TVG: A Training-free Transition Video Generation Method
with Diffusion Models
Abstract
Transition videos play a crucial role in media production, enhancing the flow and coherence of visual narratives. Traditional methods like morphing often lack artistic appeal and require specialized skills, limiting their effectiveness. Recent advances in diffusion model-based video generation offer new possibilities for creating transitions but face challenges such as poor inter-frame relationship modeling and abrupt content changes. We propose a novel training-free Transition Video Generation (TVG) approach using video-level diffusion models that addresses these limitations without additional training. Our method leverages Gaussian Process Regression () to model latent representations, ensuring smooth and dynamic transitions between frames. Additionally, we introduce interpolation-based conditional controls and a Frequency-aware Bidirectional Fusion (FBiF) architecture to enhance temporal control and transition reliability. Evaluations of benchmark datasets and custom image pairs demonstrate the effectiveness of our approach in generating high-quality smooth transition videos. The code are provided in https://sobeymil.github.io/tvg.com.
Introduction
Transition videos have been fundamental in media production, traditionally using techniques such as morphing (Wolberg 1998) to seamlessly connect segments, thus improving flow, visual appeal, and narrative coherence. With video emerging as the dominant medium on platforms such as TikTok and Kuaishou, the demand for innovative content formats such as vlogs and short films has surged. This trend underscores the critical need for effective and engaging transitions. However, traditional transition techniques often lack artistic appeal, fail to fully engage viewers, and require specialized production skills, posing challenges for creators.
Recent advancements in diffusion model-based image (Song, Meng, and Ermon 2021; Rombach et al. 2022) and video generation (Liu et al. 2024) have introduced novel methods for creating transition videos by generating intermediate frames between segments. Although these approaches offer more creative and accessible transition generation, they face limitations, especially when there is a significant disparity between frames. Existing techniques, including both open-source models (Zhang et al. 2024a; Chen et al. 2024; Xing et al. 2023) and commercial products, often produce suboptimal transitions, leading to abrupt changes, simple fades, or even the absence of transitions, as shown in Figure 1. Additionally, current video generation models are typically limited to producing short clips, making effective transition generation crucial for maintaining continuity in longer videos (Yuan et al. 2024). The inability to generate consistent, high-quality transitions could significantly hinder the broader adoption of video generation technologies.

Several factors contribute to these challenges. First, some models (Zhang et al. 2024a; Chen et al. 2024) extend and optimize image-level diffusion models, which often lack robust inter-frame relationship modeling, particularly when the primary subjects in the frames differ significantly. Although these models generally avoid abrupt transitions, they often fail to produce dynamic results, leading to outputs with simple fading effects or disruptive artifacts. Second, while video-level diffusion models (Xing et al. 2023) attempt to establish inter-frame relationships through spatio-temporal attention, these can be unstable due to issues like conditional image leakage (Zhao et al. 2024), cross-attention leakage (Yang et al. 2024), and improper activation of attention mechanisms, resulting in abrupt transitions or anomalous content.
To address these challenges, we propose a novel, training-free Transition Video Generation (TVG) approach based on video-level diffusion models. Unlike methods like SEINE (Chen et al. 2024), which require full retraining, or DiffMorpher (Zhang et al. 2024a), which relies on LoRA-based (Hu et al. 2022) fine-tuning, our approach generates video transitions without any additional training. While existing image-to-video pre-trained models demonstrate high-quality generative capabilities, they often lack effective inter-frame relationship control for transitions. Our approach avoids redundant retraining, reducing computational costs and enabling broader applicability to future, potentially more advanced video generation algorithms.
We implemented several optimizations based on DynamiCrafter (Xing et al. 2023). Building on prior work (Zhang et al. 2024a; Jang et al. 2024), we introduce a novel conditional control approach using interpolation techniques. Specifically, we blend images within the conditional latent space, enhancing motion dynamics. Additionally, we utilize spherical linear interpolation (SLERP) for prompt embeddings, enabling precise control and fine-grained adjustments of each frame’s content, addressing the lack of dynamic variation caused by conditional image leakage. We propose that the content between transition frames should adhere to a smooth stochastic process to balance dynamic motion with content continuity. To achieve this, we employ Gaussian Process Regression () to model the latent representations of the initial and final frames. The intermediate content is then mapped into this smooth feature space, improving transition quality by preventing abrupt changes while maintaining dynamic continuity. Furthermore, we observed that existing image-to-video models can produce vastly different transition videos depending on the content of the initial and final frames, even when simply swapping the two. To address this variability and enhance the reliability of transition generation, we introduced a Frequence-aware Bidirectional Fusion (FBiF) architecture. We evaluated our algorithm on existing benchmarks, including MorphBench (Zhang et al. 2024a) and TC-Bench-I2V (Feng et al. 2024), as well as on custom image pairs. The experimental results demonstrate the effectiveness of our proposed modules. Our contributions are summarized as follows:
-
1.
We propose a training-free transition video generation method based on Gaussian Process Regression () with video-level diffusion models.
-
2.
We introduce interpolation-based conditional controls to enhance temporal control and ensure smooth video transitions.
-
3.
We develop a Frequence-aware Bidirectional Fusion (FBiF) architecture to further improve the reliability of video transition generation.
Related work
Training-free Video Generation. ControlVideo (Zhang et al. 2023), adapted from ControlNet, improves video generation by introducing cross-frame interaction, interleaved-frame smoothing, and hierarchical sampling. MotionClone (Ling et al. 2024) employs temporal attention in video inversion for motion representation and cloning, while VideoElevator (Zhang et al. 2024b) decomposes sampling into temporal motion refinement and spatial quality enhancement. MVOC (Wang et al. 2024) propose a multiple video object composition method based on diffusion models with DDIM inversion features injection. These methods enhance video generation and editing capabilities by building on existing models, reducing the need for extensive retraining.
Transition Video Generation. Traditional video transitions, such as fade, dissolve, wipe, or cut, are essential for seamless scene changes in video editing. Morphing (Wolberg 1998) offers smooth transitions by finding pixel-level similarities and estimating offsets. Generative models (Van Den Oord, Vinyals et al. 2017) have advanced this by capturing semantic similarities through latent code interpolation, with applications in style transfer (Chen et al. 2018) and object transfiguration (Sauer, Schwarz, and Geiger 2022). SEINE (Chen et al. 2024) introduced a random-mask video diffusion model for text-guided transitions between different scenes, while DiffMorpher (Zhang et al. 2024a) uses LoRA parameter interpolation with image diffusion models for smooth semantic transitions. Despite these advances, achieving natural video transitions remains challenging.
