UAV-Assisted Multi-Task Federated Learning with Task Knowledge Sharing
Abstract
The rapid development of Unmanned aerial vehicles (UAVs) technology has spawned a wide variety of applications, such as emergency communications, regional surveillance, and disaster relief. Due to their limited battery capacity and processing power, multiple UAVs are often required for complex tasks. In such cases, a control center is crucial for coordinating their activities, which fits well with the federated learning (FL) framework. However, conventional FL approaches often focus on a single task, ignoring the potential of training multiple related tasks simultaneously. In this paper, we propose a UAV-assisted multi-task federated learning scheme, in which data collected by multiple UAVs can be used to train multiple related tasks concurrently. The scheme facilitates the training process by sharing feature extractors across related tasks and introduces a task attention mechanism to balance task performance and encourage knowledge sharing. To provide an analytical description of training performance, the convergence analysis of the proposed scheme is performed. Additionally, the optimal bandwidth allocation for UAVs under limited bandwidth conditions is derived to minimize communication time. Meanwhile, a UAV-EV association strategy based on coalition formation game is proposed. Simulation results validate the effectiveness of the proposed scheme in enhancing multi-task performance and training speed.
I Introduction
Unmanned Aerial Vehicle (UAV)-assisted networks are seen as an important enabler of post-5G and upcoming 6G networks. Due to their flexibility and line-of-sight (LOS) communication links, UAVs have great potential in providing emergency communications and wide-area on-demand data collection[1]. In addition, UAVs can be used to train popular machine learning models on-board, which is crucial for tasks such as trajectory planning and object recognition[2]. In a multi-UAV system, UAVs operate in a coordinated manner to support reliable and efficient communications or complete specific tasks[3][4]. UAV coordination is typically assisted by a ground base station. For instance, in an emergency rescue scenario with poor network coverage, a swarm of UAVs is controlled by a ground emergency vehicle (EV). However, since UAVs are deployed in various areas and often perform data collection dynamically[5], given the limited communication resources and energy capacity of UAVs, it is unrealistic to collect and transmit raw data from each UAV to the EV, as well as to frequently shuttle between the incident scene and the EV for charging. Given these challenges, federated learning (FL) has emerged as a promising framework for distributed data processing and model training. Taking advantage of the capabilities of the UAV data platform, it enables collaborative learning among multiple UAVs, thereby enhancing model training efficiency and accuracy[6].
Currently, most existing studies focus on single-task learning, while some multi-task FL either treats each individual model as a separate task [7][8] or learns multiple unrelated tasks concurrently [9][10]. This differs from the scenario considered in this paper. Actually, the data collected by UAVs may be used for multiple related tasks. For example, in emergency rescue scenarios, UAV images can support tasks like disaster level identification, crowd density estimation, and road feasibility analysis. Therefore, the multi-task scheme considered in this paper refers to using data collected by UAVs to complete multiple related but different tasks simultaneously. Using the traditional single-task learning framework to learn each task independently is inefficient[11]. Since multiple tasks are trained on the same image dataset, they share common underlying features and may have potential correlations, which allows for effective knowledge sharing among tasks and enables a reduction in resource consumption for training.
Studies have shown that sharing feature extractors across correlated tasks can enhance both the training speed and robustness of models[12]. However, these findings are limited to centralized training scenarios. In our scenario, each UAV is deployed in a different area or assigned a distinct but related task, leading to variations in local data collection. Integrating data features collected by multiple UAVs assigned to different tasks significantly enhances the robustness and generalization of the feature extractors. This approach allows the extractor to learn from a broader range of areas, thus improving feature extraction performance, accelerating model convergence, and boosting overall performance through mutual reinforcement among tasks[13]. In summary, the contributions of this paper are as follows:
-
•
We propose a novel UAV-assisted multi-task federated learning scheme, where the data collected by the UAVs can be used to train multiple related tasks, and the system performance and robustness can be improved by sharing knowledge among related tasks.
-
•
To balance the task performance and enhance the overall effectiveness of multiple tasks, we propose a task attention mechanism to capture the dynamic importance of each task. Specifically, we introduce the task shapley value to facilitate knowledge sharing among tasks.
-
•
Considering the dynamic environment of the network and resource constraints, we derived an expression for optimal bandwidth allocation for UAVs and introduced a UAV-EV association mechanism based on coalition formation game. Simulation results demonstrate the effectiveness of the proposed scheme.
