Uncertainty quantification by block bootstrap for differentially private stochastic gradient descent
Abstract
Stochastic Gradient Descent (SGD) is a widely used tool in machine learning. In the context of Differential Privacy (DP), SGD has been well studied in the last years in which the focus is mainly on convergence rates and privacy guarantees. While in the non private case, uncertainty quantification (UQ) for SGD by bootstrap has been addressed by several authors, these procedures cannot be transferred to differential privacy due to multiple queries to the private data. In this paper, we propose a novel block bootstrap for SGD under local differential privacy that is computationally tractable and does not require an adjustment of the privacy budget. The method can be easily implemented and is applicable to a broad class of estimation problems. We prove the validity of our approach and illustrate its finite sample properties by means of a simulation study. As a by-product, the new method also provides a simple alternative numerical tool for UQ for non-private SGD.
1 Introduction
In times where data is collected almost everywhere and anytime, privacy is an important issue that has to be addressed in any data analysis.
In the past, successful de-anonymisation attacks have been performed
(see, for example, Narayanan and Shmatikov,, 2006; Gambs et al.,, 2014; Eshun and Palmieri,, 2022) leaking private, possible sensitive data of individuals.
Differential Privacy (DP) is a framework that has been introduced by Dwork et al., (2006) to protect an individuals data against such attacks while still learning something about the population.
Nowadays, Differential Privacy has become a state-of-the-art framework which has been implemented by the US Census and large companies like Apple, Microsoft and Google (see Ding et al.,, 2017; Abowd,, 2018).
The key idea of Differential Privacy is to randomize the data or a data dependent statistic.
This additional randomness guarantees that the exchange of one individual merely changes the distribution of the randomized output.
In the last decade, numerous differentially private algorithms have been developed, see for example Wang et al., (2020); Xiong et al., (2020); Yang et al., (2023) and the references therein.
In many cases differentially private algorithms are based on already known and well studied procedures
such as empirical risk minimisation, where either the objective function (objective pertubation) or the minimizer of that function (output perturbation) is privatized, or statistical testing, where the statistic is privatized, see for example Chaudhuri et al., (2011); Vu and Slavkovic, (2009).
Two different concepts of differential privacy are distinguished in the literature:
the first one, called (global) Differential Privacy (DP) assumes
the presence of a trusted curator, who maintains and performs computations on the data and ensures that a published statistic satisfies a certain privacy guarantee.
The second one, which is considered in this paper, does not make this assumption and is called local Differential Privacy (LDP).
Here it is required that the data is collected in a privacy preserving way.
Besides privacy there is a second issue which has to be addressed in the analysis of massive data, namely the problem of computational complexity. A common and widely used tool when dealing with large-scale and complex optimization problems in big data analysis
is Stochastic Gradient Descent (SGD), which is already introduced in the early work of Robbins and Monro, (1951).
This procedure computes data based, iteratively and in an online fashion
an estimate of the minimizer
| (1) |
of a function .
The convergence properties of adaptive algorithms, such as SGD, towards are well studied, see for example
the monograph Benveniste et al., (1990) and the references therein.
Mertikopoulos et al., (2020) investigate SGD in case of non convex functions and show convergence to a local minimizer.
There also exists a large amount of work on statistical inference based on SGD estimation starting with the seminal papers of Ruppert, (1988) and Polyak and Juditsky, (1992), who establish asymptotic normality of the averaged SGD estimator for convex functions.
The covariance matrix of the asymptotic distribution has a sandwich form, say , and Chen et al., (2020) propose two different approaches to estimate this matrix. An online version for one of these methods is proposed in Zhu et al., (2021), while Yu et al., (2021) generalize these results for SGD with constant stepsize
and non convex loss functions.
Recent literature on UQ for SDG includes Su and Zhu, (2018), who propose iterative sample splitting of the path of SGD,
Li et al., (2018), who consider SGD with constant stepsize splitting the whole path into segments, and Chee et al., (2023), who construct a simple confidence interval for the last iterate of SGD.
Song et al., (2013) investigate SGD under DP and demonstrate that mini-batch SGD has a much better accuracy than estimators obtained with batch size .
However, mini-batch SGD with a batch size larger than only guarantees global DP and therefore requires the presence of a trusted curator.
Among other approaches for empirical risk minimization, Bassily et al., (2014) derive a utility bound in terms of the excess risk for an -DP SGD and
Avella-Medina et al., (2023) investigate statistical inference for noisy gradient descent under Gaussian DP.
On the other hand, statistcial inference for SGD under LDP is far less explored.
Duchi et al., (2018) show the minimax optimality of the LDP SGD median but do not provide confidence intervals for inference.
The method of Chen et al., (2020) is not always applicable (for example, for quantiles) and requires an additional private estimate of the matrix
in the asymptotic covariance matrix
of the SDG estimate. Recently,
Liu et al., (2023) propose a self-normalizing approach to obtain
distribution free locally differentially private confidence intervals
for quantiles.
However, this method is tailored to a specific model and it is well known that the nice property of distribution free inference by self-normalization comes with the price of a loss in statistical efficiency (see Dette and Gösmann,, 2020, for an example in the context of testing).
A natural alternative is the application of bootstrap, and bootstrap for SGD in the non-private case has been studied by Fang et al., (2018); Zhong et al., (2023). These authors propose a multiplier approach where SGD is executed times multiplying the updates by non-negative random variables.
However, to ensure
-LDP, the privacy budget must be split over all bootstrap versions, leading to large noise levels and high inaccuracy of the resulting estimators.
