Towards Precision in Appearance-based Gaze Estimation in the Wild
Abstract
Appearance-based gaze estimation systems have shown great progress recently, yet the performance of these techniques depend on the datasets used for training. Most of the existing gaze estimation datasets setup in interactive settings were recorded in laboratory conditions and those recorded in the wild conditions display limited head pose and illumination variations. Further, we observed little attention so far towards precision evaluations of existing gaze estimation approaches. In this work, we present a large gaze estimation dataset, PARKS-Gaze, with wider head pose and illumination variation and with multiple samples for a single Point of Gaze (PoG). The dataset contains 974 minutes of data from 28 participants with a head pose range of in both yaw and pitch directions. Our within-dataset and cross-dataset evaluations and precision evaluations indicate that the proposed dataset is more challenging and enable models to generalize on unseen participants better than the existing in-the-wild datasets. The project page can be accessed here: https://github.com/lrdmurthy/PARKS-Gaze
1 Introduction
Imagine how cool would it be if the mouse cursor on your laptop screen moves wherever you see. Appearance-based gaze estimation systems make this possible just with built-in webcams by obviating the need of infra-red (IR) illuminators and multiple camera systems. But how do you feel about the same technology when the cursor makes sudden, unexpected movements and jumps around that specific icon you are staring to select. Precision indicates the consistency of a model’s gaze predictions and is an imperative feature to build gaze-controlled applications. Precise gaze estimates allow not only for smooth interaction experience, but also useful to improve the accuracy with the help of person-specific calibration. This paper investigates this long-ignored aspect, “precision” of appearance-based gaze estimation systems and attempts to improve it.
Existing research shows that numerous applications were built using appearance-based gaze estimation systems with built-in mobile phone cameras [27], laptop cameras [18] and with commodity web cameras for various contexts like automotive [14, 12], assistive technology [21] and human-robot interaction [11]. Recent studies [30, 17] have shown the limitations of highly accurate IR-based gaze estimation systems and highlighted the robustness of appearance-based gaze estimation systems under similar operating conditions. Since appearance-based gaze estimation systems are predominantly learning-based approaches, the performance of such models under various scenarios is influenced by the diversity and characteristics of the training dataset.
Several appearance-based gaze estimation datasets like EYEDIAP [7], ColumbiaGaze [23], UT-Multiview [24] and ETH-X Gaze [28] were recorded in constrained laboratory settings. However, a model trained with a dataset collected in such restricted scenarios and due to lack of diverse scenarios like ambient illumination, head poses, inter-person variations, intra-person appearance variations like facial hair, makeup and facial expressions, will be less accurate when deployed in the real world We observed only three gaze estimation datasets [10, 32, 9] were collected outside laboratory settings so far. Even though GazeCapture involved large number of participants, it had limited gaze angle distribution and Zhang et al. [31] reported that MPIIFaceGaze contained limited head pose. Authors of Gaze360 [9] commented that GazeCapture contains outdoor scenarios partially and MPIIFaceGaze was recorded indoor. Moreover, MPIIFaceGaze [31] was recorded in static settings where artifacts like motion blur were not considered which arises in dynamic head movement settings.
For applications like gaze-controlled interfaces, dwell-time based selection techniques are widely used and allows for a hands-free interaction experience to the users. Such dwell-time based systems relies on a statically defined cumulative fixation (dwell) duration to trigger the click/selection event [19]. In order to utilize such dwell-time based techniques, the gaze estimation system must provide precise gaze estimates. But, we did not observe such precision analysis of any existing gaze estimation model in the literature.
This paper presents PARKS-Gaze, a large appearance-based gaze estimation dataset collected in both indoor and outdoor scenarios with dynamic head movement and wider head pose than existing in-the-wild datasets. Further, our proposed dataset contained large intra-person appearance variations. It also contained large number of image samples per gaze target with appearance and head pose variations to facilitate the precision analysis. We obtained data samples across wide illumination variations with a head pose range of in both yaw and pitch directions. We evaluated the proposed dataset using within and cross-dataset evaluations and observed that it is more challenging and enable the models to generalize better on unseen participants than existing in-the-wild datasets. The proposed dataset extended the dataset presented by Murthy et al. [13] and the significant additions in the present work are listed below.
-
•
The current version of dataset contains 10 more participants and 65% more data samples than earlier version.
-
•
A within-dataset evaluation is performed using existing AGE-Net, I2D-Net and Dilated-Net models.
- •
-
•
Effect of gaze estimation models and training datasets on gaze precision is presented.
| Dataset | Participants | Head Pose | Data | Region | Temporal Data | Setting |
|---|---|---|---|---|---|---|
| ColumbiaGaze [23] | 56 | 0, 30∘ | 5,880 | Frame | - | Lab |
| UT-Multiview [24] | 50 | 36∘, 36∘ | 64,000 | Eyes | - | Lab |
| EYEDIAP [7] | 16 | 25∘, 30∘ | 237 Min. | Frame | 30 Hz | Lab |
| RT-GENE [6] | 15 | 40∘, -40∘ | 122,531 | Face + Eyes | - | Lab |
| ETH-XGaze [28] | 110 | 80∘, 80∘ | Face | - | Lab | |
| GazeCapture [10] | 1474 | 30∘, [-20∘, 40∘] | Frame | - | Daily Life | |
| MPIIGaze [32] | 15 | 25∘, [-10∘,30∘] | 213,659 | Eyes | - | Daily Life |
| MPIIFaceGaze [31] | 15 | 25∘, [-10∘,30∘] | 37,667 | Face | - | Daily Life |
| PARKS-Gaze | 28 | 60∘, 60∘ | 300,961 | Face + Eyes | 6 Hz | Daily Life |
2 Related Work
2.1 Datasets
Existing appearance-based gaze estimation datasets can be broadly divided into two categories. (I) Datasets recorded in controlled environment; (II) Datasets recorded in real-world scenarios. We briefly summarized the existing datasets in Table 1. In the ’Data’ column of Table 1, the numbers represent the number of data samples available unless specified otherwise.
2.1.1 Datasets - Controlled Conditions:
ColumbiaGaze [23] was one of the first datasets created for eye gaze estimation recorded in laboratory settings. Even though the number of images (6K) were less than most of the existing datasets, it included large number of participants (N=58). Following ColumbiaGaze, UTMultiview [24] was proposed with 50 participants and 1.1M images which contained both natural eye images captured from multiple cameras and synthetic eye images. The head pose was fixed while recording UTMultiview and ColumbiaGaze captured 5 head poses from their respective participants. Subsequent datasets focused on capturing gaze data with unconstrained head pose. EYEDIAP [7] proposed one of the first video datasets for gaze estimation. EYEDIAP contained 94 videos, each of length 2-3 minutes, recorded with 16 participants. Huang et al. [8] proposed TabletGaze, a 2D gaze estimation dataset with 51 participants using Tablet PCs with 4 holding postures and 35 gaze locations. These datasets achieved limited gaze area by virtue of the screens and Tablet PCs used to record the data. We observed that subsequent datasets attempted to overcome this challenge in multiple ways. RT-GENE [6] utilized mobile eye tracking glasses and a free-viewing approach for the participants who were positioned at a distance of 0.5 to 2.9 meters from the camera to achieve wider gaze region. Since RT-GENE dataset’s face images were captured using mobile eye tracking glasses, they proposed semantic inpainting approach to remove the eye tracking glasses but [5] reported noise in the in-painted images. The most recent ETH-XGaze [28] dataset presented over 1 million images recorded with diverse head pose and gaze angle distribution. ETH-XGaze was recorded in laboratory conditions with 110 participants and they focused on capturing high resolution images with gaze angles under extreme head poses. All the above discussed datasets were recorded in controlled conditions in lab where illumination and appearance of the participant had little variation. These datasets did not capture the appearance of participants in the wild conditions and due to predefined recording setups, they failed to capture intra-person appearance variations.
2.1.2 Datasets - Real World Scenarios:
We identified three gaze estimation datasets which were recorded in daily life scenarios. Krafka et al. proposed GazeCapture [10] dataset with 1,474 participants and 2.4M images were captured using mobile devices and authors provided corresponding 2D gaze annotations. Zhang et al. proposed MPIIGaze [32] with 3D gaze annotations, where a total of 213,659 eye images were provided from 15 participants using laptop devices in daily life conditions. Further, authors released MPIIFaceGaze [31], a subset of MPIIGaze with 37667 original face images. The evaluation set of MPIIFaceGaze contained a total of 45K images, obtained by flipping a portion of images horizontally. This dataset covered diverse scenarios of illumination and appearance. Since the gaze direction range was constrained by laptops or mobile devices in both MPIIGaze and GazeCapture, Kellnhofer et al. proposed Gaze360 [9], a large scale dataset recorded using AprilTag markers and a 360∘ camera to acquire unconstrained gaze data. Gaze360 was recorded with 238 participants in 5 indoor and 2 outdoor locations and captured a total of 172K images. Further, the head pose distribution of Gaze360 is unknown [28] while having limited samples per-person and hence limited intra-person appearance variations. Since we aim to build a dataset for gaze-controlled interfaces, our work is closely related to MPIIFaceGaze and GazeCapture datasets which were recorded in daily life scenarios and we primarily consider these for further comparisons.
2.2 Gaze Estimation Models
We can broadly classify the existing gaze estimation models into Single-Channel and Multi-channel architectures. One of the first attempts was GazeNet [32], a single channel approach where a single eye image was used as the input to an architecture based on VGG-16. GazeNet reported a 5.4∘ mean angle error on MPIIGaze. This work was followed by Spatial-Weights CNN [31] where full face images were provided as input. Later, multi-channel approaches were proposed as an alternative to single-channel approaches. iTracker [10] was one of the first multi-channel architecture which used left eye image, right eye image, face crop image and face grid information as inputs. Multi-Region Dilated-Net proposed by Chen and Shi [3] employed dilated convolutions in their proposed model and used both eye images along with face image as inputs. This approach also reported 4.8∘ mean angle error as [31] did on MPIIFaceGaze. Cheng et al. proposed FAR-Net [5] which utilized the asymmetry between two eyes of same person to obtain gaze estimates. In this work, they generated confidence scores for the gaze estimates obtained from two eye images to choose the more accurate prediction. Murthy et al. [18] proposed an approach for gaze estimation based on difference mechanism and reported 4.3∘ and 8.44∘ accuracy on MPIIFaceGaze and RT-GENE datasets respectively. The difference mechanism utilized the absolute difference of the feature vectors computed from both eye images for gaze estimation. Cheng et al. [4] proposed a coarse to fine approach for building a gaze estimation method and reported 4.14∘ and 5.3∘ accuracy on MPIIFaceGaze and EYEDIAP datasets respectively. Recently, Murthy and Biswas proposed AGE-Net [16] which utilized feature-level attention mechanism to obtain a 4.09∘ and 7.44∘ error on MPIIFaceGaze and RT-GENE datasets respectively.
In summary, we observed that only two appearance-based gaze estimation datasets were collected in real world scenarios under interactive setting. Among them, MPIIFaceGaze [31] was recorded under static settings with limited head pose distribution and GazeCapture [10] contained limited gaze direction distribution. Further, no gaze estimation model was evaluated for its precision.
3 PARKS-Gaze - Dataset
The main objective of creating this dataset is to capture all naturally possible head pose appearances from participants while interacting with the display. We also wanted to capture user’s natural facial expressions and appearance variations during gaze data recordings, emulating the natural interaction scenarios. We captured large number of images for a single PoG which enable researchers to compute gaze estimation models’ precision along with accuracy. For this purpose, participants’ laptop devices were used and in-built cameras were utilized as the recording devices since it facilitated us to record in any location in unconstrained manner. Since the focus is on interactive applications like gaze-controlled interfaces, laptop devices were chosen in spite of the resultant limited gaze direction range. We recruited 28 participants and installed our custom data recording software on their laptops. We explained each participant about our experiment and obtained all necessary permissions and consent.
