Transformer for Multitemporal Hyperspectral Image Unmixing
Abstract
Multitemporal hyperspectral image unmixing (MTHU) holds significant importance in monitoring and analyzing the dynamic changes of surface. However, compared to single-temporal unmixing, the multitemporal approach demands comprehensive consideration of information across different phases, rendering it a greater challenge. To address this challenge, we propose the Multitemporal Hyperspectral Image Unmixing Transformer (MUFormer), an end-to-end unsupervised deep learning model. To effectively perform multitemporal hyperspectral image unmixing, we introduce two key modules: the Global Awareness Module (GAM) and the Change Enhancement Module (CEM). The Global Awareness Module computes self-attention across all phases, facilitating global weight allocation. On the other hand, the Change Enhancement Module dynamically learns local temporal changes by comparing endmember changes between adjacent phases. The synergy between these modules allows for capturing semantic information regarding endmember and abundance changes, thereby enhancing the effectiveness of multitemporal hyperspectral image unmixing. We conducted experiments on one real dataset and two synthetic datasets, demonstrating that our model significantly enhances the effect of multitemporal hyperspectral image unmixing.
Index Terms:
hyperspectral image unmixing, multitemporal, transformer, neural network.I Introduction
Hyperspectral remote sensing images have a diverse range of applications and offer conseutive spectral information for Earth observation missions. However, the acquired hyperspectral images (HSIs) are often influenced by sensor limitations, atmospheric conditions, illumination variations, and other factors. Consequently, each pixel in the image may encompass mixed spectral information from multiple ground objects. Hyperspectral image unmixing is conducted to extract endmembers and abundances in HSIs, where endmembers represent pure spectra while abundances denote their respective proportions [1, 2]. According to different types of mixtures, the assumptions of mixture models can be categorized into linear and nonlinear forms [3, 4]. The linear mixture model (LMM) is more straightforward to implement as it assumes that the spectrum of each observed pixel can be accurately represented by a linear combination of spectral components from multiple ground objects [5, 6].
Due to the simplicity and efficiency of LMM, a lot of studies have been conducted utilizing this methodology, which can be broadly categorized into the following five domains, including geometrical, statistical, nonnegative matrix factorization, sparse regression, and deep learning methods [1, 7]. Geometrical methods usually use the simplex set or positive cone of the data to expand the study [8, 9, 10]. Statistical methods rely on parameter estimates and probability distributions for unmixing [11, 12]. Nonnegative matrix factorization methods estimate endmembers and abundances by factorizing the HSI into two low-rank matrices [13, 14, 15]. Sparse regression methods define unmixing as a linear sparse regression problem, which is usually studied by using a prior spectral library [16, 17]. Deep learning approaches primarily employ deep neural networks to extract feature from HSI for unmixing [18, 19, 20].
In recent years, deep learning methods have made remarkable achievements in the field of hyperspectral image unmixing [7, 18, 21]. As a classical neural network architecture, the autoencoder can map high-dimensional spectral data into a low-dimensional latent space [22]. Autoencoder cascade comprehensively considers noise and prior sparsity for unmixing through a cascade structure [23]. Adding constraints through optimizing the loss function of the autoencoder is a commonly employed technique in unmixing [24]. Some studies use the advantage of variational autoencoders to learn data distribution for unmixing [25, 26]. Other researchers use autoencoders to extract spatial and spectral information of hyperspectral images for unmixing [19, 20, 27]. Spectral variability has also attracted extensive research [28, 29]. The deep learning-based method demonstrates significant efficacy in hyperspectral image unmixing, prompting this paper to also explore research utilizing the deep learning approach.
Current research primarily concentrates on single-phase hyperspectral image unmixing [30, 4]. However, considering the lengthy revisit period of satellites and their capacity to collect remote sensing data spanning extended durations, leveraging long-term series data proves more beneficial for surface change monitoring. Consequently, harnessing long-term series data for multitemporal hyperspectral image unmixing holds significant value. Compared to change detection of two time phases [31, 32, 33], multitemporal unmixing can make use of rich time information to explore the feature correlation of different time points and track the change of endmember and abundance. This is crucial for dynamic earth resource detection, land cover analysis, disaster prevention, and more [34]. Yet, accurately capturing endmember changes and understanding temporal, spatial, and spectral data pose greater challenges in multitemporal hyperspectral image unmixing.
At present, statistical-based studies are being conducted on the unmixing of multitemporal hyperspectral images. A linear mixing model across time points is explored in [35]. An online unmixing algorithm, solved via stochastic approximation, is introduced in [36]. The alternating direction multiplier method is applied in [37]. KalmanEM employs parametric endmember estimation and Bayesian filtering [38]. A hierarchical Bayesian model optimizes spectral variability and outliers in [39]. A Bayesian model considering spectral variability addresses endmember reflectance changes in [11]. In [40], a spectral-temporal Bayesian unmixing method incorporates prior information to mitigate noise effects. An unsupervised unmixing algorithm based on a variational recurrent neural network is proposed in [41].
However, the above methods often require precise definition of prior distributions, which becomes difficult when there are significant changes in endmembers over time. The dynamic nature of land cover and surface conditions leads to varying endmember spectra, making it hard to specify accurate prior distributions for all scenarios. Furthermore, the use of Monte Carlo sampling to estimate posterior distributions in statistical methods adds computational complexity, especially in high-dimensional spaces. Generating samples from the posterior distribution involves iterative procedures, which become more computationally demanding with higher data dimensionality.
The transformer, known for its powerful attention mechanism, has been widely successful across various fields [34, 42, 43, 44]. In the realm of unmixing tasks, researchers have explored its potential. For instance, a transformer-based model introduced in [45] enhances spectral and abundance maps by capturing patch correlations. In [46], a window-based transformer convolutional autoencoder tackles unmixing. Another approach in [47] utilizes a double-aware transformer to exploit spatial-spectral relationships. Meanwhile, [48] proposes a transformer-based generator for spatial-spectral information. Moreover, a U-shaped transformer network [49] and methods using spatial or spectral attention mechanisms [50, 51, 52] are employed for hyperspectral image unmixing. However, these methods primarily focus on single-phase unmixing, lacking the capacity to incorporate time information, which leads to suboptimal performance with multitemporal data. Furthermore, adapting to dynamic relationship changes between phases poses a challenge for traditional transformer models.
To address the challenge of effectively modeling multitemporal hyperspectral image unmixing and adaptively processing the dynamic changes between adjacent phases, we propose the Multi-temporal Hyperspectral Image Unmixing Transormer (MUFormer). MUFormer is an end-to-end model based on transformer, which consists of two main modules: the Global Awareness Module (GAM) and the Change Enhancement Module (CEM). The GAM synthesizes a comprehensive understanding of the hyperspectral image sequence by computing attention weights for spatial, temporal, and spectral dimensions from a global perspective. This allows for the fusion of multi-dimensional information across the entire image sequence. Conversely, the CEM focuses on capturing nuanced changes in endmember abundances between adjacent phases with high granularity. By assigning adaptive weights to different temporal phases, the sensitivity of the model to time dynamics is enhanced. Through the seamless integration of these modules, MUFormer effectively captures rich multi-dimensional information in multitemporal hyperspectral images. It has adaptability to varying time intervals within multitemporal image sequences, thereby facilitating precise unmixing across different temporal contexts. The main contributions of this paper are as follows:
-
•
We propose an end-to-end transformer-based multitemporal hyperspectral image unmixing framework MUFormer, which can achieve effective and efficient unmixing of multitemporal hyperspectral images.
