Transfer Learning with Physics-Informed Neural Networks for Efficient Simulation of Branched Flows
Abstract
Physics-Informed Neural Networks (PINNs) offer a promising approach to solving differential equations and, more generally, to applying deep learning to problems in the physical sciences. We adopt a recently developed transfer learning approach for PINNs and introduce a multi-head model to efficiently obtain accurate solutions to nonlinear systems of ordinary differential equations with random potentials. In particular, we apply the method to simulate stochastic branched flows, a universal phenomenon in random wave dynamics. Finally, we compare the results achieved by feed forward and GAN-based PINNs on two physically relevant transfer learning tasks and show that our methods provide significant computational speedups in comparison to standard PINNs trained from scratch.
1 Introduction
Differential equations are used to describe a plethora of phenomena in the physical sciences but most cannot be solved analytically. Traditionally, numerical methods have been used to approximate solutions to differential equations. Recently, Physics-Informed Neural Networks (PINNs) have emerged as an attractive alternative offering several compelling advantages. In particular, PINNs: provide solutions that are in closed form, offer a more accurate interpolation scheme [7], are more robust to the “curse of dimensionality” [4, 5, 13, 14], and do not accumulate numerical errors [6, 11].
PINNs are typically trained to solve only a single configuration of a given system (e.g., a single initial condition or set of system parameters) at once, making their practical use computationally inefficient. More recently, it was shown that one-shot transfer learning can be used to obtain accurate solutions to linear systems of ordinary differential equations (ODEs) and partial differential equations (PDEs), thereby eliminating the need to train the network from scratch for a new linear system [3, 9].
In this work, we build upon [3] by proposing a method that can be applied to non-linear systems. This method consists of two phases. First, we train a base neural network with multiple output heads, solving the system for a range of different configurations (e.g., initial conditions or potentials). We thus learn a representative basis that captures the underlying dynamics. Second, we freeze the weights of the base network and fine-tune new linear heads on a secondary transfer learning task. In doing so, we adapt the pre-trained base from one task to another and cut computational costs significantly. We demonstrate the efficacy of our approach using a system of non-linear ODEs that describes the trajectory of a particle through a weak random potential and can be used to model a universal phenomenon called branched flow [2, 12].111All code is publicly available at https://github.com/RaphaelPellegrin/Transfer-Learning-with-PINNs-for-Efficient-Simulation-of-Branched-Flows.git.
2 Background
2.1 PINN Models
This work uses PINNs that are trained in an unsupervised manner, as detailed below. We compare the performance achieved by feed forward neural networks (FFNN) and GAN models.
FFNN: The standard unsupervised neural network approach was introduced by Lagaris et al., [7] and can be used to solve differential equations of the form
| (1) |
where , and is a differential operator. During training, we sample from the domain of the equation and use this vector as input to a FFNN, which outputs the neural solution . We re-parametrise this output into to satisfy initial and boundary conditions exactly. Using automatic differentiation, we can compute the derivatives of this output with respect to each of the independent variables and build the loss by summing the squared residual over training points,
| (2) |
Note that if the network perfectly satisfies Equation 1, then Equation 2 will be zero.
DEQGAN: Bullwinkel et al., [1] noted that there is no theoretical reason to use the norm of the residuals over any other loss function and proposed DEQGAN, which extends the FFNN method to GANs and can be thought of as “learning the loss function.” Rather than computing a loss over the equation residuals, DEQGAN labels these vectors “fake” data samples and zero-centered Gaussian noise as “real” data samples. As the discriminator gets better at classifying these samples, the generator is forced to propose solutions such that the equation residuals are increasingly indistinguishable from a vector of zeros, thereby approximating the solution to the differential equation.
