Trust-region algorithms: probabilistic complexity and intrinsic noise with applications to subsampling techniques
S. Bellavia,
G. Gurioli,
B. Morini and
Ph. L. Toint
Dipartimento di Ingegneria Industriale,
Università degli Studi di Firenze, Italy. Member of the INdAM Research
Group GNCS. Email: stefania.bellavia@unifi.itDipartimento di Matematica e Informatica “Ulisse Dini”,
Università degli Studi di Firenze, Italy. Member of the INdAM Research
Group GNCS. Email: gianmarco.gurioli@unifi.itDipartimento di Ingegneria Industriale,
Università degli Studi di Firenze, Italy. Member of the INdAM Research
Group GNCS. Email: benedetta.morini@unifi.it Namur Center for Complex Systems (naXys),
University of Namur, 61, rue de Bruxelles, B-5000 Namur, Belgium.
Email: philippe.toint@unamur.be
(21 X 2021)
Abstract
A trust-region algorithm is presented for finding approximate
minimizers of smooth unconstrained functions whose values and derivatives are
subject to random noise. It is shown that, under suitable probabilistic
assumptions, the new method finds (in expectation) an -approximate minimizer of
arbitrary order in at most
inexact evaluations of the function and its derivatives,
providing the first such result for general optimality orders.
The impact of intrinsic noise limiting the validity of the assumptions is also
discussed and it is shown that difficulties are unlikely to occur in
the first-order version of the algorithm for sufficiently large gradients. Conversely,
should these assumptions fail for specific realizations, then “degraded”
optimality guarantees are shown to hold when failure occurs. These
conclusions are then discussed and illustrated in the context of subsampling
methods for finite-sum optimization.
This paper is concerned with trust-region methods for solving the
unconstrained optimization problem
(1.1)
where we assume that the values of the objective function and its
derivatives are computed subject to random noise. Our objective is
twofold. Firstly, we introduce a version of the deterministic method proposed
in [10] which is able to handle the random context and
provide, under reasonable probabilistic assumptions, a sharp evaluation
complexity bound (in expectation) for arbitrary optimality order. Secondly, we
investigate the effect of intrinsic noise (that is noise whose level cannot be
assumed to vanish) on a first-order version of our algorithm and prove
“degraded” optimality, should this noise limit the validity of our
assumptions. The new results are then detailed and illustrated in the framework of
finite-sum minimization using subsampling.
Minimization algorithms using adaptive steplength and allowing for random
noise in the objective function or derivatives’ evaluations have already
generated a significant literature
(e.g. [1, 13, 6, 16, 7, 4, 2]).
We focus here on trust-region methods, which are methods in which a trial step
is computed by approximately minimizing a model of the objective function in a
“trust region” where this model is deemed sufficiently accurate. The trial
step is then accepted or rejected depending on whether a sufficient improvement in
objective function value predicted by the model is obtained or not, the radius
of trust-region being then reduced in the latter case. We refer the reader to
[15] for an in-depth coverage of this class of algorithms and
to [17] for a more recent survey. Trust-region methods involving
stochastic errors in function/derivatives values were considered in particular in
[1, 12] and [7, 13],
the latter being the only methods (to the author’s
knowledge) handling random perturbations in both the objective function and
its derivatives. The complexity analysis of the STORM (STochastic Optimization with Random Models)
algorithm described in
[7, 13] is based on supermartingales and makes probabilistic
assumptions on the accuracy of these evaluations which become tighter when the
trust-region radius becomes small. It also hinges on the definition of a
monotonically decreasing “merit function” associated with the stochastic
process corresponding to the algorithm. The method proposed in this paper can
be viewed as an alternative in the same context, but differs from the STORM
approach in several aspects.
The first is that the method discussed here uses a model whose degree is
chosen adaptively at each iteration, requiring the (noisy) evaluation of
higher derivatives only when necessary. The second is that its scope is not
limited to searching for first- and second-order approximate minimizers, but
is capable of computing them to arbitrary optimality order. The third is that
the probabilistic accuracy
conditions on the derivatives’ estimations no longer depends on the trust-region
radius, but rather on the predicted reduction in objective function
values, which may be less sensitive to problem conditioning. Finally,
its evaluation complexity analysis makes no use of
a merit function of the type used in [7].
In [5], the impact of intrinsic random noise on the
evaluation complexity of a deterministic “noise-aware” trust-region
algorithm for unconstrained nonlinear optimization was
investigated and constrasted with that of an inexact version where noise is
fully controllable. The current paper considers the question in the more general
probabilistic framework.
Even if the analysis presented below does not depend in any way on the
choice of the optimality order , the authors are well aware that, while
requests for optimality of orders lead to
practical, implementable algorithms, this may no longer be the case for
. For high orders, the methods discussed in the paper therefore constitute an
“idealized” setting (in which complicated subproblems can be approximately
solved without affecting the evaluation complexity) and thus indicate the
limits of achievable results.
