Towards Inheritable Models for Open-Set Domain Adaptation
Abstract
There has been a tremendous progress in Domain Adaptation (DA) for visual recognition tasks. Particularly, open-set DA has gained considerable attention wherein the target domain contains additional unseen categories. Existing open-set DA approaches demand access to a labeled source dataset along with unlabeled target instances. However, this reliance on co-existing source and target data is highly impractical in scenarios where data-sharing is restricted due to its proprietary nature or privacy concerns. Addressing this, we introduce a practical DA paradigm where a source-trained model is used to facilitate adaptation in the absence of the source dataset in future. To this end, we formalize knowledge inheritability as a novel concept and propose a simple yet effective solution to realize inheritable models suitable for the above practical paradigm. Further, we present an objective way to quantify inheritability to enable the selection of the most suitable source model for a given target domain, even in the absence of the source data. We provide theoretical insights followed by a thorough empirical evaluation demonstrating state-of-the-art open-set domain adaptation performance. Our code is available at https://github.com/val-iisc/inheritune.
1 Introduction
Deep neural networks perform remarkably well when the training and the testing instances are drawn from the same distributions. However, they lack the capacity to generalize in the presence of a domain-shift [42] exhibiting alarming levels of dataset bias or domain bias [45]. As a result, a drop in performance is observed at test time if the training data (acquired from a source domain) is insufficient to reliably characterize the test environment (the target domain). This challenge arises in several Computer Vision tasks [32, 25, 18] where one is often confined to a limited array of available source datasets, which are practically inadequate to represent a wide range of target domains. This has motivated a line of Unsupervised Domain Adaptation (UDA) works that aim to generalize a model to an unlabeled target domain, in the presence of a labeled source domain.
In this work, we study UDA in the context of image recognition. Notably, a large body of UDA methods is inspired by the potential of deep CNN models to learn transferable representations [52]. This has formed the basis of several UDA works that learn domain-agnostic feature representations [26, 44, 48] by aligning the marginal distributions of the source and the target domains in the latent feature space. Several other works learn domain-specific representations via independent domain transformations [47, 5, 32] to a common latent space on which the classifier is learned. The latent space alignment of the two domains permits the reuse of the source classifier for the target domain. These methods however operate under the assumption of a shared label-set () between the two domains (closed-set). This restricts their real-world applicability where a target domain often contains additional unseen categories beyond those found in the source domain.
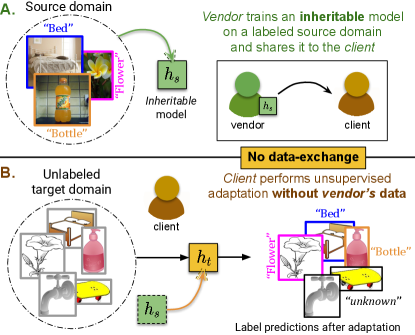
Recently, open-set DA [35, 39] has gained much attention, wherein the target domain is assumed to have unshared categories (), a.k.a category-shift. Target instances from the unshared categories are assigned a single unknown label [35] (see Fig. 1B). Open-set DA is more challenging, since a direct application of distribution alignment (e.g. as in closed-set DA [20, 44]) reduces the model’s performance due to the interference from the unshared categories (an effect known as negative-transfer [34]). The success of open-set DA relies not only on the alignment of shared classes, but also on the ability to mitigate negative-transfer. State-of-the-art methods such as [53] train a domain discriminator using the source and the target data to detect and reject target instances that are out of the source distribution, thereby minimizing the effect of negative-transfer.
In summary, the existing UDA methods assume access to a labeled source dataset to obliquely receive a task-specific supervision during adaptation. However, this assumption of co-existing source and target datasets poses a significant constraint in the modern world, where coping up with strict digital privacy and copyright laws is of prime importance [33]. This is becoming increasingly evident in modern corporate dealings, especially in the medical and biometric industries, where a source organization (the model vendor) is often restricted to share its proprietary or sensitive data, alongside a pre-trained model to satisfy the client’s specific deployment requirements [7, 14]. Likewise, the client is prohibited to share private data to the model vendor [17]. Certainly, the collection of existing open-set DA solutions is inadequate to address such scenarios.
Thus, there is a strong motivation to develop practical UDA algorithms which make no assumption about data-exchange between the vendor and the client. One solution is to design self-adaptive models that effectively capture the task-specific knowledge from the vendor’s source domain and transfer this knowledge to the client’s target domain. We call such models as inheritable models, referring to their ability to inherit and transfer knowledge across domains without accessing the source domain data. It is also essential to quantify the knowledge inheritability of such models. Given an array of inheritable models, this quantification will allow a client to flexibly choose the most suitable model for the client’s specific target domain.
Addressing these concerns, in this work we demonstrate how a vendor can develop an inheritable model, which can be effectively utilized by the client to perform unsupervised adaptation to the target domain, without any data-exchange. To summarize, our prime contributions are:
-
•
We propose a practical UDA scenario by relaxing the assumption of co-existing source and target domains, called as the vendor-client paradigm.
-
•
We propose inheritable models to realize vendor-client paradigm in practice and present an objective measure of inheritability, which is crucial for model selection.
-
•
We provide theoretical insights and extensive empirical evaluation to demonstrate state-of-the-art open-set DA performance using inheritable models.