-
•
We propose a novel Change Enhancement Module to obtain feature information at different scales and highlight fine changes by multi-scale convolution of adjacent temporal hyperspectral images.
-
•
We propose a Global Awareness Module to extract and deeply fuse multitemporal hyperspectral image features from a global perspective, which can better use multi-source domain information to promote the unmixing effect.
The remaining of this paper is organized as follows: Section II focuses on the definition of the multitemporal hyperspectral image unmixing task and we mainly introduce our proposed model framework as well as the Change Enhancement Module and the Global Awareness Module. In Section III, we will carry out experiments on a real dataset and two simulated datasets, and conduct ablation experimental research on the proposed module. Finally, we summarize the overall work of this paper in Section IV.
II Methodology
II-A Multitemporal Hyperspectral Image Unmixing
For multitemporal hyperspectral images, it is represented as , Where represents the number of time phases, represents the number of bands of the hyperspectral image, and represents the total number of the hyperspectral image pixles, respectively. For linear unmixing of multitemporal hyperspectral images, the formula for time is as follows.
| (1) |
Where represents the matrix of endmembers at time , while denotes the abundance matrix corresponding to the same timeframe, and represents the additional random noise added to simulate the real scenario, where denotes the number of endmembers. (1) can also be refined to the pixel-level form, which satisfies the linear unmixing model for every pixel in every time phase. For the hyperspectral image at each time phase, the abundance nonnegativity constraint (ANC) and the abundance sum-to-one constraint (ASC) are satisfied.
| (2) |
In the multitemporal hyperspectral image unmixing task, the hyperspectral images in different time phases have spatial-temporal correlation, and the contribution of hyperspectral bands in each time phase to unmixing is not the same, so it is necessary to jointly consider the temporal-spatial-spectral information to design the unmixing model.
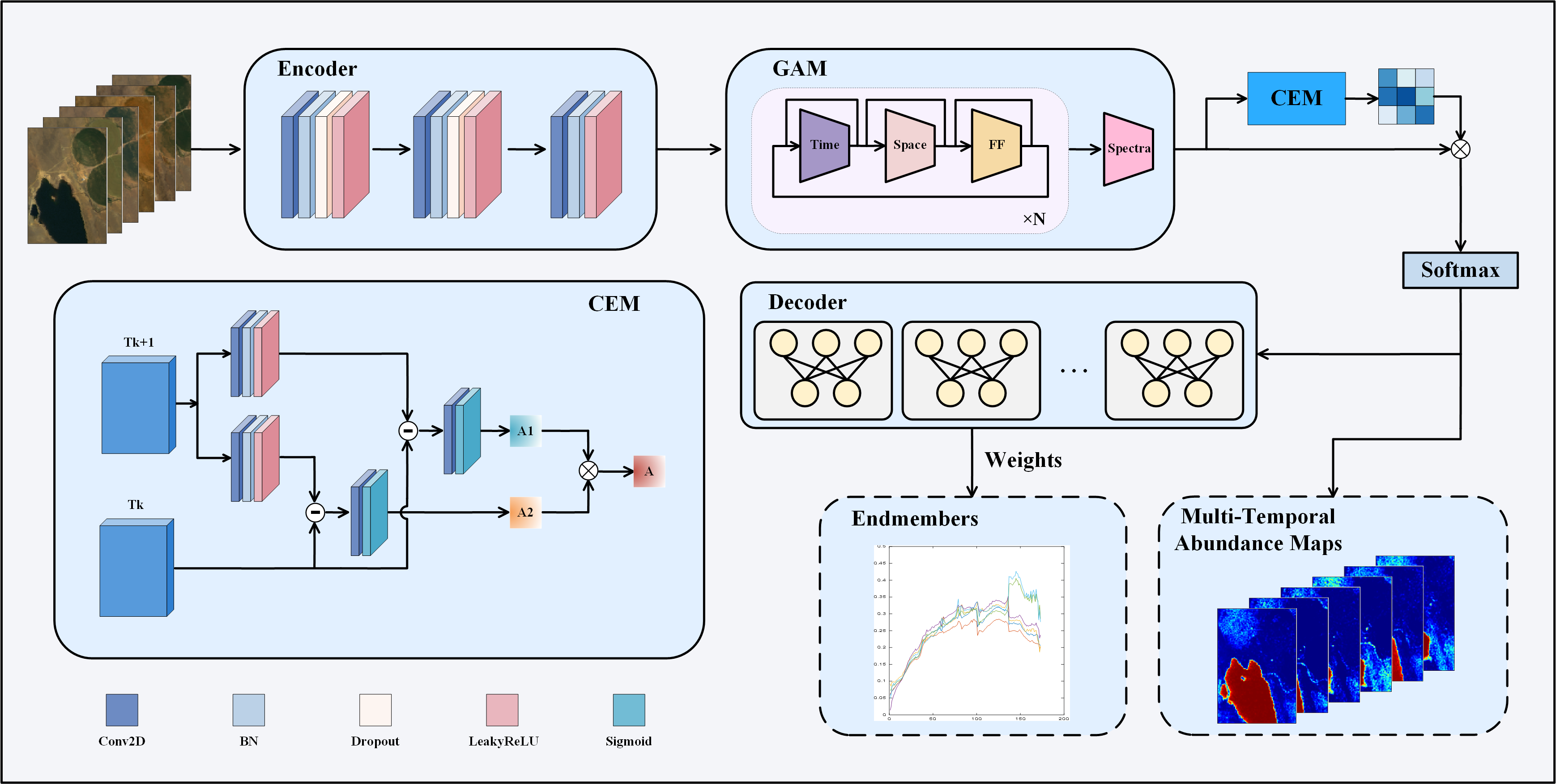
II-B Overall structure
In this section, we introduce the overall structure of the proposed MUFormer. The framework of the MUFormer model is shown in Fig. 1.
First, we input a sequence of hyperspectral images to the encoder, where , and represent the height and width of the images, the sequence represents the hyperspectral images acquired at the same location at different time instants. The encoder is mainly composed of convolutional layer, BatchNorm layer, and LeakyReLU layer. In order to prevent the model from overfitting, we add Dropout layer, which makes the neural network more robust and generalization ability [45]. Compared with transformer, CNN structure has more advantages in extracting local image features, and multitemporal feature maps containing richer semantic information can be obtained through multiple convolution operations [53, 54, 55]. At this point, the model outputs the multitemporal feature map , where , represents the number of channels retained after convolution processing, and it is a hyperparameter that can be set. Compared with the hundreds of channels of the original hyperspectral image, the channels retained here contain more important band information.
Then, we send the obtained multitemporal feature map into the GAM. With the advantages of transformer in sequence information modeling, we divide the feature map into patch blocks of the same size to calculate attention of each dimension and fuse it. Then, we use the proposed CEM module to refine the changes of adjacent phases, and send the processed feature maps into softmax to obtain the abundance maps of each phase.
In the decoder part, we establish a linear decoder for each phase, incorporating a linear layer. The weight of this linear layer is initialized using the VCA algorithm. Upon completion of the training iteration, the weight of the decoder represents the endmember matrix of the phase. Leveraging the linear decoder, we achieve the realization of the multitemporal linear unmixing model.