The paper is organized as follows. After introducing the new stochastic trust-region algorithm
in Section 2, its evaluation complexity
analysis is presented in Section 3.
Section 4 is then devoted to an in-depth discussion of the impact
of noise on the first-order instantiation of the algorithm, with a particular
emphasis on the case where noise is generated by subsampling in finite-sum
minimization context. Conclusions and perspectives are
finally proposed in Section 5.
Because our contribution borrows ideas from [4],
themselves being partly inspired by [12], repeating some material
from these sources is necessary to keep our argument understandable. We have
however done our best to limit this repetition as much as possible.
Basic notations. Unless otherwise specified, denotes the standard
Euclidean norm for vectors and matrices. For a general symmetric tensor
of order , we define
the induced Euclidean norm. We also denote by the -th
order derivative tensor of evaluated at and note that such a tensor is
always symmetric for any . is a synonym for .
denotes the
smallest integer not smaller than . Moreover, given a set , denotes its cardinality,
refers to its indicator function and indicates its complement.
All stochastic quantities live in a probability space denoted by with the probability measure and the -algebra
containing subsets of . We never explicitly define , but specify it through random variables.
finally denotes the probability of an
event and the expectation of a random variable .
2 A trust-region minimization method for problems with
randomly
perturbed function values and derivatives
We make the following assumptions on the optimization problem (1.1).
AS.1
The function is -times continuously
differentiable in , for some . Moreover, its -th
order derivative tensor is Lipschitz continuous for in the
sense that, for each , there exists a constant
such that, for all ,
(2.1)
AS.2
is bounded below in , that is there exists a constant
such that for all .
AS.2 ensures that the minimization problem (1.1) is well-posed.
AS.1 is a standard assumption in evaluation complexity analysis(1)(1)(1)It
is well-known that requesting (2.1) to hold for
all is strong. The weakest form of AS.1 which we could
use in what follows is to require (2.1) to hold for all
(the iterates of the minimization algorithm we are about to describe) and all
(where is the associated step and is arbitrary
in [0,1]). However, ensuring this condition a priori, although maybe possible for
specific applications, is hard in general, especially for a non-monotone algorithm with a
random element.. It is important because we
consider algorithms that are able to exploit all available derivatives of
and, as in many minimization methods, our approach is based on
using the Taylor expansions
(now of degree for ) given by
At a given iterate of our algorithm, we will be interested in finding a
step which makes the Taylor decrements
(2.4)
large (note that is independent of ). When this is
possible, we anticipate from the approximating properties of the Taylor
expansion that some significant decrease is also possible in . Conversely,
if cannot be made large in a neighbourhood of , we
must be close to an approximate minimizer. More formally, we define, for some
and some optimality radius ,
the measure
(2.5)
that is the maximal decrease in achievable in a ball of radius
centered at . (The practical purpose of introducing is to avoid
unnecessary computations, as discussed below.) We then define to be a -th order
-approximate minimizer (for some accuracy requests
) if and only if
(2.6)
(a vector solving the optimization problem defining
in (2.5) is called an optimality displacement) [8, 10].
In other words, a -th order -approximate
minimizer is a point from which no significant decrease of the Taylor
expansions of degree one to can be obtained in a ball of optimality radius
. This notion is coherent with standard optimality measures for low
orders(2)(2)(2)It is easy to verify that, irrespective of ,
(2.6) holds for if and only if
and that, if , if
and only if . and has the advantage of
being well-defined and continuous in for every order.
Note that is always non-negative.
This paper is concerned with the case where the values of the objective
function and of its derivatives are subject to random
noise and can only be computed inexactly (our assumptions on random noise will
be detailed below). Our notational convention will be to
denote inexact quantities with an overbar, so and
denote inexact values of and , where is a random variable causing inexactness. Thus (2.2)
and (2.4) are unavailable, and we have to consider
and the associated decrement
(2.7)
instead. For simplicity, we will often omit to mention the dependence of inexact
values on the random variable in what follows, so (2.7)
is rewritten as
(2.8)
This in turn would require that we measure optimality using
(2.9)
instead of (2.5). However, computing this exact global maximizer may be
costly, so we choose to replace the computation of (2.9) by an
approximation, that is with the computation of an optimality displacement
with such that
for some constant .
We state the Trust-Region with Noisy Evaluations (TRNE) algorithm 2
using all the ingredients we have described. The trust region radius at iteration is denoted by
instead of the standard notation .
Algorithm 2.1: The TRNEalgorithm
Step 0: Initialisation.A criticality order , a starting point and accuracy
levels are given. For a given constant , define(2.10)The constants , , , and an initial trust-region radius
are also given. Set .Step 1: Derivatives estimation.Set . For ,1.Compute derivatives’ estimates and
find an optimality displacement with such that(2.11)2.If(2.12)go to Step 2 with .Set .Step 2: Step computation.If , set and .
