Uncertainty-Aware Guidance for Target Tracking subject to
Intermittent Measurements using Motion Model Learning
Abstract
This paper presents a novel guidance law for target tracking applications where the target motion model is unknown and sensor measurements are intermittent due to unknown environmental conditions and low measurement update rate. In this work, the target motion model is represented by a transformer neural network and trained by previous target position measurements. This transformer motion model serves as the prediction step in a particle filter for target state estimation and uncertainty quantification. The particle filter estimation uncertainty is utilized in the information-driven guidance law to compute a path for the mobile agent to travel to a position with maximum expected entropy reduction (EER). The computation of EER is performed in real-time by approximating the information gain from the predicted particle distributions relative to the current distribution. Simulation and hardware experiments are performed with a quadcopter agent and TurtleBot target to demonstrate that the presented guidance law outperforms two other baseline guidance methods.
I INTRODUCTION
Target tracking refers to a capability of an agent to estimate a motion model or dynamics of a moving target based on sensor measurements. Target tracking problems arise in many robotics applications such as drone search and rescue, and the problem becomes more challenging as sensor measurements become poor or unavailable intermittently, possibly due to occlusion [1]. For example, as shown in Figure 1, when a drone (agent) tracks a ground vehicle (target) for reconnaissance, the target may be occluded by obstacles, such as buildings or vegetation, from the agent’s sensor field-of-view (FOV). When the measurements are unavailable, the agent can only predict the target position using approximated motion models. Therefore, the agent must plan its path considering the estimated motion model so that the agent can obtain target measurements once the target becomes visible and reduce the uncertainty associated with target estimate.
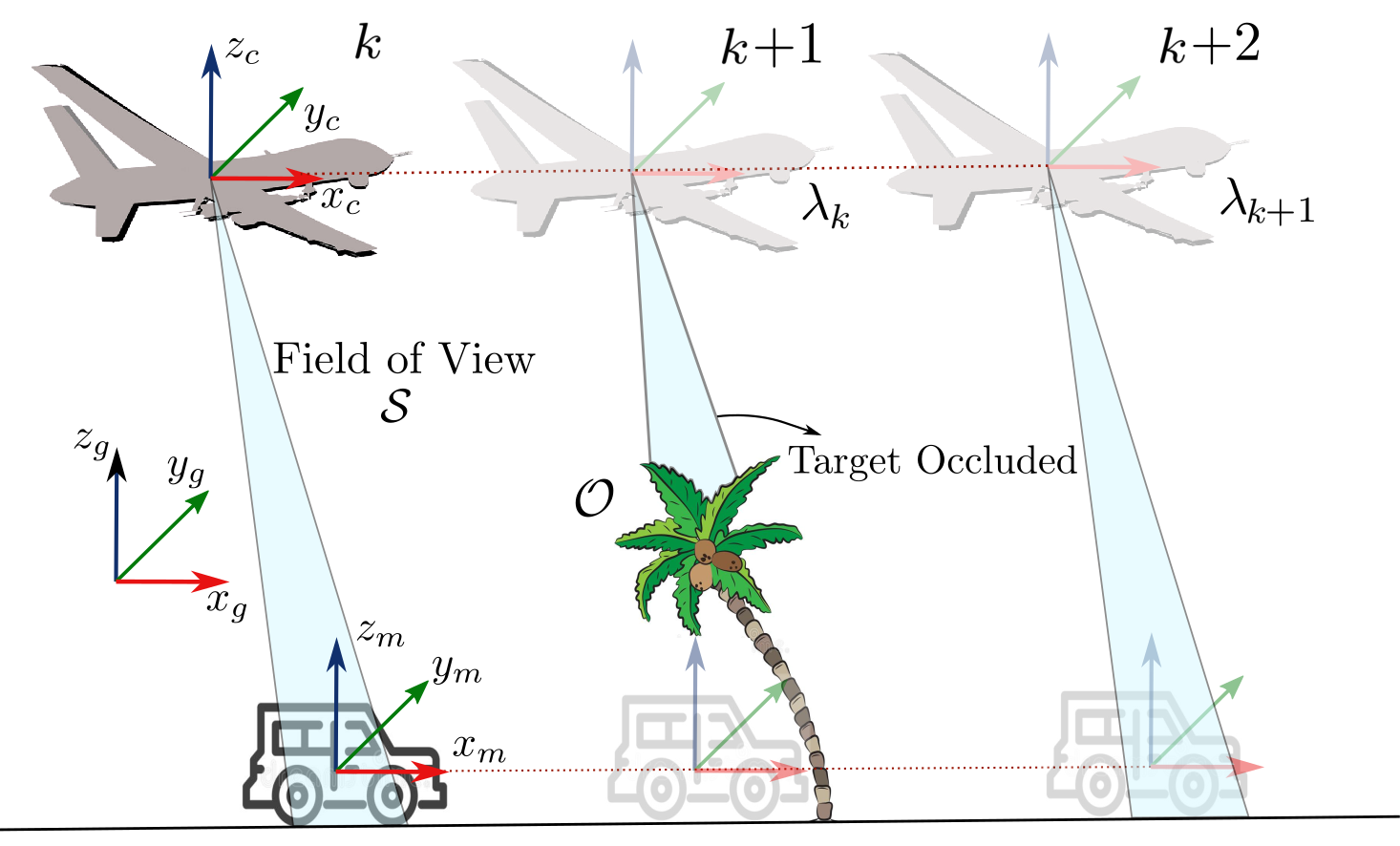
To improve the time the target is being observed, it is essential to obtain an accurate motion model to predict the target state when sensor measurements are unavailable. The agent can utilize prior observations of the target to train motion models offline; however, recent work has demonstrated a real-time method to train a motion model network [2] and attention-based deep motion model networks (DMMN) [3] based on the intermittent camera measurements obtained online. In [4] and [5], the authors study dwell-time conditions to find the time that the target can leave the sensor FOV while having a bounded estimation error. However, the agent’s guidance approach, which plans the agent’s next waypoint to observe the target and reduce the estimation uncertainty, has not been studied in the aforementioned related research that utilize learned motion models.