Preliminary
Diffusion Models
Diffusion models (Sohl-Dickstein et al. 2015; Ho, Jain, and Abbeel 2020; Rombach et al. 2022) are a class of probabilistic generative models which learns a data distribution by denoising noisy. The forward process of diffuses the data samples with a Markov process contains timesteps: The forward process is gradually adding noise to the data sample to with a Markov process contains timesteps:
| (1a) | |||
| (1b) | |||
where is a predefined variance schedule, , is derived from the variance noise schedule, and . The reverse process begins from the noise and transitions towards the original data . The reverse denoising process obtains less noisy data from the noisy input at each timestep:
| (2) |
where is the denoising function to estimate the noise added at each step and is the learnable network parameters.
Diffusion Models for Transition Video Generation
Given two input images, and , the goal of transition video generation is to produce a video sequence , starting with and ending with . The intermediate frames, to , should exhibit smooth transitions that blend the characteristics of both input images, forming a coherent sequence. This process can be formalized as a conditional distribution , modeled by a conditional diffusion process.
In video generation, Latent Diffusion Models (LDMs) (Rombach et al. 2022; Zhou et al. 2022; An et al. 2023) are commonly used to reduce computational complexity by fitting the conditional distribution within the latent space, where denoising occurs. The initial and final frames, and , anchor the sequence, with intermediate frames initialized by adding Gaussian noise. These frames are encoded into a latent representation , where , , , and represent the number of frames, channels, height, and width, respectively. A backward denoising process, such as DDIM (Song, Meng, and Ermon 2021), is applied to obtain the clean latent representation , which is then decoded into the video sequence . The reverse process typically incorporates additional denoising conditions to enhance the quality of the generated video, such as text prompt latents, , and the latent of the initial frame, .
Our base model, DynamiCrafter (Xing et al. 2023), further leverages FPS as a denoising condition. It uses CLIP (Radford et al. 2021) to encode text prompts and the initial frame, while employing a frame-wise Variational Auto-Encoder (VAE) architecture for the video encoder and decoder. The denoising process is carried out using a U-Net architecture.
Gaussian Process
A Gaussian process () (Williams and Rasmussen 2006) is a collection of random variables, any finite number of which have a joint Gaussian distribution. Consider a data set with inputs and targets consisting of data-points as , where the inputs are denoted by = , and targets by =. The goal of is to learn an unknown function that maps elements from input space to a target space, which can provide predictive distributions on test points =. Assuming the GP prior on with some additive Gaussian white noise with variance :
| (3) |
A Gaussian process regression () formulates the functional form of by drawing random variables from a multi-variate normal distribution given by , with the mean of and the covariance matrix of . , where is a mean function of the ; , where is a kernel function of the . The conditional distribution at any unseen points is given by:
| (4) |
where
| (5) |
| (6) |
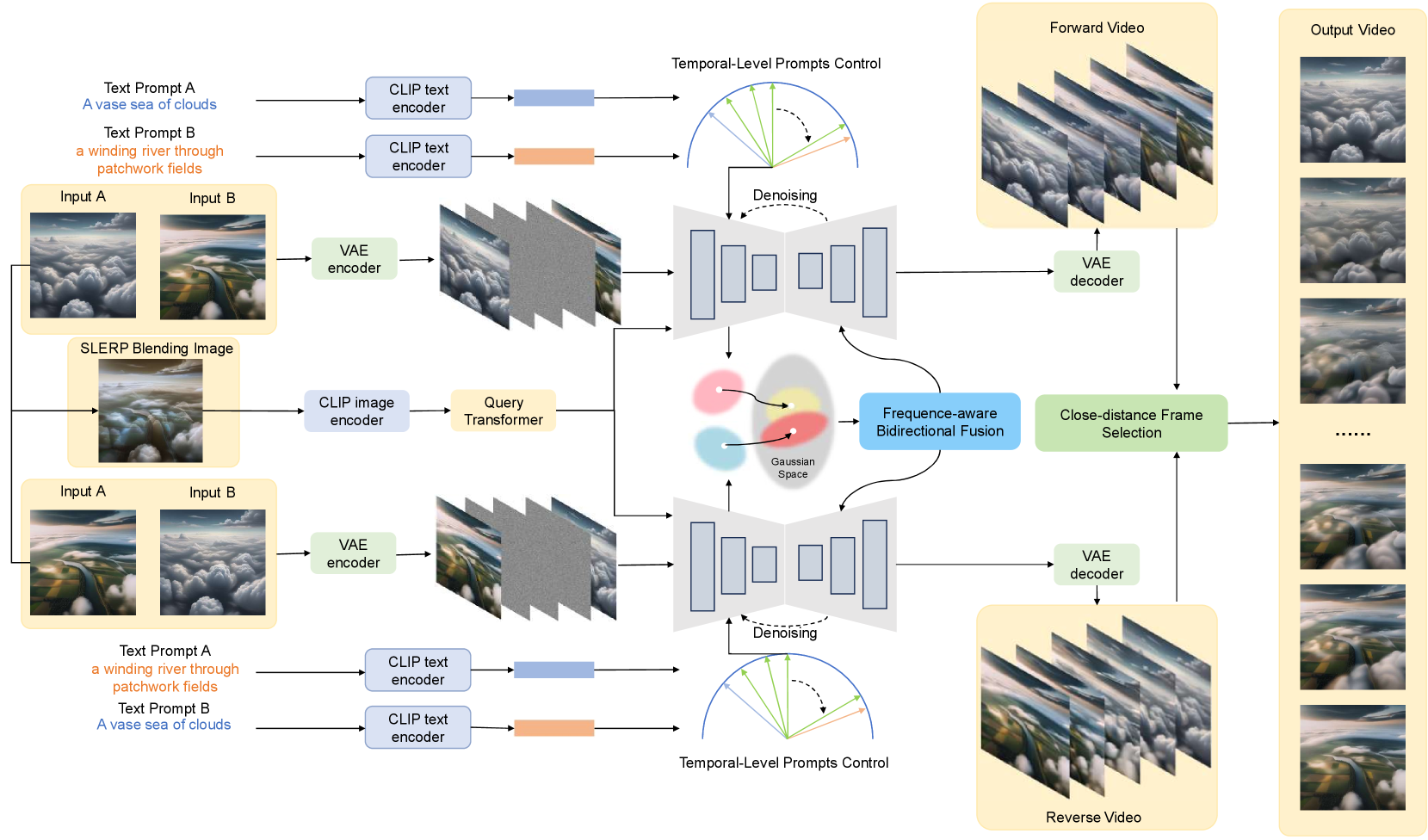
Method
Our framework is based on DynamiCrafter (Xing et al. 2023), a state-of-the-art image-to-video generative model. However, DynamiCrafter faces challenges in video transition tasks, particularly when there are significant differences between the initial and final frames, often resulting in transitions that overly depend on the starting image and appear abrupt. To address these issues, we propose a training-free TVG method, as shown in Figure 2.