3.1 Data Collection Procedure
Once a recording session was initiated by the participant, our custom software displayed a red dot within two concentric circles, dubbed as the Target, at a random location on screen. The recording procedure was divided into two phases, selection phase and fixation phase. In the selection phase, the participant had to look at the Target and click on it. We monitored the distance between the Target and mouse click position to verify whether participant selected it correctly. Once the user properly selected the Target, the Target image shrunk to a minimum size. This served as an affirmative feedback to the participant for their click action and also to obtain more precise ground truth point. Once the Target reached to a minimum size, the fixation phase could be initiated by the participant by pressing space bar on keyboard. During the Fixation phase, participants were asked to fixate on the Target while varying their head pose or facial appearance or position with respect to screen. Moreover, they were asked to be natural during fixation phase and the only constraint was to maintain their gaze at the Target point. Our data recording happened in two phases spanning over a year. In the first phase, we allowed participants to start and stop the fixation at their own pace and in second phase, we terminated each fixation after a predefined time of 7 seconds. We turned the application background to black once the fixation starts and ensured that no other screen element including cursor got displayed during the fixation phase to minimize on-screen distraction. They were also given the option to terminate a fixation before the predefined duration by pressing ’Esc’ key on keyboard in the event of any distraction or eye blinks. Participants got acquainted with the user interface and the recording software before the actual data recordings. Participants were located at different geographic locations and we instructed them to record in both indoor and outdoor locations.
3.2 Sampling and Processing
The number of sessions recorded by a single participant varied from 1 session to 23 sessions. Each session was predefined with 30 fixations, but many sessions had lesser fixations due to fixation terminations or session terminated by the participant. We recorded timestamps of participant’s click on the Target, space bar press and ’Esc’ key press during the recording session. We observed from the recordings that all participants were static till the moment they began their fixation and they stopped orienting the head once the fixation was terminated. We believed that the predefined selection and fixation phase design for data recording incorporated this head movement pattern and it allowed us to verify the attention of participant during the fixation phase. The mean duration over all fixation was 6.93 1.26 sec. From our fixation recordings, we sampled at higher frequency (6 Hz) than the procedure reported for EYEDIAP in [5, 31, 4] (2 Hz) since the dynamics in terms of facial appearances and head pose in our dataset was higher. Further, EYEDIAP dataset contains both static and dynamic sessions whereas all fixations in the proposed dataset are dynamic by design. We obtained landmarks for sampled frames using OpenFace[1]. We followed the procedure described in [29] for image and gaze data normalization. The image normalization process cancels out the roll component of head orientation and places the image at a fixed distance from a virtual camera. Further, we transformed the PoG to a normalized space using extrinsic calibration [25] of the laptop cameras, head pose and the head rotation matrix of the participant.
3.3 Dataset Characteristics
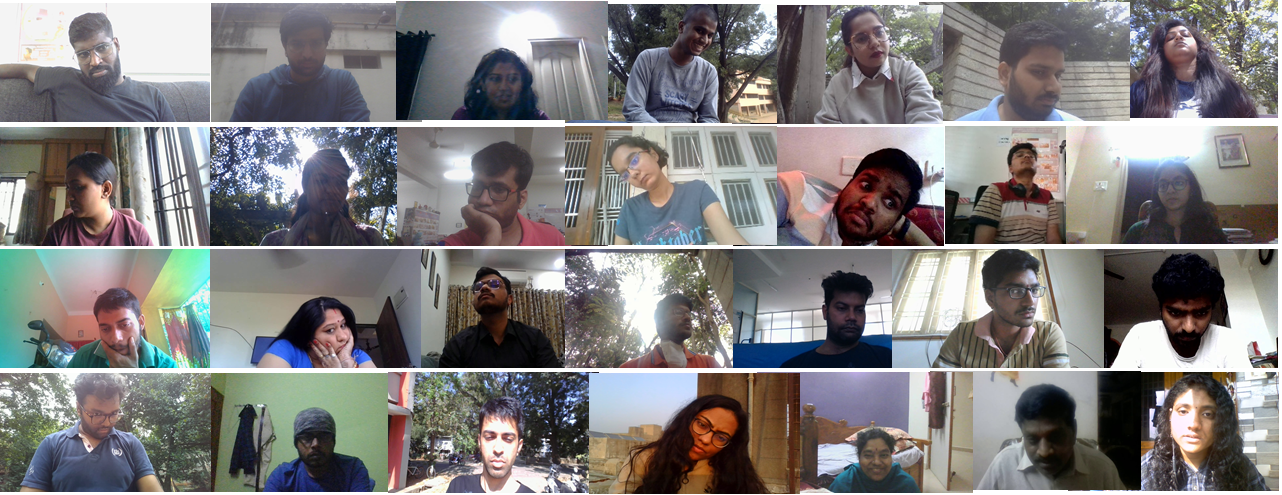
Participants (17 Male and 11 Female; 16 with spectacles; Age: [19-56] years) belong to different states of India. We recorded 974 minutes of video recordings ( Million images) over 328 sessions. The proposed dataset duration was larger than EYEDIAP (237 minutes) and data was collected in real-world conditions rather than in a lab setting. All sampled frames were manually verified and the frames with eyes closed or user distraction from Target were discarded. It was observed that the distraction can occur due to external noise while recording outdoors or the ambient environmental factors like wind or dust. Further, samples with confidence score less than 0.8 while detecting landmarks were discarded resulting in a final evaluation subset of 300,961 samples, larger than MPIIGaze [32] and Gaze360 [9]. It may be noted that Gaze360 provides data at higher sampling rate of 8 Hz, yet contain less number of samples than the proposed dataset. A few representative images from the evaluation set were presented in Figure 1.
3.3.1 Illumination
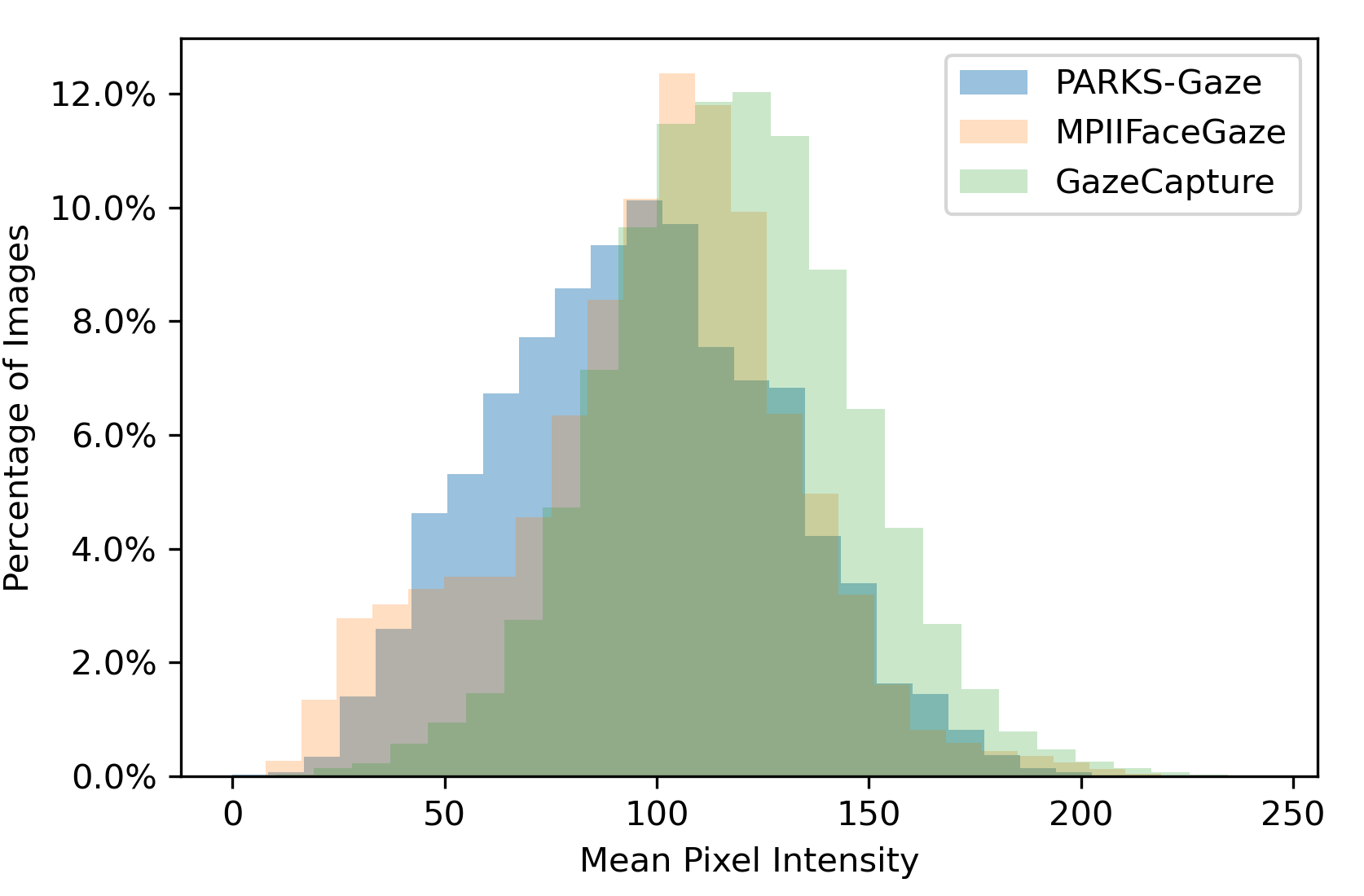
We calculated mean pixel intensity of face crops of the proposed dataset and compared with MPIIFaceGaze [31] and GazeCapture [10] datasets in Figure 2. It was observed that both MPIIFaceGaze (14.8%) and the proposed PARKS-Gaze (15%) contain similar percentage of images in low illumination range (Intensity 60) compared to GazeCapture (2.66%). Further, it is evident from the plot that the proposed dataset has higher presence than the other two datasets on the left half of the intensity histogram where facial features are difficult to discern and gaze estimation approaches [16, 5] reported lower accuracy.
