Deng et al. 2009) and are widely used in DML works for performance evaluation, where we resize the image to , do random resized cropping, and random horizontal flipping. In the test phase, the images are first resized to , then cropped back to . A linear head embeds the feature from the second last layer of the backbones to a 512-dimension hidden space. We follow the standard pre-processing introduced in other deep metric learning works (Venkataramanan et al. 2022; Zheng et al. 2021b; Roth, Vinyals, and Akata 2022; Lim et al. 2022; Zhang et al. 2022). We also adopt global max and average pooling with layer normalization on CNN backbones suggested by Teh et al. (Teh, DeVries, and Taylor 2020) to further improve the generalization of features.
In-Shop Clothes Retrieval (In-Shop) Methods Arch/Dim R@1 R@10 R@20 R@30 MS (2019) BN/512 89.7 97.9 98.5 98.8 SHM (2019) BN/512 90.7 97.8 98.5 98.8 SCT (2020) R50/512 90.0 97.5 98.1 – XBM (2020) BN/512 89.9 97.6 98.4 98.6 IBC (2021) R50/512 92.8 98.5 99.1 99.2 PA (2020) BN/512 90.4 98.1 98.8 99.0 PA+Mix (2022) R50/512 91.9 98.2 98.8 – PNCA++(2020) R50/512 90.4 98.1 98.8 99.0 PNCA + DADA (ours) R50/512 91.7 98.2 98.6 98.8 PA + DADA (ours) R50/512 93.0 98.5 98.9 99.1
ProxyAnchor ProxyNCA++ Settings R@1 MAP@R R@1 MAP@R Baseline 69.1 26.5 68.4 25.8 +Aug 69.3 (+0.2) 26.5 (+0.0) 68.5 (+0.1) 25.9 (+0.1) 70.2 (+1.1) 27.3 (+0.8) 69.2 (+0.8) 26.4 (+0.6) Aug 70.9 (+1.8) 27.8 (+1.3) 69.8 (+1.4) 26.8 (+1.0) 69.3 (+0.2) 27.0 (+0.5) 68.9 (+0.5) 26.2 (+0.4) 69.9 (+0.8) 27.4 (+0.9) 69.5 (+1.1) 26.6 (+0.8) Aug 70.4 (+1.3) 27.8 (+1.3) 69.4 (+1.0) 26.7 (+0.9) 71.4 (+2.3) 28.2 (+1.7) 69.3 (+0.9) 27.1 (+1.3) 71.6 (+2.5) 28.2 (+1.7) 69.4 (+1.0) 27.0 (+1.2) 72.0 (+2.9) 28.9 (+2.4) 69.9 (+1.5) 27.7 (+1.9) + Aug (ours) 72.9 (+3.8) 29.9(+3.4) 70.2(+1.8) 28.0 (+2.2)
Training Details. Our optimization is done using Adam () (Kingma and Ba 2015) with a decay of . We set the learning rate at for the feature generator and for our discriminators. We adopt the learning rate for the proxies as suggested in (Roth, Vinyals, and Akata 2022). For most of the experiments, we fixed the batch size to 90 as a default setting, which is consistent with (Kim et al. 2020). Empirically we apply batch normalization on the domain-level discriminator to reduce its correlation variance within the batch. For all experiments, the first layer of is set to 512. For the second layer, we assigned 128 dimensions to the CUB200 and CARS196 datasets, 8192 dimensions to the SOP datasets, and 4096 dimensions to the In-Shop datasets. We set for CUB200, and for CARS196. We select for both SOP and In-Shop datasets.
Qualitative Results
Comparing with Proxy Baselines. We compare the performance of our approach with the existing proxy-based metric learning methods and the recent state-of-the-art metric learning methods on the popular benchmarks introduced above (refer to Table 1). We observe that our DADA frameworks can significantly improve the performance of the original proxy-based DML methods (marked with ) by a large margin. Specifically, comparing with the original PA method on ResNet50, our proposed PA+DADA outperforms () on the recall@1 of CUB200 and () on the recall@1 of CARS196. On the larger datasets (SOP and In-Shop), our method is also better than the original PA and PNCA++.
