Towards Stable Co-saliency Detection and Object Co-segmentation
Abstract
In this paper, we present a novel model for simultaneous stable co-saliency detection (CoSOD) and object co-segmentation (CoSEG). To detect co-saliency (segmentation) accurately, the core problem is to well model inter-image relations between an image group. Some methods design sophisticated modules, such as recurrent neural network (RNN), to address this problem. However, order-sensitive problem is the major drawback of RNN, which heavily affects the stability of proposed CoSOD (CoSEG) model. In this paper, inspired by RNN-based model, we first propose a multi-path stable recurrent unit (MSRU), containing dummy orders mechanisms (DOM) and recurrent unit (RU). Our proposed MSRU not only helps CoSOD (CoSEG) model captures robust inter-image relations, but also reduces order-sensitivity, resulting in a more stable inference and training process. Moreover, we design a cross-order contrastive loss (COCL) that can further address order-sensitive problem by pulling close the feature embedding generated from different input orders. We validate our model on five widely used CoSOD datasets (CoCA, CoSOD3k, Cosal2015, iCoseg and MSRC), and three widely used datasets (Internet, iCoseg and PASCAL-VOC) for object co-segmentation, the performance demonstrates the superiority of the proposed approach as compared to the state-of-the-art (SOTA) methods.
Index Terms:
Co-saliency Detection, Object Co-segmentation, Recurrent Neural Network, Contrastive LossI Introduction
Image co-saliency detection (CoSOD) and object co-segmentation (CoSEG) are two important topics in computer vision. They often serves as a preliminary step for various down-streaming computer vision tasks, e.g., co-localization [1, 2], person re-identification [3] and 3D reconstruction [4, 5]. These two tasks are highly relevant but different. For an image group, to detect (segment) co-occurring objects accurately, both these two tasks need model the synergistic relationship among the common objects. Although the co-occurring objects share the same semantic category, their explicit category attributes are unknown in CoSOD or CoSEG task. That is to say, CoSOD or CoSEG methods are not supposed to model the consistency relations of common objects by using the supervision of specific category labels or other information like temporal relations, which is quite different from video sequences tasks [6, 7]. These unique features make CoSOD or CoSEG an emerging and challenging task which has been rapidly growing in recent few years [8, 9, 10, 11, 12, 13]. Different from CoSEG, CoSOD captures the saliency of the potential co-salient objects in the individual image (Intra-saliency). Consequently, our proposed method first considers the requirements to achieve high-quality co-saliency detection.
To detect co-saliency accurately, the core problem is how to stably model inter-saliency relations between an image group. Our previous [14] RCAN proposes a recurrent neural network based (RNN-based) model to address this problem. Compared to these CNN-based methods [15, 16, 17, 18, 8, 19] and graph-based methods [20, 21], the RNN-based method is able to model more robust inter-saliency relations. Specifically, the main drawback of these CNN-based and graph-based methods is that they require constant input data, suffering from sub-group instability. When dealing with image groups containing a variable number of images, these CNN-based methods and Graph-based methods detect co-salient objects by dividing the image group into image pairs or image sub-groups. Since there is no principle way of dividing image groups, this strategy inevitably makes the overall training as well as testing process unstable, which influences the application of the co-salient object detection. On the contrary, the RNN-based method can adjust an unfixed number of images in each image group, and make use of all available information in an image group.
After the work RCAN, some methods design sophisticated modules [22, 23] to address sub-group instability. However, these sophisticated modules capture a single image attribute or pair of image-pair inter-saliency relations first, and then generate the final group features by directly adding these single attributes or pair of image-pair inter-saliency relations. Since there is much noise information in single image or image-pair features and the appearance as well as the location of co-salient object varies across different images or image-pair, only simple adding operation cannot capture these variations. While the RCAN proposes a novel recurrent co-attention mechanism to address this problem.

In this paper, we revisit the sequential modeling for CoSOD task, then state the main problem of these RNN-based methods: order-sensitivity, which heavily affects the stable of proposed CoSOD model. Order-sensitivity is the inherent drawback of recurrent architecture, so RNN is only widely used in tasks which has strict order relations, such as natural language processing [25] (NLP) or video saliency detection [26]. In these tasks, the orders are pre-defined which are suitable for RNN. In contrast to NLP or video saliency detection, CoSOD tasks have no order relations between the images in an image-group. The RCAN cannot determine which orders are most suitable and different orders obviously affect its performance.
To address the above problem, in this paper we first propose a multi-path stable recurrent unit (MSRU), containing dummy orders mechanisms (DOM) and recurrent unit (RU), which can handle the unstable drawback of RCAN. Similar to GRU [27], RCAN contains a reset gate and a update gate, which help capture co-salient regions with help of spatial-channel-wise co-attention mechanism. As the appearance and the location of co-salient object varies large across images, and the previous attention mechanism in RCAN cannot capture long-range relations between different images, limiting the ability in capturing sufficient inter-saliency relations between different images. To address this problem, we design a novel non-local cross-attention (NLCA) in reset gate and a novel co-attention feature projection module (CFPM) in update gate, to fully mining common semantics in an image group. After capturing inter-saliency relations, we design another single image representation extraction branch (SIR) to process each image individually to learn intra-saliency of an image group. Finally, the outputs of these two branches are further fused through a non-local attention, which encourages rich interactions between the group and single representation to facilitate the robust co-saliency detection reasoning.
To well supervise the network, in addition to the group-wise training objective proposed in RCAN, which is used to make full use of the interactive relationships of whole images in the training group, we design a cross-order contrastive loss (COCL) to further eliminate the effects from different input orders. In particular, our proposed COCL is capable of pulling close the group feature embeddings generated from different orders, which can further enhance the stability of our network. As can be seen in Figure.1, our proposed method can achieve best performance because of proposed MSRU and COCL.
Our main contributions can be summarized as follows:
-
•
Taking the COSOD task as an example, we first investigate the capability of RNNs to model orderless sequence tasks. In addition, we state that order sensitivity is essential to network stability.
-
•
We propose a multi-path stable recurrent unit, which can collect multi-path group features generated from different orders for final stable group feature generation. In recurrent unit, we further design a novel non-local cross-attention (NLCA) and a novel co-attention feature projection module (CFPM) to fully mining common semantics in an image-group.
-
•
In additional to group-wise training objective, we design cross-order contrastive loss (COCL) to further eliminate the effects from different orders.
-
•
We validate our model on five CoSOD datasets (CoCA, CoSOD3k, Cosal2015, iCoseg and MSRC), and three widely used datasets (Internet, iCoseg and PASCAL-VOC) for object co-segmentation, the performance demonstrates the superiority of the proposed approach as compared to the state-of-the-art (SOTA) methods.
The remainder of our paper is organized as follows. Section.II reviews the previous saliency detection, co-saliency detection, object co-segmentation methods and recurrent neural network. Section.III elaborates on the proposed network architecture. Section.IV introduces the loss function in this work. Section.V provides extensive experimental results in comparison with SOTA methods and ablation studies of our proposed network. Finally, more discussion about the relations between co-saliency detection and object co-segmentation, as well as more analysis of stability problem in the CoSOD/CoSEG task are given in Section.VI, respectively.
II Related Work
We review relevant topics to the development of our approach, including saliency detection, co-saliency detection, object co-segmentation and recurrent neural networks.
II-A Saliency Detection
Salient object detection (SOD) is a fundamental task in computer vision, which is derived with the goal of detecting and segmenting the most distinctive objects from visual scenes. Over the past decades, a large amount of SOD algorithms have been developed, which can be roughly classified into traditional methods and deep learning based methods. Traditional models [28, 29, 30, 31, 32] detect salient objects by utilizing various heuristic saliency priors with hand-crafted features. Deep learning based models use various feature enhancement strategies to improve the ability of localization and awareness of salient objects [33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44], or take advantage of edge features to restore the structural details of salient objects [45, 45, 46, 47, 48]. Different from the above methods, some methods [49, 50, 51] consider leveraging predict-refine architecture or the fixation prediction framework [52, 53] to generate fine salient objects. Beyond of the scope of the paper, more detailed introduction of salient detection can be referenced in recent surveys [54, 9].
II-B Co-saliency Detection
Compared to SOD task, CoSOD needs to model inter-saliency relations among an image group. Therefore CoSOD task is more challenging than saliency detection. To model inter-saliency relations between an image group, conventional approaches [55, 56, 57, 2, 58, 59, 60, 61] utilize handcrafted features, such as color, texture and SIFT descriptors etc., and these methods rely on researcher’s prior knowledge to model the interaction between the group images, like inter-image saliency. However, low-level features and fixed hand-designed interaction models are too subjective to face the multiple challenges including background clutter, appearance variance of co-salient object across images, and similarity between co-object and non-common object, etc. Recently deep-based models simultaneously explore the intra-saliency and inter-image consistency in a supervised manner with different approaches, such as concatenation operation [15, 18], graph convolution networks (GCN) [62, 20, 21], self-learning methods [63, 64], co-clustering [65] or Transformer-based methods [66]. However, the main drawback of these methods is that they suffer from sub-group instability. While the size of each group is not fixed in real-world scenarios as well as the experimental co-saliency dataset, so only partial inter-saliency relationships will be captured, limiting the robustness of the model. To address this problem, some methods design sophisticated modules, like gradient feedback [23], correlation techniques [22], to adjust unfixed number of images in each image group. In general, these two methods simply use the adding (fusion) to generate final inter-saliency relations from sub inter-saliency relations. While the location of co-salient region and noisy region vary in differnet image, only simply adding operation cannot make fully interaction between differnet images and retain co-salient regions. RCAN [14] proposes RCAU mechanism, which can better suppress non-salient background and retain co-salient regions. As we know, recurrent architecture makes the network sensitive to input orders. In this paper, we propose MSRU to make our proposed network stable and be less sensitive to input orders. For more about CoSOD tasks, please refer to [8, 9, 10].
