Towards Searching Efficient and Accurate Neural Network Architectures in Binary Classification Problems
Abstract
In recent years, deep neural networks have had great success in machine learning and pattern recognition. Architecture size for a neural network contributes significantly to the success of any neural network. In this study, we optimize the selection process by investigating different search algorithms to find a neural network architecture size that yields the highest accuracy. We apply binary search on a very well-defined binary classification network search space and compare the results to those of linear search. We also propose how to relax some of the assumptions regarding the dataset so that our solution can be generalized to any binary classification problem. We report a 100-fold running time improvement over the naive linear search when we apply the binary search method to our datasets in order to find the best architecture candidate. By finding the optimal architecture size for any binary classification problem quickly, we hope that our research contributes to discovering intelligent algorithms for optimizing architecture size selection in machine learning.
I Introduction
In recent decades, deep neural networks (DNNs) have seen many breakthroughs to achieve or even exceed human-level performance on difficult classification and recognition tasks. Breakthroughs in many challenging applications, such as speech recognition [1] [2], image recognition [3] [5] [4], genomic classification [6], machine translation [7] [8], have been achieved due to intelligent architectures that have been designed for the task at hand.
As described in [9], one such architectural breakthrough was in computer vision to predict objects in images by AlexNet [5], VGGNet [10], GoogleNet [11], and ResNet[12] which replaced the previously used architecture designs that were based on features such as SIFT [13] and HOG [14]. Designing architectures for a specific problem and dataset enabled greater success in many other fields as well such as voice recognition [15]. However, models started to require many small design choices, increasingly sophisticated details, and many hyperparameters - parameters chosen by a user. These hyperparameters, such as the number of hidden layers, the number of nodes at each layer etc. affects the accuracy, model training duration, and architecture size directly. Therefore, recent years have seen a surge in interest in the Neural Architecture Search (NAS) field. NAS generally dictates generating a search space with all the artificial neural networks that can be designed and optimized, and then a search strategy is implemented to go over and find the best candidate among all the neural network architectures in that space. A search strategy can be optimized to skip similar candidates, and find the most accurate architectures. Zoph et al. [16] outperformed the best manually designed architecture for the CIFAR-10 dataset by finding a model architecture 1.05x faster and with 0.09% better accuracy.
In NAS, even though the accuracy of the model is the most important metric, other metrics such as memory consumption, training time, inference time, model size could also be important when choosing a search strategy.
In this study, we search for architecture sizes that would give the highest accuracy and lowest training time for a given, well-defined architecture size search space with certain assumptions. Our aim is to look at the architecture size as a hyperparameters and propose a framework for discovering the most optimal architecture size for a given problem. We specifically consider the number of hidden layers and the number of neurons at each layer for a given problem and search the most optimal settings in a deep neural network (DNN). We consider a limited set of networks that satisfy the binary classification problem. Thus, the output for all the networks only have a single output neuron. We use binary search and linear search as a way of finding the optimal architecture sizes for problems of this nature. In our experiments, we investigate the Titanic dataset and a Customer Churn dataset to compare and apply our findings. We treat the linear search method as a baseline and report qualitative and quantitative improvements via binary search over the baseline.
This paper is organized such that section II discusses related work, section III discusses the implemented search algorithms, section IV reports the experiments and results, section V concludes the paper by going over the important findings one more time, and finally section VI discusses future work.
II Related Work
Architecture size has long been considered a hyperparameter that a user picks randomly or heuristically. Yet, this hyperparameter impacts the model accuracy for a given problem significantly. Recent years have shown several studies in which hyperparameters are optimized [17][18] [19] [20]. Such studies have been limited to fixed-size models when searching for the optimal hyperparameters.
Zoph and Le [9] relaxed the fixed-space assumption using reinforcement learning. Shen et al. [21] has focused on finding the optimal architecture size for binary neural networks, which are neural networks where the weights consist of only +1 and -1 values. These two studies have proposed new frameworks for determining the architecture size of neural networks in a systematic way rather than leaving such choice seemingly ambiguous. However, such studies have taken into account different assumptions regarding the models they design when applying each approach. to limit the search space. For example, Shen et al[21] added the constraint of architecting binary neural network to only look most compact at the neural networks. This constraint that they added is only slightly similar to our assumptions in this work. Instead of a forced binarization on the weights, we simply assume that our classification problems are ones that can be implemented with binary outputs. In other words, we only investigate our search algorithms to datasets that can be solved with a model where the last layer has one node. Additionally, Alparslan et al. [22] worked on using sparsity as a heuristics to find the architecture candidates that would give the most sparse as well as accurate models.
III Methodology
Because of the fact that DNNs require training and testing on typically large datasets, it becomes increasingly difficult and time consuming to determine optimal hyperparameters.
In this work, we define model evaluation as the end-to-end training and testing of a model architecture with a constant training and testing dataset, which is specially outlined in subsubsection III-A3.
III-A Assumptions
Often in machine learning, algorithms are implemented with general assumptions in order to simplify the problem. For instance, the Naive Bayes classification algorithm relies on the assumption that all features are perfectly independent of each other given a certain class [23]. Intuitively, this is a poor assumption because features of a given class interact in some way or another. Regardless, Naive Bayes has proved time and time again to be an excellent classifier in text classification [24] [25]. Additional example is the fact that most neural networks use gradient descent algorithm as optimization algorithm. The condition to apply gradient ascent is that we have to assume the function is continuously convex and differentiable[26]. However, cost functions that are optimized by neural networks might not meet this condition. So, in theory, those neural networks don’t guarantee globally optimal solutions, but in practice, neural networks converge to a local minimum point as proven by Zhong et al. [27] [28] and Zhang et al. [29]. Just like the cases of Naive Bayes and Gradient Descent, we also make assumptions in our paper that help explain our method, but do not have to hold in order to achieve good results in practice.