Information-theoretic approaches have proven effective in planning the agent’s next waypoint when onboard sensors need to obtain certain measurements to reduce estimation uncertainty [6, 7]. These information-driven planning approaches find the best action, or waypoint, for the agent that gives the highest expected information gain with respect to the measurements at a future time step. Additionally, due to its high computational complexity, particle filters have been used to approximate the probability distributions used in the computation [8, 9, 10, 11]. These information-driven planning approaches implemented with particle filters have been proven to be effective in other applications, including simultaneous localization and mapping (SLAM) [12]. Another information-based tracking approach is demonstrated in [13], where the authors use optimal information gain to track a target with multiple agents; however, [13] assumes that the road network, along which the targets move, is known so that the cost function can use this knowledge on the road network to find the waypoints to maximize the information gain and avoid collisions with other agents.
In this paper, a novel real-time, image-based uncertainty-aware guidance law is proposed to track a moving target, with unknown dynamics model, subject to occlusions caused by unknown environmental conditions and physical limitations of the camera FOV (Problem Statement in Section II). This novel approach utilizes a transformer-based DMMN in a particle filter estimator to predict the state of a moving target, whose uncertainty is then utilized by a following novel information-driven planning algorithm that computes the path for the mobile agent to reduce the target’s localization uncertainty. This paper uses expected entropy reduction (EER) as an expected information gain in order to directly account for target’s localization uncertainty. A sampling method is developed to estimate the EER using a subset of the particles and for the DMMN to enable real-time hardware demonstration of the framework (described in Sections III and IV). This proposed uncertainty-aware guidance law for target tracking is then compared to other baseline approaches (Section V). The code and data for this paper are open-source111https://github.com/aprilab-uf/info_driven_guidance.