2.2 Transfer Learning with Multi-Head PINNs
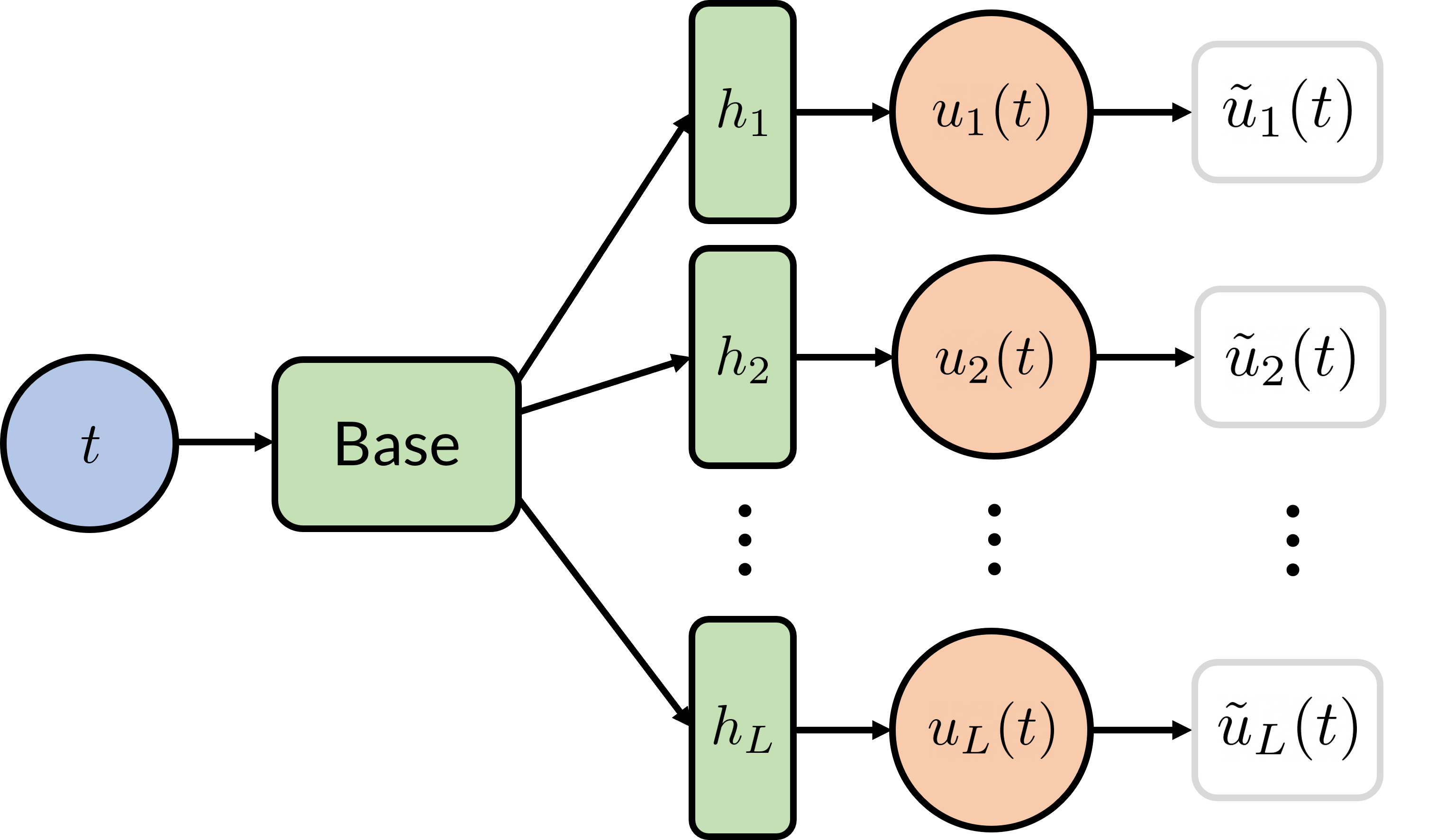
Figure 1 illustrates the multi-head architecture that we apply to FFNN and DEQGAN models to perform transfer learning. The output of the base neural network is passed to heads each of which corresponds to the solution to the system at a particular initial condition. Importantly, this architecture can be used to apply transfer learning to non-linear problems; in this work, we consider one such system of ODEs that is used to model particles moving through a weak random potential.