This binary search method that we outline in this paper can be considered as follows: a trade-off between speed and accuracy. If the assumptions are met, it finds the globally optimal solution quickly (see Table I). If the assumptions are not met, it finds, at the very least, a local optimum (see Table II). In our framework, we describe the following three assumptions that limit the problem space upon which we apply our binary search method.
III-A1 Network Architecture Assumption
We will be modeling our classification problem with an input layer, one hidden layer, and one output layer as shown below.
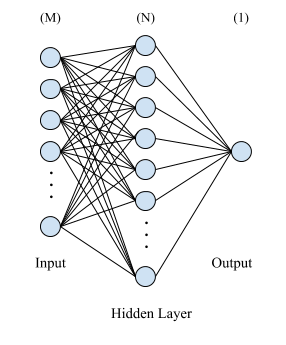
III-A2 Accuracy Distribution Assumption
Our second general assumption is that the accuracy distribution is uni-modal with respect to the number of units, , in the hidden layer. There exists only one global maximum when accuracies are plotted against each architecture with a hidden layer of dimension between and and accuracy values increase from both sides until global maximum.
III-A3 Dataset Assumptions
With respect to our dataset, we assume that there will be number of inputs but only output unit in the output layer. As a result, we are simplifying this to only binary classification problems. We suspect that specifically our linear search method in subsubsection III-C1 will be more efficient for smaller input spaces, whereas our binary search method in subsubsection III-C2 will be more efficient for larger input spaces. It follows that we can explore the relative speeds of these two methods under our respective assumptions in order to determine a general threshold for when one method should be used over the other.
III-B Datasets
III-B1 Churn dataset
Churn dataset is made public by Drexel Society of Artificial Intelligence [30]. It has 14 columns and 10000 rows where each row has information for a business that uses a cloud service and each column represents one feature regarding the customer. The dataset has specifically 14 columns but 3 of them are row number, customer id and company name which are excluded during the training process because they do not have meaning for the model. The remaining columns are features to indicate the revenue of the customer, contract duration of the customer, whether the customer has raised a ticket or renewed the contract before etc. The model that is trained on this dataset predicts whether the customer will leave the service contract or not. So, the label column is either 0 or 1 to indicate if the customer will renew the service. We train a model that has 1 input layer that consist of 11 nodes, one hidden layer that consists of D nodes and 1 output layer that consist of 1 node. Next, we find the node count, D, that would give the maximum accuracy in our model- first, via linear search and, second, via (modified) binary search. We also investigate whether the solution provided by the binary search is a globally optimal solution. In other words, if there is a global maximum in all the accuracies given by all the architecture candidates, the binary search, just like the linear search should find the globally maximum accuracy value.
III-B2 Titanic dataset
Titanic dataset is a dataset made public by Kaggle [31]. It has 14 columns and 1310 rows where each row has information for a passenger on Titanic and each column is one of many features. We use 11 features such as fare amount, gender, ticket class, cabin type etc from the dataset and the label for each sample that the model predicts is either 0 or 1 to indicate if the person survived or not. We train a model that has 1 input layer that consist of 11 nodes, one hidden that consists of D nodes and 1 output layer that consist of 1 node. The methods we follow is to find the value of D that would give the maximum accuracy in our model first via linear search and second via (modified) binary search.
III-C Search
For each model, we have a varying hidden layer of dimension, D, between the input layer and the output layer. We sweep D from 1 to to find the maximum accuracy which we treat as our baseline. In our studies, =1000 proved to be effective because we have not realized any benefits of going more than three orders of magnitude larger than the input dimensions (11 nodes) in our problems. Such linear search outlined in subsubsection III-C1 takes exactly iterations meaning we need to train and test models with different architectures to find the highest accuracy. We then assume the accuracies are fit to a distribution with a single global maximum and apply binary search to skip some number of model architectures which then helps us the training time reduce by 100 fold and achieves a maximum accuracy in around 10 iterations. We discuss ways of applying binary search to this problem in section III-C2.
III-C1 Linear Search
The usage of linear search is considered baseline in our study for the generalized dataset that follows the accuracy distribution as mentioned in subsubsection III-A3 and the two datasets described in subsection III-B. Linear search is a brute force method because one must iterate over all the elements and checking if the current element is greater than the current maximum element that has been observed so far in the search. We pick a range to constrain the search space so that finding the number of hidden layer units is a bounded problem instead of an unbounded problem. The time complexity for finding the maximum using linear search is O(n). It should be noted that although the search is greedy, this method is able to find the optimal hyperparameters perfectly in each search. Algorithm 1 formalizes this linear search algorithm.
III-C2 Binary Search
Given our assumptions, the premise of the binary search method is to implement a way to determine from which side we are approaching the cusp. Because of the fact that the slope of the distribution is generally monotonically increasing in magnitude in approaching the maximum accuracy, we model the index based on the sign of the recorded slope and the previously recorded slopes in the search.