We optimized the pre-trained model during inference in three key areas. First, we refined both conditional images and prompts to enhance the controllability of the video generation process and reduce conditional image leakage. Second, we integrated Gaussian Process Regression () into the latent space to enforce temporal consistency between frames, improving inter-frame coherence and preventing abrupt transitions. Lastly, we introduced a Frequence-aware Bidirectional Fusion (FBiF) structure, which combines bidirectional generation with frequency-domain feature fusion. To ensure the final output’s visual quality, we apply close-distance frame selection at the final stage.
Interpolation-based Conditional Controls
In our experiments, we found that DynamiCrafter often produced abrupt transitions when using input images with significantly different content, a result of conditional image leakage. To mitigate this, we applied linear interpolation to blend the two input frames and :
| (7) |
Setting to 0.5 balances information from both frames, creating a blended image that integrates details from both inputs. Other values would favor one frame over the other, which is not suitable for our video transition task. This image is then processed by CLIP to extract feature embeddings, serving as the condition . This approach leverages the pre-trained model without requiring additional training. In contrast, separate extraction and fusion of features using CLIP can create a semantic gap, complicating their integration in diffusion models and often leading to errors. Addressing this gap usually requires retraining a feature projection module, as done in StoryDiffusion (Zhou et al. 2024), but our method avoids this by fully utilizing the pre-trained model.
Traditional methods typically employ a single prompt for the entire video, limiting frame-wise control. To improve this, inspired by (Zhang et al. 2024a; Jang et al. 2024), we propose Temporal-Level Prompts Control. We begin by obtaining prompts and for the initial and final frames, then use CLIP to extract their semantic features, and . These features are interpolated using spherical linear interpolation (SLERP).
| (8) |
where is the interpolation parameter, and is the angle between the two vectors. We sample weights uniformly between 0.9 and 0.1, corresponding to the temporal progression from the initial to the final frame, creating interpolated semantic features. These features form , ensuring smooth transitions and minimizing semantic gaps, allowing for seamless integration into the diffusion model and reducing the likelihood of abrupt content changes in the video.
Latent Space Gaussian Process Regression
The denoising U-Net employs temporal-level and spatial-level Transformer modules, integrating self-attention and cross-attention to capture spatial relationships within frames and temporal relationships between frames. However, the spatial modules overlook inter-frame dependencies, while the temporal modules impose only limited inter-frame constraints through attention mechanisms. This results in poor controllability, leading to error propagation across frames and degrading the quality of transition videos.
To address these issues, we incorporate into the latent space of the U-Net within video generation models. This integration with attention modules explicitly constrains inter-frame relationships, enhancing the overall video quality.
Given a temporal-level latent vector , where represents the vector size and denotes the number of channels, we compute the attention mechanism with for both temporal and spatial attention as follows:
| (9) |
where serves as a balancing factor, controlling the trade-off between different feature contributions. We hypothesize that the transition content between two frames in a video can be modeled as a smooth stochastic process. The objective is to derive a distribution function for this process, with the first frame as the observation input and the last frame as the prediction target.
In the latent space, the features of the first and last frames are extracted from the input images, while intermediate frames are generated by denoising Gaussian noise. This allows us to construct a stochastic process distribution function based on the initial and final frames, predicting intermediate frames to ensure coherent transitions that accurately reflect the relationship between the start and end frames.
To implement this, we leverage to model the distribution function, utilizing its capability to flexibly capture the underlying data distribution and smoothly interpolate between frames while maintaining consistency with the input frames. Specifically, the first frame of is defined as where consists of data points serving as input to , as outlined in the Preliminary section. Similarly, the last frame of is defined as representing the target with data points. We employ the Radial Basis Function as the kernel to formulate the distribution function The remaining frames of are used as the input to the function, as shown in Equation 4. The mean obtained from the function, as shown in Equation 5, is then used to refine the corresponding frame features.
This approach effectively maps features into a Gaussian space, aligning inter-frame relationships with a stationary random distribution, thereby enhancing both correlation and smoothness between frames. However, due to inherent differences between the original model’s feature distribution and the Gaussian distribution, a complete substitution of the original features would necessitate further training to achieve optimal performance. To reduce computational costs and avoid additional training, we integrate these features as a penalty term within the original attention mechanism, rather than fully replacing the original features. Despite this conservative approach, it significantly enhances inter-frame information exchange and smooths transitions between frames, while maintaining compatibility with the feature distribution of the pre-trained model.
Frequence-aware Bidirectional Fusion
In practice, we observed significant quality differences in transition videos generated from two images, and , depending on whether the sequence was processed in original or reverse order. As shown in Figure 3, this issue is linked to conditional image leakage, where the transition video tends to resemble the initial image more closely. To address the shortcomings in the latter part of the video, particularly the deviations from the final frame and the lack of smoothness, we propose a Frequency-aware Bidirectional Fusion (FBiF) approach to improve overall generation quality.

As illustrated in Figure 2, we generate a forward transition video, then repeat the process by reversing the order of the input images and prompts fed into the video generation model. In the latent space, we apply to map features into a unified Gaussian space, aligning the feature distributions of both the forward and reversed videos. Let , where ; the reversed features are similarly defined as . Inspired by (Pan, Cai, and Zhuang 2022), we consider the average-pooled (avgpool) features to represent low-frequency components, while the max-pooled (maxpool) features capture high-frequency components. Since our goal is to emphasize the primary concepts in the video content rather than merely enhancing details, we employ a frequency-aware fusion method, combining the two feature sets along the temporal sequence as follows:
| (10) | ||||
where represents the fused feature at frame . The weighting factor , which varies across frames from 0.9 to 0.1, controls the contributions of the low-frequency components. The high-frequency components are weighted by a fixed factor . To ensure consistent video generation, we propose a Close-distance Frame Selection mechanism. Starting with the first frame of the forward video as a reference, we reverse the sequence of the reversed video. For each subsequent frame, we compare the perceptual loss (Zhang et al. 2018) between the next frames of both videos relative to the previous frame. The frame with the smallest distance is selected as the next frame, and this process is repeated to generate the final video.
