Training neural networks using Metropolis Monte Carlo and an adaptive variant
Abstract
We examine the zero-temperature Metropolis Monte Carlo algorithm as a tool for training a neural network by minimizing a loss function. We find that, as expected on theoretical grounds and shown empirically by other authors, Metropolis Monte Carlo can train a neural net with an accuracy comparable to that of gradient descent, if not necessarily as quickly. The Metropolis algorithm does not fail automatically when the number of parameters of a neural network is large. It can fail when a neural network’s structure or neuron activations are strongly heterogenous, and we introduce an adaptive Monte Carlo algorithm, aMC, to overcome these limitations. The intrinsic stochasticity and numerical stability of the Monte Carlo method allow aMC to train deep neural networks and recurrent neural networks in which the gradient is too small or too large to allow training by gradient descent. Monte Carlo methods offer a complement to gradient-based methods for training neural networks, allowing access to a distinct set of network architectures and principles.
I Introduction
The Metropolis Monte Carlo algorithm was developed in the 1950s in order to simulate molecular systems Metropolis et al. (1953); Gubernatis (2005); Rosenbluth (2003); Whitacre (2021). The Metropolis algorithm consists of small, random moves of particles, accepted probabilistically. It is, along with other Monte Carlo (MC) algorithms, widely used as a tool to equilibrate molecular systems Frenkel and Smit (2001). Equilibrating a molecular system is similar in key respects to training a neural network: both involve optimizing quantities derived from many degrees of freedom that interact in a nonlinear way. Despite this similarity, the Metropolis algorithm and its variants are not widely used as a tool for training neural networks by minimizing a loss function (for exceptions, see e.g. Refs. Sexton et al. (1999); Rere et al. (2015); Tripathi and Singh (2020)). Instead, this is usually done by gradient-based algorithms Schmidhuber (2015); Goodfellow et al. (2016), and sometimes by population-based evolutionary or genetic algorithms Holland (1992); Fogel and Stayton (1994); Montana and Davis (1989) to which Monte Carlo methods are conceptually related.
In this paper we address the potential of the zero-temperature Metropolis Monte Carlo algorithm and an adaptive variant thereof as tools for neural-network training 111Zero temperature means that moves that increase the loss are not accepted. This choice is motivated by the empirical success in machine learning of gradient-descent methods, and by the intuition, derived from Gaussian random surfaces, that loss surfaces possess more downhill directions at large values of the loss Dauphin et al. (2014); Bahri et al. (2020).. The class of algorithm we consider consists of taking a neural network of fixed structure, adding random numbers to all weights and biases simultaneously, and accepting this change if the loss function does not increase. For uncorrelated Gaussian random numbers this procedure is equivalent, for small updates, to normalized or clipped gradient descent in the presence of Gaussian white noise Kikuchi et al. (1991, 1992); Whitelam et al. (2021) 222Note that algorithms of this nature do not constitute random search. The proposal step is random (related conceptually to the idea of weight guessing, a method used in the presence of vanishing gradients Hochreiter and Schmidhuber (1997)) but the acceptance criterion is a form of importance sampling, and leads to a dynamics equivalent to noisy gradient descent., and so its ability to train a neural network should be similar to that of simple gradient descent (GD). We show in Section II.1 that, for a particular supervised-learning problem, this is the case, a finding consistent with results presented by other authors Sexton et al. (1999); Rere et al. (2015); Tripathi and Singh (2020).
It is sometimes stated that the ability of stochastic algorithms to train neural networks diminishes sharply as the number of network parameters increases (particularly if all network parameters are updated simultaneously). However, population-based evolutionary algorithms have been used to train many-parameter networks Salimans et al. (2017), and in Section II.2 we show that the ability of Metropolis Monte Carlo to train a fully-connected neural network is similar for networks with of order a hundred parameters or of order a million: there is not necessarily a sharp decline of acceptance rate with increasing network size.
What does thwart the Metropolis Monte Carlo algorithm is network heterogeneity. For instance, if the number of connections entering neurons differs markedly throughout the network (as is the case for networks with convolutional- and fully-connected layers) or if the outputs of neurons in different parts of a network differ markedly (as is the case for very deep networks) then stochastic weight changes of a fixed scale will saturate neurons in some parts of the network and scarcely effect change in other parts. The result is an inability to train. To address this problem we introduce a set of simple adaptive modifications of the Metropolis algorithm – a momentum-like term, an adaptive step-size scheduler, and a means of enacting heterogenous weight updates – that are borrowed from ideas commonly used with gradient-based methods. The resulting algorithm, which we call adaptive Monte Carlo or aMC, is substantially more efficient than the non-adaptive Metropolis algorithm in a variety of settings. In Section II.2 we show, for one particular problem, that the acceptance rate of aMC remains much higher than that of the Metropolis algorithm at low values of loss, and can be made almost insensitive to network width, depth, and size. In Section II.3 we show that its momentum-like term speeds the rate at which aMC can learn the high-frequency features of an objective function, much as adaptive methods such as Adam Kingma and Ba (2014) can learn high-frequency features faster than regular gradient descent. In Section II.4 we show that the Monte Carlo method can train simple recurrent neural networks in the presence of small or large gradients, where gradient-based methods fail. In Section II.5 we show aMC can train deep neural networks in which gradients are too small for gradient-based methods to train. In Section II.6 we comment on the fact that best practices for training nets using Monte Carlo methods await development. We introduce the elements of aMC throughout Section II, and summarize the algorithm in Section III.
Our conclusion is that the Metropolis Monte Carlo algorithm and its adaptive variants such as aMC are viable ways of training neural networks, if less developed and optimized than modern gradient-based methods. In particular, Monte Carlo algorithms can, for small updates, effectively sense the gradient, and they do not fail simply because the number of parameters of a neural network becomes large. Monte Carlo algorithms should be considered a complement to gradient-based algorithms because they admit different design principles for neural networks. Given a network that permits gradient flow, modern gradient-based algorithms are fast and effective Schmidhuber (2015); LeCun et al. (2015); Goodfellow et al. (2016). For large neural nets with tens of millions of parameters we find gradient-based methods to be considerably faster than Monte Carlo (Section II.6). However, Monte Carlo algorithms free us from the requirement of ensuring reliable gradient flow (and gradients can be unreliable even in differentiable systems Metz et al. (2021)). As a result, we find that Monte Carlo methods can train deep neural networks and simple recurrent neural networks in which gradients are too small (or too large) for gradient-based methods to work. There already exist solutions to these problems, namely the introduction of skip connections or more elaborate recurrent neural network architectures, but aMC requires neither of these things. One type of solution is architectural, the other algorithmic, and having both options offers more possibilities than having only one.
II Results
II.1 Metropolis Monte Carlo and its connection to gradient descent
We start with the zero-temperature Metropolis Monte Carlo algorithm. The zero-temperature limit is not often used in molecular simulation, but it and its variants are widely used (and sometimes called random-mutation hill climbing) for optimizing non-differentiable systems such as cellular automata Mitchell et al. (1993); Mitchell (1998). Consider a neural network with parameters (weights and biases) , and associated loss function . If we propose the simultaneous change of each neural-network parameter by a Gaussian random number 333In Metropolis Monte Carlo simulations of molecular systems it is usual to propose moves of one particle at a time. If we consider neural-net parameters to be akin to particle coordinates then the analog would be to make changes to one neural-net parameter at a time; see e.g. Ref. Tripathi and Singh (2020). However, there is no formal mapping between particles and a neural network, and we could equally well consider the neural-net parameters to be akin to the coordinates of a single particle, in a high-dimensional space, in an external potential equal to the loss function. In the latter case the analog would be to propose a change of all neural-net parameters simultaneously, as we do here.,
| (1) |
and accept the proposal if the loss does not increase, then, when the basic move scale is small, the values of the neural-net parameters evolve according to the Langevin equation Whitelam et al. (2021)
| (2) |
Here is training time (epoch), and is a Gaussian white noise with zero mean and variance . That is, small stochastic perturbations of a network’s weights and biases, accepted if the loss function does not increase, is equivalent to noisy clipped or normalized gradient descent on the loss function.