3.3.2 Head Pose
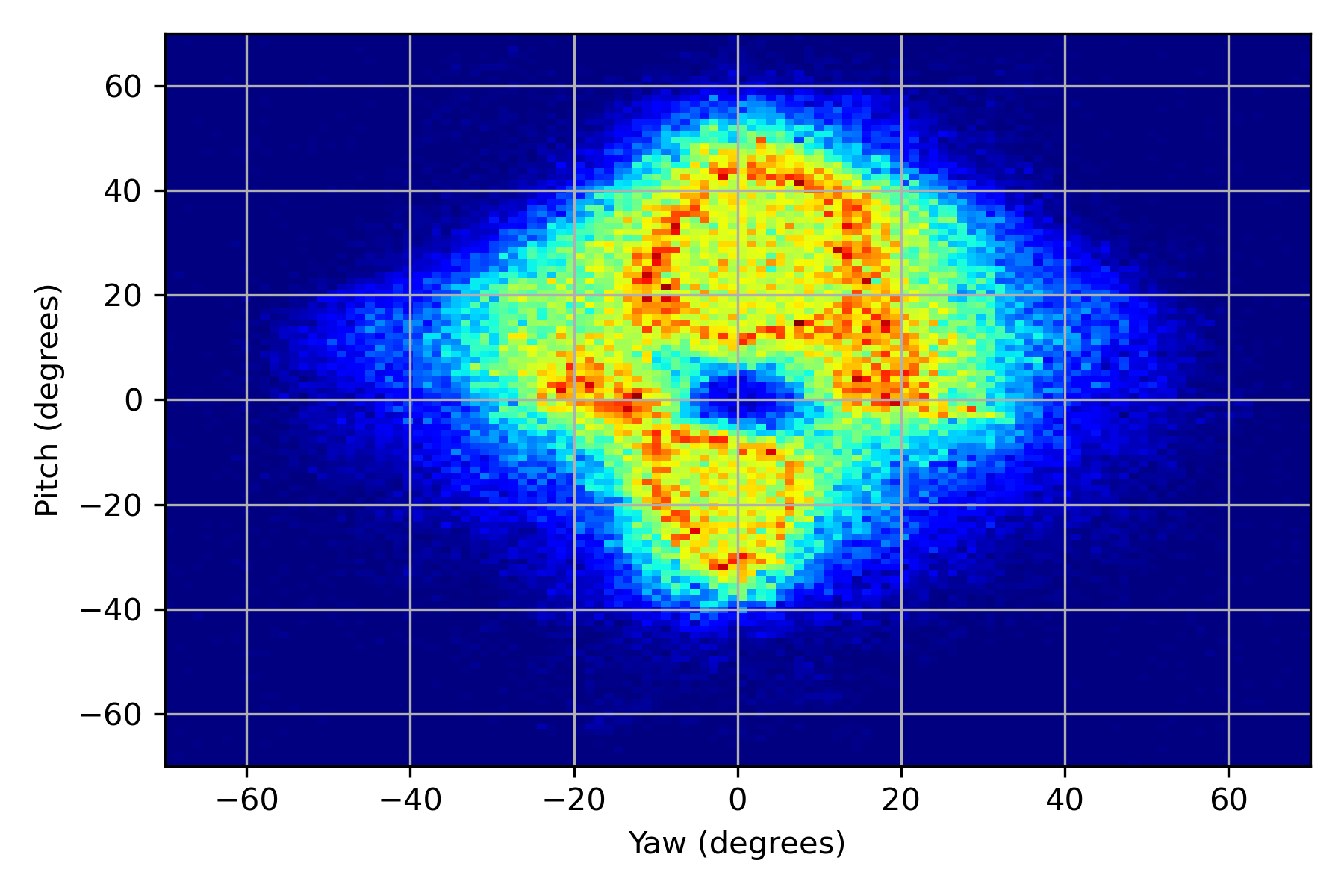
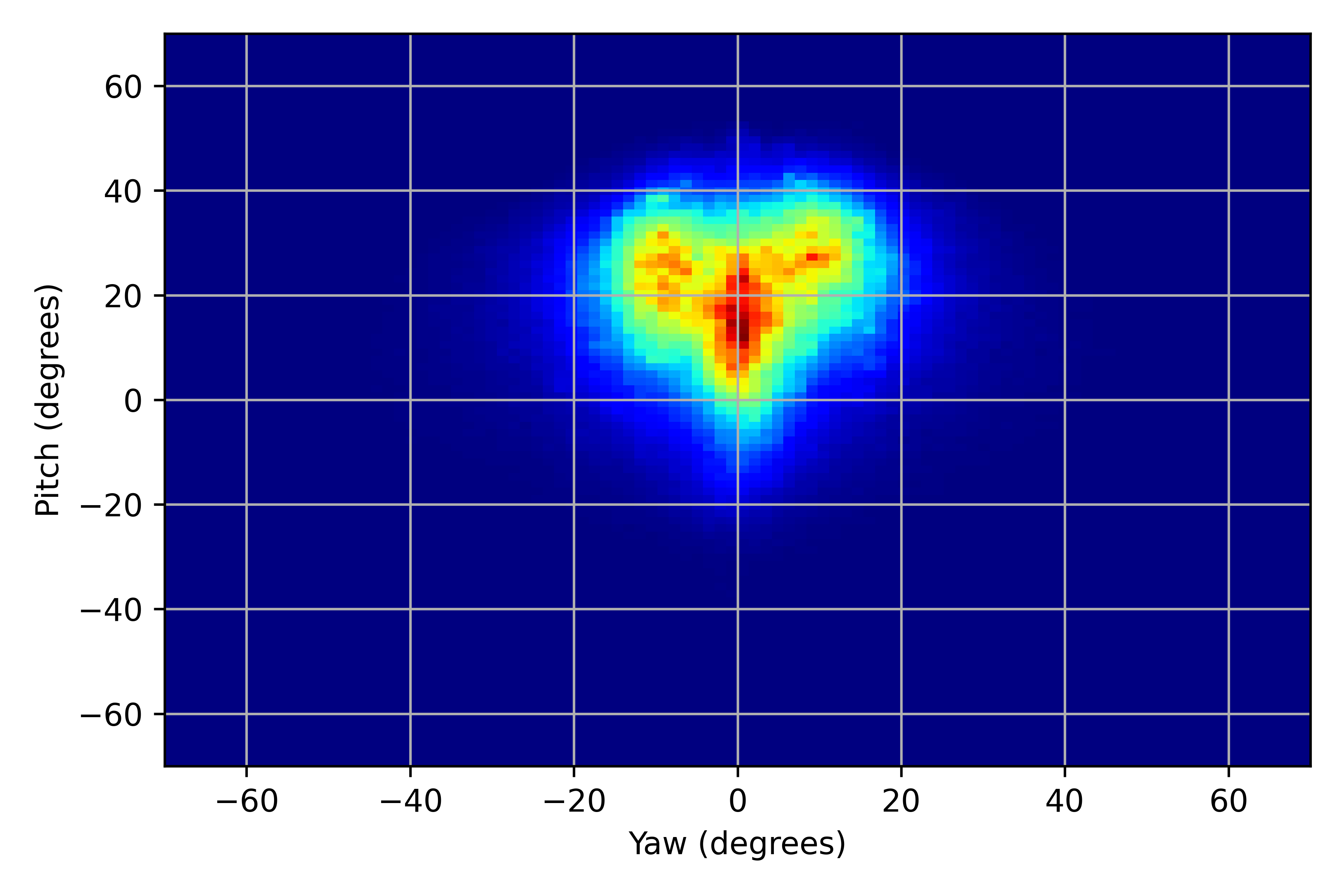
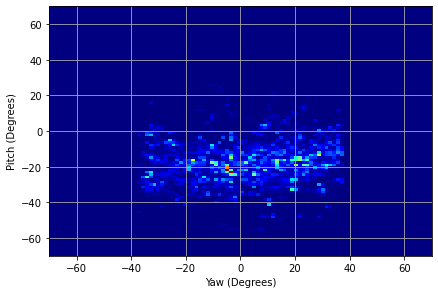
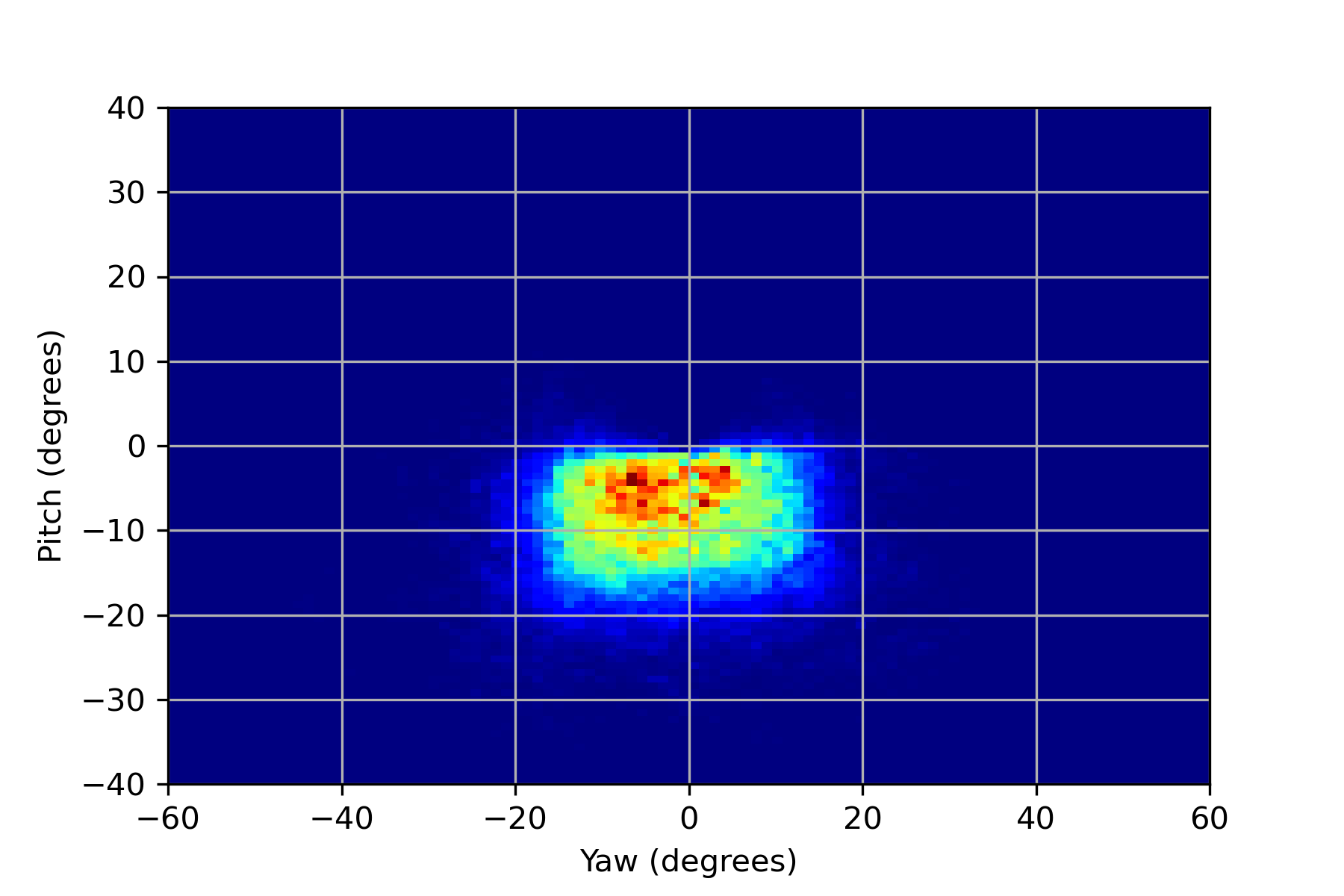
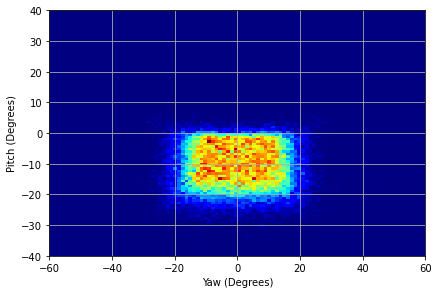
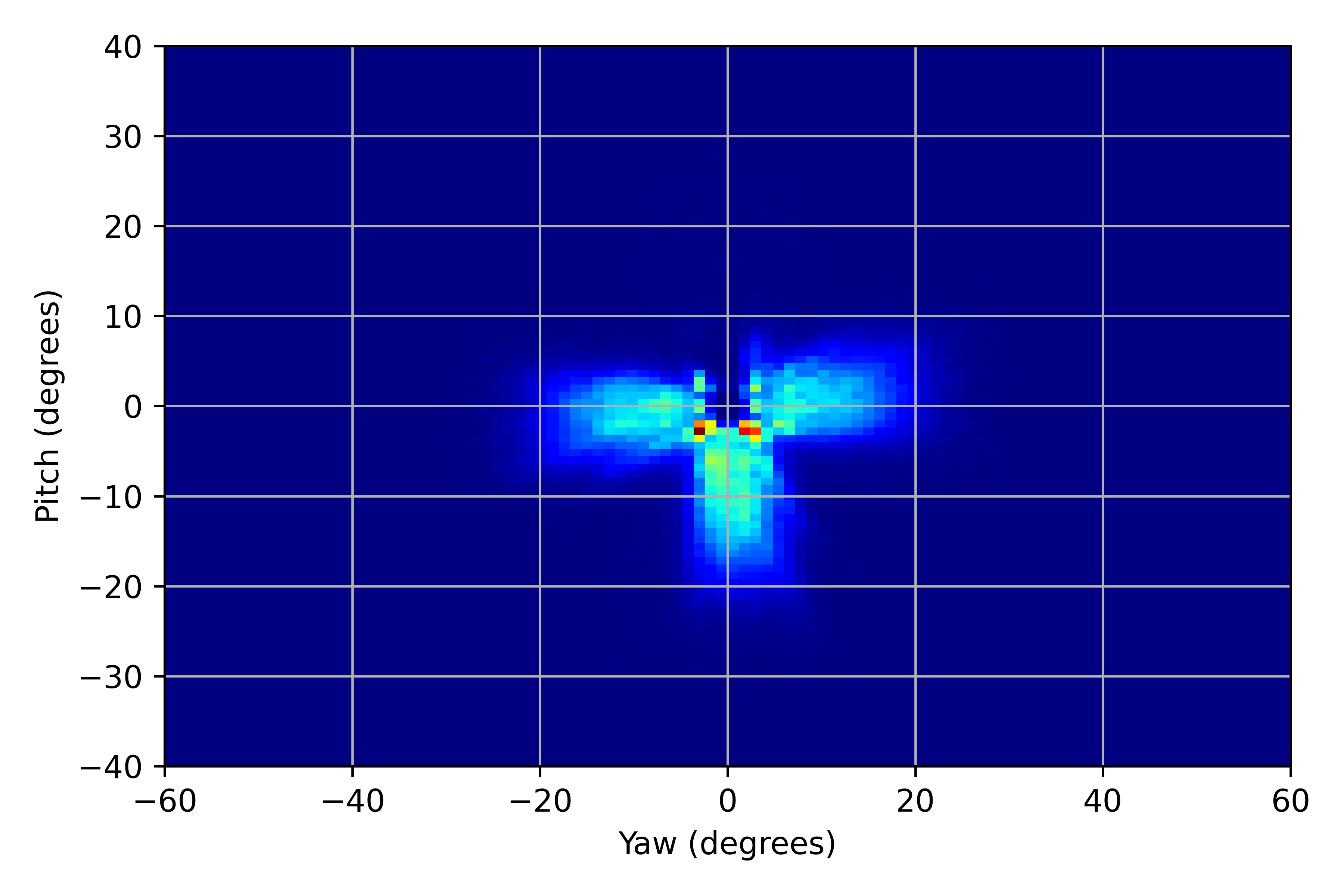
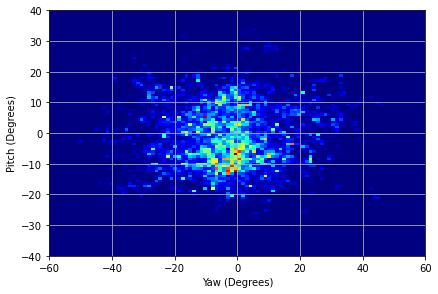
We illustrated the distribution of normalized head pitch and yaw for PARKS-Gaze, MPIIFaceGaze, GazeCapture and RT-GENE datasets in Figures 3(a), 3(b), 3(c), 3(d) respectively. It was observed that the range of head pose distribution of PARKS-Gaze dataset is in both yaw and pitch directions, largest for an in-the-wild dataset. We noted that ETH-XGaze contain larger head pose range than the proposed dataset, but we observed that our participants followed head-pose-following-gaze pattern and recorded data with naturally possible extreme head poses to gaze at the screen target. Moreover, head pose distribution of PARKS-Gaze is continuously distributed whereas ETH-X Gaze acquired discrete clusters of distribution, by the virtue of their multiple camera setup. Further, we achieved wider head pose range than other in-the-wild datasets like MPIIFaceGaze and GazeCapture.