Experiments
Experimental Setup
We implemented our Transition Video Generation approach using the pre-trained DynamiCrafter model (Xing et al. 2023). Most hyperparameters were kept at default settings, except for the FPS, which was set to 16 to enhance visual dynamics. The hyperparameter was set to 0.9, was 0.1. We used a DDIM (Song, Meng, and Ermon 2021) schedule with 10 steps during denoising. All experiments ran on a single NVIDIA A800 GPU.
For quantitative evaluation, we tested the MorphBench (Zhang et al. 2024a) and TC-Bench-I2V (Feng et al. 2024) datasets, generating 16 frames per video following established protocols (Chen et al. 2024; Zhang et al. 2024a; Feng et al. 2024). The video resolution was set to for MorphBench and for TC-Bench-I2V. For qualitative evaluation, we collected 10 image pairs from the Internet for comparison with other models and commercial products.
Qualitative results
To demonstrate the effectiveness of our algorithm, we have presented some of the results generated by our model in Figure 4. It can be seen that for different scenarios, our model exhibits strong video-transition capabilities, with the video maintaining dynamic elements while the content gradually transitions. Additionally, we compared our algorithm with several commercial products as shown, some of which were even unable to produce transition videos as shown in Figure 1. For more visualization results, we recommend readers refer to the supplementary materials.

Quantitative Results
Evaluation on TC-Bench-I2V: We evaluated our model on the TC-Bench-I2V dataset using the Transition Completion Ratio (TCR, ) and TC-Score () (Feng et al. 2024). These metrics utilize GPT-4 to provide assessments closely aligned with human perception. TCR measures the percentage of videos that successfully match the provided prompts, while TC-Score offers a comprehensive evaluation considering factors such as transition completion, object consistency, and handling of additional objects, reflecting user experiences more realistically.
Table 1 presents a comparison of our algorithm with three state-of-the-art methods across three video transition scenarios: Attribute Transition (Attribute), involving changes in color, shape, material, and texture; Object Relation Change (Object), focusing on object interactions like passing or striking; and Background Shifts (Background), such as transitions from day to night.
Our results demonstrate consistent superior performance across most metrics and scenarios. Notably, our method ranks second in TCR for the background scenario, likely due to the lower dynamic demands, which favor DiffMorpher, a frame-by-frame generation-based approach. However, in dynamic scenarios like Object Relation Change, our algorithm significantly outperforms others, aligning more closely with user experience expectations. Figure 5 illustrates comparative examples of generated results, with samples displayed every two frames.
| Methods | Attribute | Object | Background | Overall | ||||
|---|---|---|---|---|---|---|---|---|
| TCR | TC-Score | TCR | TC-Score | TCR | TC-Score | TCR | TC-Score | |
| DynamiCrafter (2023) | 16.55 | 0.745 | 13.91 | 0.707 | 25.56 | 0.795 | 16.89 | 0.738 |
| SEINE (2024) | 17.86 | 0.720 | 10.48 | 0.654 | 7.96 | 0.742 | 13.57 | 0.698 |
| DiffMorpher (2024a) | 41.82 | 0.844 | 19.57 | 0.765 | 50.00 | 0.819 | 34.45 | 0.810 |
| Ours | 41.82 | 0.877 | 30.44 | 0.822 | 38.89 | 0.864 | 36.98 | 0.853 |

Evaluation on MorphBench: Following previous work (Zhang et al. 2024a), we evaluated the fidelity and smoothness of video content using traditional metrics, specifically Frechet Inception Distance (FID, ) (Heusel et al. 2017) and Perceptual Path Length (PPL, ) (Karras et al. 2020). The results on the MorphBench dataset, summarized in Table 2, show that while our approach does not outperform all existing methods, it remains competitive with current diffusion-based models (Song, Meng, and Ermon 2021; Wang and Golland 2023; Zhang et al. 2024a; Chen et al. 2024; Xing et al. 2023). Notably, even traditional techniques like Warp&Blend surpass various generative algorithms in certain metrics, highlighting that superior quantitative scores do not necessarily translate to better visual effects in video transitions.
Our primary objective is to develop an algorithm that seamlessly transitions between the final frame of one video and the first frame of another, enhancing continuity and fluidity. Although dynamic videos, which are favored for their rich visual appeal (Roggeveen et al. 2015; Steuer et al. 1995; Coyle and Thorson 2001), often introduce greater frame variation that can reduce quantitative performance, the enhanced user experience remains paramount.