Comparing with state-of-the-art. We further compare the performance of our method with the state-of-the-art methods based on the CNN backbones as listed in Table 1 and 2. For the CARS196 dataset, our method reaches on Recall@1, which has a improvement over the previous state-of-the-art AVSL (Zhang et al. 2022) on the ResNet50 backbone. For CUB200, our method outperforms the previous state-of-the-art AVSL on Recall@1, on Recall@2, and on Recall@4. We observe that our performance on SOP and In-Shop is limited but very close to the previous state-of-the-art IBC (Seidenschwarz, Elezi, and Leal-Taixé 2021), CRT (Kan et al. 2022), and HIST (Lim et al. 2022) on a few metrics. The lesser improvement in the high-value recall of these two datasets is mainly due to the large number of classes (11318 and 3997) and the limited number of samples in each class (less than 10). This causes some difficulty for our category-level discriminator to learn the discriminative information. Nevertheless, our method still achieves good performance comparable to those of the state-of-the-art methods in all metrics and outperforms other proxy-related methods on these two datasets. We will investigate techniques to overcome this limitation in our future works.
Ablation Study
Contributions of the Objective Components. We analyze the ablation study to evaluate the contribution of each objective component of our proposed framework based on both ProxyAnchor (Kim et al. 2020) and ProxyNCA++ (Teh, DeVries, and Taylor 2020) on the CUB200 as listed in Table 3. We first notice that the data augmentation strategy (Aug) does not improve our baseline significantly in the absence of and . This is because, without those regularization losses, Aug simply boosts some redundant positive samples and the mixed features do not take part in training. We conclude that the domain-level discriminator with has higher efficiency when the category-level discriminator with helps regularize the space and avoid the inter-class ambiguity. It increases the improvement to on R@1 and on MAP@R from on R@1 and on MAP@R in comparison with the single setting. We also demonstrate that the efficiency of the category-level classifier () can be further improved by comparing the discrepancy of class prediction () between the source data and target proxies in adversarial learning. Comparing the general discrepancy L1 distance (), the proposed NWD also shows increasing performances on both R@1 and MAP@R. A similar conclusion can also be driven by the results based on ProxyNCA. Therefore, we conclude that the combination of the domain and the category-level discriminator is more suitable for proxy-based DML than the settings with any single discriminator. We also study the impact of our hyperparameters and the combination of data groups that apply domain adaptation in the Appendix.
Conclusion
In this paper, we present an adversarial domain adaptation method with data augmentation to optimize the hidden space of the data and the proxies. We overcome the initial distribution gap between them to boost the learning efficiency of deep metric learning. We propose to align the domains of the data and the initial proxies by optimizing two classifiers at different levels, and training the embedding function and the proxies against them. To enhance the density of the manifold, we propose a strategy to conduct a mixture space by mixing the features from both domains. Our experimental results based on four popular deep metric learning benchmarks demonstrate that our learning method and mixed space efficiently boost the learning efficiency of existing proxy-based methods. While our framework focuses on solving the challenge of proxy-based DML methods, we believe it can be easily extended to other related metric learning methods, and it can also benefit zero-shot and self-supervised learning works. These are interesting and challenging works for future study.
References
- Ben-David et al. (2010) Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; and Vaughan, J. W. 2010. A theory of learning from different domains. Machine learning, 79: 151–175.
- Boudiaf et al. (2020) Boudiaf, M.; Rony, J.; Ziko, I. M.; Granger, E.; Pedersoli, M.; Piantanida, P.; and Ayed, I. B. 2020. A unifying mutual information view of metric learning: cross-entropy vs. pairwise losses. In ECCV, 548–564. Springer.
- Che et al. (2017) Che, T.; Li, Y.; Jacob, A. P.; Bengio, Y.; and Li, W. 2017. Mode regularized generative adversarial networks. ICLR.
- Chen et al. (2022) Chen, L.; Chen, H.; Wei, Z.; Jin, X.; Tan, X.; Jin, Y.; and Chen, E. 2022. Reusing the Task-specific Classifier as a Discriminator: Discriminator-free Adversarial Domain Adaptation. In CVPR, 7181–7190.
- Cheng et al. (2016) Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; and Zheng, N. 2016. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In CVPR, 1335–1344.
- Chopra, Hadsell, and LeCun (2005) Chopra, S.; Hadsell, R.; and LeCun, Y. 2005. Learning a similarity metric discriminatively, with application to face verification. In CVPR, volume 1, 539–546. IEEE.
- Cui et al. (2020) Cui, S.; Wang, S.; Zhuo, J.; Li, L.; Huang, Q.; and Tian, Q. 2020. Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations. In CVPR, 3941–3950.
- Dai et al. (2019) Dai, Z.; Chen, M.; Gu, X.; Zhu, S.; and Tan, P. 2019. Batch dropblock network for person re-identification and beyond. In ICCV, 3691–3701.
