TripleRE: Knowledge Graph Embeddings via Tripled Relation Vectors
Abstract
Translation-based knowledge graph embedding has been one of the most important branches for knowledge representation learning since TransE came out. Although many translation-based approaches have achieved some progress in recent years, the performance was still unsatisfactory. This paper proposes a novel knowledge graph embedding method named TripleRE with two versions. The first version of TripleRE creatively divide the relationship vector into three parts. The second version takes advantage of the concept of residual and achieves better performance. In addition, attempts on using NodePiece to encode entities achieved promising results in reducing the parametric size, and solved the problems of scalability. Experiments show that our approach achieved state-of-the-art performance on the large-scale knowledge graph dataset ogbl-wikikg2, and competitive performance on other datasets.
1 Introduction
Knowledge graphs store huge amounts of structured data in the form of triples, with projects such as WordNet Miller (1995), Freebase Bollacker et al. (2008), YAGO Suchanek et al. (2007) and DBpedia Lehmann et al. (2015). They have gained widespread attraction from their successful use in tasks such as question answering Bordes et al. (2014), semantic parsing Berant et al. (2013), and named entity disambiguation Zheng et al. (2012) and so on.
In recent years, knowledge representation is one of the hottest topics in natural language processing as it can be applied to various tasks based on knowledge graphs, including semantic parsing, named entity disambiguation, question answering, etc. A knowledge graph contains finite number of facts represented by triplets. A triplet (h, r, t) contains three components, where h, r, t represent head entities, relations and tail entities, respectively. Knowledge representation is one of the most essential parts in research of knowledge graphs. The mission for knowledge representation is to leverage an appropriate mechanism to represent three components of triplets in numeric vectors. An ideal mechanism for representing knowledge is capable to map the components of triplets to the pre-defined vector space, such as Euclidean space, along with accuracy and some degrees of uncertainty.
The process of knowledge representation learning could be simply summarized into two phases: the encoding phase and the decoding phase. (i) The encoding phase: The purpose of the encoding phase is to set the embeddings of three components. (ii) The decoding phase: This phase usually includes scoring functions, which are equations include three components, to measure the plausibility of triplets. In other words, the decoding phase is expected to discriminate factual triplets (positive samples) and noisy triplets (negative samples) which are generated according to a selected sampling strategy.
Although many distinctive signs of progress have been achieved in recent years, from our perspectives, one of the most inspired attempts is the blending of information from the structure itself and the logical information embedded in the structure. Knowledge graphs can be viewed as a special kind of directed graphs, where nodes represent entities and edges represent relations. Based on the properties of directed graphs, structural information can be extracted by the positional information of entities in knowledge graphs. The positional information of entities generally represents centrality of the entity nodes and the distance to other nodes. Furthermore, the logical information embedded in the structure can be extracted by the pairs of connected nodes, where the connections indicate the correlation of entities, and edges and relations have equivalence.
Previously, most researches leveraged only the information from the structure of triplets and the logical information embedded in the structure in triplets to learn the knowledge representation. TransE Bordes et al. (2013) is the fundamental work of translation-based models. Inspired by TransE Bordes et al. (2013), many variants, including TransHWang et al. (2014), TransRLin et al. (2015), TransAt Qian et al. (2018), RotatE Sun et al. (2019) and PairRE Chao et al. (2020), handled some issues of TransEBordes et al. (2013), and improved the representing capacities. Translation-based models are reputational in semantics translation. However, all those approaches do not leverage any diversified information of graph structures in either the encoding phase or the decoding phase.
Structural information can be leveraged in knowledge representation by two different strategies. The first strategy is to extract structural information in the encoding phase. NodePiece Galkin et al. (2021) introduces an anchor-based approach to fix the size of entity vocabulary. Every entity can be represented by combining of a set of anchors – selected entities. The second strategy is to extract structural information in both the encoding scheme and the decoding scheme. Approaches under this strategy are highly dependent on sub-graph sampling, including GraIL Teru et al. (2020) and RedGNN Zhang and Yao , are usually based on Graph Neural Networks (GNN) Kipf and Welling (2016), and follow message passing scheme Gilmer et al. (2017). However, in addition to training complexity, the interpretability of inference is also unsatisfactory. Hence, from our perspectives, the first strategy is more valuable as it reduces the parametric size, and solves the problems of scalability.
