Uncertainty-aware Self-supervised Learning for Cross-domain Technical Skill Assessment in Robot-assisted Surgery
Abstract
Objective technical skill assessment is crucial for effective training of new surgeons in robot-assisted surgery. With advancements in surgical training programs in both physical and virtual environments, it is imperative to develop generalizable methods for automatically assessing skills. In this paper, we propose a novel approach for skill assessment by transferring domain knowledge from labeled kinematic data to unlabeled data. Our approach leverages labeled data from common surgical training tasks such as Suturing, Needle Passing, and Knot Tying to jointly train a model with both labeled and unlabeled data. Pseudo labels are generated for the unlabeled data through an iterative manner that incorporates uncertainty estimation to ensure accurate labeling. We evaluate our method on a virtual reality simulated training task (Ring Transfer) using data from the da Vinci Research Kit (dVRK). The results show that trainees with robotic assistance have significantly higher expert probability compared to these without any assistance, , which aligns with previous studies showing the benefits of robotic assistance in improving training proficiency. Our method offers a significant advantage over other existing works as it does not require manual labeling or prior knowledge of the surgical training task for robot-assisted surgery.
Index Terms:
Surgical skill assessment, surgical training, Bayesian deep learning, virtual reality, robot-assisted surgeryI Introduction
Robot-assisted minimally-invasive surgery (RAMIS) with the advance of robotic platforms, such as the da Vinci surgical system (Intuitive Surgical Inc., Sunnyvale, CA), has revolutionized surgical interventions towards a safe, precise, and less invasive approach for patient care [1, 2]. Despite benefits, robot-assisted surgery is technically complex and different for clinical operators compared to traditional open interventions [3, 4]. It requires trainees to develop fundamental technical skills, map task perception to appropriate actions, and take valid operational strategies to properly control the surgical tools [5]. Such proficiency could only be obtained by sufficient training and structured practice with appropriate feedback [6]. Therefore, understanding technical skills in various scenarios and providing accurate assessment for medical trainees has paramount relevance in the field [7].
Typically, the acquisition of technical skills for surgery is supported by verbal feedback from senior surgeons [8, 9], and assessed using methods that are largely subjective and resource-expensive, such as structured checklists and rating scales [10, 11]. Recent advent of surgical robotic platforms and Virtual Reality (VR) or computer-based simulators allows to collect a broad set of recordings that are relevant to various surgical operations [12, 13, 14, 15, 16, 17]. Together with the advancements in surgical data science, there is an increasing interest to assess technical skills using tool kinematics and endoscopic videos collected during basic training tasks [18, 19]. In addition, recent studies in training augmentation have shifted the focus towards the development of adaptive strategies for personalized, self-directed surgical training [20, 21, 22, 23]. This approach is driven by the goal of maximizing learning by adapting some training parameters to the trainee. More specifically, this adaptation relies on a quantification of the trainee’s skill where a training curricula or robotic assistance is adapted accordingly as a function of the trainee’s learning progress [22, 24, 25, 23]. Thus, an accurate and continuous skill assessment is highly relevant to enable an appropriate adaptation criterion and to provide adequate feedback and timely guidance. Taken together, these factors lead to a distinct necessity of an efficient solution for assessing skills in personalized surgical training to better train future robotic surgeons.
Pioneering surgical skill models ranging from shallow classifiers to advanced deep networks have been broadly exploited. Classical machine learning algorithms such as support vector machine (SVM), linear discriminant analysis (LDA), and hidden Markov models (HMM) are widely used to assess skills based on low-level features extracted from either videos or kinematic data [26, 27, 28, 29, 30]. In contrast, recent development of deep learning leads to an increasing popularity due to its superior end-to-end learning and automatic feature extraction capabilities. With a sufficient amount of labeled data, convolutional neural network (CNN) and its modifications could provide a high classification accuracy in several basic surgical training exercises [31, 32, 33, 34, 35]. As sequence learners, recurrent neural networks (RNN) such as long-term-short-memory (LSTM) could explore complex temporal dynamics of the sequential data and have shown a competitive accuracy for measuring skills from motion kinematics [36, 37].
In general, there are two main drawbacks that existing approaches typically feature when building a predictive model for skill assessment, particularly given broader, personalized surgical training exercises. First, all these methods only utilize the labeled data and are developed to assess skills of specific tasks in surgical training, such as Suturing, Needle Passing, and Knot Tying [38]. Despite high performance of skill assessment has been reported in these studies, their effectiveness in generalizing to new unlabeled data is less explored. In particular, the abundant unlabeled data from the complex settings of surgical training tasks can be very different from the labeled ones. It remains less known whether the model can generate meaningful skill labels given the new settings of surgical training tasks (i.e. assessing skills in a training task that is very different from the ones used to train the skill model). Secondly, most existing methods assume the availability of skill labels as the ground-truth required for modeling. However, manual labeling is time-consuming and labor-intensive as it involves significant efforts of experienced professionals to assess skills based on their case review [38]. A new approach that can jointly explore the intrinsic characteristics of unlabeled surgical data while leveraging available information of labeled data is thus desirable.
This work focuses on the cross-domain assessment of technical skills in surgical training tasks based on kinematic data. We present a two-stage framework that incorporates self-supervised learning to capture inherent knowledge from both labeled and unlabeled data. An uncertainty estimation is used to generate appropriate pseudo labels for the target domain. Our approach leverages both labeled and unlabeled data, allowing the model to capture more inherent features of kinematics that are less specific to a particular domain. Additionally, our approach does not require prior skill labeling in the target domain, enabling the assessment of skills without the constraint of labeling which is typically challenging to acquire.
The key contributions of this paper are:
-
•
A novel approach to assess surgical skills in unlabeled kinematic data for new robotic surgical training exercises.
-
•
A Bayesian self-supervised model with uncertainty regularization that learns domain-invariant features from both labeled and abundant unlabeled data.
-
•
Validation of our approach on an unlabeled dataset from standalone virtual reality simulation-based surgical training. By using pseudo labeling, we are able to extract trainees’ learning curves and demonstrate alignment with performance measures in VR training.