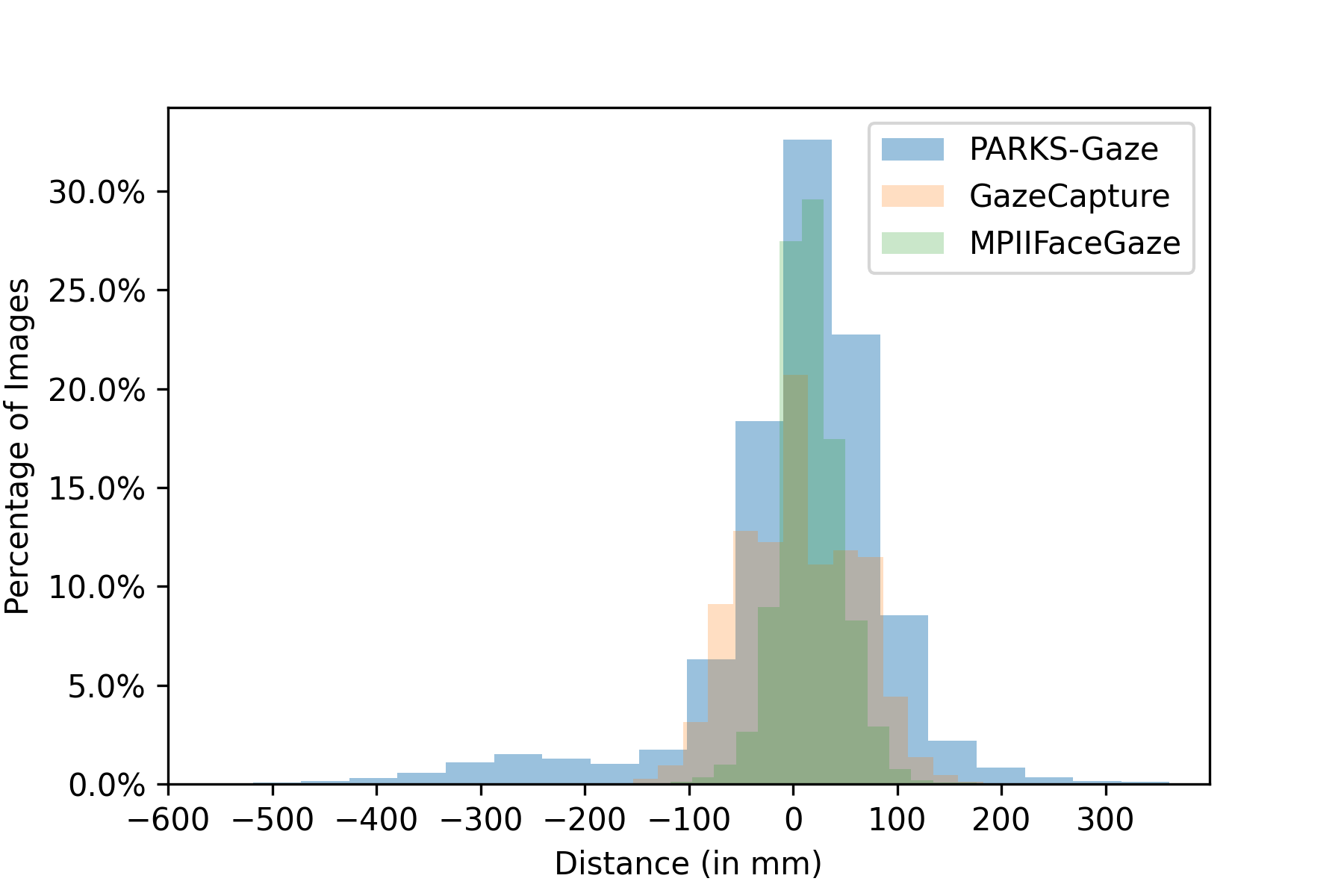
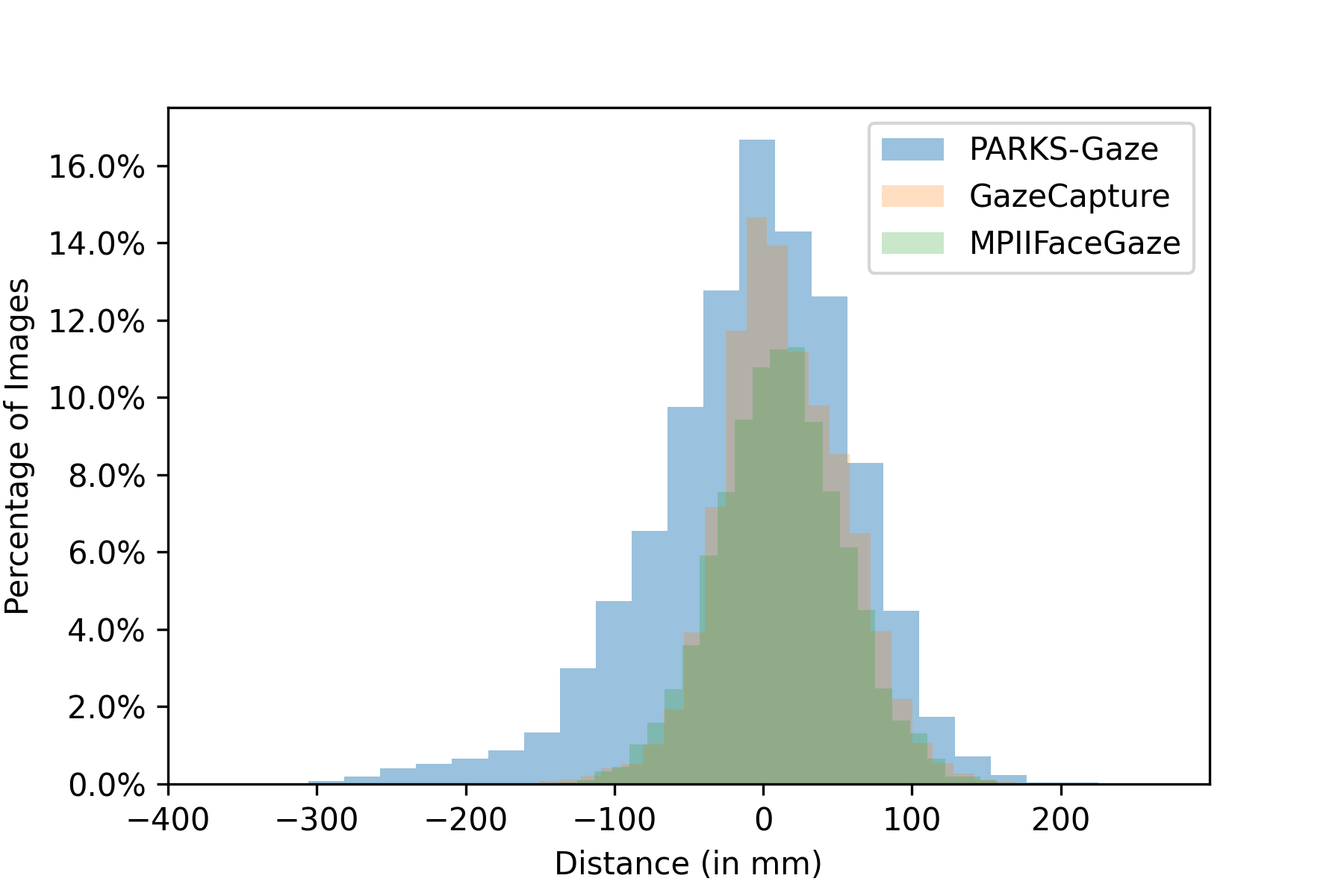
In addition to face orientation, we compared the distribution of participant’s position with respect to the camera across three datasets i.e., MPIIFaceGaze [31], GazeCapture [10] and the proposed PARKS-Gaze. We illustrated the same using histograms in Figures 4(a), 4(b), 4(c). Across all three dimensions X, Y and Z, we observed that the proposed dataset contain wider range of distances between the participant and the camera than the other two in-the-wild datasets in all three dimensions. Existing RT-GENE dataset [6] which was collected in laboratory settings with RGB-D cameras focused on large distances between the participant and the camera in Z direction with a range of 800-2800 mm, but provides little insight into the participant’s position in Y-direction. We report widest range of participant positions in all three dimensions for an in-the-wild dataset recorded in interactive setting with a digital display. We observe that the range of GazeCapture in Z-direction is limited since they utilized handheld mobile displays and MPIIFaceGaze reported narrower range in X direction compared to other two datasets.