- Deng et al. (2009) Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. Imagenet: A large-scale hierarchical image database. In CVPR, 248–255. Ieee.
- El-Nouby et al. (2021) El-Nouby, A.; Neverova, N.; Laptev, I.; and Jégou, H. 2021. Training vision transformers for image retrieval. arXiv preprint arXiv:2102.05644.
- Ermolov et al. (2022) Ermolov, A.; Mirvakhabova, L.; Khrulkov, V.; Sebe, N.; and Oseledets, I. 2022. Hyperbolic Vision Transformers: Combining Improvements in Metric Learning. In CVPR, 7409–7419.
- Ganin and Lempitsky (2015) Ganin, Y.; and Lempitsky, V. 2015. Unsupervised domain adaptation by backpropagation. In ICML, 1180–1189. PMLR.
- Ganin et al. (2016) Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; and Lempitsky, V. 2016. Domain-adversarial training of neural networks. The journal of machine learning research, 17(1): 2096–2030.
- Ge et al. (2020) Ge, Y.; Wang, H.; Zhu, F.; Zhao, R.; and Li, H. 2020. Self-supervising fine-grained region similarities for large-scale image localization. In ECCV, 369–386. Springer.
- Goldberger et al. (2004) Goldberger, J.; Hinton, G. E.; Roweis, S.; and Salakhutdinov, R. R. 2004. Neighbourhood components analysis. NIPS, 17.
- Goodfellow et al. (2020) Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2020. Generative adversarial networks. Communications of the ACM, 63(11): 139–144.
- Hadsell, Chopra, and LeCun (2006) Hadsell, R.; Chopra, S.; and LeCun, Y. 2006. Dimensionality reduction by learning an invariant mapping. In CVPR, volume 2, 1735–1742. IEEE.
- HassanPour Zonoozi and Seydi (2022) HassanPour Zonoozi, M.; and Seydi, V. 2022. A Survey on Adversarial Domain Adaptation. Neural Processing Letters, 1–41.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In CVPR, 770–778.
- Hermans, Beyer, and Leibe (2017) Hermans, A.; Beyer, L.; and Leibe, B. 2017. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737.
- Ioffe and Szegedy (2015) Ioffe, S.; and Szegedy, C. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 448–456. PMLR.
- Isola et al. (2017) Isola, P.; Zhu, J.-Y.; Zhou, T.; and Efros, A. A. 2017. Image-to-image translation with conditional adversarial networks. In CVPR, 1125–1134.
- Kan et al. (2022) Kan, S.; Liang, Y.; Li, M.; Cen, Y.; Wang, J.; and He, Z. 2022. Coded Residual Transform for Generalizable Deep Metric Learning. NeurIPS.
- Katharopoulos and Fleuret (2018) Katharopoulos, A.; and Fleuret, F. 2018. Not all samples are created equal: Deep learning with importance sampling. In ICML, 2525–2534. PMLR.
- Kim et al. (2020) Kim, S.; Kim, D.; Cho, M.; and Kwak, S. 2020. Proxy anchor loss for deep metric learning. In CVPR, 3238–3247.
- Kingma and Ba (2015) Kingma, D. P.; and Ba, J. 2015. Adam: A method for stochastic optimization. ICLR.
- Kingma and Welling (2013) Kingma, D. P.; and Welling, M. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Ko, Gu, and Kim (2021) Ko, B.; Gu, G.; and Kim, H.-G. 2021. Learning with memory-based virtual classes for deep metric learning. In CVPR, 11792–11801.
- Krause et al. (2013) Krause, J.; Stark, M.; Deng, J.; and Fei-Fei, L. 2013. 3d object representations for fine-grained categorization. In ICCV workshop, 554–561.
- Laradji and Babanezhad (2020) Laradji, I. H.; and Babanezhad, R. 2020. M-adda: Unsupervised domain adaptation with deep metric learning. Domain adaptation for visual understanding, 17–31.
- Lee et al. (2019) Lee, C.-Y.; Batra, T.; Baig, M. H.; and Ulbricht, D. 2019. Sliced wasserstein discrepancy for unsupervised domain adaptation. In CVPR, 10285–10295.
- Lee, Jin, and Jain (2008) Lee, J.-E.; Jin, R.; and Jain, A. K. 2008. Rank-based distance metric learning: An application to image retrieval. In CVPR, 1–8. IEEE.
- Lim et al. (2022) Lim, J.; Yun, S.; Park, S.; and Choi, J. Y. 2022. Hypergraph-Induced Semantic Tuplet Loss for Deep Metric Learning. In CVPR, 212–222.
