Unbounded Slice Sampling
Abstract
Slice sampling is an efficient Markov Chain Monte Carlo algorithm to sample from an unnormalized density with acceptance ratio always . However, when the variable to sample is unbounded, its “stepping-out” heuristic works only locally, making it difficult to uniformly explore possible candidates. This paper proposes a simple change-of-variable method to slice sample an unbounded variable equivalently from .
1 Introduction
Slice sampling [1] is one of the Markov Chain Monte Carlo (MCMC) methods to sample from one-dimensional distribution. Because its acceptance probability is always as opposed to famous Metropolis-Hastings algorithm [2], slice sampling is widely employed in modern statistics and machine learning problems, especially for sampling hyperparameters of a statistical model where each hyperparameter is often univariate but has a nontrivial likelihood surface.
When the variable to sample is not bounded, an algorithm called “stepping-out” [3] is usually employed to adaptively adjust the interval to sample from based on the current value of the variable. However, this “stepping-out” works only locally, thus will be potentially trapped to local modes in multimodal likelihoods. In contrast, in this paper we propose a simple method to uniformly sample from an unbounded variable through an appropriate reparametrization with a unit interval .
2 Slice sampling
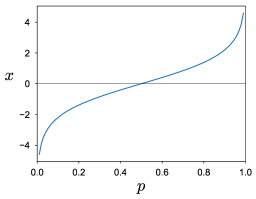
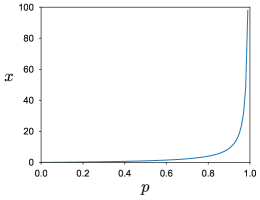
Slice sampling iteratively draws from a probability distribution
| (1) |
without knowing the normalizing constant by the following general algorithm, starting from an initial value :
In practice, Step of the Algorithm 1 is not trivial, and usually “stepping-out” heuristic [1] is employed to determine the interval from which is uniformly drawn, starting from an initial interval enclosing that is adaptively expanded.
However, the efficiency of “stepping-out” depends on setting the initial interval whose appropriate scale for the problem is not known in advance. Moreover, it works only locally: if has multiple and distant modes, it tends to wander around a single mode and will spend a very long time to explore different modes that might have higher probabilities.
On the other hand, if is bounded and known to always reside in the interval , slice sampling is very easy using the following algorithm:
This is an efficient binary search that quickly draws uniformly over the region where .
3 Unbounded slice sampling
Algorithm 2 is effective for a bounded that is known to reside in . However, even when is unbounded, we can sample through an one-to-one map between and .
General unbounded variate:
For example, using a sigmoid map
| (2) | ||||
| (3) |
for shown in Figure 1(a), for each we can associate and vice versa.
Since
| (4) |
we can alternatively sample in place of using the exchange of variables:
| (5) |
Positive variate:
When , for example we can exploit a map
| (6) |
therefore
| (7) |
leading
| (8) |
to sample and obtain by the relationship (6).
Using this reparameterization, we can slice sample an unbounded essentially by a “probabilistic binary search” always on . We included sample of MATLAB and C codes for our unbounded slice sampling in Appendix B and C.
In practice, sometimes we cannot compute a corresponding for very large (or small) using equation (2). Therefore, instead of (2) we can use
| (9) |
for some constant as shown in Figure 2. While every is mathematically equivalent, notice that usually the parameter to sample from a statistical model roughly111 This is important, because we do not enforce a strict interval to sample in this paper. resides in this regime; even if will exceed over this regime, we can safely rescale to fit into a decent interval. We empirically confirmed that usually works fine for (see Section 4).
4 Experiments
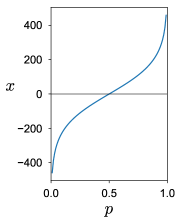
We conducted some experiments to confirm that our unbounded slice sampler correctly samples from a given distribution. Using the C code shown in Appendix A, we can easily sample from .