-
•
A data-driven, generic approach that eliminates the need for manual labeling and prior task-specific knowledge for heterogeneous surgical training exercises.
II Methodology
We aim to assess technical skills in a unlabeled surgical training task. We explicitly focus on a personalized, non-standard training task, VR simulated Ring Transfer, which is different from a typical setting of basic surgical training. We formalize the problem as a cross-domain adaptation question for skill assessment. Differently from conventional fully supervised (only trained on labeled data) and fully unsupervised learning (trained on unlabeled data) paradigms, our approach seeks to learn a model by generalizing a source for which we have labeled kinematic data with ground-truth skill labels to a target domain where no true target skill label is available.
II-A Preliminary
Formally, we denote the source domain as a group of labeled samples, , that were collected from basic skill training. Each -th sample pair is composed by the input kinematics data , associated with a corresponding skill class label . Here, is the dimension of input data and is the number of classes. Similarly, we denote the target domain as a set of unlabeled samples , . Target domain was collected from a previously unseen exercise involving robotic surgical skills, where no ground truth labels of target domain are available.
In general, domain adaption refers to a set of approaches predicting the labels of samples from target domain , using both labeled samples from source domain and unlabeled samples from the target domain itself. As follows, the goal of transferable skill assessment is to train a model overs and that enables learning of both transferable features and domain-invariant classifier. Here, the output of is the predictive class probability of skills and denotes the learned network parameters.
II-B Self-supervised Learning Protocol
Self-supervised learning, also known as self-learning, refers to a protocol that is specifically designed to learn from both labeled and unlabeled data [39]. Typically, self-learning approaches first construct an initial classifier based on the labeled data. Then, the classifier is applied to some of unlabeled data and make predictions using the model. These predictions, namely labels, are included to re-train the existing classifier in an iterative fashion until a certain stopping criterion is satisfied.
We set up a similar procedure and devoted to domain adaptation for transferable skill assessment: train a classifier on the labeled source domain, produce approximate pseudo labels of surgical exercises in target domain. Next, these pseudo-labeled target samples are treated as labeled ones and used for re-training a new classifier in target domain. Then, the classifier explores the remaining set of target domain until model learning converges or the maximum iteration number is reached. In essence, self-learning considers the information from both domains and enables to propagate knowledge from the labeled source to the unlabeled target. Therefore, it could not only exploit the hidden structures in motion kinematic data that regularize learning, but help to find a shared feature space that matches data distributions of both the domains.
We train the whole network (with parameters ) by minimizing the loss between the model output and the labels (true labels from source and labels from target), while penalizing large activation. Here, denotes the true labels in source domain , and denotes the pseudo labels of unlabeled samples in target domain , Thus, the overall loss is a weighted mixture of the cross-entropy loss of labeled source domain, , the cross-entropy loss of pseudo-labeled ones from target domain, , and a weight regularizer term:
| (1) | ||||
where and are two non-negative hyper-parameters to balance contributions of three loss components. In particular, the parameter controls the importance of -labeled target samples relative to the true labeled source samples. A larger could encourage selecting more -labels for training, whereas a smaller reduces the impact of target samples for training.
II-C Uncertainty Estimation
Jointly learning classifiers and optimizing pseudo labels on unlabeled target domain is naturally difficult since it is not possible to completely guarantee the correctness of generated pseudo labels given an existing model. The uncertainty could come from the variability in the relationship between observed tool kinematics data and the corresponding skill class outputs. Conventionally, labels were selected for self-learning by taking the class which has the maximum softmax class probability or the one with corresponding probability that is larger than a predefined threshold (chosen experimentally). The softmax function approximates relative class probabilities, but it did not capture any uncertainty or confidence information regarding the prediction outputs [40]. To cope with this issue, our strategy is first to estimate the model uncertainty of skill predictions and then seek for pseudo labels from the most confident ones in unlabeled target domain. These high-confidence pseudo labels presumably approximate the underlying true target labels and could thus better help self-learning adaptation.
Bayesian probability theory has offered us a statistically principled way to infer the uncertainty within deep learning tools [41]. Research has shown that any deep learning model can be arbitrarily interpreted into Bayesian ones, which are often referred as Bayesian neural networks. In Bayesian settings, the model uncertainty, also referred to as epistemic uncertainty, could be readily derived from the variances of prediction with respect to the distribution of network parameters , i.e., posterior . The distribution characterizes the uncertainty or confidence of model that conforms to the observed data . Although the posterior is analytically intractable, a popular approach, variational inference, can approximate it with a simpler approximating distribution that is much easier to sample with, while minimizing the Kullback-Leibler (KL) divergence between the approximating distribution and the true posterior [42]. Kendal et al. [43] show that the variational inference using stochastic Monte-Carlo dropout (MC dropout) could allow to approximate Bayesian posterior and minimize the cross-entropy loss of a network with dropout is equivalent to minimizing the KL divergence. Differently from the standard dropout that is used for regularization in training, MC approach stochastically drops out parameters of existing model at test time, which is equivalent to impose a Bernoulli distribution on parameters, to obtain the posterior approximate.
To allow uncertainty estimate for self-learning, we extend and cast our skill model into the Bayesian setting and implement MC dropout to obtain the uncertainty estimates over the current network. In practice, estimating prediction uncertainty was accomplished as follows: (1) Given an existing classifier with network parameters , we run the network with a chosen number of stochastic forward passes , where each unit has a probability of being set to 0. (2) We collect the softmax probability outputs for each skill class in the -th forward pass (). (3) From the outputs over forward passes, the final prediction of class probability and uncertainty are taken to be the average and variance of predictions of each class, as defined in Eq. 2 and Eq. 3, respectively. Further, we derive the entropy of per-class uncertainty as the overall uncertainty measure given the input data.
| (2) |
| (3) |
where denote when including MC dropout, is the current network parameter masked by the dropout during inference.
