TransGAT: Transformer-Based Graph Neural Networks for Multi-Dimensional Automated Essay Scoring
Abstract
Essay writing is a critical component of student assessment, yet manual scoring is labor-intensive and inconsistent. Automated Essay Scoring (AES) offers a promising alternative, but current approaches face limitations. Recent studies have incorporated Graph Neural Networks (GNNs) into AES using static word embeddings that fail to capture contextual meaning, especially for polysemous words. Additionally, many methods rely on holistic scoring, overlooking specific writing aspects such as grammar, vocabulary, and cohesion. To address these challenges, this study proposes TransGAT, a novel approach that integrates fine-tuned Transformer models with GNNs for analytic scoring. TransGAT combines the contextual understanding of Transformers with the relational modeling strength of Graph Attention Networks (GAT). It performs two-stream predictions by pairing each fine-tuned Transformer (BERT, RoBERTa, and DeBERTaV3) with a separate GAT. In each pair, the first stream generates essay-level predictions, while the second applies GAT to Transformer token embeddings, with edges constructed from syntactic dependencies. The model then fuses predictions from both streams to produce the final analytic score. Experiments on the ELLIPSE dataset show that TransGAT outperforms baseline models, achieving an average Quadratic Weighted Kappa (QWK) of 0.854 across all analytic scoring dimensions. These findings highlight the potential of TransGAT to advance AES systems.
keywords:
Automated Essay Scoring (AES) , Transformer Models , Graph Neural Networks (GNNs) , Graph Attention Networks (GATs) , Natural Language Processing (NLP)[1]organization=Department of Computer Science, King Abdulaziz University, city=Jeddah, state=Makkah, postcode=21589, country=Saudi Arabia
[2]organization=English Language Institute, King Abdulaziz University, city=Jeddah, state=Makkah, postcode=21589, country=Saudi Arabia
1 Introduction
Essay writing tasks are commonly used in educational settings to assess a student’s creativity, critical thinking, and subject knowledge. Such tasks require the ability to collect, synthesize, and present ideas and arguments (West et al., 2019). Essay-based assessments are integral to a variety of contexts, including classroom evaluations, university admissions, and standardized tests such as TOEFL and IELTS (Zupanc and Bosnić, 2018). Evaluation is typically conducted by educators using structured scoring rubrics designed to ensure consistency and objectivity. Scoring rubrics generally follow either a holistic or analytic approach. The holistic scoring assigns a single overall score based on general writing quality, while the analytical scoring evaluates multiple dimensions, such as organization, grammar, vocabulary, and cohesion, to provide more detailed feedback on specific writing traits (Li and Ng, 2024a).
Manual evaluation presents several challenges, especially when large volumes of essays must be evaluated within limited timeframes. Even with clear rubrics, human scoring remains vulnerable to inconsistencies, subjectivity, and rater bias, which may compromise reliability and fairness (Uto and Okano, 2020). To address these limitations, Automated Essay Scoring (AES) systems have been developed as a practical and scalable solution. By leveraging techniques from Natural Language Processing (NLP) and Machine Learning (ML), AES systems automatically evaluate written texts with minimal human intervention (Uto, 2021; Misgna et al., 2025). This automation enables consistent and objective scoring, reduces evaluation time and cost, and supports educational feedback by enabling rapid, large-scale assessments (Misgna et al., 2025; Ramesh and Sanampudi, 2022).
Early AES systems relied heavily on handcrafted features extracted from essays, such as lexical, syntactic, grammatical, and content-specific indicators. Although effective to some extent, these feature engineering approaches require significant manual effort and lack flexibility when adapting to new traits or tasks (Misgna et al., 2025). To address these limitations, neural network-based methods were introduced, enabling automatic learning of feature representations directly from text data through word embeddings. These embeddings encode semantic similarity based on context, eliminating the need for handcrafted features (Misgna et al., 2025).
Despite their success, deep learning models like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) often fail to capture global dependencies in a corpus, which are essential for holistic understanding. They mostly operate on local sequences of words and lack mechanisms to model relationships across multiple documents (Yao et al., 2019).
To address this, Graph Neural Networks (GNNs) have gained attention. GNNs can model long-range dependencies and global relationships by representing texts as graphs (Cai et al., 2018). One popular architecture, Graph Convolutional Networks (GCNs), introduced by Kipf and Welling (Kipf and Welling, 2017), has shown promising results in NLP tasks including text classification (Yao et al., 2019; Liu et al., 2020).
Recent studies have applied GCNs to AES, demonstrating their effectiveness in capturing relationships between essays and enhancing feature extraction. For instance, Ait et al. (Ait Khayi and Rus, 2020) used TF-IDF and Word2Vec to represent nodes, capturing both term importance and semantic meaning. Tan et al. (Tan et al., 2023) employed one-hot encoding to create binary vector representations, while Ma et al. (Ma et al., 2021) used GloVe embeddings to represent documents, sentences, and tokens, enabling more comprehensive modeling of semantic structures. These approaches differ primarily in how graph nodes are represented through word embeddings. Although AES models have shown promising results, several challenges and limitations remain. The following outlines these key issues.
-
1.
Traditional word embedding methods, such as TF-IDF, Word2Vec, and GloVe, produce static representations that fail to capture contextual meaning and struggle with polysemy. Consequently, the same embedding is assigned to words used in different contexts, limiting their effectiveness in tasks like AES. Pre-trained Transformer models address these shortcomings by generating dynamic, context-aware embeddings that capture rich semantic and syntactic information (She et al., 2022). However, while Transformers excel at modeling intra-textual context, they are less effective at capturing relationships across multiple texts—such as similarities and dependencies among essays. To address this limitation, recent approaches have combined Transformer-based models with GCNs, an integration that has proven effective across various NLP tasks, including text classification (She et al., 2022; Gao and Huang, 2021; Lu et al., 2020; AlBadani et al., 2022). This hybrid approach leverages the strengths of both architectures: the contextual depth of Transformers and the relational modeling capabilities of GCNs, resulting in a more robust and comprehensive solution for AES and other NLP tasks.
-
2.
Despite the advantages of GCNs, a notable limitation remains: the equal treatment of all neighboring nodes, which may lead to suboptimal modeling of node relevance. To overcome this issue, Graph Attention Networks (GATs), proposed by Veličković et al. (Veličković et al., 2017), incorporate an attention mechanism that assigns learnable weights to neighboring nodes based on their importance. GATs have achieved promising results across various NLP tasks, such as text classification and sentiment analysis, demonstrating their effectiveness in capturing complex relationships within textual data (Haitao and Fangbing, 2022; Vrahatis et al., 2024). By weighting the importance of neighboring nodes, GATs enable models to focus more effectively on the most relevant connections—an advantage particularly beneficial for AES, where the strength of relationships between essays can vary.
