Towards On-Board Panoptic Segmentation of Multispectral Satellite Images
Abstract
With tremendous advancements in low-power embedded computing devices and remote sensing instruments, the traditional satellite image processing pipeline which includes an expensive data transfer step prior to processing data on the ground is being replaced by on-board processing of captured data. This paradigm shift enables critical and time-sensitive analytic intelligence to be acquired in a timely manner onboard the satellite itself. However, at present, the on-board processing of multi-spectral satellite images is limited to classification and segmentation tasks. Extending this processing to it’s next logical level, in this paper we propose a lightweight pipeline for on-board panoptic segmentation of multi-spectral satellite images. Panoptic segmentation offers major economic and environmental insights, ranging from yield estimation from agricultural lands to intelligence for complex military applications. Nevertheless, the on-board intelligence extraction raises several challenges due to the loss of temporal observations and the need to generate predictions from a single image sample. To address this challenge, we propose a multimodal teacher network based on a cross-modality attention-based fusion strategy to improve the segmentation accuracy by exploiting data from multiple modes. We also propose an online knowledge distillation framework to transfer the knowledge learned by this multi-modal teacher network to a uni-modal student which receives only a single frame input, and is more appropriate for an on-board environment. We benchmark our approach against existing state-of-the-art panoptic segmentation models using the PASTIS multi-spectral panoptic segmentation dataset considering an on-board processing setting. Our evaluations demonstrate a substantial 10.7%, 11.9% and 10.6% increase in Segmentation Quality (SQ), Recognition Quality (RQ), and Panoptic Quality (PQ) metrics compared to the existing state-of-the-art model when it is evaluated in an on-board processing setting.
Index Terms:
on-board satellite image processing, knowledge distillation, panoptic segmentation, multispectral image processing, multi-modality fusion.I Introduction
Following the launch of Landsat-1, the first satellite to carry a multi-spectral remote sensing instrument, multi-spectral imaging of earth from space has evolved rapidly. The availability of additional spectral bands via multi-spectral remote sensing enables better segmentation and differentiation of objects compared to using the visible spectrum alone.
The traditional image analysis process for satellite image processing contains typical stages of: (i) data acquisition, (ii) data transfer from satellite to ground, (iii) centralized ground processing, and (iv) information extraction [1]. This process is slow, in particular due to the time required to down-link a high resolution multi-band image, meaning that extracted intelligence may be antiquated for effective decision making. As such, a new paradigm of algorithms are being introduced [2, 1] which can process captured satellite images on-board. This also avoids the expensive and time-consuming data transmission of the original data, and the limited transmission bandwidth can be used to convey the extracted intelligence. The rapid advancements in low-power embedded Graphic Processing Units (GPUs), such as the NVIDIA Jetson series, has further advanced this line of work [1, 3]. In line with this evolution, we propose to take the on-board processing of satellite acquired multi-spectral images to its the next logical level. Expanding from classification [4, 5] and segmentation tasks [6, 7], we seek to perform panoptic segmentation using limited on-board resources.
Since its first introduction by Kirillov et. al [8], panoptic segmentation has gained substantial traction in numerous computer vision applications. Specifically, panoptic segmentation has helped to eliminate the dichotomy between the recognition of countable objects such as people and animals, and the segregation of uncountable stuff, such as sky and roads, by proposing a unified framework to achieve both. Panoptic segmentation is essentially a multi-task architecture which jointly performs semantic segmentation and object detection (or instance segmentation), where the former is used for recognising uncountable, while the latter is employed to segregate countable objects.
Panoptic segmentation enables unmet analytic capabilities in remote sensing, ranging from monitoring urban areas and agricultural lands to military applications [9]. For instance, while semantic segmentation outputs can be used to obtain a general overview of the yield from individual crop types, instance segmentation of agricultural parcels offers an in depth analysis regarding the yield from individual parcels. Similarly, in urban monitoring, advanced intelligence regarding individual households or road/traffic conditions can be obtained by using panoptic segmentation and considering each detected instance.
In this paper, a light-weight framework for multi-spectral panoptic segmentation is proposed. Specifically, our contributions are three-fold. First, we benchmark the performance of several state-of-the-art panoptic segmentation models in the on-board processing setting using the Panoptic Agricultural Satellite TImeSeries (PASTIS) [10] dataset. To the best of our knowledge, this is the only publicly available multi-spectral dataset with panoptic annotation. Second, we propose a multi-modal fusion architecture to improve panoptic segmentation performance in the on-board computation setting. Third, we propose a novel cross modality knowledge distillation pipeline to transfer the knowledge from this aforementioned multi-modal teacher network to a light-weight uni-modal student, such that it achieves superior performance. This framework is visually illustrated in Fig. 1.