Our approach is inspired by NodePiece Galkin et al. (2021), TransAt Qian et al. (2018) and pairRE Chao et al. (2020). Our approach chooses to take advantage of NodePiece Galkin et al. (2021) in the encoding phase as it can significantly reduce the parameters of models. Then, we introduce a novel decoding method, which is inspired by the sub-relations from PairRE Chao et al. (2020) and the intuitions from TransAt Qian et al. (2018). TransAt Qian et al. (2018) believes when humans consider triple link prediction tasks, they usually make decisions based on context, not just single node and relation. We argue that the scoring function of PairRE Chao et al. (2020) is not complete, and do not follow the hypothesis of translation-based models: . Therefore, we introduce a new decoding phase (scoring function) by adding one more sub-relation term. Since our approach uses three sub-relation terms to build the semantics of entire relations, we followed the naming logic of PairRE Chao et al. (2020) and named our method TripleRE.
Our approach achieved a competitive performance in large scale datasets - ogbl-wikikg2 and ogbl-biokg Hu et al. (2020). On the benchmark ogbl-wikikg2, our method achieved the best performance. Compared with other methods, the amount of parameters is significantly reduced. In addition, experiments show that our work also has better results on small datasets such as FB15k Bordes et al. (2013) and FB15k237 Toutanova and Chen (2015).
2 Related work
This section is going to review several approaches to knowledge representation.
1) Translation distance models: Based on the translation invariance of the word embedding they found, TransE Bordes et al. (2013) expresses the relation as the translation of the entity vectors in , which is the ground-breaking work in the translation distance model. TransE Bordes et al. (2013) has the advantages of simplicity and scalability, but it cannot model complex relations and multiple relations patterns, such as symmetric relations. The core of a translation distance model is the scoring function. A better scoring function will have a better performance in modeling complex relations such as 1-N, N-1, N-N and relation patterns, such as symmetric/non-relations, inverse relations, combination relations, and sub-relations. TransX series (TransE Bordes et al. (2013), TransH Wang et al. (2014), TransD Ji et al. (2015), TransR Lin et al. (2015)) have made up for the shortcomings of TransE’s inability to express complex relationships and symmetrical relationships, but they still have many flaws, including the complexity of models and the insufficient expression of the relations. TransAt Qian et al. (2018) describes the implementation of an attention mechanism for prediction by focusing on only a part of the entity’s dimensions. RotatE Sun et al. (2019) takes inspiration from Euler’s formula and uses the rotation of the vector to express relations. At the same time, it uses complex embedding to model inverse relations. PairRE Chao et al. (2020) uses two-stage vectors to express the relations. It is capable of modeling more complex relations, such as sub-relations.
2) Bilinear models: The bilinear model is also known as the semantic matching model. For most bilinear models, their core is also the scoring function. Their score functions are based on similarity scores to measure the possibility of the triplets by matching the latent semantics of entities and relations in the embedding vector space. RESCAL Nickel et al. (2011) uses vectors to represent the embedding of the head entity and the tail entity. The relation is expressed as a matrix to model the interaction of the triple. DistMult Yang et al. (2014) imposes constraints on the relation matrix, and simplifies the calculation. ComplEX Trouillon et al. (2016) embeds the head entities, tail entities, and relations into the complex space so that it can better model the antisymmetric relations. HolE Nickel et al. (2016) combines the expressiveness of RESCAL Nickel et al. (2011) with the efficiency of DistMult Yang et al. (2014), and defines an operation called circular correlation to calculate the rationality score of fact triples. This calculation can be regarded as compressing the interaction between paired entities so that more interactive information can be captured with less calculation. Circular correlation does not satisfy the exchange law, and HolE Nickel et al. (2016) can model asymmetric relations. There is also a bilinear model based on AutoML. AutoSF Zhang et al. (2020) uses a determined search algorithm to search the score function with the best performance in the search space. It first learns a set of the converged model parameters on the training set and then searches for a better scoring function on the validation set. Compared to the translation distance models, the bilinear models have shortcomings in encoding relational patterns and leveraging logical information.
3) Neural network-based models: With the development of deep learning and the popularity of neural networks, there are many knowledge representation models based on neural networks. ConvE Dettmers et al. (2018) and R-GCN Schlichtkrull et al. (2018) can show high performance under desirable parameters, but they are also challenging to manipulate and analyze due to the many parameters and difficulty in explain.