-
3.
Most existing AES systems rely on holistic scoring, which assigns a single score to represent the overall quality of an essay. Although this approach simplifies the scoring process, it fails to assess specific aspects of writing such as grammar, vocabulary, coherence, and organization. Consequently, it limits the ability to provide detailed and targeted feedback—an essential component in educational contexts, especially for second-language learners. Holistic scoring does not reflect the full range of a student’s writing abilities, reducing its effectiveness in identifying strengths and weaknesses. Despite these drawbacks, much of the prior research has focused on holistic evaluation, often overlooking the advantages of analytic scoring, which assigns multiple scores across distinct writing dimensions and offers more informative feedback to support writing improvement (Li and Ng, 2024c).
-
4.
The Automated Student Assessment Prize (ASAP) dataset, released as part of a 2012 Kaggle competition, has become the primary benchmark for evaluating AES models, but it has notable limitations that constrain its usefulness for broader AES research. First, the dataset lacks diversity, consisting of essays written by U.S. students in grades 7 to 10, most of whom are native English speakers. This raises concerns about generalizability, particularly when applying AES models to essays written by second-language learners or students from different educational backgrounds. Second, the structure of ASAP limits its suitability for evaluating models in cross-prompt scoring. AES researchers have traditionally relied on within-prompt scoring, where models are trained and tested on the same prompt. However, this setup is often impractical in real-world applications, as AES models tend to perform poorly on unseen prompts unless retrained on new data. In response, researchers have begun exploring cross-prompt scoring, a more challenging setting where models are trained on multiple prompts and tested on essays from prompts not seen during training. Although ASAP contains eight prompts across different genres (narrative, persuasive, and source-based), using it for cross-prompt evaluation introduces complications, as scoring rubrics and writing expectations vary by genre (Li and Ng, 2024c, a). Recently, a new dataset has been introduced to address the limitations of the ASAP dataset. Composed of essays written by English Language Learners, this dataset features a larger number of prompts within the same genre (Crossley et al., 2023). These characteristics make it more suitable for training and evaluating robust AES models. Further details about the dataset are provided in the Experiments section.
In conclusion, although current AES models have made considerable advancements, there is still potential for further development in several areas. By tackling these challenges, it is possible to develop more efficient and adaptable AES models that offer deeper, more comprehensive feedback and better meet the varied requirements of educational environments.
To address these shortcomings, this paper proposes the TransGAT method, which effectively combines the contextual representation power of pre-trained Transformers with the relational modeling capabilities of GATs. It also leverages an enhanced dataset to train a more robust AES model capable of assessing essays across multiple dimensions. Additionally, this study addresses another research gap by combining cross-prompt essay scoring with multi-dimensional essay scoring. This study is the first to integrate Transformer-based embeddings with GATs for AES while jointly addressing cross-prompt and multi-dimensional scoring.
This paper is organized as follows: Section 2 provides a review of related work in the field of AES. Section 3 presents the proposed methodology, detailing the integration of Transformer models and GAT. Section 4 summarizes the experiments, including dataset details, evaluation metric used to assess performance, experimental setup, results obtained, and comparison to baseline studies. Finally, Section 5 discusses the conclusions and suggests directions for future research.
2 Related Work
This section categorizes previous studies on the AES task into two groups based on the rating scales used for writing assessment: holistic scoring and analytic scoring.
2.1 Holistic Scoring
Research on holistic essay scoring has progressed from traditional machine learning methods to deep neural networks and, more recently, to Graph Convolutional Networks (GCNs). Traditional machine learning methods relied on handcrafted features such as vocabulary, sentence length, grammatical errors, and syntactic complexity (Madala et al., 2018; Sharma and Goyal, 2020). Advanced features, including parse tree depth and type-token ratio, have also been explored (Salim et al., 2019; Janda et al., 2019; Doewes and Pechenizkiy, 2020).
Deep learning methods introduced word embeddings to automate feature extraction, initially using static embeddings like GloVe and Word2Vec with CNNs, GRUs, LSTMs, and Bi-LSTMs (Chen et al., 2020; Li et al., 2018; Cai, 2019; Zhu and Sun, 2020; Xia et al., 2019; Muangkammuen and Fukumoto, 2020; Chen and Li, 2018). Attention mechanisms further enhanced performance (Chen and Li, 2018). Transformer-based models, such as BERT, RoBERTa, and DeBERTa, provided contextualized embeddings that outperformed static embeddings in AES tasks and yielded improved results when combined with LSTMs, CNNs, Capsule Networks, and Bi-LSTMs (Wangkriangkri et al., 2020; Wang, 2023; Sharma et al., 2021; Yang and Zhong, 2021; Yang et al., 2020; Mayfield and Black, 2020; Susanto et al., 2023; Beseiso et al., 2021). Hybrid approaches integrated both static and contextual embeddings to enhance performance (Li et al., 2023; Beseiso and Alzahrani, 2020; Zhou et al., 2021). However, most deep learning models primarily focus on local word sequences without explicitly capturing global word relationships (Yao et al., 2019).
GCNs have emerged as a promising method for capturing global relationships within textual data (Ren et al., 2022; Bhatti et al., 2023). Early studies applied GCNs to short-answer scoring, leveraging one-hot encoding, TF-IDF, and Word2Vec embeddings (Tan et al., 2023; Ait Khayi and Rus, 2020). Later research extended GCNs to essay scoring using GloVe embeddings (Ma et al., 2021). However, most prior work has primarily focused on holistic scoring, evaluating overall essay quality without addressing specific writing aspects.
2.2 Analytic Scoring
Initial research in AES primarily utilized traditional machine learning algorithms combined with manually engineered features. In recent years, however, numerous studies have shown that neural network methods can more effectively capture the deep semantics of essays. For example, Li et al. (Li and Ng, 2024b) trained a simple neural network using extracted features as input and achieved state-of-the-art performance. Mathias et al. (Mathias and Bhattacharyya, 2020) compared a feature-engineering system, a string kernel-based model, and an attention-based neural network using GloVe pre-trained word embeddings to automatically extract features for scoring various essay traits, finding that the neural network delivered the best results. The introduction of deep learning further automated feature extraction through word embeddings, with models such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRUs), Long Short-Term Memory networks (LSTMs), and Bidirectional LSTMs (BiLSTMs) showing promising results (Hussein et al., 2020; Ridley et al., 2021; Shin and Gierl, 2022; Do et al., 2023; Chen and Li, 2023).