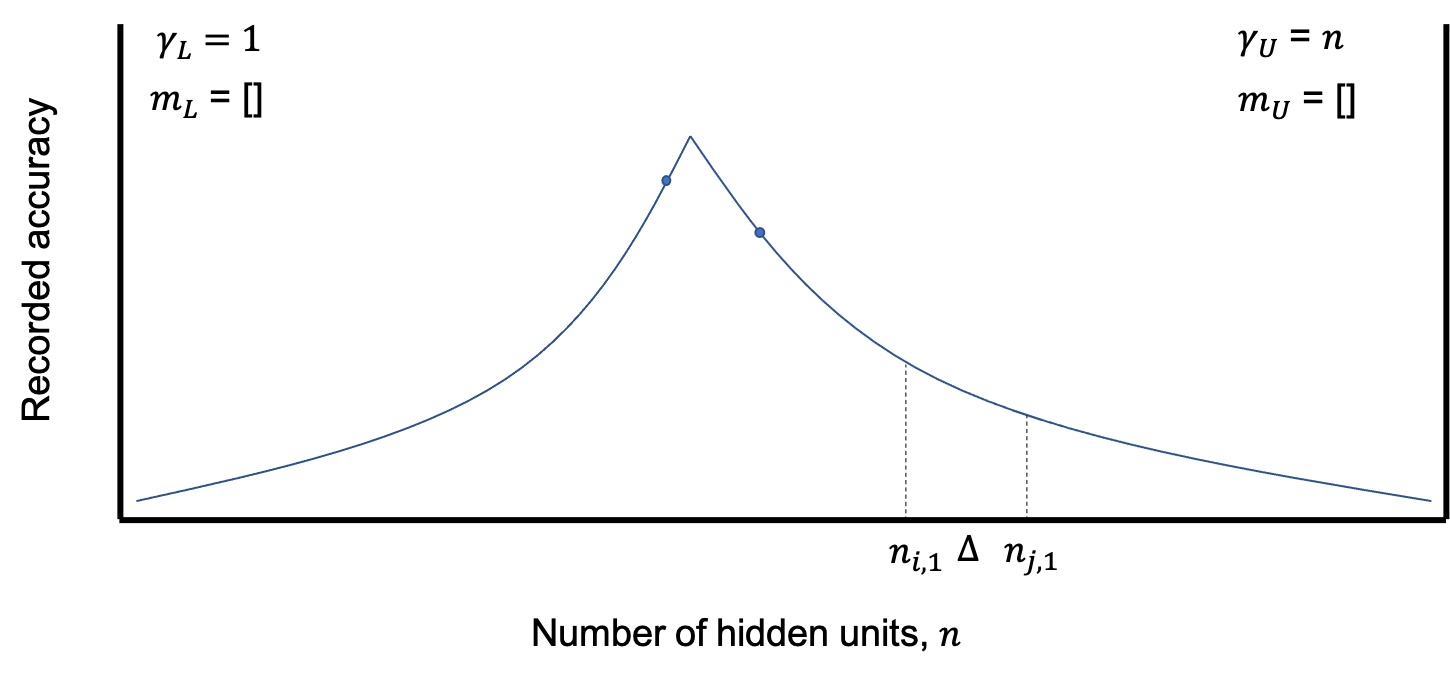
In general, binary search can halve the input space at every comparison, because the search takes advantage of the fact that the dataset is sorted. During binary search, performing one comparison to check whether the current candidate is the target in a sorted dataset can eliminate the current candidate during that comparison as well as all the other candidates worse than the current one because the dataset is sorted. In other words, linear search is removing one candidate at each step, whereas binary search is removing half of the current input space at each step. We adapt this binary search idea and perform it in a similar way using slopes. Therefore, each comparison will take at least two model evaluations for each comparison. We introduce a variable that models the distance between each model evaluation taken at and , which represent the current number of units on which we base our comparison and search. Figure 2 models the relationship between these three variables in the search algorithm.