Given the success of gradient-based training methods, this correspondence shows the potential of the Metropolis algorithm to train neural networks. Consistent with this expectation, we show in Fig. 1 that the zero-temperature Metropolis algorithm can train a neural network. For comparison, we also train the network using simple gradient descent,
| (3) |
where is the learning rate, the loss function, and the gradient operator with respect to the neural-network parameters .
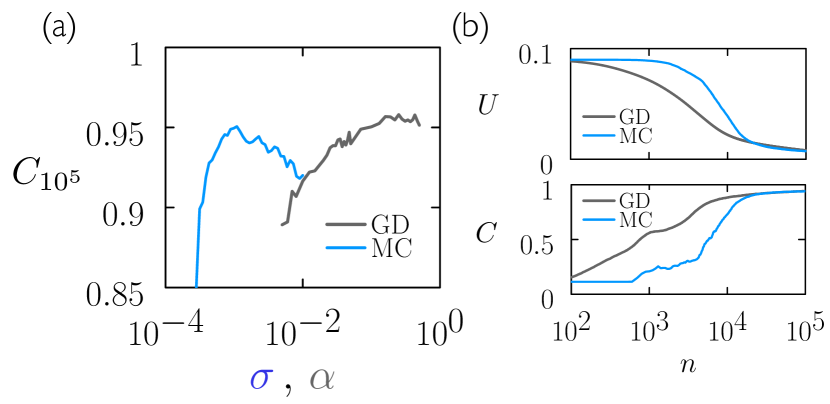
We consider a standard supervised-learning problem, recognizing MNIST images mni ; LeCun et al. (1998) using a fully-connected, two-layer neural net. The net has 784 input neurons, 16 neurons in each hidden layer, and one output layer of 10 neurons. The hidden neurons have hyperbolic tangent activation functions, and the output neurons comprise a softmax function. The net has in total 13,002 parameters nn . We did batch learning, with the loss function being the mean-squared error on the MNIST training set of size (in the standard way we consider the ground truth for each training example to be a 1-hot encoding of the class label, and take the 10 outputs of the neural network as its prediction vector).
Fig. 1(a) shows the classification accuracy on the MNIST test set of size after epochs of training. We show results for MC (blue) and GD (gray), for a range of values of step size and learning rate , respectively. The initial neural-net parameters for MC simulations were . The two algorithms behave in a similar manner: each has a range of its single parameter over which it is effective, and displays a maximum at a particular value of that parameter. The value of the maximum for GD is slightly higher than that for MC (about 96% compared to about 95%), and GD achieves near-maximal results over a broader range of its single parameter than does MC.
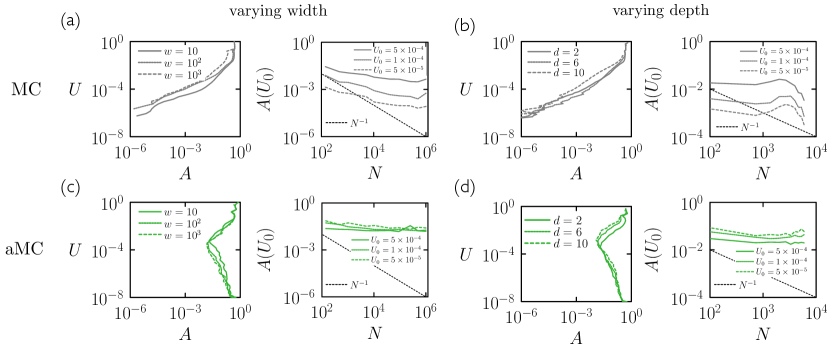
Fig. 1(b) shows loss and classification accuracy as a function of epoch for two examples from panel (a). GD trains faster with initially, but results are comparable near the end of the learning process. The learning dynamics of these algorithms is not the same: in the limit of small steps, the zero-temperature Metropolis algorithm approaches normalized or clipped gradient descent, not standard gradient descent (and its equivalence to the former would only be seen with an appropriately rescaled horizontal axis) 444We have also found the GD-MC equivalence to break down in other circumstances: for certain learning rates , the discrete-update equation (3) sometimes results in moves uphill in loss, in which case the discrete update is not equivalent to the equation , while the latter is equivalent to the small-step-size limit of the finite-temperature Metropolis algorithm Kikuchi et al. (1991, 1992); Whitelam et al. (2021).. Nonetheless, MC can in effect sense the gradient, as long as the step size is relatively small, and for this problem the range of appropriate step sizes is small compared to the effective GD step size. GD therefore trains faster, but MC has similar capacity for learning. The computational cost per epoch of the two algorithms is of similar order, with MC being cheaper per epoch for batch learning: each MC step requires a forward pass through the data, and each GD step a forward and a backward pass.
There are many things that could be done to improve the learning precision of these algorithms (no pre-processing of data was done, and a basic neural net was used 555In Fig. 8 we show that GD and MC can both train a large modern neural network to a classification accuracy in excess of 99% on the same problem.), but this comparison, given a neural net and a data set, confirms that Metropolis Monte Carlo can achieve results roughly comparable to gradient descent, even on a problem for which gradients are available. For this problem GD trains faster, but MC works. It is worth noting that this conclusion follows from considering a range of step sizes : for a single choice of step size it would be possible to conclude that MC doesn’t work at all.
Similar findings have been noted previously: simulated annealing on the Metropolis algorithm Sexton et al. (1999); Rere et al. (2015) and a variant of zero-temperature Metropolis MC (applied weight-by-weight) Tripathi and Singh (2020) were used to train neural nets with an accuracy comparable to that of gradient-based algorithms. These results, and the correspondence described in Ref. Whitelam et al. (2021) establish both theoretically and empirically the ability of Metropolis MC to train neural nets.
We next turn to the question of how the efficiency of Monte Carlo training scales with net parameters, and how to improve this efficiency by introducing adaptivity to the algorithm.
II.2 Metropolis acceptance rate as a function of net size
To examine how the efficiency of the Metropolis algorithm changes with neural-net size and architecture, we consider in this section a supervised-learning problem in which a neural net is trained by zero-temperature Metropolis MC to express the sine function on the interval . The loss is the mean-squared error between and the neural-net output , evaluated at evenly-spaced points on the interval. The neural net has one input neuron, which is fed the value , and one output, which returns . Its internal structure is fully connected, with hyperbolic tangent nonlinearities. To explore the effect of varying width (panels (a) and (c) of Fig. 2) we set the depth to 2 and varied the width from to , these choices corresponding to about to about parameters. To explore the effect of varying depth (panels (b) and (d) of Fig. 2) we set the width to 25 and varied the depth from 2 to 10, these choices corresponding to about to about parameters.