II-C Global Awareness Module
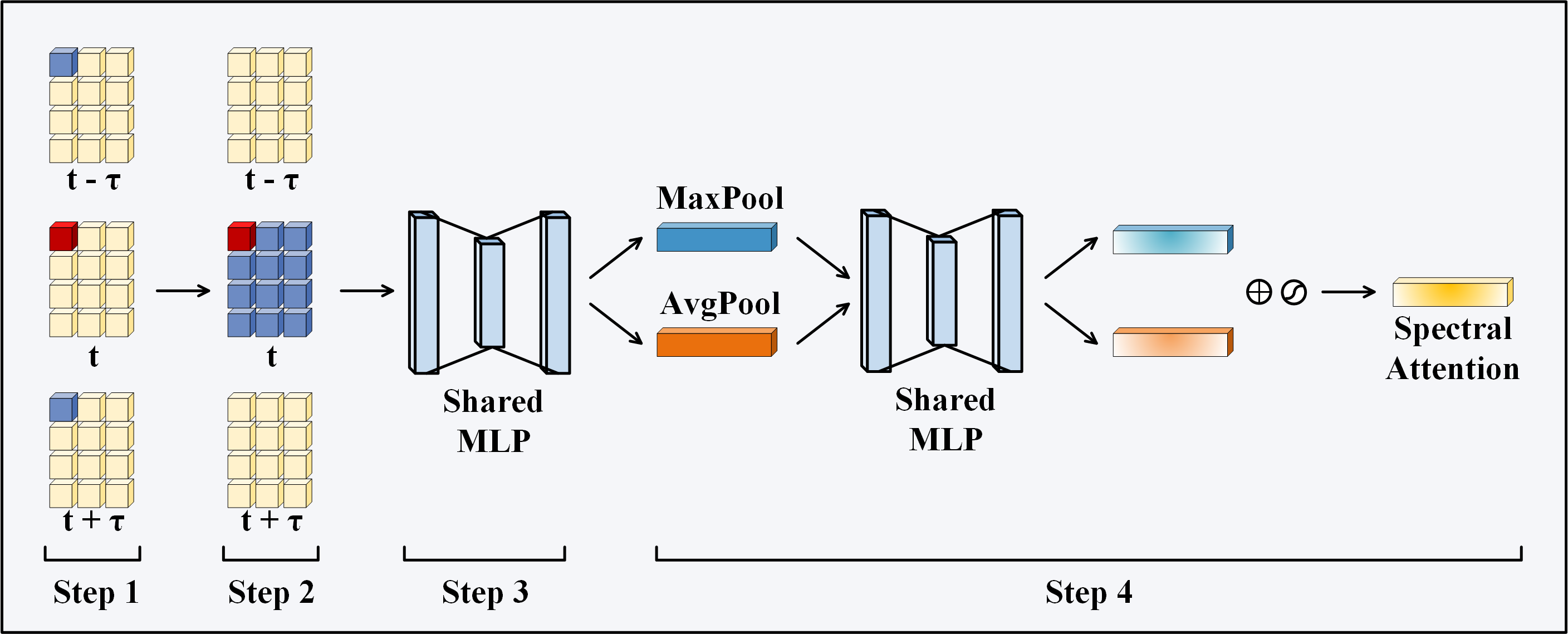
In order to calculate temporal-spatial-spectral attention from a global perspective and to deeply integrate information from multiple dimensions, we design the GAM. This module mainly contains temporal attention, spatial attention, spectral attention and forward parts. Feature maps processed by convolutional layers remove redundant bands and contain more critical information. Following the design of ViT [42], the feature map sequence is divided into non-overlapping patches , where , represents the side length of the patch and represents the number of channels processed by the encoder. We concatenate the with the original patch matrix, aggregates global features to avoid bias toward specific tokens in the sequence, and then add the position embedding vector , represents the temporal-spatial position information of the patch that can be learned. The new matrix representation is given in 3.
| (3) |
After obtaining , inspired by the work of [56], we treat the hyperspectral image sequence as frames with different time intervals, and then send them to the attention module for processing. Firstly, it is sent to the temporal attention module. In the temporal attention module, will be divided into three matrices after the linear layer, which represent query, key and value respectively, where , represents the dimension of each head, represents the number of heads,the dimensions of and are the same as . After obtaining the above three matrices, the self-attention weight size is calculated through the softmax function, and the calculation formula is as shown in 4.
| (4) |
Where represents the patch block and represents the hyperspectral image at time . By computing attention in the time dimension, we can assign reasonable weights to patches at the same location but at different moments, this enables the model to identify regions that have undergone changes at different times. By allocating higher attention to patches that exhibit significant changes throughout the time series, the model can concentrate more effectively on these key areas of change. Similarly, for patches at different positions at the same time, we also use the same way to calculate the attention weights of spatial dimensions, as shown in 5.
| (5) |
In order to solve the problem of gradient disappearance and gradient explosion in deep networks, we adopt residual connection [57]. The feature maps processed by temporal self-attention and spatial self-attention are fed into the forward module, which contains an MLP. This module can be set to multiple continuous modules, in order to prevent overfitting of the model here the model depth is set to 2. Different channels in hyperspectral images may correspond to different ground object components or features, and some channels may be affected by noise, atmospheric interference and other factors, resulting in low information quality. At the same time, the contribution of different channels to the unmixing task is not consistent [58, 59]. Combined with the above reasons, we send it to the spectral self-attention calculation module. In the spectral self-attention module, we respectively use Average pooling and Max pooling to process the channels, and then generate the channel attention vector through the full connection operation, which can adaptively adjust the weight of each channel to highlight important channel information. The ability to focus on channels with higher unmixing contributions is enhanced to improve the unmixing accuracy.The spectral self-attention mechanism is calculated as shown in 6. represents the feature map outputted by FF, and represents the sigmoid function. The schematic diagram of GAM is shown in Fig. 2.
| (6) |
Through the GAM, we dynamically assign weights to the significance of the time, space, and spectral dimensions, enabling the more precise capture of complex features within image data. This holistic attention mechanism aids models in more effectively comprehending the temporal evolution of objects or phenomena, alongside their unique spatial distributions and spectral characteristics. Concurrently, the robustness of the model is enhanced as it emphasizes crucial features while diminishing the impact of irrelevant or disruptive information. This enhancement makes our model highly skilled in dealing with the complex and fluctuating environmental conditions prevalent in hyperspectral images.
II-D Change Enhancement Module
Through the above GAM, we can obtain the temporal-spatial-spectral feature information from a global perspective. However, the acquisition time interval of hyperspectral images in different time phases is not certain. Therefore, how to adaptively deal with the feature changes of hyperspectral images between adjacent time phases is also an important issue. In order to solve this problem, we propose the CEM from the feature-level perspective, and its structure diagram is shown in the bottom left corner of Fig. 1. The CEM input is the feature map of two adjacent time phases after GAM processing, which size is . At this time, the feature map has gone through the weight allocation of global attention. In order to accurately capture the difference between adjacent temporal hyperspectral images from the feature level better, we propose to perform multi-scale convolution on the feature map at time , where the convolution kernel size is and , respectively. Then the feature maps after convolution are subtracted from the feature graphs at time. The subtracted feature maps are fed into the convolution layer and processed by the function, where the kernel size is set to . The weight vector is obtained by multiplying the obtained weights and , and the final weight vector is obtained by multiplying by . We add the obtained weight vector to , tags can provide a high-level representation of the entire sequence to facilitate learning and inference by the model. It allows the model to extract important global information from the input sequence rather than just focusing on local segments [60]. We modify by combining the output of CEM, so that the model not only allocates global information weights through the attention mechanism, but also uses convolutional neural network to reasonably deal with the change regions of adjacent time phases in the local information extraction. By this way of “coarse tuning” (GAM) plus “fine tuning” (CEM), we can reasonably simulate the changes of multitemporal features, so that our model can adaptively unmix multitemporal hyperspectral images.
| (7) |
| (8) |
| (9) |
Where and represent convolution kernel sizes of 3 and 7, respectively, followed by BN layer and LeakyReLU layer. represents a convolutional layer with a kernel size of 1 and represents the function, where is a hyperparameter that can be set empirically. We perform multi-scale convolution on the feature map, which can capture features at different scales. The smaller kernels help to capture local details and edge features, while the larger kernels are more suitable to capture larger contextual information. By using convolution kernels at both scales, a more comprehensive multi-scale feature representation can be obtained. In the process of feature fusion, the information loss that may exist in a single scale can be reduced and the expression ability of the model can be improved. Moreover, the large-scale convolution kernel may be more effective for removing some noise and unimportant detail information in the image, while the small-scale convolution kernel helps to retain important local features, which also suppresses noise to a certain extent. The ablation study on multi-scale CEM can be seen in Section IV.