- Liu et al. (2022) Liu, L.; Huang, S.; Zhuang, Z.; Yang, R.; Tan, M.; and Wang, Y. 2022. DAS: Densely-Anchored Sampling for Deep Metric Learning. ECCV.
- Liu et al. (2016) Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; and Tang, X. 2016. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In CVPR, 1096–1104.
- Lu et al. (2015) Lu, G.; Yan, Y.; Ren, L.; Song, J.; Sebe, N.; and Kambhamettu, C. 2015. Localize me anywhere, anytime: a multi-task point-retrieval approach. In ICCV, 2434–2442.
- Milbich et al. (2020) Milbich, T.; Roth, K.; Bharadhwaj, H.; Sinha, S.; Bengio, Y.; Ommer, B.; and Cohen, J. P. 2020. Diva: Diverse visual feature aggregation for deep metric learning. In ECCV, 590–607. Springer.
- Movshovitz-Attias et al. (2017) Movshovitz-Attias, Y.; Toshev, A.; Leung, T. K.; Ioffe, S.; and Singh, S. 2017. No fuss distance metric learning using proxies. In CVPR, 360–368.
- Musgrave, Belongie, and Lim (2020) Musgrave, K.; Belongie, S.; and Lim, S.-N. 2020. A metric learning reality check. In ECCV, 681–699. Springer.
- Oh Song et al. (2017) Oh Song, H.; Jegelka, S.; Rathod, V.; and Murphy, K. 2017. Deep metric learning via facility location. In CVPR, 5382–5390.
- Oh Song et al. (2016) Oh Song, H.; Xiang, Y.; Jegelka, S.; and Savarese, S. 2016. Deep metric learning via lifted structured feature embedding. In CVPR, 4004–4012.
- Patel, Tolias, and Matas (2022) Patel, Y.; Tolias, G.; and Matas, J. 2022. Recall@ k surrogate loss with large batches and similarity mixup. In CVPR, 7502–7511.
- Pei et al. (2018) Pei, Z.; Cao, Z.; Long, M.; and Wang, J. 2018. Multi-adversarial domain adaptation. In AAAI.
- Pinheiro (2018) Pinheiro, P. O. 2018. Unsupervised domain adaptation with similarity learning. In CVPR, 8004–8013.
- Qian et al. (2019) Qian, Q.; Shang, L.; Sun, B.; Hu, J.; Li, H.; and Jin, R. 2019. Softtriple loss: Deep metric learning without triplet sampling. In ICCV, 6450–6458.
- Quiñonero-Candela et al. (2008) Quiñonero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; and Lawrence, N. 2008. Covariate shift and local learning by distribution matching.
- Radford, Metz, and Chintala (2015) Radford, A.; Metz, L.; and Chintala, S. 2015. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
- Ren and Hua (2018) Ren, L.; and Hua, K. 2018. Improved image description via embedded object structure graph and semantic feature matching. In ISM, 73–80. IEEE.
- Ren et al. (2021) Ren, L.; Li, K.; Wang, L.; and Hua, K. 2021. Beyond the deep metric learning: enhance the cross-modal matching with adversarial discriminative domain regularization. In ICPR, 10165–10172. IEEE.
- Ren, Qi, and Hua (2019) Ren, L.; Qi, G.-J.; and Hua, K. 2019. Improving diversity of image captioning through variational autoencoders and adversarial learning. In WACV, 263–272. IEEE.
- Rippel et al. (2016) Rippel, O.; Paluri, M.; Dollar, P.; and Bourdev, L. 2016. Metric learning with adaptive density discrimination. ICLR.
- Roth et al. (2021) Roth, K.; Milbich, T.; Ommer, B.; Cohen, J. P.; and Ghassemi, M. 2021. Simultaneous similarity-based self-distillation for deep metric learning. In ICML, 9095–9106. PMLR.
- Roth et al. (2020) Roth, K.; Milbich, T.; Sinha, S.; Gupta, P.; Ommer, B.; and Cohen, J. P. 2020. Revisiting training strategies and generalization performance in deep metric learning. In ICML, 8242–8252. PMLR.
- Roth, Vinyals, and Akata (2022) Roth, K.; Vinyals, O.; and Akata, Z. 2022. Non-isotropy Regularization for Proxy-based Deep Metric Learning. In CVPR, 7420–7430.
- Roweis, Hinton, and Salakhutdinov (2004) Roweis, S.; Hinton, G.; and Salakhutdinov, R. 2004. Neighbourhood component analysis. NIPS, 17(513-520): 4.