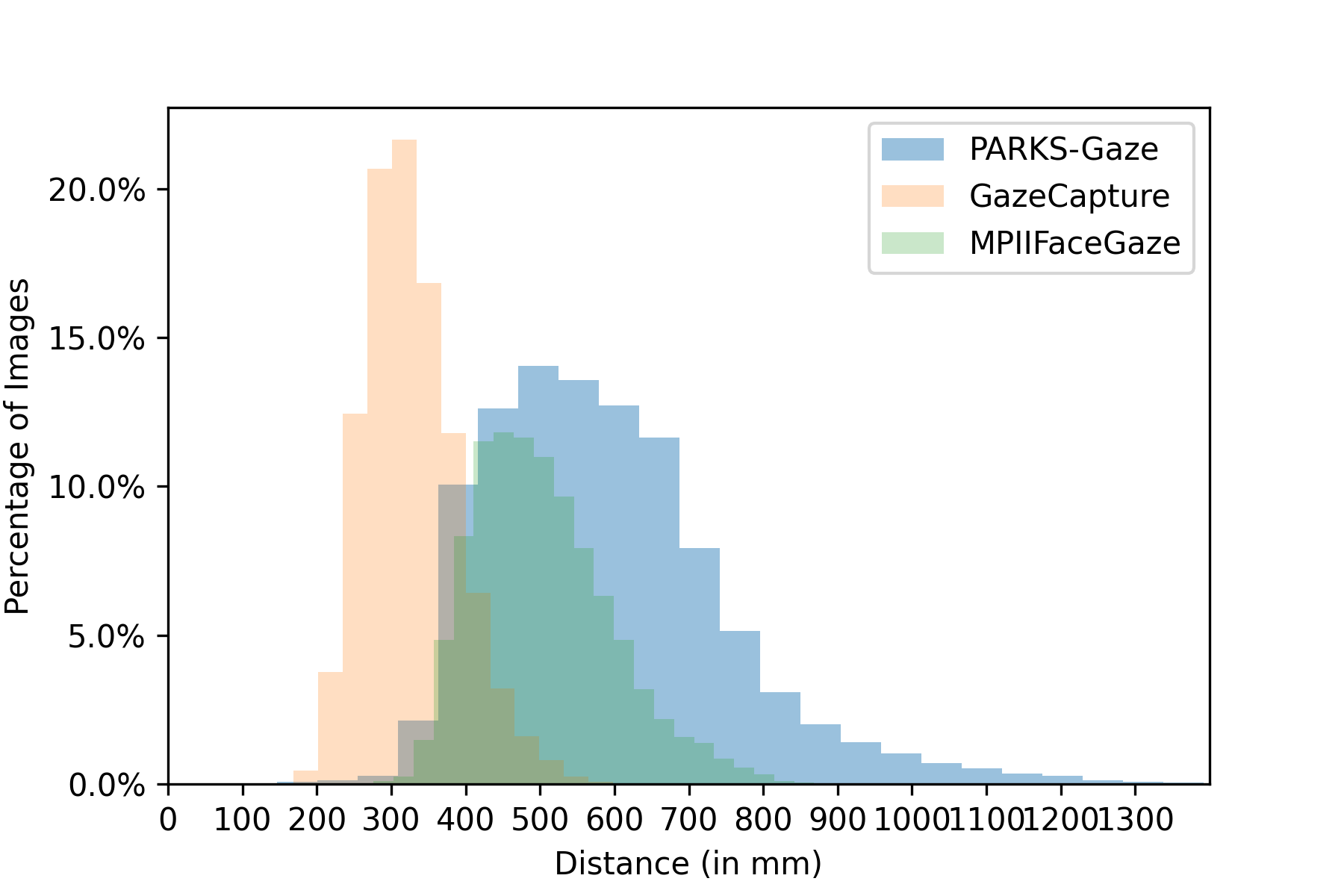
3.3.3 Gaze direction
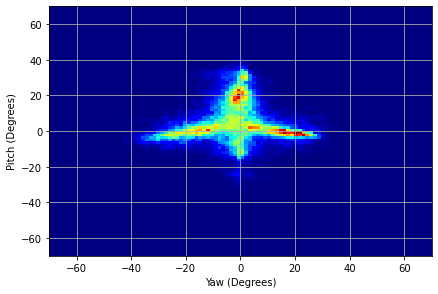
We illustrated the normalized gaze angle distribution of PARKS-Gaze dataset ranging from , [10,-30∘] in yaw and pitch directions in Figure 3(e) and we compared with MPIIFaceGaze, GazeCapture and RT-GENE datasets illustrated in Figures 3(f), 3(g), 3(h) respectively. We observed that gaze region of RT-GENE dataset is wider in both yaw and pitch directions than other 3 datasets. We achieved similar gaze distribution as MPIIFaceGaze but the latter has higher presence at boundaries.
3.3.4 Precision
The proposed dataset contain a total of 8432 fixations, each fixation with multiple images with variation in head pose, position of participant from the camera and facial appearance. This forms one of the major utility factors of our dataset. Interactive applications like gaze-typing [15], gaze controlled wheel-chair interfaces [22] require gaze estimation systems not only to be accurate but also to be precise for selection of screen elements. Since our dataset contain data from both indoor and outdoor conditions, it is useful for not only for precision evaluation of gaze estimation models, but also to train and build precise models that are robust under diverse environments.
4 Experiments
| Models | PARKS-Gaze | MPIIFaceGaze | RT-GENE | EYEDIAP |
|---|---|---|---|---|
| Spatial Weights CNN [31] | - | 4.8∘ | 10.0∘ | 6.0∘ |
| Dilated-Net [3] | 5.3∘∗ | 4.8∘ | - | - |
| FAR-Net [5] | - | 4.3∘ | 8.4∘ | 5.7∘ |
| I2D-Net [18] | 5.6∘∗ | 4.3∘ | 8.4∘ | - |
| CA-Net [4] | - | 4.1∘ | - | 5.3∘ |
| AGE-Net [16] | 5.1∘∗ | 4.1∘ | 7.4∘ | 5.2∘∗ |
4.1 Within Dataset Evaluation
We studied the performance of various existing gaze estimation models on the PARKS-Gaze dataset. We chose Dilated-Net [3], I2D-Net [18] and AGE-Net [16] since these models represent three levels of performance (4.8∘, 4.3∘ and 4.09∘ error respectively) on challenging MPIIFaceGaze dataset. We observed that other existing gaze estimation models [4, 6, 5] reported similar performance as these methods. For our with-in dataset evaluation, we have separated our 28 participants into 3 groups, Train, Validation and Test splits with 18, 4 and 6 participants in each group respectively. We ensured similar gaze and head pose distribution across three groups.
As denoted in Table 2, AGE-Net achieved state-of-the-art performance on MPIIFaceGaze, EYEDIAP, RT-GENE and on the proposed PARKS-Gaze datasets. AGE-Net recorded a mean angle error of 5.17∘ across the 6 test participants of PARKS-Gaze. Since image resolution in both MPIIFaceGaze and PARKS-Gaze datasets is same, we posit that the higher with-in dataset validation error indicate diverse conditions and more number of challenging samples in the proposed dataset than MPIIFaceGaze. Since AGE-Net achieved superior performance across all datasets, we considered it for further evaluations.
4.2 Cross-Dataset Evaluation
We conducted pair-wise cross-dataset evaluations using MPIIFaceGaze, RT-GENE, EYEDIAP, GazeCapture, ETH-XGaze and the proposed PARKS-Gaze datasets. We followed the normalization procedure described in [29] for all the above mentioned datasets. We used 960mm as the focal length of the virtual camera. The distance between the virtual camera and the image center for eye and face images is considered to be 600mm and 1000mm respectively. All the warped images are converted into grayscale and histogram equalized. Since authors of RT-Gene [6] provided the normalized images, we resized and converted them to grayscale as per the model’s requirements. In the case of EYEDIAP, we considered 14 participants with screen targets. We followed similar procedure followed in [5, 31] and sampled 1 frame for every 15 frames from VGA videos. We also considered the available frame annotations to eliminate frames with eyes closed or participant not looking at the Target from our evaluation. Since GazeCapture do not have 3D gaze annotations, we utilized the normalized gaze annotations and head pose information provided by [20]. We considered 1176, 50 and 140 participants for training, validation and test splits. For the ETH-XGaze dataset, we obtained landmarks using [2] and obtained normalized eye images from the given face images.
We summarized the results of our cross-dataset evaluation in Table 3. We ranked training datasets based on the mean angle error for each test dataset and assigned average ranking using the method described in [28]. We observed training on PARKS-Gaze dataset leads to lowest test errors for RT-GENE and GazeCapture datasets and it obtained the best rank (1.6) followed by GazeCapture (1.8) among the 6 training datasets. Further, training on GazeCapture achieved lowest test error when tested on MPIIFaceGaze, ETH-XGaze and PARKS-Gaze datasets even though its gaze distribution is smaller than the test datasets.
ETH-XGaze dataset reported 6.63∘, 7.97∘ and 11.65∘ test error on MPIIFaceGaze, GazeCapture and PARKS-Gaze dataset respectively. Since ETH-XGaze contained large number of participants and larger head angles, higher error on the proposed dataset than the MPIIFaceGaze and GazeCapture further corroborates our argument that PARKS-Gaze is more challenging than the other two datasets. Further, it reported large test errors on EYEDIAP and RT-GENE possibly due to the difference in image resolution between source and target datasets. We observed high errors as reported in [28] when tested on ETH-XGaze due to the domain gap between other datasets and ETH-XGaze in terms of head pose and gaze angle distribution. It may be noted that the results demonstrated here in Table 3 are superior to the ones obtained using the earlier version of the dataset [13].
| [31] | [6] | [7] | [10] | [28] | PARKS-Gaze | Mean Rank [28] | |
|---|---|---|---|---|---|---|---|
| MPIIFaceGaze [31] | - | 18.9∘ | 17.5∘ | 7.2∘ | 40.3∘ | 7.9∘ | 2.6 |
| RT-GENE [6] | 18.2∘ | - | 13.7∘ | 15.4∘ | 46.7∘ | 16.4∘ | 3.4 |
| EYEDIAP [7] | 24.8∘ | 23.2∘ | - | 22.5∘ | 61.0∘ | 23.6∘ | 4.8 |
| GazeCapture [10] | 5.3∘ | 18.4∘ | 19.0∘ | - | 32.3∘ | 7.2∘ | 1.8 |
| ETH-XGaze [28] | 6.6∘ | 35.1∘ | 20.2∘ | 7.9∘ | - | 11.6∘ | 3.8 |
| PARKS-Gaze | 5.9∘ | 16.9∘ | 16.5∘ | 6.5∘ | 34.1∘ | - | 1.6 |
4.3 Precision Experiments
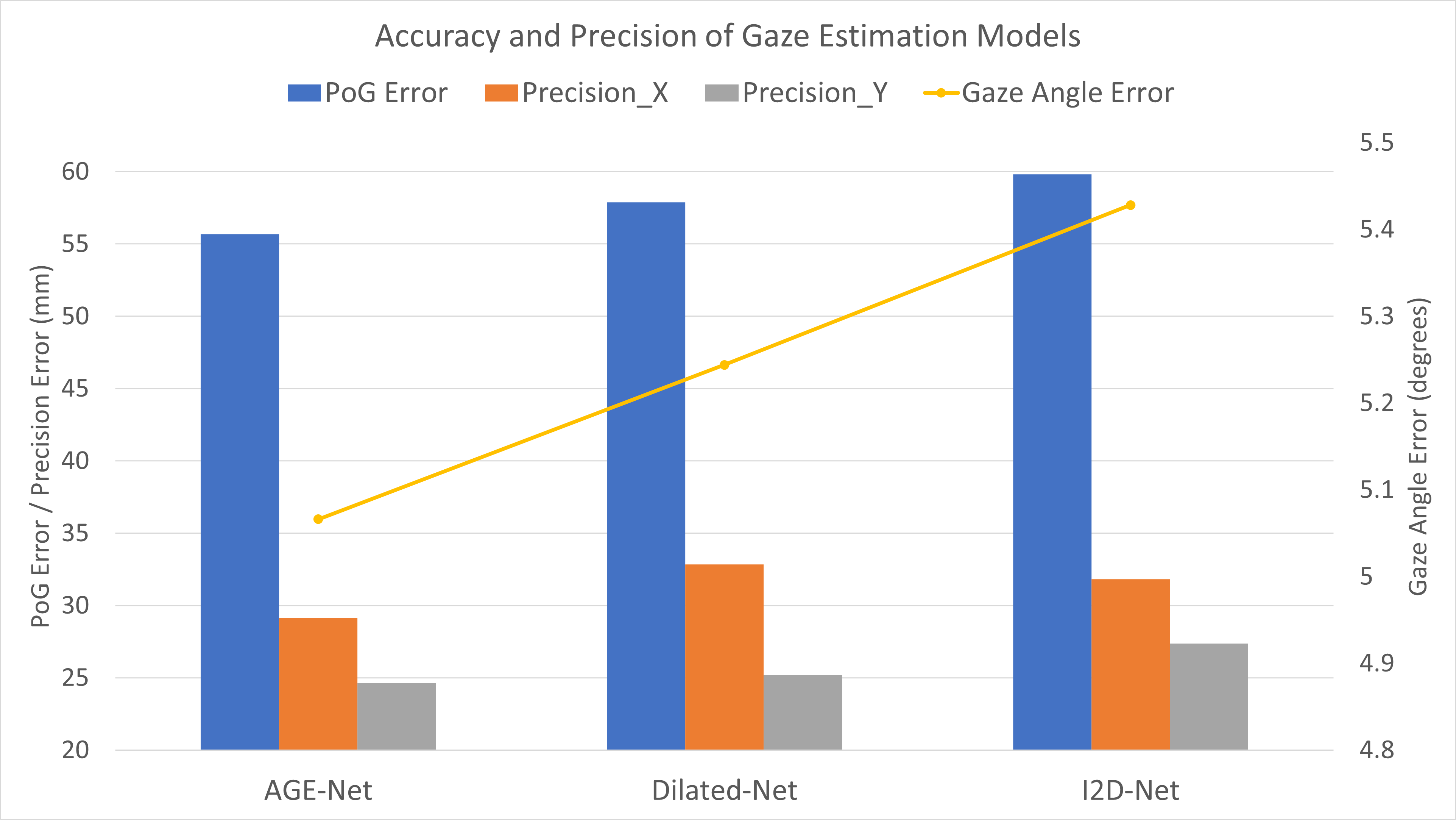
Our literature review revealed that the evaluation of gaze estimation model’s performance is predominantly confined to gaze angle errors. Such measurements do not inform us about the actual usability of such systems for interactive gaze-controlled applications. We undertook performance analysis of gaze estimation models at the PoG level investigating both accuracy and precision error. We performed these experiments in two fold. First, we performed precision analysis on the three models that we considered for our within-dataset validation. Second, we analyzed the effect of training dataset on precision error.