II-E Loss Function
In the design of loss function, we choose the weighted sum of multiple loss functions as the total loss function to better train our proposed model. Reconstruction loss and Spectral Angle Distance (SAD) loss are commonly used loss functions in unmixing tasks. At the same time, it was demonstrated in [10] that the data simplex loss plays an important role in endmember estimation, the endmembers can be further constrained by adding the data simplex loss. The total training loss function is shown in 13, including , and , where , and are artificially set hyperparameters to balance each loss function. We adopt Adam algorithm for optimization and set scheduler to dynamically adjust the learning rate.
| (10) |
| (11) |
| (12) |
| (13) |

III Experimental Results
To verify the effectiveness of MUFormer, we conducted experiments on one real dataset and two synthetic datasets. We compare our method with fully constrained least squares (FCLS), online unmixing (OU) [36], KalmanEM based on Kalman filter and maximum expectation strategy [38], DeepTrans based on transformer for single phase unmixing [45], and ReSUDNN based on variational RNN for dynamic unmixing [41]. For the single-phase unmixing algorithm, we unmix the hyperspectral images of each phase, and then merge each phase to get multitemporal results. The initialization endmember of the above method is obtained by the VCA algorithm.
In order to accurately measure the results of the experiment, we choose two main evaluation metrics. The first one is the normalized root mean square error (NRMSE), which we calculate for the abundance map, endmembers and reconstructed hyperspectral images. The second is the spectral angle mapper (SAM), whose SAM we computed for the endmember. Where represents the true abundance value of the th pixel at the th time, represents the estimated abundance value, represents the estimated endmember value, represents the th endmember value in the th pixel at the th time, similarly, represents its estimated value.
For MTHU task, we don’t consume too much computing power, we use i7-11800H CPU and RTX 3060 GPU to complete the task efficiently. For these sets of experiments, we set the number of transformer blocks to 2, and too deep networks will cause overfitting or performance degradation of the model. We set the number of attention heads to 8, and the number of epochs during the model training to 1000, so that the model is fully trained.
| (14) |
| (15) |
| (16) |
| (17) |
III-A Dataset Description
In order to accurately test the effect of our proposed model, we expand the test on three datasets, including one real dataset and two synthetic datasets, which will be described in the following expansion.
-
1.
Lake Tahoe: The dataset was acquired by the airborne Visible Infrared Imaging Spectrometer (AVIRIS) between 2014 and 2015 and contains hyperspectral images of six time phases. The size of the hyperspectral image in each time phase is pixels, and there are 173 bands after removing the water absorption band. The image contains three types of endmembers: water, soil, and vegetation, each of which produces distinct changes over time [36]. This sequence of images is shown in Fig. 3.