More recently, many AES studies have utilized transformer-based pre-trained language models—such as BERT, DistilBERT, RoBERTa, and DeBERTa—to obtain essay embeddings, followed by model fine-tuning to optimize performance (Lee and Nam, 2021; Xue et al., 2021; Ormerod, 2022; Lohmann et al., 2024; Sun and Wang, 2024; Chen et al., 2024). Several studies have enhanced these transformer models by integrating them with additional deep-learning architectures. For example, Lee et al. (Cho et al., 2024) incorporated a CNN with the output from BERT to improve local feature extraction, while another study (Lee et al., 2023) combined RoBERTa with an enhanced Bidirectional GRU (BiGRU) to boost scoring accuracy. Recent work has also begun to explore the use of large language models (LLMs), which have shown strong performance in AES tasks (Xiao et al., 2025).
However, most of these approaches primarily focus on local word sequences and often overlook the global relationships between words (Yao et al., 2019). To address this limitation, GCNs have emerged as a promising technique for capturing global dependencies within textual data (Ren et al., 2022; Bhatti et al., 2023). Building on this, the present study integrates Transformer-based contextual embeddings with GCNs for multidimensional essay scoring. Transformer models, such as BERT and DeBERTa, provide rich, context-dependent representations of essays that effectively capture semantic features. By feeding these embeddings into a GCN, the proposed hybrid approach leverages the strengths of both architectures: the deep semantic understanding from Transformers and the global relational modeling from GCNs. This combination enhances predictive performance and contributes to more accurate and robust AES outcomes.
3 Methodology
This section presents TransGAT, a hybrid method developed for analytic AES. The method consists of two main components: a fine-tuned Transformer-based model and a Transformer–GAT model. The first component extracts contextual embeddings that capture the semantic features of each essay. The second component, the Transformer–GAT model, extends the fine-tuned Transformer by integrating it with a GAT to effectively model both semantic content and syntactic structure. Within this component, two-stream predictions are performed by pairing each Transformer with a separate GAT. In each pair, the first stream generates essay-level predictions using the Transformer, while the second uses Transformer token representations within GAT, where edges are constructed based on syntactic dependencies. A detailed explanation of each component is provided in the following subsections, with the overall architecture illustrated in Figure 1.
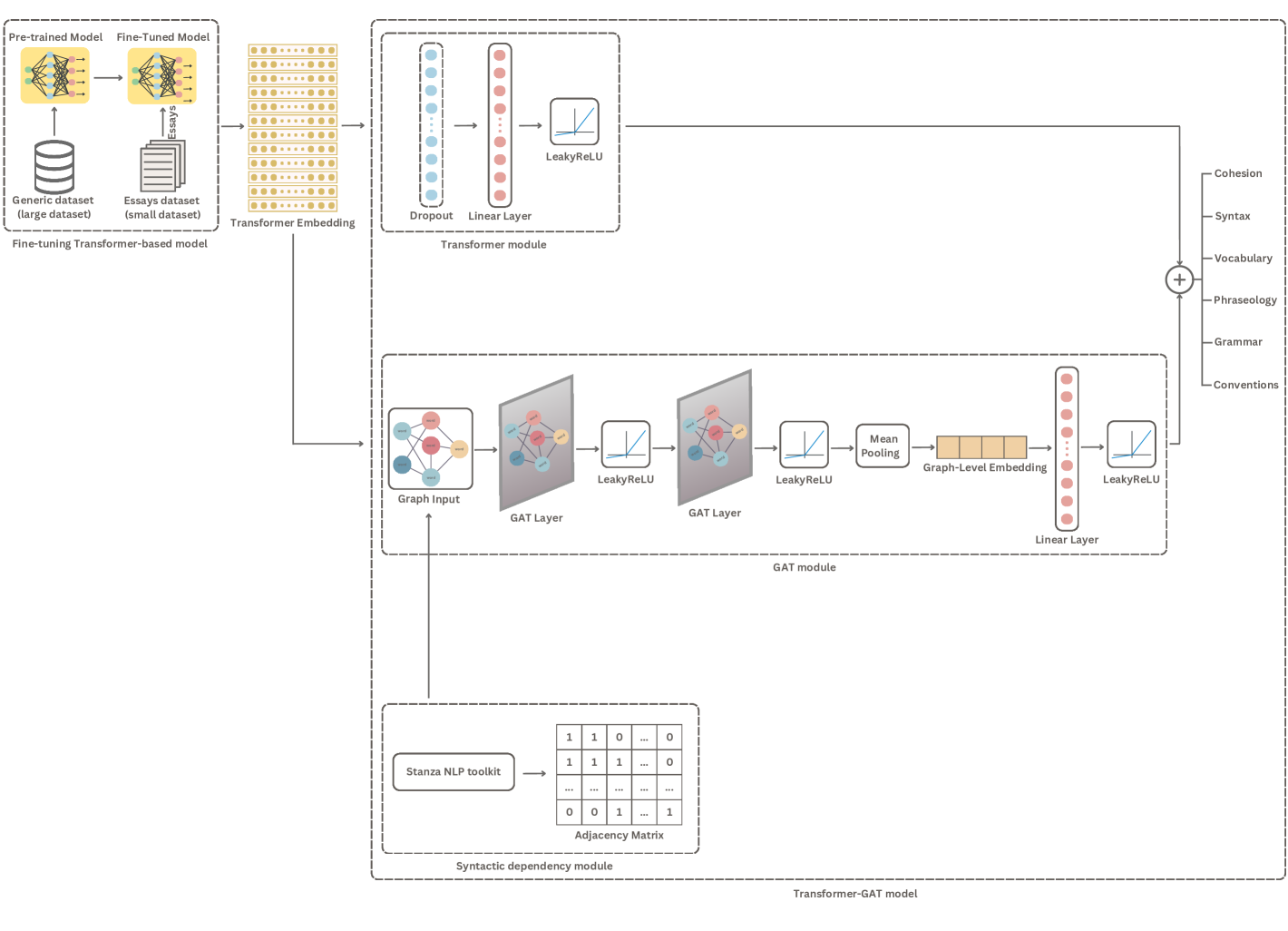
3.1 Fine-tuning Transformer-based model
Transformer-based language models like BERT have demonstrated remarkable performance in NLP tasks (Gillioz et al., 2020), building upon the Transformer architecture originally proposed by Vaswani et al. (Vaswani, 2017). Unlike traditional sequential models, the Transformer uses an encoder-decoder structure that processes entire input sequences simultaneously. Although it does not inherently encode word order, it incorporates positional encoding to retain sequence information, ensuring that word representations vary based on their positions. The self-attention mechanism allows the model to capture dependencies between all tokens in a sequence (Vaswani, 2017).
