Towards modular and programmable architecture search
Abstract
Neural architecture search methods are able to find high performance deep learning architectures with minimal effort from an expert [1]. However, current systems focus on specific use-cases (e.g. convolutional image classifiers and recurrent language models), making them unsuitable for general use-cases that an expert might wish to write. Hyperparameter optimization systems [2, 3, 4] are general-purpose but lack the constructs needed for easy application to architecture search. In this work, we propose a formal language for encoding search spaces over general computational graphs. The language constructs allow us to write modular, composable, and reusable search space encodings and to reason about search space design. We use our language to encode search spaces from the architecture search literature. The language allows us to decouple the implementations of the search space and the search algorithm, allowing us to expose search spaces to search algorithms through a consistent interface. Our experiments show the ease with which we can experiment with different combinations of search spaces and search algorithms without having to implement each combination from scratch. We release an implementation of our language with this paper111Visit https://github.com/negrinho/deep_architect for code and documentation..
1 Introduction
Architecture search has the potential to transform machine learning workflows. High performance deep learning architectures are often manually designed through a trial-and-error process that amounts to trying slight variations of known high performance architectures. Recently, architecture search techniques have shown tremendous potential by improving on handcrafted architectures, both by improving state-of-the-art performance and by finding better tradeoffs between computation and performance. Unfortunately, current systems fall short of providing strong support for general architecture search use-cases.
Hyperparameter optimization systems [2, 3, 4, 5] are not designed specifically for architecture search use-cases and therefore do not introduce constructs that allow experts to implement these use-cases efficiently, e.g., easily writing new search spaces over architectures. Using hyperparameter optimization systems for an architecture search use-case requires the expert to write the encoding for the search space over architectures as a conditional hyperparameter space and to write the mapping from hyperparameter values to the architecture to be evaluated. Hyperparameter optimization systems are completely agnostic that their hyperparameter spaces encode search spaces over architectures.
By contrast, architecture search systems [1] are in their infancy, being tied to specific use-cases (e.g., either reproducing results reported in a paper or concrete systems, e.g., for searching over Scikit-Learn pipelines [6]) and therefore lack support for general architecture search workflows. For example, current implementations of architecture search methods rely on ad-hoc encodings for search spaces, providing limited extensibility and programmability for new work to build on. For example, implementations of the search space and search algorithm are often intertwined, requiring substantial coding effort to try new search spaces or search algorithms.
Contributions
We describe a modular language for encoding search spaces over general computational graphs. We aim to improve the programmability, modularity, and reusability of architecture search systems. We are able to use the language constructs to encode search spaces in the literature. Furthermore, these constructs allow the expert to create new search spaces and modify existing ones in structured ways. Search spaces expressed in the language are exposed to search algorithms under a consistent interface, decoupling the implementations of search spaces and search algorithms. We showcase these functionalities by easily comparing search spaces and search algorithms from the architecture search literature. These properties will enable better architecture search research by making it easier to benchmark and reuse search algorithms and search spaces.
2 Related work
Hyperparameter optimization
Algorithms for hyperparameter optimization often focus on small or simple hyperparameter spaces (e.g., closed subsets of Euclidean space in low dimensions). Hyperparameters might be categorical (e.g., choice of regularizer) or continuous (e.g., learning rate and regularization constant). Gaussian process Bayesian optimization [7] and sequential model based optimization [8] are two popular approaches. Random search has been found to be competitive for hyperparameter optimization [9, 10]. Conditional hyperparameter spaces (i.e., where some hyperparameters may be available only for specific values of other hyperparameters) have also been considered [11, 12]. Hyperparameter optimization systems (e.g. Hyperopt [2], Spearmint [3], SMAC [5, 8] and BOHB [4]) are general-purpose and domain-independent. Yet, they rely on the expert to distill the problem into an hyperparameter space and write the mapping from hyperparameter values to implementations.
Architecture search
Contributions to architecture search often come in the form of search algorithms, evaluation strategies, and search spaces. Researchers have considered a variety of search algorithms, including reinforcement learning [13], evolutionary algorithms [14, 15], MCTS [16], SMBO [16, 17], and Bayesian optimization [18]. Most search spaces have been proposed for recurrent or convolutional architectures [13, 14, 15] focusing on image classification (CIFAR-10) and language modeling (PTB). Architecture search encodes much of the architecture design in the search space (e.g., the connectivity structure of the computational graph, how many operations to use, their type, and values for specifying each operation chosen). However, the literature has yet to provide a consistent method for designing and encoding such search spaces. Systems such as Auto-Sklearn [19], TPOT [20], and Auto-Keras [21] have been developed for specific use-cases (e.g., Auto-Sklearn and TPOT focus on classification and regression of featurized vector data, Auto-Keras focus on image classification) and therefore support relatively rigid workflows. The lack of focus on extensibility and programmability makes these systems unsuitable as frameworks for general architecture search research.
3 Proposed approach: modular and programmable search spaces
To maximize the impact of architecture search research, it is fundamental to improve the programmability of architecture search tools222cf. the effect of highly programmable deep learning frameworks on deep learning research and practice.. We move towards this goal by designing a language to write search spaces over computational graphs. We identify the following advantages for our language and search spaces encoded in it:
-
•
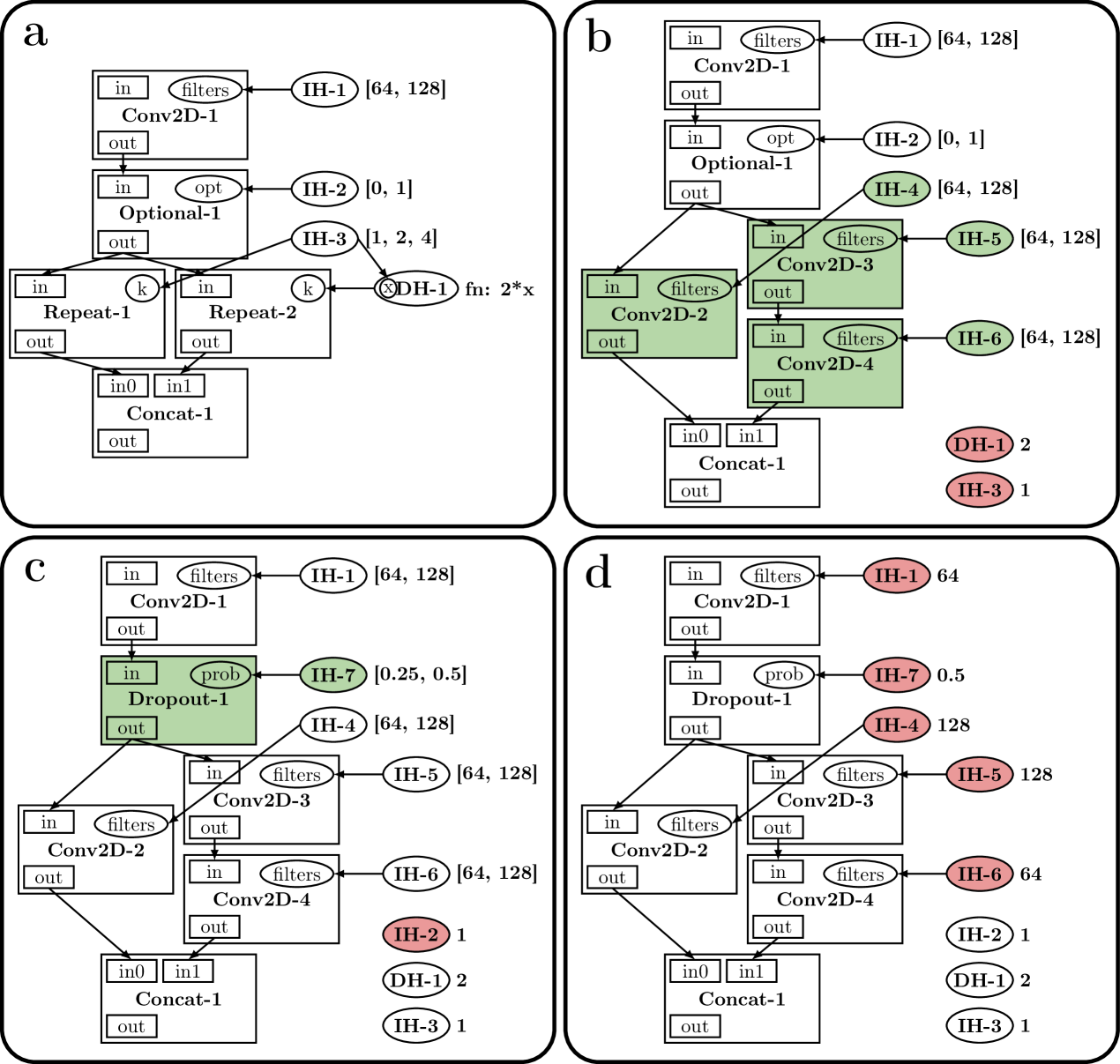
Similarity to computational graphs: Writing a search space in our language is similar to writing a fixed computational graph in an existing deep learning framework. The main difference is that nodes in the graph may be search spaces rather than fixed operations (e.g., see Figure 5). A search space maps to a single computational graph once all its hyperparameters have been assigned values (e.g., in frame d in Figure 5).