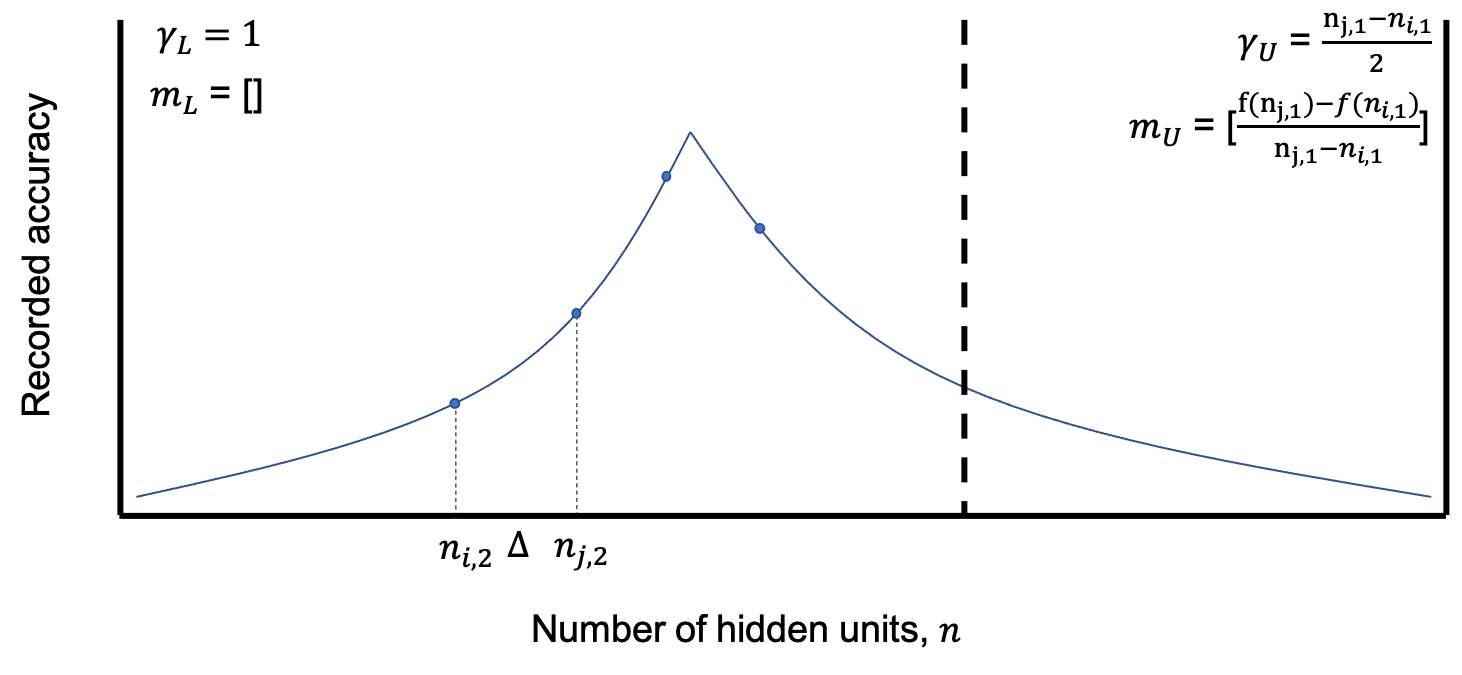
We then define and , which represent the minimum and maximum number of units in our search space, respectively. These variables will be used to keep track of the lower and upper bounds of our search. As shown in 2a, these two variables are set to and by default. If the search continues appropriately, these will approach the cusp from either side.
Moreover, we define lists and for the previously recorded slopes for the lower and upper bound side of the maximum cusp, respectively. Initially, these lists are empty as displayed in Figure 2a. As the search advances, the previously recorded slopes will be appended to either list depending on from which side the slope was taken.
After initializing these variables, the search begins by performing two model evaluations at and in Figure 2a. This would result in a negative slope, which indicates that the upper bound conditions are changed as shown in Figure 2b. The upper bound is set to the from which the slope was estimated, and the slope is appended to the list containing previously recorded slopes on the right side of the cusp, . As displayed in this figure, the search continues to the opposite side of the search space.
After each slope is calculated, we want to know whether there is enough evidence to suggest that there exists a maximum either at or near that recorded slope. We determine the probability of a maximum by evaluating a posterior shown in Equation 1.
Posterior:
| (1) | |||
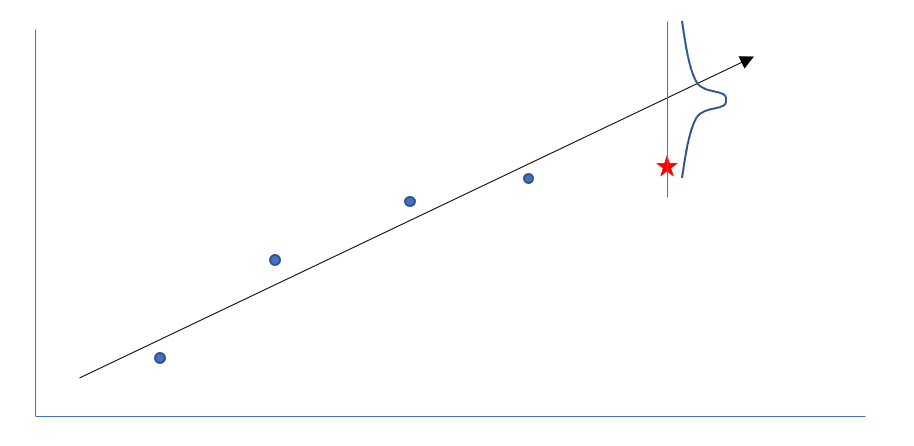
This probability can be broken down into a likelihood in Equation 2 and a prior in Equation 3. The likelihood represents the probability of observing a maximum given a history of maximums. This is implemented by modeling the next maximum with a linear regression with respect to the previously recorded maximums. This next expected maximum is then modeled as a normal distribution with a standard deviation equal to that of the regression as shown in Figure 3.
Likelihood:
| (2) |
Prior:
| (3) |
The prior calculated in Equation 3 is simply the probability of discovering the maximum at random between two points based on the initial and . Additionally, calculating prior probability takes O(1) time.
Algorithm 2 formalizes the binary search algorithm.
In algorithm 2, line 32, the that we have is a set of scripts to take a hidden layer size as input, generate a and run training and testing on it. Line 1 and 2 in algorithm 4 also uses the same to automate the training and testing for architecture candidates that iterate over. Additionally, calculating the the posterior likelihood for being a maximum for each candidate in the search space means that we need to set up a threshold to accept the current candidate as the best candidate and stop the algorithm. From empirical evidence in two datasets that we studied, 2 standard deviations () distance from the mean for a normal distribution is enough to accept any candidate as the architecture candidate with the best accuracy.