4) NodePiece: NodePiece Galkin et al. (2021) has a remarkable ability to access structural information in the knowledge graph. By filtering the anchors and encoding other nodes, the model can learn the relative position and centrality of each node in the graph. Anchor entity nodes and context relations represent each entity node, and a vocabulary is constructed for model training, which dramatically reduces the number of parameters and improves the effectiveness of the model. In addition, NodePiece has excellent cooperation with other models that leverage the logical information in a knowledge graph.
3 Methodology
The intuition of our approach is similar to the intuition of TransAt Qian et al. (2018), which tends to focus on a subset of features for link predictions according to the hierarchical routine of human cognition. Suppose there is a triplet Yao Ming, married with, , Yao Ming has multiple identities: a retired basketball player, the chairman of the Chinese Basketball Association, a husband, etc. To identify who is Yao Ming’s wife, it is supposed to pay more attention to Yao Ming’s identity on being a husband. Therefore, we need a mechanism to concentrate on Yao Ming’s features related to being a husband, and reduce attention to irrelevant features. TransAt Qian et al. (2018) follows PCA Dunteman (1989); it argues that if a feature is related to a relation r, then the variance of this feature between candidate entities and r should be large, and vice versa. Therefore, TransAt Qian et al. (2018) sets a threshold to determine whether to retain or drop out a feature from the whole feature set. In other words, TransAt Qian et al. (2018) leverages a subset of all features. Inspired by PairRE Chao et al. (2020), every relation is represented as the projections of the node, and entities are mapped to different feature spaces by performing the dot product with the relation, which is equivalent to feature filtering. After mapping entities to a specific feature space with the involvements of relations, the decision space becomes smaller, which could lead to better predictions.