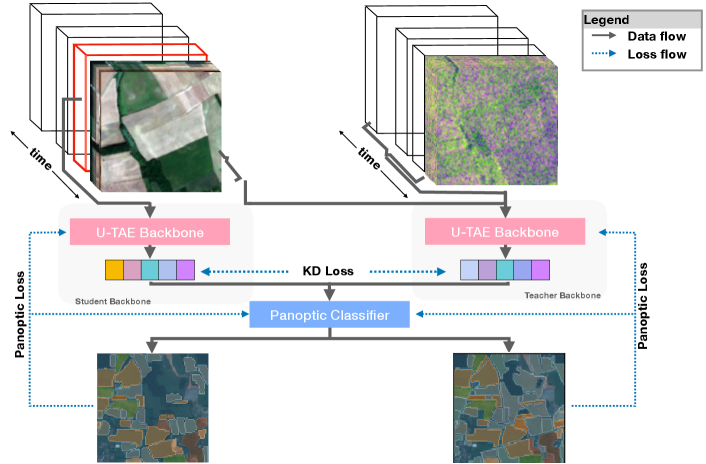
The rest of the paper is organised as follows. In Sec. II we summarise recent developments in related areas and illustrate how the proposed work deviates from these. Sec. III describes the details of the datasets used, the architectures of our multi-modal and uni-modal networks, and the knowledge distillation pipeline. Sec. IV presents the experimental results and conclusions are drawn in Sec. V.
II Related Works
II-A On-board Processing of Satellite Images
Since the launch of the quickbird satellite with high resolution cameras and high capacity on-board processing capabilities, there has been an increase in research and development related to advanced on-board satellite image processing. Numerous works have investigated on-board capabilities of object detection [11, 1], image classification [12], image selection [13], denoising and artefact removal [14], and change detection [15, 16].
Specifically, considering the most relevant literature in the domains of on-board object detection and classification, in [11] the authors benchmark a light-weight CNN based classifier for ship detection using an Nvidia Jetson TX2 GPU. The authors demonstrated the utility of such a CNN architecture over traditional machine learning techniques. More recently, A You Only Look Once v4 (YOLOv4)-Tiny [17] architecture has been benchmarked by [1] for ship detection using HISEA-1 SAR images. The Constant False Alarm Rate (CFAR) algorithm is used to first extract target regions for deep learning-based ship detection. This significantly reduces the number of image patches submitted to the computationally complex deep learning based ship detection algorithm. The detected targets from the CFAR algorithm are stored as 256 256 pixel patches which are fed to the YOLOv4-Tiny object detector. Finally, the outputs of the detector are mapped to the original SAR image coordinates using bilinear interpolation. As such, only relevant intelligence is transferred via the satellite-earth data transmission system. In a similar line of work, [12] applied transfer learning to adapt a MobileNetV2 [18] classifier pretrained on ImageNet [19] for the classification of earth-observation imagery at different ground-resolved distances. However, to the best of our knowledge, none of the existing works have investigated the use of panoptic segmentation models, which are highly computationally complex in comparison to object detectors explored to date in on-board processing scenarios.
A complementary line of research [20, 21, 22, 23] has focused on hardware and software acceleration techniques to enable efficient on-board processing of satellite images. However, these methods optimise matrix multiplication operations and standard convolution and other neural network architecture computations, enabling operation over compressed inputs, and do not propose a specific architecture for the on-board computation. Therefore, we do not review these works in detail, however, acknowledge the contributions of these works towards enabling efficient on-board AI capabilities.
II-B Knowledge Distillation
Cross modality knowledge distillation has recently gained attention, but there are limited works concerning the transfer of knowledge from a multi-modal teacher to a uni-modal student [24]. Specifically, Garcia et. al [25] has used depth and RGB images to train a multi-modal teacher while Gao et. al [26] has used multi-modal medical images as the input to the teacher. Furthermore, to the best of our knowledge, none of the existing works in cross-modality distillation have used on-line distillation.