Otherwise, compute a step such that and(2.13)Step 3: Function decrease estimation.Compute the estimate of
.Step 4: Test of acceptance.Compute(2.14)If (successful iteration), then set
; otherwise (unsuccessful iteration) set .Step 5: Trust-region radius update.SetIncrement by one and go to Step 1.
A feature of the TRNEalgorithm is that it uses an
adaptive strategy (in Step 1) to choose the model’s degree in view of the
desired accuracy and optimality order. Indeed, the model of the objective
function used to compute the step is , whose degree
can vary from an iteration to the other, depending on the “order of (inexact)
optimality” achieved at (as determined by Step 1). Also observe that,
if the trust-region radius is small (that is ), the
optimality displacement is an approximate global minimizer of
the model within the trust region, which justifies the choice
in this case. If , the step computation is
allowed to be fairly approximate as the only requirement for a step in the
trust region is (2.13). This can be interpreted as a
generalization of the familiar notions of “Cauchy” and “eigen” points
(see [15, Chapter 6]). In addition, note that, while nothing
guarantees that , the mechanism of the
algorithm ensures that .
The TRNE algorithm generates a random process. Randomness occurs
because of the random noise present in the Taylor decreases and objective
function values, the former resulting itself from the randomly perturbed
derivatives values and, as the algorithm proceeds, from the random
realizations of the iterates and steps . In the following analysis,
uppercase letters denote random quantities, while lowercase ones denote realizations of these random quantities. Thus,
given , , , etc.
In particular, we distinguish
•
, the value at a (deterministic) of the exact Taylor
decrement, that is of the Taylor decrement using the exact values of its derivatives at ;
•
, the value at a (deterministic) of an inexact Taylor
decrement, that is of a Taylor decrement using the inexact values of
its derivatives (at ) resulting from the realization of random
noise;
•
, the random variable corresponding to the exact Taylor
decrement taken at the random variables ;
•
, the random variable giving the value of the Taylor
decrement using randomly perturbed derivatives, taken at
the random variables .
Analogously, and denote the random variables associated with
the estimates of and , with their realizations and .
Similarly, the iterates , as well as the trust-region radiuses , the
indeces , the
optimality radiuses , displacements
and the steps are random variables while
, , , , , and denote their realizations.
Hence, the TRNEalgorithm generates the random process
(2.15)
in which (the initial guess) and (the initial trust-region
radius) are deterministic quantities, and where
2.1 The probabilistic setting
We now state our probabilistic assumptions on the TRNEalgorithm. For , our assumption on the past is formalized by considering the
-algebra induced by the random variables , ,…,
and , , , , …, , and let
be that induced by , ,…, and ,
, …, , , with .
We first define an event ensuring that the model is accurate enough at
iteration . At the end of Step 2 of this iteration and given
, we now define,
(2.16)
The event occurs when the -th order optimality measure
() at iteration is meaningful, while occurs when
this is the case for the model decrease. At first sight, these events may
seem only vaguely related to the accuracy of the function’s derivatives but a
closer examination gives the following sufficient condition for to
happen.
Lemma 2.2
At iteration of any realization, the inequalities
defining the event are satisfied if,
for and (2.17)and(2.18)where(2.19)
Proof.
If (2.18) holds, we have that, for every and
,
with , , given in (2.19),
(2.20)
where we have used the bound .
Now note that the definition of
in (2.9), (2.20) for
and (2.11) imply that, for any ,
Hence the inequality in the definition of holds for
. The proof of the inequalities defining is
analog to that of (2.20). We have from (2.17) that
(2.21)
where we have again used the bound .
This result immediately suggests a few comments.
•
The conditions (2.17)-(2.18) are merely sufficient,
not necessary. In particular, they ignore any possible cancellation of errors
between terms of the Taylor expansion of different degree.
•
We note that (2.17)-(2.18) require the -th
derivative to be relatively accurate along a finite and limited set of
directions, independent of problem dimension.
•
Since and are bounded by , we also note that the accuracy required by these conditions
decreases when the degree increases. Moreover, for a fixed degree,
the request is weaker for small displacements (a typical situation when a
solution is approached) than for large ones.
•
Requiring
(2.22)
instead of (2.18) is of course again sufficient to ensure the desired conclusions.
These conditions are reminiscent of the conditions required in
[7] for the STORM algorithm with , namely that,
for some constant and all in the trust-region
,
This latter condition is however stronger
than (2.17)–(2.18)
because it insists on a uniform accuracy guarantee in the full-dimensional
trust region.
Having considered the accuracy of the model, we now turn to that on the
objective function’s values. At the end of Step of the -th iteration,
we define the event
(2.23)
where and . This occurs when the difference in function values used in
the course of iteration are reasonably accurate relative to the model decrease
obtained in that iteration. Note that, because of the triangular inequality,
so that must occur if both terms on the right-hand side are bounded
above by .
