Triples-to-Text Generation with Reinforcement Learning Based Graph-augmented Structural Neural Networks
Abstract.
Considering a collection of RDF triples, the RDF-to-text generation task aims to generate a text description. Most previous methods solve this task using a sequence-to-sequence model or using a graph-based model to encode RDF triples and to generate a text sequence. Nevertheless, these approaches fail to clearly model the local and global structural information between and within RDF triples. Moreover, the previous methods also face the non-negligible problem of low faithfulness of the generated text, which seriously affects the overall performance of these models. To solve these problems, we propose a model combining two new graph-augmented structural neural encoders to jointly learn both local and global structural information in the input RDF triples. To further improve text faithfulness, we innovatively introduce a reinforcement learning (RL) reward based on information extraction (IE). We first extract triples from the generated text using a pretrained IE model and regard the correct number of the extracted triples as the additional RL reward. Experimental results on two benchmark datasets demonstrate that our proposed model outperforms the state-of-the-art baselines, and the additional reinforcement learning reward does help to improve the faithfulness of the generated text.
1. Introduction
As a sub-task of data-to-text generation, RDF-to-text generation transforms a collection of Resource Description Framework (RDF) triples into an faithful and informative text. RDF triple is a popular representation of knowledge graph, with the form of (a subject entity, a relationship, an object entity). Therefore, a given collection of RDF triples can naturally form a graph, thus allowing RDF-to-text generation to evolve into a graph-to-sequence generation problem.
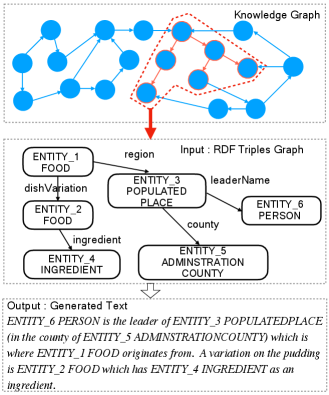
RDF-to-text generation is challenging task because both the graph structure and the semantic information of RDF triples needs to be well modeled. The example in Figure 1 shows an RDF triples graph extracted from a large-scale knowledge graph with its text description, where the nodes (e.g. “ENTITY_1 FOOD” and “ENTITY_4 INGREDIENT”) represent entities with their corresponding entity types and the edges (e.g. “dishVariation” and “ingredient”) represent the relationships connecting pairs of entities. This example is centered on the “ENTITY_1 FOOD” entity node, which is referred to as the topic entity for this example. In recent years, RDF-to-text generation has attracted increasing attention because of its fact-aware applications in knowledge-based question answering (Hao et al., 2017), data-driven text generation (Liu et al., 2018) and entity summarization (Pouriyeh et al., 2017).
RDF-to-text generation can be solved using the classical text generation paradigm, which primarily concentrate on content selection (Duboue and McKeown, 2003) and surface realization (Deemter et al., 2005). However, the critical issue of error propagation has been largely ignored, to the harm of the quality of generated texts. With the recent tremendous advances in end-to-end deep learning in the field of natural language processing, promising results have been achieved in RDF-to-text generation through the use of various sequence-to-sequence (Seq2Seq) models (Gardent et al., 2017b; Jagfeld et al., 2018; Ferreira et al., 2019). In order to feed into Seq2Seq models, the individual RDF triples in the collection need to be connected end-to-end into a sequence.
However, simply converting the collection of RDF triples into a sequence may result in the loss of important structural information. As a collection of RDF triples can be formed as a input graph, a number of graph-based methods have recently been proposed to integrate structural information for this task. Trisedya et al. (2018) proposed a triple encoder, GTR-LSTM, which captures entity relationships within and between triples by sampling different meta-paths, thus retaining the graph structure in the graph-based encoder. In addition, because the component of GTR-LSTM is still based on recurrent neural networks (RNNs), it is often unable to model the local complex structural information within triples.
On the other side, to directly encodes the collection of RDF triples of graph structure and decodes a text sequence, DGCN presented in (Marcheggiani and Perez-Beltrachini, 2018) is a graph-to-sequence (Graph2Seq) model based on an improved Graph Convolutional Networks (GCN) (Kipf and Welling, 2016). However, it is well-known that when using multi-layers (=3 layers), GCN often tends to over-fit quickly and its ability of learning longer range dependency is weakened as well. As a result, this GCN model generally performs better at modeling local information of the graph formed by triples than it does at modeling global information between RDF triples.
Although great efforts have been made to build effective models to capture both structural and semantic information in the input triples, generating an informative and faithful text is still a challenge. Through manual analysis of the generated texts, we find that the mistakes made by these end-to-end neural network models can be divided into two categories: (1) Misattribution. The subject or object corresponding to the relationship in the generated text is mistaken. For example, given a triple “(ENTITY_1 POLITICIAN, birthPlace, ENTITY_2 BIRTHPLACE)”, the generated text is ENTITY_1 is the birthplace of ENTITY_1, which obviously misidentifies the object entity. (2) Information missing. The model fails to cover the salient information of all input triples with the number of triples increasing.
In this study, we present a reinforcement learning based graph-augmented structural neural encoders framework for RDF-to-text generation to address the aforementioned issues. We first propose to harness the power of graph-based meta-paths encoder and graph convolutional encoder to jointly model both local and global structural information. Then, separated attentions are applied to two different encoder outputs to learn the final attentional hidden representation at each decoding time step. Moreover, we also design a selection mechanism inspired by pointer-generator (See et al., 2017), which controls the degree of attention given to graphs or meta-paths at each step of decoding. To improve the faithfulness of the generated text, we innovatively propose an information extraction (IE) based reinforcement learning reward. We first pretrain an IE model with ground-truth texts as inputs and triples as their predicted outputs on the same datasets. Then, we use the number of correct triples predicted by the IE model as the RL reward. Finally, we train the graph-augmented structural neural encoders by optimizing a hybrid objective function that combines both RL loss and cross entropy loss.
In this paper, our proposed graph-augmented structural neural encoders can concentrate on two different perspectives of the collection of RDF triples. A novel bidirectional Graph-based Meta-Paths (bi-GMP) encoder is used to capture global long-range dependency between the input triples, while a new bidirectional Graph Convolutional Network (bi-GCN) encoder mainly concentrates on explicitly modeling the local structural information within the triples. We further exploit an IE-based RL reward to address the two types of faithfulness mistakes summarised in the previous paragraph to a certain extent.
The main contributions we highlight are listed below:
-
•
We present a RL-based graph-augmented structural neural encoders framework by combining a bi-GMP encoder and a bi-GCN encoder for explicitly capturing the global and local structural information in the input RDF triples.
-
•
Separated attention mechanism is applied on the graph encoders and their corresponding context vectors are fused using a selection mechanism to better decode the text descriptions.
-
•
We propose an IE-based RL reward by computing the correct number of triples in the generated texts and explore the effect of this reward on RDF triple sets of different sizes.
-
•
The experimental results on two RDF-to-text datasets WebNLG and DART demonstrate the advantages of our model in BLEU, METEOR and TER metrics and faithfulness metric.