-
2.
Synthetic data1: The dataset contains six temporal hyperspectral synthetic images, each of size pixels, containing three endmembers, and three features of bands randomly sampled from the USGS library as the reference endmember matrix. To model the endmember variability, the endmembers of each pixel are obtained by multiplying the reference signatures with a piecewise linear random scaling factor of the amplitude interval [0.85,1.15]. Local pixel mutation is added to to better match the endmember changes of real scene, To simulate realistic scenarios, Gaussian noise with a SNR of 30dB was added [41].
-
3.
Synthetic data2: The second synthetic dataset contains 15 temporal hyperspectral images, each pixels in size. In order to introduce realistic spectral variability, the endmember features of each pixel and phase are randomly selected from the artificially extracted pure pixels of water, vegetation, soil, and road in Jasper Ridge HI, which contains 198 bands. To simulate realistic scenarios, Gaussian noise with a SNR of 30dB was added [41].
III-B Lake Tahoe Results
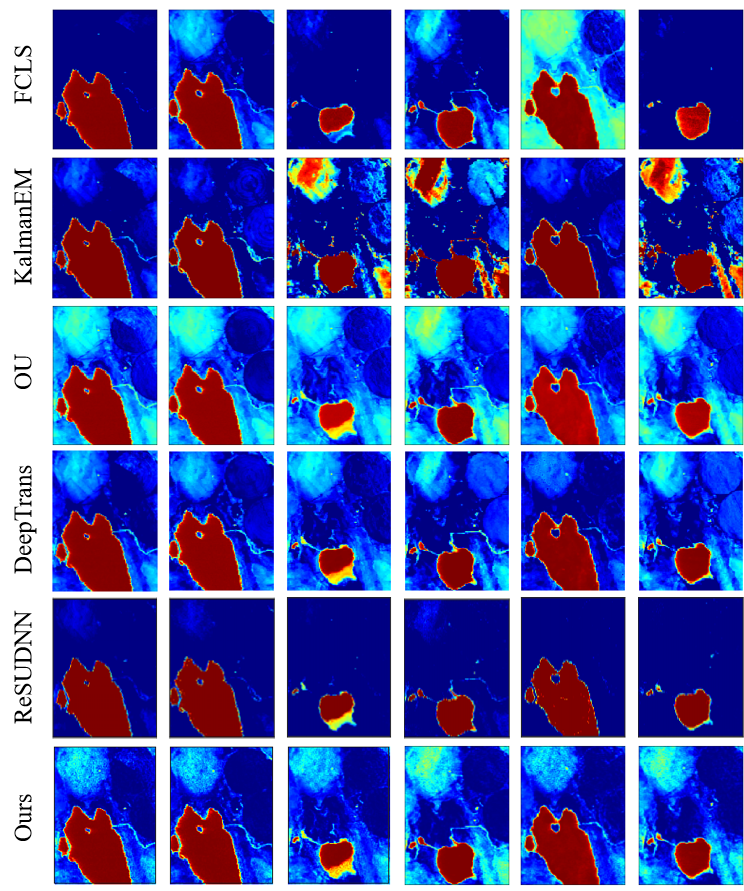
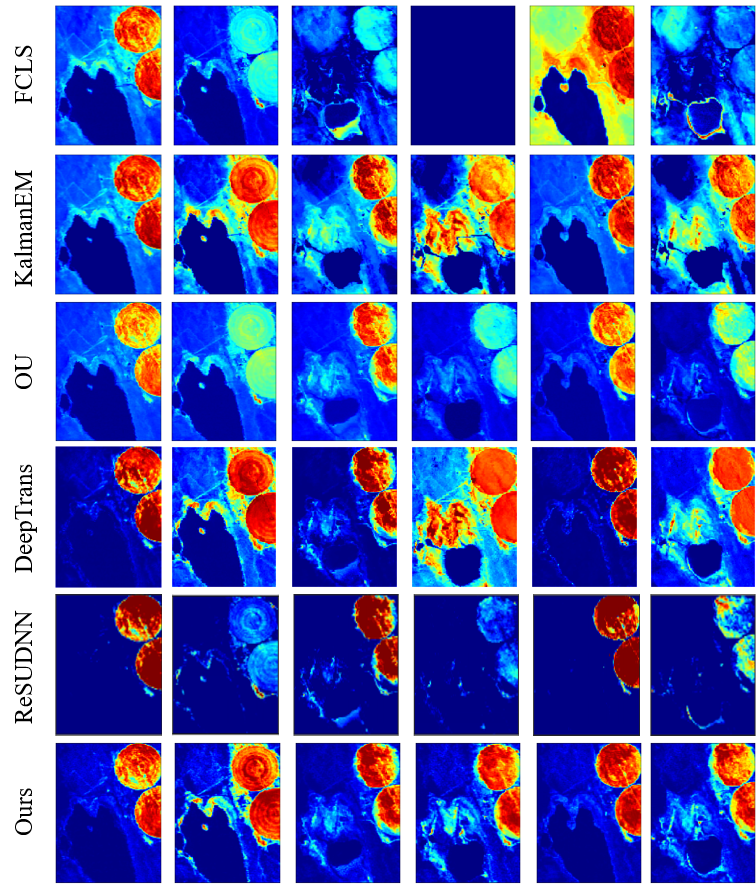
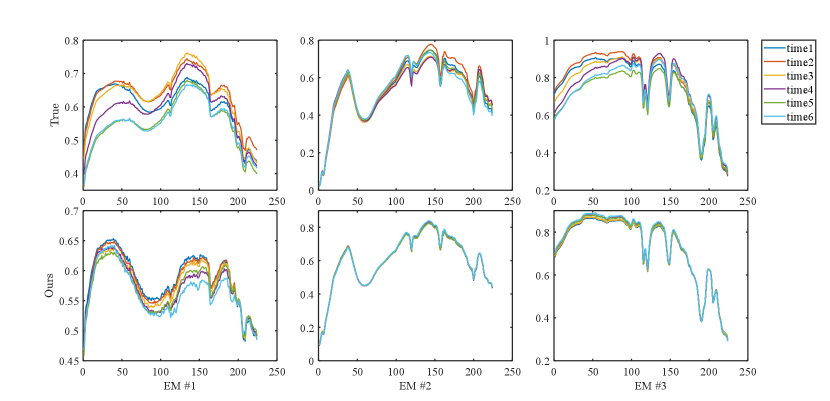
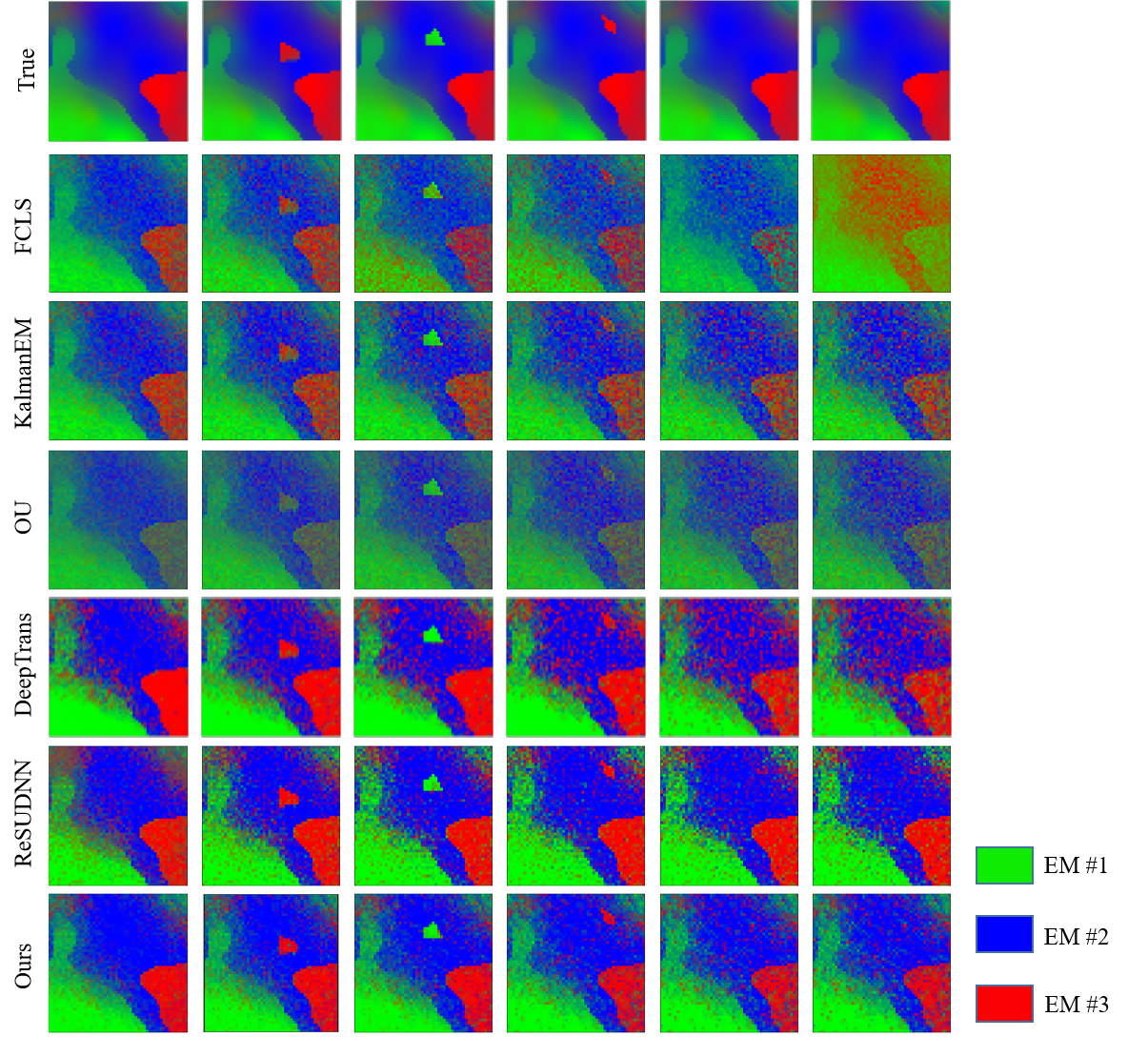
Due to the lack of real comparison results for the Lake Tahoe dataset, we only present its abundance map qualitatively, and the results are shown in Fig. 4. We alse show the results of multitemporal endmember estimation results in Fig. 7. It can be seen that the MUFormer proposed by us achieves better results in the unmixing of real multitemporal hyperspectral datasets. We can see from the results that FCLS has the worst performance, and the endmember is missing in multiple phases. There is also confusion between different endmembers. KalmanEM and OU have similar effects, but there are large errors in the abundance estimation of water and soil endmembers. Kalman filter has shortcomings in a large range of abundance changes and there are a lot of artifacts, which is because the Kalman filter sets the abundance to be continuous. When there is a large change in abundance, the effect will be affected. At the same time, in order to form a reasonable comparison, we add the DeepTrans model, which has superior performance on single-temporal hyperspectral image unmixing, as one of the comparison models. We can see that DeepTrans performs well in some individual temporal phases, but it does not consider the temporal information of multitemporal hyperspectral images, resulting in more erroneous unmixing regions. Finally, by comparing our proposed method with ReSUDNN, it can be seen that on the whole, both of them have achieved good results, and they are meticulous in the edge processing of endmembers. However, ReSUDNN has the phenomenon of misjudgment of endmembers in some phases, especially in the estimation of soil and vegetation.