This can be attributed to the fact that 95% of all data in a normal distribution can be fit into 2 standard deviation within the mean. Such usage of a predetermined acceptance threshold would mean to stop the algorithm early and save CPU time. A second choice would be to run the algorithm to completion with no early stopping until each candidate checked by the algorithm gets assigned a posterior likelihood and then pick the one with the highest posterior likelihood.
| Search | Number of evaluations | Evaluation Error | ||
| Methods | Average | Standard Deviation | Average | Standard Deviation |
| Linear | 1000 | 0 | 0 | 0 |
| Binary | 6.458 | 0.9477 | 1.152 | 0.8915 |
| Model Type, Iteration, Dropout | Linear Search Duration | Binary Search Duration | Best Model’s Training Accuracy | Best Model’s Testing Accuracy | Best Model’s Architecture |
|---|---|---|---|---|---|
| Titanic Model_100 (w/o Dropout) (4) | 100 steps | 7 steps | 81.9% | 79.6% | 24 nodes |
| Titanic Model_100 (w/ Dropout) (5) | 100 steps | 7 steps | 78.1% | 80.7% | 61 nodes |
| Titanic Model_1000 (w/o Dropout) (6) | 1000 steps | 11 steps | 81.9% | 79.6% | 787 nodes |
| Titanic Model_1000 (w/ Dropout) (7) | 1000 steps | 9 steps | 83.4% | 78.5% | 410 nodes |
| Churn Model_100 (w/o Dropout) (8) | 100 steps | 6 steps | 94.7% | 77.5% | 1 node |
| Churn Model_100 (w/ Dropout) (9) | 100 steps | 7 steps | 96.2% | 78.4% | 64 nodes |
| Churn Model_1000 (w/o Dropout) (10) | 1000 steps | 10 steps | 86.8% | 80.2 % | 804 nodes |
| Churn Model_1000 (w/ Dropout) (11) | 1000 steps | 9 steps | 83.1% | 78.2%% | 511 nodes |
IV Experiment Results and Observations
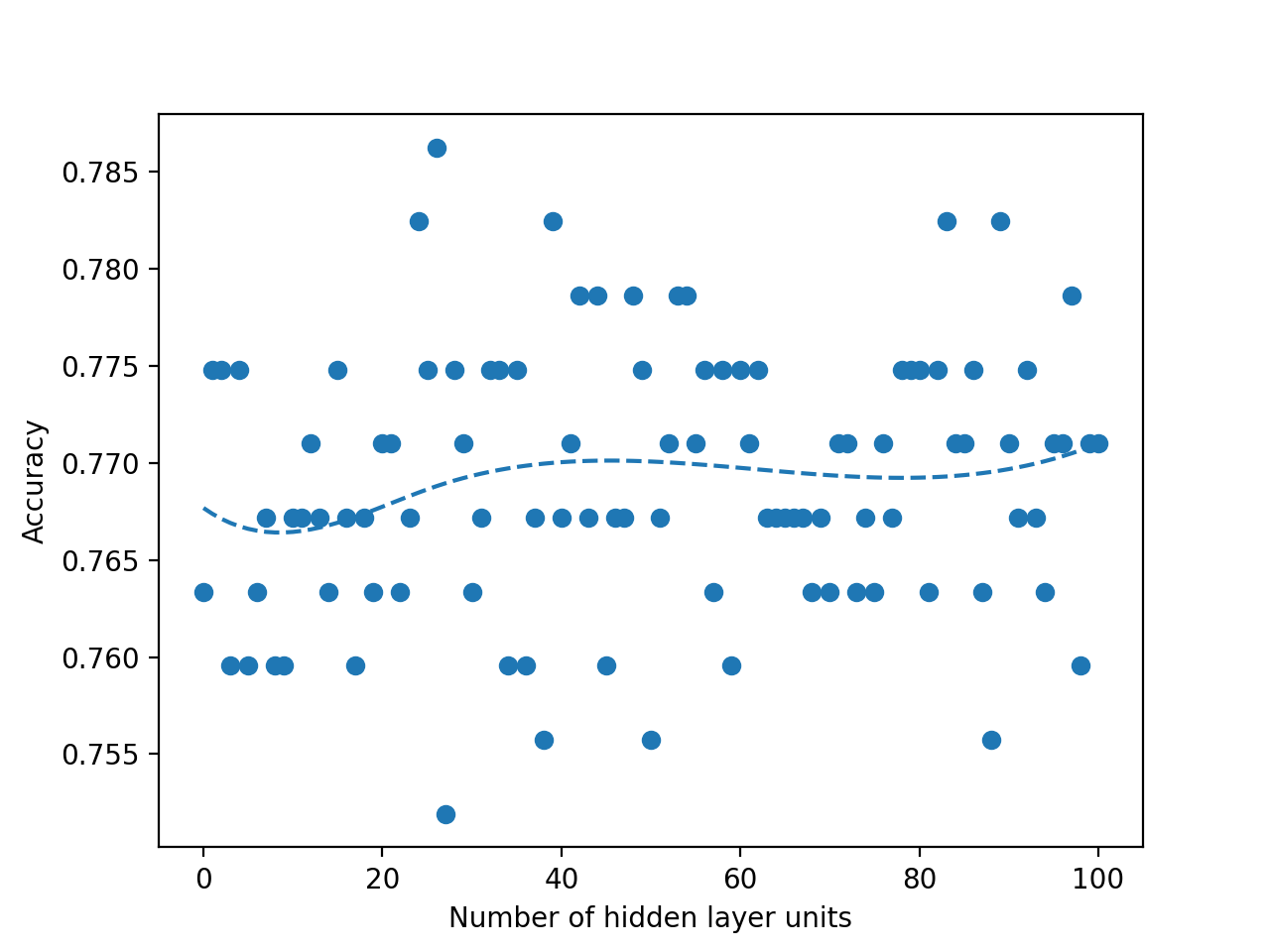
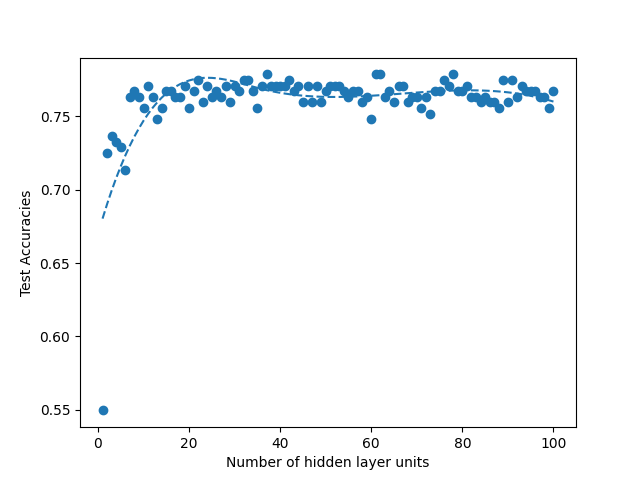
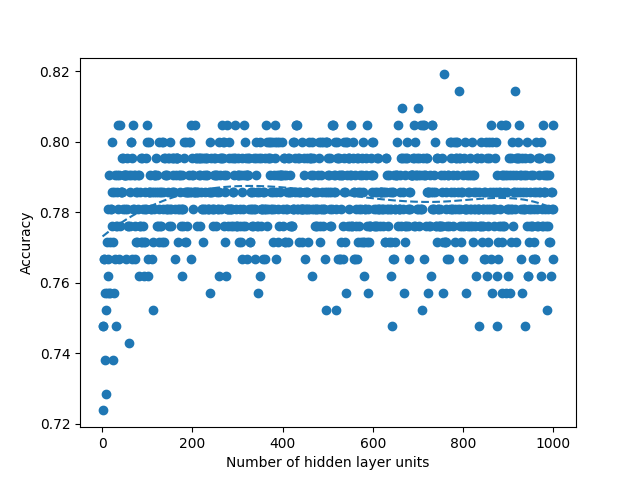
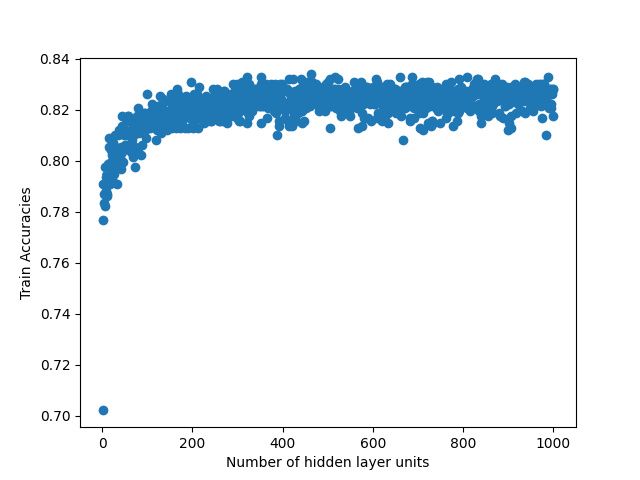