TripleREv1: Two versions of TripleRE are suggested in this paper. For the first version, we split the relations into three segments, , , and . and are the projected parts of the relation for the head entities and tail entities respectively, and is the translation part of the relation. represents the Hadamard product. The scoring function used in our decoding phase is as follows:
| (1) |
where , and .
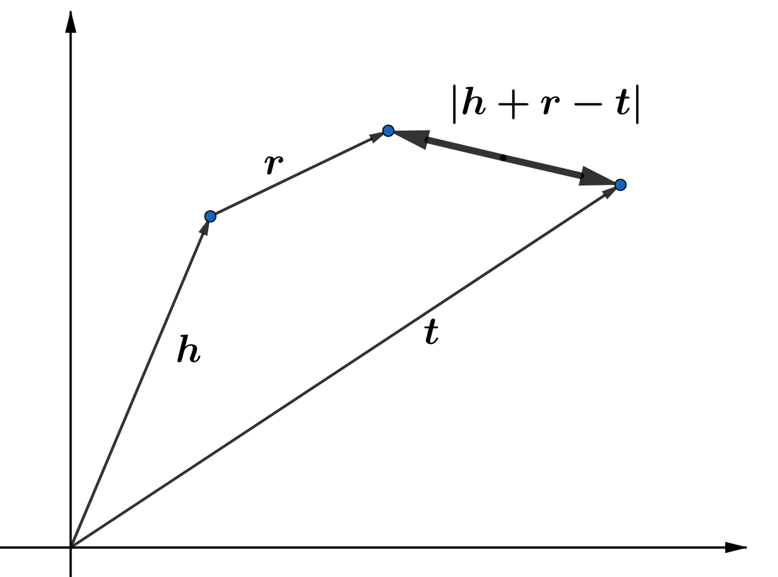
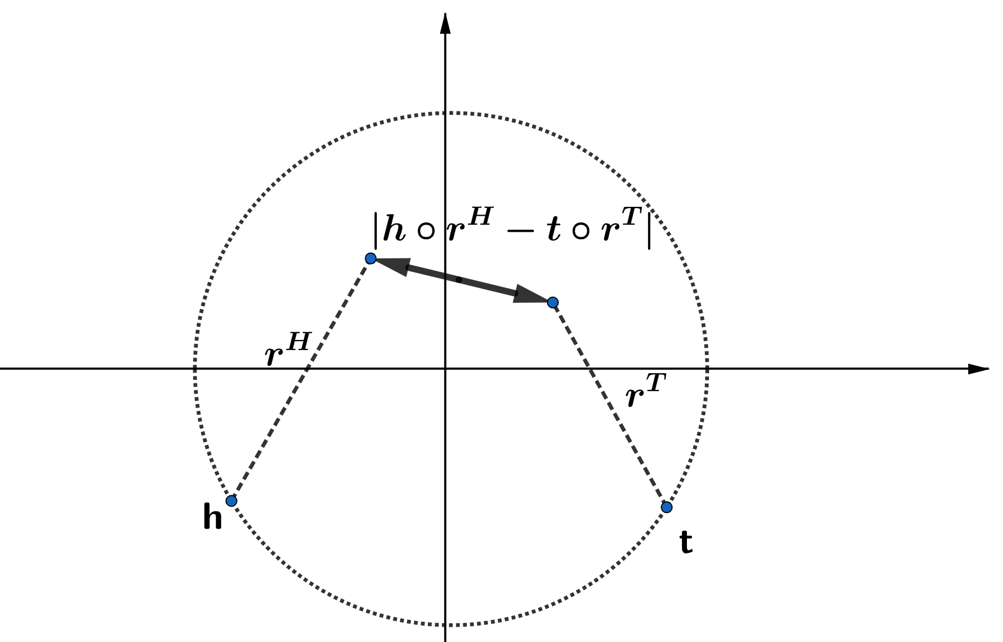
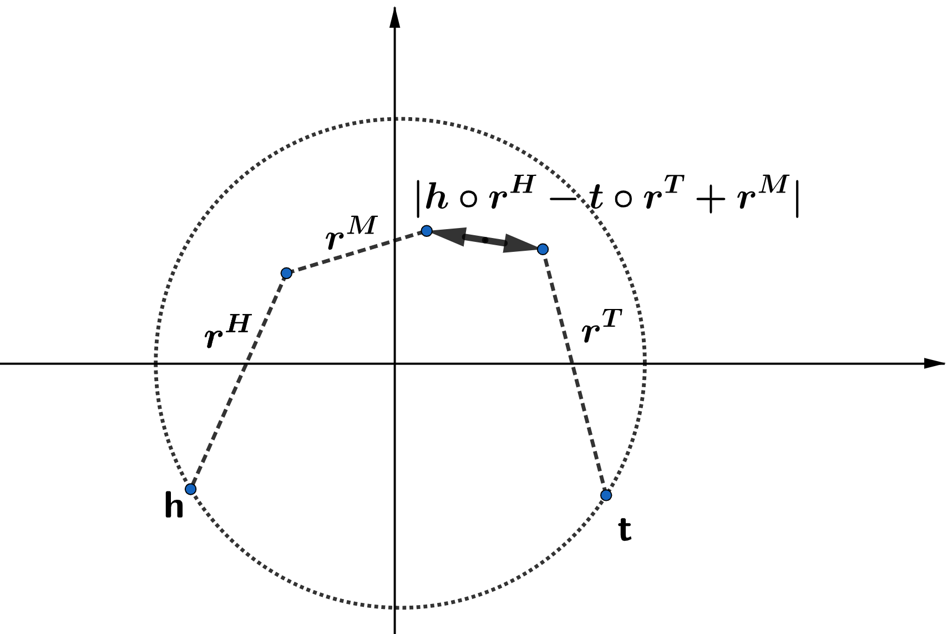
The scoring function of TripleREv1 is similar to the scoring function of PairREChao et al. (2020). However, according to Figure LABEL:fig:1, PairREChao et al. (2020) is essentially a special case of TripleREv1.
TripleREv2: TripleREv2 is a better version optimized based on TripleREv1. We believe that the segments of relations and play different roles in the decoding phase. For learning better representations of and , TripleREv2 takes advantage of the concept of residual. The original model needs to learn , , we made the following changes: , , The candidate value of is heuristically chosen, and we took 1, 0.5, 0.25 and 0.125 for u in our experiments, taking the best result as the value for . Now the model can be regarded as using TransEBordes et al. (2013) as the baseline, using and to learn the transformation of the residuals. Experiments proved that the involvement of residual mechanism does improve the performance. The scoring function of TripleREv2 is as follows:
| (2) | |||
Two parameters and are added to the scoring function, where is a constant and set default to 1, and is a unit vector.