II PROBLEM STATEMENT
This work considers the problem of finding a guidance law of an aerial agent that is tasked with tracking a moving target on the ground. The agent is equipped with a fixed downward-facing camera that uses images to measure the position the target. The agent is assumed to operate at a constant height such that the projected geometry of the camera’s field-of-view (FOV) remains constant. The target moves along a road network that is unknown to the agent and which is learned using the DMMN from measurements available a priori. To achieve the tracking objective, the agent uses the DMMN-based particle filter to estimate the target’s current position and predict the future position at any time. Using these predictions, the agent approximates the guidance law that will minimize the DMMN-based particle filter future uncertainty.
The workspace is defined as a 3D Euclidean space, , in which three coordinate frames are defined as shown in Figure 2. The inertial frame is denoted by . The agent’s camera frame, , is defined with the origin at the principal point of the camera, denoted by . The mobile target frame, denoted by , has an origin located at the center of the target, denoted as . The target is only moving along the road network on -plane, denoted by . The projected camera sensor FOV on is denoted by .
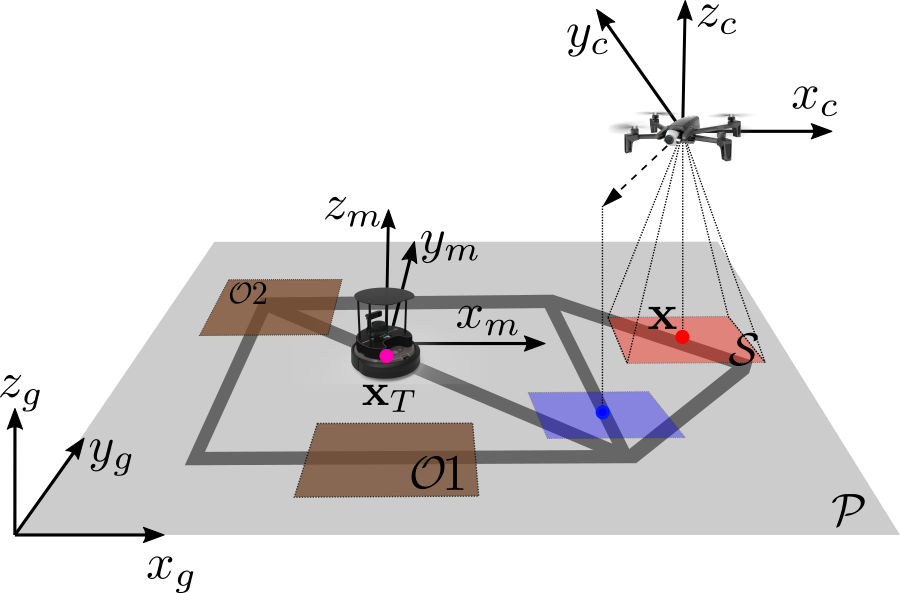
Based on the aforementioned assumptions, the target state is defined by with respect to . The center of projected sensor FOV , which is also the agent’s position, is defined by . The unknown area where the target is occluded is denoted by , where , i.e., the target is occluded when . This subset is the union of compact occlusion regions denoted by , where is the number of occlusion regions. Then, the target will be observed if and only if . When the target is observed, the agent obtains a measurement of the target state at discrete time step , denoted by , where and are the estimated target position in at . A state’s value at time step is denoted by , and the set of state’s value from time step to is denoted by .
The sensor measurement model h is assumed to be probabilistic and known, denoted by
| (1) |
where denotes a random noise from a known distribution. A set of measurements taken from time step to is denoted by . The unknown motion model is represented by
| (2) |
where is an unknown process noise. The objective of the guidance law is to find the future waypoint of an agent so that target tracking uncertainty, i.e., the uncertainty in target state estimation, is minimized.
III UNCERTAINTY-AWARE GUIDANCE WITH MOTION MODEL LEARNING
In order to learn the motion model of the target, the presented method uses a transformer-based DMMN (Section III-A), which is then inserted in target state estimation by approximating the probability distribution using particles (Section III-B). Then, the proposed guidance law computes the next waypoint to reduce the target state estimation uncertainty using expected entropy reduction (Section III-C).
