12pt \SetWatermarkScale1.1 \SetWatermarkAngle90 \SetWatermarkHorCenter202mm \SetWatermarkVerCenter170mm \SetWatermarkColordarkgray \SetWatermarkTextLate-Breaking / Demo Session Extended Abstract, ISMIR 2024 Conference
Towards Robust Transcription: Exploring Noise Injection Strategies for Training Data Augmentation
Abstract
Recent advancements in Automatic Piano Transcription (APT) have significantly improved system performance, but the impact of noisy environments on the system performance remains largely unexplored. This study investigates the impact of white noise at various Signal-to-Noise Ratio (SNR) levels on state-of-the-art APT models and evaluates the performance of the Onsets and Frames model when trained on noise-augmented data. We hope this research provides valuable insights as preliminary work toward developing transcription models that maintain consistent performance across a range of acoustic conditions.
1 Introduction
Automatic Music Transcription (AMT) is a fundamental task in Music Information Retrieval (MIR), aiming to convert audio recordings into symbolic representations, such as the Musical Instrument Digital Interface (MIDI) format. As a foundational task in Music Information Retrieval (MIR), AMT has broad applications in music education, search, creation, and musicology [1]. While AMT in general targets all musical instruments and efforts have been made for a variety of instruments [2, 3, 4], the majority of research has focused on transcribing solo piano performances [5, 6, 7, 8, 9, 10, 11, 12]. Recent advancements in piano transcription have led to significant improvements, particularly in onset detection; models trained on the MAESTRO dataset [7] have achieved onset F1 scores exceeding 95% [8, 9, 4, 10, 11, 12]. However, these results are typically based on evaluations using very clean data. Thus, the robustness of these piano transcription systems in real-world scenarios remains largely unexplored. Some previous work shows how performance degrades in altered acoustic environments [13] and how robustness can be improved through data augmentation [7, 13].
Despite the proven benefits of data augmentation in improving model robustness, there are no established guidelines for prioritizing specific techniques in AMT. While various studies have explored different data augmentation methods [7, 13, 14], there is limited clarity on how to apply these techniques effectively. For instance, when employing noise injection, several key factors must be considered, such as the type of noise (e.g., white, pink, environmental), the Signal-to-Noise-Ratio (SNR), and the ratio of clean to augmented data. However, to the best of our knowledge, these parameters are often chosen arbitrarily, highlighting the need for further investigation in this area.
In this study, we investigate the impact of white noise injection, a widely adopted technique in audio research [15, 16, 17], on piano transcription. Our analysis has two primary goals, (i) to assess the performance degradation of AMT systems across various SNR levels, and (ii) to demonstrate the effectiveness of white noise injection in enhancing the robustness of the transcription.
2 Experiments
This section outlines the experimental methods and summarizes the results. Due to the page limit constraints, detailed numerical results are not included in the main text but can be accessed, along with the experimental code, on GitHub.111https://github.com/yonghyunk1m/TowardsRobustTranscription
2.1 Exp. 1: Impact of Noise on Pre-Trained Systems
Recording piano performances in uncontrolled environments often results in widely varying SNRs due to lack of high quality equipment, background noise, reverberation, and other environmental factors. In such settings, the SNR tends to be lower than in controlled professional environments such as studios. To rigorously assess the robustness of the models under these conditions, we evaluated their performance across a broad range of SNR values, ranging from -6 dB to 45 dB, in 3 dB intervals, covering a total of 18 different SNR levels.
For this experiment, we utilized two state-of-the-art models: Onsets and Frames [5] and the model proposed by Kong et al. [8]. The Kong et al. model was tested using a publicly available pre-trained checkpoint,222https://github.com/bytedance/piano_transcription while the Onsets and Frames [5] model was re-implemented using the PyTorch framework,333https://github.com/jongwook/onsets-and-frames following the original training procedures and specifications outlined in the respective papers.