TripleRE+NodePiece: NodePiece Galkin et al. (2021) is an anchor-based method for learning a fixed-size vocabulary for any connected multi-relational graph. In NodePiece Galkin et al. (2021), an atomic set consists of anchors and all relation types, which allow a combined number of sequences to be built from a limited vocabulary of atoms. NodePiece Galkin et al. (2021) has several advantages. First, NodePieceGalkin et al. (2021) can significantly reduce the number of parameters; second, NodePiece Galkin et al. (2021) can extract certain sub-graph features; third, NodePiece Galkin et al. (2021) can be used in the encoding phase to connect with other score functions seamlessly. We use NodePiece Galkin et al. (2021) in the encoding phase and TripleRE in the decoding phase.
We followed the NodePiece Galkin et al. (2021) ablation experiment and used three different methods to encode the nodes. First, nodes are represented by K-nearest anchors and the translation part information of TripleRE; second, K-nearest anchors represent nodes, and third, nodes are represented by K-nearest anchors and full relation information.
4 Experiments
4.1 Datasets
Five datasets on different scales were selected for experiments to verify the effectiveness of the proposed approaches.Especially, results in FB15k and WN18 are only to be compared to TransAT and PairRE.
- •
-
•
ogbl-biokg: ogbl-biokg Hu et al. (2020) is a knowledge graph in fields of biomedicine, and extracted from biomedical datasets. It contains 93,773 entities, which can be classified into five categories: diseases, proteins, drugs, side effects and protein functions, and 51 relation types.
-
•
FB15k: FB15k Bordes et al. (2013) is a small-scale knowledge graph, which contains 14,951 entities and 1,345 relation types.
-
•
FB15k237: FB15k237 Toutanova and Chen (2015), a subset of FB15k, contains the same number of entities with FB15k but 237 relation types as all inverse relations are removed from FB15k.
-
•
WN18: WN18 Bordes et al. (2013) is a small-scale knowledge graph, which contains 40,943 entities and 18 relation types
4.2 Implemention
To verify the performance of our model, we conduct comparative experiments on large-scale and small-scale datasets, respectively. Considering our work is similar to the idea of TransAt Qian et al. (2018), we compare with TransAt Qian et al. (2018) on the FB15k and WN18 datasets. Details are shown in Table 1. In the implementation process, results of TransAt Qian et al. (2018) were completely trained and predicted by using its open-source code. TripleRE was also limited to train and predict in the same dimension for a fair comparison.
| - | WN18 | FB15k | ||||
| Model | MRR | Hit@10 | Dim | MRR | Hit@10 | Dim |
| TransAt | 64.46 | 95.10 | 100 | 50.77 | 78 | 200 |
| TripleRE | 77.25 | 95.41 | 100 | 67.53 | 83.03 | 200 |
PairREChao et al. (2020) conducts comparative experiments on two small datasets, FB15k and FB15k237. We trained and predicted on both datasets using baseline’s hyperparameters for comparison. The specific results are shown in Table 2, and the results of other models are taken from PairRE.
| - | FB15k | FB15k-237 | ||||||||
| Model | MR | MRR | Hit@10 | Hit@3 | Hit@1 | MR | MRR | Hit@10 | Hit@3 | Hit@1 |
| TransE | - | 0.463 | 0.749 | 0.578 | 0.297 | 357 | 0.294 | 0.465 | - | - |
| DistMult | 42 | 0.798 | 0.893 | - | - | 254 | 0.241 | 0.419 | 0.263 | 0.155 |