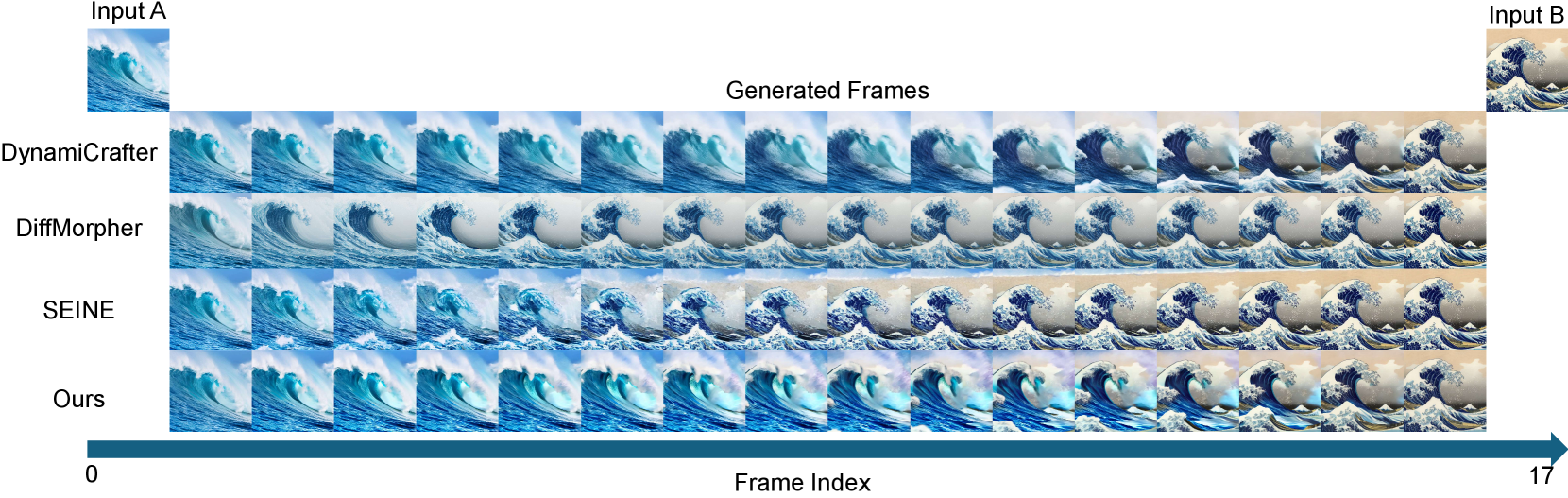
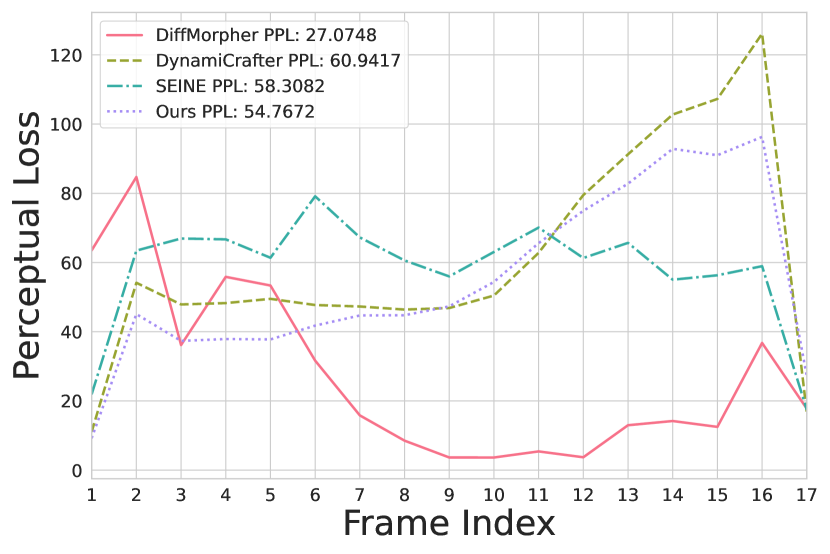
Figure 6 illustrates content generated from a pair of images in the MorphBench dataset, using identical prompts across different methods. Our method and DiffMorpher employ separate prompts for each image, while SEINE and DynamiCrafter merge the descriptions into a single prompt, transitioning from input A to input B without introducing additional content. Figure 7 presents the perceptual loss (Zhang et al. 2018) between consecutive frames and final PPL, starting with input A at frame index 0 and ending with input B at frame index 17, covering both input images and generated frames. DiffMorpher achieves the lowest PPL, indicating superior quantitative performance. This is primarily because only a small portion of the generated frames retain perceptual similarity to input A, with the rest transitioning gradually toward input B in a low-dynamic manner, resulting in final frames that closely resemble the target. Although perceptual loss is relatively high during the initial dynamic phase, it remains low thereafter, enhancing DiffMorpher’s quantitative metrics. However, this approach results in a near-static user experience, making it difficult to effectively engage the audience.
In contrast, other methods, including ours, prioritize transforming image characteristics while maintaining high dynamic variability, leading to fluctuating PPL values throughout the sequence and impacting the final quantitative results. While videos with high dynamic variability often appeal more to users, SEINE and DynamiCrafter demonstrate more abrupt transitions. SEINE fully transitions to input B midway through the sequence with minimal change afterward, while DynamiCrafter adopts the style of input B only in the final quarter, lacking the smoothness needed for a seamless transition. In contrast, our method excels at gradually blending specific regions into the style of input B while preserving natural motion, achieving both high dynamic performance and smooth, visually coherent transitions throughout the entire sequence, underscoring the superiority of our approach.
Another factor contributing to the significant perceptual loss between frames in highly dynamic content is the limitation of existing open-source video generation models, which struggle to produce longer video sequences. Typically, these models generate around 16 frames, and content beyond this length often becomes unstable. As our method is training-free, it currently cannot be extended to generate videos with more frames. Ensuring a high dynamic range under this frame limitation inevitably impacts the quality and smoothness of the video. However, this impact is acceptable under current circumstances. If more advanced open-source models for generating longer videos become available, our method should achieve further performance improvements.