Taken together, Algorithm 1 depicts the overall procedure in details. Initially, the inputs are the labeled samples from source domain and unlabeled samples of target domain . After initialization with pre-trained network parameters , our approach performs the following major steps: (1) Given current model parameters, MC-dropout variational inference was conducted to query the uncertainty of predictions over the unlabeled samples . (2) Each unlabeled sample are assigned with labels by taking the class which has the maximum average class probability. (3) Subset of target domain in which the target samples with the first lowest amounts of uncertainty are added to the current training set and simultaneously removed from unlabeled target domain . (3) Re-train a new classifier using the updated training set , and update network parameters . The classifier explores the remaining unlabeled data with smaller confidence until learning converges or maximum iteration is reached.
In our experiment, we fixed MC-dropout probability as for each dropout layer, the total number of forward passes for inference was set as as we sample prediction outputs for each input, and the number of selected target samples (-labeled) in each training iteration was . The hyper-parameters were chosen empirically as they have shown a faster training convergence for modeling. As our model may no longer achieve the best classification for source domain after adapting to the target domain, we adopt the term ”converge” to denote the best model for which it is confident enough to make a prediction for the target domain.
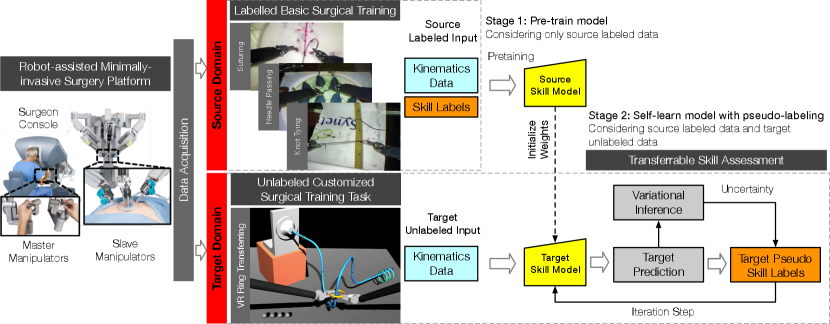
II-D Architecture
Fig 2 shows the overview of our proposed architecture. The network input is the motion kinematics measured from robot end-effectors and the output is an estimated softmax probability of skill classes that the input data is drawn from, along with an estimate of prediction uncertainty.
The network consists of two main components where the input data flows through in parallel: a convolutional component and a recurrent component. The convolution component comprises two stacked convolutional layers that extract local patterns along the length of time-series data. Each convolutional layer is followed by a ReLU activation and a standard dropout layer with 0.2 dropout rate to reduce the risk of overfitting. A global average pooling layer is then applied to sum out the spatial information. It enables the network to handle input sequences of varying lengths. Also, the global average pooling could largely reduce the number of network parameters and thus help to alleviate overfitting. In parallel, the recurrent component consisted of two bi-directional LSTMs followed by a standard dropout layer. The two sets of features from both components are concatenated and then fed through a dense layer. Finally, the network is forked at the last layer to have two outputs: the skill probability output through a layer with softmax nonlinearity, and an uncertainty estimate obtained from the aforementioned Bayesian variational inference.

| Category | Setup | Training Task | Controller | Assistance | Skill Labels | Subject | Session | Sample Size |
|---|---|---|---|---|---|---|---|---|
| Source | Dry Lab | Suturing | dVSS MTMs dVSS PSMs | N/A | Labeled | 8 | - | 120 |
| Needle Passing | ||||||||
| Knot Tying | ||||||||
| Target | Virtual Reality | Ring Transfer | dVRK MTMs simulated PSMs | Adaptive Haptic Guidance | Unlabeled | 16 | 10 | 1280 |
III Experiments
III-A Datasets
Two datasets in the field of robotic surgical training were used: the first dataset is denoted as the source domain, which contains labeled data with the skill annotations from basic surgical training tasks; the other is the target domain which contains unlabeled data collected from a VR simulation-based surgical training task that was characterized by the application of adaptive haptic guidance during its execution. Both datasets contain tool kinematics that were collected from daVinci robotic surgical systems. The kinematics of two master tool manipulators (MTMs) and two corresponding patient-side manipulators (PSMs) were monitored and captured as multi-dimensional time-series. All kinematic variables were collected with 30 Hz sampling frequency. Specifically, the source domain data contains the joint kinematic variables from each robot manipulator, including Cartesian position (3), rotation matrix (9), linear velocity (3), angular velocity (3), and gripper angle (1), resulting 76-dimensional time-series per trial, while the target domain data contains all variables except for the measures of joint linear velocity, resulting 48-dimensional time-series per trial. To align with the data measurements in two datasets, we only considered the 48 common kinematic variables. The two datasets are described below and summarized in Table I.
Source Domain Dataset
The source domain dataset are labeled kinematics samples from a public-available technical skill dataset, namely the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) [38]. Subjects were required to perform three basic surgical training tasks: Suturing, Needle Passing, and Knot Tying. Fig. 3 shows the snapshots of the training tasks from JIGSAWS. Each surgical task was completed over 5 repetitions. Eight subjects in total with varying robotic surgical experience participated in the experiment, including four novice trainees (who practice on dVSS 10 hours), two intermediate trainees (with 10 to 100 hours of practice), and two expert surgeons (with 100 hours of practice). For simplicity, in this work we only consider two-class skill labels, namely, novice and expert, and the trainees with less than 100 hours are considered as novice, although our method can be adapted into multi-class settings with novice, intermediate and expert classes.
Target Domain Dataset
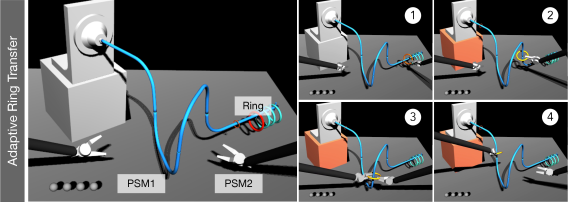
The target domain includes samples obtained from a scenario of personalized assistance-as-needed VR surgical training exercises [22]. In the experiment, each subject performed a ring transfer or steady hand task: the trainee moves a ring along a curved wire pathway, while attempting to avoid the ring and wire making contact and keeping the ring’s plane perpendicular to the wire’s tangent. Fig. 4 shows some snapshots of the ring transfer task. Sixteen subjects without medical background and with none to little experience in robotic teleoperation (12 males and 4 females, all right-handed) participated in the experiment and were randomly divided in two groups: an experimental (assisted) group and a null (non-assisted) group. The training task was carried out in 10 sessions over 5 days (2 sessions per day), where in each session subjects performed the same exercise over 8 repetitions.