II System Model
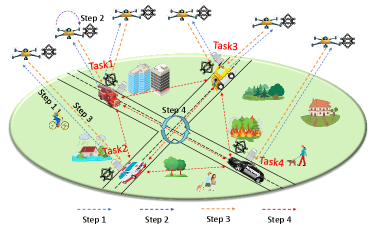
II-A Federated Learning System
The system consists of EVs indexed by and UAVs indexed by . Each EV is assigned a different task and can interact with other EVs to share task knowledge. Additionally, each EV can collect a small amount of data for model validation. Each UAV has a local dataset with data samples, and the data can be used for tasks. Since the same image dataset is used for multiple tasks, the underlying image features required by multiple tasks may be correlated. To enhance feature extraction performance, we allow multiple tasks to share feature extractors while maintaining task-specific predictors. The entire dataset is denoted by with a total number of samples . Given a data sample , where is the -dimensional input data vector, is the corresponding -dimensional ground-truth label and each dimension corresponds to a specific task. Let denote the sample-wise loss function for task on UAV , can be split into two parts , where represents the shared feature extractor and represents the unique layer of task . Thus, the local loss function that UAV measures the model error for task on its local dataset is given by
| (1) |
Accordingly, the global loss function for task is
| (2) |
We use to represent the set of all task parameters. For simplicity, we omit the subscript from and use to denote the loss function of task on UAV . Each UAV can participate in different tasks in different rounds. However, due to the limited computing resources and energy, each UAV can only participate in one training task per round. Considering the goal to improve the average performance of all tasks, the objective function of the entire network is
| (3) |
To achieve the objective outlined in (3), the training steps of the proposed scheme are given as follows:
(Step 1 UAV-EV association and Task Model Broadcast) At the beginning of each round, each UAV is assigned to an EV through the UAV-EV association algorithm. Each EV broadcasts its latest model parameters to its associated UAVs. Let denote the association indicator of UAV in rount , where indicates that UAV is associated with EV , otherwise. We use to represent the UAV association of task in round . And can be used to represent the overall UAV-EV association in round .
(Step 2 Local Model Training) Each UAV initializes and performs steps stochastic gradient descent (SGD) to update the shared layer and the task-specific layer. and are updated as follows:
| (4) |
| (5) |
where and are the feature extractor layer and task-specific layer parameters of task on UAV in the -th local iteration of the -th round, respectively. is the learning rate.
In (4), the stochastic gradient is given by , where is a mini-batch data uniformly sampled from with data samples. The update form of is similar and is omitted here.
(Step 3 Model Update Parameter Uploading ) After local model training, each UAV uploads its cumulative local stochastic gradient to its corresponding EV. is given by Note that the cumulative gradient can be expressed as , where and represent the feature extractor gradient and task-specific layer gradient respectively.
(Step 4 EV Model Aggregation and Knowledge Sharing) Each EV aggregates the latest gradient and updates the global model of task . Specifically, the feature extractor is updated as and the task predictor is updated as . Subsequently, the EVs interact to share knowledge by transmitting to one another for further fusion of the feature extractor parameters. Given that EVs possess relatively sufficient transmission resources and computing capabilities, we disregard any delays and energy consumption associated with this parameter exchange. The fused feature extractor can then be expressed as: , where .
II-B Computation Model
Let denotes the number of CPU cycles required to process one data sample when UAV participates in the training of task , represents the computation capability of UAV . Thus, if UAV participate in the training of task , the computational time of local training of is given by and the corresponding energy consumption of UAV is , where is the energy coefficient, which depends on the chip architecture.
II-C Communication Model
The air-to-ground communication link is modeled as a probabilistic superposition of LOS and NLOS channels based on the method in [14]. For the sake of brevity, the details are omitted here. We consider using the frequency division multiple access (FDMA) techniques for communication. Each UAV can be allocated a certain proportion of uplink bandwidth resources. Denote as the transmit power of UAV in round , and it has a maximum transmission power limit . Thus, the achievable transmission rate between UAV and EV in round is . is the noise power spectral density. Let denote the size of the gradient for task , if UAV is scheduled to participate in task in round , its transmission time is given by The corresponding energy consumption of UAV for transmission is .