-
•
Modularity and reusability: The building blocks of our search spaces are modules and hyperparameters. Search spaces are created through the composition of modules and their interactions. Implementing a new module only requires dealing with aspects local to the module. Modules and hyperparameters can be reused across search spaces, and new search spaces can be written by combining existing search spaces. Furthermore, our language supports search spaces in general domains (e.g., deep learning architectures or Scikit-Learn [22] pipelines).
-
•
Laziness: A substitution module delays the creation of a subsearch space until all hyperparameters of the substitution module are assigned values. Experts can use substitution modules to encode natural and complex conditional constructions by concerning themselves only with the conditional branch that is chosen. This is simpler than the support for conditional hyperparameter spaces provided by hyperparameter optimization tools, e.g., in Hyperopt [2], where all conditional branches need to be written down explicitly. Our language allows conditional constructs to be expressed implicitly through composition of language constructs (e.g., nesting substitution modules). Laziness also allows us to encode search spaces that can expand infinitely, which is not possible with current hyperparameter optimization tools (see Appendix D.1).
-
•
Automatic compilation to runnable computational graphs: Once all choices in the search space are made, the single architecture corresponding to the terminal search space can be mapped to a runnable computational graph (see Algorithm 4). By contrast, for general hyperparameter optimization tools this mapping has to be written manually by the expert.
4 Components of the search space specification language
A search space is a graph (see Figure 5) consisting of hyperparameters (either of type independent or dependent) and modules (either of type basic or substitution). This section describes our language components and show encodings of simple search spaces in our Python implementation. Figure 5 and the corresponding search space encoding in Figure 4 are used as running examples. Appendix A and Appendix B provide additional details and examples, e.g. the recurrent cell search space of [23].
Independent hyperparameters
The value of an independent hyperparameter is chosen from its set of possible values. An independent hyperparameter is created with a set of possible values, but without a value assigned to it. Exposing search spaces to search algorithms relies mainly on iteration over and value assignment to independent hyperparameters. An independent hyperparameter in our implementation is instantiated as, for example, D([1, 2, 4, 8]). In Figure 5, IH-1 has set of possible values and is eventually assigned value (shown in frame d).
Dependent hyperparameters
The value of a dependent hyperparameter is computed as a function of the values of the hyperparameters it depends on (see line 7 of Algorithm 1). Dependent hyperparameters are useful to encode relations between hyperparameters, e.g., in a convolutional network search space, we may want the number of filters to increase after each spatial reduction. In our implementation, a dependent hyperparameter is instantiated as, for example, h = DependentHyperparameter(lambda dh: 2*dh["units"], {"units": h_units}). In Figure 5, in the transition from frame a to frame b, IH-3 is assigned value 1, triggering the value assignment of DH-1 according to its function fn:2*x.
Basic modules
A basic module implements computation that depends on the values of its properties. Search spaces involving only basic modules and hyperparameters do not create new modules or hyperparameters, and therefore are fixed computational graphs (e.g., see frames c and d in Figure 5). Upon compilation, a basic module consumes the values of its inputs, performs computation, and publishes the results to its outputs (see Algorithm 4). Deep learning layers can be wrapped as basic modules, e.g., a fully connected layer can be wrapped as a single-input single-output basic module with one hyperparameter for the number of units. In the search space in Figure 1, dropout, dense, and relu are basic modules. In Figure 5, both frames c and d are search spaces with only basic modules and hyperparameters. In the search space of frame d, all hyperparameters have been assigned values, and therefore the single architecture can be mapped to its implementation (e.g., in Tensorflow).
Substitution modules
Substitution modules encode structural transformations of the computational graph that are delayed333Substitution modules are inspired by delayed evaluation in programming languages. until their hyperparameters are assigned values. Similarly to a basic module, a substitution module has hyperparameters, inputs, and outputs. Contrary to a basic module, a substitution module does not implement computation—it is substituted by a subsearch space (which depends on the values of its hyperparameters and may contain new substitution modules). Substitution is triggered once all its hyperparameters have been assigned values. Upon substitution, the module is removed from the search space and its connections are rerouted to the corresponding inputs and outputs of the generated subsearch space (see Algorithm 1 for how substitutions are resolved). For example, in the transition from frame b to frame c of Figure 5, IH-2 was assigned the value and Dropout-1 and IH-7 were created by the substitution of Optional-1. The connections of Optional-1 were rerouted to Dropout-1. If IH-2 had been assigned the value , Optional-1 would have been substituted by an identity basic module and no new hyperparameters would have been created. Figure 2 shows a search space using two substitution modules: siso_or chooses between relu and tanh; siso_repeat chooses how many layers to include. siso_sequential is used to avoid multiple calls to connect as in Figure 1.
Auxiliary functions
Auxiliary functions, while not components per se, help create complex search spaces. Auxiliary functions might take functions that create search spaces and put them together into a larger search space. For example, the search space in Figure 3 defines an auxiliary RNN cell that captures the high-level functional dependency: and . We can instantiate a specific search space as rnn_cell(lambda: siso_sequential([concat(2), one_layer_net()]), multi_layer_net).
5 Example search space
We ground discussion textually, through code examples (Figure 4), and visually (Figure 5) through an example search space. There is a convolutional layer followed, optionally, by dropout with rate or . After the optional dropout layer, there are two parallel chains of convolutional layers. The first chain has length , , or , and the second chain has double the length of the first. Finally, the outputs of both chains are concatenated. Each convolutional layer has or filters (chosen separately). This search space has distinct models.