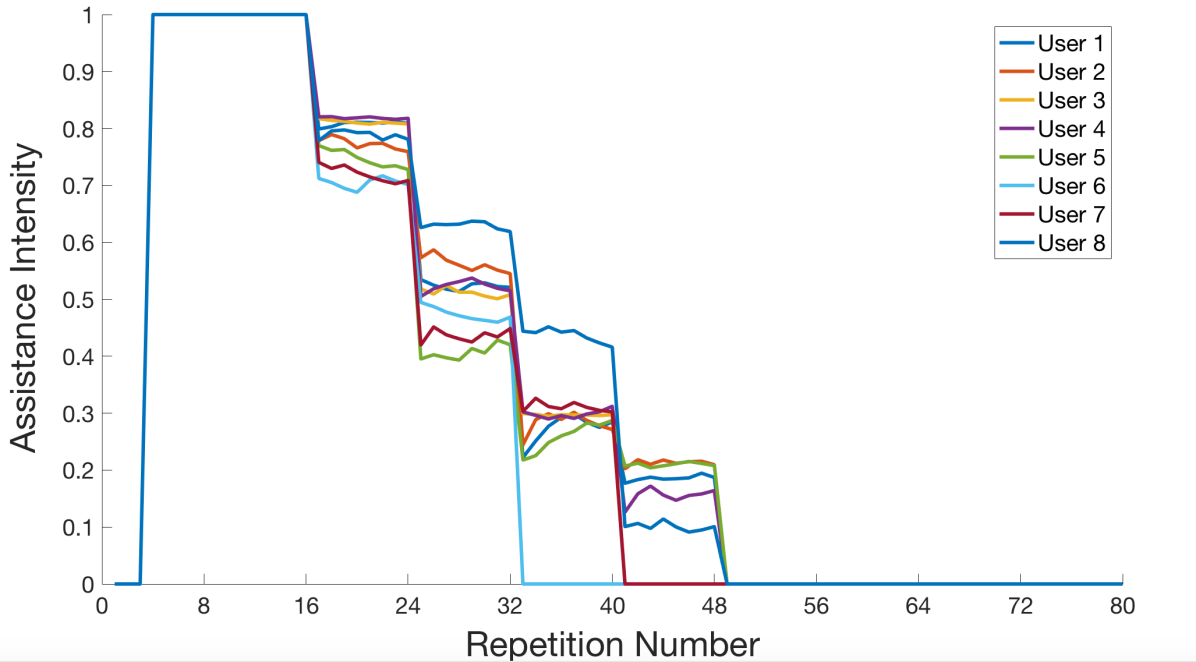
For the group with robotic assistance (Assisted), trainees received an adaptive visco-elastic haptic guidance during the training session, that means forces and torques were applied to the MTMs in order to guide the trainee towards an ideal motion. The intensity of haptic guidance was adapted to a real-time measure of the subject’s performances according to the assistance-as-needed paradigm [44, 45] in order to prevent cognitive overload at the beginning and slacking once trained. Consequently, the assistance intensity decreased all over the training as the trainees began learning how to perform the visuo-motor task. Fig. 5 shows the assistance intensity level provided for the group of subjects where each subject received full assistance after baseline assessment and the guidance was totally removed after 6 sessions.
In contrast, trainees in the non-assisted group (Non-assisted) performed the task without receiving any robotic assistance throughout all the sessions. Details regarding the design of haptic assistance can be found in [22].
III-B Implementation Details
Before feeding the motion kinematics into the network, we performed pre-processing for the raw data in two steps. First, we down-sampled data samples from both source and target domains by a factor of 30 (from the original sampling rate 30 Hz to 1 Hz). The purpose of down-sampling is to reduce unnecessary computational load. Then, normalization was also applied to each channel of all kinematics variables by subtracting the mean and dividing by the corresponding standard deviation.
We implemented our methodology in Keras with Tensorflow 1.9 API as backend based on Python 3.6. All experiments in this study were remotely run on the UTSouthwestern BioHPC server and utilized a computing cluster equipped with a NVIDIA Tesla P100 GPU with 16 GB memory and 72 CPUs with 256 GB memory running a Linux kernel. To initialize the network, we first pre-trained the network on the source domain data given the known skill labels in JIGSAWS as ground-truth. We selected the best model as the one with the minimized loss on the validation set. For training, we utilized the following hyper-parameters: 100 training epochs, stochastic gradient decent as chosen optimizer with initial learning rate as 0.001, first and second momentum of 0.9 and 0.999, and weight decay of . Before fitting the model in each epoch, the training set was randomly shuffled to achieve a robust process of model learning.
III-C Statistical Analysis of Pseudo Labeling in Target Domain
Since no ground-truth skill labeling is currently available in the target domain dataset, we perform a statistical analysis in order to check for the effectiveness of pseudo labeling for extracting skill patterns. We hypothesize that the generated pseudo labels, given the skill knowledge has been generalized from the source to the target domain in the model, can provide meaningful significant results to reveal the motor skill learning pattern during a surgical training, and also be in align with prior studies that robotic assistance would help improve the proficiency of surgical training in general. We performed a two-way ANOVA analysis to determine the significance of skill probability between the training groups of subjects, the training sessions, and the interaction between the two. Similarly, another two-way ANOVA analysis was performed to check the significance differences between the training groups (Assisted and Non-assisted), the training stage (Pre-training and Post-training), and the interaction between the two. A post-hoc Tukey comparison was used to compare different levels and highlight the significant effects within each group.