| HoIE | - | 0.524 | 0.739 | 0.759 | 0.599 | - | - | - | - | - |
| ConvE | 51 | 0.657 | 0.831 | 0.723 | 0.558 | 244 | 0.325 | 0.501 | 0.356 | 0.237 |
| ComplEx | - | 0.692 | 0.840 | 0.759 | 0.599 | 339 | 0.247 | 0.428 | 0.275 | 0.158 |
| SimpIE Kazemi and Poole (2018) | - | 0.727 | 0.838 | 0.773 | 0.66 | - | - | - | - | - |
| RotatE | 40 | 0.797 | 0.884 | 0.830 | 0.746 | 177 | 0.338 | 0.533 | 0.375 | 0.241 |
| Seek Xu et al. (2020) | - | 0.825 | 0.886 | 0.841 | 0.792 | - | - | - | - | - |
| OTE Tang et al. (2019) | - | - | - | - | - | - | 0.351 | 0.537 | 0.388 | 0.258 |
| GC-OTE Tang et al. (2019) | - | - | - | - | - | - | 0.361 | 0.550 | 0.396 | 0.267 |
| PairRE | 37.7 | 0.811 | 0.896 | 0.845 | 0.765 | 160 | 0.351 | 0.544 | 0.387 | 0.256 |
| TripleRE | 35.7 | 0.747 | 0.877 | 0.813 | 0.662 | 142 | 0.351 | 0.552 | 0.392 | 0.251 |
| - | ogbl-wikikg2 | ogbl-biokg | ||||
| Model | Test MRR | Valid MRR | #P | Test MRR | Valid MRR | #P |
| AutoSF | 0.5458 ± 0.0052 | 0.5510 ± 0.0063 | 500M | 0.8309 ± 0.0008 | 0.8317 ± 0.0007 | 93M |
| PairRE | 0.5208 ± 0.0027 | 0.5423 ± 0.0020 | 500M | 0.8164 ± 0.0005 | 0.8172 ± 0.0005 | 187M |
| RotatE | 0.4332 ± 0.0025 | 0.4353 ± 0.0028 | 1,250M | 0.7989 ± 0.0004 | 0.7997 ± 0.0002 | 187M |
| TransE | 0.4256 ± 0.0030 | 0.4272 ± 0.0030 | 1,250M | 0.7452 ± 0.0004 | 0.7456 ± 0.0003 | 187M |
| ComplEx | 0.4027 ± 0.0027 | 0.3759 ± 0.0016 | 1,250M | 0.8095 ± 0.0007 | 0.8105 ± 0.0001 | 187M |
| DistMult | 0.3729 ± 0.0045 | 0.3506 ± 0.0042 | 1,250M | 0.8043 ± 0.0003 | 0.8055 ± 0.0003 | 187M |
| TripleRE | 0.5794 ± 0.0020 | 0.6045 ± 0.0024 | 500M | 0.8191 ± 0.0014 | 0.8192 ± 0.0008 | 187M |
| TripleREv2 | 0.6045 ± 0.0017 | 0.6117 ± 0.0008 | 500M | 0.8272 ± 0.0007 | 0.8281 ± 0.0006 | 187M |
| ogbl-wikikg2 | |||
| Model | Test MRR | Valid MRR | #P |
| ComplEx-RP Chen et al. (2021) (50dim) | 0.6392 ± 0.0045 | 0.6561 ± 0.0070 | 250,167,400 |
| TripleRE | 0.5794 ± 0.0020 | 0.6045 ± 0.0024 | 500,763,337 |
| NodePiece + AutoSF | 0.5703 ± 0.0035 | 0.5806 ± 0.0047 | 6,860,602 |
| AutoSF | 0.5458 ± 0.0052 | 0.5510 ± 0.0063 | 500,227,800 |
| PairRE (200dim) | 0.5208 ± 0.0027 | 0.5423 ± 0.0020 | 500,334,800 |
| RotatE (250dim) | 0.4332 ± 0.0025 | 0.4353 ± 0.0028 | 1,250,435,750 |
| TransE (500dim) | 0.4256 ± 0.0030 | 0.4272 ± 0.0030 | 1,250,569,500 |
| ComplEx (250dim) | 0.4027 ± 0.0027 | 0.3759 ± 0.0016 | 1,250,569,500 |
| DistMult (500dim) | 0.3729 ± 0.0045 | 0.3506 ± 0.0042 | 1,250,569,500 |
| TripleRE + NodePiece | 0.6582 ± 0.0020 | 0.6616 ± 0.0018 | 7,289,002 |
| ogbl-wikikg2 | |||
| Model | Test MRR | Valid MRR | #P |
| v1 + anchor + r | 0.6262 ± 0.0015 | 0.6296 ± 0.0010 | 7,289,002 |
| v1 + anchor + | 0.6331 ± 0.0014 | 0.6422 ± 0.0020 | 7,289,002 |
| v1 + anchor | 0.6477 ± 0.0016 | 0.6527 ± 0.0013 | 6,329,002 |
| v2 + anchor + r | 0.6573 ± 0.0014 | 0.6658 ± 0.0009 | 7,289,002 |
| v2 + anchor + | 0.6582 ± 0.0020 | 0.6616 ± 0.0018 | 7,289,002 |
| v2 + anchor | 0.6627 ± 0.0018 | 0.6745 ± 0.0015 | 6,329,002 |
For TripleRE, we selected the results of a single model in the large-scale datasets ogbl-wikikg2 and ogbl-biokg for comparison. The details are shown in Table 3. In ogbl-wikikg2 and ogbl-biokg, we increased the max steps and reduced the lr to 0.0005; other hyperparameters are consistent with the baseline. For TripleREv2, another hyperparameter u needs to be adjusted compared to the baseline. We set u to 1 in ogbl-wikikg2 and set u to 0.125 in ogbl-biokg.