2 Related Work
Closed-set DA. Assuming a shared label space (), the central theme of these methods is to minimize the distribution discrepancy. Statistical measures such as MMD [51, 27, 28], CORAL [44] and adversarial feature matching techniques [10, 48, 46, 47, 40] are widely used. Recently, domain specific normalization techniques [23, 5, 4, 37] has started gaining attention. However, due to the shared label-set assumption these methods are highly prone to negative-transfer in the presence of new target categories.
Open-set DA. ATI- [35] assigns a pseudo class label, or an unknown label, to each target instance based on its distance to each source cluster in the latent space. OSVM [15] uses a class-wise confidence threshold to classify target instances into the source classes, or reject them as unknown. OSBP [39] and STA [24] align the source and target features through adversarial feature matching. However, both OSBP and ATI- are hyperparameter sensitive and are prone to negative-transfer. In contrast, STA [24] learns a separate network to obtain instance-level weights for target samples to avoid negative-transfer and achieves state-of-the-art results. All these methods assume the co-existance of source and target data, while our method makes no such assumption and hence has a greater practical significance.
Domain Generalization. Methods such as [9, 21, 8, 22, 31, 16] largely rely on an arbitrary number of co-existing source domains with shared label sets, to generalize across unseen target domains. This renders them impractical when there is an inherent category-shift among the data available with each vendor. In contrast, we tackle the challenging open-set scenario by learning on a single source domain.
Data-free Knowledge Distillation (KD). In a typical KD setup [13], a student model is learned to match the teacher model’s output. Recently, DFKD [29] and ZSKD [33] demonstrated knowledge transfer to the student when the teacher’s training data is not available. Our work is partly inspired by their data-free ideology. However, our work differs from KD in two substantial ways; 1) by nature of the KD algorithm, it does not alleviate the problem of domain-shift, since any domain bias exhibited by the teacher will be passed on to the student, and 2) KD can only be performed for the task which the teacher is trained on, and is not designed for recognizing new (unknown) target categories in the absence of labeled data. Handling domain-shift and category-shift simultaneously is necessary for any open-set DA algorithm, which is not supported by these methods.
Our formulation of an inheritable model for open-set DA is much different from prior arts - not only is it robust to negative-transfer but also facilitates domain adaptation in the absence of data-exchange.
3 Unsupervised Open-Set Domain Adaptation
In this section, we formally define the vendor-client paradigm and inheritability in the context of unsupervised open-set domain adaptation (UODA).
3.1 Preliminaries
Notation. Given an input space and output space , the source and target domains are characterized by the distributions and on respectively. Let , denote the marginal input distributions and denote the conditional output distribution of the two domains. Let denote the respective label sets for the classification tasks (). In the UODA problem, a labeled source dataset and an unlabeled target dataset are considered. The goal is to assign a label for each target instance , by predicting the class for those in shared classes (), and an ‘unknown’ label for those in unshared classes (). For simplicity, we denote the distributions of target-shared and target-unknown instances as and respectively. We denote the model trained on the source domain as (source predictor) and the model adapted to the target domain as (target predictor).
Performance Measure. The primary goal of UODA is to improve the performance on the target domain. Hence, the performance of any UODA algorithm is measured by the error rate of target predictor , i.e. which is empirically estimated as , where is the probability estimated over the instances .
3.2 The vendor-client paradigm
The central focus of our work is to realize a practical DA paradigm which is fundamentally viable in the absence of the co-existance of the source and target domains. With this intent, we formalize our DA paradigm.
Definition 1 (vendor-client paradigm). Consider a vendor with access to a labeled source dataset and a client having unlabeled instances sampled from the target domain. In the vendor-client paradigm, the vendor learns a source predictor using to model the conditional , and shares to the client. Using and , the client learns a target predictor to model the conditional .
This paradigm satisfies the two important properties; 1) it does not assume data-exchange between the vendor and the client which is fundamental to cope up with the dynamically reforming digital privacy and copyright regulations and, 2) a single vendor model can be shared with multiple clients thereby minimizing the effort spent on source training. Thus, this paradigm has a greater practical significance than the traditional UDA setup where each adaptation step requires an additional supervision from the source data [24, 39]. Following this paradigm, our goal is to realize the conditions on which one can successfully learn a target predictor. To this end, we formalize the inheritability of task-specific knowledge of the source-trained model.
3.3 Inheritability
We define an inheritable model from the perspective of learning a predictor () for the target task. Intuitively, given a hypothesis class , an inheritable model should be sufficient (i.e. in the absence of source domain data) to learn a target predictor whose performance is close to that of the best predictor in .
Definition 2 (Inheritability criterion). Let be a hypothesis class, , and . A source predictor is termed inheritable relative to the hypothesis class , if a target predictor can be learned using an unlabeled target sample when given access to the parameters of , such that, with probability at least the target error of does not exceed that of the best predictor in by more than . Formally,
| (1) |
where, and is computed over the choice of sample . This definition suggests that an inheritable model is capable of reliably transferring the task-specific knowledge to the target domain in the absence of the source data, which is necessary for the vendor-client paradigm. Given this definition, a natural question is, how to quantify inheritability of a vendor model for the target task. In the next Section, we address this question by demonstrating the design of inheritable models for UODA.