IV Results & Discussion
To validate the effectiveness of our proposed approach for assessing skills, we first analyze the class probability of skills and model uncertainty when inferring skill labels for the unlabeled surgical training. For the simplicity of discussion, we only focus on the probability of the predicted expert class. We first obtained the skill probability and uncertainty estimate of each trial and then averaged cross the eight trials in the corresponding session (8 repeated trials per session), respectively. In particular, we extract the motor learning curve from the output of skill predictions and investigate how the trainees’ skills and model uncertainty varies as a result of robotic assistance and time when surgical training proceeds. Following that, we explore and compare the skill probability with task performance metrics that were measured in real-time during each trial of the surgical training. We hypothesize that the generated pseduo labels of the unlabeled data can inform the inherent learning curve in the surgical training and align with the results informed by task performance metrics.
IV-A Skill Probability and Prediction Uncertainty
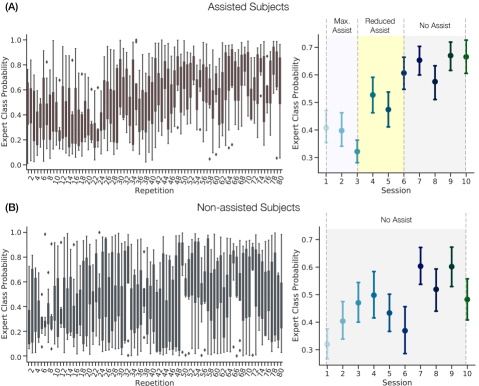
Fig. 6 (A) and (B) present the expert probability of robot-assisted and non-assisted subjects per repetition (left, averaged across corresponding group) and per session (right, averaged across all repeated trials), respectively. Table II summarizes all the statistics.
| Subject Group | Training Group | Interaction | |||
| Assisted/Non-assisted | Session | Pre/Post-training | AssistSession | AssistPre/Post-training | |
| Tukey Comparison | Non-assistedAssisted | - | Pre-trainingPost-training | - | - |
| Asteroid ∗ represents significance | |||||
In general, skill learning of both assisted and non-assisted subjects was characterized by an increase of expert class probability (or, equivalently, a decrease of beginner class probability) as the surgical training proceeded. Significant difference was found between the assisted and non-assisted subjects on the skill probability, . Specifically, the subjects with robotic assistance were associated with considerably higher probability of expert after the initial three sessions. On the other hand, non-assisted subjects who did not receive any haptic assistance showed a continuous increase of technical skills within the first four sessions. However, non-assisted subjects had the larger variances of skill probability after the session. This result can be explained by the fact that the non-assisted group underwent a management for self-improvement as the surgical training repetitions proceeded. Nevertheless, it might be more difficult for trainees to pick up the most representative, expert-relevant motion patterns without any assistance, and thus resulted in a less efficient learning outcome at the final stage of training. Importantly, the assisted subjects had a trend with continuous decrease of expert probability in the first three sessions (maximum haptic assistance). This result might be due to the fact that the advent of haptics may change the trainees’ intended motion and consequently interfere their initial learning momentum, and thus trainees would need to adapt to the changes for an improvement. Nevertheless, the assisted subjects demonstrated a considerable improvement in their skills in and after the session. The differences of skill probability in the first three session and the session can be explained by the increased familiarity of subjects such that significant improvements are shown.
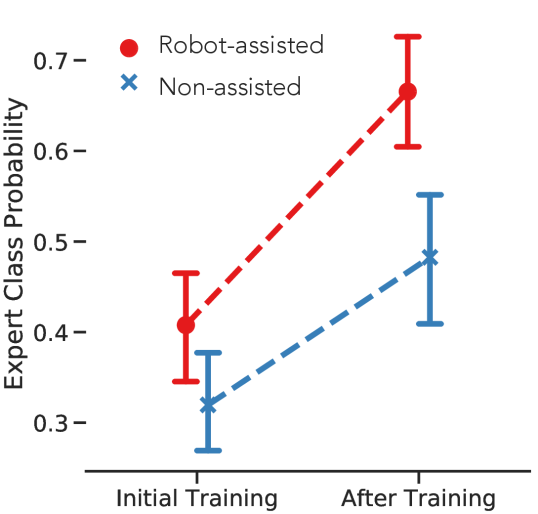
Fig. 7 compares the expert class probability between the initial training (first session) and post training (last session). The figure highlights the motor learning outcome as the result of surgical training. As shown, either assisted or non-assisted subjects have significantly higher expert probability after the training compared to the initial training session. This result confirms that repeated training practices in general could help trainees in achieving a potentially higher expertise. Note that the steeper learning curve, as revealed by the dotted lines, indicates that the robotic assistance potentially increased the rate of learning for performing the complex motor task. Even though the assistance intensity was adaptively diminished after session and no assistance was provided after session, trainees were able to improve their technical skills more efficiently and to retain this improvement even after the assistance removal.
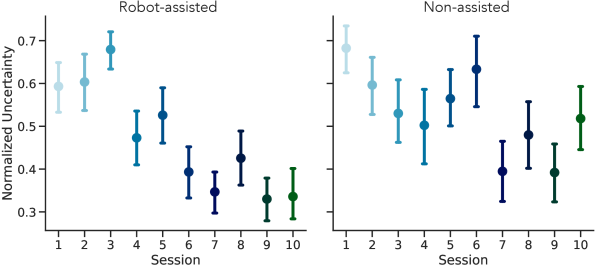
Fig. 8 shows the averaged prediction uncertainties in each session of VR surgical training. The value of uncertainty is determined by the MC-dropout variational inference and reflects the level of predictive confidence when outputting a specific skill label given an input of motion kinematics. In general, surgical skills in the initial phase of surgical training are relatively more uncertain than the final stage. As the surgical training proceeds, the level of uncertainty for assessing skill decreases. The uncertainty could come from the variability between the observed motion data of trainees and the corresponding skill output. As the consequence of iterative practice, trainees could demonstrate distinguished motion patterns that provide a higher certainty of their skill levels, with or without robot assistance. We also note that non-assisted subjects are relatively more uncertain than the assisted subjects, especially at the end of surgical training. One interpretation is that between the assisted and non-assisted group, the motion profiles of assisted subjects could demonstrate more consistent signatures that are characteristic of high expertise; in contrast, subjects without robotic assistance might carry less distinguishable skill information in the motion that is hard to measure.