In Fig. 2(a,left) we show loss as a function of Metropolis acceptance rate for three different neural-net widths. The acceptance rate tells us, for fixed step size, the fraction of directions that point downhill in loss. It provides information similar to that shown in plots of the index of the critical points of a loss surface Dauphin et al. (2014); Bahri et al. (2020), confirming that at large loss there are more downhill directions than at small loss. In Fig. 2(a,right) we plot the acceptance rate at fixed loss as a function of the number of net parameters (obtained by taking horizontal cuts across panel (a); note that more net sizes are shown in panel (b) than panel (a)).
The acceptance rate decreases with increasing net size, but relatively slowly. Upon increasing the size of the net by 4 orders of magnitude, the acceptance rate decreases by about 1 order of magnitude. We have indicated an scaling as a guide to the eye. In the extreme limit, if simultaneous parameter updates each had to be individually productive, the acceptance rate would decrease exponentially with , which is clearly not the case. The more dramatic decrease in acceptance rate is with loss: at small loss the acceptance rate becomes very small.
Similar trends are seen with depth in Fig. 2(b). The acceptance rate declines sharply with loss. It also declines with the number of parameters, slightly more rapidly than in panel (a) but not as rapidly as .
Empirically, therefore, we do not see evidence of a fundamental inability of MC to cope with large numbers of parameters. In Section II.5 we discuss how network heterogeneity can impair the Metropolis algorithm’s ability to train a network. The solution, as we discuss there, is to introduce an adaptive Monte Carlo (aMC) variant of the Metropolis algorithm. To motivate the introduction of this algorithm we show in panels (c) and (d) the aMC analog of panels (a) and (b), respectively. The trends experienced by Metropolis have been annulled, the acceptance rates of aMC remaining large and essentially constant with loss or model size over the range of parameters considered.
We now turn to a step-by-step introduction of the elements of aMC.
II.3 Adaptivity speeds learning, particularly of high-frequency features
Modern gradient-based methods are adaptive, allowing the learning rate for each neural-net parameter to differ and to change as a function of the gradients encountered during training Goodfellow et al. (2016) (adaptive learning is also used in evolutionary algorithms Hansen and Ostermeier (2001); Hansen et al. (2003); Hansen (2006)). We can copy this general idea in a simple way within a zero-temperature Metropolis Monte Carlo scheme by changing the proposed move of Eq. (1) to
| (4) |
The parameters , set initially to zero, are updated after every accepted move according to
| (5) |
where is a hyperparameter of the method. This form of adaptation is similar to the inclusion of momentum in a gradient-based scheme: the center of each parameter’s move-proposal distribution shifts in the direction of the last accepted move , with the aim of increasing the probability of generating moves that will be accepted. In addition, to remove the need for a search over the step-size parameter , we introduce a simple adaptive learning-rate schedule by setting (and ) after consecutive rejected moves. We take the initial step size to be . We refer to this adaptive Monte Carlo algorithm as aMC, specified in Section III.
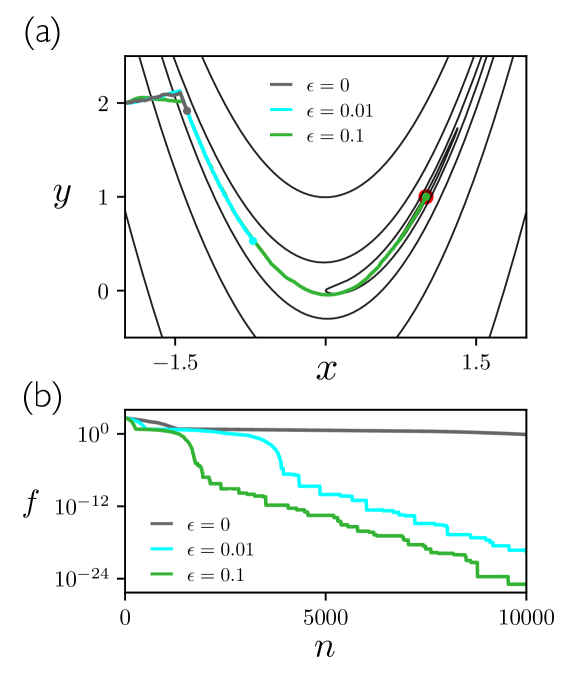
The aMC parameter can be used to influence the rate of learning. In Fig. 3 we provide a simple illustration of this fact using the two-dimensional Rosenbrock function
| (6) |
often used as a test function for optimization methods Rosenbrock (1960); Shang and Qiu (2006); Emiola and Adem (2021). The Rosenbrock function has a global minimum at that is set within a long valley surrounded by steep slopes on either side. A particle on this function moving under pure gradient descent takes a long time to reach the global minimum because gradients within the valley are small: the particle will quickly reach the valley and then move slowly along the valley floor Rosenbrock (1960); Shang and Qiu (2006). Placing a particle at the point , outside the valley, we evolve the position of the particle using aMC. We used the initial step size and rescaling parameter , and carried out three simulations for three values of . As shown in the figure, the larger is the more rapidly is the global minimum attained, with the difference between zero and nonzero epsilon being considerable. This form of adaptivity has an effect similar to that of momentum with gradient descent Goh (2017).
Returning to neural-network simulation, the aMC parameter can speed the rate at which a neural network can learn high-frequency features, much as adaptive methods do with gradient-based algorithms. The extent to which high-frequency features should be learned varies by application. For instance, if a training set contains high-frequency noise then we may wish to attenuate an algorithm’s ability to learn this noise in order to enhance its ability to generalize. This is the idea expressed in Fig. 2 of Ref. Rumelhart et al. (1995). Empirical studies show that non-adaptive versions of gradient descent sometimes generalize better than their adaptive counterparts Chen et al. (2018), in some cases because of the different abilities of these things to learn high-frequency features.
In Fig. 4 we consider a supervised-learning problem inspired by Fig. 2 of Ref. Rumelhart et al. (1995). We use gradient-based methods (GD and Adam) and aMC to train a neural network to learn the function
| (7) |
on . This function contains a low-frequency term, the logarithm, and a high-frequency term, the sine. The neural network has one input neuron, which is fed the value , one output neuron, which returns , and a single hidden layer of 100 neurons with tanh activations. The parameters of the network were set initially to random values .
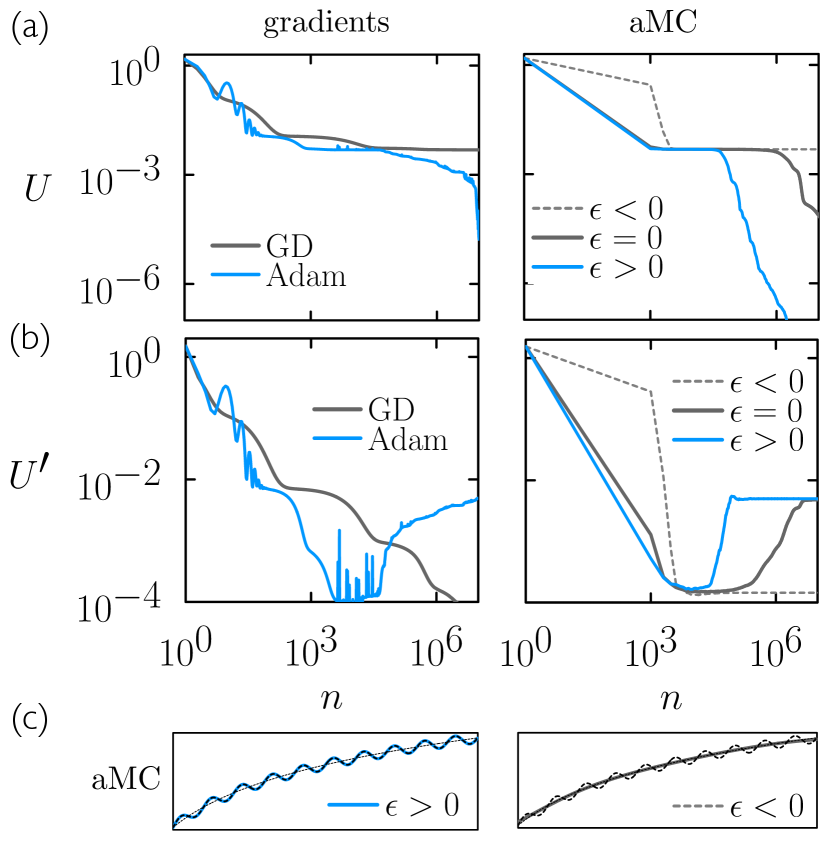
In Fig. 4(a) we show the training loss, the mean-squared difference between and the neural-net output , evaluated at 1000 evenly-spaced points over the interval. At left we show results produced using GD and Adam, and at right we show results produced using aMC for three values of , one positive (), one negative (), and zero. Of the gradient-based methods Adam trains faster than GD, while for aMC the training loss decreases fastest for positive and slowest for negative . (We did not carry out a systematic search of learning rates in order to compare directly the gradient-based and Monte Carlo methods; our intent here is to illustrate how adaptivity matters within the two classes of algorithm.)