2. Related Work
Our method is closely related with researches in the fields of RDF-to-text generation, graph neural networks (GNN) for text generation and information extraction.
2.1. RDF-to-Text Generation
The aim of RDF-to-text generation is to generate a informative, grammatically correct, faithful and fluent description for a given collection of RDF triples. Web Ontology Language to text generation (Bontcheva and Wilks, 2004; Stevens et al., 2011; Androutsopoulos et al., 2013) and knowledge base verbalization (Banik et al., 2012) were early forms of this task. Pipeline system is often used to address data-to-text generation, including two main steps: (1) content selection addresses the question of what content should be described (Barzilay and Lapata, 2005); (2) surface realization realizes the text generation process token by token (Deemter et al., 2005; Belz, 2008).
Over the past few years, a number of natural language generation (NLG) tasks based on Seq2Seq model with attention mechanism (Bahdanau et al., 2014; Luong et al., 2015) and copy mechanism (See et al., 2017; Gu et al., 2016) have achieved promising performance. A range of research work such as (Gardent et al., 2017b; Jagfeld et al., 2018) show that Seq2Seq model and its variant models perform prominently on RDF-to-text generation by flattening a collection of RDF triples into a text sequence. Ferreira et al. (2019) implemented two encoder-decoder architectures using Gated-Recurrent Units (GRU) (Cho et al., 2014) and Transformer (Vaswani et al., 2017) respectively. To improve the probability of producing high-quality texts, Zhu et al. (2019) proposed a model minimizing the Kullback-Leibler (KL) divergence between the distributions of the real text and generated text. Moryossef et al. (2019) proposed a model combining the pipeline system and neural networks to match a reference text with its corresponding text plan to train a plan-to-text generator. In addition, some work has focused solely on improving the performance of the seen split part of dataset, where the entity types have appeared in the training set. Ribeiro et al. (2020) combined two GNN encoders to encode both global and local node contexts for WebNLG seen categories. Recently, data-to-text generation has benefited from large-scale pre-trained language models (PLMs). Wang et al. (2021) and Kale and Rastogi (2020) applied T5 (Raffel et al., 2019) in this task. Moreover, Wang et al. (2021) further exploited external knowledge from Wikipedia to improve the model performance.
2.2. Graph Neural Networks
There has been a significant increase in interest in using graph neural networks for data-to-text generation.
Graph Neural Networks. Graph Neural Networks have achieved excellent performance on many natural language processing tasks where the input data can be represented as a graph. Essentially, graph neural networks are graph representation learning models that learn each node embedding using graph structure and its neighbouring node embeddings. According to (Ma and Tang, 2021), the learning process of node embeddings is referred as graph filtering, which can refine the node embeddings without modifying the graph structure. Graph filters can be roughly categorized into four classes (Wu et al., 2021): spectral-based like GCN (Kipf and Welling, 2016), spatial-based like GraphSage (Hamilton et al., 2017), attention-based like Graph Attention Network (GAT) (Veličković et al., 2017) and recurrent-based like Gated Graph Neural Network (GGNN) (Li et al., 2015). Furthermore, graph pooling operation aggregates node embeddings and produces a smaller graph with fewer nodes inspired by CNNs (Krizhevsky et al., 2012). When the smaller graph only contains one node, the node embedding is considered as the graph-level embedding for the input graph.
Graph to Sequence Learning. Sequence-to-Sequence model is a widely used encoder-decoder framework in the natural language generation field. However, when the input is graph data such as dependency graph, Abstract Meaning Representation (AMR) (Banarescu et al., 2013) graph and knowledge graph, it often needs to be linearized into a sequence before it can be fed into the Seq2Seq model, resulting in a loss of structural information in the graph. To alleviate the limitation of Seq2Seq models on encoding graph data, a number of graph-to-sequence (Graph2Seq) models have been proposed (Bastings et al., 2017; Beck et al., 2018; Song et al., 2019; Yao et al., 2020). Bastings et al. (2017) applied GCN on dependency trees of input sentences to produce word representations. Beck et al. (2018) proposed a graph-to-sequence model based on GGNN with edges being turned into additional nodes. Song et al. (2019) explored the effectiveness of AMR as a semantic representation for neural machine translation based on a graph recurrent network. Previous studies (Chen et al., 2020; Gao et al., 2019; Xu et al., 2018) applied a bidirectional graph encoder to encode an input graph and then used an attention-based LSTM (Hochreiter and Schmidhuber, 1997) decoder. To capture longer-range dependencies, Song et al. (2018) employed an LSTM to process the state transitions of the graph encoder outputs. Marcheggiani and Perez-Beltrachini (2018) used a relational graph convolutional network, which is introduced and extended in (Kipf and Welling, 2016; Bruna et al., 2013; Defferrard et al., 2016), to encode each node using its neighboring nodes, edge directions and edge labels simultaneously.
2.3. Information Extraction
The aim of Information Extraction (IE) is to extract entity pairs and their relationships within a given sentence. Information extraction is a significant task in the field of natural language processing, as it helps to mine factual knowledge from free texts. Information extraction is an inverse task of RDF-to-text generation, and there are a number of researches on both tasks on the same dataset.
As two important subtasks of information extraction, named entity recognition (NER) and relation extraction (RE) can be operated via a pipeline approach that firstly recognize entities and then conduct relation extraction (Zelenko et al., 2003; Chan and Roth, 2011). NER predicts a label for each word in a sentence indicating whether it is an entity or not. For a sentence with annotated entities, RE is essentially a relation classification task which predicts a relation label for each entity pairs. Zeng et al. (2014), Xu et al. (2015) and Sahu et al. (2019) conducted relation extraction via CNN, RNN and GNN, respectively.
Recently, researchers start to explore joint entity recognition and relation extraction. Some Seq2Seq-based methods (Zeng et al., 2018; Nayak and Ng, 2020; Zeng et al., 2020; Sui et al., 2020) directly generate relational triples. For example, Set Prediction Networks (SPN) (Sui et al., 2020) is featured by transformers, which can directly predict the final collection of triples. Other models are tagging based methods (Zheng et al., 2017; Dai et al., 2019; Wang et al., 2020), which regard the IE task as a sequence labeling problem and use specially designed tagging schema. For example, TPLinker (Wang et al., 2020) is a one-stage joint extraction model with a hand-crafted tagging schema and can discover overlapping relations sharing one or both entities. There are also other methods that represent entities and relationships in a shared parameter space, but extract the entities and relationships respectively (Miwa and Bansal, 2016; Zhang et al., 2017; Zhao et al., 2021). For example, Zhao et al. (2021) proposed a representation iterative fusion strategy on heterogeneous graph neural networks for relation extraction. After obtaining the final representations of entity nodes and relation nodes, this model uses specialised taggers to extract subjects and objects, respectively. In this paper, we pretrain the SPN on the same dataset of the RDF-to-text generation task to extract triples from the generated texts.