III PROBLEM FORMULATION AND CONVERGENCE ANALYSIS
III-A Problem Formulation
In order to minimize the expected average global loss of all tasks and reduce the total training time subject to the constrained resources of UAVs, we need to jointly optimize UAV-EV association, bandwidth allocation, and UAV transmission power. The problem is formulated as follows:
| (6) | ||||
| s.t. | (6a) | |||
| (6b) | ||||
| (6c) | ||||
| (6d) | ||||
| (6e) | ||||
| (6f) | ||||
| (6g) | ||||
The constraint in (6a) ensures that the energy consumption of each UAV in each round cannot exceed the maximum energy limit per round. Constraints (6b)-(6d) imposes restrictions on UAV-EV associations. Constraints (6e) and (6f) regulate the bandwidth allocation, and (6g) limits the transmission power of each UAV.
Since the objective function of problem involves the neural network’s loss function , the factors affecting the network’s performance are still unknown. Consequently, problem is not yet solvable. To address this, we first conduct the convergence analysis of the proposed scheme to identify the factors affecting task performance, and then formulate the problem into a solvable suboptimal form.
III-B Convergence Analysis
Assumption 1. For each UAV participating in each task , the stochastic gradient is unbiased and variance bounded
| (7) |
| (8) |
The task-specific layer properties are similar, which are omitted here.
Assumption 2. The expected squared norm of local gradients for each task and UAV is uniformly bounded
| (9) |
Assumption 3. For each task and UAV , there exist and such that:
is -Lipschitz continuous with and -Lipschitz continuous with :
| (10) |
| (11) |
is -Lipschitz continuous with and -Lipschitz continuous with , the detail is omitted here.
Based on the above assumptions, we give the upper bound of the difference in loss function between two consecutive rounds of task :
Theorem 1.
Given the UAV-EV association in round , when the learning rate , the difference in the loss function for task between two consecutive rounds is bounded by:
| (12) | ||||
where , , and
The proof is omitted here due to space limitations.
According to Theorem 1, it can be seen that task learning performance is mainly affected by the amount of associated data. Due to the dynamic UAV-EV association and the varying complexity of tasks, the training progress differs from task to task. Given the diminishing marginal effect observed in neural network training, improving overall task performance calls for greater emphasis on tasks with slower training progress. Besides, due to the differences in the quality of UAV data collected in different regions, the feature extractors of EVs associated with these high-quality data UAVs usually have better feature extraction capabilities. Through feature extractor fusion, these EVs usually bring higher performance improvements to other EVs. Therefore, EVs with a strong performance history should receive greater focus. Based on the above analysis, each task should have a dynamic task weight in different rounds. Therefore, to address problem P1, we reformulate it into the following form.
| (13) | ||||
| s.t. | (13a) | |||
where represents the sample size ratio of UAV and this problem will be addressed in section IV.
IV Proposed Algorithm
IV-A Task Attention Mechanism
In this section, we propose a task-level attention mechanism to dynamically characterize the weights of each task in each round.
IV-A1 Task Performance Balance
In a multi-task learning system, achieving a balanced performance across tasks is key to improving the system’s overall performance. Excessive performance differences among tasks may lead to longer delays and unnecessary waste of resources. To this end, we propose a dynamic weight adjustment mechanism based on historical loss, Specifically, each EV maintains the parameter to record the current weighted cumulative loss value of its own task and , where represents the loss of task when the round of training is completed, and is the parameter that balances the importance of historical cumulative loss and current loss.
Then, the loss based weight of each task can be obtained as .
IV-A2 Task Shapley Value
In this part, the concept of the Shapley value is used to quantify the marginal contribution of task in enhancing the performance of all tasks. We use to represent the EV subset, and utility function represents the accuracy of task after updating the feature extractor with the gradient of EV contained in . Then, the shapley value of task in round can be calculated as
| (14) |
Then, the cumulative Shapley value of each task is updated to , is a balancing factor similar to . To promote knowledge sharing among tasks and accelerate the training process of each task, tasks with high shapley values should receive greater focus, so the task shapley value based weight can be calculated as .
Finally, we can get the weight of each task in round based on the task attention mechanism as .
IV-B Optimal Bandwidth Allocation
Given the UAV-EV association , problem can be simplified as
| (15) | ||||
| s.t. | (15a) | |||
We first determine the transmission power for each UAV. From the previous communication model, we know that . To reduce transmission time, each UAV should operate at its highest possible transmission rate within the limits of its energy constraints. Therefore, the transmission power for each UAV is set to . Consequently, problem (14) can be rewritten as:
| (16) | ||||
| s.t. | (16a) | |||
| (16b) | ||||
where and the optimal solution of (16) is presented in Theorem 2 as follows.