III-C Synthetic Datasets Results
Due to the lack of ground truth in Lake Tahoe, we can only qualitatively compare the abundance map results. In order to compare their unmixing accuracy more precisely, we also tested them on two synthetic datasets. We performed a quantitative comparison on synthetic datasets, the results of which are shown in Table I. The results of the abundance maps for each model are shown in Fig. 8. Since the synthetic dataset 2 contains 15 phases, we only compare the MUFormer estimated abundance plot with the real one, taking into account space constraints. The comparison results are shown in Fig. 9, and the quantitative results are shown in Table II.
| FCLS | 0.537 | - | - | 0.086 | 2.7 |
| OU | 0.434 | 0.342 | 0.260 | 0.059 | 24.9 |
| KalmanEM | 0.356 | 0.124 | 0.076 | 0.061 | 2422.8 |
| DeepTrans | 0.592 | 0.381 | 0.286 | 0.133 | - |
| ReSUDNN | 0.318 | 0.117 | 0.075 | 0.089 | 479.0 |
| Ours | 0.255 | 0.110 | 0.059 | 0.079 | 132.2 |
| FCLS | 0.500 | - | - | 0.122 | 7.3 |
| OU | 0.335 | 0.256 | 0.120 | 0.055 | 60.6 |
| KalmanEM | 0.659 | 12.222 | 0.496 | 0.108 | 5937.4 |
| DeepTrans | 0.723 | 0.873 | 0.665 | 0.384 | - |
| ReSUDNN | 0.294 | 0.203 | 0.289 | 0.160 | 1231.3 |
| Ours | 0.185 | 0.162 | 0.100 | 0.153 | 223.0 |
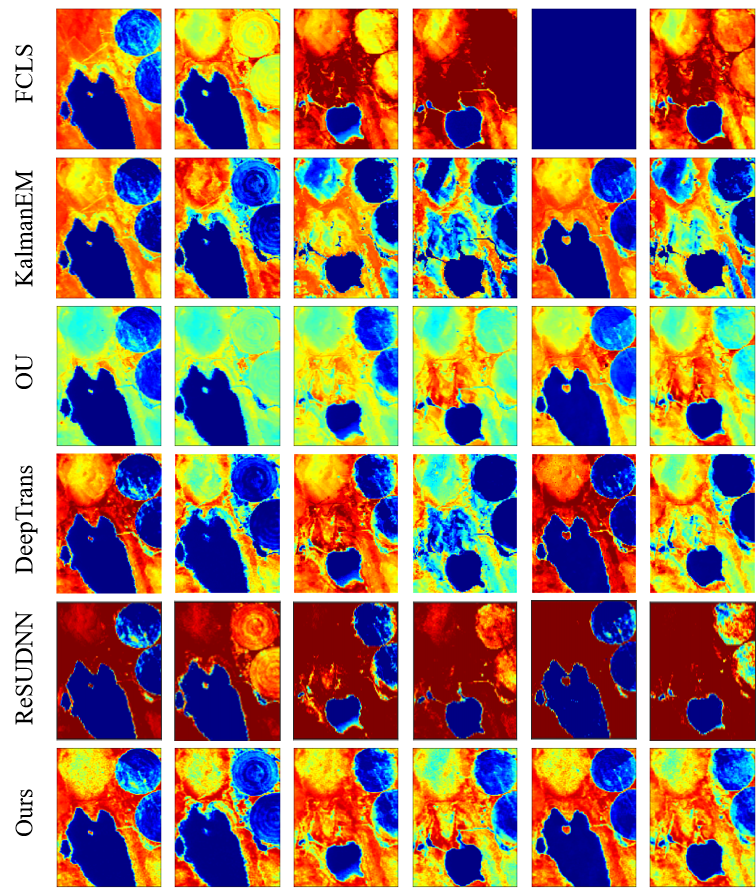
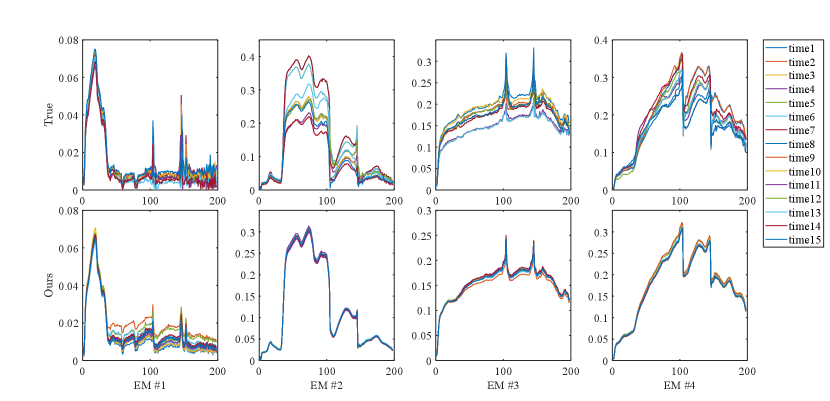
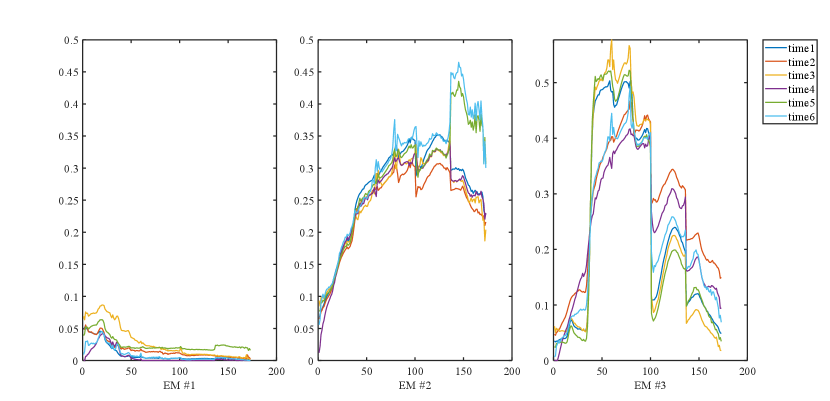
1) Discussion: From Fig. 8 and 9, we can see that each model is able to capture the abundance change from time t=2 to time t=6, but all are affected by noise to varying degrees. FCLS has a large estimation error at time t=6, OU and KalmanEM are seriously polluted by noise, and DeepTrans, as a single-temporal unmixing model, performs better at the first two moments, but it does not consider the time information, so the effect is poor for the latter moments, and there is a case of wrong estimation. As a whole, ReSUDNN and our method are closer to the true abundance map. We can see that for long time sequence hyperspectral images, our model shows excellent results, which is because transformer has a good effect on long sequence information processing. At the same time, we also combine the GAM to process the abundance transformation information of adjacent time phases, which further enhances the effect of our model in processing multitemporal hyperspectral images. In Table I and II we compare the quantitative results of the individual algorithms, it can be seen that our proposed MUFormer achieves SOTA results in three indicators of , and . Although OU has achieved good results on , the reconstruction loss cannot explain the effect of abundance and endmember estimation, so we see that his results of , and are poor, and the abundance map obtained is also affected by a lot of noise. and at the same time, the running speed is several times higher than that of KalmanEM and ReSUDNN. It is worth mentioning that synthetic dataset 2 contains 15 temporal phases, which is more challenging than synthetic dataset 1. We can see that our method has a substantial improvement, which also highlights the potential of our model in processing long sequences of multitemporal hyperspectral images. In Fig. 5 and Fig. 6, we show the results of endmember estimation of synthetic dataset 1 and 2. It can be seen that our estimation results are very close to the real endmember, but we still need to further enhance the perception ability of the model for the change of phase at different times of the same endmember.