We defined the following experimental procedure to analyse precision error on an unseen participant. As described during within-dataset evaluation, we split our dataset into 3 groups with 18, 4 and 6 participants. We name these splits as Train, Eval1, Eval2. We trained each model twice with Train split using Eval1 and Eval2 as the validation data and test data alternatively. This allowed us to investigate precision on a total of 10 unseen participants with 2504 fixations. We measured PoG error corresponding to each frame in a fixation using euclidean distance between the ground truth and the prediction in screen coordinate system measured in millimeters. We measured precision error using the standard deviation of all PoG predictions corresponding to each fixation. In Figure 5, we presented the mean fixation error, an average value of PoG errors over all fixations of all 10 participants. Similarly, we presented Mean Precision_X and Mean Precision_Y which is an average value of all precision values computed over fixations for all participants in X and Y directions. We also illustrated the mean angle error of each model across all 10 test participants using a line plot. Two paired t-tests revealed that AGE-Net obtained statistically significant improvement over I2D-Net in precision in both X (t[9] = 3.02, p = 0.007) and Y (t[9] = 5.34, p = 2E-4) dimensions. Further, AGE-Net reported significant improvement over Dilated-Net in terms of precision in X-dimension (t[9] = 3.40, p = 0.003).
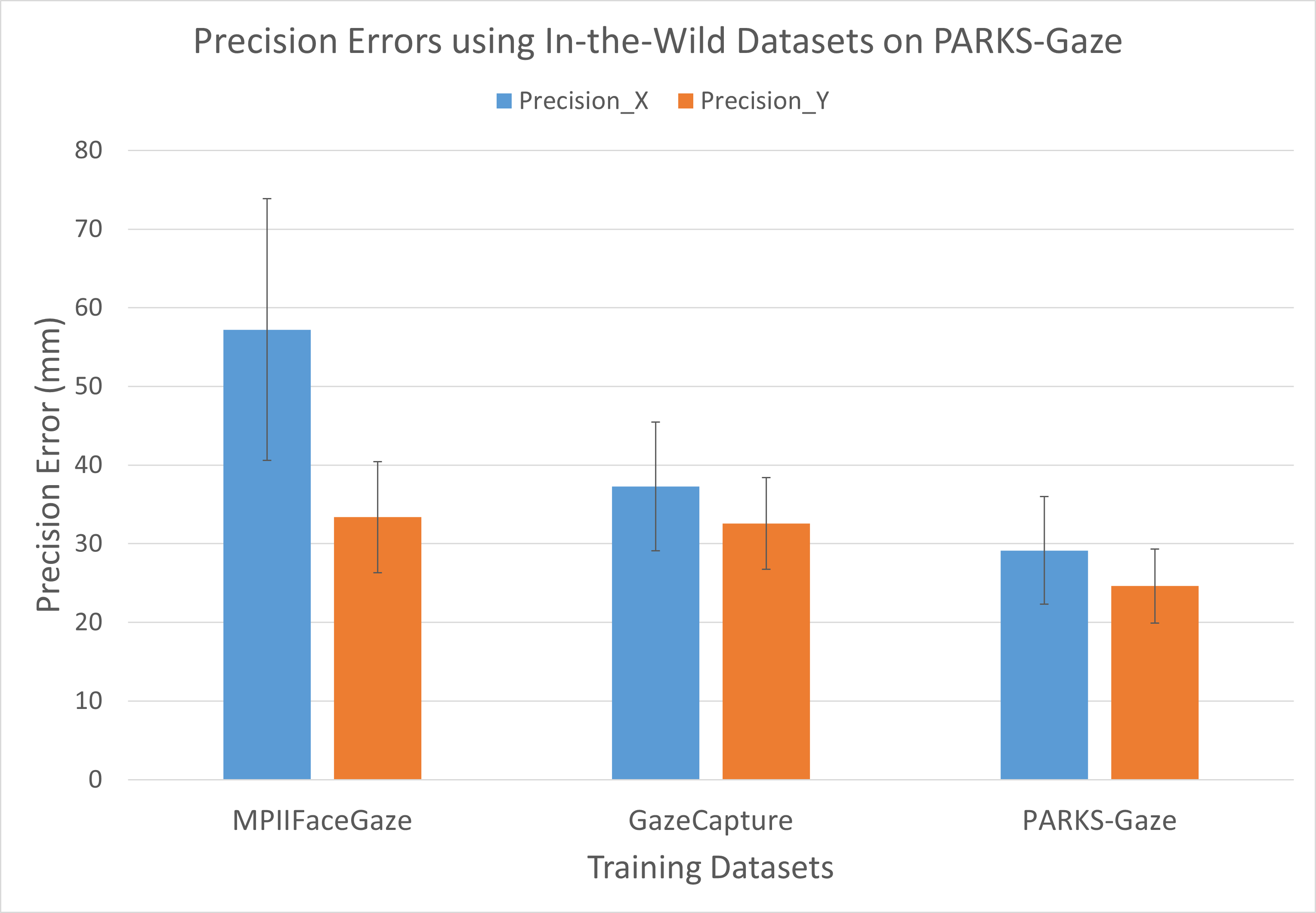
The cross-dataset evaluation reported in Section 4.2 discusses only the accuracy of the model on an unseen participant from a different dataset. Here, we investigate the effect of training dataset on precision error under similar setting. For this purpose, we consider AGE-Net model as it reported superior precision over the other two models during within-dataset precision evaluation.
We used Eval1 and Eval2 splits of the proposed PARKS-Gaze dataset and Test split of GazeCapture dataset as test datasets for precision analysis. We discarded fixations from GazeCapture test split which have only one corresponding frame. The number of frames for remaining fixations ranged from 2 to 15. Since authors of GazeCapture did not provide extrinsic calibration parameters, R, T of the camera with respect to the display, we attempted to generate them using the available information of screen points of the fixation and their corresponding representation in camera coordinate system. We were able to obtain extrinsic parameters for 23026 fixations. The R, T are essential to map gaze angle predictions to screen coordinate system.
On the Test split of PARKS-Gaze dataset, training on MPIIFaceGaze resulted in a mean precision error of 57.2 33 mm and 33.4 14 mm while training on GazeCapture resulted in a mean precision error of 37.3 16 mm and 32.6 11 mm in X and Y directions respectively. Figure 6 illustrates the precision error obtained using MPIIFaceGaze, GazeCapture datasets. We further included results obtained when the model was trained on the Train split of PARKS-Gaze dataset here for the sake of comparison. Two paired t-tests revealed that during this evaluation case, GazeCapture recorded statistically significantly lower precision error when compared to MPIIFaceGaze in X direction (X - t[9] = 3.4, p = 4E-3) while no significant difference was observed for precision error in Y direction.
Next, AGE-Net model trained on the Train split of GazeCapture dataset reported a mean precision error of 8.2 4.5 mm and 7.99 3.5 mm in X and Y directions respectively when tested on its Test split. On the Test split of GazeCapture dataset, training on MPIIFaceGaze resulted in a mean precision error of 13.2 6.5 mm and 10.4 3.8 mm while training on the proposed PARKS-Gaze resulted in a mean precision error of 9.2 4.2 mm and 8.072.8 mm in X and Y directions respectively. Two paired t-tests revealed that the proposed PARKS-Gaze dataset recorded statistically significantly lower precision error than MPIIFaceGaze on both X direction (X - t[139] = 14.5, p = 1E-29) and Y direction (Y - t[139] = 16.56, p = 6E-35). Hence, MPIIFaceGaze dataset is outperformed by both PARKS-Gaze and GazeCapture in two different scenarios in terms of precision errors.
It is worth noting that we observed no significant difference between precision errors in Y-direction obtained using PARKS-Gaze dataset and GazeCapture dataset when tested on Test split of GazeCapture dataset. Further, it may be noted that the combined mean precision error of PARKS-Gaze under cross-dataset setting (12.33 4.9 mm) is only 0.8 mm lower than the precision-error under within-dataset setting using GazeCapture (11.52 5.6 mm). GazeCapture training dataset has 1176 participants whereas PARKS-Gaze training split contained only 18 participants, yet the obtained precision errors under challenging cross-dataset setting are on-par to the errors obtained during a within-dataset evaluation. This indicates strong generalizability of the proposed dataset on unseen participants and its ability in generating precise gaze estimates.
The mean precision error for fixations in Test split of PARKS-Gaze with head pose variation was observed to be 10mm and 9.8mm in X and Y directions. This represents the scenarios where a person might be dwelling on a button with an intention to select and these values decide the design choices while building gaze-controlled interfaces. A similar analysis on GazeCapture resulted in a precision error of 13.5 mm, 14.8mm and on MPIIFaceGaze resulted in 15.7 mm, 13.7 mm precision error in X and Y directions. This indicate that the proposed dataset achieved a lower precision error on unseen participants even under limited head pose variation than existing in-the-wild datasets. Appearance-based gaze estimation is a function of many factors and the role of these factors in conjunction on the precision is not studied.
5 Effect of Head pose on Precision Error
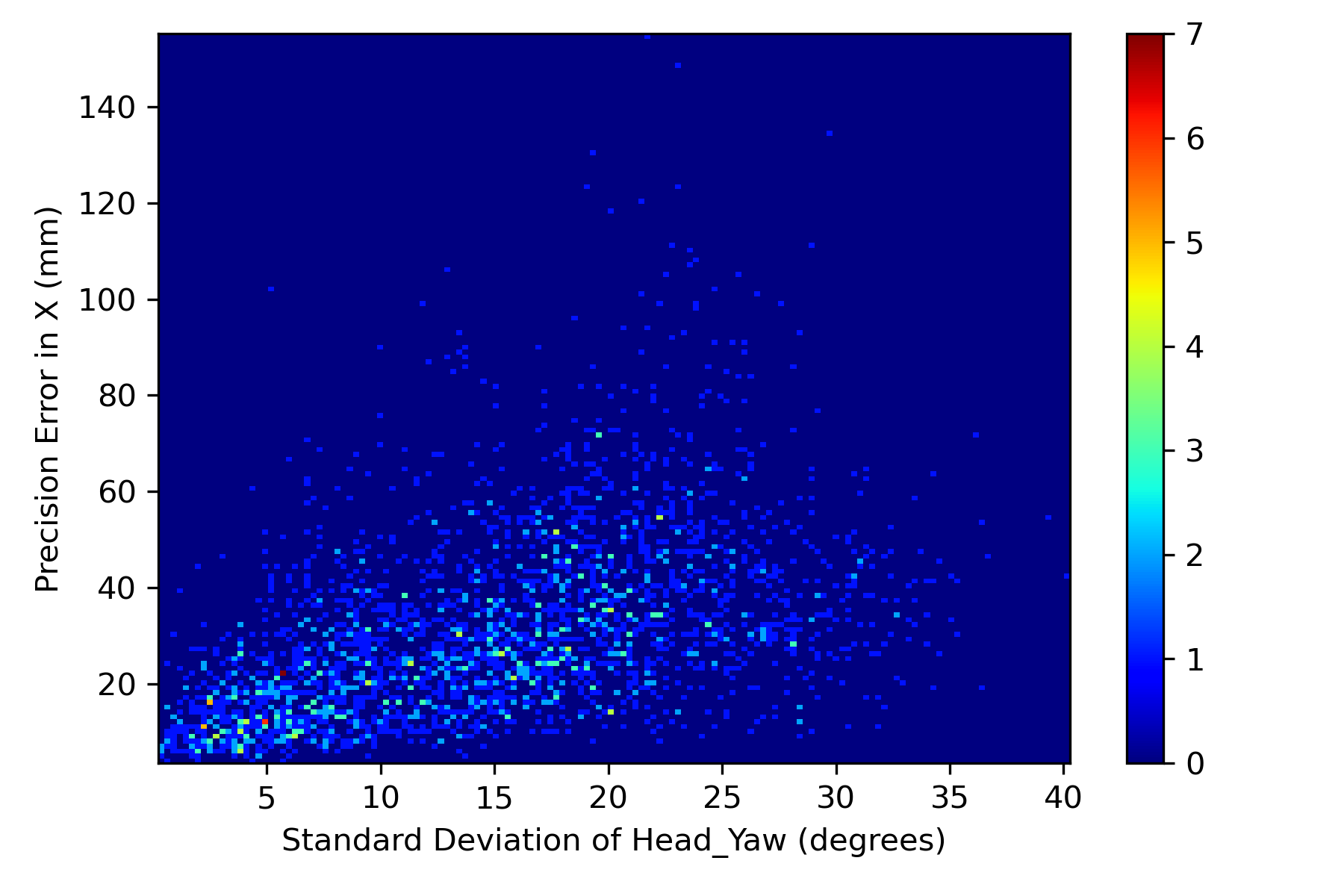
In addition to evaluating precision error of models and the effect of training dataset on the precision error, we investigated the effect of head pose variation during each fixation on the precision error. We have considered 2504 fixations which have at least 5 normalized images as some images were discarded due to less landmarks confidence score. We computed the standard deviation of head yaw and pitch during each fixation and plotted histograms against the precision errors observed during the corresponding fixation in Figures 7(a), 7(b), 7(c), 7(d). Across all the fixations, we computed correlation between the standard deviation of head pose and the precision errors in both X and Y directions. It was observed that the mean correlation between head yaw with respect to precision in X (0.46) and Y (0.42) was moderately positive. For the case of standard deviation of head pitch, we found a weak correlation of 0.18 and 0.3 with precision in X and Y directions respectively. These moderate and weak Pearson’s correlation coefficients is due to the fixations which have less head pose variation yet reported higher precision error, which can be observed in Figures 7(a), 7(b), 7(c), 7(d). We presented a qualitative analysis on such samples in the next section.