Transfer learning with multi-head PINNs is performed in two stages. First, we train the multi-head model on a given set of initial conditions until convergence. Next, we freeze the weights of the base network and fine-tune only the output heads on a second set of initial conditions. As detailed below, we use this procedure to perform two transfer learning tasks: 1) Initial Condition Transfer, which involves fine-tuning the heads on initial conditions that were not used to train the base. 2) Potential Transfer Learning, an even more challenging task that allows us to obtain solutions for new initial conditions and a different potential than the one used to train the base. Our results on these tasks suggest that the base is able to learn highly general properties of the system.
3 Experimental Results
3.1 Branched Flow
Stochastic branched flow is a universal wave phenomenon that occurs when waves propagate in random environments. Branching has been observed in tsunami waves [2], electronic flows in graphene [12], and electromagnetic waves in gravitational fields [8]. We can model a two dimensional branched flow by considering a particle with position and velocity , both functions of time , traveling through a weak random potential . With the Hamiltonian we obtain Hamilton’s equations, given by the following system of ODEs
| (3) |
For a plane wave, the initial conditions at can be chosen as [12].
We build random potentials by summing randomly distributed Gaussian functions with covariance matrix and means , , and scaling the result by , where , as in [12]. That is,
| (4) |
In the experiments presented below, we use .
3.2 Details for Hamilton’s Equations