4 Approach
How to design inheritable models? There can be several ways, depending upon the task-specific knowledge required by the client. For instance, in UODA, the client must effectively learn a classifier in the presence of both domain-shift and category-shift. Here, not only is the knowledge of class-separability essential, but also the ability to detect new target categories as unknown is vital to avoid negative-transfer. By effectively identifying such challenges, one can develop inheritable models for tasks that require vendor’s dataset. Here, we demonstrate UODA using an inheritable model.
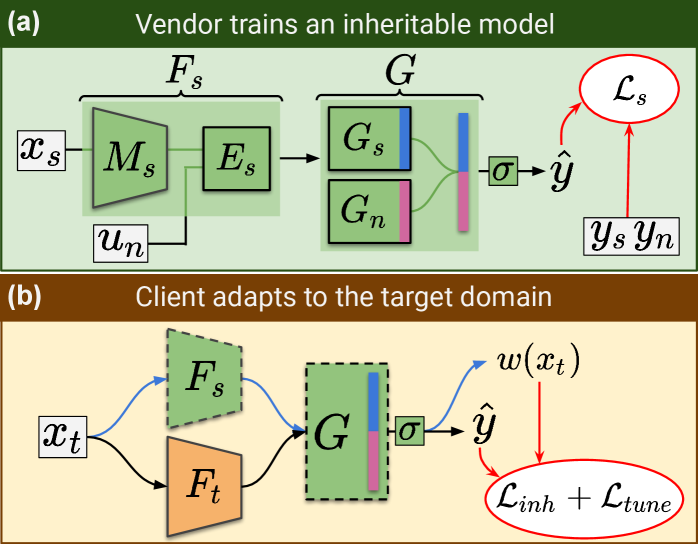
4.1 Vendor trains an inheritable model
In UODA, the primary challenge is to tackle negative-transfer. This challenge arises due to the overconfidence issue [19] in deep models, where unknown target instances are confidently predicted into the shared classes, and thus get aligned with the source domain. Methods such as [53] tend to avoid negative-transfer by leveraging a domain discriminator to assign a low instance-level weight for potentially unknown target instances during adaptation. However, solutions such as a domain discriminator are infeasible in the absence of data-exchange between the vendor and the client. Thus, an inheritable model should have the ability to characterize the source distribution, which will facilitate the detection of unknown target instances during adaptation. Following this intuition, we design the architecture.
a) Architecture. As shown in Fig. 2A, the feature extractor comprises of a backbone CNN model and fully connected layers . The classifier contains two sub-modules, a source classifier with classes, and an auxiliary out-of-distribution (OOD) classifier with classes accounting for the ‘negative’ region not covered by the source distribution (Fig. 3C). The output for each input is obtained by concatenating the outputs of and (i.e. concatenating and ) followed by softmax activation. This equips the model with the ability to capture the class-separability knowledge (in ) and to detect OOD instances (via ). This setup is motivated by the fact that the overconfidence issue can be addressed by minimizing the classifier’s confidence for OOD instances [19]. Accordingly, the confidence of is maximized for in-distribution (source) instances, and minimized for OOD instances (by maximizing the confidence of ).
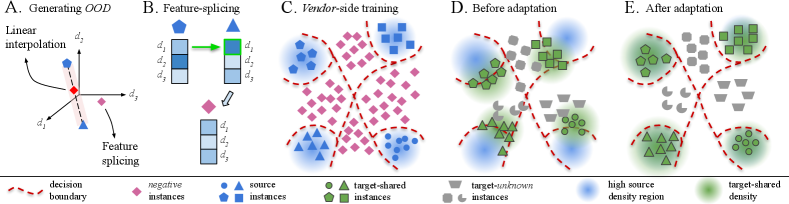
b) Dataset preparation. To effectively learn OOD detection, we augment the source dataset with synthetically generated negative instances, i.e. , where and are the marginal latent space distribution and the conditional output distribution of the negative instances respectively. We use , to model the low source-density region as out-of-distribution (see Fig. 3C). To obtain , a possible approach explored by [19] could be to use a GAN framework to generate ‘boundary’ samples. However, this is computationally intensive and introduces additional parameters for training. Further, we require these negative samples to cover a large portion of the OOD region. This eliminates a direct use of linear interpolation techniques such as mixup [55, 50] which result in features generated within a restricted region (see Fig. 3A). Indeed, we propose an efficient way to generate OOD samples, which we call as the feature-splicing technique.
Feature-splicing. It is widely known that in deep CNNs, higher convolutional layers specialize in capturing class-discriminative properties [54]. For instance, [56] assigns each filter in a high conv-layer with an object part, demonstrating that each filter learns a different class-specific trait. As a result of this specificity, especially when a rectified activation function (e.g. ReLU) is used, feature maps receive a high activation whenever the learned class-specific trait is observed in the input [6]. Consequently, we argue that, by suppressing such high activations, we obtain features devoid of the properties specific to the source classes and hence would more accurately represent the OOD samples. Then, enforcing a low classifier confidence for these samples can mitigate the overconfidence issue.