Theorem 2.
Given the UAV-EV association , the optimal bandwidth allocation ratio for each UAV is
| (17) |
where , is the Lambert-W function and is the optimal solution to problem and satisfies
| (18) |
The proof is omitted here due to space limitations.
Since the optimal bandwidth allocation requires solving the Lambert- function, to obtain a closed-form expression just through parameter iteration computation explicitly is almost impossible. Therefore, we adopt a bisection method to give the solution numerically.
IV-C Optimal UAV-EV Association
Once the association between the UAV and the EV is determined, the optimal bandwidth allocation ratio and the minimum round time are determined. Substituting the minimum time obtained in the previous section into equation (16), we can transform the problem as
| (19) | ||||
| s.t. | (19a) | |||
Since the objective function does not have a clear analytical expression at this time and the constraints contain binary constraint variables, the problem is a non-convex optimization problem. In order to optimize the association between UAVs and EVs in an efficient and feasible way, we use the coalition formation game to obtain a suboptimal solution to the problem.
First we introduce some essential concepts and definitions in the following part.
Definition 1.
All UAVs can be divided into clusters, expressed as and thus constitute a UAV-EV association strategy. We have and .
Definition 2.
Given the current UAV-EV association , the utility is given by (13) and denoted as .
Definition 3.
Given two different UAV-EV association strategies and , we define a preference order as if and only if .
Definition 4.
A UAV transferring adjustment by means that UAV with retreats its current training group and joins another training group . Causing the network utility to change from to and .
Definition 5.
A UAV exchanging adjustment means that UAV and are switched to each other’s training group. Causing the network utility to change from to and .
Definition 6.
A UAV-EV association strategy is at a stable system point if no EV and UAV can change its association strategy to obtain a higher global network utility.
Based on the above definition, we can solve (19) by continuously adjusting the UAV-EV association policy to obtain a higher utility according to the preference order. The association policy adjustment will terminate when a stable association is reached, where no UAV in the system has the motivation to leave its currently associated EV and join another EV.
After the UAV-EV association algorithm converges, the optimal UAV-EV association and resource allocation strategy will be broadcast to all UAVs. All the involved UAVs will participate in the task of its associated EV and execute local training.
V Numerical Results
We consider a cellular network with a coverage radius of 500, where UAVs and EVs are randomly distributed in the network.
V-A Datasets and local models
This work utilizes the MNIST dataset for simulation validation and some modifications are performed to make it suitable for multi-task training. The digits are first rotated, and the rotation angle is selected from the preset angle vector . In addition, the digits and background are dyed differently to simulate the different backgrounds of the images collected by UAVs. For the modified MNIST dataset, we use it to complete two tasks: digit recognition and rotation angle recognition. Both tasks require information about the shape and contours of the digits, so there are similarities in the underlying tasks. For convenience, we use the same predictor for both tasks, but the results in this article can be easily extended to the case of different predictors. The model shared layers contain 3 convolutional layers, each followed by a batch normalization layer. Each task retains its own 4 fully connected layers.
V-B Hyperparameters and baselines
We set , , and distribute training data to each UAV based on two dirichlet distributions. The parameter controls the size distribution of the UAV dataset, and the parameter controls the proportional distribution of the digit categories and rotation angles. The remaining network parameters are shown in Table . The three baseline strategies are set as follows: Strategy 1 shares the feature extractor, but UAV-EV associations are randomly associated. Strategy 2 shares the feature extractor, but each UAV is associated with its nearest EV. Strategy 3 does not share the feature extractor, and UAV-EV associations are randomly associated, which is similar to the FedAvg algorithm.