These models are highly effective at learning general-purpose language representations from large-scale unlabeled corpora, which can be transferred to various downstream tasks through transfer learning. This process involves unsupervised pre-training on extensive text data, followed by supervised fine-tuning on task-specific datasets to adapt the model to the target domain. This strategy often yields superior performance compared to training models from scratch (Schomacker and Tropmann-Frick, 2021).
This study evaluates the performance of three Transformer-based pre-trained models on the AES task, using the large version of each model for comparison. Each model was fine-tuned on the AES datasets to generate embeddings tailored to the data, which then served as the foundation for further processing.
-
1.
BERT, short for ”Bidirectional Encoder Representations from Transformers,” is a foundational model in natural language processing that introduced a deep bidirectional approach to language understanding. The large version of BERT, known as BERT-large, consists of 24 layers and 340 million parameters. It is pre-trained on large corpora using masked language modeling and next-sentence prediction tasks, allowing it to capture context from both directions in a sentence. BERT-large has achieved strong performance across a wide range of NLP benchmarks (Devlin et al., 2019).
-
2.
RoBERTa, short for ”Robustly Optimized BERT Pre-training Approach,” replicates the original BERT by optimizing hyperparameters and significantly increasing the size of the training data. The RoBERTa-large model, with 24 layers, is pre-trained on five diverse English-language datasets totaling over 160GB of text. RoBERTa has achieved state-of-the-art results in several downstream tasks across multiple benchmarks (Liu et al., 2019).
-
3.
DeBERTa, short for ”Decoding-enhanced BERT with Disentangled Attention,” further refines the BERT and RoBERTa models by introducing two novel techniques: a disentangled attention mechanism and an enhanced masked decoder. The large version of DeBERTa, DeBERTa-large, improves pretraining efficiency and model performance (He et al., 2021).
3.2 Transformer-GAT model
The model consists of four interconnected modules: a Transformer module, a syntactic dependency module, a GAT module, and a fusion module. The Transformer module leverages a fine-tuned Transformer model (described earlier) to extract contextualized embeddings from the input text, which are then passed through a dense layer to generate essay-level predictions. At the same time, the syntactic dependency module employs the Stanza toolkit to parse the syntactic structure of the text and to represent it as an adjacency matrix. In the GAT module, the contextualized word embeddings obtained from the fine-tuned Transformer model are used as node features, while the edges of the graph are defined by syntactic dependencies extracted by the syntactic dependency module. This graph is processed through two GAT layers, followed by a global mean pooling to generate a graph-level representation for prediction. Finally, the outputs of the Transformer and the GAT modules are fused to produce the final analytic scores.
3.2.1 Transformer module
This module uses the fine-tuned transformer model from the first component, which has already been trained on the essay dataset. At this stage, the Transformer model is frozen, which means that its weights are not updated during this step. Freezing the model allows us to utilize the pre-learned representations obtained during fine-tuning without further modification.
The Transformer module extracts contextualized embeddings for the input text. Specifically, it uses the embedding of the special [CLS] token, which serves as a summary representation of the entire essay. This [CLS] token embedding, denoted as , is then passed through a dense (fully connected) layer followed by a non-linear activation function, LeakyReLU, to generate predictions at the essay level for various analytic aspects.
Formally, the dense layer applies a linear transformation using a weight matrix and a bias vector , where is the embedding dimension and is the number of analytic aspects to predict. The output vector is computed as:
| (1) |
Each element of the output vector corresponds to a predicted score for one of the analytic aspects of the essay (such as grammar, cohesion, vocabulary, etc.). This approach enables the model to take advantage of the rich semantic information captured by the Transformer’s [CLS] token embedding while producing multi-dimensional outputs aligned with the analytical scoring criteria.
3.2.2 Syntactic dependency module
This module converts each essay into a syntactic text graph to incorporate structural linguistic information. The Stanza NLP toolkit is employed to analyze the syntactic dependency tree of the input text, which identifies grammatical relationships between words such as subject–verb or modifier–noun connections. This tree is then transformed into an adjacency matrix, where each entry indicates the presence of a direct syntactic relationship between a pair of words.
Based on this matrix, a graph is constructed, where nodes (with ) correspond to the tokens of an essay and denote the word embeddings of the input tokens generated by the fine-tuned Transformer model, and edges represent syntactic dependencies between the tokens. A dependency adjacency matrix is built, where if there is a syntactic relation between tokens and , and 0 otherwise. The adjacency matrix is then converted into a sparse coordinate format for graph construction.
| (2) |
The entire graph construction process is illustrated in Algorithm 1.
To enrich the graph structure, the syntactic graph is treated as undirected. This representation enables the model to capture syntactic structure more effectively, which is crucial for assessing analytic aspects such as grammar, clarity, and sentence complexity.
3.2.3 GAT module
After constructing the text graph for each document, information is propagated and updated between nodes using the GAT to obtain node representations that contain both text syntax and sequence information. Unlike the standard self-attention mechanism, which assigns attention weights globally across all nodes, the graph attention mechanism operates locally and does not require knowledge of the entire graph structure. This allows the model to flexibly assign different weights to neighboring nodes and to parallelize computation across all nodes efficiently.
The GAT accepts two inputs: the node features, which are the word embeddings produced by the fine-tuned Transformer module,
where each , is the number of nodes, and is the number of features per node. The second input is the adjacency matrix , obtained through the syntactic dependency module, which captures neighbor relationships among nodes.
Specifically, for a node and one of its neighbors , the attention coefficient is computed as:
| (3) |
where:
-
1.
is a learnable weight matrix,
-
2.
is a learnable attention vector,
-
3.
⊤ denotes transposition,
-
4.
indicates vector concatenation,
-
5.
LeakyReLU is the non-linear activation function.
The attention coefficients are then normalized using the softmax function:
| (4) |
where is the set of neighbors of node .
Using the normalized attention weights, the updated representation of node is computed as:
| (5) |
where denotes the LeakyReLU activation function.
The GAT layer produces updated node representations:
where each .
After two successive GAT layers, the updated node features are aggregated into a fixed-size graph-level representation using global mean pooling:
| (6) |
where denotes the node representation after the second GAT layer, and is the number of nodes.
This operation computes the average of all node embeddings across each feature dimension, resulting in a single graph-level vector representing the entire essay. The graph-level representation is then passed through a fully connected linear layer followed by a LeakyReLU activation function to produce the final prediction:
| (7) |
where and are trainable parameters, is the graph-level embedding, and denotes the LeakyReLU activation function.
3.2.4 Fusion module
The final essay scores are computed as a combination of both the Transformer and GAT modules:
| (8) |
where represents the predicted scores across assessment criteria.
By incorporating Transformer-based contextual embeddings alongside d-
ependency-parsing-based graph attention, the model effectively captures both semantic meaning and syntactic structure, resulting in a more robust AES system.