Feature-splicing is performed by replacing the top- percentile activations, at a particular feature layer, with the corresponding activations pertaining to an instance belonging to a different class (see Fig. 3B). Formally,
| (2) |
where, for a source image belonging to class , and is the feature-splicing operator which replaces the top- percentile activations in the feature with the corresponding activations in as shown in Fig. 3B (see Suppl. for algorithm). This process results in a feature which is devoid of the class-specific traits, but lies near the source distribution. To label these negative instances, we perform a -means clustering and assign a unique negative class label to each cluster of samples. By training the auxiliary classifier to discriminate these samples into these negative classes, we mitigate the overconfidence issue as stated earlier. We found feature-splicing to be effective in practice. See Suppl. for other techniques that we explored.
c) Training procedure. We train the model in two steps. First, we pre-train using source data by employing the standard cross-entropy loss,
| (3) |
where, is the softmax activation function. Next, we freeze the backbone model , and generate negative instances by performing feature-splicing using source features at the last layer of . We then continue the training of the modules using supervision from both and ,
| (4) |
where, and , and the output of is obtained as described in Sec. 4.1a (and depicted in Fig. 2). The joint training of and , allows the model to capture the class-separability knowledge (in ) while characterizing the negative region (in ), which renders a superior knowledge inheritability. Once the inheritable model is trained, it is shared to the client for performing UODA.
4.2 Client adapts to the target domain
With a trained inheritable model () in hand, the first task is to measure the degree of domain-shift to determine the inheritability of the vendor’s model. This is followed by a selective adaptation procedure which encourages shared classes to align while avoiding negative-transfer.
a) Quantifying inheritability. In presence of a small domain-shift, most of the target-shared instances (pertaining to classes in ) will lie close to the high source-density regions in the latent space (e.g. Fig. 3E). Thus, one can rely on the class-separability knowledge of to predict target labels. However, this knowledge becomes less reliable with increasing domain-shift as the concentration of target-shared instances near the high density regions decreases (e.g. Fig. 3D). Thus, the inheritability of for the target task would decrease with increasing domain-shift. Moreover, target-unknown instances (pertaining to classes in ) are more likely to lie in the low source-density region than target-shared instances. With this intuition, we define an inheritability metric which satisfies,
| (5) |
We leverage the classifier confidence to realize an instance-level measure of inheritability as follows,
| (6) |
where is the softmax activation function. Note that although softmax is applied over the entire output of , is evaluated over those corresponding to (shaded in blue in Fig. 2). We hypothesize that this measure follows Eq. 5, since, the source instances (in the high density region) receive the highest confidence, followed by target-shared instances (some of which are away from the high density region), while the target-unknown instances receive the least confidence (many of which lie away from the high density regions). Extending the instance-level inheritability, we define a model inheritability over the entire target dataset as,
| (7) |
A higher arises from a smaller domain-shift implying a greater inheritability of task-specific knowledge (e.g. class-separability for UODA) to the target domain. Note that is a constant for a given triplet and the value of the denominator in Eq. 7 can be obtained from the vendor.
b) Adaptation procedure. For performing adaptation to the target domain, we learn a target-specific feature extractor as shown in Fig. 2B (similar in architecture to ). is initialized from the source feature extractor , and is gradually trained to selectively align the shared classes in the pre-classifier space (input to ) to avoid negative-transfer. The adaptation involves two processes - inherit (to acquire the class-separability knowledge) and tune (to avoid negative-transfer).
Inherit. As described in Sec. 4.2a, the class-separability knowledge of is reliable for target samples with high . Subsequently, we choose top- percentile target instances based on and obtain pseudo-labels using the source model, . Using the cross-entropy loss we enforce the target predictions to match the pseudo-labels for these instances, thereby inheriting the class-separability knowledge,
| (8) |
Tune. In the absence of label information, entropy minimization [27, 11] is popularly employed to move the features of unlabeled instances towards the high confidence regions. However, to avoid negative-transfer, instead of a direct application of entropy minimization, we use as a soft instance weight in our loss formulation. Target instances with higher are guided towards the high source density regions, while those with lower are pushed into the negative regions (see Fig. 3DE). This separation is a key to minimize the effect of negative-transfer.
On a coarse level, using the classifier we obtain the probability that an instance belongs to the shared classes as . Optimizing the following loss encourages a separation of shared and unknown classes,
| (9) |
To further encourage the alignment of shared classes on a fine level, we separately calculate probability vectors for as, , and for as, , and minimize the following loss,
| (10) |
where, is the Shannon’s entropy. The total loss selectively aligns the shared classes, while avoiding negative-transfer. Thus, the final adaptation loss is,
| (11) |
We now present a discussion on the success of this adaptation procedure from the theoretical perspective.
4.3 Theoretical Insights
We defined the inheritability criterion in Eq. 1 for transferring the task-specific knowledge to the target domain. To show that the knowledge of class-separability is indeed inheritable, it is sufficient to demonstrate that the inheritability criterion holds for the shared classes. Extending Theorem 3 in [1], we obtain the following result.
Result 1. Let be a hypothesis class of VC dimension . Let be a labeled sample set of points drawn from . If be the empirical minimizer of on , and be the optimal hypothesis for , then for any , we have with probability of at least (over the choice of samples),
| (12) |
See Supplementary for the derivation of this result. Essentially, using labeled target-shared instances, one can train a predictor (here, ) which satisfies Eq. 12. However, in a completely unsupervised setting, the only way to obtain target labels is to exploit the knowledge of the vendor’s model. This is precisely what the pseudo-labeling process achieves. Using an inheritable model (), we pseudo-label the top- percentile target instances with high precision and enforce . In doing so, we condition the target model to satisfy Eq. 12, which is the inheritability criterion for shared categories (given unlabeled instances and source model ). Thus, the knowledge of class-separability is transferred to the target model during the adaptation process.