Figure 5 shows a sequence of graph transitions for this search space. IH and DH denote type identifiers for independent and dependent hyperparameters, respectively. Modules and hyperparameters types are suffixed with a number to generate unique identifiers. Modules are represented by rectangles that contain inputs, outputs, and properties. Hyperparameters are represented by ellipses (outside of modules) and are associated to module properties (e.g., in frame a, IH-1 is associated to filters of Conv2D-1). To the right of an independent hyperparameter we show, before assignment, its set of possible values and, after assignment, its value (e.g., IH-1 in frame a and in frame d, respectively). Similarly, for a dependent hyperparameter we show, before assignment, the function that computes its value and, after assignment, its value (e.g., DH-1 in frame a and in frame b, respectively). Frame a shows the initial search space encoded in Figure 4. From frame a to frame b, IH-3 is assigned a value, triggering the value assignment for DH-1 and the substitutions for Repeat-1 and Repeat-2. From frame b to frame c, IH-2 is assigned value 1, creating Dropout-1 and IH-7 (its dropout rate hyperparameter). Finally, from frame c to frame d, the five remaining independent hyperparameters are assigned values. The search space in frame d has a single architecture that can be mapped to an implementation in a deep learning framework.
6 Semantics and mechanics of the search space specification language
In this section, we formally describe the semantics and mechanics of our language and show how they can be used to implement search algorithms for arbitrary search spaces.
6.1 Semantics
Search space components
A search space has hyperparameters and modules . We distinguish between independent and dependent hyperparameters as and , where and , and basic modules and substitution modules as and , where and .
Hyperparameters
We distinguish between hyperparameters that have been assigned a value and those that have not as and . We have and . We denote the value assigned to an hyperparameter as , where and is the set of possible values for . Independent and dependent hyperparameters are assigned values differently. For , its value is assigned directly from . For , its value is computed by evaluating a function for the values of , where is the set of hyperparameters that depends on. For example, in frame a of Figure 5, for , . In frame b, and .
Modules
A module has inputs , outputs , and hyperparameters along with mappings assigning names local to the module to inputs, outputs, and hyperparameters, respectively, , , , where , , and , where is the set of all strings of alphabet . , , and are, respectively, the local names for the inputs, outputs, and hyperparameters of . Both and are bijective, and therefore, the inverses and exist and assign an input and output to its local name. Each input and output belongs to a single module. might not be injective, i.e., . A name captures the local semantics of in (e.g., for a convolutional basic module, the number of filters or the kernel size). Given an input , recovers the module that belongs to (analogously for outputs). For , we have and , but there might exist for which , i.e., two different modules might share hyperparameters but inputs and outputs belong to a single module. We use shorthands for and for . For example, in frame a of Figure 5, for we have: , , and ; and ( and are similar); . Output and inputs are identified by the global name of their module and their local name within their module joined by a dot, e.g.. Conv2D-1.in
Connections between modules
Connections between modules in are represented through the set of directed edges between outputs and inputs of modules in . We denote the subset of edges involving inputs of a module as , i.e., . Similarly, for outputs, . We denote the set of edges involving inputs or outputs of as . In frame of Figure 5, For example, in frame a of Figure 5, and .
Search spaces
We denote the set of all possible search spaces as . For a search space , we define , i.e., the set of reachable search spaces through a sequence of value assignments to independent hyperparameters (see Algorithm 1 for the description of Transition). We denote the set of terminal search spaces as , i.e. . We denote the set of terminal search spaces that are reachable from as . In Figure 5, if we let and be the search spaces in frame a and d, respectively, we have .
6.2 Mechanics
Search space transitions
A search space encodes a set of architectures (i.e., those in ). Different architectures are obtained through different sequences of value assignments leading to search spaces in . Graph transitions result from value assignments to independent hyperparameters. Algorithm 1 shows how the search space is computed, where and . Each transition leads to progressively smaller search spaces (i.e., for all for and , then ). A search space is reached once there are no independent hyperparameters left to assign values to, i.e., . For , , i.e., there are only basic modules left. For search spaces for which , we have (i.e., ) and for all , i.e., no new modules and hyperparameters are created as a result of graph transitions. Algorithm 1 can be implemented efficiently by checking whether assigning a value to triggered substitutions of neighboring modules or value assignments to neighboring hyperparameters. For example, for the search space of frame d of Figure 5, . Search spaces , , and for frames a, b, and c, respectively, are related as and . For the substitution resolved from frame b to frame c, for , we have and (see line 12 in Algorithm 1).
Traversals over modules and hyperparameters
Search space traversal is fundamental to provide the interface to search spaces that search algorithms rely on (e.g., see Algorithm 3) and to automatically map terminal search spaces to their runnable computational graphs (see Algorithm 4 in Appendix C). For , this iterator is implemented by using Algorithm 2 and keeping only the hyperparameters in . The role of the search algorithm (e.g., see Algorithm 3) is to recursively assign values to hyperparameters in until a search space is reached. Uniquely ordered traversal of relies on uniquely ordered traversal of . (We defer discussion of the module traversal to Appendix C, see Algorithm 5.)
Architecture instantiation
A search space can be mapped to a domain implementation (e.g. computational graph in Tensorflow [24] or PyTorch [25]). Only fully-specified basic modules are left in a terminal search space (i.e., and ). The mapping from a terminal search space to its implementation relies on graph traversal of the modules according to the topological ordering of their dependencies (i.e., if connects to an output of , then should be visited after ).
6.3 Supporting search algorithms
Search algorithms interface with search spaces through ordered iteration over unassigned independent hyperparameters (implemented with the help of Algorithm 2) and value assignments to these hyperparameters (which are resolved with Algorithm 1). Algorithms are run for a fixed number of evaluations , and return the best architecture found. The iteration functionality in Algorithm 2 is independent of the search space and therefore can be used to expose search spaces to search algorithms. We use this decoupling to mix and match search spaces and search algorithms without implementing each pair from scratch (see Section 7).
7 Experiments
We showcase the modularity and programmability of our language by running experiments that rely on decoupled of search spaces and search algorithms. The interface to search spaces provided by the language makes it possible to reuse implementations of search spaces and search algorithms.