II-C Object Co-Segmentation
The concept of co-segmentation was first introduced by the Rother [67], who used histogram matching to simultaneously segment out the common object from a pair of images. Following this work, a number of researchers have made further efforts to develop more effective object co-segmentation models by comparing foreground color histograms [68] or adopting more diverse features like Gabor filters [69] and SIFT [70]. In order to better explore the correspondence relationship among common objects, some existing methods [71, 72, 73, 74, 75, 76] additionally introduced prior constraints to better distinguish them from the undesired image backgrounds. However, these methods cannot obtain robust performance in real-world scenarios, where the handcrafted low-level features are too subjective to face the multiple challenges including intra-class variations and background clutters and the predefined prior knowledge cannot always provide adequate and precise constraint on the common objects.
Recent researches [77, 78, 79] use deep visual features to improve object co-segmentation and they also try to learn more robust synergetic properties among images in a data driven manner. Yuan [79] introduced a DNN-based dense conditional random field framework for object co-segmentation by cooperating co-occurrence maps which are generated using selective search [80]. Hsu [77] proposed a DNN-based method which uses the similarity between images in deep features and an additional object proposals algorithm [81] to segment the common objects. These methods achieved state-of-the-art results by substituting the features learned by DNN for engineered features. However, as feature learning and object segmentation are somehow separated in these approaches, the learned features are not tailored for segmenting the co-occurring objects, resulting in suboptimal performance. The very recent works [82, 83] proposed end-to-end deep learning methods for co-segmentation by integrating the process of feature learning and co-segmentation inferring as an organic whole. By introducing the correlation layer [83] or a semantic attention learner [82], they can utilize the relationship between the image pair and then segment the co-object in a pairwise manner. However, their siamese network structures limit their use of group-wise information which contains more sufficient synergetic relationships than image pairs. Consequently, co-segmenting common objects from image pairs has very limited robustness and practical application value when extending beyond pairwise relations. Unlike the previous methods, by introducing the recurrent architecture, our co-segmentation network is able to make use of all available information including individual image properties and the group-level synergetic relationships to meet the need for real-world applications. Recently, method [11] introduces region correspondence module which can help the network handle unfix input, while the drawback of this work is it omits how to make the model robust to different orders. One closely related topic to object co-segmentation is co-saliency detection, which aims at generating co-saliency maps for each of the images from the given image collection to highlight the common and salient objects. Compared with co-saliency detection, object co-segmentation only aims at segmenting the co-occurring objects without constraining those objects to be (co-)salient. By altering the datasets, we are able to use one network to address both CoSOD and CoSEG problems simultaneously in this paper. By the way, we find that the existing method [84] also tries to design a unified network to address these two problems. More details can be seen in Section.V and Section.VI.
II-D Recurrent Neural Network
RNN have been widely used in NLP(e.g., [25]) and speech recognition (e.g., [85]) to understand sequence data. The most popular variants of RNN included Long Short-Term Memory (LSTM [86]) and Gated Recurrent Unit (GRU [27] ). The common LSTM unit is composed of a cell and three gates (forget gate, input gate and output gate), which is designed to be capable of learning long term dependencies. Recently, the RNN (especially the LSTM and GRU) has been introduced in spatiotemporal tasks (known as convolutional RNN) for precipitation nowcasting [87], pattern recognition [88, 89], trajectory prediction [90], medical image analysis[91, 92, 93] and video saliency detection [94, 95, 26], et cetera. However, all these works process sequential data, so the variation between different images is little. While in co-saliency detection task, the location of co-salient objects varies greatly in different images. And the different gates in LSTM or GRU cannot handle these complex variations. To address this problem, RCAN propose co-attention mechanism to well model these inter-relations. However, the main drawback of the RCAN is that it makes the network sensitive to input orders. Hence, in this paper, we further design a MSRU to address order-sensitive problem.
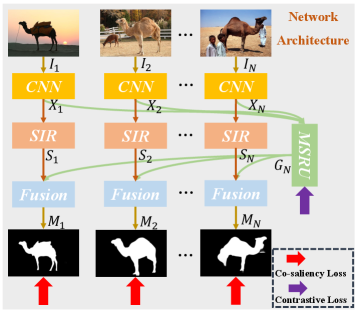
III Proposed Method
III-A Network Overview
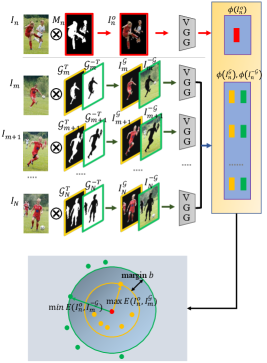
The overall architecture of the proposed approach is illustrated in Figure.2. Co-saliency detection aims at discovering the co-occurring object masks from a group of relevant images . For an input image group with an arbitrary size, our network first uses CNN to extract the semantic features of all images. Then the single image representation (SIR) branch processes each image individually to learn the intra-saliency . Meanwhile, the multi-path stable recurrent unit (MSRU) recurrently explores all images in the image group to learn the robust group representation . Finally, the outputs of these two branches are further fused through a non-local fusion module for robust co-saliency detection. The loss function of our proposed network contains co-saliency loss and cross-order contrastive loss (COCL).
III-B Intra-saliency Learning
As a basic rule in co-saliency detection, it is important to learn the unique properties of each image to capture potential co-occurring objects in the individual image. For each image in the input group , we first use a pre-trained VGG16 [96] to extract semantic features. Following [34, 46], we connect another side path to the last pooling layer in VGG-16. Hence, we obtain six side features Conv1-2, Conv2-2, Conv3-3, Conv4-3, Conv5-3 and Conv6-3 from the backbone network. Before sending the side features extracted from VGG to the SIR, we first use a convolutional operation to reduce their channel numbers for saving computation. In this paper, we set channel number suggested by works [47, 97]. For simplicity, we name side feature Conv6-3 as . So the side features of image group can be written as: . Then we construct the SIR block on , to capture the intra-saliency for each image. The SIR contains three convolutional blocks, and each block contains a convolutional operation with , followed by a batch normalization and a ReLU activation. Note that we capture intra-saliency and inter-saliency relations on three levels of backbone network (Conv4-3, Conv5-3 and Conv6-3). In this paper, we only show the intra-saliency learning and inter-saliency relations capturing in Conv6-3 for simplicity.
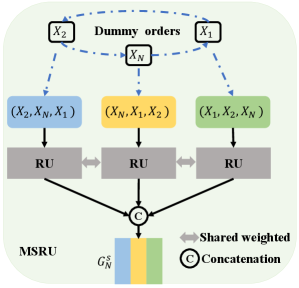
III-C Inter-saliency Relations Capturing
As images within an image group are contextually associated with each other in different ways such as common objects, similar categories, and related scenes, learning a robust group representation which contains the relevance and interaction between group images is extremely important for co-saliency referring. Our previous work RCAN [14] proposes to use a RCAU to learn the group representation for an arbitrary size group . Since the main drawback of the previous RCAU is that it makes the network sensitive to input orders, leading to unstable training and inferring procedures. To address this problem, we propose a new multi-path stable recurrent unit (MSRU, Figure.3) which can collect features from different orders for final group features generation. Next, we will describe the MSRU in detail.
The feature representations of an image sequence that contains images are written as:
| (1) |
Previous RCAU gradually update each single image feature representation to the final group feature, and the performance is easily influenced by the order of input images. An intuitive idea to solve this problem is to generate all the different orders of an image group, and then concatenate group features from these different orders for final group representations. However, this idea is impractical because totally orders are generated. Therefore, we propose a compromise approach in this paper. Specifically, the original sequence is first divided into several sub-groups by slide window with :
| (2) |
Here the window size is set as 3, and we treat the image sequence as a cycle. Hence, the group features of each sub-group is denoted as , which can be written as:
| (3) |
In this paper, we first generate multi-path feature representations of each sub-group from three different orders, then use to generate the final group feature (Figure.2).
To generate the multi-path group feature representations of each sub-group , we first propose a MSRU, which contains dummy orders mechanism (DOM) and a recurrent unit (RU). As can be seen in Figure.3, if a sub-group only contains three images , the DOM would generate three different orders { , , } of this group. Then we propose a RU to generate three group feature representations of these three different orders. Finally, we concat these three group feature representations to achieve multi-path group feature representations of this sub-group .
Before introducing our proposed RU, we make some modifications on Eq.2 and Eq.3, which can help readers better understand the process of RU. In Eq.2, we can get several sub-groups, and rewrite their notations as:
| (4) |
The images in each sub-group can be written as . means the feature of -th image in -th sub-group, where and in this paper. So the group feature of one order belong to each sub-group can be written as (). Although is the group feature of one order, to avoid the abuse of notations, also means the concated multi-path group feature representation of sub-group . Next we will show the details of our proposed RU.
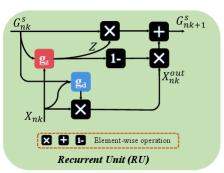
The two key modules of previous RCAU are reset gate and update gate. The goal of reset gate () is to use the synergetic relationships between the group feature and the current image to suppress the noise data in current image. The previous RCAU only uses a convolutional operation to achieve this purpose. However, this simple convolutional operation cannot capture long-range relations between group feature and current image feature. So if the co-salient regions of these two features vary largely, simple convolutional operation cannot well suppress the noise data. Inspired by non-local network, we design a new non-local cross-attention (NLCA) to fully suppress the noise data. Specifically, the input of NLCA is the group feature representation and single image representation . In the first step, is initialized with . For Query branch, we first add a convolution layer on and reshape the feature to , where . Meanwhile, for Key branch, we also use a convolution layer on and reshape the feature to . After that, we perform a matrix multiplication between the transpose of and , then apply a softmax function to calculate the spatial attention map . Each pixel value in A is defined as:
| (5) |
where , measures the position in the group feature impact on position in single image feature. Meanwhile, like Key branch, we generate feature from Value branch and perform a matrix multiplication between A and the transpose of to get denoised feature , which is defined as:
| (6) |
Finally, we reshape to , and add it with .