Combining accuracy requests on model and function values, we define
(2.24)
and say that iteration is accurate if
and the iteration is inaccurate if
.
Moreover, we say that the iteration has accurate model if
and that iteration has accurate function estimates if .
Finally we let
We will verify in what follows that the TRNEalgorithm does progress towards
an approximate minimizer satisfying (2.6) as long as the following holds.
AS.3
There exists such that ,
(2.25)
where is the event .
We notice that due to the tower property for conditional expectations
Assuming AS.3 is not unreasonable as it merely requires that an accurate model and accurate functions
“happen more often than not”, and that the discrepancy between true and
inexact function values at successful iterations does not, on average, prevent
decrease of the objective function. If either of these
condition fails, it is easy to imagine that the TRNEalgorithm could be completely
hampered by noise and/or diverge completely. Because the last condition in
(2.25) is less intuitive, we now show that it can be realistic in the
specific context where reasonable assumptions are made on the (possibly
extended) cumulative distribution of the error on the function decreases
(conditioned to ).
Theorem 2.3
Let be a differentiable monotone
increasing random function which is measurable for and such that(2.27)(2.28)(2.29)and(2.30)for . Then,(2.31)for each such that
Proof.
Consider , an arbitrary realization of the stochastic process defined
by the TRNE algorithm.
Suppose first that .
We then deduce that
(2.32)
Assume therefore that
(2.33)
for some . To further simplify notations, set
(2.34)
If we define ,
the definition of successful iterations, (2.14) and the
triangular inequality then imply that, if
then
(2.35)
This in turn ensures that
(2.36)
Moreover, we have that
where we used the fact that whenever
happens, (2.33) to derive the second equality, and the bound
to obtain the final inequality.
Now, (2.30) implies that, for
where ,
and thus
Then, employing (2.27)–(2.30), and integrating by parts
Note that the assumptions of the theorem are for instance satisfied for
the exponential case where for and measurable
for . We will return to this result in Section 4 and
discuss there the condition that should be
sufficiently large.
3 Worst-case evaluation complexity
We now turn to the evaluation complexity analysis for the TRNEalgorithm, whose aim is to derive
a bound on the expected number of iterations for which optimality fails. This
number is given by
(3.1)
We first state a crucial lower bound on the model decrease, in the spirit of
[10, Lemma 3.4].
Lemma 3.1
Consider any realization of the algorithm and assume that occurs.
Assume that (2.6) fails at iteration .
Then, there exists a such that
at Step 1 of the iteration. Moreover,(3.2)where(3.3)
Proof.
We proceed by contradiction and assume that
(3.4)
for all . Since occurs, we have that, for all ,
which contradicts the assumption that (2.6) does not hold for
and . The bound (3.2)
directly results from
where we have used (2.13) to derive the first inequality
and the definition (3.3) to obtain the equality.
The
rightmost inequality in (3.3) trivially follows from the negation of (3.4) and
(2.10).
We now search for conditions ensuring that the iteration is successful.
For simplicity of notation, given , , as in (2.1),
we define
(3.5)
Lemma 3.2
Suppose that AS.1 holds. Consider any realization of the algorithm and
suppose that (2.6) does not hold for and and that
occurs. If(3.6)
holds,
then iteration is successful.
Proof.
First, note that the minimum in (3.6) is attained at since and . Suppose now that (3.6) holds, which implies that . Let be as in Lemma 3.1, and
denote , .
Using (2.14), the triangle inequality and ,
we obtain
Invoking (2.3), the bound ,
(3.5), (3.2) and we get
The following crucial lower bound on for
accurate iterations can now be proved.
Lemma 3.3
Suppose that AS.1 holds. Consider any realization of the algorithm and
suppose that (2.6) does not hold for and ,
occurs, and that with defined in (3.6). Then(3.8)where is defined by(3.9)with defined in (3.6).
Proof.
Let be as in Lemma 3.1. By
(3.2), (3.3) we obtain
If then and the bound implies
Thus (3.8) holds by definition
of and the fact that .
If , then .
The proof is completed by noting that the form of in (3.6)
gives that .
3.1 Bounding the expected number of steps with
We now return to the general stochastic process generated by the TRNEalgorithm
and bound the expected number of steps in from above. For this
purpose, let us define, for all ,
the events
be the number of steps, in the stochastic process induced by the TRNEalgorithm and before
, such that or ,
respectively. In what follows we suppose that AS.1–AS.2 hold.
An upper bound on can be derived as follows.