We generated white noise-augmented versions of the MAESTRO v3 [7] dataset for inference. The test split, consisting of 177 recordings, was used for evaluation as defined in the dataset’s metadata. To create the augmented data, we calculated the power of each target audio sample and added scaled white noise to achieve the desired SNR levels. The resulting audio was then normalized to retain the RMS value of the original, noise-free recording. In instances where clipping occurred, we adjusted the affected sections to the maximum representable value to prevent distortion, ensuring that the integrity of the audio signal was preserved throughout the evaluation process.
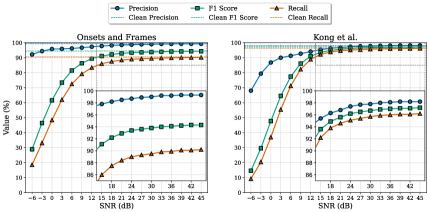
Figure 1 presents the overall results of this experiment. As the SNR level decreases, a clear decline in model performance is observed. Both the Kong et al. [8] model and Onsets and Frames [5] show a reduction in F1 scores compared to their baseline performance on clean data (96.7% and 94.5%, respectively), with around a 5% relative drop at 12 dB SNR and around a 10% relative drop at 9 dB SNR.
2.2 Exp. 2: Effect of Noise Injection during Training
To investigate whether performance degradation in noisy environments can be mitigated through data augmentation, we employed the Onsets and Frames model [5], training it with white noise-injected audio. We introduce the term Clean-to-Noise Ratio (CNR) to represent the proportion of clean to noise-injected audio sampled during training. Based on the hypothesis that the level of perturbation impacts performance, we trained the model using CNR levels of 0 (fully perturbed), 1/3, 1, 3, and (clean audio only). For each CNR, the model probabilistically samples from the clean or noisy audio. In case of noisy audio, the SNR dB value is randomly sampled from [0, 24], followed by RMS normalization and clipping prevention. This SNR range was chosen based on prior research [7, 13] and results from Sect. 2.1, where significant performance degradation was observed.
We followed the original Onsets and Frames [5] configuration throughout the training process, standardizing the number of iterations to 100k for all experiments. This decision was based on preliminary experiments with noise-injected audio, which showed that increasing the number of iterations beyond 100k did not result in lower losses.
The performance evaluation of the trained models is presented in Figure 2.
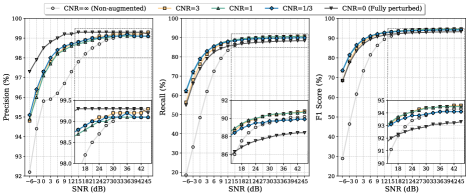
We observe that the the systems trained with noisy data all considerably outperform the system trained with clean data for low SNRs. As the SNR increases, the gap decreases, and for very high SNRs, we observe a tendency for the highly perturbed training scenarios (CNR , 0) to be outperformed by the system trained with clean data (CNR ), which in turn is slightly outperformed by the slightly perturbed training scenarios (CNR 3, 1).
To assess whether these observations are statistically significant, we conducted a series of t-tests. This analysis was performed across four distinct CNR values. Table 1 summarizes the ranges where statistically significant differences (t-statistic < 0 and p-value < 0.05) were observed in Precision, Recall, and F1 scores.
| CNR | Precision (SNR) | Recall (SNR) | F1 Score (SNR) |
|---|---|---|---|
| 3, 1 | [0, 24] | [-6, 15] | [-6, 18] |
| 1/3 | [-3, 21] | [-6, 15] | [-6, 15] |
| 0 | [-6, 30] | [-6, 9] | [-6, 12] |
These findings indicate that while training with noise-injected data can enhance model robustness, excluding clean data entirely (CNR=0) leads to performance degradation in acoustically controlled environments, such as when testing on clean data (SNR=). Thus, the absence of clean data during training adversely impacts performance under clean conditions. Moreover, the percentage of perturbed training samples is an important parameter of augmentation with impact the improvement gained and the SNR range of the improvement.