There is also ongoing research on parametric Bootstrap under DP, (see Ferrando et al.,, 2022; Fu et al.,, 2023; Wang and Awan,, 2023) who assume that the parameter of interest characterizes the distribution of the data, which is not necessarily the case for SGD.
Finally we mention Wang et al., (2022), who introduce a bootstrap procedure under Gaussian DP, where each bootstrap estimator is privately computed on a random subset.
Our Contribution: In this paper we propose a computational tractable method for statistical inference using SGD under LDP. Our approach provides a universally applicable and statistically valid method for uncertainty quantification for SDG and LDP-SGD. It is based on an application of the block bootstrap to the mean of the iterates obtained by SGD. The (multiplier) block bootstrap is a common principle in time series analysis (see Lahiri,, 2003). However, in contrast to this field, where the dependencies in the sequence of observations are quickly decreasing with an increasing lag, the statistical analysis of such an approach for SGD is very challenging. More precisely, SGD produces a sequence of highly dependent iterates, which makes the application of classical concepts from time series analysis such as mixing (see Bradley,, 2005) or physical dependence (see Wu,, 2005) impossible. Instead, we use a different technique and show the consistency of the proposed multiplier block bootstrap for the LDP-SGD under appropriate conditions on the block length and the learning rate. As a by-product our results also provide a new method of UQ for SGD and for mini-batch SGD in the non-private case.
Notations: denotes a norm on if not further specified. denotes weak convergence and denotes convergence in probability.
2 Preliminaries and Background
Stochastic Gradient Descent (SGD). Define , where is a -valued random variable and is a loss function. We consider the optimization problem (1). If is differentiable and convex, then this minimization problem is equivalent to solving
where is the gradient of . SGD computes an estimator for using noisy observations of the gradient in an iterative way. Note that does not need to be differentiable with respect to . The iterations of SGD are defined by
| (2) |
where with parameters and is the learning rate and the quantity is called measurement error in the th iteration (note that we do not reflect the dependence on and in the definition of ). The estimator of is finally obtained as the average of the iterates, that is
| (3) |
Note that the first representation in (2) can be directly used for implementation, while the second is helpful for proving probabilistic properties of SGD. For example Polyak and Juditsky, (1992) show that, under appropriate conditions, is asymptotically normal distributed where the covariance matrix of the limit distribution depends on the optimization problem and the variance of the measurement errors .
The use of only one observation in SGD yields a relatively large measurement error in each iteration which might result in inaccurate estimation of the gradient . Therefore, several authors have proposed a variant of SGD, called mini-batch SGD, where observations are used for the update. An estimator for is then given by the mean of this observations, yielding the recursion
| (4) |
where the measurement error is given by , see for example Cotter et al., (2011); Khirirat et al., (2017).
Differential Privacy (DP). The idea of differential privacy is that one individual should not change the outcome of an algorithm largely, i.e. changing one data point should not alter the result too much. Let be a measurable space. For , will be called a data base containing data points. Two data bases are called neighbouring if they only differ in one data point and are called disjoint if all data points are different. How much a single data point is allowed to change the outcome is captured in a privacy parameter . Let be a measurable space. A randomized algorithm maps onto a random variable with values in . Here we will consider either subspaces of equipped with the Borel sets or finite sets equipped with their power set.
Definition 2.1.
Let . A randomized algorithm is -differentially private (dp) if for all neighbouring and all sets
| (5) |
is also called a -dp mechanism and is said to preserve DP. If is restricted to , i.e. and contain only one data point, and (5) holds, is -local differentially private (ldp).
In this paper we work under the constraints of local differential privacy (LDP).
The following result is well known (see, for example Dwork and Roth,, 2014).
Theorem 2.1.
-
(1)
Post processing: Let be a measurable space, be an -dp mechanism and be a measurable function. Then is -dp.
-
(2)
Sequential composition: Let , be -dp mechanisms. Then that maps is -dp.
-
(3)
Parallel composition: Let , be -dp mechanisms and be disjoint. Then that maps is -dp.
Two well known privacy mechanism are the following:
Example 2.1 (Laplace Mechanism).
Let be a function. Its sensitivity is defined as . Assume that and let , where denotes a centered Laplace distribution with density
Then the randomized algorithm is -dp.
Example 2.2 (Randomized Response).
Let be a function. Denote and define for a random variable on with conditional distribution given as
where denotes a Bernoulli distribution with success probability . Then is -dp.
Local Differential Private Stochastic Gradient Descent (LDP-SGD). By Theorem˜2.1 it follows that SGD is -ldp if the noisy observations in (2) are computed in a way that preserves -LDP. Let be such an -ldp mechanism for computing . The LDP-SGD updates are then given by
| (6) |
where
| (7) |
captures the error due to measurement and
| (8) |
captures the error due to privacy. Analog to (3), the final ldp SDG estimate is defined by
| (9) |
Remark 2.1.
Song et al., (2013) also investigate mini-batch SGD under DP, where each iteration is updated as in (4) and demonstrated that mini-batch SGD with batchsize achieves higher accuracy than batchsize . Their procedure then reads
where , and . Therefore, all results presented in this paper for the LDP-SGD also hold for the DP mini-batch SGD proposed by Song et al., (2013). However, this mini-batch SGD guarantees DP, not LDP. To obtain an ldp mini-batch SGD, one would need to privatize each data, leading to the following iteration:
where are independent random variables. Our results are applicable for ldp mini batch SGD as well.
Remark 2.2.