| o 0.45X[c]—X[b]—X[c]—X[m] Parameter | Value | Parameter | Value |
|---|---|---|---|
| 10 | 2 | ||
| 2MHz | 500 | ||
| -174dBm | 100m | ||
| 0.01 | 0.8 | ||
| 0.8 | GHz |
V-C Performance Comparison
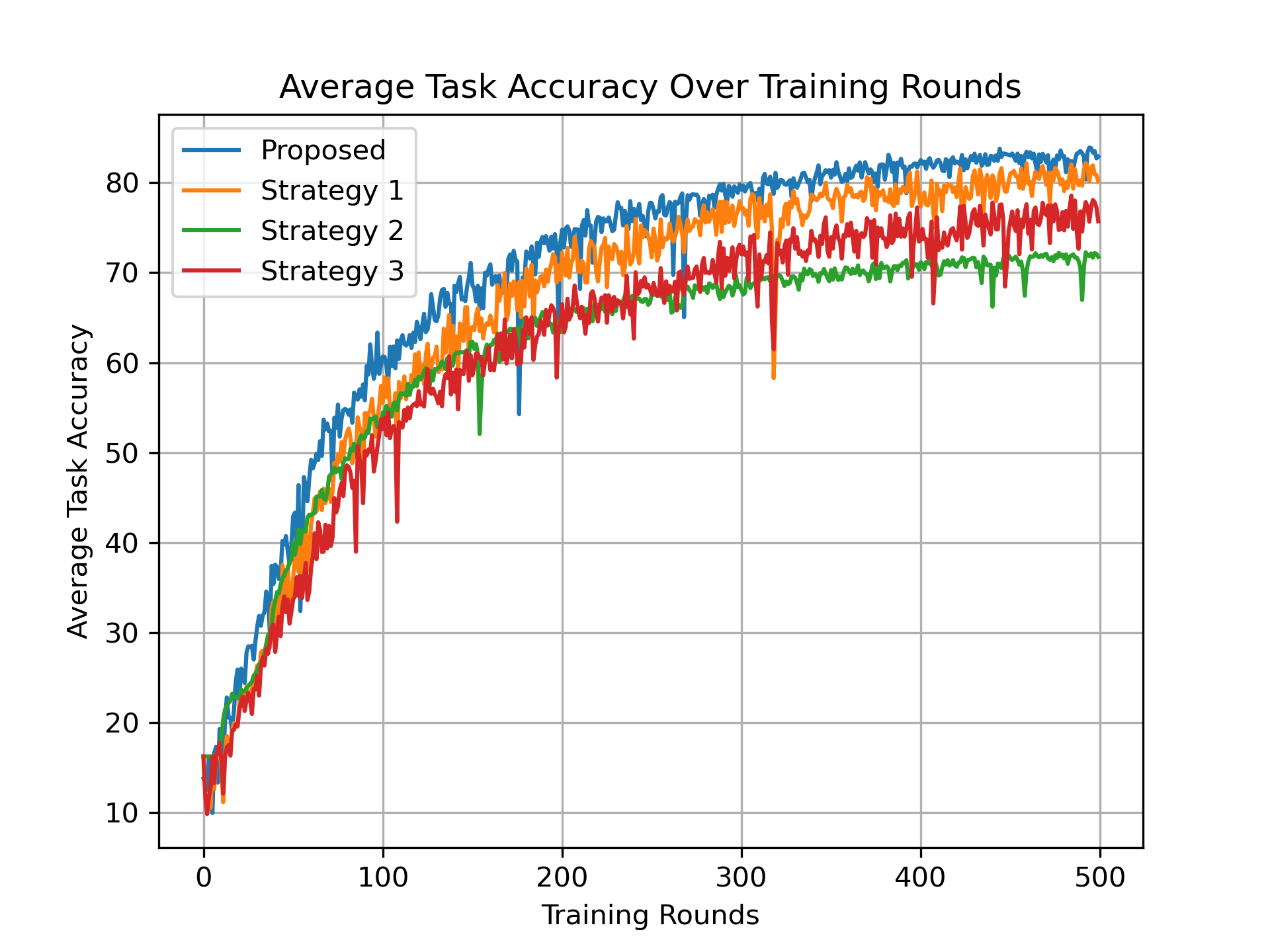
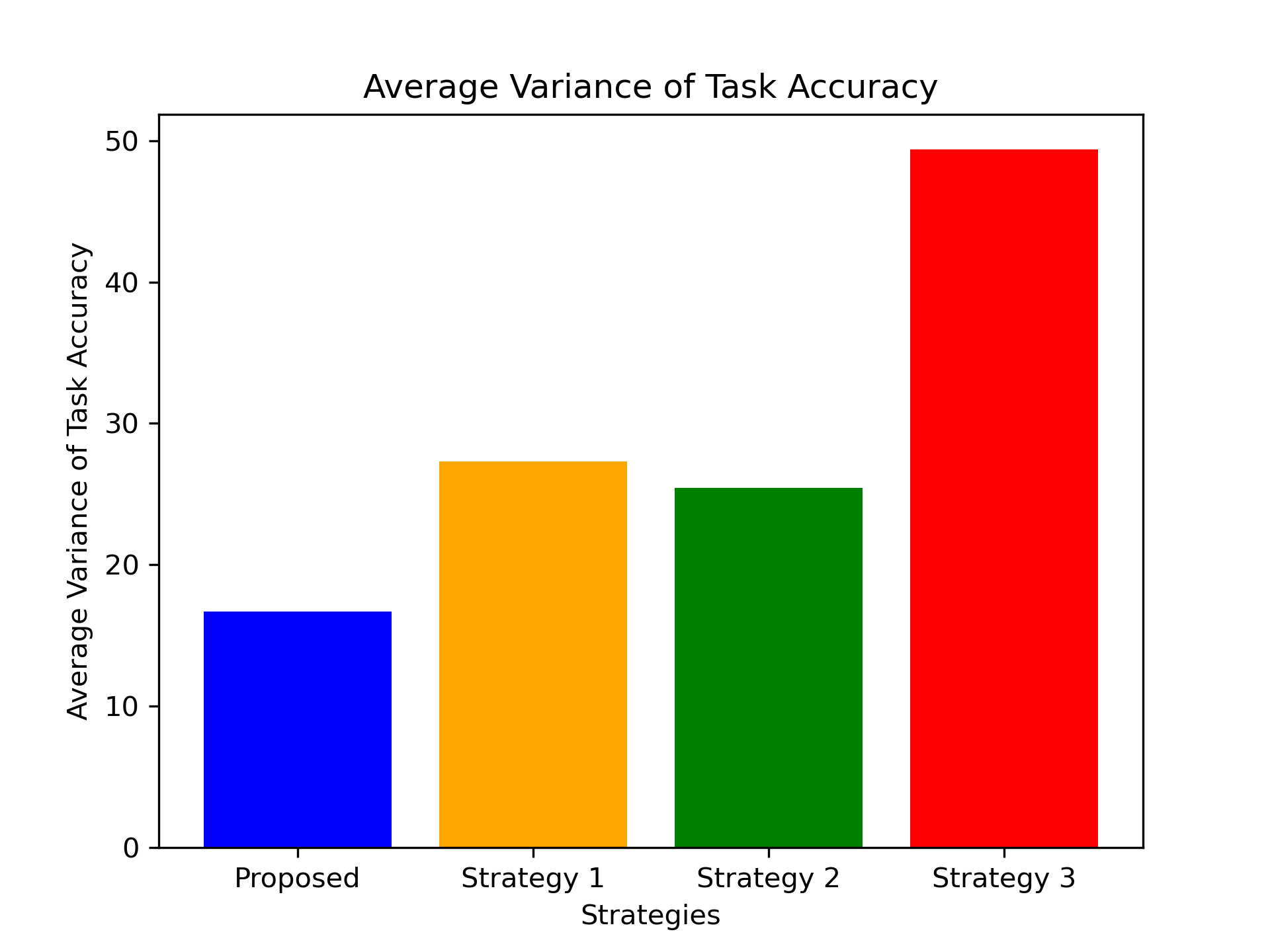
Accuracy Comparison In this part, energy and time constraints are not considered, so we set . Figure shows the average accuracy of the two tasks as the training progresses over multiple rounds. The results show that the proposed algorithm is better than the three baseline strategies. When compared to Strategy 1, the proposed algorithm achieves a improvement in final accuracy, demonstrating the effectiveness of the UAV-EV association algorithm. Moreover, Strategy 1 shows a accuracy improvement compared to Strategy 3, further confirming the effectiveness of sharing feature extractors among related tasks. Strategy 2 outperforms Strategies 1 and 3 in early training accuracy by accelerating model convergence through frequent interactions between each EV and its nearest UAVs. However, this approach weakens generalization, resulting in lower final accuracy. Figure resents the average task performance variance across all rounds for the four strategies, demonstrating that the proposed algorithm achieves a better performance balance compared to the baseline strategies.