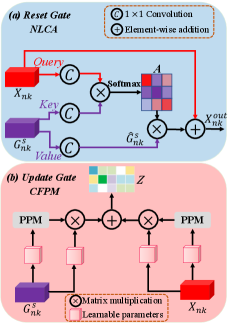
The goal of update gate () is to determine what group information should be retained in group feature and what new information should be updated from current image feature. Previous RCAU uses co-attention mechanism to explore the spatial-channel-wise variation of the co-salient object between group feature and image feature . However, the appearance as well as the location of co-salient object varies across different image and group features. Therefore, it is difficult to capture the consistency information between two differently distributed features with a spatial-channel-wise attention map. So we propose a co-attention feature projection module (CFPM) to project image and group features to the common feature subspace, which can help bridge the gap between group feature and image feature. At first, we employ pyramid pooling module (PPM [98]) to reduce the dimension of feature maps and to save the computational cost. The PPM is composed of four-scale feature bins, which are then flattened and concatenated to form a matrix of size , , . Here, the sizes of the feature bins are set to , , and , respectively. Thus, the self-affinity matrixes of and can be calculated as:
| (7) | ||||
where and denote the feature-specific similarity matrixes. Their sizes are fixed to through the PPM, which is asymmetric. , , and , indicate the learnable parameters. We further combine these two matrices as follows:
| (8) |
Finally, the row-wise normalized matrix is used to assist the update of group and image features:
| (9) | ||||
We add and to get the features :
| (10) |
In this paper, the above process would be repeated three times to get group features of one order. Finally, we concat the group features from three different orders to generate multi-path group feature ( or ) of each sub-group.
After generating sub-group features from , we apply another RU to generate the final group feature from , which is written as:
| (11) |
III-D Co-saliency Detection with Fused Representation
As described previously, the group feature is then broadcasted to each image, which allows the network to leverage the synergetic information and unique properties between the images. So the interaction of group representation and single representation are sufficiently exploited to facilitate the robust co-saliency reasoning. Thus, inspired by classic non-local network [99], we propose a non-local fusion module to well fuse single representations and group features, and get the final co-saliency maps .
IV Loss Function
To well optimize the network, we propose the co-saliency loss and cross-order contrastive loss (COCL) . Following the previous work RCAN, contains cross-entropy loss and perceptual group-wise loss, which can help the network in achieving a good co-saliency result. Moreover, we design a COCL that can further improve order-sensitive problem by pulling close the feature embedding generated from different input orders, resulting in a more stable inference and training process.
IV-A Co-saliency Loss
Let and their groundtruth denote a collection of training samples where is the number of images. After co-saliency detection, the co-saliency results are . We use the cross-entropy loss as the individual supervision for each image :
| (12) |
In addition to the cross-entropy losses, we propose a perceptual group-wise training objective to further explore the interactive relationships of whole images in the training group. Two criteria are jointly considered in the design of group-wise training objective, including 1) high cross-image similarity between the co-occurring objects and 2) high distinctness between the detected co-occurring objects and the rest of the images like background and non-common objects. We apply triplet loss as the group-wise constraint. Specifically, for a image , we can generate three masked images with its co-salient mask and groundtruth
| (13) |
where denotes element-wise multiplication and . The masked image means our current detected co-salient objects of while image and mean the real co-salient objects and non-common regions of . Then we apply the perceptual extractor [100] to all masked images and obtain their corresponding perceptual features . We apply triplet loss on each as the group-wise training objective as shown in Figure 4, formulated as:
| (14) |
where is the margin and denotes the Euclidean distance between two feature vectors. The group-wise training objective uses the hinge function to force co-saliency result to be more similar to real co-saliency objects than non-common regions. In co-saliency task, it can be beneficial to pull together co-occurring objects as much as possible. For this purpose, it is possible to replace the hinge function by a smooth approximation using the softplus function: In. The softplus function has similar behavior to the hinge, but it decays exponentially instead of having a hard cut-off, we hence refer to it as the soft-margin formulation. So the total co-saliency loss can be written as:
| (15) |
IV-B Cross-order Contrastive Loss
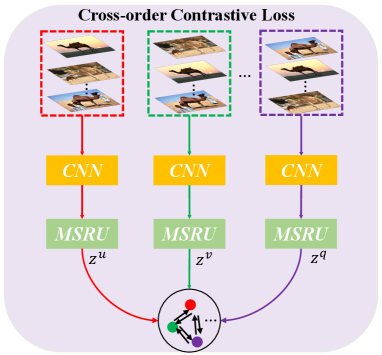
In this paper, we first propose MSRU to make our network insensitive to the input orders. A stable CoSOD network means different input orders can generate similar group features. This means we should pull close embedding spaces of different group features. So we design a cross-order contrastive loss (COCL) to achieve this purpose. However, existing contrastive losses (e.g. [101, 102, 103]) cannot be directly applied to CoSOD task, because their aim is to help the network distinguish between feature embeddings of different inputs. Data augmentations are used to embed one-view data into different spaces, which helps the network learn the distinctive feature embedding of one-view data. While in CoSOD task, we leverage contrastive loss to further pull close different group features and make our proposed model insensitive to the input orders. So we propose the cross-orders consistent mining, leveraging the high similarity of samples in one order to guide the learning process in another order. It excavates positive pairs across different orders according to the embedding similarity to promote knowledge exchange among different orders, then the size of hidden positive pairs in each order can be boosted and the extracted group features will contain different order knowledge, resulting in a more regular embedding space. Specifically, as can be seen in Figure.7, we randomly generate group features through MSRU from different orders of image group . Samples and are generated from the different orders of the same image group, and their corresponding memory banks are and :
| (16) |
where is the total number of different orders. The contrastive context of sample is the similarity set among and , and we use relation miner that generates positive samples:
| (17) |
if we want to use the knowledge of order to guide order contrastive learning, it contains two aspects: 1): we select the most similar pairs (positive) in order as the positive sets in order , i.e., , . Thus the sample shares the positive neighbors of . 2): we do not directly pull close the group feature embeddings generated from different orders, which would cause the collapse problem. We pull close the similarity of different samples. If sample is the positive sample of , so would also be the positive sample of . And we can calculate the similarities between {,} and {,}. Then we pull close these two similarities. The overall loss is conducted as:
| (18) |
Finally, the total contrastive loss can be written as:
| (19) |
Noting that all parts of our proposed network are trained jointly, so the total loss function is written as:
| (20) |
| CoCA | CoSOD3k | Cosal2015 | iCoSeg | MSRC | |||||||||||||||||
| Models | Type | MAE | MAE | MAE | MAE | MAE | |||||||||||||||
| CBCS(TIP2013) | Co | 0.641 | 0.523 | 0.313 | 0.180 | 0.637 | 0.528 | 0.466 | 0.228 | 0.656 | 0.544 | 0.532 | 0.233 | 0.797 | 0.658 | 0.705 | 0.172 | 0.676 | 0.480 | 0.630 | 0.314 |
| GWD(IJCAI2017) | Co | 0.701 | 0.602 | 0.408 | 0.166 | 0.777 | 0.716 | 0.649 | 0.147 | 0.802 | 0.744 | 0.706 | 0.148 | 0.841 | 0.801 | 0.829 | 0.132 | 0.789 | 0.719 | 0.727 | 0.210 |
| RCAN(IJCAI2019) | Co | 0.702 | 0.616 | 0.422 | 0.160 | 0.808 | 0.744 | 0.688 | 0.130 | 0.842 | 0.779 | 0.764 | 0.126 | 0.878 | 0.820 | 0.841 | 0.122 | 0.789 | 0.719 | 0.727 | 0.210 |
| CSMG(CVPR2019) | Co | 0.735 | 0.632 | 0.508 | 0.124 | 0.804 | 0.711 | 0.709 | 0.157 | 0.842 | 0.774 | 0.784 | 0.130 | 0.889 | 0.821 | 0.850 | 0.106 | 0.859 | 0.722 | 0.847 | 0.190 |
| CoEG(TPAMI2020) | Co | 0.717 | 0.616 | 0.499 | 0.104 | 0.825 | 0.762 | 0.736 | 0.092 | 0.882 | 0.836 | 0.832 | 0.077 | 0.912 | 0.875 | 0.876 | 0.060 | 0.793 | 0.696 | 0.751 | 0.188 |