For a general unbounded case , Figure 3 shows the plots of sampled from (a) , (b) , and (c) . Note that will be high on different regimes for each case: roughly for (a), for (b), and for (c), while these regimes are not known in advance, and they have different variances. Figure 3 clearly shows we can correctly sample from , even when is very large using the map (9) with . The average step of “binary search”, i.e. the number of function evaluations for the loop in Step 4 of the Algorithm 2, is for (a), for (b), and for (c).
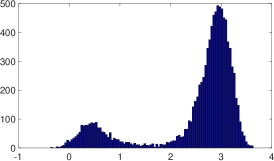
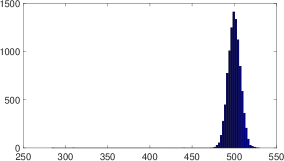
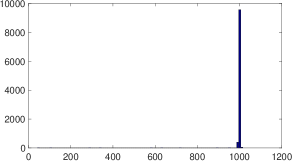
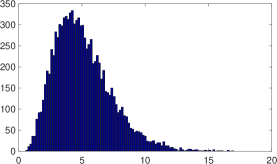
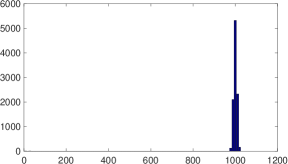
For a positive case , Figure 4 shows the results for (a) and (b) ; (a) means .
Comparison with stepping-out
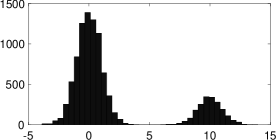
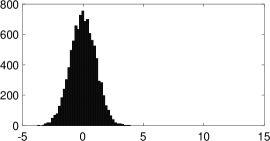
To confirm the advantage of our unbounded slice sampling, we also conducted an experiment to sample from a multimodal distribution. Specifically, Figure 5 shows a draw of samples from a Gaussian mixture model using unbounded slice sampler and “stepping-out” algorithm, respectively.
Clearly, “stepping-out” is stuck into the first mode because the sampling starts from , and this tendency remained the same over multiple simulations. Moreover, because “stepping-out” linearly increases the interval to sample from, sampling from a distant density shown in Figure 3(c) required about function evaluations at first to reach the mode, while unbounded slice sampling required only as described before, thanks to the efficient “probabilistic binary search” on .
References
- [1] Radford M. Neal. Slice sampling. Annals of Statistics, pages 705–741, 2003.
- [2] W. R. Gilks, S. Richardson, and D. J. Spiegelhalter. Markov Chain Monte Carlo in Practice. Chapman & Hall / CRC, 1996.
- [3] David J. C. MacKay. Information Theory, Inference, and Learning Algorithms. Cambridge University Press, 2003.
Appendix
Appendix A C code of easy slice sampling
#include "slice.h"
double
f (double x, void *arg)
{
return - x * (x - 1) * (x - 2) * (x - 3.5);
}
main () {
int i, N = atoi (argv[1]);
double x = 1;
for (i = 0; i < N; i++) {
x = slice_sample (x, f, NULL);
printf("%lf\n", x);
}
}
Appendix B C code for unbounded slice sampling
/*
* slice.c
* Unbounded slice sampling with ease.