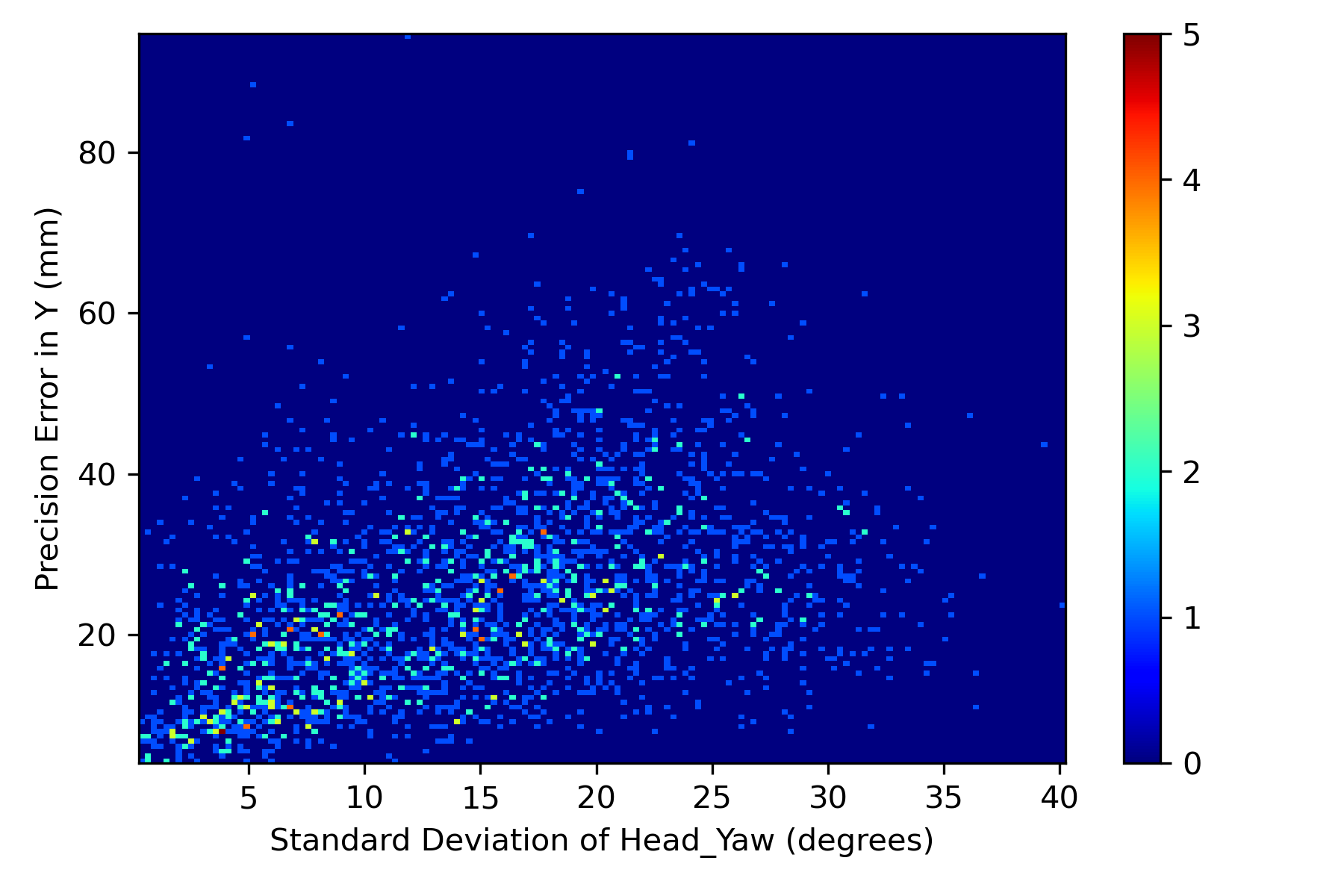
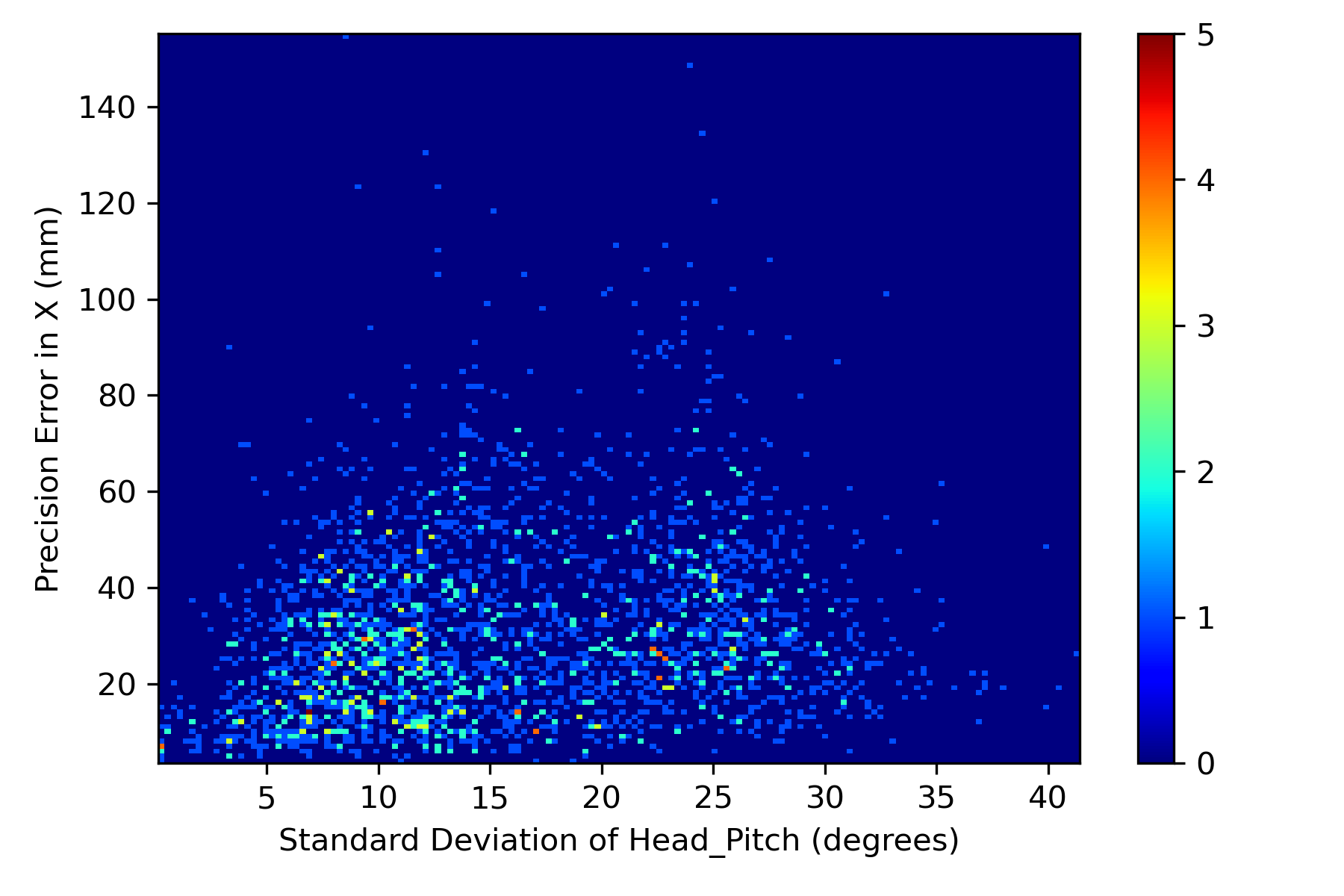
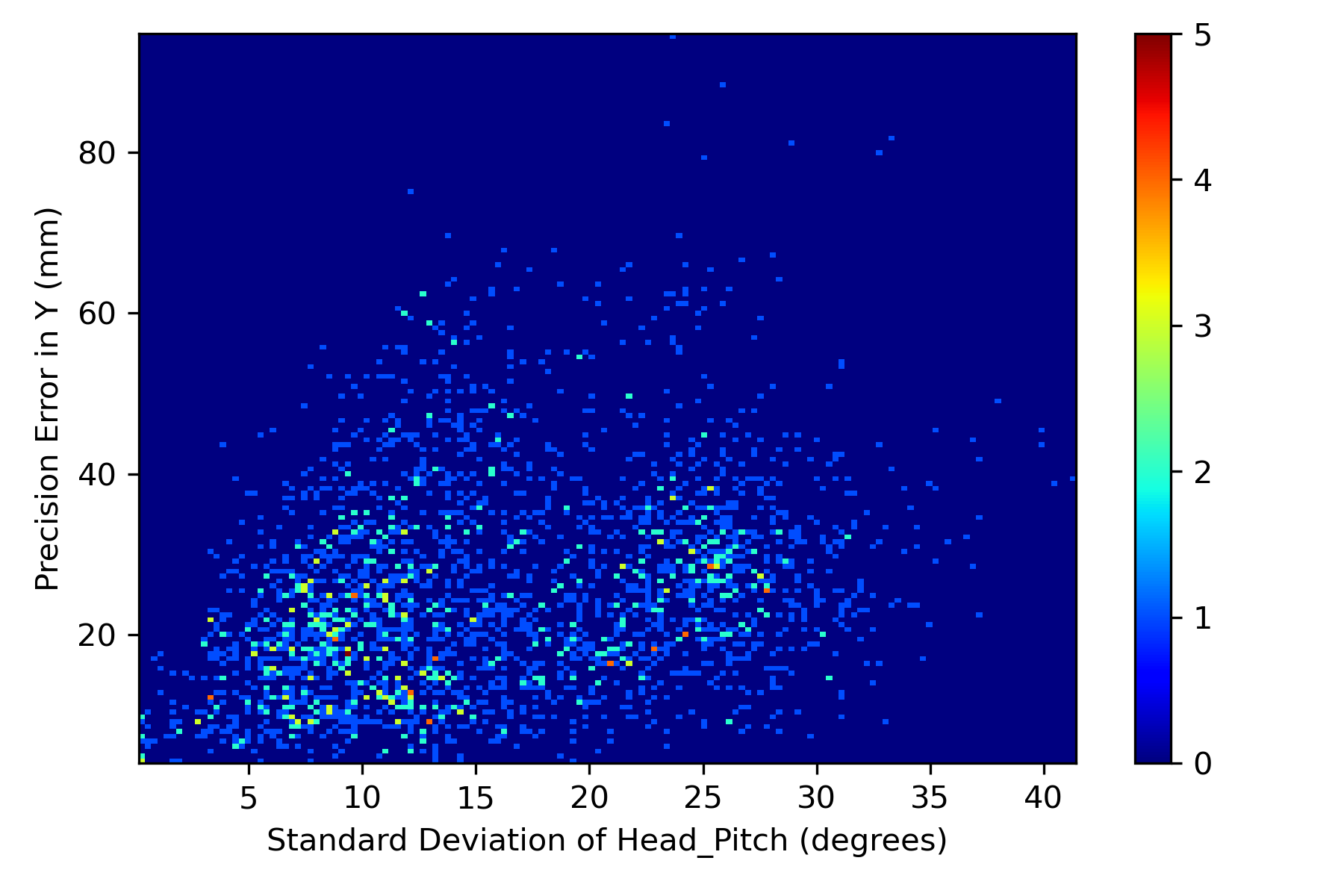
6 Qualitative Results - Precision Analysis


We observed certain fixations which reported high precision error despite low variation in the head pose. We present the normalized face images from such fixations here for qualitative observations.