In on-line distillation, both teacher and student networks are simultaneously updated, creating an end-to-end trainable pipeline. However, such mutual learning (or joint learning) in a high capacity environment is an open research question which requires further exploration and careful consideration of the relationships between the student and the teacher [24]. For instance, recently an online knowledge distillation framework that uses an ensemble of students and teacher networks is proposed in [27], and these networks are collaboratively trained. Chen et. al [28] have extended this concept to use auxiliary peers and group leaders such that more supervision is provided to the student and diverse knowledge distillation can occur. However, these application settings are quite different to the proposed on-board multispectral panoptic segmentation setting which has a unique set of challenges and requirements. Using multiple student networks is not feasible due to on-board hardware requirements. As such, by leveraging the multiple modalities that are available for the teacher network we propose to overcome the challenges with our application due to the loss of temporal information.
III Materials and Methods
III-A Datasets
III-A1 Panoptic Agricultural Satellite TImeSeries (PASTIS) [10] dataset
The PASTIS dataset is composed of 2,433 multi-spectral image patches, each with 10 spectral bands and of size 128 128 pixels, at 10m/pixel resolution. To the best of our knowledge, this is the only publicly available multi-spectral satellite image dataset with panoptic annotation. This data has been captured using the Sentinel-2 platform and four Sentinel tiles have been used. The authors have generated a time-series dataset by stacking all the available observations for each patch between September 2018 and November 2019.
However, the temporal sampling of the data is irregular as the orbital schedule of Sentinel-2 means patches are observed a different numbers of times and at different intervals. Furthermore, data providers have not processed the images if there is more than 90% cloud coverage, which leads to irregular length time-series. The temporal length of the observations ranges from 33 to 61 samples per sequence.
The dataset authors have used the publicly available French Land Parcel Identification System to retrieve the extents and the content of each parcel when annotating the patches. Within the annotations, each pixel has a semantic label that represents the crop type or the background class. Non-agricultural land is classified as the background class. In total there are 18 crop types, the background class and a void class, resulting in 20 semantic classes. The void class denotes agricultural parcels that contain crops that are not classified. The authors have also proposed a 5-fold cross validation scheme that divides the 2,433 patches into 5 splits. When splitting the data, care was taken to ensure that each fold has patches from all 4 Sentinel tiles and each split contains comparable class distributions. Furthermore, cross-contamination of data caused by adjacent patches falling into different splits was avoided.








In [10] the authors have observed that even after filtering out predominantly cloudy acquisitions, there still exists partially or completely obstructed patches. Furthermore, they highlight the utility of time-series data for resolving those obstructions and boundary ambiguities due to clouds and other atmospheric noise. For instance, in Fig. 2 we visualise the image sequence of a randomly chosen patch. Within the frames it can be seen that there exists boundary ambiguities which are indistinguishable even for humans. The multiple temporal observations can be used to eradicate these ambiguities in ground-based processing, however, in an on-board setting an AI algorithm does not have access to such historical data. In particular, when benchmarking the algorithms presented in [10] in a non-temporal (single frame) setting we illustrate how state-of-the-art methods struggle to generate accurate predictions (See Sec. IV-B). Hence we propose an on-line knowledge distillation strategy to augment a light-weight model that observes only a randomly chosen single frame of the time-series, allowing it to imagine the corresponding features from the time-series and achieve more accurate panoptic segmentation.
III-A2 PASTIS-R [29] dataset
PASTIS-R is an extension of the PASTIS dataset where the authors have combined the Sentinel-2 multi-spectral patches with the corresponding Sentinel-1 observations. Specifically, they have used Sentinel-1 data in ground range detected format and assembled these into 3-channel images (vertical polarization, horizontal polarization and the ratio of vertical over horizontal polarization). Separate observations were captured in both ascending and descending orbits, generating two 3-channel images for each observation. This multi-modal dataset has rich spectral information coming from the Sentinel-2 multi-spectral observations, while the C-band radar of Sentinel-1 captures useful geometric information as it’s immune to cloud cover [29].
Hence, this multi-modal dataset can be seen as containing complementary information to be leveraged when views are obstructed due to cloud and other illumination conditions, however, it is illogical to directly fuse the data in an on-board setting as data is captured from separate satellites. Therefore, we propose a knowledge distillation strategy where a heavy-weight multi-modal teacher guides a uni-modal single frame student such that it can imagine the unseen features which are only visible to the teacher.