3.3 Training Procedure
Both the Transformer and Transformer-GAT models are trained using Mean Squared Error (MSE) loss:
| (9) |
where:
-
1.
is the ground-truth score for the -th analytic trait,
-
2.
is the predicted score for the -th analytic trait,
-
3.
indexes the six traits: cohesion, syntax, vocabulary, phraseology, grammar, and conventions,
-
4.
is the average loss across all six traits.
4 Experiments and Discussion
This section starts by introducing the datasets utilized in the study, then outlines the approach used for performance evaluation. It proceeds with a description of the experimental setup. Following that, the experimental results are presented along with an in-depth analysis and interpretation. Lastly, the discussion compares the performance of the proposed TransGAT method against baseline models.
4.1 Dataset
The English Language Learner Insight, Proficiency, and Skills Evaluation (ELLIPSE) corpus (Crossley et al., 2023) is a publicly available dataset containing approximately 6,500 essays written by English Language Learners (ELLs) in grades 8–12. These essays were collected from statewide standardized assessments in the United States and span 29 distinct writing prompts. Each essay is annotated with both holistic and analytic proficiency scores, including evaluations of cohesion, syntax, vocabulary, phraseology, grammar, and conventions. On average, the essays contain around 430 words, most ranging between 250 and 500. Scoring is performed on a scale from 1.0 to 5.0, in 0.5-point increments. Two trained human raters evaluated each essay to ensure scoring reliability. This corpus addresses the limitations of previous analytic datasets, such as ASAP++ (Mathias and Bhattacharyya, 2018), which extended the original ASAP dataset to support analytic scoring but retained many of its constraints.
4.2 Performance Evaluation
Quadratic Weighted Kappa (QWK) is a statistical metric used to assess the level of agreement between predicted and actual scores, making it especially well-suited for evaluating AES systems. Unlike basic accuracy measures, QWK accounts for the extent of disagreement between predicted and true scores, offering a more detailed evaluation of a model’s performance (Ramnarain-Seetohul et al., 2022).
The QWK score is computed using the following formula (Ramnarain-Seetohul et al., 2022):
| (10) |
where:
-
1.
denotes the observed agreement matrix, which reflects how often each predicted score aligns with the actual score.
-
2.
refers to the expected agreement matrix, indicating the level of agreement that would be expected by random chance.
-
3.
represents the weight matrix, usually defined as:
(11) where and correspond to the predicted and actual score categories, and is the total number of distinct score levels.
QWK scores range from -1 to 1. A score of 1 reflects perfect agreement between the predicted and actual values, while a score of 0 suggests agreement no better than random chance. Negative values imply systematic disagreement. QWK incorporates a quadratic penalty, which means that larger differences between predicted and actual scores are penalized more heavily. This feature is especially important in educational settings like AES, where accurate scoring is essential, and significant errors can undermine the model’s credibility. As outlined in Table 1, QWK scores can be interpreted to assess the strength of agreement, with values below 0 indicating no agreement and those between 0.81 and 1.00 suggesting near-perfect agreement (Ramnarain-Seetohul et al., 2022).
| Kappa Value | Interpretation |
|---|---|
| 0 | No agreement |
| 0.01 - 0.20 | Slight agreement |
| 0.21 - 0.40 | Fair agreement |
| 0.41 - 0.60 | Moderate agreement |
| 0.61 - 0.80 | Substantial agreement |
| 0.81 - 1.00 | Almost perfect agreement |
4.3 Experimental Setup
The experimental setup includes configurations for both Transformer-based models and GAT models. The maximum input sequence length was determined based on model capacity: tokens for DeBERTaV3 to leverage its ability to process longer inputs, and tokens for other models, in line with their architectural constraints. The tokenizers were extended to recognize special tokens representing paragraph breaks (\n) and double spaces, which are important for preserving the linguistic structure of essays. Training and evaluation were conducted using a batch size of , and the models that achieved the best performance on the validation set were saved for subsequent analysis.
The GAT model comprised two layers and four attention heads and employed the LeakyReLU activation function. Both model types were optimized using the AdamW optimizer. The learning rate was set to for the Transformer models and for the Transformer-GAT model. A weight decay of was applied only to the Transformer models. Both setups utilized a cosine learning rate scheduler and were trained for six epochs. No dropout was applied during training, as this was found to improve regression performance.
4.4 Experimental Results
Extensive experiments were conducted by systematically varying several key factors to optimize model performance. These included using different dependency parsing tools—such as spaCy and Stanza—to construct the graph structure, tuning dropout rates to prevent overfitting, applying distinct learning rates for the Transformer and GAT components to balance their training, experimenting with various optimizers (e.g., Adam, AdamW), and testing different learning rate schedulers. Additionally, the number of GAT layers and attention heads, choice of activation functions (e.g., ReLU, LeakyReLU), and batch sizes were adjusted. These variations helped identify the optimal configuration for each analytic scoring dimension. The best results from these experiments are presented in Table 2, which reports QWK scores on the ELLIPSE dataset across six analytic scoring dimensions: Cohesion, Syntax, Vocabulary, Phraseology, Grammar, and Conventions.
| Model | Avg. QWK | Cohesion | Syntax | Vocabulary | Phraseology | Grammar | Conventions |
|---|---|---|---|---|---|---|---|
| BERT-large-GAT | 0.808 | 0.799 | 0.809 | 0.796 | 0.782 | 0.861 | 0.801 |
| RoBERTa-large-GAT | 0.854 | 0.852 | 0.852 | 0.825 | 0.861 | 0.877 | 0.859 |
| DeBERTaV3-large-GAT | 0.833 | 0.877 | 0.853 | 0.813 | 0.836 | 0.872 | 0.744 |
RoBERTa-large-GAT achieved the highest average QWK score of , reflecting its top performance in four out of six analytic dimensions among the GAT variants: Vocabulary (), Phraseology (), Grammar (), and Conventions (). In contrast, the DeBERTaV3-large-GAT model demonstrated strong performance in the remaining two dimensions, Cohesion () and Syntax (), but its lower score in Conventions () contributed to a reduced overall average.
These findings underscore RoBERTa’s ability to capture complex linguistic features, making it more suitable for this task than DeBERTaV3. One possible explanation is that RoBERTa was pre-trained on a significantly larger corpus (160GB of text) compared to DeBERTaV3’s 78GB, which may enhance its effectiveness on AES tasks—despite DeBERTaV3 generally outperforming RoBERTa in other benchmarks (He et al., 2020).