III-A Transformer-based Target Motion Model Learning
The target’s motion model is assumed unknown to the tracking agent; however, the motion model can be trained using previous measurements of the target. In this paper, the DMMN is trained offline with the input being a set of position histories , for and output a future position of the target . By default, the network predicts a single time step into the future, but by appending the prediction to the input and feeding it through the network again, the tracking agent can predict the targets future position over an arbitrary time-horizon.
In this paper, we design a DMMN transformer network based on [14] to leverage the transformer’s ability to encode sequence of features. The transformer is comprised of a position encoder, a multi-head transformer encoder, and a linear decoder with dropout and ReLU activation functions. The encoder takes the time series data and maps them to points in a high-dimensional feature space. The decoder takes these points and maps them to a predicted position. This model is generalizable to target systems that operate under dynamics that can be approximated as a mapping between a trajectory and a predicted position.
III-B Target State Estimation using Particle Filter
The target state can be recursively estimated using Bayesian inference. Specifically, the target state is estimated through two steps. The first step is called prediction, which computes
| (3) |
where represents how the target state transitions, corresponding to the motion model in (2). In this paper, a transformer-based DMMN is developed to compute this motion model as described in section III-A. The next step is called update, represented as
| (4) |
where the probability density function is computed using the measurement model in (1). It is assumed that and the covariance matrix are known.
Considering the non-linearity of the target motion model, the target state is estimated using a particle filter. In the particle filter, the probability density functions on the target state is estimated using sampling techniques [9]. At time step ,
| (5) |
where is the Dirac delta function and is the number of particles. The weights are constrained by .
III-C EER-based Guidance Law
This paper proposes a guidance law for target tracking based on EER that can be computed in real-time onboard an aerial drone. Since entropy is a function of the probability density function of target state estimation, the presented work approximates entropy using sampling-based approximation represented in (5). From [8], the entropy of target state estimation can be approximated by
| (6) |
When target measurements are unavailable, based on [11], the entropy can be approximated by the particles of the prior distribution as
| (7) |
In the guidance law, the expected value of entropy reduction should be computed as a function of the agent’s future waypoint. Let us denote the agent’s waypoint at time step as , where is a user-selected constant representing the time step horizon to plan the next waypoint. Also, denote as the measurement obtained at , and as the updated target state estimation. The information gain is set as the entropy reduction, which is represented as
| (8) |
Then, the expected information gain (or EER) is computed by integrating over all possible measurements , which is represented by
| (9) |
Since the computational complexity of EER approximation grows exponentially to the number of particles in (5), it becomes computationally expensive to run onboard a drone. Specifically, the entropy computation takes significant time due to exponential complexity. Therefore, the probability density function is approximated by sampling particles to reduce computation time. The number of particles sampled for entropy computation is denoted by . These particles are uniformly sampled from to make sure the distribution keeps the same shape. Therefore, if at , then
| (10) |
and otherwise, i.e., at ,
| (11) |
EER takes the expectation of the information gain over all the possible measurements as shown in (9). In order to reduce computation time, the number of particles to approximate the probability density function of is denoted by and is a user-defined parameter. In the expectation calculation, measurements are considered. Specifically, each of particles passes through the measurement model to consider possible measurements. In other words, from (1), each particle for , the expected measurements
| (12) |
for , are used to compute the expectation in (9). Therefore, the EER is computed using the particle-based entropies derived before,
| (13) |
Then, the proposed guidance law computes the waypoint, or goal position, at such that the EER is maximized,
| (14) |
where is the set of possible waypoints for the agent at .