3. Problem Formulation
Next, we give a formal definition of the RDF-to-text generation task. The input is a collection of RDF triples denoted as , where is a triple containing a subject entity , a relationship and an object entity . A collection of RDF triples is represented as a directed graph. The aim of this task is to generate a text description which maximizes the conditional likelihood:
| (1) |
The genereted text should represent the comprehensive and correct information of entities and relationships in the input collection of RDF triples.
In this paper, we construct two input graphs based on a collection of RDF triples. The bi-GMP encoder takes input graph as input, where denotes the entity nodes set and represents original relationships. Whilst, the bi-GCN encoder takes input graph as its input, where is composed of entity nodes and relationship nodes because relationships are seen as newly added nodes, not as edges. indicates a predefined set of edges that describes the relationship between an entity node and a relationship node, or the relationship between multiple tokens of a node. More details about the construction of the input graphs are depicted in Sec.5. Therefore, Equation 1 can also be written as follows:
| (2) |
Furthermore, we give the notation of information extraction task, whose goal is to extract all possible triples in a given sentence. Considering an input sentence , the IE model aims to extract the target RDF triple set .
4. Our Proposed Model
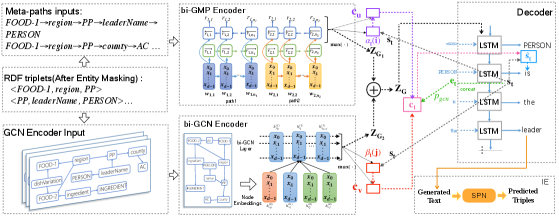
4.1. Architecture of Our Proposed Model
As shown in Fig.2, our proposed model contains four key components: a graph construction module, a combined graph-augmented encoders module, a decoder module and a post information extraction module. First, the graph construction module leverages the input RDF triples to build two input graphs. Second, after graph construction, we propose two graph-based encoders to model the input graphs and learn node embeddings and graph embeddings. Third, we employ an LSTM-based decoder to generate the text word by word. In this module, we propose separated attention mechanism on both graph-based encoders and fuse their context vectors using a selection mechanism. Fourth, a pretrained information extraction model, i.e.SPN extracts triples from the sequence generated by sampling and the sequence generated by greedy search. A reinforcement learning reward is computed based on the correct numbers of extracted triples.
In the next few sections, we first propose a graph-augmented structural neural encoders framework including two graph-based encoders. Then, we describe how to combine the two encoders for better modeling global and local information. Finally, we introduce how to compute the reward of the whole model using the pretrained information extraction model.
4.2. Bidirectional Graph-based Meta-Paths Encoder
Given a collection of RDF triples, it can be formed as a directed graph naturally with subjects and objects being nodes and relationships being edges. We refer this naturally formed graph as . For the graph , represents the entity nodes set, and represents original relationships between entities. With the purpose of encoding information depending on different meta-paths and model long-range dependencies in , we propose a novel bidirectional Graph-based Meta-Paths encoder (bi-GMP) enhanced on the basis GTR-LSTM (Trisedya et al., 2018). In contrast to GTR-LSTM, the bi-GMP encoder performs hidden state masking on different meta-paths to ensure the encoding of different meta-paths do not interfere with each other.
We select the meta-paths of using a combination of topological sort algorithm and single-source shortest path algorithm shown in Algo.1. Firstly, we find a node set with zero in-degree nodes and a node set with zero out-degree nodes. Secondly, by choosing a starting node from and a target node from , we calculate a single-source shortest path with both nodes and relationships retained in the path. Finally, a sequence containing a set of meta-paths can be selected from the graph , where . The hidden state masking means that the hidden state of the final token in is masked when to compute the hidden state of the first token in .
After obtaining the meta-paths, we initialize the word embeddings using 6B GloVe vectors111https://nlp.stanford.edu/projects/glove/ for each word in . Each word is represented as a distributed representation , where the dimension is equal to 300. Taking inspiration from the benefits of BiLSTM over LSTM, the meta-paths encoder computes the token representations in both directions for each meta-path and concatenates them together in the last step. When the word embedding is given, the hidden state is computed as follows:
| (3) | ||||
| (4) | ||||
| (5) |
where and are single LSTM units and is the concatenation operation. If the previous or the next hidden state belongs to different meta-path, an all-zero hidden state is input to or . Equation 3 and Equation 4 can be written as:
| (6) | ||||
| (7) |
where is the length of meta-path .
Finally, a set of entity node representations is output by the bi-GMP encoder, where is the expanded length of . The graph embedding of graph is computed over :
| (8) |
where is the max pooling operation over the first dimension and .
4.3. Bidirectional Graph Convolutional Networks Encoder
To better use the information in relationships, we build the input graph for bi-GCN encoder by converting relationships to nodes in the graph. For the graph , relationships are considered as graph nodes. Therefore, is composed of entity nodes and relationship nodes. Edges in may connect relationship node to entity node or entity node to entity node. More details about the construction of bi-GCN graph are illustrated in Sec.5.3.
To effectively learn the node embeddings and the graph embeddings for the constructed graph, we present the bi-GCN encoder based on the conventional GCN, which learns node embeddings from both incoming and outgoing edges. At each layer, we first compute the intermediate node representations and in both directions. Then, we fuse the two node representations at this layer to obtain the fused node representations . In particular, the fused node representations at layer can be represented as with being the number of nodes. The above calculation process is formulated as follows:
| (9) | ||||
| (10) | ||||
| (11) |
where and represent the incoming and outgoing adjacency matrices of with self-loops. And is an identity matrix representing the self-loop of each node. and are the diagonal degree matrices. , and denote trainable weight matrices. is a non-linearity function and is the concatenation operation. is the number of nodes in . Similar to the bi-GMP encoder, is also initialized with GloVe embeddings. Bidirectional node embeddings at the same layer are fused by concatenation and fed into a one-layer feed-forward neural networks before being fed to the next bi-GCN layer. We stack the bi-GCN encoder to layer and is the set of final node representations after hops of bi-GCN computation.
Similarly, we apply max pooling on to calculate the graph embedding of graph :
| (12) |
where and .
4.4. Dual Encoders Combination Strategy
To jointly learn the global and local structural information of the RDF triples input, we propose a strategy to combine the bi-GMP encoder and the bi-GCN encoder.
Both encoders produce a set of node representations. is mainly concerned with the global structural information between the triples, because the bi-GMP encoder calculates hidden states according to the traversal order obtained by the combination of topological sort algorithm and single-source shortest path algorithm. Therefore, each hidden state can retain information from one triple to multiple triples if there exists a meta-path. At the same time, better models the local structural information within the triples because each node representation is directly learned by all its one-hop neighbors. We stack the bi-GCN encoders to 2 layers and the output of bi-GCN encoder retains at most two-hop information of the graph, i.e., it is limited to one or two triples.
At last, the combined graph embedding is computed as follows:
| (13) |
where denotes component-wise addition and .
4.5. Decoder
An attention-based LSTM decoder (Luong et al., 2015) is employed for text generation. Since we have two encoder outputs, the conventional top-down attention cannot fully capture different semantic information from two completely different encoders. To better decode the text description, we first apply separated attention mechanism on both graph encoders and then fuse the context vectors using a selection mechanism inspired by pointer-generator (See et al., 2017).