III-B Knowledge Distillation Framework
In this section we introduce the structure of the multi-modal backbone that we use for our teacher network (Sec. III-B1) and the architecture of the light-weight uni-modal backbone of the student network (Sec. III-B2). In Sec. III-B3 we describe how the extracted features from these backbones are used in the panoptic classifier while Sec. III-B4 outlines the loss functions used to train the network.
III-B1 A Teacher Backbone with Cross-Modality Attention
In this section we illustrate how the proposed cross-modality attention backbone is formulated. The approach takes inspiration from the U-TAE backbone from [10], though we incorporate specific augmentations to increase its capabilities in a multi-modal setting. The spatio-temporal encoding structure is based on [10], however, prior to the decoding phase we employ cross-modality attention to extract task specific, salient information that compliments each modality.
The inputs to the teacher network, and , are spatio-temporal inputs with shapes and , respectively, where denotes the length of the time-series (i.e number of frames), indicates the width of the image and denotes its height. and represents the number of channels in the multi-spectral and radar modalities, respectively. Each spectral encoder, and (), has levels where each level is comprised of convolutions, Relu and normalisation layers. The encoder (, ) at level receives the output () of the immediately proceeding layer and generates a feature map . At each level the encoder maps are compressed using strided convolutions such that the output height , and width . All frames in the sequence are simultaneously processed by the encoders.
To perform temporal encoding, similar to [10], we use a Light-weight Temporal Attention Encoder (L-TAE) [30] which is a multi-head self-attention network with heads. The feature maps and of the last level (i.e ) are used and the L-TAE networks, and generate attention vectors, each of shape as,
| (1) |
To apply these attention maps to all encoded maps from the U-Net, interpolation is performed, where each attention vector, and in is interpolated to size and for level . The the respective channels and of the multi-spectral and radar modalities are split into consecutive groups (i.e. , each of shape ; and , each of shape ).
Then we multiply each embedding by it’s respective attention map, average the temporal sequence, and pass the resultant feature vector through a convolution layer,
| (2) |
where denotes concatenation along the channel dimension.
In [29], the authors have introduced several fusion strategies for the PASTIS-R dataset. Their evaluations using early, late, decision, and mid level fusion indicated that early fusion is the best strategy for panoptic segmentation. However, leveraging the generated attention vectors, and , we propose fusion of the multi-spectral and radar modalities using cross-modality attention. Specifically, we generate attention maps, and for each modality such that,
| (3) |
These attention maps denote how salient features are spatially arranged in a particular modality. Hence, they are important for capturing complimentary information from a second mode. We interpolate these 2D maps to match the channel dimension of the complementary mode, and generate an augmented feature such that,
| (4) |
where denotes concatenation in the channel dimension. Then the augmented feature is used by the spatial decoder.
Following the conventional U-Net network structure, the encoder map from level , , is concatenated with the decoded feature map, , from level . Each decoder block is composed of strided transposed convolutions to up sample the feature maps from the previous level. The decoder output is formally denoted as .
III-B2 A Uni-Modal Single Frame Backbone for the Student
The student backbone receives the input, , of shape , that corresponds to a single frame from the multi-spectral modality. Similar to the teacher backbone we pass it through a spatial encoder with levels and generate the feature map . However, in contrast to the teacher backbone, is of dimension . Despite the absence of the temporal dimension, the L-TAE is used in the student backbone with the motivation of capturing the channel-wise relationships with the aid of a multi-head attention formulation such that,
| (5) |
however, when applying the attention no temporal summarisation is performed. Specifically,
| (6) |
where denotes concatenation along the channel dimension. Then, similar to the teacher backbone, the spatial decoder of the student up samples these features to generate the multi-scale output features, .
III-B3 Panoptic Classifier
The panoptic classifier receives multi-scale feature maps (either from the teacher or student backbones) and produces predictions over parcels. We used the same architecture as the panoptic classifier network from [10], where it makes four predictions for each parcel: a center point, a bounding box, a binary instance mask and a class. We refer the readers to [10] for further details regarding this network’s architecture.
We use a single instance of this panoptic classifier to evaluate the predictions of both student and teacher backbones, allowing it to identify the similarities and correspondences between the feature vectors and . Note that in our formulation, the dimensions of the decoded maps from the student and teacher backbones at each level of the U-Net are identical.
III-B4 Loss Functions for On-line Knowledge Distillation
As discussed in Sec. III-B3, the panoptic classifier makes four predictions, a centerness heat map, bounding boxes, instance masks and classes, and as such [10] used four losses to supervise these predictions.