(i)
We apply [12, Lemma 2.2] to deduce that, for any
and for all realizations of Algorithm 2, one has that
(3.11)
(ii)
Both
and
belong to , because the random variable is fully determined
by the first iterations of the TRNEalgorithm. Setting we can rely on
[12, Lemma ] (with ), whose proof is detailed in the appendix, to deduce that
(3.12)
(iii)
As a consequence, given that Lemma 3.2
ensures that each iteration where occurs and
is successful, we have that
in which the last inequality follows from (3.11), with
. Taking expectation in the above inequality, using
(3.12) and recalling the rightmost definition in (3.10),
we obtain, as in [12, Lemma 2.3], that
(3.13)
3.2 Bounding the expected number of steps with
For analyzing , where is defined in
(3.10), we now introduce the following variables.
Definition 1
Consider the random process (2.15) generated by
the TRNE algorithm and define:
(3.14)
Observe that is the “closure” of in
that the inequality in its definition is no longer strict.
We immediately notice that an upper bound on
is available, once an upper bound on is
known, since
(3.15)
Using again [12, Lemma ] (with
) to give an upper bound on
, we obtain the following result, whose proof is detailed in the appendix.
Lemma 3.4
[12, Lemma 2.6]
Suppose that AS.1-AS.3 hold and let , be defined as in Definition
3.14 in the context of the stochastic process (2.15)
generated by the TRNEalgorithm. Then,(3.16)
Turning to the upper bound for , we observe that
(3.17)
Hence, bounding can be achieved by providing upper bounds on
and . Regarding the latter, we first
note that the process induced by the TRNEalgorithm ensures that
is increased by a factor on successful steps and decreased by the
same factor on unsuccessful ones.
Consequently, based on [12, Lemma ], we obtain the
following bound.
Lemma 3.5
For any and for
all realisations of Algorithm 2, we have that
From the inequality stated in the previous lemma with , recalling Definition
3.14 and taking expectations, we therefore obtain that
(3.18)
An upper bound on is given by the following lemma.
Lemma 3.6
Suppose that AS.1, AS.2 and AS.3 hold.
Then we have that(3.19)where is defined in (3.9).
Proof.
Consider any realization of the TRNEalgorithm.
i)
If iteration is successful and the
functions are accurate (i.e., )
then (2.14), (2.10) and (2.23) imply that
(3.20)
Thus
(3.21)
where . Moreover, if also occurs
with (i.e., if ) and
(2.6) fails for and , we may then use
(3.8) to deduce from (3.20) that
While inequalities (3.18) and (3.19) provide upper bounds on
and , as desired, the first still
depends on , which has to be bounded from above as well. This
can be done by following [12] once more:
Definition 3.14, (3.16) and (3.17) directly imply that
(3.31)
and hence
(3.32)
follows from (3.18) (remember that ). Thus, the
right-hand side in (3.16) is in turn bounded above because of (3.17), (3.18),
(3.32) and (3.19), giving
(3.33)
This inequality, together with (3.15) and (3.16), finally
gives the desired bound
(3.34)
We can now express our final complexity result in full.
Theorem 3.7
Suppose that AS.1–AS.3 hold, then(3.35)with , and defined as in
(3.1), (3.6) and (3.9), respectively.
Proof.
Recalling the definitions (3.10) and the bound (3.13), we obtain that
This bound and the inequality yield the desired result.
We note that the evaluation bound given by
(3.35) is known to be sharp in order of for
trust-region methods using exact evaluations of functions and derivatives (see
[11, Theorem 12.2.6]), which implies that
Theorem 3.7 is also sharp in order.
We conclude this section by noting that alternatives to the second
part of (2.25) do exist. For instance, we could assume that
for some . This condition can be used to replace the second part
of (2.25) to ensure (3.26) in the proof of Lemma 3.6 and all
subsequent arguments.
4 The impact of noise for first-order minimization
While the above theory covers inexact evaluations of the objective function
and its derivatives, it does rely on AS.3. Thus, as long as
the inexactness/noise on these values remains small enough for this assumption
to hold, the TRNE algorithm iterates ultimately
produce an approximate local minimizer. There are however practical
applications, such as minimization of finite sum using sampling strategies
(discussed in more detail below), where AS.3 may be unrealistic because of
noise intrinsic to the application. We already
saw that, under the assumptions of Theorem 2.3, a large enough
value of is sufficient for ensuring the third
condition in AS.3, but we also know from (2.23),(2.34), (2.35) and the definition of
that, at successful iterations,
whenever holds. Thus a large is only
possible if either is large or fails. But a large
is impossible close to a
(global) minimizer, and thus either (and AS.3) fails, or the guarantee
that the third condition of AS.3 holds vanishes when approaching a minimum.
Clearly, the above theory does not say anything about what happens for the
algorithm once AS.3 fails due to intrinsic noise. Of course, this does not
mean it will not proceed meaningfully, but we can’t guarantee it.
In order to improve our understanding of what can happen, we need to
consider particular realizations of the iterative process where AS.3 fails.
This is the objective of this section where we focus on the instantiation
TRNE of TRNE for first-order optimality.
Fortunately, limiting one’s ambition to first order results in subtantial
simplifications in the TRNEalgorithm.