4.5 Discussion
Table 3 presents a comparative analysis of the proposed TransGAT method against two baseline studies, as these are the only studies that utilized the ELLIPSE dataset.
| Model Group | Study | Model | Avg. QWK | Cohesion | Syntax | Vocabulary | Phraseology | Grammar | Conventions |
|---|---|---|---|---|---|---|---|---|---|
| Transformers Models | Sun et al. Sun and Wang (2024) | roberta-base | 0.825 | 0.81 | 0.83 | 0.84 | 0.80 | 0.83 | 0.84 |
| Chen et al. Chen et al. (2024) | debertaV3-base | 0.685 | 0.63 | 0.69 | 0.67 | 0.69 | 0.72 | 0.71 | |
| Transformer-GAT | TransGAT method | bert-large-GAT | 0.808 | 0.799 | 0.809 | 0.796 | 0.782 | 0.861 | 0.801 |
| roberta-large-GAT | 0.854 | 0.852 | 0.852 | 0.825 | 0.861 | 0.877 | 0.859 | ||
| debertaV-large-GAT | 0.833 | 0.877 | 0.853 | 0.813 | 0.836 | 0.872 | 0.744 |
The baseline studies, represented by Sun et al. (Sun and Wang, 2024) and Chen et al. (Chen et al., 2024), employ RoBERTa-base and DeBERTaV3-base models, respectively. Sun et al.’s RoBERTa-base achieve relatively strong performance across most dimensions, with a notably high score in Vocabulary (). Conversely, Chen et al.’s DeBERTaV3-base, despite being more recent, performs relatively lower across all dimensions, indicating a less effective adaptation to this task.
The TransGAT method, which integrates GAT with Transformer-based models, consistently improves performance over the baseline models. Specifically, the RoBERTa-large-GAT variant shows the strongest results among the baseline studies, achieving the highest scores in three dimensions: Phraseology (), Grammar (), and Conventions (). Meanwhile, the DeBERTaV3-large-GAT variant excels in Cohesion () and Syntax (), surpassing the RoBERTa-large-GAT model in these dimensions.
Although the TransGAT method generally outperforms baseline models across most analytic dimensions, it shows relatively lower performance in the Vocabulary dimension compared to Sun et al.’s RoBERTa-base model (). This could be attributed to the fact that vocabulary scoring often relies heavily on surface-level lexical richness and diversity, which the baseline RoBERTa-base model may capture more directly due to its simpler architecture and focus on token-level representations. In contrast, the integration of GAT in TransGAT emphasizes relational and contextual information across essays, which may reduce attention to details lexical features critical for vocabulary scoring.
Overall, the results highlight the advantage of incorporating GAT with Transformer architectures. The TransGAT method effectively captures richer contextual and relational information between essays, enabling superior modeling of complex linguistic features critical to AES. This is particularly evident in the RoBERTa-large-GAT model’s performance, which outperforms the baseline RoBERTa-base model across almost all analytic dimensions.
5 Conclusion
This study introduced TransGAT, a novel method for analytic AES that effectively combines the strengths of Transformer-based models and GAT. The proposed approach consists of two key components: a fine-tuned Transformer that generates rich contextual embeddings, and a GAT that incorporates syntactic structure through attention-based graph modeling. This hybrid design allows TransGAT to capture both semantic content and intra-essay structural dependencies, enabling a more accurate and nuanced evaluation of writing quality.
A key innovation in TransGAT is its two-stream prediction mechanism, where one stream produces essay-level predictions using the Transformer, while the other leverages token-level Transformer outputs within a GAT framework, using syntactic dependencies to guide edge construction. This dual approach allows the model to focus dynamically on the most relevant linguistic and structural features, which is particularly important in AES, where variations in organization, grammar, and coherence affect scoring.
Extensive experiments conducted on analytic AES tasks demonstrated that TransGAT consistently outperforms baseline models across multiple scoring dimensions. The attention-based relational modeling within GAT enhances the model’s ability to differentiate between essays with subtle variations in quality, leading to more reliable predictions. These results underscore the benefit of integrating deep language representations with graph-based relational reasoning in educational NLP.
Looking forward, future work will explore expanding TransGAT with heterogeneous graph structures that include both word-level and essay-level nodes, allowing the model to capture more complex interactions across and within essays. Another promising direction is adapting TransGAT for morphologically rich languages such as Arabic. The unique linguistic features of Arabic—including its root-based morphology, optional diacritics, and diverse dialects—pose challenges for conventional NLP pipelines. Addressing these through Arabic-specific tokenizers, morphological analyzers, and syntactic parsers will help evaluate the cross-linguistic generalizability of the proposed approach and contribute to the development of AES tools for underrepresented languages.
Acknowledgments
The project was funded by KAU Endowment (WAQF) at king Abdulaziz University, Jeddah, Saudi Arabia. The authors, therefore, acknowledge with thanks WAQF and the Deanship of Scientific Research (DSR) for technical and financial support.
References
- Ait Khayi and Rus (2020) Ait Khayi, N., Rus, V., 2020. Graph convolutional networks for student answers assessment, in: Text, Speech, and Dialogue: 23rd International Conference, TSD 2020, Brno, Czech Republic, September 8–11, 2020, Proceedings 23, Springer. pp. 532–540.
- AlBadani et al. (2022) AlBadani, B., Shi, R., Dong, J., Al-Sabri, R., Moctard, O.B., 2022. Transformer-based graph convolutional network for sentiment analysis. Applied Sciences 12, 1316.
- Beseiso and Alzahrani (2020) Beseiso, M., Alzahrani, S., 2020. An empirical analysis of bert embedding for automated essay scoring. International Journal of Advanced Computer Science and Applications 11.
- Beseiso et al. (2021) Beseiso, M., Alzubi, O.A., Rashaideh, H., 2021. A novel automated essay scoring approach for reliable higher educational assessments. Journal of Computing in Higher Education 33, 727–746.
- Bhatti et al. (2023) Bhatti, U.A., Tang, H., Wu, G., Marjan, S., Hussain, A., 2023. Deep learning with graph convolutional networks: An overview and latest applications in computational intelligence. International Journal of Intelligent Systems 2023, 8342104.
- Cai (2019) Cai, C., 2019. Automatic essay scoring with recurrent neural network, in: Proceedings of the 3rd International Conference on High Performance Compilation, Computing and Communications, pp. 1–7.
- Cai et al. (2018) Cai, H., Zheng, V.W., Chang, K.C.C., 2018. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE transactions on knowledge and data engineering 30, 1616–1637.
- Chen and Li (2018) Chen, M., Li, X., 2018. Relevance-based automated essay scoring via hierarchical recurrent model, in: 2018 International Conference on Asian Language Processing (IALP), IEEE. pp. 378–383.
- Chen et al. (2024) Chen, S., Lan, Y., Yuan, Z., 2024. A multi-task automated assessment system for essay scoring, in: International Conference on Artificial Intelligence in Education, Springer. pp. 276–283.