In Fig. 4(b) we show the pseudo-loss that expresses the mean-squared difference between the net function and the low-frequency logarithmic term of . The net is not trained to minimize , but it so happens during training that becomes small as the net first learns the low-frequency component of . Subsequently, increases as the net also learns the high-frequency component of .
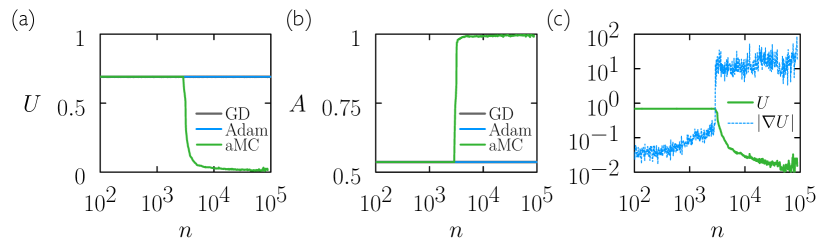
Of the gradient-based methods Adam learns high-frequency features more rapidly than GD. As it does so, the value of the pseudo-loss increases. For aMC, the parameter controls the separation of timescales between the learning of the low- and high-frequency components of . If we want to learn as quickly as possible then positive is the best choice. But if we consider the high-frequency component of to be noise, and regard as a measure of the network’s generalization error, then negative is the best choice.
Panel (c) shows the aMC net functions at a time such that the net trained using has begun to learn the high-frequency features of . At the same time the nets trained using positive and negative have learned these features completely or not at all, respectively.
II.4 Monte Carlo algorithms can train a neural network even when gradients are unreliable
Metropolis Monte Carlo and aMC can effectively sense the gradient Whitelam et al. (2021), and so can train a neural network to similar levels of accuracy as gradient descent. However, Monte Carlo algorithms can also train a neural network when gradients become unreliable, such as when they vanish or explode.
Vanishing gradients can be overcome by the intrinsic stochasticity of the Monte Carlo method. In the absence of gradients, pure gradient-based methods receive no signal Hochreiter and Schmidhuber (1997); Hochreiter (1998). However, the Metropolis Monte Carlo procedure (1) is equivalent, for vanishing gradients, to the diffusive dynamics , where is a Gaussian white noise with zero mean and variance . Thus Metropolis MC will, in the absence of gradients, enact diffusion in parameter space until nonvanishing gradients are encountered, at which point learning can resume.
Monte Carlo algorithms can also cope with exploding gradients. Moves are proposed without reference to the gradient, and so can be made on a landscape for which the gradient varies rapidly or is numerically large. Monte Carlo algorithms are also numerically stable, with moves that would induce large increases in loss being rejected but otherwise not harming the training process.
We show in this section that the ability to cope with vanishing and exploding gradients allows aMC to train recurrent neural networks that gradient-based methods cannot. Recurrent neural networks (RNNs) are designed to act on sequences, and have been applied to problems involving text, images, speech, and music Medsker and Jain (2001); Graves et al. (2013); Sutskever et al. (2014); Graves and Schmidhuber (2008). An RNN possesses a vector known as its hidden state, which acts as a form of memory. This vector is updated each time the RNN views a position in a sequence. The size of the gradient scales in general exponentially with sequence length, and so when the sequence is long, and long-term dependencies exist, the gradient tends to vanish or explode. As a result, it can be difficult to train simple RNNs using first-order gradient-based methods in order to learn long-term dependencies in sequence data Schmidhuber (2015); Wierstra et al. (2010); Bengio et al. (1994); Martens and Sutskever (2011); Bengio et al. (2013). One solution to this problem is the introduction of more elaborate and computationally expensive RNN architectures such as long short-term memory Hochreiter and Schmidhuber (1997) and gated recurrent units Cho et al. (2014); Kanai et al. (2017). These architectures can be more reliably trained by gradient-based methods than can simple RNNs.
Here we demonstrate an algorithmic solution to the problem rather than an architectural one, by showing that Monte Carlo methods can train an RNN in circumstances in which gradient-based methods cannot. We train a simple RNN with tanh activation functions to distinguish the digits of class 0 and 1 in the MNIST data set. We binarized the data, and used a vector of length 2 and a one-hot encoding to represent black or white pixels. The RNN was shown an unrolled version of each image, a sequence of 784 pixels. The RNN architecture is a two-layer stack in which the hidden state at each site in the first layer is used as input for the second layer. The dimension of the hidden state is set to 64, and the final hidden state is sent into a linear classifier. The loss function is the cross entropy between the neural network’s prediction and the ground truth.
In Fig. 5(a,b) we show the results of training the RNN using aMC and gradient-based optimizers. We stochastically subsample the training data set for each update (“mini-batching”), using 1500 samples at each step. We used gradient descent and the Adam optimizer, both with learning rate , with gradient clipping turned on (this has been shown to solve the exploding-gradient problem for some data sets Pascanu et al. (2013)), and aMC with hyperparameters (which is the Metropolis algorithm with an adaptive step-size scheduler). Gradient descent and Adam fail to train (a search over learning rates between the values and did not result in lower loss values), while aMC trains to small values of loss and a test-set accuracy of .
In Fig. 5(c) we show the size of the gradient associated with the models produced by aMC. aMC does not calculate or make use of the gradient, but we can nonetheless evaluate it for the models produced by the training process. Two distinct regimes can be seen, with the size of the gradient changing by about three orders of magnitude between them. The gradient-based algorithms cannot escape from the small-gradient regime, and when initiated from the large-gradient regime that is encountered by aMC, in which , the gradient-based integrators explode. Thus Monte Carlo can train productively in the face of two of the classic obstacles to training by gradient-based methods, small and large gradients.
Simple RNNs are known be harder to train by gradient descent than more complex RNNs, but simple RNNs possess similar or greater capacity per parameter than more complex architectures Collins et al. (2016). Methods that can train simple RNNs may therefore allow more widespread use of those architectures.
II.5 For nets with heterogeneous structures or neuron activations, the weight-update scale must be made heterogenous
For some architectures, particularly those with structural heterogeneity or heterogenous neuron activations, it is necessary to scale the Monte Carlo step-size parameter for each neural-net parameter individually. In this section we address this problem using deep neural networks for which, as in Section II.4, gradients are too small for gradient-based methods to train.