The decoder takes the combined graph embedding as its initial hidden state. At each decoding time step , the embedding of the current input (or previously generated word) and previous hidden state are fed into the decoder to update its hidden state :
| (14) |
Next, we apply the separated attention mechanism by calculating the attention align weights at this time step as follows:
| (15) |
| (16) |
where and . and are the lengths of and , respectively. is the hidden state of decoder. In this paper, we use the function as follows to compute the similarity of and :
| (17) |
where and are learnable parameters. can be or . After obtaining the attention align weights, we calculate the context vector of bi-GMP and the context vector of bi-GCN respectively:
| (18) | ||||
| (19) |
Selection mechanism uses a gcn probability to control the attention paying to the context vectors of different encoders from a global perspective. The gcn probability for time step is calculated from the decoder state and the decoder input :
| (20) |
where and are learnable parameters, is the sigmoid function and denotes concatenation operation. The fused vector for time step combining context vectors and is computed as:
| (21) |
where is used to control the proportion of different context vectors. The final attentional hidden state at this time step is:
| (22) |
where and are learnable parameters.
After obtaining an attentional decoder hidden states sequence recurrently, the decoder generates an output sequence with being the length of the sequence. The output probability distribution over the vocabulary of the current time step is calculated by:
| (23) |
where and are trainable parameters. Finally, the text generation loss is a cross entropy loss:
| (24) |
where is the collection of input RDF triples and is the -th word in the ground truth output sequence.
| Ground Truth | 1. (Alan Shepard , timeInSpace , 130170 minutes) |
| Triples | 2. (Alan Shepard , birthPlace , New Hampshire) |
| 3. (New Hampshire , bird , purple finch) | |
| Ground Truth | Alan Shepard was born in New Hampshire , the home of the purple finch , |
| Text | and spent 130170 minutes in space . |
| Generated Text | Alan Shepard was born in New Hampshire , where the purple finch is the bird . |
| SPN-predicted | 1. (Alan Shepard , birthPlace , New Hampshire) |
| Triples | 2. (New Hampshire , bird , purple finch) |
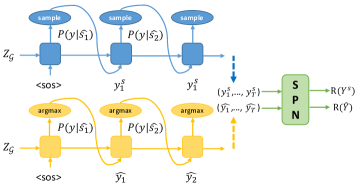
4.6. Reinforcement Learning with Information Extraction
Besides training with the generation loss , we further design an information extraction reward to generate more faithful and informative descriptive texts.
We apply a self-critical sequence training (SCST) algorithm (Rennie et al., 2017) depicted in Fig.3 to optimize the RL loss. SCST is a form of REINFORCE algorithm that, instead of estimating a “baseline” to normalize rewards and reduce variance, normalizes the rewards it experiences using the output of its own test-time inference algorithm. At each training iteration, two text sequences are generated: (1) a sampled sequence generated by multinomial sampling, which means sampling tokens according to the probability distribution ; (2) a baseline sequence generated by greedy search. The rewards of the two text sequences and are defined as the correct number of predicted triples using a pretrained IE model SPN metioned in Section 2.3. The SPN model receives the sampled sequence or the baseline sequence as input and predicts a collection of RDF triples. Tables 1 shows a ground truth triples-text pair, a prediction text generated by our proposed model based on the ground truth triples and a collection of RDF triples predicted by the SPN model based the generated text. The IE reward for this example is equal to 2 because the generated text is missing the information in the triple (Alan Shepard , timeInSpace , 130170 minutes). The RL objective is defined as follows:
| (25) |
We train our model using a hybrid objective function combining both text generation loss and RL loss, defined as:
| (26) |
where a scaling factor controls the trade-off between generation loss and RL loss.
5. Entity Masking and Graph Constructions
In this section, we first introduce the technique of entity masking and its significance. Then, we describe how to convert a collection of RDF triples to the input graphs for two encoders.
5.1. Entity Masking
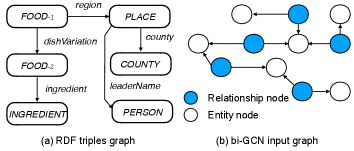
Entity masking is, as the name implies, replacing the entity names that appear in the input triples and output texts with their corresponding types. It can improve the generalization ability of the models. In this paper, we use the official dictionary provided by WebNLG. Taking into account that entities appearing in the same collection of triples may of the same type, we allocate an entity-id (eid) to each entity mention in the same collection. In this way, each entity is replaced with its eid and its entity type. For instance, the entity “Bakewell pudding”, namely “FOOD-1” in Fig. 4, is replace by “ENTITY-1 FOOD”.
5.2. RDF Triples to Meta-paths
As shown in Fig. 4(a), to find all meta-paths, we first build the zero in-degree nodes set = {FOOD-1} and the zero out-degree nodes set = {PERSON, COUNTY, INGREDIENT}. Then, we need to find the single source shortest paths from nodes in to nodes in . The three meta-paths of this example are as follows:
-
•
FOOD-1region PLACEleaderNamePERSON
-
•
FOOD-1regionPLACEcountyCOUNTY
-
•
FOOD-1dishVariationFOOD-2ingredientINGREDIENT
These meta-paths are concatenated to a text sequence and input to the bi-GMP encoder. As shown in the bi-GMP module of Fig. 2, the hidden state of the last token in path is not passed to the first token in path .
5.3. RDF Triples to bi-GCN Graph
Similar to (Marcheggiani and Titov, 2017), the relationships are regarded as additional nodes for bi-GCN encoder and the new relationship node connects to the subject and object through two new directed edges, respectively. Therefore, the new graph (Fig. 4(b)) is two times larger than the original RDF triples graph (Fig. 4(a)) in hops, increasing the difficulty to capture long-range dependency. The input triple (FOOD-1, region, PLACE) is split into two new connections “regionFOOD-1” and “regionPLACE” with the relationship “region” being a new node in the input graph. For nodes with multiple tokens, each token is split into a separate node with a new edge connecting to the root node (usually the “ENTITY-id” node). For example, the original entity “ENTITY-1 FOOD INGREDIENTS” is split into two connections “ENTITY-1FOOD” and “ENTITY-1INGREDIENTS”.
6. Experiments
6.1. Datasets
We use two open RDF-to-text generation datasets WebNLG 222https://gitlab.com/shimorina (Gardent et al., 2017a) and DART 333https://github.com/Yale-LILY/dart (Nan et al., 2021) to evaluate our proposed model. Each example in the dataset is a (triples, text) pair and one triple collection can correspond to multiple ground truth texts. An RDF triple is composed of (subject, relationship, object), in which the subject and object are either constants or entities. The WebNLG 2017 challenge dataset includes 18102 training pairs, 2268 validation pairs, and 2495 test pairs from 10 categories (Airport, Astronaut, City, Building, ComicsCharacter, Food, Monument, SportsTeam, University, WrittenWork). In addition to being divided by entity categories, the WebNLG dataset is also divided into “seen”, “unseen” and “all” categories based on whether the topic entities have been exposed in the training set.