For both the FFNN and DEQGAN models, we use networks with a base consisting of 5 hidden layers and 40 nodes. We then use linear layers for the heads. Each head is responsible for the solution to one ray, i.e., one initial condition , where , and has four outputs corresponding to , , and . For head , we denote the outputs as , , and . We use the initial value re-parameterization proposed by Mattheakis et al., [10]
| (5) |
which forces the proposed solution to be exactly when and decays this constraint exponentially in .
3.3 Transfer Learning Results
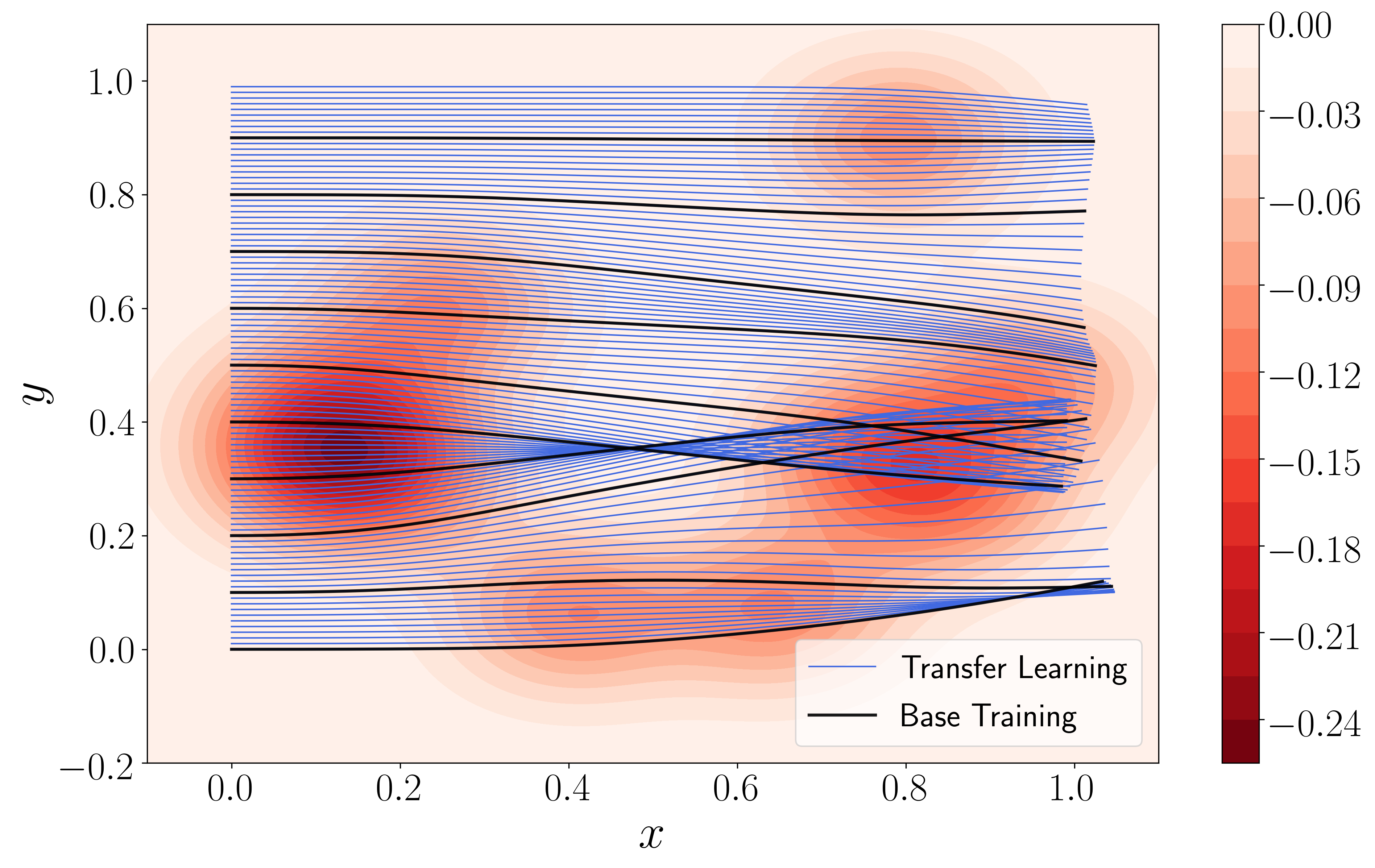
Our first transfer learning task, Initial Condition Transfer, allows us to efficiently obtain solutions to the system for many initial conditions. We used multi-head models to train the base networks on initial conditions and performed single-head transfer learning on evenly-spaced initial conditions in while keeping the potential fixed. All experiments were performed on a Microsoft Surface laptop