- Saito et al. (2018) Saito, K.; Watanabe, K.; Ushiku, Y.; and Harada, T. 2018. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, 3723–3732.
- Schroff, Kalenichenko, and Philbin (2015) Schroff, F.; Kalenichenko, D.; and Philbin, J. 2015. Facenet: A unified embedding for face recognition and clustering. In CVPR, 815–823.
- Seidenschwarz, Elezi, and Leal-Taixé (2021) Seidenschwarz, J. D.; Elezi, I.; and Leal-Taixé, L. 2021. Learning intra-batch connections for deep metric learning. In ICML, 9410–9421. PMLR.
- Sohn (2016) Sohn, K. 2016. Improved deep metric learning with multi-class n-pair loss objective. NIPS, 29.
- Suh et al. (2019) Suh, Y.; Han, B.; Kim, W.; and Lee, K. M. 2019. Stochastic class-based hard example mining for deep metric learning. In CVPR, 7251–7259.
- Tan, Yuan, and Ordonez (2021) Tan, F.; Yuan, J.; and Ordonez, V. 2021. Instance-level image retrieval using reranking transformers. In ICCV, 12105–12115.
- Teh, DeVries, and Taylor (2020) Teh, E. W.; DeVries, T.; and Taylor, G. W. 2020. Proxynca++: Revisiting and revitalizing proxy neighborhood component analysis. In ECCV, 448–464. Springer.
- Torralba and Efros (2011) Torralba, A.; and Efros, A. A. 2011. Unbiased look at dataset bias. In CVPR, 1521–1528. IEEE.
- Tzeng et al. (2017) Tzeng, E.; Hoffman, J.; Saenko, K.; and Darrell, T. 2017. Adversarial discriminative domain adaptation. In CVPR, 7167–7176.
- Venkataramanan et al. (2022) Venkataramanan, S.; Psomas, B.; Avrithis, Y.; Kijak, E.; Amsaleg, L.; and Karantzalos, K. 2022. It takes two to tango: Mixup for deep metric learning. ICLR.
- Wah et al. (2011) Wah, C.; Branson, S.; Welinder, P.; Perona, P.; and Belongie, S. 2011. The caltech-ucsd birds-200-2011 dataset.
- Wang et al. (2017) Wang, B.; Yang, Y.; Xu, X.; Hanjalic, A.; and Shen, H. T. 2017. Adversarial cross-modal retrieval. In Multimedia, 154–162.
- Wang et al. (2014) Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; and Wu, Y. 2014. Learning fine-grained image similarity with deep ranking. In CVPR, 1386–1393.
- Wang and Deng (2018) Wang, M.; and Deng, W. 2018. Deep visual domain adaptation: A survey. Neurocomputing, 312: 135–153.
- Wang et al. (2019) Wang, X.; Han, X.; Huang, W.; Dong, D.; and Scott, M. R. 2019. Multi-similarity loss with general pair weighting for deep metric learning. In CVPR, 5022–5030.
- Wang et al. (2020) Wang, X.; Zhang, H.; Huang, W.; and Scott, M. R. 2020. Cross-batch memory for embedding learning. In CVPR, 6388–6397.
- Weinberger and Saul (2009) Weinberger, K. Q.; and Saul, L. K. 2009. Distance metric learning for large margin nearest neighbor classification. Journal of machine learning research, 10(2).
- Wojke and Bewley (2018) Wojke, N.; and Bewley, A. 2018. Deep cosine metric learning for person re-identification. In WACV, 748–756. IEEE.
- Wu et al. (2017) Wu, C.-Y.; Manmatha, R.; Smola, A. J.; and Krahenbuhl, P. 2017. Sampling matters in deep embedding learning. In CVPR, 2840–2848.
- Xuan et al. (2020) Xuan, H.; Stylianou, A.; Liu, X.; and Pless, R. 2020. Hard negative examples are hard, but useful. In ECCV, 126–142. Springer.
- Yang et al. (2018) Yang, J.; She, D.; Lai, Y.-K.; and Yang, M.-H. 2018. Retrieving and classifying affective images via deep metric learning. In AAAI, volume 32.
- Yang et al. (2022) Yang, Z.; Bastan, M.; Zhu, X.; Gray, D.; and Samaras, D. 2022. Hierarchical proxy-based loss for deep metric learning. In WACV, 1859–1868.