The second dataset DART is a large and open-domain structured DAta Record to Text generation corpus collection, integrating data from WikiSQL, WikiTableQuestions, WebNLG 2017 and Cleaned E2E. The DART dataset is composed of 62659 training pairs, 6980 validation pairs, and 12552 test pairs and covers more categories since the WikiSQL and WikiTableQuestions datasets come from open-domain Wikipedia. Unlike the previous dataset, this DART dataset is not classified as “seen” and “unseen” and therefore will not be performed entity masking.
6.2. Experimental Settings and Evaluation Metrics
The vocabulary is built based on the training set, shared by the encoders and decoder. We implement our proposed model based on Graph4NLP444https://github.com/graph4ai/graph4nlp released by (Wu et al., 2021). For the hyperparameters of the model, we set 300-dimensional word embeddings and a 512-dimensional hidden state for the bi-GCN encoder, bi-GMP encoder and decoder. Adam (Kingma and Ba, 2014) is used as the optimization method with an initial learning rate 0.001 and the batch size is 50. The scaling factor controlling the trade-off between generation loss and RL loss is 0.3.
As for the evaluation metrics, we use the standard evaluation metrics of the WebNLG challenge, including BLEU (Papineni et al., 2002), METEOR (Denkowski and Lavie, 2011) and TER. BLEU looks at n-gram overlaps between the output and ground truth text with a penalty for shorter outputs. The METEOR aligns hypotheses to one or more reference translations based on exact, stem, synonym, and paraphrase matches between words and phrases. Translation Error Rate (TER) is an automatic character-level measure of the number of editing operations required to translate machine translated output into human translated reference. The metric of BLEU provided by the WebNLG 2017 challenge is multi-BLEU555The script of multi-bleu is available on https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/multi-bleu.perl, which is a weighted average of BLEU-1, BLEU-2, BLEU-3 and BLEU-4. For BLEU and METEOR, the higher the better. For TER, the lower the better.
6.3. Baselines
Our proposed combined models is compared against the following baselines:
Sequential Model
PKUWriter, which is reported in (Gardent et al., 2017b), is a sequential model containing an attention-based encoder-decoder framework based on the TensorFlow seq2seq model. The RDF triples are converted into a sequence and fed into the encoder.
GTR-LSTM
Trisedya et al. (Trisedya et al., 2018) proposed a novel graph-based triple encoder to retain the information from the collection of RDF triples.
DGCN
Marcheggiani and Perez-Beltrachini (Marcheggiani and Perez-Beltrachini, 2018) proposed to use graph convolutional networks to directly exploit the input structure.
Transformer
Ferreira et al. (Ferreira et al., 2019) introduced a comparison between neural pipeline and end-to-end approaches for RDF2Text generation using Gated-Recurrent Units (GRU) and Transformer.
Bi-GMP Model
Bi-GMP model contains a meta-paths encoder computing the token representations in the meta-paths from both directions and a one-layer attention-based LSTM decoder.
Bi-GCN Model
Bi-GCN model contains a two-layer bi-GCN encoder and a one-layer attention-based LSTM decoder.
| Model | BLEU | BLEU | BLEU | METEOR | METEOR | METEOR | TER | TER | TER |
| seen | unseen | all | seen | unseen | all | seen | unseen | all | |
| PKUWriter | 51.23 | 25.36 | 39.88 | 0.37 | 0.24 | 0.31 | 0.45 | 0.67 | 0.55 |
| GTR-LSTM | 54.00 | 29.20 | 37.10 | 0.37 | 0.28 | 0.31 | 0.45 | 0.60 | 0.55 |
| DGCN | 55.90 | - | - | 0.39 | - | - | 0.41 | - | - |
| Transformer | 56.28 | 23.04 | 42.41 | 0.42 | 0.21 | 0.32 | 0.39 | 0.63 | 0.50 |
| bi-GCN | 57.01 | 26.82 | 43.62 | 0.40 | 0.25 | 0.33 | 0.42 | 0.68 | 0.54 |
| bi-GMP | 57.25 | 24.03 | 43.32 | 0.40 | 0.22 | 0.32 | 0.43 | 0.63 | 0.52 |
| Ours | 57.96 | 24.70 | 43.62 | 0.41 | 0.23 | 0.33 | 0.40 | 0.65 | 0.52 |
| Ours + IE | 57.79 | 26.55 | 44.00 | 0.41 | 0.26 | 0.34 | 0.41 | 0.66 | 0.53 |
| Model | BLEU | METEOR | TER |
| End-to-End Transformer | 27.24 | 0.25 | 0.65 |
| Seq2Seq-Att | 29.66 | 0.27 | 0.63 |
| bi-GCN | 38.73 | 0.32 | 0.6 |
| bi-GMP | 39.43 | 0.32 | 0.57 |
| bi-GCN + bi-GMP | 39.7 | 0.32 | 0.57 |
| bi-GCN + bi-GMP + IE | 39.87 | 0.32 | 0.57 |
| WebNLG 2017 Challenge | DART | |||
| bi-GCN | 46.99 | 40.37 | 32.00 | 36.41 |
| bi-GMP | 46.81 | 40.32 | 33.56 | 37.13 |
| bi-GCN + bi-GMP | 47.10 | 40.62 | 34.50 | 37.07 |
| bi-GCN + bi-GMP + IE | 48.20 | 40.45 | 34.75 | 37.15 |
6.4. Experimental Results
Table 2 shows the experimental results on the WebNLG test dataset. Our proposed combined models achieve best results on BLEU-seen, BLEU-all and METEOR-all metrics, and also achieve comparable results on other evaluation metrics. The series of models implemented under our framework including bi-GCN, bi-GMP, bi-GCN+bi-GMP, and bi-GCN+bi-GMP+IE are 0.7 to 1.7 points and 0.9 to 1.6 points higher in BLEU-seen and BLEU-all respectively than the previous baseline models. The bi-GCN model has lower score than bi-GMP on BLEU-seen, but higher score on BLEU-unseen than bi-GMP, as well as higher score than some sequence models such as Transformer and PKUWriter, showing the better generalization ability of graph neural network model for the unseen categories.
Table 3 shows the experimental results on the DART test dataset. As shown in this table, our proposed combined models consistently outperform other baselines on all three evaluation metrics. This is because our full model could better capture the global and local graph structure of the RDF triples. The performances of the models implemented under our framework significantly surpass the sequential baselines by about 10 BLEU points. The TER score (0.6) of bi-GCN model is higher than those (0.57) of other models proposed by us, which also shows a similar trend in the WebNLG dataset. We believe that this may be because the text generated by the graph neural network states the information in the triple set in a more random order.