| Method | Metamorphosis | Animation | Overall | |||
|---|---|---|---|---|---|---|
| FID | PPL | FID | PPL | FID | PPL | |
| Warp&Blend (1998) | 79.63 | 15.97 | 56.86 | 9.58 | 67.57 | 14.27 |
| DGP (2022) | 150.29 | 29.65 | 194.65 | 27.50 | 138.20 | 29.08 |
| StyicGAN-XL (2022) | 122.42 | 41.94 | 133.73 | 33.43 | 112.63 | 39.67 |
| DDIM (2021) | 95.44 | 27.38 | 174.31 | 18.70 | 101.68 | 25.38 |
| DiffInterp (2023) | 169.07 | 108.51 | 148.95 | 96.12 | 146.66 | 105.23 |
| DynamiCrafter (2023) | 87.32 | 42.09 | 43.31 | 11.16 | 69.13 | 33.84 |
| DiffMorpher (2024a) | 70.49 | 18.19 | 43.15 | 5.14 | 54.69 | 21.10 |
| SEINE (2024) | 82.03 | 47.72 | 48.25 | 16.26 | 67.60 | 39.33 |
| Ours | 86.92 | 35.18 | 42.99 | 12.46 | 64.05 | 29.08 |
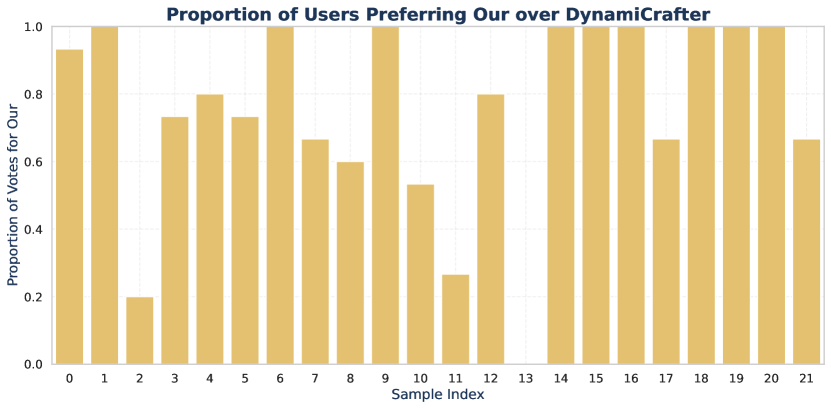
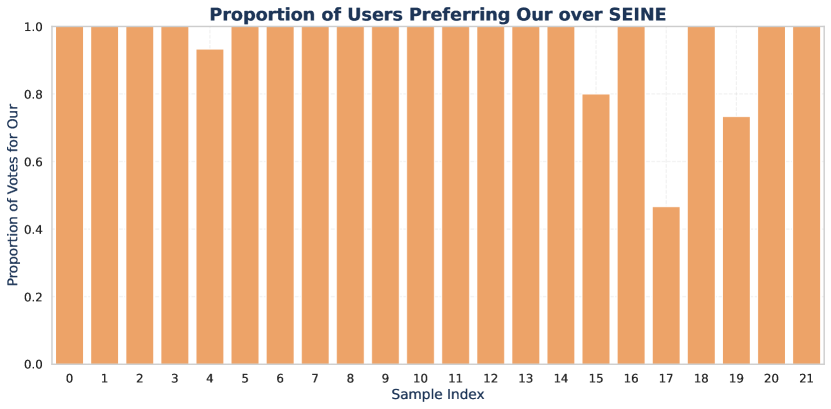
Human Evaluation: To assess the real-world user experience of our algorithm, we conducted a Human Evaluation study using 22 curated videos: 9 from MorphBench, 9 from TC-Bench, and 4 from our own dataset. 15 volunteers participated, yielding a total of 990 votes. Participants compared pairs of videos and voted on which appeared more natural and smooth across three scenarios: Ours vs. DiffMorpher, Ours vs. SEINE, and Ours vs. DynamiCrafter. The results, summarized in Table 3, indicate a strong preference for our algorithm, highlighting its effectiveness in generating smoother, more natural transitions.
| Metrics | Ours >DiffMorpher | Ours >SEINE | Ours >DynamiCrafter |
| Perference | 71.82% | 75.45% | 75.45% |
Ablation Study
To validate the effectiveness of our proposed module, we conducted ablation studies on the MorphBench dataset. The results, presented in Table 4 and Figure 8, highlight the impact of each component on overall performance. Specifically, Method A represents the baseline model, DynamiCrafter; Method B incorporates interpolation-based conditional controls; Method C integrates ; and Method D corresponds to our final model. As shown in Table 4, our approach outperforms others across key quantitative metrics. Although these metrics may not always directly correlate with final visual quality, they strongly suggest that our module significantly enhances the baseline model’s performance, especially in a training-free setting.
The qualitative results in Figure 8 further illustrate the effectiveness of our approach. In some videos, the baseline model fails to generate appropriate transitions, leading to abrupt changes or blurred content. Incorporating interpolation-based conditional controls improves transition content, though some issues with blurred frames remain. The integration of substantially improves visual quality, although it occasionally introduces artifacts. Finally, with the addition of the FBiF module, most videos exhibit smooth and visually coherent transitions, effectively addressing these challenges.
| Method | Metamorphosis | Animation | Overall | |||
|---|---|---|---|---|---|---|
| FID | PPL | FID | PPL | FID | PPL | |
| A | 87.32 | 42.09 | 43.31 | 11.16 | 69.13 | 33.84 |
| B | 89.50 | 35.68 | 35.84 | 11.27 | 70.30 | 29.17 |
| C | 90.51 | 36.25 | 42.05 | 12.45 | 72.13 | 29.90 |
| D | 86.92 | 35.18 | 42.99 | 12.46 | 64.05 | 29.08 |

Conclusion
We introduced a novel training-free transition video generation approach that combines interpolation-based conditional controls, , and FBiF. Our method consistently outperforms existing models in both quantitative metrics and visual quality, especially in dynamic scenarios. Ablation studies confirm that each component enhances the overall performance, leading to smoother and more coherent transitions. This approach shows significant potential for improving video generation without additional training, particularly in high-dynamic transitions. In the future, we plan to explore the use of entire video segments, rather than just two frames, to achieve even more seamless and effective transitions.
References
- An et al. (2023) An, J.; Zhang, S.; Yang, H.; Gupta, S.; Huang, J.-B.; Luo, J.; and Yin, X. 2023. Latent-shift: Latent diffusion with temporal shift for efficient text-to-video generation. arXiv preprint arXiv:2304.08477.
- ByteDance (2024) ByteDance. 2024. Jimeng AI. Accessed: 2024-08-10, Retrieved from https://jimeng.jianying.com.
- Chen et al. (2024) Chen, X.; Wang, Y.; Zhang, L.; Zhuang, S.; Ma, X.; Yu, J.; Wang, Y.; Lin, D.; Qiao, Y.; and Liu, Z. 2024. SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction. In ICLR. OpenReview.net.
- Chen et al. (2018) Chen, X.; Xu, C.; Yang, X.; Song, L.; and Tao, D. 2018. Gated-gan: Adversarial gated networks for multi-collection style transfer. IEEE Trans. Image Process., 28(2): 546–560.
- Coyle and Thorson (2001) Coyle, J. R.; and Thorson, E. 2001. The effects of progressive levels of interactivity and vividness in web marketing sites. Journal of advertising, 30(3): 65–77.
- Feng et al. (2024) Feng, W.; Li, J.; Saxon, M.; Fu, T.; Chen, W.; and Wang, W. Y. 2024. TC-Bench: Benchmarking Temporal Compositionality in Text-to-Video and Image-to-Video Generation. arXiv preprint arXiv:2406.08656.
- Heusel et al. (2017) Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; and Hochreiter, S. 2017. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In NeurIPS, 6626–6637.