IV-B Compare to Task Performance Measures
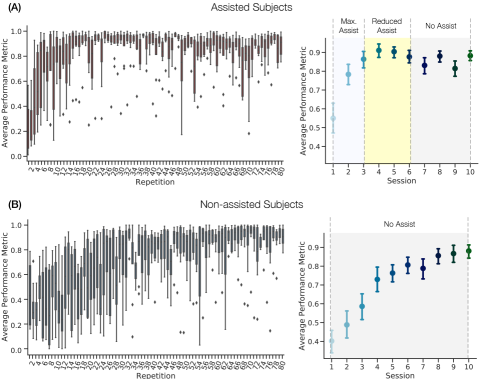
In the absence of skill labels in the target domain dataset, we evaluated the validity of the generated pseudo labels by comparing their probabilities with the task performance metrics. These metrics, which include completion time, translational root mean square errors, and rotational root mean square errors, were used as a proxy measure of technical skills to indicate motor learning in the surgical training task. The task performance metrics were collected in each training trial and the average performance for all subjects is presented in Fig. 9. As shown, a clear learning curve of the trainees is captured by the task performance metrics. Consistent with our skill predictions, the non-assisted subjects improved their performance after multiple training sessions. Additionally, the assisted subjects showed better performance improvement due to the contribution of haptic assistance.
However, the evolution of the users’ task performance metrics differs from the ones inferred from our skill predictions in terms of their slope and saturation. Specifically, the task performance metrics tend to be more sensitive to changes in assistance. We observed that, for the assisted subjects, the task performance measures rapidly improved when the maximum haptic assistance was activated, but showed relatively larger variances after the fourth session when the assistance intensity decreased. In contrast, as measured by the skill probability, the assisted subjects showed long-term persistence at the final stage of the training, indicating stable and consistent skill learning over time, even with a decrease in the intensity of haptic assistance. The discrepancy between the predicted skill and task performance metrics makes sense. The task performance metrics accurately reflect the direct impact of the physical assistance provided by the robotic system through its haptic guidance. The purpose of this guidance is to align the surgeon’s current pose with the ideal one, resulting in optimal task performance metrics, by minimizing the translation and orientation errors. On the other hand, the predicted skills reflect a more complex motor learning process and changes in these skills may not be immediately reflected in the surgeon’s performance. This could be considered an advantage of our approach for skill assessment, as it allows for the assessment of skills without any ”assistance bias” in training scenarios that include robotic feedback or guidance.
IV-C Limitations
This study focuses on adapting skill models from a fully-labeled dataset to a VR simulated training exercise and aims to investigate the transferability of skills across physical and virtual environment. The source data consists of only the labeled data of standardized training exercises, but its limited size may impact the generalizability of the skill models. To address this, future work could involve collecting a larger dataset for pretraining. The selected surgical training exercises from the source and target domains in our study are different but limited in term of the complexity. For future work, we plan to extend the analysis to include more complex tasks in boarder fields of surgical training, such as physical box trainers and wet-lab exercises [46]. We believe that a comparison of the skill models presented in our study and those measured on physical box trainers could help to provide insights into the training proficiency and outcomes across different environments [47, 48]. Additionally, a more granular analysis of the skill models at surgical phase and task level might be helpful to reveal the corresponding surgeons’ skills and workflow patterns [7, 49]. Furthermore, it would be interesting to explore the potential of this approach to generalize from technical to non-technical skill assessment in surgical training [50, 51].
V Conclusion
The present study aims to assess objective surgical skills across domains by adapting existing skill models from a labeled dataset to a virtual reality (VR) training exercise. Our method leverages the knowledge gained from basic robot-assisted surgical training exercises and enables a valid adaptation to unlabeled kinematic data.
To the best of our knowledge, this is the first study to generalize skill assessment to diverse surgical training exercises where full annotations are often difficult to obtain. We evaluated our method in a cross-domain surgical training task that employs adaptive assistance for trainees. Our approach is capable of learning domain-invariant features from both labeled and unlabeled data, and was able to construct learning curves throughout the training task. The results showed that trainees using robotic assistance have significantly higher probabilities of becoming experts compared to those without assistance (). This result is consistent with prior performance measures, indicating that proper robotic assistance can improve trainees’ learning and speed of skill acquisition. The uncertainty in generating the corresponding skill label was also significantly lower with the assistance.
Acknowledgment
This work is primarily supported by the National Science Foundation (NSF No. 1464432). This research was also supported in part by the computational resources provided by the BioHPC supercomputing facility (https://biohpc.swmed.edu), UT Southwestern Medical Center, TX, and the National Center for Advancing Translational Sciences of the National Institutes of Health under award UL1TR001105. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
References
- [1] A. R. Lanfranco, A. E. Castellanos, J. P. Desai, and W. C. Meyers, “Robotic surgery: a current perspective,” Annals of surgery, vol. 239, no. 1, p. 14, 2004.
- [2] R. A. Beasley, “Medical robots: current systems and research directions,” Journal of Robotics, vol. 2012, 2012.
- [3] M. A. Talamini, S. Chapman, S. Horgan, and W. S. Melvin, “A prospective analysis of 211 robotic-assisted surgical procedures,” Surgical Endoscopy and Other Interventional Techniques, vol. 17, no. 10, pp. 1521–1524, 2003.
- [4] J. Weber, K. Catchpole, A. J. Becker, B. Schlenker, and M. Weigl, “Effects of flow disruptions on mental workload and surgical performance in robotic-assisted surgery,” World journal of surgery, vol. 42, no. 11, pp. 3599–3607, 2018.
- [5] A. M. Okamura, “Haptic feedback in robot-assisted minimally invasive surgery,” Current opinion in urology, vol. 19, no. 1, p. 102, 2009.
- [6] S. S. Vedula, M. Ishii, and G. D. Hager, “Objective assessment of surgical technical skill and competency in the operating room,” Annual review of biomedical engineering, vol. 19, pp. 301–325, 2017.