Note that the deconvolution approach used in Wang et al., (2022) for the construction of a DP bootstrap procedure is not applicable for SGD, because it requires an additive relation of the form between a DP-private and a non-private estimator and , where the distribution of is known. For example, if the gradient is linear, that is for a matrix , and SGD and LDP-SDG are started with the same initial value , we obtain by standard calculations the representation
where . However, although the distribution of the random variables is known, the distribution of is not easily accessible and additionally depends on the unknown matrix , which makes the application of deconvolution principles not possible.
Block Bootstrap.
Bootstrap is a widely used procedure to estimate a distribution of an estimator
calculated from data (see Efron and Tibshirani,, 1994).
In the simplest case are drawn with replacement from and used to calculate
.
This procedure is repeated several times to obtain an approximation of the distribution . While it provides a valid approximation in many (but not in all) cases if are independent identically distributed, the bootstrap approximation is not correct in the case of dependent data.
A common approach to address this problem is the multiplier bootstrap which is tailored to estimators with a linear structure (Lahiri,, 2003).
For illustration of the principle, we consider the empirical mean .
Under suitable assumptions the central limit theorem for stationary sequences shows that for large sample size the distribution of can be approximated by a normal distribution,
say ,
with expectation and variance ,
where and depends in a complicated manner on the dependence structure of the data.
The multiplier block bootstrap mimics this distribution by partitioning the sample into blocks of length , say .
For each block one calculates the mean which is then multiplied with a random weight with mean and variance to obtain the estimate where .
If the dependencies between and become sufficiently small for increasing , it can be shown that the distribution of is a reasonable approximation of the distribution (for large ).
Typical conditions on the dependence structure of the data guaranteeing these approximations are formulated in terms of mixing or physical dependence coefficients (see Bradley,, 2005; Wu,, 2005).
We will not give details here, because none of these techniques will be applicable for proving the validity of the multiplier block bootstrap developed in the following section.
3 Multiplier Block Bootstrap for LDP-SGD
In this section, we will develop a multiplier block bootstrap approach to obtain the distribution of the LDP-SGD estimate defined in (9) by resampling. We also prove that this method is statistically valid in the sense that the bootstrap distribution converges weakly (conditional on the data) to the limit distribution of the estimate , which is derived first.
Our first result is a direct consequence of Theorem 2 in Polyak and Juditsky, (1992) which can be applied to LDP-SGD.
Theorem 3.1.
If Assumption˜A.1 in the supplement holds, then the LDP-SGD estimate in (9) satisfies
| (10) |
where the matrix is given by . Here is the asymptotic variance of the errors and is a linear approximation of (see Assumption˜A.1 in the supplement for more details).
Remark 3.1.
(a) Assumption˜A.1 requires the sequence of errors to be a martingale difference process
with respect to a filtration . This assumption is satisfied, if and are
martingale difference processes with respect to .
Note that the condition
is implied by
, which is satisfied for the Laplace mechanism and Randomized Response can be adjusted to fulfill this requirement.
(b)
If and are independent given and their respective covariance matrices converge in probability to and , then it holds that .
In principle ldp statistical inference based on the statistic can be made using the asymptotic distribution in Theorem 3.1 with an ldp estimator of the covariance matrix in (10). For this purpose the matrices and have to be estimated in an ldp way. While can be estimated directly from the ldp observations in (6) by
the matrix has to be estimated separately. Therefore, the privacy budget has to be split on the estimation of and on the iterations of SGD. As a consequence this approach leads to high inaccuracies since all components need to be estimated in a ldp way. Furthermore, common estimates of are based on the derivative of (with respect to ), and therefore needs to be differentiable. This excludes important examples such as quantile regression. Additionally, the computation of the inverse of can become computationally costly in high dimensions.
As an alternative we will develop a multiplier block bootstrap, which avoids these problems.
Before we explain our approach in detail we note that the bootstrap method proposed in
Fang et al., (2018) for non private SGD is not applicable in the present context.
These authors replace the recursion in (2) by
where are independent identically distributed non-negative random variables with . By applying SGD in this way times they calculate
SGD estimates , which are used to estimate the distribution of . However, for
the implementation of this approach under LDP
the privacy budget must be split onto these versions.
In other words, for the calculation of
each bootstrap replication there is only a privacy budget of left, resulting in highly inaccurate estimators.
To address these problems we propose to apply the multiplier block bootstrap principle to the iterations of LDP-SGD in order to mimic the strong dependencies in this data.
To be precise let be the block length and
the number of blocks.
Let be bounded, real-valued, independent and identically distributed random variables with and equal to .
For the given iterates by LDP-SGD in (6) we calculate a bootstrap analog of as
| (11) |
where is the LDP-SGD estimate defined in (9). We will show below that under appropriate assumptions the distribution of is a reasonable approximation of the distribution of . In practice this distribution can be obtained by generating samples of the form (11). Details are given in Algorithm˜2, where the multiplier block bootstrap is used to construct an -quantile for the distribution of , say . With these quantiles we obtain an confidence interval for as
| (12) |
Theorem 3.2.
Let Assumptions˜A.1 and A.2 in the supplement be satisfied. Let and such that and for . Let in (11) be independent identical distributed random variables independent of with and . Further assume that there exists a constant such that a.s.. Then, conditionally on ,
in probability with . Here is the asymptotic variance of the errors and is a linear approximation of (see Assumption˜A.1 in the supplement for more details).
Remark 3.2.
(a)
If we chose (which yields ), and satisfy the assumptions of Theorem˜3.2 if .