Choosing a set of heterogeneous Monte Carlo step-size parameters can be done by adapting ideas used in the development of gradient-based methods LeCun et al. (1996). Guided by that work we modify the proposal distribution of (4) to read
| (8) |
where . The are parameters that are either set to unity (a condition we call “signal norm off”) or according to Eq. (18) in Section III.2 (“signal norm on”). The parameters and are adjusted as in Section II.3. The parameters , which are straightforwardly calculated during a forward pass through the net, ensure that the scale of signal change to each neuron is roughly constant. The intent of signal norm is similar to that of layer norm Ba et al. (2016), except that the latter is an architectural solution – it entails a modification of the net, and is present at test time – while the former is an algorithmic solution and plays no role once the neural net has been trained.
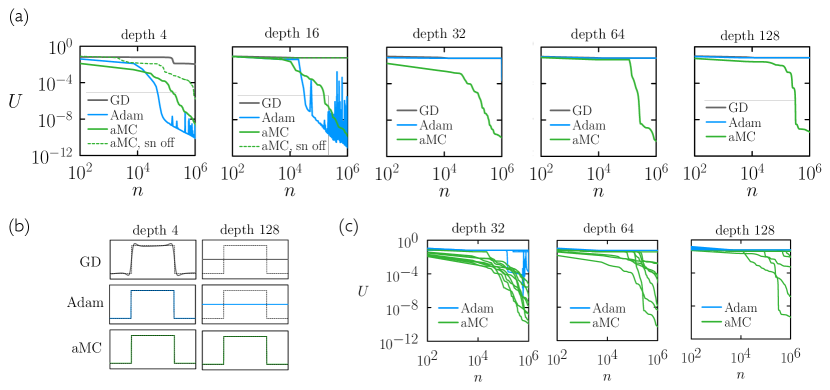
In Fig. 6 we show the results of neural networks of depth trained by aMC and by gradient-based methods to express a step function that is equal to 1/2 if and is zero otherwise. The neural nets have one input neuron, which is fed the value , and one output neuron, which returns . They have 10 neurons in the penultimate hidden layer, and 4 neurons in each of the other hidden layers, the intent being to allow very deep nets with relatively few neurons. All neurons have tanh activation functions.
In Fig. 6(a) we show loss as a function of epoch for four algorithms: GD (gray); Adam (blue); and aMC with signal norm off (green dotted) and on (green). For each algorithm we ran 20 independent simulations, 10 using Kaiming initialization Paszke et al. (2019) and 10 initialized with Gaussian random numbers , where . We plot the simulation having the smallest after epochs. As the depth of the network increases beyond 4 layers, GD and aMC with signal norm off stop learning on the timescales shown. Above 32 layers, Adam also stops learning on the timescale shown. (For depth 64 we tried a broad range of learning rates for GD and Adam, from to , none of which was successful. We also varied the Adam hyperparameters over a small range of values, without success. It may be that hyperparameters that enable training do exist, but we were not able to find them.) aMC with signal norm on continues to learn up to a depth of 128 (we also verified that aMC trains nets of depth 256), and so can successfully train deep nets in which gradient-based algorithms receive too little signal to train.
In Fig. 6(b) we show net outputs at epochs for three algorithms and two depths. As discussed in Section II.3, the adaptive algorithms Adam and aMC learn the sharp features of the target function more quickly than does GD. For the deeper net, the gradient-based algorithms GD and Adam do not receive sufficient signal to train.
In Fig. 6(c) we show 10 simulations for each of Adam and aMC for the deeper nets. The outcome of training is stochastic, resembling a nucleation dynamics with an induction time that increases with net depth. For some initial conditions both algorithms fail to train on the allotted timescale. In general, the rate of nucleation is higher for aMC than Adam, and remains measurable for all depths shown
We verified that introducing skip connections He et al. (2016) or layer norm Ba et al. (2016) to the neural nets enabled Adam to train at depth 64 (and enables aMC without signal norm to train at all depths). These architectural modifications allow gradient-based algorithms to train, but they are not required for Monte Carlo. This comparison illustrates the fact that design principles for nets trained by Monte Carlo methods differ from those trained by gradient-based methods.
II.6 Best practices for training neural nets using MC await development
In this section we first revisit Fig. 1 using aMC, and we present data indicating that numerical best practices for training nets using MC may differ from those developed for gradient-based algorithms.
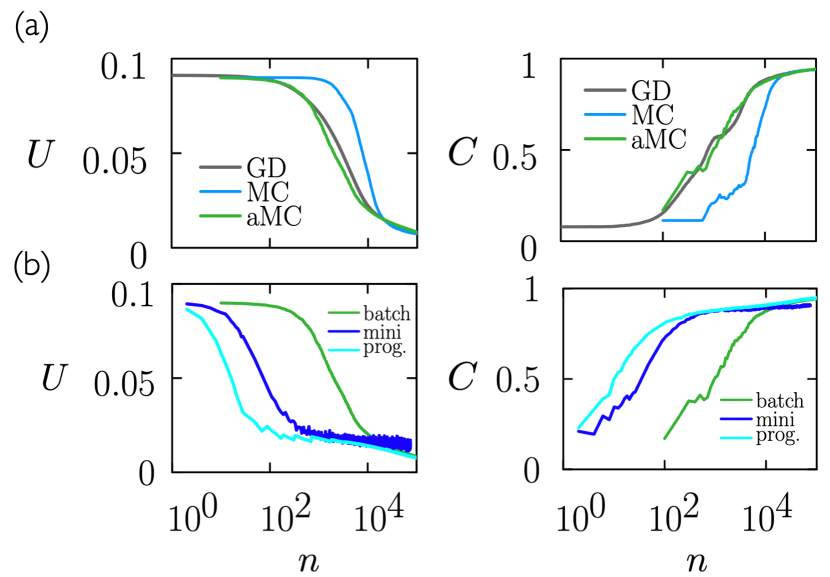
In Fig. 7(a) we reproduce Fig. 1(b) with the addition of an aMC simulation (green) in which we use aMC’s adaptive step-size attenuation (with ) and signal norm. These features allow us to choose an initial step-size parameter larger than the optimum value for Metropolis MC (see Fig. 1(a)). As a result, training proceeds faster than for MC, at a rate comparable to the GD result shown. Training-set loss and test-set accuracy at long times are similar for all three algorithms.
In Fig. 7(b) we compare the aMC result of panel (a), which uses batch learning (green), with two additional aMC results. The first (cyan) uses conventional minibatching with a minibatch size of 2000. Minibatch learning proceeds faster than batch learning, as happens with gradient-based methods, but achieves slightly larger values of training-set loss and test-set error than does batch learning. We speculate that this happens because of competing sources of stochasticity, that of the minibatch and that intrinsic to the MC algorithm. The second (cyan) uses progressive batching: training begins with a minibatch of size 500, which doubles every time the classification error rate on the minibatch falls below (aMC moves are conditioned against minibatch loss, in the usual way, not minibatch classification error, but the latter is the trigger for the doubling of the minibatch size). After doubling the minibatch size the aMC algorithm is reset ( and ). Progressive-batch learning proceeds faster than batch learning, and reaches similar final values of training-set loss and test-set accuracy. This comparison suggests that MC may respond differently than GD to procedures such as minibatch training; best practices for MC training of neural networks await development.