- Ho, Jain, and Abbeel (2020) Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising Diffusion Probabilistic Models. arXiv preprint arxiv:2006.11239.
- Hu et al. (2022) Hu, E. J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; and Chen, W. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In ICLR.
- Jang et al. (2024) Jang, Y. K.; Huynh, D.; Shah, A.; Chen, W.-K.; and Lim, S.-N. 2024. Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval. arXiv preprint arXiv:2405.00571.
- Karras et al. (2020) Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; and Aila, T. 2020. Analyzing and Improving the Image Quality of StyleGAN. In CVPR, 8107–8116.
- Kuaishou (2024) Kuaishou. 2024. KLing AI. Accessed: 2024-08-10, Retrieved from https://kling.kuaishou.com.
- Ling et al. (2024) Ling, P.; Bu, J.; Zhang, P.; Dong, X.; Zang, Y.; Wu, T.; Chen, H.; Wang, J.; and Jin, Y. 2024. MotionClone: Training-Free Motion Cloning for Controllable Video Generation. arXiv preprint arXiv:2406.05338.
- Liu et al. (2024) Liu, Y.; Zhang, K.; Li, Y.; Yan, Z.; Gao, C.; Chen, R.; Yuan, Z.; Huang, Y.; Sun, H.; Gao, J.; et al. 2024. Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177.
- LUMAAI (2024) LUMAAI. 2024. LUMA AI. Accessed: 2024-08-10, Retrieved from https://lumalabs.ai/dream-machine.
- Pan et al. (2022) Pan, X.; Zhan, X.; Dai, B.; Lin, D.; Loy, C. C.; and Luo, P. 2022. Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation. IEEE Trans. Pattern Anal. Mach. Intell., 44(11): 7474–7489.
- Pan, Cai, and Zhuang (2022) Pan, Z.; Cai, J.; and Zhuang, B. 2022. Fast vision transformers with hilo attention. NeurIPS, 35: 14541–14554.
- Radford et al. (2021) Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; and Sutskever, I. 2021. Learning Transferable Visual Models From Natural Language Supervision. In ICML.
- Roggeveen et al. (2015) Roggeveen, A. L.; Grewal, D.; Townsend, C.; and Krishnan, R. 2015. The impact of dynamic presentation format on consumer preferences for hedonic products and services. Journal of Marketing, 79(6): 34–49.
- Rombach et al. (2022) Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; and Ommer, B. 2022. High-resolution image synthesis with latent diffusion models. In CVPR, 10684–10695.
- Sauer, Schwarz, and Geiger (2022) Sauer, A.; Schwarz, K.; and Geiger, A. 2022. StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets. In SIGGRAPH, 49:1–49:10. ACM.
- Sohl-Dickstein et al. (2015) Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; and Ganguli, S. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In ICML, 2256–2265. PMLR.
- Song, Meng, and Ermon (2021) Song, J.; Meng, C.; and Ermon, S. 2021. Denoising Diffusion Implicit Models. In ICLR. OpenReview.net.
- Steuer et al. (1995) Steuer, J.; Biocca, F.; Levy, M. R.; et al. 1995. Defining virtual reality: Dimensions determining telepresence. Communication in the age of virtual reality, 33(37-39): 1.
- Van Den Oord, Vinyals et al. (2017) Van Den Oord, A.; Vinyals, O.; et al. 2017. Neural discrete representation learning. NeurIPS, 30.
- Wang and Golland (2023) Wang, C. J.; and Golland, P. 2023. Interpolating between Images with Diffusion Models. arXiv preprint arXiv:2307.12560.
- Wang et al. (2024) Wang, W.; Chen, Y.; Liu, Y.; Yuan, Q.; Yang, S.; and Zhang, Y. 2024. MVOC: a training-free multiple video object composition method with diffusion models. arXiv preprint arXiv:2406.15829.
- Williams and Rasmussen (2006) Williams, C. K.; and Rasmussen, C. E. 2006. Gaussian processes for machine learning, volume 2. MIT press Cambridge, MA.
- Wolberg (1998) Wolberg, G. 1998. Image morphing: a survey. Vis. Comput., 14(8/9): 360–372.
- Xing et al. (2023) Xing, J.; Xia, M.; Zhang, Y.; Chen, H.; Yu, W.; Liu, H.; Wang, X.; Wong, T.-T.; and Shan, Y. 2023. DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors. arXiv preprint arXiv:2310.12190.
- Yang et al. (2024) Yang, F.; Yang, S.; Butt, M. A.; van de Weijer, J.; et al. 2024. Dynamic prompt learning: Addressing cross-attention leakage for text-based image editing. NeurIPS, 36.
- Yuan et al. (2024) Yuan, Z.; Chen, R.; Li, Z.; Jia, H.; He, L.; Wang, C.; and Sun, L. 2024. Mora: Enabling generalist video generation via a multi-agent framework. arXiv preprint arXiv:2403.13248.
- Zhang et al. (2024a) Zhang, K.; Zhou, Y.; Xu, X.; Dai, B.; and Pan, X. 2024a. DiffMorpher: Unleashing the Capability of Diffusion Models for Image Morphing. In CVPR, 7912–7921.
- Zhang et al. (2018) Zhang, R.; Isola, P.; Efros, A. A.; Shechtman, E.; and Wang, O. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In CVPR, 586–595.
- Zhang et al. (2023) Zhang, Y.; Wei, Y.; Jiang, D.; Zhang, X.; Zuo, W.; and Tian, Q. 2023. Controlvideo: Training-free controllable text-to-video generation. arXiv preprint arXiv:2305.13077.
- Zhang et al. (2024b) Zhang, Y.; Wei, Y.; Lin, X.; Hui, Z.; Ren, P.; Xie, X.; Ji, X.; and Zuo, W. 2024b. Videoelevator: Elevating video generation quality with versatile text-to-image diffusion models. arXiv preprint arXiv:2403.05438.
- Zhao et al. (2024) Zhao, M.; Zhu, H.; Xiang, C.; Zheng, K.; Li, C.; and Zhu, J. 2024. Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model. arXiv preprint arXiv:2406.15735.
- Zhou et al. (2022) Zhou, D.; Wang, W.; Yan, H.; Lv, W.; Zhu, Y.; and Feng, J. 2022. Magicvideo: Efficient video generation with latent diffusion models. arXiv preprint arXiv:2211.11018.