Formally, let denote the ground truth centerness heat map, let be the predicted centerness heat map, and let there be ground truth parcels. Then is defined as,
|
|
where is a hyper-parameter and following [10] it is set to 4.
Then is defined as a set of detected parcels and denotes the predicted class of the parcel , while indicates its ground truth class. Then the class loss of parcel is defined as,
| (7) |
Let and denote the predicted and ground truth heights of the bounding boxes of parcel , and and indicate its respective width. Then,
| (8) |
defines the size loss. In addition a pixel-wise Binary Cross Entropy (BCE) loss is computed between the predicted shape, and the corresponding ground truth instance mask when it is cropped using the predicted bounding box. This can be defined as,
| (9) |
Then the complete loss function in [10] can be written as,
| (10) |
To facilitate an on-line student-teacher knowledge distillation framework we perform the following augmentations. Let denote the output of the panoptic classifier introduced in Sec. III-B3 and let denote the complete loss defined in Eq. 10. Then,
| (11) |
where denotes detaching the tensor from gradient computation. Then the final loss of our framework is defined as,
| (12) |
where and are hyper-parameters controlling the contributions of the respective loss terms.
IV Evaluations
In Sec. IV-A we first report the performance of the proposed fusion architecture when the time-series PASTIS-R dataset’s input is used. In Sec. IV-B evaluations of the state-of-the-art panoptic segmentation methods in the on-board setting without time-series data (i.e. single input frame) are provided. In Sec. IV-C, we evaluate the proposed knowledge distillation pipeline, and in Sec. IV-D we qualitatively illustrate how the student features have been augmented by the teacher.
Similar to [8] we report class averaged Segmentation Quality (SQ), Recognition Quality (RQ) and Panoptic Quality (PQ), where RQ corresponds to the quality of the detection and can be computed using,
| (13) |
where TP, FP, and FN denotes true positive, false positive and false negative, respectively. SQ is computed as the average IoU of matched segments and can be written as,
| (14) |
where denotes the detected parcels within the set of true positives. Then PQ is the product of SQ and RQ (i.e. ), thus combining the detection, classification and delineation accuracies [29].
IV-A Results of the Fusion Model
In Tab. I we report the performance of the proposed cross attention based fusion model together with the trainable parameter counts and run times. Note that the run times are reported for evaluating a single sample with 40 frames in the time-series. In addition, we report the performance of the existing baselines and attention variations for comparison. Note that due to sampling rate inconsistencies between the modalities, similar to [29], we have interpolated Radar observations to match the time stamps of the multi-spectral modality.
| Model | SQ | RQ | PQ | Parameters | Run Time |
| U-TAE+PAPS-Multispec [10] | 81.3 | 49.2 | 40.4 | 1.2M | 0.53s |
| U-TAE+PAPS-Radar | 77.2 | 39.1 | 30.8 | 1.2M | 0.38s |
| U-TAE+PAPS-Late Fusion [31] | 81.6 | 50.5 | 41.6 | 2.3M | 0.73s |
| U-TAE+PAPS-Early Fusion [31] | 82.2 | 50.6 | 42.0 | 1.7M | 0.52s |
| Self Attention Fusion | 82.3 | 53.1 | 43.8 | 2.4M | 0.89s |
| Cross Attention Fusion | 82.7 | 55.6 | 45.8 | 2.4M | 0.98s |
Analysing the results presented in Tab. I, it is clear that fusion methods have been able to achieve superior performance compared to their uni-modal counterparts. Considering the difference between the uni-modal multi-spectral baseline and the proposed Cross Modality Fusion, we observe a more than 5% increase in RQ and PQ metrics. Furthermore, attention based fusion strategies have achieved a comfortable increase over early and late fusion schemes. Most importantly, the proposed cross attention scheme yields a 0.5%, 5%, and 3.8% performance gain in SQ, RQ, and PQ metrics, respectively, compared to the previous state-of-the-art early fusion mechanism. This denotes the value of extracting salient spatial features across different modalities for informed decision making. By understanding which features are available and where they are important, the overall model is better able to adapt to noisy and occluded observations.