We note that the noise intrinsic to the Monte Carlo method provides a means of exploration even when the batch identity is kept fixed (noise also provides a way to effect change in the presence of vanishing gradients; see Section II.5 and Section II.4). For the problem discussed in this section there is a variation of about 1% in values of test-set accuracy at epochs for 30 independent MC trajectories propagated with the same set of hyperparameters. Such fluctuations could provide the basis for an additional form of importance sampling that identified and propagated the best-performing networks in a population.
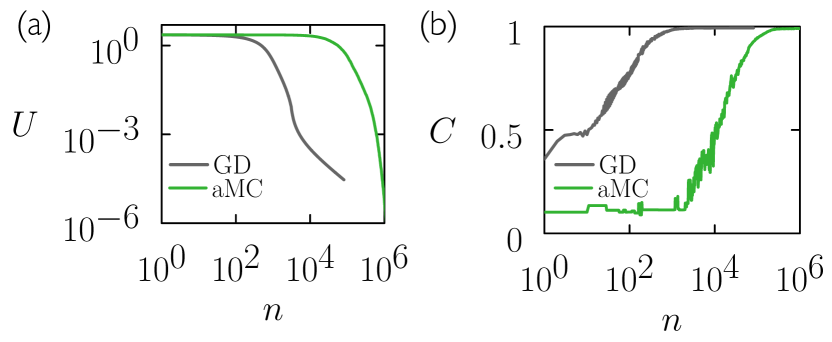
Finally, we show in Fig. 8 the analog of Fig. 1(b) for ResNET-18. ResNET-18 is a large, deep neural network with parameters He et al. (2016) (we changed the number of input channels for the first layer in order to apply it to MNIST). We applied layer normalization Ba et al. (2016), which homogenizes neuron inputs and removes (or reduces) the need for signal norm when using aMC. The gradient descent learning rate was set to and we applied gradient clipping for ; the aMC hyperparameters were , and . Two points are apparent from the plot: gradient descent trains faster than aMC, but aMC has similar ability to train in the long-time limit: both GD and aMC train to small loss and about accuracy on the MNIST test set. Thus for large modern architectures such as ResNET-18 we find training with gradients faster than training by Monte Carlo, but the latter has similar capacity for learning, suggesting that it is a promising tool for training neural networks when gradients are unreliable: see Section II.4 and Section II.5.
III Summary of aMC
III.1 An adaptive version of the Metropolis algorithm for training neural networks
In this section we summarize aMC, the adaptive Monte Carlo algorithm used in this paper. It is based on the Metropolis MC algorithm, modified to allow the move-proposal distribution to adapt in response to accepted and rejected moves. The Metropolis acceptance criterion is , where is the change of loss and is temperature. For nonzero temperature the algorithm allows moves uphill in loss. We focus here on the limit of zero temperature, which allows no uphill moves in loss. This choice is motivated by the success of gradient-descent algorithms and the intuition in deep learning (suggested by the structure of high-dimensional Gaussian random surfaces) that at large loss most stationary points on the loss surface are saddle points that can be escaped by moving downhill Dauphin et al. (2014); Bahri et al. (2020).
aMC is specified by four hyperparameters: , the initial move scale; , the rate at which the mean of the move-proposal distribution is modified; , the number of consecutive rejected moves allowed before rescaling the parameters of the move-proposal distribution; and by the choice of signal norm being on or off.
We introduce a counter to record the number of consecutive rejected moves. We initialize the parameters (weights and biases) of the neural network (e.g. using Gaussian random numbers ), and set the centers of each parameter’s move-proposal distribution to zero. aMC proceeds as follows.
-
1.
Current state. Record the current neural-network parameter set . Select the data (defining the batch, episode, etc.) and record the current value of the loss on the data (for batch learning the value is known from the previous step of the algorithm). If signal norm is on, calculate the values specified by Eq. (18), the required quantities having been calculated in the course of calculating .
-
2.
Proposed move. Propose a change
(9) of each neural-network parameter , where . Initially, and , where is the initial move scale. The parameters are set either to unity (“signal norm off”) or by Eq. (18) (“signal norm on”). Evaluate the loss at the set of coordinates resulting from the proposal (9). If 666For finite temperature the move is accepted if , where is a random number drawn uniformly on . then we accept the move and go to Step 3. Otherwise we reject the move and go to Step 4.
-
3.
Accept move. Make the proposed coordinates the current coordinates . Set . For each neural-network parameter , set
(10) using the values calculated in (9). Return to Step 1.
-
4.
Reject move. Retain the set of coordinates recorded in Step 1. Set . If then set , , and (for all ) . Return to Step 1.
The computational cost of one move is the cost to draw Gaussian random numbers and to calculate the loss function twice (once for batch learning). The memory cost is the cost to hold two versions of the model in memory, and (if and signal norm is on) the values and for each neural-net parameter. Note that the algorithm requires calculation of the loss only, and not of gradients of the loss with respect to the net parameters.
We refer to this algorithm as aMC, for adaptive Monte Carlo (the term “adaptive Metropolis algorithm” has been used in a different context Rosenthal et al. (2011)). Standard zero-temperature Metropolis Monte Carlo is recovered in the limit , and .
III.2 Signal norm: enacting heterogenous weight updates in order to keep roughly constant the change of neuron inputs
The proposal step (9) contains the parameter step size . For some applications, particularly involving deep or heterogeneous networks, it is useful to choose the in order to keep the scale of updates for each neuron approximately equal, following ideas applied to gradient-based methods LeCun et al. (1996). We call this concept signal norm; when signal norm is off, all . When it is on, we proceed as follows.
Consider the class of neural networks for which the input to neuron (its pre-activation) is
| (11) |
where the sum runs over all weights feeding into neuron ; is the fan-in of (the number of connections entering ); and is the output of neuron (the neuron that the weight connects to neuron ) given one particular evaluation of the neural network. Under the proposal (9) the change of input to neuron is approximately 777This approximation assumes that the output neurons do not change under the move. This is not true, but the intent here is to set the basic move scale, and absolute precision is not necessary.
| (12) |
We therefore have
| (13) |
and
| (14) |
where is the expectation over the move-proposal distribution (9), and is the Kronecker delta. The expected approximate variance of the change of input to neuron under the move (9) is therefore
| (15) |
This quantity, averaged over all neural-net calls required to calculate the loss, is
| (16) |
We can choose the values of the in order to ensure that the right-hand side of (16) is always . A simple way to do so is to set equal the for all weights feeding neuron , in which case
| (17) |
If all neuron outputs appearing in (17) vanish identically then the expression must be regularized; one option is to set for weights feeding a neuron whose input neurons are zero for a given pass through the data. Recall that the sum runs over the input data; the sum runs over all neurons whose connections feed ; is the fan-in of (the number of connections entering ); and is the output of neuron given a particular evaluation of the neural network. The values (17) can be calculated from the pass through the data immediately before the proposed move.
Under (17), weights on connections that feed into a neuron receiving many other connections will experience a smaller basic move scale than weights on connections that feed into a neuron receiving few connections. Similarly, weights on connections fed by active neurons will experience a smaller basic move scale than weights on connections fed by relatively inactive neurons.
Finally, if the parameter is a bias we choose .