III-D Ablation study
To fully verify the role played by our proposed CEM and GAM in the model, we launched an ablation study, the results of which are shown in Table III. From Table III, we can see that the model performance is improved to varying degrees when the CEM module and GAM are added separately, and the model effect is the best when the two modules are added at the same time. This is because through the GAM, we extract the spatial, global time and spectral information features of the multitemporal hyperspectral image. Combined with the CEM module to capture the changes between adjacent time phases, it is more conducive to our model to deal with multitemporal tasks. At the same time, as mentioned above, we processed images at different scales in CEM. In order to explore the influence of different scale processing on the unmixing effect, we carried out ablation experiments on the size of the convolution kernel, and the experimental results are shown in Table IV. From Table IV, we can see that the addition of convolution modules of different scales to has different degrees of improvement, and the fusion of features at different scales can improve the robustness of the model. We compare the two fusion methods of addition and multiplication, and it can be seen that the multiplication effect of A1 and A2 is more obvious. We believe that multiplying them enables the model to pay more attention to the relationship between features at different scales, which helps to capture the information in the image more comprehensively, especially in the presence of multiple scale structures. Moreover, the correlation between two features can be emphasized by multiplication, and the weighted attention to different regions can also be realized, making the model more flexible to learn different degrees of attention to different locations.
| Settings | ||||
|---|---|---|---|---|
| Baseline | 0.362 | 0.111 | 0.061 | 0.083 |
| + CEM | 0.274 | 0.112 | 0.060 | 0.070 |
| + GAM | 0.293 | 0.115 | 0.064 | 0.086 |
| MUFormer | 0.255 | 0.110 | 0.059 | 0.079 |
| Settings | ||||
|---|---|---|---|---|
| Baseline | 0.293 | 0.115 | 0.064 | 0.086 |
| A1 | 0.260 | 0.113 | 0.060 | 0.077 |
| A2 | 0.262 | 0.111 | 0.060 | 0.079 |
| A1 + A2 | 0.267 | 0.111 | 0.061 | 0.085 |
| 0.255 | 0.110 | 0.059 | 0.079 |
IV Conclusion
This paper proposes a multitemporal hyperspectral image unmixing method MUFormer. Different from previous methods, we propose Change Enhancement Module and Global Awareness Module to extract image information from three dimensions of time, space and spectra, and dynamically adapt to the changes of adjacent phases from the perspective of deep learning by using the advantages of transformer in processing long sequence information. The results of multiple datasets show that our model has achieved excellent results in multitemporal hyperspectral image endmember and abundance map estimation, and our method has also achieved a great advantage in running speed. We believe that the problem to be further solved for multitemporal hyperspectral image unmixing is the subtle endmember changes and abundance changes between different phases. At the same time, it is also a feasible new idea to integrate the denoising module into the unmixing, because we find that the multitemporal hyperspectral image is more susceptible to noise in the unmixing process. We hope that our model can shed new light on the task of multitemporal hyperspectral image unmixing.
Acknowledgments
We would like to acknowledge Ricardo Borsoi for providing the dataset and its accompanying documentation.
References
- [1] J. M. Bioucas-Dias, A. Plaza, N. Dobigeon, M. Parente, Q. Du, P. Gader, and J. Chanussot, “Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches,” IEEE journal of selected topics in applied earth observations and remote sensing, vol. 5, no. 2, pp. 354–379, 2012.
- [2] Q. Qu, B. Pan, X. Xu, T. Li, and Z. Shi, “Unmixing guided unsupervised network for rgb spectral super-resolution,” IEEE Transactions on Image Processing, 2023.
- [3] T. Imbiriba, J. C. M. Bermudez, and C. Richard, “Band selection for nonlinear unmixing of hyperspectral images as a maximal clique problem,” IEEE Transactions on Image Processing, vol. 26, no. 5, pp. 2179–2191, 2017.
- [4] Y. Su, Z. Zhu, L. Gao, A. Plaza, P. Li, X. Sun, and X. Xu, “Daan: A deep autoencoder-based augmented network for blind multilinear hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [5] Y. Su, X. Xu, J. Li, H. Qi, P. Gamba, and A. Plaza, “Deep autoencoders with multitask learning for bilinear hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 10, pp. 8615–8629, 2020.
- [6] A. Zouaoui, G. Muhawenayo, B. Rasti, J. Chanussot, and J. Mairal, “Entropic descent archetypal analysis for blind hyperspectral unmixing,” IEEE Transactions on Image Processing, 2023.
- [7] J. S. Bhatt and M. V. Joshi, “Deep learning in hyperspectral unmixing: A review,” in IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2020, pp. 2189–2192.
- [8] J. Nascimento and J. Dias, “Vertex component analysis: a fast algorithm to unmix hyperspectral data,” IEEE Transactions on Geoscience and Remote Sensing, vol. 43, no. 4, pp. 898–910, 2005.
- [9] L. Drumetz, J. Chanussot, C. Jutten, W.-K. Ma, and A. Iwasaki, “Spectral variability aware blind hyperspectral image unmixing based on convex geometry,” IEEE Transactions on Image Processing, vol. 29, pp. 4568–4582, 2020.
- [10] B. Rasti, B. Koirala, P. Scheunders, and J. Chanussot, “Misicnet: Minimum simplex convolutional network for deep hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- [11] H. Liu, Y. Lu, Z. Wu, Q. Du, J. Chanussot, and Z. Wei, “Bayesian unmixing of hyperspectral image sequence with composite priors for abundance and endmember variability,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- [12] Y. Woodbridge, U. Okun, G. Elidan, and A. Wiesel, “Unmixing -gaussians with application to hyperspectral imaging,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 9, pp. 7281–7293, 2019.
- [13] T. Wang, J. Li, M. K. Ng, and C. Wang, “Nonnegative matrix functional factorization for hyperspectral unmixing with non-uniform spectral sampling,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [14] T. Yang, M. Song, S. Li, and Y. Wang, “Spectral-spatial anti-interference nmf for hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [15] H.-C. Li, X.-R. Feng, R. Wang, L. Gao, and Q. Du, “Superpixel-based low-rank tensor factorization for blind nonlinear hyperspectral unmixing,” IEEE Sensors Journal, 2024.
- [16] L. Drumetz, T. R. Meyer, J. Chanussot, A. L. Bertozzi, and C. Jutten, “Hyperspectral image unmixing with endmember bundles and group sparsity inducing mixed norms,” IEEE Transactions on Image Processing, vol. 28, no. 7, pp. 3435–3450, 2019.
- [17] X. Shen, L. Chen, H. Liu, X. Su, W. Wei, X. Zhu, and X. Zhou, “Efficient hyperspectral sparse regression unmixing with multilayers,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [18] Y. Gao, B. Pan, X. Xu, X. Song, and Z. Shi, “A reversible generative network for hyperspectral unmixing with spectral variability,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [19] B. Palsson, M. O. Ulfarsson, and J. R. Sveinsson, “Convolutional autoencoder for spectral–spatial hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 1, pp. 535–549, 2020.