- [7] L. Maier-Hein, M. Eisenmann, C. Feldmann, H. Feussner, G. Forestier, S. Giannarou, B. Gibaud, G. D. Hager, M. Hashizume, D. Katic, H. Kenngott, R. Kikinis, M. Kranzfelder, A. Malpani, K. März, B. P. Müller-Stich, N. Navab, T. Neumuth, N. Padoy, A. Park, C. M. Pugh, N. Schoch, D. Stoyanov, R. H. Taylor, M. Wagner, S. S. Vedula, P. Jannin, and S. Speidel, “Surgical data science: A consensus perspective,” CoRR, vol. abs/1806.03184, 2018. [Online]. Available: http://arxiv.org/abs/1806.03184
- [8] A. Darzi, S. Smith, and N. Taffinder, “Assessing operative skill: needs to become more objective,” 1999.
- [9] S. V. Kotsis and K. C. Chung, “Application of see one, do one, teach one concept in surgical training,” Plastic and reconstructive surgery, vol. 131, no. 5, p. 1194, 2013.
- [10] M. A. Aghazadeh, I. S. Jayaratna, A. J. Hung, M. M. Pan, M. M. Desai, I. S. Gill, and A. C. Goh, “External validation of global evaluative assessment of robotic skills (gears),” Surgical endoscopy, vol. 29, no. 11, pp. 3261–3266, 2015.
- [11] R. Hatala, D. A. Cook, R. Brydges, and R. Hawkins, “Constructing a validity argument for the objective structured assessment of technical skills (osats): a systematic review of validity evidence,” Advances in Health Sciences Education, vol. 20, no. 5, pp. 1149–1175, 2015.
- [12] C. D’Ettorre, A. Mariani, A. Stilli, F. Rodriguez y Baena, P. Valdastri, A. Deguet, P. Kazanzides, R. H. Taylor, G. S. Fischer, S. P. DiMaio et al., “Accelerating surgical robotics research: A review of 10 years with the da vinci research kit,” IEEE Robotics and Automation Magazine, 2021.
- [13] A. Kumar, R. Smith, and V. R. Patel, “Current status of robotic simulators in acquisition of robotic surgical skills,” Current opinion in urology, vol. 25, no. 2, pp. 168–174, 2015.
- [14] M. A. Lerner, M. Ayalew, W. J. Peine, and C. P. Sundaram, “Does training on a virtual reality robotic simulator improve performance on the da vinci® surgical system?” Journal of Endourology, vol. 24, no. 3, pp. 467–472, 2010.
- [15] H. Abboudi, M. S. Khan, O. Aboumarzouk, K. A. Guru, B. Challacombe, P. Dasgupta, and K. Ahmed, “Current status of validation for robotic surgery simulators–a systematic review,” BJU international, vol. 111, no. 2, pp. 194–205, 2013.
- [16] J. M. Albani and D. I. Lee, “Virtual reality-assisted robotic surgery simulation,” Journal of Endourology, vol. 21, no. 3, pp. 285–287, 2007.
- [17] R. Al Bareeq, S. Jayaraman, B. Kiaii, C. Schlachta, J. D. Denstedt, and S. E. Pautler, “The role of surgical simulation and the learning curve in robot-assisted surgery,” Journal of robotic surgery, vol. 2, no. 1, pp. 11–15, 2008.
- [18] L. Maier-Hein, S. S. Vedula, S. Speidel, N. Navab, R. Kikinis, A. Park, M. Eisenmann, H. Feussner, G. Forestier, S. Giannarou, M. Hashizume, D. Katic, H. Kenngott, M. Kranzfelder, A. Malpani, K. März, T. Neumuth, N. Padoy, C. Pugh, N. Schoch, D. Stoyanov, R. Taylor, M. Wagner, G. D. Hager, and P. Jannin, “Surgical data science for next-generation interventions,” Nature Biomedical Engineering, vol. 1, no. 9, p. 691, 2017.
- [19] D. Á. Nagy, I. J. Rudas, and T. Haidegger, “Surgical data science, an emerging field of medicine,” in 2017 IEEE 30th Neumann Colloquium (NC). IEEE, 2017, pp. 000 059–000 064.
- [20] J. MacDonald, R. G. Williams, and D. A. Rogers, “Self-assessment in simulation-based surgical skills training,” The American journal of surgery, vol. 185, no. 4, pp. 319–322, 2003.
- [21] K.-C. Siu, B. J. Best, J. W. Kim, D. Oleynikov, and F. E. Ritter, “Adaptive virtual reality training to optimize military medical skills acquisition and retention,” Military medicine, vol. 181, no. suppl_5, pp. 214–220, 2016.
- [22] N. Enayati, A. M. Okamura, A. Mariani, E. Pellegrini, M. M. Coad, G. Ferrigno, and E. De Momi, “Robotic assistance-as-needed for enhanced visuomotor learning in surgical robotics training: An experimental study,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 6631–6636.
- [23] D. Zhang, B. Xiao, B. Huang, L. Zhang, J. Liu, and G.-Z. Yang, “A self-adaptive motion scaling framework for surgical robot remote control,” IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 359–366, 2019.
- [24] A. Mariani, E. Pellegrini, N. Enayati, P. Kazanzides, M. Vidotto, and E. De Momi, “Design and evaluation of a performance-based adaptive curriculum for robotic surgical training: a pilot study,” in 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2018, pp. 2162–2165.
- [25] A. Mariani, E. Pellegrini, and E. De Momi, “Skill-oriented and performance-driven adaptive curricula for training in robot-assisted surgery using simulators: A feasibility study,” IEEE Transactions on Biomedical Engineering, vol. 68, no. 2, pp. 685–694, 2020.
- [26] Y. Kassahun, B. Yu, A. T. Tibebu, D. Stoyanov, S. Giannarou, J. H. Metzen, and E. Vander Poorten, “Surgical robotics beyond enhanced dexterity instrumentation: a survey of machine learning techniques and their role in intelligent and autonomous surgical actions,” International journal of computer assisted radiology and surgery, vol. 11, no. 4, pp. 553–568, 2016.
- [27] M. J. Fard, S. Ameri, R. Darin Ellis, R. B. Chinnam, A. K. Pandya, and M. D. Klein, “Automated robot-assisted surgical skill evaluation: Predictive analytics approach,” The International Journal of Medical Robotics and Computer Assisted Surgery, vol. 14, no. 1, p. e1850, 2018.