We first note that the mechanism of Step 1 of TRNE(whose purpose is to
determine ) is no longer necessary since must be equal to one if
only (approximate) gradients are available, so we can implicitly set
and immediately branch to the step computation. This in turn simplifies
to
irrespective of the value of , and (2.13) automatically
holds. We thus observe that the simplified algorithm no longer needs
(since neither or
needs to be effectively calculated), that the computed step is the global minimizer within the trust-region and that the
constant (used in Step 1 and the start of Step 2 of the TRNEalgorithm) is no
longer necessary. The resulting streamlined TRNE algorithm is stated
as Algorithm 44.
Algorithm 4.1: The TR1NE algorithm
Step 0: Initialisation.A starting point , a maximum radius and an accuracy
level are given. The initial trust-region radius
is also given.
For a given constant , define .
Set .Step 1: Derivatives estimation.Compute the derivative estimate .Step 2: Step computation.Set .Step 3: Function decrease estimation.Compute the estimate of
.Step 4: Test of acceptance.Compute
If (successful iteration), then set
; otherwise (unsuccessful iteration) set .Step 5: Trust-region radius update.SetIncrement by one and go to Step 1.
The definition of the event in (2.16) ensures that
implies when first-order models are considered,
and thus, using also (2.23), that and then reduce to
and
respectively. Observe now that, because of the triangle inequality,
is true whenever the event
(4.1)
holds, and, since
,
it also follows that is true whenever the event
(4.2)
holds. As a consequence,
(4.3)
Our analysis of the impact of noise on the TRNE algorithm starts by
considering a relatively general form for error distributions (as we did
in Theorem 2.3) and we then specialize our arguments to the
particular case of finite sum minimization with subsampling.
4.1 Failure of AS.3 for general error distributions
At a generic iteration ,
suppose that and , are continuous and increasing random functions
from to which are measurable for and such that ,
and,
(4.4)
For sake of simplicity, assume in AS.3
and let and such that and
, and . Then,
(4.5)
(4.6)
Define
(4.7)
and note that is measurable for . Then (4.5) and (4.6) ensure that
Let as in (4.7). Then, for each iteration of
the TRNE algorithm,(4.14)
Proof.
For any realization of the TRNE algorithm we have that
Therefore, (where is the realization of ) and
ensure that
Then, implies , where the events
, and are defined in
(4.10)-(4.12), and
. We
therefore have that
Let be defined by (4.7). Then, for each iteration of
the TRNE algorithm,(4.19)Moreover, if is a realization for which
, then(4.20)
Proof. The proof is similar to that of Theorem 4.2, and is
given in appendix for completeness.
Theorems 4.2 and 4.3 indicate that the
assumptions made in AS.3 about and are likely to be
satisfied as long as the gradients remain sufficiently large, allowing the
TRNE algorithm to iterate meaningfully. Conversely,
they show that, should these assumptions fail for a particular realization of
the algorithm because of a high level of intrinsic noise, “degraded”
versions of first-order optimality conditions given by (4.16) and
(4.20) nevertheless hold when this failure occurs.
4.2 A subsampling example
We finally illustrate how intrinsic noise might affect our probabilistic
framework on an example.
Suppose that
(4.21)
where the are functions from to having Lipschitz continuous
gradients and where is so large that computing the complete value of
or its derivatives is impractical. Such a situation occurs for
instance in algorithms for deep-learning, an application of growing
importance. A well-known strategy to obtain approximations of the desired
values at an iterate is to sample the and compute the sample
averages, that is
(4.22)
where and are realizations of random
“batches”, that is randomly selected(3)(3)(3)With uniform distribution. subsets of
. Observe that Step 3 of the TRNE algorithm
computes the estimate , which we assume, in the
context of (4.21), to be
(4.23)
(using a single batch for both the function estimates). Observe that our choice to make and
dependent on implies that their random counterparts and
are measurable for (clearly we could have chosen a
more complicated dependence on the past of the random process). The mean-value
theorem then yields that, for some
in the segment ,
Note that one expects the right-hand side of this inequality
to be quite small when the trust-region radius is small or when convergence to
a local minimizer occurs and is a reasonable
approximation of . To simplify our illustration, we assume,
for the rest of this section, that there exists a constant
such that for any , for every realization
,
Returning to the random process and using the Bernstein concentration
inequality, it results from [3, Relation (7.8)] that,
for any and deterministic ,
(4.24)
Similarly,
(4.25)
for some constant . One also checks that, since and
are measurable for , so are and .