We run two experiments where first we sweep the hidden layer size from 1 to 100 and second from 1 to 1000. Picking a small value such as 100 allows us to see if the linear search would be faster than the binary search due to overhead that comes from the modifications that we do in the binary search. Such small number also allows us to see if there is a global maximum in the curve fit that we do when we plot the accuracies over the hidden layer units. When we run the same experiment with 1000, it allows us to see real improvement that binary search provides. When we run sweep from 1 to 100, we fail to observe any global maximum that would generate a curve with a single global maximum in our Figures 4, 5, 8 and 9. Absence of such global maximum fails the assumptions that we explained for the binary search to be applied, therefore, we cannot get global optimal solution via binary search for the experiment where N is 100. This proves that the binary search would fail to find the global maximum when the assumptions are not met. However, when we run the experiment with N is 1000, we observe the existence of a global maximum (albeit with the requirement of excluding the first few points), and the binary search proves to find the global maximum 100 times faster than the linear search in Figures 6, 7, 10 and 11. In Table II, for runs where iteration count is 100, we report the best accuracies and architectures found by linear search since binary search fails and can only find suboptimal accuracies. For runs where iteration count is 1000, linear and binary search find the same architectures so the reported best model accuracies are results of both search methods. Overall, the experiments agree with the assumptions that we laid out in the Section III-C2, i.e binary search risks missing the global optimum if the conditions are not met, however when the assumptions are correct, it finds the global maximum several orders of magnitude faster than the naive approach. Additionally, when we apply a dropout layer to the models, for the case of Titanic 100 (Figure 5) and Churn 1000 (Figure 11), we see a decrease in the accuracies for about 3%. Also, the best architecture candidates found are about 35% smaller and the binary search converges faster when the dropout layer was included to the Titanic and Churn models (Figures 7 and 11).