7.1 Search space experiments
| Search Space | Test Accuracy |
|---|---|
| Genetic [26] | 90.07 |
| Flat [15] | 93.58 |
| Nasbench [27] | 94.59 |
| Nasnet [28] | 93.77 |
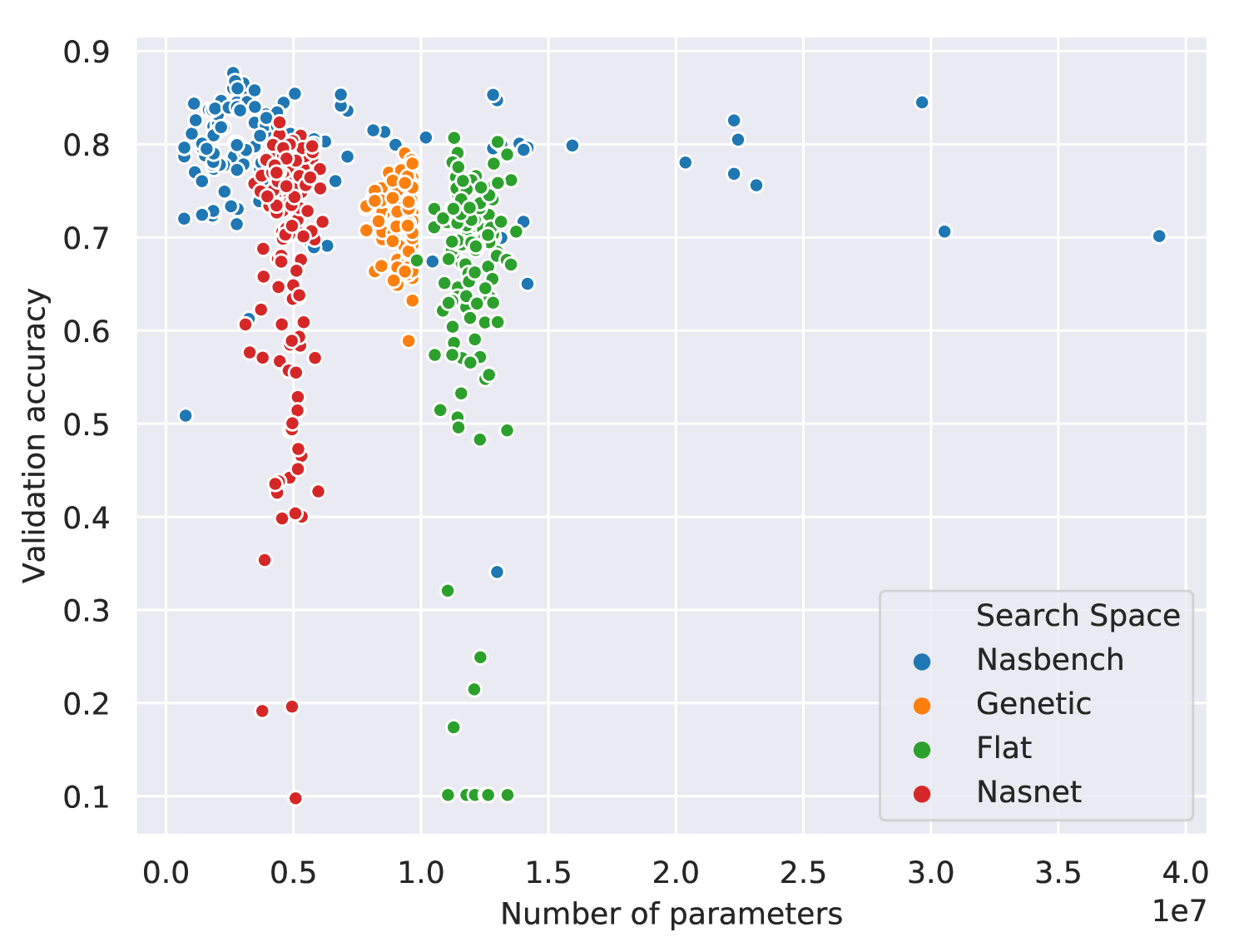
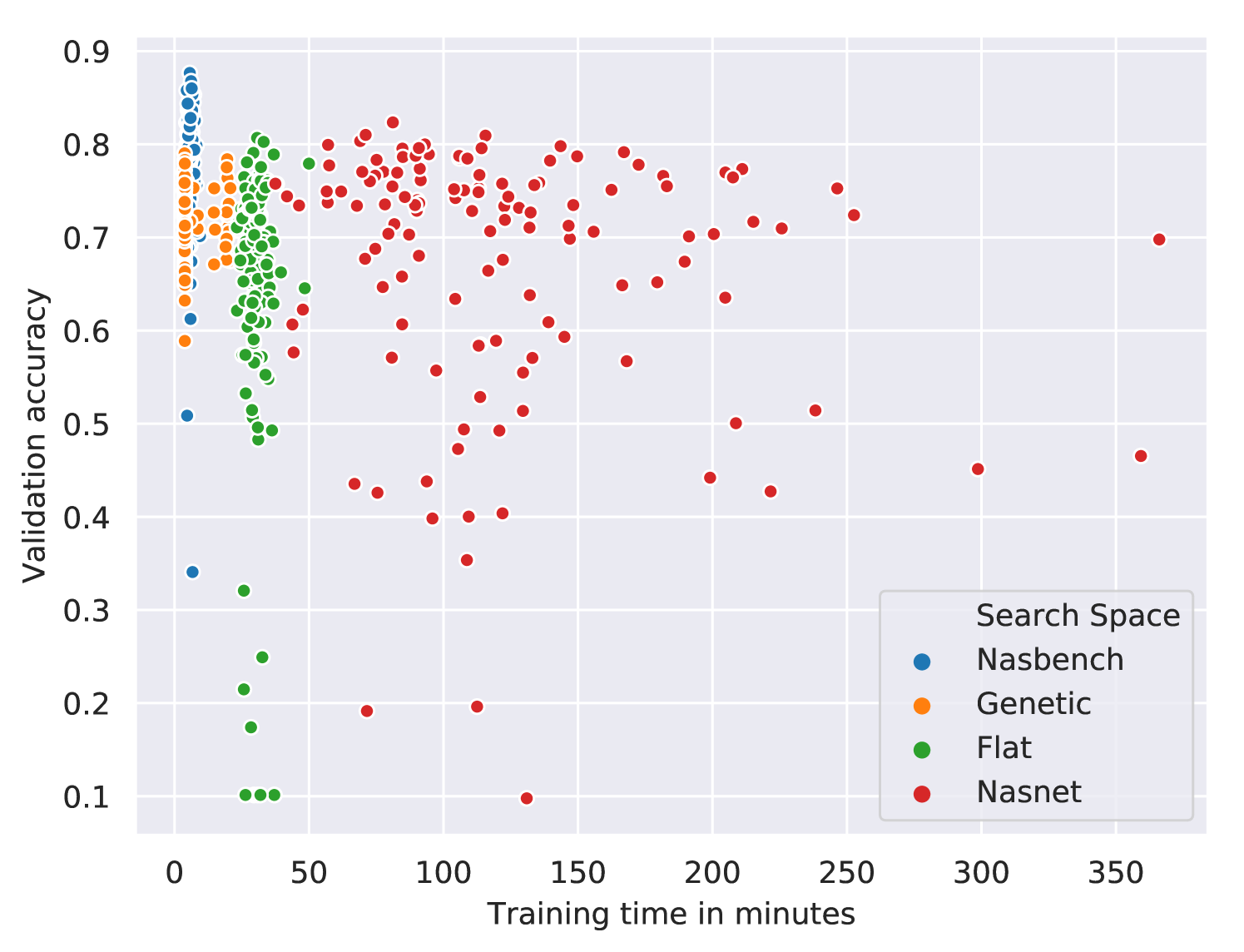
We vary the search space and fix the search algorithm and the evaluation method. We refer to the search spaces we consider as Nasbench [27], Nasnet [28], Flat [15], and Genetic [26]. For the search phase, we randomly sample architectures from each search space and train them for epochs with Adam with a learning rate of . The test results for the fully trained architecture with the best validation accuracy are reported in Table 1. These experiments provide a simple characterization of the search spaces in terms of the number of parameters, training times, and validation performances at epochs of the architectures in each search space (see Figure 8). Our language makes these characterizations easy due to better modularity (the implementations of the search space and search algorithm are decoupled) and programmability (new search spaces can be encoded and new search algorithms can be developed).