IV Conclusions
We have examined the Metropolis Monte Carlo algorithm as a tool for training neural networks, and have introduced aMC, an adaptive variant of it. Monte Carlo methods are closely related to evolutionary algorithms, which are used to train neural networks Holland (1992); Fogel and Stayton (1994); Montana and Davis (1989); Salimans et al. (2017), but the latter are usually applied to populations of neural networks; the MC algorithms we have considered here are applied to populations of size 1, just as gradient descent is. For sufficiently small moves the Metropolis algorithm is effectively gradient descent in the presence of white noise Whitelam et al. (2021). Thus on theoretical grounds the Metropolis algorithm should possess the ability to train a neural network to values of a loss function similar to those achieved by GD; this is indeed what we (and others Sexton et al. (1999); Rere et al. (2015); Tripathi and Singh (2020)) have observed empirically, both for simple neural nets and for large, modern architectures. This correspondence does not guarantee similar training times, however, and we have found gradient-based methods to be faster in general, particularly for large and heterogenous neural nets.
aMC is an adaptive version of the Metropolis algorithm. The efficiency of aMC diminishes less quickly with decreasing loss and increasing net size than does the efficiency of the Metropolis algorithm, and aMC can train faster than Metropolis, much as adaptive gradient-based methods can train faster than pure gradient descent.
The Metropolis algorithm and aMC offer a complement to gradient-based methods in that they can sense the gradient when it exists but can work without it. In particular, aMC can train nets in which the gradient is too small (or too large) to allow gradient-based methods to train on the timescales simulated. We have shown here that aMC can train deep neural networks and recurrent neural networks that gradient descent cannot train. In both cases there exist modifications to those networks that can be trained by gradient-based methods, but aMC does not require those modifications. The design principles of neural nets optimal for Monte Carlo algorithms are largely unexplored but are likely distinct from those optimal for gradient-based methods, and having both sets of algorithms offers more choices for net design than having only one.
Finally, we note that while Metropolis and aMC have a fundamental connection to gradient-based methods in the limit of small step size, Monte Carlo algorithms more generally can enact large-scale nonlocal or collective changes that cannot be made by integrating gradient-based equations of motion Swendsen and Wang (1987); Wolff (1989); Frenkel and Smit (2001); Chen and Siepmann (2001); Liu and Luijten (2004); Whitelam and Geissler (2007). The analogy suggests that improved Monte Carlo algorithms for training neural networks await development.
V Code availability
VI Acknowledgments
This work was performed as part of a user project at the Molecular Foundry, Lawrence Berkeley National Laboratory, supported by the Office of Science, Office of Basic Energy Sciences, of the U.S. Department of Energy under Contract No. DE-AC02–05CH11231. This work used resources of the National Energy Research Scientific Computing Center (NERSC), a U.S. Department of Energy Office of Science User Facility operated under Contract No. DE-AC02-05CH11231. I.T. acknowledges funding from the National Science and Engineering Council of Canada. C.C. acknowledges a mobility grant from Research Foundation – Flanders (FWO).
References
- Metropolis et al. (1953) Nicholas Metropolis, Arianna W Rosenbluth, Marshall N Rosenbluth, Augusta H Teller, and Edward Teller, “Equation of state calculations by fast computing machines,” The Journal of Chemical Physics 21, 1087–1092 (1953).
- Gubernatis (2005) James E Gubernatis, “Marshall Rosenbluth and the Metropolis algorithm,” Physics of plasmas 12, 057303 (2005).
- Rosenbluth (2003) Marshall N Rosenbluth, “Genesis of the Monte Carlo algorithm for statistical mechanics,” in AIP Conference Proceedings, Vol. 690 (American Institute of Physics, 2003) pp. 22–30.
- Whitacre (2021) Madeline Helene Whitacre, Arianna Wright Rosenbluth, Tech. Rep. (Los Alamos National Lab.(LANL), Los Alamos, NM (United States), 2021).
- Frenkel and Smit (2001) Daan Frenkel and Berend Smit, Understanding molecular simulation: from algorithms to applications, Vol. 1 (Academic Press, 2001).
- Sexton et al. (1999) Randall S Sexton, Robert E Dorsey, and John D Johnson, “Beyond backpropagation: using simulated annealing for training neural networks,” Journal of Organizational and End User Computing (JOEUC) 11, 3–10 (1999).
- Rere et al. (2015) LM Rasdi Rere, Mohamad Ivan Fanany, and Aniati Murni Arymurthy, “Simulated annealing algorithm for deep learning,” Procedia Computer Science 72, 137–144 (2015).
- Tripathi and Singh (2020) Rohun Tripathi and Bharat Singh, “Rso: A gradient free sampling based approach for training deep neural networks,” arXiv preprint arXiv:2005.05955 (2020).
- Schmidhuber (2015) Jürgen Schmidhuber, “Deep learning in neural networks: An overview,” Neural networks 61, 85–117 (2015).
- Goodfellow et al. (2016) Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep learning (MIT press, 2016).
- Holland (1992) John H Holland, “Genetic algorithms,” Scientific american 267, 66–73 (1992).
- Fogel and Stayton (1994) David B Fogel and Lauren C Stayton, “On the effectiveness of crossover in simulated evolutionary optimization,” BioSystems 32, 171–182 (1994).
- Montana and Davis (1989) David J Montana and Lawrence Davis, “Training feedforward neural networks using genetic algorithms.” in IJCAI, Vol. 89 (1989) pp. 762–767.
- Note (1) Zero temperature means that moves that increase the loss are not accepted. This choice is motivated by the empirical success in machine learning of gradient-descent methods, and by the intuition, derived from Gaussian random surfaces, that loss surfaces possess more downhill directions at large values of the loss Dauphin et al. (2014); Bahri et al. (2020).
- Kikuchi et al. (1991) K Kikuchi, M Yoshida, T Maekawa, and H Watanabe, “Metropolis Monte Carlo method as a numerical technique to solve the Fokker-Planck equation,” Chemical Physics Letters 185, 335–338 (1991).
- Kikuchi et al. (1992) K Kikuchi, M Yoshida, T Maekawa, and H Watanabe, “Metropolis Monte Carlo method for Brownian dynamics simulation generalized to include hydrodynamic interactions,” Chemical Physics letters 196, 57–61 (1992).
- Whitelam et al. (2021) Stephen Whitelam, Viktor Selin, Sang-Won Park, and Isaac Tamblyn, “Correspondence between neuroevolution and gradient descent,” Nature Communications 12, 1–10 (2021).
- Note (2) Note that algorithms of this nature do not constitute random search. The proposal step is random (related conceptually to the idea of weight guessing, a method used in the presence of vanishing gradients Hochreiter and Schmidhuber (1997)) but the acceptance criterion is a form of importance sampling, and leads to a dynamics equivalent to noisy gradient descent.
- Salimans et al. (2017) Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, and Ilya Sutskever, “Evolution strategies as a scalable alternative to reinforcement learning,” arXiv preprint arXiv:1703.03864 (2017).
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980 (2014).
- LeCun et al. (2015) Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, “Deep learning,” nature 521, 436–444 (2015).
- Metz et al. (2021) Luke Metz, C Daniel Freeman, Samuel S Schoenholz, and Tal Kachman, “Gradients are not all you need,” arXiv preprint arXiv:2111.05803 (2021).
- Mitchell et al. (1993) Melanie Mitchell, John Holland, and Stephanie Forrest, “When will a genetic algorithm outperform hill climbing?” Advances in neural information processing systems 6 (1993).
- Mitchell (1998) Melanie Mitchell, An introduction to genetic algorithms (MIT press, 1998).