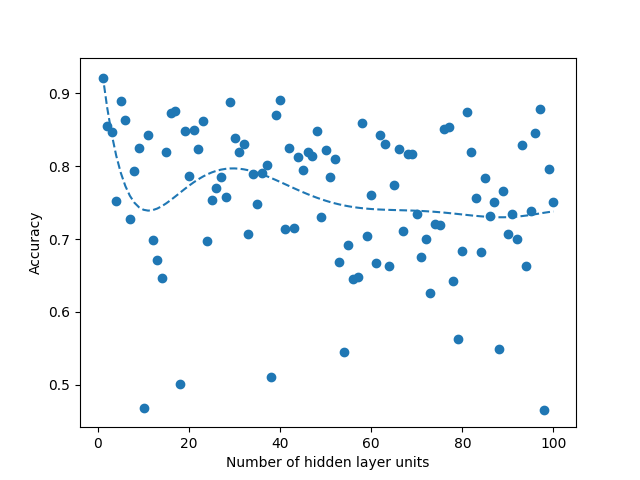
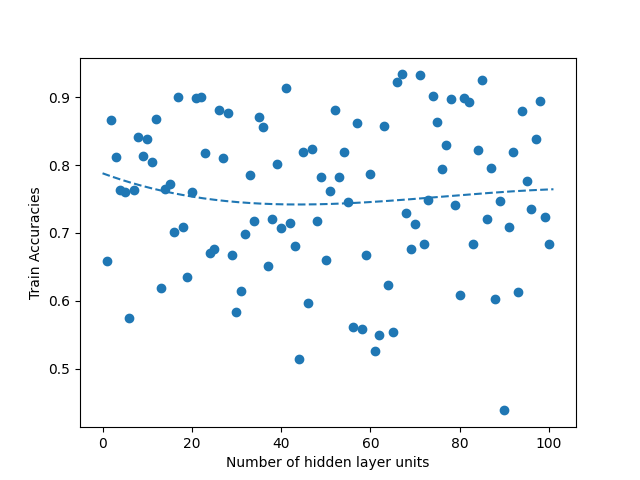
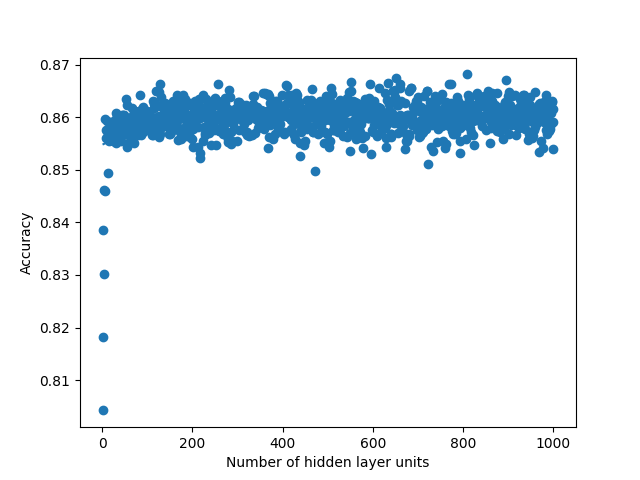
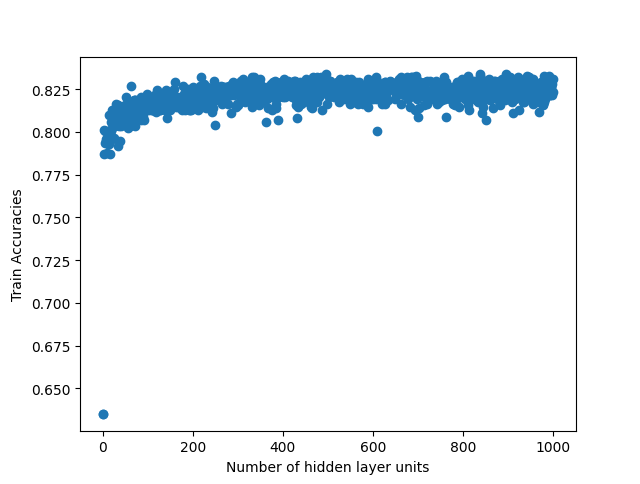
V Conclusion
In this paper, we propose a framework to find the optimal architecture size for binary classification problems. We employ linear search and binary search to find such architecture size to give the highest accuracy. We use the Titanic dataset and the Churn Rate dataset and report a 100x improvement in finding the best model architecture when we apply the modified binary search compared to the linear search. We also show what happens when the assumptions that we lay out for binary search are not met. Binary search fails to find the global maximum solution and is stuck on a local solution.
VI Future Work
In this study, we focused on datasets that can be modeled as binary classification problems where the output layer is 0 or 1. In the future, investigating these methods on multi-class classification problems or on models with more than one hidden layer can be worthwhile.
Additionally, in this paper, we assumed that the accuracy graph when plotted against the architecture size would have a convex shape leading to a global maximum. In the future, we can look into removing this assumption in order to generalize the approach to all datasets.
Acknowledgment
We would like to acknowledge Drexel Society of Artificial Intelligence for its contributions and support for this research.
References
- [1] G. Hinton et al., ”Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups,” in IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82-97, Nov. 2012, doi: 10.1109/MSP.2012.2205597.
- [2] Alparslan, K., Alparslan, Y., and Burlick, M., “Adversarial Attacks against Neural Networks in Audio Domain: Exploiting Principal Components”, arXiv e-prints, 2020.