| GICD(ECCV2020) | Co | 0.712 | 0.658 | 0.510 | 0.125 | 0.831 | 0.778 | 0.744 | 0.089 | 0.885 | 0.842 | 0.840 | 0.071 | 0.891 | 0.832 | 0.845 | 0.068 | 0.726 | 0.665 | 0.692 | 0.196 |
| ICNet(NeurIPS2020) | Co | 0.698 | 0.651 | 0.506 | 0.148 | 0.832 | 0.780 | 0.743 | 0.097 | 0.900 | 0.856 | 0.855 | 0.058 | 0.929 | 0.869 | 0.886 | 0.047 | 0.822 | 0.731 | 0.805 | 0.160 |
| CoADNet(NeurIPS2020) | Co | * | * | * | * | 0.874 | 0.822 | 0.786 | 0.078 | 0.915 | 0.861 | 0.857 | 0.063 | 0.930 | 0.878 | 0.889 | 0.045 | 0.850 | 0.782 | 0.842 | 0.132 |
| GCoNet(CVPR2021) | Co | 0.760 | 0.673 | 0.544 | 0.105 | 0.860 | 0.802 | 0.777 | 0.071 | 0.888 | 0.845 | 0.847 | 0.068 | 0.886 | 0.834 | 0.839 | 0.068 | 0.736 | 0.663 | 0.715 | 0.188 |
| CADC(ICCV2021) | Co | 0.744 | 0.681 | 0.548 | 0.132 | 0.840 | 0.801 | 0.759 | 0.096 | 0.906 | 0.866 | 0.862 | 0.064 | 0.910 | 0.868 | 0.856 | 0.063 | 0.895 | 0.821 | 0.873 | 0.115 |
| GLNet(TCyb2022) | Co | 0.716 | 0.591 | 0.441 | 0.188 | * | * | * | * | 0.925 | 0.855 | 0.885 | 0.060 | 0.930 | 0.874 | 0.899 | 0.045 | 0.890 | 0.830 | 0.869 | 0.120 |
| Ours(32) | Co | 0.776 | 0.732 | 0.616 | 0.099 | 0.888 | 0.843 | 0.820 | 0.062 | 0.934 | 0.898 | 0.902 | 0.045 | 0.948 | 0.911 | 0.916 | 0.035 | 0.881 | 0.809 | 0.870 | 0.115 |
| Ours(16) | Co | 0.770 | 0.727 | 0.608 | 0.103 | 0.883 | 0.839 | 0.815 | 0.065 | 0.929 | 0.896 | 0.897 | 0.047 | 0.942 | 0.905 | 0.907 | 0.039 | 0.875 | 0.801 | 0.865 | 0.121 |
| Ours(8) | Co | 0.765 | 0.722 | 0.603 | 0.106 | 0.879 | 0.836 | 0.811 | 0.067 | 0.924 | 0.893 | 0.893 | 0.050 | 0.937 | 0.900 | 0.901 | 0.043 | 0.871 | 0.797 | 0.859 | 0.123 |
| EGNet(ICCV2019) | Sin | 0.631 | 0.595 | 0.388 | 0.179 | 0.793 | 0.762 | 0.702 | 0.119 | 0.843 | 0.818 | 0.786 | 0.099 | 0.911 | 0.875 | 0.875 | 0.060 | 0.794 | 0.702 | 0.752 | 0.186 |
| F3Net(AAAI2020) | Sin | 0.678 | 0.614 | 0.437 | 0.178 | 0.802 | 0.772 | 0.717 | 0.114 | 0.866 | 0.841 | 0.815 | 0.084 | 0.918 | 0.879 | 0.874 | 0.048 | 0.811 | 0.733 | 0.763 | 0.161 |
| MINet(CVPR2020) | Sin | 0.634 | 0.550 | 0.387 | 0.221 | 0.782 | 0.754 | 0.707 | 0.122 | 0.847 | 0.831 | 0.805 | 0.181 | 0.846 | 0.789 | 0.784 | 0.099 | 0.769 | 0.688 | 0.729 | 0.194 |
| Airplane | Car | Horse | ||
|---|---|---|---|---|
| Li19 | 0.830 | 0.930 | 0.760 | 0.840 |
| Li21 | 0.840 | 0.920 | 0.830 | 0.863 |
| Ours | 0.868 | 0.951 | 0.802 | 0.874 |
| Li19 | 0.940 | 0.630 |
|---|---|---|
| Li21 | 0.970 | 0.740 |
| Ours | 0.973 | 0.746 |
| bear2 | brownbear | cheetah | elephant | helicopter | hotballoon | panda1 | panda2 | ||
|---|---|---|---|---|---|---|---|---|---|
| Li19 | 0.901 | 0.897 | 0.920 | 0.902 | 0.760 | 0.917 | 0.902 | 0.898 | 0.887 |
| Li21 | 0.928 | 0.941 | 0.891 | 0.916 | 0.852 | 0.951 | 0.948 | 0.921 | 0.921 |
| Ours | 0.933 | 0.934 | 0.926 | 0.932 | 0.883 | 0.964 | 0.949 | 0.902 | 0.927 |
V Experimental Results
V-A Implementation Details
Most of the previous methods [21, 24, 19] use the VGG16 as the backbone. Therefore, for a fair comparison, we also choose the VGG16 network to extract the features of each image in the group, which is the dominant reason. Moreover, the CoSOD task deals with image group data, and the core problem in CoSOD is group-feature learning, which cannot be solved by simply replacing the stronger backbones. The same conclusion is reported in the work GLNet [19]. The training set is a subset of the COCO dataset [104] (9213 images) and saliency dataset DUTS [105], as suggested by [18]. All the images are resized to the same size of for easy processing. The model is optimized by the Adam algorithm with a weight decay of 5e-4 and an initial learning rate of 1e-4. During training, the batchsize is 32. For co-saliency detection, the training of our proposed network includes two stages:
Stage1. We first train our model using DUTS dataset [105] to focus on the salient areas. Note that when training, to match the size of input group, we augment the single salient image to different images as a group using affine transformation, horizontal flipping and left-right flipping.
Stage2. We further fine-tune our model using sub-coco dataset to better focus on the co-salient areas. All the parameter settings are the same as those in Stage1.
As described, since CoSEG dose not need to detect these objects belong to salient regions, we only use Stage2 when training CoSEG model.
V-B Evaluation Datasets and Metrics
Co-saliency Detection. We employ five challenging datasets for evaluation: CoCA [23], CoSOD3k [106], Cosal2015 [107], iCoseg [108] and MSRC [109]. Cosal2015 has 50 groups and a total of 2015 images. Cosal2015 suffers from various challenging factors such as complex environments, occlusion issues, target appearance variations and background clutters, etc. CoSOD3k [106] has 160 groups and a total of 3000 images. CoSOD3k is the largest-scale and most comprehensive benchmark, which has sufficient object diversity and the complexity for size and number for instances. CoCA has 80 groups and a total of 1297 images. CoCA is a challenging dataset, since the images typically contain other multiple objects in addition to the co-salient objects which are even smaller in size. iCoseg consists of 38 groups of total 643 images. MSRC contains 7 groups of total 240 images, and each group has images.
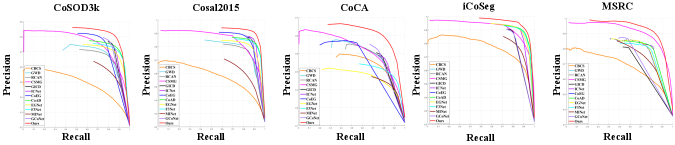
To evaluate the performance of the proposed method, we adopted five widely used criteria: (1) Precision-Recall (PR) curve, which shows the tradeoff between precision and recall for different threshold (ranging from 0 to 255). (2) The F-measure (), which denotes the harmonic mean of the precision and recall values obtained by a self-adaptive threshold ( and are the mean value and standard deviation of co-saliency map):
| (21) |
where is typically set to 0.3 as suggested in [110, 111, 112]. In this paper, we use maximum F-measure to evluate the performance. (3) Structure Measure () is adopted to evaluate the spatial structure similarities of saliency maps based on both region-aware structural similarity and object-aware structural similarity , defined as
| (22) |
where [113]. (4) The E-measure [114] is a perceptual metric that evaluates both local and global similarity between the predicted map and ground-truth simultaneously. In this paper, we use maximum E-measure . (5). Mean absolute error (MAE), which characterize the average 1-norm distance between ground truth maps and predictions. Evaluation toolbox:https://dpfan.net/CoSOD3K/.

Object Co-segmentation. We evaluate the proposed method and compare it with existing methods on three benchmarks for object co-segmentation, including the Internet dataset [70], the iCoseg dataset [108], and the PASCAL-VOC dataset [115]. These datasets are composed of real-world images with large intra-class variations, occlusions and background clutters. The Internet dataset contains images of three object categories including airplane, car and horse. Thousands of images in this dataset were collected from the Internet. Following the same setting of the previous work [77, 70, 116] , we use the same subset of the Internet dataset where 100 images per class are available. iCoseg consists of 38 groups of total 643 images which are challenging for object co-segmentation task because of the large variations of viewpoints and multiple co-occurring object instances. The PASCAL-VOC dataset contains total 1,037 images of 20 object classes from PASCAL-VOC 2010 dataset. The PASCAL-VOC dataset is more challenging and difficult than the Internet dataset due to extremely large intra-class variations and subtle figure-ground discrimination. Two widely used measures, precision () and Jaccard index (), are adapted to evaluate the performance of object co-segmentation. Precision measures the percentage of correctly segmented pixels including both object and background pixels. Jaccard index is the ratio of the intersection area of the detected objects and the ground truth to their union area.
| Models | Year | Model Size(MB) | FPS |
|---|---|---|---|
| GICD | ECCV2020 | 278.04 | 55 |
| ICNet | NeurIPS2020 | 70.41 | 80 |
| CoADNet | NeurIPS2020 | 289.23 | 14 |
| GCoNet | CVPR2021 | 540.36 | 59 |
| CADC | ICCV2021 | 392.85 | 15 |
| GLNet | TCYB2022 | 237.12 | 35 |
| GCAGC | CVPR2020 | 281.81 | 25 |
| RCAN | IJCAI2019 | 150.34 | 54 |
| Ours | * | 208.23 | 27 |
V-C Comparisons with the State-of-the-Arts
For CoSOD task, we compare our approach with 11 CoSOD models and 3 SOD models: CBCS [60], GWD [117], RCAN [14], CSMG [16], CoEG [8], GICD [23], ICNet [24], CoADNet [18], GCoNet [118], CADC [119], GLNet [19], EGNet [46], F3Net [38] and MINet [39]. For CoSEG task, we compare our approach with other 2 most SOTA methods: Li19 [120] and Li21 [11].