- [20] Y. Yu, Y. Ma, X. Mei, F. Fan, J. Huang, and H. Li, “Multi-stage convolutional autoencoder network for hyperspectral unmixing,” International Journal of Applied Earth Observation and Geoinformation, vol. 113, p. 102981, 2022.
- [21] X. Xu, X. Song, T. Li, Z. Shi, and B. Pan, “Deep autoencoder for hyperspectral unmixing via global-local smoothing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–16, 2022.
- [22] Y. Su, A. Marinoni, J. Li, J. Plaza, and P. Gamba, “Stacked nonnegative sparse autoencoders for robust hyperspectral unmixing,” IEEE Geoscience and Remote Sensing Letters, vol. 15, no. 9, pp. 1427–1431, 2018.
- [23] L. Gao, Z. Han, D. Hong, B. Zhang, and J. Chanussot, “Cycu-net: Cycle-consistency unmixing network by learning cascaded autoencoders,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2021.
- [24] Y. Qu and H. Qi, “udas: An untied denoising autoencoder with sparsity for spectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 3, pp. 1698–1712, 2018.
- [25] S. Shi, M. Zhao, L. Zhang, and J. Chen, “Variational autoencoders for hyperspectral unmixing with endmember variability,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 1875–1879.
- [26] K. Mantripragada and F. Z. Qureshi, “Hyperspectral pixel unmixing with latent dirichlet variational autoencoder,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [27] T. Ince and N. Dobigeon, “Spatial-spectral multiscale sparse unmixing for hyperspectral images,” IEEE Geoscience and Remote Sensing Letters, 2023.
- [28] T. Uezato, N. Yokoya, and W. He, “Illumination invariant hyperspectral image unmixing based on a digital surface model,” IEEE Transactions on Image Processing, vol. 29, pp. 3652–3664, 2020.
- [29] R. A. Borsoi, T. Imbiriba, and J. C. M. Bermudez, “A data dependent multiscale model for hyperspectral unmixing with spectral variability,” IEEE Transactions on Image Processing, vol. 29, pp. 3638–3651, 2020.
- [30] R. Li, B. Pan, X. Xu, T. Li, and Z. Shi, “Towards convergence: A gradient-based multiobjective method with greedy hash for hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [31] M. Wang, B. Zhu, J. Zhang, J. Fan, and Y. Ye, “A lightweight change detection network based on feature interleaved fusion and bi-stage decoding,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023.
- [32] J. Wang, Y. Zhong, and L. Zhang, “Contrastive scene change representation learning for high-resolution remote sensing scene change detection,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [33] M. Hu, C. Wu, B. Du, and L. Zhang, “Binary change guided hyperspectral multiclass change detection,” IEEE Transactions on Image Processing, vol. 32, pp. 791–806, 2023.
- [34] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [35] S. Henrot, J. Chanussot, and C. Jutten, “Dynamical spectral unmixing of multitemporal hyperspectral images,” IEEE Transactions on Image Processing, vol. 25, no. 7, pp. 3219–3232, 2016.
- [36] P.-A. Thouvenin, N. Dobigeon, and J.-Y. Tourneret, “Online unmixing of multitemporal hyperspectral images accounting for spectral variability,” IEEE Transactions on Image Processing, vol. 25, no. 9, pp. 3979–3990, 2016.
- [37] J. Sigurdsson, M. O. Ulfarsson, J. R. Sveinsson, and J. M. Bioucas-Dias, “Sparse distributed multitemporal hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 11, pp. 6069–6084, 2017.
- [38] R. A. Borsoi, T. Imbiriba, P. Closas, J. C. M. Bermudez, and C. Richard, “Kalman filtering and expectation maximization for multitemporal spectral unmixing,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [39] P.-A. Thouvenin, N. Dobigeon, and J.-Y. Tourneret, “A hierarchical bayesian model accounting for endmember variability and abrupt spectral changes to unmix multitemporal hyperspectral images,” IEEE Transactions on Computational Imaging, vol. 4, no. 1, pp. 32–45, 2017.
- [40] R. Zhuo, Y. Fang, L. Xu, Y. Chen, Y. Wang, and J. Peng, “A novel spectral-temporal bayesian unmixing algorithm with spatial prior for sentinel-2 time series,” Remote Sensing Letters, vol. 13, no. 5, pp. 522–532, 2022.
- [41] R. A. Borsoi, T. Imbiriba, and P. Closas, “Dynamical hyperspectral unmixing with variational recurrent neural networks,” IEEE Transactions on Image Processing, vol. 32, pp. 2279–2294, 2023.
- [42] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [43] S. Jia, Y. Wang, S. Jiang, and R. He, “A center-masked transformer for hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [44] C. Zhang, J. Su, Y. Ju, K.-M. Lam, and Q. Wang, “Efficient inductive vision transformer for oriented object detection in remote sensing imagery,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [45] P. Ghosh, S. K. Roy, B. Koirala, B. Rasti, and P. Scheunders, “Hyperspectral unmixing using transformer network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–16, 2022.
- [46] F. Kong, Y. Zheng, D. Li, Y. Li, and M. Chen, “Window transformer convolutional autoencoder for hyperspectral sparse unmixing,” IEEE Geoscience and Remote Sensing Letters, 2023.
- [47] Y. Duan, X. Xu, T. Li, B. Pan, and Z. Shi, “Undat: Double-aware transformer for hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–12, 2023.
- [48] L. Wang, X. Zhang, J. Zhang, H. Dong, H. Meng, and L. Jiao, “Pixel-to-abundance translation: Conditional generative adversarial networks based on patch transformer for hyperspectral unmixing,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 5734–5749, 2024.
- [49] Z. Yang, M. Xu, S. Liu, H. Sheng, and J. Wan, “Ust-net: A u-shaped transformer network using shifted windows for hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [50] X. Tao, M. E. Paoletti, Z. Wu, J. M. Haut, P. Ren, and A. Plaza, “An abundance-guided attention network for hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [51] L. Qi, X. Qin, F. Gao, J. Dong, and X. Gao, “Sawu-net: Spatial attention weighted unmixing network for hyperspectral images,” IEEE Geoscience and Remote Sensing Letters, 2023.
- [52] B. Wang, H. Yao, D. Song, J. Zhang, and H. Gao, “Ssf-net: A spatial-spectral features integrated autoencoder network for hyperspectral unmixing,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023.
- [53] X. Chen, X. Zheng, Y. Zhang, and X. Lu, “Remote sensing scene classification by local–global mutual learning,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [54] J. Yue, L. Fang, and M. He, “Spectral-spatial latent reconstruction for open-set hyperspectral image classification,” IEEE Transactions on Image Processing, vol. 31, pp. 5227–5241, 2022.
- [55] R. Xu, X.-M. Dong, W. Li, J. Peng, W. Sun, and Y. Xu, “Dbctnet: Double branch convolution-transformer network for hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [56] G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” in ICML, vol. 2, no. 3, 2021, p. 4.
- [57] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [58] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19.
- [59] M. Zhu, L. Jiao, F. Liu, S. Yang, and J. Wang, “Residual spectral–spatial attention network for hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 1, pp. 449–462, 2020.
- [60] G. Zhao, Q. Ye, L. Sun, Z. Wu, C. Pan, and B. Jeon, “Joint classification of hyperspectral and lidar data using a hierarchical cnn and transformer,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–16, 2022.