3 Conclusion
This study highlights the importance of white noise injection in improving the robustness of APT models for diverse acoustic conditions. By introducing CNR, we show that under the right conditions, noise-injected training enhances performance at lower SNR levels and is on par at high SNRs. The findings emphasize the need for carefully selecting the data augmentation parameters and imply that increased robustness to different noise environments does not need to come at a cost for clean environments. In fact, there might be ways to gain significant improvements across all SNR levels. Future work will investigate the impact on training data augmentation on other AMT systems, as well as extend data augmentation settings to be investigated.
References
- [1] E. Benetos, S. Dixon, Z. Duan, and S. Ewert, “Automatic music transcription: An overview,” IEEE Signal Processing Magazine, vol. 36, no. 1, pp. 20–30, 2019.
- [2] C.-W. Wu, C. Dittmar, C. Southall, R. Vogl, G. Widmer, J. Hockman, M. Müller, and A. Lerch, “A review of automatic drum transcription,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 9, pp. 1457–1483, 2018.
- [3] Y.-T. Wu, B. Chen, and L. Su, “Multi-instrument automatic music transcription with self-attention-based instance segmentation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2796–2809, 2020.
- [4] J. Gardner, I. Simon, E. Manilow, C. Hawthorne, and J. Engel, “MT3: Multi-Task Multitrack Music Transcription,” in Proceedings of the International Conference on Learning Representations (ICLR), 2022.
- [5] C. Hawthorne, E. Elsen, J. Song, A. Roberts, I. Simon, C. Raffel, J. Engel, S. Oore, and E. D, “Onsets and frames: Dual-objective piano transcription,” in Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2018, pp. 50–57.
- [6] T. Kwon, D. Jeong, and J. Nam, “Polyphonic piano transcription using autoregressive multi-state note model,” in Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2020, pp. 454–461.
- [7] C. Hawthorne, A. Stasyuk, A. Roberts, I. Simon, C.-Z. A. Huang, S. Dieleman, E. Elsen, J. Engel, and D. Eck, “Enabling factorized piano music modeling and generation with the MAESTRO dataset,” in Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- [8] Q. Kong, B. Li, X. Song, Y. Wan, and Y. Wang, “High-resolution piano transcription with pedals by regressing onset and offset times,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3707–3717, 2021.
- [9] Y. Yan, F. Cwitkowitz, and Z. Duan, “Skipping the frame-level: Event-based piano transcription with neural semi-crfs,” in Proceedings of Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 20 583–20 595.
- [10] W. Wei, P. Li, Y. Yu, and W. Li, “Hppnet: Modeling the harmonic structure and pitch invariance in piano transcription,” in Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2022, pp. 709–716.
- [11] K. Toyama, T. Akama, Y. Ikemiya, Y. Takida, W. Liao, and Y. Mitsufuji, “Automatic piano transcription with hierarchical frequency-time transformer,” in Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2023, pp. 215–222.
- [12] T. Kwon, D. Jeong, and J. Nam, “Towards efficient and real-time piano transcription using neural autoregressive models,” arXiv preprint arXiv:2404.06818, 2024.
- [13] D. Edwards, S. Dixon, E. Benetos, A. Maezawa, and Y. Kusaka, “A data-driven analysis of robust automatic piano transcription,” IEEE Signal Processing Letters, vol. 31, pp. 681–685, 2024.
- [14] J. Thickstun, Z. Harchaoui, D. P. Foster, and S. M. Kakade, “Invariances and data augmentation for supervised music transcription,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2241–2245.
- [15] S. Lim, N. B. Erichson, L. Hodgkinson, and M. W. Mahoney, “Noisy recurrent neural networks,” in Proceedings of Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 5124–5137.
- [16] E. Conti, D. Salvi, C. Borrelli, B. Hosler, P. Bestagini, F. Antonacci, A. Sarti, M. C. Stamm, and S. Tubaro, “Deepfake speech detection through emotion recognition: A semantic approach,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 8962–8966.
- [17] O. Eberhard, J. Hollenstein, C. Pinneri, and G. Martius, “Pink noise is all you need: Colored noise exploration in deep reinforcement learning,” in Proceedings of the International Conference on Learning Representations (ICLR), 2023.