| Configurations | CoSOD3k | Cosal2015 | PASCAL-VOC | |||||||
| MAE | MAE | |||||||||
| 1. Baseline | 0.788 | 0.718 | 0.660 | 0.139 | 0.810 | 0.750 | 0.714 | 0.140 | 0.891 | 0.575 |
| 2. Baseline+GRU | 0.859 | 0.820 | 0.795 | 0.075 | 0.914 | 0.872 | 0.874 | 0.061 | 0.927 | 0.702 |
| 3. Baseline+LSTM | 0.861 | 0.819 | 0.796 | 0.073 | 0.913 | 0.875 | 0.875 | 0.059 | 0.930 | 0.701 |
| 4. Baseline+RCAU | 0.866 | 0.826 | 0.800 | 0.071 | 0.916 | 0.878 | 0.884 | 0.054 | 0.942 | 0.720 |
| 5. Baseline+MSRU | 0.876 | 0.833 | 0.810 | 0.066 | 0.924 | 0.887 | 0.890 | 0.049 | 0.958 | 0.732 |
| 6. Baseline+MSRU+NLFM | 0.880 | 0.836 | 0.814 | 0.065 | 0.928 | 0.890 | 0.896 | 0.048 | 0.962 | 0.737 |
| 7. Baseline+MSRU+NLFM+(Ours) | 0.888 | 0.843 | 0.820 | 0.062 | 0.934 | 0.898 | 0.902 | 0.045 | 0.973 | 0.746 |
| 8. Baseline+NLFM++RCAU | 0.872 | 0.829 | 0.806 | 0.067 | 0.923 | 0.885 | 0.888 | 0.052 | 0.958 | 0.728 |
| 9. Baseline+NLFM++RCAU+DOM | 0.878 | 0.836 | 0.811 | 0.065 | 0.926 | 0.890 | 0.895 | 0.050 | 0.964 | 0.730 |
| 10. Baseline+NLFM++RU | 0.879 | 0.837 | 0.811 | 0.066 | 0.926 | 0.891 | 0.896 | 0.050 | 0.963 | 0.729 |
| 11. Baseline+NLFM++DOM+RU(-NLCA) | 0.883 | 0.839 | 0.815 | 0.065 | 0.929 | 0.893 | 0.896 | 0.048 | 0.967 | 0.736 |
| 12. Baseline+NLFM++DOM+RU(-CFPM) | 0.882 | 0.840 | 0.814 | 0.064 | 0.928 | 0.892 | 0.895 | 0.049 | 0.966 | 0.738 |
| 13. Ours() | 0.890 | 0.843 | 0.822 | 0.061 | 0.937 | 0.897 | 0.904 | 0.043 | 0.974 | 0.748 |
| 14. Ours() | 0.889 | 0.844 | 0.821 | 0.060 | 0.935 | 0.898 | 0.903 | 0.044 | 0.973 | 0.745 |
| 15. Baseline+MSRU+(8+noise) | 0.877 | 0.835 | 0.816 | 0.065 | 0.927 | 0.894 | 0.896 | 0.049 | 0.968 | 0.738 |
| 16. Baseline+MSRU+(16+noise) | 0.884 | 0.840 | 0.819 | 0.063 | 0.931 | 0.896 | 0.899 | 0.046 | 0.970 | 0.741 |
| 17. Baseline+MSRU+(32+noise) | 0.886 | 0.841 | 0.820 | 0.063 | 0.932 | 0.897 | 0.901 | 0.046 | 0.972 | 0.745 |
| Configurations | CoSOD3k | Cosal2015 | PASCAL-VOC | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MAE | |||||||||
| Ours(RU+DOM+) | ||||||||||
| Ours(RU+DOM+, std) | 0.002 | 0.002 | 0.003 | 0.001 | 0.001 | 0.003 | 0.004 | 0.002 | 0.002 | 0.001 |
| Ours(RU+) | ||||||||||
| Ours(RU+, std) | 0.006 | 0.005 | 0.007 | 0.004 | 0.007 | 0.008 | 0.006 | 0.004 | 0.005 | 0.006 |
| Ours(RU) | ||||||||||
| Ours(RU,std) | 0.009 | 0.011 | 0.011 | 0.009 | 0.010 | 0.010 | 0.010 | 0.011 | 0.010 | 0.009 |
| RCAN | ||||||||||
| RCAN(Std) | 0.011 | 0.009 | 0.008 | 0.010 | 0.011 | 0.011 | 0.009 | 0.011 | 0.009 | 0.009 |
| ICNet | * | * | ||||||||
| ICNet(Std) | 0.010 | 0.010 | 0.009 | 0.011 | 0.010 | 0.010 | 0.010 | 0.009 | * | * |
Quantitative Evaluation. From Table.I, we can see that compared to other state-of-the-art methods, our model (Ours(32)) outperforms all of other SOTA methods in all metrics. As reported in Table.I, our approach achieves good performance on different size groups (8, 16 and 32) and still consistently outperforms all the state-of-the-art methods. And the performance raises along with the group size, which emphasizes the importance of the group information completeness to robust co-saliency detection. In dataset CoCA, compared to the second ranked performance, the improvement of our proposed method reaches 2.1% for , 7.4% for , 12.4% for and 5.7% for MAE. On the challenging CoSOD3k and Cosal2015 datasets, our model capitalizes on our better consensus and significantly outperforms other methods. These results demonstrate the efficiency of the proposed framework. As shown in Fig.8, we can see that our method (the red line) achieves the highest precision on all datasets. Table.IV, Table.IV and Table.IV show the results on CoSEG datasets, it can be seen that our method can outperform all other two SOTA methods in most datasets. Finally, we show the parameter number and running time comparison with other SOTA methods, and the results are shown in the Table.V. Our proposed model runs at a competitive efficiency compared to other models. This is primarily due to the fact that cross-order contrastive loss is only used during training, and only the dummy orders mechanism (DOM) would slow the network down to some extent.
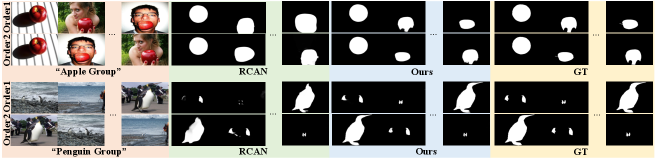
Qualitative Evaluation. Fig.9 shows the co-saliency maps generated by different methods for qualitative comparison. As can be seen, the SOD method F3N can only detect salient objects and fail to distinguish co-salient objects. The CoSOD methods perform better than the SOD methods because of considering group-wise relationships in designing the model. As can be seen in ”Baseball Group”, these CoSOD can suppress some non-co-salient regions. However, these CoSOD methods require constant input data, or only using simple adding operation to generate final group features. When facing complex real-world scenarios, they are unable to handle these challenging cases, like ”Hammer Group” and ”Axe Group”. While our proposed model can capture complete inter-saliency relations of an image-group, and make the training and inference process more stable, therefore performs much better on detecting co-salient objects. Fig.10 shows the co-segmentation maps generated by our proposed methods for qualitative comparison, which can further demonstrate the superiority of our model in CoSEG task.
V-D Ablation Studies
In this section, we first conduct evaluation on CoSOD3K, Cosal2015 and PASCAL-VOC datasets to investigate the effectiveness of various components of the proposed model. We first do architecture ablation studies, and we set the baseline model by only using single feature learning branch and replacing the recurrent neural network with concatenation operation. The baseline model is only trained with co-saliency loss alone. Moreover, we set the input orders of different models the same, so the performance changes of different models are a result of different architectures. The results are shown in Table.VI. Secondly, we further evaluate the stability of our proposed network, and the results are shown in Table.VII.
Architecture ablation studies. As can be seen in No.1 of Table.VI, even though trained with co-saliency loss , the baseline model can not well handle the co-saliency or co-segmentation task. When we replace the simple concatenation operation with typical recurrent unit, GRU or LSTM (No.2 and No.3), the performance is improved compared to baseline, which means the recurrent architecture is suitable for co-saliency detection task. Moreover, we use our previous RCAU to replace GRU or LSTM (No.4), the performance can be further improved, because proposed RCAU can generate more robust group features compared to GRU or LSTM. Then, we add our proposed MSRU (No.5), the performance has large improvement. This is because our proposed MSRU addresses the order-sensitive problem of RCAU and further improve the stability of proposed network. It should be noted that in this paper, we add GRU, LSTM, RCAU and MSRU on three levels of backbone network (Conv4-3, Conv5-3 and Conv6-3), which can help capture multi-level inter-saliency relations. Then, adding the NLFM (No.6) can further improve the performance. Finally, COCL (No.7) can further boost the performance because it can help pull close group feature embeddings generated from different orders. To further justify the denoising ability of our MSRU, we add a noise image which is randomly selected from COCO dataset to the testing groups in size 8, 16 and 32 (No.15, No.16 and No.17). As shown in results, although the noise data damages our performance a little, we still outperforms all the SOTA methods, which demonstrate the robustness of the proposed method.
We also investigate the effectiveness our proposed DOM, and NLCA or CFPM in RU. Compared No.9 to No.8, It can be seen that when adding DOM on RCAU, it can improve the performance. Compared No.10 to No.7, when removing the DOM from our proposed method, the performance would be declined. It shows the effectiveness our proposed DOM. As can be seen in No.13 and No.14, when we set window size or in DOM (Eq.3), the performance has no obvious change while the training/testing is increasing about 30%. So in this paper, we only set . When we remove the reset gate from MSRU (No.11), the performance declines on three metrics especially on MAE. This indicates the reset gate is able to suppress the noise information in the group. When we remove the update gate from MSRU (No.12), the performance declines which indicates update gate can well retain group information in group feature and determine what new information should be updated from current image feature representation. These experiments verify the effectiveness of the different modules proposed in this paper.

Stability ablation studies. During testing of our proposed method (Ours(RU+DOM+)), for each image group, we randomize 10 different orders. From Table.VII, it can be seen that performance has no obvious change. “Std” means the standard deviation of these 10 orders. This result verifies that our proposed MSRU and Contrastive Loss can let the proposed method less insensitive to the input order of group images. In the Introduction of this paper, we argue that existing sequential order modeling approaches make CoSOD networks unstable. So we do experiments on two typical methods, including RCAN [14] and ICNet [24], to verify the inferring procedure of these two methods are unstable. Because CoADNet [18] does not release their code, so we can not do experiments on CoADNet. During testing, for each image group, we randomize 10 different orders, and the results are shown in Table.VII. As can be seen in Table.VII, whether using RNN ( RCAN(Std) ), or applying some sophisticated modification on CNNs architectures ( ICNet(Std) ), can not let the CoSOD network be insensitive to the input order of group images, leading to an unstable inferring procedure. Because in sequential order modeling, both CNNs and RNNs have inherent deficiencies. In this paper, our proposed DOM and COCL can help eliminate the effects of different orders. Therefore, as can be seen in Table.VII, when we remove these two modules, our proposed network would be more sensitive to the order of images input. Through these experiments, we further verify that our proposed network greatly improves the stability of CoSOD. In Table.IV and Table.I, we test our network 10 times and select the medium performance in this paper. From the first row of the Table.VII, the worst performance of our proposed network remains SOTA. Note that the FPS of the models Ours(RU) and Ours(RU+DOM) are 44 and 27. Compared to the previous RCAN, our proposed RU is slower because we use non-local attention. Moreover, adding DOM mechanism further reduces the running speed. However, as shown in the Table.V, our proposed model still runs at a competitive efficiency compared to other SOTA models.
| Models | CoSOD3k | Cosal2015 | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE | MAE | |||||||
| Ours(Stage1) | 0.850 | 0.815 | 0.792 | 0.088 | 0.912 | 0.870 | 0.860 | 0.065 |
| Ours(Stage2) | 0.888 | 0.843 | 0.820 | 0.062 | 0.934 | 0.898 | 0.902 | 0.045 |
Training stages ablation studies. In this paper, we introduce two stage training processes for the CoSOD task. The stage1 training process helps the network capture the regions tended to be salient, and the stage2 training process helps the network learn the co-salient regions. In the Fig.11, we show some examples where the stage1 model fails but the stage2 model succeeds. In the “Apple Group” and “Baseball Group”, the stage1 model detects “salient noise” which is suppressed in the stage1 model. In the “Dumbbell Group” and “Train Group”, the object “person” is detected in the stage1, and the real co-salient objects are omitted. Because in the SOD DUTS training dataset, the person is always the salient object and the other objects are the background. After fine-tuning the stage1 model on the sub-coco dataset [104], the stage2 model would detect real co-salient objects. Quantitative comparison between the stage1 model and the stage2 model is in Table.VIII, and the stage2 model is obviously superior to the stage1 model.