with Intel i7 CPU. Figure 2(a) shows the ray trajectory solutions corresponding to the initial conditions used for base training (black) and transfer learning (blue) obtained with the FFNN model. These trajectories also illustrate branched flows.
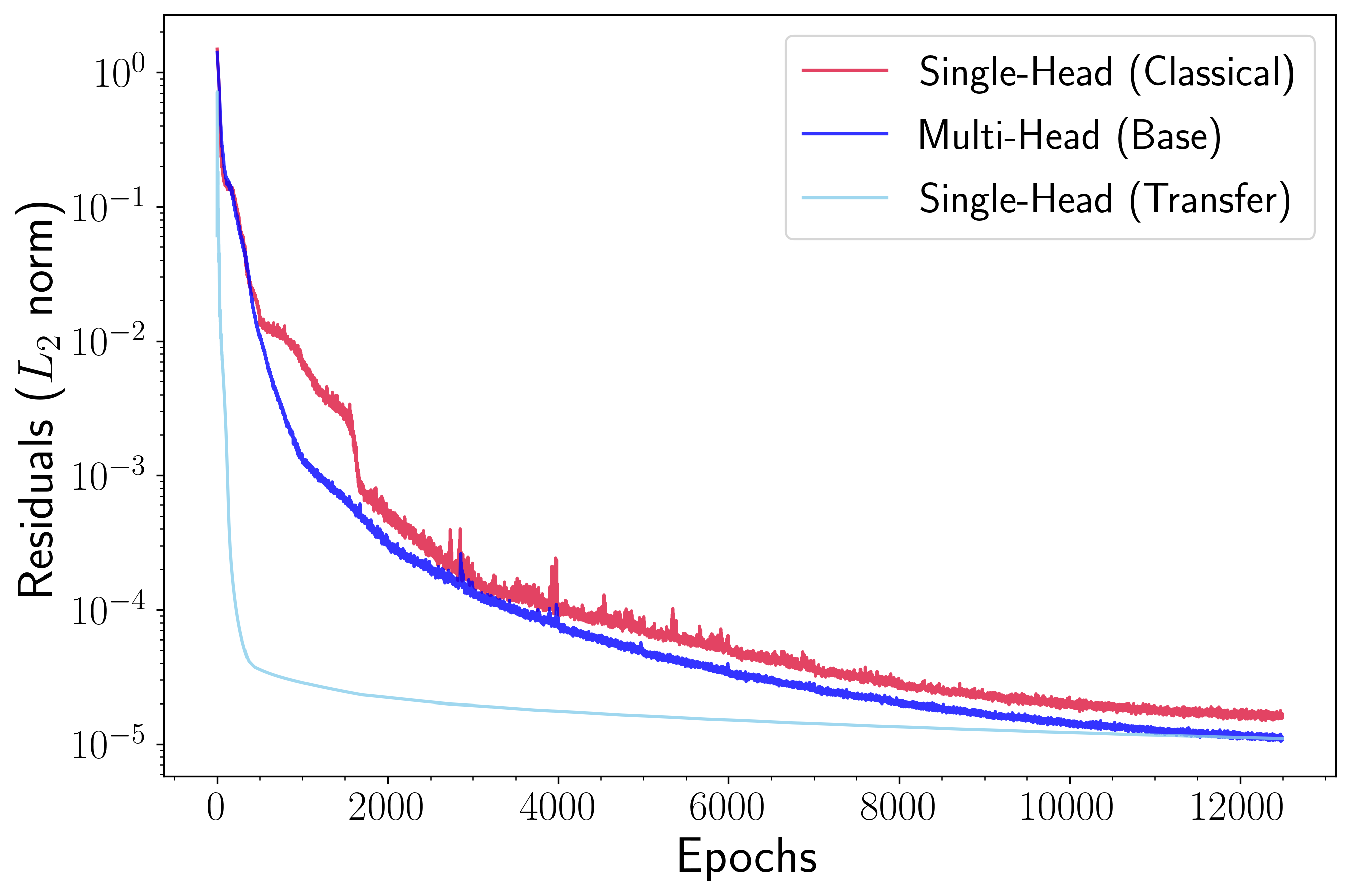
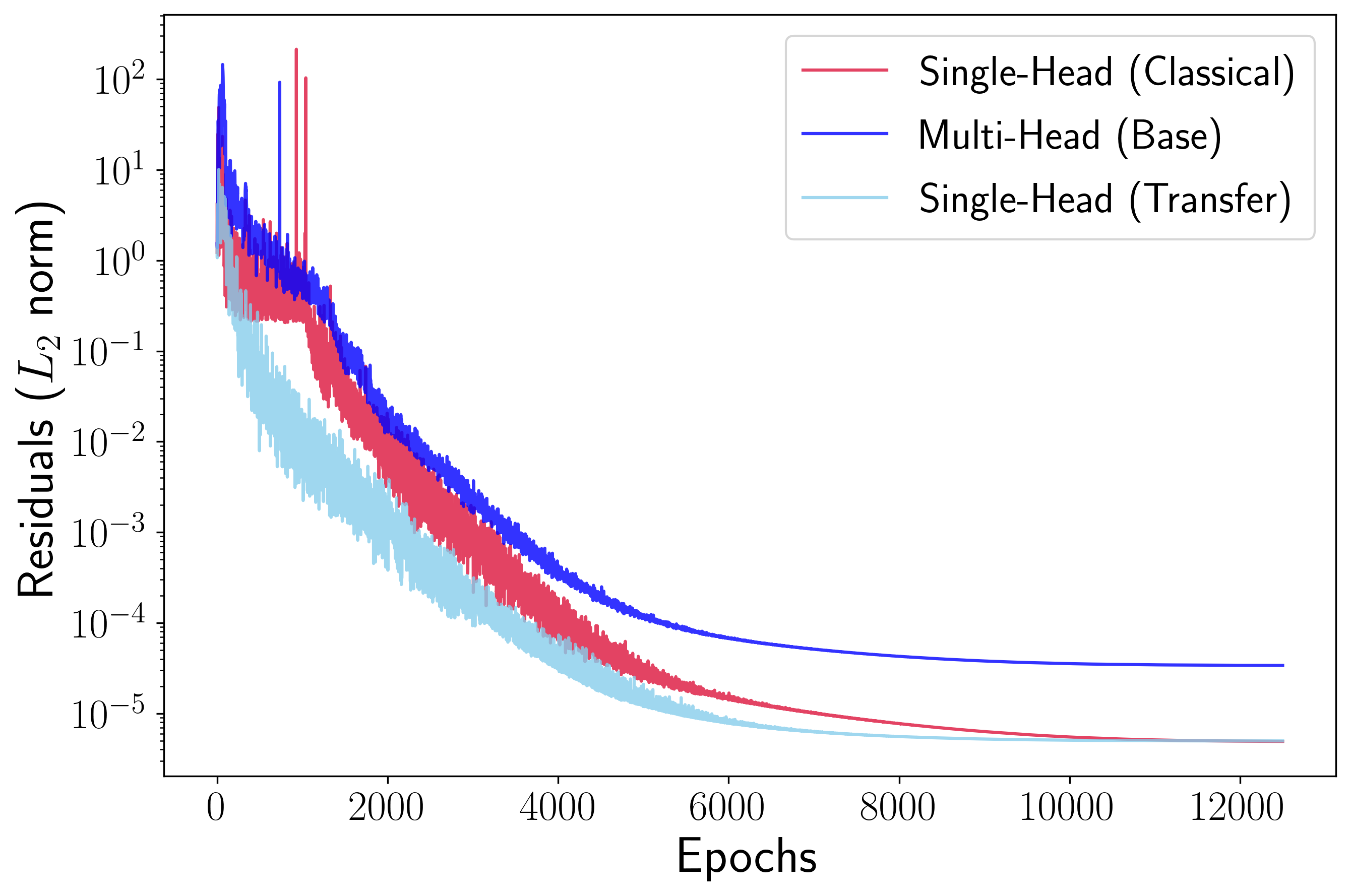
In Figure 3, we compare the losses achieved by the FFNN and DEQGAN models during base training and transfer learning. We also show the residuals for classical models that do not leverage transfer learning. Notably, we see that single-head models that use transfer learning converge more rapidly than those trained from scratch. Further, Table 1 shows that each epoch of transfer learning (bold) is also significantly faster. This is to be expected because transfer learning involves only fine-tuning linear heads, rather than training an entire base network.