IV-B Benchmarking the State-of-the-art Models in an On-board Setting
In Tab. II we benchmark the baseline models and their attention variants in an on-board setting, where we have used only a single frame from the time-series input. Note that when selecting a frame from the time-series, a random frame is selected and in the multi-modal setting we have used a pair of frames that correspond to the same timestamp from the two modalities.
| Model | Modality | SQ | RQ | PQ | Parameters | Runtimes |
| Detectron 2-FPN R-50 [32] | RGB | 40.98 | 7.43 | 4.4 | 46.0M | 0.81s |
| Detectron 2-FPN R-101 [32] | RGB | 42.14 | 5.87 | 3.6 | 65.0M | 0.85s |
| U-TAE + PAPS [10] | MutiSpec | 63.8 | 18.8 | 13.8 | 1.2M | 0.37s |
| U-TAE + PAPS-Late Fusion [31] | MutiSpec + Radar | 73.4 | 20.5 | 16.1 | 2.3M | 0.61s |
| U-TAE + PAPS-Early Fusion [31] | MutiSpec + Radar | 74.4 | 26.4 | 20.9 | 1.7M | 0.41s |
| Self Attention Fusion | MutiSpec + Radar | 74.9 | 28.8 | 23.0 | 2.4M | 0.74s |
| Cross Attention Fusion | MutiSpec + Radar | 78.1 | 31.6 | 24.7 | 2.4M | 0.81s |
Our analysis reveals the challenge in performing panoptic segmentation from a single frame, without the time-series input. Considering the performance degradation between Tabs. I and II for the U-TAE + PAPS models that receives the multispectral inputs, we observe a significant drop of 17.5%, 30.4% and 26.6% in SQ, RQ, and PQ metrics, respectively. We observe that the use of multiple modes helps mitigate the performance drop, however, we also highlight the lack of practicality in adapting such a framework to an on-board evaluation setting given the limited on-board computing power. Therefore, utilising the cross modality attention fusion model that receives a time-series input as our teacher network, we seek to augment the low capacity U-TAE + PAPS network (that receives a single frame from the multi-spectral time-series input).
IV-C Knowledge Distillation Results
In Tab. III, we report the performance of different configurations of student and teacher networks. Note that when choosing the configurations for the student network, we do not consider detectron2, nor do we consider late and early fusion methods for the teacher network, due to the low performance of these networks. Note that for the student network, only the multi-spectral modality of PASTIS-R was provided, while we have considered teacher networks using both uni-modal (multi-spectral input) and multi-modal inputs. In addition, we have used a pre-trained teacher network and trained only the student network to evaluate the off-line knowledge distillation setting. The rest of the teacher networks are jointly trained with the student and thus perform on-line knowledge distillation.
| Student | Teacher | SQ | RQ | PQ | Parameters (of student) | Run times (of student) |
| U-Net + PAPS | U-TAE + PAPS (MultiSpec) | 71.4 | 14.9 | 11.5 | 1.1M | 0.32s |
| U-TAE + PAPS | U-TAE + PAPS (MultiSpec) | 71.6 | 17.0 | 12.7 | 1.2M | 0.37s |
| U-Net + PAPS | Self-Attention Fusion | 70.2 | 23.0 | 17.6 | 1.1M | 0.32s |
| U-TAE + PAPS | Self-Attention Fusion | 73.3 | 27.8 | 21.9 | 1.2M | 0.37s |
| U-Net + PAPS | Cross Attention Fusion | 73.6 | 25.7 | 20.2 | 1.1M | 0.32s |
| U-TAE + PAPS | Cross Attention Fusion (off-line) | 74.5 | 27.3 | 21.8 | 1.2M | 0.37s |
| U-TAE + PAPS | Cross Attention Fusion | 74.5 | 30.7 | 24.4 | 1.2M | 0.37s |
Analysing the results presented in Tab. III, we observe the value of knowledge distillation across all configurations that we evaluate. Specifically, we see a 10.7%, 11.9% and 10.6% increase in SQ, RQ, and PQ metrics, respectively when the multispectral U-TAE + PAPS model is trained with a Cross Attention Fusion teacher, compared to training the U-TAE + PAPS model alone. Furthermore, we observe that on-line knowledge distillation leads to better knowledge transfer compared to the off-line setting, where the teacher model is pre-trained and frozen. We believe that this is due to the fact that on-line distillation allows the PAPS classifier to better understand how different networks behave in different evaluation conditions and act accordingly, rather than simply trying to re-create the features of the teacher from the student. Moreover, we note a significant performance gap between the U-Net and the U-TAE backbones, resulting from the introduction of L-TAE. Despite the absence of a temporal time-series input, we observe a better encoding through the L-TAE attention scheme. We would like to highlight the fact that (See eq. 1) is operating on the feature dimension of . As such, even though the authors in [10] have applied L-TAE to generate temporal attention scores for temporal summarization, we can re-purpose it to better scale the features in the backbone network which results in superior performance compared to the traditional U-Net backbone.