VI Discussion
| Airplane | Car | Horse | ||
|---|---|---|---|---|
| Li19 | 0.830 | 0.930 | 0.760 | 0.840 |
| Li21 | 0.840 | 0.920 | 0.830 | 0.863 |
| GCAGC | 0.835 | 0.919 | 0.809 | 0.854 |
| CADC | 0.833 | 0.916 | 0.806 | 0.851 |
| Ours | 0.868 | 0.951 | 0.802 | 0.874 |
| Li19 | 0.940 | 0.630 |
|---|---|---|
| Li21 | 0.970 | 0.740 |
| GCAGC | 0.951 | 0.731 |
| CADC | 0.950 | 0.735 |
| Ours | 0.973 | 0.746 |
| bear2 | brownbear | cheetah | elephant | helicopter | hotballoon | panda1 | panda2 | ||
|---|---|---|---|---|---|---|---|---|---|
| Li19 | 0.901 | 0.897 | 0.920 | 0.902 | 0.760 | 0.917 | 0.902 | 0.898 | 0.887 |
| Li21 | 0.928 | 0.941 | 0.891 | 0.916 | 0.852 | 0.951 | 0.948 | 0.921 | 0.921 |
| GCAGC | 0.921 | 0.930 | 0.916 | 0.911 | 0.845 | 0.941 | 0.941 | 0.895 | 0.913 |
| CADC | 0.922 | 0.931 | 0.918 | 0.908 | 0.840 | 0.938 | 0.939 | 0.891 | 0.911 |
| Ours | 0.933 | 0.934 | 0.926 | 0.932 | 0.883 | 0.964 | 0.949 | 0.902 | 0.927 |

In this section, we make some further discussions of CoSOD/CoSEG task, including the relations between CoSOD and CoSEG and more analysis of stability problem in the CoSOD/CoSEG task.
The relations between CoSOD and CoSEG. Both CoSOD and CoSEG aim at segmenting the co-occurring objects among an image group with unfixed image sizes, and network stability is an important factor for both two tasks, motivating us to use one RNN-based network to simultaneously address them. By the way, we find that the existing method [84] also tries to design a unified network to address these two problems. To further verify this statement, we re-train the SOTA graph-based method GCAGC [21] and CNN-based method CADC [119], then apply them to the CoSEG task. The results are in Table.XI, Table.XI and Table.XI. Compared to the CoSEG, CoSOD needs extra intra-saliency capturing module to let the network tend to focus on salient regions. GCAGC and CADC design the pertinent training mechanism, by altering the salient-based training datasets, to achieve this purpose. Herein, we only re-train these two methods on the sub-coco dataset [104]. It can be seen that these two models achieve competitive performance on the CoSEG benchmarks compared to other CoSEG models.
| Models | Cosal2015 | |||
|---|---|---|---|---|
| MAE | ||||
| CoADNet | ||||
| CoADNet(STD) | 0.020 | 0.017 | 0.020 | 0.018 |
| GCAGC | ||||
| GCAGC(STD) | 0.019 | 0.019 | 0.017 | 0.018 |
More analysis of stability problem in the CoSOD/CoSEG task. In this paper, we delve into the stability problem in the CoSOD/CoSEG task. In the most recent review article [8], stability is highlighted as one of the most important issues currently unresolved in the CoSOD task. In fact, as an inherent problem, instability exists widely in CoSOD methods. Although many CNN-based methods [8, 18, 19] and Graph-based methods [20, 21] have greatly advanced the development of CoSOD task in recent years, before our previous study [14], the stability problem remained untouched. When dealing with image groups containing a variable number of images, these CNN-based methods and Graph-based methods detect co-salient objects by dividing the image group into image pairs or image sub-groups. Since there is no principle way of dividing image groups, this strategy inevitably makes the overall training as well as testing process unstable, which influences the application of the co-salient object detection. We conduct the experiment on CNN-based method CoADNet [18] and Graph-based method GCAGC [21]. In the red boxes of Fig.12, the same image results in the different detecting results when they are in the different sub-groups. Moreover, we repeatedly test these two methods in different sub-groups of Cosal2015 for 5 times, and the performance is shown in Table.XII. It can be seen that different sub-groups heavily affect the performance and we call this problem sub-group instability. To address the sub-group instability, in our previous work RCAN [14], we propose the RNN-based framework to make use of all available information in an image group. However, as an RNN framework, when the images in the image group are assigned with different orders, RCAN faces another instability. We call this order-sensitivity problem order instability. As can be seen in the Fig.13, and the co-salient results of RCAN are variant under different orders. Hence, in this paper, we further explore how to alleviate the order instability of the RNN-based framework. In the Fig.13, when detecting the different orders, our proposed network can consistently achieve good results. Comparing the Table.XII to Table.VII, we find that introducing an RNN-based network already improves the CoSOD stability by addressing the sub-group instability. Finally, through the MSRU and COCL, the stability is further enhanced by a large margin, since the order instability is addressed. We believe that a sustained and in-depth exploration of stability issues is of great significance in advancing the CoSOD/CoSEG field.
VII Conclusion
In this paper, we revisit the sequential modeling for CoSOD (CoSEG) task, then state the one drawback of existing models: order-sensitivity, which heavily affects the stability of proposed CoSOD (CoSEG) model. In this paper, inspired by RNN-based CoSOD (CoSEG) model, we first propose a multi-path stable recurrent unit (MSRU), containing dummy orders mechanisms (DOM) and recurrent unit (RU). Our proposed MSRU can not only help CoSOD (CoSEG) model capture robust inter-image relations, but also let the model have significant reduction in order-sensitivity, leading to a more stable training and inference process. Moreover, we design a cross-order contrastive loss (COCL) that can further improve order-sensitive problem by pulling close the feature embedding generated from different input orders. The performance on five widely used CoSOD datasets and three object co-segmentation datasets demonstrates the superiority of the proposed approach as compared to the SOTA methods. Through this paper, we investigate how RNNs can model orderless sequence tasks by using the COSOD (CoSEG) task as an example. When we design the mechanisms to address the order sensitivity problem, we find that RNNs are also capable of handling orderless sequence tasks. We hope that this paper can motivate future research for visual co-analysis tasks.
References
- [1] K. D. Tang, A. Joulin, L. Li, and L. Fei-Fei, “Co-localization in real-world images,” in IEEE Conf. Comput. Vis. Pattern Recog., 2014, pp. 1464–1471.
- [2] K. R. Jerripothula, J. Cai, and J. Yuan, “CATS: co-saliency activated tracklet selection for video co-localization,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 9911, 2016, pp. 187–202.
- [3] J. Liu, Z. Zha, X. Zhu, and N. Jiang, “Co-saliency spatio-temporal interaction network for person re-identification in videos,” in IJCAI, 2020, pp. 1012–1018.
- [4] D. Zhang, J. Han, Y. Yang, and D. Huang, “Learning category-specific 3d shape models from weakly labeled 2d images,” in IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 3587–3595.
- [5] A. Mustafa and A. Hilton, “Semantically coherent co-segmentation and reconstruction of dynamic scenes,” in IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 5583–5592.
- [6] R. Cong, J. Lei, H. Fu, F. Porikli, Q. Huang, and C. Hou, “Video saliency detection via sparsity-based reconstruction and propagation,” IEEE Trans. Image Process., vol. 28, no. 10, pp. 4819–4831, 2019.
- [7] K. R. Jerripothula, J. Cai, and J. Yuan, “Efficient video object co-localization with co-saliency activated tracklets,” IEEE Trans. Circuits Syst. Video Technol., vol. 29, no. 3, pp. 744–755, 2019.
- [8] D.-P. Fan, T. Li, Z. Lin, G.-P. Ji, D. Zhang, M.-M. Cheng, H. Fu, and J. Shen, “Re-thinking co-salient object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 8, pp. 4339–4354, 2022.
- [9] R. Cong, J. Lei, H. Fu, M. Cheng, W. Lin, and Q. Huang, “Review of visual saliency detection with comprehensive information,” IEEE Trans. Circuits Syst. Video Technol., vol. 29, no. 10, pp. 2941–2959, 2019.
- [10] D. Zhang, H. Fu, J. Han, A. Borji, and X. Li, “A review of co-saliency detection algorithms: Fundamentals, applications, and challenges,” ACM Trans. Intell. Syst. Technol., vol. 9, no. 4, pp. 38:1–38:31, 2018.
- [11] C. Zhang, G. Li, G. Lin, Q. Wu, and R. Yao, “Cyclesegnet: Object co-segmentation with cycle refinement and region correspondence,” IEEE Trans. Image Process., vol. 30, pp. 5652–5664, 2021.
- [12] X. Liu and X. Duan, “Automatic image co-segmentation: a survey,” Mach. Vis. Appl., vol. 32, no. 3, p. 74, 2021.
- [13] N. Zhang, J. Han, N. Liu, and L. Shao, “Summarize and search: Learning consensus-aware dynamic convolution for co-saliency detection,” in Int. Conf. Comput. Vis., 2021.
- [14] B. Li, Z. Sun, L. Tang, Y. Sun, and J. Shi, “Detecting robust co-saliency with recurrent co-attention neural network,” in IJCAI, 2019, pp. 818–825.
- [15] L. Wei, S. Zhao, O. E. F. Bourahla, X. Li, and F. Wu, “Group-wise deep co-saliency detection,” in IJCAI, 2017, pp. 3041–3047.
- [16] K. Zhang, T. Li, B. Liu, and Q. Liu, “Co-saliency detection via mask-guided fully convolutional networks with multi-scale label smoothing,” in IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 3095–3104.
- [17] C. Wang, Z. Zha, D. Liu, and H. Xie, “Robust deep co-saliency detection with group semantic,” in AAAI, 2019, pp. 8917–8924.