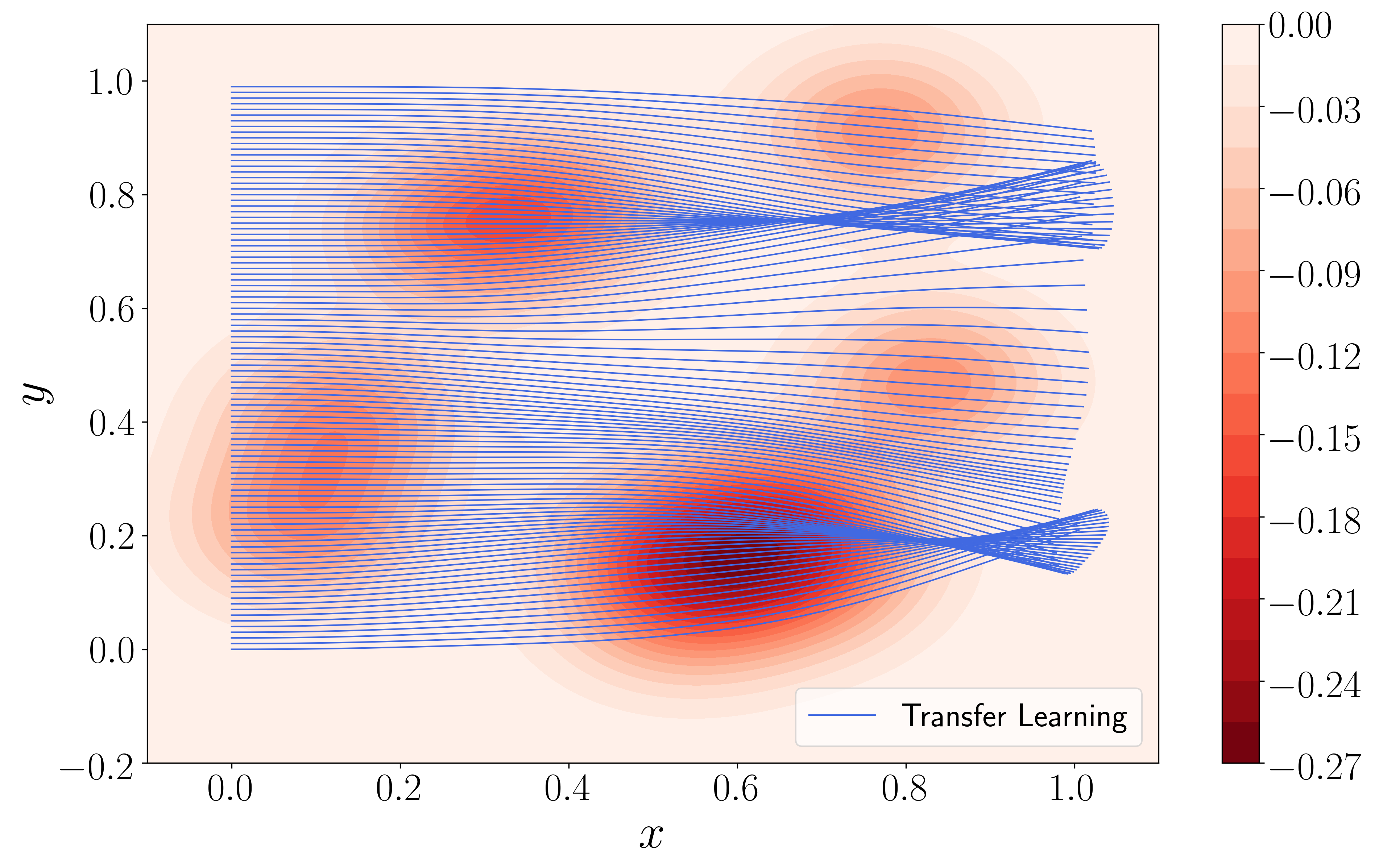
Our second transfer learning task, Potential Transfer Learning, utilizes the same pre-trained base described above. This task, however, changes not only the initial conditions, but also the potential (Equation 4). More specifically, we constructed a new potential by randomly sampling ten new Gaussian means. To avoid significantly altering the statistical properties of the system, we used the same values of and . Figure 2(b) visualizes the ray trajectories obtained using this method and suggests that the multi-head models are, indeed, able to learn highly general bases for the system.
| Epochs per second | |||
|---|---|---|---|
| Single-Head (Classical) | Multi-Head (Base) | Single-Head (Transfer) | |
| FFNN | |||
| DEQGAN | |||
4 Conclusion
In this paper, we propose a multi-head PINN architecture and a framework for performing transfer learning with non-linear systems of differential equations. In particular, we simulate branched flows with Hamilton’s equations and demonstrate that our method significantly reduces the computational cost of obtaining solutions to many initial conditions in comparison to FFNN and GAN-based models trained from scratch, without sacrificing accuracy. Finally, we show that base networks trained using our method can transfer to new initial conditions and new potentials at the same time, indicating that our method is able to learn highly general statistical properties of the system.