IV-D Qualitative Results
In Fig. 3 we present qualitative results when using a single frame from the time-series input of PASTIS-R [29]. The results when the multi-spectral U-TAE + PAPS network is trained with a multi-modal, cross modality attention fusion teacher network are presented together with the baseline U-TAE + PAPS model of [10] (trained with a single frame input) for comparisons.

Figure 3 clearly shows that the baseline U-TAE + PAPS network struggles due to cloud cover as well as the illumination inconsistencies and the resultant boundary ambiguities, leading to miss-classifications and missed detection. Correctly identified parcels are significantly fewer compared to the ground truth. Leveraging the time-series input and multi-modality observations our cross modality attention fusion teacher network has been able to positively influence the student network, which allowed the same U-TAE + PAPS student model to generate comparatively better results through the proposed knowledge distillation pipeline.
V Conclusions
In this article we formulated and evaluated different deep neural network architectures for on-board panoptic segmentation of multi-spectral satellite images. To this end, we first benchmarked existing state-of-the-art panoptic segmentation methodologies in an on-board setting and observed the performance degradation that occurs, largely due to loss of temporal data, which is needed to reduce confusion and ambiguities that arise due to cloud obstruction and other atmospheric noise. We seek to compensate for this loss of information through the introduction of an additional modality, and an augmented multi-modality fusion strategy is proposed using a cross-modality attention fusion scheme. Most importantly, we alleviated additional information processing burden caused by the introduction of multi-modality streams via a knowledge distillation pipeline, where a heavy-weight multi-modality teacher that receives a time-series input was used to guide a light-weight uni-modal student network which only receives a single frame from the multi-spectral time-series. With this approach, a significant 10.7%, 11.9% and 10.6% increase in Segmentation Quality (SQ), Recognition Quality (RQ), and Panoptic Quality (PQ) metrics was observed compared to training the baseline U-TAE + PAPS single-frame uni-modal model alone. In future work, we will investigate methods to further augment the efficiency and the performance of our student model while extending the framework to process hyper-spectral images.
References
- [1] P. Xu, Q. Li, B. Zhang, F. Wu, K. Zhao, X. Du, C. Yang, and R. Zhong, “On-board real-time ship detection in hisea-1 sar images based on cfar and lightweight deep learning,” Remote Sensing, vol. 13, no. 10, p. 1995, 2021.
- [2] J. Qiu, Z. Zhang, R. Wang, P. Wang, H. Zhang, J. Du, W. Wang, Z. Chen, Y. Zhou, H. Jia et al., “A novel weight generator in real-time processing architecture of dbf-sar,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2021.
- [3] A. Sah, Y. Sun, A. Bialkowski, K. Qin, K. Nguyen, and C. Fookes, “Machine learning onboard satellites,” SmartSat Technical Report, vol. 010, 2022.
- [4] S. Liu, H. Zhao, Q. Du, L. Bruzzone, A. Samat, and X. Tong, “Novel cross-resolution feature-level fusion for joint classification of multispectral and panchromatic remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, 2021.
- [5] Y. Gao, W. Li, M. Zhang, J. Wang, W. Sun, R. Tao, and Q. Du, “Hyperspectral and multispectral classification for coastal wetland using depthwise feature interaction network,” IEEE Transactions on Geoscience and Remote Sensing, 2021.
- [6] H. Jung, H.-S. Choi, and M. Kang, “Boundary enhancement semantic segmentation for building extraction from remote sensed image,” IEEE Transactions on Geoscience and Remote Sensing, 2021.
- [7] D. Hong, J. Yao, D. Meng, Z. Xu, and J. Chanussot, “Multimodal gans: Toward crossmodal hyperspectral–multispectral image segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 6, pp. 5103–5113, 2020.
- [8] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollár, “Panoptic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9404–9413.
- [9] O. L. F. de Carvalho, O. A. de Carvalho Júnior, A. O. de Albuquerque, N. C. Santana, D. L. Borges, R. A. T. Gomes, R. F. Guimarães et al., “Panoptic segmentation meets remote sensing,” Remote Sensing, vol. 14, no. 4, p. 965, 2022.