- Chen and Li (2023) Chen, Y., Li, X., 2023. Pmaes: prompt-mapping contrastive learning for cross-prompt automated essay scoring, in: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pp. 1489–1503.
- Chen et al. (2020) Chen, Z., Quan, Y., Qian, D., 2020. Automatic essay scoring model based on multi-channel cnn and lstm, in: BenchCouncil International Federated Intelligent Computing and Block Chain Conferences, Springer. pp. 337–346.
- Cho et al. (2024) Cho, M., Huang, J.X., Kwon, O.W., 2024. Dual-scale bert using multi-trait representations for holistic and trait-specific essay grading. ETRI Journal 46, 82–95.
- Crossley et al. (2023) Crossley, S., Tian, Y., Baffour, P., Franklin, A., Kim, Y., Morris, W., Benner, M., Picou, A., Boser, U., 2023. The english language learner insight, proficiency and skills evaluation (ellipse) corpus. International Journal of Learner Corpus Research 9, 248–269.
- Devlin et al. (2019) Devlin, J., Chang, M.W., Lee, K., Toutanova, K., 2019. Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186.
- Do et al. (2023) Do, H., Kim, Y., Lee, G.G., 2023. Prompt-and trait relation-aware cross-prompt essay trait scoring, in: Findings of the Association for Computational Linguistics: ACL 2023, pp. 1538–1551.
- Doewes and Pechenizkiy (2020) Doewes, A., Pechenizkiy, M., 2020. Structural explanation of automated essay scoring., in: EDM.
- Gao and Huang (2021) Gao, W., Huang, H., 2021. A gating context-aware text classification model with bert and graph convolutional networks. Journal of Intelligent & Fuzzy Systems 40, 4331–4343.
- Gillioz et al. (2020) Gillioz, A., Casas, J., Mugellini, E., Abou Khaled, O., 2020. Overview of the transformer-based models for nlp tasks, in: 2020 15th Conference on computer science and information systems (FedCSIS), IEEE. pp. 179–183.
- Haitao and Fangbing (2022) Haitao, W., Fangbing, L., 2022. A text classification method based on lstm and graph attention network [j]. Connection Science 34, 2466–2480.
- He et al. (2021) He, P., Gao, J., Chen, W., 2021. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing (2021). URL https://arxiv. org/abs/2111.09543 .
- He et al. (2020) He, P., Liu, X., Gao, J., Chen, W., 2020. Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654 .
- Hussein et al. (2020) Hussein, M.A., Hassan, H.A., Nassef, M., 2020. A trait-based deep learning automated essay scoring system with adaptive feedback. International Journal of Advanced Computer Science and Applications 11.
- Janda et al. (2019) Janda, H.K., Pawar, A., Du, S., Mago, V., 2019. Syntactic, semantic and sentiment analysis: The joint effect on automated essay evaluation. IEEE Access 7, 108486–108503.
- Kipf and Welling (2017) Kipf, T.N., Welling, M., 2017. Semi-supervised classification with graph convolutional networks, in: International Conference on Learning Representations (ICLR).
- Lee and Nam (2021) Lee, I., Nam, H., 2021. Automated essay scoring using recurrence over bert (robert). Applied Linguistics 37, 7–28.
- Lee et al. (2023) Lee, Y., Jeong, S., Kim, H., Kim, T.i., Choi, S.W., Kim, H., 2023. Nc2t: Novel curriculum learning approaches for cross-prompt trait scoring, in: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2204–2208.
- Li et al. (2023) Li, F., Xi, X., Cui, Z., Li, D., Zeng, W., 2023. Automatic essay scoring method based on multi-scale features. Applied Sciences 13, 6775.
- Li and Ng (2024a) Li, S., Ng, V., 2024a. Automated essay scoring: Recent successes and future directions, in: Proceedings of the 33rd International Joint Conference on Artificial Intelligence, Jeju, Republic of Korea.
- Li and Ng (2024b) Li, S., Ng, V., 2024b. Conundrums in cross-prompt automated essay scoring: Making sense of the state of the art, in: Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: long papers), pp. 7661–7681.
- Li and Ng (2024c) Li, S., Ng, V., 2024c. Icle++: Modeling fine-grained traits for holistic essay scoring, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 8458–8478.
- Li et al. (2018) Li, X., Chen, M., Nie, J., Liu, Z., Feng, Z., Cai, Y., 2018. Coherence-based automated essay scoring using self-attention, in: Chinese computational linguistics and natural language processing based on naturally annotated big data. Springer, pp. 386–397.
- Liu et al. (2020) Liu, X., You, X., Zhang, X., Wu, J., Lv, P., 2020. Tensor graph convolutional networks for text classification, in: Proceedings of the AAAI conference on artificial intelligence, pp. 8409–8416.
- Liu et al. (2019) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V., 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 .
- Lohmann et al. (2024) Lohmann, J.F., Junge, F., Möller, J., Fleckenstein, J., Trüb, R., Keller, S., Jansen, T., Horbach, A., 2024. Neural networks or linguistic features?-comparing different machine-learning approaches for automated assessment of text quality traits among l1-and l2-learners’ argumentative essays. International Journal of Artificial Intelligence in Education , 1–40.
- Lu et al. (2020) Lu, Z., Du, P., Nie, J.Y., 2020. Vgcn-bert: augmenting bert with graph embedding for text classification, in: European Conference on Information Retrieval, Springer. pp. 369–382.
- Ma et al. (2021) Ma, J., Li, X., Chen, M., Yang, W., 2021. Enhanced hierarchical structure features for automated essay scoring, in: China Conference on Information Retrieval, Springer. pp. 168–179.
- Madala et al. (2018) Madala, D.S.V., Gangal, A., Krishna, S., Goyal, A., Sureka, A., 2018. An empirical analysis of machine learning models for automated essay grading. Technical Report. PeerJ Preprints.
- Mathias and Bhattacharyya (2018) Mathias, S., Bhattacharyya, P., 2018. Asap++: Enriching the asap automated essay grading dataset with essay attribute scores, in: Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018).
- Mathias and Bhattacharyya (2020) Mathias, S., Bhattacharyya, P., 2020. Can neural networks automatically score essay traits?, in: Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, pp. 85–91.
- Mayfield and Black (2020) Mayfield, E., Black, A.W., 2020. Should you fine-tune bert for automated essay scoring?, in: Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, pp. 151–162.
- Misgna et al. (2025) Misgna, H., On, B.W., Lee, I., Choi, G.S., 2025. A survey on deep learning-based automated essay scoring and feedback generation. Artificial Intelligence Review 58, 1–40.