For TripleRE+NodePiece, since NodePiece is not suitable for the data set of biokgGalkin et al. (2021), we compared it on the large-scale data set ogbl-wikikg2, and the result shows on Table 4. For the implementation of TripleRE + NodePiece, we followed the work of NodePiece+AutoSF, and the hyperparameters are the same as NodePiece+AutoSF, except for max steps. Detailed results are shown in Table 4.
We followed NodePiece’s ablation experiments and conducted experiments on large-scale datasets ogbl-wikikg2. We tried three different node encoding methods. The first we call ”anchor + rm”; the second we call ”anchor”; the third we call ”anchor + r.” Detailed results are shown in Table 5.
The above experiments in ogbl-wikikg2 and ogbl-biokg were repeated ten times, with random numbers set from 0 to 9.
5 Main Results
As can be seen from Tables 3 and 4, TripleRE has significantly improved the performance on the large-scale datasets ogbl-wikikg2 and ogbl-biokg. On ogbl-wikikg2, TripleRE+NodePiece achieved state-of-the-art performance, and parametric size was reduced by more than three times compared with the approach in second place.
From Table 1, we can see that on the small datasets FB15k and WN18, our work has an obvious advantage over TransAt Qian et al. (2018). Table 2 shows the comparison between TripleRE and other models. The results show that our model has obtained the best performance in MR and achieved competitive results in other metrics.
Table 5 shows the various experiments we performed at TripleRE+NodePiece. We conduct three different experiments on encoding node representations for TripleREv1 and TripleREv2. The experiments in Table 5 show that the ”anchor” method works best on TripleRE+NodePiece, both Test MRR and Valid MRR achieve the best performance, and the number of parameters is also less than the lowest model (NodePiece+AutoSF), which means we have achieved the state-of-the-art with the least amount of parameters on wikikg2.
6 Conclusion and future work
The contributions of this paper can be summarized as follows:
-
•
This paper proposes a novel approach, TripleRE, in the decoding phase of knowledge representation learning. As a translation-based approach, TripleRE is advantageous in efficiency (in both training and inferencing stages) and simplicity.
-
•
In TripleREv2, it utilizes the residual mechanism to optimize knowledge representation. Considering residual mechanism has made a tremendous difference in many fields of deep learning, it is also promising to apply it to knowledge representation.
-
•
TripleRE achieved competitive performance on large-scale datasets: ogbl-wikikg2 and ogbl-biokg.
-
•
The combination of NodePiece and TripleRE achieved state-of-the-art performance in the benchmark ogbl-wikikg2.
The future work can be summarized in two directions. The first direction is to explore the methods to leverage structural information. One of the potential proposals is to improve the anchor selection method of NodePiece. Another direction is to conduct more experiments on other large-scale knowledge graphs to test the capacities of TripleRE and TripleRE+NodePiece further.
Supplemental Material Statement:
Source code for transAt in Section 4 is available from Github111https://github.com/ZJULearning/TransAt. The experimental source code at FB15k and FB15k-237 is available from Github222https://github.com/DeepGraphLearning/KnowledgeGraph- Embedding. Source code for TripleRE and TripleRE+NodePiece will be submitted via easy chair. After the review, we will open source the code on Github.
References
- Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533–1544.
- Bollacker et al. (2008) Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 1247–1250. AcM.
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems, 26.
- Bordes et al. (2014) Antoine Bordes, Jason Weston, and Nicolas Usunier. 2014. Open question answering with weakly supervised embedding models. In Joint European conference on machine learning and knowledge discovery in databases, pages 165–180. Springer.
- Chao et al. (2020) Linlin Chao, Jianshan He, Taifeng Wang, and Wei Chu. 2020. Pairre: Knowledge graph embeddings via paired relation vectors. arXiv preprint arXiv:2011.03798.