The parameter determines the number of blocks used in the multiplier bootstrap.
On the one hand we would like to have as many blocks as possible since we expect better results if more samples are available.
This would suggest to choose close to .
On the other hand, also determines the block-length , which needs to be large enough to capture the underlying strong dependence structure of the iterates of LDP-SGD.
This suggests to choose close to one.
(b) If the blocks have been calculated, the run time of the block bootstrap is of order , which is dominated by the run time of (LDP-)SGD, as long as .
4 Simulation
We will consider LDP-SGD for the estimation of a quantile and of the parameters in a quantile regression model. We investigate these models because here the gradient is not differentiable and the plug-in estimator from Chen et al., (2020) can not be used. In each scenario, we consider samples of size and privacy parameter . The stepsize of the SGD is chosen as . The confidence intervals (12) for the quantities of interest are computed by bootstrap replications. The block length is chosen as , where . The distribution of multiplier is chosen as . The empirical coverage probability and average length of the interval are estimated by simulation runs. All simulations are run in R (R Core Team,, 2023) and executed on an internal cluster with an AMD EPYC 7763 64-Core processor under Ubuntu 22.04.4.
Quantiles: Let be independent and identically distributed valued random variables with distribution function and density . Denote by the -th quantile of i.e. . We assume that in a neighborhood of , then is the (unique) root of the equation The noisy gradient is given by which can be privatized using Randomized Response, that is
where is defined in Example 2.2 and . Note that the re-scaling ensures that for all . The measurement error and the error due to privacy in (7) and (8) are given by
respectively, which define indeed martingale difference processes with respect to the filtration , where and denotes the sigma algebra generated by the random variable . The assumptions of Theorems˜3.2 and 3.1 can be verified with where
In Table˜1 we display the simulated coverage probabilities and length of the confidence intervals for the and quantile of a standard normal distribution calculated by block bootstrap (BB).
We also compare our approach with the batch mean (BM) introduced in Chen et al., (2020) and the self normalisation (SN) approach suggested in Liu et al., (2023).
We observe that BB and BM behave very similar with respect to the empirical coverage and the length of the computed confidence intervals while the confidence intervals obtained by SN are slightly larger.
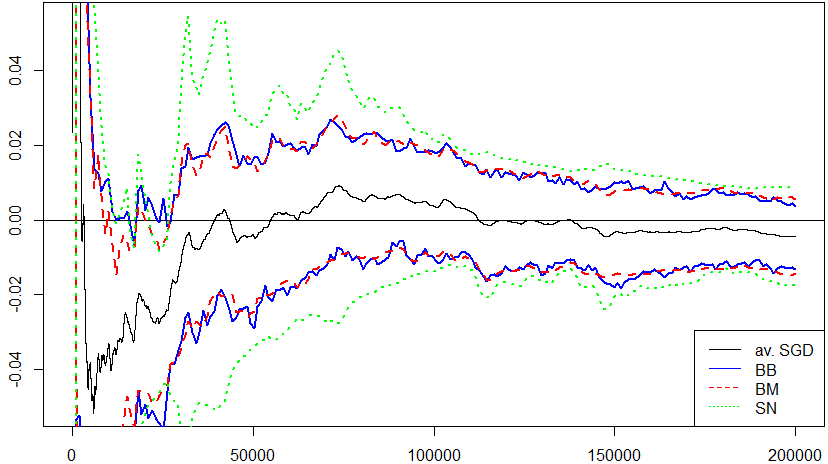
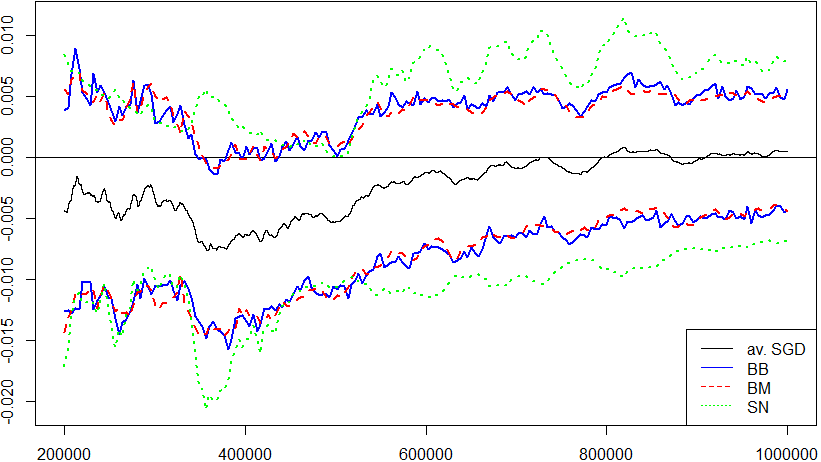
In Figure˜1 we display the trajectory of the upper and lower boundaries of a confidence interval for the quantile of a standard normal distribution for the BB, BM and SN approach.