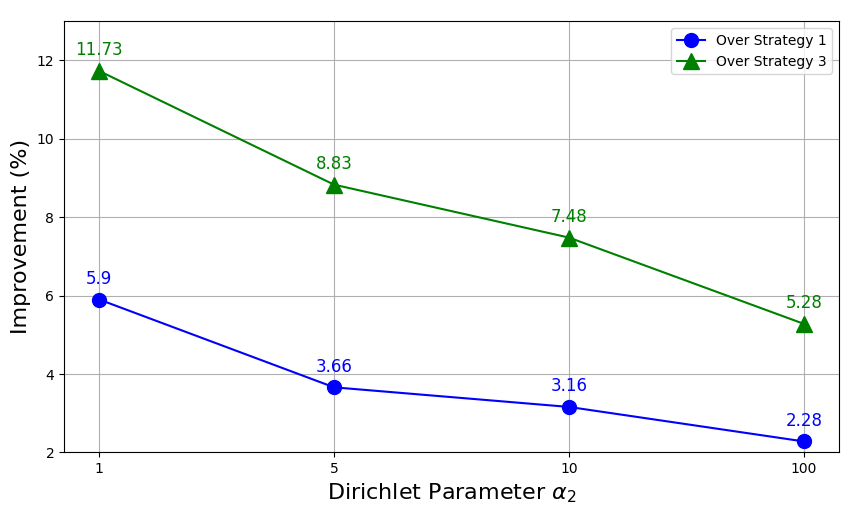
Additionally, to investigate the impact of varying degrees of non-iid UAV data, we compare the proposed scheme with Strategy 1 to demonstrate the effectiveness of the UAV-EV association algorithm, and with Strategy 3 to highlight the benefits of sharing feature extractors. Figure shows the percentage performance improvement of the proposed scheme relative to the other two strategies as varies, with fixed. The results show that improvement decreases as increases, indicating the proposed scheme performs better with higher levels of non-iid data. This confirms that sharing feature extractors enhances the model’s robustness and generalization in non-iid scenarios.
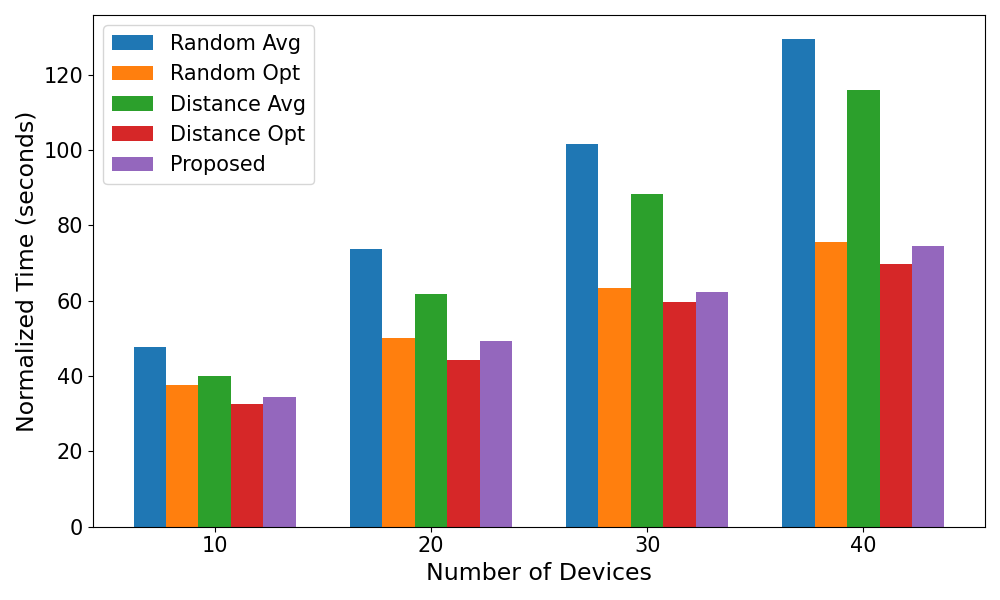
Training time comparison To verify the effectiveness of the proposed algorithm in reducing total time consumption, we set and compare the proposed algorithm with four benchmark strategies. The four benchmark strategies adopt random or nearest association, average or optimal bandwidth allocation respectively. The results in Figure show that, except for the Distance-Opt strategy with the goal of time minimization, the proposed algorithm is significantly better than the other strategies under different numbers of UAVs, proving the effectiveness and optimality of the proposed joint bandwidth allocation and UAV-EV association algorithm.