For this purpose, we conducted our sampling in two-fold. First, we sampled the fixations with head pose variation in both pitch and yaw directions less than 10∘ and the precision errors in both X and Y directions higher than the mean value in the respective dimensions. Figure 8(a) presents the sequence of normalized face images from such instances. In this setting, we observed a maximum precision error in X and Y directions to be 49.5 mm and 48.2 mm respectively. These cases can be observed in the last two rows of Fig 8(a). Visual inspection of these images allows us to consider the effect of facial expressions like smile (Row 1, 2), actions like talking (Row 3) on the gaze estimation performance thereby affecting the precision. Images from Row 5 has a distinct bright illumination effect and Row 6 reveals the variance during the cropping of face images at different head pose angles.
On the other hand, we observed the images with precision errors in X and Y directions greater than 10 mm ( 56px) with standard deviation in the head pose less than 5∘ in both pitch and yaw directions. Representative images from the fixations which fall under this category can be seen in Figure 8(b). The maximum precision error in this case was observed to be 25mm and 34mm in X and Y directions respectively and the first two rows of Figure 8(b) represent these scenarios. Row 5 in Figure 8(b) presents the case of missing portion of face image which can possibly due to the closer position of the participant with respect to the camera. We inspected the camera frames corresponding to Row 6 and observed that participant moved back and forth from the camera. Camera frames from Row 1 revealed that even though pitch and yaw variation is limited, movement in roll direction is significant. It is interesting to note that roll component of head pose is not considered as the part of the gaze estimation as we cancel out during the normalization of images. Yet in this case, significant roll movement might be one of the factors for the poor precision. Images from Row 7 presents an interesting picture where the participant recorded least head movement yet the precision error is higher than 20 mm. This fixation was recorded in bright outdoor illumination conditions with 72K lux on the face region.
Summarizing, performance of appearance-based gaze estimation systems is affected by several factors like external illumination, position of the participant, facial expressions in addition to the head pose variation.
It is widely accepted that collecting real world datasets is challenging and the ones involving human participants is even trickier. The primal contribution of this dataset is to broaden the horizons formed by existing in-the-wild dataset in terms of head poses, illumination and intra-person appearance variations. Another key contribution of this work is generating the missing piece of knowledge on ”precision” performance of gaze estimation systems. The proposed dataset was demonstrated to be challenging compared to other datasets while enabling the models to generalize well on other datasets. This indicate that we contribute an inclusive dataset along with unique scenarios which do not appear in other datasets.
7 Discussion
We presented PARKS-Gaze, a video dataset recorded in real world indoor and outdoor conditions focused on capturing wide range of head poses and intra-person appearance variations. Even though our dataset contained fewer number of participants than GazeCapture, we illustrated the utility of our dataset in cross-dataset validation and precision experiments. Existing datasets like GazeCapture and MPIIFaceGaze reported ethnic diversity in their datasets yet our dataset containing all Indian participants reported best mean rank during the cross-dataset evaluation. Future works need to investigate the role of ethnic diversity in datasets on the generalization capability of gaze estimation models.
During precision experiments, we showed that existing datasets reported higher precision errors when tested on proposed PARKS-Gaze dataset. Further, it was also demonstrated that the proposed dataset achieved on-par precision error with GazeCapture even under a cross-dataset setting. To evaluate GazeCapture and PARKS-Gaze dataset for their cross-dataset precision on a common ground, no other dataset exist at present.
We performed accuracy and precision measurements and investigated the effect of variation of head pose on precision. We shall investigate the effect of other factors like illumination and recording setting as part of our future work. We shall make this dataset available for research community with sequences of frames sampled at 6 Hz for each fixation. Future approaches can leverage techniques like Recurrent Neural Networks or Transformers [26] based Gaze estimation approaches for improved accuracy and precision.
8 Conclusion
We proposed PARKS-Gaze dataset, an appearance-based gaze estimation dataset which has broadened the boundaries of head pose and illumination characteristics of existing in-the-wild datasets. The final evaluation subset of our dataset consisted of 300,961 images and involve wide range of environments including outdoor settings. We demonstrated that proposed dataset encompasses more challenging samples and helps the model to generalize better in terms of both accuracy and precision than the existing in-the-wild gaze estimation datasets.
References
- [1] Tadas Baltrusaitis, Amir Zadeh, Yao Chong Lim, and Louis-Philippe Morency. Openface 2.0: Facial behavior analysis toolkit. In 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 59–66. IEEE, 2018.
- [2] Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, pages 1021–1030, 2017.
- [3] Zhaokang Chen and Bertram E Shi. Appearance-based gaze estimation using dilated-convolutions. In Asian Conference on Computer Vision, pages 309–324. Springer, 2018.
- [4] Yihua Cheng, Shiyao Huang, Fei Wang, Chen Qian, and Feng Lu. A coarse-to-fine adaptive network for appearance-based gaze estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 10623–10630, 2020.
- [5] Yihua Cheng, Xucong Zhang, Feng Lu, and Yoichi Sato. Gaze estimation by exploring two-eye asymmetry. IEEE Transactions on Image Processing, 29:5259–5272, 2020.
- [6] Tobias Fischer, Hyung Jin Chang, and Yiannis Demiris. Rt-gene: Real-time eye gaze estimation in natural environments. In Proceedings of the European Conference on Computer Vision (ECCV), pages 334–352, 2018.
- [7] Kenneth Alberto Funes Mora, Florent Monay, and Jean-Marc Odobez. Eyediap: A database for the development and evaluation of gaze estimation algorithms from rgb and rgb-d cameras. In Proceedings of the Symposium on Eye Tracking Research and Applications, pages 255–258, 2014.
- [8] Qiong Huang, Ashok Veeraraghavan, and Ashutosh Sabharwal. Tabletgaze: dataset and analysis for unconstrained appearance-based gaze estimation in mobile tablets. Machine Vision and Applications, 28(5):445–461, 2017.
- [9] Petr Kellnhofer, Adria Recasens, Simon Stent, Wojciech Matusik, and Antonio Torralba. Gaze360: Physically unconstrained gaze estimation in the wild. In Proceedings of the IEEE International Conference on Computer Vision, pages 6912–6921, 2019.
- [10] Kyle Krafka, Aditya Khosla, Petr Kellnhofer, Harini Kannan, Suchendra Bhandarkar, Wojciech Matusik, and Antonio Torralba. Eye tracking for everyone. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2176–2184, 2016.
- [11] Vinay Krishna Sharma, LRD Murthy, and Pradipta Biswas. Comparing two safe distance maintenance algorithms for a gaze-controlled hri involving users with ssmi. ACM Transactions on Accessible Computing (TACCESS), 15(3):1–23, 2022.
- [12] Murthy LRD, Gyanig Kumar, Modiksha Madan, Sachin Deshmukh, and Pradipta Biswas. Efficient interaction with automotive heads-up displays using appearance-based gaze tracking. In Adjunct Proceedings of the 14th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, pages 99–102, 2022.
- [13] Murthy LRD, Abhishek Mukhopadhyay, Ketan Anand, Shambhavi Aggarwal, and Pradipta Biswas. Parks-gaze-a precision-focused gaze estimation dataset in the wild under extreme head poses. In 27th International Conference on Intelligent User Interfaces, pages 81–84, 2022.
- [14] Murthy LRD, Abhishek Mukhopadhyay, and Pradipta Biswas. Distraction detection in automotive environment using appearance-based gaze estimation. In 27th International Conference on Intelligent User Interfaces, pages 38–41, 2022.
- [15] Päivi Majaranta, Ulla-Kaija Ahola, and Oleg Špakov. Fast gaze typing with an adjustable dwell time. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 357–360, 2009.
- [16] LRD Murthy and Pradipta Biswas. Appearance-based gaze estimation using attention and difference mechanism. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3137–3146. IEEE, 2021.
- [17] LRD Murthy and Pradipta Biswas. Deep learning-based eye gaze estimation for military aviation. In 2022 IEEE Aerospace Conference (AERO), pages 1–8. IEEE, 2022.
- [18] LRD Murthy, Siddhi Brahmbhatt, Somnath Arjun, and Pradipta Biswas. I2dnet-design and real-time evaluation of an appearance-based gaze estimation system. Journal of Eye Movement Research, 14(4), 2021.
- [19] Aanand Nayyar, Utkarsh Dwivedi, Karan Ahuja, Nitendra Rajput, Seema Nagar, and Kuntal Dey. Optidwell: intelligent adjustment of dwell click time. In Proceedings of the 22nd international conference on intelligent user interfaces, pages 193–204, 2017.
- [20] Seonwook Park, Shalini De Mello, Pavlo Molchanov, Umar Iqbal, Otmar Hilliges, and Jan Kautz. Few-shot adaptive gaze estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9368–9377, 2019.
- [21] Vinay Krishna Sharma, LRD Murthy, KamalPreet Singh Saluja, Vimal Mollyn, Gourav Sharma, and Pradipta Biswas. Webcam controlled robotic arm for persons with ssmi. Technology and Disability, 32(3):1–19, 2020.
- [22] Corten Clemente Singer and Björn Hartmann. See-thru: Towards minimally obstructive eye-controlled wheelchair interfaces. In The 21st International ACM SIGACCESS Conference on Computers and Accessibility, pages 459–469, 2019.
- [23] Brian A Smith, Qi Yin, Steven K Feiner, and Shree K Nayar. Gaze locking: passive eye contact detection for human-object interaction. In Proceedings of the 26th annual ACM symposium on User interface software and technology, pages 271–280, 2013.
- [24] Yusuke Sugano, Yasuyuki Matsushita, and Yoichi Sato. Learning-by-synthesis for appearance-based 3d gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1821–1828, 2014.
- [25] Kosuke Takahashi, Shohei Nobuhara, and Takashi Matsuyama. A new mirror-based extrinsic camera calibration using an orthogonality constraint. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 1051–1058. IEEE, 2012.
- [26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [27] Xiaoyi Zhang, Harish Kulkarni, and Meredith Ringel Morris. Smartphone-based gaze gesture communication for people with motor disabilities. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, pages 2878–2889, 2017.
- [28] Xucong Zhang, Seonwook Park, Thabo Beeler, Derek Bradley, Siyu Tang, and Otmar Hilliges. Eth-xgaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation. In European Conference on Computer Vision, pages 365–381. Springer, 2020.
- [29] Xucong Zhang, Yusuke Sugano, and Andreas Bulling. Revisiting data normalization for appearance-based gaze estimation. In Proc. International Symposium on Eye Tracking Research and Applications (ETRA), pages 12:1–12:9, 2018.
- [30] Xucong Zhang, Yusuke Sugano, and Andreas Bulling. Evaluation of appearance-based methods and implications for gaze-based applications. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pages 1–13, 2019.
- [31] Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. It’s written all over your face: Full-face appearance-based gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 51–60, 2017.
- [32] Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. Mpiigaze: Real-world dataset and deep appearance-based gaze estimation. IEEE transactions on pattern analysis and machine intelligence, 41(1):162–175, 2017.