Again, we observe that the confidence intervals obtained by BB and BM are quite similar and the confidence intervals obtained by SN are wider.
| 0.5 | BB | cover: | 0.880 (0.015) | 0.886 (0.014) | 0.886 (0.014) |
| length: | 0.0085 | 0.0027 | 0.0009 | ||
| BM | cover: | 0.884 (0.014) | 0.898 (0.014) | 0.896 (0.014) | |
| length: | 0.0086 | 0.0027 ( | 0.0009 | ||
| SN | cover: | 0.914 (0.013) | 0.898 (0.014) | 0.886 (0.014) | |
| length: | 0.0106 | 0.0034 | 0.0011 | ||
| 0.9 | BB | cover: | 0.828 (0.017) | 0.856 (0.016) | 0.848 (0.016) |
| length: | 0.0175 () | 0.0057 () | 0.0018 () | ||
| BM | cover: | 0.830 (0.017) | 0.868 (0.015) | 0.840 (0.016) | |
| length: | 0.0179 () | 0.0058 () | 0.0018 () | ||
| SN | cover: | 0.862 (0.015) | 0.880 (0.015) | 0.878 (0.015) | |
| length: | 0.0235 () | 0.0076 () | 0.0024 () |
Quantile Regression: Let be iid random vectors where , with and where is independent of with distribution function . We further assume that has a density in a neighbourhood of , say , with , that and that there exists a constant such that for all . If is the conditional quantile of given , it follows that and , where
which can be linearly approximated by , since a Taylor expansion at yields
The noisy observations are given by and can be privatized by the Laplace mechanism (see Example 2.1)
where is a vector of independent and identical distributed Laplacian random variables, i.e. .
The measurement error and the error due to privacy in (7) and (8) are given by
which are indeed martingale difference processes with respect to the filtration , where . The assumptions from Theorems˜3.2 and 3.1 can be verified with and
We compare the confidence intervals obtained by BB and BM where , follows a truncated standard normal distribution on the cube and is normal distributed with variance . For the generation of the truncated normal and the Laplace distribution we used the package of Botev and Belzile, (2021) and Wu et al., (2023), respectively. The simulation results are displayed in Table˜2. We observe that for BB yields too small and BM yields too large coverage probabilities, while the lengths of the confidence intervals from BB are smaller. If and the coverage probabilities from BB and BM are increasing and decreasing respectively.
| BB | cover: | 0.860 (0.016) | 0.882 (0.014) | 0.904 (0.013) | |
| length: | 0.07 | 0.016 | 0.005 | ||
| cover: | 0.862 (0.015) | 0.868 (0.015) | 0.880 (0.015) | ||
| length: | 0.228 | 0.055 | 0.016 | ||
| cover: | 0.850 (0.016) | 0.870 (0.015) | 0.882 (0.014) | ||
| length: | 0.241 | 0.054 | 0.016 | ||
| cover: | 0.844 (0.016) | 0.866 (0.015) | 0.890 (0.014) | ||
| length: | 0.243 | 0.054 | 0.016 | ||
| BM | cover: | 0.952 (0.01) | 0.932 (0.011) | 0.918 (0.012) | |
| length: | 0.103 | 0.02 | 0.005 | ||
| cover: | 0.938 (0.012) | 0.928 (0.012) | 0.896 (0.014) | ||
| length: | 0.315 | 0.076 | 0.017 | ||
| cover: | 0.948 (0.01) | 0.926 (0.012) | 0.902 (0.013) | ||
| length: | 0.335 | 0.073 | 0.017 | ||
| cover: | 0.928 (0.012) | 0.928 (0.012) | 0.898 (0.014) | ||
| length: | 0.339 | 0.073 | 0.017 |
Acknowledgments and Disclosure of Funding
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy - EXC 2092 CASA - 390781972.
References
- Abowd, (2018) Abowd, J. M. (2018). The us census bureau adopts differential privacy. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2867–2867.
- Avella-Medina et al., (2023) Avella-Medina, M., Bradshaw, C., and Loh, P.-L. (2023). Differentially private inference via noisy optimization. The Annals of Statistics, 51(5):2067–2092.
- Bassily et al., (2014) Bassily, R., Smith, A., and Thakurta, A. (2014). Private empirical risk minimization: Efficient algorithms and tight error bounds. In 2014 IEEE 55th annual symposium on foundations of computer science, pages 464–473. IEEE.
- Benveniste et al., (1990) Benveniste, A., Métivier, M., and Priouret, P. (1990). Adaptive algorithms and stochastic approximations, volume 22. Springer Science & Business Media.
- Botev and Belzile, (2021) Botev, Z. and Belzile, L. (2021). TruncatedNormal: Truncated Multivariate Normal and Student Distributions. R package version 2.2.2.
- Bradley, (2005) Bradley, R. C. (2005). Basic Properties of Strong Mixing Conditions. A Survey and Some Open Questions. Probability Surveys, 2(none):107 – 144.
- Chaudhuri et al., (2011) Chaudhuri, K., Monteleoni, C., and Sarwate, A. D. (2011). Differentially private empirical risk minimization. Journal of Machine Learning Research, 12(3).
- Chee et al., (2023) Chee, J., Kim, H., and Toulis, P. (2023). “plus/minus the learning rate”: Easy and scalable statistical inference with sgd. In International Conference on Artificial Intelligence and Statistics, pages 2285–2309. PMLR.
- Chen et al., (2020) Chen, X., Lee, J. D., Tong, X. T., and Zhang, Y. (2020). Statistical inference for model parameters in stochastic gradient descent. The Annals of Statistics, 48(1):251–273.
- Chung, (1954) Chung, K. L. (1954). On a stochastic approximation method. The Annals of Mathematical Statistics, pages 463–483.
- Cotter et al., (2011) Cotter, A., Shamir, O., Srebro, N., and Sridharan, K. (2011). Better mini-batch algorithms via accelerated gradient methods. In Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., and Weinberger, K., editors, Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc.
- Dette and Gösmann, (2020) Dette, H. and Gösmann, J. (2020). A likelihood ratio approach to sequential change point detection for a general class of parameters. Journal of the American Statistical Association, 115(531):1361–1377.