IV EXPERIMENT SETUP
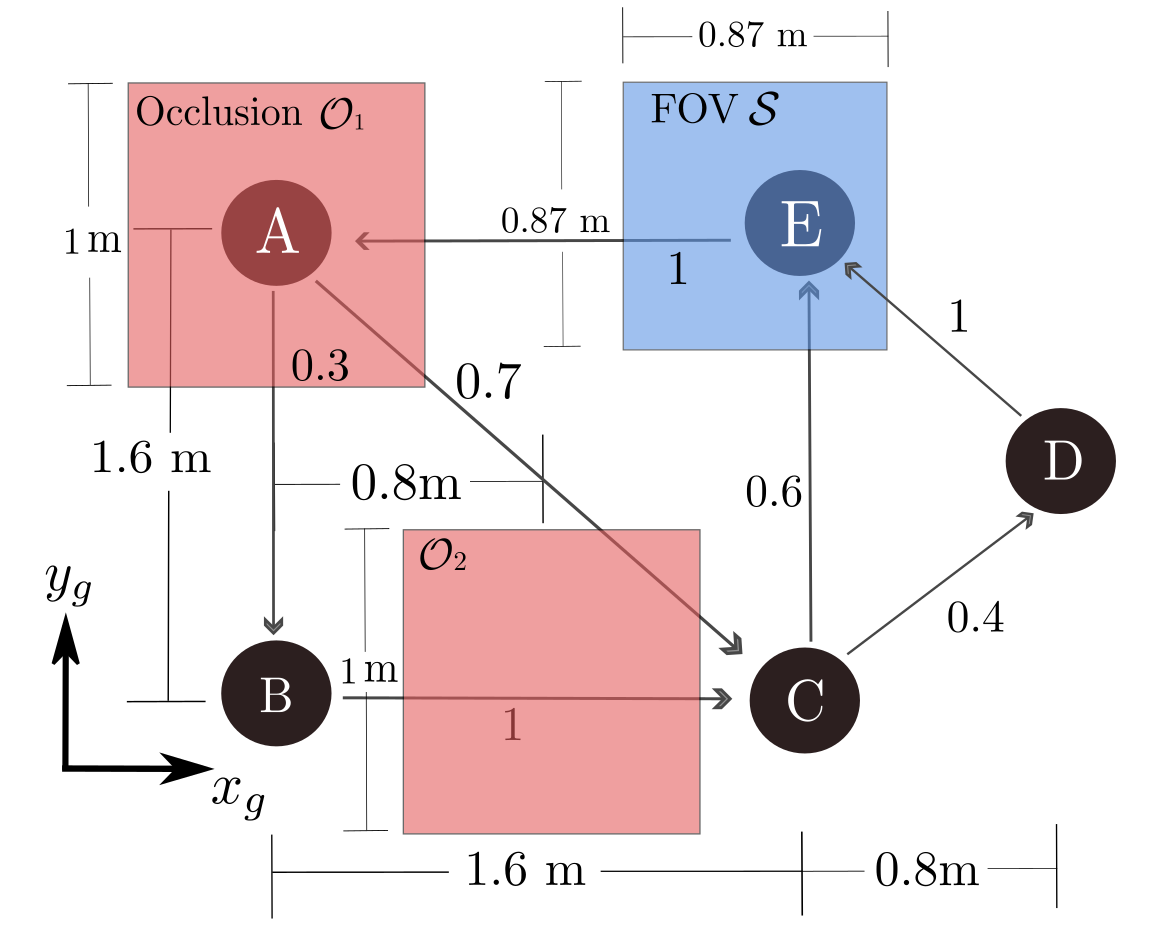
The target TurtleBot follows a road network, which is modeled as a Markov chain. As shown in Figure 3 the target can move from one node to another based on the transitioning probability, denoted in the edges in the Figure. This Markov chain-like road network model is unknown to the agent, and therefore, learned using the DMMN (Section III-A). Figure 3 shows the dimensions of the road network and where the occlusion is located. Note that there are two occlusions, one between node B and C and one in node A where one of the two stochastic decisions takes place.