Note that, with increasing number of labeled target instances (increasing ), the last term in Eq. 12 decreases. In our formulation, this is achieved by enforcing , which can be regarded as a way to self-supervise the target model. In Sec. 5 we verify that, during adaptation the precision of target predictions improves over time. This self-supervision with an increasing number of correct labels is, in effect, similar to having a larger sample size in Eq. 12. Thus, adaptation tightens the bound in Eq. 12 (see Suppl.).
5 Experiments
In this section, we evaluate the performance of unsupervised open-set domain adaptation using inheritable models.
| Method | AW | AD | DW | WD | DA | WA | Avg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OS | OS* | OS | OS* | OS | OS* | OS | OS* | OS | OS* | OS | OS* | OS | OS* | |
| ResNet | 82.51.2 | 82.70.9 | 85.20.3 | 85.50.9 | 94.10.3 | 94.30.7 | 96.60.2 | 97.00.4 | 71.61.0 | 71.51.1 | 75.51.0 | 75.21.6 | 84.2 | 84.4 |
| RTN [27] | 85.61.2 | 88.11.0 | 89.51.4 | 90.11.6 | 94.80.3 | 96.20.7 | 97.10.2 | 98.70.9 | 72.30.9 | 72.81.5 | 73.50.6 | 73.91.4 | 85.4 | 86.8 |
| DANN [10] | 85.30.7 | 87.71.1 | 86.50.6 | 87.70.6 | 97.50.2 | 98.30.5 | 99.50.1 | 100.0.0 | 75.71.6 | 76.20.9 | 74.91.2 | 75.60.8 | 86.6 | 87.6 |
| OpenMax [3] | 87.40.5 | 87.50.3 | 87.10.9 | 88.40.9 | 96.10.4 | 96.20.3 | 98.40.3 | 98.50.3 | 83.41.0 | 82.10.6 | 82.80.9 | 82.80.6 | 89.0 | 89.3 |
| ATI- [35] | 87.41.5 | 88.91.4 | 84.31.2 | 86.61.1 | 93.61.0 | 95.31.0 | 96.50.9 | 98.70.8 | 78.01.8 | 79.61.5 | 80.41.4 | 81.41.2 | 86.7 | 88.4 |
| OSBP [39] | 86.52.0 | 87.62.1 | 88.61.4 | 89.21.3 | 97.01.0 | 96.50.4 | 97.90.9 | 98.70.6 | 88.92.5 | 90.62.3 | 85.82.5 | 84.91.3 | 90.8 | 91.3 |
| STA [24] | 89.50.6 | 92.10.5 | 93.71.5 | 96.1 0.4 | 97.50.2 | 96.50.5 | 99.50.2 | 99.60.1 | 89.10.5 | 93.50.8 | 87.90.9 | 87.40.6 | 92.9 | 94.1 |
| Ours | 91.30.7 | 93.21.2 | 94.21.1 | 97.10.8 | 96.50.5 | 97.40.7 | 99.50.2 | 99.40.3 | 90.10.2 | 91.5 0.2 | 88.71.3 | 88.10.9 | 93.4 | 94.5 |
| Method | ArCl | PrCl | RwCl | ArPr | ClPr | RwPr | ClAr | PrAr | RwAr | ArRw | ClRw | PrRw | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet | 53.40.4 | 52.70.6 | 51.90.5 | 69.30.7 | 61.80.5 | 74.10.4 | 61.40.6 | 64.00.3 | 70.00.3 | 78.70.6 | 71.00.6 | 74.90.9 | 65.3 |
| ATI- [35] | 55.21.2 | 52.61.6 | 53.51.4 | 69.11.1 | 63.51.5 | 74.11.5 | 61.71.2 | 64.50.9 | 70.70.5 | 79.20.7 | 72.90.7 | 75.81.6 | 66.1 |
| DANN [10] | 54.60.7 | 49.71.6 | 51.91.4 | 69.51.1 | 63.51.0 | 72.90.8 | 61.91.2 | 63.31.0 | 71.31.0 | 80.20.8 | 71.70.4 | 74.20.4 | 65.4 |
| OSBP [39] | 56.71.9 | 51.52.1 | 49.22.4 | 67.51.5 | 65.51.5 | 74.01.5 | 62.52.0 | 64.81.1 | 69.31.1 | 80.60.9 | 74.72.2 | 71.51.9 | 65.7 |
| OpenMax [3] | 56.50.4 | 52.90.7 | 53.70.4 | 69.10.3 | 64.80.4 | 74.50.6 | 64.10.9 | 64.00.8 | 71.20.8 | 80.30.8 | 73.00.5 | 76.90.3 | 66.7 |
| STA [24] | 58.10.6 | 53.10.9 | 54.41.0 | 71.61.2 | 69.31.0 | 81.90.5 | 63.40.5 | 65.20.8 | 74.91.0 | 85.00.2 | 75.80.4 | 80.80.3 | 69.5 |
| Ours | 60.10.7 | 54.21.0 | 56.21.7 | 70.91.4 | 70.01.7 | 78.60.6 | 64.00.6 | 66.11.3 | 74.90.9 | 83.20.9 | 75.71.3 | 81.31.4 | 69.6 |
| Method | Synthetic Real | |||||||
|---|---|---|---|---|---|---|---|---|
| bicycle | bus | car | m-cycle | train | truck | OS | OS* | |
| OSVM [15] | 31.7 | 51.6 | 66.5 | 70.4 | 88.5 | 20.8 | 52.5 | 54.9 |
| MMD+OSVM | 39.0 | 50.1 | 64.2 | 79.9 | 86.6 | 16.3 | 54.4 | 56.0 |
| DANN+OSVM | 31.8 | 56.6 | 71.7 | 77.4 | 87.0 | 22.3 | 55.5 | 57.8 |
| ATI- [35] | 46.2 | 57.5 | 56.9 | 79.1 | 81.6 | 32.7 | 59.9 | 59.0 |
| OSBP [39] | 51.1 | 67.1 | 42.8 | 84.2 | 81.8 | 28.0 | 62.9 | 59.2 |
| STA [24] | 52.4 | 69.6 | 59.9 | 87.8 | 86.5 | 27.2 | 66.8 | 63.9 |
| Ours | 53.5 | 69.2 | 62.2 | 85.7 | 85.4 | 32.5 | 68.1 | 64.7 |
5.1 Experimental Details
a) Datasets. Office-31 [38] consists of 31 categories of images in three different domains: Amazon (A), Webcam (W) and DSLR (D). Office-Home [49] is a more challenging dataset containing 65 classes from four domains: Real World (Re), Art (Ar), Clipart (Cl) and Product (Pr). VisDA [36] comprises of 12 categories of images from two domains: Real (R), Synthetic (S). The label sets , are in line with [24] and [39] for all our comparisons. See Suppl. for sample images and further details.