5 Broader Impact
This paper presents techniques that we hope will increase the utility of PINNs in real-world applications. In particular, the transfer learning procedure explored in this work trains a base neural network on different configurations of the system of equations, thereby forcing the network to learn general properties of the solutions and providing possible insights into the underlying physical problem. Beyond computational speedups, we hope that this contributes to broader efforts within the research community to make PINNs more interpretable, and ultimately more widely adopted. We believe that future work focused on the theoretical foundations of PINNs will help cement these models as a third pillar within the study of differential equations, alongside analytical and numerical methods.
References
- Bullwinkel et al., [2022] Bullwinkel, B., Randle, D., Protopapas, P., & Sondak, D. (2022). Deqgan: Learning the loss function for pinns with generative adversarial networks. arXiv preprint arXiv:2209.07081.
- Degueldre et al., [2016] Degueldre, H., Metzger, J. J., Geisel, T., & Fleischmann, R. (2016). Random focusing of tsunami waves. Nature Physics, 12(3), 259–262.
- Desai et al., [2021] Desai, S., Mattheakis, M., Joy, H., Protopapas, P., & Roberts, S. (2021). One-shot transfer learning of physics-informed neural networks. arXiv preprint arXiv:2110.11286.
- Grohs et al., [2018] Grohs, P., Hornung, F., Jentzen, A., & Von Wurstemberger, P. (2018). A proof that artificial neural networks overcome the curse of dimensionality in the numerical approximation of black-scholes partial differential equations. arXiv preprint arXiv:1809.02362.
- Han et al., [2018] Han, J., Jentzen, A., & E, W. (2018). Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34), 8505–8510.
- Jin et al., [2020] Jin, H., Mattheakis, M., & Protopapas, P. (2020). Unsupervised neural networks for quantum eigenvalue problems. arXiv preprint arXiv:2010.05075.
- Lagaris et al., [1998] Lagaris, I. E., Likas, A., & Papageorgiou, D. G. (1998). Neural network methods for boundary value problems defined in arbitrarily shaped domains. arXiv preprint cs/9812003.
- Loutsenko, [2018] Loutsenko, I. (2018). On the role of caustics in solar gravitational lens imaging. Progress of Theoretical and Experimental Physics, 2018(12), 123A02.
- Mattheakis et al., [2021] Mattheakis, M., Joy, H., & Protopapas, P. (2021). Unsupervised reservoir computing for solving ordinary differential equations. arXiv preprint arXiv:2108.11417.
- Mattheakis et al., [2019] Mattheakis, M., Protopapas, P., Sondak, D., Di Giovanni, M., & Kaxiras, E. (2019). Physical symmetries embedded in neural networks. arXiv preprint arXiv:1904.08991.
- Mattheakis et al., [2022] Mattheakis, M., Sondak, D., Dogra, A. S., & Protopapas, P. (2022). Hamiltonian neural networks for solving equations of motion. Phys. Rev. E, 105, 065305.
- Mattheakis et al., [2018] Mattheakis, M., Tsironis, G., & Kaxiras, E. (2018). Emergence and dynamical properties of stochastic branching in the electronic flows of disordered dirac solids. EPL (Europhysics Letters), 122(2), 27003.
- Raissi, [2018] Raissi, M. (2018). Forward-backward stochastic neural networks: Deep learning of high-dimensional partial differential equations. arXiv preprint arXiv:1804.07010.
- Sirignano & Spiliopoulos, [2018] Sirignano, J. & Spiliopoulos, K. (2018). Dgm: A deep learning algorithm for solving partial differential equations. Journal of Computational Physics, 375, 1339–1364.