- Zhou et al. (2024) Zhou, Y.; Zhou, D.; Cheng, M.-M.; Feng, J.; and Hou, Q. 2024. StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation. arXiv preprint arXiv:2405.01434.
Appendix A Appendix A: Implementation Details
In all of our experiments, we utilized the publicly available DynamiCrafter (Xing et al. 2023) (interpolation variation@ resolution). The experiments were conducted without any model training, leveraging a PyTorch-based implementation on an Ubuntu 22.04 system. Video generation of 16 frames at a resolution of 320512 using an A800 GPU required approximately 55 seconds, with a memory usage of about 15GB, demonstrating the system’s relatively low resource consumption.
We employed the MorphBench (Zhang et al. 2024a) and TC-Bench-I2V (Feng et al. 2024) datasets datasets for our evaluations, which . Due to the high cost associated with the TC-Bench-I2V dataset, which necessitates invoking the GPT-4 API, our evaluation was limited to comparative experiments, and no ablation studies were performed. However, the prompts used were sourced from the official dataset, ensuring fairness in the comparisons.
For the MorphBench dataset, we conducted a comprehensive evaluation, including ablation studies. The prompts were primarily simple descriptions of image content, with detailed prompts provided in the supplementary material. Due to the interdependencies between our modules, the FBiF module was not ablated individually, as the absence of for unified mapping of the feature space would result in feature summation that could severely disrupt the generative model, rendering video content generation infeasible.
Appendix B Appendix B: Limitations
Our model is a training-free approach, which allows us to enhance the transition video generation performance of pre-trained models while also being subject to the inherent limitations of the base model’s generation capabilities. When employing a higher number of DDIM steps, such as 50 steps, existing image-to-video generation models are prone to a phenomenon known as conditional image leakage (Zhao et al. 2024). This issue leads to a reduction in the dynamic content of the generated videos as the number of steps increases. Consequently, our method may occasionally struggle to produce a proper transition content under these conditions. However, our success rate still exceeds that of the original model.
When using fewer steps, such as 10 steps, our method consistently outperforms the original model in terms of transition effects, as demonstrated in our experiments. Although there is a slight reduction in per-frame quality compared to the 50-step scenario, this difference does not significantly affect the user experience. As shown in Figure 9, a comparison between some frames generated with 10 steps and those with 50 steps reveals that this quality difference is negligible in terms of perceptual impact on the user.

Appendix C Appendix C: User Study
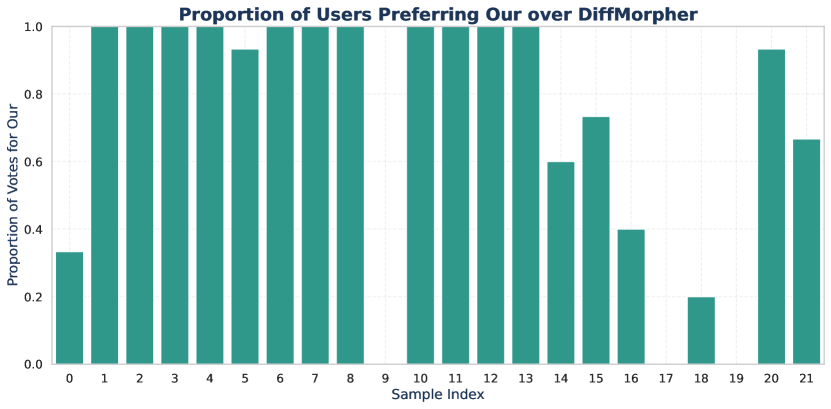
Considering that quantitative metrics are insufficient to evaluate the appeal of transitions to users, which is more critical in real-world scenarios, we conducted a survey involving 15 volunteers. The survey included 22 randomly selected videos from our dataset, evaluated through three rounds of pairwise comparisons between our method and SEINE (Chen et al. 2024), DiffMorpher (Zhang et al. 2024a), and DynamiCrafter (Xing et al. 2023). Volunteers assessed the quality of the transition videos, with examples of the questionnaire content shown in Figure 10. The results, illustrating the preference for our method in each sample, are shown in Figure 11, Figure 12and Figure 13,.
The results of the user study, combined with the findings in the main text, demonstrate that our method outperforms the other three algorithms in most cases. Among the compared methods, DiffMorpher exhibited slightly higher quality relative to SEINE and DynamiCrafter, aligning with the TC-Bench experimental results discussed earlier in the paper. We also provide examples from a subset of user evaluations, including cases with high user preference, cases with moderate disagreement (i.e., preference scores between 0.4 and 0.6), and cases with relatively lower quality samples, as illustrated in Figures 14, 15, and 16. It is evident that our approach maintains effective video transitions regardless of user preference, demonstrating consistent dynamics. In contrast, other methods exhibit unstable transition effects, which are noticeably unacceptable in certain scenarios.




Appendix D Appendix D: Qualitative results
To further demonstrate the effectiveness of our algorithm, we compared it with several state-of-the-art commercial products, including LUMA AI (LUMAAI 2024), KLing AI (Kuaishou 2024), and Jimeng AI (ByteDance 2024). Due to the varying video generation lengths of these commercial models, direct quantitative comparisons are challenging and may not be fair. Therefore, we conducted a visual comparison analysis instead. Figure 17, Figure 18,Figure 19 and Figure 20 present the results of our method compared with these commercial solutions. It is worth noting that LUMA AI and KLing AI typically generate longer videos with fixed settings, which cannot be modified. Since existing open-source models struggle to generate long sequences, we selected 16-frame segments from the commercial products that involve transition content for comparison with our method. For more comprehensive insights, the actual videos can be found in the supplementary multimedia materials. A comparative analysis of these figures reveals that our method consistently produces videos with smooth transitions, whereas the commercial products occasionally fail under varying data conditions. However, commercial products tend to generate richer details, likely because of their underlying robust models. We believe that integrating our approach into these commercial models could potentially enhance their transition generation success rate, resulting in even more seamless and refined video transitions.




Following the quantitative analysis of the TC-Bench-I2V and MorphBench datasets presented in the main text, we now provide additional visualization results generated by our model on these datasets. Figure 21 and Figure 22 presents some of these generated examples. Some videos can be viewed in the supplementary multimedia materials. Due to file size limitations for attachments, only a subset of the samples has been included.