b) Implementation. We implement the framework in PyTorch and use ResNet-50 [12] (till the last pooling layer) as the backbone models and for Office-31 and Office-Home, and VGG-16 [43] for VisDA. For inheritable model training, we use a batch size of ( source and negative instances each), and use the hyperparameters and . During adaptation, we use a batch size of 32 and set the hyperparameter . We normalize the instance weights with the weight of each batch , i.e. . During inference, an unknown label is assigned if is one of the negative classes, otherwise, a shared class label is predicted. See Supplementary for more details.
c) Metrics. In line with [39], we compute the open-set accuracy (OS) by averaging the class-wise target accuracy for classes (considering target-unknown as a single class). Likewise, the shared accuracy (OS*) is computed as the class-wise average of target-shared classes ().
5.2 Results
a) State-of-the-art comparison. In Tables 1-3, we compare against the state-of-the-art UODA method STA [24]. The results for other methods are taken from [24]. Particularly, in Table 1, we report the mean and std. deviation of OS and OS* over 3 separate runs. Due to space constraints, we report only OS in Table 2. It is evident that adaptation using an inheritable model outperforms prior arts that assume access to both vendor’s data (source domain) and client’s data (target domain) simultaneously. The superior performance of our method over STA is described as follows. STA learns a domain-agnostic feature extractor by aligning the two domains using an adversarial discriminator. This restricts the model’s flexibility to capture the diversity in the target domain, owing to the need to generalize across two domains, on top of the added training difficulties of the adversarial process. In contrast, we employ a target-specific feature extractor () which allows the target predictor to effectively tune to the target domain, while inheriting the class-separability knowledge. Thus, inheritable models offer an effective solution for UODA in practice.
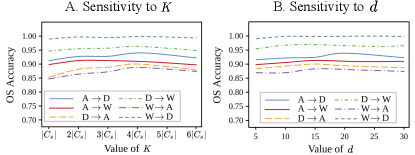
b) Hyperparameter sensitivity. In Fig. 4, we plot the adaptation performance (OS) on a range of hyperparameter values used to train the vendor’s model (, ). A low sensitivity to these hyperparameters highlights the reliability of the inheritable model. In Fig. 5C, we plot the adaptation performance (OS) on a range of values for on Office-31. Specifically, denotes the ablation where is not enforced. Clearly, the performance improves on increasing which corroborates the benefit of inheriting class-separability knowledge during adaptation.
c) Openness (). In Fig. 5A, we report the OS accuracy on varying levels of Openness [41] . Our method performs well for a wide range of Openness, owing to the ability to effectively mitigate negative-transfer.
d) Domain discrepancy. As discussed in [2], the empirical domain discrepancy can be approximated using the Proxy -distance where is the generalization error of a domain discriminator. We compute the PAD value at the pre-classifier space for both target-shared and target-unknown instances in Fig. 6B following the procedure laid out in [10]. The PAD value evaluated for target-shared instances using our model is much lower than a source-trained ResNet-50 model, while that for target-unknown is higher than a source-trained ResNet-50 model. This suggests that adaptation aligns the source and the target-shared distributions, while separating out the target-unknown instances.
5.3 Discussion

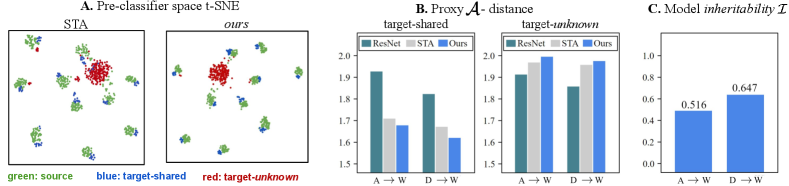
a) Model inheritability (). Following the intuition in Sec. 4.2a, we evaluate the model inheritability () for the tasks DW and AW on Office-31. In Fig. 6C we observe that for the target W, an inheritable model trained on the source D exhibits a higher value than that trained on the source A. Consequently, the adaptation task DW achieves a better performance than AW, suggesting that a vendor model with a higher model inheritability is a better candidate to perform adaptation to a given target domain. Thus, given an array of inheritable vendor models, a client can reliably choose the most suitable model for the target domain by measuring . The ability to choose a vendor model without requiring the vendor’s source data enables the application of the vendor-client paradigm in practice.