- Ding et al., (2017) Ding, B., Kulkarni, J., and Yekhanin, S. (2017). Collecting telemetry data privately. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Duchi et al., (2018) Duchi, J. C., Jordan, M. I., and Wainwright, M. J. (2018). Minimax optimal procedures for locally private estimation. Journal of the American Statistical Association, 113(521):182–201.
- Dwork et al., (2006) Dwork, C., McSherry, F., Nissim, K., and Smith, A. (2006). Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006. Proceedings 3, pages 265–284. Springer.
- Dwork and Roth, (2014) Dwork, C. and Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407.
- Efron and Tibshirani, (1994) Efron, B. and Tibshirani, R. (1994). An Introduction to the Bootstrap. Chapman & Hall/CRC Monographs on Statistics & Applied Probability. Taylor & Francis.
- Eshun and Palmieri, (2022) Eshun, S. N. and Palmieri, P. (2022). Two de-anonymization attacks on real-world location data based on a hidden markov model. In 2022 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), pages 01–09. IEEE.
- Fang et al., (2018) Fang, Y., Xu, J., and Yang, L. (2018). Online bootstrap confidence intervals for the stochastic gradient descent estimator. The Journal of Machine Learning Research, 19(1):3053–3073.
- Ferrando et al., (2022) Ferrando, C., Wang, S., and Sheldon, D. (2022). Parametric bootstrap for differentially private confidence intervals. In International Conference on Artificial Intelligence and Statistics, pages 1598–1618. PMLR.
- Fu et al., (2023) Fu, X., Xiang, Y., and Guo, X. (2023). Differentially private confidence interval for extrema of parameters. arXiv preprint arXiv:2303.02892.
- Gambs et al., (2014) Gambs, S., Killijian, M.-O., and del Prado Cortez, M. N. (2014). De-anonymization attack on geolocated data. Journal of Computer and System Sciences, 80(8):1597–1614.
- Khirirat et al., (2017) Khirirat, S., Feyzmahdavian, H. R., and Johansson, M. (2017). Mini-batch gradient descent: Faster convergence under data sparsity. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2880–2887.
- Lahiri, (2003) Lahiri, S. (2003). Resampling methods for dependent data. Springer Science & Business Media.
- Li et al., (2018) Li, T., Liu, L., Kyrillidis, A., and Caramanis, C. (2018). Statistical inference using sgd. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32.
- Liu et al., (2023) Liu, Y., Hu, Q., Ding, L., and Kong, L. (2023). Online local differential private quantile inference via self-normalization. In International Conference on Machine Learning, pages 21698–21714. PMLR.
- Mertikopoulos et al., (2020) Mertikopoulos, P., Hallak, N., Kavis, A., and Cevher, V. (2020). On the almost sure convergence of stochastic gradient descent in non-convex problems. Advances in Neural Information Processing Systems, 33:1117–1128.
- Narayanan and Shmatikov, (2006) Narayanan, A. and Shmatikov, V. (2006). How to break anonymity of the netflix prize dataset. arXiv preprint cs/0610105.
- Polyak and Juditsky, (1992) Polyak, B. T. and Juditsky, A. B. (1992). Acceleration of stochastic approximation by averaging. SIAM Journal on Control and Optimization, 30(4):838–855.
- R Core Team, (2023) R Core Team (2023). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria.
- Robbins and Monro, (1951) Robbins, H. and Monro, S. (1951). A stochastic approximation method. The annals of mathematical statistics, pages 400–407.
- Ruppert, (1988) Ruppert, D. (1988). Efficient estimations from a slowly convergent robbins-monro process. Technical report, Cornell University Operations Research and Industrial Engineering.
- Song et al., (2013) Song, S., Chaudhuri, K., and Sarwate, A. D. (2013). Stochastic gradient descent with differentially private updates. In 2013 IEEE global conference on signal and information processing, pages 245–248. IEEE.
- Su and Zhu, (2018) Su, W. J. and Zhu, Y. (2018). Uncertainty quantification for online learning and stochastic approximation via hierarchical incremental gradient descent. arXiv preprint arXiv:1802.04876.
- Vu and Slavkovic, (2009) Vu, D. and Slavkovic, A. (2009). Differential privacy for clinical trial data: Preliminary evaluations. In 2009 IEEE International Conference on Data Mining Workshops, pages 138–143. IEEE.
- Wang et al., (2020) Wang, T., Zhang, X., Feng, J., and Yang, X. (2020). A comprehensive survey on local differential privacy toward data statistics and analysis. Sensors, 20(24):7030.
- Wang and Awan, (2023) Wang, Z. and Awan, J. (2023). Debiased parametric bootstrap inference on privatized data. TPDP 2023 - Theory and Practice of Differential Privacy.
- Wang et al., (2022) Wang, Z., Cheng, G., and Awan, J. (2022). Differentially private bootstrap: New privacy analysis and inference strategies. arXiv preprint arXiv:2210.06140.
- Wu et al., (2023) Wu, H., Godfrey, A. J. R., Govindaraju, K., and Pirikahu, S. (2023). ExtDist: Extending the Range of Functions for Probability Distributions. R package version 0.7-2.
- Wu, (2005) Wu, W. B. (2005). Nonlinear system theory: Another look at dependence. Proceedings of the National Academy of Sciences, 102(40):14150–14154.
- Xiong et al., (2020) Xiong, X., Liu, S., Li, D., Cai, Z., and Niu, X. (2020). A comprehensive survey on local differential privacy. Security and Communication Networks, 2020:1–29.