VI Conclusion and Future Work
In this paper, we introduced a multi-task federated learning scheme based on task knowledge sharing. By sharing feature extractors among multiple related tasks, the overall task training acceleration and performance improvement were achieved. In addition, by analyzing the convergence of the algorithm, the joint UAV bandwidth allocation and UAV-EV association algorithm were designed to enhance training performance and reduce training time for each round. The simulation results confirm the effectiveness of the proposed algorithm. In the future, we plan to explore the underlying mechanisms for improving task performance through shared feature extractors among related tasks. Additionally, we will investigate effective methods for quantifying task correlations and design strategies to encourage collaboration in scenarios with dynamic task relevance.
References
- [1] H. Yang, J. Zhao, Z. Xiong, K. -Y. Lam, S. Sun, and L. Xiao, “Privacy-Preserving Federated Learning for UAV-Enabled Networks: Learning-Based Joint Scheduling and Resource Management,” IEEE J. Sel. Areas Commun., vol. 39, no. 10, pp. 3144–3159, 2021.
- [2] Z. Cui, T. Yang, X. Wu, H. Feng and B. Hu, “The Data Value Based Asynchronous Federated Learning for UAV Swarm Under Unstable Communication Scenarios,” IEEE Trans. Mob. Comput., vol. 23, no. 6, pp. 7165-7179, 2024.
- [3] W. He, H. Yao, T. Mai, F. Wang and M. Guizani, “Three-Stage Stackelberg Game Enabled Clustered Federated Learning in Heterogeneous UAV Swarms,” IEEE Trans. Veh. Technol., vol. 72, no. 7, pp. 9366-9380, 2023.
- [4] T. Wang, X. Huang, Y. Wu, L. Qian, B. Lin and Z. Su, “UAV Swarm-Assisted Two-Tier Hierarchical Federated Learning,” IEEE Trans. Netw. Sci. Eng., vol. 11, no. 1, pp. 943-956, 2024.
- [5] H. Zhang and L. Hanzo, “Federated Learning Assisted Multi-UAV Networks,” IEEE Trans. Veh. Technol., vol. 69, no. 11, pp. 14104-14109, 2020.
- [6] M. Fu, Y. Shi and Y. Zhou, “Federated Learning via Unmanned Aerial Vehicle,” IEEE Trans. Wirel. Commun., vol. 23, no. 4, pp. 2884-2900, 2024.
- [7] V. Smith, C. K. Chiang, M. Sanjabi, et al., “Federated Multi-Task Learning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), Long Beach, CA, USA, Dec. 2017, pp. 4427–4437.
- [8] H. Ma, X. Yuan, Z. Ding, D. Fan and J. Fang, “Over-the-Air Federated Multi-Task Learning via Model Sparsification, Random Compression, and Turbo Compressed Sensing,” IEEE Trans. Wirel. Commun., vol. 22, no. 7, pp. 4974-4988, 2023.
- [9] J. Yang, J. Jia, T. Deng, and M. Dong, “Efficient Scheduling for Multi-Job Vertical Federated Learning,” in Proc. IEEE Int. Conf. Commun. (ICC), Denver, CO, USA, 2024.
- [10] C. Zhou, J. Liu, J. Jia, et al., “Efficient Device Scheduling with Multi-Job Federated Learning,” in Proc. AAAI Conf. Artif. Intell. (AAAI), Vancouver, Canada, Feb. 2022, pp. 9971–9979.
- [11] J. Liu et al., “Multi-Job Intelligent Scheduling With Cross-Device Federated Learning,” IEEE Trans. Parallel Distrib. Syst., vol. 34, no. 2, pp. 535-551, 2023.
- [12] X. Sun, R. Panda, R. Feris, et al., “Adashare: Learning What to Share for Efficient Deep Multi-Task Learning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), Vancouver, Canada, Dec. 2020, pp. 8728–8740.
- [13] Z. Chen, W. Yi, A. Nallanathan, and G. Y. Li, “Is Partial Model Aggregation Energy-Efficient for Federated Learning Enabled Wireless Networks?,” in Proc. IEEE Int. Conf. Commun. (ICC), Rome, Italy, 2023.
- [14] X. Liu, Y. Deng and T. Mahmoodi, “Wireless Distributed Learning: A New Hybrid Split and Federated Learning Approach,” IEEE Trans. Wirel. Commun., vol. 22, no. 4, pp. 2650-2665, 2023.