b) Instance-level inheritability (). In Fig. 5D, we show the histogram of values plotted separately for target-shared and target-unknown instances, for the task AD in Office-31 dataset. This empirically validates our intuition that the classifier confidence of an inheritable model follows the inequality in Eq. 5, at least for the extent of domain-shift in the available standard datasets.
c) Reliability of . Due to the mitigation of overconfidence issue, we find the classifier confidence to be a good candidate for selecting target sample for pseudo-labeling. In Fig. 5B, we plot the prediction accuracy of the top- percentile target instances based on target predictor confidence (). Particularly, the plot for epoch- shows the pseudo-labeling precision, since the target predictor is initialized with the parameters of the source predictor. It can be seen that the top-15 percentile samples are predicted with a precision close to 1. As adaptation proceeds, improves the prediction performance of the target model, which can be seen as a rise in the plot in Fig. 5B. Therefore, the bound in Eq. 12 is tightened during adaptation. This verifies our intuition in Sec. 4.3
d) Qualitative results. In Fig. 6A we plot the t-SNE [30] embeddings of the last hidden layer (pre-classifier) features of a target predictor trained using STA [24] and our method, on the task AD. Clearly, our method performs equally well in spite of the unavailability of source data during adaptation, suggesting that inheritable models can indeed facilitate adaptation in the absence of a source dataset.
e) Training time analysis. We show the benefit of using inheritable models, over a source dataset. Consider a vendor with a labeled source domain A, and two clients with the target domains D and W respectively. Using the state-of-the-art method STA [24] (which requires labeled source dataset), the time spent by each client for adaptation using source data is 575s on an average (1150s in total). In contrast, our method (a single vendor model is shared with both the clients) results in 250s of vendor’s source training time (feature-splicing: 77s, -means: 66s, training: 154s), and an average of 69s for adaptation by each client (138s in total). Thus, inheritable models provide a much more efficient pipeline by reducing the cost on source training in the case of multiple clients (STA: 1150s, ours: 435s). See Supplementary for experiment details.
6 Conclusion
In this paper we introduced a practical vendor-client paradigm, and proposed inheritable models to address open-set DA in the absence of co-existing source and target domains. Further, we presented an objective way to measure inheritability which enables the selection of a suitable source model for a given target domain without the need to access source data. Through extensive empirical evaluation, we demonstrated state-of-the-art open-set DA performance using inheritable models. As a future work, inheritable models can be extended to problems involving multiple vendors and multiple clients.
Acknowledgements. This work is supported by a Wipro PhD Fellowship (Jogendra) and a grant from Uchhatar Avishkar Yojana (UAY, IISC_010), MHRD, Govt. of India.
References
- [1] Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains. Machine learning, 79(1-2):151–175, 2010.
- [2] Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adaptation. In NeurIPS, 2007.
- [3] Abhijit Bendale and Terrance E Boult. Towards open set deep networks. In CVPR, 2016.
- [4] Fabio Maria Cariucci, Lorenzo Porzi, Barbara Caputo, Elisa Ricci, and Samuel Rota Bulò. Autodial: Automatic domain alignment layers. In ICCV, 2017.
- [5] Woong-Gi Chang, Tackgeun You, Seonguk Seo, Suha Kwak, and Bohyung Han. Domain-specific batch normalization for unsupervised domain adaptation. In CVPR, 2019.
- [6] Hanting Chen, Yunhe Wang, Chang Xu, Zhaohui Yang, Chuanjian Liu, Boxin Shi, Chunjing Xu, Chao Xu, and Qi Tian. Data-free learning of student networks. In ICCV, 2019.
- [7] Boris Chidlovskii, Stéphane Clinchant, and Gabriela Csurka. Domain adaptation in the absence of source domain data. In ACM SIGKDD. ACM, 2016.
- [8] Zhengming Ding and Yun Fu. Deep domain generalization with structured low-rank constraint. IEEE Transactions on Image Processing, 27(1):304–313, 2017.
- [9] Antonio D’Innocente and Barbara Caputo. Domain generalization with domain-specific aggregation modules. In GCPR, 2018.
- [10] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. The Journal of Machine Learning Research, 17(1):2096–2030, 2016.
- [11] Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In NeurIPS, 2005.
- [12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [13] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [14] Nick Hynes, Raymond Cheng, and Dawn Song. Efficient deep learning on multi-source private data. arXiv preprint arXiv:1807.06689, 2018.
- [15] Lalit P Jain, Walter J Scheirer, and Terrance E Boult. Multi-class open set recognition using probability of inclusion. In ECCV, 2014.
- [16] Aditya Khosla, Tinghui Zhou, Tomasz Malisiewicz, Alexei A Efros, and Antonio Torralba. Undoing the damage of dataset bias. In ECCV, 2012.
- [17] Jakub Konečný, H. Brendan McMahan, Felix X. Yu, Peter Richtarik, Ananda Theertha Suresh, and Dave Bacon. Federated learning: Strategies for improving communication efficiency. In NeurIPS Workshop on Private Multi-Party Machine Learning, 2016.