- Note (3) In Metropolis Monte Carlo simulations of molecular systems it is usual to propose moves of one particle at a time. If we consider neural-net parameters to be akin to particle coordinates then the analog would be to make changes to one neural-net parameter at a time; see e.g. Ref. Tripathi and Singh (2020). However, there is no formal mapping between particles and a neural network, and we could equally well consider the neural-net parameters to be akin to the coordinates of a single particle, in a high-dimensional space, in an external potential equal to the loss function. In the latter case the analog would be to propose a change of all neural-net parameters simultaneously, as we do here.
- (26) http://yann.lecun.com/exdb/mnist/.
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner, et al., “Gradient-based learning applied to document recognition,” Proceedings of the IEEE 86, 2278–2324 (1998).
- (28) https://www.youtube.com/3blue1brown.
- Note (4) We have also found the GD-MC equivalence to break down in other circumstances: for certain learning rates , the discrete-update equation (3) sometimes results in moves uphill in loss, in which case the discrete update is not equivalent to the equation , while the latter is equivalent to the small-step-size limit of the finite-temperature Metropolis algorithm Kikuchi et al. (1991, 1992); Whitelam et al. (2021).
- Note (5) In Fig. 8 we show that GD and MC can both train a large modern neural network to a classification accuracy in excess of 99% on the same problem.
- Dauphin et al. (2014) Yann N Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio, “Identifying and attacking the saddle point problem in high-dimensional non-convex optimization,” Advances in neural information processing systems 27 (2014).
- Bahri et al. (2020) Yasaman Bahri, Jonathan Kadmon, Jeffrey Pennington, Sam S Schoenholz, Jascha Sohl-Dickstein, and Surya Ganguli, “Statistical mechanics of deep learning,” Annual Review of Condensed Matter Physics (2020).
- Hansen and Ostermeier (2001) Nikolaus Hansen and Andreas Ostermeier, “Completely derandomized self-adaptation in evolution strategies,” Evolutionary computation 9, 159–195 (2001).
- Hansen et al. (2003) Nikolaus Hansen, Sibylle D Müller, and Petros Koumoutsakos, “Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (cma-es),” Evolutionary computation 11, 1–18 (2003).
- Hansen (2006) Nikolaus Hansen, “The cma evolution strategy: a comparing review,” Towards A New Evolutionary Computation , 75–102 (2006).
- Rosenbrock (1960) HoHo Rosenbrock, “An automatic method for finding the greatest or least value of a function,” The computer journal 3, 175–184 (1960).
- Shang and Qiu (2006) Yun-Wei Shang and Yu-Huang Qiu, “A note on the extended rosenbrock function,” Evolutionary Computation 14, 119–126 (2006).
- Emiola and Adem (2021) Iyanuoluwa Emiola and Robson Adem, “Comparison of minimization methods for rosenbrock functions,” in 2021 29th Mediterranean Conference on Control and Automation (MED) (IEEE, 2021) pp. 837–842.
- Goh (2017) Gabriel Goh, “Why momentum really works,” Distill 2, e6 (2017).
- Rumelhart et al. (1995) David E Rumelhart, Richard Durbin, Richard Golden, and Yves Chauvin, “Backpropagation: The basic theory,” Backpropagation: Theory, architectures and applications , 1–34 (1995).
- Chen et al. (2018) Jinghui Chen, Dongruo Zhou, Yiqi Tang, Ziyan Yang, Yuan Cao, and Quanquan Gu, “Closing the generalization gap of adaptive gradient methods in training deep neural networks,” arXiv preprint arXiv:1806.06763 (2018).
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber, “Long short-term memory,” Neural computation 9, 1735–1780 (1997).
- Hochreiter (1998) Sepp Hochreiter, “The vanishing gradient problem during learning recurrent neural nets and problem solutions,” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 6, 107–116 (1998).
- Medsker and Jain (2001) Larry R Medsker and LC Jain, “Recurrent neural networks,” Design and Applications 5, 64–67 (2001).
- Graves et al. (2013) Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton, “Speech recognition with deep recurrent neural networks,” in 2013 IEEE international conference on acoustics, speech and signal processing (Ieee, 2013) pp. 6645–6649.
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V Le, “Sequence to sequence learning with neural networks,” Advances in neural information processing systems 27 (2014).
- Graves and Schmidhuber (2008) Alex Graves and Jürgen Schmidhuber, “Offline handwriting recognition with multidimensional recurrent neural networks,” Advances in neural information processing systems 21 (2008).
- Wierstra et al. (2010) Daan Wierstra, Alexander Förster, Jan Peters, and Jürgen Schmidhuber, “Recurrent policy gradients,” Logic Journal of the IGPL 18, 620–634 (2010).
- Bengio et al. (1994) Yoshua Bengio, Patrice Simard, and Paolo Frasconi, “Learning long-term dependencies with gradient descent is difficult,” IEEE transactions on neural networks 5, 157–166 (1994).
- Martens and Sutskever (2011) James Martens and Ilya Sutskever, “Learning recurrent neural networks with hessian-free optimization,” in ICML (2011).
- Bengio et al. (2013) Yoshua Bengio, Nicolas Boulanger-Lewandowski, and Razvan Pascanu, “Advances in optimizing recurrent networks,” in 2013 IEEE international conference on acoustics, speech and signal processing (IEEE, 2013) pp. 8624–8628.
- Cho et al. (2014) Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078 (2014).
- Kanai et al. (2017) Sekitoshi Kanai, Yasuhiro Fujiwara, and Sotetsu Iwamura, “Preventing gradient explosions in gated recurrent units,” Advances in neural information processing systems 30 (2017).
- Pascanu et al. (2013) Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio, “On the difficulty of training recurrent neural networks,” in International conference on machine learning (PMLR, 2013) pp. 1310–1318.
- Collins et al. (2016) Jasmine Collins, Jascha Sohl-Dickstein, and David Sussillo, “Capacity and trainability in recurrent neural networks,” arXiv preprint arXiv:1611.09913 (2016).
- LeCun et al. (1996) Yann LeCun, Léon Bottou, Genevieve B Orr, and Klaus-Robert Müller, “Effiicient backprop,” in Neural Networks: Tricks of the Trade (1996).
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450 (2016).
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems 32 (2019).
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition (2016) pp. 770–778.
- Note (6) For finite temperature the move is accepted if , where is a random number drawn uniformly on .
- Rosenthal et al. (2011) Jeffrey S Rosenthal et al., “Optimal proposal distributions and adaptive MCMC,” Handbook of Markov Chain Monte Carlo 4 (2011).
- Note (7) This approximation assumes that the output neurons do not change under the move. This is not true, but the intent here is to set the basic move scale, and absolute precision is not necessary.
- Swendsen and Wang (1987) Robert H Swendsen and Jian-Sheng Wang, “Nonuniversal critical dynamics in monte carlo simulations,” Physical review letters 58, 86 (1987).
- Wolff (1989) Ulli Wolff, “Collective Monte Carlo updating for spin systems,” Physical Review Letters 62, 361 (1989).
- Chen and Siepmann (2001) Bin Chen and J Ilja Siepmann, “Improving the efficiency of the aggregation-volume-bias Monte Carlo algorithm,” The Journal of Physical Chemistry B 105, 11275–11282 (2001).
- Liu and Luijten (2004) Jiwen Liu and Erik Luijten, “Rejection-free geometric cluster algorithm for complex fluids,” Physical Review Letters 92, 035504 (2004).
- Whitelam and Geissler (2007) Stephen Whitelam and Phillip L Geissler, “Avoiding unphysical kinetic traps in Monte Carlo simulations of strongly attractive particles,” The Journal of Chemical Physics 127, 154101 (2007).
- (68) https://github.com/reproducible-science/aMC.