7.2 Search algorithm experiments
| Search algorithm | Test Accuracy |
|---|---|
| Random | |
| MCTS [29] | |
| SMBO [16] | |
| Evolution [14] |
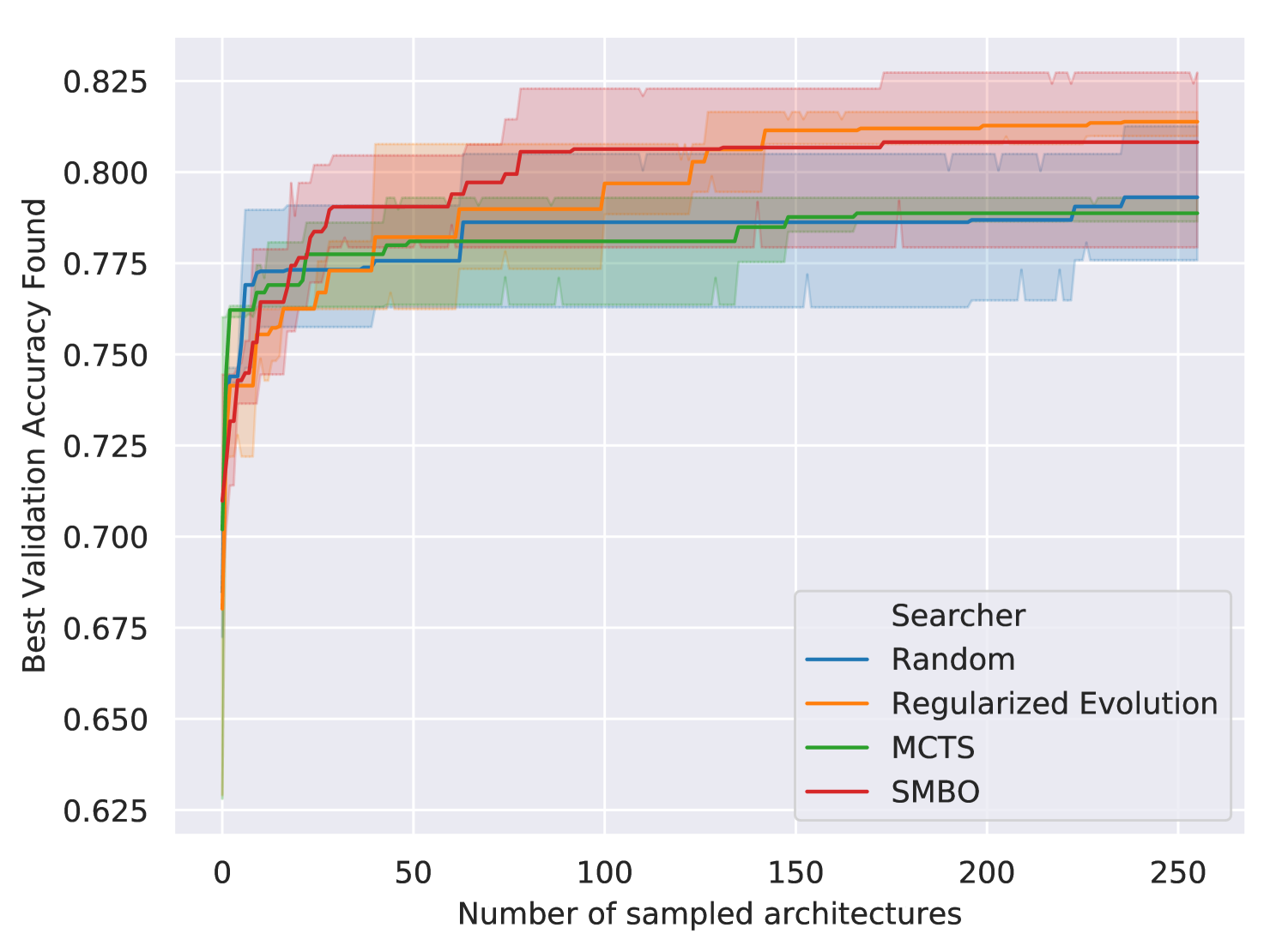
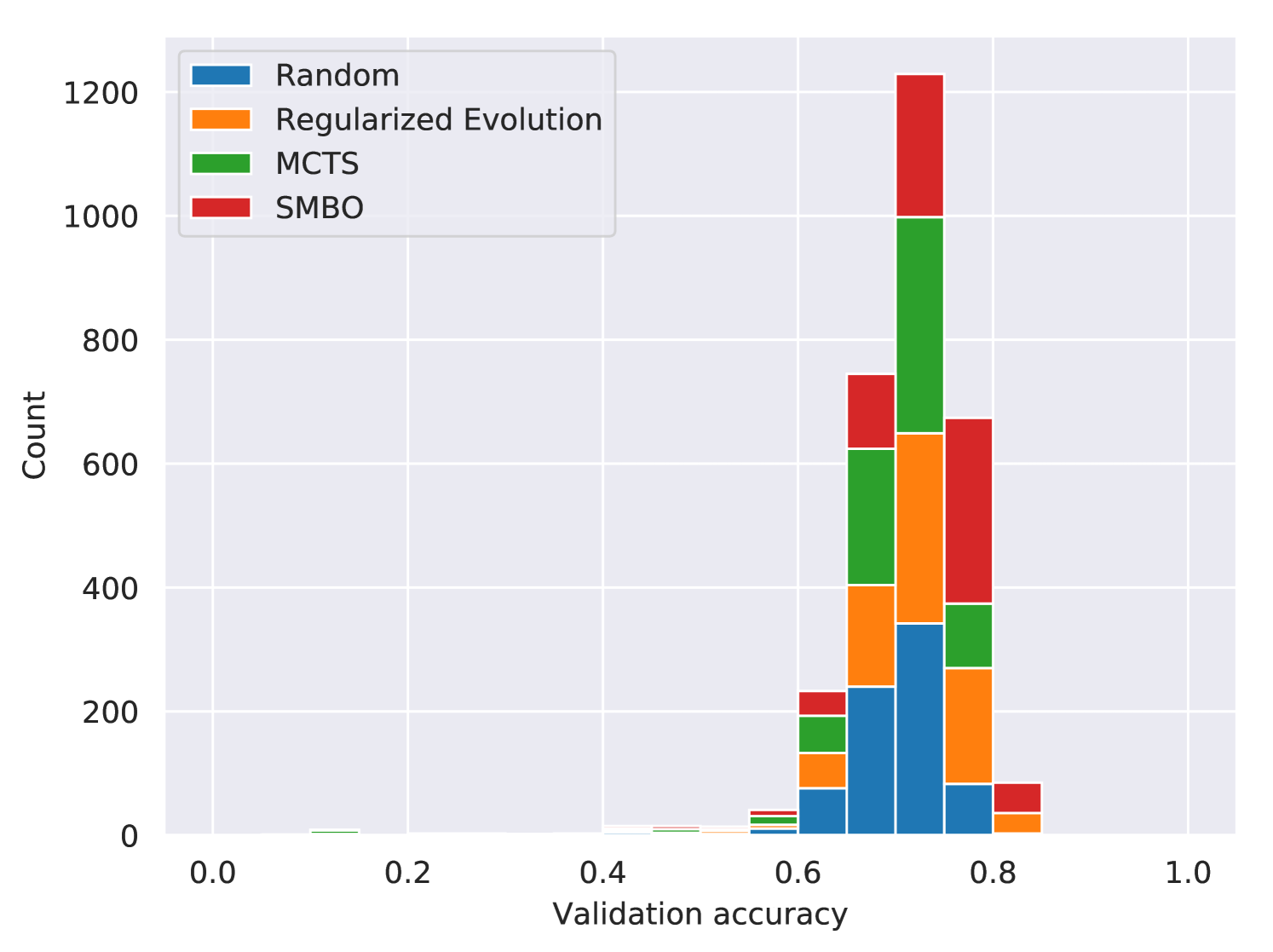
We evaluate search algorithms by running them on the same search space. We use the Genetic search space [26] for these experiments as Figure 8 shows its architectures train quickly and have substantially different validation accuracies. We examined the performance of four search algorithms: random, regularized evolution, sequential model based optimization (SMBO), and Monte Carlo Tree Search (MCTS). Random search uniformly samples values for independent hyperparameters (see Algorithm 3). Regularized evolution [14] is an evolutionary algorithm that mutates the best performing member of the population and discards the oldest. We use population size and sample size . For SMBO [16], we use a linear surrogate function to predict the validation accuracy of an architecture from its features (hashed modules sequences and hyperparameter values). For each architecture requested from this search algorithm, with probability a randomly specified architecture is returned; otherwise it evaluates random architectures with the surrogate model and returns the one with the best predicted validation accuracy. MCTS [29, 16] uses the Upper Confidence Bound for Trees (UCT) algorithm with the exploration term of . Each run of the search algorithm samples architectures that are trained for epochs with Adam with a learning rate of . We ran three trials for each search algorithm. See Figure 9 and Table 2 for the results. By comparing Table 1 and Table 2, we see that the choice of search space had a much larger impact on the test accuracies observed than the choice of search algorithm. See Appendix F for more details.