- [18] Jogendra Nath Kundu, Nishank Lakkakula, and R Venkatesh Babu. Um-adapt: Unsupervised multi-task adaptation using adversarial cross-task distillation. In ICCV, 2019.
- [19] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin. Training confidence-calibrated classifiers for detecting out-of-distribution samples. In ICLR, 2018.
- [20] Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos. Mmd gan: Towards deeper understanding of moment matching network. In NeurIPS, 2017.
- [21] Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generalization. In ICCV, 2017.
- [22] Da Li, Jianshu Zhang, Yongxin Yang, Cong Liu, Yi-Zhe Song, and Timothy M Hospedales. Episodic training for domain generalization. In ICCV, 2019.
- [23] Yanghao Li, Naiyan Wang, Jianping Shi, Xiaodi Hou, and Jiaying Liu. Adaptive batch normalization for practical domain adaptation. Pattern Recognition, 80:109–117, 2018.
- [24] Hong Liu, Zhangjie Cao, Mingsheng Long, Jianmin Wang, and Qiang Yang. Separate to adapt: Open set domain adaptation via progressive separation. In CVPR, 2019.
- [25] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
- [26] Mingsheng Long, Yue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015.
- [27] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Unsupervised domain adaptation with residual transfer networks. In NeurIPS, 2016.
- [28] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Deep transfer learning with joint adaptation networks. In ICML, 2017.
- [29] Raphael Gontijo Lopes, Stefano Fenu, and Thad Starner. Data-free knowledge distillation for deep neural networks. In NeurIPS, 2017.
- [30] Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(Nov):2579–2605, 2008.
- [31] Krikamol Muandet, David Balduzzi, and Bernhard Schölkopf. Domain generalization via invariant feature representation. In ICML, 2013.
- [32] Jogendra Nath Kundu, Phani Krishna Uppala, Anuj Pahuja, and R Venkatesh Babu. Adadepth: Unsupervised content congruent adaptation for depth estimation. In CVPR, 2018.
- [33] Gaurav Kumar Nayak, Konda Reddy Mopuri, Vaisakh Shaj, Venkatesh Babu Radhakrishnan, and Anirban Chakraborty. Zero-shot knowledge distillation in deep networks. In ICML, 2019.
- [34] Sinno Jialin Pan and Qiang Yang. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2009.
- [35] Pau Panareda Busto and Juergen Gall. Open set domain adaptation. In ICCV, 2017.
- [36] Xingchao Peng, Ben Usman, Neela Kaushik, Judy Hoffman, Dequan Wang, and Kate Saenko. Visda: The visual domain adaptation challenge. In CVPRW, 2018.
- [37] Subhankar Roy, Aliaksandr Siarohin, Enver Sangineto, Samuel Rota Bulo, Nicu Sebe, and Elisa Ricci. Unsupervised domain adaptation using feature-whitening and consensus loss. In CVPR, 2019.
- [38] Kate Saenko, Brian Kulis, Mario Fritz, and Trevor Darrell. Adapting visual category models to new domains. In ECCV, 2010.
- [39] Kuniaki Saito, Shohei Yamamoto, Yoshitaka Ushiku, and Tatsuya Harada. Open set domain adaptation by backpropagation. In ECCV, 2018.
- [40] Swami Sankaranarayanan, Yogesh Balaji, Carlos D. Castillo, and Rama Chellappa. Generate to adapt: Aligning domains using generative adversarial networks. In CVPR, June 2018.
- [41] Walter J Scheirer, Anderson de Rezende Rocha, Archana Sapkota, and Terrance E Boult. Toward open set recognition. IEEE transactions on pattern analysis and machine intelligence, 35(7):1757–1772, 2012.
- [42] Hidetoshi Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function. Journal of statistical planning and inference, 90(2):227–244, 2000.
- [43] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- [44] Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. In ECCV, 2016.
- [45] A. Torralba and A. A. Efros. Unbiased look at dataset bias. In CVPR, 2011.
- [46] Eric Tzeng, Judy Hoffman, Trevor Darrell, and Kate Saenko. Simultaneous deep transfer across domains and tasks. In ICCV, 2015.
- [47] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017.
- [48] Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474, 2014.
- [49] Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. In CVPR, 2017.
- [50] Vikas Verma, Alex Lamb, Christopher Beckham, Amir Najafi, Ioannis Mitliagkas, David Lopez-Paz, and Yoshua Bengio. Manifold mixup: Better representations by interpolating hidden states. In ICML, 2019.
- [51] Hongliang Yan, Yukang Ding, Peihua Li, Qilong Wang, Yong Xu, and Wangmeng Zuo. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In CVPR, 2017.
- [52] Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? In NeurIPS. 2014.
- [53] Kaichao You, Mingsheng Long, Zhangjie Cao, Jianmin Wang, and Michael I. Jordan. Universal domain adaptation. In CVPR, June 2019.
- [54] Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014.
- [55] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. In ICLR, 2018.
- [56] Quanshi Zhang, Ying Nian Wu, and Song-Chun Zhu. Interpretable convolutional neural networks. In CVPR, 2018.
See pages 1-1 of suppl_inh.pdf See pages 2-2 of suppl_inh.pdf See pages 3-3 of suppl_inh.pdf See pages 4-4 of suppl_inh.pdf See pages 5-5 of suppl_inh.pdf
See pages 1-1 of main_paper_bib.pdf See pages 2-2 of main_paper_bib.pdf