- Yang et al., (2023) Yang, M., Guo, T., Zhu, T., Tjuawinata, I., Zhao, J., and Lam, K.-Y. (2023). Local differential privacy and its applications: A comprehensive survey. Computer Standards & Interfaces, page 103827.
- Yu et al., (2021) Yu, L., Balasubramanian, K., Volgushev, S., and Erdogdu, M. A. (2021). An analysis of constant step size sgd in the non-convex regime: Asymptotic normality and bias. Advances in Neural Information Processing Systems, 34:4234–4248.
- Zhong et al., (2023) Zhong, Y., Kuffner, T., and Lahiri, S. (2023). Online bootstrap inference with nonconvex stochastic gradient descent estimator. arXiv preprint arXiv:2306.02205.
- Zhu et al., (2021) Zhu, W., Chen, X., and Wu, W. B. (2021). Online covariance matrix estimation in stochastic gradient descent. Journal of the American Statistical Association, pages 1–30.
Appendix A Technical assumptions
The theoretical results of this paper, in particular the consistency of the multiplier block bootstrap, are proved under the following assumptions.
Assumption A.1.
Denote . Assume that the following conditions hold:
-
(1)
There exists a differentiable function with gradient such that for some constants , , ,
-
(2)
There exist positive definite matrix and constants , , such that for all
(13) -
(3)
is a martingale-difference process with respect to a filtration , and for a constant it holds that for all
-
(4)
For the errors , there exists a decomposition of the form a positive definite matrix and a function which is continuous at the origin, such that
-
(5)
The learning rates are given by with and .
Assumption A.2.
Denote and assume that is a martingale difference process with respect to a filtration . Assume that the following holds:
- (1)
-
(2)
There exists a constant such that a.s..
-
(3)
There exists a constant with .
-
(4)
The sequence is uniformly integrable.
-
(5)
The learning rates are given by and there exists a constant such that and
(14) for every eigenvalue of the matrix in (13).
Remark A.1.
In many cases, is approximately proportional to (which follows by a Taylor expansion) and the convergence rate of is well studied, see for example Chung, (1954) and Chen et al., (2020).
If the sequence is bounded, Assumption˜A.2 (2)-(4) are satisfied.
Condition (14) is the base case of a proof by induction and can be numerically verified for different choices of the parameters and in the learning rate.
Appendix B Proofs of the results in Section 3
We will denote in this section. Furthermore, we omit the superscript "LDP" of for improved readability. In other words, we write for and for . Moreover, for the sake of simplicity, we assume that .
B.1 Proof of Theorem 3.1
This follows from Theorem 2 in Polyak and Juditsky, (1992) by observing that satisfies the assumptions stated in this reference.
B.2 Proof of Theorem 3.2
We first prove the statement in the case where the gradient is assumed to be linear. After that, Theorem˜3.2 is derived by showing that bootstrap LDP-SGD in the non linear case is asymptotically approximated by a linearized version of bootstrap LDP-SGD. The following result is shown in Section B.3.
Theorem B.1.
Assume that the conditions of Theorem˜3.2 hold and that for a positive definite matrix . Then, conditionally on
in probability, where .
From Theorem˜B.1 we conclude that Theorem˜3.2 holds. To be precise, let be the matrix in the linear approximation of the gradient in (13), let be the martingale difference process capturing the error due to measurement and privacy as in (6) and let be the matrix in Assumption˜A.1 (4). Next we define a sequence of iterates of LDP-SGD for a loss function with , that is, and for
We denote the bootstrap analogue defined as in (11) for this sequence by , that is
By Theorem˜B.1 it follows conditionally on ,
in probability. Since there is a bijection from to and from to , the corresponding sigma algebras coincide and therefore, conditionally on ,
in probability. The assertion of Theorem˜3.2 is now a consequence of
For a proof of this statement, we define
| (15) |
and note that
Here the second and third term converge to zero in probability, since does and both , converge weakly by Theorem˜3.1. For a corresponding statement regarding the first term let denote the -dimensional identity matrix and note that
since . Therefore, since a.s. by assumption, we obtain
where denotes a matrix norm. Following the same arguments as in Polyak and Juditsky, (1992), part 4 of the proof of Theorem 2, it follows that the last term converges in probability to zero.
B.3 Proof of Theorem B.1
The proof is a consequence of the following three Lemmas:
Lemma B.1.
Lemma B.2.
Conditionally on we have
in probability, where .
Lemma B.3.
Let the assumptions from Theorem˜B.1 hold, as in (17) and as in (15). Then
By the same arguments of Part 1 in the proof of Theorem 1 in Polyak and Juditsky, (1992) we obtain for the first term in (16) (note that by assumption are bounded a.s.). The fourth term is of order since converges to zero in probability and converges in distribution by Theorem˜3.1. The third term in (16) is of order as well by Lemma˜B.3. Therefore
in probability, given by Lemma˜B.2(note that the sigma algebras generated by and coincide).
Appendix C Proofs of Lemma B.1 - Lemma B.3
C.1 Proof of Lemma B.1
Obviously,
Now we use the following representation for -th iterate
to obtain
which proves the assertion of Lemma˜B.1.
C.2 Proof of Lemma B.2
We will give the proof for , the multivariate case follows by analog arguments. Define
and note that
As, conditional on , the random variables are independent we obtain by the Berry Esseen theorem that
| (18) |
where
is the variance of conditional on . Note that, by Assumption˜A.2 (1)
Moreover, as
it follows that the are uniformly bounded (note that that the fourth moment of is bounded by assumption). Therefore, by Chebyshev’s inequality, , which yields
By assumption, is bounded (since is bounded almost surely) and converges in probability. Therefore, the right hand side of (18) is of order and the assertion of the Lemma follows.