Further experiments are carried out to verify the effectiveness of reinforcement learning with information extraction in Table 4. Since each example in the dataset may contain from one to multiple triples (up to seven triples for WebNLG and more for DART), we divide each dataset into two subsets with less than or equal to three and more than three triples according to the number of triples. In particular, for the DART dataset in this table, we only consider examples containing up to seven triples. As shown in this table, BLEU-all score gains 1.1 points on subset of the WebNLG dataset after introducing the IE-based reinforcement learning reward. For the DART dataset, the introduction of IE-based RL reward results in a further improvement in BLEU-all scores for both subsets, and the improvement is more significant in the subset. This is because the information extraction model performs better in examples where the number of input triples is small. When the number of triples contained in the input text is large, it is difficult for the IE module to extract them completely, and the error propagation from extraction may also lead to limited improvement of the model.
| num of triples | 1 | 2 | 3 | 4 | 5 |
| ground truth | 0.656 | 0.612 | 0.529 | 0.482 | 0.431 |
| bi-GCN + bi-GMP | 0.517 | 0.482 | 0.409 | 0.359 | 0.326 |
| bi-GCN + bi-GMP + IE | 0.558 | 0.503 | 0.422 | 0.355 | 0.323 |
Moreover, we introduce the automatic evaluation metric FEQA (Durmus et al., 2020) used in the field of abstractive summarization to evaluate the faithfulness of generated summmaries. Given question answer pairs generated from the summary, FEQA extracts answers from the document; non-matched answers indicate unfaithful information in the summary. In our setting, we regard the sequence of input triples as a document and regard the generated text as a summary. FEQA uses the averaged F1 score of questions answered correctly for each generated text. Table 5 shows the experimental results on WebNLG test dataset. We split the dataset by the size of input triples and perform FEQA evaluation on each split. The ground truth texts, texts generated by bi-GCN+bi-GMP model, and texts generated by bi-GCN+bi-GMP+IE model are evaluated. As the table shown, the F1 scores of ground truth are the highest and the F1 scores of bi-GCN+bi-GMP+IE model are higher than bi-GCN+bi-GMP model when the size is smaller than 4, which is consistent with the results in Table 4 and verifies the effectiveness of our proposed IE-based reinforment learning reward. In particular, we do not perform FEQA on splits where the input size is larger than 5 triples, as these generated or ground truth texts are so informative that it is difficult for the model to generate reasonable questions. Our code is publicly available for research purpose. 666https://github.com/Nicoleqwerty/RDF-to-Text.
| o XX[8,l] Model | Text |
| RDF Triples | (turkey, leaderName, ahmet davutoglu), (turkey, capital, ankara), (turkey, largestCity, istanbul), (ataturk monument ( izmir ), material, bronze), (turkey, currency, turkish lira), (ataturk monument ( izmir ), inaugurationDate, 1932 - 07 - 27), (ataturk monument ( izmir ), location, turkey) |
| Reference | the lira is the official currency of turkey where ahmet davutoglu is the leader . although the largest city is istanbul the capital city is ankara . the country is the location of the bronze ataturk in izmir which was inaugurated on 27 july 1932 . |
| bi-GCN | the ataturk monument is located in izmir , turkey , where the capital is ankara and the leader is ahmet davutoglu . the currency of turkey is the lira and the leader is ahmet davutoglu . |
| bi-GMP | the ataturk monument in izmir was inaugurated on 27 july 1932 in izmir . the capital of turkey is ankara and the leader is ahmet davutoglu . |
| bi-GCN + bi-GMP | the ataturk monument in izmir , turkey , where the capital is ankara , is ahmet davutoglu . the leader of turkey is ahmet davutoglu and the currency is the lira . |
| bi-GCN + bi-GMP + IE | the ataturk monument in izmir , turkey , which is made of bronze , was inaugurated on 27 july 1932 . the capital of turkey is ankara and the currency is the lira . |
| o X—X[8,l]—X | Text | BLEU-4 |
| triples | (adams county , pennsylvania, has to its southeast, carroll county , maryland) | |
| ours | carroll county , maryland is to the southwest of adams county , pennsylvania . | 0.5337 |
| ours+ie | adams county , pennsylvania has carroll county , maryland to its southeast . | 0.9999 |
| reference | to the southeast of adams county , pennsylvania lies carroll county , maryland . | |
| triples | (antioch , california, elevationAboveTheSeaLevel, 13 . 0), (antioch , california, areaTotal, 75 . 324) | |
| ours | antioch , california is 13 . 0 square kilometres and is located at 13 . 0 . | 0.3086 |
| ours+ie | antioch , california is 13 . 0 metres above sea level and has a total area of 75 . 324 square kilometres . | 0.7801 |
| reference | antioch , california is 13 . 0 metres above sea level and has a total area of 75 . 324 sq km . |
6.5. Ablation Study
Table 2 and Table 3 indicate that there are three key factors that may affect the generated text quality. The first two factors are the bi-GCN and bi-GMP encoders. Experimental results show that the performance of combined graph-augmented structural neural encoders is better than that of the models with a single graph-based encoder. This result is as expected because it is tough for one single graph-based encoder to completely model both global and local structural information. The third factor is information extraction based reinforcement learning reward. The introduction of this reward helps the model generate more faithful texts and the improvement is particularly noticeable in the examples with less than 4 triples.
6.6. Case Study
Furthermore, we manually examine the output of different models and perform case studies to better understand the performance of different models. The triples for example in Table 6.4 is described around the entity “turkey” (involving 4 triples) and the entity “ataturk monument” (involving 3 triples). As shown in this table, we find that the models that include the bi-CCN encoder perform better in correctly predicting the relationships between entities. This is expected because the bi-GCN encoder focuses more on the local structural information and can predict relationships within triples more efficiently and accurately. However, the bi-GCN encoder cannot capture long-range dependency well, which mainly focuses on the local information around the entity “turkey” and may introduce some repeated information. Meanwhile, the bi-GMP encoder mainly concentrates on the relationships between triples and can help the full model to cover different aspects of information. In the example in Table 6.4, the bi-GMP encoder pays almost equal attention to the entity “turkey” and entity “ataturk monument”. But the bi-GMP model tends to generate incorrect triple information (monument, location, izmir) and short text. In general, our proposed models can cover more information/triples and generate more accurate texts.
As the two examples in the Table 6.4 show, the bi-GCN+bi-GMP+IE model does help to improve the faithfulness of the generated text, especially for examples with less than 4 triples. The model without IE-based RL reward may incorrectly predict relationships, such as incorrectly predicting “has to its southeast” as “to the southwest”. It may also miss some important triple information, such as missing the triple (antioch california, areaTotal, 75.324).
| Methods | Grammar | Informativity | Faithfulness |
| Reference | 4.46 | 4.82 | 4.65 |
| bi-GMP | 4.26 | 4.09 | 4.27 |
| bi-GCN | 4.21 | 3.98 | 4.44 |
| Our Full Model | 4.55 | 4.24 | 4.57 |
6.7. Human Evaluation
In order to further assess the quality of these generated texts, we handed some original RDF triples and their generated text pairs to three human evaluators. The three evaluators were gievn 200 outputs, of which 50 were reference texts, 50 were outputs of the bi-GCN model, 50 were outputs of the bi-GMP model, and 50 were outputs of the full model. They were requested to assess the generated texts from three perspectives, with each perspective rated from 1 to 5. The first perspective is Grammatical, which scores each sample in terms of coherence, absence of redundancy, and absence of grammatical errors. The second perspective is Informativity (Global), which evaluates how well the information appearing in input triples are covered. The third perspective is Faithfulness (Local), which assesses the accuracy of the entities and corresponding relationships that appear in the generated texts. We averaged the results given by the three evaluators. Table 8 indicates that our proposed model can generate more informative and faithful texts.