- [28] H. C. Lin, I. Shafran, D. Yuh, and G. D. Hager, “Towards automatic skill evaluation: Detection and segmentation of robot-assisted surgical motions,” Computer Aided Surgery, vol. 11, no. 5, pp. 220–230, 2006.
- [29] M. K. Chmarra, S. Klein, J. C. de Winter, F.-W. Jansen, and J. Dankelman, “Objective classification of residents based on their psychomotor laparoscopic skills,” Surgical endoscopy, vol. 24, no. 5, pp. 1031–1039, 2010.
- [30] L. Tao, E. Elhamifar, S. Khudanpur, G. D. Hager, and R. Vidal, “Sparse hidden markov models for surgical gesture classification and skill evaluation,” in International conference on information processing in computer-assisted interventions. Springer, 2012, pp. 167–177.
- [31] Z. Wang and A. M. Fey, “Deep learning with convolutional neural network for objective skill evaluation in robot-assisted surgery,” International Journal of Computer Assisted Radiology and Surgery, vol. 13, pp. 1959 – 1970, 2018.
- [32] A. Jin, S. Yeung, J. Jopling, J. Krause, D. Azagury, A. Milstein, and L. Fei-Fei, “Tool detection and operative skill assessment in surgical videos using region-based convolutional neural networks,” in 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018, pp. 691–699.
- [33] I. Funke, S. T. Mees, J. Weitz, and S. Speidel, “Video-based surgical skill assessment using 3d convolutional neural networks,” International journal of computer assisted radiology and surgery, vol. 14, no. 7, pp. 1217–1225, 2019.
- [34] H. I. Fawaz, G. Forestier, J. Weber, L. Idoumghar, and P.-A. Muller, “Accurate and interpretable evaluation of surgical skills from kinematic data using fully convolutional neural networks,” International Journal of Computer Assisted Radiology and Surgery, pp. 1–7, 2019.
- [35] T. S. Kim, M. O’Brien, S. Zafar, G. D. Hager, S. Sikder, and S. S. Vedula, “Objective assessment of intraoperative technical skill in capsulorhexis using videos of cataract surgery,” International journal of computer assisted radiology and surgery, vol. 14, no. 6, pp. 1097–1105, 2019.
- [36] Z. Wang and A. M. Fey, “SATR-DL: Improving surgical skill assessment and task recognition in robot-assisted surgery with deep neural networks,” in 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2018.
- [37] X. A. Nguyen, D. Ljuhar, M. Pacilli, R. M. Nataraja, and S. Chauhan, “Surgical skill levels: Classification and analysis using deep neural network model and motion signals,” Computer Methods and Programs in Biomedicine, vol. 177, pp. 1–8, 2019.
- [38] Y. Gao, S. S. Vedula, C. E. Reiley, N. Ahmidi, B. Varadarajan, H. C. Lin, L. Tao, L. Zappella, B. Béjar, D. D. Yuh, C. C. G. Chen, R. Vidal, S. Khudanpur, and G. D. Hager, “Jhu-isi gesture and skill assessment working set (jigsaws): A surgical activity dataset for human motion modeling,” in MICCAI Workshop: M2CAI, vol. 3, 2014, p. 3.
- [39] X. J. Zhu, “Semi-supervised learning literature survey,” University of Wisconsin-Madison Department of Computer Sciences, Tech. Rep., 2005.
- [40] Y. Gal, “Uncertainty in deep learning,” Ph.D. dissertation, PhD thesis, University of Cambridge, 2016.
- [41] Y. Gal and Z. Ghahramani, “Bayesian convolutional neural networks with bernoulli approximate variational inference,” arXiv preprint arXiv:1506.02158, 2015.
- [42] Gal and Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in International conference on machine learning. PMLR, 2016, pp. 1050–1059.
- [43] A. Kendall and Y. Gal, “What uncertainties do we need in bayesian deep learning for computer vision?” in Advances in neural information processing systems, 2017, pp. 5574–5584.
- [44] M. V. Radomski and C. A. T. Latham, Occupational therapy for physical dysfunction. Lippincott Williams & Wilkins, 2008.
- [45] C. Obayashi, T. Tamei, and T. Shibata, “Assist-as-needed robotic trainer based on reinforcement learning and its application to dart-throwing,” Neural Networks, vol. 53, pp. 52–60, 2014.
- [46] V. Lahanas, E. Georgiou, and C. Loukas, “Surgical simulation training systems: box trainers, virtual reality and augmented reality simulators,” International Journal of Advanced Robotics and Automation, vol. 1, no. 2, pp. 1–9, 2016.
- [47] Z. Wang, M. Kasman, M. Martinez, R. Rege, H. Zeh, D. Scott, and A. M. Fey, “A comparative human-centric analysis of virtual reality and dry lab training tasks on the da vinci surgical platform,” Journal of Medical Robotics Research, vol. 4, no. 03n04, p. 1942007, 2019.
- [48] F. R. Fathabadi, J. L. Grantner, I. Abdel-Qader, and S. A. Shebrain, “Box-trainer assessment system with real-time multi-class detection and tracking of laparoscopic instruments, using cnn,” Acta Polytechnica Hungarica, vol. 19, no. 2, 2022.
- [49] M. Uemura, P. Jannin, M. Yamashita, M. Tomikawa, T. Akahoshi, S. Obata, R. Souzaki, S. Ieiri, and M. Hashizume, “Procedural surgical skill assessment in laparoscopic training environments,” International journal of computer assisted radiology and surgery, vol. 11, no. 4, pp. 543–552, 2016.
- [50] R. Nagyné Elek and T. Haidegger, “Non-technical skill assessment and mental load evaluation in robot-assisted minimally invasive surgery,” Sensors, vol. 21, no. 8, p. 2666, 2021.
- [51] R. A. Agha, A. J. Fowler, and N. Sevdalis, “The role of non-technical skills in surgery,” Annals of medicine and surgery, vol. 4, no. 4, pp. 422–427, 2015.