C.3 Proof of Lemma B.3
We first derive an alternative representation for the expression in Lemma˜B.3. By interchanging the order of summation we obtain
where are defined by
With these notations the assertion of Lemma˜B.3 follows from the convergence
The expression on the right hand side can be decomposed into different parts according to Lemma C.1.
Lemma C.1.
and
| (21) |
In order to estimate the expressions in Lemma˜C.1 we now argue as follows. For the first term we use the Cauchy-Schwarz inequality and obtain
Note that the matrix is symmetric as it is a polynomial of the symmetric matrix . Consequently, the second term converges to if we can show that all eigenvalues of the matrix converge to zero, that is
where denotes the eigenvalue of the matrix . For this purpose we note again that the matrix is a polynomial of the symmetric matrix which implies that
and investigate the eigenvalues of the different matrices separately. In particular, we show in Section D the following results.
Lemma C.2.
If , it holds that
Lemma C.3.
If and for and , it holds that
Lemma C.4.
If and , it holds that
From these results we can conclude that
| (22) |
In order to derive a similar result for the second term in Lemma˜C.1 we consider all four terms in the trace separately. Starting with we obtain by Assumption˜A.2 that
Next we note, observing the definition of that
since can be bounded by a constant by Assumption˜A.2. By Lemma˜C.2 converges to zero which implies that
The two remaining terms and are considered in the following Lemma, which will be proved in Section D.
Lemma C.5.
Appendix D Proofs of auxiliary results
D.1 Proof of Lemma˜C.1
Observing that the bootstrap multipliers are independent of it follows that
since and . With the notation
we obtain the representation which yields
where
since for . For a similar calculation shows that
Inserting and noting that it follows
The assertion of Lemma˜C.1 now follows by a straight forward calculation adding and subtracting the terms with in the second and third sum.
D.2 Proof of Lemma C.2
As is a polynomial of the symmetric matrix we may assume without loss of generality that (change the constant in the definition of ) and obtain with the inequalities and that
Fixing a constant , the inner sum can be split at , i.e.
where and . It holds that
which yields
It is easy to see that and for . Therefore and since ,
where . Since for and , the assertion of the lemma follows.
D.3 Proof of Lemma C.3
Without loss of generality we assume that (changing the constant in the learning rate). Because is a polynomial of the symmetric matrix G it follows that
Note that
| (25) |
which follows by a direct calculation using an induction argument. With this representation we obtain
Therefore, it is left to show that
For use which gives (using the definition )
if is sufficiently large. This gives
which converges to zero since , by assumption.
D.4 Proof of Lemma C.4
As in the proof of Lemma˜C.4 we assume without loss of generality that . Observing again that is a polynomial of the symmetric matrix it follows that
We will show below that there exists a constant and a constant (which depends on the parameters of the learning rate) such that for all
| (26) | ||||
| (27) |
Recalling the definition of in (19) and using (26), (27) and Lemma˜C.3 it follows that
| (28) | ||||
since the first term in (28) converges to by Lemma˜C.4 while the second term vanishes asymptotically, which is a consequence of the following
The right hand side converges to 0 since and
Proof of (26).
We will show this result by induction over . Denote
At first we argue that there exist constants and such that (26) holds for (this particular choice of is used in the induction step).
To see this note that, for , is bounded by a constant (depending on and ).
Let be fixed and larger than this constant. In particular, the choice of does not depend on and for all .
Then, for sufficiently large, (26) holds for since the left-hand side is finite for fixed.
For the induction step we assume that (26) holds for some , then we have to show:
| (29) |
Since we assumed that (26) holds for , (29) follows from
which is equivalent to (inserting the definition of and multiplying by )
| (30) |
Since it holds that
So and therefore (29) follows from
which is implied if the following three inequalities hold
which they do for . ∎
Proof of (27).
We will show this result by induction over . By Assumption˜A.2 there exists a constant such that (27) holds for a . Therefore,
by the induction hypothesis. Showing that this is larger than is equivalent to (inserting the definition of , multiplying by )
Since , this is implied by
(note that ). By Assumption˜A.2 (5) we have , which completes the proof of Lemma˜C.4. ∎
D.5 Proof of Lemma C.5
We start by showing (23). Note that by definition of (20)
where the matrix is defined in (21) and as in Lemma˜C.1. From the Cauchy-Schwarz inequality it follows that . By Assumption˜A.2, is (up to a constant) bounded by . We will prove
| (31) | ||||
| (32) |
for every eigenvalue of from which (23) follows.
To see (31), note again that is a polynomial of the symmetric matrix and as in the proof of Lemma˜C.3 we assume without loss of generality that , which gives
If is sufficiently large, for , and therefore
By for and by applying (25), it follows that
which converges to zero.
(32) follows by similar arguments and noting that for only finitely many .
To show the second assertion (24) in Lemma˜C.5, note that by the definition (20) of and same arguments as in the proof of (23), it follows that
where . Noting is a polynomial of the symmetric matrix and assuming without loss of generality that for the corresponding eigenvalue of it holds it follows
Similar to (26) one can show by induction that ( being the constant in the learning rate)
This implies
where the sum over the first term converges to zero by the same arguments used for the convergence of and and the sum over the second term converges to zero by the same arguments used in the proof of (26). Therefore (24) follows.