One then easily verifies that is an increasing function of ,
and hence is decreasing. Letting
, we immediately obtain that conditions (2.27) and (2.28)
hold. Let us now analyze condition (2.29) and consider any realization
, where . Note that
when
(4.26)
and is large enough so that
(4.27)
Hence for all
and
In addition, since is decreasing and non-negative, we have that
proving that (2.29) also holds for the arbitrary realization . We
may therefore apply Theorem 2.3 provided is sufficiently
large(4)(4)(4)While the bound given by (4.28) is adequate for our proof, this
inequality can be pessimistic. For instance, if we set
and , the numerically computed
value of the left-hand side is 0.0556 while that of the right-hand side is 0.1818.
to ensure (4.27) and (4.26), and conclude that, under these conditions,
(2.31) holds whenever
We can also apply the analysis in Section 4.1 with
A short calculation shows that
and
, where and are
defined below (4.4). Then,
Theorems 4.2 and 4.3 hold with .
We finally illustrate the impact of intrinsic noise on the (admittedly ad-hoc)
problem of minimizing
(4.29)
where is a noise level and where
for some large integer . Suppose furthermore that the and
are computed by black-box routines, therefore
hiding their relationships.
Consider an iterate at the start of iteration of an arbitrary
realization of the TRNE algorithm(5)(5)(5)With given and . applied
to this problem. We verify that, for ,
for all . As a consequence, is the unique global minimizer of
.
Suppose, for the rest of this section, that
,
, and that
and , the cardinalities of
these two sets are known parameters. We deduce from (4.22) that
(4.31)
Thus is a zero-mean random variable with values in
, depending on the randomly chosen batch
of size . Using the hypergeometric distribution, it is
possible to show that is (in probability) a
decreasing function of .
Moreover, the use of standard tail bounds [14] reveals that, for any
,
(4.32)
in turn indicating that whenever
Occurence of and .
Let us now examine at what conditions the events and
do occur for a specific realization of
, and consider the occurence of first.
Because the minimum of first-order models in a ball of radius must
occur on the boundary, we choose
so that
Thus the quantity may be
interpreted as the local noise relative to the model decrease.
Taking (4.30) and (4.33) into account, occurs, in any
realization, whenever
(4.34)
that is
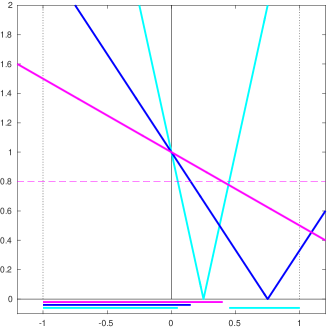
This condition may be quite weak, as shown in left picture in
Figure 4.1, where the shape of the left-hand side of (4.34)
is shown for increasing values(6)(6)(6)Magenta for 0.5, blue for 4/3 and cyan
for 4. of the local noise level as a function
of , and where the lower bound is shown as a
red horizontal dashed line. The corresponding ranges of acceptable values of
are shown below the horizontal axis (in matching
colours). The one-sided nature of the inequality defining is
apparent in the picture, where restrictions on the acceptable values of
only occur for positive values. This reflects the fact that
the model may be quite inaccurate and yet produce a decrease which is large
enough for the condition to hold.
Figure 4.1:
An illustration of conditions (4.34) (left) and
(4.36) (right) as a function of ,
for and local relative noise levels (magenta), (blue) and (cyan). Acceptable ranges for
are shown below the horizontal axis in matching colours.
The constraints on , and thus on , become
more stringent when considering the occurence of . Since, for
any realization,
,
we deduce from (4.31) that
and
(4.35)
One then verifies that occurs whenever
(4.36)
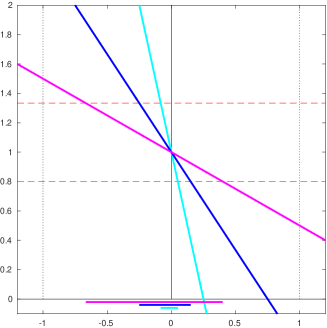
The acceptable values for are illustrated in the right
picture of Figure 4.1, which
shows the shape of the central term in (4.36) using
the same conventions than for the
left picture except that now the acceptable part of the curves lies between
the lower and upper bounds resulting from (4.36) (again shown as
dashed red lines).
A short calculation reveals that (4.36) is equivalent to requiring
This therefore defines intervals around the origin, whose
widths clearly decrease with the local relative noise level.
Because is (in probability) a decreasing function of
, this indicates that must increase with
, that is when the local relative noise is large.
Occurence of .
A similar reasoning holds when considering the event .
Given (4.23), we have that
Thus, if is small (e.g., if the optimum is close)
then satisfying (4.38) requires the left-hand side of this inequality
to be small, putting a high request on , while the inequality
is more easily satisfied if is large, irrespective of the batch sizes.
Note that, in the first case (i.e., when is small), the request on
is stronger for smaller .
Occurence of (2.31).
Given (4.32) and (4.35), we see from
Theorem 2.3 that (2.31) holds whenever
where we have used the definition of the erf function to derive the last
equality. Thus, as , gauranteeing (2.31)
requires a larger for small value of , that is
when the optimum is approached.