- [18] Q. Zhang, R. Cong, J. Hou, C. Li, and Y. Zhao, “Coadnet: Collaborative aggregation-and-distribution networks for co-salient object detection,” in Adv. Neural Inform. Process. Syst., 2020.
- [19] R. Cong, N. Yang, C. Li, H. Fu, Y. Zhao, Q. Huang, and S. Kwong, “Global-and-local collaborative learning for co-salient object detection,” IEEE Transactions on Cybernetics, 2022.
- [20] B. Jiang, X. Jiang, A. Zhou, J. Tang, and B. Luo, “A unified multiple graph learning and convolutional network model for co-saliency estimation,” in ACM Int. Conf. Multimedia, 2019, pp. 1375–1382.
- [21] K. Zhang, T. Li, S. Shen, B. Liu, J. Chen, and Q. Liu, “Adaptive graph convolutional network with attention graph clustering for co-saliency detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 9047–9056.
- [22] W. Jin, J. Xu, M. Cheng, Y. Zhang, and W. Guo, “Icnet: Intra-saliency correlation network for co-saliency detection,” in Adv. Neural Inform. Process. Syst., 2020.
- [23] Z. Zhang, W. Jin, J. Xu, and M. Cheng, “Gradient-induced co-saliency detection,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 12357, 2020, pp. 455–472.
- [24] W.-D. Jin, J. Xu, M.-M. Cheng, Y. Zhang, and W. Guo, “Icnet: Intra-saliency correlation network for co-saliency detection,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [25] T.-H. Wen, M. Gasic, N. Mrksic, P.-H. Su, D. Vandyke, and S. Young, “Semantically conditioned lstm-based natural language generation for spoken dialogue systems,” arXiv preprint arXiv:1508.01745, 2015.
- [26] J. Chen, H. Song, K. Zhang, B. Liu, and Q. Liu, “Video saliency prediction using enhanced spatiotemporal alignment network,” Pattern Recognit., vol. 109, p. 107615, 2021.
- [27] K. Cho, B. van Merrienboer, Ç. Gülçehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” in EMNLP, 2014, pp. 1724–1734.
- [28] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 20, no. 11, pp. 1254–1259, 1998.
- [29] M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, and S. Hu, “Global contrast based salient region detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 3, pp. 569–582, 2015.
- [30] J. Wang, H. Jiang, Z. Yuan, M. Cheng, X. Hu, and N. Zheng, “Salient object detection: A discriminative regional feature integration approach,” Int. J. Comput. Vis., vol. 123, no. 2, pp. 251–268, 2017.
- [31] T. Wang, L. Zhang, H. Lu, C. Sun, and J. Qi, “Kernelized subspace ranking for saliency detection,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 9912, 2016, pp. 450–466.
- [32] D. A. Klein and S. Frintrop, “Center-surround divergence of feature statistics for salient object detection,” in IEEE Int. Conf. Comput. Vis., 2011, pp. 2214–2219.
- [33] W. Wang, J. Shen, M. Cheng, and L. Shao, “An iterative and cooperative top-down and bottom-up inference network for salient object detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 5968–5977.
- [34] Q. Hou, M. Cheng, X. Hu, A. Borji, Z. Tu, and P. H. S. Torr, “Deeply supervised salient object detection with short connections,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 4, pp. 815–828, 2019.
- [35] Z. Wu, L. Su, and Q. Huang, “Cascaded partial decoder for fast and accurate salient object detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 3907–3916.
- [36] B. Wang, Q. Chen, M. Zhou, Z. Zhang, X. Jin, and K. Gai, “Progressive feature polishing network for salient object detection,” in AAAI, 2020, pp. 12 128–12 135.
- [37] Z. Chen, Q. Xu, R. Cong, and Q. Huang, “Global context-aware progressive aggregation network for salient object detection,” in AAAI, 2020, pp. 10 599–10 606.
- [38] J. Wei, S. Wang, and Q. Huang, “F3net: Fusion, feedback and focus for salient object detection,” CoRR, vol. abs/1911.11445, 2019.
- [39] Y. Pang, X. Zhao, L. Zhang, and H. Lu, “Multi-scale interactive network for salient object detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 9410–9419.
- [40] X. Zhao, Y. Pang, L. Zhang, H. Lu, and L. Zhang, “Suppress and balance: A simple gated network for salient object detection,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 12347, 2020, pp. 35–51.
- [41] S. Gao, Y. Tan, M. Cheng, C. Lu, Y. Chen, and S. Yan, “Highly efficient salient object detection with 100k parameters,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 12351, 2020, pp. 702–721.
- [42] L. Tang and B. Li, “Class: Cross-level attention and supervision for salient objects detection,” in Proceedings of the Asian Conference on Computer Vision (ACCV), November 2020.
- [43] B. Li, Z. Sun, L. Tang, and A. Hu, “Two-b-real net: Two-branch network for real-time salient object detection,” in ICASSP. IEEE, 2019, pp. 1662–1666.
- [44] L. Tang, B. Li, Y. Wu, B. Xiao, and S. Ding, “Fast: Feature aggregation for detecting salient object in real-time,” in ICASSP. IEEE, 2021, pp. 1525–1529.
- [45] W. Wang, S. Zhao, J. Shen, S. C. H. Hoi, and A. Borji, “Salient object detection with pyramid attention and salient edges,” in IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 1448–1457.
- [46] J. Zhao, J. Liu, D. Fan, Y. Cao, J. Yang, and M. Cheng, “Egnet: Edge guidance network for salient object detection,” in Int. Conf. Comput. Vis., 2019, pp. 8778–8787.
- [47] Z. Wu, L. Su, and Q. Huang, “Stacked cross refinement network for edge-aware salient object detection,” in IEEE Int. Conf. Comput. Vis., 2019, pp. 7263–7272.
- [48] H. Zhou, X. Xie, J. Lai, Z. Chen, and L. Yang, “Interactive two-stream decoder for accurate and fast saliency detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 9138–9147.
- [49] T. Wang, L. Zhang, S. Wang, H. Lu, G. Yang, X. Ruan, and A. Borji, “Detect globally, refine locally: A novel approach to saliency detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 3127–3135.
- [50] X. Qin, Z. V. Zhang, C. Huang, C. Gao, M. Dehghan, and M. Jägersand, “Basnet: Boundary-aware salient object detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 7479–7489.
- [51] L. Tang, B. Li, Y. Zhong, S. Ding, and M. Song, “Disentangled high quality salient object detection,” in Proc. IEEE Int. Conf. Comput. Vis., 2021, pp. 3580–3590.
- [52] W. Wang, J. Shen, X. Dong, and A. Borji, “Salient object detection driven by fixation prediction,” in IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 1711–1720.
- [53] W. Wang, J. Shen, X. Dong, A. Borji, and R. Yang, “Inferring salient objects from human fixations,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 8, pp. 1913–1927, 2020.
- [54] A. Borji, M. Cheng, Q. Hou, H. Jiang, and J. Li, “Salient object detection: A survey,” Comput. Vis. Media, vol. 5, no. 2, pp. 117–150, 2019.
- [55] H. Li and K. N. Ngan, “A co-saliency model of image pairs,” IEEE Trans. Image Process., vol. 20, no. 12, pp. 3365–3375, 2011.
- [56] H. Chen, “Preattentive co-saliency detection,” in IEEE Int. Conf. Image Process., 2010, pp. 1117–1120.
- [57] X. Cao, Y. Cheng, Z. Tao, and H. Fu, “Co-saliency detection via base reconstruction,” in ACM Int. Conf. Multimedia, 2014, pp. 997–1000.
- [58] K. Chang, T. Liu, and S. Lai, “From co-saliency to co-segmentation: An efficient and fully unsupervised energy minimization model,” in IEEE Conf. Comput. Vis. Pattern Recog., 2011, pp. 2129–2136.
- [59] Y. Li, K. Fu, Z. Liu, and J. Yang, “Efficient saliency-model-guided visual co-saliency detection,” IEEE Signal Process. Lett., vol. 22, no. 5, pp. 588–592, 2015.
- [60] H. Fu, X. Cao, and Z. Tu, “Cluster-based co-saliency detection,” IEEE Trans. Image Process., vol. 22, no. 10, pp. 3766–3778, 2013.
- [61] Z. Liu, W. Zou, L. Li, L. Shen, and O. Le Meur, “Co-saliency detection based on hierarchical segmentation,” IEEE Signal Processing Letters, vol. 21, no. 1, pp. 88–92, 2014.
- [62] L. Tang, B. Li, S. Kuang, M. Song, and S. Ding, “Re-thinking the relations in co-saliency detection,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 8, pp. 5453–5466, 2022.
- [63] D. Zhang, D. Meng, and J. Han, “Co-saliency detection via a self-paced multiple-instance learning framework,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 5, pp. 865–878, 2017.
- [64] D. Zhang, J. Han, J. Han, and L. Shao, “Cosaliency detection based on intrasaliency prior transfer and deep intersaliency mining,” IEEE Trans. Neural Networks Learn. Syst., vol. 27, no. 6, pp. 1163–1176, 2016.
- [65] X. Yao, J. Han, D. Zhang, and F. Nie, “Revisiting co-saliency detection: A novel approach based on two-stage multi-view spectral rotation co-clustering,” IEEE Trans. Image Process., vol. 26, no. 7, pp. 3196–3209, 2017.
- [66] L. Tang, “Cosformer: Detecting co-salient object with transformers,” CoRR, vol. abs/2104.14729, 2021.
- [67] C. Rother, T. P. Minka, A. Blake, and V. Kolmogorov, “Cosegmentation of image pairs by histogram matching - incorporating a global constraint into mrfs,” in IEEE Conf. Comput. Vis. Pattern Recog., 2006, pp. 993–1000.
- [68] S. Vicente, V. Kolmogorov, and C. Rother, “Cosegmentation revisited: Models and optimization,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 6312, 2010, pp. 465–479.
- [69] D. S. Hochbaum and V. Singh, “An efficient algorithm for co-segmentation,” in Int. Conf. Comput. Vis., 2009, pp. 269–276.
- [70] M. Rubinstein, A. Joulin, J. Kopf, and C. Liu, “Unsupervised joint object discovery and segmentation in internet images,” in IEEE Conf. Comput. Vis. Pattern Recog., 2013, pp. 1939–1946.