8 Conclusions
We design a language to encode search spaces over architectures to improve the programmability and modularity of architecture search research and practice. Our language allows us to decouple the implementations of search spaces and search algorithms. This decoupling enables to mix-and-match search spaces and search algorithms without having to write each pair from scratch. We reimplement search spaces and search algorithms from the literature and compare them under the same conditions. We hope that decomposing architecture search experiments through the lens of our language will lead to more reusable and comparable architecture search research.
9 Acknowledgements
We thank the anonymous reviewers for helpful comments and suggestions. We thank Graham Neubig, Barnabas Poczos, Ruslan Salakhutdinov, Eric Xing, Xue Liu, Carolyn Rose, Zhiting Hu, Willie Neiswanger, Christoph Dann, Kirielle Singajarah, and Zejie Ai for helpful discussions. We thank Google for generous TPU and GCP grants. This work was funded in part by NSF grant IIS 1822831.
References
- [1] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. JMLR, 2019.
- [2] James Bergstra, Dan Yamins, and David Cox. Hyperopt: A Python library for optimizing the hyperparameters of machine learning algorithms. Citeseer, 2013.
- [3] Jasper Snoek, Hugo Larochelle, and Ryan Adams. Practical Bayesian optimization of machine learning algorithms. In NeurIPS, 2012.
- [4] Stefan Falkner, Aaron Klein, and Frank Hutter. BOHB: Robust and efficient hyperparameter optimization at scale. In ICML, 2018.
- [5] Marius Lindauer, Katharina Eggensperger, Matthias Feurer, Stefan Falkner, André Biedenkapp, and Frank Hutter. SMACv3: Algorithm configuration in Python. https://github.com/automl/SMAC3, 2017.
- [6] Randal Olson and Jason Moore. TPOT: A tree-based pipeline optimization tool for automating machine learning. In Workshop on Automatic Machine Learning, 2016.
- [7] Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan Adams, and Nando De Freitas. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 2016.
- [8] Frank Hutter, Holger Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In International Conference on Learning and Intelligent Optimization, 2011.
- [9] James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization. JMLR, 2012.
- [10] Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization. JMLR, 2017.
- [11] James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. In NeurIPS, 2011.
- [12] James Bergstra, Daniel Yamins, and David Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. JMLR, 2013.
- [13] Barret Zoph and Quoc Le. Neural architecture search with reinforcement learning. ICLR, 2017.
- [14] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc Le. Regularized evolution for image classifier architecture search. AAAI, 2019.
- [15] Hanxiao Liu, Karen Simonyan, Oriol Vinyals, Chrisantha Fernando, and Koray Kavukcuoglu. Hierarchical representations for efficient architecture search. ICLR, 2018.
- [16] Renato Negrinho and Geoff Gordon. DeepArchitect: Automatically designing and training deep architectures. arXiv:1704.08792, 2017.
- [17] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. In ECCV, 2018.
- [18] Kirthevasan Kandasamy, Willie Neiswanger, Jeff Schneider, Barnabas Poczos, and Eric Xing. Neural architecture search with Bayesian optimisation and optimal transport. NeurIPS, 2018.
- [19] Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning. In NeurIPS, 2015.
- [20] Randal Olson, Ryan Urbanowicz, Peter Andrews, Nicole Lavender, Jason Moore, et al. Automating biomedical data science through tree-based pipeline optimization. In European Conference on the Applications of Evolutionary Computation, 2016.
- [21] Haifeng Jin, Qingquan Song, and Xia Hu. Efficient neural architecture search with network morphism. arXiv:1806.10282, 2018.
- [22] Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-Learn: Machine learning in Python. JMLR, 2011.
- [23] Hieu Pham, Melody Guan, Barret Zoph, Quoc Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. ICML, 2018.
- [24] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv:1603.04467, 2016.
- [25] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. 2017.
- [26] Lingxi Xie and Alan Yuille. Genetic CNN. In ICCV, 2017.
- [27] Chris Ying, Aaron Klein, Eric Christiansen, Esteban Real, Kevin Murphy, and Frank Hutter. NAS-Bench-101: Towards reproducible neural architecture search. In ICML, 2019.
- [28] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc Le. Learning transferable architectures for scalable image recognition. In CVPR, 2018.
- [29] Cameron Browne, Edward Powley, Daniel Whitehouse, Simon Lucas, Peter Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of Monte Carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 2012.
Appendix A Additional details about language components
Independent hyperparameters
An hyperparameter can be shared by instantiating it and using it in multiple modules. For example, in Figure 10, conv_fn has access to h_filters and h_stride through a closure and uses them in boths calls. There are architectures in this search space (corresponding to the possible choices for the number of filters, stride, and kernel size). The output of the first convolution is connected to the input of the second through the call to connect (line 7).
Dependent hyperparameters
Chains (or general directed acyclic graphs) involving dependent and independent hyperparameters are valid. The search space in Figure 11 has three convolutional modules in series. Each convolutional module shares the hyperparameter for the stride, does not share the hyperparameter for the kernel size, and relates the hyperparameters for the number of filters via a chain of dependent hyperparameters. Each dependent hyperparameter depends on the previous hyperparameter and on the multiplier hyperparameter. This search space has distinct architectures
Encoding this search space in our language might not seem advantageous when compared to encoding it in an hyperparameter optimization tool. Similarly to ours, the latter requires defining hyperparameters for the multiplier, the initial number of filters, and the three kernel sizes (chosen separately). Unfortunately, the encoding by itself tells us nothing about the mapping from hyperparameter values to implementations—the expert must write separate code for this mapping and change it when the search space changes. By contrast, in our language the expert only needs to write the encoding for the search space—the mapping to implementations is induced automatically from the encoding.