- Yi et al. (2014) Yi, D.; Lei, Z.; Liao, S.; and Li, S. Z. 2014. Deep metric learning for person re-identification. In ICPR, 34–39. IEEE.
- Zhang et al. (2022) Zhang, B.; Zheng, W.; Zhou, J.; and Lu, J. 2022. Attributable Visual Similarity Learning. In CVPR, 7532–7541.
- Zheng et al. (2021a) Zheng, W.; Wang, C.; Lu, J.; and Zhou, J. 2021a. Deep compositional metric learning. In CVPR, 9320–9329.
- Zheng et al. (2021b) Zheng, W.; Zhang, B.; Lu, J.; and Zhou, J. 2021b. Deep relational metric learning. In ICCV, 12065–12074.
- Zhu et al. (2020) Zhu, Y.; Yang, M.; Deng, C.; and Liu, W. 2020. Fewer is more: A deep graph metric learning perspective using fewer proxies. NeurIPS, 33: 17792–17803.
Appendix
In the appendix, we first discuss the generalized bound of our domain adaptation framework in Section A. Then, we compare our method with other similar methods in Section B. We discuss the possible extension of our method to other model backbones in Section C. We also discuss some related studies including the data domain and the discriminators in Section D. After that, we list detailed experimental settings in Section E and describe some existing limitations in Section F. We illustrate the overall architecture of our method in Figure 3 and show some examples of image retrieval results.
Appendix A Theory Insight
Notation and Definitions
We adopt the definition domain as the distribution on the space with the ground truth labeling function . In our scenario, we have source domain , the intermediate domain and the target domain . The hypothesis is a function that we search to demonstrate the labeling . For our data sample and its corresponding proxy , the risk of the hypothesis is defined as the error risk with the labeling function :
| (10) |
| (11) |
where is the hidden labeling function of the target domain. Thus, our goal is to find the bound of in the target domain where the domain adaptation is summarized to minimize the target risk in term of the source risk and other terms that affect its upper bound.
Given the set of hypothesis class , Ben-David et al. (Ben-David et al. 2010) define the symmetric difference hypothesis space , and the domain divergence where . Thus can be defined as,
To estimate domain divergence within the space of finite samples , the is further relaxed to
| (12) |
where is a empirical function introduced in (Ben-David et al. 2010) with converge rate and is the size of data samples and .
The Generalization Bound
With the definition of introduced above, for every the bound for data space and can be described as,
| (13) |
where denotes the combined risk of optimized hypothesis : .
Now we assume our source, target, and intermediate domain service three possible source-target adaptation pairs: , and . Note that does not serve as the source domain since it initially does not contain any semantic information, and its labeling space is still hidden. We combine the single bound of each source-target pair, as a convex function, to a combined boundary. In other words, by combining the source domain and intermediate domain to a single domain, our generalization bound of risks on three pairs can be inferred as the following:
Theorem A.1.
Let be a hypothesis space of VC-dimension , and and are samples of size drawn from . Then ,
| (14) | ||||
where denotes the combined risk of optimal hypothesis that , and
Proof.
We have the bound proposed in Eq. 13 for each source-target domain pair. Assume all domains have a finite sample of size ; the bounds for all pairs can be listed as follows:
| (15) | |||
| (16) | |||
| (17) |
Then we combine the convex upper bounds 15, 16 and 17 with a interpolate parameter as follows,
| (18) |
where is a interpolated empirical function. We simply replace with to get our combined upper bound. ∎
Connection to Our Objective Function
For each , we know that
| (19) |
Similarly, we can also relax our from space by specific class labels where . Thus, we get the bound of as follows,
| (20) | ||||
When the combined risk in A.1 is achieved by optimized hypothesis as a small constant, the bound mainly depends on the term and when is sufficiently large.
The term is the min-max optimize goal of our domain-level discriminator. And the category-level discriminator optimizes the risk . This shows that optimizing the risk in the target domain needs a combination of domain and category-level discriminators. Besides, the theory in (Chen et al. 2022) also conduct that is also bounded by NWD with K-Lipschits constraint where . Here we explained the intuition behind our proposed objective.
Connection between Proxy Loss and
Here, we try to roughly explain why making domain adaptation would help the proxy-based DML. We take Proxy-NCA loss as an example. Recall that Proxy-NCA has the following form:
| (21) |
The NCA loss initially follows the design of the “leave-one-out” classification paradigm (Goldberger et al. 2004) where we try to label the sample and anchor into the same class (or to select as a neighbor of x with the same label). We know that optimizing the NCA loss maximizes the probability of labeling the sample and to the same class while pushing them from others. On the other hand, we have,
| (22) |
By aligning distributions and labeling space , we know that which has the same optimizing target to the Proxy-NCA: to minimize the risk labeling and in different classes. Proxy-Anchor or other Proxy-based losses also follow this paradigm with modified NCA losses so that they initially consist of the same target.