This work is validated on hardware platforms at the Autonomous Vehicles Lab (AVL) located at the UF REEF, which houses a motion capture system with used to validate the true positions of the agent and target vehicles. The quadcopter is equipped with a NUC7i7 receiving the velocity commands from a computer running the particle filter along with the NN for predicting next target states, and the information-driven guidance. To be able to compute the filter with the DMMN, and the information-driven guidance in real time, they are run at 3 Hz and 2.5 Hz respectively. To localize itself and track the desired positions, the quadcopter computer runs the REEF Estimator and REEF Control [15] as well as a DNN adaptive portion of the controller that reduces disturbances [16]. The first results are 10 runs in simulation (Figure 4(a)) to compare estimation performance, and 3 runs in hardware (Figure 4(b)) to compare guidance performance. The hyper-parameters chosen in the simulation and in hardware are shown in Table I. We find that is appropriate for our setup because the future horizon depends on the ability of the agent to follow the goals and longer horizons resulted in the target being outside of FOV.
| Parameter | Description | Value |
|---|---|---|
| Number of samples used for prior approximation (particles) | ||
| Number of samples used for entropy and EER computation | ||
| Number of future measurements considered in EER computation per sample | ||
| Number target state histories input to transformer-based motion model | ||
| Time step horizon for waypoint planning | ||
| Multinomial resampling threshold | ||
| Uniform resampling threshold |
V RESULTS
V-A Benchmark Comparison Setup
The novel tracking and guidance method is compared with two other guidance methods as baselines. The presented novel guidance law is referred to as DMMN-EER for convenience. The DMMN-EER method computes the next waypoint as the position of the maximum EER at the future time step as shown in (14).
The first baseline guidance method with which to compare the DMMN-EER is referred to as Lawnmower and Tracking (LAWN). LAWN computes the next waypoint as the position of the last target measurement, . If a target measurement is not available, LAWN outputs a lawnmower path (boustrophedon pattern) that covers the area of interest in . This guidance law attempts to track the target without a target state estimation algorithm. The second baseline method is referred to as Particle Filter Weighted Mean (PFWM). PFWM computes the next waypoint as the estimated target position at using the weighted mean of the particle filter, denoted by
| (15) |
The third and final baseline method leverages a Kalman Filter (KF) by estimating the velocities of the target after feeding noisy position data. The guidance law for this baseline is similar to PFWM in which the agent’s goal position is the mean position estimate of the filter.
Four metrics are used to compare the performance among the four guidance methods described above. First, the tracking error, , is defined by the distance between the agent and target on , i.e.,
| (16) |
Second, the estimation error, , is defined by the distance between the the actual target position and the estimated target position computed by the weighted mean of the particle filter, i.e.,
| (17) |
Third, the determinant of the covariance matrix, , is used to measure the target estimation uncertainty at time . The covariance matrix of the particle states is computed by taking the sum of the difference between each particle and the weighted mean, i.e.,
| (18) |
The fourth metric, named is the percentage of the total time the target is seen by the agent’s FOV and therefore there is a measurement, ie. .
V-B Motion Model Learning Results
The DMMN model, presented in Section III-A, is first implemented and tested in order to demonstrate that the motion model can accurately propagate the target state. The DMMN is trained offline from half an hour of noisy position data (k samples) collected in the the road network described in Figure 3, which we assume we have access beforehand.
To demonstrate state estimation effectiveness, the DMMN is compared to two baseline motion models, where the first also uses a PF but estimates the target’s next position using an estimated velocity computed by the change in observed position from when the target was in the FOV. This velocity is randomly sampled from a range of m/s. The second baseline is a Kalman Filter (KF) that also estimates the target velocity when given noisy position inputs. The experiments consist of the identical duration (1.5 mins) and setup as the guidance experiments explained in Section V-C except the guidance goal is the true target position. The simulation 10 runs with the DMMN motion model results with a estimation error of m with standard deviation of m, the particle velocity baseline motion model results in m with standard deviation of m and the KF results in m with standard deviation m. These results clearly shows that the DMMN helps achieving a lower error in estimation.