Basic Modules
Deep learning layers can be easily wrapped as basic modules. For example, a dense layer can be wrapped as a single-input single-output module with one hyperparameter for the number of units (see left of Figure 12). A convolutional layer is another example of a single-input single-output module (see right of Figure 12). The implementation of conv2d relies on siso_tensorflow_module for wrapping Tensorflow-specific aspects (see Appendix E.1 for a discussion on how to support different domains). conv2d depends on hyperparameters for num_filters, filter_width, and stride. The key observation is that a basic module generates its implementation (calls to compile_fn and then forward_fn) only after its hyperparameter values have been assigned and it has values for its inputs. The values of the inputs and the hyperparameters are available in the dictionaries di and dh, respectively. conv2d returns a module as (inputs, outputs) (these are analogous to and on line of 12 of Algorithm 1). Instantiating the computational graph relies on compile_fn and forward_fn. compile_fn is called a single time, e.g., to instantiate the parameters of the basic module. forward_fn can be called multiple times to create the computational graph (in static frameworks such as Tensorflow) or to evaluate the computational graph for specific data (e.g., in dynamic frameworks such as PyTorch). Parameters instantiated in compile_fn are available to forward_fn through a closure.
Substitution modules
Substitution modules encode local structural transformations of the search space that are resolved once all their hyperparameters have been assigned values (see line 12 in Algorithm 1). Consider the implementation of mimo_or (i.e., mimo stands for multi-input, multi-output) in Figure 13 (top left). We make substantial use of higher-order functions and closures in our language implementation. For example, to implement a specific or substitution module, we only need to provide a list of functions that return search spaces. Arguments that the functions would need to carry are accessed through the closure or through argument binding444This is often called a thunk in programming languages.. mimo_or has an hyperparameter for which subsearch space function to pick (h_idx). Once h_idx is assigned a value, substitution_fn is called, returning a search space as (inputs, outputs) where inputs and outputs are and mentioned on line 12 of Algorithm 1. Using mappings of inputs and outputs is convenient because it allow us to treat modules and search spaces the same (e.g., when connecting search spaces). The other substitution modules in Figure 13 use substitution_fn similarly.
Auxiliary functions
Figure 15 shows how we often design search spaces. We have a high-level inductive bias (e.g., what operations are likely to be useful) for a good architecture for a task, but we might be unsure about low-level details (e.g., the exact sequence of operations of the architecture). Auxiliary functions allows us to encapsulate aspects of search space creation and can be reused for creating different search spaces, e.g., through different calls to these functions.
Appendix B Search space example
Figure 16 shows the recurrent cell search space introduced in [23] encoded in our language implementation. This search space is composed of a sequence of nodes. For each node, we choose its type and from which node output will it get its input. The cell output is the average of the outputs of all nodes after the first one. The encoding of this search space exemplifies the expressiveness of substitution modules. The cell connection structure is created through a substitution module that has hyperparameters representing where each node will get its input from. The substitution function that creates this cell takes functions that return inputs and outputs of the subsearch spaces for the input and intermediate nodes. Each subsearch space determines the operation performed by the node. While more complex than the other examples that we have presented, the same language constructs allow us to approach the encoding of this search space. Functions cell, input_node, intermediate_node, and search_space define search spaces that are fully encapsulated and that therefore, can be reused for creating new search spaces.
Appendix C Additional details about language mechanics
Ordered module traversal
Algorithm 5 generates a unique ordering over modules by starting at the modules that have outputs in (which are named by ) and traversing backwards, moving from a module to its neighboring modules (i.e., the modules that connect an output to an input of this module). A unique ordering is generated by relying on the lexicographic ordering of the local names (see lines 3 and 10 in Algorithm 5).
Architecture instantiation
Mapping an architecture relies on traversing in topological order. Intuitively, to do the local computation of a module for , the modules that depends on (i.e., which feed an output into an input of ) must have done their local computations to produce their outputs (which will now be available as inputs to ). Graph propagation (Algorithm 4) starts with values for the unconnected inputs and applies local module computation according to the topological ordering of the modules until the values for the unconnected outputs are generated. maps input and hyperparameter values to the local computation of . The arguments of and its results are sorted according to their local names (see lines 2 to 8).
Appendix D Discussion about language expressivity
D.1 Infinite search spaces
We can rely on the laziness of substitution modules to encode infinite search spaces. Figure 18 shows an example of such a search space. If the hyperparameter associated to the substitution module is assigned the value one, a new substitution module and hyperparameter are created. If the hyperparameter associated to the substitution module is assigned the value zero, recursion stops. The search space is infinite because the recursion can continue indefinitely. This search space can be used to create other search spaces compositionally. The same principles are valid for more complex search spaces involving recursion.
D.2 Search space transformation and combination
We assume the existence of functions a_fn, b_fn, and c_fn that each take one binary hyperparameter and return a search space. In Figure 19, search_space_1 repeats a choice between a_fn, b_fn, and c_fn one, two, or four times. The hyperparameters for the choice (i.e., those associated to siso_or) modules are assigned values separately for each repetition. The hyperparameters associated to each a_fn, b_fn, or c_fn are also assigned values separately.
Simple rearrangements lead to dramatically different search spaces. For example, we get search_space_2 by swapping the nesting order of siso_repeat and siso_or. This search space chooses between a repetition of one, two, or four a_fn, b_fn, or c_fn. Each binary hyperparameter of the repetitions is chosen separately. search_space_3 shows that it is simple to share an hyperparameter across the repetitions by instantiating it outside the function (line 2), and access it on the function (lines 5, 7, and 9). search_space_1, search_space_2, and search_space_3 are encapsulated and can be used as any other search space. search_space_4 shows that we can easily use search_space_1, search_space_2, and search_space_3 in a new search space (compare to search_space_2).
Highly-conditional search spaces can be created through local composition of modules, reducing cognitive load. In our language, substitution modules, basic modules, dependent hyperparameters, and independent hyperparameters are well-defined constructs to encode complex search spaces. For example, a_fn might be complex, creating many modules and hyperparameters, but its definition encapsulates all this. This is one of the greatest advantages of our language, allowing us to easily create new search spaces from existing search spaces. Furthermore, the mapping from instances in the search space to implementations is automatically generated from the search space encoding.
Appendix E Implementation details
This section gives concrete details about our Python language implementation. We refer the reader to https://github.com/negrinho/deep_architect for additional code and documentation.
E.1 Supporting new domains
We only need to extend Module class to support basic modules in the new domain. We start with the common implementation of Module (see Figure 20) for both basic and substitution modules and then cover its extension to support Keras basic modules (see Figure 21).