- Chen et al. (2021) Yihong Chen, Pasquale Minervini, Sebastian Riedel, and Pontus Stenetorp. 2021. Relation prediction as an auxiliary training objective for improving multi-relational graph representations. In 3rd Conference on Automated Knowledge Base Construction.
- Dettmers et al. (2018) Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32.
- Dunteman (1989) George H Dunteman. 1989. Principal components analysis. 69. Sage.
- Galkin et al. (2021) Mikhail Galkin, Jiapeng Wu, Etienne Denis, and William L Hamilton. 2021. Nodepiece: Compositional and parameter-efficient representations of large knowledge graphs. arXiv preprint arXiv:2106.12144.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural message passing for quantum chemistry. In International conference on machine learning, pages 1263–1272. PMLR.
- Hu et al. (2020) Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133.
- Ji et al. (2015) Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, and Jun Zhao. 2015. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 687–696.
- Kazemi and Poole (2018) Seyed Mehran Kazemi and David Poole. 2018. Simple embedding for link prediction in knowledge graphs. Advances in neural information processing systems, 31.
- Kipf and Welling (2016) Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
- Lehmann et al. (2015) Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas, Pablo N Mendes, Sebastian Hellmann, Mohamed Morsey, Patrick Van Kleef, Sören Auer, et al. 2015. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semantic web, 6(2):167–195.
- Lin et al. (2015) Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph completion. In Twenty-ninth AAAI conference on artificial intelligence.
- Miller (1995) George A Miller. 1995. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41.
- Nickel et al. (2016) Maximilian Nickel, Lorenzo Rosasco, and Tomaso Poggio. 2016. Holographic embeddings of knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30.
- Nickel et al. (2011) Maximilian Nickel, Volker Tresp, and Hans-Peter Kriegel. 2011. A three-way model for collective learning on multi-relational data. In Icml.
- Qian et al. (2018) Wei Qian, Cong Fu, Yu Zhu, Deng Cai, and Xiaofei He. 2018. Translating embeddings for knowledge graph completion with relation attention mechanism. In IJCAI, pages 4286–4292.
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In European semantic web conference, pages 593–607. Springer.
- Suchanek et al. (2007) Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. 2007. Yago: a core of semantic knowledge. In Proceedings of the 16th international conference on World Wide Web, pages 697–706. ACM.
- Sun et al. (2019) Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv preprint arXiv:1902.10197.
- Tang et al. (2019) Yun Tang, Jing Huang, Guangtao Wang, Xiaodong He, and Bowen Zhou. 2019. Orthogonal relation transforms with graph context modeling for knowledge graph embedding. arXiv preprint arXiv:1911.04910.
- Teru et al. (2020) Komal Teru, Etienne Denis, and Will Hamilton. 2020. Inductive relation prediction by subgraph reasoning. In International Conference on Machine Learning, pages 9448–9457. PMLR.
- Toutanova and Chen (2015) Kristina Toutanova and Danqi Chen. 2015. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd workshop on continuous vector space models and their compositionality, pages 57–66.
- Trouillon et al. (2016) Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex embeddings for simple link prediction. In International conference on machine learning, pages 2071–2080. PMLR.
- Vrandečić and Krötzsch (2014) Denny Vrandečić and Markus Krötzsch. 2014. Wikidata: a free collaborative knowledgebase. Communications of the ACM, 57(10):78–85.
- Wang et al. (2014) Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 28.
- Xu et al. (2020) Wentao Xu, Shun Zheng, Liang He, Bin Shao, Jian Yin, and Tie-Yan Liu. 2020. Seek: Segmented embedding of knowledge graphs. arXiv preprint arXiv:2005.00856.
- Yang et al. (2014) Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575.
- (32) Yongqi Zhang and Quanming Yao. Knowledge graph reasoning with relational digraph.
- Zhang et al. (2020) Yongqi Zhang, Quanming Yao, Wenyuan Dai, and Lei Chen. 2020. Autosf: Searching scoring functions for knowledge graph embedding. In 2020 IEEE 36th International Conference on Data Engineering (ICDE), pages 433–444. IEEE.
- Zheng et al. (2012) Zhicheng Zheng, Xiance Si, Fangtao Li, Edward Y Chang, and Xiaoyan Zhu. 2012. Entity disambiguation with freebase. In Proceedings of the The 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology-Volume 01, pages 82–89. IEEE Computer Society.