7. Conclusion
In this paper, we propose a novel framework which explores a reinforcement learning based graph-augmented structural neural encoders for RDF-to-text generation. Our approach learns local and global structural information jointly through a combination of bidirectional GCN encoder and bidirectional GMP encoder. We further exploit a reinforcement learning reward computed by a pretrained information extraction model for the generated text to improve the text faithfulness. Our future work is to further extend our proposed approach and develop a knowledge graph question answering system which can answer the question in a generated sentence.
Acknowledgements.
The work is partially supported by the National Nature Science Foundation of China (No. 61976160), Technology research plan project of Ministry of Public and Security (Grant No. 2020JSYJD01), Thirteen Five-year Research Planning Project of National Language Committee (No. YB135-149) and the Self-determined Research Funds of CCNU from the Colleges’ Basic Research and Operation of MOE (No. CCNU20ZT012, CCNU20TD001).References
- (1)
- Androutsopoulos et al. (2013) Ion Androutsopoulos, Gerasimos Lampouras, and Dimitrios Galanis. 2013. Generating natural language descriptions from OWL ontologies: the NaturalOWL system. Journal of Artificial Intelligence Research 48 (2013), 671–715.
- Bahdanau et al. (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014).
- Banarescu et al. (2013) Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2013. Abstract Meaning Representation for Sembanking. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse. Association for Computational Linguistics, Sofia, Bulgaria, 178–186. https://aclanthology.org/W13-2322
- Banik et al. (2012) Eva Banik, Claire Gardent, Donia Scott, Nikhil Dinesh, and Fennie Liang. 2012. KBGen: text generation from knowledge bases as a new shared task. In Proceedings of the Seventh International Natural Language Generation Conference. 141–145.
- Barzilay and Lapata (2005) Regina Barzilay and Mirella Lapata. 2005. Collective content selection for concept-to-text generation. In Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing. 331–338.
- Bastings et al. (2017) Jasmijn Bastings, Ivan Titov, Wilker Aziz, Diego Marcheggiani, and Khalil Sima’an. 2017. Graph Convolutional Encoders for Syntax-aware Neural Machine Translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 1957–1967.
- Beck et al. (2018) Daniel Beck, Gholamreza Haffari, and Trevor Cohn. 2018. Graph-to-Sequence Learning using Gated Graph Neural Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 273–283.
- Belz (2008) Anja Belz. 2008. Automatic generation of weather forecast texts using comprehensive probabilistic generation-space models. Natural Language Engineering 14, 4 (2008), 431–455.
- Bontcheva and Wilks (2004) Kalina Bontcheva and Yorick Wilks. 2004. Automatic report generation from ontologies: the MIAKT approach. In International conference on application of natural language to information systems. Springer, 324–335.
- Bruna et al. (2013) Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. 2013. Spectral networks and locally connected networks on graphs. arXiv preprint arXiv:1312.6203 (2013).
- Chan and Roth (2011) Yee Seng Chan and Dan Roth. 2011. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 551–560.
- Chen et al. (2020) Yu Chen, Lingfei Wu, and Mohammed J Zaki. 2020. Reinforcement learning based graph-to-sequence model for natural question generation. In ICLR.
- Cho et al. (2014) Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. 2014. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. Association for Computational Linguistics, Doha, Qatar, 103–111. https://doi.org/10.3115/v1/W14-4012
- Dai et al. (2019) Dai Dai, Xinyan Xiao, Yajuan Lyu, Shan Dou, Qiaoqiao She, and Haifeng Wang. 2019. Joint extraction of entities and overlapping relations using position-attentive sequence labeling. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 6300–6308.
- Deemter et al. (2005) Kees Van Deemter, Mariët Theune, and Emiel Krahmer. 2005. Real versus template-based natural language generation: A false opposition? Computational Linguistics 31, 1 (2005), 15–24.
- Defferrard et al. (2016) Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. 2016. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in neural information processing systems. 3844–3852.
- Denkowski and Lavie (2011) Michael Denkowski and Alon Lavie. 2011. Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems. In Proceedings of the sixth workshop on statistical machine translation. 85–91.
- Duboue and McKeown (2003) Pablo A Duboue and Kathleen R McKeown. 2003. Statistical acquisition of content selection rules for natural language generation. In Proceedings of the 2003 conference on Empirical methods in natural language processing. 121–128.
- Durmus et al. (2020) Esin Durmus, He He, and Mona Diab. 2020. FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 5055–5070.
- Ferreira et al. (2019) Thiago Castro Ferreira, Chris van der Lee, Emiel Van Miltenburg, and Emiel Krahmer. 2019. Neural data-to-text generation: A comparison between pipeline and end-to-end architectures. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 552–562.
- Gao et al. (2019) Yuyang Gao, Lingfei Wu, Houman Homayoun, and Liang Zhao. 2019. Dyngraph2seq: Dynamic-graph-to-sequence interpretable learning for health stage prediction in online health forums. In ICDM.
- Gardent et al. (2017a) Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017a. Creating Training Corpora for Micro-Planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada.
- Gardent et al. (2017b) Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017b. The webnlg challenge: Generating text from rdf data. In Proceedings of the 10th International Conference on Natural Language Generation. 124–133.
- Gu et al. (2016) Jiatao Gu, Zhengdong Lu, Hang Li, and Victor OK Li. 2016. Incorporating copying mechanism in sequence-to-sequence learning. arXiv preprint arXiv:1603.06393 (2016).
- Hamilton et al. (2017) William L Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 1025–1035.
- Hao et al. (2017) Yanchao Hao, Yuanzhe Zhang, Kang Liu, Shizhu He, Zhanyi Liu, Hua Wu, and Jun Zhao. 2017. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. 221–231.
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation 9, 8 (1997), 1735–1780.
- Jagfeld et al. (2018) Glorianna Jagfeld, Sabrina Jenne, and Ngoc Thang Vu. 2018. Sequence-to-Sequence Models for Data-to-Text Natural Language Generation: Word-vs. Character-based Processing and Output Diversity. arXiv preprint arXiv:1810.04864 (2018).
- Kale and Rastogi (2020) Mihir Kale and Abhinav Rastogi. 2020. Text-to-Text Pre-Training for Data-to-Text Tasks. In Proceedings of the 13th International Conference on Natural Language Generation. 97–102.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kipf and Welling (2016) Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016).
- Krizhevsky et al. (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25 (2012), 1097–1105.
- Li et al. (2015) Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. 2015. Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493 (2015).
- Liu et al. (2018) Tianyu Liu, Kexiang Wang, Lei Sha, Baobao Chang, and Zhifang Sui. 2018. Table-to-text generation by structure-aware seq2seq learning. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Luong et al. (2015) Minh-Thang Luong, Hieu Pham, and Christopher D Manning. 2015. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025 (2015).