V-C Hardware Guidance Experiment Results
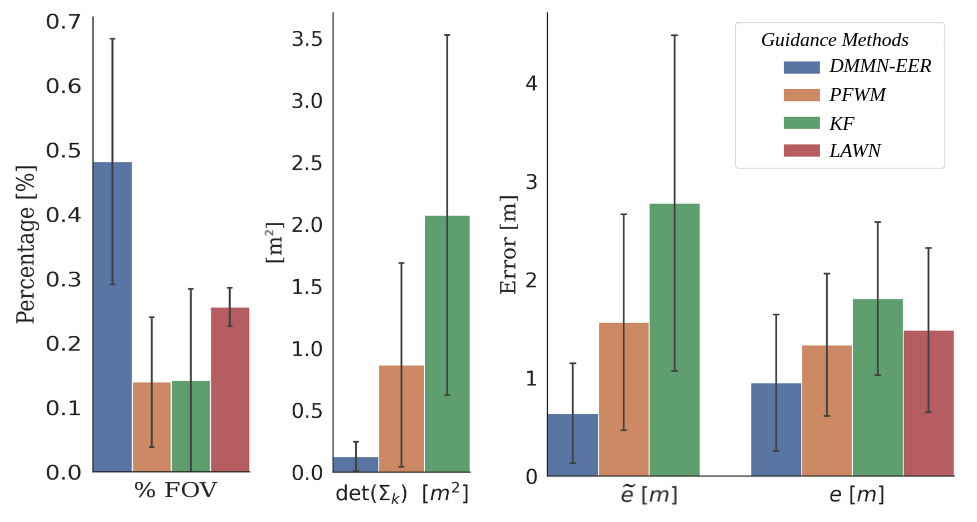
For each guidance method, the identical experiment is again performed ten times to obtain average values of performance metrics. All four guidance methods use the same DMMN as an estimation method. In Figure 5, the target tracking performance is compared using the four metrics defined in V-A. The figure shows the DMMN-EER method outperforms the other two baseline methods in each of the four quantitative evaluations metrics. When compared with the LAWN and PFWM methods, the DMMN-EER method achieves the smallest state and tracking error with the lowest distribution uncertainty and highest percent time in FOV.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1ccbf195-a8ba-4424-89fc-7e6e7ccd5f12/info_est.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1ccbf195-a8ba-4424-89fc-7e6e7ccd5f12/particles_est.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1ccbf195-a8ba-4424-89fc-7e6e7ccd5f12/KF_est.png)
The advantage of DMMN-EER is highlighted in Figure 6. In the figure, the estimation error over time of a single run is plotted, where the red vertical lines are the times when the target is occluded, and black vertical lines are the times where the target is not inside the FOV. As shown in the figure, the DMMN-EER method has a lower estimation error over time, , compared to the PFWM method. Moreover, it is noteworthy that the DMMN-EER can reduce more quickly than the other two when the target escapes the unknown occlusion zone. For all methods, the figure shows the error is increased inside and near the occlusion zones. While PFWM still has high right after the occlusion, DMMN-EER reduces efficiently because the EER-based approach can command the agent to move to the position that the target is most probable to be located at, based on the prediction from DMMN.
VI CONCLUSION
This paper presented a novel guidance law for target tracking applications where the target motion model is unknown and sensor measurements are intermittent. The target’s motion model is modeled as an attention-based deep neural network and trained using previous measurements. Then, this trained deep motion model network is used in the prediction step of a particle filter estimating the target state. The information-driven guidance law calculates the next goal position for the agent to achieve the maximum expected entropy reduction on target state estimation. Hardware experiments are conducted to compare the guidance method to other two baseline methods. The experiment results show that the presented novel guidance method reduces the target state estimation and tracking errors and estimation uncertainty.
For future work, the authors aim to validate the reliability of the result by performing a statistical difference test (e.g., one-way ANOVA). Additionally, we aim to integrate the learned motion model with an EKF to test the benefit of the PF as well as avoid the pre-training stage for model learning and perform online learning.Ultimately, we aim to explore how this uncertainty-aware guidance approach can be extended to a multi-target tracking problem in a multi-agent system.
ACKNOWLEDGMENT
This work was supported by the Task Order Contract with the Air Force Research Laboratory, Munitions Directorate at Eglin AFB, AFOSR under Award FA8651-22-F-1052 and FA8651-23-1-0003. The authors would like to thank Jared Paquet for assisting in running the hardware experiments in the Autonomous Vehicle Lab (AVL) at the UF REEF and also Aditya Penurmati for providing the Kalman Filter baseline and running experiments at the APRILab at UF.