5 Conclusions and perspectives
We have considered a trust-region method for unconstrained minimization
inspired by [10] which is adapted to handle randomly perturbed
function and derivatives values and is capable of finding approximate
minimizers of arbitrary order. Exploiting ideas of
[12, 7], we have shown that its evaluation
complexity is (in expectation) of the same order in the requested accuracy as
that known for related deterministic methods
[7, 10].
In [5], the authors have considered the effect of
intrinsic noise on complexity of a deterministic, noise tolerant variant of
the trust-region algorithm. This important question is handled here by considering
specific realizations of the algorithm under reasonable assumptions on the
cumulative distribution of errors in the evaluations of the objective function
and its derivatives. We have shown that, for such realizations, a first-order
version of our trust-region algorithms still provides “degraded” optimality
guarantees, should intrinsic noise cause the assumptions used for the
complexity analysis to fail. We have specialized and illustrated those results
in the case of sampling-based finite-sum minimization, a context of particular
interest in deep-learning applications.
We have so far developed and analyzed “noise-aware” deterministic and
stochastic algorithms for unconstrained optimization. Clearly, considering the
constrained case is a natural extension of the type of analysis presented
here.
References
[1]
A. S. Bandeira, K. Scheinberg, and L. N. Vicente.
Convergence of trust-region methods based on probabilistic models.
SIAM Journal on Optimization, 24(3):1238–1264, 2014.
[2]
S. Bellavia and G. Gurioli.
Complexity analysis of a stochastic cubic regularisation method under
inexact gradient evaluations and dynamic Hessian accuracy.
Optimization, (to appear), 2021, https://doi.org/10.1080/02331934.2021.1892104.
[3]
S. Bellavia, G. Gurioli, B. Morini, and Ph. L. Toint.
Adaptive regularization algorithms with inexact evaluations for
nonconvex optimization.
SIAM Journal on Optimization, 29(4):2881–2915, 2019.
[4]
S. Bellavia, G. Gurioli, B. Morini, and Ph. L. Toint.
Adaptive regularization for nonconvex optimization using inexact function values and randomly perturbed derivatives.
Journal of Complexity, 68, Article number 101591, 2022.
[5]
S. Bellavia, G. Gurioli, B. Morini, and Ph. L. Toint.
The impact of noise on evaluation complexity: The deterministic
trust-region case.
arXiv:2104.02519, 2021.
[6]
A. Berahas, L. Cao, and K. Scheinberg.
Global convergence rate analysis of a generic line search algorithm
with noise.
SIAM Journal on Optimization, 31(2):1489–1518, 2021.
[7]
J. Blanchet, C. Cartis, M. Menickelly, and K. Scheinberg.
Convergence rate analysis of a stochastic trust region method via
supermartingales.
INFORMS Journal on Optimization, 1(2):92–119, 2019.
[8]
C. Cartis, N. I. M. Gould, and Ph. L. Toint.
Second-Order Optimality and Beyond: Characterization and Evaluation Complexity in Convexly Constrained Nonlinear Optimization.
Foundations of Computational Mathematics, 18, 1073–1107, 2020.
[9]
C. Cartis, N. I. M. Gould, and Ph. L. Toint.
Sharp worst-case evaluation complexity bounds for arbitrary-order
nonconvex optimization with inexpensive constraints.
SIAM Journal on Optimization, 30(1):513–541, 2020.
[10]
C. Cartis, N. I. M. Gould, and Ph. L. Toint.
Strong evaluation complexity of an inexact trust-region algorithm for
arbitrary-order unconstrained nonconvex optimization.
arXiv:2011.00854, 2020.
[11]
C. Cartis, N. I. M. Gould, and Ph. L. Toint.
Evaluation complexity of algorithms for nonconvex optimization.
MPS-SIAM Series on Optimization. SIAM, Philadelphia, USA, to appear,
2021.
[12]
C. Cartis and K. Scheinberg.
Global convergence rate analysis of unconstrained optimization
methods based on probabilistic models.
Mathematical Programming, Series A, 159(2):337–375, 2018.
[13]
R. Chen, M. Menickelly, and K. Scheinberg.
Stochastic optimization using a trust-region method and random
models.
Mathematical Programming, Series A, 169(2):447–487, 2018.
[14]
V. Chvátal.
The tail of the hypergeometric distribution.
Discrete Mathematics, 25:285–287, 1979.
[15]
A. R. Conn, N. I. M. Gould, and Ph. L. Toint.
Trust-Region Methods.
MPS-SIAM Series on Optimization. SIAM, Philadelphia, USA, 2000.
[16]
C. Paquette and K. Scheinberg.
A stochastic line search method with convergence rate analysis.
SIAM Journal on Optimization, 30(1):349–376, 2020.
[17]
Y. Yuan.
Recent advances in trust region algorithms.
Mathematical Programming, Series A, 151(1):249–281, 2015.