Appendix B Comparison with Related Methods
In this section, we discuss two related works, XBM (Wang et al. 2020) and MemVir (Ko, Gu, and Kim 2021), that are intuitively close to the idea of our and other proxy-based DML works. Our approach and the XBM have something in common since both of us attempt to compare data representations with some other representations (XBM compares the data representations while ours compares class representations) that are unrelated to the training batch. MemVir, on the other hand, proposes to extend the space of the class by gradually adding the representations and class weights that are out of the batch. They all attempt to reduce the shift between the samples in batch and out of batch, which is also called semantic drift. However, there is a fundamental difference between proxy-based and XBM-related approaches, where proxy-based DML chooses to directly update the class representations in the whole data space while XBM approaches select to update a subset of data outside the batch.
Appendix C Extension to Other Backbones
Note that this paper compares our method with existing state-of-the-art proxy-based methods and other popular DML approaches that embed the images with CNN backbones (ResNet50 and InceptionBN). Some recent works that apply Vision Transformers (El-Nouby et al. 2021; Tan, Yuan, and Ordonez 2021), which is pre-trained on larger datasets (ImageNet21K) or with extremely large batch sizes (Ermolov et al. 2022; Patel, Tolias, and Matas 2022) are beyond the scope of this paper due to our limited computing resources. We anticipate that our method can be further extended with Transformer encoders (ViT) to boost its performance with larger GPU memory or parallel training with multi-GPUs in future works. We leave this extension to subsequent studies.
Appendix D Additional Studies
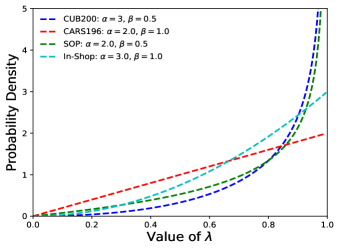
Study of the Mixing Distribution
We study the mixing domain’s performance with various sampling distributions. We evaluate the performance of our method under different probability density functions based on the . We discover that the optimized sampling density varies in different datasets. This is because of the variety of data distribution in the initial space. When the sampling approach to is equal to putting the target proxy directly as the target space without any mixing, and vice versa. As illustrated in Figure 4, we observe that the tends to be sampled larger than 0.5 for all datasets but with different probabilities, which means the mixed intermediate data domain tends to have more semantic information from the source data domain in all datasets. This also consists of our assumption that the proxy profoundly needs to be connected with the informative source domain during the DML learning progress.
Study of Confusion Matrix
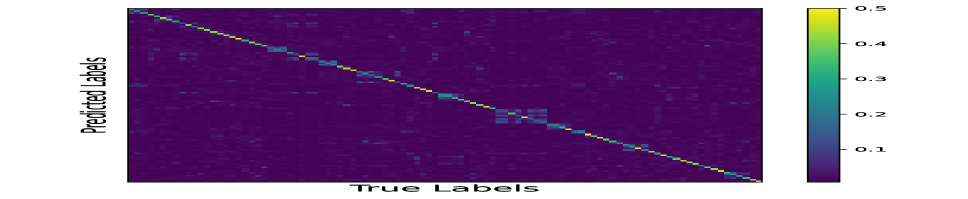
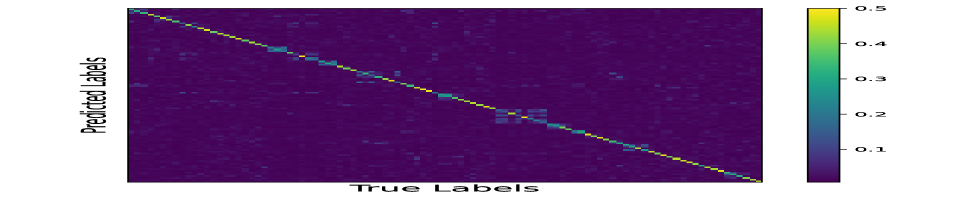
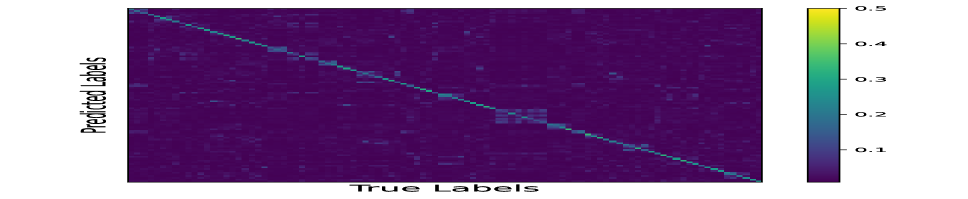
We compare the predicted probability on CUB200 from our category-level discriminator between the data source domain and target proxies. We repeat the comparison on the PA baseline, where we also train a classifier with the same architecture and initial parameters (so that the prediction on the source data is the same as our proposed method). The Figure 7 illustrates the confusion matrix. It is obvious that our proposed method has better consistency between the distribution of data samples and the proxies.