General module class
The complete implementation of Module is shown in Figure 20. Module supports the implementations of both basic modules and substitution modules. There are three types of functions in Module in Figure 20: those that are used by both basic and substitution modules (_register_input, _register_output, _register_hyperparameter, _register, _get_hyperp_values, get_io and get_hyperps); those that are used just by basic modules (_get_input_values, _set_output_values, _compile, _forward, and forward); those are used just by substitution modules (_update). We will mainly discuss its extension for basic modules as substitution modules are domain-independent (e.g., there are no domain-specific components in the substitution modules in Figure 13 and in cell in Figure 16).
Supporting basic modules in a domain relies on two functions: _compile and _forward. These functions help us map an architecture to its implementation in deep learning (slightly different functions might be necessary for other domains). forward shows how _compile and _forward are used during graph instantiation in a terminal search space. See Figure 22 for the iteration over the graph in topological ordering (determined by determine_module_eval_seq), and evaluates the forward calls in turn for the modules in the graph leading to its unconnected outputs.
_register_input, _register_output, _register_hyperparameter, and _register are used to describe the inputs and outputs of the module (i.e., _register_input and _register_output), and to associate hyperparameters to its properties (i.e., _register_hyperparameter). _register aggregates the first three functions into one. _get_hyperp_values, _get_input_values, and _set_output_values are used in _forward (see left of Figure 21. These are used in each basic module, once in a terminal search space, to retrieve its hyperparameter values (_get_hyperp_values) and its input values (_get_input_values) and to write the results of its local computation to its outputs (_set_output_values). Finally, get_io retrieves the dictionaries mapping names to inputs and outputs (these correspond to and , respectively, described in Section 6). Most inputs are named in if there is a single input and in0, in1, and so on if there is more than one. Similarly, for outputs, we have out for a single output, and out0, out1, and so if there are multiple outputs. This is often seen when connecting search spaces, e.g., lines 15 to 28 in right of Figure 15. In Figure 15, we redefine and (in line 30 to line 34) to have appropriate names for the LSTM cell, but often, if possible, we just use and for and respectively, e.g., in siso_repeat and siso_combine in Figure 13.
_update is used in substitution modules (not shown in Figure 20): for a substitution module, it checks if all its hyperparameters have been assigned values and does the substitution (i.e., calls its substitution function to create a search space that takes the place of the substitution module; e.g., see frames a, b, and c of Figure 5 for a pictorial representation, and Figure 13 for implementations of substitution modules). In the examples of Figure 13, substitution_fn returns the search space to replace the substitution module with in the form of a dictionary of inputs and a dictionary of outputs (corresponding to and on line 12 of Algorithm 1). The substitution modules that we considered can be implemented with the helper in Figure 14 (e.g., see the examples in Figure 13).
In the signature of __init__ for Module, scope is a namespace used to register a module with a unique name and name is the prefix used to generate the unique name. Hyperparameters also have a unique name generated in the same way. Figure 5 shows this in how the modules and hyperparameters are named, e.g., in frame a, Conv2D-1 results from generating a unique identifier for name Conv2D (this is also captured in the use of _get_name in the examples in Figure 12 and Figure 13). When scope is not mentioned explicitly, a default global scope is used (e.g., scope is optional in Figure 20).
Extending the module class for a domain (e.g., Keras)
Figure 21 (left) shows the extension of Module to deal with basic modules in Keras. KerasModule is the extension of Module. keras_module is a convenience function that instantiates a KerasModule and returns its dictionary of local names to inputs and outputs. siso_keras_module is the same as keras_module but uses default names in and out for a single-input single-output module, which saves the expert the trouble of explicitly naming inputs and outputs for this common case. Finally, siso_keras_module_from_keras_layer_fn reduces the effort of creating basic modules from Keras functions (i.e., the function can be passed directly creating compile_fn beforehand). These functions are analogous for different deep learning frameworks, e.g., see the example usage of siso_tensorflow_module in Figure 12.
The most general helper, keras_module works by providing the local names for the inputs (input_names) and outputs (output_names), the dictionary mapping local names to hyperparameters (name_to_hyperp), and the compilation function (compile_fn), which corresponds to the _compile_fn function of the module. Calling _compile_fn returns a function (corresponding to _forward for a module, e.g., see Figure 12).
E.2 Implementing a search algorithm
Figure 23 shows random search in our implementation. random_specify_hyperparameter assigns a value uniformly at random to an independent hyperparameter. random_specify assigns all unassigned independent hyperparameters in the search space until reaching a terminal search space (each assignment leads to a search space transition; see Figure 5). RandomSearcher encapsulates the behavior of the searcher through two main functions: sample and update. sample samples an architecture from the search space, which returns inputs and outputs for the sampled terminal search space, the sequence of value assignments that led to the sampled terminal search space, and a searcher_eval_token that allows the searcher to identify the sampled terminal search space when the evaluation results are passed back to the searcher through a call to update. update incorporates the evaluation results (e.g., validation accuracy) of a sampled architecture into the state of the searcher, allowing it to use this information in the next call to sample. For random search, update is a no-op. __init__ takes the function returning a search space (e.g., search_space in Figure 16) from which architectures are to be drawn from and any other arguments that the searcher may need (e.g., exploration term in MCTS). To implement a new searcher, Searcher needs to be extended by implementing sample and update for the desired search algorithm. unassigned_independent_hyperparameter_iterator provides ordered iteration over the independent hyperparameters of the search space. The role of the search algorithm is to pick values for each of these hyperparameters, leading to a terminal space. Compare to Algorithm 3. search_space_fn returns the dictionaries of inputs and outputs for the initial state of the search space (analogous to the search space in frame a in Figure 5).
Appendix F Additional experimental results
We present the full validation and test results for both the search space experiments (Table 3) and the search algorithm experiments (Table 4). For each search space, we performed a grid search over the learning rate with values in and an L2 penalty with values in for the architecture with the highest validation accuracy Each evaluation in the grid search was trained for 600 epochs with SGD with momentum of and a cosine learning rate schedule We did a similar grid search for each search algorithm.
| Search Space |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Genetic [26] | 79.03 | 91.13 | 90.07 | 9.4M | ||||||||
| Flat [15] | 80.69 | 93.70 | 93.58 | 11.3M | ||||||||
| Nasbench [27] | 87.66 | 95.08 | 94.59 | 2.6M | ||||||||
| Nasnet [28] | 82.35 | 94.56 | 93.77 | 4.5M |
| Search algorithm | Run |
|
|
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Random | 1 | 77.58 | 92.61 | 92.38 | |||||||||
| 2 | 79.09 | 91.93 | 91.30 | ||||||||||
| 3 | 81.26 | 92.35 | 91.16 | ||||||||||
| Mean | |||||||||||||
| MCTS [29] | 1 | 78.68 | 91.97 | 91.33 | |||||||||
| 2 | 78.65 | 91.59 | 91.47 | ||||||||||
| 3 | 78.65 | 92.69 | 91.55 | ||||||||||
| Mean | |||||||||||||
| SMBO [16] | 1 | 77.93 | 93.62 | 92.92 | |||||||||
| 2 | 81.80 | 93.05 | 92.03 | ||||||||||
| 3 | 82.73 | 91.89 | 90.86 | ||||||||||
| Mean | |||||||||||||
| Regularized evolution [14] | 1 | 80.99 | 92.06 | 90.80 | |||||||||
| 2 | 81.51 | 92.49 | 91.79 | ||||||||||
| 3 | 81.65 | 92.10 | 91.39 | ||||||||||
| Mean |