- Muangkammuen and Fukumoto (2020) Muangkammuen, P., Fukumoto, F., 2020. Multi-task learning for automated essay scoring with sentiment analysis, in: Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: Student Research Workshop, pp. 116–123.
- Ormerod (2022) Ormerod, C.M., 2022. Mapping between hidden states and features to validate automated essay scoring using deberta models. Psychological Test and Assessment Modeling 64, 495–526.
- Ramesh and Sanampudi (2022) Ramesh, D., Sanampudi, S.K., 2022. An automated essay scoring systems: a systematic literature review. Artificial Intelligence Review 55, 2495–2527.
- Ramnarain-Seetohul et al. (2022) Ramnarain-Seetohul, V., Bassoo, V., Rosunally, Y., 2022. Similarity measures in automated essay scoring systems: A ten-year review. Education and Information Technologies 27, 5573–5604.
- Ren et al. (2022) Ren, H., Lu, W., Xiao, Y., Chang, X., Wang, X., Dong, Z., Fang, D., 2022. Graph convolutional networks in language and vision: A survey. Knowledge-Based Systems 251, 109250.
- Ridley et al. (2021) Ridley, R., He, L., Dai, X.y., Huang, S., Chen, J., 2021. Automated cross-prompt scoring of essay traits, in: Proceedings of the AAAI conference on artificial intelligence, pp. 13745–13753.
- Salim et al. (2019) Salim, Y., Stevanus, V., Barlian, E., Sari, A.C., Suhartono, D., 2019. Automated english digital essay grader using machine learning, in: 2019 IEEE International Conference on Engineering, Technology and Education (TALE), IEEE. pp. 1–6.
- Schomacker and Tropmann-Frick (2021) Schomacker, T., Tropmann-Frick, M., 2021. Language representation models: An overview. Entropy 23, 1422.
- Sharma et al. (2021) Sharma, A., Kabra, A., Kapoor, R., 2021. Feature enhanced capsule networks for robust automatic essay scoring, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer. pp. 365–380.
- Sharma and Goyal (2020) Sharma, S., Goyal, A., 2020. Automated essay grading: An empirical analysis of ensemble learning techniques, in: Computational Methods and Data Engineering: Proceedings of ICMDE 2020, Volume 2. Springer, pp. 343–362.
- She et al. (2022) She, X., Chen, J., Chen, G., 2022. Joint learning with bert-gcn and multi-attention for event text classification and event assignment. IEEE Access 10, 27031–27040.
- Shin and Gierl (2022) Shin, J., Gierl, M.J., 2022. Evaluating coherence in writing: Comparing the capacity of automated essay scoring technologies. Journal of Applied Testing Technology , 04–20.
- Sun and Wang (2024) Sun, K., Wang, R., 2024. Automatic essay multi-dimensional scoring with fine-tuning and multiple regression. arXiv preprint arXiv:2406.01198 .
- Susanto et al. (2023) Susanto, H., Gunawan, A.A.S., Hasani, M.F., 2023. Development of automated essay scoring system using deberta as a transformer-based language model, in: Proceedings of the Computational Methods in Systems and Software. Springer, pp. 202–215.
- Tan et al. (2023) Tan, H., Wang, C., Duan, Q., Lu, Y., Zhang, H., Li, R., 2023. Automatic short answer grading by encoding student responses via a graph convolutional network. Interactive Learning Environments 31, 1636–1650.
- Uto (2021) Uto, M., 2021. A review of deep-neural automated essay scoring models. Behaviormetrika 48, 459–484.
- Uto and Okano (2020) Uto, M., Okano, M., 2020. Robust neural automated essay scoring using item response theory, in: International Conference on Artificial Intelligence in Education, Springer, Cham. pp. 549–561.
- Vaswani (2017) Vaswani, A., 2017. Attention is all you need. Advances in Neural Information Processing Systems .
- Veličković et al. (2017) Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y., 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 .
- Vrahatis et al. (2024) Vrahatis, A.G., Lazaros, K., Kotsiantis, S., 2024. Graph attention networks: a comprehensive review of methods and applications. Future Internet 16, 318.
- Wang (2023) Wang, J., 2023. A study of scoring english tests using an automatic scoring model incorporating semantics. Automatic Control and Computer Sciences 57, 514–522.
- Wangkriangkri et al. (2020) Wangkriangkri, P., Viboonlarp, C., Rutherford, A.T., Chuangsuwanich, E., 2020. A comparative study of pretrained language models for automated essay scoring with adversarial inputs, in: 2020 IEEE REGION 10 CONFERENCE (TENCON), IEEE. pp. 875–880.
- West et al. (2019) West, H., Malcolm, G., Keywood, S., Hill, J., 2019. Writing a successful essay. Journal of Geography in Higher Education 43, 609–617.
- Xia et al. (2019) Xia, L., Liu, J., Zhang, Z., 2019. Automatic essay scoring model based on two-layer bi-directional long-short term memory network, in: Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, pp. 133–137.
- Xiao et al. (2025) Xiao, C., Ma, W., Song, Q., Xu, S.X., Zhang, K., Wang, Y., Fu, Q., 2025. Human-ai collaborative essay scoring: A dual-process framework with llms, in: Proceedings of the 15th International Learning Analytics and Knowledge Conference, pp. 293–305.
- Xue et al. (2021) Xue, J., Tang, X., Zheng, L., 2021. A hierarchical bert-based transfer learning approach for multi-dimensional essay scoring. Ieee Access 9, 125403–125415.
- Yang et al. (2020) Yang, R., Cao, J., Wen, Z., Wu, Y., He, X., 2020. Enhancing automated essay scoring performance via fine-tuning pre-trained language models with combination of regression and ranking, in: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 1560–1569.
- Yang and Zhong (2021) Yang, Y., Zhong, J., 2021. Automated essay scoring via example-based learning, in: International Conference on Web Engineering, Springer. pp. 201–208.
- Yao et al. (2019) Yao, L., Mao, C., Luo, Y., 2019. Graph convolutional networks for text classification, in: Proceedings of the AAAI conference on artificial intelligence, pp. 7370–7377.
- Zhou et al. (2021) Zhou, X., Yang, L., Fan, X., Ren, G., Yang, Y., Lin, H., 2021. Self-training vs pre-trained embeddings for automatic essay scoring, in: China Conference on Information Retrieval, Springer. pp. 155–167.
- Zhu and Sun (2020) Zhu, W., Sun, Y., 2020. Automated essay scoring system using multi-model machine learning. MLNLP, BDIOT, ITCCMA, CSITY, DTMN, AIFZ, SIGPRO .
- Zupanc and Bosnić (2018) Zupanc, K., Bosnić, Z., 2018. Increasing accuracy of automated essay grading by grouping similar graders, in: Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics, pp. 1–6.