Study of the Adaptation Groups
Another important factor that affects the results is where to apply the domain adaptation. To investigate this we try domain adaptation on different combinations of data in the set , and . We study the efficiency of our domain-level discriminator under three different settings: (1) the original space with only the augmented samples and the original proxies adapted (labeled as + ), (2) the setting with only the augmented samples and and augmented data (labeled as + ), and (3) setting with all three set of data as proposed in main paper (labeled as + + ). For the settings (1) and (2), we set the domain label to 01 and 10 instead. As illustrated in Figure 6(d), the + + setting achieves the best overall performance and specifically overcomes the + setting for a large margin. This demonstrates the efficiency of the augmented data for domain adaptation.
Appendix E Detailed Experimental Settings
Pre-Processing
We follow the standard pre-processing procedure proposed in existing works for fairness. Specifically, we resize the image to , do random resized cropping, and random horizontal flipping with probability 0.5. In the test phase, the images are first resized to , then cropped back to .




Parameter Searching
We empirically search the dimensions of each hidden layer of our discriminators in a discrete range of . We search the second layer of the category-level classifier according to the number of classes in each dataset. We eventually set our domain-level discriminator as a single-layer MLP with a 512-dimension hidden layer. Our category-level discriminator is constructed as a 2-layer MLP where the first hidden layer has 512 dimensions.
We search our hyper-parameters from a grid where are searched in a range from to . For the parameter in Beta distribution, we also search them within the range since they control the probability of sampling between the two domains. We adopt the parameters of baseline Proxy-NCA and Proxy-Anchor as their suggested values in the original paper where the scaling factor , margin . In each iteration of training, we train the discriminator with times while training the generator for a single time. We adopt a warm-up phase where all parameters are frozen except the linear head of the generator, as suggested in (Roth, Vinyals, and Akata 2022).
Impact of Hyperparameters
We observe in Figure 6 that our discriminators are effective when the balancing factor satisfies and . In this range, the performance starts to overcome the settings with a single classifier (R@1 ). Besides, we notice that the adversarial training would not support or even damage the original metric learning system when .
We also observe that the large batch size is not a sufficient condition to achieve better performance for our method (as illustrated in Figure 6(c)) since the batch size and batch sampling also affect the quality of our mixed positive samples. Figure 6(b) also illustrates that the performance of our learning system improves with the dimension size of the features. Even though we achieve better results on larger dimensions, we only report the results on dimension 512 for fairness with other works. Note that our method is based on Proxy-Anchor where the proxy collects information across batches. Thus, the performance of our method is not sensitive to batch size (see Figure 6(c)).
Training Time and Memory
When utilizing our adversarial training, the additional cost of time and memory is very limited in our framework. In our experimental machine, the training time on CUB200 for a single epoch of our proposed method is (average in 10 epochs), including the evaluation time, when the original PA baseline holds the running time of . Even though we train the discriminators in times in each iteration, the increased time for this additional part is only around . This is because our discriminators are shallow (1 and 2 layers), and the computational complexity does not change. In terms of memory, our proposed method takes 11.3GB of GPU memory when the original baseline takes 11.2GB for the default batch size of 90. Although we increase the number of samples by mixing the features, the increased space is negligible compared to the baseline since our proposed method does not need additional forward propagation for the increased samples.
Appendix F Broader Impact and Limitation
We believe our DADA work would serve as an excellent example to inspire other researchers on proxy-based DML to focus on capturing space distributions. By investigating more solutions to compare and align the domains, future contributions would further push their limits under an aligned space with unique data distribution. The possible limitation of DADA is its learning efficiency on datasets with a large number of classes, which may cause difficulty in extending to other learning paradigms, such as continuous learning. We will focus on this interesting challenge in future works.