- [71] J. Dai, Y. N. Wu, J. Zhou, and S. Zhu, “Cosegmentation and cosketch by unsupervised learning,” in Int. Conf. Comput. Vis., 2013, pp. 1305–1312.
- [72] J. Sun and J. Ponce, “Learning dictionary of discriminative part detectors for image categorization and cosegmentation,” Int. J. Comput. Vis., vol. 120, no. 2, pp. 111–133, 2016.
- [73] X. Dong, J. Shen, L. Shao, and M.-H. Yang, “Interactive cosegmentation using global and local energy optimization,” IEEE Transactions on Image Processing, vol. 24, no. 11, pp. 3966–3977, 2015.
- [74] K. R. Jerripothula, J. Cai, and J. Yuan, “Image co-segmentation via saliency co-fusion,” IEEE Trans. Multim., vol. 18, no. 9, pp. 1896–1909, 2016.
- [75] S. Vicente, C. Rother, and V. Kolmogorov, “Object cosegmentation,” in IEEE Conf. Comput. Vis. Pattern Recog., 2011, pp. 2217–2224.
- [76] J. Hu, Z. Sun, B. Li, K. Yang, and D. Li, “Online user modeling for interactive streaming image classification,” in MMM (2), ser. Lecture Notes in Computer Science, vol. 10133. Springer, 2017, pp. 293–305.
- [77] K. Hsu, Y. Lin, and Y. Chuang, “Co-attention cnns for unsupervised object co-segmentation,” in IJCAI, 2018, pp. 748–756.
- [78] R. Quan, J. Han, D. Zhang, and F. Nie, “Object co-segmentation via graph optimized-flexible manifold ranking,” in IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 687–695.
- [79] Z. Yuan, T. Lu, and Y. Wu, “Deep-dense conditional random fields for object co-segmentation,” in IJCAI, 2017, pp. 3371–3377.
- [80] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and A. W. M. Smeulders, “Selective search for object recognition,” Int. J. Comput. Vis., vol. 104, no. 2, pp. 154–171, 2013.
- [81] P. Krähenbühl and V. Koltun, “Geodesic object proposals,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 8693, 2014, pp. 725–739.
- [82] H. Chen, Y. Huang, and H. Nakayama, “Semantic aware attention based deep object co-segmentation,” CoRR, vol. abs/1810.06859, 2018.
- [83] W. Li, O. H. Jafari, and C. Rother, “Deep object co-segmentation,” in Asian Conference on Computer Vision (ACCV), 2018.
- [84] C. Tsai, W. Li, K. Hsu, X. Qian, and Y. Lin, “Image co-saliency detection and co-segmentation via progressive joint optimization,” IEEE Trans. Image Process., vol. 28, no. 1, pp. 56–71, 2019.
- [85] S. Han, J. Kang, H. Mao, Y. Hu, X. Li, Y. Li, D. Xie, H. Luo, S. Yao, Y. Wang, H. Yang, and W. B. J. Dally, “ESE: efficient speech recognition engine with sparse LSTM on FPGA,” in FPGA, 2017, pp. 75–84.
- [86] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997.
- [87] X. Shi, Z. Chen, H. Wang, D. Yeung, W. Wong, and W. Woo, “Convolutional LSTM network: A machine learning approach for precipitation nowcasting,” in NIPS, 2015, pp. 802–810.
- [88] B. Zhao, X. Li, X. Lu, and Z. Wang, “A CNN-RNN architecture for multi-label weather recognition,” CoRR, vol. abs/1904.10709, 2019.
- [89] M. Lv, W. Xu, and T. Chen, “A hybrid deep convolutional and recurrent neural network for complex activity recognition using multimodal sensors,” Neurocomputing, vol. 362, pp. 33–40, 2019.
- [90] F. Altché and A. de La Fortelle, “An LSTM network for highway trajectory prediction,” in ITSC, 2017, pp. 353–359.
- [91] D. Yang, T. Xiong, D. Xu, S. K. Zhou, Z. Xu, M. Chen, J. H. Park, S. Grbic, T. D. Tran, S. P. Chin, D. N. Metaxas, and D. Comaniciu, “Deep image-to-image recurrent network with shape basis learning for automatic vertebra labeling in large-scale 3d CT volumes,” in MICCAI, ser. Lecture Notes in Computer Science, vol. 10435, 2017, pp. 498–506.
- [92] H. T. H. Phan, A. Kumar, D. Feng, M. J. Fulham, and J. Kim, “An unsupervised long short-term memory neural network for event detection in cell videos,” CoRR, vol. abs/1709.02081, 2017.
- [93] Y. Xu, A. Hosny, R. Zeleznik, C. Parmar, T. Coroller, I. Franco, R. H. Mak, and H. J. Aerts, “Deep learning predicts lung cancer treatment response from serial medical imaging,” Clinical Cancer Research, vol. 25, no. 11, pp. 3266–3275, 2019.
- [94] L. Jiang, M. Xu, and Z. Wang, “Predicting video saliency with object-to-motion CNN and two-layer convolutional LSTM,” CoRR, vol. abs/1709.06316, 2017.
- [95] W. Wang, J. Shen, F. Guo, M. Cheng, and A. Borji, “Revisiting video saliency: A large-scale benchmark and a new model,” in IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 4894–4903.
- [96] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Int. Conf. Learn. Represent., 2015.
- [97] L. Tang, B. Li, Y. Zhong, S. Ding, and M. Song, “Disentangled high quality salient object detection,” in IEEE Int. Conf. Comput. Vis., 2021, pp. 3560–3570.
- [98] Z. Zhu, M. Xu, S. Bai, T. Huang, and X. Bai, “Asymmetric non-local neural networks for semantic segmentation,” in Int. Conf. Comput. Vis., 2019, pp. 593–602.
- [99] X. Wang, R. B. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 7794–7803.
- [100] L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” in IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 2414–2423.
- [101] K. He, H. Fan, Y. Wu, S. Xie, and R. B. Girshick, “Momentum contrast for unsupervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 9726–9735.
- [102] T. Chen, S. Kornblith, M. Norouzi, and G. E. Hinton, “A simple framework for contrastive learning of visual representations,” in ICML, ser. Proceedings of Machine Learning Research, vol. 119, 2020, pp. 1597–1607.
- [103] J. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. Á. Pires, Z. Guo, M. G. Azar, B. Piot, K. Kavukcuoglu, R. Munos, and M. Valko, “Bootstrap your own latent - A new approach to self-supervised learning,” in Adv. Neural Inform. Process. Syst., 2020.
- [104] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: common objects in context,” in Eur. Conf. Comput. Vis., ser. Lecture Notes in Computer Science, vol. 8693, 2014, pp. 740–755.
- [105] L. Wang, H. Lu, Y. Wang, M. Feng, D. Wang, B. Yin, and X. Ruan, “Learning to detect salient objects with image-level supervision,” in IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 3796–3805.
- [106] D.-P. Fan, T. Li, Z. Lin, G.-P. Ji, D. Zhang, M.-M. Cheng, H. Fu, and J. Shen, “Re-thinking co-salient object detection,” arXiv preprint arXiv:2007.03380, 2020.
- [107] D. Zhang, J. Han, C. Li, J. Wang, and X. Li, “Detection of co-salient objects by looking deep and wide,” Int. J. Comput. Vis., vol. 120, no. 2, pp. 215–232, 2016.
- [108] D. Batra, A. Kowdle, D. Parikh, J. Luo, and T. Chen, “icoseg: Interactive co-segmentation with intelligent scribble guidance,” in IEEE Conf. Comput. Vis. Pattern Recog., 2010, pp. 3169–3176.
- [109] J. M. Winn, A. Criminisi, and T. P. Minka, “Object categorization by learned universal visual dictionary,” in Int. Conf. Comput. Vis., 2005, pp. 1800–1807.
- [110] J. Han, G. Cheng, Z. Li, and D. Zhang, “A unified metric learning-based framework for co-saliency detection,” IEEE Trans. Circuits Syst. Video Technol., vol. 28, no. 10, pp. 2473–2483, 2018.
- [111] A. Borji, M. Cheng, H. Jiang, and J. Li, “Salient object detection: A benchmark,” IEEE Trans. Image Process., vol. 24, no. 12, pp. 5706–5722, 2015.
- [112] C. Yang, L. Zhang, H. Lu, X. Ruan, and M. Yang, “Saliency detection via graph-based manifold ranking,” in IEEE Conf. Comput. Vis. Pattern Recog., 2013, pp. 3166–3173.
- [113] D. Fan, M. Cheng, Y. Liu, T. Li, and A. Borji, “Structure-measure: A new way to evaluate foreground maps,” in Int. Conf. Comput. Vis., 2017, pp. 4558–4567.
- [114] D. Fan, C. Gong, Y. Cao, B. Ren, M. Cheng, and A. Borji, “Enhanced-alignment measure for binary foreground map evaluation,” in IJCAI, 2018, pp. 698–704.
- [115] A. Faktor and M. Irani, “Co-segmentation by composition,” in Int. Conf. Comput. Vis., 2013, pp. 1297–1304.
- [116] Z. Tao, H. Liu, H. Fu, and Y. Fu, “Image cosegmentation via saliency-guided constrained clustering with cosine similarity,” in AAAI, 2017, pp. 4285–4291.
- [117] L. Wei, S. Zhao, O. E. F. Bourahla, X. Li, F. Wu, and Y. Zhuang, “Deep group-wise fully convolutional network for co-saliency detection with graph propagation,” IEEE Trans. Image Process., vol. 28, no. 10, pp. 5052–5063, 2019.
- [118] Q. Fan, D. Fan, H. Fu, C. Tang, L. Shao, and Y. Tai, “Group collaborative learning for co-salient object detection,” in IEEE Conf. Comput. Vis. Pattern Recog., 2021, pp. 12 288–12 298.
- [119] N. Zhang, J. Han, N. Liu, and L. Shao, “Summarize and search: Learning consensus-aware dynamic convolution for co-saliency detection,” in Int. Conf. Comput. Vis., 2021, pp. 4147–4156.
- [120] B. Li, Z. Sun, Q. Li, Y. Wu, and A. Hu, “Group-wise deep object co-segmentation with co-attention recurrent neural network,” in Int. Conf. Comput. Vis., 2019, pp. 8518–8527.