- Ma and Tang (2021) Yao Ma and Jiliang Tang. 2021. Deep Learning on Graphs. Cambridge University Press.
- Marcheggiani and Perez-Beltrachini (2018) Diego Marcheggiani and Laura Perez-Beltrachini. 2018. Deep Graph Convolutional Encoders for Structured Data to Text Generation. In Proceedings of the 11th International Conference on Natural Language Generation. 1–9.
- Marcheggiani and Titov (2017) Diego Marcheggiani and Ivan Titov. 2017. Encoding sentences with graph convolutional networks for semantic role labeling. arXiv preprint arXiv:1703.04826 (2017).
- Miwa and Bansal (2016) Makoto Miwa and Mohit Bansal. 2016. End-to-end relation extraction using lstms on sequences and tree structures. arXiv preprint arXiv:1601.00770 (2016).
- Moryossef et al. (2019) Amit Moryossef, Yoav Goldberg, and Ido Dagan. 2019. Step-by-step: Separating planning from realization in neural data-to-text generation. arXiv preprint arXiv:1904.03396 (2019).
- Nan et al. (2021) Linyong Nan, Dragomir Radev, Rui Zhang, Amrit Rau, Abhinand Sivaprasad, Chiachun Hsieh, Xiangru Tang, Aadit Vyas, Neha Verma, Pranav Krishna, Yangxiaokang Liu, Nadia Irwanto, Jessica Pan, Faiaz Rahman, Ahmad Zaidi, Murori Mutuma, Yasin Tarabar, Ankit Gupta, Tao Yu, Yi Chern Tan, Xi Victoria Lin, Caiming Xiong, Richard Socher, and Nazneen Fatema Rajani. 2021. DART: Open-Domain Structured Data Record to Text Generation. arXiv preprint arXiv:2007.02871 (2021).
- Nayak and Ng (2020) Tapas Nayak and Hwee Tou Ng. 2020. Effective modeling of encoder-decoder architecture for joint entity and relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8528–8535.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics. 311–318.
- Pouriyeh et al. (2017) Seyedamin Pouriyeh, Mehdi Allahyari, Krzysztof Kochut, Gong Cheng, and Hamid Reza Arabnia. 2017. Es-lda: Entity summarization using knowledge-based topic modeling. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 316–325.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683 (2019).
- Rennie et al. (2017) Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. 2017. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7008–7024.
- Ribeiro et al. (2020) Leonardo FR Ribeiro, Yue Zhang, Claire Gardent, and Iryna Gurevych. 2020. Modeling global and local node contexts for text generation from knowledge graphs. Transactions of the Association for Computational Linguistics 8 (2020), 589–604.
- Sahu et al. (2019) Sunil Kumar Sahu, Fenia Christopoulou, Makoto Miwa, and Sophia Ananiadou. 2019. Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 4309–4316.
- See et al. (2017) Abigail See, Peter J Liu, and Christopher D Manning. 2017. Get to the point: Summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368 (2017).
- Song et al. (2019) Linfeng Song, Daniel Gildea, Yue Zhang, Zhiguo Wang, and Jinsong Su. 2019. Semantic Neural Machine Translation using AMR. arXiv preprint arXiv:1902.07282 (2019).
- Song et al. (2018) Linfeng Song, Yue Zhang, Zhiguo Wang, and Daniel Gildea. 2018. A graph-to-sequence model for AMR-to-text generation. arXiv preprint arXiv:1805.02473 (2018).
- Stevens et al. (2011) Robert Stevens, James Malone, Sandra Williams, Richard Power, and Allan Third. 2011. Automating generation of textual class definitions from OWL to English. In Journal of Biomedical Semantics, Vol. 2. BioMed Central, S5.
- Sui et al. (2020) Dianbo Sui, Yubo Chen, Kang Liu, Jun Zhao, Xiangrong Zeng, and Shengping Liu. 2020. Joint entity and relation extraction with set prediction networks. arXiv preprint arXiv:2011.01675 (2020).
- Trisedya et al. (2018) Bayu Distiawan Trisedya, Jianzhong Qi, Rui Zhang, and Wei Wang. 2018. Gtr-lstm: A triple encoder for sentence generation from rdf data. In ACL, Vol. 1. 1627–1637.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems. 5998–6008.
- Veličković et al. (2017) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 (2017).
- Wang et al. (2021) Qingyun Wang, Semih Yavuz, Victoria Lin, Heng Ji, and Nazneen Rajani. 2021. Stage-wise Fine-tuning for Graph-to-Text Generation. arXiv preprint arXiv:2105.08021 (2021).
- Wang et al. (2020) Yucheng Wang, Bowen Yu, Yueyang Zhang, Tingwen Liu, Hongsong Zhu, and Limin Sun. 2020. TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics. 1572–1582.
- Wu et al. (2021) Lingfei Wu, Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Jian Pei, and Bo Long. 2021. Graph Neural Networks for Natural Language Processing: A Survey. arXiv preprint arXiv:2106.06090 (2021).
- Xu et al. (2018) Kun Xu, Lingfei Wu, Zhiguo Wang, Yansong Feng, Michael Witbrock, and Vadim Sheinin. 2018. Graph2seq: Graph to sequence learning with attention-based neural networks. arXiv preprint arXiv:1804.00823 (2018).
- Xu et al. (2015) Yan Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, and Zhi Jin. 2015. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 conference on empirical methods in natural language processing. 1785–1794.
- Yao et al. (2020) Shaowei Yao, Tianming Wang, and Xiaojun Wan. 2020. Heterogeneous graph transformer for graph-to-sequence learning. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 7145–7154.
- Zelenko et al. (2003) Dmitry Zelenko, Chinatsu Aone, and Anthony Richardella. 2003. Kernel methods for relation extraction. Journal of machine learning research 3, Feb (2003), 1083–1106.
- Zeng et al. (2014) Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. 2335–2344.
- Zeng et al. (2020) Daojian Zeng, Haoran Zhang, and Qianying Liu. 2020. Copymtl: Copy mechanism for joint extraction of entities and relations with multi-task learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 9507–9514.
- Zeng et al. (2018) Xiangrong Zeng, Daojian Zeng, Shizhu He, Kang Liu, and Jun Zhao. 2018. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 506–514.
- Zhang et al. (2017) Meishan Zhang, Yue Zhang, and Guohong Fu. 2017. End-to-end neural relation extraction with global optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 1730–1740.
- Zhao et al. (2021) Kang Zhao, Hua Xu, Yue Cheng, Xiaoteng Li, and Kai Gao. 2021. Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowledge-Based Systems 219 (2021), 106888.
- Zheng et al. (2017) Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. 2017. Joint extraction of entities and relations based on a novel tagging scheme. arXiv preprint arXiv:1706.05075 (2017).
- Zhu et al. (2019) Yaoming Zhu, Juncheng Wan, Zhiming Zhou, Liheng Chen, Lin Qiu, Weinan Zhang, Xin Jiang, and Yong Yu. 2019. Triple-to-Text: Converting RDF Triples into High-Quality Natural Languages via Optimizing an Inverse KL Divergence. arXiv preprint arXiv:1906.01965 (2019).