* $Id: unbounded.tex,v 1.17 2020/01/03 01:23:08 daichi Exp $
*
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "random.h"
static double A = 100.0;
typedef double (*likfun)(double x, void *args);
static double
expand (double p) /* p -> x */
{
return - A * log (1 / p - 1);
}
static double
shrink (double x) /* x -> p */
{
return 1 / (1 + exp(- x / A));
}
static double
expandp (double p) /* p -> (x > 0) */
{
return p / (1 - p);
}
static double
shrinkp (double x) /* (x > 0) -> p */
{
return x / (1 + x);
}
double
slice_sample (double x, likfun loglik, void *arg)
{
double st = 0, ed = 1;
double r, rnew, slice, newlik;
int iter, maxiter = 1000;
r = shrink (x);
slice = (*loglik)(x, arg) - log (A * r * (1 - r)) + log (RANDOM);
for (iter = 0; iter < maxiter; iter++)
{
rnew = unif (st, ed);
newlik = (*loglik)(expand(rnew), arg)
- log (A * rnew * (1 - rnew));
if (newlik > slice)
return expand (rnew);
else if (rnew > r)
ed = rnew;
else if (rnew < r)
st = rnew;
else
return x;
}
fprintf(stderr, "slice_sample: max iteration %d reached.\n", maxiter);
return x;
}
double
slice_sample_positive (double x, likfun loglik, void *arg)
{
double st = 0, ed = 1;
double r, rnew, slice, newlik;
int iter, maxiter = 1000;
r = shrinkp (x);
slice = (*loglik)(x, arg) - 2 * log (1 - r) + log (RANDOM);
for (iter = 0; iter < maxiter; iter++)
{
rnew = unif (st, ed);
newlik = (*loglik)(expandp(rnew), arg) - 2 * log (1 - rnew);
if (newlik > slice)
return expandp (rnew);
else if (rnew > r)
ed = rnew;
else if (rnew < r)
st = rnew;
else
return x;
}
fprintf(stderr, "slice_sample: max iteration %d reached.\n", maxiter);
return x;
}
#if 1
double
f (double x, void *arg)
{
return - x * (x - 1) * (x - 2) * (x - 3.5);
}
double
g (double x, void *arg)
{
return - 10 * (x + 1000) * (x + 1000);
}
double
h (double p, void *arg)
{
double a = 2, b = 3;
return (a - 1) * log (p) + (b - 1) * log (1 - p);
}
int
main (int argc, char *argv[])
{
int i, N = atoi(argv[1]);
double x = 0.5;
for (i = 0; i < N; i++)
{
x = slice_sample (x, g, NULL);
// x = slice_sample_positive (x, f, NULL);
printf("%.4lf\n", x);
}
}
#endif
Appendix C MATLAB code for unbounded slice sampling
function xnew = slice_sample (x,likfun,varargin)
% xnew = slice_sample (x,likfun,varargin)
% Unbounded slice sampling in MATLAB.
% $Id: unbounded.tex,v 1.17 2020/01/03 01:23:08 daichi Exp $
global A;
A = 100;
st = 0; ed = 1;
maxiter = 1000;
% function body
r = shrink (x);
slice = feval (likfun,x,varargin{:}) - log (A * r * (r - 1)) + log (rand());
% slice sampling
for iter = 1:maxiter
rnew = unif (st,ed);
xnew = expand (rnew);
newlik = feval (likfun,xnew,varargin{:}) - log (A * rnew * (rnew - 1));
if (newlik > slice)
return;
elseif (rnew > r)
ed = rnew;
elseif (rnew < r)
st = rnew;
else
return;
end
end
fprintf(stderr,’slice_sample: max iteration %d reached\n’,maxiter);
return;
function p = shrink(x)Ψ% x -> p
global A;
p = 1 / (1 + exp (- x / A));
function x = expand(p)Ψ% p -> x
global A;
x = - A * log (1 / p - 1);
function xnew = slice_sample_positive (x,likfun,varargin)
% xnew = slice_sample_positive (x,likfun,varargin)
% Unbounded slice sampling in MATLAB. (only positive)
% $Id: unbounded.tex,v 1.17 2020/01/03 01:23:08 daichi Exp $
st = 0; ed = 1;
maxiter = 1000;
% function body
r = shrinkp (x);
slice = feval (likfun,x,varargin{:}) - 2 * log (1 - r) + log (rand());
% slice sampling
for iter = 1:maxiter
rnew = unif (st,ed);
xnew = expandp (rnew);
newlik = feval (likfun,xnew,varargin{:}) - 2 * log (1 - rnew);
if (newlik > slice)
return;
elseif (rnew > r)
ed = rnew;
elseif (rnew < r)
st = rnew;
else
return;
end
end
fprintf(stderr,’slice_sample: max iteration %d reached\n’,maxiter);
return;
function p = shrinkp (x)Ψ% (x > 0) -> p
p = x / (1 + x);
function x = expandp (p)Ψ% p -> (x > 0)
x = p / (1 - p);