- [3] Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, ”Gradient-based learning applied to document recognition,” in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
- [4] Alparslan, Y., Alparslan, K., Keim-Shenk, J., Khade, S., and Greenstadt, R., “Adversarial Attacks on Convolutional Neural Networks in Facial Recognition Domain”, arXiv e-prints, 2020.
- [5] Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E, ”ImageNet Classification with Deep Convolutional Neural Networks”, published in ”Advances in Neural Information Processing Systems”, p. 1097-1105, 2012 https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- [6] Ethan J Moyer and Anup Das , ”Machine learning applications to DNA subsequence and restriction site analysis”, arXiv preprint arXiv:2011.03544, 2020.
- [7] Sutskever, I., Vinyals, O., and Le, Q. V., “Sequence to Sequence Learning with Neural Networks”, arXiv e-prints, 2014.
- [8] Bahdanau, D., Chorowski, J., Serdyuk, D., Brakel, P., and Bengio, Y., “End-to-End Attention-based Large Vocabulary Speech Recognition”, arXiv e-prints, 2015.
- [9] Zoph, B. and Le, Q. V., “Neural Architecture Search with Reinforcement Learning”, arXiv e-prints, 2016.
- [10] Simonyan, K. and Zisserman, A., “Very Deep Convolutional Networks for Large-Scale Image Recognition”, arXiv e-prints, 2014.
- [11] Szegedy, C., Liu, W., Jia, Y., et al. (2015) Going Deeper with Convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, 7-12 June 2015, 1-9. https://doi.org/10.1109/CVPR.2015.7298594
- [12] K. He, X. Zhang, S. Ren and J. Sun, ”Deep Residual Learning for Image Recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016, pp. 770-778, doi: 10.1109/CVPR.2016.90.
- [13] D. G. Lowe, ”Object recognition from local scale-invariant features,” Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 1999, pp. 1150-1157 vol.2, doi: 10.1109/ICCV.1999.790410.
- [14] N. Dalal and B. Triggs, ”Histograms of oriented gradients for human detection,” 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 2005, pp. 886-893 vol. 1, doi: 10.1109/CVPR.2005.177.
- [15] M. Schuster and K. K. Paliwal, ”Bidirectional recurrent neural networks,” in IEEE Transactions on Signal Processing, vol. 45, no. 11, pp. 2673-2681, Nov. 1997, doi: 10.1109/78.650093.
- [16] Zoph, Barret; Le, Quoc V. (2016-11-04). ”Neural Architecture Search with Reinforcement Learning”. arXiv:1611.01578
- [17] James Bergstra, R. Bardenet, Yoshua Bengio, Balázs Kégl. Algorithms for hyperparameters Optimization. 25th Annual Conference on Neural Information Processing Systems (NIPS 2011), Dec 2011, Granada, Spain. ffhal-00642998
- [18] Bergstra, J. and Yoshua Bengio. “Random Search for hyperparameters Optimization.” J. Mach. Learn. Res. 13 (2012): 281-305.
- [19] Snoek, J., Larochelle, H., and Adams, R. P., “Practical Bayesian Optimization of Machine Learning Algorithms”, arXiv e-prints, 2012.
- [20] Saxena, S. and Verbeek, J., “Convolutional Neural Fabrics”, arXiv e-prints, 2016.
- [21] Mingzhu Shen, Kai Han, Chunjing Xu, Yunhe Wang; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 0-0
- [22] Yigit Alparslan, Ethan Moyer, Edward Kim, ”Evaluating Online and Offline Traversal Algorithms for Sparse and Accurate Neural Network Architectures”, arXiv e-prints, 2021
- [23] Rish, Irina et al. ”An empirical study of the naive Bayes classifier”, IJCAI 2001 workshop on empirical methods in artificial intelligence, 2001, pp. 41–46
- [24] Ting, SL and Ip, WH and Tsang, Albert HC. ”Is Naive Bayes a good classifier for document classification”, International Journal of Software Engineering and Its Applications, 2011, pp. 37–46
- [25] Kim, Sang-Bum and Han, Kyoung-Soo and Rim, Hae-Chang and Myaeng, Sung Hyon. ”Some effective techniques for naive bayes text classification”, IEEE transactions on knowledge and data engineering, 2006, pp. 1457–1466
- [26] Chong, Edwin K. P.; Żak, Stanislaw H. (2013). ”Gradient Methods”. An Introduction to Optimization (Fourth ed.). Hoboken: Wiley. pp. 131–160. ISBN 978-1-118-27901-4.
- [27] Zhong, K., Song, Z., and Dhillon, I. S. Learning nonoverlapping convolutional neural networks with multiple kernels. arXiv preprint arXiv:1711.03440, 2017.
- [28] Zhong, K., Song, Z., Jain, P., Bartlett, P. L., and Dhillon, I. S. , ”Recovery guarantees for one-hidden-layer neural networks”, arXiv preprint arXiv:1706.03175, 2017
- [29] Zhang, X., Yu, Y., Wang, L., and Gu, Q. ,”Learning one hidden-layer relu networks via gradient descent”, arXiv preprint arXiv:1806.07808, 2018.
- [30] Churn Customer Prediction Dataset, published by Drexel Society of Artificial Intelligence, December, 2021, https://github.com/drexelai/binary-search-in-neural-nets/blob/main/ChurnModel.csv
- [31] Titanic Kaggle Dataset, https://www.kaggle.com/c/titanic-dataset/data