- [10] V. S. F. Garnot and L. Landrieu, “Panoptic segmentation of satellite image time series with convolutional temporal attention networks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4872–4881.
- [11] A. P. Arechiga, A. J. Michaels, and J. T. Black, “Onboard image processing for small satellites,” in NAECON 2018-IEEE National Aerospace and Electronics Conference. IEEE, 2018, pp. 234–240.
- [12] E. W. Gretok and A. D. George, “Onboard multi-scale tile classification for satellites and other spacecraft,” in 2021 IEEE Space Computing Conference (SCC). IEEE, 2021, pp. 110–121.
- [13] Y. Wang, S. Mei, S. Wan, Y. Wang, and Y. Li, “Onboard image selection for small-satellite based remote sensing mission,” in 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). IEEE, 2015, pp. 1618–1621.
- [14] E. Cucchetti, C. Latry, G. Blanchet, J. Delvit, and M. Bruno, “Onboard/on-ground image processing chain for high-resolution earth observation satellites,” The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. 43, pp. 755–762, 2021.
- [15] S. Sophiayati Yuhaniz and T. Vladimirova, “An onboard automatic change detection system for disaster monitoring,” International Journal of Remote Sensing, vol. 30, no. 23, pp. 6121–6139, 2009.
- [16] S. Yuhaniz, T. Vladimirova, and M. Sweeting, “Embedded intelligent imaging on-board small satellites,” in Asia-Pacific Conference on Advances in Computer Systems Architecture. Springer, 2005, pp. 90–103.
- [17] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [18] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520.
- [19] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [20] C. Adams, J. Parker, and D. Cotten, “A hardware accelerated computer vision library for 3d reconstruction onboard small satellites,” in 2021 IEEE Aerospace Conference (50100). IEEE, 2021, pp. 1–14.
- [21] J. Goodwill, D. Wilson, S. Sabogal, A. D. George, and C. Wilson, “Adaptively lossy image compression for onboard processing,” in 2020 IEEE Aerospace Conference. IEEE, 2020, pp. 1–15.
- [22] H. Hihara, K. Moritani, M. Inoue, Y. Hoshi, A. Iwasaki, J. Takada, H. Inada, M. Suzuki, T. Seki, S. Ichikawa et al., “Onboard image processing system for hyperspectral sensor,” Sensors, vol. 15, no. 10, pp. 24 926–24 944, 2015.
- [23] F. C. Bruhn, N. Tsog, F. Kunkel, O. Flordal, and I. Troxel, “Enabling radiation tolerant heterogeneous gpu-based onboard data processing in space,” CEAS Space Journal, vol. 12, no. 4, pp. 551–564, 2020.
- [24] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, no. 6, pp. 1789–1819, 2021.
- [25] N. C. Garcia, P. Morerio, and V. Murino, “Modality distillation with multiple stream networks for action recognition,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 103–118.
- [26] Z. Gao, J. Chung, M. Abdelrazek, S. Leung, W. K. Hau, Z. Xian, H. Zhang, and S. Li, “Privileged modality distillation for vessel border detection in intracoronary imaging,” IEEE transactions on medical imaging, vol. 39, no. 5, pp. 1524–1534, 2019.
- [27] Q. Guo, X. Wang, Y. Wu, Z. Yu, D. Liang, X. Hu, and P. Luo, “Online knowledge distillation via collaborative learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 020–11 029.
- [28] D. Chen, J.-P. Mei, C. Wang, Y. Feng, and C. Chen, “Online knowledge distillation with diverse peers,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 3430–3437.
- [29] V. Sainte Fare Garnot, L. Landrieu, and N. Chehata, “Multi-modal temporal attention models for crop mapping from satellite time series,” arXiv e-prints, pp. arXiv–2112, 2021.
- [30] V. S. F. Garnot and L. Landrieu, “Lightweight temporal self-attention for classifying satellite images time series,” in International Workshop on Advanced Analytics and Learning on Temporal Data. Springer, 2020, pp. 171–181.
- [31] V. Sainte Fare Garnot, L. Landrieu, and N. Chehata, “Multi-modal temporal attention models for crop mapping from satellite time series,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 187, pp. 294–305, 2022.
- [32] Y. Wu, A. Kirillov, F. Massa, W.-Y. Lo, and R. Girshick, “Detectron2,” https://github.com/facebookresearch/detectron2, 2019.