References
- [1] M. Rosencrantz, G. Gordon, and S. Thrun, “Locating moving entities in indoor environments with teams of mobile robots,” in Proceedings of the second international joint conference on Autonomous agents and multiagent systems, 2003, pp. 233–240.
- [2] A. Parikh, R. Kamalapurkar, and W. E. Dixon, “Target Tracking in the Presence of Intermittent Measurements via Motion Model Learning,” IEEE Transactions on Robotics, vol. 34, no. 3, pp. 805–819, 2018.
- [3] Z. I. Bell, R. Sun, K. Volle, P. Ganesh, S. A. Nivison, and W. E. Dixon, “Target Tracking Subject to Intermittent Measurements Using Attention Deep Neural Networks,” IEEE Control Systems Letters, vol. 7, pp. 379–384, 2023.
- [4] C. G. Harris, Z. I. Bell, R. Sun, E. A. Doucette, J. Willard Curtis, and W. E. Dixon, “Target Tracking in the Presence of Intermittent Measurements by a Network of Mobile Cameras,” in 2020 59th IEEE Conference on Decision and Control (CDC), 2020, pp. 5962–5967.
- [5] M. J. McCourt, Z. I. Bell, and S. A. Nivison, “Passivity-Based Target Tracking Robust to Intermittent Measurements,” in 2022 American Control Conference (ACC), June 2022, pp. 1626–1631.
- [6] W. Lu, G. Zhang, and S. Ferrari, “A comparison of information theoretic functions for tracking maneuvering targets,” in 2012 IEEE Statistical Signal Processing Workshop (SSP), 2012, pp. 149–152.
- [7] J. Shin, S. Chang, J. Weaver, J. C. Isaacs, B. Fu, and S. Ferrari, “Informative Multiview Planning for Underwater Sensors,” IEEE Journal of Oceanic Engineering, vol. 47, no. 3, pp. 780–798, July 2022.
- [8] Y. Boers, H. Driessen, A. Bagchi, and P. Mandal, “Particle filter based entropy,” in 2010 13th International Conference on Information Fusion, July 2010, pp. 1–8.
- [9] S. Thrun, W. Burgard, and D. Fox, Probabilistic robotics. Cambridge, Mass.: MIT Press, 2005.
- [10] G. Rui and M. Chitre, “Path Planning for Bathymetry-aided Underwater Navigation,” in 2018 IEEE/OES Autonomous Underwater Vehicle Workshop (AUV), Nov. 2018, pp. 1–6, iSSN: 2377-6536.
- [11] P. Skoglar, U. Orguner, and F. Gustafsson, “On information measures based on particle mixture for optimal bearings-only tracking,” in 2009 IEEE Aerospace conference. Big Sky, MT, USA: IEEE, Mar. 2009, pp. 1–14. [Online]. Available: http://ieeexplore.ieee.org/document/4839487/
- [12] C. Stachniss, G. Grisetti, and W. Burgard, “Information gain-based exploration using rao-blackwellized particle filters.” in Robotics: Science and systems, vol. 2, 2005, pp. 65–72.
- [13] J.-P. Ramirez-Paredes, E. A. Doucette, J. W. Curtis, and N. R. Gans, “Distributed information-based guidance of multiple mobile sensors for urban target search,” Autonomous Robots, Feb. 2018.
- [14] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” CoRR, vol. abs/1706.03762, 2017. [Online]. Available: http://arxiv.org/abs/1706.03762
- [15] J. H. Ramos, P. Ganesh, W. Warke, K. Volle, and K. Brink, “REEF Estimator: A Simplified Open Source Estimator and Controller for Multirotors,” in 2019 IEEE National Aerospace and Electronics Conference (NAECON), July 2019, pp. 606–613, iSSN: 2379-2027.
- [16] Z. Lamb, Z. I. Bell, M. Longmire, J. Paquet, P. Ganesh, and R. G. Sanfelice, “Deep nonlinear adaptive control for unmanned aerial systems operating under dynamic uncertainties,” ArXiv, vol. abs/2310.09502, 2023.